图像识别算法原理讲课讲稿

图像识别算法原理
1.计算在矩形中有多少个测试点:
a.图像在矩形中不重复圆有多少个。
b.在一条直线上可匹配的像素数是几个PIPEI_N。
c.匹配宽容度(扩展范围)KRD。
d.90度采样角度细分8个点SINCOS。
e. 采样点范围Range=(PIPEI_N+ KRD)/2.
F. 最外测试点outerR=Range+MinR.
G..圆曲率QULU=常数。
h.角度系数AngleSX=QULU*COS.
J.图像坐标X=outerR*AngleSX.
k. 角度系数AngleSY=QULU*SIN.
S. 图像坐标Y= outerR*AngleSY.
O. outerR=outerR- KRD;匹配点计算完否?NO循环到h,YES
交换PIPEI_N的高低位,加初始存储在循环下一个点。
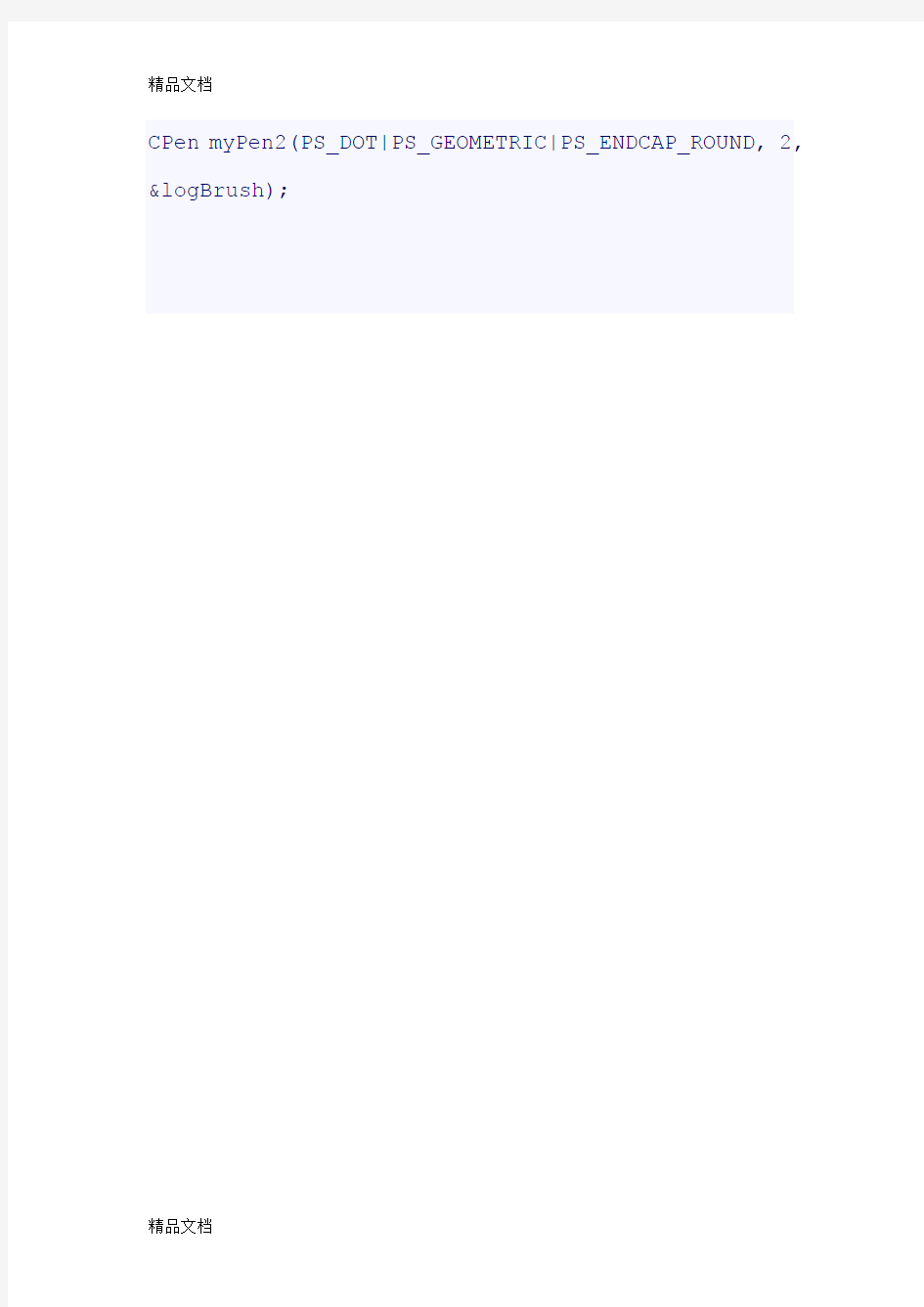
// Create a solid red pen of width 2. CPen myPen1(PS_SOLID, 2, RGB(255,0,0));
// Create a geometric pen.
LOGBRUSH logBrush;
logBrush.lbStyle = BS_SOLID;
logBrush.lbColor = RGB(0,255,0);
CPen myPen2(PS_DOT|PS_GEOMETRIC|PS_ENDCAP_ROUND, 2, &logBrush);
图像分割算法研究与实现
中北大学 课程设计说明书 学生姓名:梁一才学号:10050644X30 学院:信息商务学院 专业:电子信息工程 题目:信息处理综合实践: 图像分割算法研究与实现 指导教师:陈平职称: 副教授 2013 年 12 月 15 日
中北大学 课程设计任务书 13/14 学年第一学期 学院:信息商务学院 专业:电子信息工程 学生姓名:焦晶晶学号:10050644X07 学生姓名:郑晓峰学号:10050644X22 学生姓名:梁一才学号:10050644X30 课程设计题目:信息处理综合实践: 图像分割算法研究与实现 起迄日期:2013年12月16日~2013年12月27日课程设计地点:电子信息科学与技术专业实验室指导教师:陈平 系主任:王浩全 下达任务书日期: 2013 年12月15 日
课程设计任务书 1.设计目的: 1、通过本课程设计的学习,学生将复习所学的专业知识,使课堂学习的理论知识应用于实践,通过本课程设计的实践使学生具有一定的实践操作能力; 2、掌握Matlab使用方法,能熟练运用该软件设计并完成相应的信息处理; 3、通过图像处理实践的课程设计,掌握设计图像处理软件系统的思维方法和基本开发过程。 2.设计内容和要求(包括原始数据、技术参数、条件、设计要求等): (1)编程实现分水岭算法的图像分割; (2)编程实现区域分裂合并法; (3)对比分析两种分割算法的分割效果; (4)要求每位学生进行查阅相关资料,并写出自己的报告。注意每个学生的报告要有所侧重,写出自己所做的内容。 3.设计工作任务及工作量的要求〔包括课程设计计算说明书(论文)、图纸、实物样品等〕: 每个同学独立完成自己的任务,每人写一份设计报告,在课程设计论文中写明自己设计的部分,给出设计结果。
仪表显示的图像识别算法研究
仪表显示的图像识别算法研究 摘要:随着社会的逐渐发展,人类的生活越来越趋于智能化。本文根据当今社会对于图像识别研究的发展现状,针对目前人们生活中人工读表的弊端,提出了通过采集仪表显示的图像并进行图像识别算法处理来达到智能自动读表的方法。 为了能快速获得采集数据,减少人们生活中繁复的人工作业。本文通过多样的图像处理来代替人眼识别图像。只需要得到采集到的图像,就可以利用计算机来进行计算和识别,得出最后的数字。本文采用了一系列的图像处理方法,包括图像的去噪,二值化分割,边缘检测和基于数学形态学的膨胀腐蚀操作等。同时通过多种尝试和比较各种方法的优缺点得到了一套简易而又完善,快速的图像识别算法。 在进行多次测试试验后,本文采用数码相机来进行图像的采集,同时经过图像预处理、图像分割、图像识别等一系列流程得出了较为完善的图像采集和识别系统,为未来信息传递智能化提供了基础,对于促进工业发展或是改善生活水平都有重要的意义。 关键词:图像预处理、二值化、边缘检测、形态学、去噪、图像分割、图像匹配 The research of image recognition displayed by the instrument Abstract: With the continuous development of society, people's lives become more and more intelligent. Based on the current development in today's society for the study of image recognition, according to the present disadvantages of manual meter reading in peop le’s lives, this page proposed the way by collecting the instruments display image and then deals it with image recognizing algorithms to achieve intelligent automatic meter. In order to quickly gather data, reducing manual work in people’s lives complicated. The page uses a series of image processing to replace human eye image recognition. Just need the collected images, we can use a computer to calculate and identify, then we will arrive at a final figure. We used a variety of image processing methods, including image denoising, thresholding segmentation, expansion of edge-detection based on mathematical morphology and corrosion and so on. And
视觉检测原理介绍
技术细节 本项目应用了嵌入式中央控制及工业级图像高速传输控制技术,基于CCD/CMOS与DSP/FPGA的图像识别与处理技术,成功建立了光电检测系统。应用模糊控制的精选参数自整定技术,使系统具有对精确检测的自适应调整,实现产品的自动分选功能。 图1 控制系统流程图 光电检测系统主要通过检测被检物的一些特征参数(灰度分布,RGB分值等),从而将缺陷信息从物体中准确地识别出来,通过后续的系统进行下一步操作,主要分为以下几部分 CCD/CMOS图像采集部分 系统图像数据采集处理板中光信号检测元件CCD/CMOS采用进口的适合于高精度检测的动态分析单路输出型、保证实际数据输出速率为320MB/s的面阵CCD/CMOS。像素分别为4000*3000和1600*1200,帧率达到10FPS。使用CCD/CMOS 作为输入图像传感器,从而实现了图像信息从空间域到时间域的变换。为了保证所需的检测精度,需要确定合理的分辨率。根据被检测产品的大小,初步确定系统设计分辨率为像素为0.2mm。将CCD/CMOS接收的光强信号转换成电压幅值,再经过A/D转换后由DSP/ FPGA芯片进行信号采集,即视频信号的量化处理过程,图像采集处理过程如图所示:
