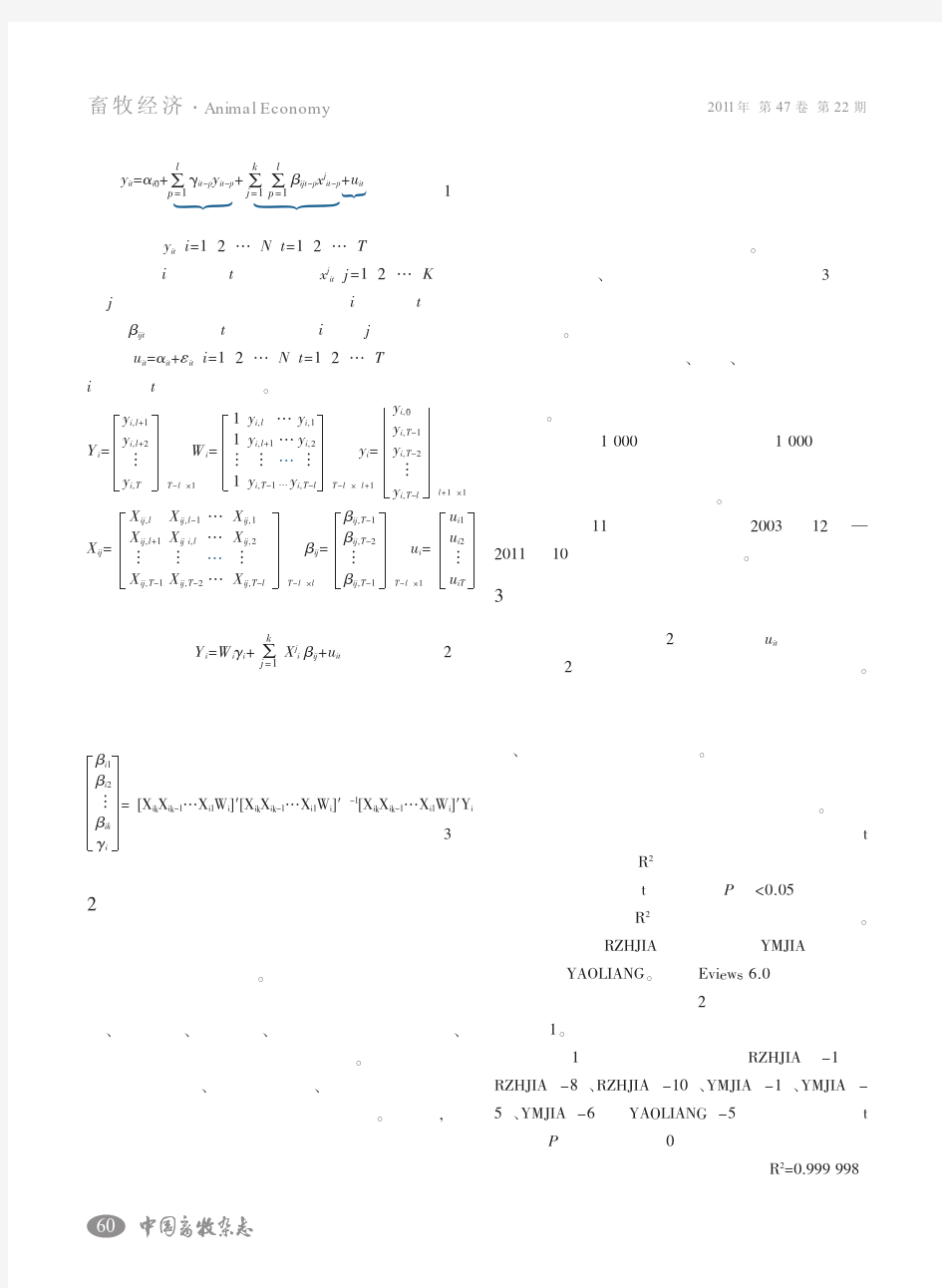
基于面板数据模型的生猪价格风险评估及预测研究_黄靖贵

MATLAB空间面板数据模型操作介绍
MATLAB空间面板数据模型操作简介 MATLAB安装:在民主湖资源站上下载MA TLAB 2009a,或者2010a,按照其中的安装说明安装MATLAB。(MATLAB较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局: 首先我们说一下MA TLAB处理空间面板数据时,数据文件是怎么布局的,熟悉eviews的同学可能知道,eviews中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中“1-94”“1-95”“1-96”“1-97”中,1是省份的代号,94,95,96,97表示年份,eviews是将每个省份的数据放在一起,再将所有省份堆放在一起。 与eviews不同,MATLAB处理空间面板数据时,面板数据的布局是(在excel中说明):先排放一个横截面上的数据(即某年所有省份的数据),再将不同年份的横截面按时间顺序堆放在一起。如图:
这里需要说明的是,MA TLAB中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。 二、数据的输入: MATLAB与excel链接:在excel中点击“工具→加载宏→浏览”,找到MA TLAB的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为:C:\Programfiles\MATLAB\R2009a\toolbox\exlink,点击excllink.xla即可完成excel与MATLAB的链接。这样的话excel中的数据就可以直接导入MATLAB中形成MATLAB的数据文件。操作完成后excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB”即表示我们希望excel 与MATLAB实现链
第9章-面板数据模型理论
5.2 面板数据模型理论 5.2.1 面板数据模型及类型。 面板数据(panel data )也称时间序列截面数据(time series and cross section data )或混合数据(pool data )。面板数据是同时在时间和截面空间上取得的二维数据。面板数据从横截面(cross section )上看,是由若干个体(entity, unit, individual )在某一时刻构成的截面观测值,从纵剖面(longitudinal section )上看是一个时间序列。 面板数据用双下标变量表示。例如: it y , N i ,,2,1 ;T t ,,2,1 其中,N 表示面板数据中含有的个体数。T 表示时间序列的时期数。若固定t 不变,?i y ),,2,1(N i 是横截面上的N 个随机变量;若固定i 不变,t y ?,),,2,1(T t 是纵剖面 上的一个时间序列。对于面板数据来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data )。若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data )。 面板数据模型是建立在面板数据之上、用于分析变量之间相互关系的计量经济模型。面板数据模型的解析表达式为: it it it it it x y T j N i ,2,1;,2,1 其中,it y 为被解释变量;it 表示截距项,),,,(21k it it it it x x x x 为k 1维解释变量向量;' 21),,,(k it it it it 为1 k 维参数向量;i 表示不同的个体;t 表示不同的时间;it 为 随机扰动项,满足经典计量经济模型的基本假设),0(~2 IIDN it 。 面板数据模型通常分为三类。即混合模型、固定效应模型和随机效应模型。 ⑴ 混合模型。 如果一个面板数据模型定义为: it it it x y T j N i ,2,1;,2,1 则称此模型为混合模型。混合模型的特点是无论对任何个体和截面,回归系数 和 都是相同的 ⑵ 固定效应模型。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model )、时间固定效应模型(time fixed effects regression model )和时间个体固定效应模型(time and entity fixed effects regression model )。 ① 个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序
信息系统安全风险的概念模型和评估模型
信息系统安全风险的概念模型和评估模型 叶志勇 摘要:本文阐述了信息系统安全风险的概念模型和评估模型,旨在为风险评估工作提供理论指导,使风险评估的过程和结果具有逻辑性和系统性,从而提高风险评估的质量和效果。风险的概念模型指出,风险由起源、方式、途径、受体和后果五个方面构成,分别是威胁源、威胁行为、脆弱性、资产和影响。风险的评估模型要求,首先评估构成风险的五个方面,即威胁源的动机、威胁行为的能力、脆弱性的被利用性、资产的价值和影响的程度,然后综合这五方面的评估结果,最后得出风险的级别。 关键词:安全风险、安全事件、风险评估、威胁、脆弱性、资产、信息、信息系统。 一个机构要利用其拥有的资产来完成其使命。因此,资产的安全是关系到该机构能否完成其使命的大事。在信息时代,信息成为第一战略资源,更是起着至关重要的作用。信息资产包括信息自身和信息系统。