SAS学习系列37. 时间序列分析Ⅰ—平稳性及纯随机性检验

37. 时间序列分析Ⅰ—平稳性及纯随机性检验
(一)基本概念
一、什么是时间序列?
为了研究某一事件的规律,依据时间发生的顺序将事件在多个时刻的数值记录下来,就构成了一个时间序列。对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的发展趋势就是时间序列分析。
例如,国家或地区的年度财政收入,股票市场的每日波动,气象变化,工厂按小时观测的产量等等。
注:随温度、高度等变化而变化的离散序列,也可以看作时间序列。
二、时间序列的特点
(1)顺序性;
(2)随机性;
(3)前后时刻(不一定相邻)的依存性;
(4)整体呈趋势性和周期性。
三、时间序列的分类
按研究对象的数目:一元时间序列、多元时间序列;
按序列统计特性:平稳时间序列、非平稳时间序列;
按分布规律:高斯时间序列、非高斯时间序列。
四、研究方法
1. 平稳时间序列分析;
2. 非平稳时间序列分析(确定性分析、随机性分析)。
五、其它
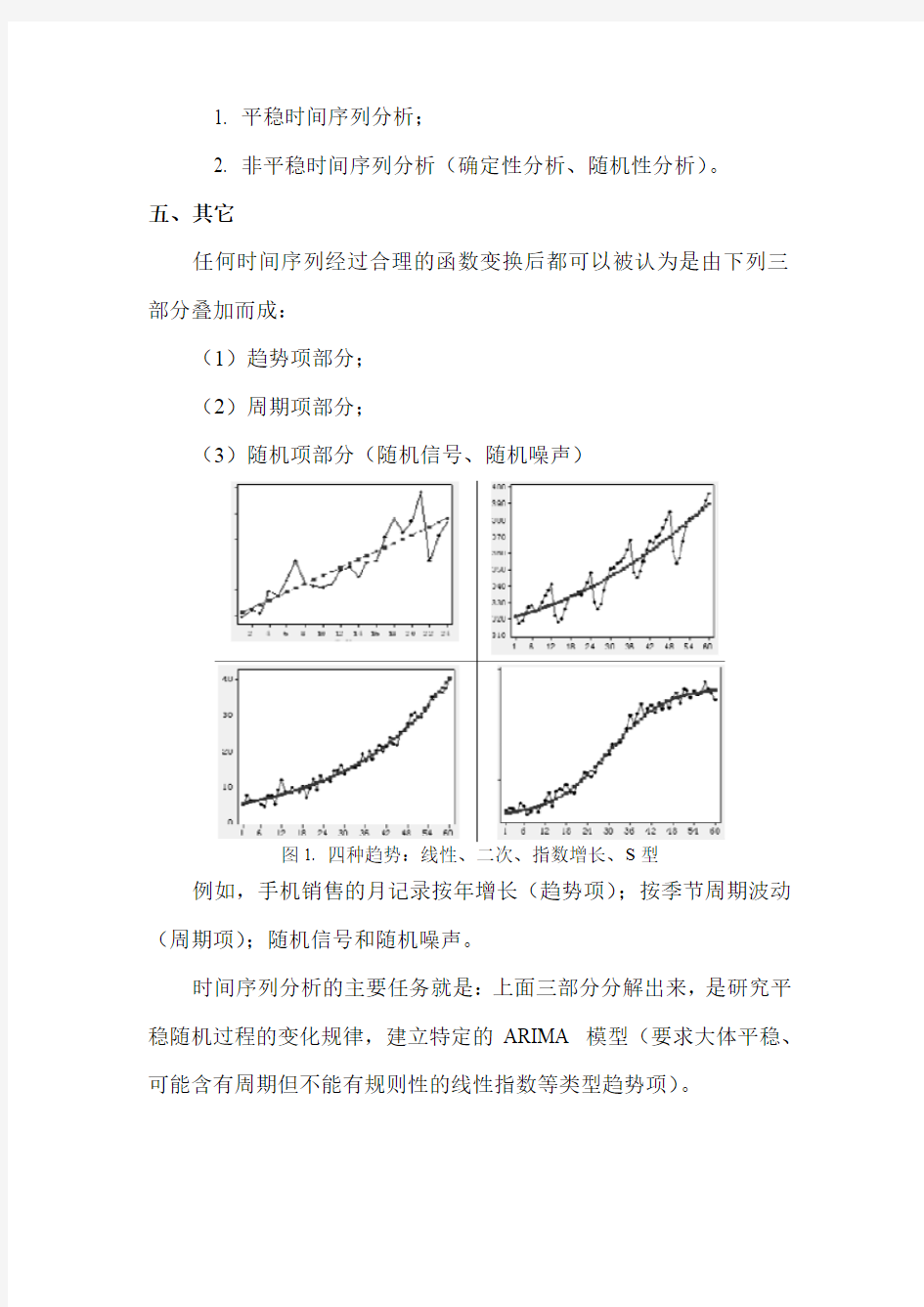
任何时间序列经过合理的函数变换后都可以被认为是由下列三部分叠加而成:
(1)趋势项部分;
(2)周期项部分;
(3)随机项部分(随机信号、随机噪声)
图1. 四种趋势:线性、二次、指数增长、S型
例如,手机销售的月记录按年增长(趋势项);按季节周期波动(周期项);随机信号和随机噪声。
时间序列分析的主要任务就是:上面三部分分解出来,是研究平稳随机过程的变化规律,建立特定的ARIMA 模型(要求大体平稳、可能含有周期但不能有规则性的线性指数等类型趋势项)。
六、方法性工具
1. 差分运算 (1)k 步差分
间隔k 期的观察值之差:Δk =x t -x t-k (2)p 阶差分
Δx t =x t -x t-1称为一阶差分;
1
1
10
(1)p
p
p p i i t t t p t p i i x x x C x ---+-=?=?
-?
=-∑称为p 阶差分;
SAS 函数实现:diff n (x ) 2. 延迟算子
延迟算子作用于时间序列,时间刻度减小1个单位(序列左移一位):B x t =x t-1, ……,B p x t =x t-p .
