时间序列的速度分析

时间序列的速度分析
一、学习目标:
1.掌握发展速度、增长速度、平均发展速度、平均增长速度指标
2.掌握定基发展速度和环比发展速度之间的关系
二、知识梳理:
1.发展速度的概念
2.发展速度的分类及联系:
3.增长速度的概念
4.增长速度的分类及联系:
5.平均发展速度的概念及计算:
6.平均增长速度的概念及计算:
三、典例解析:
1.时间序列中的速度指标包括()、()、()
()四类。
2.定基发展速度与环比发展速度的关系是:某期的定基发展速度等于相应的各环比发展速度的(),某期的环比发展速度等于该期的定基发展速度()上期的定基发展速度。
3.平均发展速度也属于(),它是对各期()求得的(),这种方法称作()或()。
4.某企业产品产量年年增加20万吨,则产量环比发展速度()
A.年年下降
B.年年增长
C.年年不变
D.不确定
5.若各环比增长速度为4%,5%,8%,9%,则定基增长速度为()
A. 4%*5%*8%*9% B 4%*5%*8%*9%—1 C.104%*105%*108%*109%
D. 104%*105%*108%*109%—1
6.用几何平均法计算平均发展速度时,被开方的数是( ) A.环比发展速度之和 B.环比发展速度的连乘积
C.报告期发展水平与基期发展水平之比
D.发展总速度
E. 报告期发展水平与基期发展水平之差
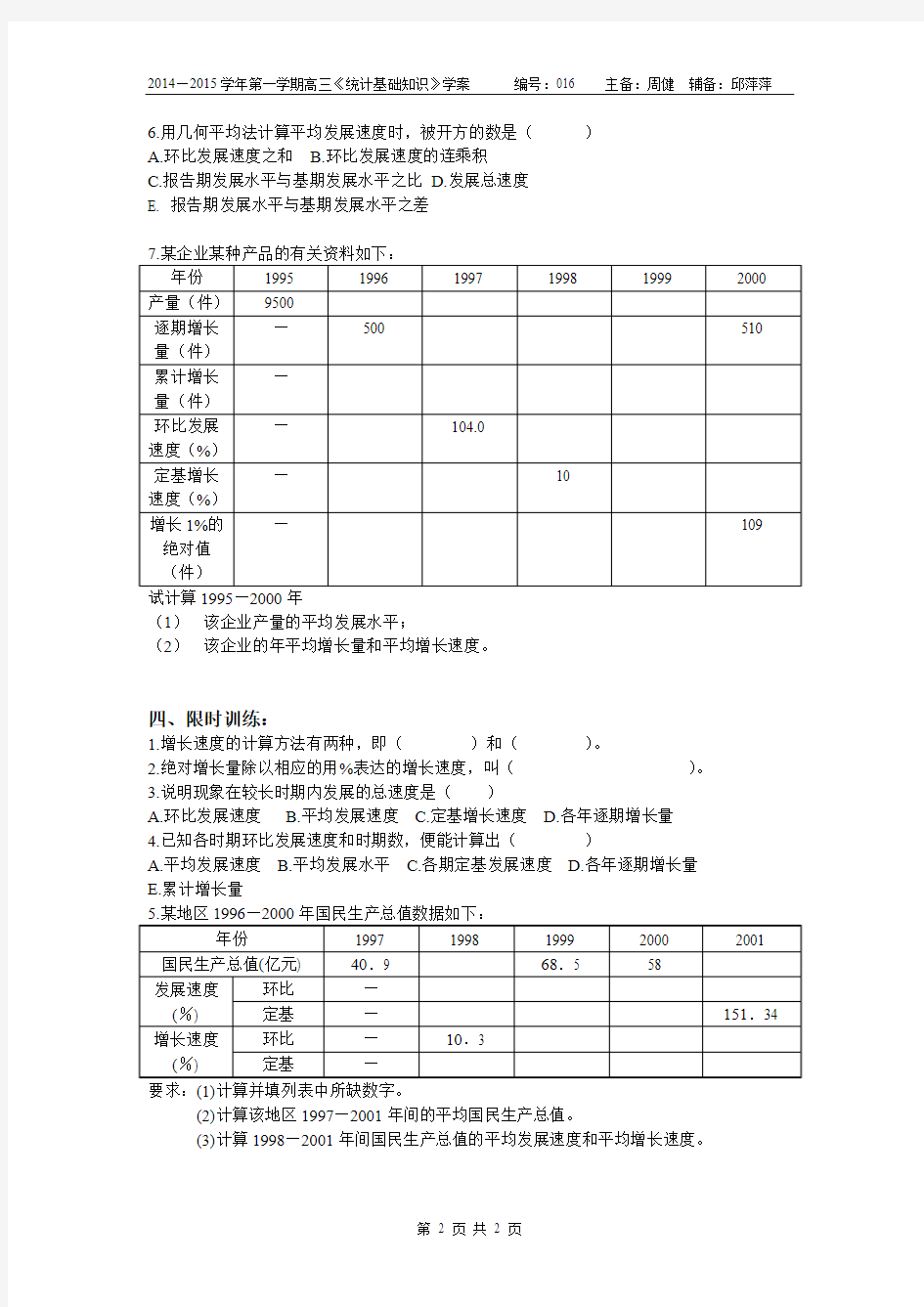
试计算1995—2000年
(1) 该企业产量的平均发展水平;
(2) 该企业的年平均增长量和平均增长速度。
四、限时训练:
1.增长速度的计算方法有两种,即( )和( )。
2.绝对增长量除以相应的用%表达的增长速度,叫( )。
3.说明现象在较长时期内发展的总速度是( )
A.环比发展速度
B.平均发展速度
C.定基增长速度
D.各年逐期增长量 4.已知各时期环比发展速度和时期数,便能计算出( )
A.平均发展速度
B.平均发展水平
C.各期定基发展速度
D.各年逐期增长量
E.累计增长量
要求:(1)计算并填列表中所缺数字。
(2)计算该地区1997—2001年间的平均国民生产总值。
(3)计算1998—2001年间国民生产总值的平均发展速度和平均增长速度。
时间序列分析方法及应用7
青海民族大学 毕业论文 论文题目:时间序列分析方法及应用—以青海省GDP 增长为例研究 学生姓名:学号: 指导教师:职称: 院系:数学与统计学院 专业班级:统计学 二○一五年月日
时间序列分析方法及应用——以青海省GDP增长为例研究 摘要: 人们的一切活动,其根本目的无不在于认识和改造世界,让自己的生活过得更理想。时间序列是指同一空间、不同时间点上某一现象的相同统计指标的不同数值,按时间先后顺序形成的一组动态序列。时间序列分析则是指通过时间序列的历史数据,揭示现象随时间变化的规律,并基于这种规律,对未来此现象做较为有效的延伸及预测。时间序列分析不仅可以从数量上揭示某一现象的发展变化规律或从动态的角度刻画某一现象与其他现象之间的内在数量关系及其变化规律性,达到认识客观世界的目的。而且运用时间序列模型还可以预测和控制现象的未来行为,由于时间序列数据之间的相关关系(即历史数据对未来的发展有一定的影响),修正或重新设计系统以达到利用和改造客观的目的。从统计学的内容来看,统计所研究和处理的是一批有“实际背景”的数据,尽管数据的背景和类型各不相同,但从数据的形成来看,无非是横截面数据和纵截面数据两类。本论文主要研究纵截面数据,它反映的是现象以及现象之间的关系发展变化规律性。在取得一组观测数据之后,首先要判断它的平稳性,通过平稳性检验,可以把时间序列分为平稳序列和非平稳序列两大类。主要采用的统计方法是时间序列分析,主要运用的数学软件为Eviews软件。大学四年在青海省上学,基于此,对青海省的GDP十分关注。本论文关于对1978年到2014年以来的中国的青海省GDP(总共37个数据)进行时间序列分析,并且对未来的三年中国的青海省GDP进行较为有效的预测。希望对青海省的发展有所贡献。 关键词: 青海省GDP 时间序列白噪声预测
时间序列分析——最经典的
【时间简“识”】 说明:本文摘自于经管之家(原人大经济论坛) 作者:胖胖小龟宝。原版请到经管之家(原人大经济论坛) 查看。 1.带你看看时间序列的简史 现在前面的话—— 时间序列作为一门统计学,经济学相结合的学科,在我们论坛,特别是五区计量经济学中是热门讨论话题。本月楼主推出新的系列专题——时间简“识”,旨在对时间序列方面进行知识扫盲(扫盲,仅仅扫盲而已……),同时也想借此吸引一些专业人士能够协助讨论和帮助大家解疑答惑。 在统计学的必修课里,时间序列估计是遭吐槽的重点科目了,其理论性强,虽然应用领域十分广泛,但往往在实际操作中会遇到很多“令人发指”的问题。所以本帖就从基础开始,为大家絮叨絮叨那些关于“时间”的故事! Long long ago,有多long?估计大概7000年前吧,古埃及人把尼罗河涨落的情况逐天记录下来,这一记录也就被我们称作所谓的时间序列。记录这个河流涨落有什么意义?当时的人们并不是随手一记,而是对这个时间序列进行了长期的观察。结果,他们发现尼罗河的涨落非常有规律。掌握了尼罗河泛滥的规律,这帮助了古埃及对农耕和居所有了规划,使农业迅速发展,从而创建了埃及灿烂的史前文明。 1 / 60
