计量经济学论文集
中国商品进口额模型研究
摘要:通过对中国商品进口额及其主要影响因素的数据分析,得到关于中国商品进口额的函数,并用计量经济学的方法,对模型进行检验,探究其增长的规律性,从而使商品进口额成为一个可预测的经济变量。
关键词:计量经济学模型多重共线性异方差性自相关性
一、研究意义
改革开放以来,随着经济的发展,人们生活水平的不断提高,人民日益增长的物质文化需要不断提高,中国的商品进口额发生了很大的变化,进口数额不断上升,从1985年的1257.8亿元到2007年的73284.6亿元。影响中国商品进口额的因素很多,这里选取教材课后练习中的数据,研究中国商品进口额和国民生产总值的数量关系,商品进口额与居民消费价格指数的数量关系,对于探究中国商品进口额增长的规律性,预测商品进口额的发展趋势具有重要意义。
二、因素分析及模型建立
1、因素分析
一国的商品进出口属于对外贸易的内容,一国对外贸易的发展情况对经济增长有着重要影响,影响对外贸易发展的因素有很多,从大的方面来说,主要是世界经济的发展情况和国内经济发展的冷热情况,还有就是一国的对外贸易政策的等因素。有研究显示,对外贸易对一国经济增长的影响主要是进口增长对经济增长有较大的促进作用。这里,对中国商品进口额的研究,主要选取国内生产总值和居民消费价格指数,国内生产总值和居民消费价格指数说明了一国的经济发展情况。经济的发展,居民的生活水平得到了提高,居民对国外商品的需求也增大,所以,对这两个因素对进口额的影响有一定的参考意义。
2、变量选取与模型建立
这里选取“中国商品进口额”为被解释变量,用Y表示,选“国内生产总值”、“居民消费价格指数”为解释变量,分别用X1、X2表示。所以,模型假定为
LnY=β0+β1㏑X1 +β2㏑X2 + μ
其中u为随机误差项。
下表为1985——2007年中国商品进口额、国内生产总值、居民你消费价格
三、参数估计
运用Eviews软件,建立方程
CREATE A 1985 2007
DATA Y Xl X2
GENR W=log(Y)
GENR Wl=log(X1)
GENR W2=log(X2)
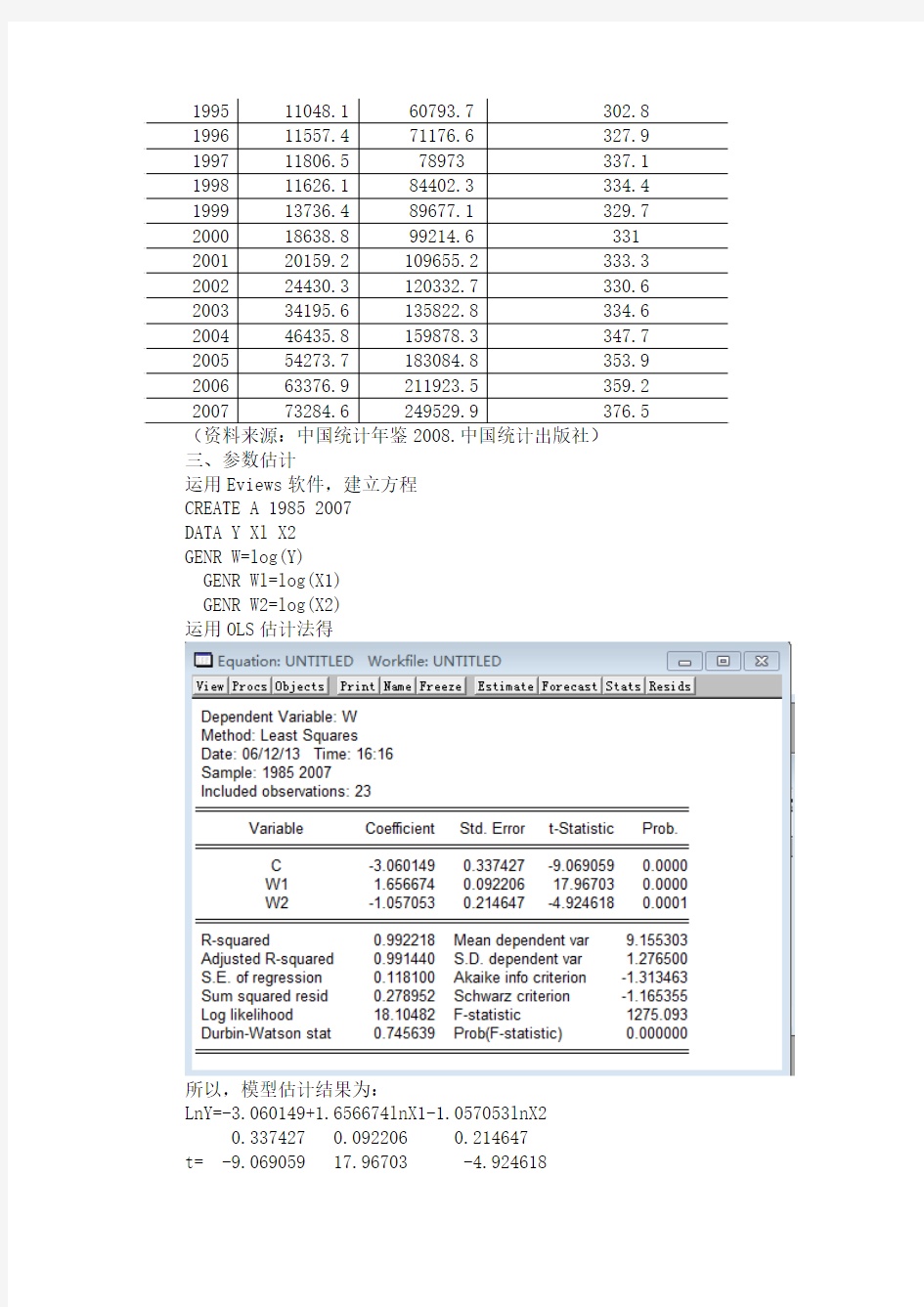
运用OLS估计法得
所以,模型估计结果为:
LnY=-3.060149+1.656674lnX1-1.057053lnX2 0.337427 0.092206 0.214647 t= -9.069059 17.96703 -4.924618
R2=0.992218 2
R=0.991440 F=1275.093 n=23
四、模型检验
1、经济意义检验:
模型估计结果说明,在假定其他变量不变的情况下,当国内生产总值每增加百分之一,商品进口额会平均增加1.78%;在假定其他变量不变的情况下,居民消费价格指数每增加1%,s商品进口额会平均减少1.51%。这与理论分析的经验判断一致。
2、统计推断检验:
A、可决系数R2=0.992218,说明所建模型整体上对样本数据的拟合较好,即解释变量“国内生产总值”“居民消费价格指数”对被解释变量的绝大部分差异做出了解释。
B、F检验
给定显著性水平α=0.05下,查F分布表查出自由度为k-1=2和n-k=20的临界值为3.49,F=1275.093>3.49,说明原方程显著,即解释变量联合起来对被解释便量有显著影响。
3、计量经济学检验:
A、多重共线性检验:
由估计模型可见,该模型R2=0.992218 2
R=0.991440可决系数较高,F 检验值为1275.093明显显著,但当α=0.05时,t临界值等于2.086,而且lnX2的回归系数不能通过t检验,这表明可能存在严重的多重共线性。由直观判断法可以看出,lnX2的t统计量的绝对值小于临界值,说明可能存在多重共线性。有简单的线性相关系数检验可知,两个变量间的相关系数很高,证实存在严重的多重共线性。所以需要对模型进行补救。
采用逐步回归法,去检验和解决多重共线性问题。分别作lnY对lnX1和lnX2的一元回归,结果如下表所示:
R最大,以lnX1为基础,顺次加入其他变量逐步回其中加入lnX1的方程2
归,结果如下表所示:
R有所增加,但其他t统计量的绝对值小于临界值,所以是当加入lnX2时2
lnX2引起了多重共线性,应当剔除。最后修正多重共线性后的结果为:LnY=-4.09067+1.2186lnX1
t= -10.6458 34.6222
R2=0.9828 2
R=0.9820 F=1198.70 DW=1.6207 n=23 这说明其他因素不变的情况下,当国内生产总值每增加1%,进口额就增长
1.22%。
B、自相关性检验
对一个样本容量为23的解释变量模型,在5%的显著性水平下,查表可得dl=1.257,du=1.437,所以DW>DU,原模型无自相关性,模型不需要补救。
五、模型应用
1、模型结果为LnY=-4.09067+1.2186lnX1
t= -10.6458 34.6222
R2=0.9828 2
R=0.9820 F=1198.70 DW=1.6207 n=23 这说明其他因素不变的情况下,当国内生产总值每增加1%,进口额就增长1.22%
3、对策建议、
第一,要坚持发展对外贸易不动摇。面对国内外经济增长放缓的新形势,中国对外贸易应进一步调整发展战略,通过加快转变发展方式来增强对外贸易的综合竞争力,促进对外贸易与国民经济的协调发展;通过不断完善对外贸易的体制和机制,不断提升对外开放水平,构建参与国际竞争新优势,稳步推进贸易强国进程。要充分认识对外贸易的积极作用,坚持发展对外贸易不动摇;积极调整发展战略,加快转变外贸发展方式;加快自主创新步伐,构建国际竞争新优势;加快产业布局调整,促进制造业梯度转移;加快建立海外营销网络,构建对外贸易发展的外部支撑体系;积极参与全球经济治理,营造良好的国际贸易环境。
第二,加快转变外贸发展方式。要改变长期以来中国对外贸易发展更多注重数量扩张,竞争力主要依靠劳动力、资源能源等生产要素的旧模式。随着中国经济快速发展和国际市场竞争加剧,传统发展模式难以为继。中国虽然是贸易大国,但还不是贸易强国。中国处在国际贸易分工价值链低端,自主知识产权、自主品牌、自主营销渠道和高技术含量、高附加值、高效益的产品比重低,与贸易强国还有较大差距。因此,要尽快转变外贸发展方式,更多地通过低碳、节能、环保等绿色技术和手段,支持出口产业向高端发展,把产品做精、把质量做优、把品牌做硬,把效益做大,不断提高产品的科技含量和附加值,不断提高产品的国际竞争力,进一步扩大绿色产品贸易份额。
第三,进一步优化进口结构,更好发挥进口的作用。一是要通过主动利用战略进口和国内产业转移、开放,搞活国内市场。在这一过程中,一方面,将培育企业的自生能力必须与进口选择相配合,通过发挥我国拥有国内大市场优势的主动权,战略选择有利于本地企业成长和发展的进口技术、商品结构,以拉动内需并提高本地企业的国际竞争能力;另一方面,要通过国内地区间产业转移和
开放,加强地区内部的经济合作、促进地区间贸易和资金的流动,不仅使得这些地区获得更多的技术模仿、学习机会,而且有利于形成有效的市场竞争机制、增强当地企业的自生能力。
第四,积极鼓励海外投资和产业外移,促使中国企业主动加快融入全球和区域经济体系,提高中国企业的自主能力和定价权,真正实现进口服务于中国可持续发展的战略调整。
第五,要灵活运用贸易政策引导进口。要进一步出台新的鼓励措施,特别是对先进适用技术、设备、仪器、材料的进口,尤其是集成电路、半导体、纳米材料、航空航天设备、医疗设备、多类仪器、能源设备、信息通讯技术产品等等,由于这些产品总体上同发达国家差距明显,大力引进应当作为今后相当长时期的重点,大力推动进口增长。
总之,对外贸易的发展过程中有机遇也有挑战,所以,要继续落实好稳外需的各项政策措施,积极开拓新兴市场,保持出口回升向好势头。进一步稳定进口促进政策,利用当前外贸回升的有利时机,调整和优化进出口结构,促进对外贸易转型升级和发展方式转变,努力实现外贸又好又快发展。
参考文献:
1、庞皓. 计量经济学[M].成都:西南财经大学出版社,2002年
2、《中国统计年鉴》2008年
3、薛荣久.《国际贸易》对外经济贸易出版社
我国人均GDP与农业人口比重、能源生产总量的关系
摘要:考察我国各年国内生产总值和农业人口占总人口比重及全国能源生产总量的关系,对他们之间数量关系的回归分析,得出了农业人口比重和能源生产总量都是人均GDP的重要制约因素的观点,为加快发展,必须保持国民经济的高速增长,以及通过转移农业剩余劳动力即通过城市化来促进国民经济的发展、促进第三产业的发展和能源生产总量投入。
关键词:人均GDP;农业从业人口比重;能源生产总量
能源生产总量是生产力水平提高和社会进步的重要表现,能源生产总量的高低是衡量现代社会经济发展程度的重要标志。加快发展中国新能源的发展可以有效地提高第一二产业的运行质速度 ,为促进国民经济更快更好的发展提供能源上的保障。依据三次产业的发展规律,第一产业的就业人口数在就业总人口数中会随着经济的不断发展而不断缩小。当今世界上的发达国家在经济发展过程中也都体现了这一规律,这是经济发展过程中的一个重要的规律。2000年中国农村人口比重高达50.1%,2010年我国农村人口的比重就下降到了38.1%,现在大多数发达国家的农村人口比重都下降到10%以内。这种规律性反映了第一产业比重对国民经济,的制约作用,这种制约机制主要表现为可以反映国民经济发展水平的数量
指标和第一产业就业人口比例之间的数量反比关系。就我们国家来说,1998年到2010年,其人均GDP与能源生产总量、农业从业人口占第一、二、三产业从业人口比重(以下称农业从业人口比重)之间存在着数量对应关系。笔者从分析国民经济统计数据入手,运用定量分析的方法研究这种对应关系,从而揭示出第一产业的发展对国民经济发展水平的制约作用以及能源生产总量对国民经济的促进作用。希望通过研究,提高广大群众特别是各级决策机关和决策人员对“保持国民经济持续、快速、健康发展”的重要性的认识,努力实现十八大提出的“全面建成小康社会,加快推进社会主义现代化”的目标。
一、主要指标的选择和简要分析
人均GDP可以用来作为反映一个国家或地区(各省区)的国民经济发展水平的主要指标之一,人均GDP反映国民经济发展水平,记作Y, Y和国
民经济发展水平是同向变动的, Y值越大表示国民经济发展水平越高。
农业从业人口比重可以作为反映国民经济发展水平的另一个主要指标,这一指标也用于表示一个国家或地区的城镇化发展水平,随着国民经济的发展,农业从业人口向非农化方向发展,农业人口比重逐渐变小。农业人口比重记作X1, X1=各省区农业从业人口/各省区第一、二、三产业从业人口, X1与国民经济发展水平呈反方向变动。
我国能源生产总量,用标准煤为衡量标准,统计数值为亿吨单位。
记作X2,X2值越大,我国每年的能源生产总量约大,国民经济发展水平的促进作用越大。
选择了上述三项指标(Y, X1, X2)之后,假定三者之间存在着这样的函数关系: Y=F (X1, X2)。以此为假设,然后对国民经济统计数据进行定量分析。分析过程中,首先采用单因素分析法分别分析Y和X1、X2的关系,然后用双因素分析法分析Y和X1、X2的关系。
二、国民经济相关数据的统计分析
采用的国民经济相关数据源于《中国统计年鉴2010年》,详见表1。
年份人均GDP(Y)农业人口比重
(X1)
能源生产
(X2)
1998 6796 49.9 12.983
1999 7159 49.8 13.194
2000 7858 50.1 13.505
2001 8622 50 14.388
2002 9398 50 15.066
2003 10542 50 17.191
2004 12336 49.1 19.665
2005 14185 46.9 21.622
2006 16500 44.8 23.217
2007 20169 42.6 24.728
2008 23708 40.8 26.055
2009 25608 39.6 27.462
2010 29992 38.1 29.692
(一)关系的单因素分析
1、分析人均GDP(Y)和农业人口比重(X1)的相关关系。经过对Y和X1之间的关系初步分析,可以判断Y和X1有近似的直线关系,所以可以采用简单线性回归
模型进行分析。Y和X1的相关系数为-0.9856
它们呈显著线性相关关系。二者关系的回归方程模型为:
Y = 92751.4731 - 1683.390644*X1 (1)
(22.91824)(-19.33754)
相关统计指标:可决系数错误!未找到引用源。=0.97144 错误!未找到引用源。
=2882.576 P值=0.000 P值近似于零。F=373.9405
因此,回归模型是显著的, 模型的经济意义比较合理,解释变量也都通过了T检
验和F检验,Y和X1之间存在明显的线性相关关系
2,分析人均GDP(Y)和能源生产总量X2的相关关系。经过对Y和X2之间的关系的初
步分析,我们可以判断Y和X2之间呈现对数函数关系,所以可以采用拟合线性回归
模型来进行分析。Y和X2的相关系数为0.9759
,它们呈显著线性相关关系。二者关系的回归方程模型为:
Y = -10527.04976 + 1274.209512*X2(2)
(-5.921119)(14.84044)
相关统计指标:
可决系数R2=0.952430; 错误!未找到引用源。错误!未找到引用源。=1766.066 F=220.2386 P=0.000 近似于零因此,各参数很合理,回归模型是显著的, Y
和X2之间存在明显的线性相关关系。
(二)关系的双因素分析
经过上面的单因素分析,我们可以判断Y和X1、X2之间分别存在明显的线性相关
关系。因此,我们可以在Y=c+b1*X1+b2*X2的假定下,对Y和X1、X2之间的关
系进行双因素分析。分析的主要结果如下:
回归方程模型为:
Y = -26522.20187 + 952.279833*X1 + 913.7741652*X2(
(-4.188026)(2.593847)(5.879191 )
相关统计指标:
可决系数R2=0.971563; 错误!未找到引用源。=1432.125 F=170.8258 P=0.000000
统计检验通过,各参数值比较明显。所以回归模型是显著的,
Y和X1、X2之间存在明显的线性相关关系。
(三)两种分析的结果比较
在上面分析Y和X1、X2的关系中,单因素分析法和双因素分析法也就是回归方程
模型(1)、(2)和(3)到底哪种方法更能有效地解释国民经济发展水平和第三产业
发展水平的关系呢?可以通过比较三个模型方程的可决系数和标准偏差的大小来
进行比较。依据上述分析可以明显地看出,回归方程模型(3)的可决系数
R2=0.971563>R2(1)=0.97144, R2=0.971563>R2(2)=0.952430;回归模
型(3)方差平方和错误!未找到引用源。(3)=1432.125<错误!未找到引用源。(1)=2882.576, 错误!未找到引用源。(3)=1432.125<错误!未找到引用源。
(2)=1766.066,所以在解释Y和X1、X2的关系中,方程(3)要优于方程(1)、(2)。通过回归模型方程(3)可以得出这样的判断,能源生产总量和农业从业人口比重都是人均GDP的重要决定因素。
三、结论和建议
人均GDP和农业从业人口比重都是决定第三产业发展水平的重要因素。
1、人均GDP (Y)与农业人口比重(X1)之间存在着负的简单线性相关关系,说明第一产业的发展水平对人均GDP有明显的制约作用。一般而言,第一产业发展水平较高的国家人均GDP也较高,特别是国家处在发展中的时候,第一产业的的就业人口转移对人均GDP有较大的拉动作用。
第一产业作为完整的国民经济体系的重要组成部分,特别是我国正朝着全面建成小康社会的目标奋进的时刻,要紧紧把握住发展这一主题,农业从业人口比重比较高,是我国目前大多数省区普遍存在的问题。要求降低农业从业人口比重,积极探索适合的转移农业富裕劳动力的途径,使得第一产业的发展水平迈上新的台阶。同时农业是第一产业,是国民经济的基础,没有农业的发展,就不会有国民经济的发展。
2·Y与全国能源生产总量(X2)的之间存在着明显正的线性相关关系,说明能源生产总量对国民经济的发展水平也有明显的推动作用。
世界各国经济发展的历史表明,能源消费与国民经济之间存在着明显的关系。能源是国民经济的命脉,能源是国家重要的战略资源,。能源是推动经济社会发展必不可少的助动力,是国民经济的基础产业,对国民经济持续、快速、健康地发展和人民生活的改善,发挥着十分重要的促进与保障作用。
3·随着第一产业就业人口比例的不断缩小以及全国能源生产总量的的提高,同时国民经济的发展水也在不断提高,是整个经济发展过程中的一个重要规律,这是世界各国在经济发展过程中所体现出来的一个重要特征。其三者的联系紧密,当第一二三产业很好的平衡发展,国家的宏观政策调节好三者之间的产业结构时,才能促进国民经济的又好又快发展。能源生产总量为国民经济发展提供动力
保证,列宁曾说过 “煤是工业的粮食。石油是工业的血液。”能源为工业发展提供了原动力,这正是它对国民经济发展的重要性所在。
参考文献:
[1]庞皓.计量经济学【M】.北京:科学出版社,2010.
[2]罗祥立. 我国第三产业与人均GDP、农业从业人口的关系[J].商业研究.2005/02
中国财政地方卫生支出的影响因素分析
内容摘要
近年来居民卫生医疗健康状况一直是全社会关注的重点民生问题。与此同时,中央及
地方各级政府也一再强调要加大公共卫生的财政支出力度。而许多地方―看病难、看病贵‖等现象似乎并没有得以解决,这个历史遗留的民生问题牵涉的方方面面是在太多,要一次性完全解决妥当似乎不是那么件容易的事。要解决问题,首先肯定要找出出现问题的原因,到底是哪些因素影响了我国卫生医疗跟不上脚步。本文着重从政府地方卫生支出的影响因素来分析,为何地方卫生支出存在不均衡的问题。
关键词:卫生医疗、财政支出、GDP 、财政收入
早在1997年《中共中央、国务院关于卫生改革与发展的决定》就提出了―中央和地方政府对卫生事业的投入,要随着经济的发展逐年增加,增加力度不低于财政支出的增长幅度‖的要求,但是我国政府的卫生支出水平仍旧偏低。从绝对量上看,我国的卫生支出从2000年的709.52亿元增长到2010年的3124.57亿元,虽然增长了4倍多,但直到2003年SARS 的爆发,政府才更加重视卫生领域的投入,政府预算支出的增长开始慢慢地与财政支出的增长相协调。1997年《中共中央、国务院关于卫生改革与发展的决定》还要求在二十世纪末―争取全社会卫生总费用占国内生产总值的5%左右‖,但是我国卫生总费用占GDP 的比重直到2010年也没有超过5%。根据Tanzi 和Schuknecht(1997)的整理,早在上个世纪90年代奥地利、法国、意大利、德国、挪威、荷兰等国医疗卫生支出占GDP 的比重就超过了8%,加拿大和美国更是超过了10%,比例最低的是爱尔兰,也达到了7.1%。
一、理论分析
研究对于影响政府财政支出的因素主要有人口密度,人均GDP ,受教育水平。本文主
要以人口密度、人均GDP 和文盲率作为人口、经济和社会三个方面的效率影响因素。所使用的所有数据均来自2010年各地中国财政年鉴、中国卫生年鉴、中国卫生统计年鉴以及中国统计年鉴
人口数:由于较多的人口数有利于降低政府支出的管理和监督成本,所以人口数与政府支出的效率应该呈正相关关系
GDP 水平:较高的经济发展水平有助于提高财政支出效率,所以GDP 越高地地区,政府财政医疗卫生支出应该越高。
卫生医疗机构数:卫生医疗机构多的地区,医疗卫生发展水平相对较高,所以卫生医疗机构数应与政府财政医疗支出成正比。
财政收入水平:财政收入高的地区说明当地政府正真能力强,能够充分利用当地资源,积极发展地方经济,说明地方经济发展水平也就较高,医疗发展水平也较高。所以财政收入高地地区政府财政卫生医疗支出也高。
二、模型设定
Y 代表政府财政医疗支出额 X1 代表人口数 X2 代表GDP 总额 X3 代表卫生医疗机构 X4代表财政收入
基于以上数据,初步建立模型
t i u X X X X Y +++++=443322110βββββ
三、数据收集:本文收集了我国2010年我国卫生医疗支出以及相关因素的部分数据
注:以上数据来自2010年中国统计年鉴
四、图形分析及理论模型建立:
1、利用Eviews软件分别绘制X1,X2,X3与Y的相关图相关图如下:
由相关图可知,解释变量与被解释变量之间存在线性相关关系,为此,可建立如下人口密度,人均GDP ,文盲率与政府卫生医疗财政支出的多元线性回归模型:
t i u X X X X Y +++++=443322110βββββ
2、用最小二乘法,利用Eviews 软件可得估计结果如下:
报告形式:
t i
u X X X X Y +++-+=43210567.00006.00049.00231.02123.29? (7.4831)(20.0044) (0.0014) (0.0004)(5.0199)
t =(3.9038) (5.2771) (-3.4521) (1.6519)
(5.0199) 2R =0.9388 2R =0.9293 DW=2.2969 F=99.6313 σ
?=19.5387
3、检验多元回归模型: 给定显著水平为0.05
拟合优度检验:2
R =0.9388接近于1,表明模型对样本数据拟合程度高。
F 检验:F=99.6313>αF (5-1,31-5)=2.74 表明模型线性关系显著,或解释变量人口密度X1,人均GDPX2,文盲率X3结合起来对被解释变量政府卫生医疗财政支出Y 有显著影响。 T 检验:人口数X1的T 统计量绝对值为5.2771>2/αt (31-5)=2.056 表明人口数量对Y 有显著影响
GDP 总量X2的T 统计量绝对值为3.4521>2/αt (31-5)=2.056 表明GDP 总量对Y 有显著影响
卫生医疗机构数X3的T 统计量绝对值为1.6519<2/αt (31-5)=2.056 表明卫生医疗机构数对Y 没有显著影响
财政收入X4的T 统计量绝对值为5.0199>2/αt (31-5)=2.052 表明财政收入对Y 有
显著影响
模型可能存在多重共线性,现对其进行计量经济检验:
4、多重共线性检验:由于选择的影响因素过多,所以估计模型之前,应先分析各个因素与被解释变量之间的关系,以及因素之间的相关程度,利用COR 命令进行相关系数检验,得相关系数矩阵为:
计量经济学题库及答案
计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用
计量经济学题库(超完整版)及答案.详解
计量经济学题库 计算与分析题(每小题10分) 1 X:年均汇率(日元/美元) Y:汽车出口数量(万辆) 问题:(1)画出X 与Y 关系的散点图。 (2)计算X 与Y 的相关系数。其中X 129.3=,Y 554.2=,2X X 4432.1∑(-)=,2Y Y 68113.6∑ (-)=,()()X X Y Y ∑--=16195.4 (3)采用直线回归方程拟和出的模型为 ?81.72 3.65Y X =+ t 值 1.2427 7.2797 R 2=0.8688 F=52.99 解释参数的经济意义。 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 (45.2) (1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 3.估计消费函数模型i i i C =Y u αβ++得 i i ?C =150.81Y + t 值 (13.1)(18.7) n=19 R 2=0.81 其中,C :消费(元) Y :收入(元) 已知0.025(19) 2.0930t =,0.05(19) 1.729t =,0.025(17) 2.1098t =,0.05(17) 1.7396t =。 问:(1)利用t 值检验参数β的显著性(α=0.05);(2)确定参数β的标准差;(3)判断一下该模型的拟合情况。 4.已知估计回归模型得 i i ?Y =81.7230 3.6541X + 且2X X 4432.1∑ (-)=,2Y Y 68113.6∑(-)=, 求判定系数和相关系数。 5.有如下表数据
计量经济学题库超完整版及答案
四、简答题(每小题5分) 令狐采学 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。 2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步调。4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的?6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么?8.总体回归模型与样本回归模型的区别与联系。 9.试述回归阐发与相关阐发的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质?11.简述BLUE 的含义。 12.对多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验? 13.给定二元回归模型:01122t t t t y b b x b x u =+++,请叙述模型的古典假定。 14.在多元线性回归阐发中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数2R 及其作用。16.罕见的非线性回归模型有几种情况? 17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或
都是或都不是。 ①t t t u x b b y ++=310②t t t u x b b y ++=log 10 ③t t t u x b b y ++=log log 10④t t t u x b b y +=)/(10 18. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=log 10②t t t u x b b b y ++=)(210 ③t t t u x b b y +=)/(10④t b t t u x b y +-+=)1(11 0 19.什么是异方差性?试举例说明经济现象中的异方差性。 20.产生异方差性的原因及异方差性对模型的OLS 估计有何影响。21.检验异方差性的办法有哪些? 22.异方差性的解决办法有哪些?23.什么是加权最小二乘法?它的基本思想是什么? 24.样天职段法(即戈德菲尔特——匡特检验)检验异方差性的基来源根基理及其使用条件。 25.简述DW 检验的局限性。26.序列相关性的后果。27.简述序列相关性的几种检验办法。 28.广义最小二乘法(GLS )的基本思想是什么?29.解决序列相关性的问题主要有哪几种办法? 30.差分法的基本思想是什么?31.差分法和广义差分法主要区别是什么? 32.请简述什么是虚假序列相关。33.序列相关和自相关的概念和规模是否是一个意思? 34.DW 值与一阶自相关系数的关系是什么?35.什么是多重共线
计量经济学题库超完整版)及答案-计量经济学题库
计量经济学题库一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。
A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是()。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有()。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指()。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性
计量经济学习题第10章 联立方程模型
第10章联立方程模型 一、单选 1、如果联立方程中某个结构方程包含了所有的变量,则这个方程为() A、恰好识别 B、过度识别 C、不可识别 D、可以识别 2、下面关于简化式模型的概念,不正确的是() A、简化式方程的解释变量都是前定变量 B、简化式参数反映解释变量对被解释的变量的总影响 C、简化式参数是结构式参数的线性函数 D、简化式模型的经济含义不明确 3、对联立方程模型进行参数估计的方法可以分两类,即:( ) A、间接最小二乘法和系统估计法 B、单方程估计法和系统估计法 C、单方程估计法和二阶段最小二乘法 D、工具变量法和间接最小二乘法 4、在结构式模型中,其解释变量( ) A、都是前定变量 B、都是内生变量 C、可以内生变量也可以是前定变量 D、都是外生变量 5、如果某个结构式方程是过度识别的,则估计该方程参数的方法可用() A、二阶段最小二乘法 B、间接最小二乘法 C、广义差分法 D、加权最小二乘法 6、当模型中第i个方程是不可识别的,则该模型是( ) A、可识别的 B、不可识别的 C、过度识别 D、恰好识别 7、结构式模型中的每一个方程都称为结构式方程,在结构方程中,解释变量可以是前定变量,也可以是( ) A、外生变量 B、滞后变量 C、内生变量 D、外生变量和内生变量 8. 在完备的结构式模型 A、Y t B.Y t – 1 C.I t D.G t 9. 在完备的结构式模型 A.方程1 B.方程2 C.方程3 D.方程1和2 10.联立方程模型中不属于随机方程的是() A.行为方程 B.技术方程 C.制度方程 D.恒等式 11.结构式方程中的系数称为() A.短期影响乘数 B.长期影响乘数 C.结构式参数 D.简化式参数 12.简化式参数反映对应的解释变量对被解释变量的 A.直接影响 B.间接影响 C.前两者之和 D.前两者之差 13.对于恰好识别方程,在简化式方程满足线性模型的基本假定的条件下,间接最小二乘估 计量具备() A.精确性 B.无偏性 C.真实性 D.一致性 二、多选 1、当结构方程为恰好识别时,可选择的估计方法是() A、最小二乘法 B、广义差分法 C、间接最小二乘法 D、二阶段最小二乘法 E、有限信息极大似然估计法 2、对联立方程模型参数的单方程估计法包括( ) A、工具变量法 B、间接最小二乘法 C、完全信息极大似然估计法 D、二阶段最小二乘法 E、三阶段最小二乘法
计量经济学题库及答案
2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入
计量经济学第十章
一:绘制时间序列图 根据1970-1991年的美国制造业固定厂房设备投资Y和销售量X的数据在Eviews中录入数据得到固定厂房设备投资Y时间序列图如下 由上图我们可以看出该时间序列可能存在趋势和截距项所以我们选择ADF检验的模型对其检验是否为平稳序列。 二:ADF检验结果
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为远远大于相应的临界值,从而不能拒绝原假设,即可以说明固定厂房设备投资Y存在单位根,是非平稳数列。 三:根据1970-1991年的美国制造业固定厂房设备投资Y和销售量X的数据在Eviews 中录入数得到销售量X的时间序列图如下 由上图我们可以看出该时间序列可能存在趋势和截距项所以我们选择ADF检验的模型对其检验是否为平稳序列。 四ADF检验结果
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为远大于相应的临界值,从而不能拒绝原假设,即可以说明销售量X存在单位根,是非平稳数列。 五:单整阶数检验
从检验的结果可以看出,在1%、5%、10%三个显着水平下,单位根检验的Mackinnon的临界值分别为、、,t检验统计量为,小于于相应的临界值,从而能拒绝原假设,即可以说明销售量X已经不存在单位根,是平稳数列。即是二阶单整。
从 检 验 的 结 果 可 以 看 出, 在 1%、 5%、 10% 三 个 显 着 水 平 下, 单 位 根 检 验 的 Mac kin non 的 临 界 值分别为、、,t检验统计量质为.小于相应的临界值,从而能拒绝原假设,即可以说明固定厂房设备投资Y已经存在单位根,是平稳数列。即是二阶单整。
计量经济学第十章习题最新版本
第10章模型设定与实践 问题 10.1 模型设定误差有哪些类型?如何诊断? 答:模型设定误差主要有以下四种类型: 1.漏掉一个相关变量; 2.包含一个无关的变量; 3.错误的函数形式; 4.对误差项的错误假定。 诊断的方法有:1.侦察是否含有无关变量;2.残差分析,拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克金龙)检验;3.拟合优度、校正拟合优度、系数显著性、系数符合的合理性。 10.2 模型遗漏相关变量的后果是什么? 答:模型遗漏相关变量的后果是:所有回归系数的估计量是有偏的,除非这个被去除的变量与每一个放入的变量都不相关。常数估计量通常也是有偏的,从而预测值是有偏的。由于放入变量的回归系数估计量是有偏的,所以假设检验是无效的。系数估计量的方差估计量是有偏的。 10.3 模型包含不相关变量的后果是什么? 答:模型包含不相关变量的后果是:系数估计量的方差变大,从而估计量的精度下降。10.4 什么是嵌套模型?什么是非嵌套模型? 答:如果两个模型不能被互相包容,即任何一个都不是另一个的特殊情形,便称这两个模型是非嵌套的。如果两个模型能互相包容,即其中一个是另一个的特殊情形,便称这两个模型是嵌套的。 10.5 非嵌套模型之间的比较有哪些方法? 答:非嵌套模型之间的比较方法有:拟合优度或校正拟合优度、AIC(Akaike’s information criterion)准则、SIC(Schwarz’s information criterion)准则和HQ(Hannnan-Qinn criterion)准则。拉姆齐(Ramsey)的RESET检验法,DM(Davidsion-MacKinnon:戴维森麦-克金龙)检验。 习题 10.6 对数线性模型在人力资源文献中有比较广泛的应用,其理论建议把工资或收入的对数
斯托克,沃森计量经济学第七章实证练习stata
E7.2 E7.3 E7.4
-------------------------------------------- (1) (2) ahe ahe -------------------------------------------- age 0.605*** 0.585*** (15.02) (16.02) female -3.664*** (-17.65) bachelor 8.083*** (38.00) _cons 1.082 -0.636 (0.93) (-0.59) (表2)Robust ci in parentheses *** p<0.01, ** p<0.05, * p<0.1 -------------------------------------------- N 7711 7711 -------------------------------------------- t statistics in parentheses * p<0.10, ** p<0.05, *** p<0.01 (表1) (1) 建立ahe 对age 的回归。截距估计值是1.082,斜率估计值是0.605。 (2) ①建立ahe 对age ,female 和bachelor 的回归。Age 对收入的效应的估计值是0.585。 ② age 回归系数的95%置信区间: (0.514,0.657) (3) 设H 0:βa,(2)-βa,(1)=0 H1:βa,(2)-βa (1)≠0 由表3,得SE ,SE(βa,(2)-βa,(1))=√(0.0403)2+(0.0365)2=0.054 t=(0.605-0.585)/0.054=0.37<1.96 所以不拒绝原假设,即在5%显著水平下age 对ahe 的效应估计没有显著差异,所以(1)中的回归没有遭遇遗漏变量偏差。 (4) B ob’s predicted ahe=0.585×26-3.664×0+8.083×0-0.636=$14.574 Alexis ’s predicted ahe=0.585×30-3.664×1+8.083×1-0.636=$21.333 VARIABLES ahe age 0.585*** (0.514 - 0.657) female -3.664*** (-4.071 - -3.257) bachelor 8.083*** (7.666 - 8.500) Constant -0.636 (-2.759 - 1.487) Observations 7,711 R-squared 0.200
计量经济学题库及答案71408
计量经济学题库(超完整版)及答案 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C )。 A .统计学 B .数学 C .经济学 D .数理统计学 2.计量经济学成为一门独立学科的标志是(B )。 A .1930年世界计量经济学会成立 B .1933年《计量经济学》会刊出版 C .1969年诺贝尔经济学奖设立 D .1926年计量经济学(Economics )一词构造出来3.外生变量和滞后变量统称为(D )。 A .控制变量 B .解释变量 C .被解释变量 D .前定变量 4.横截面数据是指(A )。 A .同一时点上不同统计单位相同统计指标组成的数据 B .同一时点上相同统计单位相同统计指标组成的数据 C .同一时点上相同统计单位不同统计指标组成的数据 D .同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C )。 A .时期数据 B .混合数据 C .时间序列数据 D .横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A .内生变量 B .外生变量 C .滞后变量 D .前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A .微观计量经济模型 B .宏观计量经济模型 C .理论计量经济模型 D .应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A .控制变量 B .政策变量 C .内生变量 D .外生变量 9.下面属于横截面数据的是()。 A .1991-2003年各年某地区20个乡镇企业的平均工业产值 B .1991-2003年各年某地区20个乡镇企业各镇的工业产值 C .某年某地区20个乡镇工业产值的合计数 D .某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。 A .设定理论模型→收集样本资料→估计模型参数→检验模型 B .设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A .虚拟变量 B .控制变量 C .政策变量 D .滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A .外生变量 B .内生变量 C .前定变量 D .滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A .横截面数据 B .时间序列数据 C .修匀数据 D .原始数据 14.计量经济模型的基本应用领域有()。 A .结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C .消费需求分析、生产技术分析、 D .季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A .函数关系与相关关系 B .线性相关关系和非线性相关关系
计量经济学 第十章 联立方程组模型
第十章 联立方程组模型 第一节 联立方程组模型概述 一、问题的提出 1、单一方程模型存在的条件是单向因果关系。 2、对于变量之间存在的双向因果关系,则需要建立联立方程组模型。 3、经济现象的表现多以系统或体系的形式进行,仅用单一方程来反映存在局限性。 二、联立方程组的概念 1、联立方程组模型的定义。 由一个以上的相互联系的单一方程组成的系统(模型),每一个单一方程中包含了一个过多个相互联系(相互依存)的内生变量。联立方程组表现的是多个变量间互为因果的联立关系。 联立方程组与单一方程的区别是估计联立方程组模型的参数必须考虑联立方程组所能提供的信息(包括联立方程组里方程之间的关联信息),而单一方程模型的参数估计仅考虑被估计方程自身所能提供的信息。 2、联立方程组模型的例子。 (1)一个均衡条件下市场供给与需求的关系。 ) 3()2(0 )1(012101110s i d i i i s i i i d i Q Q u P Q u P Q =>++=<++=βββααα 称(1)式为需求方程,(2)式为供给方程,(3)式为供需均衡式;d i Q 表示需求量,s i Q 表示供给量,i P 表示价格,i i u u 21,分别为(1)式和(2)式的随机误差项。按照经济学基本原理,商品的供给与商品的需求共同作用于价格,反过来,价格也要分别决定商品的供给与需求。这就是方程(1)与方程(2)的作用机制,如果考虑了均衡条件,这又是方程(3)的作用。因此,通过这一联
立方程组将上述商品的供需与价格的相互作用过程得到了反映。 (2)一个凯恩斯宏观经济模型。 011012(4)(5)(6) t t t t t t t t t t C Y u I Y u T C I G ββαα=++=++=++ 式中,C 表示消费,Y 表示国民总收入(又GDP ,实际上它们是有区别的),I 表示私人投资,G 表示政府支出,u1、u2分别为消费函数和投资函数中的随机误差项。 三、联立方程组模型的基本问题(即联立方程组模型的偏倚性) 1、内生解释变量与随机误差项的相关性。 2、直接对联立方程组模型运用OLS 法,所得的参数估计值是有偏的,并且是不一致的。 例如,设凯恩斯收入决定模型为 [][]01) (11)1() 0)(())(())())(((),cov(1)(11) 1(11)(111)1(1 01 2 21 11 1 1011101 1100110110≠-=-=-==-=--=-= -∴-+-=-+-+-=-+ -+-= ∴++=-+++=∴+=<<++=βσβββββββββββββββββββββU E U U E U E U Y E Y E U E U Y E Y E U Y U Y E Y I U E I Y E U I Y U I Y I U Y Y I C Y U Y C t t t t t t t t t t t t t t t t t t t t t t t t t 表明内生变量Y 在作解释变量时与随机误差U 相关。 对凯恩斯模型中的消费函数求参数的估计,有(用离差形式表示)
计量经济学题库(超完整版)及答案
四、简答题(每小题5分) 1.简述计量经济学与经济学、统计学、数理统计学学科间的关系。2.计量经济模型有哪些应用? 3.简述建立与应用计量经济模型的主要步骤。 4.对计量经济模型的检验应从几个方面入手? 5.计量经济学应用的数据是怎样进行分类的? 6.在计量经济模型中,为什么会存在随机误差项? 7.古典线性回归模型的基本假定是什么? 8.总体回归模型与样本回归模型的区别与联系。 9.试述回归分析与相关分析的联系和区别。 10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量有哪些统计性质? 11.简述BLUE 的含义。 12.对于多元线性回归模型,为什么在进行了总体显著性F 检验之后,还要对每个回归系数进行是否为0的t 检验? 13.给定二元回归模型: 01122t t t t y b b x b x u =+++,请叙述模型的古典假定。 14.在多元线性回归分析中,为什么用修正的决定系数衡量估计模型对样本观测值的拟合优度? 15.修正的决定系数2R 及其作用。 16.常见的非线性回归模型有几种情况? 17.观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=310 ②t t t u x b b y ++=log 10 ③ t t t u x b b y ++=log log 10 ④t t t u x b b y +=)/(10 18. 观察下列方程并判断其变量是否呈线性,系数是否呈线性,或都是或都不是。 ①t t t u x b b y ++=log 10 ②t t t u x b b b y ++=)(210 ③ t t t u x b b y +=)/(10 ④t b t t u x b y +-+=)1(110 19.什么是异方差性?试举例说明经济现象中的异方差性。
斯托克、沃森着《计量经济学》第九章
Chapter 9. Assessing Studies Based on Multiple Regression 9.1 Internal and External Validity Multiple regression has some key virtues: ?It provides an estimate of the effect on Y of arbitrary changes ΔX. ?It resolves the problem of omitted variable bias, if an omitted variable can be measured and included. ?It can handle nonlinear relations (effects that vary with the X’s)
Still, OLS might yield a biased estimator of the true causal effect. A Framework for Assessing Statistical Studies Internal and External Validity ?Internal validity: The statistical inferences about causal effects are valid for the population being studied.
?External validity: The statistical inferences can be generalized from the population and setting studied to other populations and settings, where the “setting” refers to the legal, policy, and physical environment and related salient features.
斯托克计量经济学课后习题实证答案
P ART T WO Solutions to Empirical Exercises
Chapter 3 Review of Statistics Solutions to Empirical Exercises 1. (a) Average Hourly Earnings, Nominal $’s Mean SE(Mean) 95% Confidence Interval AHE199211.63 0.064 11.50 11.75 AHE200416.77 0.098 16.58 16.96 Difference SE(Difference) 95% Confidence Interval AHE2004 AHE1992 5.14 0.117 4.91 5.37 (b) Average Hourly Earnings, Real $2004 Mean SE(Mean) 95% Confidence Interval AHE199215.66 0.086 15.49 15.82 AHE200416.77 0.098 16.58 16.96 Difference SE(Difference) 95% Confidence Interval AHE2004 AHE1992 1.11 0.130 0.85 1.37 (c) The results from part (b) adjust for changes in purchasing power. These results should be used. (d) Average Hourly Earnings in 2004 Mean SE(Mean) 95% Confidence Interval High School13.81 0.102 13.61 14.01 College20.31 0.158 20.00 20.62 Difference SE(Difference) 95% Confidence Interval College High School 6.50 0.188 6.13 6.87
斯托克,沃森计量经济学第四章实证练习stata操作及答案
E4.1 E4.2 E4.3 E4.4
E4.1 VARIABLES ahe age 0.605 (0.0245) Constant 1.082 (0.688) Observations 7,711 R-squared 0.029 Robust standard errors in parentheses *** p<0.01, ** p<0.05, * p<0.1 1. ① 截距估计值estimated intercept: 1.082 ② 斜率估计值estimated slope: 0.605 回归方程:ahe= 1.082+0.605*age ③ 当工人年长 1 岁,平均每小时工资增加0.605 美元。 2. Bob: 0.605*26+1.082=16.812 (美元) Alexis: 0.605*30+1.082=19.232 (美元) 答:预测Bob 的收入为每小时16.812美元,Alexis为19.232 美元。 3. 年龄不能解释不同个体收入变化的大部分。因为R-squared 反映了因变量的 全部变化能通过回归关系被自变量充分解释的比例,而分析得R-squared 的值为0.029,解释度低,说明年龄不能解释不同个体收入变化的大部分
E4.1 (0.0449) Observations 463 R-squared 0.036 Robust standard errors in parentheses *** p<0.01, ** p<0.05, * p<0.1 ① 截距估计值: 3.998 斜率估计值: 0.133 回归方程: Course_Eval=3.998+0.133*beauty lave_esruo 0a u ty a e 1. 答:两者看上去有微弱的正相关关系 2. VARIABLES course eval beauty Constant 0.133 (0.0550) 3.998
计量经济学题库及答案
计量经济学题库(超完整版)及答案 一、单项选择题(每小题1分) 1。计量经济学就是下列哪门学科得分支学科(C ). A.统计学B 。数学C 。经济学D.数理统计学 2.计量经济学成为一门独立学科得标志就是(B )。 A .1930年世界计量经济学会成立 B .1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D 。1926年计量经济学(Economics )一词构造出来 3.外生变量与滞后变量统称为(D )。 A。控制变量B .解释变量C .被解释变量 D 。前定变量 4.横截面数据就是指(A )。 A 。同一时点上不同统计单位相同统计指标组成得数据B.同一时点上相同统计单位相同统计指标组成得数据 C .同一时点上相同统计单位不同统计指标组成得数据 D .同一时点上不同统计单位不同统计指标组成得数据 5。同一统计指标,同一统计单位按时间顺序记录形成得数据列就是(C )。 A .时期数据 B .混合数据 C 。时间序列数据D.横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定得概率分布得随机变量,其数值受模型中其她变量影响得变量就是()。 A .内生变量B.外生变量 C 。滞后变量D 。前定变量 7。描述微观主体经济活动中得变量关系得计量经济模型就是(). A.微观计量经济模型B。宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型得被解释变量一定就是( )。 A 。控制变量B。政策变量C 。内生变量D .外生变量 9.下面属于横截面数据得就是()。 A .1991-2003年各年某地区20个乡镇企业得平均工业产值 B。1991-2003年各年某地区20个乡镇企业各镇得工业产值 C .某年某地区20个乡镇工业产值得合计数 D 。某年某地区20个乡镇各镇得工业产值10.经济计量分析工作得基本步骤就是()。 A 。设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 11。将内生变量得前期值作解释变量,这样得变量称为(). A .虚拟变量 B 。控制变量C.政策变量 D 。滞后变量 12.()就是具有一定概率分布得随机变量,它得数值由模型本身决定。 A。外生变量B.内生变量C.前定变量D。滞后变量 13.同一统计指标按时间顺序记录得数据列称为(). A 。横截面数据 B 。时间序列数据 C 。修匀数据 D .原始数据 14.计量经济模型得基本应用领域有()。 A 。结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D。季度分析、年度分析、中长期分析 15.变量之间得关系可以分为两大类,它们就是( ).
计量经济学第十章习题fixed
第10 章模型设定与实践 问题 10.1 模型设定误差有哪些类型?如何诊断?答:模型设定误差主要有以下四种类型: 1.漏掉一个相关变量; 2.包含一个无关的变量; 3.错误的函数形式; 4.对误差项的错误假定。 诊断的方法有:1?侦察是否含有无关变量;2?残差分析,拉姆齐(Ramsey的RESET检验法,DM (Davidsion-MacKinnon :戴维森麦-克金龙)检验; 3.拟合优度、校正拟合优度、系数显 著性、系数符合的合理性。 10.2模型遗漏相关变量的后果是什么? 答:模型遗漏相关变量的后果是:所有回归系数的估计量是有偏的,除非这个被去除的变量与每一个放入的变量都不相关。常数估计量通常也是有偏的,从而预测值是有偏的。由于放入变量的回归系数估计量是有偏的,所以假设检验是无效的。系数估计量的方差估计量是有偏的。 10.3模型包含不相关变量的后果是什么?答:模型包含不相关变量的后果是:系数估计量的方差变大,从而估计量的精度下降。 10.4什么是嵌套模型?什么是非嵌套模型? 答:如果两个模型不能被互相包容,即任何一个都不是另一个的特殊情形,便称这两个模型 是非嵌套的。如果两个模型能互相包容,即其中一个是另一个的特殊情形,便称这两个模型 是嵌套的。 10.5非嵌套模型之间的比较有哪些方法? 答:非嵌套模型之间的比较方法有:拟合优度或校正拟合优度、AIC(Akaike's information criterion )准则、SIC(Schwarz's information criterion )准则和HQ(Hannnan-Qinn criterion )准则。拉姆齐(Ramsey)的RESET检验法,DM (Davidsion-MacKinnon :戴维森麦-克金龙)检验。 习题 10.6对数线性模型在人力资源文献中有比较广泛的应用,其理论建议把工资或收入的对数 作为因变量。如果教育投资收益率为r,则接受一年教育的工资为w1 (1 r)w0, W o是基准工资(未接受教育)。如果接受教育的年限为 s,则工资为w t (1 r)t w0,取对数
斯托克、沃森着《计量经济学》第六章
Chapter 6. Linear Regression with Multiple Regressors 6.1 Omitted Variable Bias(遗漏变量偏差) OLS estimate of the Test Score/STR relation: n TestScore= 698.9 – 2.28×STR, R2 = .05, SER = 18.6 (10.4) (0.52) Is this a credible estimate of the causal effect on test scores of a change in the student-teacher ratio? 1
No: there are omitted confounding factors (family income; whether the students are native English speakers) that bias the OLS estimator: STR could be “picking up” the effect of these confounding factors. 2
Omitted Variable Bias The bias in the OLS estimator that occurs as a result of an omitted factor is called omitted variable bias. For omitted variable bias to occur, the omitted factor “Z” must be: 1.a determinant of Y; and 2.correlated with the regressor X. 3
计量经济学习题及答案
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。 14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。 15.计量经济学模型的应用可以概括为四个方面,即__________、__________、__________、__________。 16.结构分析所采用的主要方法是__________、__________和__________。 二、单选题: 1.计量经济学是一门()学科。 A.数学 B.经济 C.统计 D.测量