自相关的检验与修正
实验2 自相关的检验与修正
一、实验目的:
掌握自相关模型的检验方法与处理方法.。
二、实验内容及要求:
表1列出了1985-2007年中国农村居民人均纯收入与人均消费性支出的统计数据。
(1)利用OLS法建立中国农村居民人均消费性支出与人均纯收入的线性模型。
(2)检验模型是否存在自相关。
(3)如果存在自相关,试采用适当的方法加以消除。
表1 1985-2007年中国农村居民人均纯收入与人均消费性支出(单位:元)
实验如下:
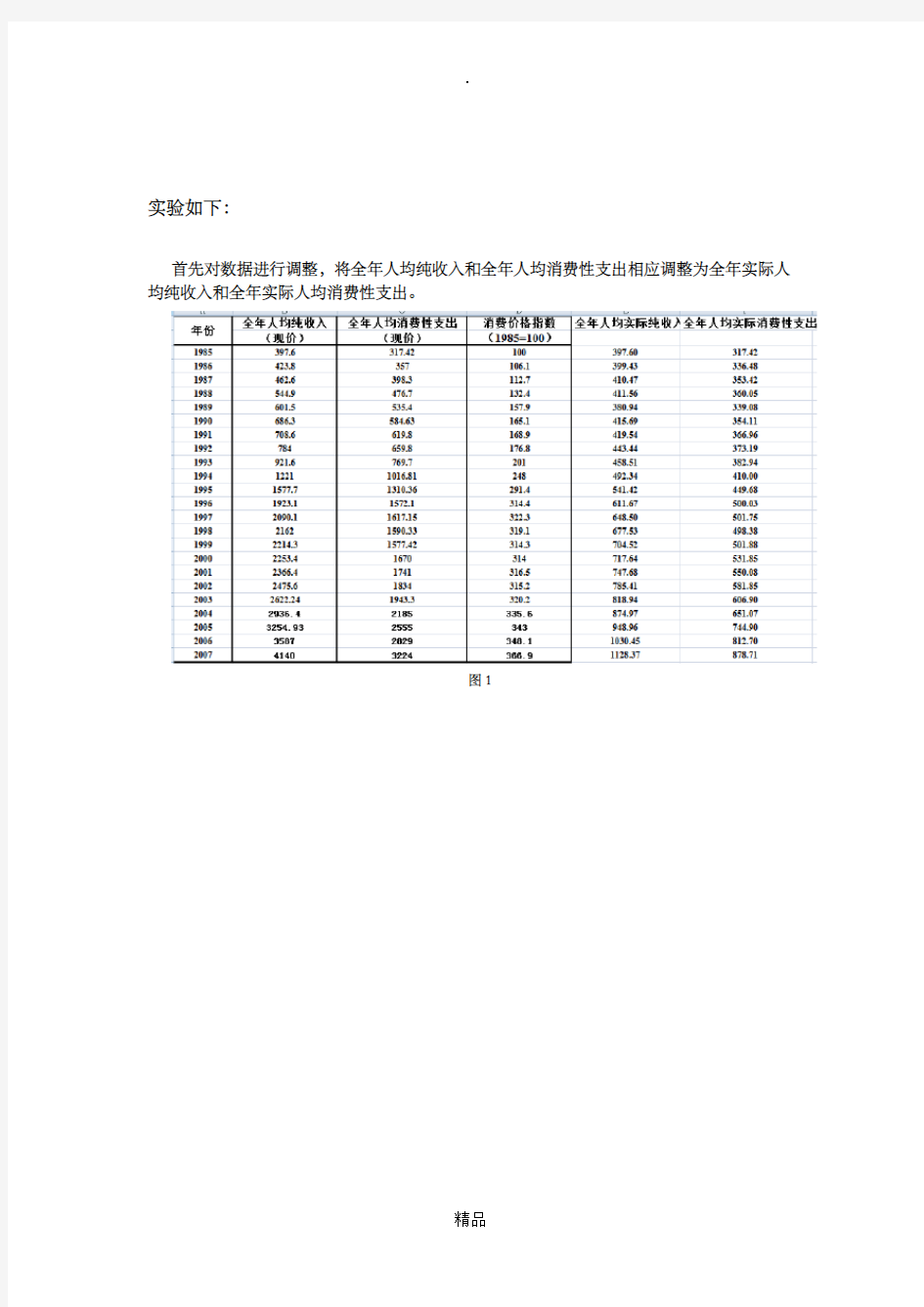
首先对数据进行调整,将全年人均纯收入和全年人均消费性支出相应调整为全年实际人均纯收入和全年实际人均消费性支出。
图1
1、用OLS估计法估计参数
图2
图3
图形分析:
图4
从图4中可以看出,中国农村居民人均消费性支出与人均纯收入存在着显著的正相关关系。
估计回归方程:
从图3中可以得出,估计回归方程为:
Y=56.21878+0.698928X
t=(3.864210)(31.99973)
R2=0.979904 F=1023.983 D.W.=0.409903
2.自相关检验
(1)图示法
图5
从图5中,可以看出残差的变化有系统模式,连续为正或连续为负,表示残差项存在一阶正自相关。
(2)DW检验
从图3中可以得到D.W.=0.409903,在显著水平去5%,n=23,k=2,d L=1.26, d U=1.44。此时0 (3)B-G检验 图6 从图6中可得到,nR2=14.90587,临界概率P=0.0006,因此辅助回归模型是显著的,即存在自相关性。又因为,e t-1,e t-2的回归系数均显著地不为0 3.自相关的修正 使用广义差分法对自相关进行修正: 图7 对原模型进行广义差分,得到广义差分方程: Y t-0.815024Y t-1=β1(1-0.815024)+β2(X t -0.815024X t-1)+u t 对广义差分方程进行回归: 图8 从图8中可以得出此时的D.W.=1.324681,在取显著水平为5%,n=23,k=2,d L=1.26, d U=1.44,模型中d L 在广义差分法无法完成修正的情况下,现建立对对数模型: 图9对双对数模型进行调整: 图10 图11 从图11中可以得出此时的D.W.=1.985950,在取显著水平为5%,n=23,k=2,d L=1.26, d U=1.44,模型中d U 如有侵权请联系告知删除,感谢你们的配合! 《计量经济学》实训报告 实训项目名称异方差模型的检验与处理 实训时间 2012-01-02 实训地点实验楼308 班级 学号 姓名 实 训 (实 践 ) 报 告 实 训 名 称 异方差模型的检验与处理 一、 实训目的 掌握异方差性的检验及处理方法。 二 、实训要求 1.求销售利润与销售收入的样本回归函数,并对模型进行经济意义检验和统计检验; 2.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 3.如果模型存在异方差,选用适当的方法对异方差进行修正,消除或减小异方差对模型的影响。 三、实训内容 建立并检验我国制造业利润函数模型,检验异方差性,并选用适当方法对其进行修正,消除或不同) 四、实训步骤 1.建立一元线性回归方程; 2.建立Workfile 和对象,录入数据; 3.分别用图形法、Goldfeld-Quant 检验、White 方法检验模型是否存在异方差; 4.对所估计的模型再进行White 检验,观察异方差的调整情况,从而消除或减小异方差对模型的影响。 五、实训分析、总结 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料。假设销售利润与销售收入之间满足线性约束,则理论模型设定为: 12i i i Y X u ββ=++ 其中i Y 表示销售利润,i X 表示销售收入。 表1 我国制造工业1998年销售利润与销售收入情况 行业名称销售利润Y 销售收入X 行业名称销售利润销售收入 食品加工业187.25 3180.44 医药制造业238.71 1264.1 食品制造业111.42 1119.88 化学纤维制品81.57 779.46 饮料制造业205.42 1489.89 橡胶制品业77.84 692.08 烟草加工业183.87 1328.59 塑料制品业144.34 1345 纺织业316.79 3862.9 非金属矿制品339.26 2866.14 服装制品业157.7 1779.1 黑色金属冶炼367.47 3868.28 皮革羽绒制品81.7 1081.77 有色金属冶炼144.29 1535.16 木材加工业35.67 443.74 金属制品业201.42 1948.12 家具制造业31.06 226.78 普通机械制造354.69 2351.68 造纸及纸品业134.4 1124.94 专用设备制造238.16 1714.73 印刷业90.12 499.83 交通运输设备511.94 4011.53 文教体育用品54.4 504.44 电子机械制造409.83 3286.15 石油加工业194.45 2363.8 电子通讯设备508.15 4499.19 化学原料纸品502.61 4195.22 仪器仪表设备72.46 663.68 1.建立Workfile和对象,录入销售收入X和销售利润Y: 图1 销售收入X和销售利润Y的录入 2.