预测模型

预测模型
概述
1.定义预测就是根据过去和现在来估计未来预测未来。它是使用历史数据或因素变量来预测需求的数学模型,是根据已掌握的比较完备的历史统计数据,运用一定的数学方法进行科学的加工整理,借以揭示有关变量之间的规律性联系,用于预测和推测未来发展变化情况的一类预测方法。
2.思维方式基本理论主要有惯性原理、类推原理和相关原理。
3.预测的核心问题预测的技术方法,或者说是预测的数学模型。
4.选择根据各种方法多有各自的研究特点、优缺点和适用范围。
这里归纳了几种使用较多的预测方法: 回归分析预测法、微分方程模型、灰色预测模型、时间序列方法和BP 神经网络预测法。对每种预测模型做了简单的介绍分析,并对灰色预测模型、时间序列方法和BP 神经网络预测法进行了比较.
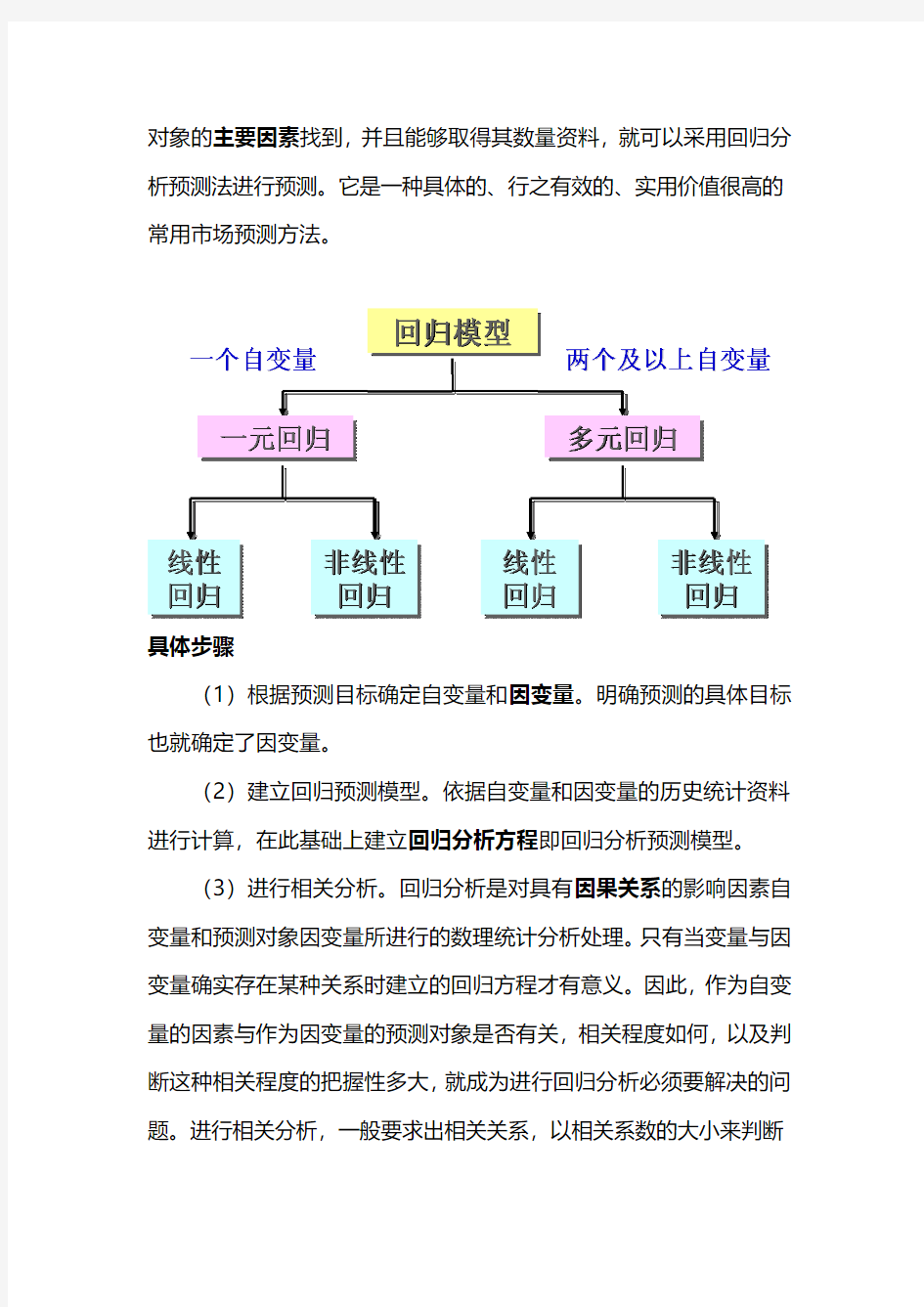
一、回归分析预测法
基本思想
回归分析预测法是在分析市场现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量关系大多表现为相关关系。因此,回归分析预测法是一种重要的市场预测方法,当我们在对市场现象未来发展状况和水平进行预测时,如果能将影响市场预测
对象的主要因素找到,并且能够取得其数量资料,就可以采用回归分析预测法进行预测。它是一种具体的、行之有效的、实用价值很高的常用市场预测方法。
具体步骤
(1)根据预测目标确定自变量和因变量。明确预测的具体目标也就确定了因变量。
(2)建立回归预测模型。依据自变量和因变量的历史统计资料进行计算,在此基础上建立回归分析方程即回归分析预测模型。
(3)进行相关分析。回归分析是对具有因果关系的影响因素自变量和预测对象因变量所进行的数理统计分析处理。只有当变量与因变量确实存在某种关系时建立的回归方程才有意义。因此,作为自变量的因素与作为因变量的预测对象是否有关,相关程度如何,以及判断这种相关程度的把握性多大,就成为进行回归分析必须要解决的问题。进行相关分析,一般要求出相关关系,以相关系数的大小来判断
自变量和因变量的相关的程度。
(4)检验回归预测模型。计算预测误差,回归预测模型是否可用于实际预测,取决于对回归预测模型的检验和对预测误差的计算。 回归方程只有通过各种检验,且预测误差较小,才能将回归方程作为预测模型进行预测。
(5)计算并确定预测值。利用回归预测模型计算预测值,并对预测值进行综合分析,确定最后的预测值。 建模原理及过程
以下主要分享一元线性回归和多元线性回归模型。 (一)一元线性回归模型
对于只涉及一个自变量的回归分析,若因变量y 与自变量x 之间为线性关系,可以用一个线性方程来表示二者之间的关系,此方程为一元线性回归模型
1、理论模型:
一元线性回归模型可表示为
01
??y x ββε=++
此模型将变量y 与x 间的关系用两部分描述。一部分是由x 的变化引起y 线性变化的部分,即:另一部分是由其他随机因素引起y 线性变化的部分,记为ε。该回归模型表达了变量x 与y 之间密切相关、但还没有到y 由x 唯一确定的密切程度的关系。
模型中,一般称y 为被解释变量(因变量),x 为解释变量(自变量)。
0?β和1?β为模型的参数,又称回归系数。ε为随机误差项,又称随机干
扰项,表示除能用 x 和 y 之间线性关系解释的因素外的其他随机因素对 y 的影响。
2、理论模型的基本假定:
(1)误差项ε是一个不可观测的且期望值为0的随机变量,即E(ε)=0。对于一个给定的x 值,y 的期望值为
01
??()E y x ββ=+
(2)对于所有的 x 值,ε的方差2
σ都相同。
(3)误差项ε是一个服从正态分布的随机变量,且相互独立,即
ε~N( 0 , 2
σ )
其中,独立性意味着对于一个特定的 x 值,它所对应的ε与其他 x 值所对应的ε不相关。对于一个特定的 x 值,它所对应的 y 值与其他 x 所对应的 y 值也不相关。
3、一元线性回归模型参数的估计
用来估计一元线性回归模型参数0?
β和1?
β的方法是最小二乘法,其要点为:
(1)它是使因变量的观察值与估计值之间的离差平方和达到最小来求得0?
β和1?
β的方法。即:
最小==-=∑∑==n
i i n
i i e y y Q 1
21
21
0)?()?,?(ββ
(2)用此法拟合的直线来代表x 与y 之间的关系与实际数据的误差比其他任何直线都小。
根据最小二乘法的要求,可得求解0?β和1?β的标准方程如下
111122
1101???n
n n i i i i i i i n n
i i i i n x y x y n x x y x βββ=====?????
-?
? ??????=????- ?
?????=-?∑∑∑∑∑
从1?β的计算公式可以看出其分母大于0。1?
β的正负取决于分子,且分子与相关系数r 的分子相同。1?
β >0时,表示x 每增加一个单位y
值平均增加的数量,即x 与y 正相关; 1?
β <0时,表示x 每增加
一个单位y 值平均减少的数量,即x 与y 负相关。
4、一元线性回归模型的检验
在根据样本数据拟合回归方程时,首先假设变量x 和y 之间存在线性关系,这种假设是否成立必须经过检验才能证实。 回归分析中的显著性检验包括两方面内容: (1)回归方程线性关系的显著性检验 (2)回归系数的显著性检验
回归方程线性关系的显著性检验是检验自变量与因变量之间线性关系是否显著。方法是:将回归均方(MSR)同残差均方(MSE)加以比较,应用F 检验分析二者之间的差别是否显著。
回归均方(MSR):回归离差平方和(SSR)()2
1?n
i i y
y =-∑除以相应的自由度(自变量的个数p=1)
残差均方(MSE):残差平方和(SSE)()2
1?n
i i y y
=-∑除以相应的自由度(n-p-1)
(注:残差是指观测值与预测值(拟合值)之间的差,即ε,即是实际观察值与回归估计值 的差。离差是指预测值与预测期望值之间的差。)
如果差别显著,两个变量之间存在线性关系,如果差别不显著,两个变量之间不存在线性关系。
回归方程线性关系的显著性检验(检验的步骤)
(1)
提出假设:
H :两变量之间的线性关系不显著 1
H
:两变量之间的线性关系显著
(2)计算检验统计量F
()()2
12
1
?1
1
~(1,2)
2
?2
n
i i n
i
i y
y SSR F F n SSE n y y
n ==-==
----∑∑
其中,F(1,n-2)表示第一自由度为1,第二自由度为n-2的F 分布。
(3) 确定显著性水平α,并根据分子自由度1和分母自由度n-2查F 分布表找出临界值F α。
(4)作出决策:若F F α>,拒绝0H ;若F F α<,接受0H 回归系数的置信区间
0β和1β置信水平为1-α
的置信区间分别为
???
?????
+-++----xx e xx
e L x n n t L x n n t 2
21022101?)2(?
,1?)2(?σ
βσβαα和 ??
???
?-+---
-
xx
e xx
e L n t L n t /?)2(?,/?)2(?
2
11
211σ
βσ
βα
α
2
σ
的置信水平为1-
α的置信区间为 ?
??
?
?
?????---)2(,)2(22221n Q n Q e e ααχχ(二)多元线性回归
(多元线性回归在工程上更为有用)
1、数学模型及定义
一般地,影响试验指标的因素不只一个,假设它们之间有如下的线性关系:
0111=+++...()
k k y x x βββε
+
1212100,,...,(),().
k y x x x k E D βββεεεσ+==>0k 其中为可观测的随机变量,为非随机的可精确观测的变量,,,....,为个未知参数,为随机变量,设
211212011122=+++,,...,,,...,...()
,,...,k i i ik i i k ik i
n x x x y n n x x x y x x βββσβββεεεεε0k i 为了估计未知参数,,....,和,我们对和作次观测得组观测值(,y )(i=1,2,3,...,n).它们满足关系式:
+i=1,2,3,...n
其中相互独立且是与同分布的随机变量。
?????
???????=n y y Y ......1,?
?
???
???????=nk n n k k x x x x x x x x x X ...1..................1 (1)
212222111211,,
1于是,()式变为:
(3)Y X βε=+
2(1)10(,).
n X n k k E COV I βεεεεσ?++==其中为阶矩阵,称为资料矩阵,为维未知的列向量,满足:,
一般称
为k 元线性回归模型,并简记为
1对()式取期望,有
011...k k
y x x βββ=+++
称为回归平面方程。
线性模型
考虑的主要问题是:
(1) 用试验值(样本值)
对未知参数和作点估计和假设检
验,从而建立y 与
之间的数量关系;
(2) 在处对y 的值作预测与控制,并对
y 作区间估计.
2、模型参数估计
21.i βσ对和作估计
用最小二乘法求的估计量:作离差平方和
选择
使Q 达到最小。
根据微积分求极值的方法,得正规方程组
00............0k Q
Q
Q
βββ??=???
??=?
????
??=???
解得估计值
()()
Y X X X T
T
1
?-=β
得到的代入回归平面方程得:
称为经验回归平面方程.称为经验回归系数.
21?1().
T k X X β
βσ-+服从维正态分布,且为的无偏估计,协 注意为:方差阵 3、进行检验。 至于非线性回归分析:
1.转换为线性回归(类似多区间低阶次差值问题的解决)
2.曲线拟合 (附:常见拟合函数表) 二、微分方程模型
1.基本思想
当我们描述实际对象的某些特性随时间 ( 或空间) 而演变的过程、分析它的变化规律、预测它的未来性态、研究它的控制手段时 ,通常要建立对象的动态微分方程模型。微分方程大多是物理或几何方面的典型问题 ,假设条件已经给出 ,只需用数学符号将已知规律表示出来 ,即可列出方程 ,求解的结果就是问题的答案 ,答案是唯一的 ,但是有些问题是非物理领域的实际问题 ,要分析具体情况或进行类比才能给出假设条件。作出不同的假设 ,就得到不同的方程。比较典型的有: 传染病的预测模型、经济增长预测模型、正规战与游击战的预测模型、药物在体内的分布与排除预测模型、人口的预测模型、烟雾的扩散与消失预测模型以及相应的同类型的预测模型。其基本规律随着时间的增长趋势是指数的形式 ,根据变量的个数建立初等微分模型:
.dx
kx dt =和
(0)x x
=
( 如传染病预测,经济增长预测,人口预测等)
可能由于实际问题的改变,会出现外在的干预等,例如传染病模型,只有健康人才可能被传染为病人,病人治愈后仍有可能成为病人或者治愈后有免疫力,政府卫生部门的干预等,都会使得所建立的初等模型失败。为此根据情况可以适当地一步步改进所建立的初等模型,从而达到我们所需要的微分方程预测模型。
2.微分方程模型的优缺点:
微分方程模型的建立基于相关原理的因果预测法。
该法的优点:短、中、长期的预测都适合,而且既能反映内部规律,反映事物的内在关系,也能分析两个因素的相关关系,精度相应的比较高,另外对初等模型的改进也比较容易理解和实现。
该法的缺点: 虽然反映的是内部规律,但是由于方程的建立是以局部规律的独立性假定为基础,故做中长期预测时,偏差有点大,而且微分方程的解比较难以得到。
三、灰色预测模型的建立与求解(GM(1.1))
灰色预测的概念
1、灰色预测法是一种对含有不确定因素的系统进行预测的方法。
2、白色系统是指一个系统的内部特征是完全已知的,即系统的信息是完全充分的。
黑色系统是指一个系统的内部信息对外界来说是一无所知的,只能通过它与外界的联系来加以观测研究。
灰色系统内的一部分信息是已知的,另一部分信息时未知的,系统内
各因素间具有不确定的关系。
3、关联度分析方法:灰色预测通过鉴别系统因素之间发展趋势的相异程度,即进行关联分析,并对原始数据进行生成处理来寻找系统变动的规律,生成有较强规律性的数据序列,然后建立相应的微分方程模型,从而预测事物未来发展趋势的状况。其用等时距观测到的反应预测对象特征的一系列数量值构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间。
4、主要任务是根据具体灰色系统的行为特征数据,充分开发并利用不多的数据中的显信息和隐信息,寻找因素间或因素本身的数学关系。通常的办法是采用离散模型,建立一个按时间作逐段分析的模型。但是,离散模型只能对客观系统的发展做短期分析,适应不了从现在起做较长远的分析、规划、决策的要求。
灰色预测的类型
①灰色时间序列预测;即用观察到的反映预测对象特征的时间序
列来构造灰色预测模型,预测未来某一时刻的特征量,或达到某一特征量的时间。
②畸变预测;即通过灰色模型预测异常值出现的时刻,预测异常值什么时候出现在特定时区内。
③系统预测;通过对系统行为特征指标建立一组相互关联的灰色预测模型,预测系统中众多变量间的相互协调关系的变化。
④拓扑预测;将原始数据作曲线,在曲线上按定值寻找该定值发生的所有时点,并以该定值为框架构成时点数列,然后建立模型预测该定
值所发生的时点。
三、为了弱化原始时间序列的随机性,在建立灰色预测模型之前,需先对原始时间序列进行数据处理,经过数据处理后的时间序列即称为生成列。灰色系统常用的数据处理方式有累加和累减、均值生成三种。 四、关联度 1、关联系数
设参考数列()()()()()()()(){}n X X X k X
0000?,...,2?,1??= 比较数列()()()()()()()(){}n X X X k X 0000,...,2,1=
则称比较数列对参考数列在k 时刻的关联系数定义为:
()()()()()()()()()()()()()()()()k X k X k X k X
k X k X k X k X
k 00000000?max max ??max max ?min min )(-+--+-=
ρρη
式中:①()()()()k X k X
00?-为第k 个点()0X 与()0?X 的绝对误差; ②()()()()k X k X
00?min min -为两级最小差; ③()()()()k X k X
00?max max -为两级最大差; ④ρ称为分辨率,0<ρ<1,一般取ρ=0.5;
⑤对单位不一,初值不同的序列,在计算相关系数前应首
先进行初值化变换。
2、关联度
()∑==n
k k n r 1
1η称为()()k X 0与()()k X
0?的关联度 GM (1,1)模型的建立(看教材)
四、时间序列分析
1.基本思想
ARMA模型(p,d,q)又称自回归求积移平均模型,其中AR指自回归,p为模型的自回归系数;MA为移动平均,q为模型的移动平均项数;d为时间序列称为平稳之前比寻取其差分的次数。
(1)AR模型
AR模型也称为自回归模型。它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测,自回归的数学公式为:
式中,为自回归模型的阶数,为模型的待定系数,为误差,为一个平稳时间序列
(2)MA模型
MA模型也称为滑动平均模型。它的预测方式是通过过去的干扰值和现在的干扰值的线性组合预测。滑动平均模型的数学公式为:
式中,为模型的阶数,为模型的待定系数,为误差,为平稳时间序列
(3)ARMA模型
自回归模型和滑动平均模型的组合,便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA,数学公式为:
2.模型建立基本步骤
Step1 对原序列进行平稳性检验与处理
建立ARMA(p,q)模型之前,首先要检验风电功率历史数据平稳,如果不平稳,就要对原始数据序列进行差分,差分后成为平稳序列,则称其为d阶单整序列,其中d为差分的次数。
Step2 根据时间序列模型的识别规则,建立相应的模型
若平稳时间序列的偏相关函数是截尾的,而自相关函数是拖尾的,则可断定此序列适合AR模型。若平稳时间序列的偏自相关函数是拖尾的,而自相关函数是截尾的,则可断定此序列适合MA模型。若平稳时间序列的偏自相关函数和自相关函数均是拖尾的,则此序列适合ARIMA模型
(注:截尾是指时间序列的自相关函数(ACF)或偏自相关函数(PACF)在某阶后均为0的性质(比如AR的PACF);拖尾是ACF或PACF并不在某阶后均为0的性质(比如AR 的ACF)。)
Step3 参数(p,q)的估计与诊断
通过Eviews或SPSS软件,得到自相关和偏相关图,观察的自相关函数和偏相关函数在多少步滞后之后就很小,这表示该时间序列可以用ARMA(p,q)模型来描述。
Step4:模型的预测
五、BP 神经网络预测法
1.BP算法简述
BP算法是一种有监督式的学习算法,其主要思想是:输入学习样本,使用反向传播算法对网络的权值和偏差进行反复的调整训练,使输出的向量与期望向量尽可能地接近,当网络输出层的误差平方和小于指定的误差时训练完成,保存网络的权值和偏差。
BP 神经网络模型,是目前神经网络学习模型中最具代表性、应用最普遍的模型。 BP 神经网络架构是由数层互相连结的神经元组成 , 通常包含了输入层、输出层及若干隐藏层 , 各层包含了若干神经元。神经网络便于依照学习法则 ,透过训练以调整连结链加权值的方式来完成目标的收敛。。
具体算法如下: 第一步,网络初始化
给各连接权值分别赋一个区间(-1,1)内的随机数,设定误差函数e ,给定计算精度值 和最大学习次数M 。
第二步,随机选取第 个输入样本及对应期望输出
()
12()(),(),,()n k x k x k x k = x
()
12()(),(),,()q k d k d k d k = o d
第三步,计算隐含层各神经元的输入和输出
1()()1,2,,n
h ih i h
i hi k w x k b h p
==-=∑
()f(())
1,2,,h h ho k hi k h p
==
1
()()1,2,p
o ho h o
h yi k w ho k b o q
==-=∑
()f(())
1,2,o o yo k yi k o q
==
第四步,利用网络期望输出和实际输出,计算误差函数对输出层的各神经元的偏导数()o k δ
o
ho o ho
e e yi w yi w ???=
???
(())
()
()
p
ho h o o h h ho
ho
w ho k b yi k ho k w w ?-?==??∑
2
1
1((()()))2(()())()q
o o o o o o
o
d k yo k d k yo k yo k yi =?-'=--?∑
第五步,利用隐含层到输出层的连接权值、输出层的 ()o k δ 和隐含层的输出计算误差函数对隐含层各神经元的偏导数()h k δ
()()o
o h ho o ho
e e yi k ho k w yi w δ???==-??? ()
()h ih h ih e e hi k w hi k w ???=
??? 1(())
()
()
n
ih i h h i i ih
ih
w x k b hi k x k w w =?-?==??∑
21
21
211
1((()()))
()2()()()
1((()f(())))
()2()()
1(((()f(())))
()2()()q
o o h o h h h q
o o h o h h q
p
o ho h o h o h h h d k yo k e ho k hi k ho k hi k d k yi k ho k ho k hi k d k w ho k b ho k ho k hi k ====?-??=
????-?=
???--?=
??∑∑∑∑
1
1
()(()())f (())()
(())f (())()
q
h o o o ho
o h q
o ho h h o ho k d k yo k yi k w hi k k w hi k k δδ==?'=--?'=--∑∑
第六步,利用输出层各神经元的 ()o k δ 和隐含层各神经元的输出来修正连接权值()ho w k 。
1()()()()()
ho o h ho
N N ho ho o h e
w k k ho k w w w k ho k μ
μδηδ+??=-=?=+ 。
第七步,利用隐含层各神经元的()h k δ 和输入层各神经元的输入修正连接权。
1()
()()()()()()
h ih h i ih h ih
N N
ih ih h i e e hi k w k k x k w hi k w w w k x k μ
μδηδ+????=-=-=???=+ 。
第八步,计算全局误差
211
1(()())2q m o o k o E d k y k m ===-∑∑
第九步,判断网络误差是否满足要求。当误差达到预设精度或学习次数大于设定的最大次数,则结束算法。否则,选取下一个学习样本及对应的期望输出,返回到第三步,进入下一轮学习。
2.建模步骤:
Step 1 建立如下网络拓扑结构 表3 网络结构 网络基本结构 输入 激发函数
输出 激发函数
学习方法
精度
10—15—1
sigmoid
函数 sigmoid
函数
梯度下降法
0.001
01X t -() 01X t n -+() …
)
(t X n 0X t n -()
…
输入层隐含层输出层
图6:网络拓朴结构图
Step 2 网络训练
1、样本数据预处理
2、利用处理后的数据对网格进行训练。
Step 3 进行预测
BP算法采用的是剃度下降法,因而易陷于局部最小并且训练时间较长。用基于生物免疫机制地既能全局搜索又能避免未成熟收敛的免疫遗传算法IGA取代传统BP算法来克服此缺点。
BP神经网络的特点
1.非线性映射能力
能学习和存贮大量输入-输出模式映射关系,而无需事先了解描述这种映射关系的数学方程。只要能提供足够多的样本模式对供网络
MATLAB模型预测控制工具箱函数
MATLAB模型预测控制工具箱函数 8.2 系统模型建立与转换函数 前面读者论坛了利用系统输入/输出数据进行系统模型辨识的有关函数及使用方法,为时行模型预测控制器的设计,需要对系统模型进行进一步的处理和转换。MATLAB的模型预测控制工具箱中提供了一系列函数完成多种模型转换和复杂系统模型的建立功能。 在模型预测控制工具箱中使用了两种专用的系统模型格式,即MPC状态空间模型和MPC传递函数模型。这两种模型格式分别是状态空间模型和传递函数模型在模型预测控制工具箱中的特殊表达形式。这种模型格式化可以同时支持连续和离散系统模型的表达,在MPC传递函数模型中还增加了对纯时延的支持。表8-2列出了模型预测控制工具箱的模型建立与转换函数。 表8-2 模型建立与转换函数 8.2.1 模型转换 在MATLAB模型预测工具箱中支持多种系统模型格式。这些模型格式包括: ①通用状态空间模型; ②通用传递函数模型; ③MPC阶跃响应模型; ④MPC状态空间模型; ⑤MPC传递函数模型。
在上述5种模型格式中,前两种模型格式是MATLAB通用的模型格式,在其他控制类工具箱中,如控制系统工具箱、鲁棒控制工具等都予以支持;而后三种模型格式化则是模型预测控制工具箱特有的。其中,MPC状态空间模型和MPC传递函数模型是通用的状态空间模型和传递函数模型在模型预测控制工具箱中采用的增广格式。模型预测控制工具箱提供了若干函数,用于完成上述模型格式间的转换功能。下面对这些函数的用法加以介绍。 1.通用状态空间模型与MPC状态空间模型之间的转换 MPC状态空间模型在通用状态空间模型的基础上增加了对系统输入/输出扰动和采样周期的描述信息,函数ss2mod()和mod2ss()用于实现这两种模型格式之间的转换。 1)通用状态空间模型转换为MPC状态空间模型函数ss2mod() 该函数的调用格式为 pmod= ss2mod(A,B,C,D) pmod= ss2mod(A,B,C,D,minfo) pmod= ss2mod(A,B,C,D,minfo,x0,u0,y0,f0) 式中,A, B, C, D为通用状态空间矩阵; minfo为构成MPC状态空间模型的其他描述信息,为7个元素的向量,各元素分别定义为: ◆minfo(1)=dt,系统采样周期,默认值为1; ◆minfo(2)=n,系统阶次,默认值为系统矩阵A的阶次; ◆minfo(3)=nu,受控输入的个数,默认值为系统输入的维数; ◆minfo(4)=nd,测量扰的数目,默认值为0; ◆minfo(5)=nw,未测量扰动的数目,默认值为0; ◆minfo(6)=nym,测量输出的数目,默认值系统输出的维数; ◆minfo(7)=nyu,未测量输出的数目,默认值为0; 注:如果在输入参数中没有指定m i n f o,则取默认值。 x0, u0, y0, f0为线性化条件,默认值均为0; pmod为系统的MPC状态空间模型格式。 例8-5将如下以传递函数表示的系统模型转换为MPC状态空间模型。 解:MATLAB命令如下:
国内物流需求预测方法文献综述
国内物流需求预测方法文献综述 (河北工程大学管理科学与工程阮俊虎) 物流需求是指一定时期内社会经济活动对生产、流通、消费领域的原材料、半成品和成品、商品以及废旧物品、废旧材料等的配置作用而产生的对物在空间、时间和费用方面的要求,涉及运输、库存、包装、装卸搬运、流通加工以及与之相关的信息需求等物流活动的诸方面[1]。物流需求的度量可以采用价值量和实物量两种度量体系。实物量意义上的物流需求主要表现为不同环节和功能的具体作业量,如货运量、库存量、加工量、配送量等;价值量意义上的物流需求是所有物流环节全部服务价值构成的综合反映,如物流成本、物流收入、供应链增值等[2]。 物流需求预测是根据物流市场过去和现在的需求状况,以及影响物流市场需求变化的因素之间的关系,利用一定的判断、技术方法和模型,对物流需求的变化及发展趋势进行预测。国内外许多专家和学者都对物流需求的预测进行了研究,提出不同的预测方法和手段。物流预测方法可以分为定性预测方法(如德尔菲法和业务人员评估法等)和定量预测方法,但多数是定量预测方法,因此,本文主要是对国内物流需求定量预测方法进行综述,归为时间序列预测方法、因果关系预测方法、组合预测方法等三类。 1.时间序列预测方法综述 时间序列预测方法是依据从历史数据组成的时间序列中找出预测对象的发展变化规律,以此作为预测依据。常用的时间序列预测模型有增长率法、移动平均法、指数平滑法、随机时间序列模型、灰色模型、以及在经济领域已经被广泛应用的混沌与分形等。 增长率法指根据预测对象在过去的统计期内的平均增长率,类推未来某期预测值的一种简便算法。该预测方法一般用于增长率变化不大,或预计过去的增长趋势在预测期内仍将继续的场合。刘劲等[3](2002)在利用增长率系数法对百色地区港口货运量进行了逐一分析。 移动平均法是用一组最近的实际数据值来预测未来一期或几期内产品的需求量的一种常用方法。当产品需求既不快速增长也不快速下降,且不存在季节性因素时,移动平均法能有效地消除预测中的随机波动。根据预测时使用的各元素的权重不同,移动平均法可以分为:简单移动平均和加权移动平均。杨荣英等[4](2001)在讨论移动平均值的基础上,提出了移动平均线方法,并介绍了运用移动平均线进行物流预测的方法。李海建等[5](2003)利用二次移动平均线模型对芜湖市物流业发展的规模进行了预测。 指数平滑法是在移动平均法基础上发展起来的一种时间序列分析预测法,它是通过计算指数平滑值,配合一定的时间序列预测模型对现象的未来进行预测。其原理是任一期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均。移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期资料更大的权重;而指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。韦司滢等[6](1999)将指数平滑法等其他多种方法应用在三峡移民工程建材配送决策支持系统中。黄荣富等[7](2003)、
LOGIT模型参数估计方法研究_金安
第4卷第1期2004年2月 交通运输系统工程与信息 Jo ur nal of T r anspo rt atio n Sy stems Eng ineer ing and Infor matio n T echno lo gy Vo l.4No.1Febr uar y 2004 文章编号:1009-6744(2004)01-0071-05 LOGIT 模型参数估计方法研究 金 安 (广州市规划局交通研究所,广州510030) 摘要: 离散选择模型,特别是L OG IT 模型在交通需求模型建立过程中,应用非常广泛,许多实际的交通政策问题都涉及到方式选择,然而L OG IT 模型的建立非常困难,尤其是效用函数及参数估计.本文重点就L O GIT 模型参数估计的有关问题进行讨论,特别是运用统计方法如何对效用函数的变量进行选取及比较不同形式效用函数. 关键词: L O GI T 模型;参数估计;t 检验;似然率检验中图分类号: N 945.12 On Methodology of Parameter Estimation in L OGIT Model JIN An (Instit ute o f T r aspo r tatio n,G uang zho u P la nning Bur eau,Guang zho u 510030,China ) Abstract : Disagg reg ate choice mo del ,especially L O GIT m odel ,hav e been used w idely in dev elo pment of tr avel demand mo del ,many pr actical tr anspor tation policy issues ar e concerned w ith mode choice.But pro cedure o f development of L OG IT mo del is difficult,especially mo del calibr atio n and for m of utility functio n.T his paper discuss r elat ional pr oblems o n development of L OG IT model,P articular emphasis is placed o n pr actical pr ocedur es for selection the co rr ect ex planato ry var iables and on compar ing differ ent ver sions of utility functio n using st atistical metho ds.Keywords : L OG IT mo del;par ameter est imation;t -test;likeliho od test CLC number : N 945.12 收稿日期:2003-11-24 金安:广州市规划局交通研究所工程师,工学硕士.研究方向为交通规划及交通需求模型. 1 引 言 实践过程中,LOGIT 模型效用函数不可能预先知道,模型师在建立LOGIT 模型最初阶段几乎没有效用函数任何信息,最多认为在效用函数中会有哪些可能的变量,但也不能确定所有的变量是否都需要,更不可能知道哪些变量需要进行函数变换或效用函数参数的具体数值是多少.这些问题只有通过拟合合适的观测数据,并检验这些模型来确定哪一个最能够描述观测数据.本文主要介绍拟合和测试LOGIT 模型方法. 2 数据的要求 估计和检验过程的第一步是选择合适的观测数据,用于建立LOGIT 方式选择模型所需的数据有: (1)对个体实际方式选择行为的观测.例如, 要建立工作出行方式选择模型,需要对上班出行者方式选择进行观测的数据. (2)所有被选择和没有被选择方式的相关属性值.这些属性可能作为模型中的变量.例如,假设总出行时间被认为是模型中的一个变量,则对于样本中每一个个体而言,所需数据包括每一种可能方式的总出行时间.如果属性数据仅包含被选择方式,LOGIT 模型就不能建立. (3)任何可能作为变量的个体属性值.例如,汽车拥有水平,则需要样本中每个个体家庭汽车拥有水平数. 3 模型的设定 所需数据收集后,下一步工作是设定一种或多种效用函数形式.设定步骤包括确定效用函数中变量、属性的函数变换以及效用函数的形式.这个步
中国证券市场股票价格预测模型综述
中国证券市场股票价格预测模型综述 王 浩 (洛阳理工学院工程管理系,洛阳 471023)* 摘 要:中国金融市场的证券价格存在着可预测成分。现有的各种统计预测方法基本都可以归纳为时间关系模型和因果关系模型两大类,详细分析了各种模型的实现方法并总结了其特点。 关键词:预测;股票价格;统计模型;综述do:i 10.3969/j .issn .1000-5757.2009.07.058 中图分类号:F830191 文献标志码:A 文章编号:1000-5757(2009)07-0058-03 一、证券市场可预测性 有效市场理论指出,证券价格呈现随机游走特征,因此技术分析和掷骰子选出的股票,最终表现相差无几。大量分析却发现中国股票价格波动具有长期记忆性,拒绝了随机游走假设,即股市涨跌存在自身的规律,无论长期和短期都存在着可预测的成分,因而技术分析是有用的,通过采用 相应策略,投资者可以获得超常利润。[1] 中国证券市场呈 现弱有效性的原因可能在于,作为一个新兴市场,法制、监管等因素造成市场信息传递效率低下,投资者在博弈中存在严重的信息和资金实力不对称,而且这种不对称状态并不能在市场中迅速消除,因此F a m a 所描述的概率上的/瞬时性0还无法达到,而这种市场结构的特点,使得某些/技术分析0成为信息挖掘的成本。 由于股票指数序列呈现高度的非线性,经典计量经济模型和时间序列模型的有效性受到了挑战。现代预测理论和统计学、信息技术、优化算法紧密结合,向复杂化和智能化方向发展。至少目前在我国,各种预测技术方兴未艾,投资者按照自己的经验采用各不相同的指标作为决策依据,在市场上低买高卖,获得了成功,也经历过失败。 二、主要预测模型1.神经网络模型 神经网络是一种大规模并行处理系统,具有良好的自学习能力、抗干扰能力和强大的非线性映射能力,能够从大量历史数据中进行聚类和学习,自动提取样本隐含的特征和规则,进而找到某些行为变化规律,可以实现任何复杂的因果关系。BP (反向传播)和RBF (径向基函数)神经网络是最常见的股市预测模型。崔建福等发现BP 模型普遍显著优于 GARCH (广义自回归条件异方差)模型,从而认为对股票价格这样波动频繁的时间序列,从非线性系统角度建模略胜于 从非平稳时间序列角度建模。[2] 由于传统算法收敛速度慢且 全局寻优能力差,更多研究将精力放在对神经网络结构和参数的改进上。丁雪梅等发现改进后BP 算法的预测结果比 回归预测、指数平滑预测和灰色预测都要好。 [3]神经网络预测方法的应用有两个明显特点。一方面,统计模式识别和数字信号处理等领域的特征选择和提取方法,如小波包最优分解方法、混沌吸引子理论、K a l m an 滤波算法、主成分分析、灰色系统理论,广泛用于神经网络输入参数的甄别。另一方面,新的网络模型不断被应用于证券预测实践以提高映射效率,如模糊神经网络和小波神经网络。预测结果明显优于普通神经网络模型。 神经网络的缺陷在于,网络结构只能事先指定或应用启发式算法在训练过程中寻找,需要在充分了解待解决问题的基础上,主要依靠个人经验来确定,没有统一的规范,往往需要通过反复改进和试验,最终才能选出一个相对较好的设计方案,并且网络训练过程易陷入局部极小点。不过,神经网络最致命缺点在于,无法表达和分析预测系统的输入输出之间的关系,难以解释系统输出结果。 2.灰色系统和随机过程模型 灰色预测普遍采用灰色系统模型,经由累加过程削弱原始数据的随机干扰,突出系统所蕴涵的内在规律,然后建立动态预测模型。马尔可夫过程是无后效性的随机过程,是一种应用极为广泛的传统方法。灰色系统GM (1,1)模型的解为指数型曲线,几何图形较为平滑,比较适用于具有增长趋势的问题,而对随机性波动较大的数据进行预测,会 58 第25卷 第7期V o.l 25 四川教育学院学报 J OURNAL OF S I CHUAN C O LLEG E OF EDU CAT I ON 2009年7月 Ju.l 2009 * 收稿日期:2009-02-23 作者简介:王浩(1973)),男,河南西峡人,副教授,硕士,研究方向:区域经济发展理论与数量分析。
利用预测模型进行自动化决策
利用预测模型进行自动化决策 敏捷是决策管理领域的关注重点及优势所在。在决策管理中,敏捷指的是能够快速调整并应对业务和市场带来的变化。决策管理技术倡导将业务逻辑从系统和应用中分离出来,然后业务人员便可以在独立的环境中管理和修改业务逻辑,并且完成对修改的部署上线。 在这过程中,尽量减少了IT人员的参与,而且也不需要经历一个完整的软件开发周期(需求,开发,测试,上线)。 相比于传统应用更新方式,决策管理的方法可以保证团队在很短的时间内就能完成对系统里业务逻辑的修改。即使某些涉及关键自动化决策的需求频繁地变更或者新增,在这种方式下也能轻松应对,这可以让你的业务更加灵活。 能够快速地对应用进行修改和完成上线是很重要的。那如何才能知道应该修改什么呢?有一些变更,比如监管要求或者合同约定的,是非常明确的。只要准确地按照监管要求或者合同约定进行部署,自动化决策将产生所需的决策结果,进而做出正确的决策。但是,许多决策的修改并没有这样直接而明显的解决方法。 光靠敏捷是不够的
通常情况下,决策是基于用户行为、市场动态、环境影响或其他的外部因素制定的。因此,这些决策常常有着很大的不确定性。例如,在信用风险决策中,需要决定是否批准一个申请,以及设定相应的信用额度和利率。相关机构如何制定最佳决策来帮助他们尽量获客的同时降低风险?这同样适用于营销决策,如追加销售和交叉销售的报价等,客户最可能接受哪个可能的报价? 预测模型提供数据洞察 这正是预测模型一展所长的地方。预测模型基于大量的历史数据,通过精密的分析技术对未来进行预测,从而帮助我们减少不确定性,并制定出更好的决策。能做到这点,预测模型是通过识别历史数据中一些能导致特定结果的模式,并在未来的交易以及客户互动中检测相同的模式,来实现对结果的预测。 预测模型指导着许多影响我们日常生活的决策。比如,你的信用卡发卡银行可能会偶尔联系你,要求你确认一些他们认为可能是盗刷的交易,因为这些交易不符合你的刷卡习惯。当你在网上购物时,商家会根据你的购买历史或者购物车中的商品推荐你可能需要的其他商品。并且你可能也注意到,在你访问的一些其他网站上也会展示类似商品的广告。这些广告与你之前访问的购物网站直接相关,
神经网络模型预测控制器
神经网络模型预测控制器 摘要:本文将神经网络控制器应用于受限非线性系统的优化模型预测控制中,控制规则用一个神经网络函数逼近器来表示,该网络是通过最小化一个与控制相关的代价函数来训练的。本文提出的方法可以用于构造任意结构的控制器,如减速优化控制器和分散控制器。 关键字:模型预测控制、神经网络、非线性控制 1.介绍 由于非线性控制问题的复杂性,通常用逼近方法来获得近似解。在本文中,提出了一种广泛应用的方法即模型预测控制(MPC),这可用于解决在线优化问题,另一种方法是函数逼近器,如人工神经网络,这可用于离线的优化控制规则。 在模型预测控制中,控制信号取决于在每个采样时刻时的想要在线最小化的代价函数,它已经广泛地应用于受限的多变量系统和非线性过程等工业控制中[3,11,22]。MPC方法一个潜在的弱点是优化问题必须能严格地按要求推算,尤其是在非线性系统中。模型预测控制已经广泛地应用于线性MPC问题中[5],但为了减小在线计算时的计算量,该部分的计算为离线。一个非常强大的函数逼近器为神经网络,它能很好地用于表示非线性模型或控制器,如文献[4,13,14]。基于模型跟踪控制的方法已经普遍地应用在神经网络控制,这种方法的一个局限性是它不适合于不稳定地逆系统,基此本文研究了基于优化控制技术的方法。 许多基于神经网络的方法已经提出了应用在优化控制问题方面,该优化控制的目标是最小化一个与控制相关的代价函数。一个方法是用一个神经网络来逼近与优化控制问题相关联的动态程式方程的解[6]。一个更直接地方法是模仿MPC方法,用通过最小化预测代价函数来训练神经网络控制器。为了达到精确的MPC技术,用神经网络来逼近模型预测控制策略,且通过离线计算[1,7.9,19]。用一个交替且更直接的方法即直接最小化代价函数训练网络控制器代替通过训练一个神经网络来逼近一个优化模型预测控制策略。这种方法目前已有许多版本,Parisini[20]和Zoppoli[24]等人研究了随机优化控制问题,其中控制器作为神经网络逼近器的输入输出的一个函数。Seong和Widrow[23]研究了一个初始状态为随机分配的优化控制问题,控制器为反馈状态,用一个神经网络来表示。在以上的研究中,应用了一个随机逼近器算法来训练网络。Al-dajani[2]和Nayeri等人[15]提出了一种相似的方法,即用最速下降法来训练神经网络控制器。 在许多应用中,设计一个控制器都涉及到一个特殊的结构。对于复杂的系统如减速控制器或分散控制系统,都需要许多输入与输出。在模型预测控制中,模型是用于预测系统未来的运动轨迹,优化控制信号是系统模型的系统的函数。因此,模型预测控制不能用于定结构控制问题。不同的是,基于神经网络函数逼近器的控制器可以应用于优化定结构控制问题。 在本文中,主要研究的是应用于非线性优化控制问题的结构受限的MPC类型[20,2,24,23,15]。控制规则用神经网络逼近器表示,最小化一个与控制相关的代价函数来离线训练神经网络。通过将神经网络控制的输入适当特殊化来完成优化低阶控制器的设计,分散和其它定结构神经网络控制器是通过对网络结构加入合适的限制构成的。通过一个数据例子来评价神经网络控制器的性能并与优化模型预测控制器进行比较。 2.问题表述 考虑一个离散非线性控制系统: 其中为控制器的输出,为输入,为状态矢量。控制
预测模型分类
预测模型分类及优缺点分析 灰色(系统)预测模型 神经网络预测模型 趋势平均预测法 1 微分方程模型 当我们描述实际对象的某些特性随时间(或空间)而演变的过程、分析它的变化规律、预测它的未来性态、研究它的控制手段时,通常要建立对象的动态微分方程模型。微分方程大多是物理或几何方面的典型.问题,假设条件已经给出,只需用数学符号将已知规律表示出来,即可列出方程,求解的结果就是问题的答案,答案是唯一的,但是有些问题是非物理领域的实际问题,要分析具体情况或进行类比才能给出假设条件。作出不同的假设,就得到不同的方程。比较典型的有:传染病的预测模型、经济增长预测模型、正规战与游击战的预测模型、药物在体内的分布与排除预测模型、人口的预测模型、烟雾的扩散与消失预测模型以及相应的同类型的预测模型。其基本规律随着时间的增长趋势是指数的形式,根据变量的个数建立初等微分模型。微分方程模型的建立基于相关原理的因果预测法。该法的优点:短、中、长期的预测都适合,而.既能反映内部规律,反映事物的内在关系,也能分析两个因素的相关关系,精度相应的比较高,另外对初等模型的改进也比较容易理解和实现。该法的缺点:虽然反映的是内部规律,但是由于方程的建立是以局部规律:的独立性假定为基础,故做中长期预测时,偏差有点大,而且微分方程的解比较难以得到。 2 时间序列法 将预测对象按照时问顺序排列起来,构成一个所谓的时间序列,从所构成的这一组时间序列过去的变化规律,推断今后变化的可能性及变化趋势、变化规律,就是时间序列预测法。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变
化、随机性变化。考虑一组给定的随时间变化的观察值,t=1,2,3,?,n},如何选取合适模型预报,t=n+1,n+3, n+k}的值。 上面的模型统称ARMA模型,是时间序列建模中最重要和最常用的预测手段。 事实上,对实际中发生的平稳时间序列做恰当的描述,往往能够得到自回归、滑动平均或混合的模型,其阶数通常不超过2。时间序列模型其实也是一种回归模型,属于定量预测,其基于的原理是,一方面承认事物发展的延续性,运用过去时间序列的数据进行统计分析就能推测事物的发展趋势;另一方面又充分考虑到偶然因素影响而产生的随机性,为了消除随机波动的影响,利用历史数据,进行统计分析,并对数据进行适当的处理,进行趋势预测。优点是简单易行,便于掌握,能够充分运用原时间序列的各项数据,计算速度快,对模型参数有动态确定的能力,精度较好,采用组合的时间序列或者把时间序列和其他模型组合效果更好。缺点是不能反映事物的内在联系,不能分析两个因素的相关关系,常数的选择对数据修匀程度影响较大,不宜取得太小,只适用于短期预测 3 灰色预测理论模型 灰色预测的基本思路是将已知的数据序列按照某种规则构成动态或非动态的 白色模块,再按照某种变化、解法来求解未来的灰色模型。它的主要特点是模型使用的不是原始数据序列,而是生成的数据序列。其核心体系是灰色模型(GM),即对原始数据作累加生成(或其他方法生成)得到近似的指数规律再进行建模的模型方法。优点是不需要很多的数据,一般只需要4个数据就够,能解决历史数据少、序列的完整性及可靠性低的问题;能利用微分方程来充分挖掘系统的本质,精度高;能将无规律的原始数据进行生成得到规律性较强的生成数列,运算简便,易于检验,具有不考虑分布规律,不考虑变化趋势。缺点是只适用于中长期的预测,只适合指数增长的预测,对波动性不好的时间序列预测结果较差。 4 BP神经网络模型
MA AB模型预测控制工具箱函数
M A T L A B模型预测控制工具箱函数 8.2系统模型建立与转换函数 前面读者论坛了利用系统输入/输出数据进行系统模型辨识的有关函数及使用方法,为时行模型预测控制器的设计,需要对系统模型进行进一步的处理和转换。MATLAB的模型预测控制工具箱中提供了一系列函数完成多种模型转换和复杂系统模型的建立功能。 在模型预测控制工具箱中使用了两种专用的系统模型格式,即MPC状态空间模型和MPC传递函数模型。这两种模型格式分别是状态空间模型和传递函数模型在模型预测控制工具箱中的特殊表达形式。这种模型格式化可以同时支持连续和离散系统模型的表达,在MPC传递函数模型中还增加了对纯时延的支持。表8-2列出了模型预测控制工具箱的模型建立与转换函数。 表8-2模型建立与转换函数 8.2.1模型转换 在MATLAB模型预测工具箱中支持多种系统模型格式。这些模型格式包括: ①通用状态空间模型; ②通用传递函数模型; ③MPC阶跃响应模型; ④MPC状态空间模型;
⑤MPC传递函数模型。 在上述5种模型格式中,前两种模型格式是MATLAB通用的模型格式,在其他控制类工具箱中,如控制系统工具箱、鲁棒控制工具等都予以支持;而后三种模型格式化则是模型预测控制工具箱特有的。其中,MPC状态空间模型和MPC传递函数模型是通用的状态空间模型和传递函数模型在模型预测控制工具箱中采用的增广格式。模型预测控制工具箱提供了若干函数,用于完成上述模型格式间的转换功能。下面对这些函数的用法加以介绍。 1.通用状态空间模型与MPC状态空间模型之间的转换 MPC状态空间模型在通用状态空间模型的基础上增加了对系统输入/输出扰动 和采样周期的描述信息,函数ss2mod()和mod2ss()用于实现这两种模型格式之间的转换。 1)通用状态空间模型转换为MPC状态空间模型函数ss2mod() 该函数的调用格式为 pmod=ss2mod(A,B,C,D) pmod=ss2mod(A,B,C,D,minfo) pmod=ss2mod(A,B,C,D,minfo,x0,u0,y0,f0) 式中,A,B,C,D为通用状态空间矩阵; minfo为构成MPC状态空间模型的其他描述信息,为7个元素的向量,各元素分别定义为: ◆minfo(1)=dt,系统采样周期,默认值为1; ◆minfo(2)=n,系统阶次,默认值为系统矩阵A的阶次; ◆minfo(3)=nu,受控输入的个数,默认值为系统输入的维数; ◆minfo(4)=nd,测量扰的数目,默认值为0; ◆minfo(5)=nw,未测量扰动的数目,默认值为0; ◆minfo(6)=nym,测量输出的数目,默认值系统输出的维数; ◆minfo(7)=nyu,未测量输出的数目,默认值为0; 注:如果在输入参数中没有指定m i n f o,则取默认值。 x0,u0,y0,f0为线性化条件,默认值均为0; pmod为系统的MPC状态空间模型格式。 例8-5将如下以传递函数表示的系统模型转换为MPC状态空间模型。 解:MATLAB命令如下:
MATLAB模型预测控制工具箱函数
M A T L A B模型预测控制 工具箱函数 TTA standardization office【TTA 5AB- TTAK 08- TTA 2C】
M A T L A B模型预测控制工具箱函数 系统模型建立与转换函数 前面读者论坛了利用系统输入/输出数据进行系统模型辨识的有关函数及使用方法,为时行模型预测控制器的设计,需要对系统模型进行进一步的处理和转换。MATLAB的模型预测控制工具箱中提供了一系列函数完成多种模型转换和复杂系统模型的建立功能。 在模型预测控制工具箱中使用了两种专用的系统模型格式,即MPC状态空间模型和MPC传递函数模型。这两种模型格式分别是状态空间模型和传递函数模型在模型预测控制工具箱中的特殊表达形式。这种模型格式化可以同时支持连续和离散系统模型的表达,在MPC传递函数模型中还增加了对纯时延的支持。表8-2列出了模型预测控制工具箱的模型建立与转换函数。 表8-2 模型建立与转换函数 模型转换 在MATLAB模型预测工具箱中支持多种系统模型格式。这些模型格式包括: ①通用状态空间模型; ②通用传递函数模型; ③MPC阶跃响应模型; ④MPC状态空间模型; ⑤MPC传递函数模型。
在上述5种模型格式中,前两种模型格式是MATLAB通用的模型格式,在其他控制类工具箱中,如控制系统工具箱、鲁棒控制工具等都予以支持;而后三种模型格式化则是模型预测控制工具箱特有的。其中,MPC状态空间模型和MPC传递函数模型是通用的状态空间模型和传递函数模型在模型预测控制工具箱中采用的增广格式。模型预测控制工具箱提供了若干函数,用于完成上述模型格式间的转换功能。下面对这些函数的用法加以介绍。 1.通用状态空间模型与MPC状态空间模型之间的转换 MPC状态空间模型在通用状态空间模型的基础上增加了对系统输入/输出扰动和采样周期的描述信息,函数ss2mod()和mod2ss()用于实现这两种模型格式之间的转换。 1)通用状态空间模型转换为MPC状态空间模型函数ss2mod() 该函数的调用格式为 pmod= ss2mod(A,B,C,D) pmod= ss2mod(A,B,C,D,minfo) pmod= ss2mod(A,B,C,D,minfo,x0,u0,y0,f0) 式中,A, B, C, D为通用状态空间矩阵; minfo为构成MPC状态空间模型的其他描述信息,为7个元素的向量,各元素分别定义为: ◆minfo(1)=dt,系统采样周期,默认值为1; ◆minfo(2)=n,系统阶次,默认值为系统矩阵A的阶次; ◆minfo(3)=nu,受控输入的个数,默认值为系统输入的维数; ◆minfo(4)=nd,测量扰的数目,默认值为0; ◆minfo(5)=nw,未测量扰动的数目,默认值为0; ◆minfo(6)=nym,测量输出的数目,默认值系统输出的维数; ◆minfo(7)=nyu,未测量输出的数目,默认值为0; 注:如果在输入参数中没有指定m i n f o,则取默认值。 x0, u0, y0, f0为线性化条件,默认值均为0; pmod为系统的MPC状态空间模型格式。 例8-5将如下以传递函数表示的系统模型转换为MPC状态空间模型。 解:MATLAB命令如下:
交通事故次数灰色预测模型——预测与决策作业
问题 :某市2004年1-6月的交通事故次数统计见下表.试建立灰色预测模型. 解: (1) 由原始数据列计算一次累加序列(1)x ,结果见下表2: (2)建立矩阵,B y : (1)(2)(1)(2)(1)(2)(1) (2)(1)(2) 11[(2)(1)211[(3)(2)21 1[(4)(3) 211[(5)(4)211[(6)(5)2x x x x B x x x x x x ??-+??? ? ??-+?????? =-+????-+??????-+???? 130.512431378.515271697.51-??? ?-????=-? ?-????-?? [] (0)(0)(0)(0)(0) (2)(3)(4)(5)(6)95130141156185T T y x x x x x ??=?? = (3)计算1()T B B -: 1 0.0000 0.0020() 0.0020 0.9726T B B -?? =???? (4)由1?(*)**T U B B B y -=,求估值?a 和?u : ? 0.1440??84.4728a U u -????==???????? 。 把?a 和?u 的估值代入时间响应方程,由(1)83x =得到时间响应方程为:
?(1)(1)0.144??(1)(1)666.6617583.6617??ak k u u x k x e e a a -? ?+=-+=-??? ? 即时间响应方程为: (1)0.144(1)666.6617583.6617k x k e +=- (5)计算拟合值(1)?()x i ,再用后减运算还原计算得模型计算值(0)?()x k ,见下表3第一列: 计算残差(0)(0)?()()()E k x k x k =-与相对残差(0)(0)(0)?()[()()]/()e k x k x k x k =-,结果见表3第3、4列; (0) x 的均值:5(0) 1 1()131.66675k X x k ===∑; (0) x 的方差:134.7355S ==; 残差的均值:5 2 1()0.181651k E E k ===-∑; 残差的方差:2 6.3519S ==; 后验差比值 2 1 S C S = = 0.1829; 现在0.67451S =0.6745X34.7355=23.4291,而所有的|()|E k E -都小于23.4291,故小误差概率 {}1|()|0.67451P P E k E S =-<= 根据0.95P ≥,0.18290.35C =≤,表示预测的等级好,由此可知预测方程
模型预测控制
云南大学信息学院学生实验报告 课程名称:现代控制理论 实验题目:预测控制 小组成员:李博(12018000748) 金蒋彪(12018000747) 专业:2018级检测技术与自动化专业
1、实验目的 (3) 2、实验原理 (3) 2.1、预测控制特点 (3) 2.2、预测控制模型 (4) 2.3、在线滚动优化 (5) 2.4、反馈校正 (5) 2.5、预测控制分类 (6) 2.6、动态矩阵控制 (7) 3、MATLAB仿真实现 (9) 3.1、对比预测控制与PID控制效果 (9) 3.2、P的变化对控制效果的影响 (12) 3.3、M的变化对控制效果的影响 (13) 3.4、模型失配与未失配时的控制效果对比 (14) 4、总结 (15) 5、附录 (16) 5.1、预测控制与PID控制对比仿真代码 (16) 5.1.1、预测控制代码 (16) 5.1.2、PID控制代码 (17) 5.2、不同P值对比控制效果代码 (19) 5.3、不同M值对比控制效果代码 (20) 5.4、模型失配与未失配对比代码 (20)
1、实验目的 (1)、通过对预测控制原理的学习,掌握预测控制的知识点。 (2)、通过对动态矩阵控制(DMC)的MATLAB仿真,发现其对直接处理具有纯滞后、大惯性的对象,有良好的跟踪性和较强的鲁棒性,输入已 知的控制模型,通过对参数的选择,来获得较好的控制效果。 (3)、了解matlab编程。 2、实验原理 模型预测控制(Model Predictive Control,MPC)是20世纪70年代提出的一种计算机控制算法,最早应用于工业过程控制领域。预测控制的优点是对数学模型要求不高,能直接处理具有纯滞后的过程,具有良好的跟踪性能和较强的抗干扰能力,对模型误差具有较强的鲁棒性。因此,预测控制目前已在多个行业得以应用,如炼油、石化、造纸、冶金、汽车制造、航空和食品加工等,尤其是在复杂工业过程中得到了广泛的应用。在分类上,模型预测控制(MPC)属于先进过程控制,其基本出发点与传统PID控制不同。传统PID控制,是根据过程当前的和过去的输出测量值与设定值之间的偏差来确定当前的控制输入,以达到所要求的性能指标。而预测控制不但利用当前时刻的和过去时刻的偏差值,而且还利用预测模型来预估过程未来的偏差值,以滚动优化确定当前的最优输入策略。因此,从基本思想看,预测控制优于PID控制。 2.1、预测控制特点 首先,对于复杂的工业对象。由于辨识其最小化模型要花费很大的代价,往往给基于传递函数或状态方程的控制算法带来困难,多变量高维度复杂系统难以建立精确的数学模型工业过程的结构、参数以及环境具有不确定性、时变性、非线性、强耦合,最优控制难以实现。而预测控制所需要的模型只强调其预测功能,不苛求其结构形式,从而为系统建模带来了方便。在许多场合下,只需测定对象的阶跃或脉冲响应,便可直接得到预测模型,而不必进一步导出其传递函数或状
Excel在经济预测与决策模型分析中的应用-定性预测方法[1]
第2章定性预测方法 定性预测,是预测人员根据自己的经验,理论水平和掌握的实际情况,对经济发展前景性质、程度做出判断。但有时可以提出数量估计,其特点为:需要的数据少,能考虑无法定量的因素,比较简便可行。它是一种不可缺少的灵活的经济预测方法。在掌握的数据不多,不够准确或无法用数字描述进行定量分析时,定性预测是一种行之有效的预测方法。如新企业,新产品生产经营的发展前景,由于缺少生产资料,以采用定性预测方法为宜。又如党和国家方针政策的变化,消费者心理的变化对市场供需变化的影响,均无法定量描述,只能通过判断方法,进行定性预测。通过定性预测,提出有预见性的建议,可以为政府和企业进行经济决策,及管理提供依据,在我国得到广泛应用。 由于定性预测主要靠预测人员经验和判断能力,易受主观因素的影响,为了提高定性预测的准确程度,应注意以下几个问题: 1)应加强经济调查,掌握各种情况,对目标分析预测更加接近实际。 2)进行有数据有情况的分析判断,使定性分析数量化,提高说服力。 3)应将定性预测和定量预测相结合,提高预测质量。 §专家调查法——德尔菲法 专家调查法是经济预测组织者通过向专家作调查,收集专家对预测意见的方法。 德尔菲法,是上世纪四十年代末期由美国兰德公司研究员赫尔默和达尔奇设计的。一九五零年就已开始使用。早期主要应用于科学技术预测方面,从六十年代中期以来,逐渐被广泛应用于预测商业和整个国民经济的发展方面。特别是在缺乏详细的充分的统计资料,无法采用其它更精确的预测方法时,这种方法具有独特优势。一般常用它和其它方法相互配合进行长期预测。 德尔菲法是由预测机构或人员采用通讯的方式和各个专家单独联系,征询对预测问题的答案,并把各专家的答案进行汇总整理,再反馈给专家征询意见。如此反复多次,最后由预测组织者综合专家意见,做出预测结论。 德尔菲法的主要过程是: 1)确定预测题目 预测题目是预测所要研究和解决的课题,即是预测的中心和目的。预测题目应根据党和国家的经济政策和经济任务来确定。应该选择那些有研究价值的或者对本单位、本地区今后发展有重要影响的课题。题目要具体明确。
预测模型与案例
预测模型 最近几年,在全国大学生数学建模竞赛常常出现预测模型或是与预测有关的题目,例如疾病的传播,雨量的预报等。什么是预测模型?如何预测?有那些方法?对此下面作些介绍。 预测作为一种探索未来的活动早在古代已经出现,但作为一门科学的预测学,是在科学技术高度发达的当今才产生的。“预测”是来自古希腊的术语。我国也有两句古语:“凡事预则立,不预则废”,“人无远虑,必有近忧”。卜卦、算命都是一种预测。中国古代著名著作“易经”就是一种专门研究预测的书,现在研究易经的人也不少。古代的预测主要靠预言家,即先知们的直观判断,或是借助于某些先兆,缺乏科学根据。预测技术的发展源于社会的需求和实践。20世纪初期风行一时的巴布生图表就是早期的市场预测资料,哈佛大学的每月指数图表为商品市场、证券市场和货币市场预测提供了依据。然而这些预测都未能揭示1929-1930年经济危期的突然暴发,使工商界深感失望。尔后,经济学家们从挫折中吸取了教训,采用趋势和循环技术对商业进行分析和预测,科学预测也因此开始萌生。20世纪30年代凯思斯提出政府干预和市场机制相结合的经济模型,1937年诺依曼又提出了扩展经济模型,对近代经济模型产生重要的影响,科学的经济和商业预测也就步入发展阶段。 技术预测开始于二次世界大战后的20世纪40年代,直到20世纪50年代未才广泛应用于工农业和军事部门。由于社会、科学技术
和经济的大量需求,预测技求才成为一门真正的科学,预测未来是当代科学的重要任务。 20世纪以来,预测技术所以得以长足进步,一方面,与社会需求有很大关系,另一方面通过社会实践和长期历史验证,表明事物的发展是可以预测的。而且借助可靠的数据和科学的方法,以及预测技术人员的努力,预测结果的可靠性和准确性可以达到很高的程度,这也是预测技术迅速发展的另一个重要原因。 科学技术、经济和社会预测的应验率也是很高的。维聂尔曾预言20世纪是电子时代,法国思想家迈希尔18世纪末到19世纪初对巴黎未来几百年的发展进行了预测。从1950年的实际情况分析,他的预测中有36%得到证实,28%接近实现,只有36%是错误的。法国哲学家和数学家冠道塞在法国大革命时期曾采用外推法进行了一系列社会预测,其中75%得到证实。沙杰尔莱特1901年在《二十世纪的发明》一书中的一些预测,其中64%得到证实。凯木弗尔特在1910年和1915年公布的25项预测中,到1941年只有3项未被证实,3项是错误的。我国明朝开国功臣刘基就预测将来是天上铁鸟飞,地上铁马跑,那时还没有火车、飞机。 预测的目的在于认识自然和社会发展规律,以及在不同历史条件下各种规律的相互作用,揭示事物发展的方向和趋势,分析事物发展的途径和条件,使人们尽早地预知未来的状况和将要发生的事情,并能动地控制其发展,使其为人类和社会进步服务。因而预测是决策的重要的前期工作。决策是指导未来的,未来既是决策的依据,又是决
交通流预测模型综述
交通流预测模型综述 摘要: 随着社会的发展,交通事故、交通堵塞、环境污染和能源消耗等问题日趋严重。为了缓解交通压力,交通专家也提出了各种不同的方法。在交通网络越来越复杂的今天,交通流预测在智能交通系统中是个热门的研究领域,因为正确的交通流预测,可以进行实时交通信号控制,交通分配、路径诱导、自动导航,事故检测等。本文从交通流短期预测模型出发,分析常见预测模型的优缺点,得出综合模型进行预测将是交通流预测领域的发展趋势。 关键字:交通流预测,智能交通系统,综合模型 Traffic flow predictive models review Abstract: With the development of society, traffic accidents, traffic jams, environmental pollution and energy consumption problems become more and more serious. In order to alleviate traffic pressure, traffic experts also puts forward all kinds of different methods. In the traffic network is more and more complex today, traffic flow predictive in intelligent transportation system is a hot research fields, because the correct traffic flow predictive, can real-time traffic signal control, traffic distribution, route guidance, automatic navigation, accident detection, etc. This article from short-term prediction model of traffic flow, analyzes the advantages and disadvantages of common prediction model, it is concluded that predict comprehensive model will be traffic flow predictive areas of development trend. Keywords:Traffic flow predictive, Intelligent transportation system, integrated model 引言 目前,有关交通流预测方面的研究已取得大量的成果,建立了多种实时交通量预测的方法,其预测精度也达到了较高水平。本文先是通过研究分析不同交通流短期预测模型的优缺点,然后对具有优势的基于神经网络的综合模型进行模型的构建。 一、交通流预测概述 (一)交通流预测的必要性 随着人们生活水平的提高,私家车的数量、人们出行的次数等越来越多,使得交通事故、交通堵塞、环境污染和能源消耗等问题日趋严重。很多城市也陷入了“拥有最宽阔的马路,也拥有最宽阔的…停车场?”的困境,严重影响了城市的运转效率,客观上阻碍了社会、经济的快速发展。多年来,世界各国的城市交通专家提出各种不同的方法,试图通过先进的智能交通手段来缓解交通拥堵问题。而实现这些系统或方法的关键,不仅要有实时的道路检测数据,更重要的是,要获得实时、可靠、准确的预测信息。再利用动态路径诱导和交通信息系统为出行者提供实时有效的道路信息,实现动态路径诱导,达到节约出行者旅行时间,缓解道路拥堵,减少污染、节省能源等的目的。因此,准确、可靠的交通预测信息是动态路径诱导系统的基础和关键。