SPSS学习系列3因子分析

31. 因子分析
一、基本原理
因子分析,是用少数起根本作用、相互独立、易于解释通常又是不可观察的因子来概括和描述数据,表达一组相互关联的变量。通常情况下,这些相关因素并不能直观观测。
因子分析是从研究相关系数矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。简言之,即用少数不可观测的隐变量来解释原始变量之间的相关性或协方差关系。
因子分析的作用是减少变量个数,根据原始变量的信息进行重组,能反映原有变量大部分的信息;原始部分变量之间多存在较显著的相关关系,重组变量(因子变量)之间相互独立;因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。
主成分分析是因子分析的特例。主成份分析的目标是降维,而因子分析的目标是找出公共因素及特有因素,即公共因子与特殊因子。
因子分析模型在形式上与线性回归模型相似,但两者有着本质的区别:回归模型中的自变量是可观测到的,而因子模型中的各公因子是不可观测的隐变量,而且两个模型的参数意义也不相同。
得到估计的因子模型后,还必须对得到的公因子进行解释。即对每个公共因子给出一种意义明确的名称,用来反映在预测每个可观察变量中这个公因子的重要性。该公因子的重要程度就是在因子模型矩
阵中相应于这个因子的系数。
由于因子载荷阵不惟一,故可对因子载荷阵进行旋转。目的是使因子载荷阵的结构简化,使载荷矩阵每列或行的元素平方值向0和1两极分化,这样的因子便于解释和命名。
每个样本都可以计算其在各个公因子上的得分,利用因子得分以及该公因子的方差贡献比例,又可以计算每个样本的综合得分。
二、因子分析实例
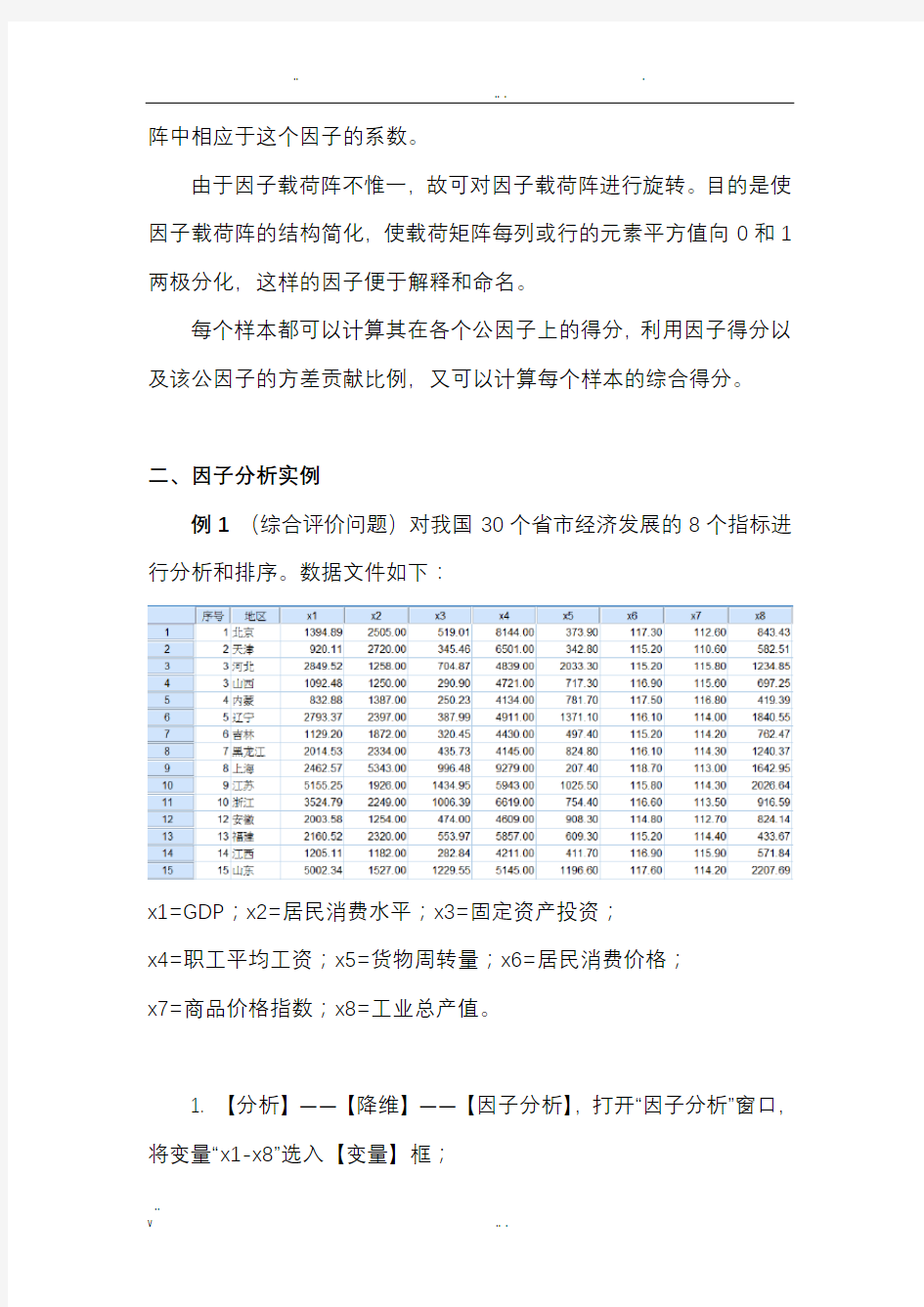
例1(综合评价问题)对我国30个省市经济发展的8个指标进行分析和排序。数据文件如下:
x1=GDP;x2=居民消费水平;x3=固定资产投资;
x4=职工平均工资;x5=货物周转量;x6=居民消费价格;
x7=商品价格指数;x8=工业总产值。
1. 【分析】——【降维】——【因子分析】,打开“因子分析”窗口,将变量“x1-x8”选入【变量】框;
2. 点【描述】,打开“描述统计”子窗口,勾选【统计量】下的“单变量描述性”、“原始分析结果”,【相关矩阵】下的“系数”、“再生”、“KMO 和Bartlett的球形度检验”;点【继续】;
3. 点【抽取】,打开“抽取”子窗口,【方法】选“主成份”,【分析】选“相关性矩阵”,【输出】勾选“未旋转因子解”、“碎石图”,【抽取】选“基于特征值:特征值大于‘1’”;点【继续】;
注1:提取公因子方法有(1)主成份法(默认),假设变量是各因子的线性组合,从解释变量的变异除非,尽量是变量的方差能被主成分所解释,适合大多数情况;
(2)未加权的最小平方法:使相关矩阵和再生相关矩阵之差的平方和达到最小;
(3)综合最小平方法:同(2),并用单值的倒数对相关系数加权;
(4)最大似然法:要求数据服从多变量正态分布,此时生成的参数估计最接近观察到相关矩阵,适宜样本量较大情况;
(5)主轴因子分解法:从原始变量的相关性出发,使变量间的相关程度尽可能地被公因子解释,但对变量方差的解释不太重视;
(6)α因子分解法:将变量看出从潜在的变量空间中抽取出的样本,计算时尽量使得变量的α信度达到最大,适合不好的数据;
(7)映像因子分解法:把一个变量看作是其它变量的多元回归,
提取公因子。
