应用统计学课程设计报告书

目录
12.2描述性分析 (2)
12.2.1频数分析 (2)
12.2.2描述性分析 (3)
12.3 均值比较和t检验 (4)
12.3.1 Means(均值)过程 (4)
12.3.2 单一样本t检验 (5)
12.3.3 双样本t检验 (6)
12.4 方差分析 (9)
12.5 相关分析 (10)
12.5.1 相关分析的原理及应用 (10)
12.5.2 偏相关分析 (11)
12.6 回归分析 (12)
12.6.1 一元线性回归分析 (12)
12.6.2 多元线性回归分析 (14)
12.7 时间序列的曲估计 (12)
.
12.8 统计图的绘制 (17)
12.8.1 条形图 (17)
12.8.2 线图 (18)
12.8.3 散点图 (19)
12.2描述性分析
12.2.1频数分析
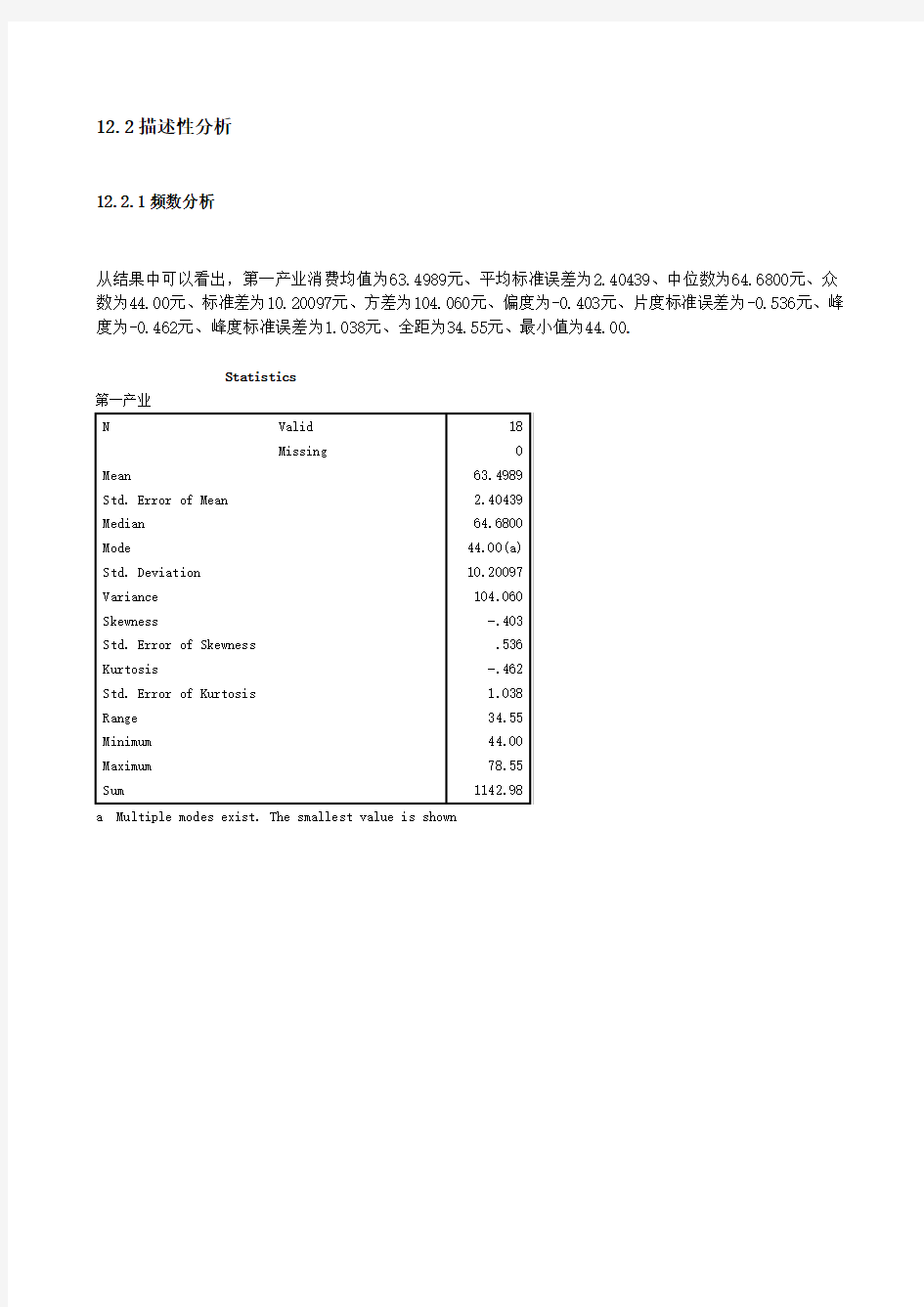
从结果中可以看出,第一产业消费均值为63.4989元、平均标准误差为2.40439、中位数为64.6800元、众数为44.00元、标准差为10.20097元、方差为104.060元、偏度为-0.403元、片度标准误差为-0.536元、峰度为-0.462元、峰度标准误差为1.038元、全距为34.55元、最小值为44.00.
