Wilcoxon符号秩检验吴喜之例子
wilcoxon符号秩检验 吴喜之例子()
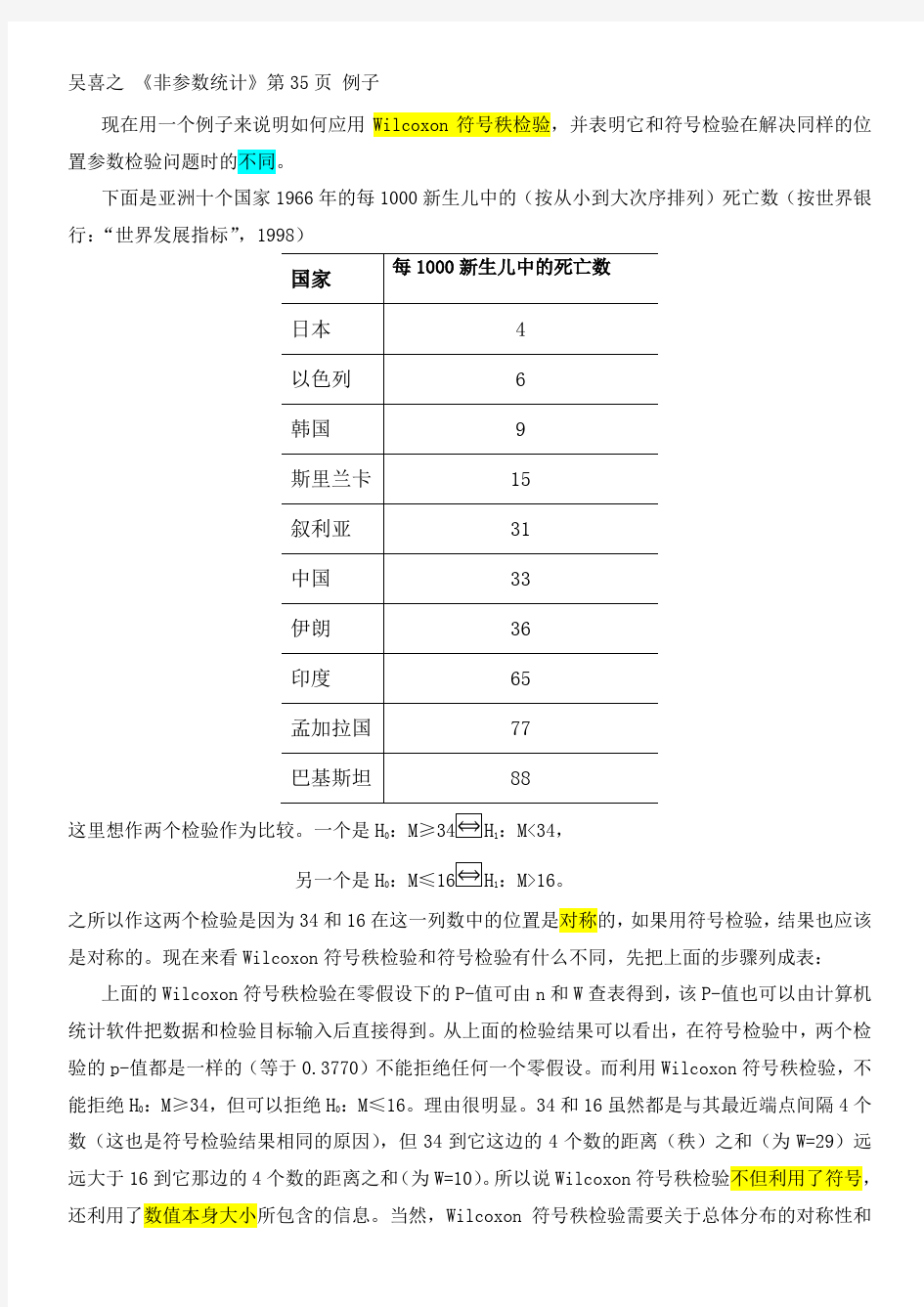
吴喜之《非参数统计》第35页例子 现在用一个例子来说明如何应用Wilcoxon符号秩检验,并表明它和符号检验在解决同样的位置参数检验问题时的不同。 下面是亚洲十个国家1966年的每1000新生儿中的(按从小到大次序排列)死亡数(按世界银行:“世界发展指标”,1998) 这里想作两个检验作为比较。一个是H 0:M≥34H 1 :M<34, 另一个是H 0:M≤16H 1 :M>16。 之所以作这两个检验是因为34和16在这一列数中的位置是对称的,如果用符号检验,结果也应该是对称的。现在来看Wilcoxon符号秩检验和符号检验有什么不同,先把上面的步骤列成表: 上面的Wilcoxon符号秩检验在零假设下的P-值可由n和W查表得到,该P-值也可以由计算机统计软件把数据和检验目标输入后直接得到。从上面的检验结果可以看出,在符号检验中,两个检验的p-值都是一样的(等于0.3770)不能拒绝任何一个零假设。而 利用Wilcoxon符号秩检验,不能拒绝H 0:M≥34,但可以拒绝H :M≤16。理由很明显。
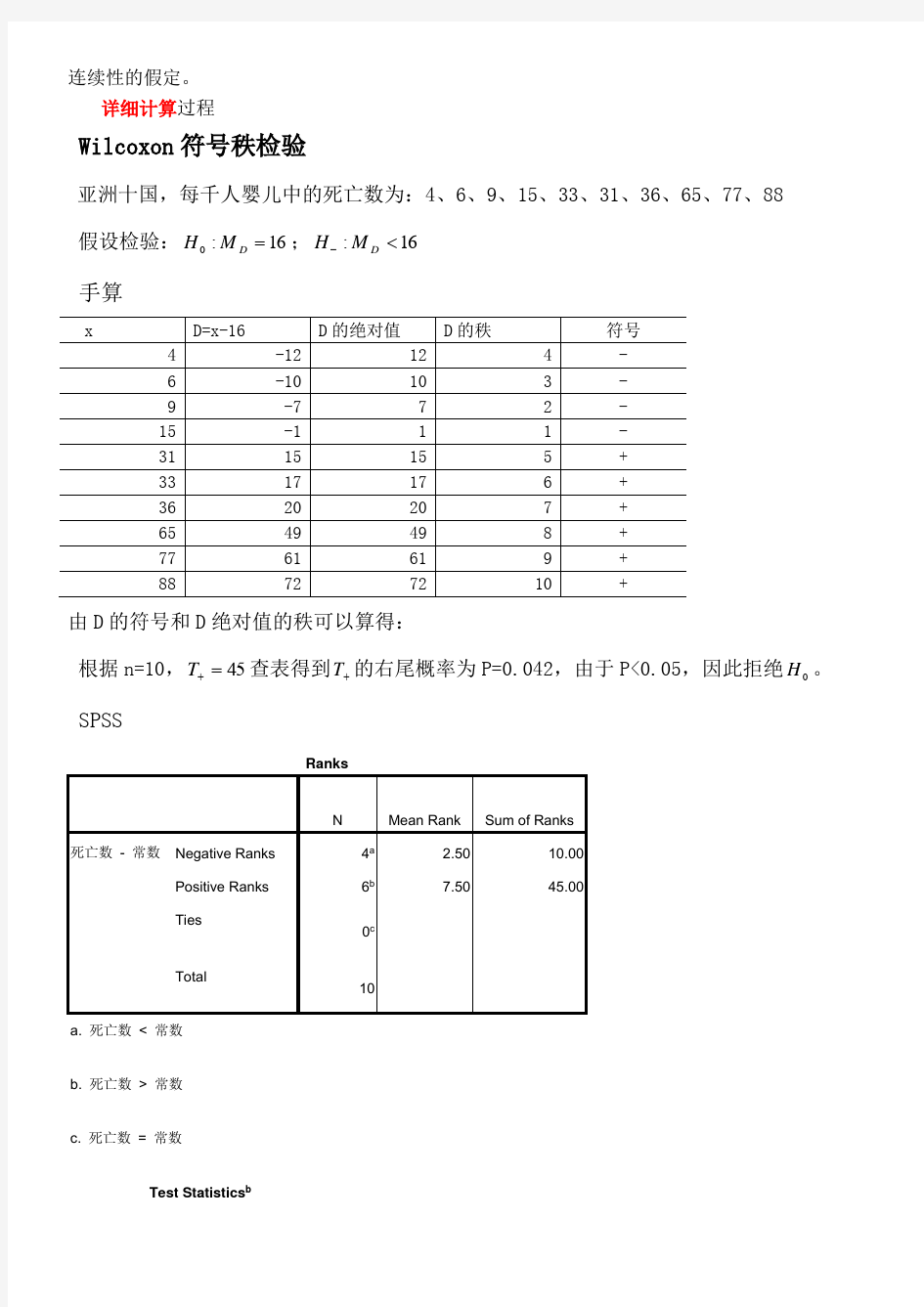
34和16虽然都是与其最近端点间隔4个数(这也是符号检验结果相同的原因),但34到它这边的4个数的距离(秩)之和(为W=29)远远大于16到它那边的4个数的距离之和(为W=10)。所以说Wilcoxon 符号秩检验不但利用了符号,还利用了数值本身大小所包含的信息。当然,Wilcoxon 符号秩检验需要关于总体分布的对称性和连续性的假定。 详细计算过程 Wilcoxon 符号秩检验 亚洲十国,每千人婴儿中的死亡数为:4、6、9、15、33、31、36、65、77、88 假设检验:16:0=D M H ;16:<-D M H 手算 由D 的符号和D 绝对值的秩可以算得: 根据n=10,45=+T 查表得到+T 的右尾概率为P=0.042,由于P<0.05,因此拒绝0H 。 SPSS
SAS讲义_第二十七课符号检验和Wilcoxon符号秩检验
第二十七课 符号检验和Wilcoxon 符号秩 检验 在统计推断和假设检验中,传统的检验统计量都叫做参数检验,因为它们都依赖于确定的概率分布,这个分布带有一组自由的参数。参数检验被认为是依赖于分布假定的。通常情况下,我们对数据进行分析时,总是假定误差项服从正态分布,这是人们易于接受的事实,因为正态分布的原始出发点就是来自于误差分布,至于当样本相当大时,数据的正态近似,这是由于大样本理论所保证的。但有些资料不一定满足上述要求,或不能测量具体数值,其观察结果往往只有程度上的区别,如颜色的深浅、反应的强弱等,此时就不适用参数检验的方法,而只能用非参数统计方法(non-parametric statistical analysis )来处理。这种方法对数据来自的总体不作任何假设或仅作极少的假设,因此在实用中颇有价值,适用面很广。 一、 单样本的符号检验 符号检验(sign test )是一种最简单的非参数检验方法。它是根据正、负号的个数来假设检验。首先需要将原始观察值按设定的规则,转换成正、负号,然后计数正、负号的个数作出检验。该检验可用于样本中位数和总体中位数的比较,数据的升降趋势的检验,特别适用于总体分布不服从正态分布或分布不明的配对资料,有时当配对比较的结果只能定性的表示,如试验前后比较结果为颜色从深变浅、程度从强变弱,成绩从一般变优秀,即不能获得具体数字,也可用符号检验,例如用正号表示颜色从深变浅,用负号表示颜色从浅变深。 用于配对资料时,符号检验的计算步骤为:首先定义成对数据指定正号或负号的规则,然后计数正号的个数+ S 及负号的个数- S ,由于在具体比较配对资料时,可能存在配对资料的前后没有变化,或等于假设中的中位数,此时仅需要将这些观察值从资料中剔除,当然样本大小n 也随之减少,故修正样本大小- + +=S S n 。当样本n 较小时,应使用二项分布确切概率计算法,当样本n 较大时,常利用二项分布的正态近似。 1. 小样本时的二项分布概率计算 当20≤n 时,+S 或- S 的检验p 值由精确计算尺度二项分布的卷积获得。在比较配对资 料试验前后有否变化,或增加或减小的假设检验时,如果我们定义试验后比试验前增加为正号,反之为负号,那么对于原假设:试验前后无变化来说,正号的个数+ S 和负号的个数- S 可 能性应当相等,即正号出现的概率p =0.5,于是+S 与- S 均服从二项分布)5.0,(n B ,对于太 大的+S 相应太小的-S ,或者太大的-S 相应太小的+ S ,都将拒绝接受原假设;对于原假设:试验后比试验前有增加来说,正号的个数+ S 大于负号的个数- S 的可能性应该大,即正号出现的概率5.0>p ,对于太小的+ S 相应太大的- S ,将拒绝接受原假设;对于原假设:试验后比试验前减小来说,正号的个数+ S 小于等于负号的个数- S 的可能性应该大,即正号出现
t检验、u检验、卡方检验、F检验、方差分析
统计中经常会用到各种检验,如何知道何时用什么检验呢,根据结合自己的工作来说一说: t检验有单样本t检验,配对t检验和两样本t检验。 单样本t检验:是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。 配对t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。 u检验:t检验和就是统计量为t,u的假设检验,两者均是常见的假设检验方法。当样本含量n较大时,样本均数符合正态分布,故可用u检验进行分析。当样本含量n小时,若观察值x符合正态分布,则用t检验(因此时样本均数符合t 分布),当x为未知分布时应采用秩和检验。 F检验又叫方差齐性检验。在两样本t检验中要用到F检验。 从两研究总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。若两总体方差相等,则直接用t检验,若不等,可采用t'检验或变量变换或秩和检验等方法。 其中要判断两总体方差是否相等,就可以用F检验。 简单的说就是检验两个样本的方差是否有显著性差异这是选择何种T检验(等方差双样本检验,异方差双样本检验)的前提条件。 在t检验中,如果是比较大于小于之类的就用单侧检验,等于之类的问题就用双侧检验。 卡方检验 是对两个或两个以上率(构成比)进行比较的统计方法,在临床和医学实验中应用十分广泛,特别是临床科研中许多资料是记数资料,就需要用到卡方检验。方差分析 用方差分析比较多个样本均数,可有效地控制第一类错误。方差分析(analysis of variance,ANOVA)由英国统计学家R.A.Fisher首先提出,以F命名其统计量,故方差分析又称F检验。 其目的是推断两组或多组资料的总体均数是否相同,检验两个或多个样本均数的差异是否有统计学意义。我们要学习的主要内容包括 单因素方差分析即完全随机设计或成组设计的方差分析(one-way ANOVA):用途:用于完全随机设计的多个样本均数间的比较,其统计推断是推断各样本所代表的各总体均数是否相等。完全随机设计(completely random design)不考虑个体差异的影响,仅涉及一个处理因素,但可以有两个或多个水平,所以亦称单因素实验设计。在实验研究中按随机化原则将受试对象随机分配到一个处理因
t检验和u检验
t检验和u检验 简而言之,t检验和u检验就是统计量为t,u的假设检验,两者均是常见的假设检验方法。当样本含量n较大时,样本均数符合正态分布,故可用u检验进行分析。当样本含量n小时,若观察值x符合正态分布,则用t检验(因此时样本均数符合t分布),当x 为未知分布时应采用秩和检验。 一、样本均数与总体均数比较的t检验 样本均数与总体均数比较的t检验实际上是推断该样本来自的总体均数µ与已知的某一总体均数µ0(常为理论值或标准值) 有无差别。如根据大量调查,已知健康成年男性的脉搏均数为72次/分,某医生在一山区随即抽查了25名健康男性,求得其脉搏均数为74.2次/分,标准差为6.0次/分,问是否能据此认为该山区成年男性的脉搏均数高于一般成年男性。 上述两个均数不等既可能是抽样误差所致,也有可能真是环境差异的影响,为此,可用t检验进行判断,检验过程如下: 1. 建立假设 H0:µ=µ0=72次/分,H0:µ>µ0,检验水准为单侧0.05。 2. 计算统计量 进行样本均数与总体均数比较的t检验时t值为样本均数与总体均数差值的绝对值除以标准误的商,其中标准误为标准差除以样本含量算术平方根的商。 3. 确定概率,作出判断 以自由度v(样本含量n减1)查t界值表,0.025
SAS系统和数据分析Wilcoxon秩和检验
第二十八课 Wilcoxon 秩和检验 一、 两样本的Wilcoxon 秩和检验 两样本的Wilcoxon 秩和检验是由Mann ,Whitney 和Wilcoxon 三人共同设计的一种检验,有时也称为Wilcoxon 秩和检验,用来决定两个独立样本是否来自相同的或相等的总体。如果这两个独立样本来自正态分布和具有相同方差时,我们可以采用t 检验比较均值。但当这两个条件都不能确定时,我们常替换t 检验法为Wilcoxon 秩和检验。 Wilcoxon 秩和检验是基于样本数据秩和。先将两样本看成是单一样本(混合样本)然后由小到大排列观察值统一编秩。如果原假设两个独立样本来自相同的总体为真,那么秩将大约均匀分布在两个样本中,即小的、中等的、大的秩值应该大约被均匀分在两个样本中。如果备选假设两个独立样本来自不相同的总体为真,那么其中一个样本将会有更多的小秩值,这样就会得到一个较小的秩和;另一个样本将会有更多的大秩值,因此就会得到一个较大的秩和。 设两个独立样本为:第一个x 的样本容量为1n ,第二个y 样本容量为2n ,在容量为21n n n +=的混合样本(第一个和第二个)中,x 样本的秩和为x W ,y 样本的秩和为y W ,且有: 2)1(21+= +++=+n n n W W y x (28.1) 我们定义: 2 )1(111+-=n n W W x (28.2) 2)1(222+-=n n W W y (28.3) 以x 样本为例,若它们在混合样本中享有最小的1n 个秩,于是2)1(11+=n n W x ,也是x W 可能取的最小值;同样y W 可能取的最小值为2 )1(22+n n 。那么,x W 的最大取值等于混合样本的总秩和减去y W 的最小值,即2 )1(2)1(22+-+n n n n ;同样,y W 的最大取值等于2 )1(2)1(11+-+n n n n 。所以,式(28.2)和式(28.3)中的1W 和2W 均为取值在0与
Wilcoxon符号秩检验
第二节Wilcoxon符号秩检验
Wilcoxon符号秩检验 符号检验只用了差的符号,但没有利用差值的 大小。 1 2 3Wilcoxon符号秩检验(Wilcoxon signed-rank test) 把差的绝对值的秩分别按照不同的符号相加作为其检验统计量。 显然,相比较于符号检验,Wilcoxon符号秩检验利用了更多的信息。
Wilcoxon符号秩检验:条件 u Wilcoxon符号秩检验需要一点总体分布的性质;它要求假 定样本点来自连续对称总体分布;而符号检验不需要知道 任何总体分布的性质。 u在对称分布中,总体中位数和总体均值是相等的;因此, 对于总体中位数的检验,等价于对于总体均值的检验。 u Wilcoxon符号秩检验实际是对对称分布的总体中位数(或 均值)的检验。
Wilcoxon符号秩检验:基本原理 u计算差值绝对值的秩。 u分别计算出差值序列里正数的秩和(W+)以及负数的秩和(W-)。 u如果原假设成立,W+与W-应该比较接近。如果W+和W-过大或过 小,则说明原假设不成立。 u将正数的秩和或者负数的秩作为检验统计量,根据其统计分布计 算p值,从而可以得出检验的结论。
具体步骤 设定原假设和备择假设。 分别计算出差值序列中正数的秩和W+以及负数的秩和W-。 根据W+和W-建立检验统计量,计算p值并得出检验的结论。 在双侧检验中检验统计量可以取为W=min(W+,W-)。显然,如果原假设成立,W+与W-应该比较接近。如果二者过大或过小,则说明原假设不成立。
秩的计算注意问题 计算差值绝对值的秩时,注意差值等于0值不参与排序。 下面一行R i就是上面一行数据Z i的秩。 Z i159183178513719 R i75918426310 数据中相同的数值称为“结”。结中数字的秩为它们所占位置的平均值 Z i159173178513719 R i758.518.5426310
表A.10 WILCOXON符号秩和检验的T临界值
. 精品 n 单尾检验的显著水平 .05 .025 .01 .005 双尾检验的显著水平 .10 .05 .02 .01 28 130 116 101 91 29 140 126 110 100 30 151 137 120 109 31 163 147 130 118 32 175 159 140 128 33 187 170 151 138 34 200 182 162 148 35 213 195 173 159 36 227 208 185 171 37 241 221 198 182 38 256 235 211 194 39 271 249 224 207 40 286 264 238 220 41 302 279 252 233 42 319 294 266 247 43 336 310 281 261 44 353 327 296 276 45 371 343 312 291 46 389 361 328 307 47 407 378 345 322 48 426 396 362 339 49 446 415 379 355 50 466 434 397 373 表B.10 WILCOXON 符号秩和检验的T 临界值* *如果要使结果显著,所得到的T 值必须等于或小于临界值,列中的横线(—)表示在列出的和的情况下,我们不能做出任何结论。 Adapted from F. Wilcoxon, S. K. Katti, and R. A. Wilcox, Critical Values and Probability Levels of the Wilcoxon Rank-Sum Test and the Wilcoxon Signed-Ranks Test. Wayne, N.J.: American Cyanamid Company, 1963. Adapted and reprinted with permission of the American Cyanamid Company 如有侵权请联系告知删除,感谢你们的配合! n 单尾检验的显著水平 .05 .025 .01 .005 双尾检验的显著水平 .10 .05 .02 .01 5 0 — — — 6 2 0 — — 7 3 2 0 — 8 5 3 1 0 9 8 5 3 1 10 10 8 5 3 11 13 10 7 5 12 17 13 9 7 13 21 17 12 9 14 25 21 15 12 15 30 25 19 15 16 35 29 23 19 17 41 34 27 23 18 47 40 32 27 19 53 46 37 32 20 60 52 43 37 21 67 58 49 42 22 75 65 55 48 23 83 73 62 54 24 91 81 69 61 25 100 89 76 68 26 110 98 84 75 27 119 107 92 83
Wilcoxon符号秩检验
Wilcoxon符号秩检验 Wilcoxon符号秩检验,手算、SPSS、R、SAS。 数据来源:《统计学(第三版)》贾俊平中国人民大学出版社 316页13.3题为分析股票的每股收益状况,在某证券市场上随机抽取10只股票,得到2006和2007年的每股收益数据如下表,分析2007年与2006年相比,每股收益是否有显著差异(α=0.05), 股票代码 2006年每股收益(元) 2007年每股收益(元) 1 0.1 2 0.26 2 0.95 0.87 3 0.20 0.24 4 0.02 0.12 5 0.05 0.13 6 0.56 0.51 7 0.31 0.35 8 0.25 0.42 9 0.16 0.37 10 0.06 0.05 手算: H:M,00D H:M,01D 2006年每股收益记为x,2007年每股收益记为y,差值d=x-y。 x y D=x-y |D| 股票代码 |D|的秩 D的符号 1 0.1 2 0.26 -0.14 0.14 8 - 2 0.95 0.87 0.08 0.08 5.5 +
3 0.20 0.2 4 -0.04 0.04 2. 5 - 4 0.02 0.12 -0.1 0.1 7 - 5 0.05 0.13 -0.08 0.08 5.5 - 6 0.56 0.51 0.05 0.05 4 + 7 0.31 0.35 -0.04 0.04 2.5 - 8 0.25 0.42 -0.17 0.17 9 - 9 0.16 0.37 -0.21 0.21 10 - 10 0.06 0.05 0.01 0.01 1 + T,5.5,4,1,10.5, T,8,2.5,7,5.5, 2.5,9,10,44.5, 通过查表得,T-的右尾概率P在0.042和0.053之间,即双尾概率P在0.084和0.106之间,大于显著性水平α=0.05,不能拒绝原假设,即认为2007年与2006年相比,每股收益没有显著差异。 SPSS计算: 步骤: 1、Analyze-Nonparametric Tests-2-Related Samples Test 2、将比较值和D两个变量移到检验配对变量框,勾选Wilcoxon符号秩检验,选择Exact,选择精确计算。 3、单击确定,进行计算。 输出结果: 秩 N 秩均值秩和 a比较 - D 负秩 3 3.50 10.50 b正秩 7 6.36 44.50 c 结 0
T检验_F检验和卡方检验
什么是Z检验? Z检验是一般用于大样本(即样本容量大于30)平均值差异性检验的方法。它是用标准正态分布的理论来推断差异发生的概率,从而比较两个平均数>平均数的差异是否显著。 当已知标准差时,验证一组数的均值是否与某一期望值相等时,用Z检验。 Z检验的步骤 第一步:建立虚无假设,即先假定两个平均数之间没有显著差异。 第二步:计算统计量Z值,对于不同类型的问题选用不同的统计 量计算方法。 1、如果检验一个样本平均数()与一个已知的总体平均数(μ0) 的差异是否显著。其Z值计算公式为: 其中: 是检验样本的平均数; μ0是已知总体的平均数; S是样本的方差; n是样本容量。 2、如果检验来自两个的两组样本平均数的差异性,从而判断它 们各自代表的总体的差异是否显著。其Z值计算公式为: 其中: 是样本1,样本2的平均数; S1,S2是样本1,样本2的标准差; n1,n2是样本1,样本2的容量。 第三步:比较计算所得Z值与理论Z值,推断发生的概率,依据 Z值与差异显著性关系表作出判断。如下表所示: 第四步:根据是以上分析,结合具体情况,作出结论。 Z检验举例 某项教育技术实验,对实验组和控制组的前测和后测的数据分别 如下表所示,比较两组前测和后测是否存在差异。 实验组和控制组的前测和后测数据表
前测实验组 n1 = 50 S1a = 14 控制组 n2 = 48 S2a = 16 后测实验组 n1 = 50 S1b = 8 控制组 n2 = 48 S2b = 14 由于n>30,属于大样本,所以采用Z检验。由于这是检验来自两 个不同总体的两个样本平均数,看它们各自代表的总体的差异是否显著,所以采用双总体的Z检验方法。 计算前要测Z的值: ∵|Z|=0.658<1.96 ∴ 前测两组差异不显著。 再计算后测Z的值: ∵|Z|= 2.16>1.96 ∴ 后测两组差异显著。 t检验是对各回归系数的显著性所进行的检验,是指在多元回归分析中,检验回归系数是否为0的时候,先用F检验,考虑整体回归系数,再对每个系数是否为零进行t检验。t检验还可以用来检验样本为来自一元正态分布的总体的期望,即均值;和检验样本为来自二元正态分布的总体的期望是否相等) 目的:比较样本均数所代表的未知总体均数μ和已知总体均数μ0。 自由度:v=n – 1 T检验注意事项 要有严密的抽样设计随机、均衡、可比 选用的检验方法必须符合其适用条件(注意:t检验的前提是资料 服从正态分布) 单侧检验和双侧检验 单侧检验的界值小于双侧检验的界值,因此更容易拒绝,犯第Ⅰ 错误的可能性大。 假设检验的结论不能绝对化 不能拒绝H0,有可能是样本数量不够拒绝H0 ,有可能犯第Ⅰ类 错误
Wilcoxon符号秩检验
Wilcoxon 符号秩检验,手算、SPSS 、R 、SAS 。 数据来源:《非参数统计(第二版)》 吴喜之 中国统计出版社 49页例3.3 下面是10个欧洲城镇每人每年平均消费的酒类相当于纯酒精数,数据已经按升序排列: 4.12 5.81 7.63 9.74 10.39 11.92 12.32 12.89 13.54 14.45 人们普遍认为欧洲各国人均年消费酒量的中位数相当于纯酒精8升,试用上述数据检验这种看法。 手算: 通过数据可以看出,中位数为11.160,明显大于8,因此可以建立如下假设: 8 M :H 8M :H 10>= 9 1354610987642=++==++++++=-+T T 查表可知P-0.032<α=0.05,因此拒绝原假设,认为欧洲各国人均年消费酒量的中位数多于8升。 SPSS 计算: 步骤: 1、Analyze-Nonparametric Tests-2-Related Samples Tests 2、将中位数和纯酒精数移入检验对变量框中,在检验类型中选择Wilcoxon ,单击精确,选择精确。 3、单击确定输出结果。 输出结果:
由输出结果可知,精确单侧显著性值P=0.032<α=0.05,与手算结果相同,因此拒绝原假设,认为欧洲各国人均年消费酒量的中位数多于8升。 R计算: > x=c(4.12,5.81,7.63,9.74,10.39,11.92,12.32,12.89,13.54,14.45) > wilcox.test(x-8,alt="greater") Wilcoxon signed rank test data: x - 8 V = 46, p-value = 0.03223 alternative hypothesis: true location is greater than 0 由输出结果可以看出单侧检验P值为0.03223<α=0.05,与以上计算方法计算结果相同,因此拒绝原假设,认为欧洲各国人均年消费酒量的中位数多于8升。 SAS计算:
t检验与方差分析
第六章数值变量资料的统计分析 数值变量资料又称计量资料,通常是指每个观察单位某项指标量的大小,一般具有计量单位。这类资料按分析的内容一般可分为两种:一种是比较几种处理之间的效应,简单地讲就是比较各处理组观察值均数、方差的大小;另一种是寻找指标间的关系,即某个(或某些)指标的取值是否受其它指标的影响。本章主要介绍不同设计类型的数值变量资料的比较。 § 样本均数与总体均数比较的 t 检验 t检验亦称 student's t 检验,主要用于下列三种情况:(1)样本均数与总体均数比较;(2)配对数值变量资料的比较;(3)两样本均数的比较。 Stata用于样本均数与总体均数比较的 t 检验的命令是: ttest 变量名= #val 这里,#val 表示总体均数。 命令中可以选用 if 语句和 in 语句对要分析的内容加一些条件限制。 对已知样本含量、均数和标准差的资料,欲将其与某总体均数进行比较,Stata 还提供了更为简洁的命令是: ttesti #obs #mean #sd #val 这里,#obs 表示样本含量,#mean 表示样本均数,#sd 表示样本标准差, #val 表示总体均数。 §两样本均数比较的t检验 一、配对设计t检验 医学研究中常将受试对象配成对子,对每对中的两个受试对象分别给予两种不同的处理,观察两种处理的结果是否一致,称为配对(设计)研究。有时以同一个受试对象先后给予两种不同的处理,观察两种处理的结果是否相同,这种配对称为自身配对。配对设计的优点是能消除或部分消除个体间的差异,使比较的结果更能真实地反映处理的效应。
配对t检验首先计算每对结果之差值,再将差值均数与0作比较。如两种处理的效应相同,则差值与0没有显著性差异。 检验假设 H0为:两种处理的效应是相同,或总体差值均数为 0。 stata用于配对样本t检验的命令是: Ttest 变量1 = 变量2 这里,这里“变量 1”和“变量 2”是成对输入的配对样本。 ttest 命令容许使用[if 表达式]和[in范围]条件限制。 或者: gen d=0 ttest d=0 二、成组设计t检验 有时无法将受试对象逐个配成对,可将受试对象随机分为两组,每组接受不同的处理,检验两组的均数,以达到比较的目的。 t检验要求两样本来自方差相同的正态总体,即各组资料达到或接近正态,两组的方差达到齐性。如两组资料偏态或方差不齐,则需要对原始数据作变量变换,如变换后仍未达到正态,可用秩和检验;如未达到方差齐性,则需用 t’检验,或用秩和检验。 Stata 提供了三种资料形式的两样本均数比较的t检验的命令,即: ttest 变量 1=变量 2, unpaired [ unequal welch ] ttest 变量, by(分组变量) [unequal welch] ttesti #obs1 #mean1 #sd1 #obs2 #mean2 #sd2 [, unequal welch ] 这里:第一个命令的数据格式是将两组数据用两个变量“变量 1”和“变量 2”分别输入,如两组的样本含量不等,则先输入样本含量大的变量,再输入样本含量少的变量,不足部分,Stata 将自动生成缺省值(用小数点表示)。也可同时输入,缺失部分用小数点表示。unpaired 是必选项,如不选,则 Stata 将作配对 t 检验。 第二个命令的数据格式是将两组数据用一个“变量”输入,再用另一个分组变量,以区分两组资料,如用 1 表示第 1 组资料,用 2 表示第 2 组资料。by(分组变量)是必选项。 第三个命令是针对已知两组资料的样本含量、均数和标准差的资料进行比较的简洁命令。这里有 6 个数据,#obs 表示样本含量,#mean 表示样本均数,#sd 表示样本标准差,l 表示第 1组,2 表示第 2 组。 第一个命令和第二个命令允许加[权数]及[in 范围] 和[if 表达式]条件。 选择项 unequal表示假设两组方差不齐,如不选表示假设两组方差达到齐性。
T检验及其与方差分析的区别
T 检验及其与方差分析的区别 假设检验是通过两组或多组的样本统计量的差别或样本统计量与总体参数的差异来推断他们相应的总体参数是否相同。 t 检验:1.单因素设计的小样本(n <50)计量资料 2.样本来自正态分布总体 3.总体标准差未知 4.两样本均数比较时,要求两样本相应的总体方差相等 ? 根据研究设计t 检验可由三种形式: – 单个样本的t 检验 – 配对样本均数t 检验(非独立两样本均数t 检验) – 两个独立样本均数t 检验 (1)单个样本t 检验 ? 又称单样本均数t 检验(one sample t test),适用于样本均数与已知总体均数μ0的比较, 其比较目的是检验样本均数所代表的总体均数μ是否与已知总体均数μ0有差别。 ? 已知总体均数μ0一般为标准值、理论值或经大量观察得到的较稳定的指标值。 ? 单样t 检验的应用条件是总体标准 未知的小样本资料( 如n <50),且服从正态分布。 (2)配对样本均数t 检验 ? 配对样本均数t 检验简称配对t 检验(paired t test),又称非独立两样本均数t 检验,适用 于配对设计计量资料均数的比较,其比较目的是检验两相关样本均数所代表的未知总体均数是否有差别。 ? 配对设计(paired design)是将受试对象按某些重要特征相近的原则配成对子,每对中 的两个个体随机地给予两种处理。 ? 应用配对设计可以减少实验的误差和控制非处理因素,提高统计处理的效率。 ? 配对设计处理分配方式主要有三种情况: ①两个同质受试对象分别接受两种处理,如把同窝、同性别和体重相近的动物配成一对,或把同性别和年龄相近的相同病情病人配成一对; ②同一受试对象或同一标本的两个部分,随机分配接受两种不同处理,如例5.2资料; ③自身对比(self-contrast)。即将同一受试对象处理(实验或治疗)前后的结果进行比较,如对高血压患者治疗前后、运动员体育运动前后的某一生理指标进行比较。 (3)两独立样本t 检验 两独立样本t 检验(two independent samples t -test),又称成组 t 检验。 ? 适用于完全随机设计的两样本均数的比较,其目的是检验两样本所来自总体的均数 是否相等。 ? 完全随机设计是将受试对象随机地分配到两组中,每组对象分别接受不同的处理, 分析比较处理的效应。或分别从不同总体中随机抽样进行研究。 ? 两独立样本t 检验要求两样本所代表的总体服从正态分布N (μ1,σ12)和N (μ2,σ 22),且两总体方差σ12、σ22相等,即方差齐性(homogeneity of variance, homoscedasticity)。 ? 若两总体方差不等,即方差不齐,可采用t ’检验,或进行变量变换,或用秩和检验方法 处理。 t 检验中的注意事项 1. 假设检验结论正确的前提 作假设检验用的样本资料,必须能代表相应的总体,同时各
t检验和方差分析的前提条件及应用误区
t检验和方差分析的前提条件及应用误区 用于比较均值的t检验可以分成三类,第一类是针对单组设计定量资料的;第二类是针对配对设计定量资料的;第三类则是针对成组设计定量资料的。后两种设计类型的区别在于事先是否将两组研究对象按照某一个或几个方面的特征相似配成对子。无论哪种类型的t检验,都必须在满足特定的前提条件下应用才是合理的。 若是单组设计,必须给出一个标准值或总体均值,同时,提供一组定量的观测结果,应用t检验的前提条件就是该组资料必须服从正态分布;若是配对设计,每对数据的差值必须服从正态分布;若是成组设计,个体之间相互独立,两组资料均取自正态分布的总体,并满足方差齐性。之所以需要这些前提条件,是因为必须在这样的前提下所计算出的t统计量才服从t分布,而t检验正是以t 分布作为其理论依据的检验方法。 值得注意的是,方差分析与成组设计t检验的前提条件是相同的,即正态性和方差齐性。 t检验是目前医学研究中使用频率最高,医学论文中最常见到的处理定量资料的假设检验方法。t检验得到如此广泛的应用,究其原因,不外乎以下几点:现有的医学期刊多在统计学方面作出了要求,研究结论需要统计学支持;传统的医学统计教学都把t检验作为假设检验的入门方法进行介绍,使之成为广大医学研究人员最熟悉的方法;t检验方法简单,其结果便于解释。简单、熟悉加上外界的要求,促成了t检验的流行。但是,由于某些人对该方法理解得不全面,导致在应用过程中出现不少问题,有些甚至是非常严重的错误,直接影响到结论的可靠性。将这些问题归类,可大致概括为以下两种情况:不考虑t检验的应用前提,对两组的比较一律用t检验;将各种实验设计类型一律视为多个单因素两水平设计,多次用t检验进行均值之间的两两比较。以上两种情况,均不同程度地增加了得出错误结论的风险。而且,在实验因素的个数大于等于2时,无法研究实验因素之间的交互作用的大小。 医学论文中常见的统计方法误用 一、等级资料用卡方检验代替秩和检验
WILCOXON符号秩和检验的T临界值
实用文档 . n 单尾检验的显著水平 .05.025.01.005 双尾检验的显著水平 .10.05.02.01 2813011610191 29140126110100 30151137120109 31 163147130118 32 175159140128 33 187170151138 34 200182162148 35 213195173159 36 227208185171 37 241221198182 38 256235211194 39 271249224207 40 286264238220 41 302279252233 42 319294266247 43 336310281261 44 353327296276 45 371343312291 46 389361328307 47 407378345322 48 426396362339 49 446415379355 50 466434397373 表B.10WILCOXON符号秩和检验的T临界值* *如果要使结果显著,所得到的T值必须等于或小于临界值,列中的横线(—)表示在列出的和的情况下,我们不能做出任何结论。 Adapted from F.Wilcoxon,S.K.Katti,and R.A.Wilcox,Critical Values and Probability Levels of the Wilcoxon Rank-Sum Test and the Wilcoxon Signed-Ranks Test.Wayne,N.J.:American Cyanamid Company,1963.Adapted and reprinted with permission of the American Cyanamid Company n 单尾检验的显著水平 .05.025.01.005 双尾检验的显著水平 .10.05.02.01 50——— 620—— 7320— 85310 98531 1010853 11131075 12171397 132117129 1425211512 1530251915 1635292319 1741342723 1847403227 1953463732 2060524337 2167584942 2275655548 2383736254 2491816961 25100897668 26110988475 271191079283
T检验及其与方差分析的区别
T检验及其与方差分析的区别 假设检验是通过两组或多组的样本统计量的差别或样本统计量与总体参数的差异来推断他们相应 的总体参数是否相同。 t 检验:1.单因素设计的小样本(n<50)计量资料 2.样本来自正态分布总体 3.总体标准差未知 4.两样本均数比较时,要求两样本相应的总体方差相等 ?根据研究设计t检验可由三种形式: –单个样本的t检验 –配对样本均数t检验(非独立两样本均数t检验) –两个独立样本均数t检验 (1)单个样本t检验 ?又称单样本均数t检验(one sample t test),适用于样本均数与已知总体均数μ0的比较,其比较目的是检验样本均数所代表的总体均数μ是否与已知总体均数μ0有差别。 ?已知总体均数μ0一般为标准值、理论值或经大量观察得到的较稳定的指标值。 ?单样t检验的应用条件是总体标准 未知的小样本资料( 如n<50),且服从正态分布。 (2)配对样本均数t检验 ?配对样本均数t检验简称配对t检验(paired t test),又称非独立两样本均数t检验,适用于配对设计计量资料均数的比较,其比较目的是检验两相关样本均数所代表的未知总体均数是否有差别。 ?配对设计(paired design)是将受试对象按某些重要特征相近的原则配成对子,每对中的两个个体随机地给予两种处理。 ?应用配对设计可以减少实验的误差和控制非处理因素,提高统计处理的效率。 ?配对设计处理分配方式主要有三种情况: ①两个同质受试对象分别接受两种处理,如把同窝、同性别和体重相近的动物配成一对,或把同性别和年龄相近的相同病情病人配成一对; ②同一受试对象或同一标本的两个部分,随机分配接受两种不同处理,如例资料; ③自身对比(self-contrast)。即将同一受试对象处理(实验或治疗)前后的结果进行比较,如对高血压患者治疗前后、运动员体育运动前后的某一生理指标进行比较。 (3)两独立样本t检验 两独立样本t 检验(two independent samples t-test),又称成组t 检验。 ?适用于完全随机设计的两样本均数的比较,其目的是检验两样本所来自总体的均数是否相等。 ?完全随机设计是将受试对象随机地分配到两组中,每组对象分别接受不同的处理,分析比较处理的效应。或分别从不同总体中随机抽样进行研究。 ?两独立样本t检验要求两样本所代表的总体服从正态分布N(μ1,σ12)和N(μ2,σ22),且两总体方差σ12、σ22相等,即方差齐性(homogeneity of variance, homoscedasticity)。 ?若两总体方差不等,即方差不齐,可采用t’检验,或进行变量变换,或用秩和检验方法处理。 t 检验中的注意事项 1.假设检验结论正确的前提作假设检验用的样本资料,必须能代表相应的总体,同时各对比组 具有良好的组间均衡性,才能得出有意义的统计结论和有价值的专业结论。这要求有严密的实验设计和抽样设计,如样本是从同质总体中抽取的一个随机样本,试验单位在干预前随机分组,有足够的样本量等。 2.检验方法的选用及其适用条件,应根据分析目的、研究设计、资料类型、样本量大小等选用适当 的检验方法。t 检验是以正态分布为基础的,资料的正态性可用正态性检验方法检验予以判断。 若资料为非正态分布,可采用数据变换的方法,尝试将资料变换成正态分布资料后进行分析。
秩和检验
第十一章秩和检验 A型选择题 1、以下对非参数检验的描述,哪一项是错误的()。 A.非参数检验方法不依赖于总体的分布类型 B.应用非参数检验时不考虑被研究对象的分布类型 C.非参数的检验效能低于参数检验 D.一般情况下非参数检验犯第二类错误的概率小于参数检验 E.B、E均不对 2、多样本计量资料比较,当分布类型不清时选择()。 A.t检验 B.u检验 C.秩和检验 D、2χ检验 E.方差分析 时()。3、符合t检验条件的数值变量资料如果采用秩和检验,不拒绝H A.第一类错误增大 B.第二类错误增大 C.第一类错误减小 D.第二类错误减小 E.两类错误都增大 4、按等级分组的资料作秩检验时,如果用H值而不用校正后的H值,则会()。 A、提高检验的灵敏度 B、会把一些无差别的总体推断成有差别 C、会把一些有差别的总体推断成无差别 D、第一、二类错误概率不变 E、一类错误增大 5、以上检验方法之中,不属于非参数检验法的是()。 A、t检验 B、符号检验 C、Kruskal-Wallis检验 D、Wilcoxon检验 E、2 χ检验 6、等级资料的比较宜用()。
A、t检验 B、秩和检验 C、F检验 D、2 检验 E、u检验 7、在进行成组设计两样本秩和检验时,以下检验假设正确的是()。 :两样本对应的总体均数相同 A、H :两样本均数相同 B、H :两样本的中位数相同 C、H :两样本对应的总体分布相同 D、H E、以上答案都不正确 8、秩和检验又叫做() A、参数检验 B、近似正态检验 C、非参数检验 D、H检验 E、Wilcoxon检验 9、当总体分布类型不清时,可采用() A、t检验 B、秩和检验 C、x2检验 D、正态检验 E、u检验 10、两个小样本比较的假设检验,应首先考虑()。 A、t检验 B.秩和检验 C.任选一种检验方法 D、资料符合哪种检验的条件 E.以上都不对
T检验及其与方差分析的区别
T检验及其与方差分析 的区别 Company number:【0089WT-8898YT-W8CCB-BUUT-202108】
T检验及其与方差分析的区别 假设检验是通过两组或多组的样本统计量的差别或样本统计量与总体参数的差异来推断他们相应的总体参数是否相同。 t 检验:1.单因素设计的小样本(n<50)计量资料 2.样本来自正态分布总体 3.总体标准差未知 4.两样本均数比较时,要求两样本相应的总体方差相等 ?根据研究设计t检验可由三种形式: –单个样本的t检验 –配对样本均数t检验(非独立两样本均数t检验) –两个独立样本均数t检验 (1)单个样本t检验 ?又称单样本均数t检验(one sample t test),适用于样本均数与已知总体均数μ0的比较,其比较目的是检验样本均数所代表的总体均数μ是否与已知总体均数μ0有差 别。 ?已知总体均数μ0一般为标准值、理论值或经大量观察得到的较稳定的指标值。 ?单样t检验的应用条件是总体标准未知的小样本资料( 如n<50),且服从正态分布。(2)配对样本均数t检验 ?配对样本均数t检验简称配对t检验(paired t test),又称非独立两样本均数t检验,适用于配对设计计量资料均数的比较,其比较目的是检验两相关样本均数所代表的未知总体均数是否有差别。
?配对设计(paired design)是将受试对象按某些重要特征相近的原则配成对子,每对中的两个个体随机地给予两种处理。 ?应用配对设计可以减少实验的误差和控制非处理因素,提高统计处理的效率。 ?配对设计处理分配方式主要有三种情况: ①两个同质受试对象分别接受两种处理,如把同窝、同性别和体重相近的动物配成一对,或把同性别和年龄相近的相同病情病人配成一对; ②同一受试对象或同一标本的两个部分,随机分配接受两种不同处理,如例资料; ③自身对比(self-contrast)。即将同一受试对象处理(实验或治疗)前后的结果进行比较,如对高血压患者治疗前后、运动员体育运动前后的某一生理指标进行比较。 (3)两独立样本t检验 两独立样本t 检验(two independent samples t-test),又称成组t 检验。 ?适用于完全随机设计的两样本均数的比较,其目的是检验两样本所来自总体的均数是否相等。 ?完全随机设计是将受试对象随机地分配到两组中,每组对象分别接受不同的处理,分析比较处理的效应。或分别从不同总体中随机抽样进行研究。 ?两独立样本t检验要求两样本所代表的总体服从正态分布N(μ1,σ12)和N(μ2,σ 2),且两总体方差σ12、σ22相等,即方差齐性(homogeneity of variance, 2 homoscedasticity)。 ?若两总体方差不等,即方差不齐,可采用t’检验,或进行变量变换,或用秩和检验方法处理。 t 检验中的注意事项 1.假设检验结论正确的前提作假设检验用的样本资料,必须能代表相应的总