八、Python MySQL(pymysql)
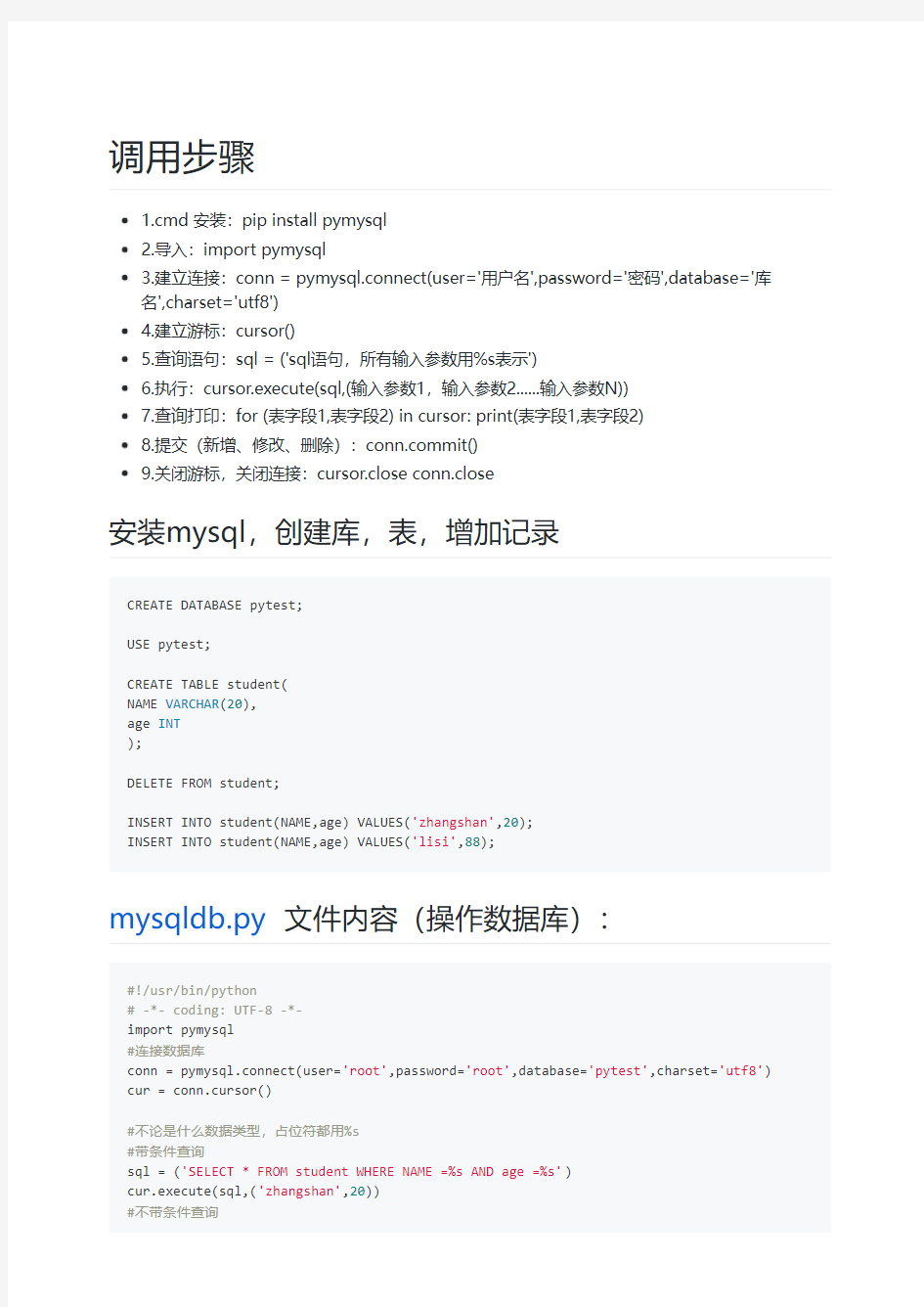

调用步骤
1.cmd 安装:pip install pymysql
2.导入:import pymysql
3.建立连接:conn = pymysql.connect(user='用户名',password='密码',database='库
名',charset='utf8')
4.建立游标:cursor()
5.查询语句:sql = ('sql语句,所有输入参数用%s表示')
6.执行:cursor.execute(sql,(输入参数1,输入参数2......输入参数N))
7.查询打印:for (表字段1,表字段2) in cursor: print(表字段1,表字段2)
8.提交(新增、修改、删除):https://www.360docs.net/doc/d8856974.html,mit()
9.关闭游标,关闭连接:cursor.close conn.close
安装mysql,创建库,表,增加记录
CREATE DATABASE pytest;
USE pytest;
CREATE TABLE student(
NAME VARCHAR(20),
age INT
);
DELETE FROM student;
INSERT INTO student(NAME,age) VALUES('zhangshan',20);
INSERT INTO student(NAME,age) VALUES('lisi',88);
mysqldb.py 文件内容(操作数据库):
#!/usr/bin/python
# ‐*‐ coding: UTF‐8 ‐*‐
import pymysql
#连接数据库
conn = pymysql.connect(user='root',password='root',database='pytest',charset='utf8') cur = conn.cursor()
#不论是什么数据类型,占位符都用%s
#带条件查询
sql = ('SELECT * FROM student WHERE NAME =%s AND age =%s')
cur.execute(sql,('zhangshan',20))
#不带条件查询
sql = ('SELECT * FROM student')
cur.execute(sql)
#将只返回一条结果,返回单个元组如('name','age')
#data = cur.fetchone()
#也将返回所有结果,返回二维元组(tuple),如(('name','age'),('name','age')) data = cur.fetchall()
#打印值
for (name,age) in data:
print(name,age)
#新增
sql=('INSERT INTO student VALUES(%s,%s)')
cur.execute(sql,('wangwu',10))
#修改
sql=('UPDATE student SET age=%s WHERE NAME=%s')
cur.execute(sql,(20,'wangwu'))
#删除
sql=('DELETE FROM student WHERE NAME =%s')
cur.execute(sql,('wangwu'))
#只要是修改了表内容的操作,后面一定要提交,否则不起作用新增修改删除
https://www.360docs.net/doc/d8856974.html,mit()
conn.close
cur.close
用python进行数据分析
用python进行数据分析 一、样本集 本样本集来源于某高中某班78位同学的一次月考的语文成绩。因为每位同学的成绩都是独立的随机变量,遂可以保证得到的观测值也是独立且随机的 样本如下: grades=[131,131,127,123,126,129,116,114,115,116,123,122,118, 121,126,121,126,121,111,119,124,124,121,116,114,116, 116,118,112,109,114,116,116,118,112,109,114,110,114, 110,113,117,113,121,105,127,110,105,111,112,104,103, 130,102,118,101,112,109,107,94,107,106,105,101,85,95, 97,99,83,87,82,79,99,90,78,86,75,66]; 二、数据分析 1.中心位置(均值、中位数、众数) 数据的中心位置是我们最容易想到的数据特征。借由中心位置,我们可以知道数据的一个平均情况,如果要对新数据进行预测,那么平均情况是非常直观地选择。数据的中心位置可分为均值(Mean),中位数(Median),众数(Mode)。其中均值和中位数用于定量的数据,众数用于定性的数据。 均值:利用python编写求平均值的函数很容易得到本次样本的平均值 得到本次样本均值为109.9 中位数:113 众数:116 2.频数分析 2.1频数分布直方图 柱状图是以柱的高度来指代某种类型的频数,使用Matplotlib对成绩这一定性变量绘制柱状图的代码如下:
用Python实现数据库编程