注2:计算特征值和特征向量时,可选择相关矩阵(不受量纲影响)或协方差矩阵(受量纲影响较大,需先进行变量标准化)计算主成分。但SPSS做因子分析时,已经包含了变量标准化过程。二者结果有差异,但在对因子解释和方差贡献率的解释上是一致的。
4. 点【旋转】,打开“旋转”子窗口,【方法】选“最大方差法”,【输出】勾选“旋转解”、“载荷图”;点【继续】;
注:(1)最大方差法:最常用,使各因子保持正交前提下的方差差异(相对载荷平方和)达到最大,方便对公因子解释;
(2)最大四次方值法:各因子方差差异化更强,并减少和每个变量有关联的因子数,简化对原变量的解释;
(3)最大平衡值法:介于方差最大正交旋转与4次方最大正交旋转之间;
(4)直接Oblimin法:斜交旋转方法,需先指定一个因子映像
的自相关范围;
(5)Promax:最常用的斜交旋转法,在方差最大正交旋转的基础上再进行斜交旋转,旋转后允许因子间存在相关,适合有具体的结果倾向时选用。
5. 用主成分法提取公因子,用回归法对因子进行估计。
点【得分】,打开“因子得分”子窗口,勾选“保存为变量”方法选“回归”、“显示因子得分系数矩阵”;点【继续】;
另外,若在【选项】子窗口,将【系数显示格式】勾选“按大小排序”,将按载荷从大到小排列变量。
点【确定】得到(部分与主成份分析结果相同,略)
KMO 和Bartlett 的检验
取样足够度的Kaiser-Meyer-Olkin 度量。.620
Bartlett 的球形度检验近似卡方231.285 df 28 Sig. .000
KMO检验变量间的偏相关是否较大,该值越大越适合做因子分析,0.7以上因子分析效果较好,0.5以下不适合做因子分析。KMO值=0.620<0.7说明变量间的重叠可能不是特别高。
Bartlett球形度检验判断相关系数矩阵是否是单位阵,原假设H0:各变量相互独立。P值<0.001<0.05, 故拒绝原假设,即变量间有较强的相关性。
公因子方差
初始提取
GDP 1.000 .945
居民消费水平 1.000 .799
固定资产投资 1.000 .902
职工平均工资 1.000 .873
货物周转量 1.000 .857
居民消费价格指数 1.000 .957
商品价格指数 1.000 .928
工业总产值 1.000 .904
提取方法:主成份分析。
公因子方差,表示各变量中所含原始信息能被提取的公因子所表示的程度。基本都在0.80以上,表示提取的公因子对各变量有较强的解释能力。
【初始特征值】表示初步提取共同因素的结果:“合计”列为每一个主成分的特征值,其值越大表示该主成分在解释8个变量的变异时越重要;“方差的%”列为每个提取因素可以解释的变异百分比;“累积%”列为解释的变异的累积百分比;8个变量(初始特征值=1)总特征值为8,第一个特征值=3.754, 3.754/8 = 46.924%即第一个“方差的%”值,累积百分比最终是100%.
【提取平方和载入】给出了旋转前的特征值、解释变异量、累积解释变异量;主成分法默认只提取≥1的特征值,共3个即3个公因子(3个是否合适借助碎石图判断),它们共可解释89.551%的变异。
【旋转平方和载入】给出了旋转后的特征值、解释变异量、累积解释变异量;旋转后,共同因素的特征值会改变,但总的特征值之和不变(解释的变异的累积百分比相同);共同性也不会改变,但每个变量在其共同因素中的负荷系数会改变。
碎石图,可以帮助决定公因子的数目。碎石图将每个公因子的特
征值(重要程度)从高到低排序绘制成一条坡度线,横轴为公因子数目。其判断标准是:取坡度线急剧下降的部分,去掉坡度线平坦的部分,从图中看选取4个共同因素是合适的。