图2 图像采集处理过程 数据处理部分 在自动检测中,是利用基于分割的图像匹配算法来进行图像的配对为基础的。图像分割的任务是将图像分解成互不相交的一些区域,每一个区域都满足特定区域的一致性,且是连通的,不同的区域有某种显著的差异性。分割后根据每个区域的特征来进行图像匹配,基于特征的匹配方法一般分为四个步骤:特征检测、建立特征描述、特征匹配、利用匹配的“特征对”求取图像配准模型参数。 算法基本步骤如下: 1)利用图像的色彩、灰度、边缘、纹理等信息对异源图像分别进行分割,提取区域特征; 2)进行搜索匹配,在每一匹配位置将实时图与基准图的分割结果进行融合,得到综合分割结果; 3)利用分割相似度描述或最小新增边缘准则找出正确匹配位置。 设实时图像分割为m个区域,用符号{A1,A2,… Am}表示,其异源基准图像分割为n个区域,用符号{B1,B2,…Bn}表示。分割结果融合方法如下: 在每一个匹配位置,即假设的图像点对应关系成立时,图像点既位于实时图中,又位于其异源基准图像中,则融合后区域点的标识记为:(A1B1,A1B2,…,A2B1,A2B2,…)。标识AiBj表示该点在实时图中位于区域i,在基准图中位于区域j。算法匹配过程如下图所示:
车辆牌照图像识别算法研究与实现本科毕设论文
Q260046902 专业做论文 西南科技大学 毕业设计(论文)题目名称:车辆牌照图像识别算法研究与实现
车辆牌照图像识别算法研究与实现 摘要:近年来随着国民经济的蓬勃发展,国内高速公路、城市道路、停车场建设越来越多,对交通控制、安全管理的要求也日益提高。因此,汽车牌照识别技术在公共安全及交通管理中具有特别重要的实际应用意义。本文对车牌识别系统中的车牌定位、字符分割和字符识别进行了初步研究。对车牌定位,本文采用投影法对车牌进行定位;在字符分割方面,本文使用阈值规则进行字符分割;针对车牌图像中数字字符识别的问题,本文采用了基于BP神经网络的识别方法。在学习并掌握了数字图像处理和模式识别的一些基本原理后,使用VC++6.0软件利用以上原理针对车牌识别任务进行编程。实现了对车牌的定位和车牌中数字字符的识别。 关键词:车牌定位;字符分割;BP神经网络;车牌识别;VC++
Research and Realization of License Plate Recognition Algorithm Abstract:In recent years, with the vigorous development of the national economy,there are more and more construct in the domestic expressway, urban road, and parking area. The requisition on the traffic control, safety management improves day by day. Therefore, license plate recognition technology has the particularly important practical application value in the public security and the traffic control. In the paper, a preliminary research was made on the license location, characters segment and characters recognition of the license plate recognition. On the license location,the projection was used to locate the license plate; On the characters segmentation, the liminal rule was used to divide the characters; In order to solve the problem of the digital characters recognition in the plate, BP nerve network was used to recognize the digital characters. After studying and mastering some basic principles of the digital image processing and pattern recognition, the task of license plate recognition was programmed with VC++ 6.0 using above principles. The license location and the digital characters recognition in the license plate were implemented. Keywords: license location, characters segmentation, BP nerve network, license plate recognition, VC++
人脸识别主要算法原理