破釜沉舟: 为网站站长.设计师.编程开发者. 提供资源!https://www.360docs.net/doc/d8856974.html, 用Python实现数据库编程 文章类别:Python 发表日期:2004-11-11 来源: CSDN 作者: wfh_178 <用PYTHON进行数据库编程> 老巫 2003.09.10 19 September, 2003 用PYTHON语言进行数据库编程, 至少有六种方法可供采用. 我在实际项目中采用,不但功能强大,而且方便快捷.以下是我在工作和学习中经验总结. 方法一:使用DAO (Data Access Objects) 这个第一种方法可能会比较过时啦.不过还是非常有用的. 假设你已经安装好了PYTHONWIN,现在开始跟我上路吧…… 找到工具栏上ToolsàCOM MakePy utilities,你会看到弹出一个Select Library的对话框, 在列表中选择'Microsoft DAO 3.6 Object Library'(或者是你所有的版本). 现在实现对数据的访问: #实例化数据库引擎 import win32com.client engine = win32com.client.Dispatch("DAO.DBEngine.35") #实例化数据库对象,建立对数据库的连接 db = engine.OpenDatabase(r"c:\temp\mydb.mdb") 现在你有了数据库引擎的连接,也有了数据库对象的实例.现在就可以打开一个recordset了. 假设在数据库中已经有一个表叫做 'customers'. 为了打开这个表,对其中数据进行处理,我们使用下面的语法: rs = db.OpenRecordset("customers") #可以采用SQL语言对数据集进行操纵 rs = db.OpenRecordset("select * from customers where state = 'OH'") 你也可以采用DAO的execute方法. 比如这样: db.Execute("delete * from customers where balancetype = 'overdue' and name = 'bill'") #注意,删除的数据不能复原了J
用python实现基本数据结构栈与队列
7 用 Python 实现基本数据结构——栈与队列 最近学习《算法导论》 ,看了栈与队列,觉得用 C 实现 没意思 (以前实现过,不过不能通用 ),遂用最近在研究的 Python 实现这两个基本的数据结构! 在一个 basicds 模块里用实现了两个类: Stack 和 Queue 及 其各自所支持的操作,写得比较笨: -) 其实完全可以写个 基类 List ,然后从 List 中派生出类 Stack 和 Queue ,这样做 可以避免一些重复代码,因为两个类有很多类似的方法,比 如 isempty, length 等等。(当然这些改进还是等待下一版再 做吧,: -)以下是模块 basicds 模块源码: basicds.py Python 语言 : 高亮代码由发芽网提供 01 class Stack(object) : 02 def __init__(self) : 03 self.stack = [] 04 05 def push(self, item) : 06 self.stack.append(it em) 08 def pop(self) :
30 09 if self.stack != [] : 10 return self.stack.pop(-1) 11 else : 12 return None 13 14 def top(self) : 15 if self.stack != [] : 16 return self.stack[-1] 17 else : 18 return None 19 20 def length(self) : 21 return len(self.stack) 22 23 def isempty(self) : 24 return self.stack == [] 25 26 27 class Queue(object) : 28 def __init__(self) : 29 self.queue = []
Python实现WEB详细过程
使用Websocket对于客户端来说无疑十分简单。websocket提供了三个简单的函数,onopen,onclose以及onmessage,顾名思义,他们分别监听socket的开启、断开和消息状态。 例如在一个WebSocket的客户端例子中,你可以这样写: 在代码中,首先创建了一个新的socket,指向websocket服务器端: var s = new WebSocket(“ws://localhost:8000/”); 然后利用三个基本函数实现状态监听。 当然这个例子并不完善,它参考了麻省理工一位研究生Mr. Yang的文章(https://www.360docs.net/doc/d8856974.html,/wp/web-sockets-tutorial-with-simple-python- server/),而你如果需要更好的客户端测试代码,可以看这里:http://cl.ly/3N3Y3t2s3U1v1h0A433u我们在新的代码里提供了完成的和服务器交互数据的功能,发送数据我们使用的函数是send(),你可以在代码中看到。 我们之所以不直接引用Yang的文章是因为Yang对服务器的理解不够完善,或者用他的话来说就是outdate。 感谢Yang为我们提供了一个简单的socket server的例子,不过可惜放在现在来说它是有问题的,当然我们还是把例子引述如下: #!/usr/bin/env python import socket, threading, time
[数据分析] 推荐 :用Python实现神经网络(附完整代码)!
在学习神经网络之前,我们需要对神经网络底层先做一个基本的了解。我们将在本节介绍感知机、反向传播算法以及多种梯度下降法以给大家一个全面的认识。 一、感知机 数字感知机的本质是从数据集中选取一个样本(example),并将其展示给算法,然后让算法判断“是”或“不是”。一般而言,把单个特征表示为xi,其中i是整数。所有特征的集合表示为,表示一个向量: , 类似地,每个特征的权重表示为其中对应于与该权重关联的特征 的下标,所有权重可统一表示为一个向量: 这里有一个缺少的部分是是否激活神经元的阈值。一旦加权和超过某个阈值,感知机就输出1,否则输出0。我们可以使用一个简单的阶跃函数(在图5-2中标记为“激活函数”)来表示这个阈值。
