支持向量机原理及matlab实现
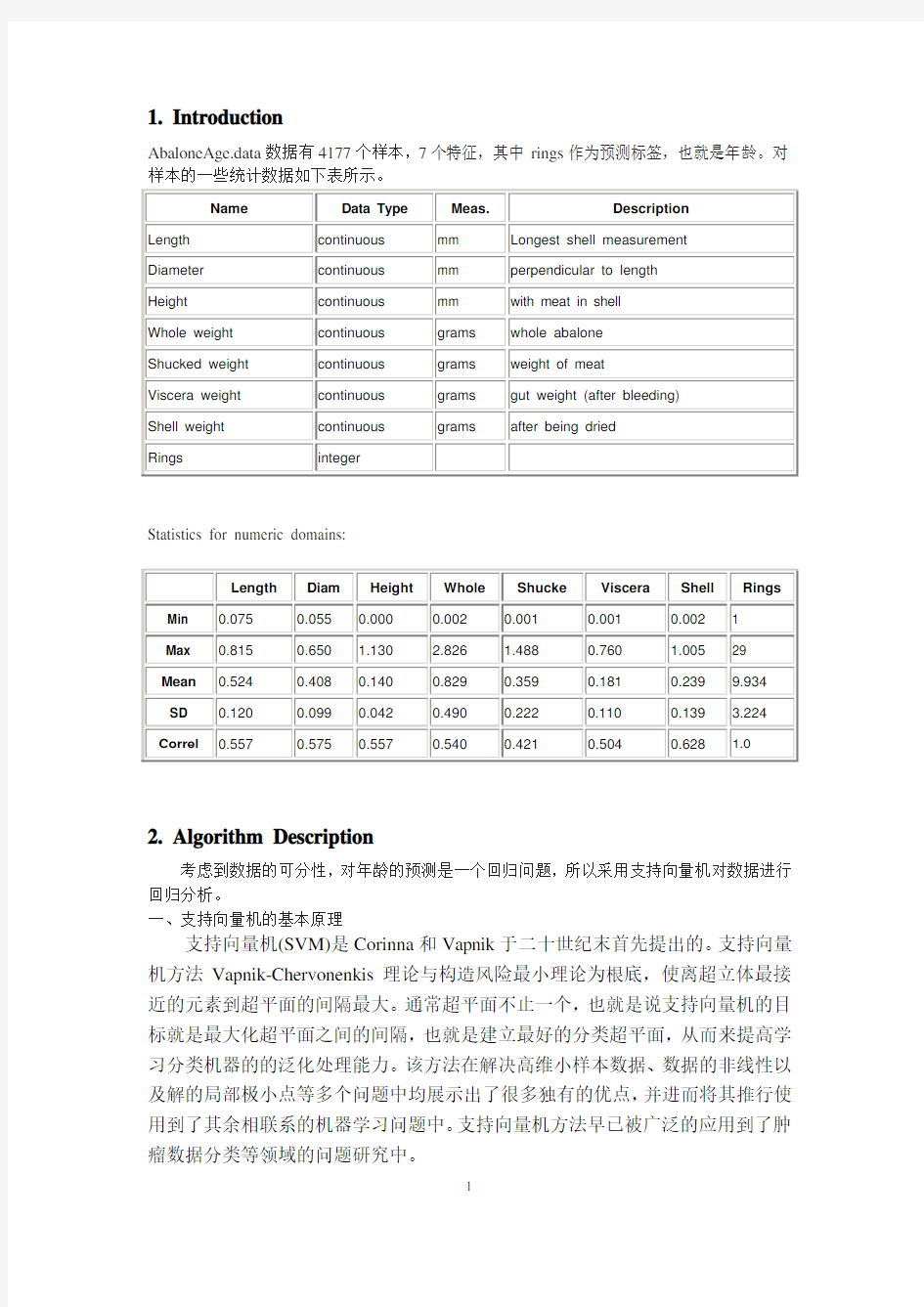

1. Introduction
Statistics for numeric domains:
2. Algorithm Description
考虑到数据的可分性,对年龄的预测是一个回归问题,所以采用支持向量机对数据进行回归分析。
一、支持向量机的基本原理
支持向量机(SVM)是Corinna和Vapnik于二十世纪末首先提出的。支持向量机方法Vapnik-Chervonenkis理论与构造风险最小理论为根底,使离超立体最接近的元素到超平面的间隔最大。通常超平面不止一个,也就是说支持向量机的目标就是最大化超平面之间的间隔,也就是建立最好的分类超平面,从而来提高学习分类机器的的泛化处理能力。该方法在解决高维小样本数据、数据的非线性以及解的局部极小点等多个问题中均展示出了很多独有的优点,并进而将其推行使用到了其余相联系的机器学习问题中。支持向量机方法早已被广泛的应用到了肿瘤数据分类等领域的问题研究中。
支持向量机的具体求解过程如下: (1) 设已知样本训练集:
()(){}()
11,,
,n
n n T x y x y X Y =∈?
其中,{}(),1,11,2,,n i i x X R y Y i n ∈=∈=-+=,i x 为特征向量。
(2) 选择适当核函数(,)i j K x x 以及参数C ,解决优化问题:
()111
1,2min n n
n
i i j j i j j i j j y y K x x αααα===-∑∑∑ 1..
0,0,1,
,n
i i
i i s t y
C i n αα==≤≤=∑
得最优解:()***
1,...,T
n ααα=。
(3) 选取α*
的正分量,计算样本分类阈值:*
*1
(,)l
i i i i j i b y y K x x α==-∑。
(4) 构造最优判别函数:
1()sgn (,)n i i i j i f x y a K x x b **=??
=+????
