生物统计上机操作第五讲 方差分析
研究生《生物统计学》课程
第五讲方差分析
主要内容:
一、单因素方差分析
二、两因素方差分析
三、多因素方差分析
一、单因素方差分析[Analyze]=>[Compare Means]=>[ One-Way ANOV A]
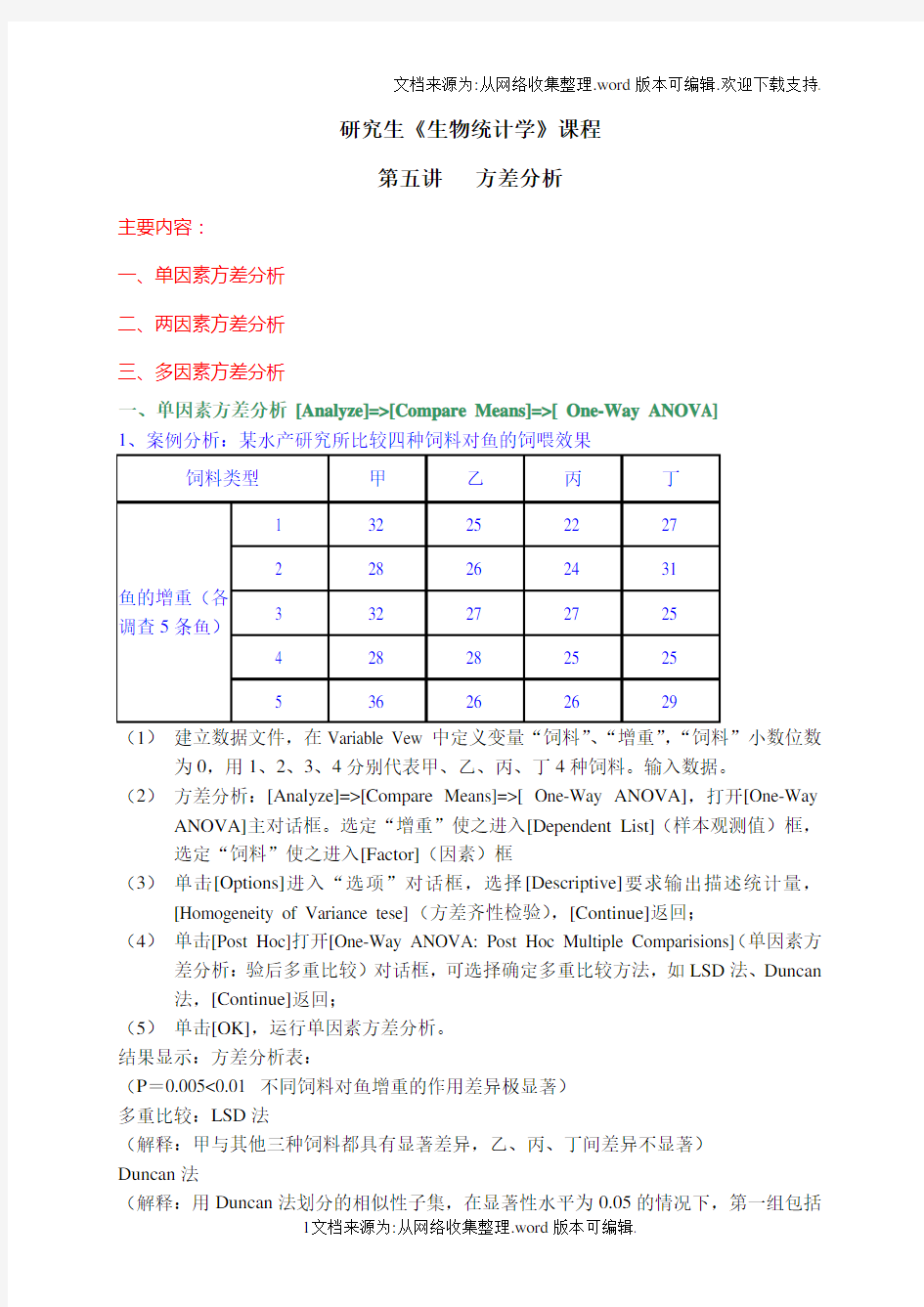
1、案例分析:某水产研究所比较四种饲料对鱼的饲喂效果
(1)建立数据文件,在Variable Vew中定义变量“饲料”、“增重”,“饲料”小数位数为0,用1、2、3、4分别代表甲、乙、丙、丁4种饲料。输入数据。
(2)方差分析:[Analyze]=>[Compare Means]=>[ One-Way ANOVA],打开[One-Way ANOVA]主对话框。选定“增重”使之进入[Dependent List](样本观测值)框,选定“饲料”使之进入[Factor](因素)框
(3)单击[Options]进入“选项”对话框,选择[Descriptive]要求输出描述统计量,[Homogeneity of Variance tese](方差齐性检验),[Continue]返回;
(4)单击[Post Hoc]打开[One-Way ANOV A: Post Hoc Multiple Comparisions](单因素方差分析:验后多重比较)对话框,可选择确定多重比较方法,如LSD法、Duncan 法,[Continue]返回;
(5)单击[OK],运行单因素方差分析。
结果显示:方差分析表:
(P=0.005<0.01 不同饲料对鱼增重的作用差异极显著)
多重比较:LSD法
(解释:甲与其他三种饲料都具有显著差异,乙、丙、丁间差异不显著)
Duncan法
(解释:用Duncan法划分的相似性子集,在显著性水平为0.05的情况下,第一组包括
丙乙丁,组内相似的概率为0.123;第二组包括甲,说明甲的均值与其他三个具有显著性差异)
2、练习:某灯泡厂用四种配料方案制成的灯丝生产了四批灯泡,在每批灯泡中作随机抽样,测量其使用寿命(单位:小时),数据如下:
问不同灯丝制成的灯泡的使用寿命是否有显著差异,存在差异则做多重比较。
3、练习:调查5个不同小麦品系株高(cm),结果见下表,比较不同品系间小麦株高差异是否显著。
二、两因素方差分析:研究两个控制变量是否对观察变量产生显著影响,不仅能分析两个因素对观测变量的影响,还能分析其交互作用对观测变量的分布产生影响。在SPSS 中,两因素方差分析是利用“General Linear Model”(一般线性模型)模块中的“Univariate”(单变量方差分析)过程来完成。
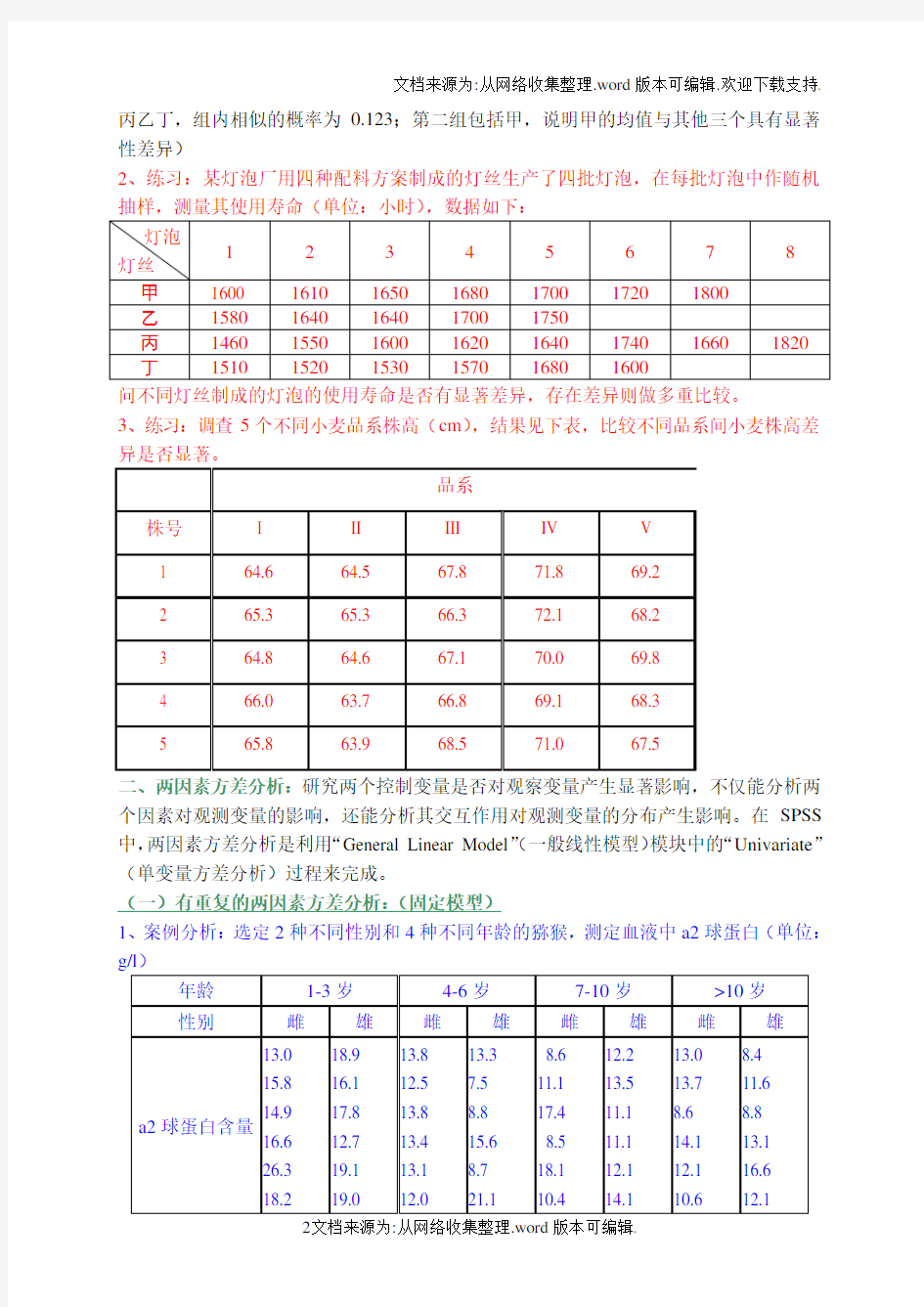
(一)有重复的两因素方差分析:(固定模型)
1、案例分析:选定2种不同性别和4种不同年龄的猕猴,测定血液中a2球蛋白(单位:
生物统计学期末考试上机考试部分 复习试卷B
云南师范大学2010~2011学年下学期期末统一考试 高级生物统计学实验(期末) 试卷 学院 专业 年级 学号 姓名 考试方式(闭卷或开卷): 闭卷 考试时量:60分钟 试卷编号(B 卷): 题号 一 二 三 四 五 总分 评卷人 得分 一、下表为某种动物在不同温度下的代谢率的变化,试比较温度对其代谢率 有无影响?并对SSR 法其进行多重比较 温度(℃) 代谢率(mlO 2/g.h ) -5 2.78 3.80 4.87 4.68 5.51 5.67 5.10 2.79 2.60 3.14 4.26 3.72 3.48 2.86 3.37 3.32 4.35 4.59 4.66 4.83 5.16 -5 -5 -5 -5 -5 -5 .00 .00 .00 .00 .00 .00 .00 5.0 5.0 5.0 5.0 5.0 5.0 5.0