SAS 函数实现:lag n (x )
用延迟算子表示k 步差分和p 阶差分为:
Δk =x t -x t-k =(1-B k )x t
0()(1)p
p
p
p i t p t i i x I B C x -=?=-=-∑
(二)平稳时间序列
一、概念
平稳时间序列按限制条件的严格程度,分为
严平稳时间序列:序列所有的统计性质都不会随着时间的推移而发生变化;
宽平稳时间序列:序列的主要性质近似稳定,即统计性质只要保证序列的二阶矩平稳,即对任意的时间t ,s ,k ,序列X t 满足:
二、平稳时间序列的统计性质
(1)均值为常数;
(2)自协方差只依赖于时间跨度; 若定义自协方差函数为
γ(t ,s ) = E(X t -μt )(X s -μs )
则可由二元函数简化为一元函数γ(t -s ),得延迟k 自协方差函数:
γ(k )=γ(t ,t +k )
由此易知平稳时间序列必具有常数方差:
D(X t )=E(X t -μt )2=γ(t ,t )=γ(0)
时间序列自相关函数:
(,)t s ρ=
延迟k 自相关函数:
()
()(0)
k k γργ=
==
基本性质:
(1)ρ(0)=1; (2)ρ(-k)= ρ
(k);
(3)自相关阵为对称负定阵;
(4)非唯一性。
注意:协方差函数和相关函数——度量两个不同事件(X t,Y t)彼此之间的相互影响的程度。
自协方差函数和自相关函数——度量用一事件(X t)在两个不同时期之间的相互影响的程度。
三、样本估计值
总体均值的估计值:
延迟k自协方差函数的估计值:
总体方差的估计值:
延迟k自相关函数的估计值:
四、平稳性检验
(1)时序图检验
若无明显的趋势性和周期性,则平稳;
(2)自相关图检验
零均值平稳序列的自相关函数要么截尾要么拖尾;若时间序列零均值化后出现缓慢衰减或周期性衰减,则说明存在趋势性和周期性(非平稳);
(3)单位根检验就是通过检验时间序列自回归特征方程的特征根是在单位圆内(平稳)还是在单位圆及单位圆外(非平稳)。通常用ADF检验法。
Dickey和Fuller (1979)利用如下的广义自回归模型
其中,Δx j,t表示x的一阶差分;x j,t-1表示延迟一期;Δx j,t-k表示延迟k 期再一阶差分;εk,t表示扰动项。
上述回归模型生成的x j,t-1的t值正好对应ADF统计量,做假设检验:H0: 非平稳;H1:平稳。t值在1%, 5%, 10% 置信水平的临界值分别为:-3.524233, -2.902358, -2.588587. 以此判断序列是否平稳。
注:若X t不平稳,可以依次对X t做一阶、二阶…差分,直到序列平稳。
例1. 平稳性检验——ADF检验的SAS实现。
代码:
data simulation;
do i=1to100;
x=rannor(1234);
output;
end;
run;
data timeseries;
set simulation;
x_1st_lag= lag1(x);
x_1st_diff= dif1(x);
x_1st_diff_1st_lag= dif1(lag1(x));
x_1st_diff_2nd_lag= dif1(lag2(x));
x_1st_diff_3rd_lag= dif1(lag3(x));
x_1st_diff_4th_lag= dif1(lag4(x));
x_1st_diff_5th_lag= dif1(lag5(x));
run;
procreg data=timeseries;
model x_1st_diff= x_1st_lag x_1st_diff_1st_lag
x_1st_diff_2nd_lag
x_1st_diff_3rd_lag
x_1st_diff_4th_lag
x_1st_diff_5th_lag;
run;
运行结果:
REG 过程
模型: MODEL1
x_1st_lag的t值= -3.39 五、纯随机性检验 若序列值彼此之间没有任何相关性,即过去的行为对未来的发展没有丝毫影响,此时称为纯随机序列。 从统计分析的角度而言,纯随机序列是没有任何分析价值的序列。因此,为了确保平稳序列还值不值得分析,还需要对平稳序列进行纯随机性检验。 1. 纯随机序列(白噪声序列) 若对任取的时间t和s,时间序列X t满足: (1)E(X t) = μ;(常数均值) (2)r(t,s) =σ2,若t=s;(方差齐性) (3)r(t,s) =0,若t≠s. (纯随机性) 则称X t为纯随机序列或白噪声序列(白光具有该特性),简记为X t~WN(μ, σ2)。白噪声序列是最简单的平稳时间序列。随机生成的1000个服从标准正态分布的白噪声序列观察值: 2. 纯随机性检验 Barlett证明:n个观察值的纯随机时间序列,延迟为k(≠0)的自相关函数ρ(k) 近似服从正态分布N(0,1/n). 由此可以构造Q BP统计量(适合样本数n≥50)和Q LB统计量(适合小样本)来检验序列的纯随机性: 再做假设检验: H0: ρ(1)=ρ(2)=…=ρ(m),即延迟≤m的序列之间相互独立; H1: 至少有一个ρ(k)≠0,即延迟≤m的序列之间有相关性。 注:m一般取值为6、12。这是因为平稳序列通常具有短期相关性,只要序列时期足够长,自相关系数都会收敛于零。 例2.数据如下表,时间间隔为天,起始时间自定义。 (1)判断该序列x t的平稳性及纯随机性; (2)判断x t的一阶差分y t的平稳性及纯随机性。 代码: data datas1; input x_t @@; time=intnx('day','01jan2014'd,_n_-1); format time monyy.; cards; 10 15 10 10 12 10 7 7 10 14 8 17 14 18 3 9 11 10 6 12 14 10 25 29 33 33 12 19 16 19 19 12 34 15 36 29 26 21 17 19 13 20 24 12 6 14 6 12 9 11 17 12 8 14 14 12 5 8 10 3 16 8 8 7 12 6 10 8 10 5 ; run; procgplot data = datas1; plot x_t*time; symboli=join v=star cv=red ci=green; run; procarima data = datas1; identifyvar=x_t nlag=24; run; data datas2; set datas1; y_t = dif1(x_t); run; procgplot data = datas2; plot y_t*time; symboli=join v=star cv=red ci=green; run; procarima data = datas2; identifyvar=y_t nlag=24; run; 运行结果: 从时序图看,X t有明显的周期性和递增递减趋势,故不平稳。 从ACF图看,X t的自相关系数递减到零的速度相当缓慢,在很长的延迟时期里,自相关系数一直为正,而后又一直为负,故判断该序列非平稳。 延迟为6、12的检验P值均小于0.05,故拒绝原假设,认为X t 为非纯随机序列(非白噪声序列)。 