一般而言我们还需要给上面的阈值表达式添加一个偏置项以确保神经元对全0的输入具有弹性,否则网络在输入全为0的情况下输出仍然为0。 注:所有神经网络的基本单位都是神经元,基本感知机是广义神经元的一个特例,从现在开始,我们将感知机称为一个神经元。 二、反向传播算法 2.1 代价函数 很多数据值之间的关系不是线性的,也没有好的线性回归或线性方程能够描述这些关系。许多数据集不能用直线或平面来线性分割。比如下图中左图为线性可分的数据,而右图为线性不可分的数据:
在这个线性可分数据集上对两类点做切分得到的误差可以收敛于0,而对于线性不可分的数据点集,我们无法做出一条直线使得两类点被完美分开,因此我们任意做一条分割线,可以认为在这里误差不为0,因此我们需要一个衡量误差的函数,通常称之为代价函数: 而我们训练神经网络(感知机)的目标是最小化所有输入样本数据的代价函数 2.2 反向传播 权重通过下一层的权重()和()来影响误差,因此我们需要一种方法来计算对误差的贡献,这个方法就是反向传播。 下图中展示的是一个全连接网络,图中没有展示出所有的连接,在全连接网络中,每个输入元素都与下一层的各个神经元相连,每个连接都有相应的权
用 Python 脚本实现对 Linux 服务器的监控
用Python 脚本实现对Linux 服务器的监控 目前Linux 下有一些使用Python 语言编写的Linux 系统监控工具比如inotify-sync(文件系统安全监控软件)、glances(资源监控工具)在实际工作中,Linux 系统管理员可以根据自己使用的服务器的具体情况编写一下简单实用的脚本实现对Linux 服务器的监控。本文介绍一下使用Python 脚本实现对Linux 服务器CPU 内存网络的监控脚本的编写。 1评论: 曹江华, 系统管理员, 中科思密达有限公司 2013 年12 月23 日 内容 Python 版本说明 Python 是由Guido van Rossum 开发的、可免费获得的、非常高级的解释型语言。其语法简单易懂,而其面向对象的语义功能强大(但又灵活)。Python 可以广泛使用并具有高度的可移植性。本文Linux 服务器是Ubuntu 12.10, Python 版本是 2.7 。如果是 Python 3.0 版本的语法上有一定的出入。另外这里笔者所说的Python 是 CPython,CPython 是用C 语言实现的Python 解释器,也是官方的并且是最广泛使用的Python 解释器。除了CPython 以外,还有用Java 实现的Jython 和用.NET 实现的IronPython,使Python 方便地和Java 程序、.NET 程序集成。另外还有一些实验性的Python 解释器比如PyPy。CPython 是使用字节码的解释器,任何程序源代码在执行之前先要编译成字节码。它还有和几种其它语言(包括 C 语言)交互的外部函数接口。 回页首工作原理:基于/proc 文件系统 Linux 系统为管理员提供了非常好的方法,使其可以在系统运行时更改内核,而不需要重新引导内核系统,这是通过/proc 虚拟文件系统实现的。/proc 文件虚拟系统是一种内核和内核模块用来向进程(process)发送信息的机制(所以叫做“/proc”),这个伪文件系统允许与内核内部数据结构交互,获取有关进程的有用信息,在运行中(on the
如何用 Python实现自动化测试
如何用 Python实现自动化测试 近期一直在看王阳明的相关书籍,他的一个观点我非常赞同,不管要学习什么一定要立志,立志是非常非常重要的,但是立志前一定要有动机,或者说要有"打击",那种让 你内心感到瓦凉瓦凉的打击!我在软件测试这个行业工作了12年之久,截至5年前,我 一直很愉悦地,内心充盈地做着黑盒测试,曾几何时我也觉得最好离"开发"远远的,因为 很多人都说:女孩子做测试挺好的~~ 但是,我遇到很一个非常现实而残忍的问题:"裁员",想想自己也挺奇葩的,在一个公司竟然待了12年之久,在这12年里,因为各种原因,我经历了大大小小的裁员有5次之多,一有裁员需求,老板第一个考虑的就是测试人员。每一次裁员,都是自己团队里的兄弟姐妹,我要亲自告诉他或她,因为公司现在裁员,需 要你离开公司,虽然你的工作是合格的,甚至是优秀的~~然后我要鼓起勇气陪着哭泣的他或她去立刻办理离职手续,一刻也不能停留~~你能想象我内心的崩溃吗?每一次我都会问为什么又是我们?每一次老板都会坦率地告诉我,为什么裁员考虑的是我们测试团队:就 是因为可取代性太强了!!我真的实实在在意识到了黑盒测试的无力。 公司在寒冬时,需要"蓄积能量",也就是需要减少开支,老板就要开始衡量,哪类研 发人员被裁,后续如果公司渡过难关后补起来比较容易,很不幸,每一次评估下来都是测 试人员。有个声音在我脑海里越来越清晰:不能这样,我们团队不能总是做可取代性强的 工作!!所以测试的发展方向是什么?我要有什么样的技能才能改观老板对我们的认知??我开始在网上找,当然也在51testing这样专业的网站上找寻,我找寻的结果是:未来的 测试应该是以自动化为主,手动测试为辅。所以测试人员必须要学会编程,因为测试是一 个无穷尽的工作,如何体现测试人员的价值,就是在单位时间内能有更多的产出,有让老 板瞠目结舌的产出!! 怎么学习Python在第二类问题中有详细说明,期间遇到的困难实在太多了,首要的 问题就是团队的信心不足,我们离开coding实在太久了,这个困难,我只能说,受到的 打击越大,越深,信心就会越足,容许我先哭一会~~ 除了这些形而上的困难,当然也有 实实在在的困难,我举一个实际且非常具体的问题:电脑1开发的脚本,可以正常运行,移植到电脑2就无法运行? 我们在开发时遇到上述问题,开发者开始一直纠结是电脑环境的问题,问题一直在发散,一直在发散,最后问题越来越复杂,搞到最后不可收拾......,最后他告诉我,这个开发任务无法进行@_@,这个小伙子成功在他的小主管的心里留下了:解决实际问题差的印象...... 他的问题在于没有回到问题的本质:Python的作用是定位,操作;就首先回到确认 窗口是否定位的思路上(当时他竟然还质疑他的小主管:窗口肯定定位了,因为在他的开 发电脑上都是定位的好好的*_*):真的发现窗口没有被成功定位。开发者就很困惑,为什么在电脑1是好的,电脑2就不行。他根本没想到是定位出的问题,所以连简单的确认动作也没做!然后再网上一通乱搜,真的越搜越晕,越搜问题越发散。
