方差分析操作

1、单因素方差分析(One-Way ANOV A)操作原理
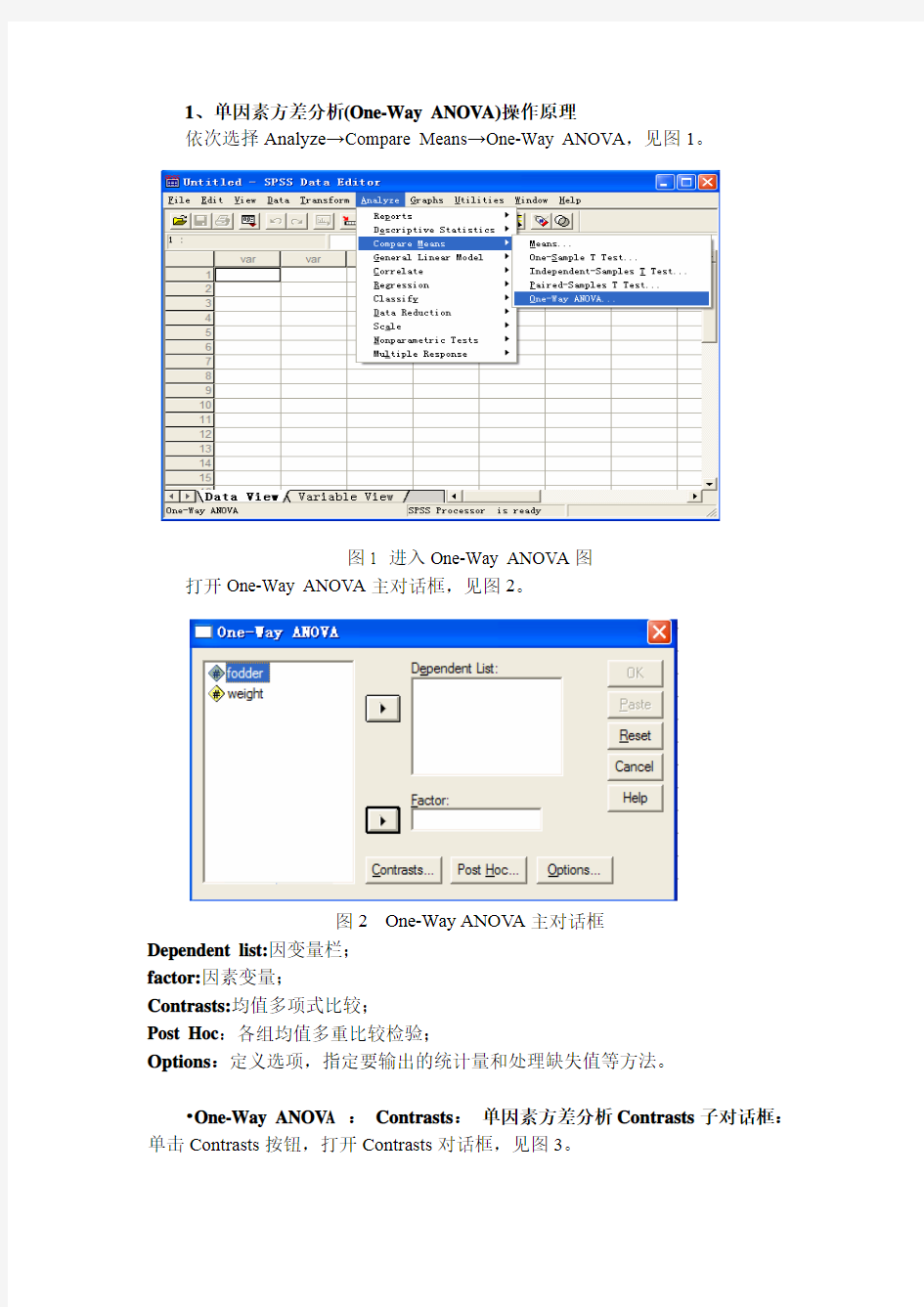
依次选择Analyze→Compare Means→One-Way ANOV A,见图1。
图1 进入One-Way ANOV A图
打开One-Way ANOV A主对话框,见图2。
图2 One-Way ANOV A主对话框
Dependent list:因变量栏;
factor:因素变量;
Contrasts:均值多项式比较;
Post Hoc:各组均值多重比较检验;
Options:定义选项,指定要输出的统计量和处理缺失值等方法。
?One-Way ANOV A : Contrasts:单因素方差分析Contrasts子对话框:单击Contrasts按钮,打开Contrasts对话框,见图3。
图3 One-Way ANOV A Contrasts子对话框
Polynominal:多项式。选择就可以激活其右边的Degree小菜单;Degree:程度:可选择linear(线性)、quadratic(二次多项式)、cubic(三次多项式)、4th(四次多项式) 、5 th(五次多项式);
Coeffients: 系数。为多项式指定各组均值的系数,因素变量有几组就输入几个系数。
Coeffients Total:系数总计。
?One-Way ANOV A :Post Hoc :单因素方差分析Post Hoc子对话框:
单击Post Hoc 按钮,打开Post Hoc子对话框,见图4。
图4 One-Way ANOV A Post Hoc子对话框
Equal variances assumed:假定方差齐性。在该条件下,由十四种比较均值的方法可供选择,常用的有以下几种:
LSD:最小显著差异法,用T检验完成各组均值之间的两两比较;
Bonferroni:修正最不显著差异法,用T检验完成各组均值之间的配对比较;
S-N-K:用student range 分布进行所有各组均值间的配对比较;
Scheffe:佛检验法,对所有可能的组合进行同步进入的配对比较;
Dunnet:修复极差法;
Dunnett:指定一组为对照组,然后将其逐个与其他组进行两两比较,此方法可选择双尾或单尾检验;
Equal variances Not Assumed:假定方差齐次。
Significance level:显著性水平,系统默认值为0.05。
?One-Way ANOV A :Options:单因素方差分析Options对话框:
单击Options 按钮,打开Options 子对话框,见图5。
图5 One-Way ANOV A Options 子对话框
Statistics:统计量;
Descriptive:描述统计量;
Fixed and random effects:描述标准离差和误差检验;
Homogeneity of variances test:方差齐次性检验;
Brown-Forsythe:布朗均值检验;
Welch:威兹均值检验;
Means Plot:均值散点图;
Missing Values:缺损值处理方法;
Exclude cases analysis by analysis:根据缺损值是因变量还是自变量从有关的分析中剔除;
Exclude cases listwise:剔除所有含有缺损值的观测值。
2.单变量方差分析(Univariate)操作原理
选择Analyze→General Lineal Model→Univariate ,即见图6。
图6 进入Univariate图得到Univariate主对话框,见图7所示:
图7 Univariate主对话框 Dependent list:因变量栏;
Fixed factor(s): 固定因素栏;
Random factor(s): 随机因素栏;
Covariare(s): 协变量栏;
WLS Weight : 加权变量栏,放入加权变量作最小二乘法( WLS)分析。Model : 设置模型按钮;
Contracts: 设置对照按钮;
Posts: 绘图按钮;
Save:储存按钮;
Options:选项按钮。
?Univariate :model:单变量方差分析model子对话框:
单击model 按钮,打开model子对话框,见图8。
图8 Univariate model子对话框
Specify Model:指定模型选项;
Factors and Covariates(默认模型):全析因模型。包括:各因素主效应,协变量效应和因素间的交互效应;
Custom:自定义模型;点击激活Factor 和 Model;
Factor:因素栏;列出源因素;
Model:模型栏,放入自定义模型个因素的构成;
Interaction:效应选项。可选择主效应(Main Effect)或任一种交互(interaction);
Sum of squares:平方和选项。可选择下列任一类平方和:
Type I:一类平方和。常用于:
平衡数据方差分析模型;任何一级交互效应之前的主效应;二级交互效应之前的一级交互效应;等等;
多项式回归模型;任何高次项之前的低次项;
单纯巢状设计模型;第二指定效应嵌套的第一指定效应,第三指定效应嵌套的第二指定效应,等等。
Type II: 二类平方和。常用于:平衡数据方差分析模型;
任何仅包含主效应的模型;
单纯巢状设计模型。
Type III: 三类平方和。系统默认值。常用于:
一类和二类平方和所使用的模型;
无空格字的平衡或不平衡数据模型。
Type IV: 四类平方和。常用于:
一类和二类平方和所使用的模型;
有无空格字的平衡或不平衡数据模型。
Include intercept in model(默认选项):模型中含有截距。
?Univariate :Contrast:单变量方差分析Contrast 子对话框:
单击Contrast按钮,打开Contrast对话框,见图9。
图9 Univariate Contrast子对话框
Factors:因素栏。列出单变量方差分析对话框的各种因素和对照方框; Change Contrast:改变对照方法;
Contrast:对照方法选项;
None(默认选项):不设立对照;
Deviation:预测变量或因素各种水平的效应与总效应比较。选择Last或First作为忽略水平;
Simple: 预测变量或因素各种水平的效应与参照效应比较。选择Last或First作为忽略水平;
Difference:除第一水平外,预测变量或因素各种水平的效应与其之前的平均效应比较。是Hlemert的逆行法;
Hlemert:除最后水平外,预测变量或因素各种水平的效应与其之后的平均效应比较;
Repested:除第一水平外,预测变量或因素各种水平的效应与前一效应比较;
Polynomial:第一自由度含有线性效应与预测变量或因素各种水平交叉;第二自由度含有二次效应等;各水平间隔假定均匀。