人脸识别主要算法原理 主流的技术基本上可以归结为三类,即:基于几何特征的方法、基于模板的方法和基于模型的方法。 1. 基于几何特征的方法是最早、最传统的方法,通常需要和其他结合才能有比较好的效果; 2. 基于模板的方法可以分为基于相关匹配的方法、特征脸方法、线性判别分析方法、奇异值分解方法、神经网络方法、动态连接匹配方法等。 3. 基于模型的方法则有基于隐马尔柯夫模型,主动形状模型和主动外观模型的方法等。 1. 基于几何特征的方法 人脸由眼睛、鼻子、嘴巴、下巴等部件构成,正因为这些部件的形状、大小和结构上的各种差异才使得世界上每个人脸千差万别,因此对这些部件的形状和结构关系的几何描述,可以做为人脸识别的重要特征。几何特征最早是用于人脸侧面轮廓的描述与识别,首先根据侧面轮廓曲线确定若干显著点,并由这些显著点导出一组用于识别的特征度量如距离、角度等。Jia 等由正面灰度图中线附近的积分投影模拟侧面轮廓图是一种很有新意的方法。 采用几何特征进行正面人脸识别一般是通过提取人眼、口、鼻等重要特征点的位置和眼睛等重要器官的几何形状作为分类特征,但Roder对几何特征提取的精确性进行了实验性的研究,结果不容乐观。
可变形模板法可以视为几何特征方法的一种改进,其基本思想是:设计一个参数可调的器官模型(即可变形模板),定义一个能量函数,通过调整模型参数使能量函数最小化,此时的模型参数即做为该器官的几何特征。 这种方法思想很好,但是存在两个问题,一是能量函数中各种代价的加权系数只能由经验确定,难以推广,二是能量函数优化过程十分耗时,难以实际应用。基于参数的人脸表示可以实现对人脸显著特征的一个高效描述,但它需要大量的前处理和精细的参数选择。同时,采用一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求,计算量也较大。 2. 局部特征分析方法(Local Face Analysis) 主元子空间的表示是紧凑的,特征维数大大降低,但它是非局部化的,其核函数的支集扩展在整个坐标空间中,同时它是非拓扑的,某个轴投影后临近的点与原图像空间中点的临近性没有任何关系,而局部性和拓扑性对模式分析和分割是理想的特性,似乎这更符合神经信息处理的机制,因此寻找具有这种特性的表达十分重要。基于这种考虑,Atick提出基于局部特征的人脸特征提取与识别方法。这种方法在实际应用取得了很好的效果,它构成了FaceIt人脸识别软件的基础。 3. 特征脸方法(Eigenface或PCA)
人脸识别主要算法原理
人脸识别主要算法原理 主流的人脸识别技术基本上可以归结为三类,即:基于几何特征的方法、基于模板的方法和基于模型的方法。 1. 基于几何特征的方法是最早、最传统的方法,通常需要和其他算法结合才能有比较好的效果; 2. 基于模板的方法可以分为基于相关匹配的方法、特征脸方法、线性判别分析方法、奇异值分解方法、神经网络方法、动态连接匹配方法等。 3. 基于模型的方法则有基于隐马尔柯夫模型,主动形状模型和主动外观模型的方法等。 1. 基于几何特征的方法 人脸由眼睛、鼻子、嘴巴、下巴等部件构成,正因为这些部件的形状、大小和结构上的各种差异才使得世界上每个人脸千差万别,因此对这些部件的形状和结构关系的几何描述,可以做为人脸识别的重要特征。几何特征最早是用于人脸侧面轮廓的描述与识别,首先根据侧面轮廓曲线确定若干显著点,并由这些显著点导出一组用于识别的特征度量如距离、角度等。Jia 等由正面灰度图中线附近的积分投影模拟侧 面轮廓图是一种很有新意的方法。 采用几何特征进行正面人脸识别一般是通过提取人眼、口、鼻等重要特征点的位置和眼睛等重要器官的几何形状作为分类特征,但Roder对几何特征提取的精确性进行了实验性的研究,结果不容乐观。
可变形模板法可以视为几何特征方法的一种改进,其基本思想是: 设计一个参数可调的器官模型(即可变形模板),定义一个能量函数,通过调整模型参数使能量函数最小化,此时的模型参数即做为该器官的几何特征。 这种方法思想很好,但是存在两个问题,一是能量函数中各种代价的加权系数只能由经验确定,难以推广,二是能量函数优化过程十分耗时,难以实际应用。基于参数的人脸表示可以实现对人脸显著特征的一个高效描述,但它需要大量的前处理和精细的参数选择。同时,采用一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求,计算量也较大。 2. 局部特征分析方法(Local Face Analysis) 主元子空间的表示是紧凑的,特征维数大大降低,但它是非局部化的,其核函数的支集扩展在整个坐标空间中,同时它是非拓扑的,某个轴投影后临近的点与原图像空间中点的临近性没有任何关系,而局部性和拓扑性对模式分析和分割是理想的特性,似乎这更符合神经信息处理的机制,因此寻找具有这种特性的表达十分重要。基于这种考虑,Atick提出基于局部特征的人脸特征提取与识别方法。这种方法在实际应用取得了很好的效果,它构成了FaceIt人脸识别软件的 基础。 3. 特征脸方法(Eigenface或PCA)
基于Matlab的图像边缘检测算法的实现及应用汇总
目录 摘要 (1) 引言 (2) 第一章绪论 (3) 1.1 课程设计选题的背景及意义 (3) 1.2 图像边缘检测的发展现状 (4) 第二章边缘检测的基本原理 (5) 2.1 基于一阶导数的边缘检测 (8) 2.2 基于二阶导的边缘检测 (9) 第三章边缘检测算子 (10) 3.1 Canny算子 (10) 3.2 Roberts梯度算子 (11) 3.3 Prewitt算子 (12) 3.4 Sobel算子 (13) 3.5 Log算子 (14) 第四章MATLAB简介 (15) 4.1 基本功能 (15) 4.2 应用领域 (16) 第五章编程和调试 (17) 5.1 edge函数 (17) 5.2 边缘检测的编程实现 (17) 第六章总结与体会 (20) 参考文献 (21)
摘要 边缘是图像最基本的特征,包含图像中用于识别的有用信息,边缘检测是数字图像处理中基础而又重要的内容。该课程设计具体考察了5种经典常用的边缘检测算子,并运用Matlab进行图像处理结果比较。梯度算子简单有效,LOG 算法和Canny 边缘检测器能产生较细的边缘。 边缘检测的目的是标识数字图像中灰度变化明显的点,而导函数正好能反映图像灰度变化的显著程度,因而许多方法利用导数来检测边缘。在分析其算法思想和流程的基础上,利用MATLAB对这5种算法进行了仿真实验,分析了各自的性能和算法特点,比较边缘检测效果并给出了各自的适用范围。 关键词:边缘检测;图像处理;MATLAB仿真