图形法检验 ⑴观察销售利润Y与销售收入X的相关图:在群对象窗口工具栏中点击 问题: 选取粮食生产为例,由经济学理论和实际可以知道,影响粮食生产y 的因素有:农业化肥施 用量x1,粮食播种面积x2,成灾面积x3,农业机械总动力x4,农业劳动力x5,由此建立以下方程: y=β0+β1x1+β2x2+β3x3+β4x4+β5x5,相关数据如下: 解: 1、检验多重共线性 (1)在命令栏中输入: ls y c x1 x2 x3 x4 x5,则有; 可以看到,可决系数R2 和 F 值都 很高,二自变量x1 到 x5 的 t 值 均较小,并且x4 和 x5 的 t 检验 不显著,说明方程很可能存在多 重共线性。 (2)对自变量做相关性分析: 将x1—— x5 作为组打开, view —— covariance analysis—— correlation ,结果如下: 可以看到x1 和 x4 的相关系数 为 0.96,非常高,说明原模型 存在多重共线性 2、多重共线性的修正 (1)逐步回归法 第一步:首先确定一个基准的解释变量,即从 x1, x2, x3, x4, x5 中选择解释 y 的最好的一个建 立基准模型。分别用 x1, x2, x3, x4, x5 对 y 求回归,结果如下: 从上面 5 个输出结果可以知道,y 对 x1 的可决系数R2=0.89(最高),因此选择 第一个方程作为基准回归模型。即: Y = 30867.31062 + 4.576114592* x1 在基准模型的基础上,逐步将x2, x3 等加入到模型中, 加入 x2,结果: 拟合优度R2=0.961395 ,显著提高; 并且参数符号符合经济常识,且均显著。 所以将模型修改为: Y= -44174.52+ 4.576460*x1+ 0.672680*x2 再加入 x3,结果: 拟合优度R2=0.984174 ,显著提高; 并且参数符号符合经济常识(成灾面积越大,粮食产 量越低),且均显著。 所以将模型修改为: Y=-12559.35+5.271306*x1+0.417257*x2-0.212103*x3 再加入 x4,结果: 拟合优度R2=0.987158 ,虽然比上一次拟 合提高了; 但是变量x4 的系数为 -0.091271 ,符号不 符合经济常识(农业机械总动力越高, 粮食产量越高),并且 x4 的 t 检验不显著。 因此应该从模型中剔除x4。 实验五自相关性 【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】 利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 【实验步骤】 一、回归模型的筛选 ⒈相关图分析 SCAT X Y 相关图表明,GDP指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。 ⒉估计模型,利用LS命令分别建立以下模型 ⑴线性模型:LS Y C X t (-6.706) (13.862) = 2 R=0.9100 F=192.145 S.E=5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX t (-31.604) (64.189) = 2 R=0.9954 F=4120.223 S.E=0.1221 ⑶对数模型:LS Y C LNX =t (-6.501) (7.200) 2R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X =t (23.716) (14.939) 2R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2 =t (3.747) (-8.235) (25.886) 2R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。 比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。双对数模型和二次多项式模型都具有很高的拟合优度,因而初步选定回归模型为这两个模型。 二、自相关性检验 ⒈DW 检验; ⑴双对数模型 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22, U d =1.42,而0<0.7062=DW 案例三 ARIMA 模型的建立 一、实验目的 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2007年中国进出口贸易总额数据运用经典B-J 方法论建立合适的ARIMA (,,p d q )模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated –regular frequency ”,在“Date specification ”栏中分别选择“Annual ”(年数据) ,分别在起始年输入1950,终止年输入2007,点击ok ,见图3-1,这样就建立了一个工作文件。点击File/Import ,找到相应的Excel 数据集,导入即可。 经济计量分析实验报告 一、实验项目 自相关性的检验及修正 二、实验日期 2015.12.13 三、实验目的 对于国内旅游总花费的有关影响因素建立多元线性回归模型,对变量进行多重共线性的检验及修正后,对随机误差项进行异方差的检验和补救及自相关性的检验和修正。 四、实验内容 建立模型,对模型进行参数估计,对样本回归函数进行统计检验,以判定估计的可靠程度,包括拟合优度检验、方程总体线性的显著性检验、变量的显著性检验,以及参数的置信区间估计。 检验变量是否具有多重共线性并修正。 