最新《计量经济学》第四章题及答案资料

第四章:多重共线性
二、简答题
1、导致多重共线性的原因有哪些?
2、多重共线性为什么会使得模型的预测功能失效?
3、如何利用辅回归模型来检验多重共线性?
4、判断以下说法正确、错误,还是不确定?并简要陈述你的理由。
(1)尽管存在完全的多重共线性,OLS 估计量还是最优线性无偏估计量(BLUE )。
(2)在高度多重共线性的情况下,要评价一个或者多个偏回归系数的个别显著性是不可能的。 (3)如果某一辅回归显示出较高的2
i R 值,则必然会存在高度的多重共线性。 (4)变量之间的相关系数较高是存在多重共线性的充分必要条件。
(5)如果回归的目的仅仅是为了预测,则变量之间存在多重共线性是无害的。
12233i i i Y X X βββ=++
来对以上数据进行拟合回归。
(1) 我们能得到这3个估计量吗?并说明理由。
(2) 如果不能,那么我们能否估计得到这些参数的线性组合?可以的话,写出必要的计
算过程。
6、考虑以下模型:
23
1234i i i i i Y X X X ββββμ=++++
由于2X 和3
X 是X 的函数,那么它们之间存在多重共线性。这种说法对吗?为什么? 7、在涉及时间序列数据的回归分析中,如果回归模型不仅含有解释变量的当前值,同时还含有它们的滞后值,我们把这类模型称为分布滞后模型(distributed-lag model )。我们考虑以下模型:
12313233i t t t t t Y X X X X βββββμ---=+++++
其中Y ——消费,X ——收入,t ——时间。该模型表示当期的消费是其现期的收入及其滞后三期的收入的线性函数。
(1) 在这一类模型中是否会存在多重共线性?为什么? (2) 如果存在多重共线性的话,应该如何解决这个问题? 8、设想在模型
12233i i i i Y X X βββμ=+++
中,2X 和3X 之间的相关系数23r 为零。如果我们做如下的回归:
1221i i i Y X ααμ=++ 1332i i i Y X γγμ=++
(1)会不会存在22??αβ=且33??γβ=?为什么? (2)1?β会等于1?α或1?γ或两者的某个线性组合吗? (3)会不会有22??var()var()βα=且33
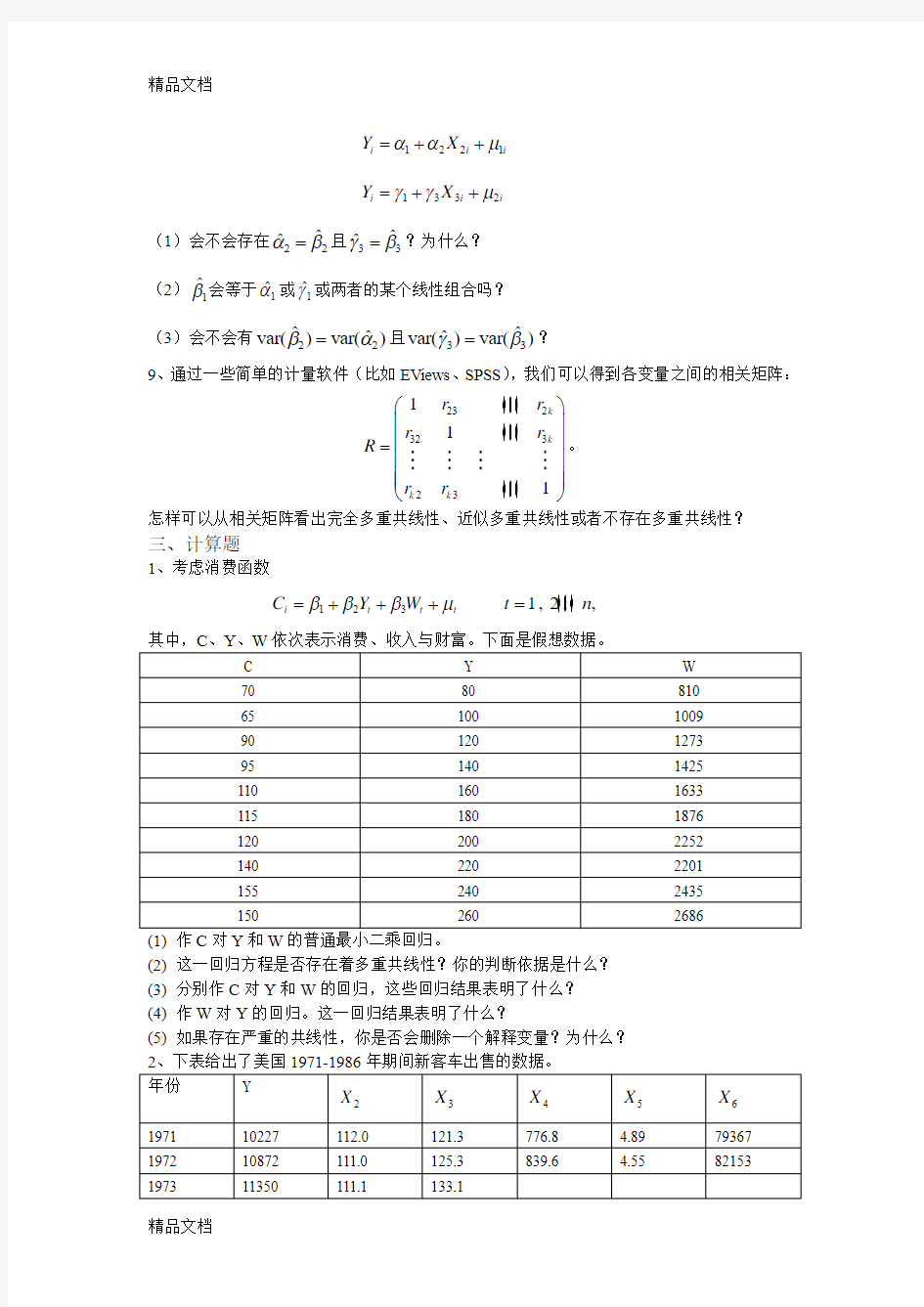
??var()var()γβ=? 9、通过一些简单的计量软件(比如EViews 、SPSS ),我们可以得到各变量之间的相关矩阵:
2323232
3
1
1 1k k k k r r r r R r r ?? ? ?