引言 边缘检测在图像处理系统中占有重要的作用,其效果直接影响着后续图像处理效果的好坏。许多数字图像处理直接或间接地依靠边缘检测算法的性能,并且在模式识别、机器人视觉、图像分割、特征提取、图像压缩等方面都把边缘检测作为最基本的工具。但实际图像中的边缘往往是各种类型的边缘以及它们模糊化后结果的组合,并且在实际图像中存在着不同程度的噪声,各种类型的图像边缘检测算法不断涌现。早在1965 年就有人提出边缘检测算子,边缘检测的传统方法包括Kirsch,Prewitt,Sobel,Roberts,Robins,Mar-Hildreth 边缘检测方法以及Laplacian-Gaussian(LOG)算子方法和Canny 最优算子方法等。 本设计主要讨论其中5种边缘检测算法。在图像处理的过程需要大量的计算工作,我们利用MATLAB各种丰富的工具箱以及其强大的计算功能可以更加方便有效的完成图像边缘的检测。并对这些方法进行比较
数据隐藏课程设计论文——图像的信息隐藏检测算法和实现
中国科学技术大学继续教育学院课程设计 论文报告 论文题目:图像的信息隐藏检测算法和实现学员姓名:黄琳 学号:TB04202130 专业:计算机科学与技术 指导教师: 日期:2007年1月20日
图像的信息隐藏检测算法和实现 [摘要] Information hiding analysis is the art of detecting the message's existence or destroying the stega nographic cover in order to blockade the secret communication. And information Information hiding includes steganography and digital watermark. The application of steganography can be traced to ancient time, and it is also an n hiding detection is the very first step in information hiding analysis. Firstlly, architectonic analysis about information hiding detection is proposed, including the analysis of digital image characteristics, image based detecting algorithms and some problems in its realization. Secondly, many detecting algorithms are introduced with theoretical analyses and experimental results in details. Thirdly, two applications of detecting technology are put forward. Finally, a detecting model used in Internet is discussed [关键词]安全信息隐藏检测 1. 引言 数字图像的信息隐藏技术是数字图像处理领域中最具挑战性、最为活跃的研究课题之一。本文概述了数字图像的信息隐藏技术,并给出了一个新的基于彩色静止数字图像的信息隐藏算法。 数字图像可分为静止图像和动态图像两种,后者一般称为视频图像。视频图像的每一帧均可看作是一幅静止图像,但是这些静止图像之间并不是相互孤立的,而是存在时间轴上的相关性。静止图像是像素(Pixel)的集合,相邻像素点所对应的实际距离称为图像的空间分辨率。根据像素颜色信息的不同,数字图像可分为二值图像、灰度图像以及彩色图像。数字图像的最终感受者是人的眼睛,人眼感受到的两幅质量非常相同的数字图像的像素值可能存在很大的差别。这样,依赖于人的视觉系统(Human Visual System,HVS)的不完善性,就为数字图像的失真压缩和信息隐藏提供了非常巨大的施展空间。 信息隐藏与信息加密是不尽相同的,信息加密是隐藏信息的内容,而信息隐藏是隐藏信息的存在性,信息隐藏比信息加密更为安全,因为它不容易引起攻击者的注意。 2. 信息隐藏技术综述 2.1信息隐藏简介 信息隐藏(Information Hiding),也称作数据隐藏(Data Hiding),或称作数字水印(Digital Watermarking)。简单来讲,信息隐藏是指将某一信号(一般称之为签字信号,Signature Signal)嵌入(embedding)另一信号(一般称之为主信号,Host Signal,或称之为掩护媒体,cover-media)的过程,掩护媒体经嵌入信息后变成一个伪装媒体(stegano-media)。这一嵌入过程需要满足下列条件:
图像识别技术浅析
图像识别技术浅析 Analysis of Image Recognition Technology 刘峰伯软件学院2010544029 【摘要】:本文描述了图像识别系统的结构与工作原理,在对图像预处理、特征提取、分类、图像匹配算法进行深入研究和分析的基础上,分析和比较了各种算法的优缺点,并讨论了其中的关键技术。 【关键词】:图像识别;预处理;特征提取;匹配 【Abstract】This paper describes the structure and working principle of an image recognition system. The advantages and disadvantages of various a1gorithms are compared on the basis of in-depth analysis of the image pre-processing, feature extraction, classification and image matching algorithms, and discussed the key technology. 【Key Word】Image Recognition;Pre-Processing;Feature Extraction;Matchi ng. 一、引言 图像识别,是利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对像的技术。随着计算机技术与信息技术的发展,图像识别技术获得了越来越广泛的应用。例如医疗诊断中各种医学图片的分析与识别、天气预报中的卫星云图识别、遥感图片识别、指纹识别、脸谱识别等,图像识别技术越来越多地渗透到我们的日常生活中。 二、图像识别系统 1、概述 自动图像识别系统的过程分为五部分:图像输入、预处理、特征提取、分类和匹配,其中预处理又可分为图像分割、图像增强、二值化和细化等几个部分。 (1)图像输入 将图像采集下来输入计算机进行处理是图像识别的首要步骤。 (2)预处理 为了减少后续算法的复杂度和提高效率,图像的预处理是必不可少的。其中