好~~从上面那个故事我们看到了 1、时间序列的定义——按照时间的顺序把随机事件变化发展的过程记录下来就构成了一个时间序列。 2、时间序列分析的定义——对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的走势就是时间序列分析。 既然有了序列,那怎么拿来分析呢? 时间序列分析方法分为描述性时序分析和统计时序分析。 1、描述性时序分析——通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律,这种分析方法就称为描述性时序分析 描述性时序分析方法具有操作简单、直观有效的特点,它通常是人们进行统计时序分析的第一步。 2 / 60
《时间序列分析及应用:R语言》读书笔记
《时间序列分析及应用:R语言》读书笔记 姓名:石晓雨学号:1613152019 (一)、时间序列研究目的主要有两个:认识产生观测序列的随机机制,即建立数据生成模型;基于序列的历史数据,也许还要考虑其他相关序列或者因素,对序列未来的可能取值给出预测或者预报。通常我们不能假定观测值独立取自同一总体,时间序列分析的要点是研究具有相关性质的模型。 (二)、下面是书上的几个例子 1、洛杉矶年降水量 问题:用前一年的降水量预测下一年的降水量。 第一幅图是降水量随时间的变化图;第二幅图是当年降水量与去年降水量散点图。 win.graph(width=4.875, height=2.5,pointsize=8) #这里可以独立弹出窗口 data(larain) #TSA包中的数据集,洛杉矶年降水量 plot(larain,ylab='Inches',xlab='Year',type = 'o') #type规定了在每个点处标记一下 win.graph(width = 3,height = 3,pointsize = 8) plot(y = larain,x = zlag(larain),ylab = 'Inches',xlab = 'Previous Year Inches')#zlag 函数(TSA包)用来计算一个向量的延迟,默认为1,首项为NA
从第二幅图看出,前一年的降水量与下一年并没有什么特殊关系。 2、化工过程 win.graph(width = 4.875,height = 2.5,pointsize = 8) data(color) plot(color,ylab = 'Color Property',xlab = 'Batch',type = 'o') win.graph(width = 3,height = 3,pointsize = 8) plot(y = color,x = zlag(color),ylab = 'Color Property',xlab = 'Previous Batch Color Property') len <- length(color) cor(color[2:len],zlag(color)[2:len])#相关系数>0.5549 第一幅图是颜色属性随着批次的变化情况。
第九章 时间序列分析习题
第九章时间序列分析习题 一、填空题 1.时间序列有两个组成要素:一是,二是。 2.在一个时间序列中,最早出现的数值称为,最晚出现的数值称为。 3.时间序列可以分为时间序列、时间序列和时间序列三种。其中是最基本的序列。 4.绝对数时间序列可以分为和两种,其中,序列中不同时间的数值相加有实际意义的是序列,不同时间的数值相加没有实际意义的是序列。 5.已知某油田1995年的原油总产量为200万吨,2000年的原油总产量是459万吨,则“九五”计划期间该油田原油总产量年平均增长速度的算式为。 6.发展速度由于采用的基期不同,分为和两种,它们之间的关系可以表达为。 7.设i=1,2,3,…,n,a i为第i个时期经济水平,则a i/a0是发展速度,a i/a i-1是发展速度。 8.计算平均发展速度的常用方法有方程式法和. 9.某产品产量1995年比1990年增长了105%,2000年比1990年增长了306.8%,则该产品2000年比1995增长速度的算式是。 10.如果移动时间长度适当,采用移动平均法能有效地消除循环变动和。 11.时间序列的波动可分解为长期趋势变动、、循环变动和不规则变动。 12.用最小二乘法测定长期趋势,采用的标准方程组是。 二、单项选择题 1.时间序列与变量数列( ) A都是根据时间顺序排列的B都是根据变量值大小排列的 C前者是根据时间顺序排列的,后者是根据变量值大小排列的 D前者是根据变量值大小排列的,后者是根据时间顺序排列的 2.时间序列中,数值大小与时间长短有直接关系的是( ) A平均数时间序列B时期序列C时点序列D相对数时间序列 3.发展速度属于( ) A比例相对数B比较相对数C动态相对数D强度相对数 4.计算发展速度的分母是( ) A报告期水平B基期水平C实际水平D计划水平 则该车间上半年的平均人数约为( ) A 296人 B 292人 C 295 人 D 300人 6.某地区某年9月末的人口数为150万人,10月末的人口数为150.2万人,该地区10月的人口平均数为( ) A150万人B150.2万人C150.1万人D无法确定 7.由一个9项的时间序列可以计算的环比发展速度( ) A有8个B有9个C有10个D有7个 8.采用几何平均法计算平均发展速度的依据是( )
数据分析-时间序列的趋势分析
数据分析-时间序列的趋势分析 无论是网站分析工具、BI报表或者数据的报告,我们很难看到数据以孤立的点单独地出现,通常数据是以序列、分组等形式存在,理由其实很简单,我们没法从单一的数据中发现什么,用于分析的数据必须包含上下文(Context)。数据的上下文就像为每个指标设定了一个或者一些参考系,通过这些参照和比较的过程来分析数据的优劣,就像中学物理上的例子,如果我们不以地面作为参照物,我们无法区分火车是静止的还是行进的,朝北开还是朝南开。 在实际看数据中,我们可能已经在不经意间使用数据的上下文了,趋势分析、比例分析、细分与分布等都是我们在为数据设置合适的参照环境。所以这边通过一个专题——数据的上下文,来总结和整理我们在日常的数据分析中可以使用的数据参考系,前面几篇主要是基于内部基准线(Internal Benchmark)的制定的,后面会涉及外部基准线(External Benchmark)的制定。今天这篇是第一篇,主要介绍基于时间序列的趋势分析,重提下同比和环比,之前在网站新老用户分析这篇文章,已经使用同比和环比举过简单应用的例子。 同比和环比的定义 定义这个东西在这里还是再唠叨几句,因为不了解定义就无法应用,熟悉的朋友可以跳过。 同比:为了消除数据周期性波动的影响,将本周期内的数据与之前周期中相同时间点的数据进行比较。早期的应用是销售业等受季节等影响较严重,为了消除趋势分析中季节性的影响,引入了同比的概念,所以较多地就是当年的季度数据或者月数据与上一年度同期的比较,计算同比增长率。 环比:反应的是数据连续变化的趋势,将本期的数据与上一周期的数据进行对比。最常见的是这个月的数据与上个月数据的比较,计算环比增长率,因为数据都是与之前最近一个周期的数据比较,所以是用于观察数据持续变化的情况。 买二送一,再赠送一个概念——定基比(其实是百度百科里附带的):将所有的数据都与某个基准线的数据进行对比。通常这个基准线是公司或者产品发展的一个里程碑或者重要数据点,将之后的数据与这个基准线进行比较,从而反映公司在跨越这个重要的是基点后的发展状况。 同比和环比的应用环境
应用时间序列分析 -
姓名:葛国峰学号:1122307851 编号:33 习题2.3 2.解: data b; input y@@; time=intnx('month','1jan1975'd,_n_-1); format time data; cards; 330.45 330.97 331.64 332.87 333.61 333.55 331.90 330.05 328.58 328.31 329.41 330.63 331.63 332.46 333.36 334.45 334.82 334.32 333.05 330.87 329.24 328.87 330.18 331.50 332.81 333.23 334.55 335.82 336.44 335.99 334.65 332.41 331.32 330.73 332.05 333.53 334.66 335.07 336.33 337.39 337.65 337.57 336.25 334.39 332.44 332.25 333.59 334.76 335.89 336.44 337.63 338.54 339.06 338.95 337.41 335.71 333.68 333.69 335.05 336.53 337.81 338.16 339.88 340.57 341.19 340.87 339.25 337.19 335.49 336.63 337.74 338.36 ; run; proc gplot; plot y*time; symbol1v=dot i=join c=black w=3; proc arima data=b; identify var=y nlag=24; run; (1)序列图:
时间序列分析案例
《时间序列分析》案例案例名 称:时间序列分析在经济预测中的应用内容要 求:确定性与随机性时间序列之比较设计作 者:许启发,王艳明 设计时 间:2003年8月
案例四:时间序列分析在经济预测中的应用 一、案例简介 为了配合《统计学》课程时间序列分析部分的课堂教学,提高学生运用统计分析方法解决实际问题的能力,我们组织了一次案例教学,其内容是:对烟台市的未来经济发展状况作一预测分析,数据取烟台市1949—1998年国内生产总值(GDP)的年度数据,并以此为依据建立预测模型,对1999年和2000年的国内生产总值作出预测并检验其预测效果。国内生产总值是指一个国家或地区所有常住单位在一定时期内生产活动的最终成果,是反映国民经济活动最重要的经济指标之一,科学地预测该指标,对制定经济发展目标以及与之相配套的方针政策具有重要的理论与实际意义。在组织实施时,我们首先将数据资料印发给学生,并讲清本案例的教学目的与要求,明确案例所涉及的教学内容;然后给学生一段时间,由学生根据资料,运用不同的方法进行预测分析,并确定具体的讨论日期;在课堂讨论时让学生自由发言,阐述自己的观点;最后,由主持教师作点评发言,取得了良好的教学效果。 经济预测是研究客观经济过程未来一定时期的发展变化趋势,其目的在于通过对客观经济现象历史规律的探讨和现状的研究,求得对未来经济活动的了解,以确定社会经济活动的发展水平,为决策提供依据。 时间序列分析预测法,首先将预测目标的历史数据按照时间的先后顺序排列,然后分析它随时间的变化趋势及自身的统计规律,外推得到预测目标的未来取值。它与回归分析预测法的最大区别在于:该方法可以根据单个变量的取值对其自身的变动进行预测,无须添加任何的辅助信息。 本案例的最大特色在于:它汇集了统计学原理中的时间序列分析这一章节的所有知识点,通过本案例的教学,可以把不同的时间序列分析方法进行综合的比较,便于学生更好地掌握本章的内容。 二、案例的目的与要求 (一)教学目的 1.通过本案例的教学,使学生认识到时间序列分析方法在实际工作中应用的必要性和可能性; 2.本案例将时间序列分析中的水平指标、速度指标、长期趋势的测定等内容有机的结合在一起,以巩固学生所学的课本知识,深化学生对课本知识的理解; 3.本案例是对烟台市的国内生产总值数据进行预测,通过对实证结果的比较和分析,使学生认识到对同一问题的解决,可以采取不同的方法,根据约束条件,从中选择一种合适的预测方法; 4.通过本案例的教学,让学生掌握EXCEL软件在时间序列分析中的应用,对统计、计量分析软件SPSS或Eviews等有一个初步的了解; 5.通过本案例的教学,有助于提高学生运用所学知识和方法分析解决问题的能力、合作共事的能力和沟通交流的能力。 (二)教学要求 1.学生必须具备相应的时间序列分析的基本理论知识; 2.学生必须熟悉相应的预测方法和具备一定的数据处理能力; 3.学生以主角身份积极地参与到案例分析中来,主动地分析和解决案例中的问题; 4.在提出解决问题的方案之前,学生可以根据提供的样本数据,自己选择不同的统计分析方法,对这一案例进行预测,比较不同预测方法的异同,提出若干可供选择的方案;
