识别oracle数据库性能瓶颈

识别数据库性能瓶颈
谢礼明
小生在oracle数据库上学习的时间也不算短,现将自己的经验总结一下。如有错误,请联系 xielm@https://www.360docs.net/doc/d16958304.html,
在我看来,数据库的性能主要取决于2部分:数据库管理和sql 语句。数据库优化除了教科书上的优化理论外,更需要针对具体情况的望闻问诊。
1、数据库管理
数据库的性能问题主要体现在:
1、硬件资源的不足。如CPU、内存、I/O、网络
2、资源设计的不合理。如SGA分配不合理、命中率低
3、锁资源不足。
下面我们将就这些问题提供多种方法进行分析
本文中的数据库为oracle 10g 、OLAP系统
1.1查看硬件资源
注意时间点要选择在数据库繁忙时段。
1.1.1查看主机配置
uname –M -- IBM,9117-MMA
prtconf | grep proc |wc –l -- 16颗cpu
prtconf –s -- Processor Clock Speed: 5008 MHz
prtconf –m -- Memory Size: 254208 MB
1.1.2机器压力测试
vmstat 10 10
我们看出空闲在1%左右,没有等待。
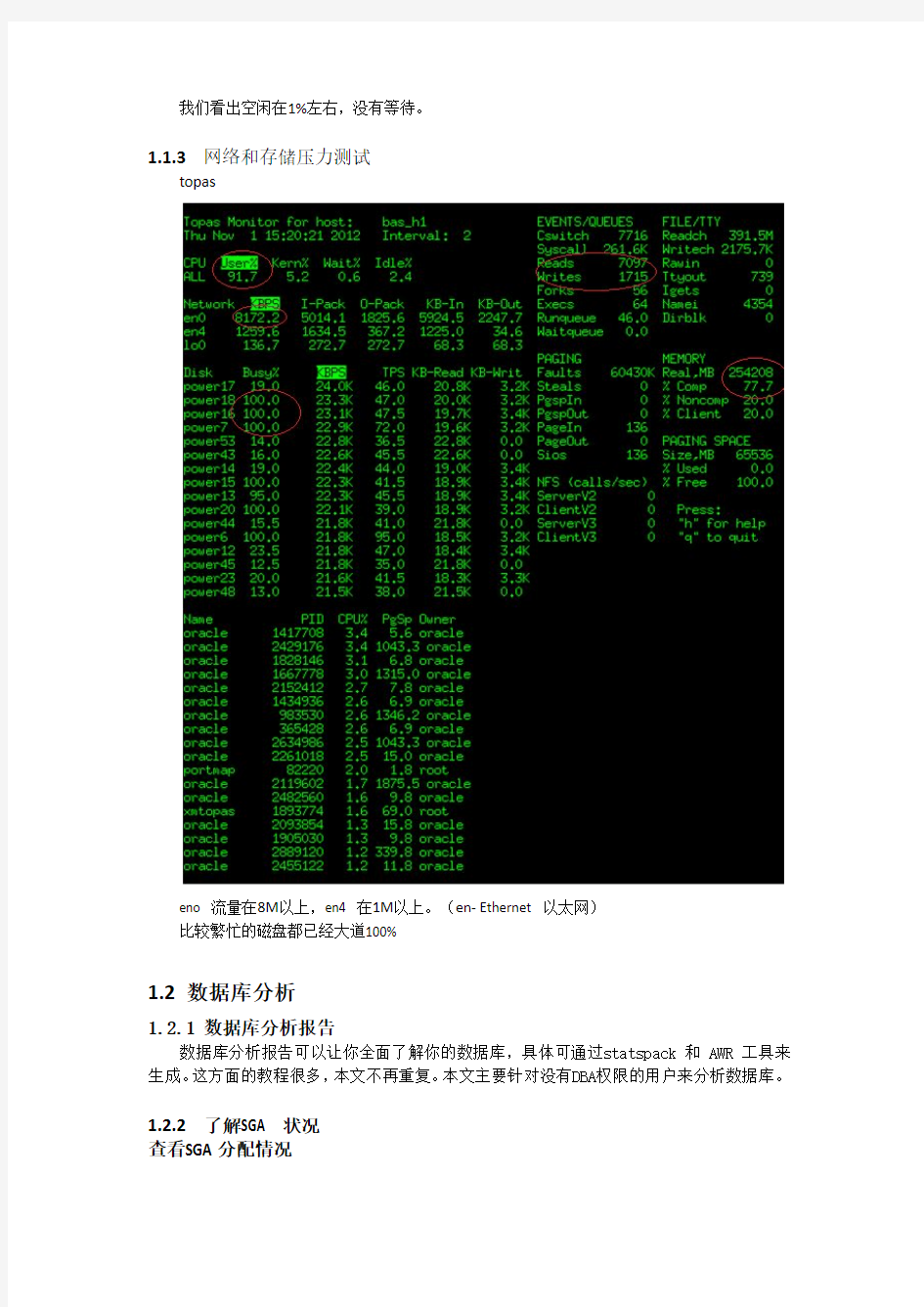
1.1.3网络和存储压力测试
topas
eno 流量在8M以上,en4 在1M以上。(en-Ethernet 以太网)
比较繁忙的磁盘都已经大道100%
1.2数据库分析
1.2.1数据库分析报告
数据库分析报告可以让你全面了解你的数据库,具体可通过statspack 和 AWR 工具来生成。这方面的教程很多,本文不再重复。本文主要针对没有DBA权限的用户来分析数据库。
1.2.2了解SGA 状况
查看SGA分配情况
SELECT*from v$parameter a WHERE https://www.360docs.net/doc/d16958304.html, IN( 'shared_pool_size', 'log_buffer', 'db_cache_size', 'java_pool_size','large_pool_size')
查看SGA使用情况
select component,current_size/1048576,min_size/1048576
from v$sga_dynamic_components;
1.2.3了解PGA状况
PGA=UGA+sort_area_size + hash_area_size+ bitmap_merge_area_siz e
sort_area_size :对信息排序所用的内存总量
sort_area_retained_size : 排序后在内存中保存排序信息的内存总量。
hash_area_size :存储散列列表所用的内存量。
--------------------------------------------------------
查询PGA总大小, 结果是24G。
SQL> show parameter pga
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_target big integer 24G
查询已经消耗的PGA,大小为4G
SQL> select round(sum(pga_alloc_mem)/1048576,1) from v$process;
ROUND(SUM(PGA_ALLOC_MEM)/10485
------------------------------
4424.1
分析sort_area_size是否足够,如果sort disk占比超过0.1,则需要扩容
SQL> select name, value from v$sysstat where name in ('sorts (memory)', 'sorts (disk)');
NAME VALUE
---------------------------------------------------------------- ----------
sorts (memory) 370150270
sorts (disk) 208320
--------------------------------------------------------
*每一个session都会占有一定的PGA资源,必要的时候,需要控制session的数量。
Select count(*) from v$session;
1.2.4临时表空间使用
存储过程报临时表空间不足,是一个常见的问题,需要引起特别重视。所以需要经常监控临时表空间的使用和对不良SQL进行优化。
临时表文件总空间大小:
SQL> SELECT round(sum(bytes)/1048576/1024) from dba_temp_files;
ROUND(SUM(BYTES)/1048576/1024)
------------------------------
83
临时表空间使用情况
select https://www.360docs.net/doc/d16958304.html,ERname,b.MACHINE,b.SID,b.SERIAL#,c.SQL_TEXT, ROUND(SUM(BLOCKS* 8192*2)/1048576,2) usered
from v$sort_usage a,
v$session b,
v$sqlarea c
where a.SESSION_ADDR = b.SADDR
AND b.SQL_ID=c.SQL_ID
group by https://www.360docs.net/doc/d16958304.html,ERname,b.MACHINE,b.SID,b.SERIAL#,c.SQL_TEXT;
结论:一共使用了9.4个G的临时表空间。目前临时表空间很充足
1.2.5回滚段争用情况
select name, waits, gets, waits/gets "Ratio"
from v$rollstat a, v$rollname b
where https://www.360docs.net/doc/d16958304.html,n = https://www.360docs.net/doc/d16958304.html,n;
1.2.6命中率
数据缓冲区的命中率
select 1-round((a.value-b.value-c.value)/d.value,2) ratio
from v$sysstat a,v$sysstat b,v$sysstat c,v$sysstat d
where https://www.360docs.net/doc/d16958304.html,='physical reads' and
https://www.360docs.net/doc/d16958304.html,='physical reads direct' and
https://www.360docs.net/doc/d16958304.html,='physical reads direct (lob)' and
https://www.360docs.net/doc/d16958304.html,='session logical reads';
结论:作为OLAP系统,算比较正常。
共享池空闲率计算方法
Select round(a.bytes/1048576,1) free,round(b.VALUE/1048576,1)
all_size,round(a.BYTES/b.VALUE,2) RATIO
From v$sgastat a,v$parameter b
Where https://www.360docs.net/doc/d16958304.html,='free memory' and a.POOL='shared pool'
AND https://www.360docs.net/doc/d16958304.html,='shared_pool_size';
结论:比较正常。
SGA 中字典缓冲区的命中率
select parameter, gets,Getmisses ,
round(getmisses/(gets+getmisses),2) "miss ratio",
ROUND((1-(sum(getmisses)/ (sum(gets)+sum(getmisses)))),2) "Hit ratio"
from v$rowcache
where gets+getmisses <>0
group by parameter, gets, getmisses;
结论:ratio都比较接近1,属于比较正常。
1.2.7v$sysstat & v$sesstat
分析v$sysstat和v$sesstat是我识别数据库瓶颈的重要方法。
我们分析凌晨2:00-4:00数据库最繁忙的时段。分析思路:每半个小时用定时任务对v$sysstat,v$sesstat,v$sql,v$session_event进行拍照。然后对其进行分析。
1.创建快照表t_stats
create table T_STATS
(
sid varchar2(20),
name varchar2(64),
class number,
value number,
time_flag number,
time_num number
) ;
create table t_sql_session
(
sid number(8),
serial# number(8),
status varchar2(20),
sql_Id varchar2(30),
sql_text varchar2(1000),
event varchar2(64),
last_call_et number,
used_temp number,
used_ublk number,
schemaname varchar2(30),
time_flag number,
time_num number
);
2.我写了一个过程p_stats完成将信息定时插入到快照表中。
3.分析数据
class说明:
1 代表事例活动
2 代表Redo buffer活动
4 代表锁
8 代表数据缓冲活动
16 代表OS活动
32 代表并行活动
64 代表表访问
128 代表调试信息
sysstat 分析
关键项分析
