WEKA数据挖掘软件在车险业务应用中的分析

新视角
132 理论研究
WEKA 数据挖掘软件在车险业务应用中的分析
水静 张瑞
(兰州商学院信息工程学院,甘肃兰州730020)
摘要:本文通过分析利用开源WEKA 数据挖掘软件,尝试帮助中小企业进行保险业务欺诈行为挖掘预测,提升中小汽车保险企业业务分析管理水平。
关键词:数据挖掘;WEKA 软件;管理水平
0.行业背景介绍
我国汽车消费日趋旺盛,每年的汽车销售量大约以20%左右的比例增长。但最近几年车险市场的经营结果却并不能令人满意,这其中机动车保险欺诈是一个非常严重的影响因素。我国北京和上海的保险监管机构估测,我国的机动车保险约有20%的欺诈。主要的保险欺诈表现形式有故意伪造保险标的,骗取保险金;未发生保险事故而谎称发生保险事故骗取保险金;故意造成被保险人死亡、伤残或疾病等人身保险事故,骗取保险金和通过重复保险骗保。如何评价欺诈风险发生的可能性及控制欺诈风险的成本问题摆在了各个汽车保险公司面前。另一方面,汽车保险作为一种财产保险,与其他险种相比具有业务量较大,拥有大量客户信息、业务数据和财务数据的特点,这就为车险业务中应用数据仓库和数据挖掘技术创造了条件,目前我国汽车保险业务缺乏进行分析的技术支持和健全的数据统计体系,许多车险公司传统的数据库技术在预测知识的表达、综合和推理方面能力比较薄弱,难以满足日益提高的预测要求。同时,传统的方法无法满足运行效率、计算性能、准确率及存储空间的要求。在这种情况下,企业有必要利用数据挖掘技术来准确、及时地对欺诈风险进行监视、评价、预警和管理,在欺诈风险发生之前对其进行预警和控制,做好欺诈防范工作。
1.数据挖掘研究内容
数据挖掘可以从已构建的大型数据库中提取规则,为企业进行决策提供可靠的理论依据。数据挖掘技术包括关联规则挖掘、分类模型挖掘、特征分析和趋势分析预测等,它综合利用统计学、机器学习和人工智能的计算、分析和推理方法,将数据转化为知识。为提高保险企业决策支持水平,增进企业竞争力,就必须应用数据挖掘技术。应用于汽车保险企业的保险业欺诈行为数据挖掘主要步骤包括数据选择、数据预处理、数据转换、数据挖掘和数据分析。第一步,企业首先要明确数据挖掘的目的和解决问题的关键,根据企业的日常处理表单或数据库系统与数据仓库,找出客户特征、客户违约欺诈相关的数据,为挖掘建立数据保证。第二步,进行数据清理,主要包括的处理内容有空缺值、噪声数据和不一致数据。对有意义的属性进行保留,根据所要选择的算法对数据进行变换,例如,Apriori 算法就不接收数值属性。清理后的数据为进一步的挖掘工作奠定了可靠的基础。第三步,
根据不同的数据挖掘算法建立一个或者多个分析模型,要求能够准确的对数据集进行建模与描述。第四步,企业开始数据挖掘,在挖掘过程中必须针对自己的企业数据特点,选取最合适的数据挖掘算法。同时完成所有模式推导与知识的获取工作。第五步,在获取数据挖掘的结果之后,企业需要结合自己的实际情况对挖掘结果进行评估,最后,充分利用数据挖掘来指导日常的工作。
2.Weka 数据挖掘应用研究
目前,全世界有很多统计分析和数据挖掘软件可以进行数据挖掘,包括SAS 的企业挖掘者和IBM 的智能挖掘者、SPSS 的CLEM ENT INE 、M egaputer 的PolyA nalyst 等。这些产品几乎覆盖了所有可能盈利的商业应用领域,这些产品使用的分析方法包括有回归、决策树、神经网络、聚类分析等等。但这些产品使用成本过高,操作复杂,对于中小企业来说未必是最好的选择,而怀卡托智能分析环境Weka 是一个基于java 、用于数据挖掘和知识发现的开源项目,被公认是数据挖掘开源项目中最著名的一个,和其他数据挖掘工具的艰深复杂不同,使用w eka 软件的技术门槛很低。中小型保险企业完全可以充分利用软件的强大功能来实现本企业的数据挖掘工作。
在WEKA 平台上进行数据挖掘的第一步是数据准备,首先输入测试数据集,再对数据进行预处理,建立模型将处理完的数据集导入一种学习方案或模型中来预测未知的实例。在拥有了良好的源数据之后,用户就可以执行相应的数据挖掘工作。WEKA 的第一个功能选择项是分类,在车辆保险数据集中,选取是否索赔作为目标属性,其它属性作为条件属性。利用决策树生成工具对表所示的数据集生成一个决策树,根据决策树和投保人的详细信息,可以预测一段时间内索赔概率的大小,并相应制订某类投保人的保险费率。
我们测试数据来源于当地某一汽车保险公司管理系统中2003至2007年间的约6500条数据。针对 可能存在欺诈 为主题,经过数据的前期整理,得出1820条可用的数据样本集。其中判定对象属性包括有索赔人年龄、性别、索赔数额、有记录罚单数量和索赔先例结果六个。该样本集既含有离散型属性,又包含连续型属性,比较适合采用处理连续型属性的决策树算法来处理,这几个性能的比较实验都是采
新视角
理论研究133
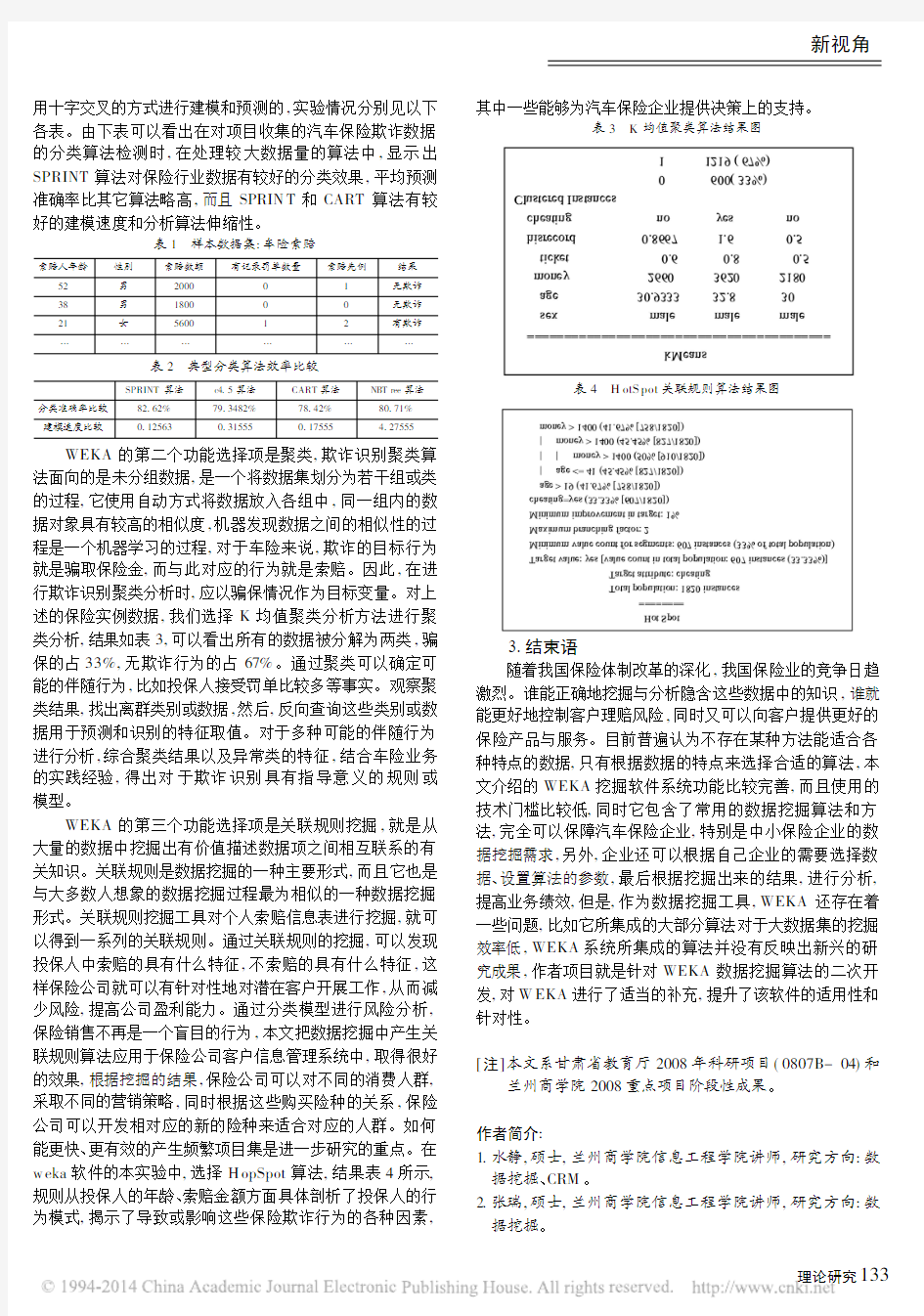
用十字交叉的方式进行建模和预测的,实验情况分别见以下各表。由下表可以看出在对项目收集的汽车保险欺诈数据的分类算法检测时,在处理较大数据量的算法中,显示出SPRINT 算法对保险行业数据有较好的分类效果,平均预测准确率比其它算法略高,而且SPRIN T 和CART 算法有较好的建模速度和分析算法伸缩性。
表1 样本数据集:车险索赔
索赔人年龄
性别索赔数额有记录罚单数量
索赔先例
结果52男200001无欺诈38男180000无欺诈21女560012有欺诈!
!
!
!
!
!
表2 典型分类算法效率比较
SPRINT 算法
c4.5算法CART 算法NBT ree 算法分类准确率比较82.62%79.3482%78.42%80.71%建模速度比较
0.12563
0.31555
0.17555
4.27555
WEKA 的第二个功能选择项是聚类,欺诈识别聚类算法面向的是未分组数据,是一个将数据集划分为若干组或类的过程,它使用自动方式将数据放入各组中,同一组内的数据对象具有较高的相似度,机器发现数据之间的相似性的过程是一个机器学习的过程,对于车险来说,欺诈的目标行为就是骗取保险金,而与此对应的行为就是索赔。因此,在进行欺诈识别聚类分析时,应以骗保情况作为目标变量。对上述的保险实例数据,我们选择K 均值聚类分析方法进行聚类分析,结果如表3,可以看出所有的数据被分解为两类,骗保的占33%,无欺诈行为的占67%。通过聚类可以确定可能的伴随行为,比如投保人接受罚单比较多等事实。观察聚类结果,找出离群类别或数据,然后,反向查询这些类别或数据用于预测和识别的特征取值。对于多种可能的伴随行为进行分析,综合聚类结果以及异常类的特征,结合车险业务的实践经验,得出对于欺诈识别具有指导意义的规则或模型。
WEKA 的第三个功能选择项是关联规则挖掘,就是从大量的数据中挖掘出有价值描述数据项之间相互联系的有关知识。关联规则是数据挖掘的一种主要形式,而且它也是与大多数人想象的数据挖掘过程最为相似的一种数据挖掘形式。关联规则挖掘工具对个人索赔信息表进行挖掘,就可以得到一系列的关联规则。通过关联规则的挖掘,可以发现投保人中索赔的具有什么特征,不索赔的具有什么特征,这样保险公司就可以有针对性地对潜在客户开展工作,从而减少风险,提高公司盈利能力。通过分类模型进行风险分析,保险销售不再是一个盲目的行为,本文把数据挖掘中产生关联规则算法应用于保险公司客户信息管理系统中,取得很好的效果,根据挖掘的结果,保险公司可以对不同的消费人群,采取不同的营销策略,同时根据这些购买险种的关系,保险公司可以开发相对应的新的险种来适合对应的人群。如何能更快、更有效的产生频繁项目集是进一步研究的重点。在w eka 软件的本实验中,选择H opSpot 算法,结果表4所示,规则从投保人的年龄、索赔金额方面具体剖析了投保人的行为模式,揭示了导致或影响这些保险欺诈行为的各种因素,
其中一些能够为汽车保险企业提供决策上的支持。
表3 K 均值聚类算法结果图
表4 H otS pot 关联规则算法结果图
3.结束语
随着我国保险体制改革的深化,我国保险业的竞争日趋激烈。谁能正确地挖掘与分析隐含这些数据中的知识,谁就能更好地控制客户理赔风险,同时又可以向客户提供更好的保险产品与服务。目前普遍认为不存在某种方法能适合各种特点的数据,只有根据数据的特点来选择合适的算法,本文介绍的WEKA 挖掘软件系统功能比较完善,而且使用的技术门槛比较低,同时它包含了常用的数据挖掘算法和方法,完全可以保障汽车保险企业,特别是中小保险企业的数据挖掘需求,另外,企业还可以根据自己企业的需要选择数据、设置算法的参数,最后根据挖掘出来的结果,进行分析,提高业务绩效,但是,作为数据挖掘工具,WEKA 还存在着一些问题,比如它所集成的大部分算法对于大数据集的挖掘效率低,WEKA 系统所集成的算法并没有反映出新兴的研究成果,作者项目就是针对WEKA 数据挖掘算法的二次开发,对W EKA 进行了适当的补充,提升了该软件的适用性和针对性。
[注]本文系甘肃省教育厅2008年科研项目(0807B-04)和
兰州商学院2008重点项目阶段性成果。作者简介:
1.水静,硕士,兰州商学院信息工程学院讲师,研究方向:数据挖掘、CRM 。
2.张瑞,硕士,兰州商学院信息工程学院讲师,研究方向:数据挖掘。
03车险业务分析指引
03 车险业务分析指引 制定目的 (一)贯彻车险经营思想通过制定《指引》,充分体现总公司车险经营思想,并严格贯彻执行。 (二)优化业务结构,提升经营效益 明确经营管控重点,提升分公司业务调控能力,促进经营效益的提升。 核心内容 (一)总体经营指标 保费收入(保费完成进度)、赔付率和应收率、及时立案率和结案率作为经营的核心内容,在车险业务分析中需要予以重点分析,分析其专门缘故,以及改善措施。 (二)各项辅助指标为保证总体和分项经营指标的完成,另有多个辅助指标需在经营过程中加以关注, 包括平均费率、车均保费、出险频度、满期保费、实收保费、及时查勘率、预估偏差率I、预估偏差率II、案均赔款、案均总赔款、已决金额、已决件数、未决金额、未决件数、立案件数、报案件数、平均结案时刻等,要通过对辅助指标的分析,找出业务经营中存在的不足与差距,保证总体经营指标的实现。 分析方法 (一)逐层分析法逐层分析方法是从面到点的分析方法。通过从整体向局部细化分析,找出业务经营中的具体咨询题。 (二)比较分析法 比较分析法是通过与上年或往年同期数据对比,分析当前经营状况的方法。 (三)趋势分析法趋势分析方法是通过记录一段时刻内的数据轨迹来判定业务进展走向的方法。
分析重点 进行车险业务分析时,应包含但不限于以下内容: (一)业务进展分析 1、业务进展分析业务进展要从多个方面加以分析,如纵向时刻分析,通过累计保费增长率、单月保费增长率、日均保费等,清晰地把握自身业务进展状况。 2、业务来源可按照业务获得的渠道进行分类分析。例如可按照中介与直销分类,也可按照团队及业务员进行分析。 (二)业务品质分析 1、赔付率 重点关注历年制赔付率与承保年度制满期赔付率情形:历年制与满期赔付率的当前状况,是第一需要关注的,另外,通过与前期对比可在一定程度上了解赔付率的变化趋势; 2、业务结构具体的维度选择要以最有利于找出阻碍整体业务质量的关键点为原则。 业务结构的分析维度有:险种产品,使用性质,所属性质,车辆种类(或加以组合), 业务结构需分析的内容有净保费、车均保费、出险频度、案均赔款、历年制赔付率、满期赔付率等。 3、保费充足性 保费充足性是衡量业务质量的重要指标,赔付率是保费充足性的体现,然而赔付率指标做为一个结果指标,存在滞后性,因此要将对赔付率的操纵,提早到对承保业务的过程监控中。 分析保费充足性时要重点关注平均费率,通过分析平均费率变化进行事前监控: 通过与前期/同期对比了解当前平均费率情形; 平均费率下降时,可从业务结构、险别产品、优待系数等多个维度查找缘故; 将平均费率与赔付率两者变化情形进行对比。由于赔付率指标具有事后性,以及目前我司业务规模较小,赔付率指标处于不稳固的状态,因此当前的赔付率水
保险行业市场分析报告(完整版)
报告编号:YT-FS-8245-61 保险行业市场分析报告 (完整版) After Completing The T ask According To The Original Plan, A Report Will Be Formed T o Reflect The Basic Situation Encountered, Reveal The Existing Problems And Put Forward Future Ideas. 互惠互利共同繁荣 Mutual Benefit And Common Prosperity
