用sed命令在文本的行尾或行首添加字符
linux shell 用sed命令在文本的行尾或行首添加字符
昨天写一个脚本花了一天的2/3的时间,而且大部分时间都耗在了sed 命令上,今天不总结一下都对不起昨天流逝的时间啊~~~
用sed命令在行首或行尾添加字符的命令有以下几种:
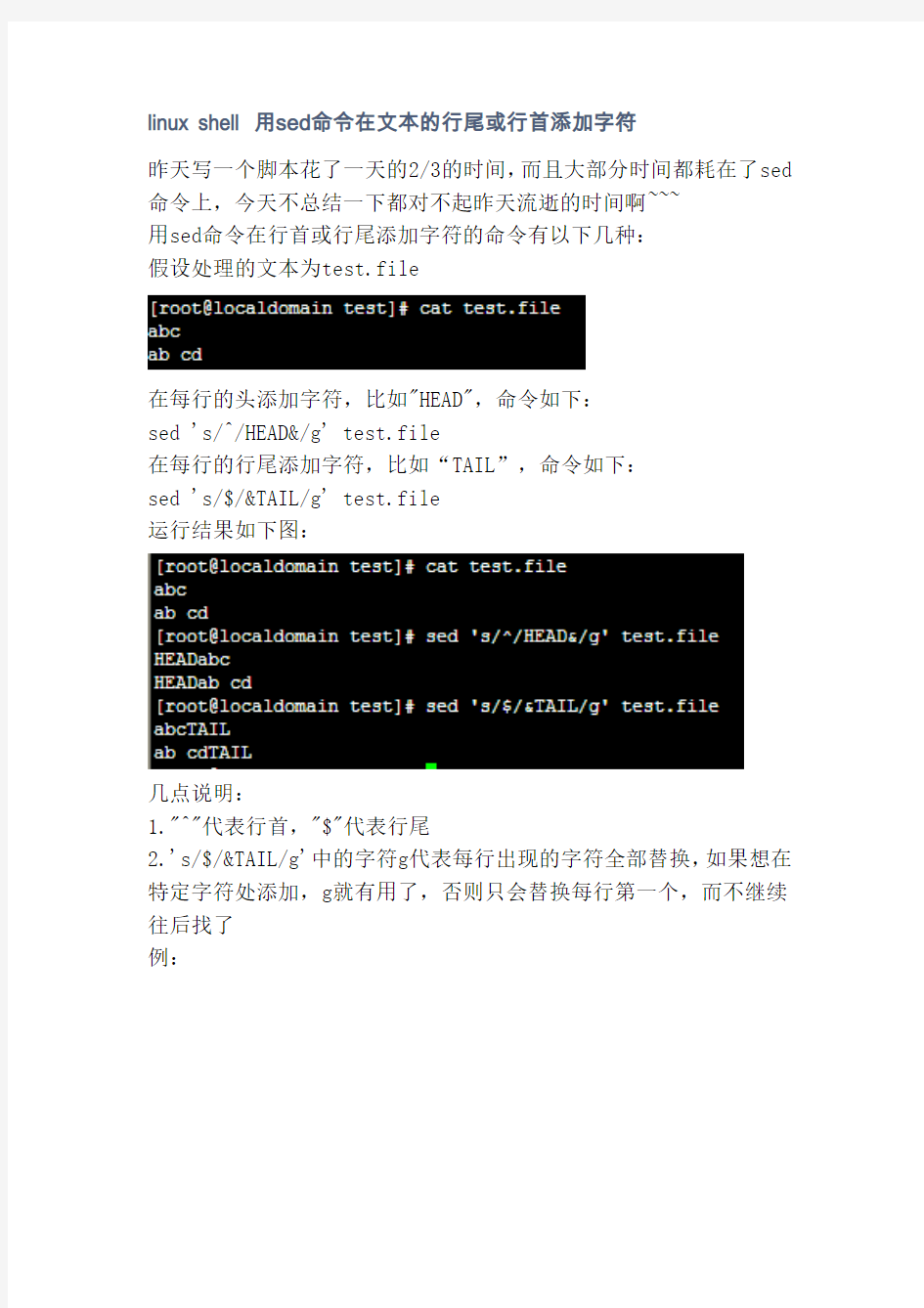
假设处理的文本为test.file
在每行的头添加字符,比如"HEAD",命令如下:
sed 's/^/HEAD&/g' test.file
在每行的行尾添加字符,比如“TAIL”,命令如下:
sed 's/$/&TAIL/g' test.file
运行结果如下图:
几点说明:
1."^"代表行首,"$"代表行尾
2.'s/$/&TAIL/g'中的字符g代表每行出现的字符全部替换,如果想在特定字符处添加,g就有用了,否则只会替换每行第一个,而不继续往后找了
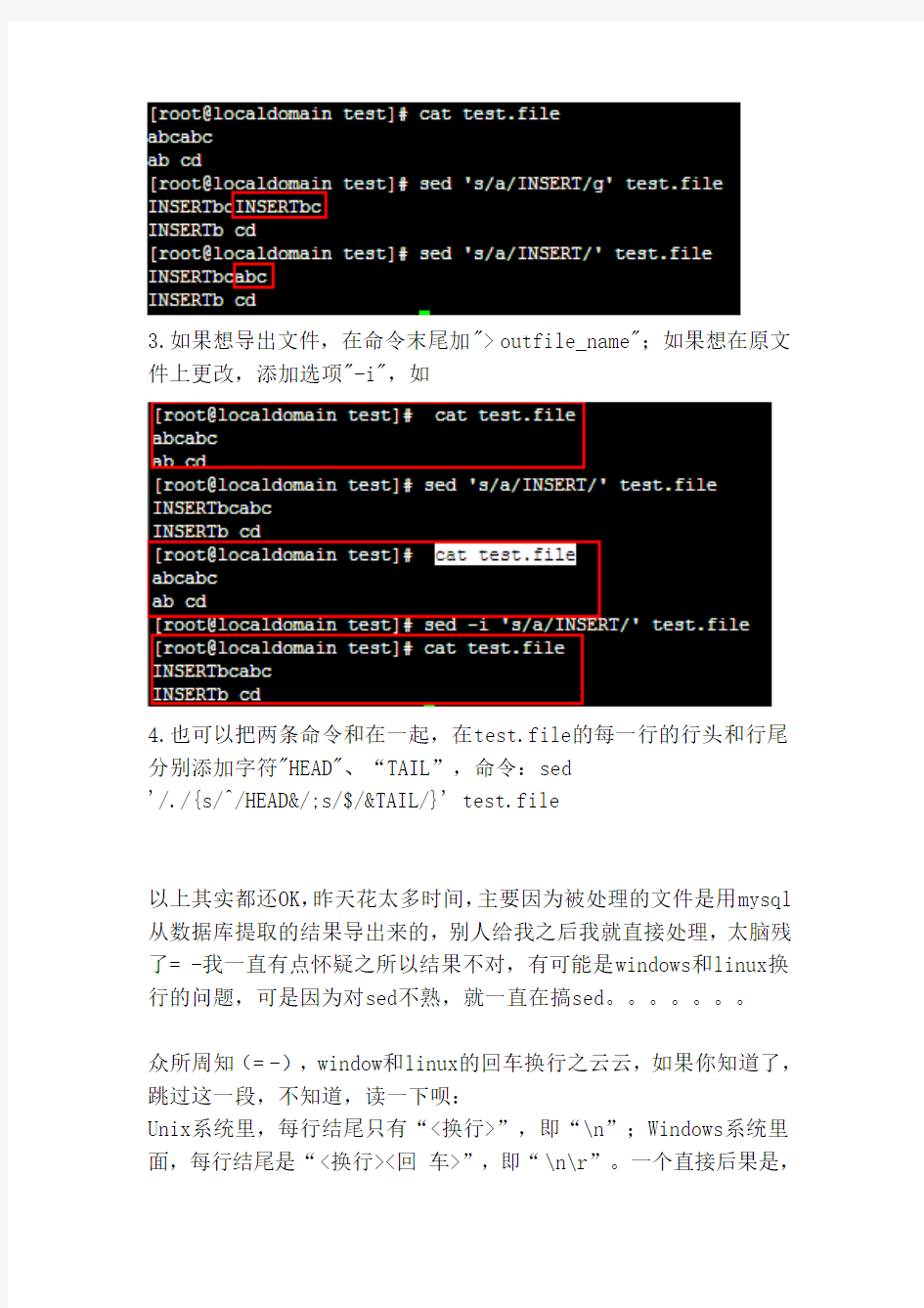
例:
3.如果想导出文件,在命令末尾加"> outfile_name";如果想在原文件上更改,添加选项"-i",如
4.也可以把两条命令和在一起,在test.file的每一行的行头和行尾分别添加字符"HEAD"、“TAIL”,命令:sed
'/./{s/^/HEAD&/;s/$/&TAIL/}' test.file
以上其实都还OK,昨天花太多时间,主要因为被处理的文件是用mysql 从数据库提取的结果导出来的,别人给我之后我就直接处理,太脑残了= -我一直有点怀疑之所以结果不对,有可能是windows和linux换行的问题,可是因为对sed不熟,就一直在搞sed。。。。。。。
众所周知(= -),window和linux的回车换行之云云,如果你知道了,跳过这一段,不知道,读一下呗:
Unix系统里,每行结尾只有“<换行>”,即“\n”;Windows系统里面,每行结尾是“<换行><回车>”,即“\n\r”。一个直接后果是,
Unix系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix下打开的话,在每行的结尾可能会多出一个^M符号。
好了,所以我的问题就出在被处理的文件的每行末尾都有^M符号,而这通常是看不出来的。可以用"cat -A test.file"命令查看。因此当我想在行尾添加字符的时候,它总是添加在行首且会覆盖掉原来行首的字符。
要把文件转换一下,有两种方法:
1.命令dos2unix test.file
2.去掉"\r" ,用命令sed -i 's/\r//' test.file
好了,这样处理完,就OK啦!!!
