实验五七虚拟变量回归分析

第七章虚拟变量回归分析
姓名:耿肃竹学号:20136878 班级:经济1302
【实验目的】目的在于学习基本的经济计量方法并利用Stata对经济中典型的数据,掌握虚拟变量的分析思路,掌握虚拟变量回归的基本操作方法,掌握虚拟变量回归的结果分析。
【实验软件】Stata是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。该软件提供的功能包含线性混合模型、均衡重复反复及多项式普罗比模式。作为流行的计量经济学软件,Stata的功能十分地全面和强大。可以毫不夸张地说,凡是成熟的计量经济学方法,在Stata中都可以找到相应的命令,而这些命令都有许多选项以适应不同的环境或满足不同的需要。【实验要求】利用stata软件学习多元回归分析的应用问题,并在回归结果中学会以下命令的使用对类型变量B生成虚拟变量Atabulate B, gen(A);对包含虚拟变量的情况进行回归regress y x1 x2…A2 A3…等命令。学会虚拟变量在回归分析中的应用进行有效分析,学以致用。
【实验内容】教材P213——C2
题目【1】C2
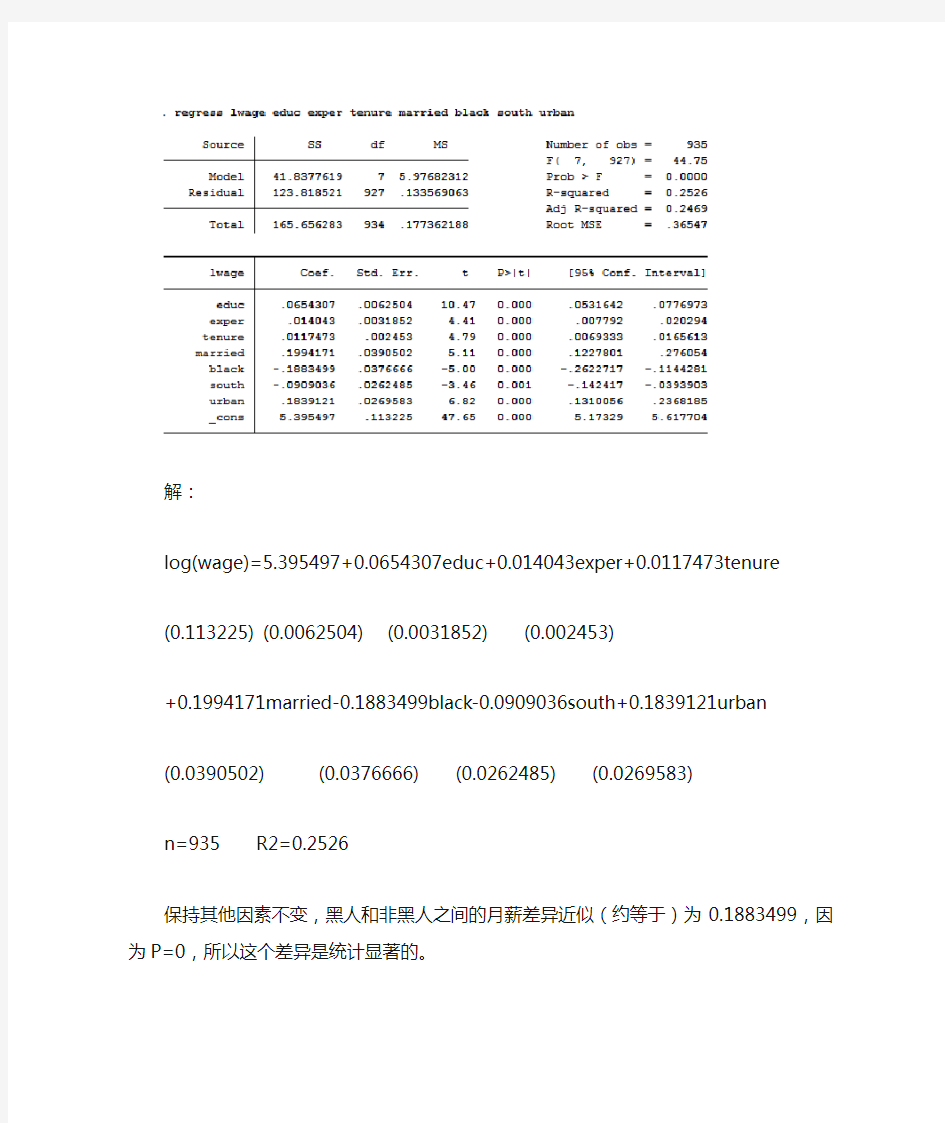
(Ⅰ)输入命令“regress lwage educ exper tenure married black south urban”:
解:
log(wage)=5.395497+0.0654307educ+0.014043exper+0.0117473tenure
(0.113225) (0.0062504) (0.0031852) (0.002453)
+0.1994171married-0.1883499black-0.0909036south+0.1839121urban (0.0390502) (0.0376666) (0.0262485) (0.0269583)
n=935 R2=0.2526
保持其他因素不变,黑人和非黑人之间的月薪差异近似(约等于)为0.1883499,因为P=0,所以这个差异是统计显著的。
(Ⅱ)输入命令”g e n e rate e x pe r sq=e x p e r*e x p e r”“ge n e rate tenuresq=tenure*tenure”“regress lwage educ expertenure married black a o u t h u r b a n e x p e r a q”:
输入命令“tese experaq”:
解:因为P=0.2260,不拒绝原假设,所以即使在20%的显著性水平上,它们也是联合不显著的。
(Ⅲ)输入命令“generate black_educ=black*educ”“regress lwage educ exper tenure married black south urban black_educ”:
解:因为P=0.263,不拒绝原假设,所以扩展原模型,使受教育汇报取决于种族,然而受教育的回报不取决于种族
(Ⅳ)输入命令“tabulate married,generate(married)”“reg lwage educ exper tenure aouth urban married*black1”:
输入命令“display 0.0094484-0.1889147”:
解:(1)以未婚黑人(即black1_married1)为基组。
(2)定义已婚黑人、未婚非黑人、已婚非黑人三个交互项。
(3)估计已婚黑人和已婚非黑人之间的工资差异为17.94663%
题目【2】C4