保险行业市场分析报告(完整版) 备注:该报告书文本主要按照原定计划完成任务后形成报告,并反映遇到的基本情况、实际取得的成功和过程中取得的经验教训、揭露存在的问题以及提出今后设想。文档可根据实际情况进行修改和使用。 一季度,单季度原保险保费收入首次突破万亿元。 保险市场增幅同比上升近21.81个百分点。一是财产 险业务平稳增长,实现原保险保费收入2154.40亿元, 同比增长8.85%,其中,车险业务实现原保险保费收 入1679.42亿元,同比增长12.08%。二是寿险业务快 速增长,实现原保险保费收入8459.28亿元,同比增 长50.18%,其中,新单业务7141.42亿元,同比增长 68.49%。三是普通寿险和健康险业务高速增长,分别 实现原保险保费收入5790.02亿元和1168.74亿元, 同比分别增长87.81%和79.23%。 业务结构发生变化。政策环境优化和保险公司不 断开拓新业务领域,民生类业务发展态势良好。责任 保险等增长较快。一季度,责任保险原保险保费收入
大数据分析的六大工具介绍
大数据分析的六大工具介绍 2016年12月 一、概述 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分学在大数据处理分析过程中六大最好用的工具。 我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设il?的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式, 相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 二.第一种工具:Hadoop Hadoop是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop是 以一种可黑、高效、可伸缩的方式进行处理的。Hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。此外,Hadoop依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地 在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下儿个优点: ,高可黑性。Hadoop按位存储和处理数据的能力值得人们信赖。,高扩展性。Hadoop是 在可用的计?算机集簇间分配数据并完成讣算任务 的,这些集簇可以方便地扩展到数以千计的节点中。 ,高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动 态平衡,因此处理速度非常快。 ,高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败 的任务重新分配。 ,Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非 常理想的。Hadoop上的应用程序也可以使用其他语言编写,比如C++。 第二种工具:HPCC HPCC, High Performance Computing and Communications(高性能计?算与通信)的缩写° 1993年,山美国科学、工程、技术联邦协调理事会向国会提交了“重大挑战项 U:高性能计算与通信”的报告,也就是被称为HPCC计划的报告,即美国总统科学战略项U ,其U的是通过加强研究与开发解决一批重要的科学与技术挑战 问题。HPCC是美国实施信息高速公路而上实施的计?划,该计划的实施将耗资百亿 美元,其主要U标要达到:开发可扩展的计算系统及相关软件,以支持太位级网络 传输性能,开发千兆比特网络技术,扩展研究和教育机构及网络连接能力。
Weka_数据挖掘软件使用指南
Weka 数据挖掘软件使用指南 1.Weka简介 该软件是WEKA的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过https://www.360docs.net/doc/bb14161955.html,/ml/weka得到。Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以看一看Weka的接口文档。在Weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。 2.Weka启动 打开Weka主界面后会出现一个对话框,如图: 主要使用右方的四个模块,说明如下: ?Explorer:使用Weka探索数据的环境,包括获取关联项,分类预测,聚簇等; ?Experimenter:运行算法试验、管理算法方案之间的统计检验的环境; ?KnowledgeFlow:这个环境本质上和Explorer所支持的功能是一样的,但是它有一个可以拖放的界面。它有一个优势,就是支持增量学习; ?SimpleCLI:提供了一个简单的命令行界面,从而可以在没有自带命令行的操作系统中直接执行Weka命令(某些情况下使用命令行功能更好一些)。 3.主要操作说明 点击进入Explorer模块开始数据探索环境。 3.1主界面 进入Explorer模式后的主界面如下:
3.1.1标签栏 主界面最左上角(标题栏下方)的是标签栏,分为五个部分,功能依次是: ?Preprocess(数据预处理):选择和修改要处理的数据; ?Classify(分类):训练和测试关于分类或回归的学习方案; ?Cluster(聚类):从数据中学习聚类; ?Associate(关联):从数据中学习关联规则; ?Select attributes(属性选择):选择数据中最相关的属性; ?Visualize(可视化):查看数据的交互式二维图像。 3.1.2载入、编辑数据 标签栏下方是载入数据栏,功能如下: ?Open file:打开一个对话框,允许你浏览本地文件系统上的数据文件(.dat); ?Open URL:请求一个存有数据的URL 地址; ?Open DB:从数据库中读取数据; ?Generate:从一些数据生成器中生成人造数据。 3.1.3其他界面说明 接下来的主界面中依次是Filter(筛选器),Currtent relation(当前关系)、Attributes(属性信息)、Selected attribute(选中的属性信息)以及Class(类信息),分别介绍如下: ?Filter 在预处理阶段,可以定义筛选器来以各种方式对数据进行变换。Filter 一栏用于对各种筛选器进行必要设置。Filter一栏的左边是一个Choose 按钮。点击这个按钮就可选择Weka中的某个筛选器。用鼠标左键点击这个choose左边的显示框,将出现GenericObjectEditor对话框。用鼠标右键点击将出现一个菜单,你可从中选择,要么在GenericObjectEditor对话框中显示相关属性,要么将当前的设置字符复制到剪贴板。 ?Currtent relation 显示当前打开的数据文件的基本信息:Relation(关系名),Instances(实例数)以及Attributes (属性个数)。
数据挖掘工具应用及前景分析
数据挖掘工具应用及前景
介绍以下数据挖掘工具分别为: 1、 Intelligent Miner 2、 SAS Enterpreise Miner 3、SPSS Clementine 4、马克威分析系统 5、GDM Intelligent Miner 一、综述:IBM的Exterprise Miner简单易用,是理解数据挖掘的好的开始。能处理大数据量的挖掘,功能一般,可能仅满足要求.没有数据探索功能。与其他软件接口差,只能用DB2,连接DB2以外的数据库时,如Oracle, SAS, SPSS需要安装DataJoiner作为中间软件。难以发布。结果美观,但同样不好理解。 二、基本内容:一个挖掘项目可有多个发掘库组成;每个发掘库包含多个对象和函数对象: 数据:由函数使用的输入数据的名称和位置。 离散化:将记录分至明显可识别的组中的分发操作。 名称映射:映射至类别字段名的值的规范。 结果:由函数创建的结果的名称和位置。 分类:在一个项目的不同类别之间的关联层次或点阵。 值映射:映射至其它值的规范。 函数: 发掘:单个发掘函数的参数。 预处理:单个预处理函数的参数。 序列:可以在指定序列中启动的几个函数的规范。 统计:单个统计函数的参数。 统计方法和挖掘算法:单变量曲线,双变量统计,线性回归,因子分析,主变量分析,分类,分群,关联,相似序列,序列模式,预测等。 处理的数据类型:结构化数据(如:数据库表,数据库视图,平面文件) 和半结构化或非结构化数据(如:顾客信件,在线服务,传真,电子邮件,网页等) 。 架构:它采取客户/服务器(C/S)架构,并且它的API提供了C++类和方法 Intelligent Miner通过其独有的世界领先技术,例如自动生成典型数据集、发现关联、发现序列规律、概念性分类和可视化呈现,可以自动实现数据选择、数据转换、数据挖掘和结果呈现这一整套数据挖掘操作。若有必要,对结果数据集还可以重复这一过程,直至得到满意结果为止。 三、现状:现在,IBM的Intelligent Miner已形成系列,它帮助用户从企业数据资产中 识别和提炼有价值的信息。它包括分析软件工具——Intelligent Miner for Data和IBM Intelligent Miner forText ,帮助企业选取以前未知的、有效的、可行的业务知识——
汽车保险市场调查报告
滁州市汽车保险市场调查报 告 目录 一、引言 二、数据统计姓名:李世磊 班级:13级汽营(2)班
三、数据分析 四、我国汽车保险发展状况分析 五、未来我国汽车保险发展趋势 六、结论 一:引言 一):调查背景 此次汽车保险市场调查开始于2014年5月21日,;利用五天的时间,在5月25日以滁州市消费者群体为中心,完成调查任务。通过汽车保险市场调查,可以科学、系统和客观地收集整理和分析市场营销的资料、数据和信息,使汽车营销企业能够制定有效的市场营销决策;可以掌握竞争者的态势,使汽车营销企业在竞争中知己知彼,保持清醒的头脑,以永远立于不败之地;可以发现新的需求和机会,几时地开发出新的产品或服务去满足这些需求;还可以了解到宏观上的国家政策、法律和法规的变化对汽车行业发展的影响,预测未来经济走向,抓住发展机会。总之,汽车市场调查是汽车营销企业取得良好经济效益的保证。因此,市场调查已成为各大汽车企业共同关注的问题。
此次调查是对社会环境、市场需求、产品、市场营销活动的信息进行判断、收集、记录、整理和分析,并进而提出问题和解决问题。 在此次调查中我们运用到了市场调查中的问卷调查法进行调查,发放了50份调查问卷,涉及各个行业,最后整理综合所有资料,得出分析报告。 二数据统计 由于调查人物较多,所以随机抽取5份来做数据统计 三、数据分析 1、投保认知数据的分析 从表中我们可以看出,车主在使用车辆的过程中最担心出现的风险是怕造成第三者的损失和本车受损,造成第三者损失的风险比较的注意,这
也是全国的车主很关心的问题,随着全国公民对人权意识的提升。当自身的财产和人生受到损伤时,会尽最大的努力扞卫自己的权利。发生交通事故后,也很容易导致汽车的损失。所以车主们在造成第三者受损和本车受损风险方面比较的在意,由于本次调查的对象属于私家车主。所以车主在本车乘客受伤风险方面也不是很在意,但这只局限于货车和私家车,对于客运汽车,事实并不是如此。 现在车主在为自己的爱车上保险时大多数认为还是比较的方便,究其原因是现在的4S店和保险公司售后服务工作做的很好,营销人员都会向顾客推荐险种,全权代理的服务让顾客们感觉到方便,所以,大多数车主在位自己的爱车上保险时都会选着在4S店或保险公司,方便且快捷! 通过前期的调查我们发现目前大多数车主对保险合同的内容不是很了解,这会造成在理赔工作中不免会遇到一些麻烦,所以汽车保险展业人员在宣营销保险的时候一定要注意对保险合同的解释,让车主们能够清楚的理解合同的内容和所指的意思。特别是免责方面的条款一定要明确列明和说明。 2、拟投险种的分析 由表中我们可以看出车主们拟投的主要险种是机动车辆损失险和第三者责任险,附加险主要是新增加设备损失险、发动机特别损失险、车身划痕损失险、交通事故精神损害责任险方面。 四、我国汽车保险发展状况分析 虽然在中国保险发展很稳定,趋势很好,但是和国外相比,还是存在很大的差距。国际精算师祝光建分析了中外车险水平的差距所在。中外差
5种数据挖掘工具分析比较
数据挖掘工具调查与研究 姓名:马蕾 学号:18082703
5种数据挖掘工具分别为: 1、 Intelligent Miner 2、 SAS Enterpreise Miner 3、SPSS Clementine 4、马克威分析系统 5、GDM Intelligent Miner 一、综述:IBM的Exterprise Miner简单易用,是理解数据挖掘的好的开始。能处理大数据量的挖掘,功能一般,可能仅满足要求.没有数据探索功能。与其他软件接口差,只能用DB2,连接DB2以外的数据库时,如Oracle, SAS, SPSS需要安装DataJoiner作为中间软件。难以发布。结果美观,但同样不好理解。 二、基本内容:一个挖掘项目可有多个发掘库组成;每个发掘库包含多个对象和函数对象: 数据:由函数使用的输入数据的名称和位置。 离散化:将记录分至明显可识别的组中的分发操作。 名称映射:映射至类别字段名的值的规范。 结果:由函数创建的结果的名称和位置。 分类:在一个项目的不同类别之间的关联层次或点阵。 值映射:映射至其它值的规范。 函数: 发掘:单个发掘函数的参数。 预处理:单个预处理函数的参数。 序列:可以在指定序列中启动的几个函数的规范。 统计:单个统计函数的参数。 统计方法和挖掘算法:单变量曲线,双变量统计,线性回归,因子分析,主变量分析,分类,分群,关联,相似序列,序列模式,预测等。 处理的数据类型:结构化数据(如:数据库表,数据库视图,平面文件) 和半结构化或非结构化数据(如:顾客信件,在线服务,传真,电子邮件,网页等) 。 架构:它采取客户/服务器(C/S)架构,并且它的API提供了C++类和方法 Intelligent Miner通过其独有的世界领先技术,例如自动生成典型数据集、发现关联、发现序列规律、概念性分类和可视化呈现,可以自动实现数据选择、数据转换、数据挖掘和结果呈现这一整套数据挖掘操作。若有必要,对结果数据集还可以重复这一过程,直至得到满意结果为止。 三、现状:现在,IBM的Intelligent Miner已形成系列,它帮助用户从企业数据资产中 识别和提炼有价值的信息。它包括分析软件工具——Intelligent Miner for Data和IBM Intelligent Miner forText ,帮助企业选取以前未知的、有效的、可行的业务知识——
大数据挖掘weka大数据分类实验报告材料
一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
中国车险市场分析
中国车险市场分析
随着近几年我国汽车市场和保险市场的不断发展壮大和完善,车险业务的发展极为迅速,机动车辆的承保面已达到50%以上,尤其是乘用车辆的承保比例更高,达到了80%。车险已成为国内保险业务中最大的险种,如1997年全国机动车辆保险费收入为287.68亿元,占财产险保险费总收入的60%左右①。我国将于2004年12月11日以后,允许外资财产保险公司经营除法定保险业务以外的全部非寿险业务,这其中就包括了汽车保险业务②。而最近几年以至今后几年中,国内汽车价格的不断下降使私家车的数量不断增加,国内的汽车保险市场自然也将迅速膨胀。巨大的市场需求,使我国的车险市场成为全球最引人注目的新兴汽车保险市场。随着外资保险公司业务经营范围的逐渐放开,汽车保险产品的供应能力将极大增强,投保人的需求也将更为多样化、选择的范围也更为广泛,各家保险公司之间的竞争也将更加激烈。与此同时,由于汽车市场的扩大,人们家用轿车的快速增加,再加上各大中城市交通的承载运营能力未能及时改善,使得车辆出险率上升,以致机动车保险的赔付率业务也随之急剧上升。由于汽车产业和保险产业之间信息的不对称,使得各大经营车险的保险公司虽通过几次调整费率(主要是家用车和营运车保费的提高及一些车型保险系数的变化)、不断推出新的车险品种,但赔付率仍然高居不下,致使一些保险公司在某些地区的车险业务曾一度处于亏损状态。可见,把“车险”仅单纯的作为保险业务,而忽视它与汽车产业的密切联系的原有“车险”运作模式已不再适应汽车和保险市场的迅速变化。可预见,未来“车险”的规模之大,保费收入之多,汽车、保险市场联系之紧密对中国汽车和保险产业的经营有着举足轻重的影响,这也必将是中外保险公司竞争、争夺的热点之一。 因此,中国车险市场正成为中国汽车市场和保险市场联系的纽带,它的发展规范与否会对汽车、保险两个市场的壮大、拓展产生重要影响。因此研究它对汽车、保险两市场的关系及两市场对它所起的作用对于两个产业的协调发展和车险市场进一步完善和规范是一个重要课题。 一、数据的选择和模型分析 车险,狭义的讲是属于保险业一部分。车险业务更是财险业务中所占比例最大的业务。而从广义来看车险又是汽车产业和保险产业的交汇点,它的生存、发展不仅受到汽车市场中各个生产企业间激烈竞争的影响,而且也受到保险市场诸如:制度、费率调整、险种创新、服务质量的制约。本文正是从广义的车险——车险市场来分析的。 (一)样本选取和模型的理论基础 本文选取的样本数据为2003年1月到2005年4月的包括车险保费收入、乘用车销售量和保费收入,共28组数据。其具体数据如表1所示: ①参见《财产保险原理和实务》,许谨良、王明初、陆熊编著,上海财经大学出版社1998 年11月第1版 ②参见《中国入世问题报告》,陈春洁、李小东等著,中国社会科学出版社2002年1月第1版
汽车保险市场调查报告
汽车保险市场调查 报告
滁州市汽车保险市场调查报 告 目录 一、引言 二、数据统计 三、数据分析姓名:李世磊 学号: 1804209 班级:13级汽营(2)班完成时间: .5.28
四、中国汽车保险发展状况分析 五、未来中国汽车保险发展趋势 六、结论 一:引言 一):调查背景 此次汽车保险市场调查开始于5月21日,;利用五天的时间,在5月25日以滁州市消费者群体为中心,完成调查任务。经过汽车保险市场调查,能够科学、系统和客观地收集整理和分析市场营销的资料、数据和信息,使汽车营销企业能够制定有效的市场营销决策;能够掌握竞争者的态势,使汽车营销企业在竞争中知己知彼,保持清醒的头脑,以永远立于不败之地;能够发现新的需求和机会,几时地开发出新的产品或服务去满足这些需求;还能够了解到宏观上的国家政策、法律和法规的变化对汽车行业发展的影响,预测未来经济走向,抓住发展机会。总之,汽车市场调查是汽车营销企业取得良好经济效益的保证。因此,市场调查已成为各大汽车企业共同关注的问题。