awk命令的用法
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。 awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是AWK 的GNU 版本。 awk其名称得自于它的创始人Alfred Aho 、Peter Weinberger 和Brian Kernighan 姓氏的首个字母。实际上AWK 的确拥有自己的语言:AWK 程序设计语言,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。 使用方法 awk '{pattern + action}' {filenames} 尽管操作可能会很复杂,但语法总是这样,其中pattern 表示AWK 在数据中查找的内容,而action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。pattern就是要表示的正则表达式,用斜杠括起来。 awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。 通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。 调用awk 有三种方式调用awk 1.命令行方式 awk [-F field-separator] 'commands' input-file(s) 其中,commands 是真正awk命令,[-F域分隔符]是可选的。input-file(s) 是待处理的文件。在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。 2.shell脚本方式 将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。 相当于shell脚本首行的:#!/bin/sh 可以换成:#!/bin/awk 3.将所有的awk命令插入一个单独文件,然后调用: awk -f awk-script-file input-file(s) 其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。 本章重点介绍命令行方式。 入门实例 假设last -n 5的输出如下
批量替换命令(sed)
原文地址 https://www.360docs.net/doc/ee9721760.html,/2009/10/unix -sed -tutorial-advanced-sed -substitutio n-examples/ 发现thegeekstuff 确实是个不错的网站,一周推送geek 教程,看了后受益颇深,特此分享此为不完整译文加上本人一些理解 1.Sed 替换分隔符 除了\外,其他的字符都可以当作Sed 的替换分隔符,如 @ % | ; : 首先创建一个输入文件path.txt 1 2 3 4 $ cat path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin:/usr/bin:/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin:/opt/omni/bin: /opt/omni/lbin :/opt/omni/sbin:/root/bin 示例一,指定@为替换分隔符,把/opt/omni/lbin 替换为/opt/tools/bin 1 2 3 4 $ sed 's@/opt/omni/lbin@/opt/tools/bin@g' path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin/:/usr/bin:/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin:/opt/omni/bin: /opt/tools/bin :/opt/omni/sbin:/root/bin 示例二,如果指定/为分隔符,那么新旧字符串的/需要用\转义 1 2 3 4 $ sed 's/\/opt\/omni\/lbin/\/opt\/tools\/bin/g' path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin/:/usr/bin:/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin:/opt/omni/bin: /opt/tools/bin :/opt/omni/sbin:/root/bin 2,使用 '&' 得到匹配的字符串 示例一,替换/usr/bin/为/usr/bin/local 1 2 3 4 $ sed 's@/usr/bin@&/local@g' path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin/:/usr/bin/local :/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin/local :/opt/omni/bin: /opt/omni/lbin:/opt/omni/sbin:/root/bin 示例二,使用&匹配整行
Linux命令
tar grep find ssh sed awk vim diff sort export args ls pwd cd gzip bzip2unzip shutdown ftp crontab service ps free top df kill rm cp mv cat mount chmod chown passwd mkdir ifconfig uname whereis whatis locate man tail less su mysql yum rpm ping date wget 1. tar 创建一个新的tar文件 $ tar cvf archive_name.tar dirname/ 解压tar文件 $ tar xvf archive_name.tar 查看tar文件 $ tar tvf archive_name.tar 更多示例:The Ultimate Tar Command Tutorial with 10 Practical Examples 2. grep 在文件中查找字符串(不区分大小写) $ grep -i "the" demo_file 输出成功匹配的行,以及该行之后的三行 $ grep -A 3 -i "example" demo_text 在一个文件夹中递归查询包含指定字符串的文件
$ grep -r "ramesh" * 更多示例:Get a Grip on the Grep! – 15 Practical Grep Command Examples 3. find 查找指定文件名的文件(不区分大小写) $ find -iname "MyProgram.c" 对找到的文件执行某个命令 $ find -iname "MyProgram.c" -exec md5sum {} \; 查找home目录下的所有空文件 $ find ~ -empty 更多示例:Mommy, I found it! — 15 Practical Linux Find Command Examples 4. ssh 登录到远程主机 $ ssh -l jsmith https://www.360docs.net/doc/ee9721760.html, 调试ssh客户端 $ ssh -v -l jsmith https://www.360docs.net/doc/ee9721760.html, 显示ssh客户端版本
LINUX sed 使用