在abaqus中使用python实现功能(1,2)
在abaqus中使用python实现的功能(一、二) By lxm9977(lxm200501@https://www.360docs.net/doc/d8856974.html,) 功能一:实行提交多个job的功能。 对象:Job object 使用:在源文件开始写上import job,源程序用mdb.jobs[name] 使用名字为name的job对象。 建立一个job对象的方法: z利用已有的inp文件中建立job:mdb.JobFromInputFile() z利用已有的cae中建立job: Job(...) 建议用第一种方法。 设定参数的方法: 9利用第一种方法建立job的时候,可以设定很多的参数,比如type,queue,userSubroutine等。格式:mdb.JobFromInputFile(name=,inputFile=,type=,queue =,userSubroutine=,…….)。 9也可以先建立一个job,然后利用job对象的setValues来设定参数,格式:job.setValues(type=,queue=,userSubroutine=,…….)。 一个简单的例子: 文件:job.py from abaqusConstants import * import job mdb.JobFromInputFile(name='job-1-1',inputFileName='Job-1.inp') #基于inp文件Job-1.inp建立名称为job-1-1的job mdb.jobs['job-1-1'].setValues(waitMinutes=1) #设定参数 mdb.jobs['job-1-1'].submit() #提交任务 mdb.jobs['job-1-1'].waitForCompletion() 运行: 在cmd下面运行:Abaqus cae nogui=job.py
朴素贝叶斯python代码实现
朴素贝叶斯 优点:在数据较少的情况下仍然有效,可以处理多类别问题 缺点:对于输入数据的准备方式较为敏感 适用数据类型:标称型数据 贝叶斯准则: 使用朴素贝叶斯进行文档分类 朴素贝叶斯的一般过程 (1)收集数据:可以使用任何方法。本文使用RSS源 (2)准备数据:需要数值型或者布尔型数据 (3)分析数据:有大量特征时,绘制特征作用不大,此时使用直方图效果更好 (4)训练算法:计算不同的独立特征的条件概率 (5)测试算法:计算错误率 (6)使用算法:一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。 准备数据:从文本中构建词向量 摘自机器学习实战。 [['my','dog','has','flea','problems','help','please'], 0 ['maybe','not','take','him','to','dog','park','stupid'], 1 ['my','dalmation','is','so','cute','I','love','him'], 0
['stop','posting','stupid','worthless','garbage'], 1 ['mr','licks','ate','my','steak','how','to','stop','him'], 0 ['quit','buying','worthless','dog','food','stupid']] 1 以上是六句话,标记是0句子的表示正常句,标记是1句子的表示为粗口。我们通过分析每个句子中的每个词,在粗口句或是正常句出现的概率,可以找出那些词是粗口。 在bayes.py文件中添加如下代码: [python]view plaincopy 1.# coding=utf-8 2. 3.def loadDataSet(): 4. postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please' ], 5. ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], 6. ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], 7. ['stop', 'posting', 'stupid', 'worthless', 'garbage'], 8. ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], 9. ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] 10. classVec = [0, 1, 0, 1, 0, 1] # 1代表侮辱性文字,0代表正常言论 11.return postingList, classVec 12. 