∑。
支持向量机内积核核函数K 的主要种类有: ① 线性内核函数 (,)(,)i j i j K x x x x = ② 多项式核函数 (,)[(,)1q i j i j
K x x x x =+ ③ 高斯径向基核函数 (RBF) 2
2
(,)e x p {}
i j
i j x x K x x σ-=- ④ 双曲正切核函数 (Sigmoid 核函数) (,)t a n h (()i j i j K x x v x x c =?+
一般地,用SVM 做分类预测时必须调整相关参数(特别是惩罚参数c 和核函数参数g ),这样才可以获得比较满意的预测分类精度,采用Cross Validation 的思想可以获取最优的参数,并且有效防止过学习和欠学习状态的产生,从而能够对于测试集合的预测得到较佳的精度。
根据输入数据的线性可分性(线性可分或近似线性可分和线性不可分),可以将支持向量机分为两大类:非线性支持向量机、线性支持向量机。
(1)线性支持向量机
若要介绍线性支持向量机,首先需要介绍下一个定义:线性分类器。A 、B 是两个不同的类别,需要在其中间加一个分类函数,这样就能够将A 、B 样本区分开,那么则说这个数据集是线性可分,其所对应的分类器便是线性分类器。对于二维空间,显然,分类函数可以看成是一条直线。同理,三维空间里分类函数就是一个平面,忽略空间的维数,分类函数就可以统称为超平面。
(2)非线性支持向量机
从前一小节可以看出来,线性支持向量机是二类分类器。但是,在现实环境和问题中,往往要解决多类别的分类的问题。那么,怎么从二类分类器扩充到多类别分类器呢?就是一个值得思考探寻的方向。从二类分类器获取多类分类器的方法有很多,但在实际应用中,采用的较多的措施是通过寻找一个合适的非线性转换函数,进而能够使数据从原始的特征空间中映射到新的特征空间中,使得数据在新的特征空间中是线性可分的。但是,寻找这样的非线性转换函数很难,并且即使能找到,要实现这种非线性的转换也很麻烦。
因此,引入了核函数,它使得甚至可以不必知道变换函数,只要一种核函数满足Mereer定理,它就对应某一变换空间中的内积,然而内积的计算却容易的多。常用的核函数主要分为四类:Gaussian核函数、Polynomial核函数、Sigmoid 核函数和Liner核函数,不同的核函数对应不同的非线性变换函数,最后会形成不同的算法。这就使得相应的优化问题变成了凸二次规划问题,不会出现传统神经网络陷入局部极值的问题,这是SVM自提出后得到快速发展的重要原因之一。
SVM的优势:(1)处理解决了样本数据较少的机器学习问题;(2)提高了学习机的泛化性能;(3) 少数支持向量决定了最后的决策函数,因此,某种程度上对高维问题有很好的辅助解决作用,提高了方法的鲁棒性;(4)完善改进了对于非线性数据分类研究的问题;(5)规避了神经网络在结构抉择问题和局部极小值问题。
SVM的劣势:(1)缺乏对数据缺失的判断能力;(2)解决非线性数据还没有完善的方案和措施,只能靠慎重的选择核函数来解决。另一方面,所有传统分类方法中,SVM的分类性能是最好的,所以在本文的对比实验中,从传统分类方法中选择了具有代表性的SVM分类器来进行对比实验。
二、SVM回归的实验步骤
①导入数据,记作X,分别将数据的特征和标签赋值给矩阵matrix和rings,如图所示。
②利用随机数,随机选择70%的样本作为训练集,余下的30%的样本作为测试集,评价模型的好坏应该从训练集和测试集两个方面考虑,使用matlab自带fitrsvm程序,对样本归一化后,训练集进行训练,得到模型Mdl。
③利用训练得到的模型,分别对训练集和测试集进行预测,并计算其与真实值之间的差距,
评价指标选择的是均方根误差和平均绝对误差。其中result_1记录了训练集真实和预测值,result_2记录了测试集真实和预测值,abe1、mse1分别表示训练集平均绝对误差和均方根误差。
④可视化测试集预测与真实年龄的差距。
3. Conclution
支持向量机是一种基于统计学习理论的模式识别方法。在模式识别等领域获得了广泛的应用。少数支持向量决定了最后的决策函数,因此,某种程度上对高维问题有很好的辅助解决作用,提高了方法的鲁棒性。
随机选择70%的样本作为训练集,30%的样本作为测试集,平均绝对误差和均方根误差作为模型的评价指标,训练集预测结果与原始数据标签的的平均绝对误差(abe)为1.5723,均方根误差(mse)为2.2745,测试集平均绝对误差(abe)1.5671,均方根误差(mse)为2.3279,说明支持向量机对数据年龄的预测具有较好的结果。
Appendix
Code:
%% 清空环境变量
clear
clc
%% 导入数据
X=load('AbaloneAge.txt');
matrix=X(:,1:6);
rings=X(:,end);
%%
% 1. 随机产生训练集和测试集
n = randperm(size(matrix,1));
%%
% 2. 训练集——70%的样本
n1=floor(size(X,1)*0.7);
p_train = matrix(n(1:n1),:);
t_train = rings(n(1:n1),:);
%%
% 3. 测试集——30%的个样本
p_test = matrix(n(n1+1:end),:);
t_test = rings(n(n1+1:end),:);
%% 数据归一化
%%
% 1. 训练集
[pn_train,inputps] = mapminmax(p_train');
pn_train = pn_train';
pn_test = mapminmax('apply',p_test',inputps);
pn_test = pn_test';
%%
% 2. 测试集
[tn_train,outputps] = mapminmax(t_train');
tn_train = tn_train';
tn_test = mapminmax('apply',t_test',outputps);
tn_test = tn_test';
Mdl = fitrsvm(pn_train,tn_train);
% yfit = predict(Mdl,pn_test);
%% SVM仿真预测
Predict_1 = predict(Mdl,pn_train);
Predict_2 = predict(Mdl,pn_test);
%%
% 1. 反归一化
predict_1 = mapminmax('reverse',Predict_1,outputps); predict_2 = mapminmax('reverse',Predict_2,outputps);
%%
% 2. 结果对比
result_1 = [t_train predict_1];
result_2 = [t_test predict_2];
re1= result_1(:,1)-result_1(:,2);
abe1 = sum(abs(re1))/size(p_train,1)
mse1 = sqrt(sum(re1.^2)/size(p_train,1))
re2= result_2(:,1)-result_2(:,2);
abe2 = sum(abs(re2))/size(p_test,1)
mse2 = sqrt(sum(re2.^2)/size(p_test,1))
figure(1)
plot(1:length(t_test),t_test,'r-*',1:length(t_test),predict_2,'b:o') grid on
legend('真实值','预测值')