= ? ? ???
。 怎样可以从相关矩阵看出完全多重共线性、近似多重共线性或者不存在多重共线性?
三、计算题
1、考虑消费函数
123i t t t C Y W βββμ=+++ 1,2,,t n =
(1) 作C 对Y 和W 的普通最小二乘回归。
(2) 这一回归方程是否存在着多重共线性?你的判断依据是什么? (3) 分别作
C 对Y 和W 的回归,这些回归结果表明了什么? (4) 作W 对Y 的回归。这一回归结果表明了什么?
(5) 如果存在严重的共线性,你是否会删除一个解释变量?为什么?
Y ——新车出售量,未经季节调整数量;
2X ——新车,消费者价格指数,1967年=100,未经季节调整; 3X ——消费者价格指数,1967年=100,未经季节调整; 4X ——个人可支配收入,10亿美元,未经季节调整; 5X ——利率,百分数,金融公司票据直接使用; 6X ——民间就业劳动人数(个人),未经季节调整。
(1) 如果你决定使用表中全部回归元作为解释变量,可能会遇到多重共线性吗?为什
么?
(2) 如果你这样认为的话,你准备怎样解决这个问题?明确你的假设并说明全部计算。 (3) 制定适当的线性或者对数线性的模型,以估计美国对汽车的需求函数。
第二部分:参考答案
一、术语解释
1、多重共线性:对于经典线性回归模型(CLRM )
n i u X X X Y i ki k i i i ,2,1 22110 =+++++=ββββ
如果上式中某两个或多个解释变量之间出现了相关性,则称为存在多重共线性。依据解释变量之间共线性的程度不同,可以分为完全多重共线性和近似多重共线性。
2、完全多重共线性与近似多重共线性:所谓完全多重共线性,是指线性回归模型中的若干解释变量或全部解释变量之间具有严格的线性关系,也就是说,对于多元线性回归模型,若各解释变量k X X X ,,,21 的之间存在如下的关系式:
02211=+++k k X X X λλλ
式中k λλλ,,,21 是不全为零的常数,则称这些解释变量之间存在完全多重共线性。 当各解释变量k X X X ,,,21 的之间存在如下的近似的线性关系:
02211≈+++k k X X X λλλ
则可以说上述解释变量之间存在近似多重共线性。还可以采用如下的方式,在近似线性关系式中,假设0≠i λ,则可将此近似线性关系表示为:
i k k i i i i i v X X X X X ++++++=++--αααα 111111
其中,/i l l λλα=i v 为随机误差项。
3、辅回归:在变量之间存在多重共线性的情况下,有一个解释变量能由其它解释变量近似的线性表示出来。为了找出哪个解释变量和其它变量有这种关系,我们可以将每个i X 对其余变量进行回归,即
i k k i i i i i v X X X X X ++++++=++--αααα 111111
这种回归叫做辅回归,它是相对于Y 对各个X 的主回归而言的。
二、简答题
1、答:
经济数据中大量存在多重共线性这一现象,主要原因在于:经济领域很难象其它实验学科那样从控制性试验中获得数据;此外,可能有经济变量结构上的原因,也有数据收集与模型设定方面的原因,具体的,有以下几种:
(1)所使用的数据收集方法。我们只能在一个有限的范围内得到观察值,无法进行重复试验。
(2)模型或从中取样的总体受到约束(经济变量的共同趋势)。 (3)模型设定的偏误。
(4)过度决定的模型。这种情况尤其容易发生在解释变量的个数大于观测值个数的情形。
由于上述原因,实际应用中,解释变量之间总会存在一定程度的线性相关,因此,问题不是多重线性有无,而是多重共线性的严重程度。
2、答:
多元线性回归模型的一个重要应用是经济预测。对于模型
∧
∧=βX Y
如果给定样本以外的解释变量的观测值0X ,就可以得到被解释变量的预测值
∧
∧=β00X Y
但是,这只是被解释变量的预测值的估计值而不是预测值。预测值仅以某一个置信水平位于
以该估计值为中心的一个区间中。对于预测的置信区间,我们利用的是构造t 统计量,得到
在给定()α-1
的置信水平下0Y 的置信区间为 ()()''1''101
02/0001
02/0X X X X t Y Y X X X X t Y -∧
-∧
+?+<<+?-αα
显然,当解释变量之间存在多重共线性时, ()1
'-X X 非常大,故而0Y 的置信区间也很
大,因此,模型的预测功能失效。 3、答:
辅回归是相对于Y 对各个X 的主回归而言的。在变量之间存在多重共线性的情况下,有一个解释变量能由其它解释变量近似的线性表示出来。为了找出哪个解释变量和其它变量有这种关系,我们可以将每个i X 对其余变量进行回归,即
i k k i i i i i v X X X X X ++++++=++--αααα 111111,
并计算相应的决定系数,分别记为2
i R 。然后,我们在建立统计量:
22(2)
(1)(1)
i i i R k F R n k -=
--+ 它服从自由度为k-2和n-k+1的F 分布。其中n 为样本大小,k 为包括常数项在内的解释变量个数。如果计算出的i F 超过了相应自由度的临界值,则认为这个i X 和其余的解释变量存在共线性;如果i F 未超过临界值,则认为这个i X 和其余的解释变量不存在共线性。这种辅回归模型检验不仅可以检验是否存在多重共线性,而且还可以得到多重共线性的具体形式。
4、答:
(1)错。如果变量之间存在完全的线性关系时,我们甚至无法估计其系数或者标准误。 (2)错。在高度多重共线性的情况下,仍然可以得到一个或者多个显著的t 值。 (3)错。OLS 估计量的方差有下式给出:
2
2
2
1
?var()1i
i
i
R x
σβ=?