人脸识别几种解决方案的对比_人脸识别技术原理介绍
人脸识别几种解决方案的对比_人脸识别技术原理介绍 人脸识别概要人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部的一系列相关技术,通常也叫做人像识别、面部识别。人脸识别特点非强制性:用户不需要专门配合人脸采集设备,几乎可以在无意识的状态下就可获取人脸图像,这样的取样方式没有强制性; 非接触性:用户不需要和设备直接接触就能获取人脸图像; 并发性:在实际应用场景下可以进行多个人脸的分拣、判断及识别; 除此之外,还符合视觉特性:以貌识人的特性,以及操作简单、结果直观、隐蔽性好等特点。 人脸识别技术原理分析人脸识别主要分为人脸检测(face detecTIon)、特征提取(feature extracTIon)和人脸识别(face recogniTIon)三个过程。 人脸检测:人脸检测是指从输入图像中检测并提取人脸图像,通常采用haar特征和Adaboost算法训练级联分类器对图像中的每一块进行分类。如果某一矩形区域通过了级联分类器,则被判别为人脸图像。 特征提取:特征提取是指通过一些数字来表征人脸信息,这些数字就是我们要提取的特征。常见的人脸特征分为两类,一类是几何特征,另一类是表征特征。几何特征是指眼睛、鼻子和嘴等面部特征之间的几何关系,如距离、面积和角度等。由于算法利用了一些直观的特征,计算量小。 不过,由于其所需的特征点不能精确选择,限制了它的应用范围。另外,当光照变化、人脸有外物遮挡、面部表情变化时,特征变化较大。所以说,这类算法只适合于人脸图像的粗略识别,无法在实际中应用。 表征特征利用人脸图像的灰度信息,通过一些算法提取全局或局部特征。其中比较常用的特征提取算法是LBP算法。LBP方法首先将图像分成若干区域,在每个区域的像素640x960邻域中用中心值作阈值化,将结果看成是二进制数。
SIFT算法实现原理步骤
SIFT 算法实现步骤 :1 关键点检测、2 关键点描述、3 关键点匹配、4 消除错配点 1关键点检测 1.1 建立尺度空间 根据文献《Scale-space theory: A basic tool for analysing structures at different scales 》我们可知,高斯核是唯一可以产生多尺度空间的核,一个图像的尺度空间,L (x,y,σ) ,定义为原始图像I(x,y)与一个可变尺度的2维高斯函数G(x,y,σ) 卷积运算。 高斯函数 高斯金字塔 高斯金子塔的构建过程可分为两步: (1)对图像做高斯平滑; (2)对图像做降采样。 为了让尺度体现其连续性,在简单 下采样的基础上加上了高斯滤波。 一幅图像可以产生几组(octave ) 图像,一组图像包括几层 (interval )图像。 高斯图像金字塔共o 组、s 层, 则有: σ——尺度空间坐标;s ——sub-level 层坐标;σ0——初始尺度;S ——每组层数(一般为3~5)。 当图像通过相机拍摄时,相机的镜头已经对图像进行了一次初始的模糊,所以根据高斯模糊的性质: -第0层尺度 --被相机镜头模糊后的尺度 高斯金字塔的组数: M 、N 分别为图像的行数和列数 高斯金字塔的组内尺度与组间尺度: 组内尺度是指同一组(octave )内的尺度关系,组内相邻层尺度化简为: 组间尺度是指不同组直接的尺度关系,相邻组的尺度可化为: 最后可将组内和组间尺度归为: ()22221 ()(),,exp 22i i i i x x y y G x y σπσσ??-+-=- ? ??()()(),,,,*,L x y G x y I x y σσ=Octave 1 Octave 2 Octave 3 Octave 4 Octave 5σ2σ 4σ8 σ 0()2s S s σσ= g 0σ=init σpre σ()() 2log min ,3O M N ??=-?? 1 12S s s σσ+=g 1()2s S S o o s σσ++=g 222s S s S S o o σσ+=g g 121 2(,,,) i n k k k σσσσ--L 1 2 S k =
最新数字图像处理算法实现精编版
2020年数字图像处理算法实现精编版
数字图像处理算法实现 ------------编程心得(1) 2001414班朱伟 20014123 摘要: 关于空间域图像处理算法框架,直方图处理,空间域滤波器算法框架的编程心得,使用GDI+(C++) 一,图像文件的读取 初学数字图像处理时,图像文件的读取往往是一件麻烦的事情,我们要面对各种各样的图像文件格式,如果仅用C++的fstream库那就必须了解各种图像编码格式,这对于初学图像处理是不太现实的,需要一个能帮助轻松读取各类图像文件的库。在Win32平台上GDI+(C++)是不错的选择,不光使用上相对于Win32 GDI要容易得多,而且也容易移植到.Net平台上的GDI+。 Gdiplus::Bitmap类为我们提供了读取各类图像文件的接口, Bitmap::LockBits方法产生的BitmapData类也为我们提供了高速访问图像文件流的途径。这样我们就可以将精力集中于图像处理算法的实现,而不用关心各种图像编码。具体使用方式请参考MSDN中GDI+文档中关于Bitmap类和BitmapData类的说明。另外GDI+仅在Windows XP/2003上获得直接支持,对于Windows 2000必须安装相关DLL,或者安装有Office 2003,Visual Studio 2003 .Net等软件。 二,空间域图像处理算法框架 (1) 在空间域图像处理中,对于一个图像我们往往需要对其逐个像素的进行处理,对每个像素的处理使用相同的算法(或者是图像中的某个矩形部分)。即,对于图像f(x,y),其中0≤x≤M,0≤y≤N,图像为M*N大小,使用算法