xlabel('样本编号')
ylabel('age')
支持向量机的matlab代码
支持向量机的matlab代码 Matlab中关于evalin帮助: EVALIN(WS,'expression') evaluates 'expression' in the context of the workspace WS. WS can be 'caller' or 'base'. It is similar to EVAL except that you can control which workspace the expression is evaluated in. [X,Y,Z,...] = EVALIN(WS,'expression') returns output arguments from the expression. EVALIN(WS,'try','catch') tries to evaluate the 'try' expression and if that fails it evaluates the 'catch' expression (in the current workspace). 可知evalin('base', 'algo')是对工作空间base中的algo求值(返回其值)。 如果是7.0以上版本 >>edit svmtrain >>edit svmclassify >>edit svmpredict function [svm_struct, svIndex] = svmtrain(training, groupnames, varargin) %SVMTRAIN trains a support vector machine classifier % % SVMStruct = SVMTRAIN(TRAINING,GROUP) trains a support vector machine % classifier using data TRAINING taken from two groups given by GROUP. % SVMStruct contains information about the trained classifier that is % used by SVMCLASSIFY for classification. GROUP is a column vector of % values of the same length as TRAINING that defines two groups. Each % element of GROUP specifies the group the corresponding row of TRAINING % belongs to. GROUP can be a numeric vector, a string array, or a cell % array of strings. SVMTRAIN treats NaNs or empty strings in GROUP as % missing values and ignores the corresponding rows of TRAINING. % % SVMTRAIN(...,'KERNEL_FUNCTION',KFUN) allows you to specify the kernel % function KFUN used to map the training data into kernel space. The % default kernel function is the dot product. KFUN can be one of the % following strings or a function handle: % % 'linear' Linear kernel or dot product % 'quadratic' Quadratic kernel % 'polynomial' Polynomial kernel (default order 3) % 'rbf' Gaussian Radial Basis Function kernel % 'mlp' Multilayer Perceptron kernel (default scale 1) % function A kernel function specified using @,
陆振波SVM的MATLAB代码解释
%构造训练样本 n = 50; randn('state',6); x1 = randn(2,n); %2行N列矩阵 y1 = ones(1,n); %1*N个1 x2 = 5+randn(2,n); %2*N矩阵 y2 = -ones(1,n); %1*N个-1 figure; plot(x1(1,:),x1(2,:),'bx',x2(1,:),x2(2,:),'k.'); %x1(1,:)为x1的第一行,x1(2,:)为x1的第二行 axis([-3 8 -3 8]); title('C-SVC') hold on; X = [x1,x2]; %训练样本d*n矩阵,n为样本个数,d为特征向量个数 Y = [y1,y2]; %训练目标1*n矩阵,n为样本个数,值为+1或-1 %训练支持向量机 function svm = svmTrain(svmType,X,Y,ker,p1,p2) options = optimset; % Options是用来控制算法的选项参数的向量 https://www.360docs.net/doc/ae3676578.html,rgeScale = 'off'; options.Display = 'off'; switch svmType case'svc_c', C = p1; n = length(Y); H = (Y'*Y).*kernel(ker,X,X); f = -ones(n,1); %f为1*n个-1,f相当于Quadprog函数中的c A = []; b = []; Aeq = Y; %相当于Quadprog函数中的A1,b1 beq = 0; lb = zeros(n,1); %相当于Quadprog函数中的LB,UB ub = C*ones(n,1); a0 = zeros(n,1); % a0是解的初始近似值 [a,fval,eXitflag,output,lambda] = quadprog(H,f,A,b,Aeq,beq,lb,ub,a0,options); %a是输出变量,它是问题的解 % Fval是目标函数在解a 处的值 % Exitflag>0,则程序收敛于解x Exitflag=0,则函数的计算达到了最大次数 Exitflag<0,则问题无可行解,或程序运行失败 % Output 输出程序运行的某些信息
支持向量机非线性回归通用MATLAB源码
