实验11_主成分分析
实验11 主成分分析
主成分分析是在降维的思想下产生的处理高维数据的方法。其方法是设法用一组互不相关的综合变量(原观测变量的线性组合)来代替原有观测变量,同时根据实际需要从中选取一个或少数几个综合变量来尽可能多地反映原有观测变量的信息,通过对少数综合变量的分析达到解决问题的目的。
11.1 实验目的
掌握使用SAS进行主成分分析的方法。
11.2 实验内容
一、使用INSIGHT作主成分分析
二、使用“分析家”作主成分分析
三、使用PRINCOMP过程作主成分分析
11.3 实验指导
一、使用INSIGHT作主成分分析
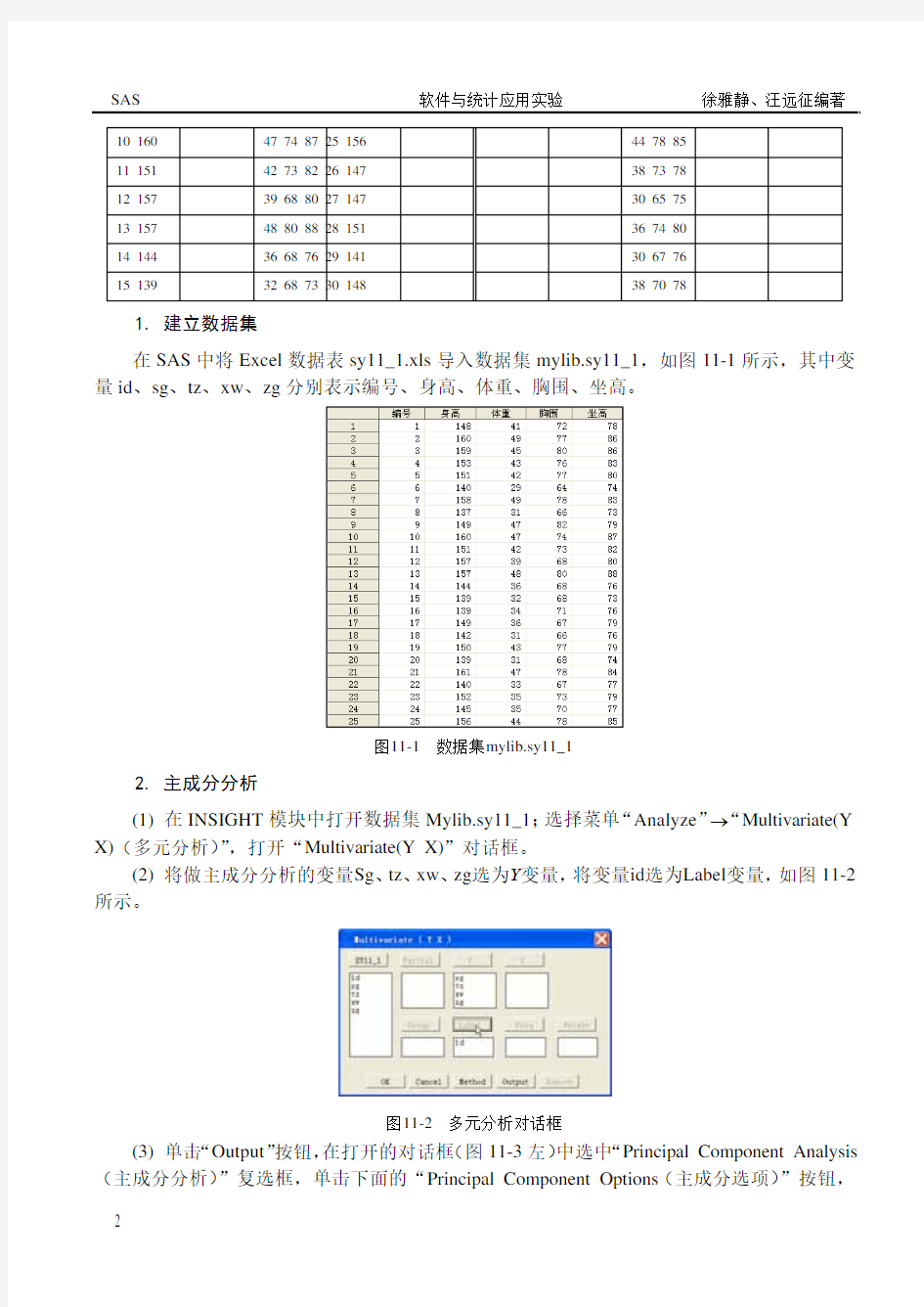
【实验11-1】随机抽取某校30名中学生,测量其身高(cm)、体重(kg)、胸围(cm)和坐高(cm)数据如表11-1(sy11_1.xls)所示。试采用INSIGHT做主成分分析。
表11-1 学生身体形态指标
编号身高体重胸围坐高编号身高体重胸围坐高
1 148 41 7
2 78 16 139 34 71 76
2 160 49 77 86 17 149 36 67 79
3 159 45 80 86 18 142 31 66 76
4 153 43 76 83 19 150 43 77 79
5 151 42 77 80 20 139 31 68 74
6 140 29 64 74 21 161 4
7 7
8 84
7 158 49 78 83 22 140 33 67 77
8 137 31 66 73 23 152 35 73 79
9 149 47 82 79 24 145 35 70 77
10 160 47 74 87 25 156 44 78 85
11 151 42 73 82 26 147 38 73 78
12 157 39 68 80 27 147 30 65 75
13 157 48 80 88 28 151 36 74 80
14 144 36 68 76 29 141 30 67 76
15 139 32 68 73 30 148 38 70 78
1. 建立数据集
在SAS中将Excel数据表sy11_1.xls导入数据集mylib.sy11_1,如图11-1所示,其中变量id、sg、tz、xw、zg分别表示编号、身高、体重、胸围、坐高。
图11-1 数据集mylib.sy11_1
2. 主成分分析
(1) 在INSIGHT模块中打开数据集Mylib.sy11_1;选择菜单“Analyze”→“Multivariate(Y X)(多元分析)”,打开“Multivariate(Y X)”对话框。
(2) 将做主成分分析的变量Sg、tz、xw、zg选为Y变量,将变量id选为Label变量,如图11-2所示。
图11-2 多元分析对话框
(3) 单击“Output”按钮,在打开的对话框(图11-3左)中选中“Principal Component Analysis (主成分分析)”复选框,单击下面的“Principal Component Options(主成分选项)”按钮,
打开“Principal Component Options ”对话框,选中“Eigenvectors (特征向量)”复选框,取消“Correlations(Structure)(相关(结构))”复选框,在最左边一栏的选项按钮中选择“All ”,如图11-3右所示。
图11-3 主成分选项对话框
(4) 三次单击“OK ”按钮,输出结果。
3. 结果分析
输出结果有4个部分:简单统计量、相关系数矩阵、相关系数矩阵的特征值以及相关系数矩阵的特征向量。
(1) 图11-4给出各变量的简单统计量。
图11-4 简单统计量
(2) 图11-5给出各变量之间的相关系数矩阵。
可以看出,身高与坐高、体重、胸围之间的相关系数均为0.7以上,呈现较强的相关性。
图11-5 相关系数矩阵
(3) 图11-6给出相关系数矩阵的特征值(Eigenvalue )、上下特征值之差(Difference )、各主成分的方差贡献率(Proportion )以及累积贡献率(Cumulative )。
图11-6 相关系数矩阵的特征值与特征向量
相关系数矩阵的特征值即各主成分的方差,可以看出,第一主成分的方差贡献率为88.53%,前两个主成分的累积贡献率已达96.36%,因此,只需用前面2个主成分就可以很好地概括这组数据。
(4) 图11-7给出相关系数矩阵的全部特征值的特征向量,据此可以写出第一和第二主成分得分:
Prin1 = 0.496966sg * + 0.514571tz * + 0.480901xw * + 0.506928zg *Prin2 = – 0.543213sg * + 0.210246tz * + 0.724621xw * – 0.368294zg
*
图11-7 两个最大特征值的特征向量
其中sg*、zg*、…分别为原始变量的标准化变量。 对于第一主成分而言,各变量所占比重均在0.5左右,且都是正值,因此第一主成分(Prin1)反映了学生身材的魁梧程度,身体高大的学生,他的4个部位的尺寸都比较大;而第二主成分中,身高和坐高的系数为负值,而体重和胸围的系数为正值,故第二主成分反映了学生的胖瘦情况。
(5) 选择菜单“Edit (编辑)”→“Observations (观测)”→“Label in Plots ”,在弹出的对话框中选中所有ID 变量值,单击“OK ”按钮返回,显示结果中的散点图上出现编号名。
图11-8 前两个主成分得分的散点图 单击散点图左下角的箭头,在弹出的菜单中选择“Reference Lines ”选项,画出参考线,如图11-8所示。
根据散点图可将全部观测
大致分为三组:每一组包括哪些学生可由散点边的序号得知。
(6) 回到INSIGHT 的数据窗口,可以看到前两个主成分的得分情况,如图11-9左所示。 单击数据窗口左上角的箭头,在弹出的菜单中选择“Sort (排序)”选项,在打开的对话框中选定排序变量PCR1,并单击“Asc/Des ”按钮将其设为降序(Des ),如图11-9右所示。
图11-9 主成分得分与选择排序变量
单击“OK ”按钮返回,得到按第一主成分得分排序的结果,如图11-10左所示。
图11-10 按第一主成分得分排序结果
二、使用“分析家”作主成分分析
【实验11-2】2003年各地区农村居民家庭平均每人生活消费支出情况如表11-2(sy11_2.xls)所示。试用主成分分析法分析评价各地区的消费情况,并给出排名结果。
表11-2 各地区农村居民家庭平均每人生活消费支出情况(单位:元)地区 食品 衣着 居住 家庭设备及服务医疗保健交通和通讯文教娱乐 其他商品及服务 北京1331.69 288.25787.84 216.25 356.31 393.35 691.39 82.22