Y t的时序图波动范围有界且没有明显的周期性、递增(递减)趋势,故可以初步判断该序列平稳。 从ACF自相关图看,延迟1阶后的样本自相关系数很快衰减到零附近,且1阶后的样本自相关系数均落在了两倍标准误的范围之内,且在零值附近波动,故可认为Y t平稳。 延迟为6、12的检验P值均小于0.05,故拒绝原假设,认为Y t 为非纯随机序列(非白噪声序列)。 应用时间序列分析实验报告 单位根检验输出结果如下:序列x的单位根检验结果: 1967 58.8 53.4 1968 57.6 50.9 1969 59.8 47.2 1970 56.8 56.1 1971 68.5 52.4 1972 82.9 64.0 1973 116.9 103.6 1974 139.4 152.8 1975 143.0 147.4 1976 134.8 129.3 1977 139.7 132.8 1978 167.6 187.4 1979 211.7 242.9 1980 271.2 298.8 1981 367.6 367.7 1982 413.8 357.5 1983 438.3 421.8 1984 580.5 620.5 1985 808.9 1257.8 1986 1082.1 1498.3 1987 1470.0 1614.2 1988 1766.7 2055.1 1989 1956.0 2199.9 1990 2985.8 2574.3 1991 3827.1 3398.7 1992 4676.3 4443.3 1993 5284.8 5986.2 1994 10421.8 9960.1 1995 12451.8 11048.1 1996 12576.4 11557.4 1997 15160.7 11806.5 1998 15223.6 11626.1 1999 16159.8 13736.5 2000 20634.4 18638.8 2001 22024.4 20159.2 2002 26947.9 24430.3 2003 36287.9 34195.6 2004 49103.3 46435.8 2005 62648.1 54273.7 2006 77594.6 63376.9 2007 93455.6 73284.6 2008 100394.9 79526.5 run; proc gplot; plot x*t=1 y*t=2/overlay; symbol1c=black i=join v=none; symbol2c=red i=join v=none w=2l=2; run; proc arima data=example6_4; identify var=x stationarity=(adf=1); identify var=y stationarity=(adf=1); run; proc arima; identify var=y crrosscorr=x; estimate methed=ml input=x plot; forecast lead=0id=t out=out; proc aima data=out; identify varresidual stationarity=(adf=2); run; 《时间序列分析》课程实验报告 一、上机练习(P124) 1.拟合线性趋势 12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 程序: data xiti1; input x@@; t=_n_; cards; 12.79 14.02 12.92 18.27 21.22 18.81 25.73 26.27 26.75 28.73 31.71 33.95 ; proc gplot data=xiti1; plot x*t; symbol c=red v=star i=join; run; proc autoreg data=xiti1; model x=t; output predicted=xhat out=out; run; proc gplot data=out; plot x*t=1 xhat*t=2/overlay; symbol2c=green v=star i=join; run; 运行结果: 分析:上图为该序列的时序图,可以看出其具有明显的线性递增趋势,故使用线性模型进行拟合:x t=a+bt+I t,t=1,2,3,…,12 分析:上图为拟合模型的参数估计值,其中a=9.7086,b=1.9829,它们的检验P值均小于0.0001,即小于显著性水平0.05,拒绝原假设,故其参数均显著。从而所拟合模型为:x t=9.7086+1.9829t. 分析:上图中绿色的线段为线性趋势拟合线,可以看出其与原数据基本吻合。 2.拟合非线性趋势 1.85 7.48 14.29 23.02 37.42 74.27 140.72 265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 程序: data xiti2; input x@@; t=_n_; cards; 1.85 7.48 14.29 23.02 37.42 74.27 140.72 265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95 ; proc gplot data=xiti2; plot x*t; symbol c=red v=star i=none; run; proc nlin method=gauss; model x=a*b**t; parameters a=0.1 b=1.1; der.a=b**t; der.b=a*t*b**(t-1); output predicted=xh out=out; run; proc gplot data=out; plot x*t=1 xh*t=2/overlay; 总结正态性检验的几种方法 1.1 正态性检验方法 1)偏度系数 样本的偏度系数(记为1g )的计算公式为 ()233133 1(1)(2)(1)(2)n i i n n g x x n n s n n s μ==-=----∑, 其中s 为标准差,3μ为样本的3阶中心距,即()331 1n i i x x n μ==-∑。 偏度系数是刻画数据的对称性指标,关于均值对称的数据其偏度系数为0,右侧更分散的数据偏度系数为正,左侧更分散的数据偏度系数为负。 (2)峰度系数 样本的峰度系数(记为2g ),计算公式为 ()2424 122 44(1)(1)3(1)(2)(3)(2)(3)(1)(1)3(1)(2)(3)(2)(3)n i i n n n g x x n n n s n n n n n n n n s n n μ=+-=-------+-=------∑, 其中s 为标准差,4μ为样本的3阶中心距,即()441 1n i i x x n μ==-∑。 当数据的总体分布为正态分布时,峰度系数近似为0,;当分布为正态分布的尾部更分散时,峰度系数为正;否则为负。当峰度系数为正时,两侧极端数据较多,当峰度系数为负时,两侧极端数据较少。 (3)QQ 图 QQ 图可以帮助我们鉴别样本的分布是否近似于某种类型的分布。现假设总体为正态分布()2 ,N μσ,对于样本12,,,n x x x L ,其顺序统计量是(1)(2)(),,,n x x x L 。设()x Φ为标准正 态分布()0,1N 的分布函数,1 ()x -Φ是反函数,对应正态分布的QQ 图是由以下的点 1()0.375,,1,2,,0.25i i x i n n -??-??Φ= ? ?+???? L , 构成的散点图,若样本数据近似为正态分布,在QQ 图上这些点近似地在直线上 y x σμ=+, 附近,此直线的斜率是标准差σ,截距式均值,μ,所以利用正态QQ 图可以做直观的正态性检验。若正态QQ 图上的点近似地在一条直线上,可以认为样本的数据来自正态分布总 时间序列分析实验报告 P185#1、某股票连续若干天的收盘价如表5-4 (行数据)所示。 表5-4 304 303 307 299 296 293301 293 301 295 284286 286 287 284 282278 281 278 277279 278 270 268 272 273 279 279280 275 271 277 278279 283 284 282 283279 280 280 279278 283 278 270 275 273 273 272275 273 273 272 273272 273 271 272 271273 277 274 274272 280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 选择适当模型拟合该序列的发展,并估计下一天的收盘价。 解: (1)通过SA漱件画出上述序列的时序图如下: 程序: data example5_1; in put x@@; time=_ n_; cards ; 304 303 307 299296 293 301 293 301 295 284286286 287 284 282 278 281 278277 279 278 270 268 272 273279279 280 275 271 277 278 279283 284 282 283 279 280 280279278 283 278 270 275 273 273272 275 273 273 272 273 272273271 272 271 273 277 274 274272 280 282 292 295 295 294290291 288 288 290 293 288 289291 293 293 290 288 287 289292288 288 285 282 286 286 287284 283 286 282 287 286 287292292 294 291 288 289 proc gplot data =example5_1; plot x*time= 1; symbol1 c=black v=star i =join; run ; 上述程序所得时序图如下: 上述时序图显示,该序列具有长期趋势又含有一定的周期性,为典型的非平稳序列。又因为该序列呈现曲线形式,所以选择2阶差分。 正态性检验的几种方法 一、引言 正态分布是自然界中一种最常见的也是最重要的分布。因此,人们在实际使用统计分析时,总是乐于正态假定,但该假定是否成立,牵涉到正态性检验。目前,正态性检验主要有三类方法:一是计算综合统计量,如动差法、Shapiro-Wilk 法(W 检验)、D ’Agostino 法(D 检验)、Shapiro-Francia 法(W ’检验)。二是正态分布的拟合优度检验,如2χ检验、对数似然比检验、Kolmogorov-Smirov 检验。三是图示法(正态概率图Normal Probability plot),如分位数图(Quantile Quantile plot ,简称QQ 图)、百分位数(Percent Percent plot ,简称PP 图)和稳定化概率图(Stablized Probability plot ,简称SP 图)等。而本文从不同角度出发介绍正态性检验的几种常见的方法,并且就各种方法作了优劣比较,还进行了应用。 二、正态分布 2.1 正态分布的概念 定义1若随机变量X 的密度函数为 ()()()+∞∞-∈= -- ,,21 2 2 2x e x f x σμπ σ 其中μ和σ为参数,且()0,,>+∞∞-∈σμ 则称X 服从参数为μ和σ的正态分布,记为()2,~σμN X 。 另我们称1,0==σμ的正态分布为标准正态分布,记为()1,0~N X ,标准正态分布随机变量的密度函数和分布函数分别用()x ?和()x Φ表示。 引理1 若()2,~σμN X ,()x F 为X 的分布函数,则()?? ? ??-Φ=σμx x F 由引理可知,任何正态分布都可以通过标准正态分布表示。 2.2 正态分布的数字特征 在对时间序列Y、X1进行回归分析时需要考虑Y与X1之间是否存在某种切实的关系,所以需要进行协整检验。 1.1利用eviews创建时间序列Y、X1: 打开eviews软件点击file-new-workfile,见对话框又三块空白处workfile structuretype处又三项选择,分别是非时间序列unstructured/undate,时间序列dated-regularfrequency,和不明英语balance panel。选择时间序列dated-regular frequency。在datespecification中选择年度,半年度或者季度等,和起始时间。右下角为工作间取名字和页数。 点击ok。 在所创建的workfile中点击object-new object,选择series,以及填写名字如Y,点击OK。 将数据填写入内。 1.2对序列Y进行平稳性检验: 此时应对序列数据取对数,取对数的好处在于可将间距很大的数据转换为间距较小的数据。 具体做法是在workfile y的窗口中点击Genr,输入logy=log(y),则生成y的对数序列logy。 再对logy序列进行平稳性检验。 点击view-United root test,test type选择ADF检验,滞后阶数中lag length 选择SIC检验,点击ok得结果如下: Null Hypothesis: LOGY has a unit root Exogenous: Constant Lag Length: 0 (Automatic based on SIC, MAXLAG=1) t-StatisticProb.* Augmented Dickey-Fuller test statistic- 2." ."09959 Test critical values:1% level- 4."602226 5% level- 3."026225 10% level - 2."0013 当检验值Augmented Dickey-Fuller test statistic的绝对值大于临界值绝对值时,序列为平稳序列。 若非平稳序列,则对logy取一阶差分,再进行平稳性检验。直到出现平稳序列。假设Dlogy和DlogX1为平稳序列。 