Reference Category:参照分类;
Last(默认选择项)以变量的最后水平作为参照水平;
First 以变量的第一水平作为参照水平。
★ Univariate:Profile plots:单变量方差分析:Profile plots形状图子对话框:单击Profile plots按钮,得到Profile plots对话框,见图10。
图10 Univariate Profile plots形状图子对话框
Factors: 因素栏。
Horizontal Axis: 分离线栏。放入定义分离线的因素(第二因素);
Separate Line:分离线栏。放入定义分离线的因素(第三因素);
Separate Plot:分离图栏。放入定义分离图的因素(第四因素);
Plots: 绘制栏。放入形状图的组成因素;
Add: 添加按钮。加因素到绘制栏;
Change: 改变按钮。改变绘制栏的因素;
Remove:删除按钮。删除绘制栏中标识的因素。
★ Univariate:Post Hoc Multiple Comparisons for Observed Means:均数间两两比较子对话框:
单击Profile ploc按钮,得到Post Hoc Multiple Comparisons for Observed Means对话框,见图11。
图11 Univariate:Post Hoc Multiple Comparisons for Observed Means子对话框:
Factor: 因素栏。列出固定因素;
Post Hoc Test for: 两两比较检验因素栏。放入将做两两比较的因素; Equal Variances Assumed: 假设方差齐同的两两比较方法;
Equal Variances Not Assumed: 假设方差不齐的两两比较方法。
★ Univariate:Save:变量存储对话框:
单击Save按钮,得到Save对话框,见图12。
图12 Univariate:Save变量存储对话框
Predicted Values:预测值选项:
Unstandardized:未标准化预测;
Weighted:加权未标准化预测;
Standard error:未标准化预测值的标准误差。
Diagnostics:诊断方法选项:
Cook’s distance: Cook’s距离。其值大表示当删除某case时,回归系数有实质上改变;
Leverage values:leverage值。它表示每个观察值对模型拟合的相对影响。Save to New File:储存参数的协方差矩阵到新文件夹选项;
Coefficient statistics: File…系数统计量。包括参数估计值,标准误差,残差自由度和显著性;并且存为文件。
Residuals:残差选项:
Unstandardized: 标准化残差。观察值与预测值之差;
Weighted: 权未标准化残差;
Standardized: 准化残差。残差除其标准误差的估计值;
Studentized: 生化残差。残差除以其标准差的估计值;
Deleted:删除残差。应变量值与调整预测值之差。
★ Univariate: Option:单变量方差分析:选择项子对话框
单击Option按钮,得到Option对话框,见图13。
图13 Univariate: Option选择项子对话框
Estimated Marginal Means:估计边缘均数选项;
Factor(s) and Factor interactions:因素栏。
列出单变量多因素方差分析对话框的各种可能的因素;
Display Means for:显示因素的边缘均数栏。放入计算边缘均数的因素;
Compare main effects:比较主要效能:
Confidence Interval Adjustment:主效应各种水平两两比较方法和置信区间选项:
SD(默认选择项):最小显著差值法;
Bonferrnoi: Bonferrnoi 法;
Sidak: sidak法。
Display:显示选项:
Descriptive statistics:统计描述。列出每个格子的均数、标准差和例数;
Estimates of effect size:估计效应大小。列出每个效应和每个参数估计值的偏eta平方。Eta平方统计量描述每个因素对总变异贡献的大小。Eta平方越大对总变异贡献就越大;
Observed power: 观察效能。列出每个效应和每个参数估计值的检验效能;
Parameter estimates:参数估计值。列出参数估计值,标准误差,t值,显著性和置信区间;
Contrast coefficient matrix:对照系数矩阵,列出L矩阵;
Homogeneity tests:齐性检验,列出每个应变量各因素务水平交叉的Levene 方差齐性检验;
Spread vs. Level plot:水平散点图。列出各个格子均数与标准差,均数与方差的散点图。有助于检验非齐性方差;
Residual plot:残差图,列出观察值,预计值和标准残差散点图,有助于检验数据假设性;
Lack of fit:拟合度不足,如果拒绝假设,提示模型中因变量与预测变量之间关系不满足;
General estimable function:广义估计函数。列出估计函数广义形式。通过L 矩阵子命令构造制定假设检验广义估计函数。
Significance Level(.05):Confidence intervals are 95%:检验水准为0.05,置信区间为95%CI。
方差分析简介
方差分析简介(一) 方差分析是我们从心理统计这门课就提到一个基本的统计方法。但或许很多人到做研究生毕业论文的时候,还没搞清楚到底方差分析是怎么一回事。我们的老师对很多基本的地方也是含糊不清。我就我几年学习和应用的理解,粗略讲一下方差分析是怎么回事。 什么是方差分析?就是对方差的分析。有人说你这不废话么?这还真不是废话。t检验就不是对方差的分析。独立样本t检验是对两个样本均值的差异进行检验,而相关样本t检验是对两个样本差异的均值进行检验。而方差分析就是对引起样本数据出现差异的若干因素影响孰强孰弱的分析。换句话说,当样本数据差异较小的时候,t检验会认为不存在差异,但方差分析可以从这较小的差异中分析出实验处理和随机误差谁对这个差异贡献更大。所以说在控制水平一定的情况下,方差分析更容易得到显著性水平高,但power较低的结果。(因为虽然差异贡献大,但本身差异不大。翻译为人话就是这个研究结果虽然显著但没什么意义。) 既然是对方差的分析,那么研究者对数据就有一定的要求。不是什么样的数据都适合做方差分析。这其中最重要最重要的,违反了就无从可谈的就是至少要等距数据(interval data)。因为至少等距数据才能做参数检验。称名数据(nominal data)和顺序数据(ordinal data)只能做非参数检验。