基于熵权灰色关联的开放式基金综合评价模型Matlab程序

基于熵权灰色关联的开放式基金综合评价模型Matlab程序
详细算法流程请见我的文库-《Garch-Var开放式基金风险度量及综合评价体系》的第二部分,综合评价体系,程序中的变量请对应文章的算法涉及变量。
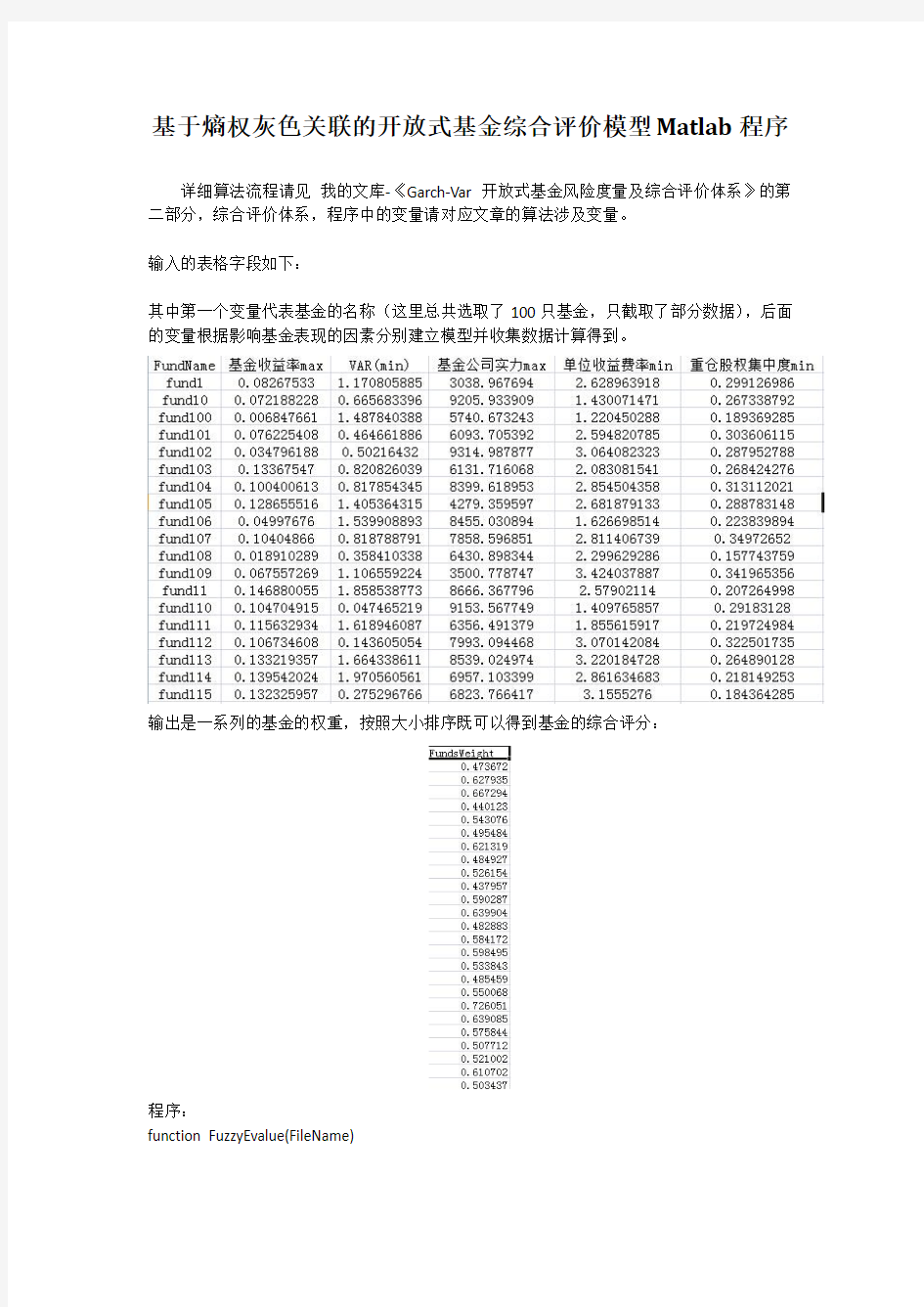
输入的表格字段如下:
其中第一个变量代表基金的名称(这里总共选取了100只基金,只截取了部分数据),后面的变量根据影响基金表现的因素分别建立模型并收集数据计算得到。
输出是一系列的基金的权重,按照大小排序既可以得到基金的综合评分:
程序:
function FuzzyEvalue(FileName)
clc;
fid = fopen(FileName);
head_ = textscan(fid, '%s %s %s %s %s %s',1,'delimiter', ',');
head = {{zeros(length(head_) - 1)}};
for i = 2:length(head_)
head{i-1}(1) = head_{i}(1);
end
clear head_
%for i = 1:length(head)
% head{i}(1)
% end
%head
inputMatrix_ = textscan(fid, '%s %f32 %f32 %f32 %f32 %f32','delimiter', ','); fclose(fid);
for j = 2:length(inputMatrix_)
inputMatrix(:,j - 1) = double(inputMatrix_{:,j});
end
alpha = 0.5;
[n,m] = size(inputMatrix);
optimalMat = zeros(1,m);
for i = 1:m
%inputMatrix(:,i)
if isempty(cell2mat(strfind(head{i}(1), 'max'))) == 0
optimalMat(i) = max(inputMatrix(:,i));
elseif isempty(cell2mat(strfind(head{i}(1), 'min'))) == 0
optimalMat(i) = min(inputMatrix(:,i));
end
end
optimalMat;
D = [optimalMat;inputMatrix];
R = zeros(n+1,m);
for i = 1:m
if isempty(cell2mat(strfind(head{i}(1), 'max'))) == 0
R(:,i) = 1.0*(D(:,i) - min(D(:,i)))/(max(D(:,i)) - min(D(:,i)));
elseif isempty(cell2mat(strfind(head{i}(1), 'min'))) == 0
R(:,i) = 1.0*(max(D(:,i)) - D(:,i))/(max(D(:,i)) - min(D(:,i)));
end
end
clearvars D inputMatrix;
R;
F = zeros(n+1,m);
H = zeros(1,m);
W = zeros(1,m);
for i = 1:m
F(:,i) = R(:,i)/sum(R(:,i));
end
F;
F(F == 0) = 1;
for j = 1:m
H(j) = -1/log(n)*sum(F(:,j).*log(F(:,j)));
end
H;
W = (1 - H)/(m - sum(H));
%sum(W)
clearvars F H;
Eps = zeros(n,m);
for j = 1:m
Eps(:,j) = (min(abs(R(1,j) - R(2:n+1,j))) + alpha*max(abs(R(1,j) - R(2:n+1,j))))./(abs(R(1,j) - R(2:n+1,j)) + alpha*max(abs(R(1,j) - R(2:n+1,j))));
end
Eps;
FundsWeight = Eps*W';
fileId = fopen('weight.csv','w');
fprintf(fileId,'%s \n','FundsWeight');
fprintf(fileId,'%f \n',FundsWeight);
fclose(fileId);
end
简单易懂的灰色关联度计算
灰色关联有什么用 灰色关联度,指的是两个系统或两个因素之间关联性大小的量度。目的,是在于寻求系统中各因素之间的主要关系,找出影响目标值的重要因素,从而掌握事物的主要特征,促进和引导系统迅速有效地发展。——这是比较“官方”的解释。我再来一个“野路子”的解释:用两种试验方法,得出两组数据A和B;用理论方法,得到理论解答C。那么,现在来比较试验方法A好还是B好?自然是看其结果,哪一个与C最吻合,哪个就最好呗,灰关联就是用来解决“谁和谁的关联程度更高”这样的问题的。 灰色关联的重要步骤 步骤不多,核心的,首先是数据的归一化处理,这是因为有时一个试验结果矩阵中的每个元素会有不同的量纲;接下来是计算灰色关联矩阵,这个过程涉及到的公式很吓人,我第一眼看的时候竟然没搞明白是什么意思,囧;最后是计算关联度,这也就是得到了最终结果。 下面来看看那个复杂的公式:(Pi为关联度矩阵中的元素) 计算方法 关于关联矩阵中各个元素的计算,我起初被严重误导,认为用Excel是无法完成的,结果还绕了一段弯路,很是丢人~当然,有高手通过Matlab计算的经验,而且还给出了实例,有兴趣的可以参考“仿真百科”里的内容。但我最终还是根据1992年出版的一本老书《灰色理论与方法——提要·题解·程序·应用》中的一个简单实例,用最简单的方法搞定了计算问题。鉴于我不知道如何把Excel 公式按照步骤,类似APDL那样摆出来,那就把那个例子与大家分享,说说计算原理步骤吧。 首先看下面四数列 A=[2,3,4,3.7] B=[60,73,84,58] C=[1204,801,1228,1270]
D=[303,298,247,251] 以A为目标,检验B、C、D与A的关联度。 步骤1.归一化,将数列中的每个元素,除以相同的一个数值,比如A的归一化过程为[2/2, 3/2 ,4/2, 3.7/2]或者更常用的均值化处理,都可以搞定。只需要这几个数列用同一种方法归一即可了。 步骤2.求差序列.经过归一化的A、B、C、D,用A分别减去B/C/D;即 E=A-B; F=A-C; G=A-D 步骤3.求两级最大和最小差值。这是一个容易让人糊涂的地方,但实际操作很简单: 设E中最大值为Emax,最小值为Emin,其余类推;这样一共就有六个数,分别是Emax;Emin;Fmax;Fmin;Gmax和Gmin。从这六个数中,再选出一个最大值和一个最小值,假设为M和N——而这就是上述公式当中双重最值的部分啦。 步骤4.带入公式,得到三组关联系数(单行)矩阵。 步骤5.计算关联度,实际上就是步骤4中,每组矩阵各个元素求和除以元素个数(求均值)。 步骤6.通过比较关联度数值,最大的那个,其对应的数列与目标数列的关联度最高。 Over.
灰色关联分析(算法步骤)
灰色关联分析 灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度[1]。 灰色系统理论是由著名学者邓聚龙教授首创的一种系统科学理论(Grey Theory),其中的灰色关联分析是根据各因素变化曲线几何形状的相似程度,来判断因素之间关联程度的方法。此方法通过对动态过程发展态势的量化分析,完成对系统内时间序列有关统计数据几何关系的比较,求出参考数列与各比较数列之间的灰色关联度。与参考数列关联度越大的比较数列,其发展方向和速率与参考数列越接近,与参考数列的关系越紧密。灰色关联分析方法要求样本容量可以少到4个,对数据无规律同样适用,不会出现量化结果与定性分析结果不符的情况。其基本思想是将评价指标原始观测数进行无量纲化处理,计算关联系数、关联度以及根据关联度的大小对待评指标进行排序。灰色关联度的应用涉及社会科学和自然科学的各个领域,尤其在社会经济领域,如国民经济各部门投资收益、区域经济优势分析、产业结构调整等方面,都取得较好的应用效果。 [2] 关联度有绝对关联度和相对关联度之分,绝对关联度采用初始点零化法进行初值化处理,当分析的因素差异较大时,由于变量间的量纲不一致,往往影响分析,难以得出合理的结果。而相对关联度用相对量进行分析,计算结果仅与序列相对于初始点的变化速率有关,与各观测数据大小无关,这在一定程度上弥补了绝对关联度的缺陷。[2] 灰色关联分析的步骤[2] 灰色关联分析的具体计算步骤如下: 第一步:确定分析数列。 确定反映系统行为特征的参考数列和影响系统行为的比较数列。反映系统行为特征的数据序列,称为参考数列。影响系统行为的因素组成的数据序列,称比较数列。 设参考数列(又称母序列)为Y={Y(k) | k= 1,2,Λ,n};比较数列(又称子序列)X i={X i(k) | k = 1,2,Λ,n},i= 1,2,Λ,m。 第二步,变量的无量纲化 由于系统中各因素列中的数据可能因量纲不同,不便于比较或在比较时难以得到正确的结论。因此在进行灰色关联度分析时,一般都要进行数据的无量纲化处理。
基于熵权的灰色关联度分析方法在汽车零部件供应商选择中的应用_(精)
收稿日期:2009-08-17作者简介:刘小国(1982-),男,研究生,主要从事管理科学与工程研究;彭玲(1983-),女,助理工程师,主要从事供应链管理工作。 基于熵权的灰色关联度分析方法在汽车零部件供应商选择中的应用 刘小国1,彭 玲2 (1. 武汉科技大学管理学院,武汉430081;2. 江铃汽车股份公司,南昌330001) 摘要:供应商选择是供应链运行的基础,运用单一的评价方法存在主观性过强的缺陷。为避免供应商选择单一评价 方法出现不足,提出了基于熵权的灰色关联度分析评价方法,该方法综合运用信息熵权和灰色关联度分析方法的长处使供应商评价选择更客观合理。并以某汽车企业供应商选择为例进行了实证研究,表明这种方法应用于汽车零部件供应商选择简便可行。 关键词:供应商选择;熵权;灰色关联度中图分类号:F407.471文献标志码:A 文章编号:1000-8772(2009)18-0098-02 一、引言 在不确定性的环境下,任何一个企业只能在某一方面拥有 一定时间内的优势。为了在竞争中获胜,摒弃过去那种“纵向一体化”模式,转而选择与产品生产各个环节最有优势的企业进行合作,构成了一条从供应商、制造商、分销商到最终用户的物流和信息流网络,这就是供应链[1]。供应商是整个供应链的“源头”,对供应商的评价和选择是供应链合作关系运行的基础。如何在供应
链伙伴关系的情况下进行供应商的评价、筛选对供应链实现目标有着重要的意义,这也是学术界和企业界都较为关注的问题。 二、供应商评价指标体系建立 供应商选择会受多种因素影响。对供应商选择和评价研究 最早是Dickson , 他通过分析170份对采购代理人和采购经理的调查结果,得到了对供应商进行评价的23项指标, 并对指标的重要性进行了分类[1],他认为质量为影响供应商选择最为重要的一个因素,交货、价格等则相当重要。 从国内的研究状况来看,文献[2]在对神龙汽车有限公司和20家零部件供应商进行调查后指出,对供应商的评价应根据供应商在质量、交货期、批量柔性、交货期与价格的权衡、价格与批量的权衡及多样性等方而的水平,得出企业评价合作伙伴的主要标准。 本文结合我国汽车企业实际情况,综合考虑以前学者研究成果,认为影响汽车零部件供应商选择的指标体系为质量、价格、交货期和信息交换程度。 质量:定性指标,收益指标,我们以交货质量合格率来表示,指在一定时期内的质量合格的产品数量占总交货量的百分比,计算方法[3]为: 交货质量合格率= m i=1ΣQ i
灰色关联模型及其应用研究
重庆三峡学院 大学生创新性实验计划项目申报表 项目名称灰色关联模型及其应用研究 项目负责人 所在院系、专业 指导教师 联系电话 电子邮件 填表日期 教务处制
项目名称灰色关联模型及其应用研究 申请经费0.3万元计划起止时间2014年5月至2015年6月 申报团队学号姓名年级所在院系、专业联系电话E-mail 2012 导师 姓名院系职称/学历E-mail 电话 申请理由(包括项目背景及自身具备的知识条件) 一、项目背景: 灰色系统理论是中国学者邓聚龙教授于1982年提出来的一门新兴理论,该理论是一种运用特定的方法描述信息不完全的系统并进行预测、决策、控制的崭新的系统理论。灰色系统理论认为任何随机过程都是在一定的幅值和一定时区变化的灰色量,并把随机过程看成灰色过程,其是控制论观点和方法的延伸,它从系统的角度出发来研究信息间的关系,即研究如何利用已知信息去揭示未知信息,也即系统的“白化”问题。灰色系统的实质为:部分信息已知部分信息未知的一类系统。灰色关联分析是灰色系统理论的主要内容之一,它是对运行机制与物理原型不清楚或者根本缺乏物理原型的灰关系序列化、模式化,进而建立灰关联分析模型,使灰关系量化、序化、显化,能为复杂系统的建模提供重要的技术分析手段。 灰色关联分析方法是一种多因素分析方法,其基本原理是通过对统计序列几何关系的比较,若序列几何形状越接近,则它们的灰关联度就越大。灰色关联分析的基本任务是基于行为因子序列的微观或宏观几何接近,以分析和确定因子之间的影响程度或对因子对主行为的贡献测度。关联分析的实质是整体比较,是有参考系的、有测度的比较。 目前,常见的灰色关联计算模型主要有以下几种:邓聚龙提出的邓氏关联度;王清印的灰色B型关联度和C型关联度;唐五湘的T型关联度;刘思峰的广义关联度;赵艳林的灰色欧几里德关联度等。
Matlab学习系列.灰色关联分析
28. 灰色关联分析 一、灰色系统理论简介 若系统的内部信息是完全已知的,称为白色系统;若系统的内部信息是一无所知(一团漆黑),只能从它同外部的联系来观测研究,这种系统便是黑色系统;灰色系统介于二者之间,灰色系统的一部分信息是已知的,一部分是未知的。 灰色系统理论以“部分信息已知、部分信息未知”的“小样本”、“贫信息”不确定型系统为研究对象,其特点是: (1)认为不确定量是灰数,用灰色数学来处理不确定量,使之量化,灰色系统理论只需要很少量的数据序列; (2)观测到的数据序列看作随时间变化的灰色量或灰色过程,通过鉴别系统因素之间发展趋势的相似或相异程度,即进行关联度分析; (3)通过累加生成和累减生成逐步使灰色量白化,从而建立相应于微分方程解的模型,从而预测事物未来的发展趋势和未来状态。 二、灰色关联度分析 1. 要定量地研究两个事物间的关联程度,可以用相关系数和相似系数等,但这需要足够多的样本数或者要求数据服从一定概率分布。 在客观世界中,有许多因素之间的关系是灰色的,分不清哪些因素之间关系密切,哪些不密切,这样就难以找到主要矛盾和主要特性。
灰因素关联分析,目的是定量地表征诸因素之间的关联程度,从而揭示灰色系统的主要特性。关联分析是灰色系统分析和预测的基础。 关联分析源于几何直观,实质上是一种曲线间几何形状的分析比较,即几何形状越接近,则发展变化趋势越接近,关联程度越大。如下图所示: x t 曲线A 与B 比较平行,则认为A 与B 的关联程度大;曲线C 与A 随时间变化的方向很不一致,则认为A 与C 的关联程度较小;曲线A 与D 相差最大,则认为两者的关联程度最小。 2. 关联度分析是分析系统中各因素关联程度的方法 步骤: (1) 计算关联系数 设参考序列为 0000{(1),(2),...,()}X x x x n = 比较序列为 {(1),(2),...,()}, 1,,i i i i X x x x n i m == 比较序列X i 对参考序列X 0在k 时刻的关联系数定义为:
灰色关联分析
2 灰色关联分析方法 在实际问题中,许多因素之间的关系是灰色的,人们很难分清哪些因素是主导因素,哪些因素是非主导因素;哪些因素之间关系密切,哪些不密切。灰色关联分析,为我们解决这类问题提供了一种行之有效的方法。 一、灰色关联分析概述 我们知道,统计相关分析是对因素之间的相互关系进行定量分析的一种有效方法。但是,我们也注意到相关系数具这样的性质: xy yx r r =,即因素y 对因素x 的相关程度与因素x 对因素y 的相关程度相等。暂且不去追究因素之间的相关程度究竟有多大。单就相关系数的这种性质而言,也是与实际情况不太相符的。譬如,在国民经济问题研究中,我们能将农业对工业的关联程度与工业对农业的关联程度等同看待吗?其次,由于地理现象与问题的复杂性,以及人们认识水平的限制,许多因素之间的关系是灰色的,很难用相关系数比较精确地度量其相关程度的客观大小。为了克服统计相关分析的上述种种缺陷,灰色系统理论中的灰色关联分析给我们提供了一种分析因素之间相互关系的又一种方法。 灰色关联分析,从其思想方法上来看,属于几何处理的范畴,其实质是对反映各因素变化特性的数据序列所进行的几何比较。用于度量因素之间关联程度的关联度,就是通过对因素之间的关联曲线的比较而得到的。 设x 1,x 2,…,x N 为N 个因素,反映各因素变化特性的数据列分别为{x 1(t)},{x 2(t)},…{x N (t)},t=1,2,…,M 。因素j x 对i x 的关联系数定义为 min max max ()1,2,3,,(1)()ij ij k t t M t k ξ?+?= =?+? (5)式中,ξij (t)为因素j x 对i x 在t 时刻的关联系数; max min ()|()()|,max max (),min min ();ij i j ij ij j j j j t x t x t t t ?=-?=??=?k 为介于[0,1]区 间上的灰数。不难看出,△ij (t)的最小值是min ?,
灰色关联分析法原理及解题步骤教学提纲
灰色关联分析法原理及解题步骤
灰色关联分析法原理及解题步骤 ---------------研究两个因素或两个系统的关联度(即两因素变化大小,方向与速度的相对性) 关联程度——曲线间几何形状的差别程度 灰色关联分析是通过灰色关联度来分析和确定系统因素间的影响程度或因素对系统主行为的贡献测度的一种方法。 灰色关联分析的基本思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密 1>曲线越接近,相应序列之间的关联度就越大,反之就越小 2>灰色关联度越大,两因素变化态势越一致 分析法优点 它对样本量的多少和样本有无规律都同样适用,而且计算量小,十分方便,更不会出现量化结果与定性分析结果不符的情况。 灰色系统关联分析的具体计算步骤如下 1》参考数列和比较数列的确定 参考数列——反映系统行为特征的数据序列 比较数列——影响系统行为的因素组成的数据序列 2》无量纲化处理参考数列和比较数列 (1)初值化——矩阵中的每个数均除以第一个数得到的新矩阵
(2)均值化——矩阵中的每个数均除以用矩阵所有元素的平均值得到的新矩阵 (3)区间相对值化 3》求参考数列与比较数列的灰色关联系数ξ(Xi) 参考数列X0 比较数列X1、X2、X3…………… 比较数列相对于参考数列在曲线各点的关联系数ξ(i) 称为关联系数,其中ρ称为分辨系数,ρ∈(0,1),常取0.5.实数第二级最小差,记为Δmin。两级最大差,记为Δmax。为各比较数列Xi曲线上的每一个点与参考数列X0曲线上的每一个点的绝对差值。记为Δoi(k)。所以关联系数ξ(Xi)也可简化如下列公式: 4》求关联度ri 关联系数——比较数列与参考数列在各个时刻(即曲线中的各点)的关联程度值,所以它的数不止一个,而信息过于分散不便于进行整体性比较。因此有必要将各个时刻
灰色关联分析法原理及解题步骤
灰色关联分析法原理及解题步骤 ---------------研究两个因素或两个系统的关联度(即两因素变化大小,方向与速度的相对性) 关联程度——曲线间几何形状的差别程度 灰色关联分析是通过灰色关联度来分析和确定系统因素间的影响程度或因素对系统主行为的贡献测度的一种方法。 灰色关联分析的基本思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密 1>曲线越接近,相应序列之间的关联度就越大,反之就越小 2>灰色关联度越大,两因素变化态势越一致 分析法优点 它对样本量的多少和样本有无规律都同样适用,而且计算量小,十分方便,更不会出现量化结果与定性分析结果不符的情况。 灰色系统关联分析的具体计算步骤如下 1》参考数列和比较数列的确定 参考数列——反映系统行为特征的数据序列 比较数列——影响系统行为的因素组成的数据序列 2》无量纲化处理参考数列和比较数列 (1)初值化——矩阵中的每个数均除以第一个数得到的新矩阵
(2)均值化——矩阵中的每个数均除以用矩阵所有元素的平均值得到的新矩阵 (3)区间相对值化 3》求参考数列与比较数列的灰色关联系数ξ(Xi) 参考数列X0 比较数列X1、X2、X3…………… 比较数列相对于参考数列在曲线各点的关联系数ξ(i) 称为关联系数,其中ρ称为分辨系数,ρ∈(0,1),常取0.5.实数第二级最小差,记为Δmin。两级最大差,记为Δmax。为各比较数列Xi曲线上的每一个点与参考数列X0曲线上的每一个点的绝对差值。记为Δoi(k)。所以关联系数ξ(Xi)也可简化如下列公式: 4》求关联度ri 关联系数——比较数列与参考数列在各个时刻(即曲线中的各点)的关联程度值,所以它的数不止一个,而信息过于分散不便于进行整体性比较。因此有必要将各个时刻(即曲线
灰色关联度分析讲解
第五章灰色关联度分析 目录 壹、何谓灰色关联度分析 ------------------------- 5-2 贰、灰色联度分析实例详说与练习 ----------------- 5-8 第五章灰色关联度分析 壹、何谓灰色关联度分析 一.关联度分析 灰色系统分析方法针对不同问题性质有几种不同做法,灰色关联度分析(Grey Relational Analysis)是其中的一种。基 本上灰色关联度分析是依据各因素数列曲线形状的接近程度 做发展态势的分析。 灰色系统理论提出了对各子系统进行灰色关联度分析的概念,意图透过一定的方法,去寻求系统中各子系统(或因素) 之间的数值关系。简言之,灰色关联度分析的意义是指在系统
发展过程中,如果两个因素变化的态势是一致的,即同步变化程度较高,则可以认为两者关联较大;反之,则两者关联度较小。因此,灰色关联度分析对于一个系统发展变化态势提供了量化的度量,非常适合动态(Dynamic)的历程分析。 灰色关联度可分成「局部性灰色关联度」与「整体性灰色关联度」两类。主要的差别在于「局部性灰色关联度」有一参考序列,而「整体性灰色关联度」是任一序列均可为参考序列。 二.直观分析 依据因素数列绘制曲线图,由曲线图直接观察因素列间的接近程度及数值关系,表一某老师给学生的评分表数据数据为例,绘制曲线图如图一所示,由曲线图大约可直接观察出该老师给分总成绩主要与考试成绩关联度较高。 表一某一老师给学生的评分表单位:分/ %
由曲线图直观分析,是可大略分析因素数列关联度,可看出考试成绩与总成绩曲线形状较接近,故较具关联度,但若能以量化分析予以左证,将使分析结果更具有说服力。 三.量化分析 量化分析四步曲: 1.标准化(无量纲化):以参照数列(取最大数的数列)为 基准点,将各数据标准化成介于0至1之间的数据最 佳。 2.应公式需要值,产生对应差数列表,内容包括:与参 考数列值差(绝对值)、最大差、最小差、ζ(Zeta) 为分辨系数,0<ζ<1,可设ζ = 0.5(采取数字最终 务必使关联系数计算:ξi(k)小于1为原则,至于
灰色关联度分析MATLAB程序
x(1,:)=[83 0.191 12.9 7.2 89.4 0.432 6.33]; x(2,:)=[75 0.189 11.6 9.1 82.3 0.453 5.87]; x(3,:)=[64 0.165 11.9 10.3 69.3 0.512 6.31]; %列出各数值,可修改 x(4,:)=[63 0.165 12.8 9.7 68.2 0.455 6.6]; x(5,:)=[56 0.211 13.2 12.6 77.5 0.317 7.12]; m=5;n=7; x0=[83 0.211 13.2 7.2 89.4 0.317 5.87]; %参考序列 for i=1:n avg(i)=0; %均值初始化 end for i=1:m for j=1:n avg(j)=avg(j)+x(i,j); end end %求均值序列 for i=1:n avg(i)=avg(i)/m; end for j=1:m for i=1:n x(j,i)=x(j,i)/avg(i); %均值化 end end for i=1:n x0(i)=x0(i)/avg(i); %参考序列均值化end for j=1:m for i=1:n delta(j,i)=abs(x(j,i)-x0(i)); %求序列差 end end max=delta(1,1); for j=1:m for i=1:n if delta(j,i)>max max=delta(j,i);
end end end %求两极差 min=0; for j=1:m xgd(j)=0; for i=1:n glxs(j,i)=0.5*max/(0.5*max+delta(j,i)); %计算关联系数及相关度 xgd(j)=xgd(j)+glxs(j,i); end xgd(j)=xgd(j)/n; end xgd %因此,A—E区与参考序列(最佳指标)的相关度分别为0.8489 0.6983 0.5588 0.5858 0.7105
五种灰色关联度分析matlab代码
灰色邓氏关联度分析 % P12 -- The Study on the Grey Relational Degree and Its Application function r1 = gld_deng(x) s = size(x); len = s(2); num = s(1); ro = 0.5; for i = 1: num x(i,:) = x(i,:)./x(i,1); end dx(num,len) = 0; for i = 2 : num for k = 1 : len dx(i,k) = abs(x(1,k) - x(i,k)); end end max_dx = max(max(dx)); min_dx = min(min(dx)); r(1,1:len-1) = 1; for i = 2 : num for k = 1 : len r(i,k) = (min_dx + ro*max_dx)/(dx(i,k) + ro*max_dx); end end r1 = sum(r(2:num,:),2)/(len); 改进灰色绝对关联度分析 % P11 -- The Study on the Grey Relational Degree and Its Application function r1 = gld_gjjd(x) s = size(x); len = s(2); num = s(1); for i = 1: num x(i,:) = x(i,:)./x(i,1); end dx(num,len-1) = 0; for i = 1 : num for j = 1 : len - 1 dx(i,j) = x(i,j+1) - x(i,j); end end c = 1; beta(1,1:len-1) = 0; w(1,1:len-1) = 0; for i = 2 : num temp = sum(abs(x(i,:) - x(1,:)),2); for k = 1 : len - 1 beta(i,k) = atan((dx(i,k) - dx(1,k))/(1 + dx(i,k)*dx(1,k))); if beta(i,k) < 0 beta(i,k) = pi + beta(i,k);
基于熵权灰色关联的开放式基金综合评价模型Matlab程序
基于熵权灰色关联的开放式基金综合评价模型Matlab程序 详细算法流程请见我的文库-《Garch-Var开放式基金风险度量及综合评价体系》的第二部分,综合评价体系,程序中的变量请对应文章的算法涉及变量。 输入的表格字段如下: 其中第一个变量代表基金的名称(这里总共选取了100只基金,只截取了部分数据),后面的变量根据影响基金表现的因素分别建立模型并收集数据计算得到。 输出是一系列的基金的权重,按照大小排序既可以得到基金的综合评分: 程序: function FuzzyEvalue(FileName)
clc; fid = fopen(FileName); head_ = textscan(fid, '%s %s %s %s %s %s',1,'delimiter', ','); head = {{zeros(length(head_) - 1)}}; for i = 2:length(head_) head{i-1}(1) = head_{i}(1); end clear head_ %for i = 1:length(head) % head{i}(1) % end %head inputMatrix_ = textscan(fid, '%s %f32 %f32 %f32 %f32 %f32','delimiter', ','); fclose(fid); for j = 2:length(inputMatrix_) inputMatrix(:,j - 1) = double(inputMatrix_{:,j}); end alpha = 0.5; [n,m] = size(inputMatrix); optimalMat = zeros(1,m); for i = 1:m %inputMatrix(:,i) if isempty(cell2mat(strfind(head{i}(1), 'max'))) == 0 optimalMat(i) = max(inputMatrix(:,i)); elseif isempty(cell2mat(strfind(head{i}(1), 'min'))) == 0 optimalMat(i) = min(inputMatrix(:,i)); end end optimalMat; D = [optimalMat;inputMatrix]; R = zeros(n+1,m); for i = 1:m if isempty(cell2mat(strfind(head{i}(1), 'max'))) == 0 R(:,i) = 1.0*(D(:,i) - min(D(:,i)))/(max(D(:,i)) - min(D(:,i))); elseif isempty(cell2mat(strfind(head{i}(1), 'min'))) == 0 R(:,i) = 1.0*(max(D(:,i)) - D(:,i))/(max(D(:,i)) - min(D(:,i))); end end clearvars D inputMatrix; R;
灰色关联度matlab源程序(完整版)
灰色关联度matlab源程序(完整版) 最 近几天一直在写算法,其实网上可以下到这些算法的源程序的,但是为了搞懂, 搞清楚,还是自己一个一个的看了,写了,作为自身的积累,而且自己的的矩 阵计算类库也迅速得到补充,以后关于算法方面,基本的矩阵运算不用再重复写了,挺好的,是种积累,下面把灰关联的matlab程序与大家分享。 灰色关联度分析法是将研究对象及影响因素的因子值视为一条线上的点,与待识别对象及影响因素的因子值所绘制的曲线进行比较,比较它们之间的贴近度,并分别量化,计算出研究对 象与待识别对象各影响因素之间的贴近程度的关联度,通过比较各关联度的大小来判断待识别对象对研究对象的影响程度。 简言之,灰色关联度分析的意义是指在系统发展过程中,如果两个因素变化的态势是一致的,即同步变化程度较高,则可以认为两者关联较大;反之,则两者关联度较小。因此,灰色关联度分析对于一个系统发展变化态势提供了量化的度量,非常适合动态(Dynamic)的历程分析。灰色关联度可分成“局部性灰色关联度”与“整体性灰色关联度”两类。主要的差别在于局部性灰色关联度有一参考序列,而整体性灰色关联度是任一序列均可为参考序列。关联度分析是基于灰色系统的灰色过程, 进行因素间时间序列的比较来确定哪些是影响大的主导因素, 是一种动态过程的研究。 关联度计算的预处理,一般初值化或者均值化,根据我的实际需要,本程序中使用的是比较序列与参考序列组成的矩阵除以参考序列的列均值等到的,当然也可以是其他方法。 %注意:由于需要,均值化方法采用各组值除以样本的各列平均值 clear;clc; yangben=[ 47.924375 25.168125 827.4105438 330.08875 1045.164375 261.374375 16.3372 6.62 940.2824 709.2752 962.1284 84.874 55.69666667 30.80333333 885.21 275.8066667 1052.42 435.81 ]; %样本数据 fangzhen=[ 36.27 14.59 836.15 420.41 1011.83 189.54 64.73 35.63 755.45 331.32 978.5 257.87 42.44 23.07 846 348.05 1025.4 296.69 59.34 39.7 794.31 334.63 1016.4 317.27
2灰色关联分析讲解
五灰色关联分析方法 在实际问题中,许多因素之间的关系是灰色的,人们很难分清哪些因素是主导因素,哪些因素是非主导因素;哪些因素之间关系密切,哪些不密切。灰色关联分析,为我们解决这类问题提供了一种行之有效的方法。 一、灰色关联分析概述 我们知道,统计相关分析是对因素之间的相互关系进行定量分析的一种有效方法。但是,我们也注意到相关系数具这样的性质: rxy=ryx,即因素y对因素 x的相关程度与因素x对因素y的相关程度相等。暂且不去追究因素之间的相关程度究竟有多大。单就相关系数的这种性质而言,也是与实际情况不太相符的。譬如,在国民经济问题研究中,我们能将农业对工业的关联程度与工业对农业的关联程度等同看待吗?其次,由于地理现象与问题的复杂性,以及人们认识水平的限制,许多因素之间的关系是灰色的,很难用相关系数比较精确地度量其相关程度的客观大小。为了克服统计相关分析的上述种种缺陷,灰色系统理论中的灰色关联分析给我们提供了一种分析因素之间相互关系的又一种方法。 灰色关联分析,从其思想方法上来看,属于几何处理的范畴,其实质是对反映各因素变化特性的数据序列所进行的几何比较。用于度量因素之间关联程度的关联度,就是通过对因素之间的关联曲线的比较而得到的。 设x1,x2,…,xN为N个因素,反映各因素变化特性的数据列分别为 {x1(t)},{x2(t)},…{xN(t)},t=1,2,…,M。因素xj对xi的关联系数定义为 ξij(t)=?min+k?max ?ij(t)+k?maxt=1,2,3, ,M(1) (5)式中,ξij(t)为因素xj对xi在t时刻的关联系数; ?ij(t)=|xi(t)-xj(t)|,?max=maxmax?ij(t),?min=minmin?ij(t);k为介于[0,1]区jjjj 间上的灰数。不难看出,△ij(t)的最小值是?min, 当它取最小值时,关联系数ξij(t)取最大值maxξij(t)=1;?ij(t)的最大值为i ?max,当它取最大值时,关联系数ξij(t)取最小值minξij(t)=i?min1? k+ 1+k??max??,即? ξij(t)是一个有界的离散函数。若娶灰色k的白化值为1,则有 1??min 1+2??max??≤ξij(t)≤1?(2) 在实际计算时,取?min=0,这时有 0.5≤ξij≤1(3) 作出函数ξij=ξij(t)随时间变化的曲线,它就被称之为关联曲线。图中的水平线,说明任何时刻的关联系数为1,它代表xi与xi本身的关联曲线ξij≡1,因为自己与自己总可以认为是密切关联的。
灰色关联度分析法在系统综合评价中的应用(精)
灰色关联度分析法在系统 综合评价中的应用 李玉辉,张建 2 (1.长沙理工大学,湖南长沙410076;2.济南市公路管理局,山东济南250013) 摘要:基于灰色系统理论,研究了灰色关联度分析法在系统综合评价中的应用。并通过实例对该方法进行了实证研究,表明了该方法的有效性。关键词:灰色关联度;综合评价;指标体系中图分类号:U491 文献标识码:A 的标准数据列,记为X0,设第一个指标值记为X0(1),第二个指标值记为X0(2),第k 个指标值记为X0(k),因此参考数据列可以用如下公式表示 X0=X0(i) i=1,2,3,,n ……………(1)比较数据列是研究的对象数据列,记为 X1,X2,,,Xm,可以用如下公式表示 X1=X1(i) i=1,2,3,,nX2=X2(i) i=1,2,3,,n,, Xm=Xm(i) i=1,2,3,, (2) 引言 系统综合评价的方法很多,如层次分析法、模糊综合评判法、主成分分析法、因子分析法等。这些方法都有各自的优点,但是也存在着一定的不足。例如模糊综合评判法是对难以精确化的复杂系统进行分析的间接评判法,这种方法的重要步骤是确定评价指标的隶属度,如果隶属函数选择的不合适,则容易引起较大的误差;层次分析法是将人们的定性思维转化为定量分析的过程,很大程度上依赖于人的经验;主成分分析法则要求有多个非线性相关的指标,指标太少的话,会在很大程度上影响评价的客观性。笔者应用灰色系统的有关理论,研究了灰色关联度分析法在系统综合评价中的应用。 1.2 关联系数 在分析参考数据列和比较数据列的关联程度时,首先分析各个指标间的关联程度,用关联系数这个概念表示,计算公式如下 Gi(J)= vMin+K#vMax (3) i(J)+K#vMax 其中,vi(J)=&Xi(J)-X0(J)&;vMin=MiinMJin&Xi(J)-X0(J)&:vMax=MiaxMJax&Xi(J)-X0(J)& Gi(J)为Xi对X0的k指标关联系数;K为分辨系数,一般在0与1之间,通过计算验证,笔者取为0.5,结果较为合理。
灰色系统预测GM(1-1)模型及其Matlab实现
灰色系统预测GM(1,1)模型及其Matlab 实现 预备知识 (1)灰色系统 白色系统是指系统内部特征是完全已知的;黑色系统是指系统内部信息完全未知的;而灰色系统是介于白色系统和黑色系统之间的一种系统,灰色系统其内部一部分信息已知,另一部分信息未知或不确定。 (2)灰色预测 灰色预测,是指对系统行为特征值的发展变化进行的预测,对既含有已知信息又含有不确定信息的系统进行的预测,也就是对在一定范围内变化的、与时间序列有关的灰过程进行 预测。尽管灰过程中所显示的现象是随机的、杂乱无章的,但毕竟是有序的、有界的,因此得到的数据集合具备潜在的规律。灰色预测是利用这种规律建立灰色模型对灰色系统进行预测。 目前使用最广泛的灰色预测模型就是关于数列预测的一个变量、一阶微分的GM(1,1)模型。它是基于随机的原始时间序列,经按时间累加后所形成的新的时间序列呈现的规律可用一阶线性微分方程的解来逼近。经证明,经一阶线性微分方程的解逼近所揭示的原始时间序列呈指数变化规律。因此,当原始时间序列隐含着指数变化规律时,灰色模型GM(1,1)的预测是非常成功的。 1 灰色系统的模型GM(1,1) 1.1 GM(1,1)的一般形式 设有变量X (0)={X (0)(i),i=1,2,...,n}为某一预测对象的非负单调原始数据列,为建立灰色预测模型:首先对X (0)进行一次累加(1—AGO, Acumulated Generating Operator)生成一次累加序列: X (1)={X (1)(k ),k =1,2,…,n} 其中 X (1)(k )= ∑ =k i 1 X (0)(i) =X (1)(k -1)+ X (0)(k ) (1) 对X (1)可建立下述白化形式的微分方程: dt dX )1(十) 1(aX =u (2) 即GM(1,1)模型。 上述白化微分方程的解为(离散响应): ∧ X (1)(k +1)=(X (0)(1)- a u )ak e -+a u (3) 或 ∧ X (1)(k )=(X (0)(1)- a u ))1(--k a e +a u (4)
灰色理论灰色预测模型和灰色关联度分析matlab通用代码
%该程序用于灰色关联分析,其中原始数据的第一行为参考序列,1至15行为正相关序列,16至17为负相关序列 clc,clear load x.txt %把原始数据存放在纯文本文件x.txt 中 %如果全为正相关序列,则将两个循环替换为下列代码 %for i=1:size(x,1) %x(i,=x(i,/x(i,1); %end for i=1:15 x(i,=x(i,:)/x(i,1); %标准化数据 end for i=16:17 x(i,:)=x(i,1)./x(i,:); %标准化数据 end data=x; n=size(data,1); ck=data(1,:);%分离参考序列 bj=data(2:n,:);m1=size(bj,1); for j=1:m1 t(j,:)=bj(j,:)-ck; end jc1=min(min(abs(t')));jc2=max(max(abs(t'))); rho=0.5;%灰色关联度为0.5 ksi=(jc1+rho*jc2)./(abs(t)+rho*jc2); r=sum(ksi')/size(ksi,2); r %灰色关联度向量 [rs,rind]=sort(r,'descend') %对关联度进行降序排序 %该函数用于灰色预测模型,其中x0为列向量,alpha一般取0.5,将第一个数据视为序号为0,k从0开始的序号矩阵 function y=huiseyuce(x0,alpha,k) n=length(x0); x1=cumsum(x0); for i=2:n z1(i)=alpha*x1(i)+(1-alpha)*x1(i-1); end z1=z1'; B=[-z1(2:n),ones(n-1,1)]; Y=x0(2:n); ab=B\Y; y1=(x0(1)-ab(2)/ab(1))*exp(-ab(1)*k)+ab(2)/ab(1);%产生预测累加生成序列 y=[x0(1) diff(y1)]%产生灰色预测数据 1 / 1
灰色预测+灰色关联分析
灰色关联分析法 根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,来衡量因素间关联程度。灰色关联分析法的基本思想是根据序列曲线几何形状的相似程度来判断其联系是否紧密。 根据评价目的确定评价指标体系, 为了评价×××我们选取下列评价指标: 收集评价数据(此步骤一般为题目中原数据,便省略) 将m 个指标的n 组数据序列排成m*n 阶矩阵: '' ' 12''' '''1212''' 1 2(1)(1)(1)(2)(2)(2)(,,,)()()()n n n n x x x x x x X X X x m x m x m ?? ? ?= ? ? ??? 对指标数据进行无量纲化 为了消除量纲的影响,增强不同量纲的因素之间的可比性,在进行关联度计算之前,我们首先对各要素的原始数据作...变换。无量纲化后的数据序列形成如下矩阵: 01010101(1)(2) (1)(2)(2)(2)(,,,)()()()n n n n x x x x x x X X X x n x n x n ?? ? ?= ? ??? 确定参考数据列 为了比较...【评价目的】,我们选取...作为参考数据列,记作 ''''0000((1),(2),,())T X x x x n = 计算0()() i x k x k -,得到绝对差值矩阵 求两级最小差和两级最大差 011min min ()()min(*,*,*,*,*,*)*n m i i k x k x k ==-== 01 1 max max ()()max(*,*,*,*,*,*)*n m i i k x k x k ==-== 求关联系数 由关联系数计算公式0000min min ()()max max ()() ()()()max max ()() i i i k i k i i i i k x k x k x k x k k x k x k x k x k ρζρ-+?-= -+?-,取 0.5ρ=,分别计算每个比较序列与参考序列对应元素的关联系数,得关联系数如 下:
matlab灰色关联度
灰色关联度matlab源程序 最近几天一直在写算法,其实网上可以下到这些算法的源程序的,但是为了搞懂,搞清楚,还是自己一个一个的看了,写了,作为自身的积累,而且自己的的矩阵计算类库也迅速得到补充,以后关于算法方面,基本的矩阵运算不用再重复写了,挺好的,是种积累,下面把灰关联的matlab程序与大家分享。 灰色关联度分析法是将研究对象及影响因素的因子值视为一条线上的点,与待识别对象及影响因素的因子值所绘制的曲线进行比较,比较它们之间的贴近度,并分别量化,计算出研究对象与待识别对象各影响因素之间的贴近程度的关联度,通过比较各关联度的大小来判断待识别对象对研究对象的影响程度。 关联度计算的预处理,一般初值化或者均值化,根据我的实际需要,本程序中使用的是比较序列与参考序列组成的矩阵除以参考序列的列均值等到的,当然也可以是其他方法。 %注意:由于需要,均值化方法采用各组值除以样本的各列平均值 clear;clc; yangben=[ 47.924375 25.168125 827.4105438 330.08875 1045.164375 261.374375 16.3372 6.62 940.2824 709.2752 962.1284 84.874 55.69666667 30.80333333 885.21 275.8066667 1052.42 435.81 ]; %样本数据 fangzhen=[ 36.27 14.59 836.15 420.41 1011.83 189.54 64.73 35.63 755.45 331.32 978.5 257.87 42.44 23.07 846 348.05 1025.4 296.69 59.34 39.7 794.31 334.63 1016.4 317.27 52.91 17.14 821.79 306.92 1141.94 122.04 4.21 4.86 181 5.52 2584.68 963.61 0.00 6.01 2.43 1791.61 2338.17 1278.08 30.87 3.01 1.58 1220.54 956.14 124 4.75 3.91 25.65 7.42 790.17 328.88 1026.01 92.82 115.80 27 926.5 350.93 1079.49 544.38 12.63 8.75 1055.50 1379.00 875.10 1.65 ]; %待判数据 [rows,cols]=size(fangzhen); p=0.5; %分辨系数 [m,n]=size(yangben);