select a.sid,https://www.360docs.net/doc/d16958304.html,,(b.time_num-a.time_num)/100 time,
case when https://www.360docs.net/doc/d16958304.html, in ('redo size') then round((b.value-a.value)/1048576/1024,1)||'g' when https://www.360docs.net/doc/d16958304.html, in ('session logical reads', 'consistent gets','db block changes','physical reads', 'physical writes','table scan blocks gotten')
then to_char(round((b.value-a.value)*16/1048576,1) )||'g'
else to_char(b.value-a.value) end dif
from t_stats a,t_stats b
where https://www.360docs.net/doc/d16958304.html,=https://www.360docs.net/doc/d16958304.html, and a.sid=b.sid
and a.time_flag=1 and b.time_flag=2
and a.sid='sys'
and (b.value-a.value) >0
and a. name in ('redo size','session logical reads','db block changes','physical reads','physical writes','user calls',
'parse count (total)','parse count (hard)','sorts (memory)','logons current','execute count');
结论:注意physical reads =731G,physical writes=60G,说明吞吐量很大;逻辑读=4752.1G,物理读=731G,说明db_cache_size设置还是比较合理的;只有sorts(memory),没有sorts(disk),说明sort_area_size比较合适;硬解析=1674,说明还比较正常。
I/0分析class in (8,16)
select a.sid,https://www.360docs.net/doc/d16958304.html,,a.class,
case when https://www.360docs.net/doc/d16958304.html, like '%byte%' then round((b.value-a.value)/1048576/1024,1) else
(b.value-a.value) end dif,
(b.time_num-a.time_num)/100 time,
row_number()over(partition by a.sid order by (b.value-a.value) desc) rn
from t_stats a,t_stats b
where https://www.360docs.net/doc/d16958304.html,=https://www.360docs.net/doc/d16958304.html, and a.sid=b.sid
and a.time_flag=1 and b.time_flag=2
and a.sid='sys'
and a.class in (8,16) -- 条件判断
and (b.value-a.value) >0
结论:1700秒内,物理读一共730G的容量,物理写一共99.8G。数据吞吐量非常大。consisten gets 一致读,指的是读取回滚段的一致性数据,
表访问分析
结论:在1700秒内,读取了460亿条记录,排序6亿多条记录
时间分析
(https://www.360docs.net/doc/d16958304.html, LIKE '%time%' OR https://www.360docs.net/doc/d16958304.html, ='CPU used by this session')
结论:user i/0wait time远大于cpu时间,说明I/O是目前数据库的瓶颈. 其他分析
latch分析
sessstat 分析
select * from (
select a.sid,https://www.360docs.net/doc/d16958304.html,,(b.value-a.value) dif,(b.time_num-a.time_num)/100 time,
row_number()over(partition by https://www.360docs.net/doc/d16958304.html, order by (b.value-a.value) desc) rn
from t_stats a,t_stats b
where https://www.360docs.net/doc/d16958304.html,=https://www.360docs.net/doc/d16958304.html, and a.sid=b.sid
and a.time_flag=1 and b.time_flag=2
and (b.value-a.value) >0
) where rn<=3 and name in ('cpu used by this session','db block gets', 'consistent gets',
'db block changes','physical reads','physical writes','redo size',
'table scans (long tables)','table scan rows gotten', 'table scan blocks gotten')
结论:在所有的会话中,2460和2790耗费的cpu排名比较高,2694和3108对回滚段读取一致性数据排名比较高,2761和2771在物理读上排名比较高。
db block gets :指从db buffer cache读取的块
physical reads:指从磁盘读入内存的OS块,内存包括SGA和PGA
1.2.8非空闲等待事件
SELECT* from v$system_event a where a.wait_class<>’Idle’ ORDER BY time_waited DESC
结论:数据库瓶颈在I/O上和dblink取数
select *from v$session_wait a where not exists(select 1 from v$event_name b where wait_class='idle' and a.event=https://www.360docs.net/doc/d16958304.html,)
结论:会话的瓶颈也是在I/O上。主要是数据的读取,和临时表空间的写。
2、sql语句
首先,我们需要对sql语句的性能进行监控,找出需要优化的sql。然后,对sql语句的逻辑和执行计划进行分析,保证最优化的sql语句。最后,跟踪sql语句,分析sql语句慢的瓶颈,为以后的优化提供参考。
2.1sql监控
2.1.1TOP 5 sql
SELECT a.sql_id,a.sql_text,a.sql_fulltext,
a.executions,parse_calls,a.disk_reads,a.buffer_gets,
round(user_io_wait_time/1000000,2) user_io_wait_time,
round(a.cpu_time/1000000,2) cpu_time,
round(elapsed_time/1000000,2) elapsed_time,
decode(executions,0,0,ROUND(disk_reads/executions,2)) per_disk_reads,
decode(executions,0,0,ROUND(buffer_gets/executions,2)) per_buffer_gets,
decode(executions,0,0,ROUND(cpu_time/1000000/executions,2)) per_cpu_time,
decode(executions,0,0,ROUND(elapsed_time/1000000/executions,2)) per_elapsed_time from v$sql a
WHERE https://www.360docs.net/doc/d16958304.html,mand_type IN(2,3,6,7)and a.EXECUTIONS >2
ORDER BY per_elapsed_time DESC
---- 可以按cpu_time,disk_reads,buffer_get进行排序
2.1.2监控运行中的sql
SELECT p.SPID,b.sid,b.serial#,b.status,a.sql_Id,a.sql_text, b.event,
round(p.pga_alloc_mem/1048576,2) "PGA(M)",https://www.360docs.net/doc/d16958304.html,ed_temp,
https://www.360docs.net/doc/d16958304.html,st_call_et run_time, m.cpu,m.scan_rows, m.physical_reads,m.logical_reads,
m.sort_rows,m.sort_memory,m.sort_disk,m.ptx2,nvl(https://www.360docs.net/doc/d16958304.html,ed_ublk,0) undo_blocks,
b.schemaname,b.program,b.module,b.machine, b.OSUSER
FROM v$sql a,v$session b,v$transaction c ,v$process p,
(SELECT session_addr,ROUND(SUM(BLOCKS*8192*2)/1048576,2) used_temp
FROM v$sort_usage GROUP BY session_addr) d,
(SELECT A.SID,sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='CPU used by this session'THEN A.VALUE END)cpu, sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='table scan rows gotten'THEN A.VALUE END) scan_rows,
sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='physical reads'THEN A.VALUE END)physical_reads,
sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='session logical reads'THEN A.VALUE END)logical_reads,
sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='sorts (rows)'THEN A.VALUE END) sort_rows,
sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='sorts (memory)'THEN A.VALUE END) sort_memory,
sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='sorts (disk)'THEN A.VALUE END) sort_disk,
sum(CASE WHEN https://www.360docs.net/doc/d16958304.html,='queries parallelized'THEN A.VALUE END) ptx2 FROM V$SESSTAT A, V$STATNAME B
WHERE A.STATISTIC# = B.STATISTIC#
AND https://www.360docs.net/doc/d16958304.html, IN('CPU used by this session','table scan rows gotten','physical reads', 'session logical reads','sorts (rows)','sorts (memory)','sorts (disk)','queries parallelized' )
GROUP BY sid ) m
WHERE a.sql_id=b.sql_id
AND b.PADDR=p.addr(+)
AND b.saddr=c.ses_addr(+)
AND b.saddr=d.session_addr(+)
AND b.sid=m.sid(+)
AND b.status='ACTIVE'
ORDER BY run_time DESC
2.2分析sql语句
拿sql举例:
SELECT a.eparchy_code,b.action_name,SUM(a.CUR_INCOME),
SUM(CASE WHEN a.CUR_ACCT_TAG='1' THEN a.VO_FEE END)
FROM mid_user_3g_info_m a,
TP_USER_ACTION_M b
WHERE https://www.360docs.net/doc/d16958304.html,ER_ID=https://www.360docs.net/doc/d16958304.html,er_id(+)
AND a.partition_id='06'
AND https://www.360docs.net/doc/d16958304.html,er_id <> ALL(SELECT user_id FROM mid_user_3g_info_m_05)
GROUP BY a.eparchy_code,b.action_name
2.2.1执行计划explain_plan
explain plan for sql语句;
select * from table(dbms_xplan.display()); -- 查看执行计划
set autotrace traceonly explain.
set autotrace trace stat.
set autotrace on; -- 只能在sqlplus下执行。
2.2.2SQL_TRACE 和tkprof
SQL_TRACE
跟踪本session
SQL>alter session set sql_trace=true;
SQL>exec dbms_session.set_sql_trace(true);
跟踪其他session
SQL>exec dbms_system.set_sql_trace_in_session(session_id, serial#,true);
tkprof
1.重要参数:user_dump_dest=
2.在user_dump_desc下找到对应的文件:orcl_ora_xxxx.trc.(xxxx是进程号。也可以认为
最新的文件即我们想找的)。
https://www.360docs.net/doc/d16958304.html,prof ora_xxx.trc abc.out(输出文件) sys=no
4.查看输出文件more abc.out
2.2.3v$sessstats 和v$mystats
可以利用runstats_pkg.rs_start \ rs_middle \ rs_stop
也可以利用上面的p_stats
后续可以开发一个全自动的分析工具,输出类似AWR的分析报告)
这个sql的SID=144.
2.2.4事件和等待
select * from v$session_wait where sid=144;
更多事件:select * from v$session_event where sid=144;
---- 我们可以知道等待事情是全表扫描引起。
2.3sql优化
针对这个sql,将<>(all) 改成not exists. 代码如下:
SELECT a.eparchy_code,b.action_name,SUM(a.CUR_INCOME),
SUM(CASE WHEN a.CUR_ACCT_TAG='1' THEN a.VO_FEE END)
FROM mid_user_3g_info_m a,
TP_USER_ACTION_M b
WHERE https://www.360docs.net/doc/d16958304.html,ER_ID=https://www.360docs.net/doc/d16958304.html,er_id(+)
AND a.partition_id='06'
AND NOT EXISTS(SELECT 1 FROM mid_user_3g_info_m_05 c WHERE https://www.360docs.net/doc/d16958304.html,er_id=https://www.360docs.net/doc/d16958304.html,er_id) GROUP BY a.eparchy_code,b.action_name
附录:
Command_type字典
1 -- CREATE TABLE
2 -- INSERT
3 -- SELECT
4 -- CREATE CLUSTER
5 -- ALTER CLUSTER
6 -- UPDATE
7 -- DELETE
8 -- DROP CLUSTER
9 -- CREATE INDEX
10 -- DROP INDEX
11 -- ALTER INDEX
12 -- DROP TABLE
13 -- CREATE SEQUENCE
14 -- ALTER INDEX
15 -- ALTER TABLE
16 -- DROP SEQUENCE
17 -- ALTER INDEX
18 -- REVOKE OBJECT
19 -- CREATE SYNONYM
20 -- ALTER INDEX
21 -- CREATE VIEW
22 -- DROP VIEW
23 -- ALTER INDEX
24 -- CREATE PROCEDURE
25 -- ALTER PROCEDURE
26 -- ALTER INDEX
27 -- NO-OP
28 -- RENAME
29 -- ALTER INDEX
30 -- AUDIT OBJECT
31 -- NOAUDIT OBJECT
32 -- ALTER INDEX
33 -- DROP DATABASE LINK
34 -- CREATE DATABASE
35 -- ALTER INDEX
36 -- CREATE ROLLBACK SEG
37 -- ALTER ROLLBACK SEG
38 -- ALTER INDEX
39 -- CREATE TABLESPACE
40 -- ALTER TABLESPACE
41 -- ALTER INDEX
42 -- ALTER SESSION
43 -- ALTER USER
44 -- ALTER INDEX
45 -- ROLLBACK
46 -- SAVEPOINT
47 -- ALTER INDEX
48 -- SET TRANSACTION
49 -- ALTER SYSTEM
50 -- ALTER INDEX
51 -- CREATE USER
52 -- CREATE ROLE
53 -- ALTER INDEX
54 -- DROP ROLE
56 -- ALTER INDEX
57 -- CREATE CONTROL FILE
59 -- CREATE TRIGGER
60 -- ALTER INDEX
61 -- DROP TRIGGER
62 -- ANALYZE TABLE
63 -- ALTER INDEX
64 -- ANALYZE CLUSTER
65 -- CREATE PROFILE
66 -- ALTER INDEX
67 -- ALTER PROFILE
68 -- DROP PROCEDURE
70 -- ALTER INDEX
71 -- CREATE SNAPSHOT LOG
72 -- ALTER SNAPSHOT LOG
73 -- ALTER INDEX
74 -- CREATE SNAPSHOT
