关于我国的基尼系数及其统计

关于我国的基尼系数及其统计《南方周末》一项对中国富豪的调查显示,绝大多数的人认为金钱给自己带来了“不安全感”。中国社会科学院研究员唐钧表示,提请注意中国越来越严重的贫富差距,不仅不是危言耸听,反而是一个明智的、理性的“里程碑式”的忠告。
就贫富差距和仇富心态的问题,《北京日报》刊登中国人民大学行政管理学研究所所长毛寿龙的评论文章指出,中国当前所谓的仇富其实并非真的仇富,而是仇恨社会不公,不少穷人往往是不公的牺牲品,是被动的。评论还指出,不少富人则往往是不公的受益者,是主动的。前些日子,网上对于袁隆平买车的新闻炒得沸沸扬扬,网民们都说,仇富也不仇恨袁隆平!其实,那是网民们借题发挥谴责那些“权力致富”的富人,社会不公的受益者。
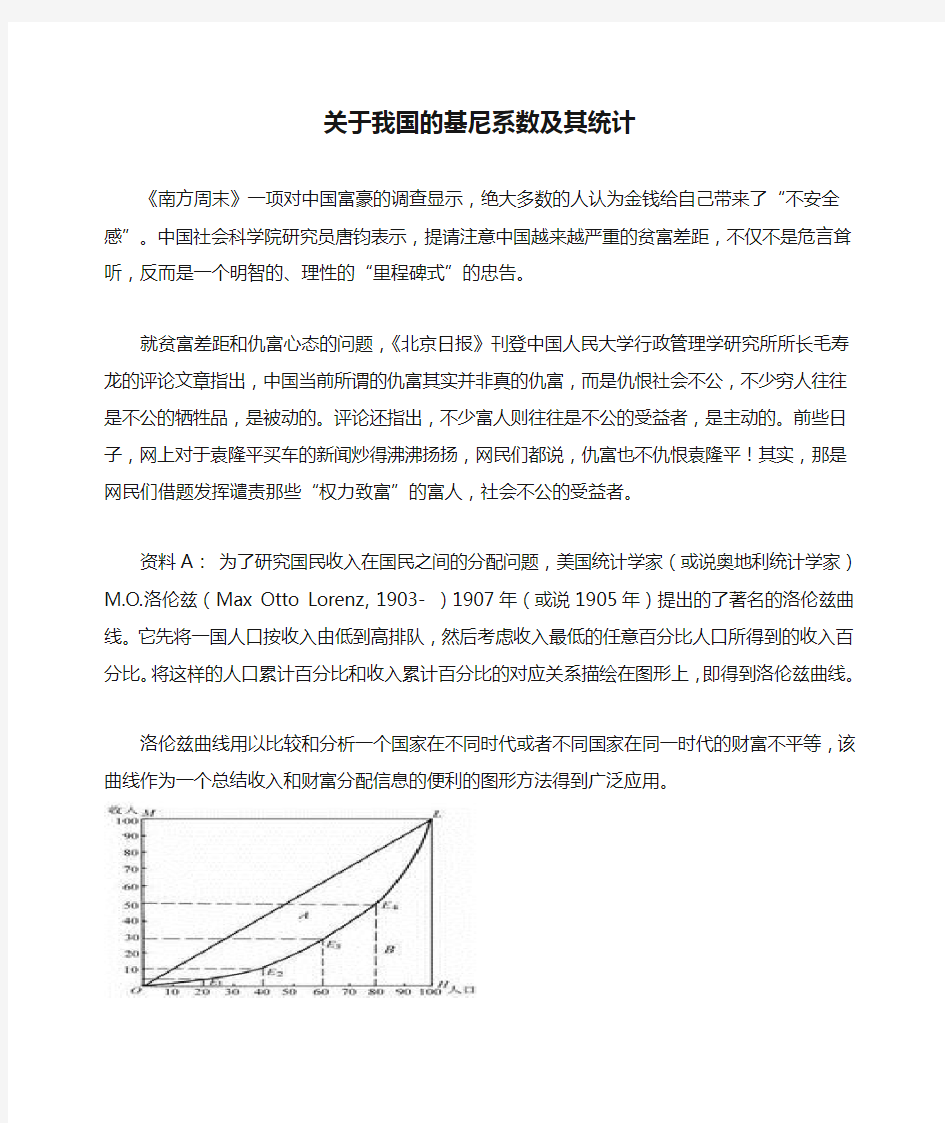
资料A:为了研究国民收入在国民之间的分配问题,美国统计学家(或说奥地利统计学家)M.O.洛伦兹(Max Otto Lorenz,1903- )1907年(或说1905年)提出的了著名的洛伦兹曲线。它先将一国人口按收入由低到高排队,然后考虑收入最低的任意百分比人口所得到的收入百分比。将这样的人口累计百分比和收入累计百分比的对应关系描绘在图形上,即得到洛伦兹曲线。
洛伦兹曲线用以比较和分析一个国家在不同时代或者不同国家在同一时代的财富不平等,该曲线作为一个总结收入和财富分配信息的便利的图形方法得到广泛应用。
图中横轴OH表示人口(按收入由低到高分组)的累积百分比,纵轴OM表示收入的累积百分比,弧线OL为洛伦兹曲线。
洛伦兹曲线的弯曲程度有重要意义。一般来讲,它反映了收入分配的不平等程度。弯曲程度越大,收入分配越不平等,反之亦然。特别是,如果所有收入都集中在一人手中,而其余人口均一无所获时,收入分配达到完全不平等,洛伦兹曲线成为折线OHL.另一方面,若任一人口百分比均等于其收入百分比,从而人口累计百分比等于收入累计百分比,则收入分配是完全平等的,洛伦兹曲线成为通过原点的45度线OL。
一般来说,一个国家的收入分配,既不是完全不平等,也不是完全平等,而是介于两者之间。相应的洛伦兹曲线,既不是折线OHL,也不是45度线OL,而是像图中这样向横轴突出的弧线OL,尽管突出的程度有所不同。
将洛伦兹曲线与45度线之间的部分A叫做“不平等面积”,当收入分配达到完全不平等时,洛伦兹曲线成为折线OHL,OHL与45度线之间的面积A+B叫做“完全不平等面积”。不平等面积与完全不平等面积之比,成为基尼系数,是衡量一国贫富差距的标准。基尼系数G=A/(A+B).显然,基尼系数不会大于1,也不会小于零。
资料B: 现在中国有赤贫人口2800万,有人说:穷人懒,穷人笨。现在社会只要勤劳一些,人人都能混碗饭吃。可谁知道这2800多万赤贫人口中,五保户占1/5,残疾
人占1/3强,生活在不宜生存的环境中者为1/4,另有一些常年被疾病困扰的、没有劳动能力的、受教育水平极低的……他们中的很多人老、病、残集于一身。这个人群是只能通过社会帮助才能生活下来的。他们如何致富呢?