13.def createVocabList(dataSet): 14. vocabSet = set([]) 15.for document in dataSet: 16. vocabSet = vocabSet | set(document) 17.return list(vocabSet) 18. 19.def setOfWords2Vec(vocabList, inputSet): 20. returnVec = [0] * len(vocabList) 21.for word in inputSet: 22.if word in vocabList: 23. returnVec[vocabList.index(word)] = 1 24.else: 25.print"the word: %s is not in my Vocabulary!" % word 26.return returnVec
用 Python 实现一个大数据搜索引擎
用Python 实现一个大数据搜索引擎 搜索是大数据领域里常见的需求。Splunk和ELK分别是该领域在非开源和开源领域里的领导者。本文利用很少的Python代码实现了一个基本的数据搜索功能,试图让大家理解大数据搜索的基本原理。 布隆过滤器(Bloom Filter) 第一步我们先要实现一个布隆过滤器。 布隆过滤器是大数据领域的一个常见算法,它的目的是过滤掉那些不是目标的元素。也就是说如果一个要搜索的词并不存在与我的数据中,那么它可以以很快的速度返回目标不存在。 让我们看看以下布隆过滤器的代码: class Bloomfilter(object): """
A Bloom filter is a probabilistic data-structure that trades space for accuracy when determining if a value is in a set. It can tell you if a value was possibly added, or if it was definitely not added, but it can't tell you for certain that it was added. """ def __init__(self,size): """Setup the BF with the appropriate size""" self.values = [False] * size self.size = size def hash_value(self,value): """Hash the value provided and scale it to fit the BF size""" return hash(value) % self.size
实验1 Python编程环境的使用
实验1 Python编程环境的使用 实验报告 15041141 范博 1. 实验目的 (1)了解Python编程环境,进行程序设计的基本训练; (2)熟悉Python语言的使用方式,编写简单python程序,包括编写和运行基本的输入、输出和数值计算程序; (3)会定义和调用函数。 2. 实验步骤(详述每一个子实验的关键语法及其实现) 2.1 实验任务1-1 关键语法:用input()语句接收用户从键盘的输入; 将这些输入依次用变量进行存放; 用print()语句将这些变量依次进行打印输入; 代码实现: 2.2 实验任务1-2 关键语法:用input()语句接收用户从键盘的输入; 将这些输入依次用变量进行存放(名字有意义);
用系统内置函数float()进行强制类型转换; 用print()语句打印输出结果; 代码实现: 2.3 实验任务1-3 关键语法:用input()语句接收用户从键盘的输入并赋值给变量; 用系统内置函数int()进行强制类型转换; if-else语句进行判断,正确输出True,否则输出 False; 用print()语句打印输出结果; 代码实现: 2.4 实验任务1-4 关键语法: 导入Python标准库中的随机模块; 用该模块中的randint()方法产生一个随机整数; 结果保存在一个变量中,并用print()语句输出; 代码实现:
2.5 实验任务1-5 关键语法: 用import math导入math模块; 用该模块中的sqrt()函数进行开平方运算; 结果保存在一个变量中,并用print()语句输出; 代码实现: 2.6 实验任务1-6 关键语法: 用def来定义一个函数; 用字符串中的lower()方法将大写字母转换为小写字母; 对函数进行调用并用print()语句进行输出; 代码实现:
用PYTHON实现黄金分割法
用Python实现黄金分割法 """ Author:Z Date:2015-12-3 """ import os,sys,time import numpy as np class node(object): def__init__(self): self.power=[] self.a=[] self.left=0.0 self.right=1.0 ##############################base function area################ def parse(self,string): """ parse str"string"into list"a"and"power" "a"means the factor of x "power"means the index of x """ self.power=[] self.a=[] string=string.replace('','') eq=string.find('=') new_string=string[(eq+1):] index=new_string.find('x') while(index!=-1): if new_string[index-1]=='*'and new_string[index-2].isdigit(): i=index-2 num="" while i>=0and new_string[i].isdigit(): num=new_string[i]+num i=i-1 if i>=0and new_string[i]=='-': num='-'+num self.a.append(float(num)) else:
