遗传算法
遗传算法程序的编写、改进及测试
姓名: 学号:
一、课题研究主要内容
1、编写基本遗传算法程序并加以改进,进行函数测试。实现方式:自行编程。
2、编写基本遗传算法程序并加以改进,进行函数测试。实现方式:MATLAB 工具箱命令行函数和图形用户接口。
3、进行遗传算法的应用研究(可参考文献,或结合课题)。
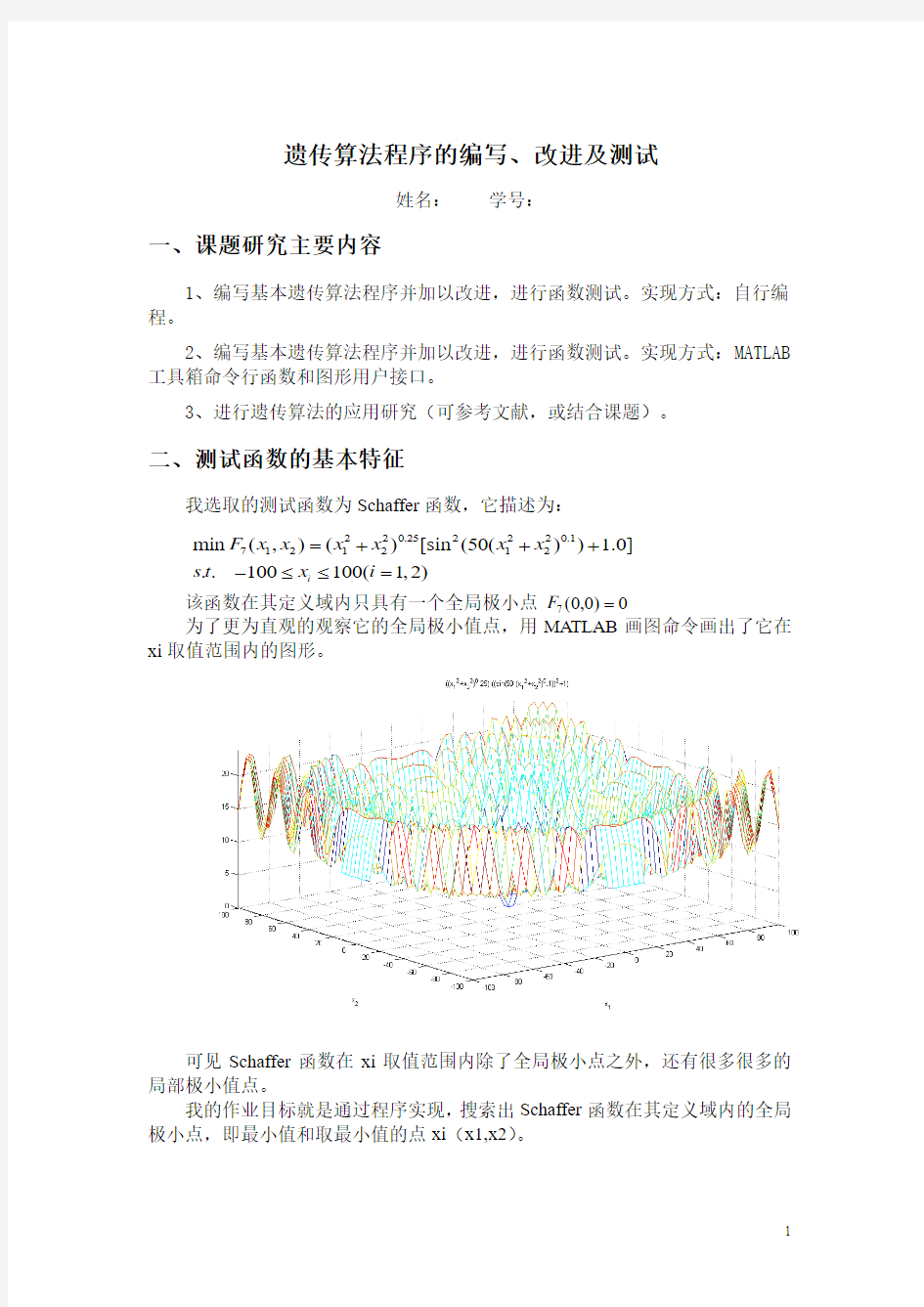
二、测试函数的基本特征
我选取的测试函数为Schaffer 函数,它描述为:
该函数在其定义域内只具有一个全局极小点 为了更为直观的观察它的全局极小值点,用MATLAB 画图命令画出了它在xi 取值范围内的图形。
可见Schaffer 函数在xi 取值范围内除了全局极小点之外,还有很多很多的局部极小值点。
我的作业目标就是通过程序实现,搜索出Schaffer 函数在其定义域内的全局极小点,即最小值和取最小值的点xi (x1,x2)。
220.252220.17121212min (,)()[sin (50()) 1.0]..100100(1,2)i F x x x x x x s t x i =+++-≤≤=0
)0,0(7=F
三用MATLAB基本命令语句编程实现遗传算法
遗传算法(Genetic Algorithm)是一类借鉴生物界的进化规律(适者生存,优胜劣汰遗传机制)演化而来的随机化搜索方法。它是由美国的J.Holland教授1975年首先提出,其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,能自动获取和指导优化的搜索空间,自适应地调整搜索方向,不需要确定的规则。
对于一个求函数最小值的优化问题(求函数最大值也类同),遗传算法作为一种全局优化搜索算法提供了一个有效的途径和通用的框架。
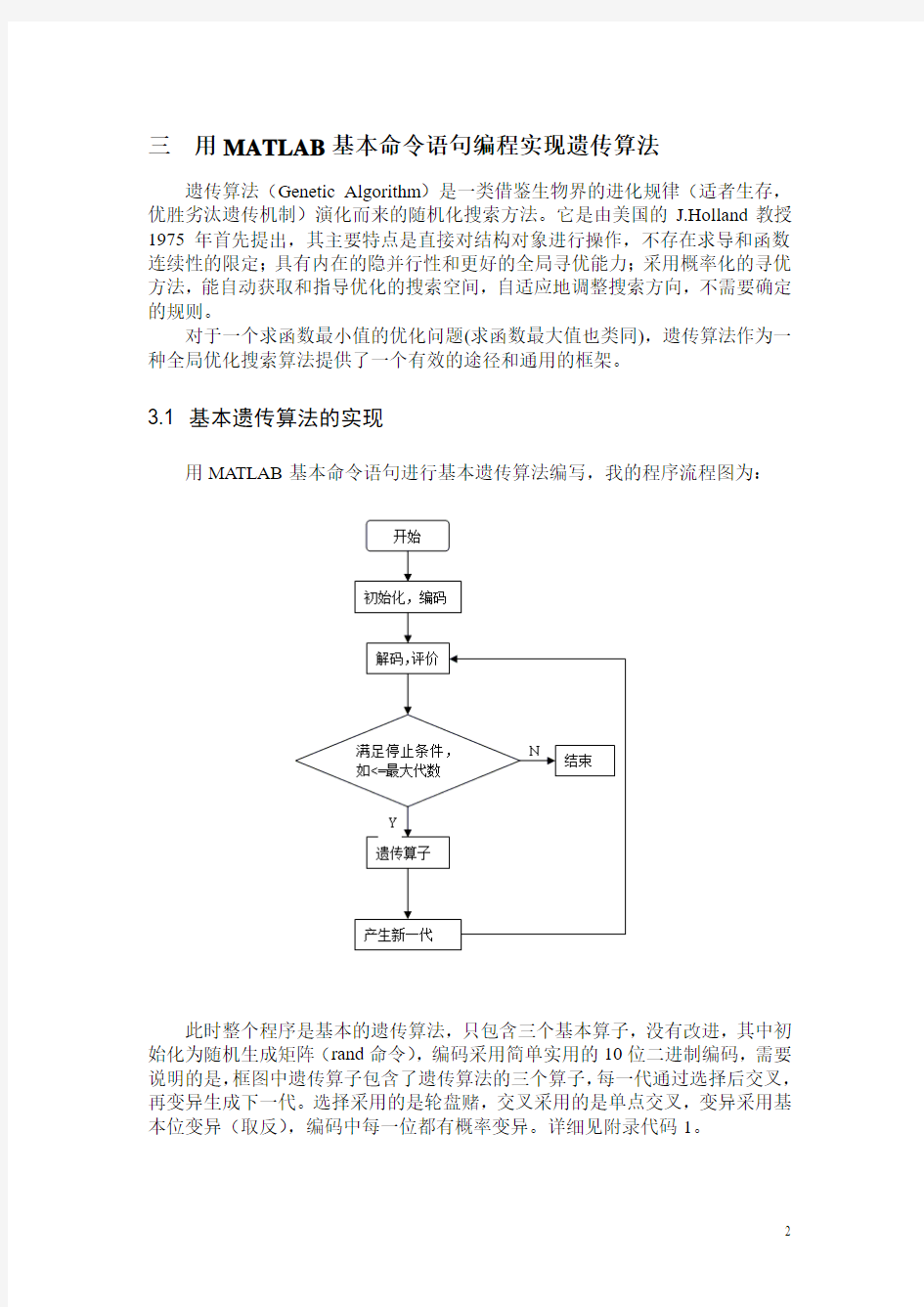
3.1 基本遗传算法的实现
用MATLAB基本命令语句进行基本遗传算法编写,我的程序流程图为:
此时整个程序是基本的遗传算法,只包含三个基本算子,没有改进,其中初始化为随机生成矩阵(rand命令),编码采用简单实用的10位二进制编码,需要说明的是,框图中遗传算子包含了遗传算法的三个算子,每一代通过选择后交叉,再变异生成下一代。选择采用的是轮盘赌,交叉采用的是单点交叉,变异采用基本位变异(取反),编码中每一位都有概率变异。详细见附录代码1。
3.2 改进的遗传算法
多次调整程序参数(种群大小、代数、码长、交叉概率、变异概率)并多次运行代码1(即基本的遗传算法),程序的运行结果变异太大,有高有低,通过改变参数值虽然运行结果能够在一定范围内去接近Schaffer函数的最小值点,但离目标值还总是差得很大一段距离。而且不管取什么参数值,从输出的图形的中可以很明显的看出,xi的取值随着代数增加跳跃在目标值的一定范围内,既没有很好的逼近目标值,也没有趋向一个稳定的值,见图3.1。
Result: k =200 MIN =1.4160 xb1 = 1.6618 xb2 =0.8798
图3.1
算法的稳定性和收敛性似乎不强,程序运行结果的准确性也不高,需要改进。
优秀个体保护法对于每代中一定数量的最优个体,使之直接进入下一代,防止优秀个体由于复制、交叉或变异中的偶然因素而被破坏掉,能够增强算法的稳定性和收敛性。在代码1.中添加了优秀个体保护法后,程序运行结果的稳定性收敛性准确性明显地提高了很多很多,效果立竿见影,xi也能很好的逼近目标值并且很好地收敛并呈阶梯状稳定,见图3.2。改进代码为附录代码2,改进的地方有标识。改进前和改进后的参数是一样的:
参数
M=200; %种群大小
T=200; %遗传运算得终止进化代数
CL=10; %二进制编码长度10位
F=0.7; %交叉概率
Bi=0.5; %变异概率
Max=100; %输入值的取值上限
Min=-100; %输入值的取值下限
Result: k = 200 MIN =0.5995 xb1 =-0.0978 xb2 =0.0978
图3.2
由于改进前和改进后程序运行差异明显,改进后明显优于改进前,且改进后的算法程序能非常好地逼近目标值,故没有做一些性能指标(如多次运行结果的峰峰值,均值,方差)来描述和对比二者的性能。
四、用MATLAB遗传算法工具箱进行函数测试
可以直接运用MATLAB遗传算法工具箱Genetic Algorithm Toolbox寻求Schaffer函数在其定义域内的全局极小值
运用MATLAB遗传算法工具箱有两种方法,一种方法是用命令行函数ga,另一种方法是用图形用户界面gatool,但他们对应的输入输出变量是一样的,对应的遗传算法源代码是一样的。
使用Genetic Algorithm Toolbox,主要有以下几个步骤:
Write an M-file that computes the function you want to optimize.
Number of variables
Genetic Algorithm Options (gaoptimset)
Run
方法一:
寻求Schaffer函数的最小值,用ga函数具体实现如下:
Step1首先要写目标函数的M文件schaffer.m,文件代码见附录
fitnessFunction = @schaffer;
Step2 变量为2,
nvars = 2;
Step3 Set Genetic Algorithm Options:
options = gaoptimset(options,'PopInitRange' ,[-1 ; 1 ]);
options = gaoptimset(options,'PopulationSize' ,1000);
options = gaoptimset(options,'CrossoverFraction' ,0.33);
options = gaoptimset(options,'Generations' ,200);
options = gaoptimset(options,'SelectionFcn' ,{ @selectiontournament 4 });
options = gaoptimset(options,'CrossoverFcn' ,@crossoversinglepoint);
options = gaoptimset(options,'MutationFcn' ,{ @mutationgaussian 1 1 });
options = gaoptimset(options,'Display' ,'off');
options = gaoptimset(options,'PlotFcns' ,{ @gaplotbestf });
Step4 run
[X,FV AL,REASON,OUTPUT,POPULATION,SCORES] = ga(fitnessFunction,nvars,options);
方法二:
若用gatool图形界面,在相应的设置项填入或选择设置,然后运行即可。
以上的设置运行结果如下(多次试验得出的设置,多次运行得出的比较好的结果):
图形为:
Status and results:
GA running.
GA terminated.
Fitness function value: 0.006667532430880696
Optimization terminated: stall generations limit exceeded.
四、作业总结
1、我把options中的PopInitRange设置为[-1 ; 1 ],使得初代个体就能在最优值(0 ,0)附近,倘若我们不知道函数的最优值点在哪里,依照函数定义域把PopInitRange设置为[-100 100],工具箱的运行结果不会在最优值点附近,而且会差很多很多。所以,如果不知道目标点位置如何设置PopInitRange,如何评估最终结果的准确性。
2、MATLAB7.0自带的遗传算法工具箱GADS好像不适用于求有约束条件的极值问题
3、由于期末在即,时间有限,所以没有对某个参数值对算法性能的影响进行讨论。
参考文献
1、李玉榕.人工智能第三章求解优化问题的智能算法.福州大学.2010
2、刘会灯、朱飞.MATLAB编程基础与典型应用.人民邮电出版社.2008
附录
%-------------------------------------------代码1:
clear all;
close all;
%遗传算法参数设定和初始化
M=200; %种群大小
T=200; %遗传运算得终止进化代数
CL=10; %二进制编码长度10位
F=0.7; %交叉概率
Bi=0.5; %变异概率
Max=100; %输入值的取值上限
Min=-100; %输入值的取值下限
G=round(rand(M,CL*2)); %初始化
NG=zeros(M,CL*2);
for k=1:1:T
T(k)=k;
for s=1:1:M
N=G(s,:);
y1=0;y2=0;
N1=N(1:1:CL); %对x1进行解码,
for i=1:1:CL
y1=y1+N1(i)*2^(i-1);
end
x1=(Max-Min)*y1/(2^CL-1)+Min;
N2=N(CL+1:1:2*CL); %对x2进行解码
for i=1:1:CL
y2=y2+N2(i)*2^(i-1);
end
x2=(Max-Min)*y2/(2^CL-1)+Min;
F(s)=-((x1^2+x2^2)^0.25)*((sin(50*(x1^2+x2^2)^0.1))^2+1); %目标函数表达式
end
Fit=F;
[Order,Index]=sort(Fit); %将适应度从小到大进行排列
BF=Order(M); %选出适应度最大得值
N=G(Index(M),:);
y1=0;y2=0;
N1=N(1:1:CL);
for i=1:1:CL
y1=y1+N1(i)*2^(i-1);
end
xb1=(Max-Min)*y1/(2^CL-1)+Min;
x1_G(k)=xb1; %为了便于最后图形输出,而引进的类似指针型变量
N2=N(CL+1:1:2*CL); %对x2进行解码
for i=1:1:CL
y2=y2+N2(i)*2^(i-1);
end
xb2=(Max-Min)*y2/(2^CL-1)+Min;
x2_G(k)=xb2;
BFI(k)=BF;
BG=G(Index(M),:);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %
%selection
ada_sum=0;
for i=1:1:M %直到累加和>=fit_n,最后的累加就是复制个体ada_sum=ada_sum+F(i);
end
for i=1:(M-10) %最后10个体留给历代最优解
r=rand*ada_sum; %随机产生一个数
ada_temp=0; %初始化累加值为0
j=1;
while(ada_temp ada_temp=ada_temp+F(j); j=j+1; end if j==1 j=1; else j=j-1; end NG(i,:)=G(j,:); end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%% %crossover for i=1:2:M Rn=rand; %Rn为0-1之间的随机数 if F>Rn %交叉条件,F=0.6,Rn<0.6时就进行交叉运算 Cn=ceil(2*CL*Rn); if or(Cn==0,Cn>=20) continue; end for j=Cn:1:2*CL %随机交换部分染色体的基因,交换的位从Cn到末位止 temp=NG(i,j); NG(i,j)=NG(i+1,j); NG(i+1,j)=temp; end end end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%% %mutation for i=1:1:M %变异运算 for j=1:1:2*CL Mr=rand; %产生基本位变异位,同样Mr是0-1之间的数 if Bi>Mr %变异条件 if NG(i,j)==0 NG(i,j)=1; else NG(i,j)=0; end end end end G=NG; end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%% %result k MIN=-BF xb1 xb2 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%% %plot subplot(3,1,3);plot(T,-BFI,'.'); xlabel('次数');ylabel('最小值'); subplot(3,1,2);plot(T,x2_G,'.black'); xlabel('次数');ylabel('X2'); subplot(3,1,1);plot(T,x1_G,'.black'); xlabel('次数');ylabel('X1'); %---------------------------------------代码2: clear all; close all; %遗传算法参数设定和初始化 M=200; %种群大小 T=200; %遗传运算得终止进化代数 CL=10; %二进制编码长度10位 F=0.7; %交叉概率 Bi=0.5; %变异概率 Max=100; %输入值的取值上限 Min=-100; %输入值的取值下限 G=round(rand(M,CL*2)); %初始化 NG=zeros(M,CL*2); for k=1:1:T T(k)=k; for s=1:1:M N=G(s,:); y1=0;y2=0; N1=N(1:1:CL); %对x1进行解码, for i=1:1:CL y1=y1+N1(i)*2^(i-1); end x1=(Max-Min)*y1/(2^CL-1)+Min; N2=N(CL+1:1:2*CL); %对x2进行解码 for i=1:1:CL y2=y2+N2(i)*2^(i-1); end x2=(Max-Min)*y2/(2^CL-1)+Min; F(s)=-((x1^2+x2^2)^0.25)*((sin(50*(x1^2+x2^2)^0.1))^2+1); %目标函数表达式 end Fit=F; [Order,Index]=sort(Fit); %将适应度从小到大进行排列 BF=Order(M);%选出适应度最大得值 N=G(Index(M),:); y1=0;y2=0; N1=N(1:1:CL); for i=1:1:CL y1=y1+N1(i)*2^(i-1); end xb1=(Max-Min)*y1/(2^CL-1)+Min; x1_G(k)=xb1; %为了便于最后图形输出,而引进的类似指针型变量 N2=N(CL+1:1:2*CL); %对x2进行解码 for i=1:1:CL y2=y2+N2(i)*2^(i-1); end xb2=(Max-Min)*y2/(2^CL-1)+Min; x2_G(k)=xb2; BFI(k)=BF; BG=G(Index(M),:); In=M; %保护10个最优个体 for i=1:1:10 BGG(i,:)=G(Index(In),:); In=In-1; end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%% %selection %采用赌盘选择法 ada_sum=0; for i=1:1:M %直到累加和>=fit_n,最后的累加就是复制个体ada_sum=ada_sum+F(i); end for i=1:(M-10) %最后10个体留给历代最优解 r=rand*ada_sum; %随机产生一个数 ada_temp=0; %初始化累加值为0 j=1; while(ada_temp ada_temp=ada_temp+F(j); j=j+1; end if j==1 j=1; else j=j-1; end NG(i,:)=G(j,:); end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%% %crossover for i=1:2:(M-10) Rn=rand; %Rn为0-1之间的随机数 if F>Rn %交叉条件,F=0.6,Rn<0.6时就进行交叉运算 Cn=ceil(2*CL*Rn); if or(Cn==0,Cn>=20) continue; end for j=Cn:1:2*CL %随机交换部分染色体的基因,交换的位从Cn到末位止 temp=NG(i,j); NG(i,j)=NG(i+1,j); NG(i+1,j)=temp; end end end %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%% %mutation for i=1:1:(M-10) %变异运算 for j=1:1:2*CL Mr=rand; %产生基本位变异位,同样Mr是0-1之间的数 if Bi>Mr %变异条件 if NG(i,j)==0 NG(i,j)=1; else NG(i,j)=0; end end end end Rs=10;%(即后10位)进行保优 for i=1:1:10 NG(M-Rs,:)=BGG(i,:); Rs=Rs-1; end G=NG; end k MIN=-BF xb1 xb2 subplot(3,1,3);plot(T,-BFI,'.'); xlabel('次数');ylabel('最小值'); subplot(3,1,2);plot(T,x2_G,'.black'); xlabel('次数');ylabel('X2'); subplot(3,1,1);plot(T,x1_G,'.black'); xlabel('次数');ylabel('X1'); 实验六 遗传算法与优化设计 一、实验目的 1. 了解遗传算法的基本原理和基本操作(选择、交叉、变异); 2. 学习使用Matlab 中的遗传算法工具箱(gatool)来解决优化设计问题; 二、实验原理及遗传算法工具箱介绍 1. 一个优化设计例子 图1所示是用于传输微波信号的微带线(电极)的横截面结构示意图,上下两根黑条分别代表上电极和下电极,一般下电极接地,上电极接输入信号,电极之间是介质(如空气,陶瓷等)。微带电极的结构参数如图所示,W 、t 分别是上电极的宽度和厚度,D 是上下电极间距。当微波信号在微带线中传输时,由于趋肤效应,微带线中的电流集中在电极的表面,会产生较大的欧姆损耗。根据微带传输线理论,高频工作状态下(假定信号频率1GHz ),电极的欧姆损耗可以写成(简单起见,不考虑电极厚度造成电极宽度的增加): 图1 微带线横截面结构以及场分布示意图 {} 28.6821ln 5020.942ln 20.942S W R W D D D t D W D D W W t D W W D e D D παπππ=+++-+++?????? ? ??? ??????????? ??????? (1) 其中πρμ0=S R 为金属的表面电阻率, ρ为电阻率。可见电极的结构参数影响着电极损耗,通过合理设计这些参数可以使电极的欧姆损耗做到最小,这就是所谓的最优化问题或者称为规划设计问题。此处设计变量有3个:W 、D 、t ,它们组成决策向量[W, D ,t ] T ,待优化函数(,,)W D t α称为目标函数。 上述优化设计问题可以抽象为数学描述: ()()min .. 0,1,2,...,j f X s t g X j p ????≤=? (2) 遗传算法属于进化算法( Evolutionary Algorithms) 的一种, 它通过模仿自然界的选择与遗传的机理来寻找最优解. 遗传算法有三个基本算子: 选择、交叉和变异. 。数值方法求解这一问题的主要手段是迭代运算。一般的迭代方法容易陷入局部极小的陷阱而出现"死循环"现象,使迭代无法进行。遗传算法很好地克服了这个缺点,是一种全局优化算法。 生物在漫长的进化过程中,从低等生物一直发展到高等生物,可以说是一个绝妙的优化过程。这是自然环境选择的结果。人们研究生物进化现象,总结出进化过程包括复制、杂交、变异、竞争和选择。一些学者从生物遗传、进化的过程得到启发,提出了遗传算法( GA)。算法中称遗传的生物体为个体( individual ),个体对环境的适应程度用适应值( fitness )表示。适应值取决于个体的染色体(chromosome),在算法中染色体常用一串数字表示,数字串中的一位对应一个基因 (gene)。一定数量的个体组成一个群体(population )。对所有个体进 行选择、交叉和变异等操作,生成新的群体,称为新一代( new generation )。遗传算法计算程序的流程可以表示如下[3]:第一步准备工作 (i)选择合适的编码方案,将变量(特征)转换为染色体(数字串,串长为m。通常用二 进制编码。 (2 )选择合适的参数,包括群体大小(个体数M)、交叉概率PC和变异概率Pm (3、确定适应值函数f (x、。f (x、应为正值。 第二步形成一个初始群体(含M个个体)。在边坡滑裂面搜索问题中,取已分析的可能滑裂 面组作为初始群体。 第三步对每一染色体(串)计算其适应值fi ,同时计算群体的总适应值。 第四步选择 计算每一串的选择概率Pi=fi/F 及累计概率。选择一般通过模拟旋转滚花轮 ( roulette ,其上按Pi大小分成大小不等的扇形区、的算法进行。旋转M次即可选出M个串来。在计算机 上实现的步骤是:产生[0,1]间随机数r,若r 第三章 遗传算法的理论基础 遗传算法有效性的理论依据为模式定理和积木块假设。模式定理保证了较优的模式(遗传算法的较优解)的样本呈指数级增长,从而满足了寻找最优解的必要条件,即遗传算法存在着寻找到全局最优解的可能性。而积木块假设指出,遗传算法具备寻找到全局最优解的能力,即具有低阶、短距、高平均适应度的模式(积木块)在遗传算子作用下,相互结合,能生成高阶、长距、高平均适应度的模式,最终生成全局最优解。Holland 的模式定理通过计算有用相似性,即模式(Pattern)奠定了遗传算法的数学基础。该定理是遗传算法的主要定理,在一定程度上解释了遗传算法的机理、数学特性以及很强的计算能力等特点。 3.1 模式定理 不失一般性,本节以二进制串作为编码方式来讨论模式定理(Pattern Theorem)。 定义3.1 基于三值字符集{0,1,*}所产生的能描述具有某些结构相似性的0、1字符串集的字符串称作模式。 以长度为5的串为例,模式*0001描述了在位置2、3、4、5具有形式“0001”的所有字符串,即(00001,10001) 。由此可以看出,模式的概念为我们提供了一种简洁的用于描述在某些位置上具有结构相似性的0、1字符串集合的方法。 引入模式后,我们看到一个串实际上隐含着多个模式(长度为 n 的串隐含着2n 个模式) ,一个模式可以隐含在多个串中,不同的串之间通过模式而相互联系。遗传算法中串的运算实质上是模式的运算。因此,通过分析模式在遗传操作下的变化,就可以了解什么性质被延续,什么性质被丢弃,从而把握遗传算法的实质,这正是模式定理所揭示的内容 定义3.2 模式H 中确定位置的个数称作该模式的阶数,记作o(H)。比如,模式 011*1*的阶数为4,而模式 0* * * * *的阶数为1。 显然,一个模式的阶数越高,其样本数就越少,因而确定性越高。 定义3.3 模式H 中第一个确定位置和最后一个确定位置之间的距离称作该模式的定义距,记作)(H δ。比如,模式 011*1*的定义距为4,而模式 0* * * * *的定义距为0。 模式的阶数和定义距描述了模式的基本性质。 下面通过分析遗传算法的三种基本遗传操作对模式的作用来讨论模式定理。令)(t A 表示第t 代中串的群体,以),,2,1)((n j t A j =表示第t 代中第j 个个体串。 1.选择算子 在选择算子作用下,与某一模式所匹配的样本数的增减依赖于模式的平均适值,与群体平均适值之比,平均适值高于群体平均适值的将呈指数级增长;而平均适值低于群体平均适值的模式将呈指数级减少。其推导如下: 设在第t 代种群)(t A 中模式所能匹配的样本数为m ,记为),(t H m 。在选择中,一个位串 j A 以概率/j j i P f f =∑被选中并进行复制,其中j f 是个体)(t A j 的适应度。假设一代中群体 大小为n ,且个体两两互不相同,则模式H 在第1+t 代中的样本数为: GATBX遗传算法工具箱函数及实例讲解 基本原理: 遗传算法是一种典型的启发式算法,属于非数值算法范畴。它是模拟达尔文的自然选择学说和自然界的生物进化过程的一种计算模型。它是采用简单的编码技术来表示各种复杂的结构,并通过对一组编码表示进行简单的遗传操作和优胜劣汰的自然选择来指导学习和确定搜索的方向。遗传算法的操作对象是一群二进制串(称为染色体、个体),即种群,每一个染色体都对应问题的一个解。从初始种群出发,采用基于适应度函数的选择策略在当前种群中选择个体,使用杂交和变异来产生下一代种群。如此模仿生命的进化进行不断演化,直到满足期望的终止条件。 运算流程: Step 1:对遗传算法的运行参数进行赋值。参数包括种群规模、变量个数、交叉概率、变异概 率以及遗传运算的终止进化代数。 Step 2:建立区域描述器。根据轨道交通与常规公交运营协调模型的求解变量的约束条件,设置变量的取值范围。 Step 3:在Step 2的变量取值范围内,随机产生初始群体,代入适应度函数计算其适应度值。 Step 4:执行比例选择算子进行选择操作。 Step 5:按交叉概率对交叉算子执行交叉操作。 Step 6:按变异概率执行离散变异操作。 Step 7:计算Step 6得到局部最优解中每个个体的适应值,并执行最优个体保存策略。 Step 8:判断是否满足遗传运算的终止进化代数,不满足则返回Step 4,满足则输出运算结果。 运用遗传算法工具箱: 运用基于Matlab的遗传算法工具箱非常方便,遗传算法工具箱里包括了我们需要的各种函数库。目前,基于Matlab的遗传算法工具箱也很多,比较流行的有英国设菲尔德大学开发的遗传算法工具箱GATBX、GAOT以及Math Works公司推出的GADS。实际上,GADS就是大家所看到的Matlab中自带的工具箱。我在网上看到有问为什么遗传算法函数不能调用的问题,其实,主要就是因为用的工具箱不同。因为,有些人用的是GATBX带有的函数,但MATLAB自带的遗传算法工具箱是GADS,GADS当然没有GATBX里的函数,因此运行程序时会报错,当你用MATLAB来编写遗传算法代码时,要根据你所安装的工具箱来编写代码。 以GATBX为例,运用GATBX时,要将GATBX解压到Matlab下的toolbox文件夹里,同时,set path将GATBX文件夹加入到路径当中。 这块内容主要包括两方面工作:1、将模型用程序写出来(.M文件),即目标函数,若目标函数非负,即可直接将目标函数作为适应度函数。2、设置遗传算法的运行参数。包括:种群规模、变量个数、区域描述器、交叉概率、变异概率以及遗传运算的终止进化代数等等。 基于新的混合遗传算法的订单生产工序顺序相关的流水车 间调度问题研究 A novel hybrid genetic algorithm to solve the make-to-order sequence-dependent flow-shop scheduling problem Mohammad Mirabi ?S. M. T. Fatemi Ghomi ?F. Jolai 2013年5月29号收到该文献,2014年3月18号录取,2014年4月9日出版.作者(2014).这篇文章在开放存取的https://www.360docs.net/doc/c311574820.html, 网站发表 摘要流水车间调度问题(FSP)用于处理m台机器n个工序的流水作业。尽管FSP是典 型的NP-hard问题,依然没有有效的算法以找到这个问题的最优解。为了减少库存,延迟和安装成本,在工作时间一定,序列相关的每台机器上解决流水车间调度排序问题,在这提出了一种有三个遗传算子的新型混合遗传算法(HGA)。该算法应用一种改进的方法来生成初始种群,并使用一种应用迭代交换过程改进初始解的改进启发式算法。我们认为订单式生产方式,工序间隔时间是基于最大安装成本的禁忌搜索算法的解。此外,与最近开发的启发式算法通过计算实验结果比较表明,该算法在解\的精度和效率方面表现出非常强的竞争力。 关键词:混合遗传算法流水作业调度序列相关 引言 流车间调度问题(FSP)作为在制造业研究的主要问题已经近七十年。在一个有M台机器的流水作业车间中有m个工位,每个工序又有一台或几台机器。此外,有n个工件在m个工位上依次加工。在经典的流水作业问题里,每个工位都有一台机器,这一领域的研究吸引了最多的人次。FSP的两个主要子问题是序列独立时间设置(SIST)和顺序相关时间设置(SDST)。SDST流水作业问题更具有现实意义,但是吸引的注意力却少得多,特别是2000年以前(Allahverdi等,2008) 在流水车间调度问题的目标是找到一个序列的机器加工的作业,以便一个给定的标准进行了优化。这里有n个工件在每台机器上操作的可能的顺序,以及(N!)*M个的可能处理顺序。流水作业调度的研究通常只参加置换序列,其中操作的处理顺序是所有机器。在这里,我们也采用这种限制。 最小化所有最大完工时间作业(成为完工期并通过的Cmax表示)是公知的,也是在文献M. Mirabi (&) Group of Industrial Engineering, Ayatollah Haeri University of Meybod, P.O. Box 89619-55133, Meybod, Iran e-mail: M.Mirabi@https://www.360docs.net/doc/c311574820.html, S. M. T. Fatemi Ghomi Department of Industrial Engineering, Amirkabir University of Technology, P.O. Box 15916-34311, Tehran, Iran e-mail: Fatemi@aut.ac.ir F. Jolai Department of Industrial Engineering, College of Engineering, University of Tehran, P.O. Box 14395-515, Tehran, Iran 遗传算法经典学习Matlab代码 遗传算法实例: 也是自己找来的,原代码有少许错误,本人都已更正了,调试运行都通过了的。 对于初学者,尤其是还没有编程经验的非常有用的一个文件 遗传算法实例 % 下面举例说明遗传算法 % % 求下列函数的最大值 % % f(x)=10*sin(5x)+7*cos(4x) x∈[0,10] % % 将 x 的值用一个10位的二值形式表示为二值问题,一个10位的二值数提供的分辨率是每为 (10-0)/(2^10-1)≈0.01。 % % 将变量域 [0,10] 离散化为二值域 [0,1023], x=0+10*b/1023, 其 中 b 是 [0,1023] 中的一个二值数。 % % % %--------------------------------------------------------------------------------------------------------------% %--------------------------------------------------------------------------------------------------------------% % 编程 %----------------------------------------------- % 2.1初始化(编码) % initpop.m函数的功能是实现群体的初始化,popsize表示群体的大小,chromlength表示染色体的长度(二值数的长度), % 长度大小取决于变量的二进制编码的长度(在本例中取10位)。 %遗传算法子程序 %Name: initpop.m %初始化 function pop=initpop(popsize,chromlength) pop=round(rand(popsize,chromlength)); % rand随机产生每个单元 为 {0,1} 行数为popsize,列数为chromlength的矩阵, % roud对矩阵的每个单元进行圆整。这样产生的初始种群。 % 2.2 计算目标函数值 % 2.2.1 将二进制数转化为十进制数(1) %遗传算法子程序 %Name: decodebinary.m %产生 [2^n 2^(n-1) ... 1] 的行向量,然后求和,将二进制转化为十进制function pop2=decodebinary(pop) [px,py]=size(pop); %求pop行和列数 for i=1:py pop1(:,i)=2.^(py-i).*pop(:,i); end pop2=sum(pop1,2); %求pop1的每行之和 % 2.2.2 将二进制编码转化为十进制数(2) % decodechrom.m函数的功能是将染色体(或二进制编码)转换为十进制,参数spoint表示待解码的二进制串的起始位置 TSP问题的遗传算法求解 摘要:遗传算法是模拟生物进化过程的一种新的全局优化搜索算法,本文简单介绍了遗传算法,并应用标准遗传算法对旅行包问题进行求解。 关键词:遗传算法、旅行包问题 一、旅行包问题描述: 旅行商问题,即TSP问题(Traveling Saleman Problem)是数学领域的一个著名问题,也称作货郎担问题,简单描述为:一个旅行商需要拜访n个城市(1,2,…,n),他必须选择所走的路径,每个城市只能拜访一次,最后回到原来出发的城市,使得所走的路径最短。其最早的描述是1759年欧拉研究的骑士周游问题,对于国际象棋棋盘中的64个方格,走访64个方格一次且最终返回起始点。 用图论解释为有一个图G=(V,E),其中V是顶点集,E是边集,设D=(d ij)是有顶点i和顶点j之间的距离所组成的距离矩阵,旅行商问题就是求出一条通过所有顶点且每个顶点只能通过一次的具有最短距离的回路。若对于城市V={v1,v2,v3,...,vn}的一个访问顺序为T=(t1,t2,t3,…,ti,…,tn),其中ti∈V(i=1,2,3,…,n),且记tn+1= t1,则旅行商问题的数学模型为:min L=Σd(t(i),t(i+1)) (i=1,…,n) 旅行商问题是一个典型组合优化的问题,是一个NP难问题,其可能的路径数为(n-1)!,随着城市数目的增加,路径数急剧增加,对与小规模的旅行商问题,可以采取穷举法得到最优路径,但对于大型旅行商问题,则很难采用穷举法进行计算。 在生活中TSP有着广泛的应用,在交通方面,如何规划合理高效的道路交通,以减少拥堵;在物流方面,更好的规划物流,减少运营成本;在互联网中,如何设置节点,更好的让信息流动。许多实际工程问题属于大规模TSP,Korte于1988年提出的VLSI芯片加工问题可以对应于1.2e6的城市TSP,Bland于1989年提出X-ray衍射问题对应于14000城市TSP,Litke于1984年提出电路板设计中钻孔问题对应于17000城市TSP,以及Grotschel1991年提出的对应于442城市TSP的PCB442问题。 遗传算法程序(一): 说明: fga.m 为遗传算法的主程序; 采用二进制Gray编码,采用基于轮盘赌法的非线性排名选择, 均匀交叉,变异操作,而且还引入了倒位操作! function [BestPop,Trace]=fga(FUN,LB,UB,eranum,popsize,pCross,pMutation,pInversion,options) % [BestPop,Trace]=fmaxga(FUN,LB,UB,eranum,popsize,pcross,pmutation) % Finds a maximum of a function of several variables. % fmaxga solves problems of the form: % max F(X) subject to: LB <= X <= UB % BestPop - 最优的群体即为最优的染色体群 % Trace - 最佳染色体所对应的目标函数值 % FUN - 目标函数 % LB - 自变量下限 % UB - 自变量上限 % eranum - 种群的代数,取100--1000(默认200) % popsize - 每一代种群的规模;此可取50--200(默认100) % pcross - 交叉概率,一般取0.5--0.85之间较好(默认0.8) % pmutation - 初始变异概率,一般取0.05-0.2之间较好(默认0.1) % pInversion - 倒位概率,一般取0.05-0.3之间较好(默认0.2) % options - 1*2矩阵,options(1)=0二进制编码(默认0),option(1)~=0十进制编 %码,option(2)设定求解精度(默认1e-4) % % ------------------------------------------------------------------------ T1=clock; if nargin<3, error('FMAXGA requires at least three input arguments'); end if nargin==3, eranum=200;popsize=100;pCross=0.8;pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==4, popsize=100;pCross=0.8;pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==5, pCross=0.8;pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==6, pMutation=0.1;pInversion=0.15;options=[0 1e-4];end if nargin==7, pInversion=0.15;options=[0 1e-4];end if find((LB-UB)>0) error('数据输入错误,请重新输入(LB 煤矿机械Coal Mine Machinery Vol.30No.12 Dec.2009 第30卷第12期2009年12月 0引言 工程机械中所用电动机的转速较高,为了满足工作机低转速的需要,一般在电动机和工作机之间安装减速器,用来降低电机的转速或增大转矩,减速器是一种机械传动装置,广泛地应用于运输机械、矿山机械和建筑机械等重型机械中。因此,减速器的设计非常重要。 遗传算法(GA)是模拟生物在自然界中优胜劣汰的自然进化过程而形成的一种具有全局范围内优化的启发式搜索算法。这种方法已在很多学科得到广泛的应用,为减速器的优化设计提供有力的保证。因此,本文采用遗传算法对两级齿轮减速器进行优化设计,并通过与惩罚函数法和模拟退火算法等优化方法计算结果进行比较,来探讨适合于减速器的优化设计方法。 1建立数学模型 两级齿轮传动减速器结构如图1所示。该减速器的总中心距 a∑=[m n1z1(1+i1)+m n2z3(1+i2)]/2cosβ(1)式中m n1、m n2—— —高速级与低速级的齿轮法面模 数; i1、i2—— —高速级与低速级传动比; z1、z3—— —高速级与低速级的小齿轮齿数: β—— —2组齿轮组的螺旋角。 1.1设计变量的确定 在进行两级齿轮传动减速器设计时,一般选择齿轮传动独立的基本参数或性能参数,如齿轮的齿数、模数、传动比、螺旋角等为设计变量。两级齿轮传动由4个齿轮组成,分别用z1、z2、z3、z4表示,高速级的传动比由i1表示,低速级传动比由i2表示,两组齿轮组的法面模数分别由m n1和m n2表示,2组齿轮的螺旋角用β表示,由于两级齿轮传动减速器的总传动比i0,在设计时会给出具体数据,并且满足i0=i1i2,可以得出i2=i0/i1,可以确定独立的参数有z1、z3、m n1、m n2、i1和β。因此,可以确定该设计变量X=[z1,z3,m n1,m n2,i1,β]T=[x1,x2,x3,x4,x5,x6]T。 图1减速器结构简图 1.2目标函数的建立 在对减速器进行优化设计时,首先要确定目标函数。确定目标函数的原则是在满足各种性能要求的前提下,使减速器的体积最小,这样设计的减速器既经济又实用,从而达到了优化的目的。要使减速器的体积最小,必须使减速器的总中心距最小。因此,以减速器的中心距最小建立目标函数为 a∑=[x3x1(1+x5)+x4x2(1+i0/x5)] 6 (2)1.3约束条件的确定 为使两级齿轮传动减速器满足强度、设计变量 基于遗传算法的齿轮减速器优化设计* 吴婷,张礼兵,黄磊 (安徽建筑工业学院机电学院,合肥230601) 摘要:对两级齿轮减速器优化设计进行了分析,建立了其优化设计的数学模型,确定了优化设计的约束条件,采用遗传算法对两级齿轮减速器进行优化设计,并通过实例说明,采用遗传算法对减速器进行优化,可以得到更加优化的设计结果。 关键词:减速器;遗传算法;优化设计 中图分类号:TH132文献标志码:A文章编号:1003-0794(2009)12-0009-03 Gear Reducer Optimal Design Based on Genetic Algorithm WU Ting,ZHANG Li-bing,HUANG Lei (School of Mechanical and Electrical Engineering,Anhui University of Architecture,Hefei230601,China)Abstract:T he optimal design of a gear reducer was analyzed,the mathematic model was established, and the restriction condition was confirmed.Design of the gear reducer was optimized with genetic algorithm and the examples showed that design of the gear reducer based on genetic algorithm can gain more optimized result. Key words:reducer;genetic algorithm;optimal design *安徽省教育厅自然基金项目(2006KJ015C) 轴1轴2轴3 z1z2 z3z4 9 最新最全的遗传算法工具箱Gaot_v5及说明 Gaot_v5下载地址:https://www.360docs.net/doc/c311574820.html,/mirage/GAToolBox/gaot/gaotv5.zip 添加遗传算法路径: 1、 matlab的file下面的set path把它加上,把路径加进去后在 2、 file→Preferences→General的Toolbox Path Caching里点击update Toolbox Path Cache更新一下,就OK了 遗传算法工具箱Gaot_v5包括许多实用的函数,各种算子函数,各种类型的选择方式,交叉、变异方式。这些函数按照功能可以分成以下几类: 主程序 ga.m提供了 GAOT 与外部的接口。它的函数格式如下: [x endPop bPop traceInfo]=ga(bounds,evalFN,evalOps,startPop,opts,termFN,termOps, selectFn,selectOps,xOverFNs,xOverOps,mutFNs,mutOps) 输出参数及其定义如表 1 所示。输入参数及其定义如表 2 所示。 表1 ga.m的输出参数 输出参数 定义 x 求得的最好的解,包括染色体和适应度 endPop 最后一代染色体(可选择的) bPop 最好染色体的轨迹(可选择的) traceInfo 每一代染色体中最好的个体和平均适应度(可选择的) 表2 ga.m的输入参数 表3 GAOT核心函数及其它函数 核心函数: (1)function [pop]=initializega(num,bounds,eevalFN,eevalOps,options)--初始种群的生成函数 【输出参数】 pop--生成的初始种群 【输入参数】 num--种群中的个体数目 bounds--代表变量的上下界的矩阵 eevalFN--适应度函数 eevalOps--传递给适应度函数的参数 options--选择编码形式(浮点编码或是二进制编码)[precision F_or_B],如 precision--变量进行二进制编码时指定的精度 F_or_B--为1时选择浮点编码,否则为二进制编码,由precision指定精度) (2)function [x,endPop,bPop,traceInfo] = ga(bounds,evalFN,evalOps,startPop,opts,... termFN,termOps,selectFN,selectOps,xOverFNs,xOverOps,mutFNs,mutOps)--遗传算法函数 【输出参数】 x--求得的最优解 endPop--最终得到的种群 bPop--最优种群的一个搜索轨迹 【输入参数】 目录 _ 一、遗产算法的由来 (2) 二、遗传算法的国内外研究现状 (3) 三、遗传算法的特点 (5) 四、遗传算法的流程 (7) 五、遗传算法实例 (12) 六、遗传算法编程 (17) 七、总结 ......... 错误!未定义书签。附录一:运行程序.. (19) 遗传算法基本理论与实例 一、遗产算法的由来 遗传算法(Genetic Algorithm,简称GA)起源于对生物系统所进行的计算机模拟研究。20世纪40年代以来,科学家不断努力从生物学中寻求用于计算科学和人工系统的新思想、新方法。很多学者对关于从生物进化和遗传的激励中开发出适合于现实世界复杂适应系统研究的计算技术——生物进化系统的计算模型,以及模拟进化过程的算法进行了长期的开拓性的探索和研究。John H.Holland教授及其学生首先提出的遗传算法就是一个重要的发展方向。 遗传算法借鉴了达尔文的进化论和孟德尔、摩根的遗传学说。按照达尔文的进化论,地球上的每一物种从诞生开始就进入了漫长的进化历程。生物种群从低级、简单的类型逐渐发展成为高级复杂的类型。各种生物要生存下去及必须进行生存斗争,包括同一种群内部的斗争、不同种群之间的斗争,以及生物与自然界无机环境之间的斗争。具有较强生存能力的生物个体容易存活下来,并有较多的机会产生后代;具有较低生存能力的个体则被淘汰,或者产生后代的机会越来越少。,直至消亡。达尔文把这一过程和现象叫做“自然选择,适者生存”。按照孟德尔和摩根的遗传学理论,遗传物质是作为一种指令密码封装在每个细胞中,并以基因的形式排列在染色体上,每个基因有特殊的位置并控制生物的某些特性。不同的基因组合产生的个体对环境的适应性不一样,通过基因杂交和突变可以产生对环境适应性强的后代。经过优胜劣汰的自然选择,适应度值高的基因结构就得以保存下来,从而逐渐形成了经典的遗传学染色体理论,揭示了遗传和变异的 一个简单实用的遗传算法c程序(转载) c++ 2009-07-28 23:09:03 阅读418 评论0 字号:大中小 这是一个非常简单的遗传算法源代码,是由Denis Cormier (North Carolina State University)开发的,Sita S.Raghavan (University of North Carolina at Charlotte)修正。代码保证尽可能少,实际上也不必查错。对一特定的应用修正此代码,用户只需改变常数的定义并且定义“评价函数”即可。注意代码的设计是求最大值,其中的目标函数只能取正值;且函数值和个体的适应值之间没有区别。该系统使用比率选择、精华模型、单点杂交和均匀变异。如果用Gaussian变异替换均匀变异,可能得到更好的效果。代码没有任何图形,甚至也没有屏幕输出,主要是保证在平台之间的高可移植性。读者可以从https://www.360docs.net/doc/c311574820.html,,目录coe/evol 中的文件prog.c中获得。要求输入的文件应该命名为…gadata.txt?;系统产生的输出文件为…galog.txt?。输入的文件由几行组成:数目对应于变量数。且每一行提供次序——对应于变量的上下界。如第一行为第一个变量提供上下界,第二行为第二个变量提供上下界,等等。 /**************************************************************************/ /* This is a simple genetic algorithm implementation where the */ /* evaluation function takes positive values only and the */ /* fitness of an individual is the same as the value of the */ /* objective function */ /**************************************************************************/ #include 摘要:基本遗传算法的操作是以个体为对象,只使用选择、交叉和变异遗传算子,遗传进化操作过程的简单框架。模式定理和积木块假设是解释遗传算法有效性的理论基础,理论分析与实际应用都表明基本的遗传算法不能处处收敛于全局最优解,因此基本遗传算法有待进一步改进。 关键词:遗传算法;遗传算法的改进 1.标准遗传算法 基本遗传算法包括选择、交叉和变异这些基本遗传算子。其数学模型可表示为: sag=(c,e,p0,n,φ,г,ψ,t) 其中c为个体的编码方法;e为个体适应度评价函数;p0为初始种群;n为种群大小;φ为选择算子;г为交叉算子;ψ为变异算子;t为遗传运算终止条件; 2 遗传算法基本方法及其改进 2.1编码方式 编码方式决定了个体的染色体排列形式,其好坏直接影响遗传算法中的选择算子、交叉算子和变异算子的运算,也决定了解码方式。 二进制编码 二进制编码使用的字符号{0,1}作为编码符号,即用一个{0,1}所组成的二进制符号串构成的个体基因型。二进制编码方法应用于遗传算法中有如下优点: 1)遗传算法中的遗传操作如交叉、变异很容易实现,且容易用生物遗传理论来解释; 2)算法可处理的模式多,增强了全局搜索能力; 3)便于编码、解码操作; 4)符合最小字符集编码原则; 5)并行处理能力较强。 二进制编码在存着连续函数离散化的映射误差,不能直接反应出所求问题的本身结构特征,不便于开发专门针对某类问题的遗传运算算子。 2.2初始种群的设定 基本遗传算法是按随机方法在可能解空间内产生一个一定规模的初始群体,然后从这个初始群体开始遗传操作,搜索最优解。初始种群的设定一般服从下列准则:1)根据优化问题,把握最优解所占空间在整个问题空间的分布范围,然后,在此分布范围内设定合适的初始群体。 2)先随机生成一定数目的个体,然后从中挑出最好的个体加入到初始群体中。该过程不断迭代,直到初始群体中个体数目达到了预先确定的种群大小。 2.3选择算子的分析 选择算子的作用是选择优良基因参与遗传运算,目的是防止有用的遗传信息丢失,从而提高全局收敛效率。常用的遗传算子: (1)轮盘赌选择机制 轮盘赌选择也称适应度比例选择,是遗传算法中最基本的选择机制,每个个体被选择进入下一代的概率为这个个体的适应度值占全部个体适应度值之和的比例。但是轮盘赌选择机制选择误差较大,不是所有高适应度值的个体都能被选中,适应度值较低但具有优良基因模式的个体被选择的概率也很低,这样就会导致早熟现象的产生。 (2)最优保存选择机制 最优保存选择机制的基本思想是直接把群体中适应度最高的个体复制到下一代,而不进行配对交叉等遗传操作。具体步骤如下: 1)找出当前群体中适应度值最高和最低的个体的集合; 遗传算法入门到掌握 读完这个讲义,你将基本掌握遗传算法,要有耐心看完。 想了很久,应该用一个怎么样的例子带领大家走进遗传算法的神奇世界呢?遗传算法的有趣应用很多,诸如寻路问题,8数码问题,囚犯困境,动作控制,找圆心问题(这是一个国外网友的建议:在一个不规则的多边形中,寻找一个包含在该多边形内的最大圆圈的圆心。),TSP问题(在以后的章节里面将做详细介绍。),生产调度问题,人工生命模拟等。直到最后看到一个非常有趣的比喻,觉得由此引出的袋鼠跳问题(暂且这么叫它吧),既有趣直观又直达遗传算法的本质,确实非常适合作为初学者入门的例子。这一章将告诉读者,我们怎么让袋鼠跳到珠穆朗玛峰上去(如果它没有过早被冻坏的话)。 问题的提出与解决方案 让我们先来考虑考虑下面这个问题的解决办法。 已知一元函数: 图2-1 现在要求在既定的区间内找出函数的最大值。函数图像如图2-1所示。 极大值、最大值、局部最优解、全局最优解 在解决上面提出的问题之前我们有必要先澄清几个以后将常常会碰到的概念:极大值、最大值、局部最优解、全局最优解。学过高中数学的人都知道极大值在一个小邻域里面左边的函数值递增,右边的函数值递减,在图2.1里面的表现就是一个“山峰”。当然,在图上有很多个“山峰”,所以这个函数有很多个极大值。而对于一个函数来说,最大值就是在所有极大值当中,最大的那个。所以极大值具有局部性,而最大值则具有全局性。 因为遗传算法中每一条染色体,对应着遗传算法的一个解决方案,一般我们用适应性函数(fitness function)来衡量这个解决方案的优劣。所以从一个基因组到其解的适应度形成一个映射。所以也可以把遗传算法的过程看作是一个在多元函数里面求最优解的过程。在这个多维曲面里面也有数不清的“山峰”,而这些最优解所对应的就是局部最优解。而其中也会有一个“山峰”的海拔最高的,那么这个就是全局最优解。而遗传算法的任务就是尽量爬到最高峰,而不是陷落在一些小山峰。(另外,值得注意的是遗传算法不一定要找“最高的山峰”,如果问题的适应度评价越小越好的话,那么全局最优解就是函数的最小值,对应的,遗传算法所要找的就是“最深的谷底”)如果至今你还不太理解的话,那么你先往下看。本章的示例程序将会非常形象的表现出这个情景。 “袋鼠跳”问题 既然我们把函数曲线理解成一个一个山峰和山谷组成的山脉。那么我们可以设想所得到的每一个解就是一只袋鼠,我们希望它们不断的向着更高处跳去,直到跳到最高的山峰(尽管袋鼠本身不见得愿意那么做)。所以求最大值的过程就转化成一个“袋鼠跳”的过程。下面介绍介绍“袋鼠跳”的几种方式。 爬山法、模拟退火和遗传算法 解决寻找最大值问题的几种常见的算法: 1. 爬山法(最速上升爬山法): 从搜索空间中随机产生邻近的点,从中选择对应解最优的个体,替换原来的个体,不断重复上述过程。因为只对“邻近”的点作比较,所以目光比较“短浅”,常常只能收敛到离开初始位置比较近的局部最优解上面。对于存在很多局部最优点的问题,通过一个简单的迭代找出全局最优解的机会非常渺茫。(在爬山法中,袋鼠最有希望到达最靠近它出发点的山顶,但不能保证该山顶是珠穆朗玛峰,或者是一个非常高的山峰。因为一路上它只顾上坡,没有下坡。) 2. 模拟退火: 这个方法来自金属热加工过程的启发。在金属热加工过程中,当金属的温度超过它的熔点(Melting Point)时,原子就会激烈地随机运动。与所有的其它的物理系统相类似,原子的这种运动趋向于寻找其能量的极小状态。在这个能量的变 基于数据挖掘的遗传算法 xxx 摘要:本文定义了遗传算法概念和理论的来源,介绍遗传算法的研究方向和应用领域,解释了遗传算法的相关概念、编码规则、三个主要算子和适应度函数,描述遗传算法计算过程和参数的选择的准则,并且在给出的遗传算法的基础上结合实际应用加以说明。 关键词:数据挖掘遗传算法 Genetic Algorithm Based on Data Mining xxx Abstract:This paper defines the concepts and theories of genetic algorithm source, Introducing genetic algorithm research directions and application areas, explaining the concepts of genetic algorithms, coding rules, the three main operator and fitness function,describing genetic algorithm parameter selection process and criteria,in addition in the given combination of genetic algorithm based on the practical application. Key words: Data Mining genetic algorithm 前言 遗传算法(genetic algorithm,GAs)试图计算模仿自然选择的过程,并将它们运用于解决商业和研究问题。遗传算法于20世界六七十年代由John Holland[1]发展而成。它提供了一个用于研究一些生物因素相互作用的框架,如配偶的选择、繁殖、物种突变和遗传信息的交叉。在自然界中,特定环境限制和压力迫使不同物种竞争以产生最适应于生存的后代。在遗传算法的世界里,会比较各种候选解的适合度,最适合的解被进一步改进以产生更加优化的解。 遗传算法借助了大量的基因术语。遗传算法的基本思想基于达尔文的进化论和孟德尔的遗传学说,是一类借鉴生物界自然选择和自然遗传机制的随机搜索算法。生物在自然界的生存繁殖,显示对其自然环境的优异自适应能力。受其启发,人们致力于对生物各种生存特性的机制研究和行为模拟。通过仿效生物的进化与遗传,根据“生存竞争”和“优胜劣汰”的原则,借助选择、交叉、变异等操作,使所要解决的问题从随机初始解一步步逼近最优解。现在已经广泛的应用于计算机科学、人工智能、信息技术及工程实践。[2]在工业、经济管理、交通运输、工业设计等不同领域,成功解决了许多问题。例如,可靠性优化、流水车间调度、作业车间调度、机器调度、设备布局设计、图像处理以及数据挖掘等。遗传算法作为一类自组织于自适应的人工智能技术,尤其适用于处理传统搜索方法难以解决的复杂的和非线性的问题。 1.遗传算法的应用领域和研 究方向 1.1遗传算法的特点 遗传算法作为一种新型、模拟生物进化过程的随机化搜索方法,在各类结 构对象的优化过程中显示出比传统优 化方法更为独特的优势和良好的性能。 它利用其生物进化和遗传的思想,所以 它有许多传统算法不具有的特点[3]: ※搜索过程不直接作用在变量上,而是 作用于由参数集进行了编码的个体 上。此编码操作使遗传算法可以直接 对结构对象进行操作。 ※搜索过程是从一组解迭代到另一组 解,采用同时处理群体中多个个体的 方法,降低了陷入局部最优解的可能 性,易于并行化。MATLAB实验遗传算法和优化设计
遗传算法的优缺点
第三章-遗传算法的理论基础
遗 传 算 法 详 解 ( 含 M A T L A B 代 码 )
遗传算法
遗传算法经典MATLAB代码
TSP问题的遗传算法求解 优化设计小论文
三个遗传算法matlab程序实例
基于遗传算法的齿轮减速器优化设计
最新最全的遗传算法工具箱及说明
遗传算法基本理论实例
一个简单实用的遗传算法c程序
遗传算法基本理论与方法
遗传算法——耐心看完,你就掌握了遗传算法
基于数据挖掘的遗传算法