ANOVA 数据 7.1972 3.598 5.684 .012 11.39718.633 18.593 20 Between Groups Within Groups Total Sum of Squares df Mean Square F Sig. 经但因素方差分析的:f=5.684, p=0.012,差异显著,说明多有作用, 数据 Duncan a 7 3.2643 7 4.32577 4.6300 1.000.484 温度231Sig. N 12Subset for alpha = .05 Means for groups in homogeneous subsets are displayed. Uses H armonic Mean Sample Size = 7.000. a. 二、为调查红绿色盲是否与性别有关,某单位调查结果如下: 色盲 非色盲 男 32 168 女 13 232 问红绿色盲是否与性别有关? 三、试用交互误差图比较不同季节某种动物的胃长(cm )的变化?并绘制出其在 95%置信带 季节 胃长(cm )
生物统计学 实验报告 大肠杆菌
A 题 细胞体内代谢物浓度预测 随着基因组、转录组、蛋白质组等各种“组学”研究计划的蓬勃开展,生命科学进入了“组学”时代。代谢组学作为系统生物学的重要分支,其研究的重点是细胞内代谢物种类与浓度的定性和定量分析以及代谢网络的构建和模拟。 对代谢物的检测及浓度测定主要采用实验方法,包括核磁共振、气相色谱-质谱联用和液相色谱-质谱联用等技术。但由于代谢物种类繁多,且大部分浓度较低(μM 数量级),尤其是胞内代谢物提取难度非常大,精确测定其浓度异常困难,而且实验测定需要消耗大量财力物力和人力,因此通过计算机方法对代谢物浓度预测和分析变得越来越重要。 活细胞的代谢物浓度由什么决定?除了一些特定的代谢和酶的作用以外,有没有那种能全局影响浓度值的性质? 试根据附件中的数据完成如下问题: 1 根据不同类型的数据,分析代谢物浓度与其物理化学性质之间的关系。 2 筛选合适的物理化学性质,建立预测代谢物浓度的预测模型,并对此模型进行评价; 1.线性插补法处理缺失数据 原理:用该列数据缺失值前一个数据和后一个数据建立线性插值,然后用缺失点在线性插值函数的函数值填充该缺失值,即: 在于消除不同变量的量纲的影响,而且标准化转化不会改变变量的相关系数。 代谢物浓度:取对数 代谢物理化性质:标准差标准化法 )1,1( m j n i S x x x j j ij ij ≤≤≤≤-=' 式中:.)(11,1121∑∑==--= =n i j ij j n i ij j x x n S x n x 3.SAS 软件建立多元线性回归方程 回归模型一般形式: u X b X b X b b Y k k +++++= (22110)
spss学习系列23.协方差分析
(一)原理 一、基本思想 在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。这种影响的变量称为协变量(一般是连续变量)。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。 协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。 协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。 当有一个协变量时,称为一元协方差分析,当有两个或两个以上的协变量时,称为多元协方差分析。
二、协方差分析需要满足的条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量;对连续变量或定距变量的协变量的测量不能有误差; (2)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;协变量的回归系数(即各回归线的斜率)是相同的,且不等于0,即各组的回归线是非水平的平行线。否则,就有可能犯第一类错误,即错误地接受虚无假设; (3) 自变量与协变量相互独立,若协方差受自变量的影响,那么协方差分析在检验自变量的效应之前对因变量所作的控制调整将是偏倚的,自变量对因变量的间接效应就会被排除; (4)各样本来自具有相同方差σ2的正态分布总体,即要求各组方差齐性。 