而对中国社会影响最大的是五亿相对贫困的农民和城市失业人群。虽然他们中的大多数人还能吃饱肚子,但孩子的学费,老人的医药费大多无力承担。许多家庭还被婚债、房债压的喘不过气来。
改革开放以来,我国在经济增长的同时,贫富差距逐步拉大,综合各类居民收入来看,基尼系数越过警戒线已是事实。我国实际的基尼系数已经大大地跨过国际警戒线0.4,“2004年国家统计局公布的数据0.47(2008年已经达到了0.486)。中国社会的贫富差距已经突破了合理的限度,总人口中20%的最低收入人口占收入的份额仅为
4.7%,而总人口中20%的最高收入人口占总收入的份额高达50%。”突出表现在收入份额差距和城乡居民收入差距进一步拉大、东中西部地区居民收入差距过大、高低收入群体差距悬殊等方面。然而对于我国的国情而言还有一些无法统计的资金:贪官腐败资金、赌客的赌金、妓女的嫖资和盗贼的赃款。这些“从业”人数十分宏大的一笔数字不小的灰色资金(尤其是前者)被溜掉了。(在我国那种排除灰色收入的基尼系数的统计则是不可信的)统计将基尼系数0.4作为监控贫富差距的警戒线,应该说,是对许多国家实践经验的一种抽象与概括,具有一定的普遍意义。有关方面的基尼系数统计工作应该认真对待。
目前,我国共计算三种基尼系数,即:农村居民基尼系数、城镇居民基尼系数和全国居民基尼系数。还有各省的基尼系数。全省的基尼系数是农村的基尼系数和城镇的基尼系数的平均值。全国的基尼系数是各省的基尼系数的平均值。有人说:“从我国的客观实际出发,在单独衡量农村居民内部或城镇居民内部的收入分配差距时,可以将各自的基尼系数警戒线定为0.4;而在衡量全国居民之间的收入分配差距时,可以将警戒线上限定为0.5,实际工作中按0.45操作。”这些统计计算的方法合理吗?
中国的东西部的发展差异是那么大,各个地方的基尼系数应该是各各不同的。要较为精确地统计一个国家的基尼系数是不可能的。以往我们往往只能够得到一个及其粗略的统计。不过随着社会信息和交通的长足进步,方便了我们的统计。发达的信息产业和交通事业,使我们的国家越来越象一个村子,那么我们就不可以将城乡分别孤立地统计。现在乡下人早上在城里卖菜,下午在地里种菜,那是上方普通的事。我们也不能够将各个省份分别统计基尼系数。因为落后地区的农民去发达地区打工现在是十分常见的流行的打工工潮;发达地区的人去某些“原生态”的落后地区旅游考察的“农家游”也逐渐成为一种时尚。因而,统计某一地区的即时的基尼系数应该包括那里所有的人,不能够仅仅统计本地人而排除外地人,应该把打工的、旅游的、乞丐以及流窜犯罪的盗贼等都统计之内。因为这些人也是该地区实际社会生活中实实在在存在的人群。(反之,那种排除外地人的基尼系数统计则是造假。)如果按照我的要求来统计,那么我们会发现发达地区城市的基尼系数会高得多,因为那些城市里居住的富翁和乞丐都特别多。事实上,如今那些城市的贫富差异是特别的大,社会治安也是特别令人担忧的。由于人口的流动日益频繁,全国各个地区的基尼系数正在慢慢地趋于接近。
邓小平说:“让一部分人先富起来!”当时,他是为了鼓励勤劳致富而提出来的。可是改革30年中国基尼系数已接近0.5。中国创造的这个拉大贫富差异的奇迹,究竟是喜还是悲?如果在拉大贫富差异的过程是基于社会公平竞争,我们似乎还是难以非议;然而,由于社会的权力集中、权力垄断、权力传代,事实上导致了有权人先富起来。邓小平又曾经说过,如果我们的改革造成社会的贫富差异加大,那么我们的改革开放是失败的。我们如果拿他的话作为标准来判断——我们的改革是成功还是失败呢?
中国基尼系数的发展情况
中国基尼系数的发展情况 (08级预防医学李琪学号:0855041057)改革开放以来,我国在经济增长的同时,贫富差距逐步拉大,综合各类居民收入来看,基尼系数越过警戒线已是不争的事实。来自国家统计局的数据显示,自2000年开始,我国的基尼系数已越过0.4的警戒线,并逐年上升。1978年我国基尼系数为0.317,2006年则升至0.496。 这意味着,中国社会的贫富差距已突破了合理的限度,统计显示,总人口中20%的最低收入人口占收入的份额仅为4.7%,而总人口中20%的最高收入人口占总收入的份额高达50%。这突出表现在收入份额差距和城乡居民收入差距进一步拉大、东中西部地区居民收入差距过大、高低收入群体差距悬殊等方面。2006年,城镇居民中20%最高收入组(25410.8元)是20%最低收入组(4567.1元)的5.6倍;农村居民中20%最高收入组(8474.8元)是20%最低收入组(1182.5元)的7.2倍。 长期以来,针对中国的基尼系数,研究者一直持不同观点。 一方面,乐观者认为,我国的基尼系数超过0.4的国际警戒线,但因城乡差距大是造成我国基尼系数较高的原因之一,因此不能照搬国际统计口径。而且,我国经济处在发展上升阶段,从总体上看,贫困人口是逐步在下降和减少,人民群众的生活水平逐步提高。同时,由于我国居民分布在城乡分割的二元结构中,再加上城乡分割的户籍制度和就业制度,居民很难体会到城乡之间的收入差距。而无论是城镇内部还是农村内部的基尼系数都仍处于合理区间内。 另一方面,也有研究者认为,近几年我国基尼系数连续上升,并都在警戒线以上,贫困地区和贫困群体较之富裕地区和富裕群体差距较大,因此提醒说,若不采取相关措施,我国的贫富差距还有可能继续恶化。 “中国基尼系数最低的地方是浙江,最高的地方是贵州。浙江的老百姓创业多,民营企业多,中等收入人群庞大,而贵州个体私营经济少。贵州、甘肃、青海等地的基尼系数都高。”周天勇对本刊记者表示,中国基尼系数居高的原因有二:一是中小企业发展不充分,中等收入人群太少;二是从产业结构上看,农业领域中很多的人分很少的“蛋糕”,平均收入太少,而第三产业中的服务行业发展也很不充分。“基本思路是加快将农民从农业领域中转移出来,发展中小企业,扩大中等收入人群,让更多人充分就业,这样基尼系数才可能降下来。”周天勇
基尼系数计算方法
基尼系数计算方法 国际上通常用基尼系数来判定收入分配均等程度。市场经济国家衡量收入差距的一般标准为:基尼系数在0.2以下表示绝对平均; 0.2-0.3之间表示比较平均;0.3-0.4之间表示较为合理;0.4-0.5之间表示差距较大;0.5以上说明收入差距悬殊。 计算基尼系数,可以用收入分组数据计算,将总户数按人均收入等分成若干组,按由低到高的顺序排列,然后计算出每组的人口数和收入,以及每组的人口和收入占总人口和总收入的比重。实际应用中的计算公式是: 公式中:Y是按收入分组后各组的人口数占总人口数的比重;W 是按收入分组后,各组人口所拥有的收入占收入总额的比重;根据人口比重和收入比重计算出基尼系数。 附: 基尼系数(Gini coefficient)是20世纪初意大利经济学家基尼根据洛伦茨曲线提出的判断分配平等程度的指标(如下图),设实际收入分配曲线和收入分配绝对平等曲线之间的面积为A,实际收入分配曲线右下方的面积为B。并以A除以(A+B)的商表示不平等程度。这个数值被称为基尼系数或称洛伦茨系数。如果A为零,基尼系数为零,表示收入分配完全平等;如果B为零则系数为1,收入分配绝对不平等。该系数可在零和1之间取任何值。收入分配越是趋向平等,