-∑ 从此式可以看出,一个很高的2i R 可被一个很低的2
?σ
或者很高的2
i
x
∑抵消掉。
(4)错。如果一个模型只有两个回归元,两两之间的高度相关系数便表示存在多重共线性。但是在变量之间存在多重共线性的前提下,可能是几个变量之间的关系。变量之间的相关系数较高是存在多重共线性的充分非必要条件。
(5)不确定。如果观测到共线性在后来的样本数据中继续存在,或许无害。但如果不是这样,或者目的在于做出精确的估计的话,多重共线性便成为问题。如果仅仅要是预测的话,预测有效的前提条件是模型结构的稳定。
5、答:
(1)不能。通过对2X 和3X 的观察,我们可以知道它们存在以下的关系:
3221i i X X =-,所以可知变量2X 和3X 是完全线性相关的。
(2)把方程写成
1223213232122(21)()(2)i i i i
i i
i i
Y X X X X βββμββββμααμ=++-+=-+++=++
其中113223,2αββαββ=-=+。
因此,我们可以唯一的估计出1α和2α,但无法估计出原始的β,因为两个方程无法解出三个未知数。
6、答:
这种说法不正确。因为2
x 和3
x 都是x 的非线性函数,把它们包括在回归模型中并不违反经典性线性回归模型的基本假设。多重共线性的相关是指的变量之间的线性相关。
7、答:
(1)是的。经济时间序列数据有同向变动的趋势。在这里,收入的滞后变量一般也可以相同的方向变动。
(2)在遇到时间序列数据存在线性相关性时,我们一般都是采用一阶或者高阶差分变换来消除共线性。
8、答:
(1)是的。这是因为2X 和3X 之间的相关系数为0,所以β系数的表达式
2233232
222
2323()()()()
?()()()i i i i i i i i i i i y x x y x x x x x x x β-=-∑∑∑∑∑∑∑、
2322233
2
2
2
2323()()()()
?()()()
i i i i i i i i i i i y x x y x x x x x x x β-=-∑∑∑∑∑∑∑
中的交叉乘积项消失,从而变成与α和γ系数同样的表示式。 (2)是它们的一个线性组合。证明如下:
12233
12222
23333
?????????Y X X Y X Y X Y X Y X βββααβαγβ=--=-=-=-=- 因此有1
11???Y βαγ=+-。
(3)不是。原因如下:
2222
2322
2
2232???var(),(0)(1)
i i
r x r x σ
σ
β==
=-∑∑
222
2??v a r ()
i
x
σ
α=∑。
9、答:
我们可以利用相关矩阵的行列式来判断多重共线性与否,可以利用R 的行列式大小来判断多重共线性的强弱。
(1) 若R 的行列式为0时,则存在完全的共线性。
(2) 若R 的行列式很小接近于0时,则存在近似的共线性。 (3) 若R 的行列式为1时,则变量正交、不存在共线性。
三、计算题
1、解:
(1)使用EViews 软件进行回归 Dependent Variable: SER01 Method: Least Squares
Date: 07/02/06 Time: 19:32 Sample: 1 10
C 24.33698 6.280051 3.875284 0.0061 W -0.034952 0.030120 -1.160433 0.2839 R-squared
0.968182 Mean dependent
var
111.0000 Adjusted R-squared 0.959092 S.D. dependent var 31.42893 S.E. of regression 6.356758 Akaike info criterion 6.780239 Sum squared resid 282.8586 Schwarz criterion 6.871015 Log likelihood -30.90120 F-statistic 106.5019 回归得到的方程为:
???24.340.030.87i
Y W Y =-+。 (2)有。R-squared 的值为0.968182,但是系数W 通过不过显著性检验。
(3)
C
24.45455 6.413817 3.812791 0.0051
var
Adjusted R-squared 0.957319 S.D. dependent var 31.42893
S.E. of regression 6.493003 Akaike info criterion 6.756184
Sum squared resid 337.2727 Schwarz criterion 6.816701
Log likelihood -31.78092 F-statistic 202.8679
C 26.45198 8.446165 3.131833 0.0140
111.0000
R-squared 0.933241 Mean dependent
var
Adjusted R-squared 0.924896 S.D. dependent var 31.42893
S.E. of regression 8.613107 Akaike info criterion 7.321304
Sum squared resid 593.4849 Schwarz criterion 7.381821
Log likelihood -34.60652 F-statistic 111.8346
在这两个回归中,系数是显著的,而在同时对两个变量进行回归时,却存在部分系数的不显著,说明变量之间存在多重共线性。
(4)
C -3.363636 73.70690 -0.045635 0.9647
R-squared 0.987611 Mean dependent
1760.000
var
Adjusted R-squared 0.986062 S.D. dependent var 632.0272
S.E. of regression 74.61690 Akaike info criterion 11.63947
Sum squared resid 44541.45 Schwarz criterion 11.69998
Log likelihood -56.19734 F-statistic 637.7133
1760.000
R-squared 0.987607 Mean dependent
var
Adjusted R-squared 0.987607 S.D. dependent var 632.0272
S.E. of regression 70.35864 Akaike info criterion 11.43973
Sum squared resid 44553.05 Schwarz criterion 11.46999
不管是否带上常数项,R-squared的值都非常大(>0.98),而且Y的系数都通过显著性检验,说明W和Y存在高度的共线性。
(5)在满足模型的经济含义的前提下(以免造成模型设置失误),我们还是可以通过舍去W或者Y来消除共线性的
2、解:
(1)首先我们发现各个变量在数量级上存在较大差别,所以我们一般考虑对数线性回归模型。如果我们的对数回归模型中包含了所有的解释变量,则得到如下的结果:Dependent Variable: LOG(Y)
Method: Least Squares
Date: 07/02/06 Time: 20:31
Sample: 1971 1986
LOG(X2) 1.790153 0.873240 2.050012 0.0675
LOG(X3) -4.108518 1.599678 -2.568341 0.0280
LOG(X4) 2.127199 1.257839 1.691154 0.1217
LOG(X5) -0.030448 0.121848 -0.249884 0.8077
R-squared 0.854803 Mean dependent
var
9.204273
Adjusted R-squared 0.782205 S.D. dependent var 0.119580
S.E. of regression 0.055806 Akaike info criterion -2.65387
4
Sum squared resid 0.031143 Schwarz criterion -2.36415
3
Log likelihood 27.23099 F-statistic 11.77442
我们发现R-squared=0.854803>0.80,LOG(X4) 、LOG(X5) 、LOG(X6)都不能通过0.10的显著性检验。我们可以得出结论,各变量之间存在多重共线性。
(2)由于有5个解释变量,我们可以考虑消除部分解释变量重新对参数进行估计,以得到正确的回归方程。
我们首先得到个解释变量之间的相关系数矩阵:
X2 X3 X4 X5 X6
X2 1 0.996864584
32 0.991353674
836
0.525829679
627
0.972144554
185
X3 0.996864584
32 1 0.991273632
989
0.543312899
977
0.965239229
554
X4 0.991353674
836 0.991273632
989
1 0.461436278
037
0.972615371
514
X5 0.525829679
627 0.543312899
977
0.461436278
037
1 0.536184793
714
X6 0.972144554
185 0.965239229
554
0.972615371
514
0.536184793
714
1
我们发现只有X5与其它变量的相关系数较低,其余几个变量之间的相关系数都较高(>0.95),所以我们认为X5是可以留在模型中的,对于其他几个变量的选择问题就要考虑模型的实际经济含义以及各变量之间的经济关系。
从不同的角度出发,可能会去掉不同的变量。以下是考虑问题的一个角度:新车CPI
和一般的CPI高度相关(0.997),PDI和新车CPI之间也高度相关(0.991);PDI与就业水平也密切相关,两者的相关系数高达0.972。我们可以考虑去掉一般CPI和PDI。
(3)我们利用保留的X2、X5、X6来估计模型:
Dependent Variable: LOG(Y)
Method: Least Squares
Date: 07/02/06 Time: 20:52
Sample: 1971 1986
LOG(X2) -1.037839 0.330227 -3.142805 0.0085
LOG(X5) -0.294929 0.073704 -4.001514 0.0018
R-squared 0.684855 Mean dependent
9.204273
var
Adjusted R-squared 0.606069 S.D. dependent var 0.119580
S.E. of regression 0.075053 Akaike info criterion -2.12893
Sum squared resid 0.067595 Schwarz criterion -1.93578
3
Log likelihood 21.03144 F-statistic 8.692569
计量经济学题库及答案
计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用
统计学原理计算题试题及答案(最新整理)
电大专科统计学原理计算题试题及答案 计算题 1某单位40名职工业务考核成绩分别为 68 89 8884 86 87 75 73 72 68 75 82 9758 81 54 79 76 95 76 71 60 9065 76 72 76 85 89 92 64 57 83 81 78 77 72 61 70 81 单位规定:60分以下为不及格,60 — 70分为及格,70 — 80分为中,80 — 90 分为良,90 — 100分为优。 要求: (1)将参加考试的职工按考核成绩分为不及格、及格、中、良、优五组并编制一张考核成绩次数分配表; (2)指出分组标志及类型及采用的分组方法; (3)分析本单位职工业务考核情况。 解:(1) (2)分组标志为”成绩",其类型为" 的开放组距式分组,组限表示方法是重叠组限; (3)本单位的职工考核成绩的分布呈两头小,中间大的”正态分布”的形态, 说明大多数职工对业务知识的掌握达到了该单位的要求。 2.2004年某月份甲、乙两农贸市场农产品价格和成交量、成交额资料如下 价格(元/斤) 甲市场成交额(万元) 乙市场成交量(万斤) 品种
试问哪一个市场农产品的平均价格较高?并说明原因 解:先分别计算两个市场的平均价格如下: 甲市场平均价格 X m 5.5 1.375 (元 /斤) m/x 4 乙市场平均价格 X xf 5.3 1.325 (元 / 斤) f 4 说明:两个市场销售单价是相同的,销售总量也是相同的,影响到两个市场 平均价格高低不同的原因就在于各种价格的农产品在两个市场的成交量不同 3. 某车间有甲、乙两个生产组,甲组平均每个工人的日产量为 36件, 标准差为9.6件;乙组工人日产量资料如下:
计量经济学试题与答案修改汇总
《计量经济学》复习资料 第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的___数量关系_______为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为______经济理论____、______统计学____、___数学_______三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的____理论______关系,用______确定____性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间的____定量_____关系,用_____随机_____性的数学方程加以描述。3.经济数学模型是用___数学方法_______描述经济活动。第一章绪论 4.计量经济学根据研究对象和内容侧重面不同,可以分为___理论_______计量经济学和___应用_______计量经济学。 5.计量经济学模型包括____单方程模型______和___联立方程模型_______两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即选择变量、确定变量之间的数学关系、拟定模型中待估计参数的取值范围。 7.确定理论模型中所包含的变量,主要指确定__解释变量________。 8.可以作为解释变量的几类变量有_外生经济_变量、_外生条件_变量、_外生政策_变量和_滞后被解释_变量。 9.选择模型数学形式的主要依据是_经济行为理论_。 10.研究经济问题时,一般要处理三种类型的数据:_时间序列_数据、_截面_数据和_虚变量_数据。 11.样本数据的质量包括四个方面_完整性_、_可比性_、_准确性_、_一致性_。
12.模型参数的估计包括_对模型进行识别_、_估计方法的选择_和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是_经济意义检验、_统计检验、_计量经济学检验和_预测检验。 14.计量经济模型的计量经济检验通常包括随机误差项的_异方差_检验、_序列相关_检验、解释变量的_多重共线性_检验。 15.计量经济学模型的应用可以概括为四个方面,即_结构分析_、_经济预测_、_政策评价_、_检验和发展经济理论_。 16.结构分析所采用的主要方法是_弹性分析_、_乘数分析_和_比较静力分析_。 二、单选题: 1.计量经济学是一门(B)学科。 A.数学 B.经济 C.统计 D.测量 2.狭义计量经济模型是指(C)。 A.投入产出模型 B.数学规划模型 C.包含随机方程的经济数学模型 D.模糊数学模型 3.计量经济模型分为单方程模型和(C)。 A.随机方程模型 B.行为方程模型 C.联立方程模型 D.非随机方程模型 4.经济计量分析的工作程序(B) A.设定模型,检验模型,估计模型,改进模型 B.设定模型,估计参数,检验模型,应用模型 C.估计模型,应用模型,检验模型,改进模型 D.搜集资料,设定模型,估计参数,应用模型 5.同一统计指标按时间顺序记录的数据列称为(B) A.横截面数据 B.时间序列数据 C.修匀数据 D.平行数据
统计学原理(第五版)》习题计算题答案详解
《统计学原理(第五版)》习题计算题答案详解 第二章 统计调查与整理 1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404 第三章 综合指标 1. 见教材P432 2. %86.12270 25 232018=+++= 产量计划完成相对数 3. 所以劳动生产率计划超额%完成。 4. %22.102% 90% 92(%)(%)(%)=== 计划完成数实际完成数计划完成程度指标 一季度产品单位成本,未完成计划,还差%完成计划。 5. %85.011100%8% 110% 1=?++==计划完成数实际完成数计划完成程度指标计划完成数;所以计划完成数实际完成数标因为,计划完成程度指%105%103= = 1.94%%94.101% 103% 105,比去年增长解得:计划完成数==()得出答案)将数值带入公式即可以计算公式, 上的方程,给大家一个很多同学都不理解也可以得出答案,鉴于(根据第三章天)。 个月零天(也即是个月零(月)也就是大约)(上年同季(月)产量达标季(月)产量超出计划完成产量 达标期完成月数计划期月数超计划提前完成时间达标期提前完成时间完成计划的时间万吨。根据公式:提前多出万吨,比计划数万吨产量之和为:季度至第五年第二季度方法二:从第四年第三PPT PPT 6868825.8316-32070 -7354-60--3707320181718=+=+=+==+++()天完成任务。个月零 年第四季度为止提前(天),所以截止第五)(根据题意可设方程:万吨完成任务。天达到五年第二季度提前万吨。根据题意,设第万吨达到原计划,还差万吨产量之和为:季度至第五年第一季度方法一:从第四年第二6866891 -91*20)181718(1916707016918171816=++++=+++x x x
计量经济学题库及答案
2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入
统计学计算题答案..