支持向量机非线性回归通用MA TLAB源码 支持向量机和BP神经网络都可以用来做非线性回归拟合,但它们的原理是不相同的,支持向量机基于结构风险最小化理论,普遍认为其泛化能力要比神经网络的强。大量仿真证实,支持向量机的泛化能力强于BP网络,而且能避免神经网络的固有缺陷——训练结果不稳定。本源码可以用于线性回归、非线性回归、非线性函数拟合、数据建模、预测、分类等多种应用场合,GreenSim团队推荐您使用。 function [Alpha1,Alpha2,Alpha,Flag,B]=SVMNR(X,Y,Epsilon,C,TKF,Para1,Para2) %% % SVMNR.m % Support Vector Machine for Nonlinear Regression % All rights reserved %% % 支持向量机非线性回归通用程序 % GreenSim团队原创作品,转载请注明 % GreenSim团队长期从事算法设计、代写程序等业务 % 欢迎访问GreenSim——算法仿真团队→https://www.360docs.net/doc/ae3676578.html,/greensim % 程序功能: % 使用支持向量机进行非线性回归,得到非线性函数y=f(x1,x2,…,xn)的支持向量解析式,% 求解二次规划时调用了优化工具箱的quadprog函数。本函数在程序入口处对数据进行了% [-1,1]的归一化处理,所以计算得到的回归解析式的系数是针对归一化数据的,仿真测 % 试需使用与本函数配套的Regression函数。 % 主要参考文献: % 朱国强,刘士荣等.支持向量机及其在函数逼近中的应用.华东理工大学学报 % 输入参数列表 % X 输入样本原始数据,n×l的矩阵,n为变量个数,l为样本个数 % Y 输出样本原始数据,1×l的矩阵,l为样本个数 % Epsilon ε不敏感损失函数的参数,Epsilon越大,支持向量越少 % C 惩罚系数,C过大或过小,泛化能力变差 % TKF Type of Kernel Function 核函数类型 % TKF=1 线性核函数,注意:使用线性核函数,将进行支持向量机的线性回归 % TKF=2 多项式核函数 % TKF=3 径向基核函数 % TKF=4 指数核函数 % TKF=5 Sigmoid核函数 % TKF=任意其它值,自定义核函数 % Para1 核函数中的第一个参数 % Para2 核函数中的第二个参数 % 注:关于核函数参数的定义请见Regression.m和SVMNR.m内部的定义 % 输出参数列表 % Alpha1 α系数 % Alpha2 α*系数 % Alpha 支持向量的加权系数(α-α*)向量
四种支持向量机用于函数拟合与模式识别的Matlab示
四种支持向量机用于函数拟合与模式识别的Matlab示四种支持向量机用于函数拟合与模式识 别的Matlab示 四种支持向量机用于函数拟合与模式识别的Matlab示例程序(转)2010-08-08 10:02使用要点: 应研学论坛人工智能与模式识别版主magic_217之约,写一个关于针对初学者的四种支持向量机工具箱的详细使用说明。同时也不断有网友向我反映看不懂我的源代码,以及询问如何将该工具箱应用到实际数据分析等问题,其中有相当一部分网友并不了解模式识别的基本概念,就急于使用这个工具箱。本文从模式识别的基本概念谈起,过渡到神经网络模式识别,逐步引入到这四种支持向量机工具箱的使用。 本文适合没有模式识别基础,而又急于上手的初学者。作者水平有限,欢迎同行批评指正~ 模式识别基本概念 [1] 模式识别的方法有很多,常用有:贝叶斯决策、神经网络、支持向量机等等。特别说明的是,本文所谈及的模式识别是指"有老师分类",即事先知道训练样本所属的类别,然后设计分类器,再用该分类器对测试样本进行识别,比较测试样本的实际所属类别与分类器输出的类别,进而统计正确识别率。正确识别率是反映分类器性能的主要指标。 分类器的设计虽然是模式识别重要一环,但是样本的特征提取才是模式识别最关键的环节。试想如果特征矢量不能有效地描述原样本,那么即使分类设计得再好也无法实现正确分类。工程中我们所遇到的样本一般是一维矢量,如:语音信号,或者是二维矩阵,如:图片等。特征提取就是将一维矢量或二维矩阵转化成一个维
数比较低的特征矢量,该特征矢量用于分类器的输入。关于特征提取,在各专业领域中也是一个重要的研究方向,如语音信号的谐振峰特征提取,图片的PCA特征提取等等。 [2]神经网络模式识别 神经网络模式识别的基本原理是,神经网络可以任意逼近一个多维输入输出函数。以三类分类:I、II、III为例,神经网络输入是样本的特征矢量,三类样本的神经网络输出可以是[1;0;0]、[0;1;0]、[0;0;1],也可以是[1;-1;-1]、[-1;1;-1]、[-1;-1;1]。将所有样本中一部分用来训练网络,另外一部分用于测试输出。通常情况下,正确分类的第I类样本的测试输出并不是[1;0;0]或是[1;-1;-1],而是如[0.1;0;-0.2]的输出。也是就说,认为输出矢量中最大的一个分量是1,其它分量是0或是-1就可以了。 [3]支持向量机的多类分类 支持向量机的基本理论是从二类分类问题提出的。我想绝大部分网友仅着重于理解二类分类问题上了,我当初也是这样,认识事物都有一个过程。二类分类的基本原理固然重要,我在这里也不再赘述,很多文章和书籍都有提及。我觉得对于工具箱的使用而言,理解如何实现从二类分类到多类分类的过渡才是最核心的内容。下面我仅以1-a-r算法为例,解释如何由二类分类器构造多类分类器。 二类支持向量机分类器的输出为[1,-1],当面对多类情况时,就需要把多类分类器分解成多个二类分类器。在第一种工具箱LS_SVMlab中,文件 Classification_LS_SVMlab.m中实现了三类分类。训练与测试样本分别为n1、 n2,它们是3 x15的矩阵,即特征矢量是三维,训练与测试样本数目均是15;由于是三类分类,所以训练与测试目标x1、x2的每一分量可以是1、2或是3,分别对应三类,如下所示: n1=[rand(3,5),rand(3,5)+1,rand(3,5)+2];
MATLAB-智能算法30个案例分析-终极版(带目录)
MATLAB 智能算法30个案例分析(终极版) 1 基于遗传算法的TSP算法(王辉) 2 基于遗传算法和非线性规划的函数寻优算法(史峰) 3 基于遗传算法的BP神经网络优化算法(王辉) 4 设菲尔德大学的MATLAB遗传算法工具箱(王辉) 5 基于遗传算法的LQR控制优化算法(胡斐) 6 遗传算法工具箱详解及应用(胡斐) 7 多种群遗传算法的函数优化算法(王辉) 8 基于量子遗传算法的函数寻优算法(王辉) 9 多目标Pareto最优解搜索算法(胡斐) 10 基于多目标Pareto的二维背包搜索算法(史峰) 11 基于免疫算法的柔性车间调度算法(史峰) 12 基于免疫算法的运输中心规划算法(史峰) 13 基于粒子群算法的函数寻优算法(史峰) 14 基于粒子群算法的PID控制优化算法(史峰) 15 基于混合粒子群算法的TSP寻优算法(史峰) 16 基于动态粒子群算法的动态环境寻优算法(史峰) 17 粒子群算法工具箱(史峰) 18 基于鱼群算法的函数寻优算法(王辉) 19 基于模拟退火算法的TSP算法(王辉) 20 基于遗传模拟退火算法的聚类算法(王辉) 21 基于模拟退火算法的HEV能量管理策略参数优化(胡斐)
22 蚁群算法的优化计算——旅行商问题(TSP)优化(郁磊) 23 基于蚁群算法的二维路径规划算法(史峰) 24 基于蚁群算法的三维路径规划算法(史峰) 25 有导师学习神经网络的回归拟合——基于近红外光谱的汽油辛烷值预测(郁磊) 26 有导师学习神经网络的分类——鸢尾花种类识别(郁磊) 27 无导师学习神经网络的分类——矿井突水水源判别(郁磊) 28 支持向量机的分类——基于乳腺组织电阻抗特性的乳腺癌诊断(郁磊) 29 支持向量机的回归拟合——混凝土抗压强度预测(郁磊) 30 极限学习机的回归拟合及分类——对比实验研究(郁磊) 智能算法是我们在学习中经常遇到的算法,主要包括遗传算法,免疫算法,粒子群算法,神经网络等,智能算法对于很多人来说,既爱又恨,爱是因为熟练的掌握几种智能算法,能够很方便的解决我们的论坛问题,恨是因为智能算法感觉比较“玄乎”,很难理解,更难用它来解决问题。 因此,我们组织了王辉,史峰,郁磊,胡斐四名高手共同写作MATLAB智能算法,该书包含了遗传算法,免疫算法,粒子群算法,鱼群算法,多目标pareto算法,模拟退火算法,蚁群算法,神经网络,SVM等,本书最大的特点在于以案例为导向,每个案例针对一
