数据归一化方法

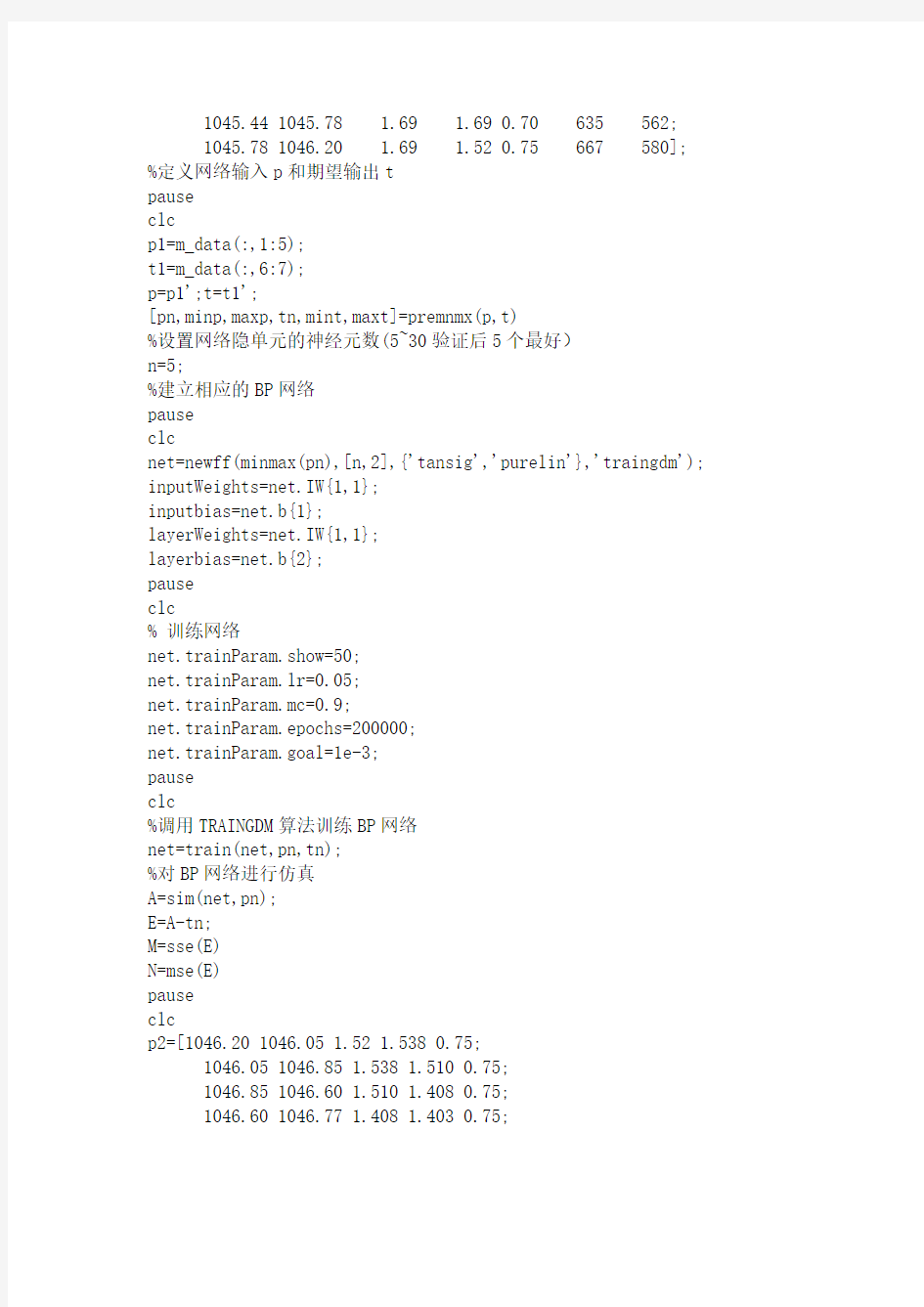
数据归一化汇总
=================================
归一化化定义:我是这样认为的,归一化化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。
在matlab里面,用于归一化的方法共有三种:
(1)premnmx、postmnmx、tramnmx
(2)prestd、poststd、trastd
(3)是用matlab语言自己编程。
premnmx指的是归一到[-1 1],prestd归一到单位方差和零均值。(3)关于自己编程一般是归一到[0.1 0.9] 。具体用法见下面实例。
为什么要用归一化呢?首先先说一个概念,叫做奇异样本数据,所谓奇异样本数据数据指的是相对于其他输入样本特别大或特别小的样本矢量。
下面举例:
m=[0.11 0.15 0.32 0.45 30;
0.13 0.24 0.27 0.25 45];
其中的第五列数据相对于其他4列数据就可以成为奇异样本数据(下面所说的网络均值bp)。奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛,所以对于训练样本存在奇异样本数据的数据集在训练之前,最好先进形归一化,若不存在奇异样本数据,则不需要事先归一化。
具体举例:
close all
clear
echo on
clc
%BP建模
%原始数据归一化
m_data=[1047.92 1047.83 0.39 0.39 1.0 3500 5075;
1047.83 1047.68 0.39 0.40 1.0 3452 4912;
1047.68 1047.52 0.40 0.41 1.0 3404 4749;
1047.52 1047.27 0.41 0.42 1.0 3356 4586;
1047.27 1047.41 0.42 0.43 1.0 3308 4423;
1046.73 1046.74 1.70 1.80 0.75 2733 2465;
1046.74 1046.82 1.80 1.78 0.75 2419 2185;
1046.82 1046.73 1.78 1.75 0.75 2105 1905;
1046.73 1046.48 1.75 1.85 0.70 1791 1625;
1046.48 1046.03 1.85 1.82 0.70 1477 1345;
1046.03 1045.33 1.82 1.68 0.70 1163 1065;
1045.33 1044.95 1.68 1.71 0.70 849 785;
1044.95 1045.21 1.71 1.72 0.70 533 508;
1045.21 1045.64 1.72 1.70 0.70 567 526;
1045.64 1045.44 1.70 1.69 0.70 601 544;
1045.44 1045.78 1.69 1.69 0.70 635 562;
1045.78 1046.20 1.69 1.52 0.75 667 580]; %定义网络输入p和期望输出t
pause
clc
p1=m_data(:,1:5);
t1=m_data(:,6:7);
p=p1';t=t1';
[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t)
%设置网络隐单元的神经元数(5~30验证后5个最好)
n=5;
%建立相应的BP网络
pause
clc
net=newff(minmax(pn),[n,2],{'tansig','purelin'},'traingdm'); inputWeights=net.IW{1,1};
inputbias=net.b{1};
layerWeights=net.IW{1,1};
layerbias=net.b{2};
pause
clc
% 训练网络
net.trainParam.show=50;
net.trainParam.lr=0.05;
net.trainParam.mc=0.9;
net.trainParam.epochs=200000;
net.trainParam.goal=1e-3;
pause
clc
%调用TRAINGDM算法训练BP网络
net=train(net,pn,tn);
%对BP网络进行仿真
A=sim(net,pn);
E=A-tn;
M=sse(E)
N=mse(E)
pause
clc
p2=[1046.20 1046.05 1.52 1.538 0.75;
1046.05 1046.85 1.538 1.510 0.75;