第 1 页/共 12 页 1、下表是某保险公司160名推销员月销售额的分组数据。书p26 按销售额分组(千元) 人数(人) 向上累计频数 向下累计频数 12以下 6 6 160 12—14 13 19 154 14—16 29 48 141 16—18 36 84 112 18—20 25 109 76 20—22 17 126 51 22—24 14 140 34 24—26 9 149 20 26—28 7 156 11 28以上 4 160 4 合计 160 —— —— (1) 计算并填写表格中各行对应的向上累计频数; (2) 计算并填写表格中各行对应的向下累计频数; (3)确定该公司月销售额的中位数。 按上限公式计算:Me=U- =18-0.22=17,78 2、某厂工人按年龄分组资料如下:p41 工人按年龄分组(岁) 工人数(人) 20以下 160 20—25 150 25—30 105 30—35 45 35—40 40 40—45 30 45以上 20 合 计 550 要求:采用简捷法计算标准差。《简捷法》 3、试根据表中的资料计算某旅游胜地2004年平均旅游人数。P50 表:某旅游胜地旅游人数 时间 2004年1月1日 4月1日 7月1日 10月1日 2005年1月1 日 旅游人数(人) 5200 5000 5200 5400 5600 4、某大学2004年在册学生人数资料如表3-6所示,试计算该大学2004年平均在册学生人数. 时间 1月1日 3月1日 7月1日 9月1日 12月31日 在册学生人数(人) 3408 3528 3250 3590 3575
计量经济学期末考试题库(完整版)与答案
计量经济学题库 、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量 4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量 9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量 B.控制变量 C.政策变量 D.滞后变量 12.( B )是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量 B.内生变量 C.前定变量 D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据 B.时间序列数据 C.修匀数据 D.原始数据 14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价 B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、 D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是( A )。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指( D )。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系 D.变量间不确定性的依存关系
计量经济学试题
一、填空题(本大题共10小题,每空格1分,共20分) 1、数理经济模型揭示经济活动中各个因素之间的_理论_关系,用__确定___性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间的___定量____关系,用__随机___性的数学方程加以描述。 2、选择模型数学形式的主要依据是____经济行为理论______。 3、被解释变量的观测值i Y 与其回归理论值)(Y E 之间的偏差,称为___随机误差 项_______;被解释变量的观测值i Y 与其回归估计值i Y ? 之间的偏差,称为___残差_______。 4、对计量经济学模型作统计检验包括__拟合优度检验、方程的显著性检验、变量的显著性检验 5、总体平方和TSS 反映__被解释变量观测值与其均值__之离差的平方和;回归平方和ESS 反映了_被解释变量其估计值与其均值之离差的平方和;残差平方和RSS 反映了_被解释变量观测值与其估计值之差的平方和。 6、在多元线性回归模型中,解释变量间呈现线性关系的现象称为_多重共线____问题。 7、工具变量法并没有改变原模型,只是在原模型的参数估计过程中用工具变量“替代” 随机解释变量 8、以截面数据为样本建立起来的计量经济模型中的随机误差项往往存在_异方差_________。 9、在联立方程模型中,___内生变量_______既可作为被解释变量,又可以在不同的方程中作为解释变量。 10多元线性回归中,如果自变量的量纲不同,需要对样本原始数据进行 __标准化__处理,然后用最小二乘法去估计未知参数,这样做的目的是可以考察各个自变量的__相对重要性_。 二、选择题(本大题共15小题,每小题2分,共30分) 1、下图中“{”所指的距离是( B ) A. 随机误差项 B. 残差 C. i Y 的离差 D. i Y ?的离差 2、总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是(B )。 X 1?β+ i Y
《统计学》计算题型与参考答案
《统计学》计算题型 (第二章)1.某车间40名工人完成生产计划百分数(%)资料如下:9065 100 102 100 104 112 120 124 98 110110 120 120 114 100 109 119 123 107 110 99 132 135 107 107 109 102 102 101 110 109 107 103 103 102 102 102 104 104 要求: (1)编制分配数列;(4分) (2)指出分组标志及其类型;(4分) (3)对该车间工人的生产情况进行分析。(2分) 解答: (1)
(2)分组标志:生产计划完成程度 类型:数量标志 (3)从分配数列可以看出,该计划未能完成计划的有4人,占10%,超额完成计划在10%以内的有22人,占55%,超额20%完成的有7人,占17.5%。反映该车间,该计划完成较好。 (第三章)2.2005年9份甲、乙两农贸市场某农产品价格和成交量、成交额资料如下: 试问哪一个农贸市场农产品的平均价格较高?(8分)并分析说明原因。(2分) 解答: (1)x 甲=∑∑m x m 1=24 8.41 6.36.314.24.21246.34.2?+?+?++=30/7=4.29(元) x 乙= ∑∑f xf = 1 241 8.426.344.2++?+?+?=21.6/7=3.09(元) (2)原因分析:甲市场在价格最高的C 品种成交量最高,而乙市场是在最低的价格A 品种成交量最高,根据权数越大其对应的变量值对平均数的作用越大的原理,可知甲市场平均价格趋近于C ,而乙市场平均价格却趋近于A ,所以甲市场平均价格高于乙市场平均价格。
统计学练习题及答案