本文提到的资产可以泛指各种形态的资产,但主要针对信息资产及其相关资产。 资产与风险是天生的一对矛盾,资产价值越高,面临的风险就越大。风险管理就是要缓解这一对矛盾,将风险降低的可接受的程度,达到保护资产的目的,最终保障机构能够顺利完成其使命。风险管理包括三个过程:风险评估、风险减缓和评价与评估。风险评估是风险管理的第一步。本文对风险的概念模型和评估模型进行了研究,旨在为风险评估工作提供理论指导,使风险评估的过程和结果具有逻辑性和系统性,从而提高风险评估的质量和效果。 一、风险的概念模型 安全风险(以下简称风险)是一种潜在的、负面的东西,处于未发生的状态。与之相对应,安全事件(以下简称事件)是一种显在的、负面的东西,处于已发生的状态。风险是事件产生的前提,事件是在一定条件下由风险演变而来的。图1给出了风险与事件之间的关系。 图1 风险与事件之间的关系 风险的构成包括五个方面:起源、方式、途径、受体和后果。它们的相互关系可表述为:风险的一个或多个起源,采用一种或多种方式,通过一种或多种途径,侵害一个或多个受体,造成不良后果。它们各自的内涵解释如下: ? 风险的起源是威胁的发起方,叫做威胁源。 ? 风险的方式是威胁源实施威胁所采取的手段,叫做威胁行为。 ? 风险的途径是威胁源实施威胁所利用的薄弱环节,叫做脆弱性或漏洞。 ? 风险的受体是威胁的承受方,即资产。 ? 风险的后果是威胁源实施威胁所造成的损失,叫做影响。 图2描绘了风险的概念模型,可表述为:威胁源利用脆弱性,对资产实施威胁行为,造成影响。其中的虚线表示威胁行为和影响是潜在的,虽处于未发生状态,但具有发生的可能性。 潜在 (未发生状态) 显在 (已发生状态)
eviews面板数据实例分析
1、已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp,不变价格)与人均收入(ip,不变价格)居民,利用数据(1)建立面板数据(panel data)工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。 年人均消费(consume)与人均收入(income)数据以及消费者价格指数(p)分别见表9、1,9、2与9、3。 表9、1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据人均消费1996 1997 1998 1999 2000 2001 2002 CONSUMEAH 3607、43 3693、55 3777、41 3901、81 4232、98 4517、65 4736、52 CONSUMEBJ 5729、52 6531、81 6970、83 7498、48 8493、49 8922、72 10284、6 CONSUMEFJ 4248、47 4935、95 5181、45 5266、69 5638、74 6015、11 6631、68 CONSUMEHB 3424、35 4003、71 3834、43 4026、3 4348、47 4479、75 5069、28 CONSUMEHLJ 3110、92 3213、42 3303、15 3481、74 3824、44 4192、36 4462、08 CONSUMEJL 3037、32 3408、03 3449、74 3661、68 4020、87 4337、22 4973、88 CONSUMEJS 4057、5 4533、57 4889、43 5010、91 5323、18 5532、74 6042、6 CONSUMEJX 2942、11 3199、61 3266、81 3482、33 3623、56 3894、51 4549、32 CONSUMELN 3493、02 3719、91 3890、74 3989、93 4356、06 4654、42 5342、64 CONSUMENMG 2767、84 3032、3 3105、74 3468、99 3927、75 4195、62 4859、88 CONSUMESD 3770、99 4040、63 4143、96 4515、05 5022 5252、41 5596、32 CONSUMESH 6763、12 6819、94 6866、41 8247、69 8868、19 9336、1 10464 CONSUMESX 3035、59 3228、71 3267、7 3492、98 3941、87 4123、01 4710、96 CONSUMETJ 4679、61 5204、15 5471、01 5851、53 6121、04 6987、22 7191、96 CONSUMEZJ 5764、27 6170、14 6217、93 6521、54 7020、22 7952、39 8713、08 表9、2 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均收入(元)数据人均收入1996 1997 1998 1999 2000 2001 2002 INCOMEAH 4512、77 4599、27 4770、47 5064、6 5293、55 5668、8 6032、4 INCOMEBJ 7332、01 7813、16 8471、98 9182、76 10349、69 11577、78 12463、92 INCOMEFJ 5172、93 6143、64 6485、63 6859、81 7432、26 8313、08 9189、36 INCOMEHB 4442、81 4958、67 5084、64 5365、03 5661、16 5984、82 6679、68 INCOMEHLJ 3768、31 4090、72 4268、5 4595、14 4912、88 5425、87 6100、56 INCOMEJL 3805、53 4190、58 4206、64 4480、01 4810 5340、46 6260、16 INCOMEJS 5185、79 5765、2 6017、85 6538、2 6800、23 7375、1 8177、64 INCOMEJX 3780、2 4071、32 4251、42 4720、58 5103、58 5506、02 6335、64 INCOMELN 4207、23 4518、1 4617、24 4898、61 5357、79 5797、01 6524、52 INCOMENMG 3431、81 3944、67 4353、02 4770、53 5129、05 5535、89 6051 INCOMESD 4890、28 5190、79 5380、08 5808、96 6489、97 7101、08 7614、36 INCOMESH 8178、48 8438、89 8773、1 10931、64 11718、01 12883、46 13249、8 INCOMESX 3702、69 3989、92 4098、73 4342、61 4724、11 5391、05 6234、36 INCOMETJ 5967、71 6608、39 7110、54 7649、83 8140、5 8958、7 9337、56 INCOMEZJ 6955、79 7358、72 7836、76 8427、95 9279、16 10464、67 11715、6 表9、3 1996—2002年中国东北、华北、华东15个省级地区的消费者物价指数物价指数1996 1997 1998 1999 2000 2001 2002 PAH 109、9 101、3 100 97、8 100、7 100、5 99
企业信用风险评估模型分析
企业信用风险评估模型 企业信用风险评估是构建社会信用体系的重要构成要素,也是企业信用风险管理的 核心环节。企业信用风险评估涉及四个基本的概念,即信用、信用风险、信用风险管理以及信用风险评估。本节重点为厘清基本概念,并介绍相关企业信用风险评估操作。 I —、企业信用风险评估概念 企业信用风险评估是对企业信用情况进行综合评定的过程,是利用各种评估方法,分析受评企业信用关系中的履约趋势、偿债能力、信用状况、可信程度并进行公正审查和评估的活动。 信用风险评估具体内容包括在收集企业历史样本数据的基础之上,运用数理统计方法与各种数学建模方法构建统计模型与数学模型,从而对信用主体的信用风险大小进行量化测度。 I 二、企业信用风险评估模型构建 (一)信用分析瘼型概述 — 在信用风险评估过程中所使用的工具——信用分析模型可以分为两类,预测性模型和管理性模型。预测性模型用于预测客户前景,衡量客户破产的可能性;管理性模型不具有预测性,它偏重于均衡地揭示和理解客户信息,从而衡量客户实力。 计分模型 Altman的Z计分模型是建立在单变量度量指标的比率水平和绝对水平基础上的多变量模型。这个模型能够较好地区分破产企业和非破产企业。在评级的对象濒临破产时,Z 计分模型就会呈现出这些企业与基础良好企业的不同财务比率和财务趋势。 2.巴萨利模型
巴萨利模型(Bathory模型)是以其发明者Alexander Bathory的名字命名的客户资信分析模型。此模型适用于所有的行业,不需要复杂的计算。其主要的比率为税前利润/营运资本、股东权益/流动负债、有形资产净值/负债总额、营运资本/总资产。 Z计分模型和巴萨利模型均属于预测性模型。 3.营运资产分析模型 营运资产分析模型同巴萨利模型一样具有多种功能,其所需要的资料可以从一般的财务报表中直接取得。营运资产分析模型的分析过程分为两个基本的阶段:第一阶段是计算营运资产(working worth);第二阶段是资产负债表比率的计算。从评估值的计算公式中可以看出,营运资产分析模型流动比率越高越好,而资本结构比率越低越好。 《 营运资产分析模型是管理性模型,与预测性模型不同,它着重于流动性与资本结构比率的分析。由于净资产值中包含留存收益,因而营运资产分析可以反映企业的业绩。 □第三章企业征信业务 又因为该模型不需要精确的业绩资料,可以有效地适用于调整后的账目。通过营运资产和资产负债表比率的计算,确定了衡量企业规模大小的标准,并对资产负债表的评估方法进行了考察,可以确定适当的信用限额。 4.特征分析模型 特征分析模型采用特征分析技术对客户所有财务和非财务因素进行归纳分析;从客户的种种特征中选择出对信用分析意义最大、直接与客户信用状况相联系的若干特征,把它们编为几组,分别对这些因素评分并综合分析,最后得到一个较为全面的分析结果。 (二)企业信用风险评估模型构建① 1.预测性风险模型构建——Z计分模型
Eviews面板大数据之固定效应模型
Eviews 面板数据之固定效应模型 在面板数据线性回归模型中,如果对于不同的截面或不同的时间序列,只是模型的截距项是不同的,而模型的斜率系数是相同的,则称此模型为固定效应模型。固定效应模型分为三类: 1.个体固定效应模型 个体固定效应模型是对于不同的纵剖面时间序列(个体)只有截距项不同的模型: 2 K it i k kit it k y x u λβ==++∑ (1) 从时间和个体上看,面板数据回归模型的解释变量对被解释变量的边际影响均是相同的,而且除模型的解释变量之外,影响被解释变量的其他所有(未包括在回归模型或不可观测的)确定性变量的效应只是随个体变化而不随时间变化时。 检验:采用无约束模型和有约束模型的回归残差平方和之比构造F 统计量,以检验设定个体固定效应模型的合理性。F 模型的零假设: 01231:0N H λλλλ-===???== ()1 (1,(1)1)(1) RRSS URSS N F F N N T K URSS NT N K --= ---+--+ RRSS 是有约束模型(即混合数据回归模型)的残差平方和,URSS 是无约束模型ANCOVA 估计的残差平方和或者LSDV 估计的残差平方和。 实践: 一、数据:已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp ,不变价格)和人均收入(ip ,不变价格)居民,利用数据(1)建立面板数据(panel data )工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。年人均消费(consume )和人均收入(income )数据以及消费者价格指数(p )分别见表1,2和3。 表1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据
MATLAB空间面板数据模型操作介绍
MATLAB 空间面板数据模型操作简介 MATLAB 安装: 在民主湖资源站上下载 MA TLAB 2009a ,或者 2010a ,按照其中的安装说明 安装 MATLAB 。( MATLAB 较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局 首先我们说一下 MA TLAB 处理空间面板数据时,数据文件是怎么布局的,熟悉 eviews 的同学 可能知道, eviews 中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间 序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中 “1-94”“1-95” “1-96” “ 1-97”中, 1是省份的代号, 94,95,96,97 表示年份, eviews 是将每个省 份的数据放在一起,再将所有省份堆放在一起。 与 eviews 不同, MATLAB 处理空间面板数据时,面板数据的布局是(在 excel 中说明): 先排 放一个横截面上的数据(即某年所有省份的数据) ,再将不同年份的横截面按时间顺序堆放在一起。 如图:
这里需要说明的是, MA TLAB 中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。二、数据的输入: MATLAB 与 excel链接:在 excel中点击“工具→加载宏→浏览” ,找到 MA TLAB 的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为: C:\Programfiles\MATLAB\R2009a\toolbox\exlink ,点击 excllink.xla 即可完成 excel 与 MATLAB 的链接。这样的话 excel 中的数据就可以直接导入 MATLAB 中形成 MATLAB 的数据文件。操作完成后 excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB ”即表示我们希望 excel 与
EViews面板数据模型估计教程
EViews 6.0 beta在面板数据模型估计中的应用 来自免费的minixi 1、进入工作目录cd d:\nklx3,在指定的路径下工作是一个良好的习惯 2、建立面板数据工作文件workfile (1)最好不要选择EViews默认的blanaced panel 类型 Moren_panel (2)按照要求建立简单的满足时期周期和长度要求的时期型工作文件
3、建立pool对象 (1)新建对象 (2)选择新建对象类型并命名 (3)为新建pool对象设置截面单元的表示名称,在此提示下(Cross Section Identifiers: (Enter identifiers below this line )输入截面单元名称。,建议采用汉语拼音,例如29个省市区的汉语拼音,建议在拼音名前加一个下划线“_”,如图
关闭建立的pool对象,它就出现在当前工作文件中。 4、在pool对象中建立面板数据序列 双击pool对象,打开pool对象窗口,在菜单view的下拉项中选择spreedsheet (展开表) 在打开的序列列表窗口中输入你要建立的序列名称,如果是面板数据序列必须在序列名后添加“?”。例如,输入GDP?,在GDP后的?的作用是各个截面单元的占位符,生成了29个省市区的GDP的序列名,即GDP后接截面单元名,再在接时期,就表示出面板数据的3维数据结构(1变量2截面单元3时期)了。
请看工作文件窗口中的序列名。展开表(类似excel)中等待你输入、贴入数据。 (1)打开编辑(edit)窗口
(2)贴入数据 (3)关闭pool窗口,赶快存盘见好就收6、在pool窗口对各个序列进行单位根检验 选择单位根检验 设置单位根检验
安全风险评估模型
4.2安全风险评估模型 4.2.1建立安全风险评价模型和评价等级 ⑴建立原则 参考安全系统工程学中的“5M”模型和“SHELL”模型。由于影响危化行业安全风险的因素是一个涉及多方面的因素集,且诸多指标之间各有隶属关系,从而形成了一个有机的、多层次的系统。因此,一般称评价指标为指标体系,建立一套科学、有效、准确的指标体系是安全风险评价的关键性一环。指标体系的建立应遵循以下基本原则[]:①目标性原则;②适当性原则;③可操作性原则;④独立性原则。由此辨识出危化安全风险评价的基本要素,并分析、确定其相互隶属关系,从而建立合理的安全风险评价指标体系[]。 ⑵安全风险指标体系 以厂房安全风险综合评价体系为例,如下图所示。
厂房安全风险综合评价体系A 危害因素A 1 被动措施A 2 主动措施A 3 安全管理A 4 事故处理能力A 5 物质危险性A 11 物质数量A 12 生产过程A 13 存放方式A 14 厂房层数A 15 使用年限A 16 耐火等级A 21 防火间距A 22 安全疏散A 23 防爆设计A 24 自动报警及安全联动控制系统A 31 通风与防排烟系统A 32 室内安全防护系统A 33 其他安全措施A 34 安全责任制A 41 应急预案A 42 安全培训A 43 安全检查A 44 安全措施维护A 45 安全通道A 51 安全人员战斗力A 52 图4.1 厂房安全风险评价指标体系 ⑶建立指标评价尺度和系统评价等级 经过研究和分析,并依据相关法规、标准,给出如下指标评价尺度和系统评价等级,如表4-1和表4-2所示。 各指标的定性评价 好 较好 中等 较差 差 各指标的对应等级 E 1 E 2 E 3 E 4 E 5 各指标对应的分数 5 4 3 2 1 系统安全分区间 [4.5,5] [3.5,4.5] (2.5,3.5) (1.5,2.5) [1,1.5] 各指标对应的分数 5 4 3 2 1 设最低层评价指标C i 的得分为P Ci ,其累积权重为W Ci ,则系统安全分S.V.为: ∑=?=1 ..i C C i i W P V S (4-1) 4.2.2利用AHP 确定指标权重 在调查分析研究的基础上,采用对不同因素两两比较的方法,即表3-1的1~9标度法,构造不同层次的判断矩阵。然后,求解出个评价指标的相对权重及累积权重。对判断矩阵的计
空间面板数据分析——R的splm包资料
空间面板数据分析——R的splm包 (任建辉,暨南大学) The splm package provides methods for fitting spatial panel data by maximum likelihood and GM. 安装R软件及其编辑器Rstudio 网址:https://www.360docs.net/doc/b04317050.html, https://www.360docs.net/doc/b04317050.html,/ 下载好Rstudio以后,操作都可以Rstudio中完成了,包括命令的编写、命令运行、图形展示,最方便的要数查看数据了。 R界面 Rstudio界面,形如matlab
下面进入正题,了解splm包中的数据、命令及结果展示。所有命令都写在编辑窗口(studio 左上区域),可以单独的运行每行命令,也可选取一段一起执行,点run按钮。 1、首先,安装splm包并导入,命令如下: intall.packages(“splm”),选择最近的下载点 library(splm) > library(splm) 载入需要的程辑包:MASS 载入需要的程辑包:nlme 载入需要的程辑包:spdep 载入需要的程辑包:sp 载入需要的程辑包:Matrix 载入需要的程辑包:plm 载入需要的程辑包:bdsmatrix 载入程辑包:‘bdsmatrix’ 下列对象被屏蔽了from ‘package:base’: backsolve 载入需要的程辑包:Formula 载入需要的程辑包:sandwich 载入需要的程辑包:zoo 载入程辑包:‘zoo’ 下列对象被屏蔽了from ‘package:base’: as.Date, as.Date.numeric 载入需要的程辑包:spam 载入需要的程辑包:grid Spam version 0.40-0 (2013-09-11) is loaded. Type 'help( Spam)' or 'demo( spam)' for a short introduction and overview of this package. Help for individual functions is also obtained by adding the suffix '.spam' to the function name, e.g. 'help( chol.spam)'. 载入程辑包:‘spam’ 下列对象被屏蔽了from ‘package:bdsmatrix’:
几种信息安全评估模型知识讲解
1基于安全相似域的风险评估模型 本文从评估实体安全属性的相似性出发,提出安全相似域的概念,并在此基础上建立起一种网络风险评估模型SSD-REM 风险评估模型主要分为评估操作模型和风险分析模型。评估操作模型着重为评估过程建立模型,以指导评估的操作规程,安全评估机构通常都有自己的操作模型以增强评估的可实施性和一致性。风险分析模型可概括为两大类:面向入侵的模型和面向对象的模型。 面向入侵的风险分析模型受技术和规模方面的影响较大,不易规范,但操作性强。面向对象的分析模型规范性强,有利于持续评估的执行,但文档管理工作较多,不便于中小企业的执行。针对上述问题,本文从主机安全特征的相似性及网络主体安全的相关性视角出发,提出基于安全相似域的网络风险评估模型SSD-REM(security-similar-domain based riskevaluation model)。该模型将粗粒度与细粒度评估相结合,既注重宏观上的把握,又不失对网络实体安全状况的个别考察,有助于安全管理员发现保护的重点,提高安全保护策略的针对性和有效性。 SSD-REM模型 SSD-REM模型将静态评估与动态评估相结合,考虑到影响系统安全的三个主要因素,较全面地考察了系统的安全。 定义1评估对象。从风险评估的视角出发, 评估对象是信息系统中信息载体的集合。根据抽象层次的不同,评估对象可分为评估实体、安全相似域和评估网络。 定义2独立风险值。独立风险值是在不考虑评估对象之间相互影响的情形下,对某对象进行评定所得出的风险,记为RS。 定义3综合风险值。综合风险值是在考虑同其发生关联的对象对其安全影响的情况下,对某对象进行评定所得出的风险,记为RI。 独立域风险是在不考虑各评估实体安全关联的情况下,所得相似域的风险。独立网络风险是在不考虑外界威胁及各相似域之间安全关联的情况下,所得的网络风险 评估实体是评估网络的基本组成元素,通常立的主机、服务器等。我们以下面的向量来描述{ID,Ai,RS,RI,P,μ} 式中ID是评估实体标识;Ai为安全相似识;RS为该实体的独立风险值;RI为该实体合风险值;P为该实体的信息保护等级,即信产的重要性度量;属性μ为该实体对其所属的域的隶属
风险评估模型
风险审计预估要素确定(底稿) 第315号国际审计准则(IsA315)要求从六方面了解被审计单位及其环境: (1)行业状况、监管环境以及其他外部因素; (2)被审计单位的性质; (3)被审计单位对会计政策的选择和运用: (4)被审计单位的目标、战略以及相关经营风险; (5)被审计单位财务业绩的衡量和评价; (6)内部控制 ISA315将被审计单位的战略以及相关经营风险与其他五个需要考虑的因素并列,对重大错报风险的分解过于粗略,实务中难以实篇。我国学者汪国平认为:重大错报风险应从宏观经济因素、行业因素、微观因素三方面分解,微观因素包括:法人治理结构、持续经营能力、可能使管理层舞弊的因素、内部控制制度、战略规划、财务状况六个因素,这样的划分,较为全面概括了重大错报风险的影响因素。 风险评估审计:审计风险--------> 道德风险*1+固有风险*β(式1)-------> 重大*1+非重大*α(式2) 1.道德风险(不可控制风险) 包括:可能使管理层舞弊的因素,管理层或股东有损害企业利益的等等行为,审计人员职业道德,风险值只有0和1,和重大事项风险相同,但重大风险的风险值可以通过展开后续审计减少可以控制的风险,降低后的重大风险事项和非重大风险事项的综合值才是应该被财务报表使用者参考的数据。 2.固有风险(可控制风险) 包括:固有风险=重大错报风险*1+非重大错报风险*α 3.重大风险(重大错报风险) 包括:与管理层沟通的有效性 客户持续经营能力,是否能保证持续经营 客户主体赔偿能力,是否能维持合理的资产结构 法人治理结构是否合理,股东是否拥有绝对的控制权 4.非重大风险=(外部环境风险+行业风险+企业内部风险)*α 包括:外部环境风险→宏观市场风险=①预测市场需求变化→预期销售收入增加率/减少率*+②整个行业的风险特点→同类比上市公司市场利润最高与最低的差值* 企业内部风险=③客户企业生产能力即供给状况→客户企业吸取资本的能力→当年实收资本/平均总资产*+④客户持续经营能力→营运能力综合指标+偿债能力综合指标*+⑤诉讼风险 1.1道德风险 包括:可能使管理层舞弊的因素,管理层或股东有损害企业利益的等等行为,审计人员职业道德 1.2固有风险=外部环境风险+行业风险+企业内部风险 外部环境风险→宏观市场风险=①预测市场需求变化→预期销售收入增加率/减少率*+②整个行业的风险特点→同类比上市公司市场利润最高与最低的差值*
空间面板数据分析R的splm包
空间面板数据分析——R的s p l m包 (任建辉,暨南大学) The splm package provides methods for fitting spatial panel data by maximum likelihood and GM. 安装R软件及其编辑器Rstudio 网址:https://www.360docs.net/doc/b04317050.html, 下载好Rstudio以后,操作都可以Rstudio中完成了,包括命令的编写、命令运行、图形展示,最方便的要数查看数据了。 R界面 Rstudio界面,形如matlab 下面进入正题,了解splm包中的数据、命令及结果展示。所有命令都写在编辑窗口(studio左上区域),可以单独的运行每行命令,也可选取一段一起执行,点run按钮。 1、首先,安装splm包并导入,命令如下: intall.packages(“splm”),选择最近的下载点 library(splm) > library(splm) 载入需要的程辑包:MASS 载入需要的程辑包:nlme 载入需要的程辑包:spdep 载入需要的程辑包:sp 载入需要的程辑包:Matrix 载入需要的程辑包:plm 载入需要的程辑包:bdsmatrix 载入程辑包:‘bdsmatrix’ 下列对象被屏蔽了from ‘package:base’: backsolve
载入需要的程辑包:Formula 载入需要的程辑包:sandwich 载入需要的程辑包:zoo 载入程辑包:‘zoo’ 下列对象被屏蔽了from ‘package:base’: 载入需要的程辑包:spam 载入需要的程辑包:grid Spam version 0.40-0 (2013-09-11) is loaded. Type 'help( Spam)' or 'demo( spam)' for a short introduction and overview of this package. Help for individual functions is also obtained by adding the suffix '.spam' to the function name, e.g. 'help( chol.spam)'. 载入程辑包:‘spam’ 下列对象被屏蔽了from ‘package:bdsmatrix’: backsolve 下列对象被屏蔽了from ‘package:base’: backsolve, forwardsolve 载入需要的程辑包:ibdreg 载入需要的程辑包:car 载入需要的程辑包:lmtest 载入需要的程辑包:Ecdat 载入程辑包:‘Ecdat’ 下列对象被屏蔽了from ‘package:car’: Mroz 下列对象被屏蔽了from ‘package:nlme’: Gasoline 下列对象被屏蔽了from ‘package:MASS’: SP500 下列对象被屏蔽了from ‘package:datasets’: Orange 载入需要的程辑包:maxLik 载入需要的程辑包:miscTools Please cite the 'maxLik' package as: Henningsen, Arne and Toomet, Ott (2011). maxLik: A package for maximum likelihood es timation in R. Computational Statistics 26(3), 443-458. DOI 10.1007/s00180-010-0217 -1. If you have questions, suggestions, or comments regarding the 'maxLik' package, plea se use a forum or 'tracker' at maxLik's R-Forge site: Warning message: 程辑包‘Matrix’是用R版本3.0.3 来建造的 注意:在导入splm时,如果发现还有其他配套的包没有安装,需要先安装。 2、接着,查看数据及结构,命令如下:
消防安全风险评估模型研究
City Fire Risk Assessment Model Based on the Adaptive Genetic Algorithm and BP Network JIAO AIHONG Department of Fire Commanding Chinese People’s Armed Police Forces Academy Lang fang China, 065000 e-mail:ylzmyradio@https://www.360docs.net/doc/b04317050.html, YUAN LIZHE No.3 Department Nanjing Artillery Academy Langfang China, 065000 e-mail:ylzmyradio@https://www.360docs.net/doc/b04317050.html, Abstract—Based on the risk evaluation index system of city fire, a comprehensi ve evaluati on model wi th the adapti ve geneti c algorithm and BP neural network (AGA-BP) is established in the arti cle.In former process of the hybri d algori thm, the adapti ve geneti c algori thm i s appli ed to adjust wei ghts and thresholds of the three-layer BP neural network and train the BP neural network for locati ng the global opti mum, and the error back propagat i on algor i thm i s used to search i n ne ghborhoods of the approx mate opt mal solut on n the later process. The program wri tten i n VB6.0 i s used to learn some samples of c i ty f i re r i sk accord i ng to the AGA-BP algorithm and the general BP algorithm. The results show that the learning precision of AGA-BP algorithm is more correctly than that of the general BP algorithm. The training speed and convergence rate of the former i s s i gn i f i cantly i mproved because of the combi nati on of AGA and BP algori thm. It i s helpful to realize automated evaluation for city fire risk. Keywords-fire risk assessment; adaptive genetic algorithm; back propagation algorithm I.I NTRODUCTION City fire risk assessment is given a comprehensive evaluation conclusion on the probability of fire accidents and the vulnerability assessment of city facilities and the resistance ability of fire in the city,which is based on statistical analysis of city history fire data and hazard identification of the heavy danger sources. At present, the research on city fire risk assessment work is still very weak. Some foreign scholars are mainly concerationed on how to assess the city fire risk and reduce city fire losses and giving some assessment methods. It is helpful to plan city fire force and give a fire safety grade to the district by the fire risk evaluation conclusion. The home researchers is mostly focused on giving a synthetic evaluation conslusion for a certain producing enterprise or a particular building, while for fire risk assessment of the whole city is at a early stage presently. With the development of economy, there are more and more large and high buildings in big cities,and the spatial morphology is changing, and the population is increasing, and the wealth concentrated increasingly, oil, gas, electricity and decoration materials are widespread used in our living life, so the structure of city is complex, and the number of city fire hazards is growing.The safety evaluation methods in common use is including safety check list method, accident type and analysis method, fuzzy synthetic evaluation method, accident tree method, analytic hierarchy process and so on. These methods are short of further studies about the effect factors of fire, because the city security against fire as a whole, density of population, quantity of electricity and other factors are fireare interrelated, interaction and mutual checks each other. So, we need to notice that the evaluation process is dynamic and nonlinear. If we use artificial neural networks (ANN) and expert system to simulate the judgement reasoning and the decision-making process of city fire risk evaluation process, the limitations of traditional methods and the subjectiveness of experts can be avoided because of its good evaluation model structure and working platform. II.E RROR B ACK PROPAGATION AL GORITHM Figure 1three-layer BP network structure . The The three-layer BP neural network structure is shown in Fig.1. Error back propagation algorithm is one of the most popular neural network learning algorithms,which has been used widely in many fields, such as pattern recognition, fault diagnosis and automatic controls[1]. The BP algorithm trains a given feed-forward multilayer neural network for a given set of input patterns with known samples. When each entry of the sample set is presented to the network, the network examines its output response to the sample input pattern. The output response is then compared to the known and desired output and the error value is calculated. Based 2012 International Conference on Industrial Control and Electronics Engineering