另外,也要参考选取的合理性:选择的公因子包含的变量数不能太少。
正常情况下需要将【抽取】的公因子数设为4重新做因子分析:在原窗口点【抽取】,打开“抽取”子窗口,选择【抽取】下的“因子的固定数量”,在【要提取的因子】框输入“4”;点【继续】;
但由于本例中变量数较少,故保持原来的3个公因子。
成份矩阵a
成份
1 2 3
GDP .884 .385 .120
居民消费水平.606 -.596 .277
固定资产投资.911 .163 .213
职工平均工资.465 -.725 .362
货物周转量.486 .737 -.279
旋转前(实际上是主成分分析的结果),8个变量在3个公因子上的载荷矩阵,载荷值越大表示该变量与其共同因素的关联越大。由该矩阵可以计算每个变量的共同性、每个公因子的特征值、再生相关矩阵。
公因子结构表达式(因子模型,前3项为共同因素,εi为特殊因子):
Z x1 = 0.884*F1 + 0.385*F2 + 0.120*F3 + ε1
……
Z x8 = 0.822*F1 + 0.429*F2 + 0.210*F3 + ε8
其中,Z xi为x i的标准化变量,Fi的表达式同【第30篇:主成份分析】中的表示。
共同性为每个变量在各公因子上载荷的平方和,如变量“固定资产投资”的共同性为:0.9112 + 0.1632 +0.2132 =0.902
公因子的特征值是该公因子上所有载荷的平方和,如公因子1的特征值为(注意这些特征值是从大到小排列):
0.9112 + 0.8842 + 0.8222 + …+ (-0.510)2=3.754
关性居民消费水平.341 .799a.515 .814 -.222 -.243 -.611 .301 固定资产投资.894 .515 .902a.383 .503 -.254 -.376 .864 职工平均工资.176 .814 .383 .873a-.409 -.136 -.563 .148 货物周转量.680 -.222 .503 -.409 .857a-.280 .017 .657 居民消费价格
指数
-.257 -.243 -.254 -.136 -.280 .957a.814 -.142 商品价格指数-.268 -.611 -.376 -.563 .017 .814 .928a-.163 工业总产值.917 .301 .864 .148 .657 -.142 -.163 .904a
残差b GDP -.074 .056 .011 -.062 -.015 .004 -.044 居民消费水平-.074 -.089 -.098 .071 .008 .019 .062 固定资产投资.056 -.089 .013 -.073 -.026 .017 -.072 职工平均工资.011 -.098 .013 .053 -.009 .020 -.049 货物周转量-.062 .071 -.073 .053 .027 .005 .002
居民消费价格
指数
-.015 .008 -.026 -.009 .027 -.051 .017 商品价格指数.004 .019 .017 .020 .005 -.051 -.029 工业总产值-.044 .062 -.072 -.049 .002 .017 -.029
提取方法:主成份分析。
a. 重新生成的公因子方差
b. 将计算观察到的相关性和重新生成的相关性之间的残差。有11 (39.0%) 个绝对值大于0.05的非冗余残差。
旋转成份矩阵a
成份
1 2 3
GDP .955 .124 -.131