检验是否存在异方差并补救。 检验是否存在相关性并修正。 五、实验步骤 1、建立模型。 以国内旅游总花费Y 作为被解释变量,以年底总人口表示人口增长水平,以旅行社数量表示旅行社的发展情况,以城市公共交通运营数表示城市公共交通运行状况,以城乡居民储蓄存款年末增加值表示城乡居民储蓄存款增长水平。 2、模型设定为: t t t t t μβββββ+X +X +X +X +=Y 443322110t 其中:t Y — 国内旅游总花费(亿元) t 1X — 年底总人口(万人) t 2X — 旅行社数量(个) t 3X — 城市公共交通运营数(辆) t 4X — 城乡居民储蓄存款年末增加值(亿元) 3、对模型进行多重共线性检验。 4、检验异方差是否存在并补救。 5、检验自相关性是否存在并修正。 六、实验结果 消除多重共线性及排除异方差性之后的回归模型为:2382963.08388.301?X Y +-= 检验 I 、图示法 1、1-t e ,t e 散点图 -1,500 -1,000 -500 500 1,000 1,500 -2,000 -1,00001,0002,000 ET(-1) E T 大部分落在第Ⅰ,Ⅲ象限,表明随机误差项存在正自相关。 2、t e 折线图 -1,500 -1,000 -500 500 1,000 1,500 86 88 90 92 94 96 98 00 02 04 06 08 10 RESID Ⅱ、解析法 1、D-W 检验 财经学院 本科实验报告 学院(部)统计学院 实验室313 课程名称计量经济学 学生姓名 学号1204100213 专业统计学 教务处制 2014年12 月15 日 《异方差》实验报告 五、实验过程原始记录(数据、图表、计算等) 一.选择数据 1.建立工作文件并录入数据File\New\workfile, 弹出Workfile create 对话框中选择数据类型。Object\new object\group,按向上的方向键,出现两个obs 后输入数据. 中国地2006年各地区农村居民家庭人均纯收入与消费支出 单位:元 城市 y x1 x2 城市 y x1 x2 5724.5 958.3 7317.2 2732.5 1934.6 1484.8 3341.1 1738.9 4489 3013.3 1342.6 2047 2495.3 1607.1 2194.7 3886 1313.9 3765.9 2253.3 1188.2 1992.7 广西 2413.9 1596.9 1173.6 2772 2560.8 781.1 2232.2 2213.2 1042.3 3066.9 2026.1 2064.3 2205.2 1234.1 1639.7 2700.7 2623.2 1017.9 2395 1405 1597.4 2618.2 2622.9 929.5 1627.1 961.4 1023.2 8006 532 8606.7 2195.6 1570.3 680.2 4135.2 1497.9 4315.3 2002.2 1399.1 1035.9 6057.2 1403.1 5931.7 2181 1070.4 1189.8 2420.9 1472.8 1496.3 1855.5 1167.9 966.2 3591.4 1691.4 3143.4 2179 1274.3 1084.1 2676.6 1609.2 1850.3 2247 1535.7 1224.4 3143.8 1948.2 2420.1 2032.4 2267.4 469.9 2229.3 1844.6 1416.4 二.对数据进行参数估计,得出多元线性回归模型 1.模型设定为εβββ+++=23121i i i X X Y Yi ----人均消费支出 X1--从事农业经营的纯收入 X2--其他来源的纯收入 2.点Quick\estimate equation,在弹出的对话框中输入”Y C X ”,结果如下: 附件二:实验报告格式(首页) 山东轻工业学院实验报告成绩 课程名称计量经济学指导教师实验日期 2013-5-25 院(系)商学院专业班级实验地点二机房 学生姓名学号同组人无 实验项目名称多重共线性的检验与修正 一、实验目的和要求 掌握Eviews软件的操作和多重共线性的检验与修正 二、实验原理 Eviews软件的操作和多重共线性的检验修正方法 三、主要仪器设备、试剂或材料 Eviews软件,计算机 四、实验方法与步骤 (1)准备工作:建立工作文件,并输入数据: CREATE EX-7-1 A 1974 1981; TATA Y X1 X2 X3 X4 X5 ; (2)OLS估计: LS Y C X1 X2 X3 X4 X5; (3)计算简单相关系数 COR X1 X2 X3 X4 X5 ; (4)多重共线性的解决 LS Y C X1; LS Y C X2; LS Y C X3; LS Y C X4; LS Y C X5; LS Y C X1 X3; LS Y C X1 X3 X2; LS Y C X1 X3 X4; LS Y C X1 X3 X5; 五、实验数据记录、处理及结果分析 (1)建立工作组,输入以下数据: 98.45 560.20 153.20 6.53 1.23 1.89 100.70 603.11 190.00 9.12 1.30 2.03 102.80 668.05 240.30 8.10 1.80 2.71 133.95 715.47 301.12 10.10 2.09 3.00 140.13 724.27 361.00 10.93 2.39 3.29 关于x y的散点图 由散点图可以判断出才可能存在异方差。运用怀特检验判断是否有异方差 White Heteroskedasticity Test: F-statistic 5.71174 5 Probability 0.00831 1 Obs*R-squared 8.98267 0 Probability 0.01120 6 由此可见,1%的显著水平上存在异方差。运用加权最小二乘法消除异方差: Dependent Variable: Y Method: Least Squares Date: 10/29/14 Time: 14:46 Sample: 1 31 Included observations: 31 Weighting series: 1/ABS(RESID) Variable Coeffici ent Std. Error t-Statistic Prob. C -2171.3 76 418.8113 -5.184616 0.0000 X 0.97610 4 0.022593 43.20372 0.0000 Weighted Statistics R-squared 0.99927 0 Mean dependent var 16676.9 9 Adjusted R-squared 0.99924 5 S.D. dependent var 18232.7 8 S.E. of regression 501.062 0 Akaike info criterion 15.3336 8 Sum squared resid 728082 9. Schwarz criterion 15.4261 9 Log likelihood -235.67 20 F-statistic 1866.56 1 Durbin-Watson stat 1.37353 7 Prob(F-statistic) 0.00000 0 Unweighted Statistics R-squared 0.92681 6 Mean dependent var 17975.6 8 Adjusted R-squared 0.92429 2 S.D. dependent var 5667.54 2 S.E. of regression 1559.42 4 Sum squared resid 705223 38 Durbin-Watson stat 1.57587 5 由上表,f检验的伴随概率为0.000000,说明在1%的显著水平上,拒绝原假设,t检验的伴随概率为0.0000,说明在1%的显著水平上,拒绝原假设y x 之间存在显著的线性关系,该模型很好的反映了实际情况,所以消除了异方差。 实验异方差的检验与修正 实验目的 1、理解异方差的含义后果、 2、学会异方差的检验与加权最小二乘法 实验容 一、准备工作。建立工作文件,并输入数据,用普通最小二乘法估计方程(操作 步骤与方法同前),得到残差序列。 表2列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。 表2 我国制造工业1998年销售利润与销售收入情况 二、异方差的检验 1、图形分析检验 ⑴观察销售利润(Y)与销售收入(X)的相关图(图3-1):SCAT X Y 图3-1 我国制造工业销售利润与销售收入相关图 从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。这说明变量之间可能存在递增的异方差性。 ⑵残差分析 首先将数据排序(命令格式为:SORT 解释变量),然后建立回归方程。在方程窗口中点击Resids按钮就可以得到模型的残差分布图(或建立方程后在Eviews工作文件窗口中点击resid对象来观察)。 图3-2 我国制造业销售利润回归模型残差分布 图3-2显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性。 2、Goldfeld-Quant检验 ⑴将样本安解释变量排序(SORT X)并分成两部分(分别有1到10共11个样本合19到28共10个样本) ⑵利用样本1建立回归模型1(回归结果如图3-3),其残差平方和为2579.587。 SMPL 1 10 LS Y C X 图3-3 样本1回归结果 ⑶利用样本2建立回归模型2(回归结果如图3-4),其残差平方和为63769.67。 SMPL 19 28 LS Y C X 图3-4 样本2回归结果 ⑷计算F 统计量:12/RSS RSS F ==63769.67/2579.59=24.72,21RSS RSS 和分别是模型1和模型2的残差平方和。 取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而 44.372.2405.0=>=F F ,所以存在异方差性 3、White 检验 ⑴建立回归模型:LS Y C X ,回归结果如图3-5。 实验五 自相关性【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。表5-1 我国城乡居民储蓄存款与GDP 统计资料(1978年=100)年份 存款余额Y GDP 指数X 年份存款余额Y GDP 指数X 1978 210.60100.019895146.90271.31979 281.00107.619907034.20281.71980 399.50116.019919107.00307.61981 523.70122.1199211545.40351.41982 675.40133.1199314762.39398.81983 892.50147.6199421518.80449.31984 1214.70170.0199529662.25496.51985 1622.60192.9199638520.84544.11986 2237.60210.0199746279.80592.01987 3073.30234.0199853407.47638.219883801.50260.7【实验步骤】一、回归模型的筛选 ⒈相关图分析SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而 加以比较分析。⒉估计模型,利用LS 命令分别建立以下模型⑴线性模型: LS Y C X x y 5075.9284.14984?+-= (-6.706) (13.862)=t =0.9100 F =192.145 S.E =5030.8092R ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX 、管路敷设技术护层防腐跨接地线弯曲半径标高等,要求技术交底。管线敷设技术中包含线槽、管架等多项方式,为解决高中语文电气课件中管壁薄、接口不严等问题,合理利用管线敷设技术。线缆敷设原则:在分线盒处,当不同电压回路交叉时,应采用金属隔板进行隔开处理;同一线槽内,强电回路须同时切断习题电源,线缆敷设完毕,要进行检查和检测处理。、电气课件中调试写复杂设备与装置高中资料试卷调试方案,编写重要设备高中资料试卷试验方案以及系统启动方案;对整套启动过程中高中资料试卷电气设备进行调试工作并且进行过关运行高中资料试卷技术指导。对于调试过程中高中资料试卷技术问题,作为调试人员,需要在事前掌握图纸资料、设备制造厂家出具高中资料试卷试验报告与相关技术资料,并且了解现场设备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规、电气设备调试高中资料试卷技术工况进行自动处理,尤其要避免错误高中资料试卷保护装置动作,并且拒绝动作,来避免不必要高中资料试卷突然停机。因此,电力高中资料试卷保护装置调试技术,要求电力保护装置做到准确灵活。对于差动保护装置高中资料试卷调试技术是指发电机一变压器组在发生内部故障时,需要进行外部电源高中资料试卷切除从而采用高中资料试卷主要保护装置。 异方差性的检验和补救 一、研究目的和要求 表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型,检验其是否存在异方差,并加以补救。 表1 我国制造工业1998年销售利润与销售收入情况 二、参数估计 EVIEWS 软件估计参数结果如下 Dependent Variable: Y Method: Least Squares Date: 06/01/16 Time: 20:16 Sample: 1 28 Included observations: 28 Variable Coefficient Std. Error t-Statistic Prob. C 12.03349 19.51809 0.616530 0.5429 X 0.104394 0.008442 12.36658 0.0000 R-squared 0.854694 Mean dependent var 213.4639 Adjusted R-squared 0.849105 S.D. dependent var 146.4905 S.E. of regression 56.90455 Akaike info criterion 10.98938 Sum squared resid 84191.34 Schwarz criterion 11.08453 Log likelihood -151.8513 Hannan-Quinn criter. 11.01847 F-statistic 152.9322 Durbin-Watson stat 1.212781 Prob(F-statistic) 0.000000 用规范的形式将参数估计和检验结果写下 2?12.033490.104394(19.51809)(0.008442) =(0.616530) (12.36658)0.854694152.9322 i Y X t R F =+ = = 三、 检验模型的异方差 (一) 图形法 1. 相关关系图 X Y X Y 相关关系图 计量经济学实验报告成绩 课程名称计量经济学指导教师苏卫东实验日期 2014-6-24 院(系)财政与金融学院专业班级金融二专实验地点实验楼八机房 学生姓名单一芳学号 201212041018 同组人无 实验项目名称多重共线性的检验与修正 一、实验目的和要求 1、理解多重共线性的含义与后果 2、掌握Eviews软件的操作和多重共线性的检验与修正 二、实验原理 Eviews软件的操作和多重共线性的检验修正方法 三、主要仪器设备、试剂或材料 Eviews软件,计算机 四、实验方法与步骤 1、准备工作:建立工作文件,并输入数据 CREATE A 1974 1981; DATA Y X1 X2 X3 X4 X5 2、OLS估计: LS Y C X1 X2 X3 X4 X5; 3、计算简单相关系数 COR X1 X2 X3 X4 X5 4、多重共线性的解决 LS Y C X1; LS Y C X2; LS Y C X3; LS Y C X4; LS Y C X5; LS Y C X1 X3; LS Y C X1 X3 X2; LS Y C X1 X3 X4; LS Y C X1 X3 X5 五、实验数据记录、处理及结果分析 1、建立工作组,输入以下数据: obs Y X1 X2 X3 X4 X5 1974 98.45 560.2 153.2 6.53 1.23 1.89 1975 100.7 603.11 190 9.12 1.3 2.03 1976 102.8 668.05 240.3 8.1 1.8 2.71 1977 133.95 715.47 301.12 10.1 2.09 3 1978 140.13 724.27 361 10.93 2.39 3.29 1979 143.11 736.13 420 11.85 3.9 5.24 1980 146.15 748.91 497.16 12.28 5.13 6.83 1981 144.6 760.32 501 13.5 5.47 8.36 1982 148.94 774.92 529.2 15.29 6.09 10.07 1983 158.55 785.3 552.72 18.1 7.97 12.57 1984 169.68 795.5 771.16 19.61 10.18 15.12 1985 162.14 804.8 811.8 17.22 11.79 18.25 1986 170.09 814.94 988.43 18.6 11.54 20.59 1987 178.69 828.73 1094.65 23.53 11.68 23.37 2、OLS估计 LS Y C X1 X2 X3 X4 X5 Dependent Variable: Y Method: Least Squares Date: 06/24/14 Time: 18:45 Sample: 1974 1987 Included observations: 14 Variable Coefficient Std. Error t-Statistic Prob. C -3.650950 30.00144 -0.121692 0.9061 X1 0.125752 0.059087 2.128275 0.0660 X2 0.072656 0.037445 1.940317 0.0883 X3 2.681426 1.258639 2.130418 0.0658 X4 3.405866 2.444896 1.393052 0.2011 X5 -4.430561 2.194164 -2.019248 0.0781 R-squared 0.970397 Mean dependent var 142.7129 实验2 自相关的检验与修正 一、实验目的: 掌握自相关模型的检验方法与处理方法.。 二、实验容及要求: 表1列出了1985-2007年中国农村居民人均纯收入与人均消费性支出的统计数据。 (1)利用OLS法建立中国农村居民人均消费性支出与人均纯收入的线性模型。 (2)检验模型是否存在自相关。 (3)如果存在自相关,试采用适当的方法加以消除。 表1 1985-2007年中国农村居民人均纯收入与人均消费性支出(单位:元) 实验如下: 首先对数据进行调整,将全年人均纯收入和全年人均消费性支出相应调整为全年实际人均纯收入和全年实际人均消费性支出。 图1 1、用OLS估计法估计参数 图2 图3 图4 从图4中可以看出,中国农村居民人均消费性支出与人均纯收入存在着显著的正相关关系。 估计回归方程: 从图3中可以得出,估计回归方程为: Y=56.21878+0.698928X t=(3.864210)(31.99973) R2=0.979904 F=1023.983 D.W.=0.409903 (1)图示法 图5 从图5中,可以看出残差的变化有系统模式,连续为正或连续为负,表示残差项存在一阶正自相关。 (2)DW检验 从图3中可以得到D.W.=0.409903,在显著水平去5%,n=23,k=2,d L=1.26, d U=1.44。此时0 时间 地点 实验题目 多重共线性的诊断与修正 一、实验目的与要求: 要求目的:1、对多元线性回归模型的多重共线性的诊断; 2、对多元线性回归模型的多重共线性的修正。 二、实验内容 根据书上第四章引子“农业的发展反而会减少财政收入”,1978-2007年的财政收入,农业增加值,工业增加值,建筑业增加值等数据,运用EV 软件,做回归分析,判断是否存在多重共线性,以及修正。 三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等) (一)模型设定及其估计 经分析,影响财政收入的主要因素,除了农业增加值,工业增加值,建筑业增加值以外,还可能与总人口等因素有关。研究“农业的发展反而会减少财政收入”这个问题。 设定如下形式的计量经济模型:i Y =1β+2β2X +3β3X +4β4X +5β5X +6β6X +7β7X +i μ 其中,i Y 为财政收入CS/亿元;2X 为农业增加值NZ/亿元;3X 为工业增加值GZ/亿元;4X 为建筑业增加值JZZ/亿元;5X 为总人口TPOP/万人;6X 为最终消费CUM/亿元;7X 为受灾面积SZM/千公顷。 