LINUX SED 1. Sed简介 2. 定址 3. Sed命令 4. 选项 5. 元字符集 6. 实例 7. 脚本 1. Sed简介 sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。以下介绍的是Gnu版本的Sed 3.02。 2. 定址 可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这两行为起止的行的范围(包括行数表示的那两行)。如1,3表示1,2,3行,美元符号($)表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定。 3. Sed命令 调用sed命令有两种形式: * sed [options] 'command' file(s) * sed [options] -f scriptfile file(s) a\ 在当前行后面加入一行文本。 b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 c\ 用新的文本改变本行的文本。 d 从模板块(Pattern space)位置删除行。 D 删除模板块的第一行。 i\ 在当前行上面插入文本。 h 拷贝模板块的内容到内存中的缓冲区。 H 追加模板块的内容到内存中的缓冲区 g
获得内存缓冲区的内容,并替代当前模板块中的文本。 G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 l 列表不能打印字符的清单。 n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 p 打印模板块的行。 P(大写) 打印模板块的第一行。 q 退出Sed。 r file 从file中读行。 t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 w file 写并追加模板块到file末尾。 W file 写并追加模板块的第一行到file末尾。 ! 表示后面的命令对所有没有被选定的行发生作用。 s/re/string 用string替换正则表达式re。 = 打印当前行号码。 # 把注释扩展到下一个换行符以前。 以下的是替换标记 * g表示行内全面替换。 * p表示打印行。 * w表示把行写入一个文件。 * x表示互换模板块中的文本和缓冲区中的文本。
sed替换命令
sed替换 让我们看一下 sed 最有用的命令之一,替换命令。使用该命令,可以将特定字符串或匹配的规则表达式用另一个字符串替换。下面是该命令最基本用法的示例: Linux代码 1.$ sed -e 's/foo/bar/' myfile.txt 上面的命令将 myfile.txt 中每行第一次出现的 'foo'(如果有的话)用字符串'bar' 替换,然后将该文件内容输出到标准输出。请注意,我说的是每行第一次出现,尽管这通常不是您想要的。在进行字符串替换时,通常想执行全局替换。也就是说,要替换每行中的所有出现,如下所示: Linux代码 1.$ sed -e 's/foo/bar/g' myfile.txt 在最后一个斜杠之后附加的 'g' 选项告诉 sed 执行全局替换。 关于 's///' 替换命令,还有其它几件要了解的事。首先,它是一个命令,并且只是一个命令,在所有上例中都没有指定地址。这意味着,'s///' 还可以与地址一起使用来控制要将命令应用到哪些行,如下所示: Linux代码 1.$ sed -e '1,10s/enchantment/entrapment/g' myfile 2.txt 上例将导致用短语 'entrapment' 替换所有出现的短语 'enchantment',但是只在第一到第十行(包括这两行)上这样做。 Linux代码 1.$ sed -e '/^$/,/^END/s/hills/mountains/g' myfile3.txt
该例将用 'mountains' 替换 'hills',但是,只从空行开始,到以三个字符 'END' 开始的行结束(包括这两行)的文本块上这样做。 关于 's///' 命令的另一个妙处是 '/' 分隔符有许多替换选项。如果正在执行字符串替换,并且规则表达式或替换字符串中有许多斜杠,则可以通过在 's' 之后指定一个不同的字符来更改分隔符。例如,下例将把所有出现的 /usr/local 替换成 /usr: Linux代码 1.$ sed -e 's:/usr/local:/usr:g' mylist.txt 在该例中,使用冒号作为分隔符。如果不指定分隔符,则变成了如下: Linux代码 1.$ sed -e 's/usr/local/usrg' mylist.txt 这样就不能执行了 如果需要在规则表达式中指定分隔符字符,可以在它前面加入反斜杠。 规则表达式混乱 目前为止,我们只执行了简单的字符串替换。虽然这很方便,但是我们还可以匹配规则表达式。例如,以下 sed 命令将匹配从 '<' 开始、到 '>' 结束、并且在其中包含任意数量字符的短语。下例将删除该短语(用空字符串替换): Linux代码 1.$ sed -e 's/<.*>//g' myfile.html 这是要从文件除去 HTML 标记的第一个很好的 sed 脚本尝试,但是由于规则表达式的特有规则,它不会很好地工作。原因何在?当 sed 试图在行中匹配规则表达式时,它要在行中查找最长的匹配。在我的前一篇 sed 文章中,这不成问题,因为我们使用的是 'd' 和 'p' 命令,这些命令总要删除或打印整行。但是,在使用 's///' 命令时,确实有很大不同,因为规则表达式匹配的整个部分将被
常用LINUX命令及脚本
常用LINUX命令及shell脚本 说明:本文档介绍的命令只说明比较有用的参数,要查看命令详情请‘MAN‘ 第一部分常用LINUX命令 (1) 1,基础命令 (1) 2,系统性能情况查看命令 (5) 3,网络命令 (6) 4,日志处理 (7) 5,其它命令 (9) 第二部分ftp命令说明 (9) 第三部分shell脚本 (10) 1批量创建目录 (10) 2,过滤出日志中昨天产生的线程挂起日志及详情代码 (11) 第一部分常用LINUX命令 1,基础命令 who 用于查看当前在线上的用户情况 参数: -m 显示当前用户名及详情 -q 显示用户的登陆帐号和登陆用户的数量 w 显示目前登入系统的用户信息 参数: -f 开启显示用户从何处登入系统 范例: was@linux-was:/tmp> w -f 00:55:11 up 48 min, 1 user, load average: 0.00, 0.02, 1.86 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT was pts/0 192.168.10.2 00:30 0.00s 0.84s 0.00s w –f JCPU指的是与该tty终端连接的所由进程占用的时间,不包括过去的后台作业时间;PCPU 指
的是当前进程(即w项中显示的)所占用的时间 id 查看显示目前登陆账户的uid和gid及所属分组及用户名 linux-was:~ # id uid=0(root) gid=0(root) groups=0(root) was@linux-was:/tmp> id uid=1000(was) gid=100(users) groups=16(dialout),33(video),100(users) hostname 显示当前主机名 ls 显示当前文件和目录 参数: -l 列出文件的详细信息 -a 列出目录下的所有文件,包括以 . 开头的隐含文件 -t 以时间排序 -r 对目录反向排序 -S 按文件大小排序 同时此命令也可查看文件或目录权限 pwd 查看”当前工作目录“的完整路径 当你在终端进行操作时,你都会有一个当前工作目录。 在不太确定当前位置时,就会使用pwd来判定当前目录在文件系统内的确切位置 参数: -P 输出物理路径,针对链接的参数 cd 进入特定的目录 参数: /指定目录进入指定的目录 .. 返回上一级目录 touch 创建文件 mkdir 创建目录 参数: -p 此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录