Statistics
第一产业
N Valid 18
Missing 0
Mean 63.4989
Std. Error of Mean 2.40439
Median 64.6800
Mode 44.00(a)
Std. Deviation 10.20097
Variance 104.060
Skewness -.403
Std. Error of Skewness .536
Kurtosis -.462
Std. Error of Kurtosis 1.038
Range 34.55
Minimum 44.00
Maximum 78.55
Sum 1142.98
a Multiple modes exist. The smallest value is shown
第一产业
Frequency Percent Valid Percent Cumulative Percent
Valid 44.00 1 5.6 5.6 5.6
44.76 1 5.6 5.6 11.1
53.61 1 5.6 5.6 16.7
55.70 1 5.6 5.6 22.2
56.99 1 5.6 5.6 27.8
58.17 1 5.6 5.6 33.3
58.86 1 5.6 5.6 38.9
62.00 1 5.6 5.6 44.4
64.12 1 5.6 5.6 50.0
65.24 1 5.6 5.6 55.6
65.80 1 5.6 5.6 61.1
68.83 1 5.6 5.6 66.7
69.30 1 5.6 5.6 72.2
70.72 1 5.6 5.6 77.8
73.28 1 5.6 5.6 83.3
76.41 1 5.6 5.6 88.9
76.64 1 5.6 5.6 94.4
78.55 1 5.6 5.6 100.0
Total 18 100.0 100.0
12.2.2描述性分析
利用SPSS求第一产业的Z分数,在数据窗口中,新变量“Z第一产业”表示“第一产业”Z分数。如图所示Descriptive Statistics
12.3 均值比较和t检验12.3.1 Means(均值)过程
Report 生活消费
ANOVA Table
Measures of Association
(1)处理样本数统计,如图所示。其中Ilude栏表示参加分析计算的样本数,从表中可知全部样本共有18个参考分析,占到全部样本的100%,即分析计算中没有因数据缺测或其他原因等导致的exclued。
(2)变量分组统计结果,如图所示,可以看出生活消费20世纪的平均值为238.3300,标准差41.42102,,21世准差纪平均值为418.5950,标准差为80.12879 。结果表明生活消费两个世纪里有很大差异,21世纪比20世纪的生活消费明显高
12.3.2 单一样本t检验
One-sample T Test 过程的输出比较简单,在结果输出窗口中包含描述性统计表和t检验表。
(1)输出结果第一个表,基本描述性统计量表,从表中可知,参与分析的样品为18,平均消费量为2784.616。标准差为816.63712,均值误差为192.48321。
(2)输出结果第二个表,单一样本t检验表,从表中可知,自由度df=17,根据公式计算的t值等于
4.076。对应的临界置信水平为0.001。95%的置信区间为(378.5120,1190.7202)。计算的t值对
应的临界置信水平远远小于的设置的0.05,因此拒绝原假设Ho,表明生活消费与原设想水平存在明显差异。如图
One-Sample Statistics
One-Sample Test
12.3.3 双样
本t检验
Independent-Samples T Test的输出比较简单,在结果输出窗口中包含描述性统计表和t检验表两个输出结果如图所示
,
(1)描述性统计表。给出了一些基本描述性统计量。由输出结果可以看出,连个世纪生活消费的平均值分别为238.33,418.5950,标准差分别为41.42102,80.12879,均值误差分别为
13.09848,28.32981。
(2)T检验表,表示双样本T检验结果,F的相伴概率为3.986,大于显著性水平0.05.,接受方差相等的零假设,可疑认为两个世纪里的生活消费方差无显著性差异,然后看方差相等时的t检验结果。也就是第一行方差相等的t检验结果,t统计量的相伴概率为0.000小于0.05,不接受t检验
的零假设,也就是说领个世纪的生活消费平均值存在差异。
Descriptives 能源终端消费量
[DataSet1]
ANOVA 能源终端消费量
Correlations
12.4 方差分析
结果解读:我重点解读描述性统计表.方差分析表.各族均值折线图
(1)输出结果文件中的第一个表格为描述性统计量表。从表中可知,输出的统计量表包括各组样本均值,标准差,标准误差,均值95%置信度区间,最小值和最大值,如各组参与分析的样
本数都为1,总样本数为18。
(2)输出结果文件中的第二个表格方差分析表。总离差平方和为11337235.100,组间离差平方和为11337235.100,组内离差平方和为0,组间离差平方和中能被线性解释的部分为
10139187.127,方差检验0,对应的相伴概率为0,小于显著性水平0.05,以此认为18组中
至少有一组能与另外一组差异显著。
(3)输出结果图,各组均值折线图,可以看出91和95年的均值相对较少。
Correlations
能源终端
消费量第三产业
能源终端消费量Pearson Correlation 1 .934(**)
Sig. (2-tailed) .000
Sum of Squares and Cross-products 11337235.
100
2239987.5
73
Covariance 666896.18
2 131763.97
5
N 18 18 第三产业Pearson Correlation .934(**) 1
Sig. (2-tailed) .000
Sum of Squares and Cross-products 2239987.5
73
506884.34
5
Covariance 131763.97
5
29816.726
N 18 18 ** Correlation is significant at the 0.01 level (2-tailed).