此次调查是对社会环境、市场需求、产品、市场营销活动的信息进行判断、收集、记录、整理和分析,并进而提出问题和解决问题。 在此次调查中我们运用到了市场调查中的问卷调查法进行调查,发放了50份调查问卷,涉及各个行业,最后整理综合所有资料,得出分析报告。 二数据统计 由于调查人物较多,因此随机抽取5份来做数据统计 三、数据分析 1、投保认知数据的分析 从表中我们能够看出,车主在使用车辆的过程中最担心出现的风险是怕造成第三者的损失和本车受损,造成第三者损失的风险比较的注意,这也是全国的车主很关心的问题,随着全国公民对人权意识的提升。当自身的财产和人生受到损伤时,会尽最大的
大数据处理分析的六大最好工具
大数据处理分析的六大最好工具 来自传感器、购买交易记录、网络日志等的大量数据,通常是万亿或EB的大小,如此庞大的数据,寻找一个合适处理工具非常必要,今天我们为大家分享在大数据处理分析过程中六大最好用的工具。 【编者按】我们的数据来自各个方面,在面对庞大而复杂的大数据,选择一个合适的处理工具显得很有必要,工欲善其事,必须利其器,一个好的工具不仅可以使我们的工作事半功倍,也可以让我们在竞争日益激烈的云计算时代,挖掘大数据价值,及时调整战略方向。本文转载自中国大数据网。 CSDN推荐:欢迎免费订阅《Hadoop与大数据周刊》获取更多Hadoop技术文献、大数据技术分析、企业实战经验,生态圈发展趋势。 以下为原文: 大数据是一个含义广泛的术语,是指数据集,如此庞大而复杂的,他们需要专门设计的硬件和软件工具进行处理。该数据集通常是万亿或EB的大小。这些数据集收集自各种各样的来源:传感器、气候信息、公开的信息、如杂志、报纸、文章。大数据产生的其他例子包括购买交易记录、网络日志、病历、事监控、视频和图像档案、及大型电子商务。大数据分析是在研究大量的数据的过程中寻找模式,相关性和其他有用的信息,可以帮助企业更好地适应变化,并做出更明智的决策。 Hadoop Hadoop 是一个能够对大量数据进行分布式处理的软件框架。但是Hadoop 是以一种可靠、高效、可伸缩的方式进行处理的。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop 还是可伸缩的,能够处理PB 级数据。此外,Hadoop 依赖于社区服务器,因此它的成本比较低,任何人都可以使用。
车险销售工作总结分析(精选多篇)
车险销售工作总结(精选多篇) 第一篇:车险部工作总结 车险业务管理部十月份理赔工作总结 按照既定的工作计划与安排,车险业务管理部十月份的理赔工作主要围绕业务培训和强化管理等方面做了几项重点工作。 一、主要工作及成效 (一)加大了理赔业务的培训力度,采取“定期和集中”的视频培训方式对全省理赔客服人员进行了全方位的业务培训。一是针对询报价工作中存在的问题,组织了询报价专项培训,在规范询报价工作的基础上对实际操作做了重点提示,同时结合定损工作传授了部分典型车辆的配臵和配件更换经验;二是针对现场查勘工作中的问题和薄弱环节,结合总公司的《车险现场查勘环节执行手册》和《理赔实务规程》组织了《车险现场查勘操作规范与要点》专项视频培训,总结和归纳了现场查勘的九个重要节点、现场查勘的八项准备工作、现场查勘拍照的五要求和五步曲,并对现场查勘记录的规范撰写、常见事故现场的查勘要点、主要风险点的查勘要点和疑点案件特征及对策进行了详细地讲解;三是结合总公司近期将推出的简易赔案项目,完成了《车险简易赔案项目及实务操作简介》转培训。 (二)加大了理赔内勤的轮训力度,采取“面对面、一对一”的现场培训方式,以系统操作、单证收集、简易赔案
理算、未决赔案清理等为培训要点,先后对秦皇岛、廊坊、唐山、沧州等机构的理赔内勤进行了较为全面和系统的培训与指导。本次轮训将对规范操作、提高质量和效率起到积极的促进作用。 (三)完成了“1000元以下车险赔案免现场查勘方案”的论证,从不符合保监要求并会影响信誉和服务水平、不符合总公司规定并会影响第一现场查勘率、客户上传损失照片缺乏操作性并会导致结案率指标的恶化、损失1000元以下难以界定并存在一定的道德风险等四个角度做了分析和阐述,得出了暂不宜推行此方案的结论,并对加强理赔服务、改善服务水平提出了建设性的意见。 (四)组织学习、探讨了山东省分公司车险业务的管理经验。。。。 二、存在的主要问题 各机构理赔客服中心存在的普遍问题集中体现为“责任心差,执行力弱”;而省公司车险部存在的突出问题则是“管理薄弱”。 (一)责任心差。概况地讲,责任心差就是“三个缺乏”,一是缺乏实事求是和一查到底的精神,二是缺乏对自己负责、对公司负责的精神,三是缺乏深入学习和钻研理赔业务的精神。表现在具体工作中就是:对事故现场没有按照规范要求仔细查勘,更多的是流于形式、走了过场;对于可疑案
汽车保险市场调查报告
州市汽车保险
场调查 报告目录姓名:李世磊 学号:20131804209 班级:13级汽营(2)班完成时间:2014.5.28
一、引言 二、数据统计 三、数据分析 四、我国汽车保险发展状况分析 五、未来我国汽车保险发展趋势 六、结论 一:引言 一):调查背景 此次汽车保险市场调查开始于2014年5月21日,;利用五天的时间,在5月25日以滁州市消费者群体为中心,完成调查任务。通过汽车保险市场调查,可以科学、系统和客观地收集整理和分析市场营销的资料、数据和信息,使汽车营销企业能够制定有效的市场营销决策;可以掌握竞争者的态势,使汽车营销企
业在竞争中知己知彼,保持清醒的头脑,以永远立于不败之地;可以发现新的需求和机会,几时地开发出新的产品或服务去满足这些需求;还可以了解到宏观上的国家政策、法律和法规的变化对汽车行业发展的影响,预测未来经济走向,抓住发展机会。总之,汽车市场调查是汽车营销企业取得良好经济效益的保证。因此,市场调查已成为各大汽车企业共同关注的问题。 此次调查是对社会环境、市场需求、产品、市场营销活动的信息进行判断、收集、记录、整理和分析,并进而提出问题和解决问题。 在此次调查中我们运用到了市场调查中的问卷调查法进行调查,发放了50份调查问卷,涉及各个行业,最后整理综合所有资料,得出分析报告。 二数据统计 由于调查人物较多,所以随机抽取5份来做数据统计
三、数据分析 1、投保认知数据的分析 从表中我们可以看出,车主在使用车辆的过程中最担心出现的风险是怕造成第三者的损失和本车受损,造成第三者损失的风险比较的注意,这也是全国的车主很关心的问题,随着全国公民对人权意识的提升。当自身的财产和人生受到损伤时,会尽最大的努力捍卫自己的权利。发生交通事故后,也很容易导致汽车的损失。所以车主们在造成第三者受损和本车受损风险方面比较的在意,由于本次调查的对象属于私家车主。所以车主在本车乘客受伤风险方面也不是很在意,但这只局限于货车和私家车,对于客运汽车,事实并不是如此。 现在车主在为自己的爱车上保险时大多数认为还是比较的方便,究其原因是现在的4S店和保险公司售后服务工作做的很好,营销人员都会向顾客推荐险种,全权代理的服务让顾客们感觉到方便,所以,大多数车主在位自己的爱车上保险时都会选着在4S店或保险公司,
数据挖掘WEKA实验报告
数据挖掘-WEKA 实验报告一 姓名及学号:杨珍20131198 班级:卓越计科1301 指导老师:吴珏老师
一、实验内容 1、Weka 工具初步认识(掌握weka程序运行环境) 2、实验数据预处理。(掌握weka中数据预处理的使用) 对weka自带测试用例数据集weather.nominal.arrf文件,进行一下操作。 1)、加载数据,熟悉各按钮的功能。 2)、熟悉各过滤器的功能,使用过滤器Remove、Add对数据集进行操作。 3)、使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity 属性值为high的全部实例。 4)、使用离散化技术对数据集glass.arrf中的属性RI和Ba进行离散化(分别用等宽,等频进行离散化)。 (1)打开已经安装好的weka,界面如下,点击openfile即可打开weka自带测试用例数据集weather.nominal.arrf文件
(2)打开文件之后界面如下: (3)可对数据进行选择,可以全选,不选,反选等,还可以链接数据库,对数
据进行编辑,保存等。还可以对所有的属性进行可视化。如下图: (4)使用过滤器Remove、Add对数据集进行操作。
(5)点击此处可以增加属性。如上图,增加了一个未命名的属性unnamed.再点击下方的remove按钮即可删除该属性. (5)使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity属性值为high的全部实例。 没有去掉之前: (6)去掉其中一个属性之后:
weka实验报告
基于w e k a的数据分类分析实验报告1 实验目的 (1)了解决策树C4.5和朴素贝叶斯等算法的基本原理。 (2)熟练使用weka实现上述两种数据挖掘算法,并对训练出的模型进行测试和评价。 2 实验基本内容 本实验的基本内容是通过基于weka实现两种常见的数据挖掘算法(决策树C4.5和朴素贝叶斯),分别在训练数据上训练出分类模型,并使用校验数据对各个模型进行测试和评价,找出各个模型最优的参数值,并对模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 3 算法基本原理 (1)决策树C4.5 C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。C4.5由J.Ross Quinlan在ID3 的基础上提出的。ID3算法用来构造决策树。决策树是一种类似流程图的树结构,其中每个内部节点(非树叶节点)表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶节点存放一个类标号。一旦建立好了决策树,对于一个未给定类标号的元组,跟踪一条有根节点到叶节点的路径,该叶节点就存放着该元组的预测。决策树的优势在于不需要任何领域知识或参数设置,适合于探测性的知识发现。 从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。 属性选择度量又称分裂规则,因为它们决定给定节点上的元组如何分裂。属性选择度量提供了每个属性描述给定训练元组的秩评定,具有最好度量得分的属性被选作给定元组的分裂属性。目前比较流行的属性选择度量有--信息增益、增益率和Gini指标。
2017年车险市场投资分析报告
2017年车险市场投资分析报告
目录 第一节商业车险费改激发车险创新动力 (4) 一、传统车险模式痛点多:赔付率高、理赔效率低 (4) 二、商车费改全国推开,车险创新迎来爆发 (5) 三、智能网联助力车险模式升级,UBI有望渐成主流 (7) 第二节 UBI保险市场掀起合作浪潮,产业链协同推进加快 (11) 一、国外UBI发展处于领先位置 (11) 二、保险、运营商、车企掀起合作浪潮 (12) 三、中国UBI保费拥有千亿级市场空间 (15) 第三节受益于UBI落地,智能网联有望驶入快车道 (17) 一、UBI离落地已不远 (17) 二、硬件先行,前装T-BOX最受益 (18) 三、驾驶行为数据价值大,数据服务弹性大 (22) 第四节投资分析 (26) 一、重点推荐车载终端硬件 (26) 二、提前布局数据服务领域 (27)
图表目录 图表1:从各大财险公司数据看车险综合成本率高 (4) 图表2:从车险生命周期看成本增长路径 (5) 图表3:智能网联主推传统车险向新型车险UBI升级 (7) 图表4:UBI各级数据模型间的衔接流程 (8) 图表5:智能网联助推车险定价模式从保额定价向使用定价过渡 (9) 图表6:意大利UBI渗透率最高 (11) 图表7:美国UBI保单数量最多 (11) 图表8:全球领先的UBI保险公司 (12) 图表9:UBI产业链:车载终端+运营商+数据服务+保险 (12) 图表10:预计2020年UBI市场规模达到1400亿 (15) 图表11:政策要求建立车企、地方、国家三级监管平台 (18) 图表12:2012-2016年新能源汽车销量 (21) 图表13:2012-2016年新能源汽车销量 (22) 图表14:评驾科技已逐步建立基于UBI产业链的合作体系 (24) 图表15:驾驶行为模型是评驾科技的核心产品 (25) 表格目录 表格1:政策推动商车险费市场化改革 (6) 表格2:ADAS有效降低事故发生频率 (10) 表格3:险企与UBI保险产业链公司积极开展合作 (13) 表格4:目前市场上有三种主流合作模式 (15) 表格5:政策强制新能源汽车必须装车载终端 (17) 表格6:T-Box产品表 (19) 表格7:OBD产品表 (20) 表格8:T-BOX与OBD相比更有优势 (21) 表格9:国内多家UBI数据服务公司顺利获得融资 (23)