1046.85 1046.60 1.510 1.408 0.75;
1046.60 1046.77 1.408 1.403 0.75;
1046.77 1047.18 1.403 1.319 0.75];
p2=p2';
p2n=tramnmx(p2,minp,maxp);
a2n=sim(net,p2n);
a2=postmnmx(a2n,mint,maxt)
echo off
pause
clc
程序说明:所用样本数据(见m_data)包括输入和输出数据,都先进行归一化,还有一个问题就是你要进行预测的样本数据(见本例p2)在进行仿真前,必须要用tramnmx函数进行事先归一化处理,然后才能用于预测,最后的仿真结果要用postmnmx进行反归一,这时的输出数据才是您所需要的预测结果。
个人认为:tansig、purelin、logsig是网络结构的传递函数,本身和归一化没什么直接关系,归一化只是一种数据预处理方法。
由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:(by james)
1、线性函数转换,表达式如下:
y=(x-MinValue)/(MaxValue-MinValue)
说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
2、对数函数转换,表达式如下:
y=log10(x)
说明:以10为底的对数函数转换。
3、反余切函数转换,表达式如下:
y=atan(x)*2/PI
归一化是为了加快训练网络的收敛性,可以不进行归一化处理
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布;
当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。
归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9
0.1 0.1]就要比用[1 0 0]要好。
但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。
关于用premnmx语句进行归一化:
premnmx语句的语法格式是:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T)
其中P,T分别为原始输入和输出数据,minp和maxp分别为P中的最小值和最大值。mint和maxt分别为T的最小值和最大值。
premnmx函数用于将网络的输入数据或输出数据进行归一化,归一化后的数据将分布在[-1,1]区间内。
我们在训练网络时如果所用的是经过归一化的样本数据,那么以后使用网络时所用的新数据也应该和样本数据接受相同的预处理,这就要用到tramnmx。
下面介绍tramnmx函数:
[Pn]=tramnmx(P,minp,maxp)
其中P和Pn分别为变换前、后的输入数据,maxp和minp分别为premnmx函数找到的最大值和最小值。
matlab中的归一化处理有三种方法
1. premnmx、postmnmx、tramnmx
2. restd、poststd、trastd
3. 自己编程
具体用那种方法就和你的具体问题有关了
(by happy)
pm=max(abs(p(i,: ))); p(i,: )=p(i,: )/pm;
和
for i=1:27
p(i,: )=(p(i,: )-min(p(i,: )))/(max(p(i,: ))-min(p(i,: )));
end 可以归一到0 1 之间
0.1+(x-min)/(max-min)*(0.9-0.1)其中max和min分别表示样本最大值和最小值。
这个可以归一到0.1-0.9
补充一个吧,归一还可以用 mapminmax。
这个函数可以把矩阵的每一行归一到[-1 1].
[y1,PS] = mapminmax(x1). 其中x1 是需要归一的矩阵 y1是结果
当需要对另外一组数据做归一时,比如SVM 中的 training data用以上方法归一,而test data就可以用下面的方法做相同的归一了
y2 = mapminmax('apply',x2,PS)
当需要把归一的数据还原时,可以用以下命令
x1_again = mapminmax('reverse',y1,PS)
你的回复和评价是我发帖的动力!:D
[ Last edited by yingzhilian on 2009-6-9 at 20:55 ]
作者:sunxiao
顶一个吧,建议修改笑脸,哈哈
作者:yingzhilian
应大家要求,笑脸改掉了
作者:ljling
很好啊,还没看完,支持
作者:menglv17
好东东,顶起!!!!