1.3对Dlogy和DlogX1进行协整检验 点击窗口quick-equation estimation,输入DLOGY C DLOGX1,点击ok,得到运行结果,再点击proc-make residual series进行残差提取得到残差序列,再对残差序列进行平稳性检验,若残差为平稳序列,则Dlogy与Dlogx1存在协整关系。 《统计软件实验报告》SPSS软件的上机实践应用 时间序列分析 数学与统计学学院 一、实验内容: 时间序列是指一个依时间顺序做成的观察资料的集合。时间序列分析过程中最常用的方法是:指数平滑、自回归、综合移动平均及季节分解。 本次实验研究就业理论中的就业人口总量问题。但人口经济的理论和实践表明,就业总量往往受到许多因素的制约,这些因素之间有着错综复杂的联系,因此,运用结构性的因果模型分析和预测就业总量往往是比较困难的。时间序列分析中的自回归求积分移动平均法(ARIMA)则是一个较好的选择。对于时间序列的短期预测来说,随机时序ARIMA是一种精度较高的模型。 我们已辽宁省历年(1969-2005)从业人员人数为数据基础建立一个就业总量的预测时间序列模型,通过spss建立模型并用此模型来预测就业总量的未来发展趋势。 二、实验目的: 1.准确理解时间序列分析的方法原理 2.学会实用SPSS建立时间序列变量 3.学会使用SPSS绘制时间序列图以反应时间序列的直观特征。 4.掌握时间序列模型的平稳化方法。 5.掌握时间序列模型的定阶方法。 6.学会使用SPSS建立时间序列模型与短期预测。 7.培养运用时间序列分析方法解决身边实际问题的能力。 三、实验分析: 总体分析: 先对数据进行必要的预处理和观察,直到它变成稳态后再用SPSS对数据进行分析。 数据的预处理阶段,将它分为三个步骤:首先,对有缺失值的数据进行修补,其次将数据资料定义为相应的时间序列,最后对时间序列数据的平稳性进行计算观察。 数据分析和建模阶段:根据时间序列的特征和分析的要求,选择恰当的模型进行数据建模和分析。 四、实验步骤: SPSS的数据准备包括数据文件的建立、时间定义和数据期间的指定。 SPSS的时间定义功能用来将数据编辑窗口中的一个或多个变量指定为时间序列变量,并给它们赋予相应的时间标志,具体操作步骤是: 1.选择菜单:Date→Define Dates,出现窗口: 资料的正态性检验汇总 作者:huaxie 来源:【整理】发布时间:2009-4-22 浏览: 567 访问者: 58.23.96.242 摘要提示:本文汇总了通常在对资料进行正态性检验时遇到的问题,比如Kolmogorov-Smirnov检验(简称K-S检验),还是Shapiro-Wilk检验, SPSS里面用哪个过程,SAS程序等。 SPSS和SAS常用正态检验方法 如何在spss中进行正态分布检验 一、图示法 1、P-P图 以样本的累计频率作为横坐标,以安装正态分布计算的相应累计概率作为纵坐标,把样本值表现为直角坐标系中的散点。如果资料服从整体分布,则样本点应围绕第一象限的对角线分布。 2、Q-Q图 以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐标,把样本表现为指教坐标系的散点。如果资料服从正态分布,则样本点应该呈一条围绕第一象限对角线的直线。 以上两种方法以Q-Q图为佳,效率较高。 3、直方图 判断方法:是否以钟形分布,同时可以选择输出正态性曲线。 4、箱式图 判断方法:观测离群值和中位数。 5、茎叶图 类似与直方图,但实质不同。 二、计算法 1、偏度系数(Skewness)和峰度系数(Kurtosis) 计算公式: g1表示偏度,g2表示峰度,通过计算g1和g2及其标准误σg1及σg2然后作U 检验。两种检验同时得出U 【时间简“识”】 说明:本文摘自于经管之家(原人大经济论坛) 作者:胖胖小龟宝。原版请到经管之家(原人大经济论坛) 查看。 1.带你看看时间序列的简史 现在前面的话—— 时间序列作为一门统计学,经济学相结合的学科,在我们论坛,特别是五区计量经济学中是热门讨论话题。本月楼主推出新的系列专题——时间简“识”,旨在对时间序列方面进行知识扫盲(扫盲,仅仅扫盲而已……),同时也想借此吸引一些专业人士能够协助讨论和帮助大家解疑答惑。 在统计学的必修课里,时间序列估计是遭吐槽的重点科目了,其理论性强,虽然应用领域十分广泛,但往往在实际操作中会遇到很多“令人发指”的问题。所以本帖就从基础开始,为大家絮叨絮叨那些关于“时间”的故事! Long long ago,有多long?估计大概7000年前吧,古埃及人把尼罗河涨落的情况逐天记录下来,这一记录也就被我们称作所谓的时间序列。记录这个河流涨落有什么意义?当时的人们并不是随手一记,而是对这个时间序列进行了长期的观察。结果,他们发现尼罗河的涨落非常有规律。掌握了尼罗河泛滥的规律,这帮助了古埃及对农耕和居所有了规划,使农业迅速发展,从而创建了埃及灿烂的史前文明。 好~~从上面那个故事我们看到了 1、时间序列的定义——按照时间的顺序把随机事件变化发展的过程记录下来就构成了一个时间序列。 2、时间序列分析的定义——对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的走势就是时间序列分析。 既然有了序列,那怎么拿来分析呢? 时间序列分析方法分为描述性时序分析和统计时序分析。 1、描述性时序分析——通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律,这种分析方法就称为描述性时序分析 ?描述性时序分析方法具有操作简单、直观有效的特点,它通常是人们进行统计时序分析的第一步。 spss 数据正态分布检验方法及意义判读 要观察某一属性的一组数据是否符合正态分布,可以有两种方法(目前我知道这两种,并且这两种方法只是直观观察,不是定量的正态分布检验): 1:在spss里的基本统计分析功能里的频数统计功能里有对某个变量各个观测值的频数直方图中可以选择绘制正态曲线。具体如下:Analyze-----Descriptive S tatistics-----Frequencies,打开频数统计对话框,在Statistics里可以选择获得各种描述性的统计量,如:均值、方差、分位数、峰度、标准差等各种描述性统计量。在Charts里可以选择显示的图形类型,其中Histograms选项为柱状图也就是我们说的直方图,同时可以选择是否绘制该组数据的正态曲线(With nor ma curve),这样我们可以直观观察该组数据是否大致符合正态分布。如下图: 从上图中可以看出,该组数据基本符合正态分布。 2:正态分布的Q-Q图:在spss里的基本统计分析功能里的探索性分析里面可以通过观察数据的q-q图来判断数据是否服从正态分布。 具体步骤如下:Analyze-----Descriptive Statistics-----Explore打开对话框,选择Plots选项,选择Normality plots with tests选项,可以绘制该组数据的q-q 图。图的横坐标为改变量的观测值,纵坐标为分位数。若该组数据服从正态分布,则图中的点应该靠近图中直线。 纵坐标为分位数,是根据分布函数公式F(x)=i/n+1得出的.i为把一组数从小到大排序后第i个数据的位置,n为样本容量。若该数组服从正态分布则其q-q图应该与理论的q-q图(也就是图中的直线)基本符合。对于理论的标准正态分布,其q-q图为y=x直线。非标准正态分布的斜率为样本标准差,截距为样本均值。 如下图: 河南工程学院课程设计 《时间序列分析课程设计》学生姓名学号: 学院:理学院 专业班级: 专业课程:时间序列分析课程设计指导教师: 2017年 6 月 2 日 目录 1. 实验一澳大利亚常住人口变动分析..... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。 2. 实验二我国铁路货运量分析........... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。 3. 实验三美国月度事故死亡数据分析...... 错误!未定义书签。 实验目的............................................... 错误!未定义书签。 实验原理............................................... 错误!未定义书签。 实验内容............................................... 错误!未定义书签。 实验过程............................................... 错误!未定义书签。课程设计体会 ............................ 错误!未定义书签。 正态性检验的一般方法 姓名:蓝何忠 学号:1101200203 班号:1012201 正态性检验的一般方法 【摘要】:正态分布是自然界中一种最常见的也是最重要的一种分布.因此,人们在实际使用统计分析时,总是乐于正态假定,但该假定是否成立,牵涉到正态性检验.在一般性的概率统计教科书中,只是把这个 问题放在一般性的分布拟合下作简短处理,而这种万精油式的检验方法,对正态性检验不具有特效.鉴于此,该文从不同角度出发介绍正态性检验的几种常见的方法,并且就各种方法作了优劣比较, 【引言】一般实际获得的数据,其分布往往未知。在数据分析中,经常要判断一组数据的分布是否来自某一特定的分布,比如对于连续性分布,常判断数据是否来自正态分布,而对于离散分布来说,常判断是否来自二项分布.泊松分布,或判断实际观测与期望数是否一致,然后才运用相应的统计方法进行分析。 几种正态性检验方法的比较。 2?一、拟合优度检验: (1)当总体分布未知,由样本检验总体分布是否与某一理论分布一致。 H0: 总体X的分布列为p{X=}=,i=1,2,…… H1:总体 X. 的分布不为 构造统计量 为真时H0发生的理为为样本中发生的实际频数,其中论频数。2)检验原理(2?意味着对于,=,观测频数与期望频数完全一致,若=0,则即完全拟合。 2?观察频数与期望频数越接近,则值越小。 2?当原假设为真时,有大数定理,与不应有较大差异,即值应较小。 2?若值过大,则怀疑原假设。 2?拒绝域为R={d} ,判断统计量是否落入拒绝域,得出结论。 二、Kolmogorov-Smirnov正态性检验: Kolmogorov-Smirnov检验法是检验单一样本是否来自某一特定它的 检验方法是以样本数比如检验一组数据是否为正态分布。分布。. 据的累积频数分布与特定理论分布比较,若两者间的差距很小,则推论该样本取自某特定分布族。即对于假设检验问题: H0:样本所来自的总体分布服从某特定分布 H1:样本所来自的总体分布不服从某特定分布 统计原理:Fo(x)表示分布的分布函数,Fn(x)表示一组随机样本的累计概率函数。 #}n1,2,,x{x?,i?i?)F(x n n : x)差距的最大值,定义如下式Fn为Fo(x)与(D设 D=max|Fn(x)-Fo(x)| P{Dn>d}=a. a,对于给定的位健康男性在未进食前的血糖浓度如表所示,试测验这组35例如: =6的正态分布,标准差数据是否来自均值μ=80σ87 77 92 68 80 78 84 77 81 80 80 77 92 86 76 80 81 75 77 72 81 90 84 86 80 68 77 87 76 77 78 92 75 80 78 n=35 检验过程如下:健康成人男性血糖浓度服从正态分布 H0:假设健康成人男性血糖浓度不服从正态分布 H1: 计算过程如表: 时间序列平稳性验 ————————————————————————————————作者:————————————————————————————————日期: 时间序列平稳性检验分析 姓名xxx 学院xx学院 专业xxxx 学号xxxxxxxxxx 时间序列平稳性分析检验 时间序列是一个计量经济学中的概念,时间序列分析中首先遇到的问题是关于时间 序列数据的平稳性问题。 一、时间序列平稳性的定义 假定某个时间序列是由某一随机过程(stochastic process)生成的,即假定时间序列{X t}(t=1, 2, …)的每一个数值都是从一个概率分布中随机得到,如果满足下列条件: ?1)均值E(Xt)=u是与时间t 无关的常数; ?2)方差V ar(Xt)=σ2是与时间t 无关的常数; ?3)协方差Cov(Xt, Xt+k)= γk 是只与时期间隔k有关,与时间t 无关 的常数。 则称该随机时间序列是平稳的(stationary),而该随机过程是一平稳随机过程(stationary stochastic process)。 eg: 一个最简单的随机时间序列是一具有零均值同方差的独立分布序列: Xt=μt ,μt~N(0,σ2) 该序列常被称为是一个白噪声。 由于Xt具有相同的均值与方差,且协方差为零,由定义,一个白噪声序列是平稳的。 eg:另一个简单的随机时间列序被称为随机游走,该序列由如下随机过程生成: Xt=Xt-1+μt 这里,μt是一个白噪声。容易知道该序列有相同的均值:E(Xt)=E(Xt-1) 为了检验该序列是否具有相同的方差,可假设Xt的初值为X0,则易知 X1=X0+μ1 X2=X1+μ2=X0+μ1+μ2 …… Xt=X0+μ1+μ2+…+μt 由于X0为常数,μt是一个白噪声,因此Var(Xt)=tσ2 即Xt的方差与时间t有关而非常数,它是一非平稳序列 二、时间序列平稳性检验的方法 对时间序列进行平稳性检验中,实际上假定了时间序列是由具有白噪声随机误差项 的一阶自回归过程AR(1)生成的。但在实际检验中,时间序列可能由更高阶的自回归过 程生成的,或者随机误差项并非是白噪声,这样用OLS法进行估计均会表现出随机误 差项出现自相关(autocorrelation),导致DF检验无效。另外,如果时间序列包含有明 第三章平稳时间序列分析 选择合适的模型拟合1950-2008年我国邮路及农村投递线路每年新增里程数序列,见表1: 表1 1950-2008年我国邮路及农村投递线路每年新增里程数序列 一、时间序列预处理 (一)时间序列平稳性检验 1.时序图检验 (1)工作文件的创建。打开EViews6.0软件,在主菜单中选择File/New/Workfile, 在弹出的对话框中,在Workfile structure type中选择Dated-regular frequency(时间序列数据),在Date specification下的Frequency中选择Annual(年度数),在Start date中输入“1950”(表示起始年 份为1950年),在End date中输入“2008”(表示样本数据的结束年份为2008年),然后单击“OK”,完成工作文件的创建。 (2)样本数据的录入。选择菜单中的Quick/Empty group(Edit Series)命令,在弹出的Group对话框中,直接将数据录入,并分别命名为year(表示年份),X(表示新增里程数)。 (3)时序图。选择菜单中的Quick/graph…,在弹出的Series List中输入“year x”,然后单击“确定”,在Graph Options中的Specifi中选择“XYLine”,然后按“确定”,出现时序图,如图1所示: 图1 我国邮路及农村投递线路每年新增里程数序列时序图从图1中可以看出,该序列始终在一个常数值附近随机波动,而且波动的围有界,因而可以初步认定序列是平稳的。为了进一步确认序列的平稳性,还需要分析其自相关图。 2.自相关图检验 选择菜单中的Quick/Series Statistics/Correlogram...,在Series Name 中输入x(表示作x序列的自相关图),点击OK,在Correlogram Specification 中的Correlogram of 中选择Level,在Lags to include中输入24,点击OK,得到图2: 正态性检验方法的比较 理论部分 正态分布是许多检验的基础,比如F检验,t检验,卡方检验等在总体不是正太分布是没有任何意义。因此,对一个样本是否来自正态总体的检验是至关重要的。当然,我们无法证明某个数据的确来自正态总体,但如果使用效率高的检验还无法否认总体是正太的检验,我们就没有理由否认那些和正太分布有关的检验有意义,下面我就对正态性检验方法进行简单的归纳和比较。 一、图示法 1. P-P图 以样本的累计频率作为横坐标,以按照正态分布计算的相应累计概率作为纵坐标,以样本值表现为直角坐标系的散点。如果数据服从正态分布,则样本点应围绕第一象限的对角线分布。 2. Q-Q图 以样本的分位数作为横坐标,以按照正态分布计算的相应分位点作为纵坐标,把样本表现为直角坐标系的散点。如果数据服从正太分布,则样本点应围绕第一象限的对角线分布。 以上两种方法以Q-Q图为佳,效率较高。 3. 直方图(频率直方图) 判断方法:是否以钟型分布,同时可以选择输出正态性曲线。 4. 箱线图 判断方法:观察矩形位置和中位数,若矩形位于中间位置且中位数位于矩形的中间位置,则分布较为对称,否则是偏态分布。 5. 茎叶图 判断方法:观察图形的分布状态,是否是对称分布。 二、偏度、峰度检验法(冒牌K-S 检验法): 1. S ,K 的极限分布 样本偏度系数() 3 32 2B S B =;该系数用于检验对称性,S>0时,分布呈正偏态,S<0时, 分布呈负偏态。 样本峰度系数() 4 2 23B K B = -;该系数用于检验峰态,K>0时为尖峰分布,S<0时为 扁平分布;当S=0,K=0时分布呈正态分布。 0H :F(x)服从正态分布 1H :F(x)不服从正态分布 当原假设为真时,检验统计量 ~N(0,1) ~N (0,1) 对于给定的α, R ||={| >λ?| >λ} 其中14 u α - λ= 2. Jarque-Bera 检验(偏度和峰度的联合分布检验法) 检验统计量为 JB 22164n k S K -??= + ??? ()2 2χ~,JB 过大或过小时,拒绝原假设。 三、非参数检验方法 1. Kolmogorov-Smirnov 正态性检验(基于经验分布函数(ECDF )的检验) ()()0max ||n D F x F x =- ()n F x 表示一组随机样本的累计概率函数,()0F x 表示分布的分布函数。 当原假设为真时,D 的值应较小,若过大,则怀疑原假设,从而,拒绝域为 {}R D d =>。对于给定的α,{}p P D d α=>=,又?{}n n p P D D =≥ 2. Lilliefor 正态性检验 该检验是对Kolmogorov-Smirnov 检验的修正,参数未知 时,由22??,X S μσ==可计算得检验统计量?n D 的值。 3. Shapiro-Wilk(W 检验) 检验统计量: 时间序列分析SAS软件实验报告: 以我国2002第一季度到2012年第一季度国内生产总值数据(季节效应模型)分析 班级:统计系统计0姓名: 学号: 指导老师: 20 年月日 时间序列分析报告 一、前言 【摘要】2012年3月5日温家宝代表国务院向大会作政府工作报告。温家宝在报告中提出,2012年国内生产总值增长7.5%。这是我国国内生产总值(GDP)预期增长目标八年来首次低于8%。 温家宝说,今年经济社会发展的主要预期目标是:国内生产总值增长7.5%;城镇新增就业900万人以上,城镇登记失业率控制在4.6%以内;居民消费价格涨幅控制在4%左右;进出口总额增长10%左右,国际收支状况继续改善。同时,要在产业结构调整、自主创新、节能减排等方面取得新进展,城乡居民收入实际增长和经济增长保持同步。 他指出,这里要着重说明,国内生产总值增长目标略微调低,主要是要与“十二五”规划目标逐步衔接,引导各方面把工作着力点放到加快转变经济发展方式、切实提高经济发展质量和效益上来,以利于实现更长时期、更高水平、更好质量发展。提出居民消费价格涨幅控制在4%左右,综合考虑了输入性通胀因素、要素成本上升影响以及居民承受能力,也为价格改革预留一定空间。 对于这一预期目标的调整,温家宝解释说,主要是要与“十二五”规划目标逐步衔接,引导各方面把工作着力点放到加快转变经济发展方式、切实提高经济发展质量和效益上来,以利于实现更长时期、更高水平、更好质量发展。 央行货币政策委员会委员李稻葵表示,未来若干年中国经济增长速度会有所放缓,这个放缓是必要的,是经济发展方式转变的一个必然要求。 【关键词】“十二五”规划目标国内生产总值增长率增速放缓提高发展质量附表:国内生产总值(2012年1季度) 绝对额(亿元)比去年同期增长(%) 国内生产总值107995.0 8.1 第一产业6922.0 3.8 第二产业51450.5 9.1 第三产业49622.5 7.5 注1:绝对额按现价计算,增长速度按不变价计算。注2:该表为初步核算数据。 GDP环比增长速度 环比增长速度(%) 2011年1季度 2.2 2季度 2.3 3季度 2.4 4季度 1.9 2012年1季度 1.8 注:环比增长速度为经季节调整与上一季度对比的增长速度。 此表是我国2012年第一季度国内生产总值及与2011年同期比较来源:前瞻网 河南工程学院课程设计《时间序列分析课程设计》学生姓名学号: 学院:理学院 专业班级: 专业课程:时间序列分析课程设计 指导教师: 2017年6月2日 目录 1. 实验一澳大利亚常住人口变动分析 (1) 1.1 实验目的 (1) 1.2 实验原理 (1) 1.3 实验内容 (2) 1.4 实验过程 (3) 2. 实验二我国铁路货运量分析 (8) 2.1 实验目的 (8) 2.2 实验原理 (8) 2.3 实验内容 (9) 2.4 实验过程 (10) 3. 实验三美国月度事故死亡数据分析 (14) 3.1 实验目的 (14) 3.2 实验原理 (15) 3.3 实验内容 (15) 3.4 实验过程 (16) 课程设计体会 (19) 1.实验一澳大利亚常住人口变动分析 1971年9月—1993年6月澳大利亚常住人口变动(单位:千人)情况如表1-1所示(行数据)。 表1-1 (1)判断该序列的平稳性与纯随机性。 (2)选择适当模型拟合该序列的发展。 (3)绘制该序列拟合及未来5年预测序列图。 1.1 实验目的 掌握用SAS软件对数据进行相关性分析,判断序列的平稳性与纯随机性,选择模型拟合序列发展。 1.2 实验原理 (1)平稳性检验与纯随机性检验 对序列的平稳性检验有两种方法,一种是根据时序图和自相关图显示的特征做出判断的图检验法;另一种是单位根检验法。 (2)模型识别 先对模型进行定阶,选出相对最优的模型,下一步就是要估计模型中未知参数的值,以确定模型的口径,并对拟合好的模型进行显著性诊断。 (3)模型预测 模型拟合好之后,利用该模型对序列进行短期预测。 1.3 实验内容 (1)判断该序列的平稳性与纯随机性 时序图检验,根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常识值附近波动,而且波动的范围有界。如果序列的时序图显示该序列有明显的趋势性或周期性,那么它通常不是平稳序列。 对自相关图进行检验时,可以用SAS 系统ARIMA 过程中的IDENTIFY 语句来做自相关图。 而单位根检验我们用到的是DF 检验。以1阶自回归序列为例: 11t t t x x φε-=+ 该序列的特征方程为: 0λφ-= 特征根为: λφ= 当特征根在单位圆内时: 11φ< 该序列平稳。 当特征根在单位圆上或单位圆外时: 11φ≥ 该序列非平稳。 对于纯随机性检验,既白噪声检验,可以用SAS 系统中的IDENTIFY 语句来输出白噪声检验的结果。 (2)选择适当模型拟合该序列的发展 实验6 时间序列分析的spss应用 6.1 实验目的 学会运用SPSS统计软件创建时间数列,熟练掌握长期趋势线性模型拟合和季节变动测定的SPSS方法与技能。 6.2 相关知识(略) 6.3 实验内容 6.3.1 用SPSS统计软件创建时间序列的创建 6.3.2用SPSS统计软件处理长期趋势线性模型的拟合(最小二乘法、指数平滑法)及预测。 6.3.3掌握测定季节变动规律的SPSS测定方法。 6.4实验要求 6.4.1准备实验数据 6.4.2用SPSS统计软件创建彩电出口数量的时间序列 6.4.3用最小二乘法测定长期趋势,拟合线性趋势方程,并进行趋势预测。 6.4.4测定彩电出口数量的季节变动规律。 6.4.5用指数平滑法预测2014和2015年的彩电出口数量。 6.5 实验步骤 6.5.1 实验数据 为了研究某国彩电出口的情况,某研究机构收集了从2003-2013年某国彩电出口的月度数据,如表6-1所示。 表6-1 我国2003-2013年的我国彩电出口的月度数据(单位:万台)1月2月3月4月5月6月7月8月9月10月11月12月2003年12.53 13.73 24.45 28.75 32.45 31.11 25.94 32.98 43.49 42.94 63.29 77.28 2004年30.01 39.63 29.77 42.74 32.25 31.94 32.27 32.59 32.92 30.98 47.44 52.82 2005年24.08 16.42 31.24 29.33 31.88 30.09 28.08 32.99 44.99 47.57 50.36 75.19 2006年39.02 25.81 43.38 37.34 39.22 39.87 51.10 50.99 55.16 62.78 57.75 72.20 2007年28.76 39.38 46.10 39.41 38.74 40.18 45.59 43.31 46.68 54.17 53.65 61.12 2008年28.87 21.23 35.82 26.97 32.33 24.53 29.39 31.96 38.22 39.24 52.95 68.41 时间序列分析实验报告 P185#1、某股票连续若干天的收盘价如表5—4(行数据)所示。 表5-4 304 303 307 299 296 293 301293 301 295 284 286 286 287 284 282 278 281278 277 279 278 270 268 272 273 279 279 280 275271 277 278 279 283284 282 283 279 280 280 279 278 283278270 275 273 273 272 275 273273272 273 272273 271 272 271 273 277 274 274 272280 282 292 295 295 294 290 291 288 288 290 293 288 289 291 293 293 290288 287 289 292 288 288 285 282 286 286 287 284 283 286 282 287 286 287 292 292 294 291 288 289 选择适当模型拟合该序列的发展,并估计下一天的收盘价。 解: (1)通过SAS软件画出上述序列的时序图如下: 程序: data example5_1; input x@@; time=_n_; cards; 304 303 307299 296293 301 293 301 295 284 286 286 287 284 282 278 281278 277 279 278 270268 272 273279 279 280275 271 277 278 279 283 284 282 283 279 280 280 279 278 283 278 270 275 273273 272 275 273 273 272 273 272 273 271272 271 273 277 274274 272 280 282 292295 295 294 290 291288 288 290 293288 289 291 293 293 290 288 287 289 292 288 288 285 282 286 286 287 284283 286 282 287 286 287 292 292 294 291 288 289 ; proc gplot data=example5_1; plotx*time=1; symbol1c=blackv=star i=join; run; 上述程序所得时序图如下:多元时间序列建模分析
时间序列分析实验报告(3)
总结正态性检验的几种方法
时间序列分析实验报告
正态性检验的几种方法
利用eviews实现时间序列的平稳性检验与协整检验
spss时间序列模型
资料的正态性检验汇总
时间序列分析_最经典的
spss_数据正态分布检验方法及意义
应用时间序列实验报告
正态性检验的一般方法汇总
时间序列平稳性验
时间序列实验报告
SPSS 正态性检验方法
时间序列分析实验报告
应用时间序列实验报告
实验·6时间序列分析报告地spss应用
时间序列分析实验报告70946