75 -- ALTER SNAPSHOT
76 -- ALTER INDEX
77 -- CREATE TYPE
78 -- DROP TYPE
79 -- ALTER INDEX
80 -- ALTER TYPE
81 -- CREATE TYPE BODY
82 -- ALTER INDEX
83 -- DROP TYPE BODY
84 -- DROP LIBRARY
85 -- ALTER INDEX
86 -- TRUNCATE CLUSTER
100 -- LOGON
101 -- ALTER INDEX
102 -- LOGOFF BY CLEANUP
103 -- SESSION REC
104 -- ALTER INDEX
105 -- SYSTEM NOAUDIT
106 -- AUDIT DEFAULT
107 -- ALTER INDEX
108 -- SYSTEM GRANT
109 -- SYSTEM REVOKE
110 -- ALTER INDEX
111 -- DROP PUBLIC SYNONYM
112 -- CREATE PUBLIC DATABASE LINK 113 -- ALTER INDEX
115 -- REVOKE ROLE
116 -- ALTER INDEX
117 -- USER COMMENT
118 -- ENABLE TRIGGER
119 -- ALTER INDEX
120 -- ENABLE ALL TRIGGERS
explan plan的结果:
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------
-----------
Plan hash value: 2287284788
---------------------------------------------------------------------
-----------
| Id | Operation | Name | Rows | Bytes
|TempS
---------------------------------------------------------------------
-----------
| 0 | SELECT STATEMENT | | 156 | 13260 |
| 1 | HASH GROUP BY | | 156 | 13260 |
|* 2 | FILTER | | | |
|* 3 | HASH JOIN OUTER | | 2306K| 186M| | 4 | PARTITION RANGE SINGLE| | 695K| 18M| |* 5 | TABLE ACCESS FULL | MID_USER_3G_INFO_M | 695K| 18M| | 6 | PARTITION LIST ALL | | 2581K| 140M|
| 7 | TABLE ACCESS FULL | TP_USER_ACTION_M | 2581K| 140M| |* 8 | TABLE ACCESS FULL | MID_USER_3G_INFO_M_05 | 1 | 10 |
---------------------------------------------------------------------
-----------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter( NOT EXISTS (SELECT /*+ */ 0 FROM "MID_USER_3G_INFO_M_05" "MID_USE
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
LNNVL("USER_ID"<>:B1)))
3 - access("A"."USER_ID"="B"."USER_ID"(+))
5 - filter("A"."PARTITION_ID"='06')
8 - filter(LNNVL("USER_ID"<>:B1))
tkprof 输出结果
SELECT a.eparchy_code,b.action_name,SUM(a.CUR_INCOME),SUM(CASE WHEN a.CUR_ACCT_TAG='1' THEN a.VO_FEE END)
FROM mid_user_3g_info_m a,
TP_USER_ACTION_M b
WHERE https://www.360docs.net/doc/d16958304.html,ER_ID=https://www.360docs.net/doc/d16958304.html,er_id(+)
AND a.partition_id='06'
AND https://www.360docs.net/doc/d16958304.html,er_id <> ALL(SELECT user_id FROM mid_user_3g_info_m_05)
GROUP BY a.eparchy_code,b.action_name
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 1 688.52 4401.40 34125644 34661570 0 0 ------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 688.52 4401.40 34125644 34661570 0 0 Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 61
Rows Row Source Operation
------- ---------------------------------------------------
0 HASH GROUP BY (cr=0 pr=0 pw=0 time=33 us)
1732 FILTER (cr=34644950 pr=34118939 pw=3038 time=5362498329 us)
1733 HASH JOIN OUTER (cr=39158 pr=39976 pw=3038 time=6937947 us)
695429 PARTITION RANGE SINGLE PARTITION: 6 6 (cr=37650 pr=37408 pw=0
time=8363235 us)
695429 TABLE ACCESS FULL MID_USER_3G_INFO_M PARTITION: 6 6 (cr=37650 pr=37408
pw=0 time=8363232 us)
79053 PARTITION LIST ALL PARTITION: 1 12 (cr=1508 pr=1483 pw=0 time=1739341 us) 79053 TABLE ACCESS FULL TP_USER_ACTION_M PARTITION: 1 12 (cr=1508 pr=1483 pw=0 time=1739320 us)
0 TABLE ACCESS FULL MID_USER_3G_INFO_M_05 (cr=34605792 pr=34078963 pw=0 time=4392685406 us)
JOB
DECLARE
v_job number ; -- out number
v_what VARCHAR(4000);
v_nextdate DATE ;--下次(第一次)运行时间,
v_interval VARCHAR2(200);--计算下次运行时间
BEGIN
v_what :='DECLARE
v_time number;
v_date DATE;
v_max_time number;
BEGIN
v_time := dbms_utility.get_time;
v_date :=trunc(SYSDATE,''mi'');
begin
select nvl(max(time_flag),0)+1 into v_max_time from t_stats;
exception when others then
v_max_time :=1;
end ;
if v_max_time>10 then
return;
end if;
-- 插入记录
insert into t_stats
(sid, name, class,value,time_flag,time,time_num)
select ''sys'', name ,class,value,v_max_time,v_date,v_time from v$sysstat
union all
select to_char(sid), name,class, value,v_max_time,v_date,v_time from v$sesstat a,v$statname b where a.statistic#=b.statistic#
UNION ALL
select ''latch'', name,null,gets,v_max_time,v_date,v_time from v$latch;
-- 插入sql和session信息
INSERT INTO t_sql_session
(
sid ,
serial# ,
status ,
sql_Id ,
sql_text ,
event ,
last_call_et ,
used_temp ,
used_ublk ,
schemaname ,
time_flag ,
TIME ,
time_num
)
SELECT b.sid,b.serial#,b.status,a.sql_Id,a.sql_text, b.event, https://www.360docs.net/doc/d16958304.html,st_call_et , https://www.360docs.net/doc/d16958304.html,ed_temp,nvl(https://www.360docs.net/doc/d16958304.html,ed_ublk,0),b.schemaname ,v_max_time,v_date,v_time
FROM v$sql a,v$session b,v$transaction c ,
(SELECT session_addr,ROUND(SUM(BLOCKS*8192*2)/1048576,2) used_temp FROM
sys.v_$sort_usage GROUP BY session_addr) d
WHERE a.sql_id=b.sql_id
AND b.saddr=c.ses_addr(+)
AND b.saddr=d.session_addr(+)
ORDER BY last_call_et DESC;
COMMIT;
END;';
v_nextdate := to_date('20121130','yyyymmdd');
v_interval := 'sysdate + 1/48';
dbms_job.submit(v_job,v_what,v_nextdate,v_interval);
commit;
end;
2020年(Oracle管理)Oracle SQL性能优化方法
(Oracle管理)Oracle SQL性能优化方法
OracleSQL性能优化方法探讨 Oracle性能优化方法(SQL篇)1 1综述2 2表分区的应用2 3访问Table的方式3 4共享SQL语句3 5选择最有效率的表名顺序5 6WHERE子句中的连接顺序.6 7SELECT子句中避免使用’*’6 8减少访问数据库的次数6 9使用DECODE函数来减少处理时间7 10整合简单,无关联的数据库访问8 11删除重复记录8 12用TRUNCATE替代DELETE9 13尽量多使用COMMIT9 14计算记录条数9 15用Where子句替换HAVING子句9 16减少对表的查询10 17通过内部函数提高SQL效率.11 18使用表的别名(Alias)12 19用EXISTS替代IN12 20用NOT EXISTS替代NOT IN13 21识别低效执行的SQL语句13
22使用TKPROF 工具来查询SQL性能状态14 23用EXPLAIN PLAN 分析SQL语句14 24实时批量的处理16
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要经过反反复复的过程。在数据库建立时,就能根据应用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有很大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积累经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来说明对数据库性能如何进行优化。 2表分区的应用 对于海量数据的表,可以考虑建立分区以提高操作效率。建立分区一般以关键字为分区的标志,也可以以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时可以进行说明: createtableTABLENAME(
OracleSQL性能优化方法
OracleSQL性能优化方法 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访咨询Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访咨询数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访咨询 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14运算记录条数 (9) 15用Where子句替换HA VING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11) 18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及储备参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存体会,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用咨询题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建立分区一样以关键字为分区的标志,也能够以其他字段作为分区的标志,但效率不如关键字高。建立分区的语句在建表时能够进行讲明: create table TABLENAME(
( O管理)ORACLESL性能优化(内部培训资料)
(O管理)ORACLESL性能优化(内部培训资料)
ORACLESQL性能优化系列(一) 1.选用适合的ORACLE优化器 ORACLE的优化器共有3种: a.RULE(基于规则) b.COST(基于成本) c.CHOOSE(选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS.你当然也在SQL句级或是会话(session)级对其进行覆盖. 为了使用基于成本的优化器(CBO,Cost-BasedOptimizer),你必须经常运行analyze命令,以增加数据库中的对象统计信息(objectstatistics)的准确性. 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关.如果table已经被analyze过,优化器模式将自动成为CBO,反之,数据库将采用RULE形式的优化器. 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(fulltablescan),你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器.
2.访问Table的方式 ORACLE采用两种访问表中记录的方式: a.全表扫描 全表扫描就是顺序地访问表中每条记录.ORACLE采用一次读入多个数据块(databaseblock)的方式优化全表扫描. b.通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,,ROWID包含了表中记录的物理位置信息..ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系.通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高. 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中.这块位于系统全局区域SGA(systemglobalarea)的共享池(sharedbufferpool)中的内存可以被所有的数据库用户共享.因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路
ORACLE 性能优化
ORACLE 数据库性能优化 参考书目: 《ORACLE 9i Database Performance Tuning Guide and Reference》《ORACLE 9i Database Reference》 《ORACLE 9i SQL Reference》 《ORACLE 9i Database Administrator’s Guide》
一、数据库实例创建过程参数确定 在创建数据库实例过程中,需要确定以下几个参数: 1. 数据块大小(DB_BLOCK_SIZE) 该参数指明了ORACLE所处理的数据存贮于数据文档以及SGA内存中的数据块大小。 该参数的可选择的范围为:4k,8k,16k,32k,64k。对于OLTP系统而言,取值可以为4K或8K,对于DSS系统而言,则可以取较大的数据,如32K或64K 建议统一取8K(即8192) 说明 DB_BLOCK_SIZE的大小将影响创建表时的EXTENT的大小。例如指定db_block_size=16K,某表空间的EXTENT MANAGEMENT 为local autoallocate,则其系统将extent的大小最小指定为1M.所以将可能导致空间的浪费。 2. 字符集(Character set) 该参数确定数据库以何种字符集来存贮CHAR以及V ARCHAR、V ARCHAR2等字符类型的值。对于ORACLE数据字典中的字符(如表及字段的COMMENT 内容)具有同样的作用。因此需要考虑如字符集的使用。对于国际项目,因为数据库中的comment内容(包括表及字符、存贮过程中的中文字符等内容)可能性需要以中文存贮,而用户业务数据使用的字符可能性是使用本地的语言,基于此,该参数需要选择支持UNICODE的字符编码的字符集。目前ORACLE9i支持以下二种UNICODE字符集: ?UTF8 ?AL32UTF8 建议统一取AL32UTF8
Oracle数据库性能优化
1系统问题 XX公司BI系统上线运行以来,客户反映系统目前存在着下面的几个问题,涉及到数据库和ETL. 问题一:表空间增长太快,每个月需增加3—5G空间。 问题二:ETL JOB会经常导致数据库产生表空间不足错误。 2系统优化分析 2.1分析思路 要解决表空间的问题,我们必须搞清楚下面几个问题: 思路一:真正每个月数据仓库增量是多少空间 目的:得出一个正确的月表空间增长量。 思路二:目前的数据仓库表空间是是如何分布的。 目的:找出那些对象是最占空间,分析其合理性。 2.2分析过程 要得到真实的数据分布必须对表进行分析,首先需要对数据仓库的oracle数据库进行表分析,。执行下面脚本可以对数据库进行表分析。
脚本一 analyze table SA_IMS_PRODUCT_GROUP compute statistics; analyze table SA_CONSUMP_ACT_DEL compute statistics; analyze table SA_FINANCE_ACT compute statistics; analyze table SA_CONSUMP_TGT_DEL compute statistics; analyze table SA_FACT_IS compute statistics; analyze table SA_CPA compute statistics; analyze table SA_REF_TERR_ALIGNMENT_DEL compute statistics; analyze table SA_IMS_MTHLC_BK compute statistics; analyze table SA_IMS_CHPA compute statistics; analyze table SA_FINANCE_PNL compute statistics; analyze table SA_CUST_TARG_SEG compute statistics; analyze table SA_CONSUMP_ACT compute statistics; analyze table SA_FINANCE_BS compute statistics; analyze table SA_FINANCE_BGT_QTY compute statistics; analyze table SA_CONSUMP_ACT0423 compute statistics; analyze table SA_CALLS compute statistics; analyze table SA_COMPANY_DAILY_SALES_ALL compute statistics; analyze table SA_IMS_MTHLC compute statistics; analyze table SA_IMS_MTHUS compute statistics; analyze table SA_CONSUMP_TGT compute statistics; analyze table TEST_TABLE compute statistics; analyze table SA_DOCTOR_CYCLE_EXTRACT compute statistics; analyze table SA_EXCHANGE_ACT compute statistics;
系统参数设置-Oracle性能优化(精)
一、SGA 1、Shared pool tunning Shared pool的优化应该放在优先考虑,因为一个cache miss在shared pool中发生比在data buffer中发生导致的成本更高,由于dictionary数据一般比library cache中的数据在内存中保存的时间长,所以关键是library cache的优化。 Gets:(parse)在namespace中查找对象的次数; Pins:(execution)在namespace中读取或执行对象的次数; Reloads:(reparse在执行阶段library cache misses的次数,导致sql需要重新解析。 1)检查v$librarycache中sql area的gethitratio是否超过90%,如果未超过90%,应该检查应用代码,提高应用代码的效率。Select gethitratio from v$librarycache where namespace=’sql area’; 2 v$librarycache中reloads/pins的比率应该小于1%,如果大于1%,应该增加参数shared_pool_size的值。Select sum(pins “executions”,sum(reloads “cache misses”,sum(reloads/sum(pins from v$librarycache; reloads/pins>1%有两种可能,一种是library cache空间不足,一种是sql中引用的对象不合法。 3)shared pool reserved size一般是shared pool size的10%,不能超过50%。 V$shared_pool_reserved中的request misses=0或没有持续增长,或者free_memory 大于shared pool reserved size的50%,表明shared pool reserved size过大,可以压缩。 4)将大的匿名pl/sql代码块转换成小的匿名pl/sql代码块调用存储过程。 5)从9i开始,可以将execution plan与sql语句一起保存在library cache中,方便进行性能诊断。从v$sql_plan中可以看到execution plans。 6)保留大的对象在shared pool中。大的对象是造成内存碎片的主要原因,为了腾出空间许多小对象需要移出内存,从而影响了用户的性能。因此需要将一些常用的大的对象保留在shared pool中,下列对象需要保留在shared pool中: a. 经常使用的存储过程; b. 经常操作的表上的已编译的触发器 c. Sequence,因为Sequence移出shared pool后可能产生号码丢失。查找没有保存在library cache中的大对象: Select * from v$db_object_cache where sharable_mem>10000 and type in ('PACKAGE','PROCEDURE','FUNCTION','PACKAGE BODY' and kept='NO'; 将这些对象保存在library cache中:Execute dbms_shared_pool.keep(‘package_name’; 对应脚本:dbmspool.sql 7查找是否存在过大的匿名pl/sql代码块。两种解决方案:A.转换成小的匿名块调用存储过程 B.将其保留在shared pool中查找是否存在过
Oracle SQL性能优化方法研究
Oracle SQL性能优化方法探讨 Oracle性能优化方法(SQL篇) (1) 1综述 (2) 2表分区的应用 (2) 3访问Table的方式 (3) 4共享SQL语句 (3) 5选择最有效率的表名顺序 (5) 6WHERE子句中的连接顺序. (6) 7SELECT子句中幸免使用’*’ (6) 8减少访问数据库的次数 (6) 9使用DECODE函数来减少处理时刻 (7) 10整合简单,无关联的数据库访问 (8) 11删除重复记录 (8) 12用TRUNCATE替代DELETE (9) 13尽量多使用COMMIT (9) 14计算记录条数 (9) 15用Where子句替换HAVING子句 (9) 16减少对表的查询 (10) 17通过内部函数提高SQL效率 (11)
18使用表的不名(Alias) (12) 19用EXISTS替代IN (12) 20用NOT EXISTS替代NOT IN (13) 21识不低效执行的SQL语句 (13) 22使用TKPROF 工具来查询SQL性能状态 (14) 23用EXPLAIN PLAN 分析SQL语句 (14) 24实时批量的处理 (16)
1综述 ORACLE数据库的性能调整是个重要,却又有难度的话题,如何有效地进行调整,需要通过反反复复的过程。在数据库建立时,就能依照顾用的需要合理设计分配表空间以及存储参数、内存使用初始化参数,对以后的数据库性能有专门大的益处,建立好后,又需要在应用中不断进行应用程序的优化和调整,这需要在大量的实践工作中不断地积存经验,从而更好地进行数据库的调优。 数据库性能调优的方法 ●调整内存 ●调整I/O ●调整资源的争用问题 ●调整操作系统参数 ●调整数据库的设计 ●调整应用程序 本文针对应用程序的调整,来讲明对数据库性能如何进行优化。 2表分区的应用 关于海量数据的表,能够考虑建立分区以提高操作效率。建
ORACLE性能优化31条
1.ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO,Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze 命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE 形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率,ROWID包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在内存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的内存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同,ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大大地提高了SQL 的执行性能并节省了内存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 当你向ORACLE提交一个SQL语句,ORACLE会首先在这块内存中查找相同的语句。这里需要注明的是,ORACLE对两者采取的是一种严格匹配,要达成共享,SQL语句必须完全相同(包括空格,换行等)。 数据库管理员必须在init.ora中为这个区域设置合适的参数,当这个内存区域越大,就可以保留更多的语句,当然被共享的可能性也就越大了。 共享的语句必须满足三个条件: A、字符级的比较:当前被执行的语句和共享池中的语句必须完全相同。 B、两个语句所指的对象必须完全相同: C、两个SQL语句中必须使用相同的名字的绑定变量(bind variables)。 4.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表driving table)将被最先处理。在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基础表。当ORACLE处理多个表时,会运用排序及合并的方式连接它们。首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出的记录与第一个表中合适记录进行合并。 如果有3个以上的表连接查询,那就需要选择交叉表(intersection table)作为基础表,交叉表是指
Oracle性能优化
ORACLE的优化器共有3种 A、RULE (基于规则) b、COST (基于成本) c、CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER_MODE参数的各种声明,如RULE,COST,CHOOSE,ALL_ROWS,FIRST_ROWS 。你当然也在SQL句级或是会话(session)级对其进行覆盖。 为了使用基于成本的优化器(CBO, Cost-Based Optimizer) ,你必须经常运行analyze 命令,以增加数据库中的对象统计信息(object statistics)的准确性。 如果数据库的优化器模式设置为选择性(CHOOSE),那么实际的优化器模式将和是否运行过analyze命令有关。如果table已经被analyze过,优化器模式将自动成为CBO ,反之,数据库将采用RULE形式的优化器。 在缺省情况下,ORACLE采用CHOOSE优化器,为了避免那些不必要的全表扫描(full table scan) ,你必须尽量避免使用CHOOSE优化器,而直接采用基于规则或者基于成本的优化器。 2.访问Table的方式 ORACLE 采用两种访问表中记录的方式: A、全表扫描 全表扫描就是顺序地访问表中每条记录。ORACLE采用一次读入多个数据块(database block)的方式优化全表扫描。 B、通过ROWID访问表 你可以采用基于ROWID的访问方式情况,提高访问表的效率, ROWID 包含了表中记录的物理位置信息。ORACLE采用索引(INDEX)实现了数据和存放数据的物理位置(ROWID)之间的联系。通常索引提供了快速访问ROWID的方法,因此那些基于索引列的查询就可以得到性能上的提高。 3.共享SQL语句 为了不重复解析相同的SQL语句,在第一次解析之后,ORACLE将SQL语句存放在存中。这块位于系统全局区域SGA(system global area)的共享池(shared buffer pool)中的存可以被所有的数据库用户共享。因此,当你执行一个SQL语句(有时被称为一个游标)时,如果它和之前的执行过的语句完全相同, ORACLE就能很快获得已经被解析的语句以及最好的执行路径。ORACLE的这个功能大提高了SQL的执行性能并节省了存的使用。 可惜的是ORACLE只对简单的表提供高速缓冲(cache buffering),这个功能并不适用于多表连接查询。
Oracle性能优化
y物理模型CheckList (Oracle,性能) 1. 系统级优化 数据库参数配置 合理分配SGA及其内部参数(经验值如下): SGA=phy*(60%-80%) Share pool=SAG*45% DB Cache=SGA*45% Log Buffer: 1~3M 注:Oracle9i在Windows下有bug,是由Windows下的SGA最大 值有2G的限制造成的 注意调整process和open cursor参数,这两个参数直接影响 数据库的session量 分离表和索引:将表和索引建立在不同的表空间,决不要将 不属于Oracle内部系统的对象存放到SYSTEM表空间。同 时,确保数据表空间和索引表空间置于不同的硬盘,减少I/O 竞争; 如果是企业版数据库,大表可以考虑采取分区存储措施,提 高系统的性能; 优化Export和Import工作:使用较大的BUFFER(比如10MB , 10,240,000)可以提高EXPORT和IMPORT的速度 定期分析查询计划,提高数据库的性能;
2. 索引相关 要对经常查询的字段建立索引,但是由于索引管理的开销, 在增删改操作频繁的情况下避免建立不必要的索引; 对于只读或者接近只读的场合,如数据仓库,对于势值比较 小的列可以考虑使用bitmap索引; 如果索引是建立在多个列上, 只有在它的第一个列(leading column)被where子句引用时,优化器才会选择使用该索引. 3. SQL相关 Oracle的From子句表的顺序:记录越多的表放在越前面 (左); Oracle的where子句表达式的顺序:过滤掉最大数目记录的条 件放到where子句的末尾; Select子句中避免使用‘*’,增加了查询表的列的开销; 在执行结果等效的情况下,使用Truncate代替Delete; 为了在查询过程中要尽量使用索引,对于like语句避免使用 右匹配或者中间匹配的模糊查询; 将过滤条件尽可能放到Where子句中,而不是放到Having子 句中; 在SQL语句中,要减少对表的查询,特别是在含有子查询的 SQL子句中; 使用表的别名可以减少解析的时间并避免引起歧义; 使用exists替代in; 用NOT EXISTS替代NOT IN; 通常情况下,采用表连接的方式比exists更有效率; 当提交一个包含一对多表信息(比如部门表和雇员表)的查询
Oracle性能优化总结
个人理解,数据库性能最关键的因素在于IO,因为操作内存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化,物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化物理优化: 一、优化内存
V$ROWCACHE视图结构
3.管理员可以通过下述语句来查看数据缓冲区的使用情况 select name,value from v$sysstat where name in ('db block gets', 'consistent gets ', 'physical reads'); 数据缓冲区使用命中率(physical reads除以db block gets加consistent gets之和)一定要小于10%,否则需要增加数据缓冲区大小 4.管理员可以通过执行下述语句,查看日志缓冲区的使用情况 select name,value from v$sysstat where name in ('redo entries','redo log space requests') 根据查询出的结果可以计算出日志缓冲区的申请失败率:requests除以entries 申请失败率应该解决与0,否则说明日志缓冲区开设太小,需要增加Oracle数据库的日志缓冲区 二、物理I/0的优化 1.在磁盘上建立数据文件前首先运行磁盘碎片整理程序 为了安全地整理磁盘碎片,需关闭打开数据文件的实例,并且停止服务。如果有足够的连续磁盘空间建立数据文件,那么就容易避免数据文件产生碎片。 2.不要使用磁盘压缩(Oracle文件不支持磁盘压缩) 3.不要使用磁盘加密
oracle数据库性能调优
Centos6.5操作系统下,oracle数据库性能调优 1.在liunx下对数据库性能调优,首先要考虑操作系统级别的问题如:如CPU、内存、IO的瓶颈,再考虑oracle本身参数的设置。 1. 可通过top 命令判断是否为CPU瓶颈,如果oracle进程占用CPU过多,可考虑为CPU的问题。 目前我们针对的主要是内存和磁盘的问题。 2.Oracle数据库内存参数的优化 ?与oracle相关的系统内核参数 ?SGA、PGA参数设置 (1)系统内核参数 修改/etc/sysctl.conf 这个文件,加入以下的语句: kernel.shmmax = 2147483648 kernel.shmmni = 4096 kernel.shmall = 2097152 kernel.sem = 250 32000 100 128 fs.file-max = 65536 参数依次为: Kernel.shmmax:共享内存段的最大尺寸(以字节为单位)。 Kernel.shmmni:系统中共享内存段的最大数量。 Kernel.shmall:共享内存总量,以页为单位。 fs.file-max:文件句柄数,表示在Linux系统中可以打开的文件数量。 net.ipv4.ip_local_port_range:应用程序可使用的IPv4端口范围。 可通过sysctl -p 查看内核参数的值,请确认各个内核参数只有一个,避免出现一个内核参数出现好几次的情况,导致正确的参数别覆盖。
需要注意的几个问题 关于Kernel.shmmax Oracle SGA 由共享内存组成,如果错误设置SHMMAX可能会限制SGA 的大小,SHMMAX设置不足可能会导致以下问题:ORA-27123:unable to attach to shared memory segment,如果该参数设置小于Oracle SGA设置,那么SGA就会被分配多个共享内存段。这在繁忙的系统中可能成为性能负担,带来系统问题。 Oracle建议Kernel.shmmax最好大于sga,以让oracle共享内存区SGA在一个共享内存段中,从而提高性能。 Oracle 11g实现了数据库所有内存块的全自动化管理,使得动态管理SGA和PGA成为现实。 日志文件及表空间文件的大小及位置也是影响性能的一个因素,排查过程如下。 应用 iotop -ao 命令查看oracle对磁盘读写对资源的占用情况, ora_lgwr_first进行对磁盘的访问较多。 使用
oracle性能优化简介
ORACLE SQL性能优化 我要讲的题目是Oracle SQL性能优化,只是Oracle性能优化中的一项。Oracle的性能优化包含很多方面,比如调整物理存取,调整逻辑存取,调整内存使用,减少网络流量等。这里选择SQL性能优化是因为这部分内容我们测试人员最容易接触到,另外开发人员写SQL脚本时有时很随意,不知不觉就会造成程序性能上的下降。 1.选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表 driving table)将被最先处理. 在FROM子句中包含多个表的情况下,你必须选择记录条数最少的表作为基 础表.当ORACLE处理多个表时, 会运用排序及合并的方式连接它们.首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行派序,然后扫描 第二个表(FROM子句中最后第二个表),最后将所有从第二个表中检索出 的记录与第一个表中合适记录进行合并. 例如: 表 TAB1 16,384 条记录 表 TAB2 1 条记录 选择TAB2作为基础表 (最好的方法) select count(*) from tab1,tab2 执行时间0.96秒 选择TAB2作为基础表 (不佳的方法)
select count(*) from tab2,tab1 执行时间26.09秒 如果有3个以上的表连接查询, 那就需要选择交叉表(intersection table)作为基础表, 交叉表是指那个被其他表所引用的表. 例如: EMP表描述了LOCATION表和CATEGORY表的交集. SELECT * FROM LOCATION L , CATEGORY C, EMP E WHERE E.EMP_NO BETWEEN 1000 AND 2000 AND E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN 将比下列SQL更有效率 SELECT * FROM EMP E , LOCATION L , CATEGORY C WHERE E.CAT_NO = C.CAT_NO AND E.LOCN = L.LOCN AND E.EMP_NO BETWEEN 1000 AND 2000 2.WHERE子句中的连接顺序. ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾.
oracle性能优化(简单版)
--数据库巡检或性能优化方法各异,但首要的是要发现数据库性能瓶颈,系统自带的statspack,或awr太耗时, --以下是本人常用的方法,共享之 --1、查询数据库等待事件top10,关注前前几个等待事件,关注前三个等待事件是否有因果或关联关系 --oracle 9i select t2.event,round(100*t2.time_waited/(t1.w1+t3.cpu),2) event_wait_percent from ( SELECT SUM(time_waited) w1 FROM v$system_event WHERE event NOT IN ('smon timer','pmon timer','rdbms ipc message','Null event','parallel query dequeue','pipe get', 'client message','SQL*Net message to client','SQL*Net message from client','SQL*Net more data from client', 'dispatcher timer','virtual circuit status','lock manager wait for remote message','PX Idle Wait', 'PX Deq: Execution Msg','PX Deq: Table Q Normal','wakeup time manager','slave wait','i/o slave wait', 'jobq slave wait','null event','gcs remote message','gcs for action','ges remote message','queue messages') ) t1, (select * from ( select t.event,t.total_waits,t.total_timeouts,t.time_waited,t.average_wait,rownum num from (select event,total_waits,total_timeouts,time_waited,average_wait from v$system_event where event not in ('smon timer','pmon timer','rdbms ipc message','Null event','parallel query dequeue','pipe get', 'client message','SQL*Net message to client','SQL*Net message from client','SQL*Net more data from client', 'dispatcher timer','virtual circuit status','lock manager wait for remote message','PX Idle Wait', 'PX Deq: Execution Msg','PX Deq: Table Q Normal','wakeup time manager','slave wait','i/o slave wait', 'jobq slave wait','null event','gcs remote message','gcs for action','ges remote message','queue messages') order by time_waited desc ) t) where num<11) t2, (SELECT VALUE CPU FROM v$sysstat WHERE NAME LIKE 'CPU used by this session' ) t3 --oracle10g select t2.event,round(100*t2.time_waited/(t1.w1+t3.cpu),2) event_wait_percent from ( SELECT SUM(time_waited) w1 FROM v$system_event WHERE event NOT IN ('smon timer','pmon timer','rdbms ipc message','Null event','parallel query dequeue','pipe get','client message','SQL*Net message to client','SQL*Net message from client','SQL*Net more data from client','dispatcher timer','virtual circuit status','lock manager wait for remote message','PX Idle Wait','PX Deq: Execution Msg','PX Deq: Table Q Normal','wakeup time manager','slave wait', 'i/o slave wait','jobq slave wait','null event','gcs remote message','gcs for action','ges remote
Oracle性能优化总结
个人理解,数据库性能最关键的因素在于IO,因为操作存是快速的,但是读写磁盘是速度很慢的,优化数据库最关键的问题在于减少磁盘的IO,就个人理解应该分为物理的和逻辑的优化,物理的是指oracle产品本身的一些优化,逻辑优化是指应用程序级别的优化 物理优化: 一、优化存
3.管理员可以通过下述语句来查看数据缓冲区的使用情况 select name,value from v$sysstat where name in('db block gets','consistent gets','physica l reads'); 数据缓冲区使用命中率(physical reads除以db block gets加consistent gets之和)一定要小于10%,否则需要增加数据缓冲区大小 4.管理员可以通过执行下述语句,查看日志缓冲区的使用情况 select name,value from v$sysstat where name in ('redo entries','redo log space requests') 根据查询出的结果可以计算出日志缓冲区的申请失败率:requests除以entries 申请失败率应该解决与0,否则说明日志缓冲区开设太小,需要增加Oracle数据库的日志缓冲区 二、物理I/0的优化 1.在磁盘上建立数据文件前首先运行磁盘碎片整理程序 为了安全地整理磁盘碎片,需关闭打开数据文件的实例,并且停止服务。如果有足够的连续磁盘空间建立数据文件,那么就容易避免数据文件产生碎片。 2.不要使用磁盘压缩(Oracle文件不支持磁盘压缩) 3.不要使用磁盘加密 加密像磁盘压缩一样加了一个处理层,降低磁盘读写速度。如果担心自己的数据可能泄露,可以使用dbms_obfuscation包和label security选择性地加密数据的敏感部分 4.使用RAID raid使用应注意: 选择硬件raid超过软件raid;日志文件不要放在raid5卷上,因为raid5读性能高而写性能差;把日志文件和归档日志放在与控制文件和数据文件分离的磁盘控制系统上 5.分离页面交换文件到多个磁盘物理卷 跨越至少两个磁盘建立两个页面文件。可以建立四个页面文件并在性能上受益,确保所有页面文件的大小之和至少是物理存的两倍。
Oracle性能调优原则
Oracle性能调优原则 任何事情都有它的源头,要解决问题,也得从源头开始,影响ORACLE性能的源头非常多,主要包括如下方面:数据库的硬件配置:CPU、内存、网络条件1. CPU:在任何机器中CPU的数据处理能力往往是衡量计算机性能的一个标志,并且ORACLE是一个提供并行能力的数据库系统,在CPU方面的要求就更高了,如果运行队列数目超过了CPU处理的数目,性能就会下降,我们要解决的问题就是要适当增加CPU的数量了,当然我们还可以将需要许多资源的进程KILL掉;2. 内存:衡量机器性能的另外一个指标就是内存的多少了,在ORACLE中内存和我们在建数据库中的交换区进行数据的交换,读数据时,磁盘I/O必须等待物理I/O操作完成,在出现ORACLE 的内存瓶颈时,我们第一个要考虑的是增加内存,由于I/O的响应时间是影响ORACLE性能的主要参数,我将在这方面进行详细的讲解3. 网络条件:NET*SQL负责数据在网络上的来往,大量的SQL会令网络速度变慢。比如10M的网卡和100的网卡就对NET*SQL有非常明显的影响,还有交换机、集线器等等网络设备的性能对网络的影响很明显,建议在任何网络中不要试图用3个集线器来将网段互联。OS参数的设置下表给出了OS的参数设置及说明,DBA可以根据实际需要对这些参数进行设置内核参数名说明bufpages对buffer空间不按静态分配,采用动态分配,使bufpages值随nbuf一起对
buffer空间进行动态分配。Create_fastlinks对HFS文件系统允许快速符号链接dbc_max_pct加大最大动态buffer空间所占物理内存的百分比,以满足应用系统的读写命中率的需要。Dbc_min_pct设置最小动态buffer空间所占物理内存的百分比desfree提高开始交换操作的最低空闲内存下限,保障系统的稳定性,防止出现不可预见的系统崩溃(Crash)。Fs_async允许进行磁盘异步操作,提高CPU 和磁盘的利用率lotsfree提高系统解除换页操作的空闲内存的上限值,保证应用程序有足够的可用内存空间。Maxdsiz针对系统数据量大的特点,加大最大数据段的大小,保证应用的需要。(32位)maxdsiz_64bitmaximum process data segment size for 64_bitMaxssiz加大最大堆栈段的大小。(32_bit)maxssiz_64bit加大最大堆栈段的大小。(64_bit)Maxtsiz提高最大代码段大小,满足应用要求maxtsiz_64bit原值过大,应调小Minfree提高停止交换操作的自由内存的上限Shmem允许进行内存共享,以提高内存的利用率Shmmax设置最大共享内存段的大小,完全满足目前的需要Timeslice由于系统的瓶颈主要反映在磁盘I/O上,因此降低时间片的大小,一方面可避免因磁盘I/O不畅造成CPU的等待,从而提高了CPU的综合利用率。另一方面减少了进程的阻塞量。Unlockable_mem提高了不可锁内存的大小,使可用于换页和交换的内存空间扩大,用以满足系统对内存管理的要求。用户SQL质量以上讲的都是硬件方面的东西,在条件有限的条件下,我们可以调整应用程序的SQL质量:1. 不要进行全表扫描(Full Table Scan):全表扫描