sed命令用法
sed命令行格式为: sed [-nefri] ‘command’输入文本/文件 常用选项: -n∶取消默认的输出,使用安静(silent)模式。在一般sed 的用法中,所有来自STDIN的资料一般都会被列出到屏幕上。但如果加上-n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来 -e∶进行多项编辑,即对输入行应用多条sed命令时使用. 直接在指令列模式上进行sed 的动作编辑 -f∶指定sed脚本的文件名. 直接将sed 的动作写在一个档案内,-f filename 则可以执行filename 内的sed 动作 -r∶sed 的动作支援的是延伸型正则表达式的语法。(预设是基础正则表达式语法) -i∶直接修改读取的文件内容,而不是由屏幕输出 常用命令: a ∶新增,a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行) c ∶取代,c 的后面可以接字串,这些字串可以取代n1,n2 之间的行 d ∶删除,因为是删除,所以d 后面通常不接任何内容 i ∶插入,i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行) p∶列印,亦即将某个选择的资料印出。通常p 会与参数sed -n 一起用 s∶取代,可以直接进行替换的工作。通常这个s 的动作可以搭配正则表达式。例如 1,20s/old/new/g 定址 定址用于决定对哪些行进行编辑。地址的形式可以是数字、正则表达式、或二者的结合。如果没有指定地址,sed将处理输入文件的所有行。 地址是一个数字,则表示行号;是“$"符号,则表示最后一行。例如: sed -n '3p'datafile 只打印第三行 只显示指定行范围的文件内容,例如: # 只查看文件的第100行到第200行 sed -n '100,200p' mysql_slow_query.log 地址是逗号分隔的,那么需要处理的地址是这两行之间的范围(包括这两行在内)。范围可以用数字、正则表达式、或二者的组合表示。例如:
Linux命令集
文件和目录 cd /home 进入'/ home' 目录' cd .. 返回上一级目录 cd ../.. 返回上两级目录 cd 进入个人的主目录 cd ~user1 进入个人的主目录 cd - 返回上次所在的目录 pwd 显示工作路径 ls 查看目录中的文件 ls -F 查看目录中的文件 ls -l 显示文件和目录的详细资料 ls -a 显示隐藏文件 ls *[0-9]* 显示包含数字的文件名和目录名 tree 显示文件和目录由根目录开始的树形结构(1) lstree 显示文件和目录由根目录开始的树形结构(2) mkdir dir1 创建一个叫做'dir1' 的目录' mkdir dir1 dir2 同时创建两个目录 mkdir -p /tmp/dir1/dir2 创建一个目录树 rm -f file1 删除一个叫做'file1' 的文件' rmdir dir1 删除一个叫做'dir1' 的目录' rm -rf dir1 删除一个叫做'dir1' 的目录并同时删除其内容rm -rf dir1 dir2 同时删除两个目录及它们的内容 mv dir1 new_dir 重命名/移动一个目录 cp file1 file2 复制一个文件 cp dir/* . 复制一个目录下的所有文件到当前工作目录 cp -a /tmp/dir1 . 复制一个目录到当前工作目录 cp -a dir1 dir2 复制一个目录 ln -s file1 lnk1 创建一个指向文件或目录的软链接
ln file1 lnk1 创建一个指向文件或目录的物理链接 touch -t 0712250000 file1 修改一个文件或目录的时间戳- (YYMMDDhhmm) file file1 outputs the mime type of the file as text iconv -l 列出已知的编码 iconv -f fromEncoding -t toEncoding inputFile > outputFile creates a new from the given input file by assuming it is encoded in fromEncoding and converting it to toEncoding. find . -maxdepth 1 -name *.jpg -print -exec convert "{}" -resize 80x60 "thumbs/{}" \; batch resize files in the current directory and send them to a thumbnails directory (requires convert from Imagemagick) 文件搜索 find / -name file1 从'/' 开始进入根文件系统搜索文件和目录 find / -user user1 搜索属于用户'user1' 的文件和目录 find /home/user1 -name \*.bin 在目录'/ home/user1' 中搜索带有'.bin' 结尾的文件 find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件 find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件 find / -name \*.rpm -exec chmod 755 '{}' \; 搜索以'.rpm' 结尾的文件并定义其权限 find / -xdev -name \*.rpm 搜索以'.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备 locate \*.ps 寻找以'.ps' 结尾的文件- 先运行'updatedb' 命令 whereis halt 显示一个二进制文件、源码或man的位置 which halt 显示一个二进制文件或可执行文件的完整路径
sed简单应用实例及详解
$ sed -n '/test/w file' example-----在example中所有包含test的行都被写入file里。 追加命令:a命令 * $ sed '/^test/a\\--->this is a example' example<-----'this is a example'被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。 插入:i命令 $ sed '/test/i\\ new line -------------------------' example 如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。 下一个:n命令 * $ sed '/test/{ n; s/aa/bb/; }' example-----如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。 变形:y命令 * $ sed '1,10y/abcde/ABCDE/' example-----把1--10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。 退出:q命令 * $ sed '10q' example-----打印完第10行后,退出sed。 保持和获取:h命令和G命令 * $ sed -e '/test/h' -e '$G example-----在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。 保持和互换:h命令和x命令 * $ sed -e '/test/h' -e '/check/x' example -----互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。 7. 脚本 Sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
西班牙语命令式变位和用法总结
西班牙语命令式变位和 用法总结 Modified by JACK on the afternoon of December 26, 2020
西语堂--西班牙语命令式变位和用法总结 一.肯定命令式变位和用法总结。 1.肯定命令式的变位。(命令式只有现在时态,没有第一人称“我”。)规则动词的变位。例如: verbo túusted nosotros vosotros ustedes cantar cant a cant e cant emos cant ad cant en comer com e com a com amos com ed com an vivir viv e viv a viv amos viv id viv an 常用不规则动词的变位。见下表: verbo túusted Nosotros vosotros ustedes ir ve vaya vayamos id vayan venir ven venga vengamos venid vengan
hacer haz haga hagamos haced hagan decir di diga digamos Decid digan salir sal salga salgamos salid salgan Oír oye oiga oigamos oíd oigan ser sésea seamos sed sean tener ten tenga tengamos tened tengan Poner pon ponga pongamos poned pongan 2. 肯定命令式使用时应注意的几点: 直接宾语代词和间接宾语代词都应直接连写在变位动词后面,顺序为间宾在 前,直宾在后,并且在变位动词重读音节加上重音符号。 例如: Dímelo . límpiatelas . llévenselo . póngaselos .
sed_4.2.1_man_中文
本文参照sed 4.2.1的man原文翻译。蓝色字体为man原文,黑色字体是我的译文。 水平有限,难免错漏,欢迎各位指正! GNU文档的精髓在info页,而不是man页。 当然更希望有同仁将sed的info页翻译出来,方便大家更扎实地运用好sed这个功能强大的工具。 翻译者:李启训。 NAME 名称 sed - stream editor for filtering and transforming text 用于过滤和转换文本的流编辑器。 SYNOPSIS 提要 sed [OPTION]... {script-only-if-no-other-script} [input-file]... DESCRIPTION 描述 Sed is a stream editor. A stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline). While in some ways similar to an editor which permits scripted edits (such as ed), sed works by making only one pass over the input(s), and is consequently more efficient. But it is sed's ability to filter text in a pipeline which particularly distinguishes it from other types of editors. Sed 是一个流编辑器。流编辑器用于转换输入流(文件或者来自管道)的基本文本。虽然在某些方面它类似于允许脚本编辑的编辑器(比如ed),但是sed只对一次传递的输入进行操作,当然更加高效。除此以外,因为sed能够过滤来自管道中的文本,这明显区别于其他类型的编辑器。 -n, --quiet, --silent suppress automatic printing of pattern space 抑制模式空间的自动输出。 -e script, --expression=script add the script to the commands to be executed 添加脚本给命令,以便执行。 -f script-file, --file=script-file add the contents of script-file to the commands to be executed 添加脚本文件的内容,以便执行。 --follow-symlinks follow symlinks when processing in place 就地处理时跟随符号链接。 -i[SUFFIX], --in-place[=SUFFIX] edit files in place (makes backup if extension supplied) 就地编辑文件(如果提供扩展,则备份文件)。 -l N, --line-length=N specify the desired line-wrap length for the `l' command 为l命令指定所预期的行的长度。 --posix disable all GNU extensions. 禁用所有GNU扩展。 -r, --regexp-extended use extended regular expressions in the script. 在脚本中使用扩展正则表达式。 -s, --separate consider files as separate rather than as a single continuous
西班牙语命令式变位和用法总结
西语堂--西班牙语命令式变位和用法总结 一.肯定命令式变位和用法总结。 1.肯定命令式的变位。(命令式只有现在时态,没有第一人称“我”。)规则动词的变位。例如: verbo túusted nosotros vosotros ustedes cantar cant a cant e cant emos cant ad cant en comer com e com a com amos com ed com an vivir viv e viv a viv amos viv id viv an 常用不规则动词的变位。见下表: verbo túusted Nosotros vosotros ustedes ir ve vaya vayamos id vayan venir ven venga vengamos venid vengan
hacer haz haga hagamos haced hagan decir di diga digamos Decid digan salir sal salga salgamos salid salgan Oír oye oiga oigamos oíd oigan ser sésea seamos sed sean tener ten tenga tengamos tened tengan Poner pon ponga pongamos poned pongan 2. 肯定命令式使用时应注意的几点: 直接宾语代词和间接宾语代词都应直接连写在变位动词后面,顺序为间宾在 前,直宾在后,并且在变位动词重读音节加上重音符号。 例如: Dímelo . límpiatelas . llévenselo . póngaselos .
linux sed命令参数及用法详解
sed sed 编辑器是 Linux 系统管理员的工具包中最有用的资产之一, 因此,有必要彻底地了解其应用 Linux 操作系统最大的一个好处是它带有各种各样的实用工具。存在如此之多不同的实用工具,几乎不可能知道并了解所有这些工具。可以简化关键情况下操作的一个实用工具是 sed。它是任何管理员的工具包中最强大的工具之一,并且可以证明它自己在关键情况下非常有价值。 sed 实用工具是一个“编辑器”,但它与其它大多数编辑器不同。除了不面向屏幕之外,它还是非交互式的。这意味着您必须将要对数据执行的命令插入到命令行或要处理的脚本中。当显示它时,请忘记您在使用 Microsoft Word 或其它大多数编辑器时拥有的交互式编辑文件功能。sed 在一个文件(或文件集)中非交互式、并且不加询问地接收一系列的命令并执行它们。因而,它流经文本就如同水流经溪流一样,因而 sed 恰当地代表了流编辑器。它可以用来将所有出现的 "Mr. Smyth" 修改为 "Mr. Smith",或将 "tiger cub" 修改为 "wolf cub"。流编辑器非常适合于执行重复的编辑,这种重复编辑如果由人工完成将花费大量的时间。其参数可能和一次性使用一个简单的操作所需的参数一样有限,或者和一个具有成千上万行要进行编辑修改的脚本文件一样复杂。sed 是 Linux 和UNIX 工具箱中最有用的工具之一,且使用的参数非常少。 sed 的工作方式 sed 实用工具按顺序逐行将文件读入到内存中。然后,它执行为该行指定的所有操作,并在完成请求的修改之后将该行放回到内存中,以将其转储至终端。完成了这一行上的所有操作之后,它读取文件的下一行,然后重复该过程直到它完成该文件。如同前面所提到的,默认输出是将每一行的内容输出到屏幕上。在这里,开始涉及到两个重要的因素—首先,输出可以被重定向到另一文件中,以保存变化;第二,源文件(默认地)保持不被修改。sed 默认读取整个文件并对其中的每一行进行修改。不过,可以按需要将操作限制在指定的行上。 该实用工具的语法为: sed [options] '{command}' [filename] 在这篇文章中,我们将浏览最常用的命令和选项,并演示它们如何工作,以及它们适于在何处使用。 替换命令 sed 实用工具以及其它任何类似的编辑器的最常用的命令之一是用一个值替换
linux Sed命令详解
linux sed命令详解 1. Sed简介 sed 是一种在线编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区 中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成 后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并 没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文 件的反复操作;编写转换程序等。以下介绍的是Gnu版本的Sed 3.02。 2. 定址 可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这 两行为起止的行的范围(包括行数表示的那两行)。如1,3表示1,2,3行,美元符号($) 表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定。 3. Sed命令 1)调用sed命令有两种形式: 2)sed [options] 'command' file(s) 3)sed [options] -f scriptfile file(s) 4)a\ 在当前行后面加入一行文本。 5)b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 6)c\ 用新的文本改变本行的文本。 7)d 从模板块(Pattern space)位置删除行。 8)D 删除模板块的第一行。 9)i\ 在当前行上面插入文本。 10)h 拷贝模板块的内容到内存中的缓冲区。 11)H 追加模板块的内容到内存中的缓冲区
12)g 获得内存缓冲区的内容,并替代当前模板块中的文本。 13)G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 14)l 列表不能打印字符的清单。 15)n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 16)N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 17)p 打印模板块的行。 18)P(大写)打印模板块的第一行。 19)q 退出Sed。 20)r file 从file中读行。 21)t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 22)T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 23)w file 写并追加模板块到file末尾。 24)W file 写并追加模板块的第一行到file末尾。 25)! 表示后面的命令对所有没有被选定的行发生作用。 26)s/re/string 用string替换正则表达式re。 27)= 打印当前行号码。 28)# 把注释扩展到下一个换行符以前。 以下的是替换标记 1)g表示行内全面替换。 2)p表示打印行。 3)w表示把行写入一个文件。 4)x表示互换模板块中的文本和缓冲区中的文本。
Linux中文本处理
Linux文本处理——sed、awk命令引入: 有一个例子:在服务器日志fresh.log中,找到所有报错的日期。$ sed -n `/Error/p` fresh.log | awk `{print $1}` Linux 三大利器: grep:查找一行指令,轻松搞定 sed:行编辑器 awk:文本处理工具 正则表达式》》》sed基本处理》》》awk更为复杂的处理 1.正则表达式 场景: 查找——查找所有包含‘Linux’的行 取出——取出以‘abc’开头的所有单词 匹配——匹配两位数、密码、qq号、身份证号等 正则表达式学习的方法: 1.单个字符表示 2.字符串表示 3.表达式 示例: 以cat /etc/passwd文档为例。 首先将这个文档拷贝到~/. 下 cp /etc/passwd ~/.
grep查找文件内容:grep+查找内容+文件/文档 grep ‘mooc’ passwd 正则表达式单字符 字符:1.特定字符2. 范围内字符3.任意字符 1.特定字符:某个具体的字符‘1’ ‘a’ grep ‘1’ passwd 2.范围内字符:单个字符[] 数字字符:[0-9], [259] grep ‘[0-9]’ passwd 小写字符:[a-z] 大写字符:[A-Z] 大小写字符:[a-zA-Z] 数字之外的字符:[a-zA-Z, :_/-().] 反向字符:^ 取反:[^0-9], [^0] 3.任意字符:. ‘[.]’ 指小数点。‘\.’ 指本来的意思,小数点。正则表达式其他符号: 边界字符:头尾字符 ^: ^root头字符注意与[^]的区别。 $ : flase$尾字符
sed命令使用
文本间隔: -------- # 在每一行后面增加一空行 sed G # 将原来的所有空行删除并在每一行后面增加一空行。 # 这样在输出的文本中每一行后面将有且只有一空行。 sed '/^$/d;G' # 在每一行后面增加两行空行 sed 'G;G' # 将第一个脚本所产生的所有空行删除(即删除所有偶数行) sed 'n;d' # 在匹配式样“regex”的行之前插入一空行 sed '/regex/{x;p;x;}' # 在匹配式样“regex”的行之后插入一空行 sed '/regex/G' # 在匹配式样“regex”的行之前和之后各插入一空行 sed '/regex/{x;p;x;G;}' 编号: -------- # 为文件中的每一行进行编号(简单的左对齐方式)。这里使用了“制表符” # (tab,见本文末尾关于'\t'的用法的描述)而不是空格来对齐边缘。 sed = filename | sed 'N;s/\n/\t/' # 对文件中的所有行编号(行号在左,文字右端对齐)。 sed = filename | sed 'N; s/^/ /; s/ *\(.\{6,\}\)\n/\1 /' # 对文件中的所有行编号,但只显示非空白行的行号。 sed '/./=' filename | sed '/./N; s/\n/ /' # 计算行数(模拟 "wc -l") sed -n '$=' 文本转换和替代: --------
# Unix环境:转换DOS的新行符(CR/LF)为Unix格式。 sed 's/.$//' # 假设所有行以CR/LF结束 sed 's/^M$//' # 在bash/tcsh中,将按Ctrl-M改为按Ctrl-V sed 's/\x0D$//' # ssed、gsed 3.02.80,及更高版本 # Unix环境:转换Unix的新行符(LF)为DOS格式。 sed "s/$/`echo -e \\\r`/" # 在ksh下所使用的命令 sed 's/$'"/`echo \\\r`/" # 在bash下所使用的命令 sed "s/$/`echo \\\r`/" # 在zsh下所使用的命令 sed 's/$/\r/' # gsed 3.02.80 及更高版本 # DOS环境:转换Unix新行符(LF)为DOS格式。 sed "s/$//" # 方法 1 sed -n p # 方法 2 # DOS环境:转换DOS新行符(CR/LF)为Unix格式。 # 下面的脚本只对UnxUtils sed 4.0.7 及更高版本有效。要识别UnxUtils版本的 # sed可以通过其特有的“--text”选项。你可以使用帮助选项(“--help”)看 # 其中有无一个“--text”项以此来判断所使用的是否是UnxUtils版本。其它DOS # 版本的的sed则无法进行这一转换。但可以用“tr”来实现这一转换。 sed "s/\r//" infile >outfile # UnxUtils sed v4.0.7 或更高版本 tr -d \r