天津887.14 183.28377.55 76.96 167.67 198.50 379.44 48.97
河北639.10 114.97311.46 71.65 101.63 149.52 186.48 25.28
山西620.62 149.73169.55 55.03 81.22 119.00 213.15 26.09
内蒙古731.12 121.81246.85 65.73 124.42 192.00 256.17 32.46
辽宁813.66 147.72289.86 68.42 132.63 170.60 218.99 42.20
吉林799.16 118.08253.45 57.63 153.75 173.82 221.70 37.98
黑龙江676.14 119.05309.48 48.63 135.20 157.90 188.22 27.08
上海2004.14 250.301436.72 296.51 332.77 587.02 675.56 86.55
江苏1118.55 140.56441.87 137.74 142.11 268.53 379.15 75.86
浙江1635.64 229.47774.99 206.69 306.31 496.08 531.11 104.84
安徽734.75 79.55 281.28 74.96 87.14 126.07 184.64 27.87
福建1222.23 144.58398.15 146.66 128.95 278.43 296.65 99.85
江西986.07 99.85 264.12 62.68 91.98 141.69 223.80 37.39
山东891.82 134.30341.69 92.17 138.80 187.03 291.33 56.07
河南726.57 96.36 238.44 63.32 91.39 100.17 160.94 31.49
湖北930.98 80.19 223.41 73.00 95.55 122.05 223.92 52.53
湖南1111.27 106.16271.97 79.63 105.23 146.85 270.54 47.51
广东1402.04 117.68469.48 121.85 137.43 286.66 305.86 86.35
广西899.07 61.12 323.28 63.69 74.81 121.45 175.55 32.26
海南947.10 52.59 147.69 75.80 96.05 107.80 158.32 59.44
重庆831.63 70.49 212.38 76.68 89.42 102.40 180.28 20.03
四川941.70 85.94 224.80 64.85 91.36 105.19 202.27 30.92
贵州674.71 54.46 170.56 41.51 46.62 49.59 128.13 19.59
云南744.58 57.27 257.65 51.42 79.93 59.54 131.49 23.82
西藏669.91 114.6685.99 53.34 21.27 37.06 32.22 15.68
陕西572.67 85.15 236.33 63.52 106.66 97.33 267.87 25.86
甘肃586.38 74.02 201.57 57.45 96.18 109.34 191.83 20.08
青海775.89 113.88192.17 60.94 115.73 145.85 131.71 26.98
宁夏680.15 109.19286.09 56.09 116.31 170.52 178.34 40.44
新疆667.11 135.65254.63 50.92 116.48 99.04 112.93 28.54
1. 建立数据集
在SAS中将Excel数据表sy11_2.xls导入数据集mylib.sy11_2,如图11-11所示。其中变量dq、sp、yz、jz、sb、yl、jttx、wjyl、qt分别表示地区、食品、衣着、居住、家庭设备及服务、医疗保健、交通和通讯、文教娱乐、其他商品及服务。
图11-11 数据集mylib.sy11_2
2. 主成分分析
(1) 在“分析家”中打开数据集Mylib.sy11_2。
(2) 选择菜单“Statistics(统计)”→“Multivariate(多元分析)”→“Principal Components (主成分分析)”,打开“Principal Components”对话框。
(3) 在对话框中选择主成分分析的变量,如图11-12所示。
图11-12 Principal Components对话框图11-13 设置保存得分数据
(4) 单击“Save Data”按钮,打开“Principal Components:Save Data”对话框,在该对
话框中选择存储数据。
选中“Create and save scores data”,如图11-13右所示。单击“OK”返回。
(5) 单击“Plots”按钮,打开“Principal Components:Plots”对话框,设置图形输出。在“Scree Plot (碎石图)”选项卡中(图11-14),选中“Create scree plot(建立碎石图)”复选框。单击“OK”返回。
(6) 单击“OK”按钮,输出结果。
图11-14 图形设置
3. 结果分析
输出结果包括4个部分:简单统计量、相关系数矩阵、相关系数矩阵的特征值以及相关系数矩阵的特征向量。
(1) 图11-15给出变量的简单统计量,图中显示6项指标中食品和居住是最为重要的,其标准差高出其他变量。
图11-15 简单统计量
(2) 图11-16给出各变量之间的相关系数矩阵,可以看出变量之间大多有较强的相关性。
图11-16 相关系数矩阵
(3) 图11-17左给出相关系数矩阵的特征值(Eigenvalues)、上下特征值之差(Difference)、
各主成分的方差贡献率(proportion)以及累积贡献率(Cumulative)。第一主成分的方差贡献率为86.49%,远远大于其它主成分,说明第一主成分已经代表了绝大部分信息。
在“分析家”左边的管理窗口中双击“Scree plot”项,打开的“Scree plot”对话框(图6-17右)显示特征值的“碎石图”,很直观地看到第一特征值远远大于其它特征值,同样可以说明第一主成分已经代表了绝大部分信息。
图11-17 相关系数矩阵的特征值
(4) 图11-18给出相关系数矩阵的特征向量,由最大特征值所对应的特征向量可以写出第一主成分的表达式。
Prin1 = 0.35sp* + 0.33yz* + 0.36jz* + 0.37sb* + 0.36yl* + 0.37jttx*+0.36wjyl* + 0.32qt*
第一主成分中各变量所占比重大致相等,且均为正数,说明第一主成份是对所有指标的一个综合测度,作为综合指标,可以用来将观测排序。
图11-18 相关系数矩阵的特征向量
(5) 在“分析家”窗口中,双击左边项目管理中的“Scores Table”项,打开“Scores Table”对话框。
选择菜单“File”→“Save as By SAS Name”,将其保存为数据表Scores。
在VIEWTABLE中打开数据表Scores。选择菜单“Data”→“Hide/Unhide”,将除“dq”、“Prin1”外的变量都隐藏起来,如图11-19所示。
图11-19 隐藏变量
单击“OK”返回。在主菜单“Edit”中选择“Edit Mode”,改为编辑模式,以便修改;
然后,选择菜单“Data ”→“Sort ”,可以按主成分Prin1排序,结果如图11-20所示。
排序结果大致反映了2003年各地区的消费水平,上海、北京、浙江、福建、广东等消费水平位居前列,而重庆、甘肃、云南、贵州和西藏位居后五名,其消费水平相对较第低。
图11-20 按第一主成分排序
三、使用PRINCOMP 过程作主成分分析
【实验11-3】对表11-2中数据,使用PRINCOMP 过程作主成分分析。
图11-21 第1主成分得分排
序
对数据集sy11_2执行主成分分析的过程代码如下:
proc princomp data = Mylib.sy11_2 out = w1;
/* 选项out = w1指定将主成分得分存入文件w1中 */ var sp yz jz sb yl jttx wjyl qt; run;
proc sort data = w1;
by Descending prin1 ; /* 选项Descending 指定降序排序*/ run;
proc print data = w1; var dq prin1; run;
执行PRINCOMP 过程得到如下五方面的内容:简单统计量,
相关阵或协方差阵,从大到小排序的特征值和每个主成分贡献率及累计贡献率,全部特征向量等。
执行SORT过程将数据集w1中的观测按第一主成分得分prin1降序排序。
执行PRINT过程则将排序后的数据集w1中dq(地区)、prin1(第一主成分得分)输出,
如图11-21所示。
11.4 上机演练
【练习11-1】2003年全国各地区的市政建设指标如表11-3(lx11_1.xls)所示。试用主成
分分析方法对各地区的市政建设情况作出评价。
表11-3 各地区市政建设指标
地区年末实有道路长度年末实有道路面积城市排水管道长度城市污水日处理能力城市路灯
北京7947.7 10569.8 6649.3 216.1 256032 天津4084.1 5489.0 9123.7 76.0 178826 河北7736.7 14133.8 8911.3 242.3 286120 山西4421.0 6371.1 2858.4 91.9 204034 内蒙古3393.1 5344.4 3785.1 88.8 193870 辽宁10203.6 14885.0 9120.3 376.0 634979 吉林4485.9 6950.5 4713.6 139.8 171797 黑龙江8839.1 10654.5 5465.0 252.8 337943 上海9802.0 15933.0 5882.0 519.6 237623 江苏25540.8 31859.1 20342.5 906.6 970896 浙江10341.7 16743.2 15331.2 501.7 565675 安徽6931.2 11355.4 5982.0 292.1 231452 福建4355.0 6091.6 4957.3 162.5 219511 江西3430.5 5466.0 2952.6 74.0 255084 山东20915.2 34165.7 18152.6 462.5 550687 河南5987.0 12409.6 7801.3 231.1 351287 湖北13837.6 18815.0 8314.7 412.0 277892 湖南5368.9 7980.8 4404.0 223.0 224858 广东18408.7 30323.8 23321.0 489.3 844968 广西4268.4 6326.9 3430.5 206.7 271357 海南1074.8 2184.1 1822.3 41.2 64122 重庆3278.8 4784.1 3267.5 71.0 165155 四川7840.0 13295.8 8282.2 116.4 505575 贵州1804.1 2079.3 1988.9 8.0 84032 云南2430.8 3270.9 2557.2 146.8 144560 西藏407.9 429.0 220.2 11085 陕西2909.1 4686.4 2801.6 48.8 111729
甘肃2967.5 5281.7 2591.4 61.1 100579 青海514.3 843.5 485.0 8.5 20322 宁夏1044.6 1797.3 669.7 37.0 100513 新疆3482.0 5124.8 2460.5 122.8 158580
11.5 实验报告
完成一篇论文(包括:背景、数据来源、分析方法和过程、结果分析及评价等内容)
主成分分析案例
姓名:XXX 学号:XXXXXXX 专业:XXXX 用SPSS19软件对下列数据进行主成分分析: ……
一、相关性 通过对数据进行双变量相关分析,得到相关系数矩阵,见表1。 表1 淡化浓海水自然蒸发影响因素的相关性 由表1可知: 辐照、风速、湿度、水温、气温、浓度六个因素都与蒸发速率在0.01水平上显著相关。 分析:各变量之间存在着明显的相关关系,若直接将其纳入分析可能会得到因多元共线性影响的错误结论,因此需要通过主成份分析将数据所携带的信息进行浓缩处理。 二、KMO和球形Bartlett检验 KMO和球形Bartlett检验是对主成分分析的适用性进行检验。 KMO检验可以检查各变量之间的偏相关性,取值范围是0~1。KMO的结果越接近1,表示变量之间的偏相关性越好,那么进行主成分分析的效果就会越好。实际分析时,KMO统计量大于0.7时,效果就比较理想;若当KMO统计量小于0.5时,就不适于选用主成分分析法。 Bartlett球形检验是用来判断相关矩阵是否为单位矩阵,在主成分分析中,若拒绝各变量独立的原假设,则说明可以做主成分分析,若不拒绝原假设,则说明这些变量可能独立提供一些信息,不适合做主成分分析。
由表2可知: 1、KMO=0.631<0.7,表明变量之间没有特别完美的信息的重叠度,主成分分析得到的模型又可能不是非常完善,但仍然值得实验。 2、显著性小于0.05,则应拒绝假设,即变量间具有较强的相关性。 三、公因子方差 公因子方差表示变量共同度。表示各变量中所携带的原始信息能被提取出的主成分所体现的程度。 由表3可知: 几乎所有变量共同度都达到了75%,可认为这几个提取出的主成分对各个变量的阐释能力比较强。 四、解释的总方差 解释的总方差给出了各因素的方差贡献率和累计贡献率。
主成分分析法matlab实现,实例演示
利用Matlab 编程实现主成分分析 1.概述 Matlab 语言是当今国际上科学界 (尤其是自动控制领域) 最具影响力、也是 最有活力的软件。它起源于矩阵运算,并已经发展成一种高度集成的计算机语言。它提供了强大的科学运算、灵活的程序设计流程、高质量的图形可视化与界面设计、与其他程序和语言的便捷接口的功能。Matlab 语言在各国高校与研究单位起着重大的作用。主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。 1.1主成分分析计算步骤 ① 计算相关系数矩阵 ?? ? ???? ???? ?? ?=pp p p p p r r r r r r r r r R 2 122221 11211 (1) 在(3.5.3)式中,r ij (i ,j=1,2,…,p )为原变量的xi 与xj 之间的相关系数,其计算公式为 ∑∑∑===----= n k n k j kj i ki n k j kj i ki ij x x x x x x x x r 1 1 2 2 1 )() () )(( (2) 因为R 是实对称矩阵(即r ij =r ji ),所以只需计算上三角元素或下三角元素即可。
② 计算特征值与特征向量 首先解特征方程0=-R I λ,通常用雅可比法(Jacobi )求出特征值 ),,2,1(p i i =λ,并使其按大小顺序排列,即0,21≥≥≥≥p λλλ ;然后分别求 出对应于特征值i λ的特征向量),,2,1(p i e i =。这里要求i e =1,即112 =∑=p j ij e ,其 中ij e 表示向量i e 的第j 个分量。 ③ 计算主成分贡献率及累计贡献率 主成分i z 的贡献率为 ),,2,1(1 p i p k k i =∑=λ λ 累计贡献率为 ) ,,2,1(11 p i p k k i k k =∑∑==λ λ 一般取累计贡献率达85—95%的特征值m λλλ,,,21 所对应的第一、第二,…,第m (m ≤p )个主成分。 ④ 计算主成分载荷 其计算公式为 ) ,,2,1,(),(p j i e x z p l ij i j i ij ===λ (3)
主成分分析法总结
主成分分析法总结 在实际问题研究中,多变量问题是经常会遇到的。变量太多,无疑会增加分析问题的难度与复杂性,而且在许多实际问题中,多个变量之间是具有一定的相关关系的。 因此,人们会很自然地想到,能否在相关分析的基础上,用较少的新变量代替原来较多的旧变量,而且使这些较少的新变量尽可能多地保留原来变量所反映的信息? 一、概述 在处理信息时,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠,例如,高校科研状况评价中的立项课题数与项目经费、经费支出等之间会存在较高的相关性;学生综合评价研究中的专业基础课成绩与专业课成绩、获奖学金次数等之间也会存在较高的相关性。而变量之间信息的高度重叠和高度相关会给统计方法的应用带来许多障碍。 为了解决这些问题,最简单和最直接的解决方案是削减变量的个数,但这必然又会导致信息丢失和信息不完整等问题的产生。为此,人们希望探索一种更为有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。主成分分析正式这样一种能够有效降低变量维数,并已得到广泛应用的分析方法。 主成分分析以最少的信息丢失为前提,将众多的原有变量综合成较少几个综合指标,通常综合指标(主成分)有以下几个特点: ↓主成分个数远远少于原有变量的个数 原有变量综合成少数几个因子之后,因子将可以替代原有变量参与数据建模,这将大大减少分析过程中的计算工作量。 ↓主成分能够反映原有变量的绝大部分信息 因子并不是原有变量的简单取舍,而是原有变量重组后的结果,因此不会造成原有变量信息的大量丢失,并能够代表原有变量的绝大部分信息。 ↓主成分之间应该互不相关 通过主成分分析得出的新的综合指标(主成分)之间互不相关,因子参与数据建模能够有效地解决变量信息重叠、多重共线性等给分析应用带来的诸多问题。 ↓主成分具有命名解释性 总之,主成分分析法是研究如何以最少的信息丢失将众多原有变量浓缩成少数几个因子,如何使因子具有一定的命名解释性的多元统计分析方法。 主成分分析的具体步骤如下: (1)计算协方差矩阵 计算样品数据的协方差矩阵:Σ=(s ij )p ?p ,其中 1 1()() 1n ij ki i kj j k s x x x x n ==---∑i ,j=1,2,…,p (2)求出Σ的特征值 i λ及相应的正交化单位特征向量i a Σ的前m 个较大的特征值λ1≥λ2≥…λm>0,就是前m 个主成分对应的方差,i λ对应的单 位特征向量 i a 就是主成分Fi 的关于原变量的系数,则原变量的第i 个主成分Fi 为:
主成分分析实验报告
项目名称实验4―主成分分析 所属课程名称多元统计分析(英)项目类型综合性实验 实验(实训)日期2012年 4 月15 日
实验报告4 主成分分析(综合性实验) (Principal component analysis) 实验原理:主成分分析利用指标之间的相关性,将多个指标转化为少数几个综合指标,从而达到降维和数据结构简化的目的。这些综合指标反映了原始指标的绝大部分信息,通常表示为原始指标的某种线性组合,且综合指标间不相关。利用矩阵代数的知识可求解主成分。
实验题目:下表中给出了不同国家及地区的男子径赛记录:(t8a6) Country 100m (s) 200m (s) 400m (s) 800m (min) 1500m (min) 5000m (min) 10,000m (min) Marathon (mins) Argentina 10.39 20.81 46.84 1.81 3.7 14.04 29.36 137.72 Australia 10.31 20.06 44.84 1.74 3.57 13.28 27.66 128.3 Austria 10.44 20.81 46.82 1.79 3.6 13.26 27.72 135.9 Belgium 10.34 20.68 45.04 1.73 3.6 13.22 27.45 129.95 Bermuda 10.28 20.58 45.91 1.8 3.75 14.68 30.55 146.62 Brazil 10.22 20.43 45.21 1.73 3.66 13.62 28.62 133.13 Burma 10.64 21.52 48.3 1.8 3.85 14.45 30.28 139.95 Canada 10.17 20.22 45.68 1.76 3.63 13.55 28.09 130.15 Chile 10.34 20.8 46.2 1.79 3.71 13.61 29.3 134.03 China 10.51 21.04 47.3 1.81 3.73 13.9 29.13 133.53 Columbia 10.43 21.05 46.1 1.82 3.74 13.49 27.88 131.35 Cook Islands 12.18 23.2 52.94 2.02 4.24 16.7 35.38 164.7 Costa Rica 10.94 21.9 48.66 1.87 3.84 14.03 28.81 136.58 Czechoslovakia 10.35 20.65 45.64 1.76 3.58 13.42 28.19 134.32 Denmark 10.56 20.52 45.89 1.78 3.61 13.5 28.11 130.78 Dominican Republic 10.14 20.65 46.8 1.82 3.82 14.91 31.45 154.12 Finland 10.43 20.69 45.49 1.74 3.61 13.27 27.52 130.87 France 10.11 20.38 45.28 1.73 3.57 13.34 27.97 132.3 German (D.R.) 10.12 20.33 44.87 1.73 3.56 13.17 27.42 129.92 German (F.R.) 10.16 20.37 44.5 1.73 3.53 13.21 27.61 132.23 Great Brit.& N. Ireland 10.11 20.21 44.93 1.7 3.51 13.01 27.51 129.13 Greece 10.22 20.71 46.56 1.78 3.64 14.59 28.45 134.6 Guatemala 10.98 21.82 48.4 1.89 3.8 14.16 30.11 139.33 Hungary 10.26 20.62 46.02 1.77 3.62 13.49 28.44 132.58 India 10.6 21.42 45.73 1.76 3.73 13.77 28.81 131.98
主成分分析PCA(含有详细推导过程以及案例分析matlab版)
主成分分析法(PCA) 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 I. 主成分分析法(PCA)模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。 主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求 0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ??????? ??=np n n p p x x x x x x x x x X 21 222 21112 11()p x x x ,,21=
主成分分析法精华讲义及实例
主成分分析 类型:一种处理高维数据的方法。 降维思想:在实际问题的研究中,往往会涉及众多有关的变量。但是,变量太多不但会增加计算的复杂性,而且也会给合理地分析问题和解释问题带来困难。一般说来,虽然每个变量都提供了一定的信息,但其重要性有所不同,而在很多情况下,变量间有一定的相关性,从而使得这些变量所提供的信息在一定程度上有所重叠。因而人们希望对这些变量加以“改造”,用为数极少的互补相关的新变量来反映原变量所提供的绝大部分信息,通过对新变量的分析达到解决问题的目的。 一、总体主成分 1.1 定义 设 X 1,X 2,…,X p 为某实际问题所涉及的 p 个随机变量。记 X=(X 1,X 2,…,Xp)T ,其协方差矩阵为 ()[(())(())], T ij p p E X E X X E X σ?∑==-- 它是一个 p 阶非负定矩阵。设 1111112212221122221122T p p T p p T p p p p pp p Y l X l X l X l X Y l X l X l X l X Y l X l X l X l X ?==+++? ==+++?? ??==+++? (1) 则有 ()(),1,2,...,, (,)(,),1,2,...,. T T i i i i T T T i j i j i j V ar Y V ar l X l l i p C ov Y Y C ov l X l X l l j p ==∑===∑= (2) 第 i 个主成分: 一般地,在约束条件 1T i i l l =
及 (,)0,1,2,..., 1.T i k i k C ov Y Y l l k i =∑==- 下,求 l i 使 Var(Y i )达到最大,由此 l i 所确定的 T i i Y l X = 称为 X 1,X 2,…,X p 的第 i 个主成分。 1.2 总体主成分的计算 设 ∑是12(,,...,) T p X X X X =的协方差矩阵,∑的特征值及相应的正交单位化特 征向量分别为 120p λλλ≥≥≥≥ 及 12,,...,, p e e e 则 X 的第 i 个主成分为 1122,1,2,...,,T i i i i ip p Y e X e X e X e X i p ==+++= (3) 此时 (),1,2,...,,(,)0,. T i i i i T i k i k V ar Y e e i p C ov Y Y e e i k λ?=∑==??=∑=≠?? 1.3 总体主成分的性质 1.3.1 主成分的协方差矩阵及总方差 记 12(,,...,) T p Y Y Y Y = 为主成分向量,则 Y=P T X ,其中12(,,...,)p P e e e =,且 12()()(,,...,),T T p Cov Y Cov P X P P Diag λλλ==∑=Λ= 由此得主成分的总方差为 1 1 1 ()()()()(),p p p T T i i i i i i V ar Y tr P P tr P P tr V ar X λ ==== =∑=∑=∑= ∑∑∑ 即主成分分析是把 p 个原始变量 X 1,X 2,…,X p 的总方差
实验六主成分分析报告
实验六 主成分分析 一、实验目的 通过本次实验,掌握SPSS 及ENVI 的主成分分析方法。 二、有关概念 1. 主成分分析的概念 主成分分析(又称因子分析),是将多个实测变量转换为少数几个不相关的 综合指标的多元统计分析方法。代表各类信息的综合指标就称为因子或主成份。 主成分分析的数学模型可写为: m m x a x a x a x a z 131********++++= m m x a x a x a x a z 23232221212++++= m m x a x a x a x a z 33332321313++++= ……… m nm n n n n x a x a x a x a z ++++= 332211 其中,x 1、x 2、 x 3、 x 4 …x m 为原始变量;z 1、 z 2、 z 3、 z 4 …z n 为主成份,且有m ≥n 。 写成矩阵形式为:Z=AX 。Z 为主成份向量,A 为主成份变换矩阵,X 为原始变 量向量。主成份分析的目的是把系数矩阵A 求出,主成份Z1、Z2、Z3…在总方差中所占比重依次递减。 从理论上讲m=n 即有多少原始变量就有多少主成份,但实际上前面几个主成 份集中了大部分方差,因此取主成份数目远远小于原始变量的数目,但信息损失很小。 因子分析的一个重要目的还在于对原始变量进行分门别类的综合评价。如果 因子分析结果保证了因子之间的正交性(不相关)但对因子不易命名,还可以通过对因子模型的旋转变换使公因子负荷系数向更大(向1)或更小(向0)方向变化,使得对公因子的命名和解释变得更加容易。进行正交变换可以保证变换后各因子仍正交,这是比较理想的情况。如果经过正交变换后对公因子仍然不易解释,也可进行斜交旋转。 2. 因子提取方法 SPSS 提供的因子提取方法有: ①Principal components 主成份法。该方法假设变量是因子的纯线性组合。
R语言主成分分析的案例
R 语言主成分分析的案例
R 语言也介绍到案例篇了,也有不少同学反馈说还是不是特别明白一些基础的东西,希望能 够有一些比较浅显的可以操作的入门。其实这些之前 SPSS 实战案例都不少,老实说一旦用 上了开源工具就好像上瘾了,对于以前的 SAS、clementine 之类的可视化工具没有一点 感觉了。本质上还是觉得要装这个、装那个的比较麻烦,现在用 R 或者 python 直接简单 安装下,导入自己需要用到的包,活学活用一些命令函数就可以了。以后平台上集成 R、 python 的开发是趋势,包括现在 BAT 公司内部已经实现了。 今天就贴个盐泉水化学分析资料的主成分分析和因子分析通过 R 语言数据挖掘的小李 子: 有条件的同学最好自己安装下 R,操作一遍。 今有 20 个盐泉,盐泉的水化学特征系数值见下表.试对盐泉的水化学分析资料作主成分分 析和因子分析.(数据可以自己模拟一份)
其中 x1:矿化度(g/L);
x2:Br?103/Cl; x3:K?103/Σ 盐; x4:K?103/Cl; x5:Na/K; x6:Mg?102/Cl; x7:εNa/εCl.
1.数据准备
导入数据保存在对象 saltwell 中 >saltwell<-read.table("c:/saltwell.txt",header=T) >saltwell
2.数据分析
1 标准误、方差贡献率和累积贡献率
>arrests.pr<- prcomp(saltwell, scale = TRUE) >summary(arrests.pr,loadings=TRUE)
2 每个变量的标准误和变换矩阵
>prcomp(saltwell, scale = TRUE)
3 查看对象 arests.pr 中的内容
>> str(arrests.pr)
主成分分析法实例
1、主成分法: 用主成分法寻找公共因子的方法如下: 假定从相关阵出发求解主成分,设有p 个变量,则可找出p 个主成分。将所得的p 个主成分按由大到小的顺序排列,记为1Y ,2Y ,…,P Y , 则主成分与原始变量之间存在如下关系: 11111221221122221122....................p p p p p p p pp p Y X X X Y X X X Y X X X γγγγγγγγγ=+++?? =+++??? ?=+++? 式中,ij γ为随机向量X 的相关矩阵的特征值所对应的特征向量的分量,因为特征向量之间彼此正交,从X 到Y 得转换关系是可逆的,很容易得出由Y 到 X 得转换关系为: 11112121212122221122....................p p p p p p p pp p X Y Y Y X Y Y Y X Y Y Y γγγγγγγγγ=+++?? =+++??? ?=+++? 对上面每一等式只保留钱m 个主成分而把后面的部分用i ε代替,则上式变为: 111121211 2121222221122................. ...m m m m p p p mp m p X Y Y Y X Y Y Y X Y Y Y γγγεγγγεγγγε=++++??=++++????=++++? 上式在形式上已经与因子模型相一致,且i Y (i=1,2,…,m )之间相互独立,且i Y 与i ε之间相互独立,为了把i Y 转化成合适的公因子,现在要做的工作只是把主成分i Y 变为方差为1的变量。为完成此变换,必须将i Y 除以其标准差,由主成分分析的知识知其标准差即为特征根的平方根 i λ/i i i F Y λ=, 1122m m λγλγλγ,则式子变为:
主成分分析法及其在SPSS中的操作
一、主成分分析基本原理 概念:主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法。从数学角度来看,这是一种降维处理技术。 思路:一个研究对象,往往是多要素的复杂系统。变量太多无疑会增加分析问题的难度和复杂性,利用原变量之间的相关关系,用较少的新变量代替原来较多的变量,并使这些少数变量尽可能多的保留原来较多的变量所反应的信息,这样问题就简单化了。 原理:假定有n 个样本,每个样本共有p 个变量,构成一个n ×p 阶的数据矩阵, 记原变量指标为x 1,x 2,…,x p ,设它们降维处理后的综合指标,即新变量为 z 1,z 2,z 3,… ,z m (m ≤p),则 系数l ij 的确定原则: ①z i 与z j (i ≠j ;i ,j=1,2,…,m )相互无关; ②z 1是x 1,x 2,…,x P 的一切线性组合中方差最大者,z 2是与z 1不相关的x 1,x 2,…,x P 的所有线性组合中方差最大者; z m 是与z 1,z 2,……,z m -1都不相关的x 1,x 2,…x P , 的所有线性组合中方差最大者。 新变量指标z 1,z 2,…,z m 分别称为原变量指标x 1,x 2,…,x P 的第1,第2,…,第m 主成分。 从以上的分析可以看出,主成分分析的实质就是确定原来变量x j (j=1,2 ,…, p )在诸主成分z i (i=1,2,…,m )上的荷载 l ij ( i=1,2,…,m ; j=1,2 ,…,p )。 ?????? ? ???????=np n n p p x x x x x x x x x X 2 1 2222111211 ?? ??? ? ?+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z 22112222121212121111............
主成分分析、因子分析实验报告--SPSS
对2009年我国88个房地产上市公司的因子分析 分析结果: 表1 KMO 和 Bartlett 的检验 取样足够度的 Kaiser-Meyer-Olkin 度量。.637 Bartlett 的球形度检验近似卡方398.287 df 45 Sig. .000 由表1可知,巴特利特球度检验统计量的观测值为398.287,相应的概率p值接近0,小于显著性水平 (取0.05),所以应拒绝原假设,认为相关系数矩阵与单位矩阵有显著差异。同时,KMO值为0.637,根据Kaiser给出的KMO度量标准(0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合)可知原有变量不算特别适合进行因子分析。 表2 公因子方差 初始提取市盈率 1.000 .706 净资产收益率 1.000 .609 总资产报酬率 1.000 .822 毛利率 1.000 .280 资产现金率 1.000 .731 应收应付比 1.000 .561 营业利润占比 1.000 .782 流通市值 1.000 .957 总市值 1.000 .928 成交量(手) 1.000 .858 提取方法:主成份分析。 表2为公因子方差,即因子分析的初始解,显示了所有变量的共同度数据。第一列是因子分析初始解下的变量共同度,它表明,对原有10个变量如果采用主成分分析方法提取所有特征根(10个),那么原有变量的所有方差都可被解释,变量的共同度均为1(原有变量标准化后的方差为1)。事实上,因子个数小于原有变量的个数才是因子分析的目标,所以不可提取全部特征根;第二列是在按指定提取条件(这里为特征根大于1)提取特征根时的共同度。可以看到,总资产报酬率、成交量、流
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 公司销售净利率(X1)资产净利率(X2)净资产收益率(X3)销售毛利率(X4) 歌华有线五粮液用友软件太太药业浙江阳光烟台万华方正科技红河光明贵州茅台中铁二局红星发展伊利股份青岛海尔湖北宜化雅戈尔福建南纸43.31 17.11 21.11 29.55 11.00 17.63 2.73 29.11 20.29 3.99 22.65 4.43 5.40 7.06 19.82 7.26 7.39 12.13 6.03 8.62 8.41 13.86 4.22 5.44 9.48 4.64 11.13 7.30 8.90 2.79 10.53 2.99 8.73 17.29 7.00 10.13 11.83 15.41 17.16 6.09 12.97 9.35 14.3 14.36 12.53 5.24 18.55 6.99 54.89 44.25 89.37 73 25.22 36.44 9.96 56.26 82.23 13.04 50.51 29.04 65.5 19.79 42.04 22.72 第一,将EXCEL中的原始数据导入到SPSS软件中; 注意: 导入Spss的数据不能出现空缺的现象,如出现可用0补齐。 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。 所做工作: a. 原始数据的标准化处理
主成分分析法PCA的原理
主成分分析法原理简介 1.什么是主成分分析法 主成分分析也称主分量分析,是揭示大样本、多变量数据或样本之间内在关系的一种方法,旨在利用降维的思想,把多指标转化为少数几个综合指标,降低观测空间的维数,以获取最主要的信息。 在统计学中,主成分分析(principal components analysis, PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。 2.主成分分析的基本思想 在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 对同一个体进行多项观察时必定涉及多个随机变量X1,X2,…,X p,它们之间都存在着相关性,一时难以综合。这时就需要借助主成分分析来概括诸多信息的主要方面。我们希望有一个或几个较好的综合指标来概括信息,而且希望综合指标互相独立地各代表某一方面的性质。
教育信息处理(实验九因子分析与主成分分析)实验报告-示例
1、对北京18个区县中等职业教育发展水平进行聚类。X1:每万人中职在校生数;X2:每万人中职招生数;X3:每万人中职毕业生数;X4:每万人中职专任教师数;X5:本科以上学校教师占专任教师的比例;X6:高级教师占专任教师的比例;X7:学校平均在校生人数;X8:国家财政预算中职经费占国内生产总值的比例;X9:生均教育经费。 具体步骤如下: 1、导入数据,建立数据文件(data.sav) 2、选择聚类分析(分析—分类—系统聚类分析),选择变量,分群选择个 案方式 3、聚类分析描述统计(统计量—合并进程表;聚类成员—单一方案—聚类 数3) 4、聚类分析绘制(树状图;冰柱—所有聚类,方向—垂直) 5、聚类分析方法(聚类方法—组间联接,度量标准—区间—平方Euclidean
距离) 6、聚类分析保存(聚类成员—单一方案—聚类数3) 7、保存实验结果,并分析结果 结果与分析: (1)输出结果文件中的第一部分如下图1所示。 图1中可以看出18个样本都进入了聚类分析,但有效样本为14个,缺失14个。 (2)输出结果文件中的第二部分为系统聚类分析的凝聚状态表如图2所示。
第一列表示聚类分析的步骤,可以看出本例中共进行了17个步骤的分析; 第二列和第三列表示某步聚类分析中,哪两个样本或类聚成了一类; 第四列表示两个样本或类间的距离,从表格中可以看出,距离小的样本之间先聚类; 第五列和第六列表示某步聚类分析中,参与聚类的是样本还是类。0表示样本,数字n(非零)表示第n步聚类产生的类参与了本步聚类; 第七列表示本步聚类结果在下面聚类的第几步中用到。 图2给中第一行表示,第二个样本和第四个样本最先进行了聚类,样本间的距离为4803.026,这个聚类的结果将在后面的第六步
主成分分析 实例
§8 实例 实例1 计算得 1x =71.25,2x =67.5 分析1:基于协差阵∑ 求主成分。 369.6117.9117.9214.3S ?? = ??? 特征根与特征向量(S无偏,用SPSS ) Factor 1 Factor 2 11x x - 0.880 -0.474 22x x - 0.474 0.880 特征值 433.12 150.81 贡献率 0.7417 0.2583 注:样本协差阵为无偏估计11(11)1n n n S X I X n n ''= --, 所以,第一、二主成分的表达式为 112212 0.88(71.25)0.47(67.5) 0.47(71.25)0.88(67.5)y x x y x x =-+-?? =--+-? 第一主成分是英语与数学的加权和(反映了综合成绩),且英语的权数要大于数学的权数。1y 越大,综合成绩越好。(综合成分) 第二主成分的两个系数异号(反映了两科成绩的均衡性)。不妨将英语称为文科,数学称为理科。2y 越大,说明偏科(文、理成绩不均衡),2y 越小,越接近于零,说明不偏科(文、理成绩均衡)。(结构成分)
问题:英语的权数为何大?如何解释? 分析2: 基于相关阵R 求主成分。因为 1x =71.25,2x =67.5 所以相关阵 11R ? =? ? ? 解得R 的特征根为:1λ=1.419,2λ=0.581,对应的单位特征向量分别为: Factor 1 Factor 2 11 1x x s - 0.707 0.707 22 2 x x s - 0.707 -0.707 特征根 1.419 0.581 贡献率 0.709 0.291 所以,第一、二主成分的表达式为 12112271.2567.50.7070.70717.9813.6971.2567.50.7070.70717.9813.69x x y x x y --? =+=+?? ? --?=-=-?? 1122120.039(71.25)0.052(67.5) 0.039(71.25)0.052(67.5)y x x y x x =-+-?? =---? 112212 0.0390.052 6.273 0.0390.0520.671y x x y x x =+-?? =-+? * 2*11707.0707.0x x y += *2*12707.0707.0x x y -= 基于相关阵的更说明了: 第一主成分是英语与数学的加权总分。 第二主成分是对两科成绩均衡性的度量。 此例说明:基于协差阵与基于相关阵的主成分分析的结果不一致。结合此例的实际背景,经对比分析可知,基于协差阵的主成分分析更符合实际。
主成分分析法概念及例题
主成分分析法 [ 编辑 ] 什么是主成分分析法 主成分分析也称 主分量分析 ,旨在利用降维的思想,把多 指标 转化为少数几个综合指标。 在 统计学 中,主成分分析( principal components analysis,PCA )是一种简化数据集的技 术。它是一个线性变换。 这个变换把数据变换到一个新的坐标系统中, 使得任何数据投影的第一 大方差 在第一个坐标 (称为第一主成分 )上,第二大方差在第二个坐标 (第二主成分 )上,依次类推。 主成分分析经常用减少数据集的维数, 同时保持数据集的对 方差 贡献最大的特征。 这是通过保留 低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是, 这也不是一定的,要视具体应用而定。 [ 编辑 ] , PCA ) 又称: 主分量分析,主成分回归分析法 主成分分析( principal components analysis
主成分分析的基本思想 在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [ 编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [ 编辑] 主成分分析的主要作用
主成分分析计算方法和步骤
主成分分析计算方法和步骤: 在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。而主成分分析法可以很好地解决这一问题。 主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。 主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。 结合数据进行分析 本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了0.963,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。 表5-6 相关系数矩阵 本科院校 数招生人数教育经费投入 相关性师生比0.279 0.329 0.252 重点高校数0.345 0.204 0.310 教工人数0.963 0.954 0.896 本科院校数 1.000 0.938 0.881 招生人数0.938 1.000 0.893 教育经费投 0.881 0.893 1.000 入
主成分分析实验报告
项目名称实验4—主成分分析 所属课程名称多元统计分析(英) 项目类型综合性实验_____________ 实验(实训)日期2012年4 月15日
二、实验(实训)容: 【项目容】 主成分分析。 【方案设计】 题目: 由原始数据求主成分。 【实验(实训)过程】(步骤、记录、数据、程序等)附后 【结论】(结果、分析) 附后 三、指导教师评语及成绩: 评语: 成绩:指导教师签名: 批阅日期: 实验报告4 主成分分析(综合性实验) (Prin cipal comp onent an alysis) 实验原理:主成分分析利用指标之间的相关性,将多个指标转化为少数几个综合指标,从而达到降维和数据结构简化的目的。这些综合指标反映了原始指标的绝
大部分信息,通常表示为原始指标的某种线性组合,且综合指标间不相关。利用矩阵代数的知识可求解主成分 实验题目:下表中给出了不同国家及地区的男子径赛记录:(t8a6) Country 100m 200m 400m 800m 1500m 5000m 10,000m Marathon (s) (s) (s) (min) (min) (min) (min) (mins) Argentina 10.39 20.81 46.84 1.81 3.7 14.04 29.36 137.72 Australia 10.31 20.06 44.84 1.74 3.57 13.28 27.66 128.3 Austria 10.44 20.81 46.82 1.79 3.6 13.26 27.72 135.9 Belgium 10.34 20.68 45.04 1.73 3.6 13.22 27.45 129.95 Bermuda 10.28 20.58 45.91 1.8 3.75 14.68 30.55 146.62 Brazil 10.22 20.43 45.21 1.73 3.66 13.62 28.62 133.13 Burma 10.64 21.52 48.3 1.8 3.85 14.45 30.28 139.95 Canada 10.17 20.22 45.68 1.76 3.63 13.55 28.09 130.15 Chile 10.34 20.8 46.2 1.79 3.71 13.61 29.3 134.03 China 10.51 21.04 47.3 1.81 3.73 13.9 29.13 133.53 Columbia 10.43 21.05 46.1 1.82 3.74 13.49 27.88 131.35 Cook Islands 12.18 23.2 52.94 2.02 4.24 16.7 35.38 164.7 Costa Rica 10.94 21.9 48.66 1.87 3.84 14.03 28.81 136.58 Czechoslovakia 10.35 20.65 45.64 1.76 3.58 13.42 28.19 134.32 Denmark 10.56 20.52 45.89 1.78 3.61 13.5 28.11 130.78 Dominican Republic 10.14 20.65 46.8 1.82 3.82 14.91 31.45 154.12 Finland 10.43 20.69 45.49 1.74 3.61 13.27 27.52 130.87 France 10.11 20.38 45.28 1.73 3.57 13.34 27.97 132.3 German (D.R.) 10.12 20.33 44.87 1.73 3.56 13.17 27.42 129.92 German (F.R.) 10.16 20.37 44.5 1.73 3.53 13.21 27.61 132.23 Great Brit.& N. Ireland 10.11 20.21 44.93 1.7 3.51 13.01 27.51 129.13