用Python实现内推外插法
用Python实现内推外插法 """ Author: Z Date: 2015-12-3 """ import numpy as np class node(object): def __init__(self): self.power = [] self.a = [] def set(self,ar,p): for i in xrange(len(ar)): self.a.append(ar[i]) self.power.append(p[i]) def printf(self): print 'a[] is: ', for i in xrange(np.array(self.a).shape[0]): print self.a[i], print ' ' print 'power[] is: ', for i in xrange(np.array(self.power).shape[0]): print self.power[i], print ' ' ############################# base function area ##################### def parse(self,string): """ parse str "string" into list "a" and "power" "a" means the factor of x "power" means the index of x """ self.power = [] self.a = [] string = string.replace(' ','') eq = string.find('=') new_string = string[(eq+1):]
python简单推荐系统(含完整代码)
似乎咱的产品七,八年前就想做个推荐系统的,就是类似根据用户的喜好,自动的找到用户喜欢的电影或者节目,给用户做推荐。可是这么多年过去了,不知道是领导忘记了还是怎么了,连个影子还没见到。 而市场上各种产品的都有了推荐系统了。比如常见的各种购物网站京东,亚马逊,淘宝之类的商品推荐,视频网站优酷的的类似影片推荐,豆瓣音乐的音乐推荐…… 一个好的推荐系统推荐的精度必然很高,能够真的发现用户的潜在需求或喜好,提高购物网詀的销量,让视频网站发现用户喜欢的收费电影…可是要实现一个高精度的推荐系统不是那么容易的,netflix曾经悬赏高额奖金寻找能给其推荐系统的精确度提高10%的人,可见各个公司对推荐系统的重视和一个好的推荐系统确实能带来经济效益。 下面咱以电影电视的推荐系统为例,一步一步的来实现一个简单的推荐系统吧,由于比较简单,整个推荐系统源码不到100行,大概70-80行吧,应该很容易掌握。为了快速开发原型,咱采用Python代码来演示 1.推荐系统的第一步,需要想办法收集信息 不同的业务,不同的推荐系统需要收集的信息不一样针对咱要做的电影推荐,自然是每个用户对自己看过的电影的评价了,如下图所示: Kai Zhou对Friends打分是4分,对Bedtime Stories打分是3分,没有对RoboCop 打分Shuai Ge没有对Friends打分,对Bedtime Stories打分是3.5分……为简单,咱将此数据存成csv文件,形成一个二维的矩阵,假设存在D:\train.csv,数据如下: Name,Friends,Bedtime Stories,Dawn of the Planet of the Apes,RoboCop,Fargo,Cougar Town Kai Zhou,4,3,5,,1,2Shuai Ge,,3.5,3,4,2.5,4.5 Mei Nv,3,4,2,3,2,3xiaoxianrou,2.5,3.5,3,3.5,2.5,3fengzhi,3,4,,5,3.5,3mein v,,4.5,,4,1,mincat,3,3.5,1.5,5,3.5,3alex,2.5,3,,3.5,,4 先从csv文件中加载二维矩阵,代码如下: def load_matrix(): matrix={}
Python基本操作题
1.请补充横线处的代码,让Python 帮你随机选一个饮品吧! import ____①____ random.seed(1) listC = ['加多宝','雪碧','可乐','勇闯天涯','椰子汁'] print(random. ____②____ (listC)) 参考答案: import random random.seed(1) listC = ['加多宝','雪碧','可乐','勇闯天涯','椰子汁'] print(random.choice(listC)) 2.请补充横线处的代码,listA中存放了已点的餐单,让Python帮你增加一个“红烧肉”,去掉一个“水煮干丝”。 listA = ['水煮干丝','平桥豆腐','白灼虾','香菇青菜','西红柿鸡蛋汤'] listA. ____①____ ("红烧肉") listA.____②____ ("水煮干丝") print(listA) 参考代码: listA = ['水煮干丝','平桥豆腐','白灼虾','香菇青菜','西红柿鸡蛋汤'] listA.append("红烧肉") listA.remove("水煮干丝") print(listA) 3.请补充横线处的代码。dictMenu中存放了你的双人下午套餐(包括咖啡2份和点心2份)的价格,让Python帮忙计算并输出消费总额。 dictMenu = {'卡布奇洛':32,'摩卡':30,'抹茶蛋糕':28,'布朗尼':26} ___①____ for i in ____②____: sum += i print(sum) 参考代码: dictMenu = {'卡布奇洛':32,'摩卡':30,'抹茶蛋糕':28,'布朗尼':26} sum = 0 for i in dictMenu.values(): sum += i print(sum) 4.获得输入正整数 N,反转输出该正整数,不考虑异常情况。 参考代码: N = input() print(N[::-1]) 5. 给定一个数字123456,请采用宽度为25、右对齐方式打印输出,使用加号“+”填充。 参考代码: print("{:+>25}".format(123456)) 6.给定一个数字12345678.9,请增加千位分隔符号,设置宽度为30、右对齐方式打印输出,使用空格填充。 参考代码:
基于Python爬虫技术实现
2019.09 1概述 这是一个快速变化的时代,这是一个信息膨胀最快 的时代。数据围绕着人们的日常生活,在这个人人都离不开互联网的时代,人们对信息获取要求越来越高,内容也五花八门。当微信上传播一条被广泛关注的信息时,瞬间就会被几十万甚至几百万的网友所获取和转播,其信息推广速度和推广范围远远超过传统媒体。一分钟之内会发生什么?通过对2018年的数据进行分析,得出的结果相当惊人:谷歌搜索次数达到370万次,电子邮件发送量达到1.87亿封,电商平台花费达到86.28万美元。每天不断产生的各种各样的信息,虽然已经有了像Google、百度这样优秀的通用搜索引擎,但却不能适用所有的情况和需要。对学术搜索来说,一个合理的结果显示和排序是非常重要的。 2 网络爬虫的实现应用及相关技术 2.1爬虫的应用场景 在现实生活中,一直都在使用爬虫这门技术,常用的搜索引擎的百度、谷歌等。除此之外,还有其他 数据需求,当爬取数据、分析数据时,就会借助网络爬虫技术。 如在淘宝上买一部新手机,预计一个价位,再针对符合条件的手机进行分析,看网友评价和市场反馈,最终确定符合要求的手机。如表1所示。2.2反爬虫技术 基于Python 的网络爬虫,在Python 语言强大的支 撑下,使得网络爬虫拥有所见即所爬的强大功能。这便是现在数据被盗取情况泛滥的主要原因之一。为保护网站服务器不被群体爬虫所攻击,防止服务器数据被盗,有些网站增加了反爬虫技术。如图1、图2所示。 基于Python 爬虫技术实现 望江龙,王晓红* (武汉商学院信息工程学院,武汉430056) 摘 要:随着科技时代的飞快发展,使用技术和创新来搜索数据,是大数据研究的方向。基于Python 的网络爬虫提取数据是目前使用频率较高的一种技术方式,Python 语言简洁、开发速度快、可以跨平台的特点,通过第三方request 库对网页进行获取返回值的内容。通过Python 3种筛选方式对网页中的数据进行快速的匹配。使用正则、XPath 和Beautiful Soup 这3种筛选技术对某个网页中的图片和文字进行提取。这样不仅能很精准地找到网页中所需数据,而且能自动快速地将这些数据永久地保存下来,大大减少寻找数据的时间。当爬虫技术的不断优化,功能也越来越强,数据盗取情况日益严重,很多网站采用了反爬虫技术,因此正常的数据搜集需要一定的反反爬虫技术手段。关键词:Python 语言;第三方库;反反爬虫;网络爬虫技术;数据提取;数据处理 表1在某电商平台上按照用户需求筛选出来的信息 作者简介:望江龙(2000-),男,研究方向:数据提取;王晓红(1969-),女,通讯作者,硕士,副教授, 研究方向:计算机模式识别、图像识别等。收稿日期: 2019-06-04 图1 爬虫被反爬虫拦截 图2无法获取网页的源代码 18
入门级Python应用程序教程(含完整代码)
入门级Python应用程序---伺服电机控制 v信@宝德,百度@baode_w 前言 本文只适合像作者这样的入门级小白,大虾级别的请忽略。 由于作者水平有限,不当之处,欢迎批评指正。 本文所述应用程序只考虑功能实现,不考虑程序优化。 一、应用环境 系统环境:Window 10; Python版本:3.7; IDE:PyCharm; 界面设计:PYQT5; 电机:光毓机电RMD-S系列电机; 控制端口:RS-485,使用USB转485模块。 二、准备环境 软件安装及环境变量设置方法网上较多,请自行查阅,这里不再赘述。 双击打开PyCharm,新建一个New Project,注意添加项目的环境依赖venv。配置下Python3.7的依赖环境库venv library root,External Libraries—>Python 3.7(venv) —>venv library root—>pyvenv.cfg,将值改成“true”,如下图。 为PyCharm添加外部工具,File→Settings→Tools→External Tools→“+”。
以PYQT5为例,单击“+”,弹出新建外部工具对话框,如下图所示。 对话框中Name是在IDE中的显示名字,可以自定义填写。Tool Settings需填写两项,Program项单击浏览Python3.7根目录“Python37\Lib\site-packages\pyqt5_tools\designer.exe”(当然,你得先安装有PYQT5,>_<),Working directory项填入“$ProjectFileDir$”,其他选项默认即可,单击“OK”保存。 其他外部工具如PYUIC、PYRCC等,添加过程类似。 三、编写程序 在项目中新建两个py文件,其中一个py文件(PTContrl.py)关联QT界面的信号(Signal)和槽(Slot),另外一个py文件(PTMainPRO.py)用来编写主程序,如此便于分离QT界面和逻辑程序,避免修改界面时对主程序存在干扰,当修改QT界面时,QT只会更新PTContrl.py,不会更新主程序。 主程序中需要包含PTContrl完成调用,以及主程序需要加载一些要用到的模块,如sys、serial、Qtimer等,如下图所示。