(Ⅰ) 解:(1)预计:β1<0,β2>0,β3<0,β4>0,β5>0,β6>0 (2)β2没有把握,因为它是二次项系数。
(Ⅱ)输入命令“regress colgpa hsizesq hsperc sat female athlete”:
解:(1)以形式报告结果:
colgpa=1.241365-0.0568543hsize+0.0046754hsizesq-0.0132126hsperc
(0.0794923)(0.0163563) (0.0022494) (0.0005728)
+0.0016464sat+0.1548814female+0.1693064athlete
(0.0000668) (0.0180047) (0.0423492)
n=4137 R2=0.2925
(2)估计运动员与非运动员之间GPA的差异是16.93064%,
t=0.1693064/0.0423492=3.998,是统计显著的。
(Ⅲ)输入命令“regress colgpa hsize hsizesq hsperc female athlete”:
解:(1)从模型中去掉sat后,athlete的系数变为0.0054487,标准误变为0.0447871,从实际上和统计上都是不显著的
(2)因为模型中没有控制变量sat,第(2)小题在模型中加了sat,运动员的表现比非运动员的表现好,此时虽然没有控制sat变量,结果仍然一样(Ⅳ)输入命令“tabulate athlete,generate(athlete)”:
输入命令“regress colgpa hsize hsizesq hsperc sat femanonath”:
解:(1)形式报告结果:
colgpa=1.241575-0.0568006hsize+0.0046699hsizesq-0.0132114hsper c
(0.0795453)(0.163671) (0.0022507) (0.000573)
+0.0016462sat+0.1674185femaath+0.1546151malenonath
(0.0000669) (0.0484877) (0.0183122)
+0.3297256maleath
(0.0840593)
n=4137 R2=0.2925
(2)femaath是female和athlete的交互项,其他条件不变的情况下,
女性作为运动员比非运动员的colgpa预计高0.1674185,t=0.1674185/0.0484877=3.45>1.96,双侧检验下,在5%的显著性水平上是统计显著的,即在其他条件不变的情况下,女生是否为运动员是有差别的。
(Ⅴ)解:(1)sat对colgpa的影响不会因性别不同而不同。
(2)在第(2)小题的模型中加入了female、sat这些变量,它的t值很小,这无法为sat对colgpa的影响因性别不同而不同提供依据。【心得体会】以上两道题目已经基本完成,我有如下体会。
【1】自变量并不是定量尺度,而是定性尺度的时候,使用虚拟变量。虚拟变量的使用,要知道变量的取值,依据取值来确定生成虚拟变量的个数。一般,取值有多少个,就生成多少个虚拟变量。
【2】学会了使用命令“tabulate edulevel, generate(edulevel)“和命令”regress lnwage edulevel2 edulevel3 edulevel4 exp expsq“在第二题中第四小题目中,对黑人的具体分类从一开始就没有确定,导致初次结果中的数据非常混乱,之后想到要建立在一个基组的前提下开始运算,才让数据变得清晰。【3】不过在做以上两道题目的时候也发现了一些问题,比如输入关于对各个因素是否会有影响的命令会迟疑很久,一直搞不太清楚。所以希望老师多多指教,在课堂上认真地听了讲解,所以这一次实验也没有遇到太多的问题。
