计量经济学自相关性
实验自相关性
一实验目地:掌握自相关性模型的检验方法与处理方法
二实验要求:做自相关性模型的图形法检验和DW检验,使用广义最小二乘法和广义差分法进行修正。
三实验原理:图形法检验、DW检验、广义最小二乘法和广义差分法。
四实验内容:
中国1995~2013年全社会固定资产投资总额X与第三产业总产值Y的统
计资料如下表所示。
年份全社会固定资产投资(X)第三产业业增加值(Y)
1995 20019.3 19978.4603
1996 22913.5 23326.24265
1997 24941.1 26988.14714
1998 28406.2 30580.46571
1999 29854.7 33873.44469
2000 32917.7 38713.95385
2001 37213.5 44361.61054
2002 43499.9 49898.90182
2003 55566.6 56004.72631
2004 70477.43 64561.29201
2005 88773.6129 74919.27517
2006 109998.1624 88554.88436
2007 137323.9381 111351.9478
2008 172828.3998 131339.9871
2009 224598.7679 148038.036
2010 251683.7688 173595.984
2011 311485.1254 205205.0237
2012 374694.7355 231934.4791
2013 446294.0902 262203.7924
五实验步骤:
在经济系统中,经济变量前后期之间很可能有关联,使得随机误差项不能满足无自相关性的假设。本案例将探讨随机误差项不满足无自相关性的古典假定的参数估计问题。着重讨论自相关性模型的图形法检验、DW检验与广义最小二乘估计和广义差分法。
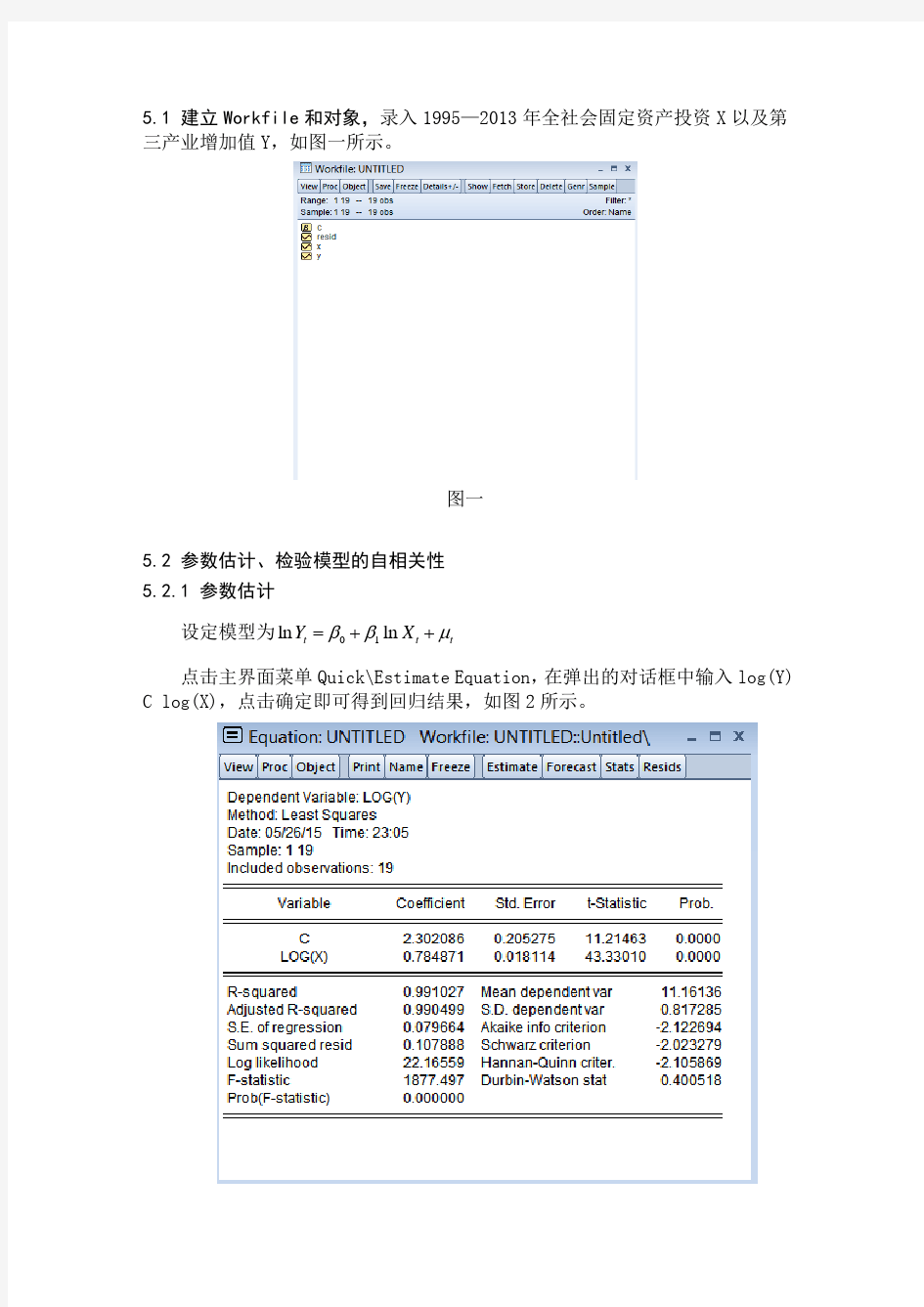
5.1 建立Workfile 和对象,录入1995—2013年全社会固定资产投资X 以及第三产业增加值Y ,如图一所示。
图一
5.2 参数估计、检验模型的自相关性 5.2.1 参数估计
设定模型为01ln ln t t t Y X ββμ=++
点击主界面菜单Quick\Estimate Equation ,在弹出的对话框中输入log(Y) C log(X),点击确定即可得到回归结果,如图2所示。
根据图2中数据,得到模型的估计结果为:
()()
43.3311.210.7848X 2.3020Y ?ln t
t +=
0.991027
R 2= 0.990499R 2= 0.400518.W .D = 1877.497F = 0.107888RSS =
该回归方程的可决系数较高,回归系数显著。对样本容量为19、一个解析
变量的模型、5%的显著性水平,查D.W.统计表可知, 1.40d 1.18d U L ==,
模型中..L DW d <,显然模型中存在正自相关。
下面对模型的自相关性进行检验。
5.2.2 检验模型的自相关性
点击Eviews 方程输出窗口的按钮Resids 可以得到残差图,如图3所示。
图三
图3的残差图中,残差的变动有系统模式,连续为正和连续为负,表明残差存在一阶正自相关,模型中t 统计量和F 统计量的结论不可信,需要采取补救措施。
点击工作文件窗口工具栏中的Object\Generate Series …,在弹出的对话框中输入et=resid,如图4所示,点击OK 得到残差序列et 。
图四
点击Quick\Graph\Line Graph,在弹出的对话框中输入:et,再点击OK,
得到残差项~
t
e与时间的关系图,如图5所示,
图五
点击Quick\Graph\Scatter,在弹出的对话框中输入:et(-1) et,再点击
OK,得到残差项~
t
e与~1t e 时间的关系图,如图6所示。
图六
从图5和图6中可以看出,随机干扰项呈现正相关。
由于时间序列数据容易出现为回归现象,因此做回归分析是须格外谨慎的。本例中,Y和X都是事件序列书记,因此有理由怀疑较高的2R部分是由这一共
同的变化趋势带来的。为了排除事件序列模型中的这种随时间变动而具有的共同变化趋势的影响,一种解决方案是在模型中引入时间趋势项,将这种影响分离出来。点击Quick\Graph\Line Graph,在弹出对话框中输入:X Y,再点击OK,得到去社会固定资产投资X与第三产业增加值Y的变动图,如图7所示。
图七
由图7可以看出,由于全社会固定资产投资X 与工业增加值Y 均呈现非线
性变化态势,我们引入时间变量),,,(19......21T T 以平方的形式出现。 点击工作文件窗口工具栏中的Object\ Generate Series …,在弹出的对话
框中输入T=@TREND+1,点击OK 得到时间变量序列T 。
点击主界面菜单Quick\Estimate Equation ,在弹出的对话框中输入log(Y) C log(X) T^2,点击确定即可得到回归结果,如图8所示。
图八
从图8中的数据,我 们可以看到T^2的系数估计非常的小,而且其伪概率P 值为0.3026,即接受其系数为0的原假设,于是不通过假设检验。 我们认为原模型不存在虚假序列相关的成分,所以我们仍然采用原模型,即不引入时间趋势项。即原模型中较低的D.W.值是纯序列相关引起的。
5.3 使用广义最小二乘法估计模型
是假设存在一阶自相关1t t t μρμε-=+,然后使用广义最小二乘法进行估计。 对于原模型01ln ln t t t Y X ββμ=++,存在序列相关性,于是要找到一个可逆矩阵D ,用1D -左乘上式两边,得到一个新的模型:
111101ln ln t t t D Y D D X D ββμ----=++
即
*0**1*Y X ββμ=++
由一阶自相关假设1t t t μρμε-=+,可得:
211000001000001000000100000100
1D ρρρρρ
-??-?
?-????-??=?
???????-??-?
?
因为样本容量较大时可根据1../2DW ρ=-计算,又0.400518.W .D =,因此得0.799741=ρ,由此,我们可以直接计算新产生的序列*Y 跟*X 。
点击工作文件窗口工具栏中的Object\Generate Series …,在弹出的对话框中输入命令:lny=log(y),来产生取了自然对数后的Y 序列。同样的,使用命令yx=-0.79974*lny(-1)+lny ,来产生新的序列*Y ,此时产生的*Y ,只有后n-1项,我们必须人工计算2*111*ln Y Y ρ=-,然后补充到新产生的yx 序列中去。
同样的操作,我们也产生*X ,即为xx 序列,其第一项也是要人工计算然后补充的。产生的新序列如图9、10所示。
图九 图十
于是我们就可以对新序列*Y (yx)跟*X (xx)进行最小二乘估计了。 点击主界面Quick\Estimate Equation ,在弹出的对话框中输入yx C xx ,点击确定即可得到回归结果如图11所示。
图11
根据图11中的数据,可得到广义最小二乘法估计的结果:
()()
42.559450.32-0.989653X -0.020718Y *
*+=
0.990702R 2= 0.990155R 2= 0.581702.W .D =
可见D.W.值已经有所改善,但模型仍具有序列相关性。
计量经济学——时间序列
课程论文 题目:第三产业产值的影响因素分析 学院财会学院_ 专业会计专硕 班级会计专硕1501 课程名称计量经济学(课程设计) 学号 学生姓名 60 指导教师赵卫亚 成绩 二○一五年十二月
第三产业产值的影响因素分析 摘要:本文利用计量经济分析方法和1990—2010年的时间序列统计资料,建立了我国第三产业产值影响因素模型。建模过程中,处理了模型中的协整检验、自相关性等问题。本文认为我国第三产业产值主要受GDP和我国城乡居民存款储蓄的影响,因此需要引起足够的重视,正确开展工作,促进第三产业的发展。 关键词:第三产业产值;时间序列分析;GDP;城乡居民存款储蓄 一、引言 第三产业是指除第一二产业以外的其他行业。自从我国进入改革开放以来,我国不仅在积极发展第一产业和第二产业的同时,也在积极扶植第三产业的发展。我国属于发展中国家,仅靠出口农产品或初级工业品很难在国际社会中立有一足之地。进入21世纪,第三产业的发展迫切需要成为促进经济发展的主要动力。这主要是因为第三产业基本以服务业为主,这就使其具有了行业多,范围广等特点,从而能够提供更多的就业机会,相对于其他产业服务业的就业门滥相对来说也较低,能吸纳农村等剩余劳动力,并且第三产业的发展,也能有效地促进第一产业和第二产业的发展,加速推进我国的工业化和现代化进程,提高我国的综合国力。我国的第三产业较其他发达国家仍有很大的差距,所以加快本国第三产业发展迫在眉睫。 第三产业不仅在占国民生产总值比重方面不断提高,其内部的产业结构也在不断地发生着变化。最初我国第三产业的发展主要集中以餐饮等为主的传统服务业上,而随着新型服务业的产生,我国开始侧重向金融保险业、房地产业等方面的发展,其数量和质量的提高使得第三产业在我国经济发展的过程中产生的作用也越来越显著。 因此,研究第三产业产值的影响因素分析具有实际意义。 二、文献综述 江小涓、李辉(2004)建立了一个多元回归模型来分析收入水平、消费结构、城市化以及其他因素对第三产业未来发展的影响,提出第三产业比例随着人均GDP水平增长而增加[1]。郭彩霞(2009)对1978到2008年相关数据进行实证分析,得到要想加快农村现代化就必须要促进第三产业的发展结论[2]。王小宁(2009)认为第三产业固定资产的投资对第三产业产值具有重大的影响[3]。徐群、于德淼、赵春阁在对第三产业发展研究时主要是利用线性回归模型来对我国第三产业的影响因素进行分析,对我国第三产业发展现状的研究和趋势预测就是利用的主成分分析和逐步回归分析方法[4]。
计量经济学习题
《计量经济学》 习题 河北经贸大学应用经济学教研室 2004年7月
第一章绪论 ⒈为什么说计量经济学是经济理论、数学和经济统计学的结合? ⒉为什么说计量经济学是一门经济学科?它在经济学科体系中的地位是什么?它在经济研究中的作用是什么? ⒊建立与应用计量经济学模型的主要步骤有哪些? ⒋计量经济学模型有哪些主要应用领域?各自的原理是什么? ⒌下列假想模型是否属于揭示因果关系的计量经济学模型?为什么? ⑴St=112.0+0.12Rt 其中,St为第t年农村居民储蓄增加额(亿元),Rt为第t年城镇居民可支配收入总额(亿元)。 ⑵S t-1=4432.0+0.30R t 其中,S t-1为第(t-1)年底农村居民储蓄余额(亿元),Rt为第t年农村居民纯收入总额(亿元)。 ⒍指出下列假想模型中两个最明显的错误,并说明理由: RS t=8300.0-0.24RI t+1.12IV t 其中,RS t为第t年社会消费品零售总额(亿元),RI t为第t年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t为第t年全社会固定资产投资总额(亿元)。 第二章一元线性回归模型
⒈ 对于设定的回归模型作回归分析,需对模型作哪些假定,这些假定为什么是必要的? ⒉ 试说明利用样本决定系数R 2为什么能够判定回归直线与样本观测值的拟和优度。 ⒊ 说明利用) (0∧ βS 、)(1∧βS 衡量 ∧ β、∧ 1β对 β、1β估计稳定性的道理。 ⒋ 为什么对 ∧ β、∧ 1β进行显著性检验?试述检验方法及步骤。 ⒌ 对于求得的回归方程为什么进行显著性检验?试述检验方法及步骤。 ⒍ 阐述回归分析的步骤。 ⒎ 试述计量经济模型与一般的经济模型有什么不同? ⒏ 一元线性回归模型有时采用如下形式: i i i X Y μβ+=1 模型中的截距为零,叫做通过原点的回归模型。试证明该模型中: (1) ∑∑=∧ 21i i i X Y X β (2) ∑ = ∧ 2 2 1)var(i X μ σ β ⒐ 下述结果是从一个样本中获得的,该样本包含某企业的销售额(Y )及相应价格(X )的11个观测值。 18 .519_ =X ; 82 .217_ =Y ; ∑=3134543 2 i X ; ∑=1296836 i i Y X ; ∑=539512 2i Y (1)估计销售额对价格的样本回归直线,并解释其结果。 (2)回归直线的判定系数是多少? ⒑ 已知某地区26年的工农业总产值与货运周转量的数据见下表。试作一元线性回归分析,若下一年计划该地区工农业总产值为8亿元,预测货运周转量。
计量经济学期末考试重点
第一章绪论 1、什么是计量经济学?由哪三组组成? 答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科。 统计学、经济理论和数学三者结合起来便构成了计量经济学。 2、计量经济学的内容体系,重点是理论计量和应用计量和经典计量经济学理论方法方面的特 征 答:1)广义计量经济学和狭义计量经济学 2)初、中、高级计量经济学3)理论计量经济学和应用计量经济 理论计量经济学是以介绍、研究计量经济学的理论与方法为主要内容,侧重于理论与方法的数学证明与推导,与数理统计联系极为密切。除了介绍计量经济模型的数学理论基础、普遍应用的计量经济模型的参数估计方法与检验方法外,还研究特殊模型的估计方法与检验方法,应用了广泛的数学知识。 应用计量经济学则以建立与应用计量经济学模型为主要内容,强调应用模型的经济学和经济统计学基础,侧重于建立与应用模型过程中实际问题的处理。本课程是二者的结合。 4)、经典计量经济学和非经典计量经济学 经典计量经济学(Classical Econometrics)一般指20世纪70年代以前发展并广泛应用的计量经济学。 经典计量经济学在理论方法方面特征是: ⑴模型类型—随机模型; ⑵模型导向—理论导向; ⑶模型结构—线性或者可以化为线性,因果分析,解释变量具有同等地位,模型具有明
确的形式和参数; ⑷数据类型—以时间序列数据或者截面数据为样本,被解释变量为服从正态分布的连续随机变量; ⑸估计方法—仅利用样本信息,采用最小二乘方法或者最大似然方法估计模型。 经典计量经济学在应用方面的特征是: ⑴应用模型方法论基础—实证分析、经验分析、归纳; ⑵应用模型的功能—结构分析、政策评价、经济预测、理论检验与发展; ⑶应用模型的领域—传统的应用领域,例如生产、需求、消费、投资、货币需求,以及宏观经济等。 5)、微观计量经济学和宏观计量经济学 3、为什么说计量经济学是经济学的一个分支?(4点和综述) 答:(1)、从计量经济学的定义看 (2)、从计量经济学在西方国家经济学科中的地位看 (3)、从计量经济学与数理统计学的区别看 (4)、从建立与应用计量经济学模型的全过程看 综上所述,计量经济学是一门经济学科,而不是应用数学或其他。 4、理论模型的设计主要包含三部分工作,即选择变量,确定变量之间的数学关系,拟定模型 中待估计参数的数值范围。 5、常用的样本数据:时间序列,截面,面板(虚变量数据是错的,改为面板数据。主要要求时间数据序列数据和截面数据) 答:1、时间序列是一批按照时间先后排列的统计数据。 要注意问题:
计量经济学--自相关性的检验及修正
经济计量分析实验报告 一、实验项目 自相关性的检验及修正 二、实验日期 2015.12.13 三、实验目的 对于国内旅游总花费的有关影响因素建立多元线性回归模型,对变量进行多重共线性的检验及修正后,对随机误差项进行异方差的检验和补救及自相关性的检验和修正。 四、实验内容 建立模型,对模型进行参数估计,对样本回归函数进行统计检验,以判定估计的可靠程度,包括拟合优度检验、方程总体线性的显著性检验、变量的显著性检验,以及参数的置信区间估计。 检验变量是否具有多重共线性并修正。 检验是否存在异方差并补救。 检验是否存在相关性并修正。 五、实验步骤 1、建立模型。 以国内旅游总花费Y 作为被解释变量,以年底总人口表示人口增长水平,以旅行社数量表示旅行社的发展情况,以城市公共交通运营数表示城市公共交通运行状况,以城乡居民储蓄存款年末增加值表示城乡居民储蓄存款增长水平。 2、模型设定为: t t t t t μβββββ+X +X +X +X +=Y 443322110t 其中:t Y — 国内旅游总花费(亿元) t 1X — 年底总人口(万人) t 2X — 旅行社数量(个) t 3X — 城市公共交通运营数(辆) t 4X — 城乡居民储蓄存款年末增加值(亿元) 3、对模型进行多重共线性检验。 4、检验异方差是否存在并补救。 5、检验自相关性是否存在并修正。 六、实验结果
消除多重共线性及排除异方差性之后的回归模型为:2382963.08388.301?X Y +-= 检验 I 、图示法 1、1-t e ,t e 散点图 -1,500 -1,000 -500 500 1,000 1,500 -2,000 -1,00001,0002,000 ET(-1) E T 大部分落在第Ⅰ,Ⅲ象限,表明随机误差项存在正自相关。 2、t e 折线图 -1,500 -1,000 -500 500 1,000 1,500 86 88 90 92 94 96 98 00 02 04 06 08 10 RESID Ⅱ、解析法 1、D-W 检验
第九章时间序列计量经济学模型案例
第九章时间序列计量经济学模型案例 1、1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图和差分图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。 表9.1 中国人口时间序列数据(单位:亿人) 年份人口y t 年份人口y t年份人口y t年份人口y t年份人口y t 1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517 1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985 1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121 1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389 1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626 1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761 1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786 1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743 1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627 1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823 1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171 (1)画时间序列图 y的数据窗口 打开 t 得到中国人口序列图
计量经济学例题
一、单项选择题 4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据 B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据 D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型 B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型 D.确定模型导向→确定变量及方程式→估计模型→应用模型 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析
18.表示x 和y 之间真实线性关系的是( C )。 A .01???t t Y X ββ=+ B .01()t t E Y X ββ=+ C .01t t t Y X u ββ=++ D .01t t Y X ββ=+ 19.参数β的估计量?β具备有效性是指( B )。 A .?var ()=0β B .?var ()β为最小 C .?()0ββ-= D .?()ββ-为最小 25.对回归模型i 01i i Y X u ββ+=+进行检验时,通常假定i u 服从( C )。 A .2i N 0) σ(, B . t(n-2) C .2N 0)σ(, D .t(n) 26.以Y 表示实际观测值,?Y 表示回归估计值,则普通最小二乘法估计参数的准则是使( D )。 A .i i ?Y Y 0∑(-)= B .2i i ?Y Y 0∑(-)= C .i i ?Y Y ∑(-)=最小 D .2i i ?Y Y ∑(-)=最小 27.设Y 表示实际观测值,?Y 表示OLS 估计回归值,则下列哪项成立( D )。 A .?Y Y = B .?Y Y = C .?Y Y = D .?Y Y = 28.用OLS 估计经典线性模型i 01i i Y X u ββ+=+,则样本回归直线通过点___D______。 A .X Y (,) B . ?X Y (,) C .?X Y (,) D .X Y (,) 29.以Y 表示实际观测值,?Y 表示OLS 估计回归值,则用OLS 得到的样本回归直线i 01i ???Y X ββ+=满足( A )。 A .i i ?Y Y 0∑(-)= B .2i i Y Y 0∑(-)= C . 2i i ?Y Y 0∑(-)= D .2i i ?Y Y 0∑(-)= 30.用一组有30个观测值的样本估计模型i 01i i Y X u ββ+=+,在0.05的显著性水平下对1β的显著性作t 检验,则1β显著地不等于零的条件是其统计量t 大于( D )。 A .t 0.05(30) B .t 0.025(30) C .t 0.05(28) D .t 0.025(28) 31.已知某一直线回归方程的决定系数为0.64,则解释变量与被解释变量间的线性相关系数为( B )。 A .0.64 B .0.8 C .0.4 D .0.32
计量经济学名词解释与简答
相关分析:主要研究随机变量间的相关形式及相关程度。 回归分析:研究一个变量关于另一个变量的依赖关系的计算方法和理论。 高斯马尔科夫定理:普通最小二乘估计量具有线性性、无偏性和有效性等优良性质,是最佳线性无偏估计量。 高斯马尔科夫假定:(1)模型设立正确 (2)无完全共线性 (3)可识别性 (4) 零均值、同方差。无序列相关假定(5) 解释变量与随机项不相关 计量经济学模型:揭示经济活动中各种因素之间的定量关系,用随机性的数学方程加以描述。广义计量经济学:利用经济理论、统计学和数学定量研究经济现象的经济计量方法的统称,包括回归分析方法、投入产出分析方法、时间序列分析方法等。 狭义计量经济学:以揭示经济现象中的因果关系为目的,在数学上主要应用回归分析方法。计量经济学: 是经济学的一个分支学科,是以揭示经济活动中的客观存在的数量关系为内容的分支学科。 计量经济学模型成功的三要素:理论、方法和数据。 滞后变量模型:把过去时期的,具有滞后作用的变量叫做滞后变量,含有滞后变量的模型称为滞后变量模型。 多重共线性:如果某两个或多个解释变量之间出现了相关性,则称为存在多重共线性。 多重共线性的后果:(1)完全共线性下参数估计量不存在(2)近似共线性下普通最小二乘法参数估计量的方差变大(3)参数估计量经济含义不合理(4)变量的显著性检验和模型的预测功能失去意义。 多重共线性的检验:(1)检验多重共线性是否存在(2)判明存在多重共线性的范围。 克服多重共线性的方法:(1)排出引起共线性的变量(2)差分法(3)减小参数估计量的方差。完全共线性:对于多元线性回归模型,其基本假设之一是解释变量,,…,是相互独立的,如果存在,i=1,2,…,n,其中c不全为0,即某一个解释变量可以用其他解释变量的线性组合表示,则称为完全共线性。 异方差性:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。 异方差性的后果:(1)参数估计量非有效(2)变量的显著性检验失去意义(3)模型的预测失效异方差性的检验方法:(1)图示检验法(2)帕克检验和戈里瑟检验(3)G-Q检验(4)怀特检验。异方差性的修正:最常用的方法是加权最小二乘法,即对原模型加权,使之变成一个新的不存在异方差的模型,然后采用OLS法估计其参数。 序列相关性:多元线形回归模型的基本假设之一是模型的随机干扰项相互独立或不相关。如果模型的随机干扰项违背了相互独立的基本假设,称为存在序列相关性。 序列相关性的后果:(1)参数估计量非有效(2)变量的显著性检验失去意义(3)模型的预测失败。 序列相关性的检验方法:(1)图示法(2)回归检验法(3)杜宾—瓦森检验法(4)拉格朗日乘法检验。 序列相关性的补救:(1)广义最小二乘法(2)广义差分法(3)随机干扰项相关系数的估计(4)广义差分法在计量经济学软件中的实现。 最小二乘估计量的性质:(1)线形性(2)无偏性(3)有效性(4)渐近无偏性(5)一致性(6)渐进有效性。 最小样本容量:即从最小二乘原理和最大似然原理出发,欲得到参数估计量,不管其质量如何,所要求的样本容量的下限。 随机干扰项:即随机误差项,是一个随机变量,是针对总体回归函数而言的。 无偏性:是指参数估计量的均值(期望)等于模型的参数值。
所有计量经济学检验方法(全)
计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R - ==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数)1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方 和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 )1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临 界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t 检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:βi =0 (i=1,2…k );H1:βi ≠0 给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 统计量 )1(~1??? ----'--= k n t k n c S t ii i i i i i e e βββββ 在(1-α)的置信水平下βi 的置信区间是 ( , ) ββααββ i i t s t s i i -?+?2 2 ,其中,t α/2为显著性 水平为α、自由度为n-k-1的临界值。 五、异方差检验 1. 帕克(Park)检验与戈里瑟(Gleiser)检验 试建立方程: i ji i X f e ε+=)(~2 或 i ji i X f e ε+=)(|~|
计量经济学中相关证明
课本中相关章节的证明过程 第2章有关的证明过程 2.1 一元线性回归模型 有一元线性回归模型为:y t = β0 + β1 x t + u t 上式表示变量y t 和x t之间的真实关系。其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项,β0称常数项,β1称回归系数(通常未知)。上模型可以分为两部分。(1)回归函数部分,E(y t) = β0 + β1 x t, (2)随机部分,u t。 图2.8 真实的回归直线 这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。 以收入与支出的关系为例。 假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。所以,在经济问题上“控制其他因素不变”实际是不可能的。 回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。 回归模型存在两个特点。(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。
计量经济学作业序列相关性
< 序列相关实验报告> <1>第一问 D.W.检验 命令: Data y c x Genr lny=log(y) Genr lnx=log(x) Ls lny c lnx
Dependent Variable: LNY Method: Least Squares Date: 12/10/12 Time: 15:39 Sample: 1980 2007 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 1.588478 0.134220 11.83492 0.0000 LNX 0.854415 0.014219 60.09058 0.0000 R-squared 0.992851 Mean dependent var 9.552256 Adjusted R-squared 0.992576 S.D. dependent var 1.303948 S.E. of regression 0.112351 Akaike info criterion -1.465625 Sum squared resid 0.328192 Schwarz criterion -1.370468 Log likelihood 22.51875 Hannan-Quinn criter. -1.436535 F-statistic 3610.878 Durbin-Watson stat 0.379323 Prob(F-statistic) 0.000000 D.W.检验结果表明,在5%显著性水平下,n=28,k=2(包含常数项),查表得,dl=1.33,du=1.48,由于D.W.=0.379 1.编辑输入某市1991-2011年国内生产总值X 和出口总额Y 、通过OLS 估计法进行回归分析得到线性回归结果 线性回归方程:i X ?0.288354-3398.045i Y ?+= (-1.0118467) (17.5565) --t 统计量 R 2 =0.9419 F=308.2308 2.自相关检验 (1)图示法(e 与e(-1)的散点图、残差序列图、相关图和Q 统计量检验) (2)D .W .检验:给定显著水平a=0.05,得到临界水平值d L =1.22、d U =1.42。从回归分析中查得DW=0.5235 (3)LM 检验 给定显著水平a=0.05,得临界值X2 0.05 (1)=3.84,根据回归结果知n*R2=11.578, 与临界值比较得n*R2>X2 0.05 (1)故认为存在一阶序列相关。 3.序列相关修正 (1)广义差分法 ○1DW =0.5235估计p值为0.74做广义差分,创建新序列DY DX、进行线性回归 对结果做DW 2检验,存在自相关。○2再次做差分p估计值为1-DW 2 /2,创建新序 列LY LX、对回归结果做DW 3 检验,从而得到不存在自相关。○3检验最终结果序列相关性,可得不存在序列相关。 (2)科克栏内-奥克特迭代法 在用OLS估参时同时选择c和X,AR(p)作为解释变量可得参数β 0,β 1, p p 的估计 值,AR(p)即为随即干扰项的p阶自回归。根据DW统计量逐次引入AR(p)直到满意。所以引入AR(1),AR(2)对迭代一次与迭代二次的回归结果分别检验,得迭代二次回归结果不存在自相关。 重庆科技学院学生实验报告 五、实验记录与处理(数据、图表、计算等) 一、估计回归方程 工业增加值主要由全社会固定资产投资决定。为了考察全社会固定资产投资对工业 增加值的影响,可使用如下模型:Y i = 1 β β+ i X;其中,X表示全社会固定资产投资, Y表示工业增加值。下表列出了中国1998-2000的全社会固定资产投资X与工业增加值Y的统计数据。 单位:亿元年份固定资产投资X工业增加值Y年份固定资产投资X工业增加值Y 1980910.91996.519915594.58087.1 198********.419928080.110284.5 19821230.42162.3199313072.314143.8 19831430.12375.6199417042.119359.6 19841832.92789199520019.324718.3 19852543.23448.7199622913.529082.6 19863120.63967199724941.132412.1 19873791.74585.8199828406.233387.9 19884753.85777.2199929854.735087.2 19894410.46484200032917.739570.3 199045176858 由此实验结果可知模型估计结果为: Y=668.0114+1.181861X (2.24039)(61.0963) R2=0.994936,R2=0.994669,SE=951.3388,D.W.=1.282353。 二、序列相关性的检验 (1)图示检验法 通过残差与残差滞后一期的散点图可以判断,随机干扰项存在正序列相关性。 (2)回归检验法: 一阶回归检验 t e =0.356978e 1-t +εt 可见该模型存在一阶自相关 (3)D.W 检验法 由普通最小二乘法的估计结果知:D.W.=1.282353。在本例中,在5%的显著性水平下,解释变量个数为2,样本容量为21,查表得DL=1.22,DU=1.42,而D.W.=1.282353,DW 位于下限与上限之间,所以一阶序列相关性不能确定。 三、序列相关的补救 广义差分法估计模型 由D.W.=1.282353,得到一阶自相关系数的估计值ρ=1-DW/2=0.6412 则DY=Y-0.6412*Y(-1), DX=X-0.6412*X(-1);以DY 为因变量,DX 为解释变量,用OLS 法做回归模型,这样就生成了经过广义差分后的模型。 计量经济学中相关证明https://www.360docs.net/doc/cb14029757.html,work Information Technology Company.2020YEAR 课本中相关章节的证明过程 第2章有关的证明过程 2.1 一元线性回归模型 有一元线性回归模型为:y t = 0 + 1 x t + u t 上式表示变量y t 和x t之间的真实关系。其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项,0称常数项,1称回归系数(通常未知)。上模型可以分为两部分。(1)回归函数部分,E(y t) = 0 + 1 x t,(2)随机部分,u t。 图2.8 真实的回归直线 这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。 以收入与支出的关系为例。 假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。所以,在经济问题上“控制其他因素不变”实际是不可能的。 回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。 回归模型存在两个特点。(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。 通常,线性回归函数E(y t) = 0 + 1 x t是观察不到的,利用样本得到的只是对E(y t) = 0 + 1 x t 的估计,即对0和1的估计。 在对回归函数进行估计之前应该对随机误差项u t做出如下假定。 (1) u t 是一个随机变量,u t 的取值服从概率分布。 (2) E(u t) = 0。 (3) D(u t) = E[u t - E(u t) ]2 = E(u t)2 = 2。称u i 具有同方差性。 (4) u t 为正态分布(根据中心极限定理)。以上四个假定可作如下表达:u t N (0,)。 1.什么是计量经济学?它与经济学、统计学和数学的关系怎样? 答:1、计量经济学是一门运用经济理论和统计技术来分析经济数据的科学和艺术,它以经济理论为指导,以客观事实为依据,运用数学、统计学的方法和计算机技术,研究带有随机影响的经济变量之间的数量关系和规律。2、经济理论、数学和统计学知识是在计量经济学这一领域进行研究的必要前提,这三者中的每一个对于真正理解现代经济生活中的数量关系是必要的,但不充分,只有结合在一起才行。 2计量经济学三个要素是什么? 经济理论、经济数据和统计方法。 3.计量经济学模型的检验包括哪几个方面?其具体含义是什么? 答:(1)经济意义检验,即根据拟定的符号、大小、关系,对参数估计结果的可靠性进行判断(2)统计检验,由数理统计理论决定。包括:拟合优度检验、总体显着性检验。(3)计量经济学检验,由计量经济学理论决定。包括:异方差性检验、序列相关性检验、多重共线性检验。(4)模型预测检验,由模型应用要求决定。包括:稳定性检验:扩大样本重新估计;预测性能检验:对样本外一点进行实际预测。 4.计量经济学方法与一般经济数学方法有什么区别? 答:计量经济学揭示经济活动中各因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各因素之间的理论关系,用确定性的数学方程加以描述。 5.计量经济学模型研究的经济关系有那两个基本特征? 答:一是随机关系,二是因果关系 6.计量经济学研究的对象和核心内容是什么? 答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律。计量经济学的核心内容包括两个方面:一是方法论,即计量经济学方法或者理论计量经济学。二是应用,即应用计量经济学。无论是理论计量经济学还是应用计量经济学,都包括理论、方法和数据三种要素。 7.计量经济学中应用的数据类型怎样?举例解释其中三种数据类型的结构。 答:计量经济模型:WAGE=f(EDU,EXP,GEND,μ) 1)时间序列数据是按时间周期收集的数据,如年度或季度的国民生产总值。 2)横截面数据是在同一时间点手机的不同个体的数据。如世界各国某年国民生产总值。 3)混合数据是兼有时间序列和横截面成分的数据,如1985—2010世界各国GDP数据。 8.建立与应用计量经济学模型的主要步骤有哪些? (1)理论模型的设计(2)样本数据的收集(3)模型参数的估计(4)模型的检验 9.用OLS建立多元线性回归模型,有哪些基本假设? 1、回归模型是线性的,模型设定无误且含有误差项 2、误差项总体均值为零 3、所有解释变量与误差项都不相关 4、误差项互不相关(不存在序列相关性) 5、误差项具有同方差 6、任何一个解释变量都不是其他解释变量的完全线性函数 7、误差项服从正态分布。 10.随机误差项包含哪些因素影响? 所有计量经济学检验方法(全) 计量经济学所有检验方法 一、拟合优度检验 可决系数 TSS RSS TSS ESS R -== 12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。 该统计量越接近于1,模型的拟合优度越高。 调整的可决系数 ) 1/() 1/(12---- =n TSS k n RSS R 其中:n-k-1为残差 平方和的自由度,n-1为总体平方和的自由度。将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。 二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。 原假设与备择假设: H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0 统计量 ) 1/(/--= k n RSS k ESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临界值F α(k,n-k-1),由样本求出统计量F的数值,通过 F>F α(k,n-k-1)或F≤F α (k,n-k-1)来拒绝或接受 原假设H ,以判定原方程总体上的线性关系是否显著成立。 三、变量的显著性检验(t检验) 对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。 原假设与备择假设:H0:β i =0 (i=1,2…k); H1:β i ≠0 给定显著性水平α,可得到临界值t α/2 (n-k-1),由样本求出统计量t的数值,通过 |t|> t α/2(n-k-1) 或|t|≤t α /2 (n-k-1) 来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。 四、参数的置信区间 参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近”。 1.1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。 表8 中国人口时间序列数据(单位:亿人) 年份人口y t年份人口y t年份人口y t年份人口y t年份人口y t 1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517 1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985 1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121 1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389 1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626 1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761 1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786 1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743 1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627 1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823 1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171 (1)画时间序列图 打开 y的数据窗口 t 计量经济学中相关证明Newly compiled on November 23, 2020 课本中相关章节的证明过程 第2章有关的证明过程 一元线性回归模型 有一元线性回归模型为:y t = 0 + 1 x t + u t 上式表示变量y t 和x t之间的真实关系。其中y t 称被解释变量(因变量),x t称解释变量(自变量),u t称随机误差项,0称常数项,1称回归系数(通常未知)。上模型可以分为两部分。(1)回归函数部分,E(y t) = 0 + 1 x t, (2)随机部分,u t。 图真实的回归直线 这种模型可以赋予各种实际意义,收入与支出的关系;如脉搏与血压的关系;商品价格与供给量的关系;文件容量与保存时间的关系;林区木材采伐量与木材剩余物的关系;身高与体重的关系等。 以收入与支出的关系为例。 假设固定对一个家庭进行观察,随着收入水平的不同,与支出呈线性函数关系。但实际上数据来自各个家庭,来自各个不同收入水平,使其他条件不变成为不可能,所以由数据得到的散点图不在一条直线上(不呈函数关系),而是散在直线周围,服从统计关系。随机误差项u t中可能包括家庭人口数不同,消费习惯不同,不同地域的消费指数不同,不同家庭的外来收入不同等因素。所以,在经济问题上“控制其他因素不变”实际是不可能的。 回归模型的随机误差项中一般包括如下几项内容,(1)非重要解释变量的省略,(2)人的随机行为,(3)数学模型形式欠妥,(4)归并误差(粮食的归并)(5)测量误差等。 回归模型存在两个特点。(1)建立在某些假定条件不变前提下抽象出来的回归函数不能百分之百地再现所研究的经济过程。(2)也正是由于这些假定与抽象,才使我们能够透过复杂的经济现象,深刻认识到该经济过程的本质。 通常,线性回归函数E(y t) = 0 + 1 x t是观察不到的,利用样本得到的只是对E(y t) = 0 + x t 的估计,即对0和1的估计。 1 在对回归函数进行估计之前应该对随机误差项u t做出如下假定。 (1) u t 是一个随机变量,u t 的取值服从概率分布。 (2) E(u t) = 0。 (3) D(u t) = E[u t - E(u t) ]2 = E(u t)2 = 2。称u i 具有同方差性。 (4) u t 为正态分布(根据中心极限定理)。以上四个假定可作如下表达:u t N (0,)。 (5) Cov(u i, u j) = E[(u i - E(u i) ) ( u j - E(u j) )] = E(u i, u j) = 0, (i j )。含义是不同观测值所对应的随机项相互独立。称为u i 的非自相关性。 (6) x i是非随机的。 (7) Cov(u i, x i) = E[(u i - E(u i) ) (x i - E(x i) )] = E[u i (x i - E(x i) ] = E[u i x i - u i E(x i) ] = E(u i x i) = 0. u i与x i相互独立。否则,分不清是谁对y t的贡献。 (8) 对于多元线性回归模型,解释变量之间不能完全相关或高度相关(非多重共线性)。 在假定(1),(2)成立条件下有E(y t) = E(0+ 1 x t+ u t) = 0+ 1 x t。 4.2 序列相关王中昭制作§ 违反了随机扰动项 之间相互独立的假 定,称为序列相关。 ●学习内容: 王中昭制作 ?一、序列相关定义及其类型 ?二、实际经济问题中的序列相关性 ?三、序列相关性的后果 ?四、序列相关性的检验 ?五、序列相关性的修正 王中昭制作 ?1、序列相关(或称自相关)的定义: ?在线性回归模型基本假定4中,我们假设随机扰动项序列的各项之间不相关,如果这一假定不满足,则称之为序列相关。即用符号表示为: j i E Cov j i j i ≠≠=当 0)(),(μμμμ一、序列相关定义及其类型 王中昭制作 ?称为一阶序列相关,即μi =ρμi-1+εi ,,i=1,2,…,n,-1<ρ<1 ?其中ρ称为自协方差系数或者一阶自相关系数。 这是常见的序列相关, 除此之外统称为高阶序列相关。如:μi =ρ1μi-1+ρ2μi-2+εi ,称为二阶序列相关。 1 ,2,1 0)(1-=≠+n i E i i μμ如果仅存在 ●2、类型 王中昭制作 ?1、经济发展的惯性?2、模型设定偏误?3、滞后效应 ?4、对数据的处理可能会导致序列相关? 5、由随机扰动项本身特性所决定 ●二、实际经济问题中的序 列相关性 ●1、经济发展的惯性 王中昭制作 ?大多数经济时间序列都有一个明显的特 点,就是它的惯性。表现在时间序列数据不 同时间的前后关联上。众所周知,GDP、价 格指数、生产、消费、就业和失业等时间序 列都呈现周期循环。相继的观测值很可能是 相互依赖的。这样就导致经济变量的前后期 (或前后若干期)出现相关,从而使随机误 差项相关。 ?这是最常见的序列相关现象。计量经济学 自相关 实验报告
计量经济学序列相关性实验分析
计量经济学中相关证明
计量经济学简答题 经典
所有计量经济学检验方法(全)
第八章 时间序列计量经济学模型(DOC)
计量经济学中相关证明
计量经济学序列相关