汽车保险市场调查报告
汽车保险市场调查报告文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
滁州市汽车保险市场调查报 告 目录一、引言姓名:李世磊 班级:13级汽营(2)班
二、数据统计 三、数据分析 四、我国汽车保险发展状况分析 五、未来我国汽车保险发展趋势 六、结论 一:引言 一):调查背景 此次汽车保险市场调查开始于2014年5月21日,;利用五天的时间,在5月25日以滁州市消费者群体为中心,完成调查任务。通过汽车保险市场调查,可以科学、系统和客观地收集整理和分析市场营销的资料、数据和信息,使汽车营销企业能够制定有效的市场营销决策;可以掌握竞争者的态势,使汽车营销企业在竞争中知己知彼,保持清醒的头脑,以永远立于不败之地;可以发现新的需求和机会,几时地开发出新的产品或服务去满足这些需求;还可以了解到宏观上的国家政策、法律和法规的变化对汽车行业发展的影响,预测未来经济走向,抓住发展机会。总之,
汽车市场调查是汽车营销企业取得良好经济效益的保证。因此,市场调查已成为各大汽车企业共同关注的问题。 此次调查是对社会环境、市场需求、产品、市场营销活动的信息进行判断、收集、记录、整理和分析,并进而提出问题和解决问题。 在此次调查中我们运用到了市场调查中的问卷调查法进行调查,发放了50份调查问卷,涉及各个行业,最后整理综合所有资料,得出分析报告。 二数据统计 由于调查人物较多,所以随机抽取5份来做数据统计 三、数据分析 1、投保认知数据的分析
从表中我们可以看出,车主在使用车辆的过程中最担心出现的风险是怕造成第三者的损失和本车受损,造成第三者损失的风险比较的注意,这也是全国的车主很关心的问题,随着全国公民对人权意识的提升。当自身的财产和人生受到损伤时,会尽最大的努力扞卫自己的权利。发生交通事故后,也很容易导致汽车的损失。所以车主们在造成第三者受损和本车受损风险方面比较的在意,由于本次调查的对象属于私家车主。所以车主在本车乘客受伤风险方面也不是很在意,但这只局限于货车和私家车,对于客运汽车,事实并不是如此。 现在车主在为自己的爱车上保险时大多数认为还是比较的方便,究其原因是现在的4S店和保险公司售后服务工作做的很好,营销人员都会向顾客推荐险种,全权代理的服务让顾客们感觉到方便,所以,大多数车主在位自己的爱车上保险时都会选着在4S店或保险公司,方便且快捷! 通过前期的调查我们发现目前大多数车主对保险合同的内容不是很了解,这会造成在理赔工作中不免会遇到一些麻烦,所以汽车保险展业人员在宣营销保险的时候一定要注意对保险合同的解释,让车主们能够清楚的理解合同的内容和所指的意思。特别是免责方面的条款一定要明确列明和说明。 2、拟投险种的分析 由表中我们可以看出车主们拟投的主要险种是机动车辆损失险和第三者责任险,附加险主要是新增加设备损失险、发动机特别损失险、车身划痕损失险、交通事故精神损害责任险方面。 四、我国汽车保险发展状况分析
数据挖掘主要工具软件简介
数据挖掘主要工具软件简介 Dataminning指一种透过数理模式来分析企业内储存的大量资料,以找出不同的客户或市场划分,分析出消费者喜好和行为的方法。前面介绍了报表软件选购指南,本篇介绍数据挖掘常用工具。 市场上的数据挖掘工具一般分为三个组成部分: a、通用型工具; b、综合/DSS/OLAP数据挖掘工具; c、快速发展的面向特定应用的工具。 通用型工具占有最大和最成熟的那部分市场。通用的数据挖掘工具不区分具体数据的含义,采用通用的挖掘算法,处理常见的数据类型,其中包括的主要工具有IBM 公司Almaden 研究中心开发的QUEST 系统,SGI 公司开发的MineSet 系统,加拿大Simon Fraser 大学开发的DBMiner 系统、SAS Enterprise Miner、IBM Intelligent Miner、Oracle Darwin、SPSS Clementine、Unica PRW等软件。通用的数据挖掘工具可以做多种模式的挖掘,挖掘什么、用什么来挖掘都由用户根据自己的应用来选择。 综合数据挖掘工具这一部分市场反映了商业对具有多功能的决策支持工具的真实和迫切的需求。商业要求该工具能提供管理报告、在线分析处理和普通结构中的数据挖掘能力。这些综合工具包括Cognos Scenario和Business Objects等。 面向特定应用工具这一部分工具正在快速发展,在这一领域的厂商设法通过提供商业方案而不是寻求方案的一种技术来区分自己和别的领域的厂商。这些工
具是纵向的、贯穿这一领域的方方面面,其常用工具有重点应用在零售业的KD1、主要应用在保险业的Option&Choices和针对欺诈行为探查开发的HNC软件。 下面简单介绍几种常用的数据挖掘工具: 1. QUEST QUEST 是IBM 公司Almaden 研究中心开发的一个多任务数据挖掘系统,目的是为新一代决策支持系统的应用开发提供高效的数据开采基本构件。系统具有如下特点: (1)提供了专门在大型数据库上进行各种开采的功能:关联规则发现、序列模式发现、时间序列聚类、决策树分类、递增式主动开采等。 (2)各种开采算法具有近似线性(O(n))计算复杂度,可适用于任意大小的数据库。 (3)算法具有找全性,即能将所有满足指定类型的模式全部寻找出来。 (4)为各种发现功能设计了相应的并行算法。 2. MineSet MineSet 是由SGI 公司和美国Standford 大学联合开发的多任务数据挖掘系统。MineSet 集成多种数据挖掘算法和可视化工具,帮助用户直观地、实时地发掘、理解大量数据背后的知识。MineSet 2.6 有如下特点: (1)MineSet 以先进的可视化显示方法闻名于世。MineSet 2.6 中使用了6 种可视化工具来表现数据和知识。对同一个挖掘结果可以用不同的可视化工具以各种形式表示,用户也可以按照个人的喜好调整最终效果, 以便更好地理解。MineSet 2.6 中的可视化工具有Splat Visualize、Scatter Visualize、Map