居民消费水平.219 .841 -.209
固定资产投资.872 .351 -.137
职工平均工资.048 .925 -.121
货物周转量.751 -.507 -.192
居民消费价格指数-.135 -.013 .969
商品价格指数-.104 -.496 .819
工业总产值.944 .109 -.014
提取方法:主成份。
旋转法:具有Kaiser 标准化的正交旋转法。
a. 旋转在5 次迭代后收敛。
采用方差最大正交旋转法旋转后的公因子载荷矩阵,旋转的目的是为了让载荷大的越大、小的越小(载荷平方和不变),从而更容易区分各变量的归属。由于是正交转轴,故表中系数可视为变量与共同因素的相关系数矩阵(因素结构或加权矩阵),等于旋转前的公因子载荷矩阵乘以成份转换矩阵。
标准定为选择载荷大于0.75的变量,可看出
公因子1包含变量:GDP、工业总产值、固定资产投资、货物周转量;从而,可命名为总量因子;
公因子2包含变量:职工平均工资、居民消费水平;从而,可命名为消费因子;
公因子3包含变量:居民消费价格指数、商品价格指数;从而,可命名为价格因子。
成份转换矩阵
成份 1 2 3
1 .817 .407 -.408
2 .548 -.769 .331
3 .179 .49
4 .851
提取方法:主成份。
旋转法:具有Kaiser 标准化的正交旋转法。
成份得分系数矩阵
成份
1 2 3
GDP .306 .011 .047
居民消费水平.025 .387 .040
固定资产投资.270 .129 .075
职工平均工资-.025 .451 .096
货物周转量.248 -.319 -.139
居民消费价格指数.070 .180 .653
商品价格指数.077 -.098 .462
工业总产值.317 .026 .123
提取方法:主成份。
旋转法:具有Kaiser 标准化的正交旋转法。
成分得分矩阵给出了各主成分在每个变量上的载荷,从而得到计算公式:
F1=0.306 Z x1+0.025 Z x2+0.270 Z x3-0.025 Z x4+0.248 Z x5
+0.070 Z x6+0.077 Z x7+0.317 Z x8
F2=0.011 Z x1+0.387 Z x2+0.129 Z x3+0.451 Z x4-0.319 Z x5
+0.180 Z x6-0.098 Z x7+0.026 Z x8
F3=0.047 Z x1+0.040Z x2+0.075 Z x3+0.096 Z x4-0.139 Z x5
+0.653 Z x6+0.462Z x7+0.123 Z x8
注:该计算公式本质上与利用“旋转成分矩阵”得到的主成分计算公式是等价的,区别是前者的标准差是1.
成份得分协方差矩阵
成份 1 2 3
1 1.000 .000 .000
2 .000 1.000 .000
3 .000 .000 1.000
提取方法:主成份。
旋转法:具有Kaiser 标准化的正交旋转法。
各公因子的得分保存为新变量(默认为):FAC1_1~FAC3_1
这3个公因子分别从三个不同方面反映了各地经济发展状况,若要用1个综合得分来综合评价各省市经济发展,可以按各公因子对应的方差贡献率的比例为权重计算综合得分:
Score = 40.092/89.551*FAC1_1+27.708/89.551*FAC2_1+21.752/89.551*FAC3_1 注:上述数值来自前文“解释的总方差”表。
【计算变量】,【排序个案】,
得到
注意:若有反向变量,需要先转化为正向。