洛伦茨曲线的弧度越小,基尼系数也越小,反之,收入分配越是趋向不平等,洛伦茨曲线的弧度越大,那么基尼系数也越大。 洛伦茨曲线 图中,横轴P代表人口累计比重,纵轴I代表收入累计比重(比重常用百分数表达)。一般可把人口按收入水平由低到高分成5等份,即低收入组、中下收入组、中等收入组、中上收入组和高收入组。计算每组(20%)人口占有社会总收入的比重。
基尼系数及计算方法
基尼系数及计算方法 2009-03-14 07:56:56| 分类:理财知识| 标签:|字号大中小订阅 基尼系数 居民收入分配的差异程度,是当前人们所普遍关心的一个问题。收入分配差异的合理与否,一方面可以反映按劳分配原则的实现情况;另一方面是保障居民生活和社会稳定的重要条件。衡量收入差异状况最重要、最常用的指标是基尼系 数(即吉尼系数)。 基尼系数(Gini coefficient)是20世纪初意大利经济学家基尼根据洛伦茨曲线提出的判断分配平等程度的指标(如下图),设实际收入分配曲线和收入分配绝对平等曲线之间的面积为A,实际收入分配曲线右下方的面积为B。并以A 除以(A+B)的商表示不平等程度。这个数值被称为基尼系数或称洛伦茨系数。如果A为零,基尼系数为零,表示收入分配完全平等;如果B为零则系数为1,收入分配绝对不平等。该系数可在零和1之间取任何值。收入分配越是趋向平等,洛伦茨曲线的弧度越小,基尼系数也越小,反之,收入分配越是趋向不平等,洛伦茨曲线的弧度越大,那么基尼系 数也越大。
洛伦茨曲线 图中,0M为45度线,在这条线上,每10%的人得到10%的收入,表明收入分配完全平等,称为绝对平等线。OPM表明收入分配极度不平等,全部收入集中在1个人手中,称为绝对不平等线。介于二线之间的实际收入分配曲线就是洛伦茨曲线。它表明:洛伦茨曲线与绝对平等线OM越接近,收入分配越平等;与绝对不平等线OPM越接近,收入分配越不平等。 实际应用中的计算公式是: 公式中:是按收入分组后各组的人口数占总人口数的比重;是按收入分组后,各组人口所拥有的收入占收入总 额的比重;是从i=1到i的累计数,如, =Y1+Y2+Y3….+Yi。
比较世界各国的基尼系数与中国发展过程中基尼系数的变化及原因
比较世界各国的基尼系数与中国发展过程中基尼系数的变 化及原因 在全部居民收入中,用于进行不平均分配的那部分收入占总收入的百分比。基尼系 数最大为“1”,最小等于“0”。前者表示居民之间的收入分配绝对不平均,即100%的收入被一个单位的人全部占有了;而后者则表示居民之间的收入分配绝对平均,即人与 人之间收入完全平等,没有任何差异。但这两种情况只是在理论上的绝对化形式,在实 际生活中一般不会出现。因此,基尼系数的实际数值只能介于0~1之间,基尼系数越 小收入分配越平均,基尼系数越大收入分配越不平均。通常把0.4作为贫富差距的警戒线,大于这一数值容易出现社会动荡。 基尼指数通常把0.4作为收入分配差距的“警戒线”,根据黄金分割律,其准确值 应为0.382。一般发达国家的基尼指数在0.24到0.36之间,美国偏高,为0.45 。中 国国家统计局基尼公布基尼系数2013年为0.473,2012年为0.474,2010年为0.481。根据西南财经大学教授甘犁主持,西南财经大学中国家庭金融调研中心发布统计报告称2010年为0.61,已跨入收入差距悬殊行列,财富分配非常不均。但这个数据存在争论,被很多业内学者质疑。学者岳希明和李实在《华尔街日报》撰文称甘犁主持的报告称其 统计样本过小和住户收入所需信息上存在问题,所以统计值过大。甘犁随后在2013年1月24日在《华尔街日报》撰文回应相应问题。2013年2月5日岳希明和李实再次在 《华尔街日报》发表文章,认为甘犁的回应没有很好地回答大部分的质疑,他们对西南 财经大学公开的项目数据进行再次计算,进行再质疑。国家发改委社会发展研究所所长 杨宜勇认为,西财的基尼系数更像是银行金融资产的基尼系数,而不是收入的基尼系数。 北京大学中国家庭动态跟踪调查显示2012年中国基尼系数为0.49。 瑞士:0.25–0.29 美国:0.45 中国:0.473
基尼系数及计算方法
基尼系数及计算方法 居民收入分配的差异程度,是当前人们所普遍关心的一个问题。收入分配差异的合理与否,一方面可以反映按劳分配原则的实现情况;另一方面是保障居民生活和社会稳定的重要条件。衡量收入差异状况最重要、最常用的指标是基尼系数(即吉尼系数)。 基尼系数(Gini coefficient)是20世纪初意大利经济学家基尼根据洛伦茨曲线提出的判断分配平等程度的指标(如下图),设实际收入分配曲线和收入分配绝对平等曲线之间的面积为A,实际收入分配曲线右下方的面积为B。并以A除以(A+B)的商表示不平等程度。这个数值被称为基尼系数或称洛伦茨系数。如果A为零,基尼系数为零,表示收入分配完全平等;如果B为零则系数为1,收入分配绝对不平等。该系数可在零和1之间取任何值。收入分配越是趋向平等,洛伦茨曲线的弧度越小,基尼系数也越小,反之,收入分配越是趋向不平等,洛伦茨曲线的弧度越大,那么基尼系数也越大。 洛伦茨曲线 图中,0M为45度线,在这条线上,每10%的人得到10%的收入,表明收入分配完全平等,称为绝对平等线。OPM表明收入分配极度不平等,全部收入集中在1个人手中,称为绝对不平等线。介于二线之间的实际收入分配曲线就是洛伦茨曲线。它表明:洛伦茨曲线与绝对平等线OM越接近,收入分配越平等;与绝对不平等线OPM越接近,收入分配越不平等。 实际应用中的计算公式是:
公式中:是按收入分组后各组的人口数占总人口数的比重;是按收入分组后,各组人口所拥有的收入占收入总额的比重;是从i=1到i的累计数,如,=Y1+Y2+Y3….+Yi。
计算基尼系数,可以用收入分组数据计算,也可用分户数据计算。但要注意的是,无论分组还是分户计算,均应先对数据按收入从低到高排序,分组计算时,一般应使分组的组距相等。用分组数据计算的基尼系数要明显小于分户数据的计算值,特别是当分组的组数不多时,差距更大。用分户数据计算基尼系数时,采用的计算指标不同,也会出现不同的结果。一般有两种计算方法,一种方法是按户总收入排序,按户计算基尼系数,此时,为每户收入占总收入的比例,为调查户数的倒数;另一种计算方法是按每户家庭的人均收入排序,此时,为每户人口占全部人口的比例,为本户人均收入占人均收入之和的比例。这两种计算方法,结果是有差异的,按人均收入计算的基尼系数要大于按户收入计算的基尼数据。在用基尼系数时进行不同地区、不同时期的收入差距比较时,应注意计算方法的一致性,不同计算方法得出的基尼系数是没有可比性的。 国际上通常用基尼系数来判定收入分配均等程度。基尼系数是界于0-1之间的数值,当基尼系数为0时,表示绝对平等;基尼系数越大,不均等程度越高;当基尼系数为1时,表示绝对不平等。市场经济国家衡量收入差距的一般标准为:基尼系数在0.2以下表示绝对平均;0.2-0.3之间表示比较平均;0.3-0.4之间表示较为合理;0.4-0.5之间表示差距较大; 0.5以上说明收入差距悬殊。例如:依据全国城市住户调查收入分组资料,计算出的基尼系数1978年为0.16,1988年为0.23,2000年为0.32,说明1978年我国城市居民个人收入差距不大,比较平均;1988年以后城市居民个人收入差距已经开始拉开,到2000年城市居民个人收入差距逐步拉大。 用基尼系数分析居民收入的差异,是一种比较普遍的方法。其特点:一是方法本身具有科学性,基尼系数的计算是将社会经济现象数学化了的办法,能从整体上反映居民集团内部收入分配的差异程度。二是基尼系数反映收入分配的差异程度精确、灵敏,可以反映差异程度细微的和连续的变化。三是在经济工作中可以作为一个综合经济参数纳入国家的计划管理和宏观调控之中。四是基尼系数在国际上应用广泛,便于在实际工作加强横向联系比较,学习和借鉴外地区和国外的经验。 推介一个简便易用的基尼系数计算公式 近年来,我国经济生活中,在国民经济整体快速发展的同时,不同行业、不同地区、不同个人之间的社会收入分配差距明显拉大,引起了社会各界人士的广泛关注,基尼系数也随之成为当前我国经济生活中最流行的经济学语词之一。 但是,对于如何计算基尼系数,目前国内经济学教科书鲜有介绍。就笔者手头所有的十几种经济学教科书来讲,绝大多数都只限于介绍定义,而没有具体计算公式。只有臧日宏编者《经济学》(中国农业大学出版社2002年7月第1版)和王健、修长柏主编《西方经济学》(中国农业大学出版社2004年10月第1版)这两种教科书给出了基尼系数的计算公式,但该公式推导过程相当复杂,理解记忆比较困难,实际计算烦琐。为此,笔者经反复思索,找到了一种简便易用的计算方法,并于笔者所著《经济学——入门与创新》(中国农业出版
ecel计算基尼系数法简单实用
E X C E L计算基尼系数法 简单实用 The latest revision on November 22, 2020
收入差距基尼系数的EXCEL算法 一、理论背景 为了研究国民收入在国民之间的分配问题,美国统计学家(或说奥地利统计学家).洛伦兹(Max Otto Lorenz,1903- )1907年(或说1905年)提出的了着名的洛伦兹曲线。它先将一国人口按收入由低到高排队,然后考虑收入最低的任意百分比人口所得到的收入百分比。将这样的人口累计百分比和收入累计百分比的对应关系描绘在图形上,即得到洛伦兹曲线。 洛伦兹曲线用以比较和分析一个国家在不同时代或者不同国家在同一时代的财富不平等,该曲线作为一个总结收入和财富分配信息的便利的图形方法得到广泛应用。 图1中横轴OH表示人口(按收 入由低到高分组)的累积百分比, 纵轴OM表示收入的累积百分比,弧 线OL为洛伦兹曲线。 洛伦兹曲线的弯曲程度有重要 意义。一般来讲,它反映了收入分 配的不平等程度。弯曲程度越大, 收入分配越不平等,反之亦然。特 别是,如果所有收入都集中在1人 图1 手中,而其余人口均一无所获时, 收入分配达到完全不平等,洛伦兹曲线成为折线OHL。另一方面,若任一人口百分比均等于其收入百分比,从而人口累计百分比等于收入累计百分比,则收入分配是完全平等的,洛伦兹曲线成为通过原点的45度线OL。 一般来说,一个国家的收入分配,既不是完全不平等,也不是完全平等,而是介于两者之间。相应的洛伦兹曲线,既不是折线OHL,也不是45度线OL,而是像图中这样向横轴突出的弧线OL,尽管突出的程度有所不同。
中国基尼系数的估算研究重点
经济评论2009年第3期ECONOMIC REVIEW No.32009 中国基尼系数的估算研究 王祖祥张奎孟勇* 摘要:中国的收入不平等受到了国内外的广泛关注。公开出版物上的收入分配数据 都是分组形式的,这给收入不平等的测算带来困难。本文采用城乡收入分配统计分布的 构造方法,利用中国统计年鉴(1995-2005)的收入分配数据估算了我国的基尼系数。 结果表明,我国目前城镇与农村两部门内部的基尼系数都不大,都没有超过0.34,但从 2003年开始,我国的加总基尼系数已经超过了0.44,远远越过了警戒水平0.4。实际上, 基尼系数的分解公式说明,影响我国收入不平等程度的关键因素是目前巨大的城乡收入 差距,是这一因素决定了我国的基尼系数必然很大。 关键词:收入分配洛伦兹曲线基尼系数密度函数 中国的收入不平等程度受到了国内外的广泛关注,出现了各种各样的基尼系数估计值。我国每年在中国统计年鉴中都发布收入分配数据,但一般认为利用该数据难以估算基尼系数(王学力,2000),一是因为这种数据是分组形式的,城镇收入分配数据中只列出了从低到高若干个收入组的平均收入与人口份额,农村收入分配中只给出了各个收入区间及各个区间内的家庭百分数,二是城乡数据分列。实际上,寻求收入分配的统计分布是现代收入分配分析活跃的研究领域,洛伦兹曲线正是从收入分配的密度函数出发而定义的,又按定义,基尼系数是洛伦兹曲线与平等收入线之间面积的2倍,可见基尼系数的估算应建立在收入分配统计分布或洛伦兹曲线的准确测算的基础上。实际工作中,在只有分组数据可用的条件下,可以先估计收入分配的密度函数,从而得到相应的洛伦兹曲线,或直接估算洛伦兹曲线,最后再估计基尼系数。国外经济理论文献中基尼系数的估算一般遵循两种途径,一是利用分户数据直接估计收入分配的密度函数从而估算基尼系数,二是利用分组数据估计洛伦兹曲线,然后再估算基尼系数。我国统计部门的城乡收入分配调查的分户数据不对外公开,因此本文考虑使用统计年鉴中的分组数据。实际上,使用统计年鉴中的数据时,城镇基尼系数的估算可以使用第二种方法,而对于农村收入分配数据,由于缺少各个收入区间内的平均收入信息使得不能利用第二种方法。王祖祥(2006)提出了根据我国收入分配分组数据构造收入分配密度函数的方法,估算了我国中部六省的基尼系数。使用这种方法,只要相关部门提供信息量不高的分组数据,就可以计
基尼系数的四种计算方法
基尼系数的四种计算方法
基尼系数的计算方法及数学推导 2001金融三班袁源 摘要:本文归纳了基尼系数的四种计算方法:直接计算法、拟合曲线法、分组计算法和分 解法,并进行了数学推导和证明。在此基 础上,文章比较了各种算法优缺点,分析 了误差可能产生的环节。 关键词:洛伦茨曲线基尼系数 一、洛伦茨曲线和基尼系数 1905年,统计学家洛伦茨提出了洛伦茨曲线,如图一。将社会总人口按收入由低到高的顺序平均分为10个等级组,每个等级组均占10%的人口,再计算每个组的收入占总收入的比重。然后以人口累计百分比为横轴,以收入累计百分比为纵轴,绘出一条反映居民收入分配差距状况的曲线,即为洛伦茨曲线。
为了用指数来更好的反映社会收入分配的平等状况,1912年,意大利经济学家基尼根据洛伦茨曲线计算出一个反映收入分配平等程度的指标,称为基尼系数(G )。在上图中,基尼系数定义为: G= S A S A+B 式(1) 当A 为0时,基尼系数为0,表示收入分配绝对平等;当B 为0时,基尼系数为1,表示收入分配绝对不平等。基尼系数在0~1之间,系数越大,表示越不均等,系数越小,表示越均等。 二、基尼系数的计算方法 式(1)虽然是一个极为简明的数学表达式,但它并不具有实际的可操作性。为了寻求具有可操作性的估算方法,自基尼提出基尼比率以来,图
许多经济学家和统计学家都进行了这方面的探索。在已有的研究成果中,主要有四种有代表性的估算方法,结合自己的计算,笔者将它们归纳为直接计算法、拟合曲线法、分组计算法和分解法。 1、直接计算法 直接计算法在基尼提出收入不平等的一种度量时,就已经给出了具体算法,而且这种算法并不依赖于洛伦茨曲线,它直接度量收入不平等的程度。定义 Y j-Y i∣/n2, 0≤△≤2u △=n n∑∑ ∣ j=1 i=1 式(2) 式中,△是基尼平均差,∣Y j-Y i∣是任何一对收入样本差的绝对值,n是样本容量,u是收入均值。定义 G=△/2u, 0≤G≤ 1 式(3) 可以证明:G=△/2u=2S A(证明过程见附录一),而由式(1)G= S A/ S A+B,S A+B=1/2,G=2S A,因此,式(2)中定义的G即为基尼系数,综合式(2)、(3),基尼系数的计算方法为:
中国农村、城镇以及全国居民历年来的基尼系数
中国农村、城镇以及全国居民历年来的基尼系数 农村居民1981-1999的基尼系数:0.246、0.2417、0.2416、0.2439、0.2267、0.3042、03045、0.3026、0.3099、0.3099、0.3072、0.3072、0.3134、0.3292、0.3210、0.3415、0.3210、0.3415、0.3299、0.3285、0.3369、0.3361 城镇居民1981-1999的基尼系数:0.15、0.15、0.15、0.16、0.19、0.19、0.20、0.23、0.23、0.23、0.24、0.25、0.27、0.30、0.28、0.28、0.29、0.295、 中国居民1981-1999的基尼系数:0.288、0.2496、0.2461、0.297、0.2656、0.2968、0.3052、0.382、0.349、0.343、0.324、0.376、0.33592、0.436、0.445、0.458、0.403、0.403、0.397 差异:一,中国居民收入的基尼系数在1981-1999年基本上是呈上升趋势的,基尼系数最大为0.458,表示收入差距较大;最小的为0.2496,表示比较平均,中国居民收入整体上来说相对合理。 二,城镇居民收入基尼系数在1981-1999年基本上是呈上升趋势的饿,最小为0.15,最大为0.3,表示比较平均,说明城镇居民收入水平是较高的。 三,农村居民收入水平相对于前两者来说是较差的,由以上的数据可以得出。 各自反映的问题:一,中国居民收入整体上来说还是很乐观的,但贫富差距在扩大。二,城镇居民收入整体上水平较高,但基尼系数在逐
中国官方首次公布2003至2012年基尼系数
中国官方首次公布2003至2012年基尼系数 中新网1月18日电国务院新闻办公室今日举行新闻发布会,国家统计局局长马建堂介绍2012年国民经济运行情况。马建堂表示,中国全国居民收入的基尼系数,2012年中国的基尼系数为0.474,2008年基尼系数曾达到0.491,此后逐步回落。这说明我国加快收入分配改革、缩小收入差距的紧迫性。 马建堂表示,全国居民的基尼系数的计算和发布需要城乡住户调查从城乡分开的、城乡收入概念不一致的调查制度,走向全国统一的城乡可比的住户调查制度。也就是说,基尼系数是反映全国居民的收入差异情况,要计算它,就需要全国居民的收入是多少,分等份的收入是多少。过去城乡分开的住户调查,大家也注意到了,只有分城乡的农村居民人均纯收入和城镇居民人均可支配收入,没有全国居民的可支配收入,没有可比的同样指标的城乡居民的收入。 经过近两年的准备,统计局对原有的城乡分开的住户调查制度进行了重大改革,从去年12月1日开始,全国40万户居民已经按照全国统一的城乡可比的统计标准、指标体系进行记帐。根据这个新的全国统一城乡可比的统计标准分类口径,我们对历史的分城乡的老口径的住户基础资料,特别是收入资料,进行了整理、计算,然后得出2003年到2011年全国居民基尼系数。 马建堂介绍称,中国全国居民收入的基尼系数,2003年是0.479,2004年是0.473,2005年0.485,2006年0.487,2007年0.484,2008年0.491。然后逐步回落,2009年0.490,2010年0.481,2011年0.477,2012年0.474。 据悉,马建堂分析称,第一,这些数据、这个曲线说明了我们国家加快收入分配改革、缩小收入差距的紧迫性。因为0.47到0.49之间的基尼系数不算低。第二,说明了从2008年金融危机以后,随着我国各级政府采取了惠民生的若干强有力的措施,中国的基尼系数从2008年最高的0.491逐步地有所回落。
中国的基尼系数
中国的基尼系数 中国2012年基尼系数为2013年1月18日,国务院新闻办公室举行新闻发布会,国家统计局局长马建堂介绍了2012年国民经济运行情况: 2012全年GDP首次突破50万亿元,比上年增长%,实现经济增长%的目标。此外,马建堂还公布了2003年-2012年的基尼系数,其中,2012年基尼系数为,该系数自2008年起逐年回落。详细数字见后面表1和图1。国家统计局公布的基尼系数西南财经世界银行阿根廷大学巴西俄罗斯墨西哥2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 Gini 2003年到2011年基尼系数,是按照新标准、新口径、老资料计算出来的,不排除2013年会按照新标准取得的新数据,对这些历史数据进行适当修订。西南财经大学近日公布的一份中国家庭金
融调查结果显示,2010年中国家庭的基尼系数为,大大高于的全球平均水平。报告最后指出,“当前中国的家庭收入差距巨大,世所少见。” 关于两个数据为何存在差异的问题,马建堂解释,无论官方统计还是民间调查,都应该是统计体系的有机组成部分,都需要建立科学的统计制度,规范的抽样方法,适量的、妥当的样本数目,以及严谨的发布态度。规范的民间调查,应该是官方统计的重要的、有益的补充。马建堂列举了几个国家的基尼系数。2009年,阿根廷、巴西、俄罗斯,墨西哥2008年的基尼系数是、印度2005年的基尼系数是。他表示,世界银行测算的中国基尼系数2008年是。马建堂称,世界银行计算的中国居民收入基尼系数与统计局的数据接近,后者数据还略高一些。他指出,经过近两年的准备,我们对原有的城乡分开的住户调查制度进行了重大改革,从去年12月1日开始,全国40万户居民已经按照全国统一的城乡可比
历年世界各国GDP排名 中国GDP总值、世界排名、人口及外汇储备统计数据
历年世界各国GDP排名中国GDP总值、世界排名、人口及外汇储备统计数据 (一)中国GDP总值、世界排名、人口及外汇储备统计数据 1949年中国GDP世界排名第X位:179.56亿美元(50年国家外汇储备:1.57亿美元)人口5.42亿 1952年中国GDP世界排名第X位:276亿美元[679亿](外汇储备:1.08亿美元)人口5.75亿 1962年中国GDP世界排名第X位:467亿美元[1149.3亿](外汇储备:0.81亿美元)人口6.73亿 1970年中国GDP世界排名第13位:916亿美元[2252.7亿](外汇储备:0.88亿美元)人口8.30亿 1978年中国GDP世界排名第15位:2683亿美元(国家外汇储备:1.67亿美元)人口9.63亿 1980年中国GDP世界排名第7位:3332亿美元(国家外汇储备:-12.96亿美元)人口9.87亿 1990年中国GDP世界排名第10位:3638亿美元(国家外汇储备:110.93亿美元)人口11.43亿 1995年中国GDP世界排名第7位:6913亿美元(国家外汇储备:735.97亿美元)人口12.11亿 2000年中国GDP世界排名第6位:10801亿美元(国家外汇储备:1655.74亿美元)人口12.67亿
2001年中国GDP世界排名第6位:11592亿美元(国家外汇储备:2121.65亿美元)人口12.76亿 2002年中国GDP世界排名第6位:12371亿美元(国家外汇储备:2864.07亿美元)人口12.85亿 2003年中国GDP世界排名第7位:14099亿美元(国家外汇储备:4032.51亿美元)人口12.92亿 2004年中国GDP世界排名第6位:19787亿美元(国家外汇储备:6099.32亿美元)人口12.99亿 2005年中国GDP世界排名第5位:22564亿美元(国家外汇储备:8189亿美元)人口13.09亿 2006年中国GDP世界排名第4位:26448亿美元(国家外汇储备:10663亿美元)人口13.10亿 2007年中国GDP世界排名第3位:29330亿美元/预测(汇率按7.8计算)(国家外汇储备:12020亿 (二)历年世界各国GDP排名 1970——2009世界GDP排名1970年世界各国(地区)GDP总值排名(除苏联外,按当时汇率) 01----美国--------1,0255亿美元 02----日本----------2068亿美元 03----西德----------2037亿美元
excel计算基尼系数法,简单实用
收入差距基尼系数的EXCEL算法 一、理论背景 为了研究国民收入在国民之间的分配问题,美国统计学家(或说奥地利统计学家).洛伦兹(Max Otto Lorenz,1903- )1907年(或说1905年)提出的了著名的洛伦兹曲线。它先将一国人口按收入由低到高排队,然后考虑收入最低的任意百分比人口所得到的收入百分比。将这样的人口累计百分比和收入累计百分比的对应关系描绘在图形上,即得到洛伦兹曲线。 洛伦兹曲线用以比较和分析一个国家在不同时代或者不同国家在同一时代的财富不平等,该曲线作为一个总结收入和财富分配信息的便利的图形方法得到广泛应用。 图1中横轴OH表示人口(按 收入由低到高分组)的累积百分 比,纵轴OM表示收入的累积百 分比,弧线OL为洛伦兹曲线。 洛伦兹曲线的弯曲程度有 重要意义。一般来讲,它反映了 收入分配的不平等程度。弯曲程 度越大,收入分配越不平等,反 之亦然。特别是,如果所有收入都集中在1人手中,而其余人口均一无所获时,收入分配达到完全不平等,洛伦兹曲线成为折线OHL。另
一方面,若任一人口百分比均等于其收入百分比,从而人口累计百分比等于收入累计百分比,则收入分配是完全平等的,洛伦兹曲线成为通过原点的45度线OL。 一般来说,一个国家的收入分配,既不是完全不平等,也不是完全平等,而是介于两者之间。相应的洛伦兹曲线,既不是折线OHL,也不是45度线OL,而是像图中这样向横轴突出的弧线OL,尽管突出的程度有所不同。 将洛伦兹曲线与45度线之间的部分A叫做“不平等面积”,当收入分配达到完全不平等时,洛伦兹曲线成为折线OHL,OHL与45度线之间的面积A+B叫做“完全不平等面积”。不平等面积与完全不平等面积之比,成为基尼系数,是衡量一国贫富差距的标准。基尼系数G=A/(A+B)。显然,基尼系数不会大于1,也不会小于零。 二、计算原理 网上有很多文章对基尼系数的计算方法有着深入的探讨,但都公式复杂吓人,涉及到积分、协方差等概念的运用,不易理解和操作,令人望而却步。本文提出的是样本区间微分面积离散累积法,完全通俗易懂,在EXCEL中只利用四则运算就能得出非常精确的结果。以图2为例: ——条件1:ODGF围成一个长 方形,其中D在OH轴的40%位置 (表示累计人数占总人数的 40%),F在OM轴的10%位置(表 示累计收入占总收入的10%),G
基尼系数及其计算方法
基尼系数及其计算方法 居民收入分配的差异程度,是当前人们所普遍关心的一个问题。收入分配差异的合理与否,一方面可以反映按劳分配原则的实现情况;另一方面是保障居民生活和社会稳定的重要条件。衡量收入差异状况最重要、最常用的指标是基尼系数(即吉尼系数)。 基尼系数(Ginicoefficient)是20世纪初意大利经济学家基尼根据洛伦茨曲线提出的判断分配平等程度的指标(如下图),设实际收入分配曲线和收入分配绝对平等曲线之间的面积为A,实际收入分配曲线右下方的面积为B。并以A除以(A+B)的商表示不平等程度。这个数值被称为基尼系数或称洛伦茨系数。如果A为零,基尼系数为零,表示收入分配完全平等;如果B为零则系数为1,收入分配绝对不平等。该系数可在零和1之间取任何值。收入分配越是趋向平等,洛伦茨曲线的弧度越小,基尼系数也越小,反之,收入分配越是趋向不平等,洛伦茨曲线的弧度越大,那么基尼系数也越大。 洛伦茨曲线 图中,0M为45度线,在这条线上,每10%的人得到10%的收入,表明收入分配完全平等,称为绝对平等线。OPM表明收入分配极度不平等,全部收入集中在1个人手中,称为绝对不平等线。介于二线之间的实际收入分配曲线就是洛伦茨曲线。它表明:洛伦茨曲线与绝对平等线OM越接近,收入分配越平等;与绝对不平等线OPM越接近,收入分配越不平等。 实际应用中的计算公式是: 公式中:是按收入分组后各组的人口数占总人口数的比重;是按收入分组后,各组人口所拥有的收入占收入总额的比重;是从i=1到i 的累计数,如,=Y1+Y2+Y3….+Yi。 计算基尼系数,可以用收入分组数据计算,也可用分户数据计算。但要注意的是,无论分组还是分户计算,均应先对数据按收入从低到高排序,分组计算时,一般应使分组的组距相等。用分组数据计算的基尼系数要明显小于分户数据的计算值,特别是当分组的组数不多时,差距更大。用分户数据计算基尼系数时,采用的计算指标不同,也会出现不同的结果。一般有两种计算方法,一种方
基尼系数的四种计算方法
基尼系数的计算方法及数学推导 金融三班袁源 摘要:本文归纳了基尼系数的四种计算方法:直接计算法、拟合曲线法、分组计算法和分解法,并进行了数学推导和证明。在此基础上,文章比较了各种算法优缺点,分析了误差可能产生的环节。 关键词:洛伦茨曲线基尼系数 一、洛伦茨曲线和基尼系数 年,统计学家洛伦茨提出了洛伦茨曲线,如图一。将社会总人口按收入由低到高的顺序平均分为个等级组,每个等级组均占%的人口,再计算每个组的收入占总收入的比重。然后以人口累计百分比为横轴,以收入累计百分比为纵轴,绘出一条反映居民收入分配差距状况的曲线,即为洛伦茨曲线。 图一 为了用指数来更好的反映社会收入分配的平等状况,年,意大利经济学家基尼根据洛伦茨曲线计算出一个反映收入分配平等程度的指标,称为基尼系数()。在上图中,基尼系数定义为: 式()当为时,基尼系数为,表示收入分配绝对平等;当为时,基尼系数为,表示收入分配绝对不平等。基尼系数在~之间,系数越大,表示越不均等,系数越小,表示越均等。 二、基尼系数的计算方法 式()虽然是一个极为简明的数学表达式,但它并不具有实际的可操作性。为了寻求具有可操作性的估算方法,自基尼提出基尼比率以来,许多经济学家和统计学家都进行了这方面的探索。在已有的研究成果中,主要有四种有代表性的估算方法,结合自己的计算,笔者将它们归纳为直接计算法、拟合曲线法、分组计算法和分解法。 、直接计算法 直接计算法在基尼提出收入不平等的一种度量时,就已经给出了具体算法,而且这种
算法并不依赖于洛伦茨曲线,它直接度量收入不平等的程度。定义 △=∑∑∣-∣, ≤△≤式() 式中,△是基尼平均差,∣-∣是任何一对收入样本差的绝对值,是样本容量,是收入均值。定义 △, ≤≤式() 可以证明:△=(证明过程见附录一),而由式(),,,因此,式()中定义的即为基尼系数,综合式()、(),基尼系数的计算方法为: ∑∑∣-∣式()直接计算法只涉及居民收入样本数据的算术运算,很多学者认为理论上看,只要不存在来源于样本数据方面的误差,就不存在产生误差的环节。实际上,在附录一证明过程当中将看到,直接计算法依然采用了以直代曲法计算面积,只不过这个过程在样本数据范围内达到了最小近似,其精确度直接取决于样本数据本身。因此,可以认为它不带任何误差的计算了样本数据的基尼系数值。 、拟合曲线法 拟合曲线法计算基尼系数的思路是采用数学方法拟合出洛伦茨曲线,得出曲线的函数表达式,然后用积分法求出的面积,计算基尼系数。通常是通过设定洛伦茨曲线方程,用回归的方法求出参数,再计算积分。例如,设定洛伦茨曲线的函数关系式为幂函数:αβ式() 根据选定的样本数据,用回归法求出洛伦茨曲线,例如,α=,β.求积分 ∫式() 计算 -=-式()拟合曲线法的在两个环节容易产生谬误:一是拟合洛伦茨曲线,得出函数表达式的过程中,可能产生误差;二是拟合出来的函数应该是可积的,否则就无法计算。 、分组计算法 这种方法的思路有点类似用几何定义计算积分的方法,在轴上寻找个分点,将洛伦茨曲线下方的区域分成部分,每部分用以直代曲的方法计算面积,然后加总求出面积。分点越多,就越准确,当分点达到无穷大时,则为精确计算。 图二 假设分为组,每组的收入为,则每个部分的面积为: ∑+∑∑式() 加总得到:
中国总体基尼系数的变化趋势(2000-2009)
社会民生改善是科学发展观以人为本的内在要求,随着中国经济社会发展整体水平的不断提高和经济发展方式的加快转变,与民生状况息息相关的收入分配问题、特别是居民收入不均的问题正得到越来越多的社会关注。衡量居民收入不均水平的指标很多,其中基尼系数以其在世界各国的广泛应用而占有非常重要的地位。科学计算基尼系数有助于准确把握收入不均的总体程度,为收入分配改革等相关民生政策的制定和实施提供参考。尤其是在“二元经济”结构下,中国现行的统计数据又是城乡分割的,于是全国总体基尼系数的准确计算更是引起很多学者和研究机构的兴趣。 计算基尼系数的方法主要有几何图形法(面积法)、平均差(或相对平均差)法、协方差法、矩阵法等。在计算中国总体基尼系数时使用较多的方法主要有:对居民收入分布函数的拟合(张金水、胡杨梅,2005)、直接对洛仑兹曲线进行拟合(王祖祥,2001;成邦文,2005)、基于组间和组内基尼系数进行分解和加权计算(董静、李子奈,2004;李虎,2005;程永宏,2007;洪兴建,2008、2009)等。应用不同的算法,得到的总体基尼系数也不尽相同。一些算法或多或少存在分组较粗使组内收入差距体现不充分、组间存在较多重叠,以及函数拟合(包括对收入分布函数和洛仑兹曲线的拟合)优度不高等问题。 鉴于上述情况,本文尝试以2000~2009年相关公开数据(主要是《中国统计年鉴》等资 中国总体基尼系数的变化趋势 —— —基于2000~2009年数据的全国人口细分算法尹虹潘 刘姝伶
料)为基础,按照现实中影响全国居民收入不均的地区、城乡、贫富①“三大差距”对全国人口进行尽可能的细分,以便更好地计算全国总体基尼系数并分析其变化趋势。 一、对全国人口进行分组的要求 计算基尼系数的重要基础是科学地进行全国居民分组,并获取不同居民组的人口和收入水平等一些核心指标。本文的基本思路是人口细分,细分本身就可以体现出更多的细节,包括绘制洛仑兹曲线及计算基尼系数都将会更加细腻和准确。从理论上讲,如果能细分到单个居民的话,将可以完全准确地计算出基尼系数,现实中固然不可能做到这一点,但在条件允许的情况下尽量细分将是有益的。对全国人口进行细分时主要应体现以下两点要求。 一是尽可能同时体现地区差距、城乡差距和贫富差距“三大差距”。在中国当前所处的发展阶段,按收入群体来进行划分,则大国经济中不同地区之间的经济发展水平差距、“二元经济”结构下的城乡发展水平差距,以及城镇内部和农村内部存在的收入贫富差距,是影响中国居民收入总体不均程度的主要因素。全国的总体基尼系数基本上可以分解为这三大差距,因此合理的人口分组就应该能够同时体现出不同地区的居民收入水平、城乡的不同收入水平和贫富差距的影响。 二是尽可能降低地区之间、城乡之间的收入水平重叠的影响。根据当前中国公开发布的统计数据(主要是《中国统计年鉴》等资料),对城镇居民和农村居民的收入分组是割裂的,缺少城乡混合的收入分组数据。其中,农村高收入组别的人均收入水平高于城镇部分低收入组别的人均收入水平,这意味着城乡各自的收入水平分布必然存在重叠。与此同时,不同地区之间也存在类似的收入分布重叠问题。如果分组不能很好地解决不同收入组之间的分布重叠现象,那么也势必难以准确反映跨城乡、跨地区的收入水平总体分布规律和特征。 二、基于公开统计数据的全国人口细分 下面将以2009年为例(主要利用2010年《中国统计年鉴》等数据)介绍全国人口细分方式。 (一)不同数据的匹配处理 这里先对要用到的数据进行匹配处理,消除不同数据间的不一致。 1.城乡人口数据匹配②。计算中将会使用全国城乡人口数、分省城乡人口数,但在2010年《中国统计年鉴》中各省的城镇人口之和不等于全国总的城镇人口,各省的农村人口之和 ①广义上说,各种收入差距体现的都是贫富区别,但把地区和城乡差距都单列之后,这里所说的贫富 是狭义的,即专指同一地区的城镇(或农村)内部收入差距。 ②下面将分别使用常住人口和户籍人口两种口径的城乡人口划分方式来计算基尼系数,这里所做的 是常住人口口径的人口匹配,各省户籍人口之和与全国户籍人口数相等,故无需再做匹配处理。
中国基尼系数与人均GDP的因果关系检验1987-2008
中国基尼系数与人均GDP的因果关系检验1987-2008 姓名:潘煜学校:重庆理工大学学号:10702010122 摘要:运用时间序列经济计量技术对1987-2008年中国基尼系数与人均GDP的关系进行实证检验,发现:中国的基尼系数与人均GDP之间存在长期均衡的协整关系,且不存在从基尼系数到人均GDP的Granger因果关系。实证结果显示,需要辨证地看待中国的基尼系数与人均GDP之间的关系。 关键词:基尼系数;人均GDP;协整;Granger因果关系 一、引言 为了有效地促进经济增长和发展,在经典的经济增长模型如R&D模型、AK 类模型、Solow模型之外,许多学者开始研究与经济增长有关的其他因素如出口、财政赤字、通货膨胀率、金融发展、基尼系数等与经济增长的关系。为了能够更好的了解基尼系数与中国人均GDP的关系,需要有大量的实证研究来检验基尼系数与经济增长之间的关系,一般使用协整检验和因果检验方法。 本文拟以年度数据为样本,运用协整检验和Granger因果关系检验等时间序列经济计量技术、以Eviews5.0计量经济学软件为工具来检验中国基尼系数与人均GDP的关系,为中国实施恰当的宏观经济政策提供实证支持。基尼系数的公式为:G=1+∑YiPi-2∑(∑Pi)′Yi。首先采用广泛使用的ADF法检验经济时间序列变量的平稳性,再采用“Johansen极大似然法”进行变量之间的协整关系检验型,然后进行变量之间的Granger因果关系检验,以确定变量之间是否存在长期稳定的均衡关系、是否存在短期动态调整机制和是否存在Granger因果关系。本文的结构安排如下:第一部分为引言,必要的文献综述和描述拟运用的检验模型;第二部分进行实证分析,得出模型的估计结果和检验;第三部分为简要的结论与政策含义。 二、实证分析 1.样本考察 本次数据的样本区间为1987-2008年,数据是来自《新中国五十年统计资料汇编》和中国国家统计局网站。 2.单位根检验 运用ADF法进行单位根检验的结果显示,拟检验变量的原水平序列的ADF 值大于Mackinnon临界值,而一阶差分以后ADF值小于Mackinnon临界值(见表1),因此,这些变量都是非平稳的且是I(1)的。单位根检验最佳滞后阶数按照AIC(Akaike Information Criterion)准则确定,AIC值越小,则滞后阶数越佳。
历年世界各国GDP排名中国GDP总值、世界排名、人口及外汇储备统计数据
历年世界各国GDP排名?中国GDP总值、世界排名、人口及外汇储备统计数据 (一)?中国GDP总值、世界排名、人口及外汇储备统计数据 1949年中国GDP世界排名第X位:179.56亿美元(50年国家外汇储备: 1.57亿美元)人口5.42亿 1952年中国GDP世界排名第X位:276亿美元[679亿](外汇储备:1.08亿美元)人口 5.75亿 1962年中国GDP世界排名第X位:467亿美元[1149.3亿](外汇储备:0.81亿美元)人口6.73亿 1970年中国GDP世界排名第13位:916亿美元[2252.7亿](外汇储备:0.88亿美元)人口8.30亿 1978年中国GDP世界排名第15位:2683亿美元(国家外汇储备: 1.67亿美元)人口9.63亿 1980年中国GDP世界排名第7位:3332亿美元(国家外汇储备:-12.96亿美元)人口9.87亿 1990年中国GDP世界排名第10位:3638亿美元(国家外汇储备:110.93亿美元)人口11.43亿 1995年中国GDP世界排名第7位:6913亿美元(国家外汇储备:735.97亿美元)人口12.11亿 2000年中国GDP世界排名第6位:10801亿美元(国家外汇储备:1655.74亿美元)人口12.67亿
2001年中国GDP世界排名第6位:11592亿美元(国家外汇储备:2121.65亿美元)人口12.76亿 2002年中国GDP世界排名第6位:12371亿美元(国家外汇储备:2864.07亿美元)人口12.85亿 2003年中国GDP世界排名第7位:14099亿美元(国家外汇储备:4032.51亿美元)人口12.92亿 2004年中国GDP世界排名第6位:19787亿美元(国家外汇储备:6099.32亿美元)人口12.99亿 2005年中国GDP世界排名第5位:22564亿美元(国家外汇储备:8189亿美元)人口13.09亿 2006年中国GDP世界排名第4位:26448亿美元(国家外汇储备:10663亿美元)人口13.10亿 2007年中国GDP世界排名第3位:29330亿美元/预测(汇率按7.8计算)(国家外汇储备:12020亿 (二)历年世界各国GDP排名 1970——2009世界GDP排名1970年世界各国(地区)GDP总值排名(除苏联外,按当 时汇率) 01----美国--------1,0255亿美元 02----日本----------2068亿美元 03----西德----------2037亿美元 04----法国----------1470亿美元 05----英国----------1236亿美元