Matlab-SVM整理
SVM整理 1各种svm程序包 1.1 matlab高级版本中自带的svm函数 我现在使用的matlab版本为matlab 7.6.0(R2008a)这个版本中已经自带svm算法,分别为生物信息工具箱(bioinformatics toolbox)中svmclassify函数和svmtrain函数,为上下级关系。 SVMStruct=svmtrain(Training,Group)%svmtrain的输入为样本点training和样本的分类情况group,输出为一个分类器svmstruct. 核函数,核参数,和计算方法等都是可选的,如SVMStruct = svmtrain(…, ‘Kernel_Function’, Kernel_FunctionValue, …) 但是切记切记一定要成对出现。 然后,将分类器和testing sample带入svmclassify中,可以得到分类结果和准确度。 举个例子 svmStruct=svmtrain(data(train,:),groups(train),’Kernel_Function’,'rbf’,'Kernel_FunctionValue’,’5′,’showplot’,true); %用了核宽为5的径向基核,且要求作图 %这里我觉得原作者的写法有误,应该是svmStruct = svmtrain(data(train,:),groups(train),... 'Kernel_Function','rbf','RBF_Sigma',5,'showplot',true); classes = svmclassify(svmStruct,data(test,:),’showplot’,true); %要求输出检测样本点的分类结果,且画图表示。 tip 1: 有归一化scale功能,可以通过调参数实现 tip 2: 计算方法可选qp,smo,ls tip 3: 有个关于soft margin的盒子条件,我不太明白是干嘛的,谁懂得话,就给我讲讲哈 tip 4: 画出来的图很难看 to sum up: 挺好的 1.2较早使用的工具箱SVM and Kernel Methods Matlab Toolbox 2005年法国人写的,最近的更新为20/02/2008 下载的地址为http://asi.insa-rouen.fr/enseignants/~arakotom/toolbox/index.html 这是我最早开始用的一个工具箱,我很喜欢,到现在还是,对于svm的初学者是个很好的toolbox. 有详细的说明和很多的demo和例子, 包含现今几乎所有的有关svm的成熟算法和数据预处理方法(pca及小波等)。 最最重要的是有回归!!! 且函数简单,容易改动延伸。
支持向量机matlab实现源代码知识讲解
支持向量机m a t l a b 实现源代码
edit svmtrain >>edit svmclassify >>edit svmpredict function [svm_struct, svIndex] = svmtrain(training, groupnames, varargin) %SVMTRAIN trains a support vector machine classifier % % SVMStruct = SVMTRAIN(TRAINING,GROUP) trains a support vector machine % classifier using data TRAINING taken from two groups given by GROUP. % SVMStruct contains information about the trained classifier that is % used by SVMCLASSIFY for classification. GROUP is a column vector of % values of the same length as TRAINING that defines two groups. Each % element of GROUP specifies the group the corresponding row of TRAINING % belongs to. GROUP can be a numeric vector, a string array, or a cell % array of strings. SVMTRAIN treats NaNs or empty strings in GROUP as % missing values and ignores the corresponding rows of TRAINING. % % SVMTRAIN(...,'KERNEL_FUNCTION',KFUN) allows you to specify the kernel % function KFUN used to map the training data into kernel space. The % default kernel function is the dot product. KFUN can be one of the % following strings or a function handle: % % 'linear' Linear kernel or dot product % 'quadratic' Quadratic kernel % 'polynomial' Polynomial kernel (default order 3) % 'rbf' Gaussian Radial Basis Function kernel % 'mlp' Multilayer Perceptron kernel (default scale 1) % function A kernel function specified using @, % for example @KFUN, or an anonymous function % % A kernel function must be of the form % % function K = KFUN(U, V) % % The returned value, K, is a matrix of size M-by-N, where U and V have M % and N rows respectively. If KFUN is parameterized, you can use % anonymous functions to capture the problem-dependent parameters. For % example, suppose that your kernel function is % % function k = kfun(u,v,p1,p2) % k = tanh(p1*(u*v')+p2); % % You can set values for p1 and p2 and then use an anonymous function: % @(u,v) kfun(u,v,p1,p2).
matlab四种支持向量机工具箱
matlab四种支持向量机工具箱 [b]使用要点:[/b] 应研学论坛<<人工智能与模式识别>>版主magic_217之约,写一个关于针对初学者的<<四种支持向量机工具箱>>的详细使用说明。同时也不断有网友向我反映看不懂我的源代码,以及询问如何将该工具箱应用到实际数据分析等问题,其中有相当一部分网友并不了解模式识别的基本概念,就急于使用这个工具箱。本文从模式识别的基本概念谈起,过渡到神经网络模式识别,逐步引入到这四种支持向量机工具箱的使用。 本文适合没有模式识别基础,而又急于上手的初学者。作者水平有限,欢迎同行批评指正! [1]模式识别基本概念 模式识别的方法有很多,常用有:贝叶斯决策、神经网络、支持向量机等等。特别说明的是,本文所谈及的模式识别是指“有老师分类”,即事先知道训练样本所属的类别,然后设计分类器,再用该分类器对测试样本进行识别,比较测试样本的实际所属类别与分类器输出的类别,进而统计正确识别率。正确识别率是反映分类器性能的主要指标。 分类器的设计虽然是模式识别重要一环,但是样本的特征提取才是模式识别最关键的环节。试想如果特征矢量不能有效地描述原样本,那么即使分类设计得再好也无法实现正确分类。工程中我们所遇到的样本一般是一维矢量,如:语音信号,或者是二维矩阵,如:图片等。特征提取就是将一维矢量或二维矩阵转化成一个维数比较低的特征矢量,该特征矢量用于分类器的输入。关于特征提取,在各专业领域中也是一个重要的研究方向,如语音信号的谐振峰特征提取,图片的PCA特征提取等等。 [2]神经网络模式识别 神经网络模式识别的基本原理是,神经网络可以任意逼近一个多维输入输出函数。以三类分类:I、II、III为例,神经网络输入是样本的特征矢量,三类样本的神经网络输出可以是[1;0;0]、[0;1;0]、[0;0;1],也可以是[1;-1;-1]、[-1;1;-1]、[-1;-1;1]。将所有样本中一部分用来训练网络,另外一部分用于测试输出。通常情况下,正确分类的第I类样本的测试输出并不是[1;0;0]或是[1;-1;-1],而是如 [0.1;0;-0.2]的输出。也是就说,认为输出矢量中最大的一个分量是1,其它分量是0或是-1就可以了。 [3]支持向量机的多类分类 支持向量机的基本理论是从二类分类问题提出的。我想绝大部分网友仅着重于理解二类分类问题上了,我当初也是这样,认识事物都有一个过程。二类分类的基本原理固然重要,我在这里也不再赘述,很多文章和书籍都有提及。我觉得对于工具箱的使用而言,理解如何实现从二类分类到多类分类的过渡才是最核心的内容。下面我仅以1-a-r算法为例,解释如何由二类分类器构造多类分类器。二类支持向量机分类器的输出为[1,-1],当面对多类情况时,就需要把多类分类器分解成多个二类分类器。在第一种工具箱LS_SVMlab中,文件Classification_LS_SVMlab.m中实现了三类分类。训练与测试样本分别为n1、n2,它们是3 x 15的矩阵,即特征矢量是三维,训练与测试样本数目均是15;由于是三类分类,所以训练与测试目标x1、x2的每一分量可以是1、2或是3,
Matlab8个例子
1、囧 function happynewyear axis off; set(gcf,'menubar','none','toolbar','none'); for k=1:20 h=text(rand,rand,... ['\fontsize{',num2str(unifrnd(20,50)),'}\fontname {隶书} 新年快乐'],... 'color',rand(1,3),'Rotation',360 * rand); pause(0.5) End 2、小猫进洞 function t=cat_in_holl(n) t=zeros(1,n); for k=1:n c=unifdnd(3,1); while c~=1 if c==2 t(k)=t(k)+4; else t(k)=t(k)+6; end c=unifdnd(3,1); end t(k)=t(k)+2; End
3、 Slow function example2_3_6s tic;A=unidrnd(100,10,7); B=zeros(10,3); for m=1:10 a=A(m,:); b=[4,6,8]; for ii=1:3 dd=a(a==b(ii)); if isempty(dd)==0 b(ii)=0; end end B(m,:)=b; toc end A,B Fast function example2_3_6fast2 clear A = unidrnd(100,1000000,7); B = repmat([4,6,8],1000000,1); tic;C = [any(AA == 4,2) any(AA == 6,2) any(AA == 8,2)]; B(C) = 0; Toc 4、随机行走法 function [mx,minf]=randwalk(f,x,lamda,epsilon,N) %随机行走法求函数的极小值。输入f为所求函数的句柄, %x为初始值。lamda为步长。epsilon为控制lamda的减小的阈值,即lamda 减小到epsilon时 %迭代停止。
支持向量机matlab实例及理论_20131201
支持向量机matlab分类实例及理论 线性支持向量机可对线性可分的样本群进行分类,此时不需要借助于核函数就可较为理想地解决问题。非线性支持向量机将低维的非线性分类问题转化为高维的线性分类问题,然后采用线性支持向量机的求解方法求解。此时需要借助于核函数,避免线性分类问题转化为非线性分类问题时出现的维数爆炸难题,从而避免由于维数太多而无法进行求解。 第O层:Matlab的SVM函数求解分类问题实例 0.1 Linear classification %Two Dimension Linear-SVM Problem, Two Class and Separable Situation %Method from Christopher J. C. Burges: %"A Tutorial on Support Vector Machines for Pattern Recognition", page 9 %Optimizing ||W|| directly: % Objective: min "f(A)=||W||" , p8/line26 % Subject to: yi*(xi*W+b)-1>=0, function (12); clear all; close all clc; sp=[3,7; 6,6; 4,6;5,6.5] % positive sample points nsp=size(sp); sn=[1,2; 3,5;7,3;3,4;6,2.7] % negative sample points nsn=size(sn) sd=[sp;sn] lsd=[true true true true false false false false false] Y = nominal(lsd) figure(1); subplot(1,2,1) plot(sp(1:nsp,1),sp(1:nsp,2),'m+'); hold on plot(sn(1:nsn,1),sn(1:nsn,2),'c*'); subplot(1,2,2) svmStruct = svmtrain(sd,Y,'showplot',true);
支持向量机Matlab示例程序
2008-10-31 19:32 支持向量机Matlab示例程序 四种支持向量机用于函数拟合与模式识别的Matlab示例程序 [1]模式识别基本概念 模式识别的方法有很多,常用有:贝叶斯决策、神经网络、支持向量机等等。特别说明的是,本文所谈及的模式识别是指“有老师分类”,即事先知道训练样本所属的类别,然后设计分类器,再用该分类器对测试样本进行识别,比较测试样本的实际所属类别与分类器输出的类别,进而统计正确识别率。正确识别率是反映分类器性能的主要指标。 分类器的设计虽然是模式识别重要一环,但是样本的特征提取才是模式识别最关键的环节。试想如果特征矢量不能有效地描述原样本,那么即使分类设计得再好也无法实现正确分类。工程中我们所遇到的样本一般是一维矢量,如:语音信号,或者是二维矩阵,如:图片等。特征提取就是将一维矢量或二维矩阵转化成一个维数比较低的特征矢量,该特征矢量用于分类器的输入。关于特征提取,在各专业领域中也是一个重要的研究方向,如语音信号的谐振峰特征提取,图片的PCA特征提取等等。 [2]神经网络模式识别 神经网络模式识别的基本原理是,神经网络可以任意逼近一个多维输入输出函数。以三类分类:I、II、III为例,神经网络输入是样本的特征矢量,三类样本的神经网络输出可以是[1;0;0]、[0;1;0]、[0;0;1],也可以是[1;-1;-1]、[-1;1;-1]、[-1;-1;1]。将所有样本中一部分用来训练网络,另外一部分用于测试输出。通常情况下,正确分类的第I类样本的测试输出并不是[1;0;0]或是[1;-1;-1],而是如[;0;]的输出。也是就说,认为输出矢量中最大的一个分量是1,其它分量是0或是-1就可以了。 [3]支持向量机的多类分类 支持向量机的基本理论是从二类分类问题提出的。我想绝大部分网友仅着重于理解二类分类问题上了,我当初也是这样,认识事物都有一个过程。二类分类的基本原理固然重要,我在这里也不再赘述,很多文章和书籍都有提及。我觉得对于工具箱的使用而言,理解如何实现从二类分类到多类分类的过渡才是最核心的内容。下面我仅以1-a-r算法为例,解释如何由二类分类器构造多类分类器。 二类支持向量机分类器的输出为[1,-1],当面对多类情况时,就需要把多类分类器分解成多个二类分类器。在第一种工具箱LS_SVMlab中,文件中实现了三类分类。训练与测试样本分别为n1、n2,它们是3 x 15的矩阵,即特征矢量是三维,训练与测试样本数目均是15;由于是三类分类,所以训练与测试目标x1、x2的每一分量可以是1、2或是3,分别对应三类,如下所示: n1 = [rand(3,5),rand(3,5)+1,rand(3,5)+2]; x1 = [1*ones(1,5),2*ones(1,5),3*ones(1,5)];???? n2 = [rand(3,5),rand(3,5)+1,rand(3,5)+2]; x2 = [1*ones(1,5),2*ones(1,5),3*ones(1,5)];???? 1-a-r算法定义:对于N类问题,构造N个两类分类器,第i个分类器用第i类训练样本作为正的训练样本,将其它类的训练样本作为负的训练样本,此时分类器的判决函数不取符号函数sign,最后的输出是N个两类分类器输出中最大的那一类。
支持向量机(SVM)原理及应用概述分析
支持向量机(SVM )原理及应用 一、SVM 的产生与发展 自1995年Vapnik (瓦普尼克)在统计学习理论的基础上提出SVM 作为模式识别的新方法之后,SVM 一直倍受关注。同年,Vapnik 和Cortes 提出软间隔(soft margin)SVM ,通过引进松弛变量i ξ度量数据i x 的误分类(分类出现错误时i ξ大于0),同时在目标函数中增加一个分量用来惩罚非零松弛变量(即代价函数),SVM 的寻优过程即是大的分隔间距和小的误差补偿之间的平衡过程;1996年,Vapnik 等人又提出支持向量回归 (Support Vector Regression ,SVR)的方法用于解决拟合问题。SVR 同SVM 的出发点都是寻找最优超平面(注:一维空间为点;二维空间为线;三维空间为面;高维空间为超平面。),但SVR 的目的不是找到两种数据的分割平面,而是找到能准确预测数据分布的平面,两者最终都转换为最优化问题的求解;1998年,Weston 等人根据SVM 原理提出了用于解决多类分类的SVM 方法(Multi-Class Support Vector Machines ,Multi-SVM),通过将多类分类转化成二类分类,将SVM 应用于多分类问题的判断:此外,在SVM 算法的基本框架下,研究者针对不同的方面提出了很多相关的改进算法。例如,Suykens 提出的最小二乘支持向量机 (Least Square Support Vector Machine ,LS —SVM)算法,Joachims 等人提出的SVM-1ight ,张学工提出的中心支持向量机 (Central Support Vector Machine ,CSVM),Scholkoph 和Smola 基于二次规划提出的v-SVM 等。此后,台湾大学林智仁(Lin Chih-Jen)教授等对SVM 的典型应用进行总结,并设计开发出较为完善的SVM 工具包,也就是LIBSVM(A Library for Support Vector Machines)。LIBSVM 是一个通用的SVM 软件包,可以解决分类、回归以及分布估计等问题。 二、支持向量机原理 SVM 方法是20世纪90年代初Vapnik 等人根据统计学习理论提出的一种新的机器学习方法,它以结构风险最小化原则为理论基础,通过适当地选择函数子集及该子集中的判别函数,使学习机器的实际风险达到最小,保证了通过有限训练样本得到的小误差分类器,对独立测试集的测试误差仍然较小。 支持向量机的基本思想:首先,在线性可分情况下,在原空间寻找两类样本的最优分类超平面。在线性不可分的情况下,加入了松弛变量进行分析,通过使用非线性映射将低维输
支持向量机Matlab示例程序
支持向量机M a t l a b示 例程序 Document serial number【KK89K-LLS98YT-SS8CB-SSUT-SST108】
2008-10-3119:32支持向量机Matlab示例程序 四种支持向量机用于函数拟合与模式识别的Matlab示例程序 [1]模式识别基本概念 模式识别的方法有很多,常用有:贝叶斯决策、神经网络、支持向量机等等。特别说明的是,本文所谈及的模式识别是指“有老师分类”,即事先知道训练样本所属的类别,然后设计分类器,再用该分类器对测试样本进行识别,比较测试样本的实际所属类别与分类器输出的类别,进而统计正确识别率。正确识别率是反映分类器性能的主要指标。 分类器的设计虽然是模式识别重要一环,但是样本的特征提取才是模式识别最关键的环节。试想如果特征矢量不能有效地描述原样本,那么即使分类设计得再好也无法实现正确分类。工程中我们所遇到的样本一般是一维矢量,如:语音信号,或者是二维矩阵,如:图片等。特征提取就是将一维矢量或二维矩阵转化成一个维数比较低的特征矢量,该特征矢量用于分类器的输入。关于特征提取,在各专业领域中也是一个重要的研究方向,如语音信号的谐振峰特征提取,图片的PCA特征提取等等。 [2]神经网络模式识别 神经网络模式识别的基本原理是,神经网络可以任意逼近一个多维输入输出函数。以三类分类:I、II、III为例,神经网络输入是样本的特征矢量,三类样本的神经网络输出可以是[1;0;0]、[0;1;0]、[0;0;1],也可以是[1;-1;-1]、[-1;1;-1]、[-1;-1;1]。将所有样本中一部分用来训练网络,另外一部分用于测试输出。通常情况下,正确分类的第I类样本的测试输出并不是[1;0;0]或是[1;-1;-1],而是如[0.1;0;-0.2]的输出。也是就说,认为输出矢量中最大的一个分量是1,其它分量是0或是-1就可以了。 [3]支持向量机的多类分类 支持向量机的基本理论是从二类分类问题提出的。我想绝大部分网友仅着重于理解二类分类问题上了,我当初也是这样,认识事物都有一个过程。二类分类的基本原理固然重要,我在这里也不再赘述,很多文章和书籍都有提及。我觉得对于工具箱的使用而言,理解如何实现从二类分类到多类分类的过渡才是最核心的内容。下面我仅以1-a-r算法为例,解释如何由二类分类器构造多类分类器。 二类支持向量机分类器的输出为[1,-1],当面对多类情况时,就需要把多类分类器分解成多个二类分类器。在第一种工具箱LS_SVMlab中,文件Classification_LS_SVMlab.m中实现了三类分类。训练与测试样本分别为n1、n2,它们是3x15的矩阵,即特征矢量是三维,训练与测试样本数目均是15;由于是三类分类,所以训练与测试目标x1、x2的每一分量可以是1、2或是3,分别对应三类,如下所示: n1=[rand(3,5),rand(3,5)+1,rand(3,5)+2]; x1=[1*ones(1,5),2*ones(1,5),3*ones(1,5)]; n2=[rand(3,5),rand(3,5)+1,rand(3,5)+2]; x2=[1*ones(1,5),2*ones(1,5),3*ones(1,5)]; 1-a-r算法定义:对于N类问题,构造N个两类分类器,第i个分类器用第i类训练样本作为正的训练样本,将其它类的训练样本作为负的训练样本,此时分类器的判决函数不取符号函数sign,最后的输出是N个两类分类器输出中最大的那一类。 在文件Classification_LS_SVMlab.m的第42行:codefct='code_MOC',就是设置由二类到多类编码参数。当第42行改写成codefct='code_OneVsAll',再去掉第53行最后的引号,按F5运行该文件,命令窗口输出有:codebook= 1-1-1 -11-1 -1-11 old_codebook= 123 比较上面的old_codebook与codebook输出,注意到对于第i类,将每i类训练样本做为正的训练样本,其它的训练样本作为负的训练样本,这就是1-a-r算法定义。这样通过设置codefct='code_OneVsAll'就实现了支持向量机的1-a-r多类算法。其它多类算法也与之雷同,这里不再赘述。值得注意的是:对于同一组样本,不同的编码方案得到的训练效果不尽相同,实际中应结合实际数据,选择训练效果最好的编码方案。 [4]核函数及参数选择 常用的核函数有:多项式、径向基、Sigmoid型。对于同一组数据选择不同的核函数,基本上都可以得到相近的
MATLAB-智能算法30个案例分析-终极版(带目录)
MATLAB 智能算法30 个案例分析(终极版)1基于遗传算法的TSP算法(王辉) 2 基于遗传算法和非线性规划的函数寻优算法(史峰) 3基于遗传算法的BP神经网络优化算法(王辉) 4设菲尔德大学的MATLAB遗传算法工具箱(王辉) 5基于遗传算法的LQR空制优化算法(胡斐) 6 遗传算法工具箱详解及应用(胡斐) 7 多种群遗传算法的函数优化算法(王辉) 8 基于量子遗传算法的函数寻优算法(王辉) 9多目标ParetO最优解搜索算法(胡斐) 10基于多目标ParetO的二维背包搜索算法(史峰) 11 基于免疫算法的柔性车间调度算法(史峰) 12 基于免疫算法的运输中心规划算法(史峰) 13 基于粒子群算法的函数寻优算法(史峰) 14 基于粒子群算法的PID 空制优化算法(史峰) 15基于混合粒子群算法的TSP寻优算法(史峰) 16 基于动态粒子群算法的动态环境寻优算法(史峰) 17 粒子群算法工具箱(史峰) 18 基于鱼群算法的函数寻优算法(王辉) 佃基于模拟退火算法的TSP算法(王辉) 20 基于遗传模拟退火算法的聚类算法(王辉) 21基于模拟退火算法的HEV能量管理策略参数优化(胡斐)
22蚁群算法的优化计算一一旅行商问题(TSP优化(郁磊) 23 基于蚁群算法的二维路径规划算法(史峰) 24 基于蚁群算法的三维路径规划算法(史峰) 25 有导师学习神经网络的回归拟合——基于近红外光谱的汽油辛烷值预测(郁磊) 26 有导师学习神经网络的分类——鸢尾花种类识别(郁磊) 27 无导师学习神经网络的分类——矿井突水水源判别(郁磊) 28 支持向量机的分类——基于乳腺组织电阻抗特性的乳腺癌诊断 (郁磊) 29 支持向量机的回归拟合——混凝土抗压强度预测(郁磊) 30 极限学习机的回归拟合及分类——对比实验研究(郁磊) 智能算法是我们在学习中经常遇到的算法,主要包括遗传算法,免疫算法,粒子群算法,神经网络等,智能算法对于很多人来说,既爱又恨,爱是因为熟练的掌握几种智能算法,能够很方便的解决我们的论坛问题,恨是因为智能算法感觉比较“玄乎” ,很难理解,更难用它来解决问题。 因此,我们组织了王辉,史峰,郁磊,胡斐四名高手共同写作 MATLAB智能算法,该书包含了遗传算法,免疫算法,粒子群算法,鱼群算法,多目标pareto 算法,模拟退火算法,蚁群算法,神经网络,SVM 等,本书最大的特点在于以案例为导向,每个案例针对一个实际问题,给出