2014统计学练习题及答案 一判断题 1、某企业全部职工的劳动生产率计划在去年的基础上提高8%,计划执行结果仅提高4%,则劳动生产率的任务仅实现一半。(错) 2、在统计调查中,调查标志的承担者是调查单位。( 错) 3、制定调查方案的首要问题是确定调查对象。( 错) 4、正相关指的就是因素标志和结果标志的数量变动方向都是上升的。( 错) 5、现象之间的函数关系可以用一个数学表达式反映出来。(对) 6.上升或下降趋势的时间序列,季节比率大于1,表明在不考虑其他因素影响时,由于季.的影响使实际值高于趋势值,(对) 7.特点是“先对比,后综合。”(错 8.隔相等的时点数列计算平均发展水平时,应用首尾折半的方法。( 错) 9.均数指数的计算特点是:先计算所研究对象各个项目的个体指数;然后将个体指数进行加权平均求得总指数。( 错) 10.和样本指标均为随机变量。( 错) 11.距数列中,组数等于数量标志所包含的变量值的个数。(对) 12.中值是各组上限和下限之中点数值,故在任何情况下它都能代表各组的一般水平。( 错) 13.标志和数量标志都可以用数值表示,所以两者反映的内容是相同的。(错) 14.变异度指标越大,均衡性也越好。( 对) 15.于资料的限制,使综合指数的计算产生困难,就需要采用综合指数的变形公式平均数指数。( 错) 16.计量是随机变量。(对) 17.数虽然未知,但却具有唯一性。(错) 18.标和数量标志都可以用数值表示,所以两者反映的内容是相同的(错) 19.以经常进行,所以它属于经常性调查(错) 20.样本均值来估计总体均值,最主要的原因是样本均值是可知的。()答案未 21.工业普查中,全国工业企业数是统计总体,每个工业企业是个体。(错) 22.标志的承担者,标志是依附于个体的。(对) 23.志表明个体属性方面的特征,其标志表现只能用文字来表现,所以品质标志不能转化为统计指标。(错) 24.标和数量标志都可以用数值表示,所以两者反映的内容是相同的。(错) 25.计指标都是用数值表示的,所以数量标志就是统计指标。(错) 26.标及其数值可以作为总体。(错) 27.润这一标志可以用定比尺度来测定。(错) 28.统计学考试成绩分别为55分,78分,82分,96分,这4个数字是数量指标。(错) 29.术学派注重对事物性质的解释,而国势学派注重数量分析。(错) 30.是统计研究现象总体数量的前提。(对) 31.析中,平均发展速度的计算方法分水平法和方程两种。(错) 32.数值越大,说明相关程度越高:同理,相关系数的数值越小,说明相关程度越低(对 33.志是总体同质性特征的条件,而不变标志是总体差异性特征的条件。(错) 34.度具有另外三种尺度的功能。(对) 35.民旅游意向的问卷中,“你最主要的休闲方式是什么?”,这一问题应归属于事实性问题
斯托克,沃森计量经济学第七章实证练习stata
E7.2 E7.3 E7.4
-------------------------------------------- (1) (2) ahe ahe -------------------------------------------- age 0.605*** 0.585*** (15.02) (16.02) female -3.664*** (-17.65) bachelor 8.083*** (38.00) _cons 1.082 -0.636 (0.93) (-0.59) (表2)Robust ci in parentheses *** p<0.01, ** p<0.05, * p<0.1 -------------------------------------------- N 7711 7711 -------------------------------------------- t statistics in parentheses * p<0.10, ** p<0.05, *** p<0.01 (表1) (1) 建立ahe 对age 的回归。截距估计值是1.082,斜率估计值是0.605。 (2) ①建立ahe 对age ,female 和bachelor 的回归。Age 对收入的效应的估计值是0.585。 ② age 回归系数的95%置信区间: (0.514,0.657) (3) 设H 0:βa,(2)-βa,(1)=0 H1:βa,(2)-βa (1)≠0 由表3,得SE ,SE(βa,(2)-βa,(1))=√(0.0403)2+(0.0365)2=0.054 t=(0.605-0.585)/0.054=0.37<1.96 所以不拒绝原假设,即在5%显著水平下age 对ahe 的效应估计没有显著差异,所以(1)中的回归没有遭遇遗漏变量偏差。 (4) B ob’s predicted ahe=0.585×26-3.664×0+8.083×0-0.636=$14.574 Alexis ’s predicted ahe=0.585×30-3.664×1+8.083×1-0.636=$21.333 VARIABLES ahe age 0.585*** (0.514 - 0.657) female -3.664*** (-4.071 - -3.257) bachelor 8.083*** (7.666 - 8.500) Constant -0.636 (-2.759 - 1.487) Observations 7,711 R-squared 0.200
计量经济学期末考试题库完整版)及答案
计量经济学题库、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是(A )。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是( D )。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.( B )是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是( A )。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指( D )。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性
计量经济学期末考试试卷集含答案
财大计量经济学期末考试标准试题 计量经济学试题一 (1) 计量经济学试题一答案 (4) 计量经济学试题二 (9) 计量经济学试题二答案 (11) 计量经济学试题三 (15) 计量经济学试题三答案 (18) 计量经济学试题四 (22) 计量经济学试题四答案 (25) 计量经济学试题一 课程号:课序号:开课系:数量经济系 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。() 2.多元回归模型统计显着是指模型中每个变量都是统计显着的。() 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。() 4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。()5.线性回归是指解释变量和被解释变量之间呈现线性关系。() R的大小不受到回归模型中所包含的解释变量个数的影响。()6.判定系数2 7.多重共线性是一种随机误差现象。()
8.当存在自相关时,OLS估计量是有偏的并且也是无效的。() 9.在异方差的情况下,OLS估计量误差放大的原因是从属回归的2R变大。()10.任何两个计量经济模型的2R都是可以比较的。() 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 三.下面是我国1990-2003年GDP对M1之间回归的结果。(5分) 1.求出空白处的数值,填在括号内。(2分) 2.系数是否显着,给出理由。(3分) 四.试述异方差的后果及其补救措施。(10分) 五.多重共线性的后果及修正措施。(10分) 六.试述D-W检验的适用条件及其检验步骤?(10分) 七.(15分)下面是宏观经济模型 变量分别为货币供给M、投资I、价格指数P和产出Y。 1.指出模型中哪些是内是变量,哪些是外生变量。(5分) 2.对模型进行识别。(4分) 3.指出恰好识别方程和过度识别方程的估计方法。(6分) 八、(20分)应用题 为了研究我国经济增长和国债之间的关系,建立回归模型。得到的结果如下:Dependent Variable: LOG(GDP) Method: Least Squares Date: 06/04/05 Time: 18:58 Sample: 1985 2003 Included observations: 19 Variable Coefficient Std. Error t-Statistic Prob.
(完整版)统计学复习题答案
一、主要术语 描述统计 ....:研究数据收集、处理和描述的统计学分支。 推断统计 ....:研究如何利用样本数据来推断总体特征的统计学分支。 观测数据 ....:在没有对事物进行人为控制的条件下,通过调查或观测而收集到的数据。 实验数据 ....:在实验中控制实验对象而收集到的数据。 异众比率 ....:非众数组的频数占总频数的比率。 四分位差 ....:也称为内距或四分间距,上四分位数与下四分位数之差. 。 显著性水平 .....:假设检验中发生第Ⅰ类错误的概率,记为 P-.值.:也称观察到的显著性水平或实测显著性水平,是根据样本观测值计算出来的概率。 拟合优度检验 ......:根据样本观测结果与原假设为真条件下期望结果的吻合程度,来检验总体是否服从某种分布。一般地,可以用于任何假设的概率分布。 独立性检验 .....:检验两个分类变量之间是否存在相关关系。 多个总体比例差异检验 ..........:检验多个总体比例是否都相等。 消费者物价指数 .......:又称居民消费价格指数,反映一定时期内城乡居民所购买的生活消费品价格和服务项目价格的变动程度的一种相对数。 生产者价格指数 .......:反映企业产品出厂价格变动趋势和变动程度的一种相对数。 股票价格指数 ......:是反映某一股票市场上多种股票价格变动趋势的一种相对 二.简答和计算P41—P42: 2.2比较概率抽样和非概率抽样的特点。举例说明什么情况下适合采用概率抽样,什么情况下适合采用非概率抽样。 概率抽样的特点:简单随机抽样、系统抽样(等距抽样)、分层抽样(类型抽样)和整群抽样。非概率抽样的特点:方便抽样、定额抽样、立意抽样、滚雪球抽样和空间抽样。 2.6你认为应当如何控制调查中的回答误差? 回答误差是指被调查者接受调查时给出的答案与实际不符。导致回答误差的原因有多种,主要有理解误差、记忆误差及意识误差。 调查一方在调查时可协助被调查者一方共同完成调查,被调查方不了解的调查方可帮助解释、阐明,这样可减少误差。 2.7怎样减少无回答?请通过一个例子,说明你所考虑到的减少无回答的具体措施。 可通过优选与培训采访人员、加强调查队伍管理、准确定位调查对象、保证问卷的送达率等加以预防,采取物质奖励、消除疑虑、提前告知和事中提醒等加以控制,采用多次访问、替换被调查单位、随机化回答技术等方法来降低无回答率。 2.8如何设计调查方案? 第一步:确定调查目的 第二步:确定调查对象和调查单位 第三步:确定调查项目和调查表 第四步:调查表格和问卷的设计 第五步:确定调查时间和调查方法等
计量经济学试题库和答案
计量经济学题库(超完整版)及答案 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C )。 A .统计学 B .数学 C .经济学 D .数理统计学 2.计量经济学成为一门独立学科的标志是(B )。 A .1930年世界计量经济学会成立 B .1933年《计量经济学》会刊出版 C .1969年诺贝尔经济学奖设立 D .1926年计量经济学(Economics )一词构造出来3.外生变量和滞后变量统称为(D )。 A .控制变量 B .解释变量 C .被解释变量 D .前定变量 4.横截面数据是指(A )。 A .同一时点上不同统计单位相同统计指标组成的数据 B .同一时点上相同统计单位相同统计指标组成的数据 C .同一时点上相同统计单位不同统计指标组成的数据 D .同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C )。 A .时期数据 B .混合数据 C .时间序列数据 D .横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A .内生变量 B .外生变量 C .滞后变量 D .前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A .微观计量经济模型 B .宏观计量经济模型 C .理论计量经济模型 D .应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A .控制变量 B .政策变量 C .内生变量 D .外生变量 9.下面属于横截面数据的是()。 A .1991-2003年各年某地区20个乡镇企业的平均工业产值 B .1991-2003年各年某地区20个乡镇企业各镇的工业产值 C .某年某地区20个乡镇工业产值的合计数 D .某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。 A .设定理论模型→收集样本资料→估计模型参数→检验模型 B .设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A .虚拟变量 B .控制变量 C .政策变量 D .滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A .外生变量 B .内生变量 C .前定变量 D .滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A .横截面数据 B .时间序列数据 C .修匀数据 D .原始数据 14.计量经济模型的基本应用领域有()。 A .结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C .消费需求分析、生产技术分析、 D .季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A .函数关系与相关关系 B .线性相关关系和非线性相关关系
统计学计算题答案(课后)
9. (1)工人日产量平均数: 45 60 55 140 65 260 75 150 85 50 660 =64.85(件 / 人) (2)通过观察得知,日产量的工人数最多为 260人,对应的分组为 60~70,则众数在60~70这一组中,则众数的取值范围在 60~70 之间。 利用下限公式计算众数: n x f i i i 1 n f i i 1 众数M ° (f m f m 1 )
=65.22 (件) (3)首先进行向上累计,计算出各组的累计频数: 10.(1)全距 只=最大的标志值一最小的标志值 =95—55=40 x f ⑵平均日装配部件数x ―」 55 4 65 12 75 24 85 6 95 4 50 =73.8 (个) n _ X i x f i i 1 n 260 140 (260 140 (260 15C) (70 60) 660 1 2 330.5 比较各组的累计频数和 330.5,确定中位数在60~70这一组 利用下限公式计算中位数: ~~2- S m 1 M e L 壬 60 660 200 2 (70 60) 65(件) 260 ⑷分析:由于x M e M o , 所以该数列的分布状态为左偏。 平均差 A.D
f i i 1 |55 73.8 4 |65 73.8| 12 |75 73.8| 24 |85 73.8 6 |95 73.8 4 4 12 24 6 4 =7.232 (件)
⑷标准差系数V -100% x 9.93 73.8 13.46% X i f i 30 4 50 25 70 84 90 126 110 28 267 =81.16 (件) 乙企业的平均日产量X 乙 xf j 30 2 50 8 70 30 90 42 110 18 2 (X i X) f i i 1 n f i i 1 2 2 2 2 2 (55 73.8) 4 (65 73.8) 12 (75 73.8) 24 (85 73.8) 6 (95 73.8) 4 ⑶方差 4 12 24 6 4 =98.56 (个) 标准差 n (x x)2 f i i 1 n 、、98.56 9.93(件) 13. 甲企业的平均日产量x 甲
计量经济学试题及答案最新
计量经济学试题及答案(3) ⒈(12分)某人试图建立我国煤炭行业生产方程,以煤炭产量为被解释变量,经过理论和经验分析,确定以固定资产原值、职工人数和电力消耗量变量作为解释变量,变量的选择是正确的。于是建立了如下形式的理论模型: 煤炭产量= 固定资产原值+ 职工人数+ 电力消耗量+μ 选择2000年全国60个大型国有煤炭企业的数据为样本观测值;固定资产原值用资产形成年当年价计算的价值量,其它采用实物量单位;采用OLS方法估计参数。指出该计量经济学问题中可能存在的主要错误,并简单说明理由。 ⒉(12分)以表示粮食产量,表示播种面积,表示化肥施用量,经检验,它们取对数后都是变量且互相之间存在关系。同时经过检验并剔除不显著的变量(包括滞后变量),得到如下粮食生产模型: (1) ⑴写出长期均衡方程的理论形式; ⑵写出误差修正项ecm的理论形式; ⑶写出误差修正模型的理论形式; ⑷指出误差修正模型中每个待估参数的经济意义。 ⒊(6分)对于上述粮食生产模型(1),假设所有解释变量与随机误差项都不相关。 ⑴如果采用普通最小二乘法估计,用非矩阵形式写出关于参数估计量的正规方程组; ⑵从以上正规方程组出发说明,为什么不能采用分部回归方法分别估计每个参数; ⒋(9分)投资函数模型 为一完备的联立方程计量经济模型中的一个方程,模型系统包含的内生变量为C(居民消费总额)、I(投资总额)和Y(国内生产总值),先决变量为(政府消费)、和。样本容量为。 ⑴可否用狭义的工具变量法估计该方程?为什么? ⑵如果采用2SLS估计该方程,分别写出2SLS估计量和将它作为一种工具变量方法的估计量的矩阵表达式; ⑶如果采用GMM方法估计该投资函数模型,写出一组等于0的矩条件。 ⒌(6分)建立城镇居民食品类需求函数模型如下: 其中V为人均购买食品支出额、Y为人均收入、为食品类价格、为其它商品类价格。 ⑴指出参数估计量的经济意义是否合理,为什么? ⑵为什么经常采用交叉估计方法估计需求函数模型? ⒍(9分)选择两要素一级CES生产函数的近似形式建立中国电力行业的生产函数模型: 其中Y为发电量,K、L分别为投入的资本与劳动数量,t为时间变量。 ⑴指出参数γ、ρ、m的经济含义和数值范围;
统计学计算题及答案
1002 1050 1 ■ 1050 1020 汇2 = 1032 (人) 上半年平均人数: 1002 1050 1 1050 1020 2 1020 1008 3 二 1023 计算题 1 .某公司某年9月末有职工250人,10月上旬的人数变动情况是:10月4日新招 聘12名大学生上岗,6日有4名老职工退休离岗,8日有3名青年工人应征入伍, 同日又有3名职 工辞职离 岗,9日招聘7名营销人员上岗。试计算该公司 10月上旬的平均在岗人数。 af 250 3 262 2 258 2 252 1 259 2 答案1 . a 256 送 f 3+2+2+1+2 要求:⑴具体说明这个时间序列属于哪一种时间序列。 (2)分别计算该银行2001年第一季度、第二季度和上半年的平均现金库存额。 1)这是个等间隔的时点序列 (答案: 3° - a , - a 2,a 3 亠,亠 a n 」-3n 2 - 2 n 第一季度的平均现金库存额: 500 520 + 480 +450 + 2 2 3 第二季度的平均现金库存额: 二480 (万元) 500 580 550 600 2 2 3 上半年的平均现金库存额: = 566 .67(万元) 500 580 + 480 + …+550 +600 + 2 -------------------------------------------- J 二 52 3 .33,或 = 480 566.67 = 523.33 6 答:该银行2001年第一季度平均现金库存额为 480万元,第二季度平均现金库存额为 566.67 万元,上半年的平均现金库存额为 523.33万元. 3某单位上半年职工人数统计资料如下: 要求计算:①第一季度平均人数;②上半年平均人数 答案:第一季度平均人数 2 12 3
计量经济学题库(超完整版)及答案.
计量经济学题库 计算与分析题(每小题10分) 1 X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3=,Y 554.2=,2 X X 4432.1∑(-)=, 2 Y Y 68113.6∑ (-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。 问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2 Y Y 68113.6∑(-)=, 求判定系数和相关系数。 5.有如下表数据