既然要分析方差,就得有均值,有方差。 第二重要的是要正态分布的数据。为什么要强调数据正态分布呢?这要从平均数说起,平均数,从定义上来说,是一组数据中唯一对其离均差之和为0的数值。如果数据呈正态分布,平均数就是一组数据中最具有代表性的那个值。好比说一次考试全班的平均分为81.6分,我们大概可以知道有两个事实:1)多数同学考试分数是七八十分,2)如果你高于82分说明你考的还算不错,低于81分就说明考得不够理想。这个高低差距越大,这个结论的信心就越强。这两个结论是基于考试分数是基本上的正态分布推断出来的。如果不是正态分布怎么样呢?拿工资说话,以我所在的圣安东尼奥市为例,这个城市适合工作年龄的人,大约有55%的“蓝领”,30%的“白领”,14%学生或自由职业者,和1%的绝对高收入者。这个差别有多大呢?“蓝领”的税后工资大约是年收入25,000~45,000,白领大约是50,000~80,000,而超高收入者,例如蒂姆邓肯同学,他的税后收入大约是20,000,000。如果算个平均数,统计局说圣安东尼奥市人民平均收入高达50,000,大家过着幸福美满的生活。那55%的蓝领和14%的学生肯定想抽这个发
方差分析实验报告
非参数检验 实验报告 方差分析 学院: 参赛队员: 参赛队员: 参赛队员: 指导老师:
目录 一、实验目的 (1) 1.了解方差分析的基本内容; (1) 2.了解单因素方差分析; (1) 3.了解多因素方差分析; (1) 4.学会运用spss软件求解问题; (1) 5.加深理论与实践相结合的能力。 (1) 二、实验环境 (1) 三、实验方法 (1) 1. 单因素方差分析; (1) 2. 多因素方差分析。 (1) 四、实验过程 (1) 问题一: (1) 1.1实验过程 (1) 1.1.1输入数据,数据处理; (1) 1.1.2单因素方差分析 (1) 1.2输出结果 (3) 1.3结果分析 (3) 1.3.1描述 (3) 1.3.2方差性检验 (4) 1.3.3单因素方差分析 (4) 问题二: (4) 2.1实验步骤 (5) 2.1.1命名变量 (5) 2.1.2导入数据 (5) 2.1.3单因素方差分析 (5) 2.1.4输出结果 (7) 2.2结果分析 (7) 2.2.1描述 (7) 2.2.2方差性检验 (8)
2.2.3单因素方差分析 (8) 问题三: (8) 3.1提出假设 (8) 3.2实验步骤 (8) 3.2.1数据分组编号 (8) 3.2.2多因素方差分析 (9) 3.2.3输出结果 (13) 3.3结果分析 (14) 五、实验总结 (14)
方差分析 一、实验目的 1.了解方差分析的基本内容; 2.了解单因素方差分析; 3.了解多因素方差分析; 4.学会运用spss软件求解问题; 5.加深理论与实践相结合的能力。 二、实验环境 Spss、office 三、实验方法 1.单因素方差分析; 2.多因素方差分析。 四、实验过程 问题一: 1.1.1输入数据,数据处理; 1.1.2单因素方差分析 选择:分析→比较均值→单因素AVONA;
spss方差分析操作示范-步骤-例子
第五节方差分析的SPSS操作 一、完全随机设计的单因素方差分析 1.数据 采用本章第二节所用的例1中的数据,在数据中定义一个group变量来表示五个不同的组,变量math表示学生的数学成绩。数据输入格式如图6-3(为了节省空间,只显示部分数据的输入): 图 6-3 单因素方差分析数据输入 将上述数据文件保存为“6-6-1.sav”。 2.理论分析 要比较不同组学生成绩平均值之间是否存在显著性差异,从上面数据来看,总共分了5个组,也就是说要解决比较多个组(两组以上)的平均数是否有显著的问题。从要分析的数据来看,不同组学生成绩之间可看作相互独立,学生的成绩可以假设从总体上服从正态分布,在各组方差满足齐性的条件下,可以用单因素的方差分析来解决这一问题。单因素方差分析不仅可以检验多组均值之间是否存在差异,同时还可进一步采取多种方法进行多重比较,发现存在差异的究竟是哪些均值。 3.单因素方差分析过程 (1)主效应的检验 假如我们现在想检验五组被试的数学成绩(math)的均值差异是否显著性,可依下列操作进行。 ①单击主菜单Analyze/Compare Means/One-Way Anova…,进入主对话框,请把math选入到因变量表列(Dependent list)中去,把group选入到因素(factor)中去,如图6-4所示:
图6-4:One-Way Anova主对话框 ②对于方差分析,要求数据服从正态分布和不同组数据方差齐性,对于正态性的假设在后面非参数检验一章再具体介绍;One-Way Anova可以对数据进行方差齐性的检验,单击铵钮Options,进入它的主对话框,在Homogeneity-of-variance项上选中即可。设置如下图6-5所示: 图6-5:One-Way Anova的Options对话框 点击Continue,返回主对话框。 ③在主对话框中点击OK,得到单因素方差分析结果 4.结果及解释 (1)输出方差齐性检验结果 Test of Homogeneity of Variances MATH Levene Statistic df1 df2 Sig. 1.238 4 35 .313 上表结果显示,Levene方差齐性检验统计量的值为1.238,Sig=0.313>0.05,所以五个组的方差满足方差齐性的前提条件,如果不满足方差齐性的前提条件,后面方差分析计算F统计量的方法要稍微复杂,本章我们只考虑方差齐性条件满足的情况。 (2)输出方差分析主效应检验结果(方差分析表)
SPSS——单因素方差分析详解
SPSS——单因素方差分析 来源:李大伟的日志 单因素方差分析 单因素方差分析也称作一维方差分析。它检验由单一因素影响的一个(或几个相互独立的)因变量由因素各水平分组的均值之间的差异是否具有统计意义。还可以对该因素的若干水平分组中哪一组与其他各组均值间具有显著性差异进行分析,即进行均值的多重比较。One-Way ANOVA过程要求因变量属于正态分布总体。如果因变量的分布明显的是非正态,不能使用该过程,而应该使用非参数分析过程。如果几个因变量之间彼此不独立,应该用Repeated Measure 过程。 [例子] 调查不同水稻品种百丛中稻纵卷叶螟幼虫的数量,数据如表1-1所示。 表1-1 不同水稻品种百丛中稻纵卷叶螟幼虫数 数据保存在“data1.sav”文件中,变量格式如图1-1。 图1-1 分析水稻品种对稻纵卷叶螟幼虫抗虫性是否存在显著性差异。
1)准备分析数据 在数据编辑窗口中输入数据。建立因变量“幼虫”和因素水平变量“品种”,然后输入对应的数值,如图1-1所示。或者打开已存在的数据文件“data1.sav”。 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“Compare Means”项,在右拉式菜单中点击“0ne-Way ANOVA”项,系统 打开单因素方差分析设置窗口如图1-2。 图1-2 单因素方差分析窗口 3)设置分析变量 因变量:选择一个或多个因子变量进入“Dependent List”框中。本例选择“幼虫”。 因素变量:选择一个因素变量进入“Factor”框中。本例选择“品种”。 4)设置多项式比较 单击“Contrasts”按钮,将打开如图1-3所示的对话框。该对话框用于设置均值的多项式比较。
SPSS学习系列2方差分析报告
22. 方差分析 一、方差分析原理 1. 方差分析概述 方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。 方差分析是对总变异进行分析。看总变异是由哪些部分组成的,这些部分间的关系如何。 方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks’∧检验)。 方差分析可用于: (1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料; (2)可对两因素间交互作用差异进行显著性检验; (3)进行方差齐性检验。 要比较几组均值时,理论上抽得的几个样本,都假定来自正态总体,且有一个相同的方差,仅仅均值可以不相同。还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。所谓的方差是离均差平方和除以自由度,在方差分析中常简称为均方(Mean Square)。
2. 基本思想 基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。 根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总自由度也被分成相应的各个部分,各部分的离均差平方除以各自的自由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。 方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。 效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来自回归的变异项),等等。 当分析和确定了各个效应项S后,根据原始观察资料可计算出各个离均差平方和SS,再根据相应的自由度df,由公式MS=SS/df,求出均方MS,最后由相应的均方,求出各个变异项的F值,F值实际上是两个均方之比值,通常情况下,分母的均方是误差项的均方。
方差分析的基本思想
第一节方差分析的基本思想 1、方差分析的意义 前述的t检验和u检验适用于两个样本均数的比较,对于k个样本均数的比较,如果仍用t检验或u检验, 需比较次,如四个样本均数需比较次。假设每次比较所确定的 检验水准=0.05,则每次检验拒绝H0不犯第一类错误的概率为1-0.05=0.95;那么6次检验都不犯第一类错误的概率为(1-0.05)6=0.7351,而犯第一类错误的概率为0.2649,因而t检验和u检验不适用于多个样本均数的比较。用方差分析比较多个样本均数,可有效地控制第一类错误。方差分析(analysis of variance,ANOVA)由英国统计学家R.A.Fisher首先提出,以F命名其统计量,故方差分析又称F检验。 2、方差分析的基本思想 下面通过表5.1资料介绍方差分析的基本思想。 例如,有4组进食高脂饮食的家兔,接受不同处理后,测定其血清肾素血管紧张素转化酶(ACE)浓度(表5.1),试比较四组家兔的血清ACE浓度。 表5.1对照组及各实验组家兔血清ACE浓度(u/ml) (
由表5.1可见,26只家兔的血清ACE浓度各不相同,称为总变异;四组家兔的血清ACE浓度均数也各不相同,称为组间变异;即使同一组内部的家兔血清ACE 浓度相互间也不相同,称为组内变异。该例的总变异包括组间变异和组内变异两部分,或者说可把总变异分解为组间变异和组内变异。组内变异是由于家兔间的个体差异所致。组间变异可能由两种原因所致,一是抽样误差;二是由于各组家兔所接受的处理不同。正如第四章所述,在抽样研究中抽样误差是不可避免的,故导致组间变异的第一种原因肯定存在;第二种原因是否存在,需通过假设检验作出推断。假设检验的方法很多,由于该例为多个样本均数的比较,应选用方差分析。 方差分析的检验假设H0为各样本来自均数相等的总体,H1为各总体均数不等或不全相等。若不拒绝H0时,可认为各样本均数间的差异是由于抽样误差所致,而不是由于处理因素的作用所致。理论上,此时的组间变异与组内变异应相等,两者的比值即统计量F为1;由于存在抽样误差,两者往往不恰好相等,但相差不会太大,统计量F应接近于1。若拒绝H0,接受H1时,可认为各样本均数间的差异,不仅是由抽样误差所致,还有处理因素的作用。此时的组间变异远大于组内变异,两者的比值即统计量F明显大于1。在实际应用中,当统计量F值远大于1且大于某界值时,拒绝H0,接受H1,即意味着各样本均数间的差异,不仅是由抽样误差所致,还有处理因素的作用。 (5.1) 方差分析的基本思想是根据研究目的和设计类型,将总变异中的离均差平方和SS及其自由度分别分解成相应的若干部分,然后求各相应部分的变异;再用各部分的变异与组内(或误差)变异进行比较,得出统计量F值;最后根据F值的大小确定P值,作出统计推断。 例如,完全随机设计的方差分析,是将总变异中的离均差平方和SS及其自由度 分别分解成组间和组内两部分,SS组间/组间和SS组内/组内分别为组间变异(MS组间)和组内变异(MS组内),两者之比即为统计量F(MS组间/MS组内)。 又如,随机区组设计的方差分析,是将总变异中的离均差平方和SS及其自由度 分别分解成处理间、区组间和误差3部分,然后分别求得以上各部分的变异(MS 处理、MS 区组和MS误差),进而得出统计量F值(MS处理/MS误差、MS区组/MS误差)。 3、方差分析的计算方法 下面以完全随机设计资料为例,说明各部分变异的计算方法。将N个受试对象随机分为k组,分别接受不同的处理。归纳整理数据的格式、符号见下表:
方差分析
方差分析(Analysis of variance,简称ANOVA)为资料分析中常见的统计模型,主要为探讨连续型(Continuous)资料型态之因变量(Dependent variable)与类别型资料型态之自变量(Independent variable)的关系,当自变项的因子中包含等于或超过三个类别情况下,检定其各类别间平均数是否相等的统计模式,广义上可将T检定中变异数相等(Equality of variance)的合并T检定(Pooled T-test)视为是方差分析的一种,基于T检定为分析两组平均数是否相等,并且采用相同的计算概念,而实际上当方差分析套用在合并T检定的分析上时,产生的F值则会等于T检定的平方项。 方差分析依靠F-分布为机率分布的依据,利用平方和(Sum of square)与自由度(Degree of freedom)所计算的组间与组内均方(Mean of square)估计出F值,若有显著差异则考量进行事后比较或称多重比较(Multiple comparison),较常见的为Scheffé's method、Tukey-Kramer method与Bonferroni correction,用于探讨其各组之间的差异为何。 在方差分析的基本运算概念下,依照所感兴趣的因子数量而可分为单因子方差分析、双因子方差分析、多因子方差分析三大类,依照因子的特性不同而有三种型态,固定效应方差分析(fixed-effect analysis of variance)、随机效应方差分析(random-effect analysis of variance)与混合效应方差分析(Mixed-effect analaysis of variance),然而第三种型态在后期发展上被认为是Mixed model的分支,关于更进一步的探讨可参考Mixed model 的部份。 方差分析优于两组比较的T检定之处,在于后者会导致多重比较(multiple comparisons)的问题而致使第一型错误(Type one error)的机会增高。因此比较多组平均数是否有差异则是方差分析的主要命题。 在统计学中,方差分析(ANOVA)是一系列统计模型及其相关的过程总称,其中某一变量的方差可以分解为归属于不同变量来源的部分。其中最简单的方式中,方差分析的统计测试能够说明几组数据的平均值是否相等,因此得到两组的t测试。在做多组双变量t测试的时候,错误的几率会越来越大,特别是I型错误。因此,方差分析只在二到四组平均值的时候比较有效。 背景和名称[ 方差分析(ANOVA)是一种特殊形式的统计假设测试,广泛应用于实验数据的分析中。统计假设测试是一种根据数据进行决策的方法。测试结果(通过原假设进行计算)如果不仅仅是因为运气,则在统计学上称为显著。统计显著的结果(当可能性的p值小于临界的“显著值”)则可以推翻原假设。 在方差分析的经典应用中,原假设是假设所有数据组都是整体测试对象的完全随机抽样。这说明所有方法都有相同效果(或无效果)。推翻原假设说明不同的方法,会得到不同的效果。在操作中,假设测试限定I类型错误(假阳性导致的假科学论断)达到某一具体的值。实验者也希望II型错误(假阴性导致的缺乏科学发现)有限。II型错误受到多重因素作用,例如取样范围(很可能与试验成本有关),相关度(当实验标准高的时候,忽视发现的可能性也大)和效果范围(当对一般观察者来说效果明显,II型错误发生率就低)。 ANOVA的模式型态[编辑]
SPSS处理多元方差分析报告例子
实验三多元方差分析 一、实验目的 用多元方差分析说明民族和城乡对人均收入和文化程度的影响。 二、实验要求 调查24个社区,得到民族与城乡有关数据如下表所示,其中人均收入为年 均,单位百元。文化程度指15岁以上小学毕业文化程度者所占百分比。试依此 数据通过方差分析说明民族和城乡对人均收入和文化程度的影响。 三、实验内容 1.依次点击“分析”---- “常规线性模型”----“多变量”,将“人均收入”和“文化程 度”加到“因变量”中,将“民族”和“居民”加到“固定因子”中,如下图一所示。 民族农村城市 人均收入文化程度人均收入文化程度 1 46,50,60,68 70,78,90,93 52,58,72,75 82,85,96,98 2 52,53,63,71 71,75,86,88 59,60,73,77 76,82,92,93 3 54,57,68,69 65,70,77,81 63,64,76,78 71,76,86,90
【图一】 2.点击“选项”,将“输出”中的相关选项选中,如下图二所示: 【图二】 3.点击“继续”,“确定”得到如下表一的输出:
【表一】 常规线性模型 主体间因子 值标签N 民族 1.00 1 8 2.00 2 8 3.00 3 8 居民 1.00 农村12 2.00 城市12 描述性统计量 民族居民均值标准差N 人均收入1 农村56.0000 9.93311 4 城市64.2500 11.02648 4 总计60.1250 10.66955 8 2 农村59.7500 8.99537 4 城市67.2500 9.10586 4 总计63.5000 9.28901 8 3 农村62.0000 7.61577 4 城市70.2500 7.84750 4 总计66.1250 8.40812 8 总计农村59.2500 8.45442 12 城市67.2500 8.89458 12 总计63.2500 9.41899 24 文化程度1 农村82.7500 10.68878 4 城市90.2500 7.93200 4 总计86.5000 9.59166 8
SPSS多因素方差分析报告
体育统计与SPSS读书笔记(八)—多因素方差分析(1) 具有两个或两个以上因素的方差分析称为多因素方差分析。 多因素是我们在试验中会经常遇到的,比如我们前面说的单因素方差分析的时候,如果做试验的不是一个年级,而是多个年纪,那就成了双因素了:不同教学方法的班级,不同年级。如果再加上性别上的因素,那就成了三因素了。如果我们把实验前和试验后的数据用一个时间的变量来表示,那又多了一个时间的因素。如果每个年级都是不同的老师来上,那又多了一个老师的因素,等等等等,所以我们在设计试验的时候都要进行充分考虑,并确定自己只研究哪些因素。 下面用例子的形式来说说多因素方差分析的运用。还是用前面说单因素的例子,前面的例子说了只在五年级抽三个班进行不同教学方法的试验,现在我们还要在初二和高二各抽三个班进行不同教学方法的试验。形成年级和不同教学法班级双因素。 分析: 1.根据实验方案我们划出双因素分析的表格,可以看出每个单元格都是有重复数据(也就是不只一个数据), 年级 不同教学方法的班级 定性班 定量班 定性定量班 五年级 (班级每个人) (班级每个人) (班级每个人) 初中二年级 (班级每个人) (班级每个人) (班级每个人) 高中二年级 (班级每个人) (班级每个人) (班级每个人) 2.因为有重复数据,所以存在在数据交互效应的可能。我们来看看交效应的含义:如果在A因素的不同水平上,B因素对因变量的影响不同,则说明A、B两因素间存在交互作用。交互作用是多因素实验分析的一个非常重要的内容。如因素间存在交互作用而又被忽视,则常会掩盖因素的主效应的显著性,另一方面,如果对因变量Y,因素A与B之间存在交互作用,则已说明这两个因素都Y对有影响,而不管其主效应是否具有显著性。在统计模型中考虑交互作用,是系统论思想在统计方法中的反映。在大多数场合,交互作用的信息比主效应的信息更为有用。根据上面的判断。根据上面的说法,我也无法判断是否有交互作用,不像身高和体重那么直接。这里假设他们之间有交互作用。
方差分析实验报告
篇一:spss的方差分析实验报告 实 验 报告 篇二:方差分析实验报告 方差分析实验报告 学生姓名:琚锦涛学号:091230126 一.实验目的 根据方差分析的相关方法,利用excel中的相关工具,将数据收集,整理,从而了解方差分析的特点和性质。 二.实验内容 1.单因素方差分析 利用以下数据进行单因素方差分析,判断不同产地的原材料是否显著影响产品的质量指标; 2.双因素方差分析 利用以下数据进行双因素方差分析,检验因素a与因素b搭配下是否对其有显著差异,交互作用是否显著; 三.实验结果分析 1.单因素方差分析由以上数据可知,p-value=0.2318>0.05,因此可得出:原材料产地的这一质量指标无显著影响。 2.双因素方差分析 样本、列及交互的p-value远小于0.05,由此可得出燃料和推进器两因素对于火箭影响显著。数据来源:《应用统计学》第二版;篇三:单因素方差分析实验报告 天水师范学院数学与统计学院 实验报告 实验项目名称单因素方差分析所属课程名称实验类型设计型实验日期2011.11.22 班级 09统计一班学号 291050146 姓名成绩 【实验目的】 通过测量数据研究各个因素对总体的影响效果,判定因素在总变异中的重要程度 【实验原理】 比较因素a的r个水平的差异归结为比较这r个总体的均值.即检验假设 ho : μ1 = μ2 = … = μr, h1 : μ1, μ2, … , μr 不全相等给定显著水平α,用p 值检验法, 当p值大于α时,接受原假设ho,否则拒绝原假设ho 【实验环境】 r 2.13.1 pentinu(r)dual-core cpu e6700 3.20ghz 3.19ghz,2.00gb的内存【实验方案】 准备数据,查找相关r程序代码并进行编写运行得出结果进行分析总结 【实验过程】(实验步骤、记录、数据、分析) 1.根据四种不同配方下的元件寿命数据 材料使用寿命 a1 1600 1610 1650 1680 1700 1700 1780 a2 1500 1640 1400 1700 1750 a3 1640 1550 1600 1620 1640 1600 1740 1800 a4 1510 1520 1530 1570 1640 1600 2.利用主函数aov()编写该数据的方差分析r程序 3.运行得出结果 df sum sq mean sq f value pr(>f) a3 49212 16404 2.1659 0.1208 residuals 22 166622 7574
方差分析简介复习课程
方差分析简介 1. 引言 方差分析(analysis of variance,简称ANOV A)是一种假设检验方法,即基本思想可概述为:把全部数据的总方差分解成几部分,每一部分表示某一影响因素或各影响因素之间的交互作用所产生的效应,将各部分方差与随机误差的方差相比较,依据F分布作出统计推断,从而确定各因素或交互作用的效应是否显著。因为分析是通过计算方差的估计值进行的,所以称为方差分析。 方差分析的主要目标是检验均值间的差别是否在统计意义上显著。如果只比较两个均值,事实上方差分析的结果和t检验完全相同。只所以很多情况下采用方差分析,是因为它具有如下两个优点:(1)方差分析可以在一次分析中同时考察多个因素的显著性,比t检验所需的观测值少;(2)方差分析可以考察多个因素的交互作用。 方差分析的缺点是条件有些苛刻,需要满足如下条件:(1)各样本是相互独立的;(2)各样本数据来自正态总体(正态性:normality);(3)各处理组总体方差相等(方差齐性:homogeneity of variance)。因此在作方差分析之前,要作正态性检验和方差齐性检验,如不满足上述要求,可考虑作变量变换。常用的变量变换方法有平方根变换,平方根反正弦变换、对数变换及倒数变换等。 方差分析在医药、制造业、农业等领域有重要应用,多用于试验优化和效果分析中。 2. 单因素方差分析 2.1 基本概念 (1)试验指标:在一项试验中,用来衡量试验效果的特征量称为试验指标,有时简称指标,也称试验结果,通常用y表示。它类似于数学中的因变量或目标函数。试验指标用数量表示称为定量指标,如速度、温度、压力、重量、尺寸、寿命、硬度、强度、产量和成本等。不能直接用数量表示的指标称为定性指标。如颜色,人的性别等。定性指标也可以转化为定量指标,方法是用不同的数表示不同的指标值。(2)试验因素:试验中,凡对试验指标可能产生影响的原因都称为因素(factor),也称因子或元,类似于数学中的自变量。需要在试验中考察研究的因素,称为试验因素,有时也称为因素,通常用大写字母A、B、C、……表示。在试验中,有些因素能严格控制,称为可控因素;有些因素难以控制,称为不可控因素。试验因素是试验中的已知条件,能严格控制,所以是可控因素。通常把未被选作试验因素的可控因素和不可控因素都称为条件因素,统称为试验条件。 (3)因素水平:因素在试验中所处的各种状态或所取的不同值,称为该因素的水平(level),也简称为水平或位级,通常用下标1、2、3、……表示。若一个因素取K种状态或K个值,就称该因素为K水平因素。因素的水平,有的可以取得具体值,如6Kg、10cm;有的只能取大致范围或某个模糊概念,如软、硬、大、小、好、较好等;但
方差分析资料报告几个案例
方差分析方法 方差分析是统计分析方法中,最重要、最常用的方法之一。本文应用多个实例来阐明方差分析的应用。在实际操作中,可采用相应的统计分析软件来进行计算。 1. 方差分析的意义、用途及适用条件 1.1 方差分析的意义 方差分析又称为变异数分析或F检验,其基本思想是把全部观察值之间的变异(总变异),按设计和需要分为二个或多个组成部分,再作分析。即把全部资料的总的离均差平方和(SS)分为二个或多个组成部分,其自由度也分为相应的部分,每部分表示一定的意义,其中至少有一个部分表示各组均数之间的变异情况,称为组间变异(MS组间);另一部分表示同一组个体之间的变异,称为组变异(MS组),也叫误差。SS除以相应的自由度(υ),得均方(MS)。如MS组间>MS组若干倍(此倍数即F值)以上,则表示各组的均数之间有显著性差异。 方差分析在环境科学研究中,常用于分析试验数据和监测数据。在环境科学研究中,各种因素的改变都可能对试验和监测结果产生不同程度的影响,因此,可以通过方差分析来弄清与研究对象有关的各个因素对该对象是否存在影响及影响的程度和性质。 1.2 方差分析的用途 1.2.1 两个或多个样本均数的比较。 1.2.2 分离各有关因素,分别估计其对变异的影响。 1.2.3 分析两因素或多因素的交叉作用。 1.2.4 方差齐性检验。 1.3 方差分析的适用条件 1.3.1 各组数据均应服从正态分布,即均为来自正态总体的随机样本(小样本)。 1.3.2 各抽样总体的方差齐。 1.3.3 影响数据的各个因素的效应是可以相加的。 1.3.4 对不符合上述条件的资料,可用秩和检验法、近似F值检验法,也可以经过变量变换,使之基本符合后再按其变换值进行方差分析。一般属Poisson分布的计数资料常用平方根变换法;属于二项分布的百分数可用反正弦函数变换法;当标准差与均数之间呈正比关系,用平方根变换法又不易校正时,也可用对数变换法。 2. 单因素方差分析(单因素多个样本均数的比较) 根据某一试验因素,将试验对象按完全随机设计分为若干个处理组(各组的样本含量可相等或不等),分别求出各组试验结果的均数,即为单因素多个样本均数。 用方差分析比较多个样本均数的目的是推断各种处理的效果有无显著性差异,如各组方差齐,则用F检验;如方差不齐,用近似F值检验,或经变量变换后达到方差齐,再用变换值作F检验。如经F检验或近似F值检验,结论为各总体均数不等,则只能认为各总体均数之间总的来说有差异,但不能认为任何两总体均数之间都有差异,或某两总体均数之间有差异。必要时应作均数之间的两两比较,以判断究竟是哪几对总体均数之间存在差异。 在环境科学研究中,常常要分析比较不同季节对江、河、湖水中某种污染物的含量
方差分析两两比较
方差分析中均值比较的方法 最近看文献时,多数实验结果用到方差分析,但选的方法不同,主要有LSD,SNK-q,TukeyHSD法等,从百度广库里找了一篇文章,大概介绍这几种方法,具体公式不列了,软件都可以计算。这几种方法主要用于方差分析后,对均数间进行两两比较。 均数间的两两比较根据研究设计的不同分为两种类型:一种常见于探索性研究,在研究设计阶段并不明确哪些组别之间的对比是更为关注的,也不明确哪些组别问的关系已有定论、无需再探究,经方差分析结果提示“ 概括而言各组均数不相同”后,对每一对样本均数都进行比较,从中寻找有统计学意义的差异:另一种是在设计阶段根据研究目的或专业知识所决定的某些均数问的比较.常见于证实性研究中多个处理组与对照组、施加处理后的不同时间点与处理前比较。最初的设计方案不同.对应选择的检验方法也不同.下面分述两种不同设计均数两两比较的方法选择。 1. 事先计划好的某对或某几对均数间的比较:适用于证实性研究。在设计时就设定了要比较的组别,其他组别间不必作比较。常用的方法有:Dunnett-t 检验、LSD-t 检验(Fisher ’s least significant dif ference t test) 。这两种方法不管方差分析的结果如何——即便对于P稍大于检验水平α进行所关心组别间的比较。 1.1 LSD-t检验即最小显著法,是Fisher于1935年提出的,多用于检验某一对或某几对在专业上有特殊探索价值的均数间的两两比较,并且在多组均数的方差分析没有推翻无效假设H0时也可以应用。该方法实质上就是t检验,检验
水准无需作任何修正,只是在标准误的计算上充分利用了样本信息,为所有的均数统一估计出一个更为稳健的标准误,因此它一般用于事先就已经明确所要实施对比的具体组别的多重比较。由于该方法本质思想与t 检验相同,所以只适用于两个相互独立的样本均数的比较。LSD法单次比较的检验水准仍为α ,因此可以认为该方法是最为灵敏的两两比较方法.另一方面,由于LSD法侧重于减少第Ⅱ类错误,势必导致此法在突出组间差异的同时,有增大I类错误的倾向。 1.2 Dunnett-t(新复极差法)检验,Duncan 1955年在Newman及Keuls的复极差法(muhiple range method)基础上提出,该方法与Tukey法相类似。适用于n-1个试验组与一个对照组均数差别的多重比较,多用于证实性研究。Dunnett-t统计量的计算公式与LSD-t检验完全相同。 实验组和对照组的样本均数和样本含量。需特别指出的是Dunnett—t检验有专门的界值表,不同于t检验的界值表。 一般认为,比较组数k≥3时,任何两个样本的平均数比较会牵连到其它平均数的对比关系,而使比较数再也不是两个相互独立的样本均数的比较.这是LSD-t无法克服的缺点。Dunnett—t针对这一问题提出.在同一显著水平上两个均数的最小显著差数随着这二个平均数在多个平均数中所占的极差大小而不同,根据不同平均数间的对比关系来调整相应的显著差别(critical range)的大小。 2. 多个均数的两两事后比较:适用于探索性研究,即各处理组两两问的对比关系都要回答,一般要将各组均数进行两两组合,分进行检验。常用的方法有:SNK-q(Student-Newman-Keuls q)法、Duncan法、Tukey法和Scheffe法。值得注意
基于MATLAB的方差分析
基于MATLAB 的方差分析 (重庆科技学院 数理学院) 摘要:方差分析是重要的,应用广泛的实验数据统计分析方法,其实质是检验多个变量均 值的一致性。运用MATLAB 软件进行单因子及双因子方差分析。 关键字:方差分析,MATLAB,单因子,双因子。 1 引言 方差分析是分析试验(或观测)数据的一种统计方法。在工农业生产和科学研究中, 经常要分析各种因素及因素之间的交互作用对研究对象某些指标值的影响。在方差分析中,把试验数据的总波动(总变差或总方差)分解为由所考虑因素引起的波动(各因素的变差)和随机因素引起的波动(误差的变差),然后通过分析比较这些变差来推断哪些因素对所考察指标的影响是显著的,哪些是不显著的。 2 单因子方差分析 某个可控制因素A 对结果的影响大小可通过如下实验来间接地反映,在其它所有可控制因素都保持不变的情况下,只让因素A 变化,并观测其结果的变化,这种试验称为“单因素试验”。因素A 的变化严格控制在几个不同的状态或等级上进行变化,因素A 的每个状态或等级成为因素A 的一个水平。若因素A 设定了s 个水平,则分别记为 A 1,A 2,…,A s 。 数学模型: 2(,),1,2,...,.i i X N i s μσ= (1) 显著性影响问题转化为因素A 不同水平下各随机变量总体的均值是否相等问题,即检验假设 012:s H μμμ== =是否成立 (2) 记号 ij x : 不同水平下的试验结果,i=1,2,…,s ;j=1,2,…,n i ; n=n 1+n 2+…+n s :试验总数; 总平均:11 1i n s ij i j x x n ===∑∑;
利用SPSS做方差分析报告教程
利用SPSS做方差分析教程 在分享了SPSS安装包后,除了问我SPSS怎么安装的外,还有人问怎么做方差分析的。其实大家如果林业应用统计理论部分还记得的话,是可以用Excel来做方差分析的,不过稍显繁琐一点。当然,既然部分人已经装好了SPSS,而且SPSS做方差分析有具有很大的方便性,今天我就分享一下如何利用SPSS做方差分析。 方差分析可分为单变量单因素、单变量多因素和多变量多因素方差分析三种,单变量单因素在林业应用统计书中第228页有详细介绍,相对简单,在这里不做重复,需要的同学可自行查阅。不过,操作方法都大同小异,只在输入数据和选项上有所不同。 在这里不对方差分析的理论部分进行介绍,一句话来说,方差分析是用来比较不同处理之间是否存在显著性差异的。在我看来,大家的试验类型还是以单变量多因素为主的,如果分不清变量与因素,可以再去看书,也不再展开了。 下面我以书中第172页例三为例,做单变量多因素的方差分析。 为了从三个水平的氮肥和三个水平的磷肥中选择最有利树苗生长的最佳水平组合,设计了两因素试验,每个水平组合重复4次,结果如下表,试进行方差分析。 磷肥氮肥 B1 B2 B3 A1 51 59 33 35 21 22 35 34 16 32 36 21 A2 57 69 60 50 53 48 43 46 18 32 28 24 A3 58 45 63 69 65 48 57 54 40 43 36 29 表1 氮肥和磷肥树苗生长的生物量 可以看出大多数我们所进行的试验都可以归类于这种试验类型,特别是组培、嫁接、生根、或者不同处理之间测各种指标的试验,以下就在SPSS中输入数据。
方差分析
第六章 方差分析 第五章所介绍的t 检验法适用于样本平均数与总体平均数及两样本平均数间的差异显著性检验,但在生产和科学研究中经常会遇到比较多个处理优劣的问题,即需进行多个平均数间的差异显著性检验。这时,若仍采用t 检验法就不适宜了。这是因为: 1、检验过程烦琐 例如,一试验包含5个处理,采用t 检验法要进行2 5C =10次两两 平均数的差异显著性检验;若有k 个处理,则要作k (k-1)/2次类似的检验。 2、无统一的试验误差,误差估计的精确性和检验的灵敏性低 对同一试验的 多个处理进行比较时,应该有一个统一的试验误差的估计值。若用t 检验法作两两比较,由于每次比较需计算一个21x x S ,故使得各次比较误差的估计不统一,同时没有充分利用资料所提供的信息而使误差估计的精确性降低,从而降低检验的灵敏性。例如,试验有5个处理,每个处理重复6次,共有30个观测值。进行t 检验时,每次只能利用两个处理共12个观测值估计试验误差,误差自由度为2(6-1)=10;若利用整个试验的30个观测值估计试验误差,显然估计的精确性高,且误差自由度为5(6-1)=25。可见,在用t 检法进行检验时,由于估计误差的精确性低,误差自由度小,使检验的灵敏性降低,容易掩盖差异的显著性。 3、推断的可靠性低,检验的I 型错误率大 即使利用资料所提供的全部信息估 计了试验误差,若用t 检验法进行多个处理平均数间的差异显著性检验,由于没有考虑相互比较的两个平均数的秩次问题,因而会增大犯I 型错误的概率,降低推断的可靠性。 由于上述原因,多个平均数的差异显著性检验不宜用t 检验,须采用方差分析法。 方差分析(analysis of variance)是由英国统计学家R.A.Fisher 于1923年提出的。这种方法是将k 个处理的观测值作为一个整体看待,把观测值总变异的平方和及自由度分解为相应于不同变异来源的平方和及自由度,进而获得不同变异来源总体方差估计值;通过计算这些总体方差的估计值的适当比值,就能检验各样本所属总体平均数是否相等。方差分析实质上是关于观测值变异原因的数量分析,它在科学研究中应用十分广泛。 本章在讨论方差分析基本原理的基础上,重点介绍单因素试验资料及两因素试验资料的方差分析法。在此之前,先介绍几个常用术语。 1、试验指标(experimental index ) 为衡量试验结果的好坏或处理效应的高低,在 试验中具体测定的性状或观测的项目称为试验指标。由于试验目的不同,选择的试验指标也不相同。在畜禽、水产试验中常用的试验指标有:日增重、产仔数、产奶量、产蛋率、瘦肉率、某些生理生化和体型指标(如血糖含量、体高、体重)等。 2、试验因素(experimental factor ) 试验中所研究的影响试验指标的因素叫试验因 素。如研究如何提高猪的日增重时,饲料的配方、猪的品种、饲养方式、环境温湿度等都对日增重有影响,均可作为试验因素来考虑。当试验中考察的因素只有一个时,称为单因素试验;若同时研究两个或两个以上的因素对试验指标的影响时,则称为两因素或多因素试验。试验因素常用大写字母A 、B 、C 、…等表示。 3、因素水平(level of factor ) 试验因素所处的某种特定状态或数量等级称为因素水 平,简称水平。如比较3个品种奶牛产奶量的高低,这3个品种就是奶牛品种这个试验因素
方差分析实例分析
方差分析实例分析 摘要:为研究货架的高度和宽度两个因素的影响,本文基于shelf 数据,分别对高度和宽度进行方差分析。首先对数据进行高度和宽度进行分组,并进行描述性统计分析。其次,利用Bartlett 检验进行方差其次性检验,以检验数据在不同的水平下方差是否相同。最后,利用aov()函数进行单因素方差分析、交互作用的双因素方差分析。其结果表明:单因素方差分析结果表明:高度的bottom 、middle 、top 三个水平设置要求不相同,宽度的reg 、wide 两个水平设置要求相同。三个高度设置的需求和两个宽度设置的要求之间的关系是一样的。 关键词:方差其次性检验;方差分析;高度;宽度;货架 1 引言 方差分析是在20世纪20年代发展起来的一种统计方法,它是由英国统计学家费希尔在进行实验设计时为解释实验数据而首先引入的。从形式上看,方差分析是比较多个总体的均值是否相等;但是其本质上是研究变量之间的相互关系。方差分析主要用于研究一个数值因变量与一个或多个分类自变量的关系。方差分析(analysis of variance ,ANOV A )就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。 本文基于shelf 数据,分别对高度和宽度进行方差分析。首先对数据进行高度和宽度进行分组,并进行描述性统计分析。其次,利用Bartlett 检验进行方差其次性检验,以检验数据在不同的水平下方差是否相同。最后,利用aov()函数进行单因素方差分析和有交互作用的双因素方差分析,以说明三个层次高度的要求是否相同,两个层次的宽度要求是否相同,以 及宽度设置的需求和高度之间的关系。 2货架数据描述性统计分析 对shelf 数据进行三个层次高度进行分组,分别分为bottom 、middle 、top 三个层次。对宽度进行reg 、wide 两个层次进行分组。表1给出了shelf 数据的原始数据表,表2给出了高度 三个层次的描述性统计结果,表3给出了宽度两个层次的描述性统计结果。 从表2可看出,bottom 的平均值为55.8,方差为6.136;middle 的平均值为77.2,方差为9.628;top 的平均值为51.5,方差为2.716。其结果表明:三个水平的货架高度平均值存在差异,但是其方差也有差别。表3可看出,reg 的平均值为60.8,方差为129.4050;wide 的平均值为62.2,方差为165.2775。货架的宽度wide 的方差较大,其说明货架的宽度wide 的波动性较大。 height width Mean reg wide bottom 58.20 55.70 55.8 bottom 53.70 52.50 bottom 55.80 58.90 Mean 55.90 55.70 middle 73.00 76.20 77.2 middle 78.10 78.40 middle 75.40 82.10 Mean 75.50 78.90