作者:yinjj
总结得不错哟!!!:D
作者:26925596
支持五星级
matlab归一化处理数据
matlab 中归一化的几种方法及其各自的适用条件 关于神经网络(matlab)归一化的整理 关于神经网络归一化方法的整理 由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:(by james) 1、线性函数转换,表达式如下: y=(x-MinValue)/(MaxValue-MinValue) 说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。 2、对数函数转换,表达式如下: y=log10(x) 说明:以10为底的对数函数转换。 3、反余切函数转换,表达式如下: y=atan(x)*2/PI 归一化是为了加快训练网络的收敛性,可以不进行归一化处理 归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布; 当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。 归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。 但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。 关于用premnmx语句进行归一化: premnmx语句的语法格式是:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T) 其中P,T分别为原始输入和输出数据,minp和maxp分别为P中的最小值和最大值。mint 和maxt分别为T的最小值和最大值。 premnmx函数用于将网络的输入数据或输出数据进行归一化,归一化后的数据将分布在[-1,1]区间内。 我们在训练网络时如果所用的是经过归一化的样本数据,那么以后使用网络时所用的新数据也应该和样本数据接受相同的预处理,这就要用到tramnmx。 下面介绍tramnmx函数: [Pn]=tramnmx(P,minp,maxp) 其中P和Pn分别为变换前、后的输入数据,maxp和minp分别为premnmx函数找到的最大值和最小值。 (by terry2008) matlab中的归一化处理有三种方法 1. premnmx、postmnmx、tramnmx
归一化方法
1.1 1.2 归一化方法 数据的归一化的目的是将不同量纲和不同数量级大小的数据转变成可以相互进行数学运算的具有相同量纲和相同数量级的具有可比性的数据。数据归一化的方法主要有线性函数法、对数函数法、反余切函数法等 线性函数法 对于样本数据x (n ),n =1,2,……,N ,归一化后的样本数据可以采用三种表示方法,分别是最大最小值法、均值法和中间值法。最大最小值法用于将样本数据归一化到[0,1]范围内;均值法用于将数据归一化到任意范围内,但最大值与最小值的符号不可同时改变;中间值法用于将样本数据归一化到[-1,1]范围内,三种方法的公式分别如式(0-1)、式(0-2)、式(0-3)所示。 ()(()min(()))(max(())min(())),1,2, ,y k x k x n x n x n k N =--= (0-1) 1 () 1(),1,2, ,,()N i x k y k A k N x x i N x ==== ∑ (0-2) ()(),1,2,,1 (max(()))2 min(())mid x n x k x y k k N x n -= =- (0-3) max(())min((),1,2, ,2 ) mid x n n n N x x += = (0-4) 其中min(x (n ))表示样本数据x (n )的最小值,max(x (n ))表示样本数据x (n )的最大值,x 表示样本数据x (n )的均值,mid x 为样本数据x (n )的中间值,A 为调节因子,是一个常数,用于根据工程实际需要来调节样本数据的范围。 对数函数法 对于样本数据x (n ),n =1,2,……,N,归一化后的样本数据y (n )用公式表示为: 10()log (()),1,2, ,y k x k k N == (0-5) 对数函数法主要用于数据的数量级非常大的场合。 反余切函数法 对于样本数据x (n ),n =1,2,……,N ,归一化后的样本数据y (n )用公式表示为:
遥感数据预处理
遥感讲座——遥感影像预处理 据预处理是遥感应用的第一步,也是非常重要的一步。目前的技术也非常成熟,大多数的商业化软件都具备这方面的功能。预处理的大致流程在各个行业中有点差异,而且注重点也各有不同。下面是预处理中比较常见的流程。 1、数据预处理一般流程 数据预处理的过程包括几何精校正、配准、图像镶嵌与裁剪、去云及阴影处理和光谱归一化几个环节,具体流程图如图所示。 各个行业应用会有所不同,比如在精细农业方面,在大气校正方面要求会高点,因为它需要反演;在测绘方面,对几何校正的精度要求会很高。 2、数据预处理的各个流程介绍 (一)几何精校正与影像配准 引起影像几何变形一般分为两大类:系统性和非系统性。系统性一般有传感器本身引起的,有规律可循和可预测性,可以用传感器模型来校正;非系统性几何变形是不规律的,它可以是传感器平台本身的高度、姿态等不稳定,也可以是地球曲率及空气折射的变化以及地形的变化等。 在做几何校正前,先要知道几个概念: 地理编码:把图像矫正到一种统一标准的坐标系。 地理参照:借助一组控制点,对一幅图像进行地理坐标的校正。 图像配准:同一区域里一幅图像(基准图像)对另一幅图像校准
影像几何精校正,一般步骤如下, (1)GCP(地面控制点)的选取 这是几何校正中最重要的一步。可以从地形图(DRG)为参考进行控制选点,也可以野外GPS测量获得,或者从校正好的影像中获取。选取得控制点有以下特征: 1、GCP在图像上有明显的、清晰的点位标志,如道路交叉点、河流交叉点等; 2、地面控制点上的地物不随时间而变化。 GCP均匀分布在整幅影像内,且要有一定的数量保证,不同纠正模型对控制点个数的需求不相同。卫星提供的辅助数据可建立严密的物理模型,该模型只需9个控制点即可;对于有理多项式模型,一般每景要求不少于30个控制点,困难地区适当增加点位;几何多项式模型将根据地形情况确定,它要求控制点个数多于上述几种模型,通常每景要求在30-50个左右,尤其对于山区应适当增加控制点。 (2)建立几何校正模型 地面点确定之后,要在图像与图像或地图上分别读出各个控制点在图像上的像元坐标(x,y)及其参考图像或地图上的坐标(X,Y),这叫需要选择一个合理的坐标变换函数式(即数据校正模型),然后用公式计算每个地面控制点的均方根误差(RMS)根据公式计算出每个控制点几何校正的精度,计算出累积的总体均方差误差,也叫残余误差,一般控制在一个像元之内,即RMS<1。 (3)图像重采样 重新定位后的像元在原图像中分布是不均匀的,即输出图像像元点在输入图像中的行列号不是或不全是正数关系。因此需要根据输出图像上的各像元在输入图像中的位置,对原始图像按一定规则重新采样,进行亮度值的插值计算,建立新的图像矩阵。常用的内插方法包括: 1、最邻近法是将最邻近的像元值赋予新像元。该方法的优点是输出图像仍然保持原来的像元值,简单,处理速度快。但这种方法最大可产生半个像元的位置偏移,可能造成输出图像中某些地物的不连贯。 2、双线性内插法是使用邻近4个点的像元值,按照其距内插点的距离赋予不同的权重,进行线性内插。该方法具有平均化的滤波效果,边缘受到平滑作用,而产生一个比较连贯的输出图像,其缺点是破坏了原来的像元值。 3、三次卷积内插法较为复杂,它使用内插点周围的16个像元值,用三次卷积函数进行内插。这种方法对边缘有所增强,并具有均衡化和清晰化的效果,当它仍然破坏了原来的像元值,且计算量大。 一般认为最邻近法有利于保持原始图像中的灰级,但对图像中的几何结构损坏较大。后两种方法虽然对像元值有所近似,但也在很大程度上保留图像原有的几何结构,如道路网、水系、地物边界等。
数据标准化.归一化处理
数据的标准化 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”
和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化 这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。步骤如下: 求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; .进行标准化处理:zij=(xij-xi)/si,其中:zij为标准化后的变量值;xij为实际变量值。 将逆指标前的正负号对调。标准化后的变量值围绕0上下波动,
MATLAB统计分析与应用:40个案例分析
MATLAB统计分析与应用:40个案例分析 ISBN:9787512400849 分类号:C819 /115 出版社:北京航空航天大学出版社 【内容简介】 本书从实际应用的角度出发,以大量的案例详细介绍了MA TLAB环境下的统计分析与应用。 本书主要内容包括:利用MA TLAB制作统计报告或报表;从文件中读取数据到MA TLAB;从MA TLAB中导出数据到文件;数据的平滑处理、标准化变换和极差归一化变换;生成一元和多元分布随机数;蒙特卡洛方法;参数估计与假设检验;Copula理论及应用实例;方差分析;基于回归分析的数据拟合;聚类分析;判别分析;主成分分析;因子分析;图像处理中的统计应用等。 本书可以作为高等院校本科生、研究生的统计学相关课程的教材或教学参考书,也可作为从事数据分析与数据管理的研究人员的参考用书。 【目录】 第1章利用MA TLAB生成Word和Excel文档 1.1 组件对象模型(COM) 1.1.1 什么是CoM 1.1.2 CoM接口 1.2 MA TLAB中的ActiveX控件接口技术 1.2.1 actxcontrol函数 1.2.2 actxcontrollist函数 1.2.3 actxcontrolselect函数 1.2.4 actxserver函数 1.2.5 利用MA TLAB调用COM对象 1.2.6 调用actxserver函数创建组件服务器 1.3 案例1:利用MA TLAB生成Word文档 1.3.1 调用actxserver函数创建Microsoft Word服务器 1.3.2 建立Word文本文档 1.3.3 插入表格 1.3.4 插入图片 1.3.5 保存文档 1.3.6 完整代码 1.4 案例2:利用MA TLAB生成Excel文档 1.4.1 调用actxserver函数创建Microsoft Excel服务器 1.4.2 新建Excel工作簿 1.4.3 获取工作表对象句柄 1.4.4 插入、复制、删除、移动和重命名工作表 1.4.5 页面设置 1.4.6 选取工作表区域 1.4.7 设置行高和列宽 1.4.8 合并单元格 1.4.9 边框设置 1.4.10 设置单元格对齐方式
数据归一化方法大全
数据归一化方法大全 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”和“按小数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。 一、m ax Min标准化 - M i n标准化方法是对原始数据进行线性变换。设minA和maxA分别- m a x 为属性A的最小值和最大值,将A的一个原始值x通过m ax Min标准化映射 - 成在区间[0,1]中的值'x,其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化 这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。 z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。 用Excel进行z-score标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其实标准化的公式很简单。 步骤如下: 1.求出各变量(指标)的算术平均值(数学期望)xi和标准差si ; 2.进行标准化处理: zij=(xij-xi)/si 其中:zij为标准化后的变量值;xij为实际变量值。 3.将逆指标前的正负号对调。 标准化后的变量值围绕0上下波动,大于0说明高于平均水平,小于0说明低于平均水平。
基于Matlab的归一化二阶系统课程设计
Matlab 实训设计(一) 二阶系统变阻尼比的动态仿真系统的设计 一.设计一个二阶系统的变阻尼比的动态仿真系统 二.步骤 (1)程序功能描述 1. 典型二阶系统的传递函数为 ω ωωξ22 2 2)(n n n S s ++= Φ 2. 归一化二阶系统的单位阶跃响应 1、ζ=0(无阻尼)时,系统处于等幅振荡,超调量最大,为100%,并且系统发生不衰减的振荡,永远达不到稳态。 2、0<ζ<1(欠阻尼)时,系统为衰减振荡。为了获得满意的二阶系统的瞬态响应特性,通常阻尼比在0.4~0.8的范围内选择。这时系统在响应的快速性、稳定性等方面都较好。 3、在ζ=1(临界阻尼)及ζ>1(过阻尼)时,二阶系统的瞬态过程具有单调上升的特性,以ζ=1时瞬态过程最短。 (2)程序界面设计 图形界面中的grid on 、grid off 分别是网格和绘图框的打开和关闭按钮
(3)程序测试运行 在编辑框中+还可以输入如0:0.1:0.8的阻尼系数数组,这表示把0到0.8之间的长度以0.1为跨距等份,再以每点的数据得到响应曲线,上式就包含了 ze-ta=0、0.1、0.2···、0.8总共8个阻尼比下的响应曲线
三.控件属性设置 (1)String %显示在控件上的字符串 (2)Callback 回调函数 (3)enable 表示控件是否有效 (4)Tag 控件标记,用于标识控件 四.设计:实现如下功能的系统界面 (1)在编辑框中,可以输入表示阻尼比的标量成行数组、数值,并在按了Enter 键后,在轴上画出图形,坐标范围x[1,15],y[0,2]。 (2)在点击grid on或者grid off键时,在轴上显示或删除“网格线”。(3)在菜单[options]下,有两个下拉菜单[Box on]和[Box off],缺省值为off。(4)所设计界面和其上图形,都按比例缩放。 五.各个控件属性设置 (1)在图形窗中设置 Name 我的设计 Rize on %图窗可以缩放 Tag figure1 %生成handles. figure1 (2)在轴框中 Units normalizen Box off坐标轴不封闭 Tag axes1 XLim[0,15]%x范围 YLim[1,2]%y范围 (3)静态文件框1 fontsize 0.696 fritunits normalizen String“归一化二阶阶跃响应” Tag text1 Horizontalignment Center
归一化方法
1.1 归一化方法 数据的归一化的目的是将不同量纲和不同数量级大小的数据转变成可以相互进行数学运算的具有相同量纲和相同数量级的具有可比性的数据。数据归一化的方法主要有线性函数法、对数函数法、反余切函数法等 线性函数法 对于样本数据x (n ),n =1,2,……,N ,归一化后的样本数据可以采用三种表示方法,分别是最大最小值法、均值法和中间值法。最大最小值法用于将样本数据归一化到[0,1]范围内;均值法用于将数据归一化到任意范围内,但最大值与最小值的符号不可同时改变;中间值法用于将样本数据归一化到[-1,1]范围内,三种方法的公式分别如式(2-1)、式(2-2)、式(2-3)所示。 ()(()min(()))(max(())min(())),1,2,,y k x k x n x n x n k N =--= (0-1) 1 () 1(),1,2,,,()N i x k y k A k N x x i N x ====∑ (0-2) ()(),1,2,,1 (max(()))2 min(())mid x n x k x y k k N x n -= =- (0-3) max(())min((),1,2,,2 ) mid x n n n N x x += = (0-4) 其中min(x (n ))表示样本数据x (n )的最小值,max(x (n ))表示样本数据x (n )的最大值,x 表示样本数据x (n )的均值,mid x 为样本数据x (n )的中间值,A 为调节因子,是一个常数,用于根据工程实际需要来调节样本数据的范围。 对数函数法 对于样本数据x (n ),n =1,2,……,N,归一化后的样本数据y (n )用公式表示为: 10()log (()),1,2,,y k x k k N == (0-5) 对数函数法主要用于数据的数量级非常大的场合。 反余切函数法 对于样本数据x (n ),n =1,2,……,N ,归一化后的样本数据y (n )用公式表示为: 2 ()arctan(()),1,2,,y k x k k N π = = (0-6) 反余切函数法主要用于将角频率等变量转换到[-1,1]范围。
数据归一化方法
数据归一化汇总 ================================= 归一化化定义:我是这样认为的,归一化化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。 在matlab里面,用于归一化的方法共有三种: (1)premnmx、postmnmx、tramnmx (2)prestd、poststd、trastd (3)是用matlab语言自己编程。 premnmx指的是归一到[-1 1],prestd归一到单位方差和零均值。(3)关于自己编程一般是归一到[0.1 0.9] 。具体用法见下面实例。 为什么要用归一化呢?首先先说一个概念,叫做奇异样本数据,所谓奇异样本数据数据指的是相对于其他输入样本特别大或特别小的样本矢量。 下面举例: m=[0.11 0.15 0.32 0.45 30; 0.13 0.24 0.27 0.25 45]; 其中的第五列数据相对于其他4列数据就可以成为奇异样本数据(下面所说的网络均值bp)。奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛,所以对于训练样本存在奇异样本数据的数据集在训练之前,最好先进形归一化,若不存在奇异样本数据,则不需要事先归一化。 具体举例: close all clear echo on clc %BP建模 %原始数据归一化 m_data=[1047.92 1047.83 0.39 0.39 1.0 3500 5075; 1047.83 1047.68 0.39 0.40 1.0 3452 4912; 1047.68 1047.52 0.40 0.41 1.0 3404 4749; 1047.52 1047.27 0.41 0.42 1.0 3356 4586; 1047.27 1047.41 0.42 0.43 1.0 3308 4423; 1046.73 1046.74 1.70 1.80 0.75 2733 2465; 1046.74 1046.82 1.80 1.78 0.75 2419 2185; 1046.82 1046.73 1.78 1.75 0.75 2105 1905; 1046.73 1046.48 1.75 1.85 0.70 1791 1625; 1046.48 1046.03 1.85 1.82 0.70 1477 1345; 1046.03 1045.33 1.82 1.68 0.70 1163 1065; 1045.33 1044.95 1.68 1.71 0.70 849 785; 1044.95 1045.21 1.71 1.72 0.70 533 508; 1045.21 1045.64 1.72 1.70 0.70 567 526; 544; 601 0.70 1.69 1045.64 1045.44 1.70
数据标准化归一化处理
数据的标准化化准数据标常我们通需要先将,在分数据析之前 数据标准,利用标准化后的数据进行数据分析。normalization)(同趋化处化也就是统计数据的指数化数据标准化处理主要包括数据。 不同性质数据数据同趋化理和无量纲化处理处理主要解决两个方面。 问题,对不同性质指标直接加总不能正确反映不同作用力的综合结使所有指标对测评方案的作用力须先考虑改变逆指标数据性质,果,数据数据无量纲化处理主要解决再加总才能得出正确结果。同趋化,的可比性。去除数据的单
位限制,将其转化为无量纲的纯数值,便于有很不同单位或量级的指标能够进行比较和加权。数据标准化的方法标准化”和“按小Z-score“、多种,常用的有“最小—最大标准化” 数定标标准化”等。经过上述标准化处理,原始数据均转换为无量纲 可以进行综合指标值都处于同一个数量级别上,即各化指标测评值, 测评分析。 一、Min-max 标准化 min-max标准化方法是对原始数据进行线性变换。设minA和maxA 分别为属性A的最小值和最大值,将A的一个原始值x通过min-max 标准化映射成在区间[0,1]中的值x',其公式为: 新数据=(原数据-极小值)/(极大值-极小值) 二、z-score 标准化这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用z-score标准化到x'。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。 新数据=(原数据-均值)/标准差 spss默认的标准化方法就是z-score标准化。用Excel进行z-score 标准化的方法:在Excel中没有现成的函数,需要自己分步计算,其
数据归一化和两种常用的归一化方法
数据归一化和两种常用的归一化方法 数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,如此的情况会阻碍到数据分析的结果,为了消除指标之间的量纲阻碍,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据通过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。以下是两种常用的归一化方法: 一、min-max标准化(Min-Max Normalization) 也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下: 其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。 二、Z-score标准化方法 这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。通过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为: 其中为所有样本数据的均值,为所有样本数据的标准差。
“[学校计划]下学期英语教研组计划”学校工作计划 别详一、指导思想: 在教务处的领导下,团结奋斗,协调好各备课组间的关系。仔细学习新的教学大纲,巩固进展爱校爱生、教书育人,富有进取精神、乐观积极向上的融洽的教研新风貌,在上届中招取得良好成绩的基础上,为把我组的教研水平提高到一具新的台阶而努力奋斗。 二、奋斗目标: 1、开展学习新大纲的活动,稳步扎实地抓好素养教育; 2、加强教研治理,为把我组全体教师的教学水平提高一具新层面而奋斗; 3、协调处理好学科关系,在各备课内积极加强集体备课活动,在教学过程中要求各备课组按照"五个一"要求,做好教研工作,即"统一集体备课,统一内容,统一进度,统一作业,统一测试"。 4、配合各备课组,搞好第二课堂活动,把创新教育理念灌输到教书育人的过程中。 三、具体措施: 1、期初及期中后召集全组教师会议,布置教研活动安排及进行新大纲学习; 2、降实各备课组教学进度表及教学打算; 3、有的放矢地开展第二课堂活动 初一年组织学生单词竞赛; 初二年组织学生进行能力比赛; 初三年组织学生进听力比赛; 其中初一年有条件的话多教唱英文歌曲,培养学生学习英语的兴趣,含介绍英美文化背景常识。 4、各备课组降实好课外辅导打算,给学有余力的部分学生制造条件,积极备战英语"奥赛"。 5、要求各科任教师,积极主动及时地反馈教情学情,并提出整改意见,指出努力方向; 6、针对别同年段学生的别同表现,注意做好学生的思想教育工作,寓思想教育于教学工作中; 7、降实本学期教研听评课工作安排。
matlab图像处理归一化
matlab图像处理为什么要归一化和如何归一化 一、为什么归一化 1. 基本上归一化思想是利用图像的不变矩寻找一组参数使其能够消除其他变换函数对图像变换的影响。也就是转换成唯一的标准形式以抵抗仿射变换 图像归一化使得图像可以抵抗几何变换的攻击,它能够找出图像中的那些不变量,从而得知这些图像原本就是一样的或者一个系列的。 因为我们这次的图片有好多都是一个系列的,所以老师把这个也作为我研究的一个方向。 我们主要要通过归一化减小医学图片由于光线不均匀造成的干扰。 2.matlab里图像数据有时候必须是浮点型才能处理,而图像数据本身是0-255的UNIT型数据所以需要归一化,转换到0-1之间。 3.归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。目的是为了: (1).避免具有不同物理意义和量纲的输入变量不能平等使用 (2).bp中常采用sigmoid函数作为转移函数,归一化能够防止净输入绝对值过大引起的神经元输出饱和现象 (3).保证输出数据中数值小的不被吞食 3.神经网络中归一化的原因 归一化是为了加快训练网络的收敛性,可以不进行归一化处理 归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布;当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。 归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。 但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。 二、如何归一化 matlab中的归一化处理有三种方法 1. premnmx、postmnmx、tramnmx 2. restd、poststd、trastd 3. 自己编程 (1)线性函数转换,表达式如下: y=(x-MinValue)/(MaxValue-MinValue) 说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。 (2)对数函数转换,表达式如下: y=log10(x)
归一化与反归一化
为什么要归一化? 答:为了减少数据中存在的奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。其次保证程序运行时收敛加快。 ============外一篇有关mapminmax的用法详解by faruto================================== 几个要说明的函数接口: [Y,PS] = mapminmax(X) [Y,PS] = mapminmax(X,FP) Y = mapminmax('apply',X,PS) X = mapminmax('reverse',Y,PS) 用实例来讲解,测试数据x1 = [1 2 4], x2 = [5 2 3]; >> [y,ps] = mapminmax(x1) y = -1.0000 -0.3333 1.0000 ps = name: 'mapminmax' xrows: 1 xmax: 4 xmin: 1 xrange: 3 yrows: 1 ymax: 1 ymin: -1 yrange: 2 其中y是对进行某种规范化后得到的数据,这种规范化的映射记录在结构体ps中.让我们来看一下这个规范化的映射到底是怎样的? Algorithm
It is assumed that X has only finite real values, and that the elements of each row are not all equal. ?y = (ymax-ymin)*(x-xmin)/(xmax-xmin) + ymin; ?[关于此算法的一个问题.算法的假设是每一行的元素都不想相同,那如果都相同怎么办?实现的办法是,如果有一行的元素都相同比 如xt = [1 1 1],此时xmax = xmin = 1,把此时的变换变为y = ymin,matlab内部就是这么解决的.否则该除以0了,没有意义!] 也就是说对x1 = [1 2 4]采用这个映射f: 2*(x-xmin)/(xmax-xmin)+(-1),就可以得到y = [ -1.0000 -0.3333 1.0000] 我们来看一下是不是: 对于x1而言xmin = 1,xmax = 4; 则y(1) = 2*(1 - 1)/(4-1)+(-1) = -1; y(2) = 2*(2 - 1)/(4-1)+(-1) = -1/3 = -0.3333; y(3) = 2*(4-1)/(4-1)+(-1) = 1; 看来的确就是这个映射来实现的. 对于上面algorithm中的映射函数其中ymin,和ymax是参数,可以自己设定,默认为-1,1; 比如: >>[y,ps] = mapminmax(x1) >> ps.ymin = 0; >> [y,ps] = mapminmax(x1,ps) y = 0 0.3333 1.0000 ps = name: 'mapminmax' xrows: 1 xmax: 4 xmin: 1
归一化系数的计算
在区域生态环境状况评价时,用到生态环境状况指数,其中关于归一化系数的问题,我有几点看法: 1、归一化系数适用于什么范围? 归一化系数,应该是对数据的标准化的一种方法,或者叫做对数据的无量纲化。就是把反应生态环境质量的各个数据通过数据的无量纲化,统一到同一个层面上,便于比较。这个归一化系数起的就是这个作用(用到的标准化方法应该叫做最大值法标准化)。 对单个区域,如一个县,或者某个开发区、流域等没有办法用,只有针对几个县(区)、省、全国,一组数据,才可能有最大值、最小值。具有相对性,非绝对性。 2、全省、全国的数据,如何用? 在使用归一化系数时,不是必须用本省的归一化系数,归一化系数不是必须用全国或者全省的数据。如果能找到一系列的县域的数据,可以计算,几个县也可以弄出自己的系数。但一般情况下是运用本年度的全国的数据或者全省的数据,多年来生态环境状况指数是一个考核的指数,这方面的数据是有统计的。 3、归一化系数是定值吗? 归一化系数是动态变化的,不是定值,随着时间、生态质量而变化。即是透过同一个时间段内的一系列数据算出来的。(比如2008年,全河北省的138个县的归一化系数) 4、A最大值,如何计算? 如几个县的生物丰度,(0.35×林地面积+0.21×草地面积+0.28×水域湿地面积……)/全县面积,取最大的一个县的值。即比如县A、B、C、D、E、F的生物丰度分别是0.56、0.23、0.36、0.85、0.02、0.22,则最大值便是0.85,其归一化指数是100/0.85. 5、如果沿海发达地区,无论是评价一个县,还是多个县,应参考全国的数据? 这个问题的回答是,国家没有这方面的规定。
关于神经网络(matlab)归一化的整理
关于神经网络(matlab)归一化的整理 关于神经网络归一化方法的整理 由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:(by james) 1、线性函数转换,表达式如下: y=(x-MinValue)/(MaxValue-MinValue) 说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。 2、对数函数转换,表达式如下: y=log10(x) 说明:以10为底的对数函数转换。 3、反余切函数转换,表达式如下: y=atan(x)*2/PI 归一化是为了加快训练网络的收敛性,可以不进行归一化处理 归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在-1--+1之间是统计的坐标分布。归一化有同一、统一和合一的意思。无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测的,归一化是同一在0-1之间的统计概率分布; 当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。为了避免出现这种情况,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于0或与其均方差相比很小。 归一化是因为sigmoid函数的取值是0到1之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。所以这样做分类的问题时用[0.9 0.1 0.1]就要比用[1 0 0]要好。 但是归一化处理并不总是合适的,根据输出值的分布情况,标准化等其它统计变换方法有时可能更好。 关于用premnmx语句进行归一化: premnmx语句的语法格式是:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T) 其中P,T分别为原始输入和输出数据,minp和maxp分别为P中的最小值和最大值。mint 和maxt分别为T的最小值和最大值。 premnmx函数用于将网络的输入数据或输出数据进行归一化,归一化后的数据将分布在[-1,1]区间内。 我们在训练网络时如果所用的是经过归一化的样本数据,那么以后使用网络时所用的新数据也应该和样本数据接受相同的预处理,这就要用到tramnmx。 下面介绍tramnmx函数: [Pn]=tramnmx(P,minp,maxp) 其中P和Pn分别为变换前、后的输入数据,maxp和minp分别为premnmx函数找到的最大值和最小值。 (by terry2008) matlab中的归一化处理有三种方法 1. premnmx、postmnmx、tramnmx 2. restd、poststd、trastd 3. 自己编程 具体用那种方法就和你的具体问题有关了
数据归一化的Matlab实现
数据归一化汇总 ============外一篇有关mapminmax的用法详解by faruto================================== 几个要说明的函数接口: [Y,PS]=mapminmax(X) [Y,PS]=mapminmax(X,FP) Y=mapminmax('apply',X,PS) X=mapminmax('reverse',Y,PS) 用实例来讲解,测试数据x1=[124],x2=[523]; >>[y,ps]=mapminmax(x1) y= -1.0000-0.3333 1.0000 ps= name:'mapminmax' xrows:1 xmax:4 xmin:1 xrange:3 yrows:1 ymax:1 ymin:-1
yrange:2 其中y是对进行某种规范化后得到的数据,这种规范化的映射记录在结构体ps中.让我们来看一下这个规范化的映射到底是怎样的? Algorithm It is assumed that X has only finite real values,and that the elements of each row are not all equal. ?y=(ymax-ymin)*(x-xmin)/(xmax-xmin)+ymin; ?[关于此算法的一个问题.算法的假设是每一行的元素都不想相同,那如果都相同怎么办?实现的办法是,如果有一行的元素都相同比 如xt=[111],此时xmax=xmin=1,把此时的变换变为y= ymin,matlab内部就是这么解决的.否则该除以0了,没有意义!] 也就是说对x1=[124]采用这个映射f:2*(x-xmin)/(xmax-xmin)+(-1),就可以得到y=[-1.0000-0.3333 1.0000] 我们来看一下是不是:对于x1而言xmin=1,xmax=4; 则y(1)=2*(1-1)/(4-1)+(-1)=-1; y(2)=2*(2-1)/(4-1)+(-1)=-1/3=-0.3333; y(3)=2*(4-1)/(4-1)+(-1)=1; 看来的确就是这个映射来实现的. 对于上面algorithm中的映射函数其中ymin,和ymax是参数,可以自己设定,默认为-1,1;
用MATLAB实现大数据挖掘地一种算法
一、数据挖掘的目的 数据挖掘(Data Mining)阶段首先要确定挖掘的任务或目的。数据挖掘的目的就是得出隐藏在数据中的有价值的信息。数据挖掘是一门涉及面很广的交叉学科,包括器学习、数理统计、神经网络、数据库、模式识别、粗糙集、模糊数学等相关技术。它也常被称为“知识发现”。知识发现(KDD)被认为是从数据中发现有用知识的整个过程。数据挖掘被认为是KDD过程中的一个特定步骤,它用专门算法从数据中抽取模式(patter,如数据分类、聚类、关联规则发现或序列模式发现等。数据挖掘主要步骤是:数据准备、数据挖掘、结果的解释评估。 二、数据挖掘算法说明 确定了挖掘任务后,就要决定使用什么样的挖掘算法。由于条件属性在各样本的分布特性和所反映的主观特性的不同, 每一个样本对应于真实情况的局部映射。建立了粗糙集理论中样本知识与信息之间的对应表示关系, 给出了由属性约简求约简决策表的方法。基于后离散化策略处理连续属性, 实现离散效率和信息损失之间的动态折衷。提出相对值条件互信息的概念衡量单一样本中各条件属性的相关性, 可以充分利用现有数据处理不完备信息系统。 本次数据挖掘的方法是两种,一是找到若干条特殊样本,而是找出若干条特殊条件属性。最后利用这些样本和属性找出关联规则。(第四部分详细讲解样本和属性的选择) 三数据预处理过程 数据预处理一般包括消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换(如把连续值数据转换为离散型数据,以便于符号归纳,或是把离散型数据转换为连续)。 本文使用的数据来源是名为“CardiologyCategorical”的excel文件中的“源数据”。该数据表共303行,14个属性。即共有303个样本。将该数据表的前200行设为训练样本,剩下后的103行作为测试样本,用基于粗糙集理论的属性约简的方法生成相应的规则,再利用测试样本对这些规则进行测试。 首先对源数据进行预处理,主要包括字符型数据的转化和数据的归一化。 数据预处理的第一步是整理源数据,为了便于matlab读取数据,把非数字数据转换为离散型数字数据。生成lisanhua.xsl文件。这一部分直接在excel工作表中直接进行。 步骤如下: 将属性“sex”中的“Male”用“1”表示,“Female”用“2”表示; 将属性“chest pain type”中的“Asymptomatic”用“1”表示,“Abnormal Angina”用“2”表示,“Angina”用“3”表示,“NoTang”用“4”表示;
归一化处理
数据归一化处理 1.我有一个问题不太明白,神经网络在训练时,先对数据进行归一化处理,按照常理训练完之后应该对数据再进行反归一化啊,可是再很多资料上根本就看不出有反归一化这个步骤,而且很多时候训练效果不是很好。请问,哪个大侠能帮帮我啊 2.看一下MATLAB里的premnmx函数和postmnmx函数.它们一个是归一一个是反归一 3.并不是归一化的数据训练效果就好 4.我也遇到过类似的问题,有篇论文就是用postmnmx函数.效果不好可能是样本数据不太准. 5.可以采用标准化PRESTD,效果很好。 6.样本数据和测试数据是否放在一起归一化? 7.应该将样本数据和测试数据放在一起归一化,不然如果测试数据中有的值比样本数据最大值还大,岂不是超过1了? 神经网络训练的时候,应该考虑极值情况,即归一化的时候要考虑你所需要识别参数的极值,以极值作分母,这样可能效果更好一点。 8.激发函数如果选用的是倒s型函数,应不存在归一化的问题吧 9.我想问大家一下:在神经网络中,只有一个函数即:purelin这个函数对训练的输出数据不用归一化,而象logsig 和tansig函数都要归一化(如果数据范围不在[-1,1]或[0,1]之间).那既然用purelin函数可以不用归一化,为何又是还用归一化呢? 用神经网络里的PRESTD, PREPCA, POSTMNMX, TRAMNMX等函数归一化和直接用purelin这个函数有什么区别啊? 我作负荷预测时,象不用归一化的效果很好呀! 10.purelin没有作归一化啊,你用logsig 和tansig作为神经元激励函数,输出范围自然限制在[-1,1]或[0,1]之间了 11. 我所知道的关于归一化: 归一化化定义:我是这样认为的,归一化化就是要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。 在matlab里面,用于归一化的方法共有三中,(1)premnmx、postmnmx、tramnmx(2)prestd、poststd、trastd(3)是用matlab语言自己编程。premnmx指的是归一到[-1 1],prestd归一到单位方差和零均值。(3)关于自己编程一般是归一到[0.1 0.9] 。具体用法见下面实例。 为什么要用归一化? 为什么要用归一化呢?首先先说一个概念,叫做奇异样本数据,所谓奇异样本数据数据指的是相对于 其他输入样本特别大或特别小的样本矢量。 下面举例: m=[0.11 0.15 0.32 0.45 30; 0.13 0.24 0.27 0.25 45]; 其中的第五列数据相对于其他4列数据就可以成为奇异样本数据(下面所说的网络均值bp)。奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛,所以对于训练样本存在奇异样本数据的数据集在训练之前,最好先进形归一化,若不存在奇异样本数据,则不需要事先归一化。 具体举例: close all clear echo on clc %BP建模 %原始数据归一化 m_data=[1047.92 1047.83 0.39 0.39 1.0 3500 5075; 1047.83 1047.68 0.39 0.40 1.0 3452 4912;