虚拟变量案例
虚拟变量(dummy variable) 在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。这些因素也应该包括在模型中。 由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。这种变量称作虚拟变量,用D表示。虚拟变量应用于模型中,对其回归系数的估计与检验方法与定量变量相同。 1.截距移动 设有模型, y t = 0 + 1 x t + 2D + u t , 其中y t,x t为定量变量;D为定性变量。当D= 0 或1时,上述模型可表达为, + 1x t + u t , (D = 0) y t = (0 + 2) + 1x t + u t , (D = 1) D =0 D = 1 +2 图8.1 测量截距不同 D= 1或0表示某种特征的有无。反映在数学上是截距不同的两个函数。若2显著不为零,说明截距不同;若2为零,说明这种分类无显著性差异。 例:中国成年人体重y(kg)与身高x(cm)的回归关系如下: –105 + x D = 1 (男) y = - 100 + x - 5D = – 100 + x D = 0 (女) 注意: ①若定性变量含有m个类别,应引入m-1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummy variable trap)。 ②关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。
③定性变量中取值为0所对应的类别称作基础类别(base category)。 ④对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。如: 1 (大学) D =0 (中学) -1 (小学)。 【案例1】中国季节GDP数据的拟合(虚拟变量应用,file:case1及case1-solve) GDP序列图不用虚拟变量的情形若不采用虚拟变量,得回归结果如下, GDP = 1.5427 + 0.0405 T (11.0) (3.5) R2 = 0.3991, DW = 2.6,s.e. = 0.3 定义 1 (1季度) 1 (2季度) 1 (3季度) D1 = D2 = D3 = 0 (2, 3,4季度) 0 (1, 3, 4季度) 0 (1, 2, 4季度) 第4季度为基础类别。 GDP = 2.0922 + 0.0315 T – 0.8013 D1 – 0.5137 D2– 0.5014 D3 (64.2) (15.9) (-24.9) (-16.1) (-15.8) R2 = 0.9863, DW = 1.96,s.e. = 0.05 附数据如下: 年GDP t D1D2D3 1996:11.31561100 1996:21.66002010
虚拟变量回归模型
虚拟变量回归模型 以下是为大家整理的虚拟变量回归模型的相关范文,本文关键词为虚拟,变量,回归,模型,内蒙古,科技,大学,课程,计量经济学,您可以从右上方搜索框检索更多相关文章,如果您觉得有用,请继续关注我们并推荐给您的好友,您可以在综合文库中查看更多范文。 内蒙古科技大学
实验报告 课程名:计量经济学实验项目名称:单方程线性回归模型的扩展——虚拟变量回归模型 院(系):专业班级:姓名:学号: 1 内蒙古科技大学 实验地点:经管机房 实验日期:20XX年4月18日 实验目的:掌握虚拟变量回归模型的建立、参数估计和统计检验。实验内容: 1)生成趋势变量2)生成季节虚拟变量3)生成分段虚拟变量4)建立虚拟变量回归模型 5)虚拟变量回归模型的参数估计和统计检验实验方法、步骤和结果: 一、生成趋势变量 1、建立新的工作文件,导入数据并且重命名
2、点击quick,generateseries生成序列,t=@trend(1990:1)+1 2 并填写公式内蒙古科技大学 3、打开gDp,点击View,graph,line生成趋势图。 根据趋势图可以看出近似分段虚拟变量,需剔除季节的影响 3 内蒙古科技大学 二、生成季节虚拟变量 生成虚拟变量,点击quick----generateseries输入公式
D2=@seas(2)D3=@seas(3)D4=@seas(4) 三、生成分段虚拟变量 1、为了研究1997年金融危机对香港经济的影响,以1997年为分界点。设d5=0,将sample改为1990第一季度到1997年第四季度。 4 内蒙古科技大学 2、设d5=1,将sample改为1998年第一季度到20XX年第四季度。 四、建立虚拟变量回归模型 gDp^=?^1+?^2t+?^3d2t+?^4d3t+?^5d4t+?^6d5t+?^7d5t*t 五、虚拟变量回归模型的参数估计和统计检验点击quick,
第八章 虚拟变量回归 思考题
第八章 虚拟变量回归 思考题 8.1 什么是虚拟变量 ? 它在模型中有什么作用 ? 8.2 虚拟变量为何只选 0 、 1, 选 2 、 3 、 4 行吗 ? 为什么 ? 8.3 对 (8.10) 式的模型 , 如果选择一个虚拟变量 1,01D ?? =??-? 大专及大专以上,高中 ,高中以下 这样的设置方式隐含了什么假定 ? 这一假定合理吗 ? 8.4 引入虚拟解释变量的两种基本方式是什么 ? 它们各适用于什么情况 ? 8.5 四种加法方式引入虚拟变量会产生什么效应? 8.6 引入虚拟被解释变量的背景是什么?含有虚拟被解释变量模型的估计方法有哪些 ? 8.7 设服装消费函数为 12233t i i i i Y D D X u αααβ=++++ 其中, i X =收入水平 ;Y = 年服装消费支出 ; 1,30D ?=? ?大专及大学以上 ,其他 ;1,20D ?=??女性,其他 试写出不同人群组的服装消费函数模型。 8.8 利用月度数据资料 ,为了检验下面的假设,应引入多少个虚拟解释变量 ? 1) 一年里的 12 个月全部表现出季节模式 ; 2) 只有 2 月、 6 月、 8 月、 10 月和 12 月表现出季节模式。 练习题 8.1 1971 年 ,Sen 和 Sztvastava 在研究贫富国之间期望寿命的差异时 , 利用 101 个国家的数据 , 建立了如下回归模型 []? 2.409.39ln 3.36(ln 7)i i i i Y X D X =-+-- (4.37)(0.857)(2.42) R2=0.752 其中 ,X 是以美元计的人均收入 ;Y 是以年计的期望寿命 ; Sen 和 Srimstava 认为人均收入的临界值为 1097 美元 (ln1097=7), 若人均收入超过 1097 美元 , 则被认定为富国 ; 若人均收入低于1097美元 , 被认定为贫穷国。括号内的数值为对应参数估计值的t 值。 1) 解释这些计算结果。 2) 回归方程中引入(ln 7)i i D X =-的原因是什么?如何解释这个回归解释变量? 3) 如何对贫穷国进行回归 ? 又如何对富国进行回归 ? 4)这个回归结果中可得到的一般结论是什么 ?
Eviews虚拟变量实验报告
实验四虚拟变量 【实验目的】 掌握虚拟变量的基本原理,对虚拟变量的设定和模型的估计与检验,以及相关的Eviews操作方法。 【实验内容】 试根据1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立 【实验步骤】 1、相关图分析 根据表中数据建立人均收入X与彩电拥有量Y的相关图(SCAT X Y)。从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,
因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 2、构造虚拟变量 构造虚拟变量 1D (DATA D1),并生成新变量序列: GENR XD=X*D1 3、估计虚拟变量模型 LS Y C X D1 XD 得到估计结果:
我国城镇居民彩电需求函数的估计结果为: XD D X Y 009.0873.31012.0611.571-++=∧ (16.25) (9.03) (8.32) (-6.59) 366,066.1..,9937.02===F e s R 再由t 检验值判断虚拟变量的引入方式,并写出各类家庭的需求函数。 虚拟变量的回归系数的t 检验都是显著的,且模型的拟合优度很高,说明我国城镇居民低收入家庭与中高收入家庭对彩电的消费需求,在截距和斜率上都存在着明显差异,所以以加法和乘法方式引入虚拟变量是合理的。 低收入家庭与中高收入家庭各自的需求函数为: 低收入家庭: X Y 012.0611.57+=∧ 中高收入家庭: X X Y 003.0484.89)009.0012.0()873.31611.57(+=-++=∧ 由此可见我国城镇居民家庭现阶段彩电消费需求的特点: 对于人均年收入在3300元以下的低收入家庭,需求量随着收入水平的提高而快速上升,人均年收入每增加1000元,百户拥有量将平均增加12台;对于人均年收入在4100元以上的中高收入家庭,虽然需求量随着收入水平的提高也在增加,但增速趋缓,人均年收入每增加1000元,百户拥有量只增加3台。
回归分析方法及其应用中的例子
3.1.2 虚拟变量的应用 例3.1.2.1:为研究美国住房面积的需求,选用3120户家庭为建模样本,回归模型为: 123log log P Y βββ++logQ= 其中:Q ——3120个样本家庭的年住房面积(平方英尺) 横截面数据 P ——家庭所在地的住房单位价格 Y ——家庭收入 经计算:0.247log 0.96log P Y -+logy=4.17 2 0.371R = ()() () 上式中2β=0.247-的价格弹性系数,3β=0.96的收入弹性系数,均符合经济学的常识,即价格上升,住房需求下降,收入上升,住房需求也上升。 但白人家庭与黑人家庭对住房的需求量是不一样的,引进虚拟变量D : 01i D ?=?? 黑人家庭 白人家庭或其他家庭 模型为:112233log log log log D P D P Y D Y βαβαβα+++++logQ= 例3.1.2.2:某省农业生产资料购买力和农民货币收入数据如下:(单位:十亿元) ①根据上述数据建立一元线性回归方程:
? 1.01610.09357y x =+ 20.8821R = 0.2531y S = 67.3266F = ②带虚拟变量的回归模型,因1979年中国农村政策发生重大变化,引入虚拟变量来反映农村政策的变化。 01i D ?=?? 19791979i i <≥年 年 建立回归方程为: ?0.98550.06920.4945y x D =++ ()() () 20.9498R = 0.1751y S = 75.6895F = 虽然上述两个模型都可通过显着性水平检验,但可明显看出带虚拟变量的回归模型其方差解释系数更高,回归的估计误差(y S )更小,说明模型的拟合程度更高,代表性更好。 3.5.4 岭回归的举例说明 企业为用户提供的服务多种多样,那么在这些服务中哪些因素更为重要,各因素之间的重要性差异到底有多大,这些都是满意度研究需要首先解决的问题。国际上比较流行并被实践所验证,比较科学的方法就是利用回归分析确定客户对不同服务因素的需求程度,具体方法如下: 假设某电信运营商的服务界面包括了A1……Am 共M 个界面,那么各界面对总体服务满意度A 的影响可以通过以A 为因变量,以A1……Am 为自变量的回归分析,得出不同界面服务对总体A 的影响系数,从而确定各服务界面对A 的影响大小。 同样,A1服务界面可能会有A11……A1n 共N 个因素的影响,那么利用上述方法也可以计算出A11……A1n 对A1的不同影响系数,由此确定A1界面中的重要因素。 通过两个层次的分析,我们不仅得出各大服务界面对客户总体满意度影响的大小以及不同服务界面上各因素的影响程度,同时也可综合得出某一界面某一因素对总体满意度的影响大小,由此再结合用户满意度评价、与竞争对手的比较等因素来确定每个界面细分因素在以后工作改进中的轻重缓急、重要性差异等,从而起到事半功倍的作用。 例 3.5.4:对某地移动通信公司的服务满意度研究中,利用回归方法分析各服务界面对总体满意度的影响。 a. 直接进入法 显然,这种方法计算的结果中,C 界面不能通过显着性检验,直接利用分析结果是错误
计量经济学作用-虚拟变量回归
虚拟变量回归 实验目的:分析1965~1970年美国制造业利润和销售额,季度的关系。 实验要求:假定利润不仅与销售额有关,而且和季度因素有关 (1) 如果认为季度影响使利润平均值发生变异,应如何引入虚拟变量? (2) 如果认为季度影响使利润对销售额的变化率发生变异,应如何引入虚拟变 量? (3) 如果认为上诉两种情况都存在,又当如何引入虚拟变量? (4) 对上述三种情况分别估计利润模型,进行对比分析。 实验原理:最小二乘法原理 实验步骤: 由于有四个季度,因此引入三个季度虚拟变量: 其它一季度???=012D 其它二季度???=013D 其它三季度? ??=014D 一、如果认为季度影响使利润平均值发生变异,应以加法类型引入三个虚拟变量,设其模型为:u X D D D Y t t t +++++=βαααα4433221 对模型进行回归,得到以下回归结果: Dependent Variable: Y Method: Least Squares Date: 11/26/10 Time: 15:02 Sample: 1965Q1 1970Q4 Included observations: 24 Variable Coefficien t Std. Error t-Statistic Prob. C 6910.449 1922.350 3.594792 0.0019 X 0.038008 0.011670 3.256914 0.0041 D2 -187.7317 660.1218 -0.284390 0.7792 D3 1169.320 637.0766 1.835446 0.0821 D4 -417.1182 640.8333 -0.650900 0.5229 R-squared 0.517642 Mean dependent var 12838.54 Adjusted R-squared 0.416093 S.D. dependent var 1433.284 S.E. of regression 1095.227 Akaike info criterion 17.01836 Sum squared resid 22790932 Schwarz criterion 17.26379 Log likelihood -199.2204 F-statistic 5.097454 Durbin-Watson stat 0.396350 Prob(F-statistic) 0.005810 Y t ^=6910.449-187.7317D 2+1169.320D 3-417.1182D 4+0.038008X t Se=(1922.350) (660.1218) (637.0766) (640.8333) (0.011670)
计量经济学实验7虚拟变量模型
实验七虚拟变量 【实验目的】 掌握虚拟变量的设置方法。 【实验内容】 一、试根据表7-1的1998年我国城镇居民人均收入与彩电每百户拥有量的统计资料建立我国城镇居民彩电需求函数; 资料来源:据《中国统计年鉴1999》整理计算得到 二、试建立我国税收预测模型(数据见实验一); 三、试根据表7-2的资料用混合样本数据建立我国城镇居民消费函数。
最低收入户 2397.6 2476.75 0 2523.1 2617.8 1 低收入户 2979.27 3303.17 0 3137.34 3492.27 1 中等偏下户 3503.24 4107.26 0 3694.46 4363.78 1 中等收入户 4179.64 5118.99 0 4432.48 5512.12 1 中等偏上户 4980.88 6370.59 0 5347.09 6904.96 1 高收入户 6003.21 7877.69 0 6443.33 8631.94 1 最高收入户 7593.95 10962.16 8262.42 12083.79 1 资料来源:据《中国统计年鉴》1999-2000整理计算得到 【实验步骤】 一、我国城镇居民彩电需求函数 ⒈相关图分析; 键入命令:SCAT X Y ,则人均收入与彩电拥有量的相关图如7-1所示。 从相关图可以看出,前3个样本点(即低收入家庭)与后5个样本点(中、高收入)的拥有量存在较大差异,因此,为了反映“收入层次”这一定性因素的影响,设置虚拟变量如下: ?? ?=低收入家庭 中、高收入家庭 1D 图7-1 我国城镇居民人均收入与彩电拥有量相关图 ⒉构造虚拟变量; 方式1:使用DATA 命令直接输入;
虚拟变量的分析
虚拟变量(dummy variable ) 在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。这些因素也应该包括在模型中。 由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。这种变量称作虚拟变量,用D 表示。虚拟变量应用于模型中,对其回归系数的估计与检验方法与定量变量相同。 1.截距移动 设有模型, y t = β0 + β1 x t + β2D + u t , 其中y t ,x t 为定量变量;D 为定性变量。当D = 0 或1时,上述模型可表达为, y t =?? ?=+++=++1 )(012010D u x D u x t t t t βββββ 020 40 60 20 40 60 X Y 图8.1 测量截距不同 D = 1或0表示某种特征的有无。反映在数学上是截距不同的两个函数。若β2显著不为零,说明截距不同;若β2为零,说明这种分类无显著性差异。 例:中国成年人体重y (kg )与身高x (cm )的回归关系如下: –105 + x D = 1 (男) y = - 100 + x - 5D = – 100 + x D = 0 (女) 注意: ① 若定性变量含有m 个类别,应引入m -1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummy variable trap )。 ② 关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。 ③ 定性变量中取值为0所对应的类别称作基础类别(base category )。 ④ 对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。如: 1 (大学) D = 0 (中学) -1 (小学)。 β0 β0+β2 D = 1 D =0
实验五七虚拟变量回归分析
第七章虚拟变量回归分析 姓名:耿肃竹学号:20136878 班级:经济1302 【实验目的】目的在于学习基本的经济计量方法并利用Stata对经济中典型的数据,掌握虚拟变量的分析思路,掌握虚拟变量回归的基本操作方法,掌握虚拟变量回归的结果分析。 【实验软件】Stata是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。该软件提供的功能包含线性混合模型、均衡重复反复及多项式普罗比模式。作为流行的计量经济学软件,Stata的功能十分地全面和强大。可以毫不夸张地说,凡是成熟的计量经济学方法,在Stata中都可以找到相应的命令,而这些命令都有许多选项以适应不同的环境或满足不同的需要。【实验要求】利用stata软件学习多元回归分析的应用问题,并在回归结果中学会以下命令的使用对类型变量B生成虚拟变量Atabulate B, gen(A);对包含虚拟变量的情况进行回归regress y x1 x2…A2 A3…等命令。学会虚拟变量在回归分析中的应用进行有效分析,学以致用。 【实验内容】教材P213——C2 题目【1】C2 (Ⅰ)输入命令“regress lwage educ exper tenure married black south urban”:
解: log(wage)=5.395497+0.0654307educ+0.014043exper+0.0117473tenure (0.113225) (0.0062504) (0.0031852) (0.002453) +0.1994171married-0.1883499black-0.0909036south+0.1839121urban (0.0390502) (0.0376666) (0.0262485) (0.0269583) n=935 R2=0.2526 保持其他因素不变,黑人和非黑人之间的月薪差异近似(约等于)为0.1883499,因为P=0,所以这个差异是统计显著的。 (Ⅱ)输入命令”g e n e rate e x pe r sq=e x p e r*e x p e r”“ge n e rate tenuresq=tenure*tenure”“regress lwage educ expertenure married black a o u t h u r b a n e x p e r a q”: