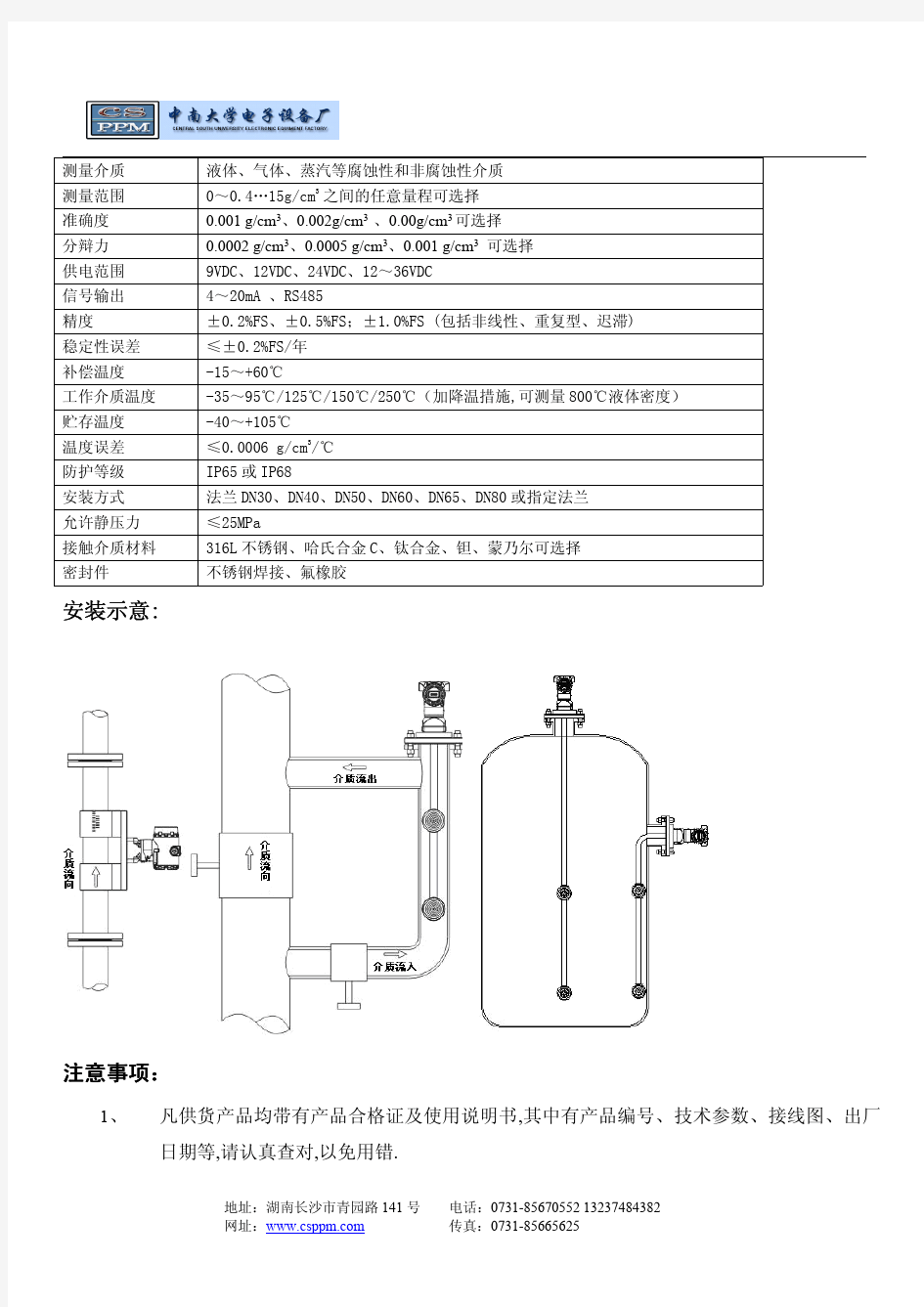
密度传感器

液体密度传感器的工作原理和应用
液体密度传感器的工作原理和应用 液体密度传感器就是指可以感受得到液体密度的,并且可以把它转换成为可以利用的输出信号的传感器。 液体密度传感器可以分为六类:电容式、超声波式、音叉式、谐振式、射线式和振动管式液体密度传感器。 电容式液体密度传感器 它是根据在不相同的待测液体中,标准物体的浮力的不同,这样就会导致跟标准物体连接起来的电容的两个极板间的距离发生变化,然后引起电容发生变化。因为不同的液体密度传感器适用的场合不相同,所以在实际应用的时候,应该要视所要测量的液体的性质还有对测量精度的要求等等的情况而选择适合的传感器。 超声波密度传感器 它的超声波的频率是高于20kHz的机械波和超声波只可以以纵波的形式在液体介质中传播。它传播的相位、频率、速度还有衰减度都会受到介质性质的有关影响,所以呢,它可以根据超声波的某些传播性质与液体密度之间的相应关系来测量液体的密度。它主要的优点有:它可以实现非接触的测量,测量精度比较高,响应比较快;而且它没有运动的部件,所以测量的稳定性比较好;它没有放射性,对人体是没有害的。而它的缺点就是液体介质中存有杂质,例如,泡泡可以导致超声波信号衰减严重;在精度测量粘性的介质的时候,需要考虑介质粘度的有关影响;它会使某些测量导致不稳定。 音叉式液体密度传感器
它是根据在液体中,质量小的音叉振动时,它的固有的频率的变化,这样来测量液体的密度的。要得到高精度测量的结果,就需要检测谐振频率的时候,变化很微小,所以需要合理地设计振动单元,让振动单元可以得到一个比较高的机械品质因数。音叉通常用玻璃或者不锈钢制成。 谐振式液体密度传感器 谐振式测量原理是根据谐振子的振动的特性来工作的。在工作过程中,谐振子能够等效地作为一个单自由度的系统,随着系统的固有频率而振动,而系统的固有频率仅仅跟系统中的等效弹性系数和等效质量有关。谐振式液体密度传感器测量原理则是通过系统中的液体和弹性敏感元件相接触导致系统的等效质量的改变,造成系统的固有频率发生变化。根据测量系统的固定频率的变化就可以知道待测液体的密度。 射线式液体密度传感器 射线式液体密度传感器的主要缺点是:它的分辨力不是很高;它需要有一个比较长的时间得稳定性;它需要放射性射线源。 它的优点就是:传感器对液体的流动没有产生阻力,对流量的大小也是没有限制的,而且它可以测量多相液体的密度;它在测量时是不接触待测的液体的,所以它能够实现非接触测量。 振动管式液体密度传感器 振动管式液体密度传感器可以合理地安排驱动部件,能够让管在同一个平面里面振动,它所测得的密度就是在管内流动的液体的平均
各种聚类算法及改进算法的研究
论文关键词:数据挖掘;聚类算法;聚类分析论文摘要:该文详细阐述了数据挖掘领域的常用聚类算法及改进算法,并比较分析了其优缺点,提出了数据挖掘对聚类的典型要求,指出各自的特点,以便于人们更快、更容易地选择一种聚类算法解决特定问题和对聚类算法作进一步的研究。并给出了相应的算法评价标准、改进建议和聚类分析研究的热点、难点。上述工作将为聚类分析和数据挖掘等研究提供有益的参考。 1 引言随着经济社会和科学技术的高速发展,各行各业积累的数据量急剧增长,如何从海量的数据中提取有用的信息成为当务之急。聚类是将数据划分成群组的过程,即把数据对象分成多个类或簇,在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大。它对未知数据的划分和分析起着非常有效的作用。通过聚类,能够识别密集和稀疏的区域,发现全局的分布模式,以及数据属性之间的相互关系等。为了找到效率高、通用性强的聚类方法人们从不同角度提出了许多种聚类算法,一般可分为基于层次的,基于划分的,基于密度的,基于网格的和基于模型的五大类。 2 数据挖掘对聚类算法的要求(1)可兼容性:要求聚类算法能够适应并处理属性不同类型的数据。(2)可伸缩性:要求聚类算法对大型数据集和小数据集都适用。(3)对用户专业知识要求最小化。(4)对数据类别簇的包容性:即聚类算法不仅能在用基本几何形式表达的数据上运行得很好,还要在以其他更高维度形式表现的数据上同样也能实现。(5)能有效识别并处理数据库的大量数据中普遍包含的异常值,空缺值或错误的不符合现实的数据。(6)聚类结果既要满足特定约束条件,又要具有良好聚类特性,且不丢失数据的真实信息。(7)可读性和可视性:能利用各种属性如颜色等以直观形式向用户显示数据挖掘的结果。(8)处理噪声数据的能力。(9)算法能否与输入顺序无关。 3 各种聚类算法介绍随着人们对数据挖掘的深入研究和了解,各种聚类算法的改进算法也相继提出,很多新算法在前人提出的算法中做了某些方面的提高和改进,且很多算法是有针对性地为特定的领域而设计。某些算法可能对某类数据在可行性、效率、精度或简单性上具有一定的优越性,但对其它类型的数据或在其他领域应用中则不一定还有优势。所以,我们必须清楚地了解各种算法的优缺点和应用范围,根据实际问题选择合适的算法。 3.1 基于层次的聚类算法基于层次的聚类算法对给定数据对象进行层次上的分解,可分为凝聚算法和分裂算法。 (1)自底向上的凝聚聚类方法。这种策略是以数据对象作为原子类,然后将这些原子类进行聚合。逐步聚合成越来越大的类,直到满足终止条件。凝聚算法的过程为:在初始时,每一个成员都组成一个单独的簇,在以后的迭代过程中,再把那些相互邻近的簇合并成一个簇,直到所有的成员组成一个簇为止。其时间和空间复杂性均为O(n2)。通过凝聚式的方法将两簇合并后,无法再将其分离到之前的状态。在凝聚聚类时,选择合适的类的个数和画出原始数据的图像很重要。 [!--empirenews.page--] (2)自顶向下分裂聚类方法。与凝聚法相反,该法先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终结条件。其主要思想是将那些成员之间不是非常紧密的簇进行分裂。跟凝聚式方法的方向相反,从一个簇出发,一步一步细化。它的优点在于研究者可以把注意力集中在数据的结构上面。一般情况下不使用分裂型方法,因为在较高的层很难进行正确的拆分。 3.2 基于密度的聚类算法很多算法都使用距离来描述数据之间的相似性,但对于非凸数据集,只用距离来描述是不够的。此时可用密度来取代距离描述相似性,即基于密度的聚类算法。它不是基于各种各样的距离,所以能克服基于距离的算法只能发现“类圆形”的聚类的缺点。其指导思想是:只要一个区域中的点的密度(对象或数据点的数目)大过某个阈值,就把它加到与之相近的聚类中去。该法从数据对象的分布密度出发,把密度足够大的区域连接起来,从而可发现任意形状的簇,并可用来过滤“噪声”数据。常见算法有DBSCAN,DENCLUE 等。[1][2][3]下一页 3.3 基于划分的聚类算法给定一个N个对象的元组或数据库,根据给定要创建的划分的数目k,将数据划分为k个组,每个组表示一个簇类(<=N)时满足如下两点:(1)每个组至少包含一个对象;(2)每个对
【CN109708995A】基于微波光子技术的液体密度传感器系统【专利】
(19)中华人民共和国国家知识产权局 (12)发明专利申请 (10)申请公布号 (43)申请公布日 (21)申请号 201910123571.7 (22)申请日 2019.02.18 (71)申请人 南方科技大学 地址 518000 广东省深圳市南山区桃源街 道学苑大道1088号 (72)发明人 邵理阳 肖冬瑞 顾国强 宋章启 陈晓龙 潘权 张伟 刘言军 (74)专利代理机构 北京易捷胜知识产权代理事 务所(普通合伙) 11613 代理人 齐胜杰 (51)Int.Cl. G01N 9/24(2006.01) (54)发明名称基于微波光子技术的液体密度传感器系统(57)摘要本发明公开一种基于微波光子技术的液体密度传感器系统,该系统包括:激光器发出激光输入电光调制器,电光调制器接受射频信号源发出的微波信号对输入的激光进行调制,产生的调制光信号经滤波器后,得到调制滤波后的光信号通过光开关中导通的第一端口和第三端口进入第一级Sagnac环,经过第一级Sagnac环干涉后的光信号经过隔离器进入第二级Sagnac环,经过第二级Sagnac环干涉后的光信号由光电探测器转换为电信号发送至信号解调单元,信号解调单元根据射频信号源发出的同步射频信号对电信号进行解调并输出;其中,第二级Sagnac环的部分结构位于被检测对象中。上述系统的双环结构可产生游标效应,并能够精确的对被检测的液体密度进行检查, 提高检测精度。权利要求书2页 说明书8页 附图2页CN 109708995 A 2019.05.03 C N 109708995 A
权 利 要 求 书1/2页CN 109708995 A 1.一种基于微波光子技术的液体密度传感器系统,其特征在于,包括:激光器(1)、电光调制器(2)、射频信号源(3)、滤波器(4)、光开关(5)、信号解调单元(19)、第一级Sagnac环、第二级Sagnac环、隔离器(10)和光电探测器(18); 其中,所述激光器(1)发出激光输入所述电光调制器(2),所述电光调制器(2)接受所述射频信号源(3)发出的微波信号对输入的激光进行调制,产生的调制光信号经所述滤波器(4)后,得到调制滤波后的光信号通过光开关(5)中导通的第一端口(501)和第三端口(503)进入第一级Sagnac环,经过第一级Sagnac环干涉后的光信号经过所述隔离器(10)进入第二级Sagnac环,经过第二级Sagnac环干涉后的光信号由所述光电探测器(18)转换为电信号发送至信号解调单元(19),所述信号解调单元(19)根据所述射频信号源(3)发出的同步射频信号对所述电信号进行解调并输出; 其中,所述第二级Sagnac环的部分结构位于被检测对象中。 2.根据权利要求1所述的系统,其特征在于,还包括:第一耦合器(11); 所述光开关包括第二端口(502); 所述光开关(5)的第一端口(501)和第二端口(502)导通时,经过滤波器(4)后的调制滤波的光信号经过第一耦合器(11)后进入第二级Sagnac环; 其中,所述信号解调单元(19)用于控制所述光开关(5)的第一端口(501)与第二端口(502)或第三端口(503)的导通。 3.根据权利要求2所述的系统,其特征在于,所述第一级Sagnac环包括: 耦合器一(6)、偏振控制器一(7)、两段单模光纤一(8)和边孔光纤一(9); 其中,耦合器一(6)、偏振控制器一(7)、第一段单模光纤一(8)、边孔光纤一(9)和第二段单模光纤一(8)、耦合器一(6)依次连接,形成第一级Sagnac环; 所述调制滤波后的光信号从耦合器一(6)的输入端子(601)进入耦合器一(6),并从耦合器一(6)的输出端子一(603)和输出端子二(604)分别进入第一级Sagnac环,进入第一级Sagnac环的两束光信号分别经过所述偏振控制器一(7)、第一段单模光纤一(8)和边孔光纤一(9)、第二段单模光纤一(8)后,在耦合器一(6)处相遇发生干涉; 所述耦合器一(6)的输出端子一(603)连接所述第一级Sagnac环的偏振控制器一(7); 所述耦合器一(6)的输出端子二(604)连接所述第一级Sagnac环的第二段单模光纤一(8)。 4.根据权利要求3所述的系统,其特征在于,所述第二级Sagnac环包括: 耦合器二(13)、偏振控制器二(14)、掺铒光纤(15)、两段单模光纤二(16)和边孔光纤二(17); 其中,耦合器二(13)、偏振控制器二(14)、掺铒光纤(15)、第一段单模光纤二(16)和边孔光纤二(17)、第二段单模光纤二(16)依次连接,形成第二级Sagnac环; 经过隔离器(10)之后的光信号通过第一耦合器(11)的输入端子(1102)进入第一耦合器(11),由第一耦合器(11)的输出端子(1104)输出有效的光信号; 所述有效的光信号通过耦合器二(13)的输入端子(1301)进入耦合器二(13),耦合器二(13)的输出端子一(1303)和输出端子二(1304)分别进入第二级Sagnac环,进入第二级Sagnac环的两束光信号分别经过所述偏振控制器二(14)、掺铒光纤(15)、单模光纤二(16)和边孔光纤二(17)后,在耦合器二(13)处相遇发生干涉; 2
各种密度聚类算法
什么是聚类?聚类:- 将一个对象的集合分割成几个类,每个类内的对象之间是相似的,但与其他类的对象是不相似的。评判聚类好坏的标准:1 ,能够适用于大数据量。 2 ,能应付不同的数据类型。 3 ,能够发现不同类型的聚类。 4 ,使对专业知识的要求降到最低。 5 ,能应付脏数据。 6 ,对于数据不同的顺序不敏感。 7 ,能应付很多类型的数据。 8 ,模型可解释,可使用。 二,聚类所基于的数据类型。 聚类算法通常基于“数据矩阵”和“ Dissimilarity 矩阵”。 怎么样计算不同对象之间的距离? 1 ,数值连续的变量(体重,身高等):度量单位的选取对于聚类的结果的很重要的。例如将身高的单位从米变为尺,将体重的单位从公斤变为磅将对聚类的结果产生很大的影响。为了避免出现这种情况,我们必须将数据标准化:将数据中的单位“去掉”。 A, 计算绝对背离度。B, 计算标准量度。下面我们考虑怎样来计算两个对象之间的差异。 1 ,欧几里得距离。 2 ,曼哈顿距离。这两种算法有共同之处:d(i,j)>=0,d(i,i)=0, d(i,j)=d(j,i),d(i,j)= 钻井液密度传感器概述 智能在线密度计(也称在线密度变送器)是一种用于连续在线测量液体浓度和密度的设备,可直接用于工业生产过程中。J 智能在线密度计采用差压式密度计的原理能根据介质在一定垂直距离上的差压值算 出密度值,并自动进行温度补偿,精度高,可靠性好,安装使用简单。 为二线制密度变送器,主要用于工业过程控制,在线密度计根据浓度与密度的大小产生相应的4-20mA信号,可通过数字通信进行远程校准与监测。 钻井液密度传感器特点 1、本在线密度计适用于流动或静止液体, 适合于管道和罐体安装。 2、采用一体化结构的两线制变送器,无活动部件,维护简单。 3、连续在线测量液体密度和温度,无过程中断.可直接用于生产过程控制。 4、四位半数字液晶显示。 5、温度和密度两参数可同时显示,便于进行行业标密换算。 6、密度计有几种不同的触液材质。 7、安装使用方便,插入液体即可显示读数。 8、简化维修,无需定期清洗。 9、在线密度计校准无需标准参考源、无需实验室校准、无过程中断。 10、本质安全型可用于危险现场. 卫生型可安装于食品生产现场。 钻井液密度传感器技术指标 1、输出:4-20mA电流输出,叠加数字信号(HART协议) 2、精度:0.001g/cm3 3、密度量程:0-2g/cm3 ;0-3g/cm3 4、仪表电源:16-30VDC供电,推荐使用24VDC 5、分辨率:0.001g/cm3 6、温度量程:0-100℃温度精度:0.2℃ 7、环境温度:-10~60℃ 8、湿度范围:0-90% 钻井液密度传感器应用领域 1、奶制品业(炼乳、乳糖、乳酪、干乳酪、乳酸等) 2、采矿(煤、钾碱、盐水、磷酸盐、钙化合物、石灰石、铜、金等) 3、食品加工(番茄汁、葡萄汁、柠檬汁、番茄酱、糖蜜、植物油、果糖浆、果冻、果酱等) 4、纸浆与造纸业(黑浆、绿浆、纸浆清洗、蒸发器、苛性碱等) 5、饮料加工(啤酒、软饮料、果酒、速溶咖啡、麦芽等) 6、化工(烧碱、酸、尿素、清洁剂、聚合物密度、乙二醇、 国内外在线密度计的差异 目前国内外常用的液体密度计和比重计有浮子式密度计、放射性同位素密度计、振动式密度计和差压式密度计。 一、浮子式密度计 物体在流体内受到的浮力与流体密度有关,流体密度越大浮力越大。如果规定被测样品的温度(例如规定25℃),则仪器也可以用比重数值作为刻度值。这类仪器中最简单的是目测浮子式玻璃比重计, 简称玻璃比重计。 注:这种密度计只能大概估算密度值,无法保证精准度,也无信号输出。 二、放射性同位素密度计 又称为核辐射密度计,在国内也有人叫伽玛密度计。这种原理的密度计出现较早,技术成熟。美国TN公司生产的Density PRO核子密度计和最新推出的Density PRO增强型核辐射密度计由于其测量精度高,响应速度快及核子密度计独有的非接触测量方式等优点,使其非常适用于工矿企业在线介质密度测量要求,尤其适用于被测物粗糙坚硬,有腐蚀性或高温、高压的恶劣条件。核子密度计主要用于检测液体、固体(例如气载煤粉)、矿浆、水泥浆等物质的密度及对金属矿浆浓度(密度)的检测,对其它液体过程反应密度检测,典型应用如电厂脱硫工程中对石膏浆密度的检测以及矿山对各种矿浆的密度检测。美国热电集团TN DensityPRO核密度检测器和测量部分一体化的设计,使其能够使用在更多的过程应用场合。TN Density PRO 整合的探测测量设计能利用相当小的放射源,可以应用于被测管径在1寸(25.4mm)到42寸(1066.8mm)的任何工业密度测量现场。 美国TN公司原装进口的Density PRO核子密度计测量精度:±0.0001g/ml 一个完整系统包括GAMMA射线源、一体型检测器(变送器)(Model 9719A或Model 9720A可选)就地显示或远传单元Model 9723A、 Model9734手操器设置和标定仪表及安装硬件。 注:此核子密度计国内外均有生产,价格在几十万到百万元不等。由于该密度计具有的放射性,对生物有一定的危害。安装时需获得国家卫生管理部门审批,且一定要在现场准备单独存放的房间,生产和维护成本较高,放射源较难处理。 三、超声波密度计/浓度计 在悬浮颗粒浓度测量方面以验证明超声波在淤泥中的衰减量与悬浮颗粒浓度有关。 二个超声波换能器的作用是用于发送和接收波束。二个换能器齐平地安装在管段的两侧,或组装成一个传感器。两个换能器之间的距离和工作频率的选择取决于不同的应用。 测量结果不受振动、温度、粘度或颜色的影响。 在不同的工业领域里,测量系统已被用于测量颗粒浓度从0.2-60%的淤浆。 注:此种密度计目前国内暂无生产厂家,价格在十几万元左右。此种密度计因靠振荡微波原理,视介质液体中颗粒成分通常在检测浆液一到二年后,探头会有一定的磨损,造成以后的使用精度锐减;而且此种进口仪表在国内一般没有售后中心,仪表的维护费很高,维护费用差不多是一台表的价格,处理时间也很长。 四、珠海万山仪表公司竖管道式智能在线密度计 一、层次聚类 1、层次聚类的原理及分类 1)层次法(Hierarchical methods)先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并,直到合成了一个类。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最短距离。 层次聚类算法根据层次分解的顺序分为:自下底向上和自上向下,即凝聚的层次聚类算法和分裂的层次聚类算法(agglomerative和divisive),也可以理解为自下而上法(bottom-up)和自上而下法(top-down)。自下而上法就是一开始每个个体(object)都是一个 类,然后根据linkage寻找同类,最后形成一个“类”。自上而下法就是反过来,一开始所有个体都属于一个“类”,然后根据linkage排除异己,最后每个个体都成为一个“类”。这两种路方法没有孰优孰劣之分,只是在实际应用的时候要根据数据特点以及你想要的“类”的个数,来考虑是自上而下更快还是自下而上更快。至于根据Linkage判断“类” 的方法就是最短距离法、最长距离法、中间距离法、类平均法等等(其中类平均法往往被认为是最常用也最好用的方法,一方面因为其良好的单调性,另一方面因为其空间扩张/浓缩的程度适中)。为弥补分解与合并的不足,层次合并经常要与其它聚类方法相结合,如循环定位。 2)Hierarchical methods中比较新的算法有BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies利用层次方法的平衡迭代规约和聚类)主要是在数据量很大的时候使用,而且数据类型是numerical。首先利用树的结构对对象集进行划分,然后再利用其它聚类方法对这些聚类进行优化;ROCK(A Hierarchical Clustering Algorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering Algorithm Using Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂度很高,O(n^2)。 2、层次聚类的流程 凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。这里给出采用最小距离的凝聚层次聚类算法流程: (1) 将每个对象看作一类,计算两两之间的最小距离; (2) 将距离最小的两个类合并成一个新类; (3) 重新计算新类与所有类之间的距离; (4) 重复(2)、(3),直到所有类最后合并成一类。 超声波传感器 [摘要] 超声波传感器是利用超声波的特性研制而成的传感器。超声波是一种振动频率高于声波的机械波,由换能晶片在电压的激励下发生振动产生的,它具有频率高、波长短、绕射现象小,特别是方向性好、能够成为射线而定向传播等特点。超声波对液体、固体的穿透本领很大,尤其是在阳光不透明的固体中,它可穿透几十米的深度。超声波碰到杂质或分界面会产生显著反射形成反射成回波,碰到活动物体能产生多普勒效应。因此超声波检测广泛应用在工业、国防、生物医学等方面 [关键字]:结构、工作原理超声波流量测量超声波探伤总结1.结构、工作原理 超声波传感器是利用超声波的特性研制而成的传感器。超声波是一种振动频率高于声波的机械波,由换能晶片在电压的激励下发生振动产生的,它具有频率高、波长短、绕射现象小,特别是方向性好、能够成为射线而定向传播等特点。超声波对液体、固体的穿透本领很大,尤其是在阳光不透明的固体中,它可穿透几十米的深度。超声波碰到杂质或分界面会产生显著反射形成反射成回波,碰到活动物体能产生多普勒效应。因此超声波检测广泛应用在工业、国防、生物医学等方面以超声波作为检测手段,必须产生超声波和接收超声波。完成这种功能的装置就是超声波传感器,习惯上称为超声换能器,或者超声探头。 图1.超声波传感器 超声波探头主要由压电晶片组成,既可以发射超声波,也可以接收超声波。小功率超声探头多作探测作用。它有许多不同的结构,可分直探头(纵波)、斜探头(横波)、表面波探头(表面波)、兰姆波探头(兰姆波)、双探头(一个探头反射、一个探头接收)等。 超声探头的核心是其塑料外套或者金属外套中的一块压电晶片。构成晶片的材料可以有许多种。晶片的大小,如直径和厚度也各不相同,因此每个探头的性能是不同的,我们使用前必须预先了解它的性能。超声波传感器的主要性能指标包括: (1)工作频率。工作频率就是压电晶片的共振频率。当加到它两端的交流电压的频率和晶片的共振频率相等时,输出的能量最大,灵敏度也最高。 (2)工作温度。由于压电材料的居里点一般比较高,特别时诊断用超声波探头使用功率较小,所以工作温度比较低,可以长时间地工作而不产生失效。医疗用的超声探头的温度比较高,需要单独的制冷设备。 (3)灵敏度。主要取决于制造晶片本身。机电耦合系数大,灵敏度高;反之,灵敏度低。 北京科技大学科技成果——超声波在线液体密度计的研制项目简介 超声波液体密度计是一种在线的液体测量仪器。将超声波探头装于罐,容器或者管道内,利用超声波声速和液体密度的关系。当管道内流体参数变化后,超声信号也随之变化,计算机对变化了超声信号进行数字处理,从而精确地测量液体的密度。 目前国内各行业对液体浓度测量,大多仍采用人工采样,化学分析的方法,国外也无更先进的实时测量仪表,该仪器的成果水平属国内首创,超声波探头装于罐,容器或者管道内部,需要直接接触被测液体,可显示管内液体的瞬态密度;有温度自动补偿,测量精度优于0.2%。还可显示生产过程中密度随时间的曲线变化,并可打印输出;有标准电压、电流输出,开关量信号输出作控制用。 主要技术指标 1、被测液体粘度:100厘泊; 2、密度测量精度:0.25%; 3、超声波换能器,纵波探头; 4、超声波频率:200Hz-5MHz; 5、标准输出:0-5V,0-10mA,4-20mA 6、电源电压:220VAC±5% 应用范围 密度是很多液态工业产品的一项重要指标,在很多工业生产过程中,都需要用密度来控制某些生产过程。测量密度的方法有很多种, 如振动管式密度计,超声波密度计等。随着控制要求的不断提高,超声波密度计越来越体现出其优越的性能。用超声波来测量液体密度,其优点主要在于它实现了测量的非接触性和连续性,如果与控制系统连接,就可以随时控制液体的密度,使其保持一定的均匀性。从而大大地节省了时间并提高了工艺精度。 经济效益分析 (1)投资额、规模、收益(包括设备投资、水电费用、原料等)单台仪表在4000元左右的成本,进口同类产品售价在2-3万元。投资额在20-30万元。 (2)市场前景预测 该测量仪器在石油,化工,医药,油脂加工,食品饮料,环境保护等领域控制与提高产品质量、产量、降低原材料及能源消耗方面有广泛应用前景。 一,什么是聚类? 聚类: - 将一个对象的集合分割成几个类,每个类内的对象之间是相似的,但与其他类的对象是不相似的。评判聚类好坏的标准: 1 ,能够适用于大数据量。 2 ,能应付不同的数据类型。 3 ,能够发现不同类型的聚类。 4 ,使对专业知识的要求降到最低。 5 ,能应付脏数据。 6 ,对于数据不同的顺序不敏感。 7 ,能应付很多类型的数据。 8 ,模型可解释,可使用。 二,聚类所基于的数据类型。 聚类算法通常基于“数据矩阵”和“ Dissimilarity 矩阵”。 怎么样计算不同对象之间的距离? 1 ,数值连续的变量(体重,身高等):度量单位的选取对于聚类的结果的很重要的。例如将身高的单位从米变为尺,将体重的单位从公斤变为磅将对聚类的结果产生很大的影响。为了避免出现这种情况,我们必须将数据标准化:将数据中的单位“去掉”。 A, 计算绝对背离度。 B, 计算标准量度。 下面我们考虑怎样来计算两个对象之间的差异。 1 ,欧几里得距离。 2 ,曼哈顿距离。这两种算法有共同之处: d(i,j)>=0,d(i,i)=0, d(i,j)=d(j,i),d(i,j)= 各种聚类算法的比较 聚类的目标是使同一类对象的相似度尽可能地小;不同类对象之间的相似度尽可能地大。目前聚类的方法很多,根据基本思想的不同,大致可以将聚类算法分为五大类:层次聚类算法、分割聚类算法、基于约束的聚类算法、机器学习中的聚类算法和用于高维度的聚类算法。摘自数据挖掘中的聚类分析研究综述这篇论文。 1、层次聚类算法 1.1聚合聚类 1.1.1相似度依据距离不同:Single-Link:最近距离、Complete-Link:最远距离、Average-Link:平均距离 1.1.2最具代表性算法 1)CURE算法 特点:固定数目有代表性的点共同代表类 优点:识别形状复杂,大小不一的聚类,过滤孤立点 2)ROCK算法 特点:对CURE算法的改进 优点:同上,并适用于类别属性的数据 3)CHAMELEON算法 特点:利用了动态建模技术 1.2分解聚类 1.3优缺点 优点:适用于任意形状和任意属性的数据集;灵活控制不同层次的聚类粒度,强聚类能力 缺点:大大延长了算法的执行时间,不能回溯处理 2、分割聚类算法 2.1基于密度的聚类 2.1.1特点 将密度足够大的相邻区域连接,能有效处理异常数据,主要用于对空间数据的聚类 1)DBSCAN:不断生长足够高密度的区域 2)DENCLUE:根据数据点在属性空间中的密度进行聚类,密度和网格与处理的结合 3)OPTICS、DBCLASD、CURD:均针对数据在空间中呈现的不同密度分不对DBSCAN作了改进 2.2基于网格的聚类 2.2.1特点 利用属性空间的多维网格数据结构,将空间划分为有限数目的单元以构成网格结构; 1)优点:处理时间与数据对象的数目无关,与数据的输入顺序无关,可以处理任意类型的数据 2)缺点:处理时间与每维空间所划分的单元数相关,一定程度上降低了聚类的质量和准确性 2.2.2典型算法 1)STING:基于网格多分辨率,将空间划分为方形单元,对应不同分辨率2)STING+:改进STING,用于处理动态进化的空间数据 3)CLIQUE:结合网格和密度聚类的思想,能处理大规模高维度数据4)WaveCluster:以信号处理思想为基础 2.3基于图论的聚类 2.3.1特点 转换为组合优化问题,并利用图论和相关启发式算法来解决,构造数据集的最小生成数,再逐步删除最长边 1)优点:不需要进行相似度的计算 2.3.2两个主要的应用形式 1)基于超图的划分 2)基于光谱的图划分 2.4基于平方误差的迭代重分配聚类 2.4.1思想 逐步对聚类结果进行优化、不断将目标数据集向各个聚类中心进行重新分配以获最优解 聚类算法: 1. 划分法:K-MEANS算法、K-M EDOIDS算法、CLARANS算法; 1)K-means 算法: 基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。 K-Means聚类算法主要分为三个步骤: (1)第一步是为待聚类的点寻找聚类中心 (2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去 (3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心 反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止 下图展示了对n个样本点进行K-means聚类的效果,这里k取2: (a)未聚类的初始点集 (b)随机选取两个点作为聚类中心 (c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去 (d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心 (e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去 (f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心 优点: 1.算法快速、简单; 2.对大数据集有较高的效率并且是可伸缩性的; 3.时间复杂度近于线性,而且适合挖掘大规模数据集。 缺点: 1. 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。 2. 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响。 第37卷第11期 2000年11月计算机研究与发展JOU RNAL O F COM PU T ER R ESEA RCH &D EV ELO PM EN T V o l 137,N o 111N ov .2000 原稿收到日期:1999209220;修改稿收到日期:1999212209.本课题得到国家自然科学基金项目(项目编号69743001)和国家教委博士点教育基金的资助.周水庚,男,1966年生,博士研究生,高级工程师,主要从事数据库、数据仓库和数据挖掘以及信息检索等的研究.周傲英,男,1965年生,教授,博士生导师,主要从事数据库、数据挖掘和W eb 信息管理等研究.曹晶,女,1976年生,硕士研究生,主要从事数据库、数据挖掘等研究.胡运发,男,1940年生,教授,博士生导师,主要从事知识工程、数字图书馆、信息检索等研究. 一种基于密度的快速聚类算法 周水庚 周傲英 曹 晶 胡运发 (复旦大学计算机科学系 上海 200433) 摘 要 聚类是数据挖掘领域中的一个重要研究方向.聚类技术在统计数据分析、模式识别、图像处理等领域有广泛应用.迄今为止人们提出了许多用于大规模数据库的聚类算法.基于密度的聚类算法DBSCAN 就是一个典型代表.以DBSCAN 为基础,提出了一种基于密度的快速聚类算法.新算法以核心对象邻域中所有对象的代表对象为种子对象来扩展类,从而减少区域查询次数,降低I O 开销,实现快速聚类.对二维空间数据测试表明:快速算法能够有效地对大规模数据库进行聚类,速度上数倍于已有DBSCAN 算法. 关键词 空间数据库,数据挖掘,聚类,密度,快速算法,代表对象 中图法分类号 T P 311.13;T P 391 A FAST D ENSIT Y -BASED CL USTER ING AL G OR ITH M ZHOU Shu i 2Geng ,ZHOU A o 2Y ing ,CAO J ing ,and HU Yun 2Fa (D ep a rt m en t of Co mp u ter S cience ,F ud an U n iversity ,S hang ha i 200433) Abstract C lu stering is a p rom ising app licati on area fo r m any fields including data m in ing ,statistical data analysis ,p attern recogn iti on ,i m age p rocessing ,etc .In th is paper ,a fast den sity 2based clu stering algo rithm is developed ,w h ich con siderab ly speeds up the o riginal DB SCAN algo rithm .U n like DB SCAN ,the new DB SCAN u ses on ly a s m all num ber of rep resen tative ob jects in a co re ob ject’s neighbo rhood as seeds to exp and the clu ster so that the execu ti on frequency of regi on query can be decreased ,and con sequen tly the I O co st is reduced .Experi m en tal resu lts show that the new algo rithm is effective and efficien t in clu stering large 2scale databases ,and it is faster than the o riginal DB SCAN by several ti m es . Key words spatial database ,data m in ing ,clu stering ,den sity ,fast algo rithm ,rep resen tative ob jects 1 概 述 近10多年来,数据挖掘逐渐成为数据库研究领域的一个热点[1].其中,聚类分析就是广为研究的问题之一.所谓聚类,就是将数据库中的数据进行分组,使得每一组内的数据尽可能相似而不同组内的数据尽可能不同.聚类技术在统计数据分析、模式识别、图像处理等领域都有广泛的应用前景.迄今为止,人们已经提出了许多聚类算法[2~7].所有这些算法都试图解决大规模数据的聚类问题.以基于密度的聚类算法DB SCAN [4]为基础,本文提出一种基于密度的快速聚类算法.通过选用核心对象附近区域包含的所有对象的代表对象作为种子对象来扩展类,快速算法减少了区域查询的次数,从而减低了聚类时间和I O 开销 .本文内容安排如下:首先在第2节中介绍基于密度的聚类算法DB SCAN 的基本思想,并分析它的局限 DENCLUE2.0:Fast Clustering based on Kernel Density Estimation Alexander Hinneburg1and Hans-Henning Gabriel2 1Institute of Computer Science Martin-Luther-University Halle-Wittenberg,Germany hinneburg@informatik.uni-halle.de 2Otto-von-Guericke-University Magdeburg,Germany Hans-Henning.Gabriel@web.de Abstract.The Denclue algorithm employs a cluster model based on kernel density estimation.A cluster is de?ned by a local maximum of the estimated density function.Data points are assigned to clusters by hill climbing,i.e.points going to the same local maximum are put into the same cluster.A disadvantage of Denclue1.0is,that the used hill climbing may make unnecessary small steps in the beginning and never converges exactly to the maximum,it just comes close. We introduce a new hill climbing procedure for Gaussian kernels,which adjusts the step size automatically at no extra costs.We prove that the procedure converges exactly towards a local maximum by reducing it to a special case of the expectation maximization algorithm.We show experimentally that the new procedure needs much less iterations and can be accelerated by sampling based methods with sacri?cing only a small amount of accuracy. 1Introduction Clustering can be formulated in many di?erent ways.Non-parametric methods are well suited for exploring clusters,because no generative model of the data is assumed.Instead,the probability density in the data space is directly estimated from data instances.Kernel density estimation[15,14]is a principled way of doing that task.There are several clustering algorithms,which exploit the adaptive nature of a kernel density estimate.Examples are the algorithms by Schnell [13]and Fukunaga[5]which use the gradient of the estimated density function. The algorithms are also described in the books by Bock[3]and Fukunaga[4] respectively.The Denclue framework for clustering[7,8]builds upon Schnells algorithm.There,clusters are de?ned by local maxima of the density estimate. Data points are assigned to local maxima by hill climbing.Those points which are assigned to the same local maximum are put into a single cluster. However,the algorithms use directional information of the gradient only. The step size remains?xed throughout the hill climbing.This implies certain disadvantages,namely the hill climbing does not converges towards the local maximum,it just comes close,and the number of iteration steps may be large钻井液密度传感器
现时国内外密度计的差异
(完整word版)各种聚类算法介绍及对比
课程结业-超声波传感器论文
北京科技大学科技成果——超声波在线液体密度计的研制
各种密度聚类算法
各种聚类算法的比较
聚类算法比较
一种基于密度的快速聚类算法
密度聚类算法 DENCLUE 2.0