图1: 1978~2007年财政收入及其影响因素数据 年份 财政收入CS/亿元 农业增加值NZ/亿元 工业增加值GZ/亿元 建筑业 增加值 JZZ/亿 元 总人口 TPOP/万 人 最终消费 CUM/亿元 受灾面 积SZM/ 千公顷 1978 1132.3 1027.5 1607 138.2 96259 2239.1 50790 1979 1146.4 1270.2 1769.7 143.8 97542 2633.7 39370 1980 1159.9 1371.6 1996.5 195.5 98705 3007.9 44526 1981 1175.8 1559.5 2048.4 207.1 100072 3361.5 39790 1982 1212.3 1777.4 2162.3 220.7 101654 3714.8 33130 1983 1367 1978.4 2375.6 270.6 103008 4126.4 34710 1984 1642.9 2316.1 2789 316.7 104357 4846.3 31890 1985 2004.8 2564.4 3448.7 417.9 105851 5986.3 44365 1986 2122 2788.7 3967 525.7 107507 6821.8 47140 1987 2199.4 3233 4585.8 665.8 109300 7804.6 42090 1988 2357.2 3865.4 5777.2 810 111026 9839.5 50870 1989 2664.9 4265.9 6484 794 112704 11164.2 46991 1990 2937.1 5062 6858 859.4 114333 12090.5 38474 1991 3149.48 5342.2 8087.1 1015.1 115823 14091.9 55472 1992 3483.37 5866.6 10284.5 1415 117171 17203.3 51333 1993 4348.95 6963.8 14188 2266.5 118517 21899.9 48829 1994 5218.1 9572.7 19480.7 2964.7 119850 29242.2 55043 实验六多元线性回归和多重共线性 姓名:何健华 学号:201330110203 班级:13金融数学2班 一 实验目的: 掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二 实验要求: 应用教材P140例子4.3.1案例做多元线性回归模型,并识别和修正多重共线性。 三 实验原理: 普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。 四 预备知识: 最小二乘法估计的原理、t 检验、F 检验、R 2值。 五 实验步骤: 有关的研究分析表明,影响国内旅游市场收入的主要因素,除了国内旅游人数和旅游支出外,还可能与基础设施有关。因此考虑影响国内旅游收入Y (单位为亿元)的以下几个因素:国内旅游人数X1、城镇居民人均旅游支出X2(单位为元)、农村居民人均旅游支出X3(单位为元)、并以公路里程X4(单位为万公里)和铁路里程X5(单位为万公里)作为相关设施的代表,根据这些变量建立如下的计量经济模型: 01122334455y x x x x x ββββββμ=++++++ 为了估计上述模型,从《中国统计年鉴》收集到1994年到2003年的有关统计数据。 Year Y X1 X2 X3 X4 X5 1994 1023.5 52400 414.7 54.9 111.78 5.9 1995 1375.7 62900 464 61.5 115.7 5.97 1996 1638.4 63900 534.1 70.5 118.58 6.49 1997 2112.7 64400 599.8 145.7 122.64 6.6 1998 2391.2 69450 607 197 127.85 6.64 1999 2831.9 71900 614.8 249.5 135.17 6.74 2000 3175.5 74400 678.6 226.6 140.27 6.87 2001 3522.4 78400 708.3 212.7 169.8 7.01 2002 3878.4 87800 739.7 209.1 176.52 7.19 2003 3442.3 87000 684.9 200 180.98 7.3 1、 请用普通最小二乘方法估计模型参数; 2、 检验模型是否存在多重共线性,如果存在共线性,试采用适当的方法消除共线性。 实验四 序列相关的检验与修正 实验目的 1、理解序列相关的含义后果、 2、学会序列相关的检验与消除方法 实验内容 利用下表资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 表3 我国城乡居民储蓄存款与GDP 统计资料(1978年=100) 一、模型的估计 0、准备工作。建立工作文件,并输入数据。 1、相关图分析 SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数等不同形式,进而加以比较分析。 2、估计模型,利用LS 命令分别建立以下模型 ⑴线性模型: LS Y C X x y 5075.9284.14984?+-= =t (-6.706) (13.862) 2R =0.9100 F =192.145 S.E =5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX x y ln 9588.20753.8?ln +-= =t (-31.604) (64.189) 2R =0.9954 F =4120.223 S.E =0.1221 3、选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这种函数形式设置是不当的。而且,这个模型的拟合优度也较双对数模型低,所以又可舍弃线性模型。双对数模型具有很高的拟合优度,因而初步选定回归模型为双对数回归模型。 