车牌识别系统工作原理流程
识别流程 车牌自动识别是一项利用车辆的动态视频或静态图像进行牌照号码、牌照颜色自动识别的模式识别技术。 其硬件基础一般包括触发设备(监测车辆是否进入视野)、摄像设备、照明设备、图像采集设备、识别车牌号码的处理机(如计算机)等,其软件核心包括车牌定位算法、车牌字符分割算法和光学字符识别算法等。 某些车牌识别系统还具有通过视频图像判断是否有车的功能称之为视频车辆检测。 一个完整的车牌识别系统应包括车辆检测、图像采集、车牌识别等几部分。 当车辆检测部分检测到车辆到达时触发图像采集单元,采集当前的视频图像。车牌识别单元对图像进行处理,定位出牌照位置,再将牌照中的字符分割出来进行识别,然后组成牌照号码输出。 车辆检测 车辆检测可以采用埋地线圈检测、红外检测、雷达检测技术、视频检测等多种方式。 采用视频检测可以避免破坏路面、不必附加外部检测设备、不需矫正触发位置、节省
开支,而且更适合移动式、便携式应用的要求。 系统进行视频车辆检测,需要具备很高的处理速度并采用优秀的算法,在基本不丢帧的情况下实现图像采集、处理。 若处理速度慢,则导致丢帧,使系统无法检测到行驶速度较快的车辆,同时也难以保证在有利于识别的位置开始识别处理,影响系统识别率。因此,将视频车辆检测与牌照自动识别相结合具备一定的技术难度。 武汉车牌识别 号码识别 为了进行车牌识别,需要以下几个基本的步骤: 1、牌照定位,定位图片中的牌照位置; 2、牌照字符分割,把牌照中的字符分割出来; 3、牌照字符识别,把分割好的字符进行识别,*终组成牌照号码。 车牌识别过程中,牌照颜色的识别依据算法不同,可能在上述不同步骤实现,通常与车牌识别互相配合、互相验证。
图像识别匹配技术原理要点
第1章绪论 1.1研究背景及意义 数字图像,又称数码图像或数位图像,就是二维图像用有限数字数值像素的表示。通常,像素在计算机中保存为二维整数数组的光栅图像,这些值经常用压缩格式进行传输与储存。数字图像可以由许多不同的输入设备与技术生成,例如数码相机、扫描仪、坐标测量机等,也可以从任意的非图像数据合成得到,例如数学函数或者三维几何模型,三维几何模型就是计算机图形学的一个主要分支。数字图像处理领域就就是研究它们的变换算法。 数字图像处理(Digital Image Processing)就是通过计算机对图像进行去除噪声、增强、复原、分割、提取特征等处理的方法与技术。数字图像处理的产生与迅速发展主要受三个因素的影响:一就是计算机的发展;二就是数学的发展(特别就是离散数学理论的创立与完善);三就是广泛的农牧业、林业、环境、军事、工业与医学等方面的应用需求的增长。 图像配准(Image registration)就就是将不同时间、不同传感器(成像设备)或不同条件下(天候、照度、摄像位置与角度等)获取的两幅或多幅图像进行匹配、叠加的过程,它已经被广泛地应用于遥感数据分析、计算机视觉、图像处理等领域。 图像配准的方法迄今为止,在国内外的图像处理研究领域,已经报道了相当多的图像配准研究工作,产生了不少图像配准方法。总的来说,各种方法都就是面向一定范围的应用领域,也具有各自的特点。比如计算机视觉中的景物匹配与飞行器定位系统中的地图匹配,依据其完成的主要功能而被称为目标检测与定位,根据其所采用的算法称之为图像相关等等。 基于灰度信息的图像配准方法一般不需要对图像进行复杂的预先处理,而就是利用图像本身具有灰度的一些统计信息来度量图像的相似程度。主要特点就是实现简单,但应用范围较窄,不能直接用于校正图像的非线性形变,在最优变换的搜索过程中往往需要巨大的运算量。经过几十年的发展,人们提出了许多基于灰度信息的图像配准方法,大致可以分为三类:互相关法(也称模板匹配法)、序贯相似度检测匹配法、交互信息法。 目前主要图像配准方法有基于互信息的配准方法,基于相关性的配准方法与基于梯度的配准方法。其中基于梯度的方法基本很少单独使用,而作为一个辅助
车辆牌照图像识别算法的实现
本科毕业设计(论文) 车辆牌照图像识别算法的实现(题目二号宋体)学院名称:电气信息工程学院(四号宋体) 专业:通信工程 班级:通信 学号: 姓名:张 指导教师姓名:孙 指导教师职称:副教授 二〇一年六月 [空一行、字号小] (中文题目为号黑体居中) [空一行、字号小] 摘要:××××××××××××××××××(字左右,小四号宋体)×××××××××××××××××…… 关键词:×××;××××;×××××;×××(个,小四号宋体) 摘要应回答好个方面问题: ①(直接写出研究目的); ②(简述过程和方法); ③(罗列主要结果或结论); ④(通过②和③两方面内容具体展示文中创新之处)。
(号,居中对齐) [空一行、字号小] :××××××(小号)××××××××××××××××××××××……:×××;××××;×××××;×××(小号) 要求和中文摘要对应。 中实词首字母要大写。 一般采用第三人称、单数、现在时。
目录(号黑体居中) [空一行、字号小] 前言(号黑体)........................................ 错误!未指定书签。第章章标题(号黑体)................................................. 节标题(小宋体,倍行距,内侧缩进字符)............................ 小节标题(小宋体,倍行距, 内侧缩进字符)....................... 小节标题....................................................... 节标题 小节标题....................................................... 小节标题....................................................... 小节标题....................................................... 第章章标题............................................................. 节标题 小节标题....................................................... 小节标题....................................................... 节标题 小节标题....................................................... 小节标题....................................................... ................................(略) 参考文献(号黑体)...................................................... 致谢(号黑体) .......................................................... 附录标题(可选)....................................................... 附录标题(可选)....................................................... 注:目录中的内容一般列出“章”、“节”、“小节”三级标题即可。
人脸识别主要算法原理doc资料
人脸识别主要算法原 理
人脸识别主要算法原理 主流的人脸识别技术基本上可以归结为三类,即:基于几何特征的方法、基于模板的方法和基于模型的方法。 1. 基于几何特征的方法是最早、最传统的方法,通常需要和其他算法结合才能有比较好的效果; 2. 基于模板的方法可以分为基于相关匹配的方法、特征脸方法、线性判别分析方法、奇异值分解方法、神经网络方法、动态连接匹配方法等。 3. 基于模型的方法则有基于隐马尔柯夫模型,主动形状模型和主动外观模型的方法等。 1. 基于几何特征的方法 人脸由眼睛、鼻子、嘴巴、下巴等部件构成,正因为这些部件的形状、大小和结构上的各种差异才使得世界上每个人脸千差万别,因此对这些部件的形状和结构关系的几何描述,可以做为人脸识别的重要特征。几何特征最早是用于人脸侧面轮廓的描述与识别,首先根据侧面轮廓曲线确定若干显著点,并由这些显著点导出一组用于识别的特征度量如距离、角度等。Jia 等由正面灰度图中线附近的积分投影模拟侧面轮廓图是一种很有新意的方法。 采用几何特征进行正面人脸识别一般是通过提取人眼、口、鼻等重要特征点的位置和眼睛等重要器官的几何形状作为分类特征,但
Roder对几何特征提取的精确性进行了实验性的研究,结果不容乐观。 可变形模板法可以视为几何特征方法的一种改进,其基本思想是:设计一个参数可调的器官模型(即可变形模板),定义一个能量函数,通过调整模型参数使能量函数最小化,此时的模型参数即做为该器官的几何特征。 这种方法思想很好,但是存在两个问题,一是能量函数中各种代价的加权系数只能由经验确定,难以推广,二是能量函数优化过程十分耗时,难以实际应用。基于参数的人脸表示可以实现对人脸显著特征的一个高效描述,但它需要大量的前处理和精细的参数选择。同时,采用一般几何特征只描述了部件的基本形状与结构关系,忽略了局部细微特征,造成部分信息的丢失,更适合于做粗分类,而且目前已有的特征点检测技术在精确率上还远不能满足要求,计算量也较大。 2. 局部特征分析方法(Local Face Analysis) 主元子空间的表示是紧凑的,特征维数大大降低,但它是非局部化的,其核函数的支集扩展在整个坐标空间中,同时它是非拓扑的,某个轴投影后临近的点与原图像空间中点的临近性没有任何关系,而局部性和拓扑性对模式分析和分割是理想的特性,似乎这更符合神经信息处理的机制,因此寻找具有这种特性的表达十分重要。基于这种考虑,Atick提出基于局部特征的人脸特征提取与识
车牌识别技术的实现原理和实现方式
车牌识别技术的实现原理和实现方式 图像采集:通过高清摄像抓拍主机对卡口过车或车辆违章行为进行实时、不间断记录、采集。预处理:图片质量是影响车辆识别率高低的关键因素,因此,需要对高清摄像抓拍主机采集到的原始图像进行噪声过滤、自动白平衡、自动曝光以及伽马校正、边缘增强、对比度调整等处理。 车牌定位:车牌定位的准确与否直接决定后面的字符分割和识别效果,是影响整个车牌识别率的重要因素。其核心是纹理特征分析定位算法,在经过图像预处理之后的灰度图像上进行行列扫描,通过行扫描确定在列方向上含有车牌线段的候选区域,确定该区域的起始行坐标和高度,然后对该区域进行列扫描确定其列坐标和宽度,由此确定一个车牌区域。通过这样的算法可以对图像中的所有车牌实现定位。 字符分割:在图像中定位出车牌区域后,通过灰度化、灰度拉伸、二值化、边缘化等处理,进一步精确定位字符区域,然后根据字符尺寸特征提出动态模板法进行字符分割,并将字符大小进行归一化处理。 字符识别:对分割后的字符进行缩放、特征提取,获得特定字符的表达形式,然后通过分类判别函数和分类规则,与字符数据库模板中的标准字符表达形式进行匹配判别,就可以识别出输入的字符图像。 结果输出:将车牌识别的结果以文本格式输出。 车辆牌照的识别是基于图像分割和图像识别理论, 对含有车辆号牌的图像进行分析处理,从而确定牌照在图像中的位置,并进一步提取和识别出文本字符。 识别步骤概括为:车牌定位、车牌提取、字符识别。三个步骤地识别工作相辅相成,各自的有效率都较高,整体的识别率才会提高。 识别速度的快慢取决于字符识别,字符的识别目前的主要应用技术为比对识别样本库, 即将所有的字符建立样本库,字符提取后通过比对样本库实现字符的判断, 识别过程中将产生可信度、倾斜度等中间结果值;另一种是基于字符结构知识的字符识别技术, 更加有效的提高识别速率和准确率,适应性较强。 车牌识别系统实现的方式主要分为两种:一种是静态图像图片的识别, 另一种是动态视频流的实时识别。 静态图像识别技术的识别有效率较大程度上受限于图像的抓拍质量,为单帧图像识别,目前市场产品识别速度平均为200毫秒;而动态视频流的识别技术适应性较强,识别速度快,它实现了对视频每一帧图像进行识别,增加识别比对次数,择优选取车牌号, 关键在于较少的受到单帧图像质量的影响,目前市场产品识别较好的时间为10毫秒。 车牌识别的原理是什么?车牌识别停车场管理系统将摄像机在入口拍摄的车辆车牌号码图象自动识别并转换成数字信号。做到一卡一车,车牌识别的优势在于可以把卡和车对应起来,使管理提高一个档次,卡和车的对应的优点在于长租卡须和车配合使用,杜绝一卡多