三、基本理论 1. 观测值=均值+分组变量影响+协变量影响+随机误差. 即 ()ij i ij ij y u t x x βε=++-+ (1) 其中,X 为所有协变量的平均值。 注:在方差分析中,协变量影响是包含在随机误差中的,在协方差分析中需要分离出来。 用协变量进行修正,得到修正后的y ij (adj)为 (adj)()ij ij ij i ij y y x x u t βε=--=++ 就可以对y ij (adj)做方差分析了。关键问题是求出回归系数β. 2. 总离差=分组变量离差+协变量离差+随机误差,
生物统计学期末考试题
生物统计学期末考试题 一名词解释(每题2分,共10分) 1.生物统计学期末考试题 2.样本:从总体中抽出的若干个体所构成的集合称为样本 3.方差:用样本容量n来除离均差平方和,得到的平方和,称为方差 4.标准差:方差的平方根就是标准差 5.标准误:即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度, 反映的是样本均数之间的变异。 6.变异系数:将样本标准差除以样本平均数,得出的百分比就是变异系数 7.抽样:通常按相等的时间间隔对信号抽取样值的过程。 8.总体参数:所谓总体参数是指总体中对某变量的概括性描述。 9.样本统计量:样本统计量的概念很宽泛(譬如样本均值、样本中位数、样本方差等等),到现在 为止,不是所有的样本统计量和总体分布的关系都能被确认,只是常见的一些统计量和总体分布之间 的关系已经被证明了。 10.正态分布:若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布, 正态分布又名 高斯分布 11.假设测验:又称显著性检验,就是根据总体的理论分布和小概率原理,对未知或不完全知道的总 体提出两种彼此对立的假设,然后由样本的实际结果,经过一定的计算,做出在一定概率意义上应该 接受的那种假设的推断。 12.方差分析:又称“变异数分析”或“F检验”,用于两个及两个以上样本均数差别的显著性检验。 13.小概率原理:一个事件如果发生的概率很小的话,那么它在一次试验中是几乎不可能发生的,但 在多次重复试验中几乎是必然发生的,数学上称之小概率原理。 15.决定系数:决定系数定义为相关系数r的平方 16.随机误差:在实际相同条件下,多次测量同一量值时,其绝对值和符号无法预计的测量误差。 17.系统误差:它是在一定的测量条件下,对同一个被测尺寸进行多次重复测量时,误差值的大小和 符号(正值或负值)保持不变;或者在条件变化时,按一定规律变化的误差 二. 判断题(每题2分,共10分) 1. 在正态分布N(μ ;σ)中,如果σ相等而μ不等,则曲线平移, ( ) 2. 如果两个玉米品种的植株高度的平均数相同,我们可以认为这两个玉米品种是来自同一总体() 3. 当我们说两个处理平均数有显著差异时,则我们有99%的把握肯定它们来自不同总体. 4小概率原理是指小概率事件在一次试验中可以认为不可能发生() 5 激素处理水稻种子具有增产效应,现在在5个试验区内种植经过高、中、低三种剂量的激素处理的水稻种此试验称为三处理五重复试验() 6.系统误差是不可避免的,并且可以用来计算试验精度。() 7.精确度就是指观察值与真值之间的差异。() 8. 实验设计的三个基本原则是重复、随机、局部控制。() 9. 正交试验设计就是从全部组合的处理中随机选取部分组合进行试验。() 10.如果回归方程Y=3+1.5X的R2=0.64,则表明Y的总变异80%是X造成。() 三. 简答题(每题5分共20分) 1. 完全随机试验设计与随机区组试验设计有什么不同? 2. 什么是小概率原理?在统计推断中有何 作用? 3. 什么是多重比较中的FISHER氏保护测验?4. 样本的方差计算中,为什么要离均差平方和 除以n-1而不是除以n? 5. 如果两个变量X和Y的相关系数小于0.5,是否它们就没有显著相关性? 6. 单尾测验与双尾测验有何异同?
生物统计学重要知识点
生物统计学重要知识点 (说明:下列知识点为考试内容,没涉及的不需要复习。注意加粗的部分为重中之重,一定要弄懂。大家要进行有条理性的复习,望大家考出好成绩!) 第一章概论(容易出填空题和名词解释) 1、生物统计学的目的、内容、作用及三个发展阶段 2、生物统计学的基本特点 3、会解释总体、个体、样本、样本容量、变量、参数、统计数、效应和互作 4、会区分误差(随机误差和系统误差)与错误以及产生的原因 5、会区分准确度和精确度 第二章试验资料的整理与特征数的计算(容易出填空和名词解释) 1、随机抽样必须满足的两个条件 2、能看懂次数分布表和次数分布图,会计算全距、组数、组距、组限和组中值 3、会求平均数(算数、加权和几何)、中位数、众数,算术平均数的重要特性 4、会求极差、方差、标准差和变异系数,理解标准差的性质 第三章概率与概率分布(选择、填空和计算) 1、理解事件、频率及概率,事件的相互关系,加法定理和乘法定理的运用 2、概率密度函数曲线的特点和大数定律 3、二项分布、泊松分布和正态分布的概率函数和标准分布图像特征,会计算概率值 4、理解分位数的概念,弄清什么时候用单尾,什么时候用双尾 5、样本平均数差数的分布 第四章统计推断(计算) 1、无效假设和备择假设、显著水平、双尾检验和单尾检验、假设检验的两类错误,会根据 小概率原理做出是否接受无效假设的判断 2、总体方差已知和未知情况下如何进行U检验 3、一个样本平均数的t检验(例4.5) 成组数据平均数比较的t检验(例4.6和4.7) 4、一个样本频率的假设检验(例4.11),知道连续性矫正 5、参数的区间估计(置信区间)和点估计
生物统计学实验指导
《生物统计学》实验教学教案 [实验项目] 实验一平均数标准差及有关概率的计算 [教学时数] 2课时。 [实验目的与要求] 1、通过对平均数、标准差、中位数、众数等数据的计算,掌握使用计算机计算统计量的方法。 2、通过对正态分布、标准正态分布、二项分布、波松分布的学习,掌握使用计算机计算有关概率和分位数的方法。为统计推断打下基础。 [实验材料与设备] 计算器、计算机;有关数据资料。 [实验内容] 1、平均数、标准差、中位数、众数等数据的计算。 2、正态分布、标准正态分布有关概率和分位数的计算。 3、二项分布有关概率和分位数的计算。 4、波松分布有关概率和分位数的计算。 [实验方法] 1、平均数、标准差、中位数、众数等数据的计算公式。 平均数=Average(x1x2…x n) 几何平均数=Geomean(x1x2…x n) 调和平均数=Harmean(x1x2…x n) 中位数=median(x1x2…x n) 众数=Mode(x1x2…x n) 最大值=Max(x1x2…x n) 最小值=Min(x1x2…x n) 平方和(Σ(x- )2)=Devsq(x1x2…x n) x 样本方差=Var (x1x2…x n) 样本标准差=Stdev(x1x2…x n) 总体方差=Varp(x1x2…x n) 总体标准差=Stdevp(x1x2…x n) 2、正态分布、标准正态分布有关概率和分位数的计算。 一般正态分布概率、分位数计算:
概率=Normdist(x,μ,σ,c) c 取1时计算 -∞-x 的概率 c 取0时计算 x 的概率 分位数=Norminv(p, μ, σ) p 取-∞到分位数的概率 练习: 猪血红蛋白含量x 服从正态分布N(12.86,1.332),(1) 求猪血红蛋白含量x 在11.53—14.19范围内的概率。(0.6826)(2) 若P(x <1l )=0.025,P(x >2l )=0.025,求1l ,2l 。 (10.25325) L1=10.25 L2=15.47 标准正态分布概率、分位数计算: 概率=Normsdist(x) c 取1时计算 -∞--x 的概率 c 取0时计算 x 的概率 分位数=Normsinv(p) p 取-∞到分位数的概率 练习: 1、已知随机变量u 服从N(0,1),求P(u <-1.4), P(u ≥1.49), P (|u |≥2.58), P(-1.21≤u <0.45),并作图示意。 参考答案: (0.080757,0.06811,0.00988,0.5605) 2、已知随机变量u 服从N(0,1),求下列各式的αu 。 (1) P(u <-αu )+P(u ≥αu )=0.1; 0.52 (2) P(-αu ≤u <αu )=0.42; 0.95 参考答案: [1.644854, 0.63345; 0.553385, 1.959964] 3、二项分布有关概率和分位数的计算。 概率=Binomdist(x,n,p,c) c 取1时计算 0-x 的概率 c 取0时计算 x 的概率 练习: 1、已知随机变量x 服从二项分布B (100,0.1),求μ及σ。 参考答案: 见P48,μ= np, σ=(npq)0.5 2、已知随机变量x 服从二项分布B(10,0.6),求P(2≤x ≤6),P(x ≥7),P(x<3)。 参考答案: 0.6054, 0.38228, 0.012295 4、波松分布有关概率和分位数的计算。 概率=Poisson(x,λ,c) c 取1时计算 0-x 的概率 c 取0时计算 x 的概率 练习: ),(m n Permut C m n =
方差分析和协方差分析,协变量和控制变量
方差分析和协方差分析,协变量和控制变量 方差分析 方差分析(Analysis of Variance,简称ANOVA),又称“变异数分析”或“F检验”,是R.A.Fisher发明的,用于两个及两个以上样本均数差别的显著性检验。由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。 方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。 假定条件和假设检验? 1. 方差分析的假定条件为:(1)各处理条件下的样本是随机的。(2)各处理条件下的样本是相互独立的,否则可能出现无法解析的输出结果。(3)各处理条件下的样本分别来自正态分布总体,否则使用非参数分析。(4)各处理条件下的样本方差相同,即具有齐效性。 2. 方差分析的假设检验假设有K个样本,如果原假设H0样本均数都相同,K个样本有共同的方差σ,则K个样本来自具有共同方差σ和相同均值的总体。如果经过计算,组间均方远远大于组内均方,则推翻原假设,说明样本来自不同的正态总体,说明处理造成均值的差异有统计意义。否则承认原假设,样本来自相同总体,处理间无差异。 作用 一个复杂的事物,其中往往有许多因素互相制约又互相依存。方差分析的目的是通过数据分析找出对该事物有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。方差分析是在可比较的数组中,把数据间的总的“变差”按各指定的变差来源进行分解的一种技术。对变差的度量,采用离差平方和。方差分析方法就是从总离差平方和分解出可追溯到指定来源的部分离差平方和,这是一个很重要的思想。经过方差分析若拒绝了检验假设,只能说
生物统计学考试题及答案
生物统计学考试题及答案
重庆西南大学 2012 至 2013 学年度第 2 期 生物统计学 试题(A ) 试题使用对象: 2011 级 专 业(本科) 命题人: 考试用时 120 分钟 答题方式采用: 一:判断题;(每小题1分,共10分 ) 1、正确无效假设的错误为统计假设测验的第一类错误。( ) 2、标准差为5,B 群体的标准差为12,B 群体的变异一定大于A 群体。( ) 3、一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 4、30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已 知84.321,05.0=χ)。 ( ) 5、固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于推断处理的总体。( ) 6、率百分数资料进行方差分析前,应该对资料数据作反正弦转换。( ) 7、比较前,应该先作F 测验。 ( ) 8、验中,测验统计假设H 00:μμ≥ ,对H A :μμ<0 时,显著水平为5%,则测验的αu 值为1.96( ) 9、行回归系数假设测验后,若接受H o :β=0,则表明X 、Y 两变数无相关关系。( ) 10、株高的平均数和标准差为30150±=±s y (厘米),果穗长的平均数和标准差为s y ±1030±=(厘米),可认为该玉米的株高性状比果穗性状变异大。 ( ) 二:选择题;(每小题2分,共10分 ) 1分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。
A 、[-9.32,11.32] B 、[-4.16,6.16] C 、[-1.58,3.58] D 、都不是 2、态分布不具有下列哪种特征( )。 A 、左右对称 B 、单峰分布 C 、中间高、两头低 D 、概率处处相等 3、一个单因素6个水平、3次重复的完全随机设计进行方差分析,若按最小显著差数法进行多重比较,比较所用的标准误及计算最小显著差数时查表的自由度分别为( )。 A 、 2MSe/6 , 3 B 、 MSe/6 , 3 C 、 2MSe/3 , 12 D 、 MSe/3 , 12 4、已知),N(~x 2σμ,则x 在区间]96.1,[σμ+-∞的概率为( )。 A 、0.025 B 、0.975 C 、0.95 D 、0.05 5、 方差分析时,进行数据转换的目的是( )。 A. 误差方差同质 B. 处理效应与环境效应线性可加 C. 误差方差具有正态性 D. A 、B 、C 都对 三、简答题;(每小题6分,共30分 ) 1、方差分析有哪些步骤? 2、统计假设是?统计假设分类及含义? 3、卡方检验主要用于哪些方面? 4、显著性检验的基本步骤? 5、平均数有哪些?各用于什么情况? 四、计算题;(共4题、50分) 1、进行大豆等位酶Aph 的电泳分析,193份野生大豆、223份栽培大豆等位基因型的次数列于下表。试分析大豆Aph 等位酶的等位基因型频率是否因物种而不同。( 99 .52 05.0,2=χ, 81 .7205.0,3=χ)(10分) 野生大豆和栽培大豆Aph 等位酶的等位基因型次数分布 物 种 等位基因型 1 2 3 野生大豆 29 68 96
生物统计学 (2)
生物统计学 名词解释: 1.生物统计学:是数理统计在生物学研究中的应用,它是应用数理统计的原理,运用 统计方法来认识、分析、推断和解释生命过程中的各种现象和试验调查资料的科学。 2.总体:具有相同性质或属性的个体所组成的集合称为总体,它是指研究对象的全 体; 3.个体:组成总体的基本单元称为个体; 4.样本:从总体中抽出若干个体所构成的集合称为样本; 5.样本容量:样本中所包含的个体数目称为样本容量。 6.集中性:资料中的观测值从某一数值为中心而分布的性质。 7.离散性:是变量有差离中心分散变异的性质。 8.变量(变数):指相同性质的事物间表现差异性或差异特征的数据。 9.常数:表示能代表事物特征和性质的数值,通常由变量计算而来,在一定过程中是 不变的。 10.参数:描述总体特征的数量称为参数,也称参量。常用希腊字母表示参数,例如用 μ表示总体平均数,用σ表示总体标准差; 11.统计数:描述样本特征的数量称为统计数,也称统计量。常用拉丁字母表示统计数, 例如用x表示样本平均数,用S表示样本标准差。 12.效应:通过施加试验处理,引起试验差异的作用称为效应。效应是一个相对量,而 非绝对量,表现为施加处理前后的差异。效应有正效应与负效应之分。 13.互作(连应):是指两个或两个以上处理因素间相互作用产生的效应。互作也有正效 应(协同作用)与负效应(拮抗作用)之分。 14.准确性:也叫准确度,指在调查或试验中某一试验指标或性状的观测值与其真值接 近的程度。 15.精确性:也叫精确度,指调查或试验中同一试验指标或性状的重复观测值彼此接近 的程度。 16.随机误差(抽样误差):这是由于试验中无法控制的内在和外在的偶然因素所造成。 随机误差越小,试验精确性越高。 17.系统误差(片面误差):这是由于试验条件控制不一致、测量仪器不准、试剂配制 不当、试验人员粗心大意使称量、观测、记载、抄录、计算中出现错误等人为因素而引起的。系统误差影响试验的准确性。只要以认真负责的态度和细心的工作作风是完全可以避免的。 18.试验误差:在试验过程中,由于试验条件及人为的一些因素而造成的试验结果与真 实值之间的偏差,来源于试验材料固有的差异和外界因素(管理措施、试验条件等)。 19.数量性状:是指能够以计数和测量或度量的方式表示其特征的性状。 20.质量性状:是指能观察到而不能直接测量的性状 21.次数资料:由质量性状量化得来的资料叫做次数资料。 22.试验:是对已有的或没有的事物加以处理的方法。 23.大数定律:是概率论中用来阐述大量随机现象平均结果稳定性的一系列定律的总称。 主要内容:样本容量越大,样本统计数与总体参数之差越小。 24.泊松分布:是一种可以用来描述和分析随机地发生在单位空间或时间里的稀有事件 的概率分布,也是一种离散型随机变量的分布。 25.假设检验:又称显著性检验,就是根据总体的理论分布和小概率原理,对未知或不完 全知道的总体提出两种彼此对立的假设,然后由样本的实际原理,经过一定的计算,
协方差分析
第十一节协方差分析 (analysis of covariance) 在各种试验设计中,对应变量(dependent variable)Y 研究时,常希望其他可能影响Y的变量在各组间保持基本一致,以达到均衡可比。例如:比较几种药物的降压作用,各试验组在原始血压、性别、年龄等指标应无差异。
第十一节协方差分析 有时这些变量不能控制,须在统计分析时,通过一定方法来消除这些变量的影响后,再对应变量y作出统计推断。称这些影响变量为协变量(Covariate)。 如果所控制的变量是分类变量时,可用多因素的方差分析; 当要控制的变量是连续型变量时,可用协方差分析,以消除协变量的影响,或将协变量化成相等后,对y的修正均数进行方差分析。
第十一节协方差分析 例如:比较几种不同饲料对动物体重增加的作用,可把动物的进食量作为协变量。 比较大学生和运动员的肺活量时,可把身高作为协变量。 比较治疗后二组舒张压的大小,可把治疗前的舒张压作为协变量。
第十一节协方差分析 协方差分析的基本原理: 协方差分析是把直线回归和方差分析结合起来的一种统计分析方法。当不同处理结果的y值受协变量x的影响时,先找出y与x的直线关系,求出把x值化为相等后y的修正均数,然后进行比较,这样就能消除x对y的影响,更恰当地评价各种处理的作用。
协方差分析的步骤 ±观察指标服从正态分布、方差齐性、各观察相互独立H检验分组因素与协变量x是否有交互作用。对上例,即是否雌雄羔羊进食量相同,它们的体重增加量却不相同。如检验结果分组因素与协变量x间没有交互作用,即说明雌雄羔羊进食量相同的情况下,它们的体重增加量是相同的。进行第二项检验: H检验协变量与应变量之间是否存在线性关系。如果不存在线性关系,则不能简单地运用协方差分析,因为协方差分析是利用协变量x与应变量y之间的线性回归关系扣除协变量x对y的影响。必要时可考虑进行变量转换。如果检验结果协变量与应变量之间存在线性关系,则进行第三项检验: H进一步扣除x对y影响的前提下,检验各组的修正均数差别是否有统计学意义。
生物统计学考试试卷及答案
考试轮次:2017-2018学年第一学期期末考试试卷编号 考试课程:[120770] 生物统计与实验设计命题负责人曾汉元 适用对象:生物与食品工程学院生物科学专业2015级审查人签字 考核方式:上机考试试卷类型:A卷时量:150分钟总分:100分 注意:答案中要求保留必要的计算和推理过程,全部答案保存为一个Word文档,文件名 为学号最后两位数+姓名。考试结束后不要关机。提交答卷后,请到主机看一下是否提交成功。第1题12分,第3题5分,第10题13分,其余的题各10分。 1、下表为某大学96位男生的体重测定结果(单位:kg),请根据资料分别计算以下指标:(1)算术平均数;(2)几何平均数;(3)中位数;(4)众数;(5)极差;(6)方差;(7)标准差;(8)变异系数;(9)标准误。(10) 绘制各体重分布柱形图。 66 69 64 65 64 66 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 66 68 64 65 71 61 62 69 70 68 65 63 66 65 67 66 74 64 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 2、已知1000株水稻的株高服从正态分布N(97,3 2),求: (1)株高在94cm以上的概率? (2)株高在90~99cm之间的概率? (3)株高在多少cm之间的中间概率占全体的99%? 3.已知某批30个小麦样品的平均蛋白质含量为14.5%,σ=2.50%,试进行95%置信度下的蛋白质含量的区间估计和点估计。 4、有一大麦杂交组合,F2代的芒性状表型有钩芒、长芒和短芒三种,观察计得其株数依次分别为348、11 5、157,试检验其比率是否符合9:3:4的理论比率。 5、某医院用某种中药治疗7例再生障碍性贫血患者,现将血红蛋白含量(g/L)变化的数据列在下面,假定资料满足各种假设测验所要求的前提条件,问:治疗前后之间的差别有无显著性意义? 患者编号 1 2 3 4 5 6 7 治疗前血红蛋白含量65 75 50 76 65 72 68 治疗后血红蛋白含量82 112 125 85 80 105 128
生物统计学期末复习题
统计选择题 1,由于(1,研究对象本身的性质)造成我们所遇到的各种统计数据的不齐性。 2,研究某一品种小麦株高,因为该品种小麦是个极大的群体,其数量甚至于是个天文数字,该体属于(4,无限总体) 3,从总体中(2,随机抽出)一部分个体称为样本。 4,用随机抽样方法从总体中获得一个样本的过程称为(3,抽样) 5,身高,体重,年龄这一类数据属于(3,连续型数据;1,度量数据) 6,每10个中男性人数,每亩麦田中杂草株数,喷洒农药后每100只害虫中死虫数等,这一类数据属于(1,离散型数据;2,计数数据) 7,把频数按其组值的顺序排列起来,称为(3,频数分布) 8,以组值作为一个边,相应的频数为另一个边,做成的连续矩形图称为(2,直方图)9,绘制(4,多边形图)的方法是在坐标平面内点上各点(中值,频数),以线段连接各点,最高和最低非零频数点与相邻零频数点相连。 10,累积频数图是根据(3,累积频数表)直接绘出的。 11,样本数据总和除以样本含量,称为(算数平均数 12,已知样本平方和为360,样本含量为10,以下4种结果中(2,6.0)是正确的标准差。 13,概率的古典定义是(2,基本事件数与事件总数之比) 14,下面第(2,概率是事物所固有的特性) 15,对于事件A和B,P(A∪B)等于(2,P(AB)) 16,对于事件A和事件B,P(A|B)等于(P(AB)/P(B)) 17,对于任意事件A和B,P(AB)等于(P(B)P(B|A)) 18,下述(3随机试验中所输入的变量)项称为随机变量 19,关于连续型随机变量,有以下4种提法,其中(1,可取某一区间内的任何数值)20,总体平均数可以用以下4种符号中的一种表示,它是(2,μ) 21,样本标准差可以用以下4种符号中的一种表示,它是(1,s) 22,在养鱼场中,A鱼塘的面积占10%,A鱼塘中鱼的发病率为1%,问从养鱼场中任意捕捞一条鱼,它既是A鱼塘,又是生病的鱼的概率是(4,0.003) 23,以下4点是描述连续型随机变量特征的,其中(2,f(x)=lim △x→0P(x 协方差分析的基本原理 1.协方差分析的提出 无论是单因素方差分析还是多因素方差分析,它们都有一些人为可以控制的控制变量。在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。又比如,考查受教育程度对个人工资是否有显著影响,这时必须考虑工作年限因素。一般情况下,工作年限越长,工资就越高。在研究此问题时必须排除工作年限因素的影响,才能得出正确的结论。再如,如果要了解接受不同处理的小白鼠经过一段时间饲养后体重增加量有无差别,已知体重的增加和小白鼠的进食量有关,接受不同处理的小白鼠其进食量可能不同,这时为了控制进食量对体重增加的影响,可在统计阶段利用协方差分析(Analysis of Covariance),通过统计模型的校正使得各组在“进食量”这个变量的影响上相等,即将进食量作为协变量,然后分析不同处理对小白鼠体重增加量的影响。 为了更加准确地控制变量不同水平对结果的影响,应该尽量排除其它在实验设计阶段难以控制或者是无法严格控制的因素对分析结果的影响。利用协方差分析就可以完成这样的功能。协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。当有一个协变量时,称为一元协方差分析,当有两个或两个以上的协变量时,称为多元协方差分析。以下将以一元协方差分析为例,讲述协方差分析的基本思想和步骤。 2.协方差分析的计算公式 以单因素协方差分析为例,总的变异平方和表示为: Q Q Q Q ++ 总控制变量协变量随机变量 = 协方差分析仍然采用F检验,其零假设 H为多个控制变量的不同水平下,各总体平均值没有显著差异。 F统计量计算公式为: 2 2 S F S 控制变量 控制变量 随机变量 =, 2 2 S F S 协变量 协变量 随机变量 = 以上F统计量服从F分布。SPSS将自动计算F值,并根据F分布表给出相应的相伴概率值。 如果F 控制变量 的相伴概率小于或等于显著性水平,则控制变量的不同水平对观察变量产生了显著的影响;如 果F 协变量 的相伴概率小于或等于显著性水平,则协变量的不同水平对观察变量产生了显著的影响。 3.协方差分析需要满足的假设条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量; (2)对连续变量或定居变量的协变量的测量不能有误差; (3)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;(4)协变量的回归系数是相同的。在分类变量形成的各组中,协变量的回归系数(即各回归线的斜率)必须是相等的,即各组的回归线是平行线。如果违背了这一假设,就有可能犯第一类错误,即错误地接受虚无假设。 研究生《生物统计学》课程 第五讲方差分析 主要内容: 一、单因素方差分析 二、两因素方差分析 三、多因素方差分析 一、单因素方差分析[Analyze]=>[Compare Means]=>[ One-Way ANOVA] 1、案例分析:某水产研究所比较四种饲料对鱼的饲喂效果 (1)建立数据文件,在Variable Vew中定义变量“饲料”、“增重”,“饲料”小数位数为0,用1、2、3、4分别代表甲、乙、丙、丁4种饲料。输入数据。 (2)方差分析:[Analyze]=>[Compare Means]=>[ One-Way ANOVA],打开[One-Way ANOVA]主对话框。选定“增重”使之进入[Dependent List](样本观测值)框,选定“饲料”使之进入[Factor](因素)框 (3)单击[Options]进入“选项”对话框,选择[Descriptive]要求输出描述统计量, [Homogeneity of Variance tese](方差齐性检验),[Continue]返回; (4)单击[Post Hoc]打开[One-Way ANOVA: Post Hoc Multiple Comparisions](单因素方差分析:验后多重比较)对话框,可选择确定多重比较方法,如LSD法、Duncan 法,[Continue]返回; (5)单击[OK],运行单因素方差分析。 结果显示:方差分析表: (P=0.005<0.01 不同饲料对鱼增重的作用差异极显著) 多重比较:LSD法 (解释:甲与其他三种饲料都具有显著差异,乙、丙、丁间差异不显著) Duncan法 23. 协方差分析 一、基本原理 1. 基本思想 在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。这种影响的变量称为协变量(一般是连续变量)。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。 协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。 协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。 当有一个协变量时,称为一元协方差分析,当有两个或两个以上 的协变量时,称为多元协方差分析。 2. 协方差分析需要满足的条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量;对连续变量或定距变量的协变量的测量不能有误差; (2)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;协变量的回归系数(即各回归线的斜率)是相同的,且不等于0,即各组的回归线是非水平的平行线。否则,就有可能犯第一类错误,即错误地接受虚无假设; (3) 自变量与协变量相互独立,若协方差受自变量的影响,那么协方差分析在检验自变量的效应之前对因变量所作的控制调整将是偏倚的,自变量对因变量的间接效应就会被排除; (4)各样本来自具有相同方差σ2的正态分布总体,即要求各组方差齐性。 二、协方差理论 1. 观测值=均值+分组变量影响+协变量影响+随机误差. 即 ()ij i ij ij y u t x x βε=++-+ (1) 其中,X 为所有协变量的平均值。 注:在方差分析中,协变量影响是包含在随机误差中的,在协方差分析中需要分离出来。 用协变量进行修正,得到修正后的y ij (adj)为 (adj)()ij ij ij i ij y y x x u t βε=--=++ 第一章 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A. 正态分布的算术平均数和几何平均数相等. B. 正态分布的算术平均数和中位数相等. C. 正态分布的中位数和几何平均数相等. D. 正态分布的算术平均数、中位数、几何平均数均相等。 4. 如果对各观测值加上一个常数a ,其标准差( D )。 A. 扩大√a 倍 B.扩大a 倍 C.扩大a 2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是( C )。 A. 标准差 B.方差 C.变异系数 D.平均数 第三章 12 2--∑∑n n x x )( 渤海大学学生实验报告 课程名称:生物统计学实验任课教师:何余堂 实验室名称:计算机室房间号:理工Ⅱ--205 实验时间:2012-6-14 学院化学化工与食品安全学院专业食品质量与安 全 班级10-10 姓名宋帅婷学号10150142同组人其余19人 实验项目统计数据的整理及次数分布 表/图的制作 组 别第二组 实验成绩 一、实验目的 1、掌握Excel数据输入、输出与编辑方法; 2、掌握Excel用于描述性统计的基本菜单操作及命令; 3、掌握数据整理的基本方法; 4、熟练制作次数分布表/图。 二、实验原理 当观测值较多(n>30)时,宜将观测值分成若干组,以便统计分析。将观测值分组后,制成次数分布表,即可看到资料的集中和变异情况。 连续性资料的整理,需要先确定全距、组数、组距、组中值及组限,然后将全部观测值计数归组。分组结束后,将资料中的每一观测值逐一归组,统计每组内所包含的观测值个数,制作次数分布表。利用Excel的数据统计工具可以辅助完成上述工作。 三、实验步骤 1、加载分析工具库 单击Excel程序“工具”菜单中的“数据分析”命令可以浏览已有的分析工具。如果在“工具”菜单上没有“数据分析”命令,应在“工具”菜单上运行“加载宏”命令,在“加载宏”对话框中选择“分析工具库”。 2、练习 某地80例30~40岁健康男子血清总胆固醇(mol/L)测定结果如下: 4.77 4.56 5.18 4.38 4.03 5.16 4.88 4.52 4.47 5.38 3.37 4.37 5.77 4.89 5.85 5.10 5.55 4.38 3.40 3.89 6.14 5.39 4.79 4.09 5.85 3.04 4.31 3.91 4.60 3.95 6.30 5.12 5.32 3.35 4.79 4.55 4.58 2.70 4.47 3.56 4.77 4.56 5.18 4.38 4.03 5.16 4.88 4.52 4.47 5.38 3.37 4.37 5.77 4.89 5.85 5.10 5.55 4.38 3.40 3.89 6.14 5.39 4.79 4.09 5.85 3.04 4.31 3.91 4.60 3.95 6.30 5.12 5.32 3.35 4.79 4.55 4.58 2.70 4.47 3.56 5.21spss协方差分析的基本原理-最棒的
生物统计上机操作第五讲 方差分析
23. 协方差分析
生物统计学期末复习题库及答案
生物统计学实验