基于聚类分析的非参数回归短时交通流预测方法

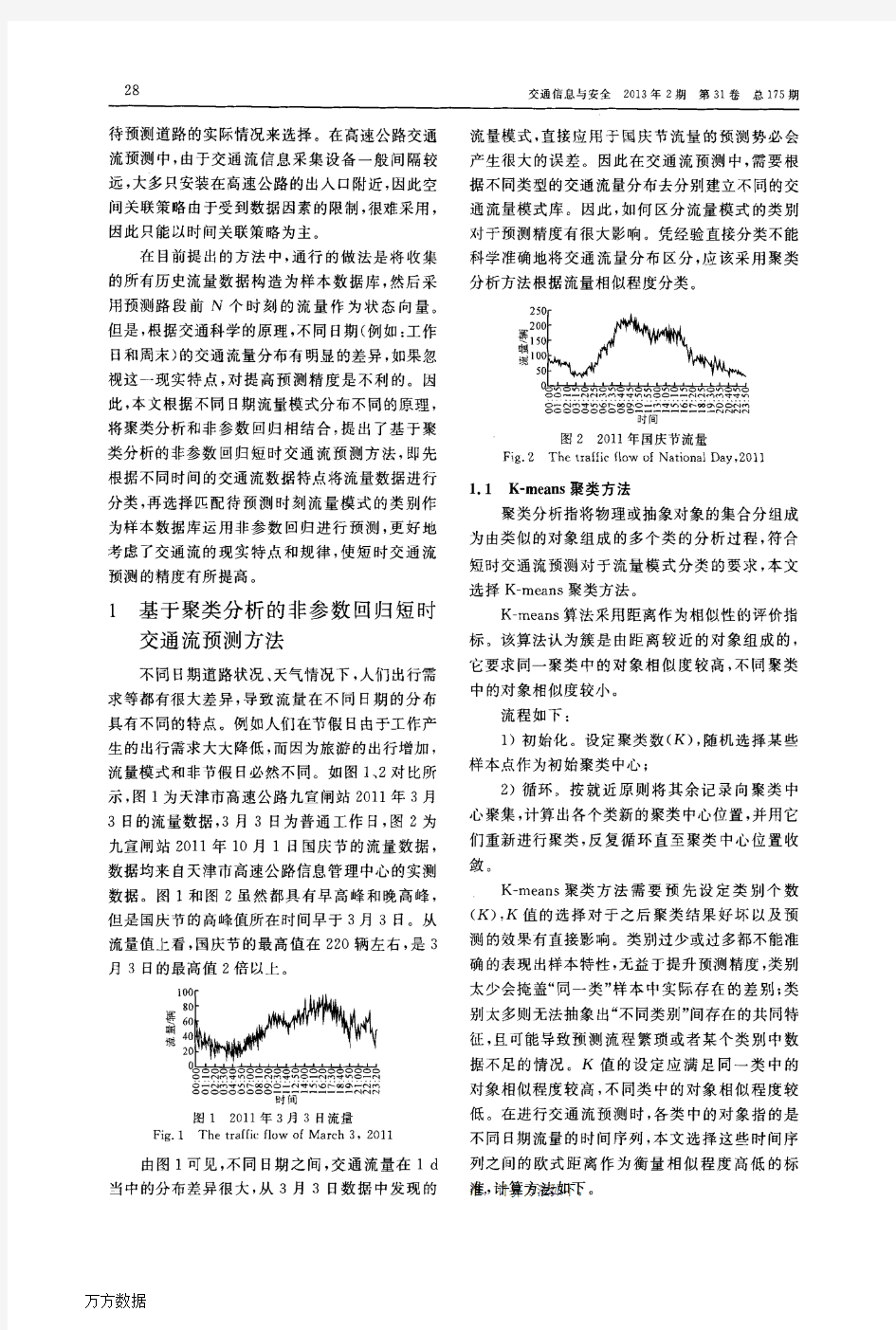
基于聚类分析的非参数回归短时交通流预测方法
作者:刘洋, 马寿峰, LIU Yang, MA Shoufeng
作者单位:天津大学管理与经济学部 天津300072
刊名:
交通信息与安全
英文刊名:Journal of Transport Information and Safety
年,卷(期):2013,31(2)
参考文献(13条)
1.贺国光;李宇;马寿峰基于数学模型的短时交通流预测方法探讨 2000(12)
2.韩超;宋 苏;王成红基于ARIMA模型的短时交通流实时自适应预测 2004(07)
3.张晓利基于小波分析与神经网络的交通流短时预测方法 2007(04)
4.高为;陆百川;贠天鹂基于时空特性和RBF神经网络的短时交通流预测 2011(01)
5.石永辉;鲍俊;严忠贞混合智能算法在城市道路短时交通流量预测中的研究 2011(04)
6.宫晓燕;汤淑明基于非参数回归的短时交通流量预测与事件检测综合算法 2003(01)
7.张涛;陈先;谢美萍基于K近邻非参数回归的短时交通流预测方法 2010(02)
8.贠天鹂;李淑庆;高 为基于过程神经元网络与遗传算法的交通流预测 2010(05)
9.张敬磊;王晓原基于非线性组合模型的交通流预测方法 2010(05)
10.Smith B L Traffic flow forecasting:comparison of modeling approaches 1997(123)
11.王晓原;吴磊;张开旺非参数小波算法的交通流预测方法 2005(10)
12.贾 宁;马寿峰;钟石泉基于遗传算法优化和KD树的交通流非参数回归预测方法 2012(07)
13.钱海峰;陈阳舟;李振龙核函数法与最邻近法在短时交通流预测应用中的对比研究 2008(06)本文链接:https://www.360docs.net/doc/dd1879030.html,/Periodical_jtyjsj201302007.aspx
相关分析与回归分析的异同
问:请详细说明相关分析与回归分析的相同与不同之处 相关分析与回归分析都是研究变量相互关系的分析方法,相关分析是回归分析的基础,而回归分析则是认识变量之间相关程度的具体形式。 下面分为三个部分详细描述两种分析方法的异同: 第一部分:相关分析 一、相关的含义与种类 (一)相关的含义 相关是指自然与社会现象等客观现象数量关系的一种表现。 相关关系是指现象之间确实存在的一定的联系,但数量关系表现为不严格相互依存关系。即对一个变量或几个变量定一定值时,另一变量值表现为在一定范围内随机波动,具有非确定性。如:产品销售收入与广告费用之间的关系。 (二)相关的种类 1. 根据自变量的多少划分,可分为单相关和复相关 2. 根据相关关系的方向划分,可分为正相关和负相关 3. 根据变量间相互关系的表现形式划分,线性相关和非线性相关 4.根据相关关系的程度划分,可分为不相关、完全相关和不完全相关 二、相关分析的意义与内容 (一)相关分析的意义 相关分析是研究变量之间关系的紧密程度,并用相关系数或指数来表示。其目的是揭示现象之间是否存在相关关系,确定相关关系的表现形式以及确定现象变量间相关关系的密切程度和方向。 (二)相关分析的内容 1. 明确客观事物之间是否存在相关关系 2. 确定相关关系的性质、方向与密切程度 三、直线相关的测定 (一)相关表与相关图 1. 相关表 在定性判断的基础上,把具有相关关系的两个量的具体数值按照一定顺序平行排列在一张表上,以观察它们之间的相互关系,这种表就称为相关表。 2. 相关图
把相关表上一一对应的具体数值在直角坐标系中用点标出来而形成的散点图则称为相关图。利用相关图和相关表,可以更直观、更形象地表现变量之间的相互关系。 (二)相关系数 1. 相关系数的含义与计算 相关系数是直线相关条件下说明两个变量之间相关关系密切程度的统计分析指标。相关系数的理论公式为: y x xy r δδδ2= (1)xy 2δ 协方差 x δ x 的标准差 y δ y 的标准差 (2)xy 2δ 协方差对相关系数r 的影响,决定:???<>数值的大小正、负)或r r r (00 简化式 ()()2222∑∑∑∑∑∑∑-?--= y y n x x n y x xy n r 变形:分子分母同时除以2 n 得 r =???????????? ??-???????????? ??-?-∑∑∑∑∑∑∑2222n y n y n x n x n y n x n xy =()[]()[]2222y y x x y x xy -*-?-=y x y x xy δδ-?- n x x x ∑-=2)(δ=()[]n x x x x ∑+?-222=()222x n x x n x +??-∑∑ = () 22x x - 2. 相关系数的性质
空间聚类的研究现状及其应用_戴晓燕
空间聚类的研究现状及其应用* 戴晓燕1 过仲阳1 李勤奋2 吴健平1 (1华东师范大学教育部地球信息科学实验室 上海 200062) (2上海市地质调查研究院 上海 200072) 摘 要 作为空间数据挖掘的一种重要手段,空间聚类目前已在许多领域得到了应用。文章在对已有空间聚类分析方法概括和总结的基础上,结合国家卫星气象中心高分辨率有限区域分析预报系统产品中的数值格点预报(HLAFS)值,运用K-均值法对影响青藏高原上中尺度对流系统(MCS)移动的散度场进行了研究,得到了一些有意义的结论。 关键词 空间聚类 K-均值法 散度 1 前言 随着GPS、GI S和遥感技术的应用和发展,大量的与空间有关的数据正在快速增长。然而,尽管数据库技术可以实现对空间数据的输入、编辑、统计分析以及查询处理,但是无法发现隐藏在这些大型数据库中有价值的模式和模型。而空间数据挖掘可以提取空间数据库中隐含的知识、空间关系或其他有意义的模式等[1]。这些模式的挖掘主要包括特征规则、差异规则、关联规则、分类规则及聚类规则等,特别是聚类规则,在空间数据的特征提取中起到了极其重要的作用。 空间聚类是指将数据对象集分组成为由类似的对象组成的簇,这样在同一簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大,即相异度较大。作为一种非监督学习方法,空间聚类不依赖于预先定义的类和带类标号的训练实例。由于空间数据库中包含了大量与空间有关的数据,这些数据来自不同的应用领域。例如,土地利用、居住类型的空间分布、商业区位分布等。因此,根据数据库中的数据,运用空间聚类来提取不同领域的分布特征,是空间数据挖掘的一个重要部分。 空间聚类方法通常可以分为四大类:划分法、层次法、基于密度的方法和基于网格的方法。算法的选择取决于应用目的,例如商业区位分析要求距离总和最小,通常用K-均值法或K-中心点法;而对于栅格数据分析和图像识别,基于密度的算法更合适。此外,算法的速度、聚类质量以及数据的特征,包括数据的维数、噪声的数量等因素都影响到算法的选择[2]。 本文在对已有空间聚类分析方法概括和总结的基础上,结合国家卫星气象中心高分辨率有限区域分析预报系统产品中的数值格点预报(HLAFS)值,运用K-均值法对影响青藏高原上中尺度对流系统(MCS)移动的散度场进行了研究,得到了一些有意义的结论。 2 划分法 设在d维空间中,给定n个数据对象的集合D 和参数K,运用划分法进行聚类时,首先将数据对象分成K个簇,使得每个对象对于簇中心或簇分布的偏离总和最小[2]。聚类过程中,通常用相似度函数来计算某个点的偏离。常用的划分方法有K-均值(K-means)法和K-中心(K-medoids)法,但它们仅适合中、小型数据库的情形。为了获取大型数据库中数据的聚类体,人们对上述方法进行了改进,提出了K-原型法(K-prototypes method)、期望最大法EM(Expectation Maximization)、基于随机搜索的方法(ClAR ANS)等。 K-均值法[3]根据簇中数据对象的平均值来计算 ——————————————— *基金项目:国家自然科学基金资助。(资助号: 40371080) 收稿日期:2003-7-11 第一作者简介:戴晓燕,女,1979年生,华东师范大学 地理系硕士研究生,主要从事空间数 据挖掘的研究。 · 41 · 2003年第4期 上海地质 Shanghai Geology
SPSS聚类分析和判别分析论文
S P S S聚类分析和判别分析 论文 Prepared on 22 November 2020
基于聚类分析的我国城镇居民消费结构实证分析摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示),对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和服务八项指标,分别用来反映较高、中等、较低居民消费结构。
回归分析方法及其应用中的例子
3.1.2 虚拟变量的应用 例3.1.2.1:为研究美国住房面积的需求,选用3120户家庭为建模样本,回归模型为: 123log log P Y βββ++logQ= 其中:Q ——3120个样本家庭的年住房面积(平方英尺) 横截面数据 P ——家庭所在地的住房单位价格 Y ——家庭收入 经计算:0.247log 0.96log P Y -+logy=4.17 2 0.371R = ()() () 上式中2β=0.247-的价格弹性系数,3β=0.96的收入弹性系数,均符合经济学的常识,即价格上升,住房需求下降,收入上升,住房需求也上升。 但白人家庭与黑人家庭对住房的需求量是不一样的,引进虚拟变量D : 01i D ?=?? 黑人家庭 白人家庭或其他家庭 模型为:112233log log log log D P D P Y D Y βαβαβα+++++logQ= 例3.1.2.2:某省农业生产资料购买力和农民货币收入数据如下:(单位:十亿元) ①根据上述数据建立一元线性回归方程:
? 1.01610.09357y x =+ 20.8821R = 0.2531y S = 67.3266F = ②带虚拟变量的回归模型,因1979年中国农村政策发生重大变化,引入虚拟变量来反映农村政策的变化。 01i D ?=?? 19791979i i <≥年 年 建立回归方程为: ?0.98550.06920.4945y x D =++ ()() () 20.9498R = 0.1751y S = 75.6895F = 虽然上述两个模型都可通过显着性水平检验,但可明显看出带虚拟变量的回归模型其方差解释系数更高,回归的估计误差(y S )更小,说明模型的拟合程度更高,代表性更好。 3.5.4 岭回归的举例说明 企业为用户提供的服务多种多样,那么在这些服务中哪些因素更为重要,各因素之间的重要性差异到底有多大,这些都是满意度研究需要首先解决的问题。国际上比较流行并被实践所验证,比较科学的方法就是利用回归分析确定客户对不同服务因素的需求程度,具体方法如下: 假设某电信运营商的服务界面包括了A1……Am 共M 个界面,那么各界面对总体服务满意度A 的影响可以通过以A 为因变量,以A1……Am 为自变量的回归分析,得出不同界面服务对总体A 的影响系数,从而确定各服务界面对A 的影响大小。 同样,A1服务界面可能会有A11……A1n 共N 个因素的影响,那么利用上述方法也可以计算出A11……A1n 对A1的不同影响系数,由此确定A1界面中的重要因素。 通过两个层次的分析,我们不仅得出各大服务界面对客户总体满意度影响的大小以及不同服务界面上各因素的影响程度,同时也可综合得出某一界面某一因素对总体满意度的影响大小,由此再结合用户满意度评价、与竞争对手的比较等因素来确定每个界面细分因素在以后工作改进中的轻重缓急、重要性差异等,从而起到事半功倍的作用。 例 3.5.4:对某地移动通信公司的服务满意度研究中,利用回归方法分析各服务界面对总体满意度的影响。 a. 直接进入法 显然,这种方法计算的结果中,C 界面不能通过显着性检验,直接利用分析结果是错误
Mann-Kendall法(非参数检验方法)程序
Mann-Kendall法(非参数检验方法)程序 统计知识2009-02-02 13:47:51 阅读986 评论1 字号:大中小订阅 Mann-Kendall法(非参数检验方法)用于气候突变检测 program main implicit none c This is a program for testing climate jump i by use of c 'Mann-Kendall test'. c------------------------------------------------- integer,parameter :: iy=100 integer i real x(iy),u1(iy),u2(iy) c-------Read Data c------- open(31,file='d: mk.txt ',form='formatted') do i=1,50 x(i)=0.5 x(i+50)=-0.5 end do c-------Mann-Kendall test method call MKtest (iy,x,u1,u2) c------ do i=1,iy write(31,10)i,x(i),u1(i),u2(i) end do 10 format(1x,i4,4f8.2) stop end !c------------------------------------------------------------------ subroutine MKtest(m,x,u1,u2) dimension x(m),u1(m),u2(m) dimension xr(m),ur(m) !work array do i=1,m xr(i)=x(m+1-i) end do call MKrank(m,x,u1) call MKrank(m,xr,ur) do i=1,m u2(i)=-ur(m+1-i) enddo return end !c------------------------------------------------------------------
肤色在各颜色空间的聚类分析
肤色在各颜色空间的聚类分析 摘要肤色是人体表面最显著的特征之一。对不同肤色在RGB、YCbCr颜色空间内和同一肤色在不同亮度环境下的聚类情况进行深入的分析研究,发现肤色在YCbCr空间内聚类效果更好,更适合做肤色分割。然后在此基础上对黑色肤色、黄色肤色及白色肤色在YCbCr空间内进行肤色分割,达到较好的分割效果。 关键词肤色;颜色空间;肤色分割;YCbCr空间 肤色是人体表面最显著的特征之一,由于它对姿势、旋转、表情等变化不敏感,因此将人体的肤色特征应用于人脸检测与识别、表情识别、手势识别具有很大的优势,所以肤色特征是人脸识别、表情识别、与手势识别中最为常用的分割方法。然而,若要利用肤色进行分割,我们首先应该对肤色以及肤色的聚类情况进行分析。 世界上的人种主要有三种,即尼格罗—澳大利亚人种(黑色皮肤),蒙古人种(黄色皮肤),欧罗巴人种(白色皮肤)。尽管人的肤色因人种的不同而不同,呈现出不同的颜色,但是有学者指出:排除亮度、周围环境等对肤色的影响后,皮肤的色调基本一致。本文对在不同环境下的不同肤色进行取样,然后分别在RGB、YCbCr颜色空间进行统计,从而对比分析肤色在各颜色空间聚类的情况。 1肤色在各颜色空间的聚类比较 1.1不同肤色在RGB和YCbCr颜色空间上的分布 图1—图2给出了黄色、黑色和白色肤色分别在RGB、YCbcr空间的分布情况。 由图1—图2可以得出,不同肤色在RGB、YCbCr空间的分布有如下特征: 1)不同肤色在不同颜色空间均分布在很小的范围内。 2)不同肤色在不同颜色空间内不是随机分布,而是在某固定区域呈聚类分布。 3)不同肤色在YCbCr空间内分布的聚类状态要好于在RGB空间内分布的聚类状态。 4)不同肤色在亮度上的差异远远高于在色度上的差异。 1.2肤色在不同亮度下的分布 图3—图4给出了不同亮度下的同一肤色分别在RGB、YCbCr空间的分布情况。图(a)至图(d)的肤色来源于同一人在不同亮度下的照片。
第七章 spss非参数估计
第七章非参数检验 1、为分析不同年龄段人群对某商品满意程度的异同,进行随机调查收集到以下数据:请选择恰当的非参数检验方法,以恰当形式组织上述数据,分析不同年龄段人群对该商品满意程度的分布状况是否一致。 原假设:不同年龄段人群对该商品满意程度的分布无显著差异。 步骤:建立SPSS数据数据→加权个案→对频次进行加权→分析→非参数检验→旧对话框→两个独立样本→把年龄段导入分组变量、满意程度导入检验变量列表→确定 表7-1 检验统计量a 满意程度 最极端差别绝对值.121 正.121 负.000 Kolmogorov-Smirnov Z 2.217 渐近显著性(双侧) .000 a. 分组变量: 年龄段 分析:从上表中可以看出,在显著水平为0.05下得到的sig值均为0.00<0.05,故拒绝原假设,即认为不同年龄段人群对该商品满意程度的分布存在显著差异。 2、利用习题二第6题数据,选择恰当的非参数检验方法,分析本次存款金额的总体分布与正态分布是否存在显著差异。 原假设:本次存款金额的总体分布与正态分布无显著差异 步骤:分析→非参数检验→旧对话框→单个独立样本K-S检验→本次存款金额导入检验变量列表→正太分布检验→确定 表7-2 单样本 Kolmogorov-Smirnov 检验 本次存款金额 N 282 正态参数a,b均值4738.09 标准差10945.569 最极端差别绝对值.333 正.292 负-.333 Kolmogorov-Smirnov Z 5.585 渐近显著性(双侧) .000 a. 检验分布为正态分布。 b. 根据数据计算得到。 分析:如上表,在显著水平为0.05下得到的sig值均为0.00<0.05,故拒绝原假设,认为本次存款金额的分布与正太分布有显著差异。 3、利用习题二第6题数据,选择恰当的非参数检验方法,分析不同常住地人群本次存款金
数学建模模拟题,图论,回归模型,聚类分析,因子分析等 (48)
第11章第2题 摘要 本题分析4 种化肥和3 个小麦品种对小麦产量的影响,以及二者交互作用对小麦产量的影响,可视为两因素方差分析,即化肥和小麦品种两个因素,4种化肥可看作是化肥的四个不同水平,3个小麦品种也可以看作是小麦品种的三个不同水平。 试验的目的是分析化肥的四个不同水平以及小麦品种的三个不同水平对小麦产量有无显着性影响。 关键词:方差分析显着性化肥种类小麦品种
一.问题重述 为了分析4 种化肥和3 个小麦品种对小麦产量的影响,把一块试验田等分成36个小块,分别对3种种子和四种化肥的每一种组合种植3 小块田,产量如表1所示(单位公斤),问不同品种、不同种类的化肥及二者的交互作用对小麦产量有无显着影响。 二.问题分析 本题意在分析四种化肥和三种小麦品种对小麦产量的影响,以及二者交互作用对小麦产量的影响,为两因素方差分析问题,即化肥和小麦品种两个因素,4种化肥可看作是化肥的四个不同水平,3个小麦品种也可以看作是小麦品种的三个不同水平。通过对这两种因素的不同水平及交互作用的分析,从而分析 4 种化肥和3 个小麦品种对小麦产量的影响。 三.模型假设 1.假设只有化肥种类和小麦品种两个因素,其他因素对试验结果不构成影响。 2.假设不存在数据记录错误。 3.假设每一块试验田本身各项指标相同,不会影响结果。 四.符号说明 数字1,2,3,4——不同的化肥种类 数字1,2,3——不同的小麦品种 五.模型建立 将化肥种类和小麦品种视为两个因素,四种化肥种类看作是化肥种类的四个不同水平,三个小麦品种看作是小麦品种的三个不同水平,将表1的数据进行整理,如表2所示。
六.模型求解 将表2数据导入到spss软件中,进行两因素方差检验,得到结果如下:表3
非参数统计分析方法总结
非参数统计分析方法 一单样本问题 1,二项式检验:检验样本参数是否与整体参数有什么关系。 样本量为n,给定一个实数M0(代表题目给出的分位点数),和分位点∏(0.25,0.5,0.75)。用S-记做样本中比M0小的数的个数,S+记做样本中比M0大的数的个数。如果原假设H0成立那么S-与n的比之应为∏。 H0:M=M0 H1:M≠MO或者M>M0或者M 长度长) Spss步骤:分析—非参数检验—游程 得出统计量R和p值 当p值小于0.05时拒绝原假设,没有充足理由证明该数据出现是随机的 二,两个样本位置问题 1,Brown—Mood中位数检验 给出两个样本比较两个样本的中位数或者四分位数等是否相等或者有一定关系,设一个中值为M1,一个为M2 H0:M1=M2. H1:M1≠M2或者M1>M2或者M1 第六章 相关与回归分析方法 第一部分 习题 一、单项选择题 1.单位产品成本与其产量的相关;单位产品成本与单位产品原材料消耗量的相关 ( )。 A.前者是正相关,后者是负相关 B.前者是负相关,后者是正相关 C.两者都是正相关 D.两者都是负相关 2.样本相关系数r 的取值范围( )。 A.-∞<r <+∞ B.-1≤r ≤1 C. -l <r <1 D. 0≤r ≤1 3.当所有观测值都落在回归直线 01y x ββ=+上,则x 与y 之间的相关系数( )。 A.r =0 B.r =1 C.r =-1 D.|r|=1 4.相关分析与回归分析,在是否需要确定自变量和因变量的问题上( )。 A.前者无需确定,后者需要确定 B.前者需要确定,后者无需确定 C.两者均需确定 D.两者都无需确定 5.直线相关系数的绝对值接近1时,说明两变量相关关系的密切程度是( )。 A.完全相关 B.微弱相关 C.无线性相关 D.高度相关 6.年劳动生产率x(千元)和工人工资y(元)之间的回归方程为y=10+70x ,这意味着年劳动生产率每提高1千元时,工人工资平均( )。 A.增加70元 B.减少70元 C.增加80元 D.减少80元 7.下面的几个式子中,错误的是( )。 A. y= -40-1.6x r=0.89 B. y= -5-3.8x r =-0.94 C. y=36-2.4x r =-0.96 D. y= -36+3.8x r =0.98 8.下列关系中,属于正相关关系的有( )。 A.合理限度内,施肥量和平均单产量之间的关系 B.产品产量与单位产品成本之间的关系 C.商品的流通费用与销售利润之间的关系 D.流通费用率与商品销售量之间的关系 9.直线相关分析与直线回归分析的联系表现为( )。 A.相关分析是回归分析的基础 B.回归分析是相关分析的基础 C.相关分析是回归分析的深入 D.相关分析与回归分析互为条件 10.进行相关分析,要求相关的两个变量( )。 A.都是随机的 B.都不是随机的 C.一个是随机的,一个不是随机的 D.随机或不随机都可以 11.相关关系的主要特征是( )。 A.某一现象的标志与另外的标志之间存在着确定的依存关系 B.某一现象的标志与另外的标志之间存在着一定的关系,但它们不是确定的关系 C.某一现象的标志与另外的标志之间存在着严重的依存关系 D.某一现象的标志与另外的标志之间存在着函数关系 12.相关分析是研究( )。 A.变量之间的数量关系 B.变量之间的变动关系 C.变量之间相互关系的密切程度 D.变量之间的因果关系 13.现象之间相互依存关系的程度越低,则相关系数( )。 A.越接近于0 B.越接近于-1 C.越接近于1 D.越接近于0.5 14.在回归直线01y x ββ=+中,若10 β<,则x 与y 之间的相关系数( )。 A. r=0 B. r=1 C. 0<r <1 D. —l <r <0 15.当相关系数r=0时,表明( )。 A.现象之间完全无关 B.相关程度较小 北京建筑工程学院 理学院信息与计算科学专业实验报告 课程名称《数据分析》实验名称《主成分分析和聚类分析》实验地点:基础楼C-423日期__2016.5.5_____ 姓名张丽芝班级信131 学号201307010108___指导教师王恒友成绩 (1)熟悉利用主成分分析进行数据分析,能够使用SPSS软件完成数据的主成分分析; (2)熟悉利用聚类分析进行数据分析,能够运用主成分分析的结果,做进一步分析,如聚类分析、回归分析等,能够使用SPSS软件完成该任务。 【实验要求】 根据各个题目的具体要求,分别运用SPSS软件完成实验任务。 【实验内容】 1、表4.9(数据见exercise4_5.txt)给出了1991年我国30个省市、城镇居民的月平均 消费数据,所考察的八个指标如下:(单位均为元/人) X1: 人均粮食支出; X2:人均副食支出; X3: 人均烟酒茶支出; X4: 人均其他副食支出; X5:人均衣着商品支出; X6: 人均日用品支出; X7: 人均燃料支出; X8: 人均非商品支出。 (1)求样本相关系数矩阵R。 (2)从R出发做主成分分析,求出各主成分的贡献率及前两个主成分的累积贡献率; 2、(1)对题1中的数据,按照原有的八个指标,对30个省份进行聚类,给出分为3类的聚类结果。 (2)利用题1得到的前2个主成分指标,分别按最短距离法(最近邻居距离)、最长距离法(最远邻居距离)、类平均距离法(组间平均距离)、重心距离法;其中距离均采用欧式平方距离,对样本进行谱系聚类分析,并画出谱系聚类图;给出分为3类的聚类结果。并与(1)的结果进行比较 【实验步骤】(此部分主要包括实验过程、方法、结果、对结果的分析、结论等) 1 1) 非参数估计方法:能处理任意的概率分布,而不必假设密度函数的形式已知。直接用已知类别的样本去估计总体密度分布。 我采用的数据是UCI数据库中的联合循环电厂数据集,包含9568个样本。该电厂每小时输出的电能由周围的温度(T),数据范围是从1.81到37.11;环境压力(AP),数据范围从992.89到1033.30;相对湿度(RH),数据范围从25.56到100.16;抽真空(V),数据范围从25.36到81.56四个属性决定。 我采用了Matlab中的princomp()函数对数据进行降维,得出的第一个主成分的贡献率是70.6217%,第二个主成分的贡献率为22.0507%。按照理论来说,应该选择前两个主成分,也就是二维的数据,因为前两个主成分的累积贡献率达到百分之九十多。但是由于数据样本数太多,如果选择二维数据的话,Matlab运行时间太长,所以我选择了贡献率为70.6217%的一维数据,数据范围从393.2851到495.7022。 1.给出一组统计数据,绘制出它的概率分布曲线,matlab的统计工具箱中有直接的函数,就是:Ksdensity 核心平滑密度估计 [f,xi] = ksdensity(x) 计算样本向量x的概率密度估计,返回在xi点的概率密度f,此时我们使用plot(xi,f)就可以绘制出概率密度曲线。 我所采用的数据的真实的概率密度曲线如图 . 2.用方窗进行估计,我选择的样本个数分别为1、200和6000,分别在窗长度为0.25、1和4 三种情况下进行了估计和比较,仿真结果如图所示。 由仿真结果可以看出:当N=1时,概率密度曲线是一个以第一个样本为中心的长方形,与窗函数差不多;当N=200及N=6000时,当h=0.25时,曲线起伏较大,噪声较大,当h=1时,曲线起伏减小,在h=4的情况下,曲线趋于平坦。尤其在N=6000时,曲线接近数据真实的概率密度曲线。 3. 用正态窗进行估计,我选择的样本个数分别为1、200和6000,分别在窗长度为0.25、1和20三种情况下进行了估计和比较,仿真结果如图所示。 回归分析与相关分析联系、区别?? 简单线性回归分析是对两个具有线性关系的变量,研究其相关性,配合线性回归方程,并根据自变量的变动来推算和预测因变量平均发展趋势的方法。 回归分析(Regression analysis)通过一个变量或一些变量的变化解释另一变量的变化。 主要内容和步骤:首先依据经济学理论并且通过对问题的分析判断,将变量分为自变量和因变量,一般情况下,自变量表示原因,因变量表示结果;其次,设法找出合适的数学方程式(即回归模型)描述变量间的关系;接着要估计模型的参数,得出样本回归方程;由于涉及到的变量具有不确定性,接着还要对回归模型进行统计检验,计量经济学检验、预测检验;当所有检验通过后,就可以应用回归模型了。 回归的种类 回归按照自变量的个数划分为一元回归和多元回归。只有一个自变量的回归叫一元回归,有两个或两个以上自变量的回归叫多元回归。 按照回归曲线的形态划分,有线性(直线)回归和非线性(曲线)回归。 相关分析与回归分析的关系 (一)相关分析与回归分析的联系 相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。 (二)相关分析与回归分析的区别 1.相关分析中涉及的变量不存在自变量和因变量的划分问题,变量之间的关系是对等的;而在回归分析中,则必须根据研究对象的性质和研究分析的目的,对变量进行自变量和因变量的划分。因此,在回归分析中,变量之间的关系是不对等的。 2.在相关分析中所有的变量都必须是随机变量;而在回归分析中,自变量是确定的,因变量才是随机的,即将自变量的给定值代入回归方程后,所得到的因变量的估计值不是唯一确定的,而会表现出一定的随机波动性。 3.相关分析主要是通过一个指标即相关系数来反映变量之间相关程度的大小,由于变量之间是对等的,因此相关系数是唯一确定的。而在回归分析中,对于互为因果的两个变量(如人的身高与体重,商品的价格与需求量),则有可能存在多个回归方程。 需要指出的是,变量之间是否存在“真实相关”,是由变量之间的内在联系所决定的。相关分析和回归分析只是定量分析的手段,通过相关分析和回归分析,虽然可以从数量上反映变量之间的联系形式及其密切程度,但是无法准确判断变量之间内在联系的存在与否,也无法判断变量之间的因果关系。因此,在具体应用过程中,一定要注意把定性分析和定量分析结合起来,在定性分析的基础上展开定量分析。 你应该要掌握的7种回归分析方法 标签:机器学习回归分析 2015-08-24 11:29 4749人阅读评论(0) 收藏举报 分类: 机器学习(5) 目录(?)[+] :原文:7 Types of Regression Techniques you should know!(译者/帝伟审校/翔宇、朱正贵责编/周建丁) 什么是回归分析? 回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。 回归分析是建模和分析数据的重要工具。在这里,我们使用曲线/线来拟合这些数据点,在这种方式下,从曲线或线到数据点的距离差异最小。我会在接下来的部分详细解释这一点。 我们为什么使用回归分析? 如上所述,回归分析估计了两个或多个变量之间的关系。下面,让我们举一个简单的例子来理解它: 比如说,在当前的经济条件下,你要估计一家公司的销售额增长情况。现在,你有公司最新的数据,这些数据显示出销售额增长大约是经济增长的2.5倍。那么使用回归分析,我们就可以根据当前和过去的信息来预测未来公司的销售情况。 使用回归分析的好处良多。具体如下: 1.它表明自变量和因变量之间的显著关系; 2.它表明多个自变量对一个因变量的影响强度。 回归分析也允许我们去比较那些衡量不同尺度的变量之间的相互影响,如价格变动与促销活动数量之间联系。这些有利于帮助市场研究人员,数据分析人员以及数据科学家排除并估计出一组最佳的变量,用来构建预测模型。 我们有多少种回归技术? 有各种各样的回归技术用于预测。这些技术主要有三个度量(自变量的个数,因变量的类型以及回归线的形状)。我们将在下面的部分详细讨论它们。 对于那些有创意的人,如果你觉得有必要使用上面这些参数的一个组合,你甚至可以创造出一个没有被使用过的回归模型。但在你开始之前,先了解如下最常用的回归方法: 1.Linear Regression线性回归 它是最为人熟知的建模技术之一。线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。 判别分析(Discriminant Analysis) 一、概述: 判别问题又称识别问题,或者归类问题。 判别分析是由Pearson于1921年提出,1936年由Fisher首先提出根据不同类别所提取的特征变量来定量的建立待判样品归属于哪一个已知类别的数学模型。 根据对训练样本的观测值建立判别函数,借助判别函数式判断未知类别的个体。 所谓训练样本由已知明确类别的个体组成,并且都完整准确地测量个体的有关的判别变量。 训练样本的要求:类别明确,测量指标完整准确。一般样本含量不宜过小,但不能为追求样本含量而牺牲类别的准确,如果类别不可靠、测量值不准确,即使样本含量再大,任何统计方法语法弥补这一缺陷。 判别分析的类别很多,常用的有:适用于定性指标或计数资料的有最大似然法、训练迭代法;适用于定量指标或计量资料的有:Fisher二类判别、Bayers多类判别以及逐步判别。半定量指标界于二者之间,可根据不同情况分别采用以上方法。 类别(有的称之为总体,但应与population的区别)的含义——具有相同属性或者特征指标的个体(有的人称之为样品)的集合。如何来表征相同属性、相同的特征指标呢? 同一类别的个体之间距离小,不同总体的样本之间距离大。 距离是一个原则性的定义,只要满足对称性、非负性和三角不等式的函数就可以称为距 绝对距离 马氏距离:(Manhattan distance) 设有两个个体(点)X与Y(假定为一维数据,即在数轴上)是来自均数为μ,协方差阵为∑的总体(类别)A的两个个体(点),则个体X与Y的马氏距离为 (,)X与总体(类别)A的距离D X Y= (,) 为D X A= 明考斯基距离(Minkowski distance):明科夫斯基距离 欧几里德距离(欧氏距离) 二、Fisher两类判别 一、训练样本的测量值 A类训练样本 第八章相关与回归分析 114、什么叫相关分析? 研究两个或两个以上变量之间相关程度大小以及用一定涵数来表达现象相互关系的方法。 115、什么叫相关关系? 相关关系是一种不完全确定的依存关系,即因素标志的每一个数值都可能有若干结果标志的数值与之对应。 116、判定现象之间有无相关关系的方法有哪些? 判断现象之间有无相关关系,首先要对其作定性分析,否则很可能把虚假相关现象拿来作相关分析。相关表和相关图都是判定现象之间有无相关关系的重要方法。而相关系数主要是用来测定现象之间相关的密切程度的指标,估计标准误差是判定回归方程式代表性大小的指标。所以判断方法有客观现象作定性分析、编制相关表、绘制相关图。 117、什么叫相关系数? 测定变量之间相关密切程度和相关方向的指标。 118、相关系数有何特点? 参与相关分析的两个变量是对等的,不分自变量与因变量,因此相关系数只有一个。相关系数有正负号反映相关关系的方向中,正负瓜果正相关,负号反映负相关。计算相关系数的两个变量都是随机变量。 119、某产品产量与单位成本的相关系数是-0.8;(乙)产品单位成本与利润率的相关系数是-0.95;(乙)比(甲)的相关程度高吗? 相关系数是说明相关程度大小的指标,相关系数的取值范围在±1之间,相关系数越接近±1,说明两变量相关程度越高,越接近于0,说明相关程度越低。因此,(乙)比(甲)的相关程度高。 120、什么叫回归分析? 对具有相关关系的两个或两个以上变量之间数量变化的一般关系进行测定,确定一个相应的数学表达式,已从一个已知量推算另一个未知量,为估计预测提供一个重要方法。 121、与相关分析相比,回归分析有什么特点? 两个变量是不对等的,必须区自变量与因变量;因变量是随机的,自变量是可以控制的;对于一个没有因果关系的两个变量,可以求得两个回归方程,一个是Y倚X的回归方程,另一个是X倚Y的回归方程。 122、回归方程中回归系数的涵义是什么? 回归系数表示:当自变量X每增减一个单位时,因变量Y的平均增减值。 123、当所有的观测值都落在直线y c=a+bx上时,则x与y之间的相关系数为多少? 聚类分析与判别分析区别1 2 聚类分析和判 3 别分析就是这样的分类方法 4 , 5 目前它们已经成为 6 比较标准的数据分类方法。 7 我们常说 8 “物以类聚、 9 人以群分” 10 , 11 就是聚类分 12 析和判别分析最简单、 13 14 最朴素的阐释 15 , 16 并且这一成 17 语也道明了这两种方法的区别与联系 , 18 19 都是分类 20 技术 , 21 22 但它们是分别从不同的角度来对事物分类 的 23 24 , 25 或者说 , 26 27 是两种互逆的分类方式。聚类分析与 28 判别分析都是多元统计中研究事物分类的基本方 29 法 30 , 31 但二者却存在着较大的差异。 32 一、 33 聚类分析与判别分析的基本概念 34 1 35 、 36 聚类分析 37 又称群分析、 38 点群分析。 39 根据研究对象特征对 40 研究对象进行分类的一种多元分析技术 , 41 42 把性质 相近的个体归为一类 1 2 , 3 使得同一类中的个体都具 4 有高度的同质性 5 , 6 不同类之间的个体具有高度的 异质性。 7 8 根据分类对象的不同分为样品聚类和变量聚类。9 2 、 10 11 判别分析 12 是一种进行统计判别和分组的技术手段。根 13 据一定量案例的一个分组变量和相应的其他多元14 变量的已知信息 15 , 16 确定分组与其他多元变量之间 17 的数量关系 18 , 19 建立判别函数 , 20 21 然后便可以利用这一 22 数量关系对其他未知分组类型所属的案例进行判23 别分组。 24 判 25 别 26 分 27 析 28 中 29 的 30 因 变 31 32 量 33 或 34 判 35 别 36 准 则 37 38 是 39 定 类 40 41 变 42 量 , 43 44 而自变量或预测变量基本上是定距变量。 第3章回归预测方法 思考与练习(参考答案) 1.简要论述相关分析与回归分析的区别与联系。 答:相关分析与回归分析的主要区别: (1)相关分析的任务是确定两个变量之间相关的方向和密切程度。回归分析的任务是寻找因变量对自变量依赖关系的数学表达式。 (2)相关分析中,两个变量要求都是随机变量,并且不必区分自变量和因变量;而回归分析中自变量是普通变量,因变量是随机变量,并且必须明确哪个是因变量,哪些是自变量; (3)相关分析中两变量是对等的,改变两者的地位,并不影响相关系数的数值,只有一个相关系数。而在回归分析中,改变两个变量的位置会得到两个不同的回归方程。 联系为: (1)相关分析是回归分析的基础和前提。只有在相关分析确定了变量之间存在一定相关关系的基础上建立的回归方程才有意义。 (2)回归分析是相关分析的继续和深化。只有建立了回归方程才能表明变量之间的依赖关系,并进一步进行预测。 2.某行业8个企业的产品销售额和销售利润资料如下: 根据上述统计数据: (1)计算产品销售额与利润额的相关系数; r ,说明销售额与利润额高度相关。 解:应用Excel软件数据分析功能求得相关系数0.9934 (2)建立以销售利润为因变量的一元线性回归模型,并对回归模型进行显著性检验(取α=); 解:应用Excel 软件数据分析功能求得回归方程的参数为: 7.273,0.074a b =-= 据此,建立的线性回归方程为 ?7.2730.074Y x =-+ ① 模型拟合优度的检验 由于相关系数0.9934r =,所以模型的拟合度高。 ② 回归方程的显著性检验 应用Excel 软件数据分析功能得0.05 ?=450.167(1,6) 5.99F F >=,说明在α=水平下回归效果显著. ③ 回归系数的显著性检验 0.025?=21.22(6) 2.447t t >=,说明在α=水平下回归效果显著. 实际上,一元线性回归模型由于自变量只有一个,因此回归方程的显著性检验与回归系数b 的显著性检验是等价的。 (3)若企业产品销售额为500万元,试预测其销售利润。 根据建立的线性回归方程 ?7.2730.074Y x =-+,当销售额500x =时,销售利润?29.73Y =万元。 3.某公司下属企业的设备能力和劳动生产率的统计资料如下: 该公司现计划新建一家企业,设备能力为千瓦/人,试预测其劳动生产率,并求出其95%的置信区间。 全国各省经济的聚类分析及判别分析 唐鹏钧(DY1001109) 摘要:利用SPSS软件对全国31个省、直辖市、自治区(浙江、湖南、甘肃除外)的主要经济指标进行聚类分析,将其经济分成4种类型,并对浙江、湖南、甘肃进行类型判别分析。通过这两个方法对全国各省进行经济分类。本文选取了7项经济指标作为决定经济类型的影响因素,各项数据均来自2010年国家统计年鉴。分析结果表明:北京市和上海市为第一类经济类型;江苏省和山东省为第三类型;广东省为第四类经济;其他25个省、直辖市、自治区均属于第二类型。 关键词:聚类分析、判别分析、经济类型 0引言 聚类分析是根据研究对象的特征对研究对象进行分类的多元统计分析技术的总称。它直接比较各事物之间的性质,将性质相近的归为一类,将性质差别较大的归入不同的类。系统聚类分析又称集群分析,是聚类分析中应用最广的一种方法,它根据样本的多指标(变量)、多个观察数据,定量地确定样品、指标之间存在的相似性或亲疏关系,并据此连结这些样品或指标,归成大小类群,构成分类树状图或冰柱图。 判别分析是根据多种因素(指标)对事物的影响来实现对事物的分类,从而对事物进行判别分类的统计方法。判别分析适用于已经掌握了历史上分类的每一个类别的若干样品,希望根据这些历史的经验(样品),总结出分类的规律性(判别函数)来指导未来的分类。 聚类分析与判别分析都是研究分类的,但是它们有所区别: (1)聚类分析一般寻求客观的分类方法,在进行聚类分析以前,对总体到底有几种类型并不知道。判别分析则是在总体类型划分已知,在各总体分布或来自总体训练样本的基础上,对当前的新样本判定它们属于哪个总体。 (2)两类方法的建立的模型不一样,因此在处理某些特定的问题时,就会得第六章相关与回归分析方法
主成分分析和聚类分析
非参数估计方法能处理任意的概率分布而不必假设密度
回归分析与相关分析联系 区别
你应该要掌握的7种回归分析方法
判别分析及聚类分析
相关系数与回归分析
聚类分析与判别分析区别
第3章 回归预测方法
全国各省经济的聚类分析及判别分析