Descriptive Statistics
12.5 相关分析
12.5.1 相关分析的原理及应用
结果解读:
(1)描述性统计表。从表中看出,两个变量的样本数都为18,能源终端消费量的均值为2784.6161,标准差为816.63712,;第三产业的均值为547.6189,标准差为172.6752。相关系数极显著性统计表。能源终端消费量和第三产业的相关系数r=0.934显著性水平为0.000,因此可见能源终端消费量和第三
(2)产业的相关性十分显著。
Descriptive Statistics
Correlations
Control Variables 能源终端
消费量第二产业第三产业
-none-(a) 能源终端消费量Correlation 1.000 .989 .934
Significance (2-tailed) . .000 .000
df 0 16 16 第二产业Correlation .989 1.000 .875
Significance (2-tailed) .000 . .000
df 16 0 16 第三产业Correlation .934 .875 1.000
Significance (2-tailed) .000 .000 .
df 16 16 0 第三产业能源终端消费量Correlation 1.000 .993
Significance (2-tailed) . .000
df 0 15
第二产业Correlation .993 1.000
Significance (2-tailed) .000 .
df 15 0 (3) a Cells contain zero-order (Pearson) correlati ons
12.5.2 偏相关分析
结果解读:
(1)描述性统计表。从表中可知,参与分析的能源终端消费量和第三产业,第二产业3个变量的样本数都为18,其中能源终端消费量的均值为2784.6161,标准差为816.63712,。
第三产业的均值为1855.0511,标准差为551.63283,。第二产业的均值为547.6189,标
准差为172.67520。
变量间的相关系数,偏相关系数和显著性检验结果。能源终端消费量和第二产业的相关系数为0.989,显著性水平为0.000,即能源终端消费量和第二产业是相关的;以第三产业为控制变量,能源终端消费量和第二产业的相关系数为0.993,显著性水平为0.000,可知在扣除第三产业的基础上能源终端消费量和第二产业仍然相关性显著。
Model Summary(b)
a Predictors: (Constant), 第三产业
b Dependent Variable: 能源终端消费量
ANOVA(b)
a Predictors: (Constant), 第三产业
b Dependent Variable: 能源终端消费量
Coefficients(a)
a Dependent Variable: 能源终端消费量12
12.6 回归分析
12.6.1 一元线性回归分析
结果解读:
(1)常用统计量。相关系数R=0.934,决定系数R2=0.873,而调整绝对系数R2=0.865,回归估计的标准差S=299.83744,模型拟合效果很理想。
(2)方差分析表。从表中知离差平方和=11337235.100,残差平方和=1438439.888,回归平方和=9898795.212。回归的显著性检验中,统计量为F=110.106,,对应的置信水平为
0.000,小于0.05,因此可认为方程是极显著的。
(3)回归系数分析表。从表中可以看出,常数项为364.617,回归系数=4.419,回归系数检验统计量t=10.493,相伴概率值为0.000小于0.001。由此可知回归方程为
y=364.617+4.419x
Descriptive Statistics
Correlations
能源终端
消费量第二产业第三产业Pearson Correlation 能源终端消费量 1.000 .989 .934
第二产业.989 1.000 .875
第三产业.934 .875 1.000 Sig. (1-tailed) 能源终端消费量. .000 .000
第二产业.000 . .000
第三产业.000 .000 . N 能源终端消费量18 18 18
第二产业18 18 18
第三产业18 18 18 Variables Entered/Removed(b)
a All requested variables entered.
b Dependent Variable: 能源终端消费量
Model Summary
a Predictors: (Constant), 第三产业, 第二产业
ANOVA(b)
a Predictors: (Constant), 第三产业, 第二产业
b Dependent Variable: 能源终端消费量
12.6.2 多元线性回归分析
结果解读:
(1)描述统计表。参与分析的能源终端消费量,第二产业,第三产业的样本数均为18,其对应的均值分别为2784.6161,1855.0511,547.6189,其对应的标准差分别为
816.63712,551.63183,172..67520。
(2)相关系数表。第一栏给出了三个变量两两相关的系数表,因变量能源终端消费量和自变量第二产业的相关系数最大,两个自变量之间存在一定程度的相关。第二栏给出了五个
变量之间两两相关的显著性检验结果表。最后一栏给出了各个变量的样本数。
(3)第三个表依次列出了模型对自变量的筛选过程,即变量进入退出模型的情况。第一二产业都进入模型1。
(4)回归方程拟合总结表。模型1第二产业的相关系数R=0.999,决定系数R2=0.998,调整绝对系数=0.998,误差估计值=37.00117。
(5)回归方程的方差分解及检验结果。模型1的第二产业的F=4132.937,P=0.000,可见方差极其显著。
12.7 时间序列的曲线估计
结果解读:+
1.第一部分输出相关统计量和参数的值有Model Descripion ,case procession,Summary和Model Summary and parameter Estimates
2.输出的结果文件中第二部分表示新增加了四个变量FIT-1,FIT-2,FIT-3,FIT-4,分别代表线性函数,三次函数,幂函数,指数函数条件下进行回归分析是y的预测值。
3.第三部分输出的是观察值和线性函数,三次函数,幂函数和指数函数四种曲线的预测值的对比图。从对比图中可以看出,指数函数的曲线与样本的实际观察值没有拟合,所以不能采用指数函数进行回归分析。4由于在Curve Estimation 对话框中选了save项,且在save variables框中选择了Predicatedvalues 选项和Predict through项,并且在Observation框中输入了27,因此在SPSS数据编辑窗口中就新增了FIT-1,FIT-2,FIT-3,FIT-等四个变量的预测值,同时窗口下方还新增了9个个案,他们分别代表2008—2017年的预测值。
Model Description
Model Name MOD_1
Dependent Variable 1 第一产业
Equation 1 Linear
2 Cubic
3 Power(a)
4 Exponential(a)
Independent Variable Case sequence
Constant Included
Variable Whose Values Label Observations in Plots
Unspecified
Tolerance for Entering Terms in Equations .0001
a The model requires all non-missing values to be positive.
Case Processing Summary
N
Total Cases 18
Excluded Cases(a) 0
Forecasted Cases 0
Newly Created Cases 0
a Cases with a missing value in any variable are excluded from the analysis.
Variable Processing Summary
Model Summary and Parameter Estimates Dependent Variable: 第一产业
12.8 统计图的绘制12.8.1 条形图
应用统计学试题及答案解析
北京工业大学经济与管理学院2007-2008年度 第一学期期末 应用统计学 主考教师 专业: 学号: 姓名: 成绩: 1 C 2 B 3 A 4 C 5 B 6 B 7 A 8 A 9 C 10 C 一.单选题(每题2分,共20分) 1. 在对工业企业的生产设备进行普查时,调查对象是 A 所有工业企业 B 每一个工业企业 C 工业企业的所有生产设备 D 工业企业的每台生产设备 2. 一组数据的均值为20, 离散系数为0.4, 则该组数据的标准差为 A 50 B 8 C 0.02 D 4 3.某连续变量数列,其末组为“500以上”。又知其邻组的组中值为480,则末组的组中值为 A 520 B 510 C 530 D 540 4. 已知一个数列的各环比增长速度依次为5%、7%、9%,则最后一期的定基增长速度为 A .5%×7%×9% B. 105%×107%×109% C .(105%×107%×109%)-1 D. 1%109%107%1053 5.某地区今年同去年相比,用同样多的人民币可多购买5%的商品,则物价增(减)变化的百分 比为 A. –5% B. –4.76% C. –33.3% D. 3.85%
6.对不同年份的产品成本配合的直线方程为x y 75.1280? -=, 回归系数b= -1.75表示 A. 时间每增加一个单位,产品成本平均增加1.75个单位 B. 时间每增加一个单位,产品成本平均下降1.75个单位 C. 产品成本每变动一个单位,平均需要1.75年时间 D. 时间每减少一个单位,产品成本平均下降1.75个单位 7.某乡播种早稻5000亩,其中20%使用改良品种,亩产为600 公斤,其余亩产为500 公 斤,则该乡全部早稻亩产为 A. 520公斤 B. 530公斤 C. 540公斤 D. 550公斤 8.甲乙两个车间工人日加工零件数的均值和标准差如下: 甲车间:x =70件,σ=5.6件 乙车间: x =90件, σ=6.3件 哪个车间日加工零件的离散程度较大: A 甲车间 B. 乙车间 C.两个车间相同 D. 无法作比较 9. 根据各年的环比增长速度计算年平均增长速度的方法是 A 用各年的环比增长速度连乘然后开方 B 用各年的环比增长速度连加然后除以年数 C 先计算年平均发展速度然后减“1” D 以上三种方法都是错误的 10. 如果相关系数r=0,则表明两个变量之间
应用统计学期末练习题+答案
班级: 课程名称: 应用统计学 一、单选题 1.统计指标按其计量单位不同可分为( A ) A、实物指示和价值指标 B、数量指标和质量指标 C、时点指标和时期指标 D、客观指标和主观指标 2.下列中属于比较相对指标的是( D )。 A.女性人口在总人口中的比例B.医生人数在总人口中的比重 C.党团员在总人口中的比例 D.北京人口相当于上海人口的百分比 3.当相关关系的一个变量动时,另一个变量相应地发生变动,但这种变动是不均等的,这称为( C )。 A、线性相关 B、直线相关 C、非线性相关 D、非完全相关 4.数量指标指数和质量指标指数,是按其( C )不同的划分的。 A.反映对象范围的 B.对比的基期的 C.所表明的经济指标性质的 D.同度量因素的 5.平均发展速度的计算方法有( D ) A、简单算术平均数 B、加权算术平均数 C、调和平均数 D、几何平均法 E、方程法 6.某地区生活品零售价格上涨6%,生活品销售量增长8%,那么生活品销售额是( D )。 A.下降114.48% B.下降14.48% C.增长114.48% D.增长14.48% 7.2000年北京市三次产业比重分别是3.7%、38.0%和58.3%,这些指标是( D ) A、动态相对指标 B、强度相对指标 C、平均指标 D、结构相对指标 8.能形成连续变量数列的数量标志有( B ) A、企业的从业人员数量 B、企业的生产设备台数 C、企业的工业增加值 D、企业从业人员工资总额 E、企业的利税总额 9.对某市100个工业企业全部职工的工资状况进行调查,则总体单位是( B )。 A.每个企业 B.每个职工 C.每个企业的工资总额 D.每个职工的工资水平 10.抽样估计就是根据样本指标数值对总体指标数值做出( B )。 A、直接计算 B、估计和推断 C、最终结论 D、一定替代 11.对比分析不同水平的变量数列之间标志变异程度,应使用( D )。 A.全距B.平均差 C.标准差 D.变异系数 12.两个变量之间的变化方向相反,一个上升而另一个是下降,或者一个下降而另一个是上升,这是 ( B )。
应用统计学练习题(含答案)
应用统计学练习题 第一章绪论 一、填空题 1.统计工作与统计学的关系是__统计实践____和___统计理论__的关系。 2.总体是由许多具有_共同性质_的个别事物组成的整体;总体单位是__总体_的组成单位。 3.统计单体具有3个基本特征,即__同质性_、__变异性_、和__大量性__。 4.要了解一个企业的产品质量情况,总体是_企业全部产品__,个体是__每一件产品__。 5.样本是从__总体__中抽出来的,作为代表_这一总体_的部分单位组成的集合体。 6.标志是说明单体单位特征的名称,按表现形式不同分为__数量标志_和_品质标志_两种。 7. 8.统计指标按其数值表现形式不同可分为__总量指标__、__相对指标_和__平均指标__。 9.指标与标志的主要区别在于: (1)指标是说明__总体__特征的,而标志则是说明__总体单位__特征的。 (2)标志有不能用__数量__表示的_品质标志_与能用_数量_表示的_数量标志_,而指标都是能用_数量_表示的。 10.一个完整的统计工作过程可以划分为_统计设计_、_统计调查_、_统计整理_和__统计分析__4个阶段。 二、单项选择题 1.统计总体的同质性是指(A)。 A.总体各单位具有某一共同的品质标志或数量标志 B.总体各单位具有某一共同的品质标志属性或数量标志值 C.总体各单位具有若干互不相同的品质标志或数量标志 D.总体各单位具有若干互不相同的品质标志属性或数量标志值 2.设某地区有800家独立核算的工业企业,要研究这些企业的产品生产情况,总体是( D)。
A.全部工业企业 B.800家工业企业 C.每一件产品 D.800家工业企业的全部工业产品 3.有200家公司每位职工的工资资料,如果要调查这200家公司的工资水平情况,则统计总体为(A)。 A.200家公司的全部职工 B.200家公司 C.200家公司职工的全部工资 D.200家公司每个职工的工资 4.一个统计总体( D)。 A.只能有一个标志 B.可以有多个标志 C.只能有一个指标 D.可以有多个指标 5.以产品等级来反映某种产品的质量,则该产品等级是(C)。 A.数量标志 B.数量指标 C.品质标志 D.质量指标 6.某工人月工资为1550元,工资是( B )。 A.品质标志 B.数量标志 C.变量值 D.指标 7.某班4名学生金融考试成绩分别为70分、80分、86分和95分,这4个数字是( D)。 A.标志 B.指标值 C.指标 D.变量值 8.工业企业的职工人数、职工工资是(D)。 A.连续变量 B.离散变量 C.前者是连续变量,后者是离散变量 D.前者是离散变量,后者是连续变量 9.统计工作的成果是(C)。 A.统计学 B.统计工作 C.统计资料 D.统计分析和预测 10.统计学自身的发展,沿着两个不同的方向,形成(C)。 A.描述统计学与理论统计学 B.理论统计学与推断统计学 C.理论统计学与应用统计学 D.描述统计学与推断统计学
应用统计学试题及答案
应用统计学试题及答案 LG GROUP system office room 【LGA16H-LGYY-LGUA8Q8-LGA162】
二、单项选择题(每题1分,共10分) 1.重点调查中的重点单位是指( ) A.处于较好状态的单位 B.体现当前工作重点的单位 C.规模较大的单位 D.在所要调查的数量特征上占有较大比重的单位 2.根据分组数据计算均值时,利用各组数据的组中值做为代表值,使用这一代表值的假定条件是()。 A.各组的权数必须相等 B.各组的组中值必须相等 C.各组数据在各组中均匀分布 D.各组的组中值都能取整数值 3.已知甲、乙两班学生统计学考试成绩:甲班平均分为70分,标准差为分;乙班平均分为75分,标准差为分。由此可知两个班考试成绩的离散程度() A.甲班较大 B.乙班较大 C.两班相同 D.无法作比较 4.某乡播种早稻5000亩,其中20%使用改良品种,亩产为600公斤,其余亩产为500公斤,则该乡全部早稻平均亩产为() 公斤公斤公斤公斤 5.时间序列若无季节变动,则其各月(季)季节指数应为() A.100% % % % 6.用最小平方法给时间数列配合直线趋势方程y=a+bt,当b<0时,说明现象的发展趋势是() A.上升趋势 B.下降趋势 C.水平态势 D.不能确定 7.某地区今年和去年相比商品零售价格提高12%,则用同样多的货币今年比去年少购买()的商品。 8.置信概率表达了区间估计的() A.精确性 B.可靠性 C.显着性 D.规范性 9.H 0:μ=μ ,选用Z统计量进行检验,接受原假设H 的标准是() A.|Z|≥Z α B.|Z|
应用统计学试题和答案分析
六、计算题:(要求写出计算公式、过程,结果保留两位小数,共4题,每题10分) 1、某快餐店对顾客的平均花费进行抽样调查,随机抽取了49名顾客构成一个简单随机样本,调查结果为:样本平均花费为元,标准差为元。试以%的置信水平估计该快餐店顾客的总体平均花费数额的置信区 间;(φ(2)=)49=n 是大样本,由中心极限定理知,样本均值的极限分布为正态分布,故可用正态分布对总体均值进行区间估计。 已知:8.2,6.12==S x 0455.0=α 则有: 202275 .02 ==Z Z α 平均误差=4.07 8 .22==n S 极限误差8.04.022 2 =?==? n S Z α 据公式 x x ±=±? 代入数据,得该快餐店顾客的总体平均花费数额%的置信区间为(,) 3 要求:①、利用最小二乘法求出估计的回归方程;②、计算判定系数R 。 附:10805 1 2 ) (=∑-=i x x i 8.3925 1 2 ) (=∑-=i y y i 58=x 2.144=y 3题 解 ① 计算估计的回归方程: ∑∑∑∑∑--= )(22 1x x n y x xy n β) ==-??-?290 217900572129042430554003060 = =-= ∑∑n x n y ββ)) 1 0 – ×58= 估计的回归方程为:y ) =+x ② 计算判定系数: 4 计算下列指数:①拉氏加权产量指数;②帕氏单位成本总指数。 4题 解: ① 拉氏加权产量指数
= 1 000 00 1.1445.4 1.13530.0 1.08655.2 111.60%45.430.055.2q p q q p q ?+?+?==++∑∑ ② 帕氏单位成本总指数= 11100053.633.858.5 100.10%1.1445.4 1.13530.0 1.08655.2q p q q p q ++==?+?+?∑∑ 模拟试卷(二) 一、填空题(每小题1分,共10题) 1、我国人口普查的调查对象是 ,调查单位是 。 2、___ 频数密度 =频数÷组距,它能准确反映频数分布的实际状况。 3、分类数据、顺序数据和数值型数据都可以用 饼图 条图 图来显示。 4、某百货公司连续几天的销售额如下:257、276、297、252、238、310、240、236、265,则其下四分位数 5、某地区2005年1季度完成的GDP=30亿元,2005年3季度完成的GDP=36亿元,则GDP 年度化增长率6、某机关的职工工资水平今年比去年提高了5%,职工人数增加了2%,则该企业工资总额增长了 % 。 7、对回归系数的显着性检验,通常采用的是 t 检验。 8、设置信水平=1-α,检验的P 值拒绝原假设应该满足的条件是 p e M >o M ③、x >o M >e M 3、比较两组工作成绩发现σ甲>σ乙,x 甲>x 乙,由此可推断 ( )
应用统计学习题及答案
应用统计学习题及答案 简答题 1.简述普查和抽样调查的特点。 答: 普查是指为某一特定目的而专门组织的全面调查,它具有以下几个特点: <1)普查通常具有周期性。 <2)普查一般需要规定统一的标准调查时间,以避免调查数据的重复或遗漏,保证普查结果的准确性。 <3)普查的数据一般比较准确,规划程度也较高。 <4)普查的使用范围比较窄。 抽样调查指从调查对象的总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推断总体数量特征的一种数据收集方法。它具有以下几个特点:b5E2RGbCAP <1)经济性。这是抽样调查最显著的一个特点。 <2)时效性强。抽样调查可以迅速、及时地获得所需要的信息。<3)适应面广。它适用于对各个领域、各种问题的调查。 <4)准确性高。 2.为什么要计算离散系数? 答: 离散系数是指一组数据的标准差与其相应得均值之比,也称为变异系数。 对于平均水平不同或计量单位不同的不同组别的变量值,是不能用方差和标准差比较离散程度的。为消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。离散系数的作用主要是用于比较不同总体或样本数据的离散程度。离散系数大的说明数据的离散程度也就大,离散系数小的说明数据的离散程度也就小。p1EanqFDPw
3、加权算术平均数受哪几个因素的影响?若报告期与基期相比各组平均数没变,则总平均数的变动情况可能会怎样?请说明原因。DXDiTa9E3d 答: 加权算术平均数受各组平均数喝次数结构<权数)两因素的影响。若报告期与基期相比各组平均数没变,则总平均数的变动受次数结构<权数)变动的影响,可能不变、上升、下降。如果各组次数结构不变,则总平均数;如果组平均数高的组次数比例上升,组平均数低的组次数比例下降,则总平均数上升;如果组平均数低的组次数比例上升,组平均数高的组次数比例下降,则总平均数下降。RTCrpUDGiT 4.解释相关关系的含义,说明相关关系的特点。 答: 变量之间存在的不确定的数量关系为相关关系。 相关关系的特点:一个变量的取值不能由另一个变量唯一确定,当变量x取某个值时,变量y的取值可能有几个;变量之间的相关关系不能用函数关系进行描述,但也不是无任何规律可循。通常对大量数据的观察与研究,可以发现变量之间存在一定的客观规律。 5PCzVD7HxA 5.解释抽样推断的含义。 答: 简单说,就是用样本中的信息来推断总体的信息。总体的信息通常无法获得或者没有必要获得,这时我们就通过抽取总体中的一部分单位进行调查,利用调查的结果来推断总体的数量特征。jLBHrnAILg 6.回归分析与相关分析的区别是什么? 答: <1)相关分析所研究的两个变量是对等关系,而回归分析所研究的两个变量不是对等关系;<2)对于两个变量X和Y来说,相关分析
应用统计学:参数估计习题及答案
简答题 1、矩估计的推断思路如何?有何优劣? 2、极大似然估计的推断思路如何?有何优劣? 3、什么是抽样误差?抽样误差的大小受哪些因素影响? 4、简述点估计和区间估计的区别和特点。 5、确定重复抽样必要样本单位数应考虑哪些因素? 计算题 1、对于未知参数的泊松分布和正态分布分别使用矩法和极大似然法进行点估计,并考量估计结果符合什么标准 2、某学校用不重复随机抽样方法选取100名高中学生,占学生总数的10%,学生平均体重为50公斤,标准差为48.36公斤。要求在可靠程度为95%(t=1.96)的条件下,推断该校全部高中学生平均体重的范围是多少? 3、某县拟对该县20000小麦进行简单随机抽样调查,推断平均亩产量。根据过去抽样调查经验,平均亩产量的标准差为100公斤,抽样平均误差为40公斤。现在要求可靠程度为95.45%(t=2)的条件下,这次抽样的亩数应至少为多少? 4、某地区对小麦的单位面积产量进行抽样调查,随机抽选25公
顷,计算得平均每公顷产量9000公斤,每公顷产量的标准差为1200公斤。试估计每公顷产量在8520-9480公斤的概率是多少?(P(t=1)=0.6827, P(t=2)=0.9545, P(t=3)=0.9973) 5、某厂有甲、乙两车间都生产同种电器产品,为调查该厂电器产品的电流强度情况,按产量等比例类型抽样方法抽取样本,资料如下: 试推断: (1)在95.45%(t=2)的概率保证下推断该厂生产的全部该种电器产品的平均电流强度的可能范围 (2)以同样条件推断其合格率的可能范围 (3)比较两车间产品质量 6、采用简单随机重复和不重复抽样的方法在2000件产品中抽查200件,其中合格品190件,要求: (1)计算样本合格品率及其抽样平均误差
《应用统计学》练习试题和答案解析
《应用统计学》本科 第一章导论 一、单项选择题 1.统计有三种涵义,其基础就是( )。 (1)统计学 (2)统计话动 (3)统计方法 (4)统计资料 2.一个统计总体( )。 (1)只能有个标志 (2)只能有一个指标 (3)可以有多个标志 (4)可以有多个指标 3.若要了解某市工业生产设备情况,则总体单位就是该市( )。 (1)每一个工业企业 (2)每一台设备 (3)每一台生产设备 (4)每一台工业生产设备 4.某班学生数学考试成绩分刷为65分、71分、80分与87分,这四个数字就是( )。 (1)指标 (2)标志 (3)变量 (4)标志值 5.下列属于品质标志的就是( )。 (1)工人年龄 (2)工人性别 (3)工人体重 (d)工人工资 6.现要了解某机床厂的生产经营情况,该厂的产量与利润就是( )。 (1)连续变量 (2)离散变量 ()3前者就是连续变量,后者就是离散变量 (4)前者就是离散变量,后者就是连续变量 7.劳动生产率就是( )。 (1)动态指标 (2)质量指标 (3)流量指标 (4)强度指标 8.统计规律性主要就是通过运用下述方法经整理、分析后得出的结论( )。 (1)统计分组法 (2)大量观察法 (3)练台指标法 (4)统计推断法 9.( )就是统计的基础功能。 (1)管理功能 (2)咨询功能 (3)信息功能 (4)监督功能 10.( )就是统计的根本准则,就是统计的生命线。 (1)真实性 (2)及时件 (3)总体性 (4)连续性 11.构成统计总体的必要条件就是( )。 (1)差异性 (2)综合性 (3)社会性 (4)同质性 12.数理统计学的奠基人就是( )。 (1) 威廉·配第 (2)阿亭瓦尔 (3)凯特勒 (4)恩格尔 13.统汁研究的数量必须就是( )。 (1)抽象的量 (2)具体的量 (3)连续不断的量 (4)可直接相加量 14.数量指标一般表现为( )。 (1)平均数 (2)相对数 (3)绝对数 (1)众数 15.指标就是说明总体特征的.标志则就是说明总体单位特征的,所以( )。 (1)指标与标志之同在一定条件下可以相互变换 (2)指标与标志都就是可以用数值表示的 (3)指标与标志之间不存在戈系 (4)指标与标志之间的关系就是固定不变的 答案:一、1(2) 2(4)3(4)4(4)5(2)6(4)7(2)8(2)9(3)10(1)11(4)12(3)13(2)14(3)15(1) 二、1× 2× 3√ 4× 5√ 6× 7√ 8× 9√ 10× 11× 12× 二、判析题 l.统计学就是一门研究现象总体数量方面的方法论科学,所以它不关心、也不考虑个别现象的数量特征。 ( ) 2.三个同学的成绩不同.因此仃在三个变量 ( ) 3.统计数字的具体性就是统讣学区别于数学的根本标志。 ( ) 4.统计指标体系就是许多指标集合的总称。 ( ) 5.一般而言,指标总就是依附在总体上,而总体单位则就是标志的直接承担者。( ) 6.统计研究小的变异就是指总体单位质的差别。 ( ) 7.社会经济统计就是在质与量的联系中.观察与研究社会经济现象的数量方面。( ) 8.运用大量观察法必须对研究对象的所有单位进行观察调查。( )
应用统计学练习题及答案(精简版)
应用统计学练习题 第一章?绪论 一、填空题 1.统计工作与统计学得关系就是__统计实践____与___统计理论__得关系。 2.总体就是由许多具有_共同性质_得个别事物组成得整体;总体单位就是__总体_得组成单位。 3.统计单体具有3个基本特征,即__同质性_、__变异性_、与__大量性__。 4.要了解一个企业得产品质量情况,总体就是_企业全部产品__,个体就是__每一件产品__。 5.样本就是从__总体__中抽出来得,作为代表_这一总体_得部分单位组成得集合体。 6.标志就是说明单体单位特征得名称,按表现形式不同分为__数量标志_与_品质标志_两种。 7.性别就是_品质标志_标志,标志表现则具体体现为__男__或__女_两种结果。 二、单项选择题 1.统计总体得同质性就是指(A )。 A、总体各单位具有某一共同得品质标志或数量标志 B、总体各单位具有某一共同得品质标志属性或数量标志值 C、总体各单位具有若干互不相同得品质标志或数量标志 D、总体各单位具有若干互不相同得品质标志属性或数量标志值 2.设某地区有800家独立核算得工业企业,要研究这些企业得产品生产情况,总体就是( D )。 A、全部工业企业????B、800家工业企业 C、每一件产品????? D、800家工业企业得全部工业产品 3.有200家公司每位职工得工资资料,如果要调查这200家公司得工资水平情况,则统计总体为( A )。
A、200家公司得全部职工??B、200家公司 C、200家公司职工得全部工资?D、200家公司每个职工得工资 4.一个统计总体(D )。 A、只能有一个标志? B、可以有多个标志 C、只能有一个指标?? D、可以有多个指标 5.以产品等级来反映某种产品得质量,则该产品等级就是( C)。 A、数量标志??? B、数量指标 C、品质标志????D、质量指标 6.某工人月工资为1550元,工资就是( B )。 A、品质标志???????B、数量标志 C、变量值??? D、指标 测 7.统计学自身得发展,沿着两个不同得方向,形成(C)。 A、描述统计学与理论统计学?? B、理论统计学与推断统计学 C、理论统计学与应用统计学???? D、描述统计学与推断统计学 三、多项选择题 1.统计得含义包括( ACD)。 A、统计资料?B、统计指标???C、统计工作 D、统计学?E、统计调查 2.统计研究运用各种专门得方法,包括( ABCDE )。 A、大量观察法??B、统计分组法??C、综合指标法 D、统计模型法? E、统计推断法 3.下列各项中,哪些属于统计指标?( ACDE ) A、我国2005年国民生产总值 B、某同学该学期平均成绩 C、某地区出生人口总数 D、某企业全部工人生产某种产品得人均产量 E、某市工业劳动生产率 4.统计指标得表现形式有(BCE )。
应用统计学试题和答案分析
六、计算题:(要求写出计算公式、过程,结果保留两位小数,共4题,每题10分) 1、某快餐店对顾客的平均花费进行抽样调查,随机抽取了49名顾客构成一个简单随机样本,调查结果为:样本平均花费为12.6元,标准差为2.8元。试以95.45%的置信水平估计该快餐店顾客的总体平均花费数额的置信区间;(φ(2)=0.9545)49=n 是大样本,由中心极限定理知,样本均值的极限分布为正态分布,故可用正态分布对总体均值进行区间估计。 已知:8.2,6.12==S x 0455.0=α 则有: 202275 .02 ==Z Z α 平均误差=4.07 8 .22==n S 极限误差8.04.022 2 =?==?n S Z α 据公式 x x ±=±? 代入数据,得该快餐店顾客的总体平均花费数额95.45%的置信区间为(11.8,13.4) 附: 10805 1 2 ) (=∑-=i x x i 8.3925 1 2 ) (=∑-=i y y i 58=x 2.144=y 179005 1 2 =∑=i x i 1043615 1 2 =∑=i y i 424305 1 =∑=y x i i i 3题 解 ① 计算估计的回归方程: ∑∑∑∑∑--= )(22 1x x n y x xy n β ==-??-?290 217900572129042430554003060 =0.567 =-= ∑∑n x n y ββ 1 0144.2 – 0.567×58=111.314 估计的回归方程为:y =111.314+0.567x ② 计算判定系数: