多种类型地回归模型

数学建模第二次作业
例一:(线性模型)
针叶松数据该数据包含70棵针叶松的测量数据,其中y 表示体积(单位立方英尺),x 1为树的直径(单位:英寸),x 2为树的高度(单位:英尺)。 x 1 4.6 4.4 5.0 5.1 5.1 … 19.4 23.4 x 2 33 38 40 49 37 … 94 104 解答:
(1)问题分析:
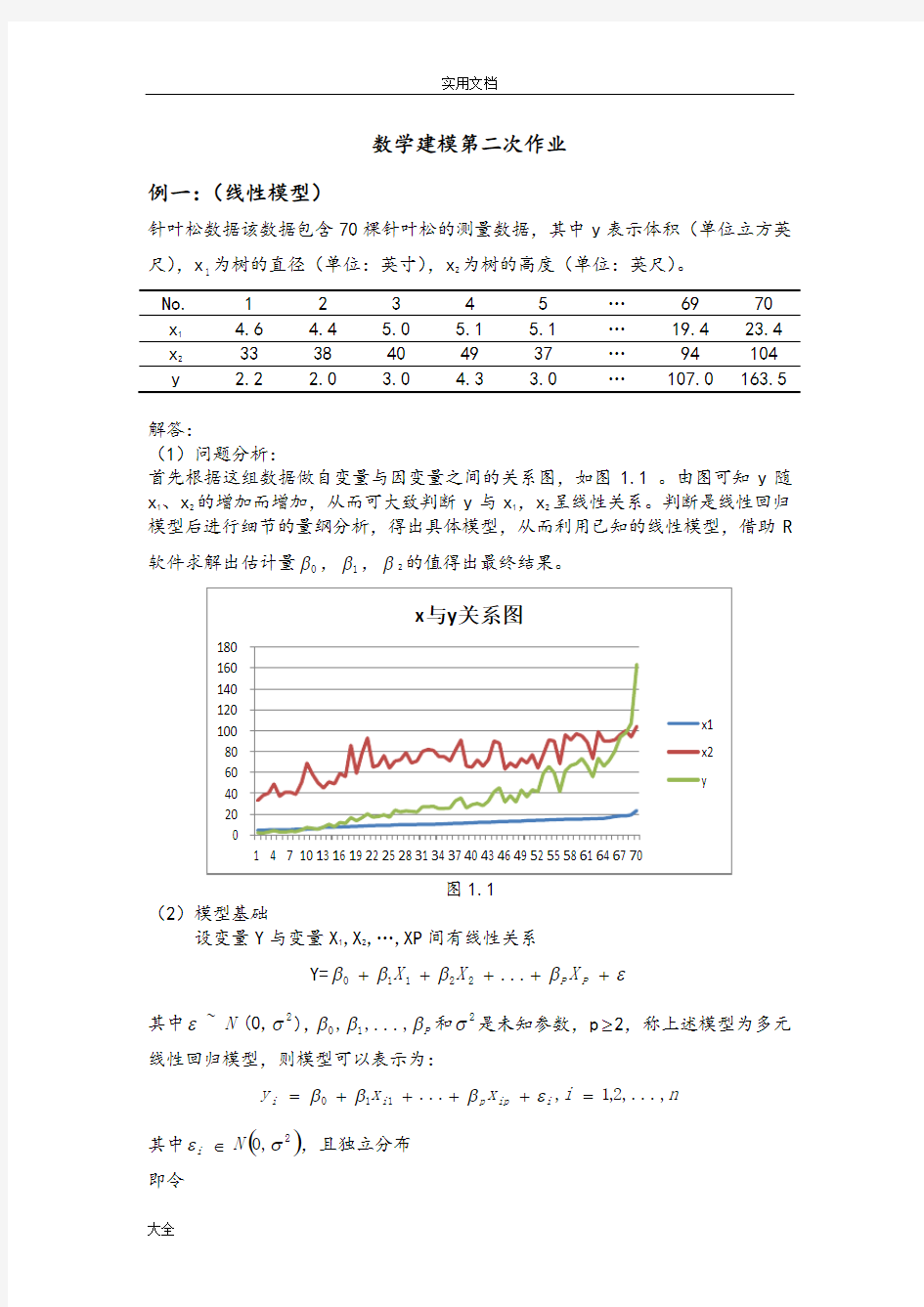
首先根据这组数据做自变量与因变量之间的关系图,如图1.1 。由图可知y 随x 1、x 2的增加而增加,从而可大致判断y 与x 1,x 2呈线性关系。判断是线性回归模型后进行细节的量纲分析,得出具体模型,从而利用已知的线性模型,借助R 软件求解出估计量0β,1β,β2的值得出最终结果。
图1.1
(2)模型基础
设变量Y 与变量X 1,X 2,…,XP 间有线性关系
Y=εββββ+++++P P X X X (22110)
其中N ~ε(0,2σ),P βββ,...,,10和2σ是未知参数,p ≥2,称上述模型为多元线性回归模型,则模型可以表示为:
n i x x y i ip p i i ,...,2,1,...110=++++=εβββ
其中()
2,0σεN i ∈,且独立分布 即令
?
?
??
????????=n y y
y y 21,??????????????=p ββββ 10,???
???
?
????
???=np n n p p x x x x x x x x x X ...1...1 (12)
1
222
2111211
,?
???
????????=n εε
εε 21
则多元线性回归模型可表示为
εβ+=X Y ,
其中Y 是由响应变量构成的n 维向量,X 是n ?(p+1)阶设计矩阵,β是p+1维
向量,并且满足
E (ε)=0,Var (ε)=2σI n
与一元线性回归类似,求参数β的估计值β
?,就是求最小二乘函数 Q (β)=
()()ββX y X y T
--
达到最小的β的值。
β的最小二乘估计
()
y X X X T T 1
?-=β
从而得到经验回归方程
P P X X Y βββ
????11+++=
(3)问题求解:
由于体积与长度的量纲不一致,为了使等式两边量纲统一,首先利用excel 软件对数据进行预处理,即对y 进行三次开方的处理。
其中,选择线的性模型为:i i i i x x y εβββ+++=221103,i=1,…,70
3
y 计算结果如下表1.1
0β=0.0329
1β=0.1745 2β=0.0142
根据计算结果可以将x 1,x 2的值带入回归方程求解y 值,将所得y 值(实验值)与真实y 值(观测值)进行比较达到检验模型模拟优度的目的,得下图1.2
图1.2
由图1.2得,回归系数和回归方程检验都是显著的,模型模拟结果较好。 则该题结果为:i i i x x y 2130142.01745.000329.0++=
(4)模型评价:
①模型优点:选取线性回归模型有效反应了自变量与因变量之间的内在关系,在利用线性模型的基础上,注意到保持等式两边量纲的一致性,体现模型的严谨性。
②模型缺点:当x 值增大时,y 实验值增长速度加快,模拟出现偏差。
例二:(非线性模型)欧洲野兔
No. 1 2 4 5 … 70 71 X 15 15 18 28 … 768 860 y 21.66 22.75 31.25 44.79 … 232.12 246.70
这组数据包含71组观测值,其中y 为在澳大利亚的欧洲野兔干燥眼球重量(单位:毫克)的对数值,x 为野兔相应的年龄(单位:天)。、
解答:
(1)问题分析:要求澳大利亚的欧洲野兔年龄与干燥眼球重量之间的关系,首先应该大致分析两者之间的线性关系。确定其大致性关系后进一步具体化分析,得出澳大利亚的欧洲野兔年龄与干燥眼球重量之间的具体模型并建立函数模型,通过对未知参数的求解得出最终结果。本题中,通过spss 模型进行初步估计后建模具体求解 (2)问题求解:
利用spss 软件对野兔年龄(自变量x)与干燥眼球重量(因变量y )进行画图初步分析,所得结果如图2.1
图2.1
由图2.1可知,x、y两者呈非线性关系,故需用非线性回归模型进行进一步估计。
(2)由(1)知x、y两者呈非线性关系,则用曲线估计中的线性、对数、逆模型、
二次项、立方、幂次、复合、S、logistic、增长、指数分布等11种模型进行拟合,所得结果如表2.1,拟合效果图见图2.2.
图2.2
由表2.1知三次模拟的R方值0.979与其他10种模拟中相比最大,证明三次模型模拟的效果最好。观察图2.2可进一步验证三次模型模拟所得曲线与观测值最接近,故用三次模型进行具体模拟。
(3)由(2)知x、y两者符合三次非线性模型,则设x、y之间的函数关系为y i=b1-b2(xi-b3)^(-1)+c过spss软件求解得相关参数b1、b2、b3、c如表2.2
由表2.2知,b1=1.035、b2=-0.002、b3=1.0616
?、c=17.289,则x、y之
10-
间函数关系为:
y i=1.035–(-0.002)*(xi-1.0616
?)+ 17.289。其函数图象如图2.3
10-
图2.3
(3)模型评价:
①模型优点:该模型充分考虑x、y变量之间的非线性关系,经过多种模拟模型的相互比较筛选,得出模拟效果最好的三次非线性模型模拟函数,结果比较可靠,从函数图象来看模拟值与真实值之间较为接近,模拟效果较好。
②模型缺点:从最终的模拟模式图中我们可以看到当自变量年龄较大时,重量的真实值与模拟值差异增大,模拟效果变差。
例三(分类数据模型):降雨数据
123,4
表示偏少,y=2表示正常,y=3表示偏多。
解答:
(1)问题分析
考虑多因素的影响时,对于反应变量为分类变量时(如本题的预报因子),用线性回归模型就不合适,因此可以采用logistic回归模型进行统计分析,由于题目中响应变量(降雨情况)是由3种不同的取值,于是便可以利用多分类的
Logistic 模型。 (2) 模型基础
① 设y 是一个响应变量有c 个取值,从0到c-1,并且y=0是一个参照
组,协变量x=(p x x x ,,,21 ),那么可以得到y 的条件概率:
P (y=k|x )=
∑-=+
1
1
)
()
(1c j
x g x g i k e
e
其中k=0,1,2,...,c-1.由此得到相应的logistic 回归模型:
)
(x g k e =()()
???
?
????==x y P x k y P 0ln =p kp k k x βββ+++ 10
② 最小二乘估计
对y 每一个取值进行n 次独立观测,可以得到如下矩阵:
??????? ??-12
1
2222111211n n n p p y y y y y y y y y
=???????
??np
n p p x x x x x x 1221111111??
??
?
?
?
??---p c p
p
c c ,1211,12111
0,12010
βββββββββ
令 Y=????
?
??
??-12
1
22221
11211
n n n p p y y y y y y
y y y
, X=??
??
?
?
?
??np n p p x x x x x x 1221
111111 B=????
?
?
?
??---p c p
p
c c ,1211,121110,12010βββββββββ
记B=(121,...,,-c βββ),则有Y=XB 成立. 于是可以得到β的最小二乘估计:
[]
Y X X X T T
1
-=β
③ 似然函数
为构造似然函数,利用二进制编码表示观测值,规定如果y=0那么y 0=1,y 1=y 2=…=y c-1=0;如果y=1,那么y 0=0,y 1=1,y 2=…=y c-1=0;以此类
推,可以得出无论y 取何值,总有∑-==1
01c j j y 成立,可得似然函数:
l ])(...
)()([)(11011
1i
c i
i
y i c n
i y i y i o x x x --=∏=
πππβ=()[
]∏∏=-=?
?????n
i c j y
i j ji
x 110
π(*)
其中()()
i i j x j y P x ==π
对(*)式两端取对数得似然函数:
L (β)=()[]∑∑-==1
01ln c j n
i i i ji x y π
(3) 模型求解:
本题中,c=3,可以取y=2作为参照组,通过Stata 软件中的mlogit 命令,建立多类结果的logistic 回归,如下图3.1
图3.1
从图中可以得出:
logit (21y y →)=543.8623.50471.136.716.124321+-+-x x x x logit (23y y →)=18.9001.057.011.138.43321-+-+-x x x x
(4)模型评价
本题将二分类logistic 回归模型的知识推广到多分类logistic 回归模型,有效的解决了多种响应变量的分类数据问题。
例4.非参数模拟实验
数据产生自
()n i n i r Y i i ,,1,/ =+=σε,
其中,n=1000,)1,
0(~,1.0N i εσ=,估计函数表达式 解答:
(1)问题分析:
对于非参数回归主要有核回归,样条回归以及局部多项式回归,
利用所给公式通
过matlab 生成的1000个随机数据,考虑到核回归多用于密度估计的随机样本回归,便采用非参数回归中的核回归,通过最小均方误差比较,选取最优核Epanechnikov 核,然后通过缺一交叉验证选取带宽h=0.04 ,模拟出离散曲线图。最后通过曲线图,估计出函数表达式。 (2)模型基础
在非参数核函数估计领域里,有两个基本工具:核函数K (u )和带宽(h ),前者包含点x 区间中观测值的权重,而后者主要控制包含观测值的多少
在核函数回归中,需要进行核函数和带宽的选择,其中和函数有4种不同的形式,依据最优均方误差可以发现Epanechnikov 核是最优的核函数,即
())u ()u 1(4
3
u 2I K -=,其中I(?)为示性函数,满足
I (u )=??
???≤1,01u ,
1 u
利用缺一交叉验证选择带宽: CV (h )=
[]2
1
1
)
n (2
)
(1)(?1
)(?n
1∑∑
==-??
????--=-n
i n
i ii i i i i i
L x r Y n
x r Y
这里)(?i r -指未用数据点(x i ,Y i )时所得到的估计,ii L 为光滑矩阵L 的第i 个对角元,其
中L=(l (x 1),…,l (x n ))T
(3)模型求解
首先由原始数据画出相应散点图进行趋势预估,所得图形见下图4.1
图4.1
接着,用样条回归以及局部多项式回归进行拟合分析,Epanechnikov
核函
数进行平滑估计。得到如图4.2左图所示趋势图。将原始数据与平滑曲线相互统一后画出散点趋势图如图4.2右图所示
图4.2
由图4.2可知,函数拟合效果与真实数据趋势相近,但存在一些波动的点,接下来我们进行进一步的模型检验。
②缺一交叉验证:
利用matlab通过缺一交叉验证选取带宽h=0.04,计算求出cv(h)的结果。
其中,所得cv(h)=0.0377,该值小于带宽h=0.04,证明拟合效果较好。
③函数求解
从拟合图像中,可以看到函数具有正弦函数特征,与doppler函数图有一致性,故用matlab进行具体函数参数求解。首先用sin函数拟合,发现当所叠加的正余弦函数增加时,拟合度增大,当其达到8次叠加时,拟合效果最好,故设F1(x)=a0+a1*cos(x*w)+b1*sin(x*w)+a2*cos(2*x*w) + b2*sin(2*x*w) + a3*cos(3*x*w) + b3*sin(3*x*w) +a4*cos(4*x*w) + b4*sin(4*x*w) + a5*cos(5*x*w) + b5*sin(5*x*w) +a6*cos(6*x*w) + b6*sin(6*x*w) + a7*cos(7*x*w) + b7*sin(7*x*w) + a8*cos(8*x*w) + b8*sin(8*x*w)
进一步观察x较小时的拟合情况,发现差异较大,由此我们猜想最后的函数由两个函数叠加而成。通过寻找,发现指数函数在x较小时特征与图中起始段接近,故再次设指数函数为:
F2(x)=a0 +a1*cos(x*w)+b1*sin(x*w)+a2*cos(2*x*w)+b2*sin(2*x*w) + a3*cos(3*x*w) + b3*sin(3*x*w) + a4*cos(4*x*w) + b4*sin(4*x*w) + a5*cos(5*x*w) + b5*sin(5*x*w) + a6*cos(6*x*w) + b6*sin(6*x*w) + a7*cos(7*x*w) + b7*sin(7*x*w) + a8*cos(8*x*w) + b8*sin(8*x*w)
将两个函数叠加即可求得最终函数,即F(X)=F1(x)*F2(x),其中,正弦函数与指数函数各参数值见下表4.11及4.12
表4.11
最终模拟出离散曲线图如下图4.3
由拟合图4.3我们可以看到当x较小时模拟值与真实值变化趋势一致,随着x的增大模拟值与真实值不断接近后趋于一致,说明模型建立较为合理。
(4)模型评价
模型优点:拟值与真实值不断接近后趋于一致,模型的建立较为合理,所寻找的模拟函数比较严谨;
模型缺点:对数据事先未进行预处理——异常数据的删除与剔除,对结果有一定影响,使得模拟结果不够完善
例5.猪数据
解答:
(1) 问题分析:根据表中数据可知,这是纵向数据模型,通过观察48头猪体
重随时间曲线,可发现他们呈线性递增,因此可以观察他们曲线斜率的变化和初始体重的差异,用最小二乘核估计得到未知参数。
(2) 模型基础
①先设β已知,估计m(.),基于
i i i i )(m -εβ+=X Z Y T
选择带宽h n ,得到m(x)的核估计:
()()i n
i
ni T
i n
i
ni Z x W Y W x ∑∑==-=
1
1
)(x ,m ?β
β 其中()∑=????
??-???? ??=n i i n x X K h X K W 1n i ni h /x -x 。
记
②估计β,基于
()()i i i T i X m Z X m Y εβ+-=-)?(?21i
得到β的最小二乘估计β
?。 ③得到m(x)的最终估计:
()∑∑==-=
n
i
n
i
i ni T
i ni Z x W Y x W x 1
1
)(?)(m ?β
④调整带宽n h 直到得到满意的结果
(3) 模型求解
根据体重和时间的数据,得到他们的线形图像如图5.1
图5.1
从图像可以看出48头猪的体重随时间呈线性增加,构造线性回归方程 (1)线性递增
y βα+=ij ij j ε+x
),0(~,x 2σεN j ij j = i=1,...,48,j=1,...,9
(2)初始体重的差异
),0(~2i νN U
,x y ij ij i j U εβα+++=
(3)斜率的变化
ij j i i j ij x W U x εβα++++=y ,
)N(0,~2i τW
用向量的形式表示为:
,x y i i i i i b Z εβ++=
,),(,),...,(9,1,T
T i i i y y y βαβ==
T
Z X ??
?
???==987654321111111111i
i
()},diag{,),0(~,b 2
22
i i i τν==D D N W U T
()),0(~,,9291i i I N T
i σεεε =
所以
α=1.043
β=0.876
例6.葡萄糖数据
从服从标准计量的葡萄糖后0,0.5,1,1.5,2,3,4和5小时的实验者的血样里取得,目的是研究对照组和肥胖病人组是否有显著差异。 解答:
(1)问题分析: 根据所给数据,画出肥胖病人和对照组血液的葡萄糖含量的离散点,并依据离散点大致判断出曲线模型为抛物线模型,通过对比控制组与肥胖组的无机磷平均测量值,利用分段线性模型求出估计量的大小。
(2)模型解答:
首先求出全体病人的无机磷平均测量值如表6.1
然后画出全体病人无机磷平均测量值图
全体病人无机磷测量图
根据图像可以大致判断出是抛物线模型: ??
??
??????===++=25169425.1125.0054325.115.0011111111
,),...,(,
33,...,1,y i 81X y y y i b Z X T
i i i i i i i i εβ
考虑组别差异:
控制组 参照组
分别用抛物线模型拟合,不妨考虑分段线性模型,以肥胖组为例:
I=14,...,33
()T
i i i y y 81,...,y =,T
X ????
??????=3210000022225.115.0011111111i
()T 321ββββ,,=
,
y i i i i i b Z X εβ++=
附录
例题一代码:
volume<-data.frame(
X1=c(4.6,4.4,5,5.1,5.1,5.2,5.2,5.5,5.5,5.6,5.9,5.9,7.5,7.6,7.6,7. 8,8,8.1,8.4,8.6,8.9,9.1,9.2,9.3,9.3,9.8,9.9,9.9,9.9,10.1,10.2,10.2,10 .3,10.4,10.6,11,11.1,11.2,11.5,11.7,12,12.2,12.2,12.5,12.9,13,13.1,13 .1,13.4,13.8,13.8,14.3,14.3,14.6,14.8,14.9,15.1,15.2,15.2,15.3,15.4,1 5.7,15.9,16,16.8,17.8,18.3,18.3,19.4,23.4),
X2=c(33,38,40,49,37,41,41,39,50,69,58,50,45,51,49,59,56,86,59,78, 93,65,67,76,64,71,72,79,69,71,80,82,81,75,75,71,81,91,66,65,72,66,72, 90,88,63,69,65,73,69,77,64,77,91,90,68,96,91,97,95,89,73,99,90,90,91, 96,100,94,104),
Y=c(1.30,1.26,1.44,1.63,1.44,1.43,1.52,1.50,1.71,1.93,1.86,1.78,1 .97,2.18,2.00,2.30,2.23,2.56,2.39,2.55,2.72,2.57,2.61,2.69,2.58,2.88, 2.80,2.85,2.83,2.80,3.00,3.00,3.01,2.93,2.94,2.95,3.20,3.28,2.96,3.07 ,3.11,3.04,3.19,3.46,3.56,3.16,3.36,3.16,3.51,3.32,3.51,3.46,3.89,4.0 3,3.90,3.46,3.95,4.06,4.09,4.18,4.04,3.81,4.19,4.04,4.15,4.31,4.54,4. 61,4.75,5.47)
)
lm.sol<-lm(Y~X1+X2,data=volume)
summary(lm.sol)
Call:
lm(formula = Y ~ X1 + X2, data = volume)
Residuals:
Min 1Q Median 3Q Max
-0.182052 -0.043575 -0.000207 0.030547 0.272404
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.0328978 0.0382649 0.86 0.393
X1 0.1744526 0.0037541 46.47 <2e-16 ***
X2 0.0141562 0.0008655 16.36 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’1
Residual standard error: 0.0752 on 67 degrees of freedom
Multiple R-squared: 0.9938, Adjusted R-squared: 0.9936
F-statistic: 5376 on 2 and 67 DF, p-value: < 2.2e-16
例题三代码:
. mlogit y x1 x2 x3 x4
Iteration 0: log likelihood = -26.852306 Iteration 1: log likelihood = -11.741686 Iteration 2: log likelihood = -9.2828456 Iteration 3: log likelihood = -7.8941646 Iteration 4: log likelihood = -7.1510985 Iteration 5: log likelihood = -6.9007646 Iteration 6: log likelihood = -6.8404666 Iteration 7: log likelihood = -6.8279326 Iteration 8: log likelihood = -6.8257308 Iteration 9: log likelihood = -6.8252199 Iteration 10: log likelihood = -6.8250961 Iteration 11: log likelihood = -6.8250714 Iteration 12: log likelihood = -6.8250674 Iteration 13: log likelihood = -6.8250664 Iteration 14: log likelihood = -6.8250662 Multinomial logistic regression
Number of obs = 25
LR chi2(8)= 40.05
Prob > chi=0.0000
Log likelihood = -6.8250662
Pseudo R2 = 0.7458
例题四代码
(1)拟合代码
clear;clc;
data=csvread('Doppler data.csv',0,0,[0 0 999 1]); data(:,1);
for n=1:1000
s=0;
ss=0;
for i=1:n
u(i)=(data(n,1)-data(i,1))/0.04;
if abs(u(i))<=1
Iu=1;
else
Iu=0;
end
ku(i)=3/4*(1-u(i)*u(i))*Iu;
s=s+ku(i);
end
for i=1:n
Lx(i)=ku(i)/s;
ss=ss+Lx(i)*data(i,2);
end
rx(n)=ss;
end
u';
ku;
rx';
plot(data(:,1),rx)
(2)交叉验证代码
clear;clc;
data=csvread('Doppler data.csv',0,0,[0 0 999 1]); data(:,1);
for n=1:1000
s=0;
ss=0;
for i=1:n
u(i)=(data(n,1)-data(i,1))/0.04;
if abs(u(i))<=1
Iu=1;
else
Iu=0;
end
ku(i)=3/4*(1-u(i)*u(i))*Iu;
s=s+ku(i);
end
for i=1:n
Lx(n,i)=ku(i)/s;
ss=ss+Lx(n,i)*data(i,2);
end
rx(n)=ss;
end
u';
ku;
rx';
sss=0;
for i=2:1000
fenzi=data(i,2)-rx(i);
fenmu=1-Lx(i,i);
pingfang=(fenzi/fenmu)*(fenzi/fenmu);
sss=sss+pingfang;
end
cv=sss/1000
(3)函数近似拟合代码
f(x) =
a0 + a1*cos(x*w) + b1*sin(x*w) +
a2*cos(2*x*w) + b2*sin(2*x*w) + a3*cos(3*x*w) + b3*sin(3*x*w) +
a4*cos(4*x*w) + b4*sin(4*x*w) + a5*cos(5*x*w) + b5*sin(5*x*w) +
a6*cos(6*x*w) + b6*sin(6*x*w) + a7*cos(7*x*w) + b7*sin(7*x*w) +
a8*cos(8*x*w) + b8*sin(8*x*w)
a0 = 0.04889 (0.04419, 0.0536)
a1 = 0.1437 (0.1367, 0.1507)
b1 = -0.03541 (-0.04462, -0.02621)
a2 = 0.04867 (0.03115, 0.06619)
b2 = -0.2151 (-0.2221, -0.2082)
a3 = -0.1666 (-0.1736, -0.1597)
b3 = 0.01951 (0.002284, 0.03673)
a4 = 0.1144 (0.1076, 0.1212)
b4 = -0.01195 (-0.02464, 0.0007377)
a5 = -0.0953 (-0.1021, -0.08847)
b5 = 0.01149 (-0.001948, 0.02493)
a6 = 0.07141 (0.06125, 0.08158)
b6 = -0.05863 (-0.06908, -0.04818)
a7 = -0.00623 (-0.01569, 0.00323)
b7 = 0.06512 (0.05819, 0.07206)
a8 = -0.04734 (-0.05905, -0.03562)
b8 = -0.04572 (-0.05654, -0.03491)
w = 6.844 (6.788, 6.9)
f(x) =
a0 + a1*cos(x*w) + b1*sin(x*w) +
a2*cos(2*x*w) + b2*sin(2*x*w) + a3*cos(3*x*w) + b3*sin(3*x*w) + a4*cos(4*x*w) + b4*sin(4*x*w) + a5*cos(5*x*w) + b5*sin(5*x*w) + a6*cos(6*x*w) + b6*sin(6*x*w) + a7*cos(7*x*w) + b7*sin(7*x*w) + a8*cos(8*x*w) + b8*sin(8*x*w)
a1 = -435.2 (-8.273e+06, 8.272e+06)
b1 = 0.4375 (0.4112, 0.4637)
c1 = 0.1035 (-1.91, 2.117)
a2 = 0.6663 (-11.77, 13.1)
b2 = 0.75 (0.6539, 0.8461)
c2 = 0.07264 (-0.07378, 0.2191)
a3 = 0.02385 (-0.01945, 0.06715)
b3 = 0.8146 (0.8031, 0.8262)
c3 = 0.0083 (-0.01057, 0.02717)
a4 = 0.8247 (0.7699, 0.8795)
b4 = 0.2952 (0.2945, 0.296)
c4 = 0.02837 (0.0267, 0.03004)
a5 = -0.003565 (-0.08559, 0.07846)
b5 = 0.7108 (0.674, 0.7475)
c5 = 0.001976 (-0.05161, 0.05556)
a6 = 0.5432 (-16.08, 17.17)
b6 = 0.8427 (0.2355, 1.45)
c6 = 0.08476 (-0.1546, 0.3242)
a7 = -0.4557 (-25.15, 24.24)
b7 = 0.7795 (-0.2541, 1.813)
c7 = 0.1049 (-0.2728, 0.4826)
a8 = 435.7 (-8.272e+06, 8.273e+06) b8 = 0.4375 (0.4097, 0.4653)
c8 = 0.1033 (-1.908, 2.115)
非线性回归分析
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果: 通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
常见非线性回归模型
常见非线性回归模型 1.简非线性模型简介 非线性回归模型在经济学研究中有着广泛的应用。有一些非线性回归模型可以通 过直接代换或间接代换转化为线性回归模型,但也有一些非线性回归模型却无 法通过代换转化为线性回归模型。 柯布—道格拉斯生产函数模型 y AKL 其中L和K分别是劳力投入和资金投入, y是产出。由于误差项是可加的, 从而也不能通过代换转化为线性回归模型。 对于联立方程模型,只要其中有一个方程是不能通过代换转化为线性,那么这个联立方程模型就是非线性的。 单方程非线性回归模型的一般形式为 y f(x1,x2, ,xk; 1, 2, , p) 2.可化为线性回归的曲线回归 在实际问题当中,有许多回归模型的被解释变量y与解释变量x之间的关系都不是线性的,其中一些回归模型通过对自变量或因变量的函数变换可以转化为
线性关系,利用线性回归求解未知参数,并作回归诊断。如下列模型。 (1)y 0 1e x (2)y 0 1x2x2p x p (3)y ae bx (4)y=alnx+b 对于(1)式,只需令x e x即可化为y对x是线性的形式y01x,需要指出的是,新引进的自变量只能依赖于原始变量,而不能与未知参数有关。 对于(2)式,可以令x1=x,x2=x2,?,x p=x p,于是得到y关于x1,x2,?, x p 的线性表达式y 0 1x12x2 pxp 对与(3)式,对等式两边同时去自然数对数,得lnylnabx ,令 y lny, 0 lna, 1 b,于是得到y关于x的一元线性回归模型: y 0 1x。 乘性误差项模型和加性误差项模型所得的结果有一定差异,其中乘性误差项模型认为yt本身是异方差的,而lnyt是等方差的。加性误差项模型认为yt是等 方差的。从统计性质看两者的差异,前者淡化了y t值大的项(近期数据)的作用, 强化了y t值小的项(早期数据)的作用,对早起数据拟合得效果较好,而后者则 对近期数据拟合得效果较好。 影响模型拟合效果的统计性质主要是异方差、自相关和共线性这三个方面。 异方差可以同构选择乘性误差项模型和加性误差项模型解决,必要时还可以使用 加权最小二乘。
多元线性回归模型
多元线性回归模型 一、单选题 1.可决定系数2R 是指( ) A 、剩余平方和占总离差平方和的比重 B 、总离差平方和占回归平方和的比重 C 、回归平方和占总离差平方和的比重 D 、回归平方和占剩余平方和的比重 2.调整的多重可决定系数2R 和2R 多重可决定系数之间的关系是( ) A 、22 11n R R n k -=-- B 、22111 n R R n k -=--- C 、2211(1)1n R R n k -=-+-- D 、2211(1)1n R R n k -=---- 3.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算的多重可决定系数为0.8500,则调整后的可决定系数为( ) A 、0.8603 B 、0.8389 C 、0.8655 D 、0.8327 4.设k 为模型中参数的个数,则回归平方和为( ) A 、2 1 ()n i i Y Y =-∑ B 、21?()n i i i Y Y =-∑ C 、21?()n i i Y Y =-∑ D 、21 ()n i i Y Y =-∑ 5.最常用的统计检验准则包括拟合优度检验、变量的显著性检验和( ) A 、方程的显著性检验 B 、多重共线性检验 C 、异方差检验 D 、预测检验 6.设k 为回归模型中参数的个数(不含截距项),n 为样本容量,RSS 为残差平方和,ESS 为回归平方和,则对总体回归模型进行显著性检验时构造的F 统计量为( ) A 、ESS F TSS = B 、//(1) ESS k F RSS n k =-- C 、/1/(1)ESS k F TSS n k =- -- D 、RSS F TSS =
多元线性回归模型习题及答案
多元线性回归模型 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定 系数为,则调整后的多重决定系数为( D ) A. B. C. 下列样本模型中,哪一个模型通常是无效 的(B ) A. i C (消费)=500+i I (收入) B. d i Q (商品需求)=10+i I (收入)+i P (价格) C. s i Q (商品供给)=20+i P (价格) D. i Y (产出量)=0.6i L (劳动)0.4i K (资本) 3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在的显著性水平上对 1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C ) A. )30(05.0t B. )28(025.0t C. )27(025.0t D. )28,1(025.0F 4.模型 t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明 模型中存在( C ) A.异方差性 B.序列相关 C.多重共线性 D.高拟合优度 6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) (n-k+1) (n-k-2) (n-k-1) (n-k+2) 7. 调整的判定系数 与多重判定系数 之间有如下关系( D ) A.2 211n R R n k -=-- B. 22111 n R R n k -=--- C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=---- 8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。 A.只有随机因素 B.只有系统因素 C.既有随机因素,又有系统因素 、B 、C 都不对 9.在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):( C ) A n ≥k+1 B n 第四节 非线形回归模型 一、 可线性化模型 在非线性回归模型中,有一些模型经过适当的变量变换或函数变换就可以转化成线性回归模型,从而将非线性回归模型的参数估计问题转化成线性回归模型的参数估计,称这类模型为可线性化模型。在计量经济分析中经常使用的可线性化模型有对数线性模型、半对数线性模型、倒数线性模型、多项式线性模型、成长曲线模型等。 1.倒数模型 我们把形如: u x b b y ++=110;u x b b y ++=1110 (3.4.1) 的模型称为倒数(又称为双曲线函数)模型。 设:x x 1*=,y y 1*=,即进行变量的倒数变换,就可以将其转化成线性回归模型。 倒数变换模型有一个明显的特征:随着x 的无限扩大,y 将趋于极限值0b (或0/1b ),即有一个渐进下限或上限。有些经济现象(如平均固定成本曲线、商品的成长曲线、恩格尔曲线、菲利普斯曲线等)恰好有类似的变动规律,因此可以由倒数变换模型进行描述。 2.对数模型 模型形式: u x b b y ++=ln ln 10 (3.4.2) (该模型是将u b e Ax y 1=两边取对数,做恒等变换的另一种形式,其中A b ln 0=)。 上式lny 对参数0b 和1b 是线性的,而且变量的对数形式也是线性的。因此,我们将以上模型称为双对数(double-log)模型或称为对数一线性(log-liner)模型。 令:x x y y ln ,ln **==代入模型将其转化为线性回归模型: u x b b y ++=*10* (3.4.3) 变换后的模型不仅参数是线性的,而且通过变换后的变量间也是线性的。 模型特点:斜率1b 度量了y 关于x 的弹性: 我国农民收入影响因素的回归分析 本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。?农民收入水平的度量常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。二是农业剩余劳动力转移水平。三是城市化、工业化水平。四是农业产业结构状况。五是农业投入水平。考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。 一、计量经济模型分析 (一)、数据搜集 根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。 资料来源《中国统计年鉴2006》。 (二)、计量经济学模型建立 我们设定模型为下面所示的形式: 利用Eviews 软件进行最小二乘估计,估计结果如下表所示: DependentVariable:Y Method:LeastSquares Sample: Includedobservations:19 Variable Coefficient t-Statistic Prob. C X1 X3 X4 X5 X6 X7 X8 R-squared Meandependentvar AdjustedR-squared 表1最小二乘估计结果 回归分析报告为: () ()()()()()()()()()()()()()()() 2345678 2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66 R Df DW F ====二、计量经济学检验 (一)、多重共线性的检验及修正 ①、检验多重共线性 (a)、直观法 从“表1最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4x6 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为(ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110(3、2、11) 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110(3、2、12) 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义就是,当其她自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min (2) 1 2211012 →++++-=??? ??-=∑∑==∧ n a ka k a a a n a a a x b x b x b b y y y Q (3、2、13) 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110) ,...,2,1(0202(3、2、14) 将方程组(3、2、14)式展开整理后得: 一、邹式检验(突变点检验、稳定性检验) 1.突变点检验 1985—2002年中国家用汽车拥有量(t y ,万辆)与城镇居民家庭人均可支配收入(t x ,元),数据见表。 表 中国家用汽车拥有量(t y )与城镇居民家庭人均可支配收入(t x )数据 年份 t y (万辆) t x (元) 年份 t y (万辆) t x (元) 1985 1994 1986 1995 4283 1987 1996 1988 1997 1989 1998 1990 1999 5854 1991 2000 6280 1992 2001 1993 2002 下图是关于t y 和t x 的散点图: 从上图可以看出,1996年是一个突变点,当城镇居民家庭人均可支配收入突破元之后,城镇居民家庭购买家用汽车的能力大大提高。现在用邹突变点检验法检验1996年是不是一个突变点。 :两个字样本(1985—1995年,1996—2002年)相对应的模型回归参数相等H H :备择假设是两个子样本对应的回归参数不等。 1 在1985—2002年样本范围内做回归。 在回归结果中作如下步骤(邹氏检验): 1、 Chow 模型稳定性检验(lrtest) 用似然比作chow检验,chow检验的零假设:无结构变化,小概率发生结果变化* 估计前阶段模型 * 估计后阶段模型 * 整个区间上的估计结果保存为All * 用似然比检验检验结构没有发生变化的约束 得到结果如下; (如何解释) 2.稳定性检验(邹氏稳定性检验) 以表为例,在用1985—1999年数据建立的模型基础上,检验当把2000—2002年数据加入样本后,模型的回归参数时候出现显著性变化。 * 用F-test作chow间断点检验检验模型稳定性 * chow检验的零假设:无结构变化,小概率发生结果变化 * 估计前阶段模型 * 估计后阶段模型 * 整个区间上的估计结果保存为All 多元线性回归模型公式 HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量y 受k 个自变量k x x x ,...,,21的影响,其n 组观测值为 (ka a a a x x x y ,...,,,21),n a ,...,2,1=。那么,多元线性回归模型的结构形式为: a ka k a a a x x x y εββββ+++++=...22110() 式中: k βββ,...,1,0为待定参数; a ε为随机变量。 如果k b b b ,...,,10分别为k ββββ...,,,210的拟合值,则回归方程为 ?=k k x b x b x b b ++++...22110() 式中: 0b 为常数; k b b b ,...,,21称为偏回归系数。 偏回归系数i b (k i ,...,2,1=)的意义是,当其他自变量j x (i j ≠)都固定时,自变量i x 每变化一个单位而使因变量y 平均改变的数值。 根据最小二乘法原理,i β(k i ,...,2,1,0=)的估计值i b (k i ,...,2,1,0=)应该使 ()[]min ...212211012→++++-=??? ??-=∑∑==∧n a ka k a a a n a a a x b x b x b b y y y Q () 有求极值的必要条件得 ???????==??? ??--=??=??? ??--=??∑∑=∧=∧n a ja a a j n a a a k j x y y b Q y y b Q 110),...,2,1(0202() 将方程组()式展开整理后得: ?????????????=++++=++++=++++=++++∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑∑===================n a a ka k n a ka n a ka a n a ka a n a ka n a a a k n a ka a n a a n a a a n a a n a a a k n a ka a n a a a n a a n a a n a a k n a ka n a a n a a y x b x b x x b x x b x y x b x x b x b x x b x y x b x x b x x b x b x y b x b x b x nb 11221211101 121221221121012111121211121011112121110)(...)()()(...)(...)()()()(...)()()()(...)()( () 方程组()式,被称为正规方程组。 如果引入一下向量和矩阵: 则正规方程组()式可以进一步写成矩阵形式 B Ab =(3.2.15’) 多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据 设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024 二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量 y 受 k 个自变量 x 1, x 2 ,..., x k 的影响,其 n 组观测值为( y a , x 1 a , x 2 a ,..., x ka ), a 1,2,..., n 。那么,多元线性回归模型的结构形式为: y a 0 1 x 1a 2 x 2 a ... k x ka a () 式中: 0 , 1 ,..., k 为待定参数; a 为随机变量。 如果 b 0 , b 1 ,..., b k 分别为 0 , 1 , 2 ..., k 的拟合值,则回归方程为 ?= b 0 b 1x 1 b 2 x 2 ... b k x k () 式中: b 0 为常数; b 1, b 2 ,..., b k 称为偏回归系数。 偏回归系数 b i ( i 1,2,..., k )的意义是,当其他自变量 x j ( j i )都固定时,自变量 x i 每变 化一个单位而使因变量 y 平均改变的数值。 根据最小二乘法原理, i ( i 0,1,2,..., k )的估计值 b i ( i 0,1,2,..., k )应该使 n 2 n 2 Q y a y a y a b 0 b 1 x 1a b 2 x 2a ... b k x ka min () a 1 a 1 有求极值的必要条件得 Q n 2 y a y a b 0 a 1 () Q n 2 y a y a x ja 0( j 1,2,..., k) b j a 1 将方程组()式展开整理后得: 对多元线性回归模型的各种检验方法 对于形如 u X X X Y k k +++++=ββββ 22110 (1) 的回归模型,我们可能需要对其实施如下的检验中的一种或几种检验: 一、 对单个总体参数的假设检验:t 检验 在这种检验中,我们需要对模型中的某个(总体)参数是否满足虚拟假设0 H :j j a =β,做出具有统计意义(即带有一定的置信度)的检验,其中j a 为某个给定的已知数。特别是,当j a =0时,称为参数的(狭义意义上的)显著性检验。如果拒绝0H ,说明解释变量j X 对 被解释变量Y 具有显著的线性影响,估计值j β?才敢使 用;反之,说明解释变量j X 对被解释变量Y 不具有显 著的线性影响,估计值j β?对我们就没有意义。具体检验 方法如下: (1) 给定虚拟假设 0H :j j a =β; (2) 计算统计量 )?(?)?()(?j j j j j j Se a Se E t βββββ-=-= 的数值; 11?)?(++-==j j jj jj j C C Se 1T X)(X ,其中σβ (3) 在给定的显著水平α下(α不能大于1.0即 10%,也即我们不能在置信度小于90%以下的前提下做结论),查出双尾t (1--k n )分布的临界值2/αt ; (4) 如果出现 2/αt t >的情况,检验结论为拒绝 0H ;反之,无法拒绝0H 。 t 检验方法的关键是统计量 )?(?j j j Se t βββ-=必须服从已 知的t 分布函数。什么情况或条件下才会这样呢?这需要我们建立的模型满足如下的条件(或假定): (1) 随机抽样性。我们有一个含n 次观测的随机样(){}n i Y X X X i ik i i ,,2,1:,,,,21 =。这保证了误差u 自身的随机性,即无自相关性, 1.3非线性回归问题, 知识目标:通过典型案例的探究,进一步学习非线性回归模型的回归分析。 能力目标:会将非线性回归模型通过降次和换元的方法转化成线性化回归模型。 情感目标:体会数学知识变化无穷的魅力。 教学要求:通过典型案例的探究,进一步了解回归分析的基本思想、方法及初步应用. 教学重点:通过探究使学生体会有些非线性模型通过变换可以转化为线性回归模型,了解在解决实际问题的 过程中寻找更好的模型的方法. 教学难点:了解常用函数的图象特点,选择不同的模型建模,并通过比较相关指数对不同的模型进行比较. 教学方式:合作探究 教学过程: 一、复习准备: 对于非线性回归问题,并且没有给出经验公式,这时我们可以画出已知数据的散点图,把它与必修模块《数学1》中学过的各种函数(幂函数、指数函数、对数函数等)的图象作比较,挑选一种跟这些散点拟合得最好的函数,然后采用适当的变量代换,把问题转化为线性回归问题,使其得到解决. 二、讲授新课: 1. 探究非线性回归方程的确定: 1. 给出例1:一只红铃虫的产卵数y 和温度x 有关,现收集了7组观测数据列于下表中,试建立y 与x 之间的/y 个 2. 讨论:观察右图中的散点图,发现样本点并没有分布在某个带状区域内,即两个变量不呈线性相关关系,所以不能直接用线性回归方程来建立两个变量之间的关系. ① 如果散点图中的点分布在一个直线状带形区域,可以选线性回归模型来建模;如果散点图中的点分布在一个曲线状带形区域,就需选择非线性回归模型来建模. ② 根据已有的函数知识,可以发现样本点分布在某一条指数函数曲线y =2C 1e x C 的周围(其中12,c c 是待定的参数),故可用指数函数模型来拟合这两个变量. ③ 在上式两边取对数,得21ln ln y c x c =+,再令ln z y =,则21ln z c x c =+,可以用线性回归方程来拟合. ④ 利用计算器算得 3.843,0.272a b =-=,z 与x 间的线性回归方程为 0.272 3.843z x =-,因此红铃虫的产卵数对温度的非线性回归方程为0.272 3.843x y e -=. ⑤ 利用回归方程探究非线性回归问题,可按“作散点图→建模→确定方程”这三个步骤进行. 其关键在于如何通过适当的变换,将非线性回归问题转化成线性回归问题. 三、合作探究 例 2.:炼钢厂出钢时所用的盛钢水的钢包,在使用过程中,由于钢液及炉渣对包衬耐火材料的侵蚀,使其容积不断增大,请根据表格中的数据找出使用次数 x 与增大的容积y 之间的关系. 农业网络信息 AGRICULTURE NETWORK INFORMATION ·研究与开发· 2011年第1期 巧用Excel 解决多元非线性回归分析 龚江,石培春,李春燕 (石河子大学农学院,石河子832003) 摘 要:非线性回归是回归分析的重要内容和难点,而多元非线性回归在农业生产中有重要的应用。应用Excel “工具” 菜单“数据分析”选项中的“回归”分析工具,以二元二次非线性回归为例,阐述了用Excel 做多元非线性回归的详细过程,并与SPSS 软件做的结果进行比较,证明使用Excel 做多元非线性回归完全可行,且操作简单、易行,并就方程的统计意义进行了分析。 关键词:Excel ;多元;非线性回归中图分类号:S126 文献标识码:A 文章编码:1672-6251(2011)01-0046-03 Application of Excel Software in Multi-nonlinear Regress Analysis GONG Jiang,SHI Peichun,LI Chunyan (Agriculture College of Shihezi Univerity,Shihezi 832003) Abstract:Nonlinear regress analysis was a difficult and significant method of regress analysis ,the application of which was important in agriculture production.In this paper,with the multi-linear regression analysis by “data analysis ”tool of Microsoft Excel as example,a 2times nonlinear regress analysis ’s process was described,and the results showed that the output was same with SPSS software ,then the statistical significance of the 2times nonlinear regress equation was analyzed.Key words:Excel software;multi analysis;nonlinear regress 注:新疆石河子大学农学院一类课程“生物统计学”支助。 作者简介:龚江(1976-),男,硕士,讲师,研究方向:生物统计教学和植物营养。收稿日期:2010-12-10 大量统计软件的问世,使统计分析在科研领域迅速普及应用。众所周知,统计软件如SAS 、SPSS 等虽然功能强大,但较难掌握,并且市面上出售的统计软件大都是盗版软件,不但运行结果的可靠性无法保证,也侵犯了知识产权。对于大多数科研工作者,尤其是基层的科研工作者来说,经常使用的统计软件与涉及的方法也很有限,主要集中在方差分析、回归与相关分析等少数几种方法上,并不需要包罗万象、功能强大的统计软件。而正版统计软件也由于其价格不菲,难以被大多数科研工作者承受。Excel 是Office 家族的一个成员,是功能强大、使用方便的电子表格式数据综合管理与分析系统,可用来记录和整理试验数据。另外,Excel 也具备一些统计运算的功能 [1] ,若能 巧妙地使用,也可以解决一些较为复杂的农业统计运算问题,如多元非线性回归的问题等,其统计结果和 SPSS 软件结果一致。 1Excel 统计功能的安装 单击Microsoft Excel 中文版菜单栏中“工具”的 “加载宏”命令,在“加载宏”对话框中选定“分析工具库”,再按“确定”钮(见图1), “数据分析” 这一项就出现在工具菜单栏中(见图2)。若Excel “工具”中的“加载宏”没有“分析工具库”,则将 Office Excel 中文专业版光盘放入光驱中,运行“安装”程序,点击“添加/删除”按钮,出现“Microsoft Office 维护”对话框后,在“选项”一栏中,选中“Microsoft Excel ”,然后单击“更改选项”按钮,出现新的对话框,再选中“加载宏”继续单击“更改选项”按钮,在新的对话框中选取分析工具库,确定即可,之后按照安装向导的指示即可顺利安装。 图1Excel 统计功能的安装 企业销售额影响因素分析及回归模型学号:1003131014 姓名:李绍林班级:10级人力资源管理 一、问题提出 (一)研究问题: 随着市场经济的进一步发展,也加剧了企业在市场运行中的不确定性,如何在复杂多变的市场中占据主导,如何在经济流通的过程中,充分利用各种有利的因素,来确保企业销售额的增长,如何控制经济流通中的各项开支,如何组合来服务于企业销售额的增长。因此,在这里通过分析某家公司的企业销售状况,试图研究影响企业销售额的各因素及其之间的关系,建立企业销售额及其因素的回归模型,并进行经济分析。(二)数据来源 某企业开支与销售额关系表: 二、定性分析 为了研究企业销售额的影响因素,我们对相关数据进行简单的定性分析,并各因素同因变量的相关关系做了一个简单的预测。 个人可支配收入反映一个地区或市场上消费者的购买能力,单独来看,应与企业的销售额呈正相关关系,即企业产品的目标市场群体的个人可支配收入起高,企业所能获得的销售额也会相应提高。 商业回扣是企业为了改善销售商之间的关系,同时加强同销售商之间的合作,通过商业回扣的方式来吸引销售商,商业回扣作为企业的一个重要的营销策略,这也会减少企业的利润,商业回扣作为影响企业销售额的重要因素,商业回扣投入情况同企业的销售额多少有一定的关系。 商品价格能够通过企业产品的需求来影响企业的销售量,两者共同作用于企业的销售额,是影响企业销售额的一个关系因子。如何制定价格策略来提高企业的销售额,具有重要的现实意义。 研究与发展经费反映企业的研发能力和对市场的捕捉能力,能够适应市场需求来适应开发新的产品,不断开拓新的市场,提高产品的质量和水平,这能够为企业的扩大市场份额和企业销售额的提高。 广告费用是企业为了对产品进行推广和让消费者更好地了解产品和创造需求,引导消费者的购买欲望,同时有利于树立产品和企业的形象。当然广告费用的支出也是影响企业销售额的一个重要因子。 销售费用是企业为了产品的销售在产品的流通和销售过程中发生的一系列费用的总和,其与企业的销售额有一定的关系。 因此,我们选择企业的销售额作为被解释变量y ,选取个人可支配收入、商业回扣、商品价格、研究与发展经费、广告费、销售费作为解释变量,分别设其为x1、x2、x3、x4、x5、x6 。 三、相关分析 (一)数据基本描述 Descriptive Statistics 多元线性回归模型练习 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得可决系数为0.8500,则调整后的可决系数为( D ) A. 0.8603 B. 0.8389 C. 0.8655 D.0.8327 2.用一组有30个观测值的样本估计模型 01122t t t t y b b x b x u =+++后,在0.05的 显著性水平上对1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C ) A. ) 30(05.0t B. ) 28(025.0t C. ) 27(025.0t D. ) 28,1(025.0F 3.线性回归模型 01122......t t t k kt t y b b x b x b x u =+++++ 中,检验 0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) A.t(n-k+1) B.t(n-k-2) C.t(n-k-1) D.t(n-k+2) 4. 调整的可决系数 与多元样本判定系数 之间有如下关系( D ) A. 2211n R R n k -= -- B. 22 1 11n R R n k -=--- C. 2211(1)1n R R n k -=- +-- D. 221 1(1) 1n R R n k -=---- 5.对模型Y i =β0+β1X 1i +β2X 2i +μi 进行总体显著性F 检验,检验的零假设是( A ) A. β1=β2=0 B. β1=0 C. β2=0 D. β0=0或β1=0 6.设k 为回归模型中的参数个数,n 为样本容量。则对多元线性回归方程进行 显著性检验时,所用的F 统计量可表示为( B ) A. )1() (--k RSS k n ESS B . C . )1()1()(2 2---k R k n R D .)() 1/(k n TSS k ESS -- 7.多元线性回归分析中(回归模型中的参数个数为k ),调整后的可决系数2 R 与可决系数2 R 之间的关系( A ) ) 1 ( ) 1 ( 2 2 - - k R k R - n 研究在线性关系相关性条件下,两个或者两个以上自变量对一个因变量,为多元线性回归分析,表现这一数量关系的数学公式,称为多元线性回归模型。多元线性回归模型是一元线性回归模型的扩展,其基本原理与一元线性回归模型类似,只是在计算上为复杂需借助计算机来完成。 计算公式如下: 设随机y与一般变量X1,X2,L X k的线性回归模型为: 其中°, 1,L k是k 1个未知参数,°称为回归常数,「L k称为回归系数;y称为被解释变量;x1, X2,L x k是k个可以精确可控制的一般变量,称为解释变量。 当P 1时,上式即为一元线性回归模型,k 2时,上式就叫做多元形多元回归模型。是随机误差,与一元线性回归一样,通常假设 同样,多元线性总体回归方程为y °1x1 2x2 L k x k 系数1表示在其他自变量不变的情况下,自变量乂[变动到一个单位时引起的因变量y 的平均单位。其他回归系数的含义相似,从集合意义上来说,多元回归是多维空间上的一个平面。 多元线性样本回归方程为:? ?° ?1x1 ?2x2 L ?k x k 多元线性回归方程中回归系数的估计同样可以采用最小二乘法。由残差平方和:SSE (y ?) 0 根据微积分中求极小值得原理,可知残差平方和SSE存在极小值。欲使SSE达到 最小,SSE对 °, 1丄k的偏导数必须为零。 将SSE对 ° ,1丄k求偏导数,并令其等于零,加以整理后可得到k 1各方程 SSE 式:—— 2 (y ?) ° i 通过求解这一方程组便可分别得到°, 1,L k的估计值,彳,?…?k回归 系数的估计值,当自变量个数较多时,计算十分复杂,必须依靠计算机独立完成。现在,利用SPSS,只要将数据输入,并指定因变量和相应的自变量,立刻就能得到结果。 对多元线性回归,也需要测定方程的拟合程度、检验回归方程和回归系数的显着性。 多元非线性回归 目录 1 什么是多元非线性回归分析 2 多元非线性回归分析方程 3 多元非线性回归分析模型[1] 什么是多元非线性回归分析 多元非线性回归分析是指包含两个以上变量的非线性回归模型。对多元非线性回归模型求解的传统做法,仍然是想办法把它转化成标准的线性形式的多元回归模型来处理。有些非线性回归模型,经过适当的数学变换,便能得到它的线性化的表达形式,但对另外一些非线性回归模型,仅仅做变量变换根本无济于事。属于前一情况的非线性回归模型,一般称为内蕴的线性回归,而后者则称之为内蕴的非线性回归。 多元非线性回归分析方程 如果自变数X_1,X_2,\cdots,X_m与依变数Y皆具非线性关系,或者有的为非线性有的为线性,则选用多元非线性回归方程是恰当的。例如,二元二次多项式回归方程为:{y}=a+b_{11}x_1+b_{21}x_2+b_{12}x_1^2+b_{22}x_2^2+b_{11 \times22}x_1x_2 令b_1=b_{11},b_2=b_{21},b_3=b_{12},b_4=b_{22},b_5=b_{11\tim es22},及x_3=x_1^2,x_4=x_2^2,x_5=x_1\cdot x_2,于是上式化为 五元一次线性回归方程: \widehat{y}=a+b_1x_1+b_2x_2+b_3x_3+b_4x_4+b_5x_5 这样以来,便可按多元线性回归分析的方法,计算各偏回归系数,建立二元二次多项式回归方程。 多元非线性回归分析模型[1] 一、常见的内蕴多元性回归模型 只要对模型中的变量进行数学变换,比如自然对数变换等,就可以将其转化具有标准形式特征的多元线性回归模型。 1.多重弹性模型 (y_1;x_{11},x_{12}\cdots,x_{1k}),(y_2;x_{21},x_{22}\cdots,x_{2k}),\ cdots,(y_n;x_{n1},x_{n2}\cdots,x_{nk})是一组对的样本观察资料,则称存在下列关系的非线性回归模型为多重弹性模型 y_i=\beta_0x_{i1}^{\beta_1}x_{i2}^{\beta_2}\cdots x_{ik}^{\beta_k}e^{\epsilon_{i}} (1) 上述模型中的各解释变量的幂,能够说明解释变量的相对变化对被解释变量产生的相对影响,我们正式从这一角度说它是多重弹性模型的。 2.Cobb-Dauglas生产函数模型 y_i=AK_{i}^aL_i^{\beta}e^{\epsilon_{i}},i=1,2,\cdots,n (2) 其中,yi表示产出总量,Ki为资本要素,Li为劳动力要素,A、计量经济学基础_非线性回归模型
多元线性回归模型案例
多元线性回归模型公式
第三章多元线性回归模型(stata)
多元线性回归模型公式定稿版
(完整word版)多元线性回归模型案例分析
多元线性回归模型公式().docx
多元线性回归模型的各种检验方法
非线性回归分析(教案)
巧用Excel解决多元非线性回归分析
多元线性回归分析模型
多元线性回归模型练习题及答案
多元线性回归模型原理
多元非线性回归