时间序列分析及其应用
时间序列分析及其应用 摘要:本文介绍了目前时间序列分析的发展状况以及应用情况,对常见的几种趋势拟合及其预测方法进行了简要叙述。 关键词:时间序列趋势建模 1 引言 时间序列分析是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。它包括一般统计分析(如自相关分析,谱分析等),统计模型的建立与推断,以及关于时间序列的最优预测、控制与滤波等内容。经典的统计分析都假定数据序列具有独立性,而时间序列分析则侧重研究数据序列的互相依赖关系。后者实际上是对离散指标的随机过程的统计分析,所以又可看作是随机过程统计的一个组成部分。时间序列是按时间顺序的一组数字序列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来 事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势。二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。 2 时间序列分析的趋势及建模 时间序列分析的成分有:(1)长期趋势,即时间序列随时间的变化而逐渐增加或减少的长期变化的趋势;(2)季节变动,即时间序列在一年中或固定时间内,呈现出的固定规则的变动;(3)循环变动,即
沿着趋势线如钟摆般地循环变动;(4)不规则变动,即在时间序列中由于随机因素影响所引起的变动。 时间序列建模基本步骤是:用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据;根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并能发现跳点和拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,在建模时应考虑进去,如果是反常现象,则应把跳点调整到期望值。拐点则是指时间序列从上升趋势突然变为下降趋势的点。如果存在拐点,则在建模时必须用不同的模型去分段拟合该时间序列,例如采用门限回归模型。然后辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。 主要的趋势拟合方法有平滑法、趋势线法和自回归模型。对于很多情况,时间序列具有季节趋势,比如气象学中的气温、降雨量,水文学中雨季和干季的河流水量等等。这就需要分析时间序列时,将季节趋势考虑在内。季节性预测法的基本步骤是(1)对原时间序列求移动平均,以消除季节变动和不规则变动,保留长期趋势;(2)将原序列y除以其对应的趋势方程值(或平滑值),分离出季节变动(含不规则变动),即季节系数=tsci/趋势方程值(tc或平滑值);(3)将月度(或季度)的季节指标加总,以由计算误差导致的值去除理论加总值,得到一个校正系数,并以该校正系数乘以季节性指标从而获得调整后季节性指标;(4)求预测模型,若求下一年度的预测值,延长趋势线即可;若求各月(季)的预测值,需以趋势值乘以各月份(季
第九章、时间序列分析
第九章、时间序列分析 一、单项选择题(在每小题的四个备选答案中,选出一个正确答案) 1.构成时间序列的两个基本要素是() A.主词与宾词 B.变量与频数 C.现象所属时间与指标数值 D.现象所属时间与次数 2.下面数列哪个属于时间序列( ) A.学生按成绩分组形成的数列 B.人口按性别分组形成的数列 C.家禽按重量分组形成的数列 D.产量按时间先后形成的数列 3.把最近10年来每年的居民储蓄存款额按时间先后排列形成的时间序列称为( ) A.变量序列 B.时期序列 C.时点序列 D.平均数序列 4.某企业2006年1月初职工人数为190人,2月初职工人数为215人,3月初职工人数为220人,4月初职工人数为230人.则第一季度的平均职工人数为( ) A.209人 B.208人 C.214人 D.215人 5.在时间序列中,累计增长量等于与之对应的各个逐期增长量之( ) A.和 B.差 C.积 D.商 6.在时间序列中,定基发展速度等于相应各期环比发展速度之( ) A.和 B.差 C.积 D.商 7.根据间隔不相等的间断时点序列计算平均发展水平的方法是( ) A.简单算术平均法 B.加权序时平均法 C.加权算术平均法 D.首尾折半法 8.已知环比增长速度分别为20%、15%、12%和8%,则定基增长速度为()A.20%×15%×12%×8% B. 120%×115%×112%×108% C.(20%×15%×12%×8%)-100% D. (120%×115%×112%×108%)-100% 9.某产品产量2006年比2001年增长了35%,那么该产品产量的平均发展速度是 ( ) A.35%的5次方根 B.135%的5次方根 C.35%的6次方根 D. 135%的6次方根 10.某企业历年产量发展速度资料如下:2000-2003各年均为110%,2004-2006各 年均为108%,则该企业2000-2006年产量平均发展速度为( ) A. B. C. D. 11.有某公司2002-2006年商品销售额资料,以该时间序列中间项为原点,配合直 线趋势方程y=610+73t,利用该直线趋势方程预测2008年商品销售额为( )
应用时间序列分析简答题
1.简述非平稳时间序列的确定性因素分解方法及其优缺点:确定性因素分解方法产生于长期的实践。序列的各种变化可以归纳为三大因素的影响:(1)长期趋势波动,包括长期趋势和无固定周期的循环波动(2)季节性变化,包括所有具有固定周期的循环波动(3)随机波动,包括除了长期趋势波动和季节性变化之外的其他因素的综合因素。优点:原理简单;操作方便;易于理解。缺点:(1)只能提取强劲的确定性信息,对随机性信息浪费严重(2)它把所有序列的变化归纳为四大因素的综合影响,却始终无法提供明确有效的方法判断各大因素之间明确的作用关系。 2.比较传统的统计分析与时间序列分析数据结构并说明引入序列平稳性的意义: (1)根据数理统计学常识,传统的统计分析的随机变量越少越好,而每个变量获得的样本信息越多越好。因为随机变量越少,分析的过程越简单,而样本容量越大,分析的结果越可靠。(2)时间序列数据分析的结构有它的特殊性。对随机序列{…,1x ,2x ,…t x …}而言,它在任意时刻t 的序列值t x 都是一个随机变量,而且由于时间的不可重复性,该变量在任意一个时刻只能获得唯一的一个样本观察值。(3)时间序列分析的数据结构的样本信息太少,如果没有其他的辅助信息,通常这种数据结构是没有办法进行分析的。序列的平稳性概念的提出可以有效地解决这个困难。 3.什么是模型识别?模型识别的基本原则是什么?计算出样本自相关系数和偏自相关系数的值之后,就要根据他们表现出来的性质,选择适当的ARMA 模型拟合观察值序列。这个根据样本自相关关系数和偏自相关系数的性质估计自相关阶数p ?和移动平均阶数q ?的过程即是模型识别过程。ARMA 模型定阶基本原则如下表: 4.简述单整和协整分析的含义。(1)单整是处理伪回归问题的一种方式。如果一个时间序列经过一次差分变成平稳的,则称原序列是1阶单整的,记为I (1)。一般地,如果时间序列经过d 次差分后变成平稳序列,而经过d-1次差分仍不平稳,则称原序列是d 阶单整序列,记为I (d )。(2)假定回归模型t k 1i it i 0t y εχββ++=∑=
第八章 时间序列分析
第八章时间序列分析与预测 【课时】6学时 【本章内容】 § 时间序列的描述性分析 时间序列的含义、时间序列的图形描述、时间序列的速度分析 § 时间序列及其构成分析 时间序列的构成因素、时间序列构成因素的组合模型 § 时间序列趋势变动分析 移动平均法、指数平滑法、模型法 § 时间序列季节变动分析 [ 原始资料平均法、趋势-循环剔除法、季节变动的调整 § 时间序列循环变动分析 循环变动及其测定目的、测定方法 本章小结 【教学目标与要求】 1.掌握时间序列的四种速度分析 2.掌握时间序列的四种构成因素 3.掌握时间序列构成因素的两种常用模型 4.掌握测定长期趋势的移动平均法 5.了解测定长期趋势的指数平滑法 6.; 7.掌握测定长期趋势的线性趋势模型法 8.了解测定长期趋势的非线性趋势模型法 9.掌握分析季节变动的原始资料平均法 10.掌握分析季节变动的循环剔出法 11.掌握测定循环变动的直接法和剩余法 【教学重点与难点】 1.对统计数据进行趋势变动分析,利用移动平均法、指数平滑法、线性模型法求得数 据的长期趋势; 2.对统计数据进行季节变动分析,利用原始资料平均法、趋势-循环剔除法求得数据 的季节变动; 3.对统计数据进行循环变动分析,利用直接法、剩余法求得循环变动。 【导入】 ; 很多社会经济现象总是随着时间的推移不断发展变化,为了探索现象随时间而发展变化的规律,不仅要从静态上分析现象的特征、内部结构以及相互关联的数量关系,而且应着眼于现象随时间演变的过程,从动态上去研究其发展变动的过程和规律。这时需要一些专门研究按照时间顺序观测的序列数据的统计分析方法,这就是统计学中的时间序列分析。 通过介绍一些时间序列分析的例子,让同学们了解时间序列的应用,并激发学生学习本章知识的兴趣。 1.为了表现中国经济的发展状况,把中国经济发展的数据按年度顺序排列起来,
第9章时间序列分析
第9章 时间序列分析——练习题 ●1. 某汽车制造厂2003年产量为30万辆。 (1)若规定2004—2006年年递增率不低于6%,其后年递增率不低于5%,2008年该厂汽车产量将达到多 少 (2)若规定2013年汽车产量在2003年的基础上翻一番,而2004年的增长速度可望达到%,问以后9年应 以怎样的速度增长才能达到预定目标 (3)若规定2013年汽车产量在2003年的基础上翻一番,并要求每年保持%的增长速度,问能提前多少时 间达到预定目标 解:设i 年的发展水平为x i ,则由已知得:x 2003=30, (1)又知: 320042005200620032004200516%x x x x x x ≥+(),2 200720082006200715%x x x x ≥+(),求x 2008 由上得 32200820072008 200320032007 (16%)(15%)x x x x x x =≥++ 即为 322008 1.061.0530 x ≥,从而2008年该厂汽车产量将达到 得 x 2008≥30× 3 1.06×2 1.05= 30× = (万辆) 从而按假定计算,2008年该厂汽车产量将达到万辆以上。 (2)规定 20132003 2x x =,2004 2003x x =1+7.8% 由上得 =107.11%== 可知,2004年以后9年应以%的速度增长,才能达到2013年汽车产量在2003年的基础上翻一番 的目标。 (3)设:按每年%的增长速度n 年可翻一番, 则有 2013 2003 1.0742n a a = = 所以 1.074log 20.30103 log 29.70939log1.0740.031004 n == ==(年) 可知,按每年保持%的增长速度,约年汽车产量可达到在2003年基础上翻一番的预定目标。 原规定翻一番的时间从2003年到2013年为10年,故按每年保持%的增长速度,能提前年即3个月
数据分析时间序列的趋势分析
数据分析时间序列的趋 势分析 Pleasure Group Office【T985AB-B866SYT-B182C-BS682T-STT18】
数据分析-时间序列的趋势分析无论是网站分析工具、BI报表或者数据的报告,我们很难看到数据以孤立的点单独地出现,通常数据是以序列、分组等形式存在,理由其实很简单,我们没法从单一的数据中发现什么,用于分析的数据必须包含上下文(Context)。数据的上下文就像为每个指标设定了一个或者一些参考系,通过这些参照和比较的过程来分析数据的优劣,就像中学物理上的例子,如果我们不以地面作为参照物,我们无法区分火车是静止的还是行进的,朝北开还是朝南开。 在实际看数据中,我们可能已经在不经意间使用数据的上下文了,趋势分析、比例分析、细分与分布等都是我们在为数据设置合适的参照环境。所以这边通过一个专题——数据的上下文,来总结和整理我们在日常的数据分析中可以使用的数据参考系,前面几篇主要是基于内部基准线(Internal Benchmark)的制定的,后面会涉及外部基准线(External Benchmark)的制定。今天这篇是第一篇,主要介绍基于时间序列的趋势分析,重提下同比和环比,之前在网站新老用户分析这篇文章,已经使用同比和环比举过简单应用的例子。 同比和环比的定义 定义这个东西在这里还是再唠叨几句,因为不了解定义就无法应用,熟悉的朋友可以跳过。 同比:为了消除数据周期性波动的影响,将本周期内的数据与之前周期中相同时间点的数据进行比较。早期的应用是销售业等受季节等影响较严重,为了消除趋势分析中季节性的影响,引入了同比的概念,所以较多地就是当年的季度数据或者月数据与上一年度同期的比较,计算同比增长率。
实验·6-时间序列分析的spss应用
实验6 时间序列分析的spss应用 6.1 实验目的 学会运用SPSS统计软件创建时间数列,熟练掌握长期趋势线性模型拟合和季节变动测定的SPSS方法与技能。 6.2 相关知识(略) 6.3 实验内容 6.3.1 用SPSS统计软件创建时间序列的创建 6.3.2用SPSS统计软件处理长期趋势线性模型的拟合(最小二乘法、指数平滑法)及预测。 6.3.3掌握测定季节变动规律的SPSS测定方法。 6.4实验要求 6.4.1准备实验数据 6.4.2用SPSS统计软件创建彩电出口数量的时间序列 6.4.3用最小二乘法测定长期趋势,拟合线性趋势方程,并进行趋势预测。 6.4.4测定彩电出口数量的季节变动规律。 6.4.5用指数平滑法预测2014和2015年的彩电出口数量。 6.5 实验步骤 6.5.1 实验数据 为了研究某国彩电出口的情况,某研究机构收集了从2003-2013年某国彩电出口的月度数据,如表6-1所示。 表6-1 我国 2003-2013年的我国彩电出口的月度数据(单位:万台)1月2月3月4月5月6月7月8月9月10月11月12月2003年12.53 13.73 24.45 28.75 32.45 31.11 25.94 32.98 43.49 42.94 63.29 77.28 2004年30.01 39.63 29.77 42.74 32.25 31.94 32.27 32.59 32.92 30.98 47.44 52.82 2005年24.08 16.42 31.24 29.33 31.88 30.09 28.08 32.99 44.99 47.57 50.36 75.19 2006年39.02 25.81 43.38 37.34 39.22 39.87 51.10 50.99 55.16 62.78 57.75 72.20 2007年28.76 39.38 46.10 39.41 38.74 40.18 45.59 43.31 46.68 54.17 53.65 61.12 2008年28.87 21.23 35.82 26.97 32.33 24.53 29.39 31.96 38.22 39.24 52.95 68.41
《统计学》案例——时间序列趋势分析
《统计学》案例——时间序列趋势分析 囤积粮食可以创高价吗 1、问题的提出 某贸易公司是经营粮油副食品的批发公司,基于前4年当地的消费物价指数的变化,该公司认为今后两年内消费物价指数将有大幅度上涨,为此该公司计划囤积粮食至下一年(第6年)以创高价。这个计划是否可行? 2、方法的选择 根据下表的数据,可采用时间序列的趋势分析方法和季节变动分析方法,进行相应的分析预测,以了解消费物价指数的发展趋势。 表2
3、消费物价指数的预测 根据题意需预测出第6年各季的物价指数,若指数升幅较大,那么粮食价格将会提高,否则囤积货物只会增加保管成本而不可能得到高价。在物价指数预测中,循环变动和不规则变动难以准确预测,故仅考虑长期趋势与季节变动的影响。 本案例分析应用EXCEL软件。 (1)计算移动平均数。输出结果见下表和图: 表3.
(2)分离长期趋势T。 对于T×C,按照表8.14中时间顺序,用最小平方法建立长期趋势模型yc=111.498+1.173t ,据以计算各期趋势值T(见上表)。 (3)分离季节变动S。 首先剔除长期趋势的影响y/T×C,即T×C×S×I/T×C=S×I;然后根据S×I序列计算各期季节比率S。计算结果为:1季度季节比率=0.9773,2季度季节比率=0.9874,3季度季节比率=1.0076,4季度季节比率=1.0277。 (4)预测第6年各季消费物价指数。 首先需要根据时间序列模型计算第6年各季的趋势值,即将t=19、20、21、22分别代入yc=111.498+1.173t 计算得第6年各季度趋势值: 1季的趋势值为133.79 2季趋势值为134.96 3季趋势值为136.14 4季趋势值为137.31 然后分别乘以各自季节比率得到各季预测值, 1季物价指数=133.79×0.9773=130.75% 2季物价指数=134.96×0.9874=133.26% 3季物价指数=136.14×1.0076=137.17% 4季物价指数=137.31×1.0277=141.11%。 4、案例分析 仅从第6年各季消费物价指数的预测值看,指数确有一定的增幅,因此期待
应用时间序列分析
应用时间序列分析Newly compiled on November 23, 2020
国内生产总值与财政支出总额关系的分析 摘要:许多文献已经论证过财政政策在实现经济长期增长中的作用,我们在前人研究的基础上从财政支出结构角度分析我国政府财政支出和国内生产总值的相关关系,研究财政支出对经济增长的促进作用。同时,尝试探讨存在财政风险和积极财政政策淡出的情况下,应该如何优化财政支出结构,积极的财政政策应怎么样淡出,以避免财政风险的扩大,并进一步提出相关的建议。我们此次是采用时间序列分析的方法分析财政支出总额对GDP的影响。 关键词:国内生产总值财政支出总额时间序列分析 一、引言 财政支出与GDP之间的关系一直是经济学界关注的话题。20世纪30年代,凯恩斯提出了财政支出乘数理论,认为在有效的需求不足的情况下,增加政府支出,扩大社会总需求,从而减少失业,促进经济的增长;当需求过大时,通过减少财政支出抑制社会总需求,以实现供求平衡,促进经济的稳定和增长。随着新增长理论的出现,一部分经济学家认为政府可以实行一定的财政支出政策和税收政策,促进技术的进步,从而可以促进经济的增长,已经有许多的文献研究了财政支出和经济增长之间的关系。 国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标。它不但可反映一个国家的经济表现,更可以反映一国的国力与财富。 财政支出也称公共财政支出,是指在市场经济条件下,政府为提供公共产品和服务,满足社会共同需要而进行的财政资金的支付。财政支出是国家将通过各种形式筹集上来的财政收入进行分配和使用的过程,它是整个财务分配活动的第二阶段。财政支出增长的原因有经济原因、政治原因,社会性原因和国际关系等。 经济增长离不开政府的宏观调控,货币政策和财政政策作为宏观调控的主要手段,货币政策由国家统一实施,对于地方政府财政政策的制定与实施是地方政府效能的一种体现。财政政策的核心是通过政府的收入和支出调节有效需求,实现一定的政策目标。它包括一是财政收入政策,即通过增税或减税及税种的选择投资和消费需求,实现收入和资金的再分配。二是财政支出政策,即通过政府预算支出的增减及财政赤字的增减影响总需求。三是财政补贴。 本文应用时间序列分析的相关方法,旨在研究我国财政支出与GDP的关系,以反映我国财政对宏观经济运行的调控。 二、数据的选取 本文选取的数据来自《中国统计年鉴2009》1981—2008年的国内生产总值时间序列和财政支出总额的时间序列,记国内生产总值的年度数据序列为{X t},记财政支出总额的年度数据序列为{Y t}。详见表1:
时间序列的趋势分析
2.2.1 移动平均法 ? 基本思想 ? 假定在一个比较短的时间间隔里,序列值之间的差异主要是由随机波动造成的。根据这种假定,我们可以用一定时间间隔内的平均值作为某一期的估计值 ? 分类 ?n 期中心移动平均? n 期移动平均 n 期移动平均 )(1~11+--+++=n t t t t x x x n x 4-t x 3-t x 2-t x 1 -t x t x 5 ~1234 t t t t t t x x x x x x ++++=----5期移动平均
移动平均期数确定原则 ? 事件的发展有无周期性 ?以周期长度作为移动平均的间隔长度,以消除周期效应的影响? 对趋势平滑的要求 ?移动平均的期数越多,拟合趋势越平滑? 对趋势反映近期变化敏感程度的要求 ? 移动平均的期数越少,拟合趋势越敏感 n 期中心移动平均 ??? ??? ?++++++++++++=+-++---+--++----为偶数,为奇数,n x x x x x n n x x x x x n x n t n t t n t n t n t n t t n t n t t )2121(1)(1 ~2121222112112121 5 ~2112 ++--++++=t t t t t t x x x x x x 2-t x 1 -t x t x 1+t x 2 +t x 5 期中心移动平均
例2.3:病事假人数的移动平均 18 6.5 12.6 24 4.5 11.8 21 2.5 106.412.4164.411.6132.48.2 76.312.6114.311.0102.38.656.213.484.210.482.29.016.113.644.110.032.19.6205.514.0283.59.6181.510.4125.414.2173.49.4111.410.8105.314.6133.39.681.311.695.213.293.271.212.435.112.463.141.15项移动平均病事假人 数 时间 5项移动平 均 病事假人数 时间 5项移动平均 病事假人数 时间 510152025 301 4 7 10 13 16 19 22 25 28 时间 病事假人数 实际值预测值
时间序列分析方法及应用
民族大学 毕业论文 论文题目:时间序列分析方法及应用—以省GDP增长 为例研究 学生姓名:学号: 指导教师:职称: 院系:数学与统计学院 专业班级:统计学 二○一五年月日
时间序列分析方法及应用 ——以省GDP增长为例研究 摘要: 人们的一切活动,其根本目的无不在于认识和改造世界,让自己的生活过得更理想。时间序列是指同一空间、不同时间点上某一现象的相同统计指标的不同数值,按时间先后顺序形成的一组动态序列。时间序列分析则是指通过时间序列的历史数据,揭示现象随时间变化的规律,并基于这种规律,对未来此现象做较为有效的延伸及预测。时间序列分析不仅可以从数量上揭示某一现象的发展变化规律或从动态的角度刻画某一现象与其他现象之间的在数量关系及其变化规律性,达到认识客观世界的目的。而且运用时间序列模型还可以预测和控制现象的未来行为,由于时间序列数据之间的相关关系(即历史数据对未来的发展有一定的影响),修正或重新设计系统以达到利用和改造客观的目的。从统计学的容来看,统计所研究和处理的是一批有“实际背景”的数据,尽管数据的背景和类型各不相同,但从数据的形成来看,无非是横截面数据和纵截面数据两类。本论文主要研究纵截面数据,它反映的是现象以及现象之间的关系发展变化规律性。在取得一组观测数据之后,首先要判断它的平稳性,通过平稳性检验,可以把时间序列分为平稳序列和非平稳序列两大类。主要采用的统计方法是时间序列分析,主要运用的数学软件为Eviews软件。大学四年在省上学,基于此,对省的GDP十
分关注。本论文关于对1978年到2014年以来的中国的省GDP(总共37个数据)进行时间序列分析,并且对未来的三年中国的省GDP进行较为有效的预测。希望对省的发展有所贡献。 关键词: 省GDP 时间序列白噪声预测 Abstract: All activities of people,its fundamental purpose is to understand and transform the world,let your life more ideal.The time sequence is the same in different numerical statistical indicators refer to the same space,different time points of a certain phenomenon,according to a set of dynamic time series sequence formation.Time series analysis is through the time series of historical data,to reveal the rules of change over time,and based on this rule,extension and forecast for the future of this phenomenon is more effective.Development and changes of time series analysis can not only reveal a phenomenon from the quantity or describe the intrinsic relationship between a regular phenomenon and other phenomena from the dynamic point of view,to achieve the purpose of understanding the objective world.And the application of time series model can predict and control the future behavior of the phenomenon,the relationship between the time series data(historical data have a certain impact on the future development),modified or re design of the system to achieve
数据分析 时间序列的趋势分析
数据分析-时间序列的趋势分析无论是网站分析工具、BI报表或者数据的报告,我们很难看到数据以孤立的点单独地出现,通常数据是以序列、分组等形式存在,理由其实很简单,我们没法从单一的数据中发现什么,用于分析的数据必须包含上下文(Context)。数据的上下文就像为每个指标设定了一个或者一些参考系,通过这些参照和比较的过程来分析数据的优劣,就像中学物理上的例子,如果我们不以地面作为参照物,我们无法区分火车是静止的还是行进的,朝北开还是朝南开。 在实际看数据中,我们可能已经在不经意间使用数据的上下文了,趋势分析、比例分析、细分与分布等都是我们在为数据设置合适的参照环境。所以这边通过一个专题——数据的上下文,来总结和整理我们在日常的数据分析中可以使用的数据参考系,前面几篇主要是基于内部基准线(Internal Benchmark)的制定的,后面会涉及外部基准线(External Benchmark)的制定。今天这篇是第一篇,主要介绍基于时间序列的趋势分析,重提下同比和环比,之前在网站新老用户分析这篇文章,已经使用同比和环比举过简单应用的例子。 同比和环比的定义 定义这个东西在这里还是再唠叨几句,因为不了解定义就无法应用,熟悉的朋友可以跳过。 同比:为了消除数据周期性波动的影响,将本周期内的数据与之前周期中相同时间点的数据进行比较。早期的应用是销售业等受季节等影响较严重,为了消除趋势分析中季节性的影响,引入了同比的概念,所以较多地就
是当年的季度数据或者月数据与上一年度同期的比较,计算同比增长率。 环比:反应的是数据连续变化的趋势,将本期的数据与上一周期的数据进行对比。最常见的是这个月的数据与上个月数据的比较,计算环比增长率,因为数据都是与之前最近一个周期的数据比较,所以是用于观察数据持续变化的情况。 买二送一,再赠送一个概念——定基比(其实是百度百科里附带的):将所有的数据都与某个基准线的数据进行对比。通常这个基准线是公司或者产品发展的一个里程碑或者重要数据点,将之后的数据与这个基准线进行比较,从而反映公司在跨越这个重要的是基点后的发展状况。 同比和环比的应用环境 其实同比、环比没有严格的适用范围或者针对性的应用,一切需要分析在时间序列上的变化情况的数据或者指标都可以使用同比和环比。 但是我的建议是为网站的目标指标建立同比和环比的数据上下文,如网站的收益、网站的活跃用户数、网站的关键动作数等,这类指标需要明确长期的增长趋势,同比和环比能够为网站整体运营的发展状况提供有力的参考。 还有个建议就是不要被同比和环比最原始或者最普遍的应用所束缚住:同比就是今年每个月或每季度的数据与去年同期比,环比就是这个月的数据与上个月比。对于方法的应用需要根据实际的应用的环境,进行合理的变通,选择最合适的途径。所以同比和环比不一定以年为周期,也不一定是每月、季度为时间粒度的统计数据,我们可以根据需要选择任意合适的周期,比如你们公司的产品运营是以周、半月、甚至每年的特定几个月为周期循环变动,