二、模型自相关的检验 1.图示法 其一,残差序列e t 的变动趋势图。菜单:Quick→Graph→line ,在对话框中输入resid ;或者用命令操作,直接在命令行输入:line X 。 其二,作e t-1和e t 之间的散点图。菜单:Quick→Graph→Scatter ,在对话框中输入resid(-1) resid ;或者用命令操作,直接在命令行输入:scat resid(-1) resid 。 2.DW 检验 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22,U d =1.42,而0<0.7062=DW 序列相关的检验及修正 例题:中国居民总量消费函数 数据: 年份 GDP CONS CPI TAX GDPC X Y 1978 3605.6 1759.1 46.21 519.28 7802.6 6678.9 3806.8 1979 4092.6 2011.5 47.07 537.82 8694.7 7552.1 4273.4 1980 4592.9 2331.2 50.62 571.70 9073.3 7943.9 4605.3 1981 5008.8 2627.9 51.90 629.89 9650.9 8437.2 5063.4 1982 5590.0 2902.9 52.95 700.02 10557.1 9235.1 5482.3 1983 6216.2 3231.1 54.00 775.59 11511.5 10075.2 5983.5 1984 7362.7 3742.0 55.47 947.35 13273.3 11565.4 6746.0 1985 9076.7 4687.4 60.65 2040.79 14965.7 11600.8 7728.6 1986 10508.5 5302.1 64.57 2090.37 16274.6 13037.2 8211.4 1987 12277.4 6126.1 69.30 2140.36 17716.3 14627.8 8840.0 1988 15388.6 7868.1 82.30 2390.47 18698.2 15793.6 9560.3 1989 17311.3 8812.6 97.00 2727.40 17846.7 15034.9 9085.2 1990 19347.8 9450.9 100.00 2821.86 19347.8 16525.9 9450.9 1991 22577.4 10730.6 103.42 2990.17 21830.8 18939.5 10375.7 1992 27565.2 13000.1 110.03 3296.91 25052.4 22056.1 11815.1 1993 36938.1 16412.1 126.20 4255.30 29269.5 25897.6 13004.8 1994 50217.4 21844.2 156.65 5126.88 32057.1 28784.2 13944.6 1995 63216.9 28369.7 183.41 6038.04 34467.5 31175.4 15467.9 1996 74163.6 33955.9 198.66 6909.82 37331.9 33853.7 17092.5 1997 81658.5 36921.5 204.21 8234.04 39987.5 35955.4 18080.2 1998 86531.6 39229.3 202.59 9262.80 42712.7 38140.5 19363.9 1999 91125.0 41920.4 199.72 10682.58 45626.4 40277.6 20989.6 2000 98749.0 45854.6 200.55 12581.51 49239.1 42965.6 22864.4 2001 108972.4 49213.2 201.94 15301.38 53962.8 46385.6 24370.2 2002 120350.3 52571.3 200.32 17636.45 60079.0 51274.9 26243.7 2003 136398.8 56834.4 202.73 20017.31 67281.0 57407.1 28034.5 2004 160280.4 63833.5 210.63 24165.68 76095.7 64622.7 30306.0 2005 188692.1 71217.5 214.42 28778.54 88001.2 74579.6 33214.0 2006 221170.5 80120.5 217.65 34809.72 101617.5 85624.1 36811.6 1、 建立回归模型,模型的OLS 估计 t t t X Y μββ++=10 (1)录入数据 打开EViews6,点“File ” “New ”“Workfile ”计量经济学异方差的检验与修正
(完整版)多重共线性检验与修正.doc
eviews自相关性检验
试验一异方差的检验与修正-时间序列分析
计量经济学--自相关性的检验及修正
异方差的检验与修正
(整理)多重共线性的检验与修正
自相关性检验
实验异方差地检验与修正
【免费下载】eviews自相关性检验
异方差性的检验和补救
多重共线性的检验与修正
自相关地检验与修正
EViews计量经济学实验报告-多重共线性的诊断与修正
实验六多元线性回归和多重共线性
计量经济学实验四 序列相关的检验与修正
序列相关的检验和修正