python的不同实现
这里的实现指的是符合Python语言规范的Python解释程序以及标准库等。这些实现虽然实现的是同一种语言,但是彼此之间,特别是与CPython之间还是有些差别的。 下面分别列出几个主要的实现。 1.CPython:这是Python的官方版本,使用C语言实现,使用最为广泛,新的语言特性一般也最先出现在这里。 CPython实现会将源文件(py文件)转换成字节码文件(pyc文件),然后运行在Python虚拟机上。 2.Jython:这是Python的Java实现,相比于CPython,它与Java语言之间的互操作性要远远高于CPython和C语言之间的互操作性。 在Python中可以直接使用Java代码库,这使得使用Python可以方便地为Java 程序写测试代码,更进一步,可以在Python中使用Swing等图形库编写GUI程序。 Jython会将Python代码动态编译成Java字节码,然后在JVM上运行转换后的程序,这意味着此时Python程序与Java程序没有区别,只是源代码不一样。 在Python 中写一个类,像使用Java 类一样使用这个类是很容易的事情。 你甚至可以把Jython 脚本静态地编译为Java 字节码。 示例代码:https://www.360docs.net/doc/d8856974.html,ngimportSystemSystem.out.write('Hello World!\n') 3.Python for .NET:它实质上是CPython实现的.NET托管版本,它与.NET库和程序代码有很好的互操作性。 4.IronPython:不同于Python for .NET,它是Python的C#实现,并且它将Python代码编译成C#中间代码(与Jython类似)(我的添加:应理解成:IronPython 会将Python代码动态编译成C#中间代码,然后在CLR上运行转换后的程序,这意味着此时Python程序与C#程序没有区别,只是源代码不一样。),然后运行,它与.NET语言的互操作性也非常好。 5.PyPy:Python的Python实现版本,原理是这样的,PyPy运行在CPython (或者其它实现)之上,用户程序运行在PyPy之上。 它的一个目标是成为Python语言自身的试验场,因为可以很容易地修改PyPy解释器的实现(因为它是使用Python写的)。 6.Stackless:CPython的一个局限就是每个Python函数调用都会产生一个C 函数调用。这意味着同时产生的函数调用是有限制的,因此Python难以实现用户级的线程库和复杂递归应用。 一旦超越这个限制,程序就会崩溃。Stackless的Python实现突破了这个限制,一个C栈帧可以拥有任意数量的Python栈帧。这样你就能够拥有几乎无穷的函数调用,并能支持巨大数量的线程。 Stackless唯一的问题就是它要对现有的CPython解释器做重大修改。所以它几乎是一个独立的分支。另一个名为Greenlets的项目也支持微线程。 它是一个标准的C扩展,因此不需要对标准Python解释器做任何修改。
用python实现的websocket代码
用python实现的websocket代码 ubuntu下python2.76 windows Python 2.79, chrome37 firefox35通过 代码是在别人(cddn有人提问)基础上改的, 主要改动了parsedata和sendmessage这2个函数. 改代码参考下面了这段文档. 主要是第5条, 发送的数据长度分别是8bit和16bit和64 bit(即127, 65535,和2^64-1)三种情况 发送和收取是一样的, 例如 1.长度小于125时(由于使用126, 127用作标志位.) 2. 数据长度在128-65525之间时, Payload Length位设为126, 后面额外使用16bit表示长度(前面的126不再是长度的一部分) 3.数据长度在65526-2^64-1之间时, Payload Length位设为127, 后面额外使用64bit表示长度(前面的127不再是长度的一部分) 1.Fin (bit 0): determines if this is the last frame in the message. This would be set to 1 on the end of a series of frames, or in a single-frame message, it would be set to 1 as it is both the first and last frame. 2.RSV1, RSV2, RSV3 (bits 1-3): these three bits are reserved for websocket extensions, and should be 0 unless a specific extension requires the use of any of these bytes. 3.Opcode (bits 4-7): these four bits deterimine the type of the frame. Control frames communicate WebSocket state, while non-control frames communicate data. The various types of codes include: