hadoop MapReduce实例解析

1、MapReduce理论简介
1.1 MapReduce编程模型
MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是"任务的分解与结果的汇总"。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce 负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce处理过程
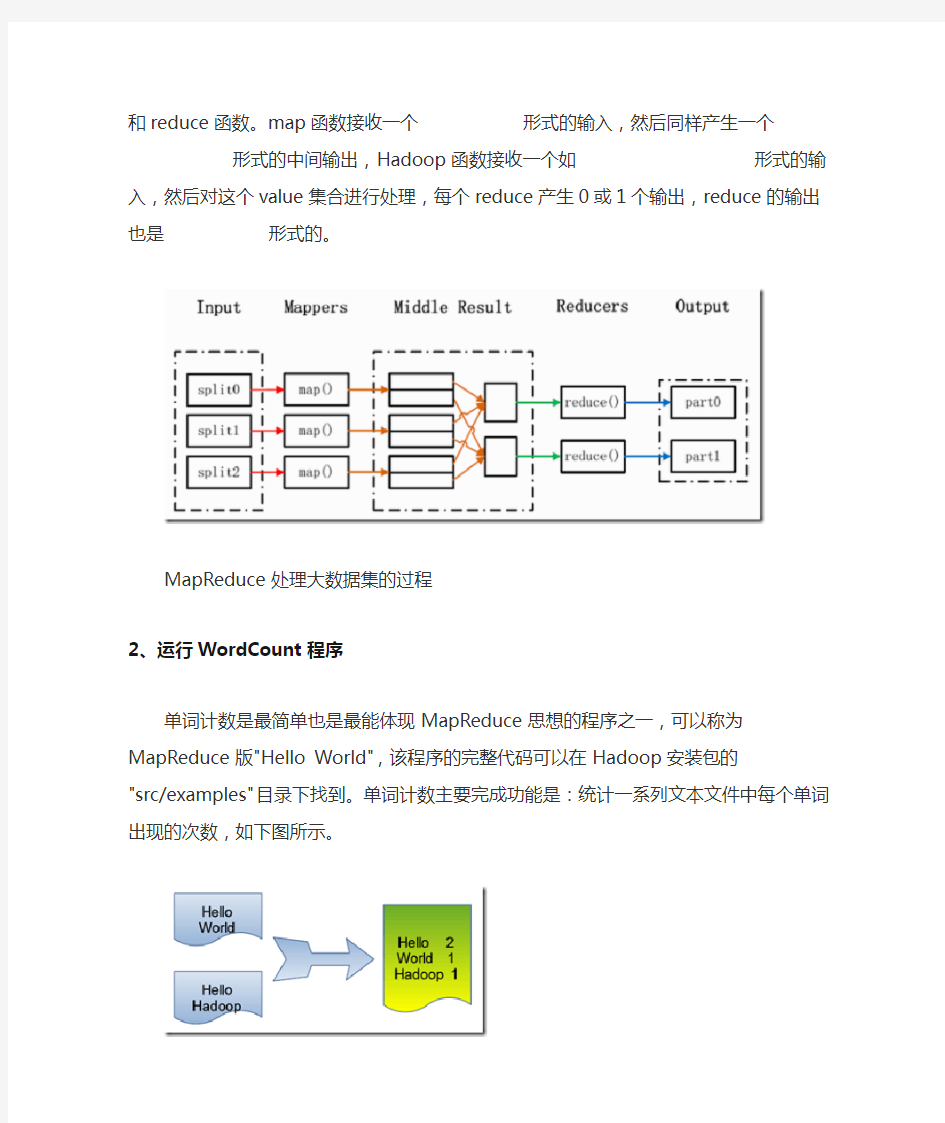
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map函数接收一个
MapReduce处理大数据集的过程
2、运行WordCount程序
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。
2.1 准备工作
现在以"hadoop"普通用户登录"Master.Hadoop"服务器。
1)创建本地示例文件
首先在"/home/hadoop"目录下创建文件夹"file"。
接着创建两个文本文件file1.txt和file2.txt,使file1.txt内容为"Hello World",而file2.txt的内容为"Hello Hadoop"。
2)在HDFS上创建输入文件夹
3)上传本地file中文件到集群的input目录下
2.2 运行例子
1)在集群上运行WordCount程序
备注:以input作为输入目录,output目录作为输出目录。
已经编译好的WordCount的Jar在"/usr/hadoop"下面,就是
"hadoop-examples-1.0.0.jar",所以在下面执行命令时记得把路径写全了,不然会提示找不到该Jar包。
2)MapReduce执行过程显示信息
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID 号:job_201202292213_0002,而且得知输入文件有两个(Total input paths to process : 2),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。比如说,在本例中,map的task数量是2个,reduce 的task数量是一个。map的输入record数是2个,输出record数是4个等信息。
2.3 查看结果
1)查看HDFS上output目录内容
从上图中知道生成了三个文件,我们的结果在" part-r-00000 "中。
2)查看结果输出文件内容
3、WordCount源码分析
3.1 特别数据类型介绍
Hadoop提供了如下内容的数据类型,这些数据类型都实现了WritableComparable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储,以及进行大小比较。
BooleanWritable:标准布尔型数值
ByteWritable:单字节数值
DoubleWritable:双字节数
FloatWritable:浮点数
IntWritable:整型数
LongWritable:长整型数
Text:使用UTF8格式存储的文本
NullWritable:当
3.2 旧的WordCount分析
1)源代码程序
packageorg.apache.hadoop.examples;
importjava.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class Map extends MapReduceBase implements Mapper
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector
throws IOException {
String line = value.toString();
StringTokenizertokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer
public void reduce(Text key, Iterator
OutputCollector
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception { JobConfconf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
3)主方法Main 分析
public static void main(String[] args) throws Exception {
JobConfconf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
首先讲解一下Job 的初始化过程。main 函数调用Jobconf 类来
对MapReduce Job 进行初始化,然后调用setJobName() 方法命名这个Job 。对Job进行合理的命名有助于更快地找到Job,以便在JobTracker和Tasktracker的页面中对其进行监视。
JobConfconf = new JobConf(WordCount. class ); conf.setJobName("wordcount" );
接着设置Job输出结果
设置为"IntWritable",相当于Java中的int类型。
conf.setOutputKeyClass(Text.class );
conf.setOutputValueClass(IntWritable.class );
然后设置Job处理的Map(拆分)、Combiner(中间结果合并)以及Reduce (合并)的相关处理类。这里用Reduce类来进行Map产生的中间结果合并,避免给网络数据传输产生压力。
conf.setMapperClass(Map.class );
conf.setCombinerClass(Reduce.class );
conf.setReducerClass(Reduce.class );
接着就是调用setInputPath()和setOutputPath()设置输入输出路径。
conf.setInputFormat(TextInputFormat.class );
conf.setOutputFormat(TextOutputFormat.class );
(1)InputFormat和InputSplit
InputSplit是Hadoop定义的用来传送给每个单独的map 的数据,InputSplit 存储的并非数据本身,而是一个分片长度和一个记录数据位
置的数组。生成InputSplit的方法可以通过InputFormat() 来设置。
当数据传送给map 时,map会将输入分片传送到InputFormat ,InputFormat 则调用方法getRecordReader() 生成RecordReader,RecordReader再通过creatKey()、creatValue() 方法创建可供map处理的
InputFormat
|
|---BaileyBorweinPlouffe.BbpInputFormat
|---ComposableInputFormat
|---CompositeInputFormat
|---DBInputFormat
|---DistSum.Machine.AbstractInputFormat
|---FileInputFormat
|---CombineFileInputFormat
|---KeyValueTextInputFormat
|---NLineInputFormat
|---SequenceFileInputFormat
|---TeraInputFormat
|---TextInputFormat
其中TextInputFormat 是Hadoop 默认的输入方法,在TextInputFormat中,每个文件(或其一部分)都会单独地作为map的输入,而这个是继承自FileInputFormat的。之后,每行数据都会生成一条记录,每条记录则表示成
key值是每个数据的记录在数据分片中字节偏移量,数据类型是LongWritable ;
value值是每行的内容,数据类型是Text 。
(2)OutputFormat
每一种输入格式都有一种输出格式与其对应。默认的输出格式是TextOutputFormat ,这种输出方式与输入类似,会将每条记录以一行的形式存入文本文件。不过,它的键和值可以是任意形式的,因为程序内容会调
用toString() 方法将键和值转换为String 类型再输出。
3)Map类中map方法分析
public static class Map extends MapReduceBase implements Mapper
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector
throws IOException {
String line = value.toString();
StringTokenizertokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
Map类继承自MapReduceBase ,并且它实现了Mapper接口,此接口是一个规范类型,它有4种形式的参数,分别用来指定map的输入key值类型、输入value值类型、输出key值类型和输出value值类型。在本例中,因为使用的是TextInputFormat,它的输出key值是LongWritable类型,输出value值是Text类型,所以map的输入类型为
实现此接口类还需要实现map方法,map方法会具体负责对输入进行操作,在本例中,map方法对输入的行以空格为单位进行切分,然后使
用OutputCollect 收集输出的
4)Reduce类中reduce方法分析
public static class Reduce extends MapReduceBase implements Reducer
public void reduce(Text key, Iterator
OutputCollector
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
Reduce类也是继承自MapReduceBase 的,需要实现Reducer接口。Reduce 类以map的输出作为输入,因此Reduce的输入类型是
3.3 新的WordCount分析
1)源代码程序
packageorg.apache.hadoop.examples;
importjava.io.IOException;
importjava.util.StringTokenizer;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.Mapper;
importorg.apache.hadoop.mapreduce.Reducer;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat; importorg.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throwsIOException, InterruptedException {
StringTokenizeritr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer
privateIntWritable result = new IntWritable();
public void reduce(Text key, Iterable
int sum = 0;
for (IntWritableval : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main (String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingAr gs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
1)Map过程
public static class TokenizerMapper
extends Mapper
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throwsIOException, InterruptedException {
StringTokenizeritr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
Map过程需要继承org.apache.hadoop.mapreduce包中Mapper 类,并重
写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。然后StringTokenizer类将每一行拆分成为一个个的单词,并将
2)Reduce过程
public static class IntSumReducer
extends Reducer
privateIntWritable result = new IntWritable();
public void reduce(Text key, Iterable
int sum = 0;
for (IntWritableval : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer 类,并重写其reduce方法。Map过程输出
3)执行MapReduce任务
public static void main (String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingAr gs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job
的一些方法对任务的参数进行相关的设置。此处设置了使用TokenizerMapper 完成Map过程中的处理和使用IntSumReducer完成Combine和Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion() 方法执行任务。
4、WordCount处理过程
本节将对WordCount进行更详细的讲解。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成
框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows 和Linux环境会不同)。
图4-1 分割过程
2)将分割好的
图4-2 执行map方法
3)得到map方法输出的
图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce 方法进行处理,得到新的
图4-4 Reduce端排序及输出结果
5、MapReduce新旧改变
Hadoop最新版本的MapReduce Release 0.20.0的API包括了一个全新的Mapreduce JAVA API,有时候也称为上下文对象。
新的API类型上不兼容以前的API,所以,以前的应用程序需要重写才能使新的API发挥其作用。
新的API和旧的API之间有下面几个明显的区别。
?新的API倾向于使用抽象类,而不是接口,因为这更容易扩展。例如,你可以添加一个方法(用默认的实现)到一个抽象类而不需修改类之前的实现方法。
在新的API中,Mapper和Reducer是抽象类。
?新的API是在org.apache.hadoop.mapreduce包(和子包)中的。之前版本的API则是放在org.apache.hadoop.mapred中的。
?新的API广泛使用context object(上下文对象),并允许用户代码与MapReduce系统进行通信。例如,MapContext基本上充当着JobConf的OutputCollector和Reporter的角色。
?新的API同时支持"推"和"拉"式的迭代。在这两个新老API中,键/值记录对被推mapper中,但除此之外,新的API允许把记录从map()方法中拉出,这也适用于reducer。"拉"式的一个有用的例子是分批处理记录,而不是一个接一个。
?新的API统一了配置。旧的API有一个特殊的JobConf对象用于作业配置,这是一个对于Hadoop通常的Configuration对象的扩展。在新的API中,这种区别没有了,所以作业配置通过Configuration来完成。作业控制的执行由Job类来负责,而不是JobClient,它在新的API中已经荡然无存。
软件开发计划实例
软件项目开发计划编号:G/GZU-YYXXX-SRT-GXDK 版本号: 作者:方勇 学号:27# 目录
概述 本系统是为贵州省高校开展国家助学贷款而开发的,各高校对贷款工作的有效管理提供可靠的平台,使学生对国家助学贷款的申请,学校贷款管理机构和银行的审批及其间的各种信息交互均通过网络实现,完成学校对贷款管理的信息化,系统化,增强贷款的安全性。同时,本系统对整个贷款的发放情况提供跟踪和交互的支持,并能够生成各种条件下的详细统计信息,从而实现国
家助学贷款从申请、管理到打印全部信息化。逐步形成一套实用、方便、快键、有效的助学贷款辅助管理系统。 一.过程计划 根据SRT项目的要求及项目小组的计划安排,将贵州高校助学贷款管理系统的开发计划规划如下:
三.进度安排 3.1甘特图 项目进度表 高校贷款系统开发周期的进度如下: 四.项目资源的分配 人员配置计划 依据可行性调查报告,我们的系统主要分为以下几个部分: 1、教育部门管理模块 2、高校贷款管理模块
3、银行贷款管理模块 4、贷款学生管理模块 各模块之间都由三人共同开发。在具体实现阶段包括程序设计、数据库设计及界面设计方面的具 体任务分配如下: 程序设计有梁建娟,方勇共同负责,数据库设计有祝江、梁建娟共同设计, 界面设计由三人共同设计,总体功能由三人共同实际调查和讨论决定。 总的项目设计由方勇负责。 开发环境 由于本系统是贵州大学SRT的一个学生实验项目,只有利用自己学习时间创造环境,利用课余 时间来进行项目的开发,经过小组讨论决定,系统统一使用HTML,ASP,VBSCRIPT,JAVASCRIPT等语言开发技术,对系统的程序主要存储在服务器端,浏览的时间动态生成WEB页面。即在服务器端执行,然后将结果返回给用户。 培训计划 下列培训课程需要对指定的人员(以支持项目开发)进行: 以上计划是项目小组必须要学习和准备的基础知识,为以后正式开发项目做好充分的准备。 运行环境 本系统需在WIN98/WINME/+sp4以上/WIN2000/WINXP(均为中文版、以上)环境下运行。 硬件配置: Microsoftwindows支持的VGA或更高分辨率显示器,建议分辨率1024*768,不能低于 800*600,色彩不低于256色,使用小字体。 预算 在经费有限的情况下,将所有的经费预算如下:
电商平台测试报告实例范文
FMS客服管理系统测试报告 拟制*** 日期2015-05-26 审核日期 批准日期 深圳市**电子商务有限公司 版权所有侵权必究 (供内部使用)
修订记录
**测试报告机密 目录 1概述 ........................................................................................................... 错误!未定义书签。 1.1被测对象概述....................................................................................... 错误!未定义书签。 1.2测试方案概述....................................................................................... 错误!未定义书签。2测试时间、地点及人员.............................................................................. 错误!未定义书签。3环境描述.................................................................................................... 错误!未定义书签。4测试覆盖分析............................................................................................. 错误!未定义书签。 4.1测试覆盖分析....................................................................................... 错误!未定义书签。 4.2缺陷统计与分析................................................................................... 错误!未定义书签。 4.2.1缺陷统计 ........................................................................................ 错误!未定义书签。 4.2.2缺陷分析 ........................................................................................ 错误!未定义书签。5测试总结和建议......................................................................................... 错误!未定义书签。 5.1软件质量评估....................................................................................... 错误!未定义书签。 5.2软件风险.............................................................................................. 错误!未定义书签。 5.3测试结论.............................................................................................. 错误!未定义书签。 5.4测试建议.............................................................................................. 错误!未定义书签。6测试过程评估............................................................................................. 错误!未定义书签。 6.1测试设计评估....................................................................................... 错误!未定义书签。 6.2测试执行评估....................................................................................... 错误!未定义书签。 6.2.1其他风险和规避措施...................................................................... 错误!未定义书签。 6.2.2测试维度分析................................................................................. 错误!未定义书签。 6.3交付的测试工作产品............................................................................ 错误!未定义书签。 **机密,未经许可不得扩散第3页,共12页
软件项目计划书模板
软件项目计划书 第一章项目概述(理论教学时可用“引言”) 1.1目的 1.2 项目背景 1.3项目的范围和目标 1.3.1范围描述(问题定义阶段产生,对应的文档为:《系统目标与范围说明书》) 1.3.2主要功能(可行性分析报告) (1)概述 (2)系统流程图 应包含旧系统的系统流程图(调研的实际情况)和新系统的系统流程图(你想像中的样 子) (3)功能描述 抽出其中的功能 1.3.3性能(可选) 1.3.4技术约束(可选) 第二章项目估算 2.1使用的历史数据 2.2使用的评估技术 2.3工作量、成本、时间估算 第三章风险评估 3.1风险识别 列出最高的10大风险(数字10是参考) 3.2风险应对策略 对列出的风险应有哪些策略去应对 第四章项目进度计划 4.1项目任务分解 我们从软件工程角度来分,大致有如下的任务: 可行性研究报告 项目开发计划 软件需求分析 数据库设计 总体设计 界面设计
网页设计 相关美工设计 详细设计 测试计划 操作手册 测试分析报告 项目开发总结 维护修改建议 4.2 时间安排 可以使用时限图(甘特图) 。 也可以是文字描述任务的时间安排。 第五章关键问题 可以是技术因素、也可以是非技术因素,总而言之,是系统成败的最重要因素。第六章软件配置 开发平台、开发工具、数据库平台 第七章人员组织 人员及其角色 第八章附录 相关文档、资料、数据等 注:一、在进度安排中应体现如下阶段: (1)问题定义与可行性分析 (2)项目规划 (3)需求分析 (4)总体设计(含两部分:软件结构总体设计和数据库设计)
(5)详细设计 (6)编程 (7)测试(单元测试、集成测试) (8)运行与系统维护 注:二、在进度安排中应独立体现如下文档: (1)项目开发计划 (2)测试计划 (3)操作手册 注:三、关于封面(单独成页)
软件测试总报告-实例(珍藏版).doc
软件工程测试总结报告****信息科技有限公司
目录 1. 测试概述 (3) 1.1. 编写目的 (3) 1.2. 测试范围 (3) 1.3. 参考资料 (3) 2. 测试计划执行情况 (3) 2.1. 测试类型 (3) 2.2. 测试环境与配置 (4) 2.3. 测试人员 (4) 2.4. 测试问题总结 (4) 3. 测试总结 (5) 3.1. 测试用例执行结果 (5) 3.2. 测试问题解决 (7) 3.3. 测试结果分析 (8) 4. 综合评价 (8) 4.1. 软件能力 (8) 4.2. 建议 (8)
1.测试概述 1.1.编写目的 本测试报告为****网的测试报告,目的在于总结测试阶段的测试情况以及分析测试结果,描述系统是否符合用户需求,是否已达到用户预期的功能目标,并对测试质量进行分析。 测试报告参考文档提供给用户、测试人员、开发人员、项目管理者、其他管理人员和需要阅读本报告的高层经理阅读。 1.2.测试范围 测试主要根据用户需求说明书和软件需求规格说明书以及相应的文档进行系统测试,包括功能测试、性能测试、安全性和访问控制测试、用户界面测试以及兼容性测试等,而单元测试和集成测试由开发人员来执行。 主要功能包括:用户登录、注册信息、社区论坛、专家与咨询、找信息、知识培训、用户个人中心、搜索。 1.3.参考资料 2.测试计划执行情况 2.1.测试类型
2.2.测试环境与配置 2.3.测试人员 2.4.测试问题总结 在整个系统测试执行期间,项目组开发人员高效地及时解决测试人员提出的各种缺陷,在一定程度上较好的保证了测试执行的效率以及测试最终期限。
项目实施方案范例
项目实施方案范例 一、项目实施方案概述 软件产品,特别是行业解决方案软件产品不同于一般的商品,用户购买软件产品之后,不能立即进行使用,需要软件公司的技术人员在软件技术、软件功能、软件操作等方面进行系统调试、软件功能实现、人员培训、软件上线使用、后期维护等一系列的工作,我们将这一系列的工作称为软件项目实施。大量的软件公司项目实施案例证明,软件项目是否成功、用户的软件使用情况是否顺利、是否提高了用户的工作效率和管理水平,不仅取决于软件产品本身的质量,软件项目实施的质量效果也对后期用户应用的情况起到非常重要的影响。项目实施规范主要包括项目启动阶段、需求调研确认阶段、软件功能实现确认阶段、数据标准化初装阶段、系统培训阶段、系统安装测试及试运行阶段、总体验收阶段、系统交接阶段等八个阶段工作内容,每个阶段下面有不同的工作事项,各个阶段之间都是承上启下关系,上一阶段的顺利完成是保证下一阶段的工作开展的基础。下面将按照每个项目实施阶段分别介绍。 二、项目实施方案介绍 (一)项目启动阶段 此阶段处于整个项目实施工作的最前期,由成立项目组、前期调研、编制总体项目计划、启动会四个阶段组成。 此阶段主任务: 公司:在合同签定后,指定项目经理,成立项目组,授权项目
组织完成项目目标。 公司项目组:进行前期项目调研,与用户共同成立项目实施组织,编制《总体项目计划》,召开项目启动会。 商务经理:配合公司项目组,将积累的项目和用户信息转交给项目组。将项目组正式介绍给用户,配合项目组建立与用户的联系。 用户:成立项目实施组织,配合前期调研和召开启动会,签署《总体项目计划》和《项目实施协议》。 1、成立项目组 部门经理接到实施申请后,任命项目经理,指定项目目标,由部门经理及项目经理一起指定项目组成员及成员任务,并报总经理签署《项目任务书》。 2、前期调研 项目经理及项目组成员,在商务人员配合下,建立与用户的联系,对合同、用户进行调研。填写《用户及合同信息表》。在项目商务谈判中,商务经理积累了大量的信息,项目组首先应收集商务和合同信息,并与商务经理一起识别那些个体和组织是项目的干系人,确定他们的需求和期望,如何满足和影响这些需求、期望以确保项目能够成功。 3、编制《项目总体计划》 《项目总体计划》是一个文件或文件的集合,随着项目信息不断丰富和变化,会被不断变更,主要介绍项目目标、主要项目阶段、里程碑、可交付成果。通常包括以下几方面内容:
系统测试报告实例(新)
XX系统测试总结报告
1引言 1.1 编写目的 编写该测试总结报告主要有以下几个目的 1.通过对测试结果的分析,得到对软件质量的评价 2.分析测试的过程,产品,资源,信息,为以后制定测试计划提供参考 3.评估测试测试执行和测试计划是否符合 4.分析系统存在的缺陷,为修复和预防bug提供建议 1.2 背景 1.3 用户群 主要读者:XX项目管理人员,XX项目测试经理 其他读者:XX项目相关人员。 1.4 定义 严重bug:出现以下缺陷,测试定义为严重bug ?系统无响应,处于死机状态,需要其他人工修复系统才可复原。 ?点击某个菜单后出现“The page cannot be displayed”或者返回异常错误。 ?进行某个操作(增加、修改、删除等)后,出现“The page cannot be displayed”或者返回异常错误 ?当对必填字段进行校验时,未输入必输字段,出现“The page cannot be displayed”或者返回异常错误 ?系统定义不能重复的字段输入重复数据后,出现“The page cannot be displayed”或者返回异常错误 1.5 测试对象 略
1.6 测试阶段 系统测试 1.7 测试工具 Bugzilla缺陷管理系统 1.8 参考资料 《XX需求和设计说明书》 《XX数据字典》 《XX后台管理系统测试计划》 《XX后台管理系统测试用例》 《XX项目计划》 2测试概要 XX后台管理系统测试从2007年7月2日开始到2007年8月10日结束,共持续39天,测试功能点174个,执行2385个测试用例,平均每个功能点执行测试用例13.7个,测试共发现427个bug,其中严重级别的bug68个,无效bug44个,平均每个测试功能点2.2个bug。 XX总共发布11个测试版本,其中B1—B5为计划内迭代开发版本(针对项目计划的基线标识),B6-B8为回归测试版本。计划内测试版本,B1—B4测试进度依照项目计划时间准时完成测试并提交报告,其中B4版本推迟一天发布版本,测试通过增加一个人日,准时完成测试。B5版本推迟发布2天,测试增加2个人日,准时完成测试。 B6-B11为计划外回归测试版本,测试增加5个工作人日的资源,准时完成测试。 XX测试通过Bugzilla缺陷管理工具进行缺陷跟踪管理,B1—B4测试阶段都有详细的bug分析表和阶段测试报告。 2.1 进度回顾
软件项目计划书编写说明
软件项目计划书编写说明 一、项目计划书格式 根据《GB8567-88计算机软件产品开发文件编制指南》中项目开发计划的要求,结合实际情况调整后的《项目计划书》内容索引如下: 1 引言 1.1 编写目的 1.2 背景 1.3 定义 1.4 参考资料 1.5 标准、条约和约定 2 项目概述 2.1项目目标 2.2产品目标与范围 2.3假设与约束 2.4 项目工作范围 2.5 应交付成果 2.5.1 需完成的软件 2.5.2 需提交用户的文档 2.5.3 须提交内部的文档 2.5.4 应当提供的服务 2.6 项目开发环境 2.7 项目验收方式与依据 3 项目团队组织 3.1 组织结构 3.2 人员分工 3.3 协作与沟通 3.3.1 内部协作 3.3.2 外部沟通 4 实施计划 4.1 风险评估及对策 4.2 工作流程 4.3 总体进度计划 4.4 项目监控 4.4.1 质量控制计划 4.4.2 进度监控计划 4.4.3 预算监控计划 4.4.4 配置管理计划 5 支持条件 5.1 内部支持(可选) 5.2 客户支持(对项目而言)
5.3 外包(可选) 6 预算(可选) 6.1 人员成本 6.2 设备成本 6.3 其它经费预算 6.4 项目合计经费预算 7 关键问题 8专题计划要点 二、项目计划书的编写说明 1 引言 1.1 编写目的 说明编写这份项目计划的目的,并指出预期的读者。 作用:本节是为了说明编制“项目计划书”亦即本文档的意图和希望达到的效果。注意这里的“目的”不是“项目目标”,而是为了说明本文档的目的与作用。“项目目标”在2.1中说明。 意义:使项目成员和项目干系人了解项目开发计划书的作用、希望达到的效果。开发计划书的作用一般都是“项目成员以及项目干系人之间的共识与约定,项目生命周期所有活动的行动基础,以便项目团队根据本计划书开展和检查项目工作。” 例如可以这么写:为了保证项目团队按时保质地完成项目目标,便于项目团队成员更好地了解项目情况,使项目工作开展的各个过程合理有序,因此以文件化的形式,把对于在项目生命周期内的工作任务范围、各项工作的任务分解、项目团队组织结构、各团队成员的工作责任、团队内外沟通协作方式、开发进度、经费预算、项目内外环境条件、风险对策等内容做出的安排以书面的方式,作为项目团队成员以及项目干系人之间的共识与约定,项目生命周期内的所有项目活动的行动基础,项目团队开展和检查项目工作的依据。 常见的问题:把项目本身的“项目目标”误作编制项目开发计划的目的。 1.2 背景 主要说明项目的来历,一些需要项目团队成员知道的相关情况。主要有以下内容: 项目的名称:经过与客户商定或经过立项手续统一确定的项目名称,一般与所待开发的软件系统名称有较大的关系,如针对“XX系统”开发的项目名称是“XX系统开发”。 项目的委托单位:如果是根据合同进行的软件开发项目,项目的委托单位就是合同中的甲方;如果是自行研发的软件产品,项目的委托单位就是本企业。 项目的用户(单位):软件或网络的使用单位,可以泛指某个用户群。注意项目的用户或单位有时与项目的委托单位是同一个,有时是不一样的。如海关的报关软件、税务的报税软件,委托单位是海关或税务机关,但使用的用户或单位不仅有海关或税务机关,还包括需要报关、报税的企业单位。 项目的任务提出者:本企业内部提出需要完成此项目的人员,一般是领导或商务人员;注意项目的任务提出者一般不同于项目的委托单位,前者一般是企业内部的人员。如果是内部开发项目,则两者的区别在于前者指人,后者指单位。 项目的主要承担部门:有些企业根据行业方向或工作性质的不同把软件开发分成不同的部门(也有的分为不同事业部)。项目的特点就是其矩阵式组织,一般一个项目的项目成员可能由不同的部门组成,甚至可能由研发部门、开发部门、测试部门、集成部门、服务部门等等其中几个组成。需要根据项目所涉及的范围确定本项目的主要承担部门。 项目建设背景:从政治环境上、业务环境上说明项目建设背景,说明项目的大环境、来龙去脉。这有利于项目成员更好地理解项目目标和各项任务。
软件项目管理案例教程第4版前十二章课后习题答案
第一章 一、填空题 1.敏捷模型包括(4)个核心价值,对应(12)个敏捷原则。 2.项目管理包括(启动过程组)、(计划过程组)、(执行过程组)、(控制过程组)、(收尾过程组)5个过程组。 二、判断题 1、搬家属于项目。(√) 2、项目是为了创造一个唯一的产品或提供一个唯一的服务而进行的永久性的努力。(×) 3、过程管理就是对过程进行管理,目的是要让过程能够被共享、复用,并得到持续的改进。(√) 4、项目具有临时性的特征。(√) 5、日常运作存在大量的变更管理,而项目基本保持连贯性的。(×) 6、项目开发过程中可以无限制地使用资源。(×) 7、相比传统开发的预测性过程,敏捷开发属于自适应过程(√) 三、选择题 1、下列选项中不是项目与日常运作的区别的是(C) A. 项目是以目标为导向的,日常运作是通过效率和有效性体现的。 B. 项目是通过项目经理及其团队工作完成的,而日常运作是职能式的线性管理。 C.项目需要有专业知识的人来完成,而日常运作的完成无需特定专业知识。 D.项目是一次性的,日常运作是重复性的。 2、以下都是日常运作和项目的共同之处,除了(D) A.由人来做 B.受限于有限的资源 C.需要规划、执行和控制 D.都是重复性工作 3、下面选项中不是PMBOK的知识域的是(A) A.招聘管理 B.质量管理 C.围管理 D.风险管理 4、下列选项中属于项目的是(C) A.上课 B.社区保安 C.野餐活动 D.每天的卫生保洁 5、下列选项中正确的是(C) A.一个项目具有明确的目标而且周期不限 B.一个项目一旦确定就不会发生变更 C.每个项目都有自己的独特性 D.项目都是一次性的并由项目经理独自完成 6、(B)是为了创造一个唯一的产品或提供一个唯一的服务而进行的临时性的努力。
软件测试总报告-实例(珍藏版)
软件工程测试总结报告 ****信息科技 目录 1.测试概述 (3) 1.1.编写目的 (3) 1.2.测试围 (3) 1.3.参考资料 (3)
2.测试计划执行情况 (3) 2.1.测试类型 (3) 2.2.测试环境与配置 (4) 2.3.测试人员 (4) 2.4.测试问题总结 (4) 3.测试总结 (5) 3.1.测试用例执行结果 (5) 3.2.测试问题解决 (7) 3.3.测试结果分析 (8) 4.综合评价 (8) 4.1.软件能力 (8) 4.2.建议 (8)
1.测试概述 1.1.编写目的 本测试报告为****网的测试报告,目的在于总结测试阶段的测试情况以及分析测试结果,描述系统是否符合用户需求,是否已达到用户预期的功能目标,并对测试质量进行分析。 测试报告参考文档提供给用户、测试人员、开发人员、项目管理者、其他管理人员和需要阅读本报告的高层经理阅读。 1.2.测试围 测试主要根据用户需求说明书和软件需求规格说明书以及相应的文档进行系统测试,包括功能测试、性能测试、安全性和访问控制测试、用户界面测试以及兼容性测试等,而单元测试和集成测试由开发人员来执行。 主要功能包括:用户登录、注册信息、社区论坛、专家与咨询、找信息、知识培训、用户个人中心、搜索。 1.3.参考资料 2.测试计划执行情况 2.1.测试类型
2.2.测试环境与配置 2.3.测试人员 2.4.测试问题总结 在整个系统测试执行期间,项目组开发人员高效地及时解决测试人员提出的各种缺陷,在一定程度上较好的保证了测试执行的效率以及测试最终期限。
3.测试总结 3.1.测试用例执行结果
软件项目管理计划书案例完整
学生宿舍信息管理系统项目计划书
目录 第一章前言---------------------------------------------------------2 1.1项目开发背景-------------------------------------------------2 1.2项目开发目的-------------------------------------------------2 1.3项目开发意义-------------------------------------------------2 第二章范围计划-------------------------------------------------------3 2.1项目工作分解结构--------------------------------------------3 2.2软件生命周期模型---------------------------------------------5 2.2.1软件生命周期模型图示表示-----------------------------------6 2.2.2软件生命周期模型详细文档-----------------------------------6 (一)软件规划----------------------------------------------6 (二)需求开发----------------------------------------------7 (三)软件结构设计-------------------------------------------8 (四)数据库设计-------------------------------------------10 (五)实施-------------------------------------------------10 (六)系统集成----------------------------------------------10 (七)提交-------------------------------------------------11 (八)维护-------------------------------------------------11 第三章进度计划------------------------------------------------------11 3.1甘特图-----------------------------------------------------11 3.2网络图(单代号或双代号)-------------------------------------12
软件开发计划(实例)
软件项目开发计划 编号:G/GZU-YYXXX-SRT-GXDK 版本号:V1.0 作者:方勇 学号:27#
目录 概述........................................................................................................... 错误!未定义书签。一.过程计划................................................................................................... 错误!未定义书签。二.规模、工作量的估算............................................................................... 错误!未定义书签。三.进度安排.. (3) 3.1甘特图 (5) 3.2 项目进度表 (5) 四.项目资源的分配 (5) 4.1 人员配置计划 (5) 4.2 开发环境............................................................................................ 错误!未定义书签。 4.3 培训计划............................................................................................ 错误!未定义书签。 4.4运行环境 (6) 4.5 预算 (6) 4.6验收标准 (7) 五.质量计划 (9) 5.1 质量目标 (9) 5.2 复审计划 (9) 六.风险管理计划 (10) 6.1 风险列表............................................................................................ 错误!未定义书签。七.项目跟踪计划. (10) 7.1 任务跟踪............................................................................................ 错误!未定义书签。 7.2 问题跟踪............................................................................................ 错误!未定义书签。 7.3 客户反馈............................................................................................ 错误!未定义书签。 7.4 项目进度报告.................................................................................... 错误!未定义书签。 7.5项目里程碑报告................................................................................. 错误!未定义书签。八.项目团队 (12) 8.1 组织结构............................................................................................ 错误!未定义书签。 8.2 角色和职责........................................................................................ 错误!未定义书签。九.配置管理计划. (15) 9.1 组织和职责........................................................................................ 错误!未定义书签。 9.2 用户权限............................................................................................ 错误!未定义书签。 9.3 环境状态............................................................................................ 错误!未定义书签。 9.4 目录结构............................................................................................ 错误!未定义书签。 9.5 配置项和存储.................................................................................... 错误!未定义书签。 9.6 配置项管理方法................................................................................ 错误!未定义书签。 9.7 数据备份............................................................................................ 错误!未定义书签。十计划的维护................................................................................................. 错误!未定义书签。
系统测试报告实例
中南医院系统测试总结报告
1引言 1.1编写目的 编写该测试总结报告主要有以下几个目的 1.通过对测试结果的分析,得到对软件质量的评价 2.分析测试的过程,产品,资源,信息,为以后制定测试计划提供参考 3.评估测试测试执行和测试计划是否符合 4.分析系统存在的缺陷,为修复和预防bug提供建议1.2背景 1.3用户群 主要读者:XX项目管理人员,XX项目测试经理 其他读者:XX项目相关人员。 1.4定义 严重bug:出现以下缺陷,测试定义为严重bug 系统无响应,处于死机状态,需要其他人工修复系统才可复原。 值班人员信息更新有错误。 排班表样式界面需要改进。 排班池领导和值班人员未分类。 值晚班时间是从当天17.30—第二天08:00,没有考虑第二天00:01后的值班情况。
事件统计分析——事件分类统计页出现参数无效。 点击某个菜单后出现“The page cannot be displayed”或者返回异常错误。 进行某个操作(增加、修改、删除等)后,出现“The page cannot be displayed” 或者返回异常错误 当对必填字段进行校验时,未输入必输字段,出现“The page cannot be displayed” 或者返回异常错误 系统定义不能重复的字段输入重复数据后,出现“The page cannot be displayed” 或者返回异常错误 1.5测试对象 略 1.6测试阶段 系统测试 2测试概要 中南医院值班系统测试从2012年9月2日开始到2007年9月20日结束,共持续39天,测试功能点174个,执行2385个测试用例,平均每个功能点执行测试用例13.7个,测试共发现427个bug,其中严重级别的bug68个,无效bug44个,平均每个测试功能点2.2个bug。 中南医院值班系统总共发布3个测试版本,其中B1—B5为计划内迭代开发版本(针对项目计划的基线标识),B6-B8为回归测试版
项目管理-软件质量计划书_模板及实例实战
XX系统 质量计划书 拟制:日期:2014/5/10 审核:日期:
1.介绍 1.1.文档目的 为了健全和完善XXX系统设计开发的质量管理体系,促进质量管理活动系统化、规范化,以确保所交付的XXX系统能够满足规定的各项具体需求。 1.2.文档范围 本质量管理计划涵盖所有与XXX系统设计开发有关的质量目标和具体措施, 涉及需求分析阶段、设计阶段、编码阶段、测试阶段、工程实施阶段。 本质量管理计划由以下几个部分组成: 介绍:即本章节,概要介绍文档目的、范围、缩略词、参考资料。 项目概述:开发系统概述、质量管理的角色和职责、生命周期各阶段的主要交付物。 项目生命周期各阶段的质量检查点:列出各阶段的质量检查计划表,包括责任人、检查时间、检查任务。 质量检查和确认技术:描述针对不同的对象而采用的特定的质量控制方法和技术及质量问题的级别和处理流程等。 项目生命周期各阶段的量化质量目标。 1.3 缩写 PM –项目经理 QA –质量保证 SA –系统分析工程师 A&D –系统设计员 RA –需求分析员 PC –流程审核员 SCM –软件配置管理员
2.项目概述 一个现代化医院的综合管理是否先进是直接通过其信息化水平来体现的,“XXX系统”是国内先进的信息化管理系统,该系统包含住院登记、病房护士站、医生站、价格管理、成本核算、药库管理等40多个子系统,可以满足各个部门的业务信息处理和信息共享。 “XXX系统”还可开发制作触摸屏,以供患者了解医院信息,查找专家资料,方便查询各种费用收取情况。该系统还能为住院病人提供每日住院清单,使患者明白、放心治疗。 2.1.项目组织结构 为了实现有效的项目管理,开发小组将划分为技术队伍和QA 队伍。项目经理对技术队伍进行任务分配和进度检查,技术经理对技术队伍进行技术指导和检查。技术队伍又划分为:需求分析人员、系统设计人员、软件开发人员、美工设计人员、配置管理员、产品包装人员。QA 队伍对整个项目的质量保证负责,直接向质量保证经理汇报。QA 队伍划分为:流程检查人员和测试人员 2.2.质量管理 2.2.1.质量管理的角色和职责 质量控制是XXX系统组每个成员的职责; 质量保证经理对整个项目的质量全权负责, 并签字确认; 项目经理负责任务的分配和监督项目进度,制定相关的工作计划和联系客户; QA 队伍负责制订、检查和督促本计划的实施,及时发现项目工作中的问题,并通过评审总结报告、项目周报等形式向各项目组成员汇报质量活动的结果; 项目功能小组各组长在每个软件开发生命周期阶段结束后,总结本模块的软件质量状况和质量目标的实现情况,以确保整个项目目标的实现。对质量目标应定期进行考核,以追求质量 管理体系的持续改进; 流程检查人员负责通过检查文档审核开发各阶段是否可以通过; 测试人员负责对软件的质量和对需求实现的程度进行把关,并定期整理测试情况分析报告交项目经理、系统分析人员; 配置管理员负责有关软件配置项及项目各生命周期交付文档管理和变更控制工作; 医院信息系统管理人员负责反映质量要求,参与软件开发过程的质量控制,并监督本计划的执行情况。
软件测试用例实例(非常详细)汇总
软件测试用例实例(非常详细)汇总
1、兼容性测试 在大多数生产环境中,客户机工作站、网络连接和数据库服务器的具体硬件规格会有所不同。客户机工作站可能会安装不同的软件例如,应用程序、驱动程序等而且在任何时候,都可能运行许多不同的软件组合,从而占用不同的资源。 测试 目的 配置说明操作系 统 系统 软件 外设应用软件结果 服务器Windo w2000( S) Windo wXp Windo w2000( P) Windo w2003 用例编号TestCase_LinkWorks_W orkEvaluate 项目名称LinkWorks
1.1.
1.2. 疲劳强度测试用例 强度测试也是性能测试是的一种,实施和执行此类测试的目的是找出因资源不足或资源争用而导致的错误。如果内存或磁盘空间不足,测试对象就可能会表现出一些在正常条件下并不明显的缺陷。而其他缺陷则可能由于争用共享资源(如数据库锁或网络带宽)而造成的。强度测试还可用于确定测试对象能够处理的最大工作量。测试目的 测试说明 前提条件连续运行8小时,设置添加 10用户并发 测试需求输入/ 动作 输出/响应是否正常运行 功能1 2小时 4小时 6小时 8小时功能1 2小时 4小时 6小时
8小时 一、功能测试用例 此功能测试用例对测试对象的功能测试应侧重于所有可直接追踪到用例或业务功能和业务规则的测试需求。这种测试的目标是核实数据的接受、处理和检索是否正确,以及业务规则的实施是否恰当。主要测试技术方法为用户通过GUI (图形用户界面)与应用程序交互,对交互的输出或接受进行分析,以此来核实需求功能与实现功能是否一致。 用例标识LinkWorks_ WorkEvaluate _02 项目 名称 https://www.360docs.net/doc/f115611153.html, 开发人员模块 名称 WorkEvaluate 用例参考工作考核系统界面设计
案例-软件测试报告模板案例
软件测试报告模板适用于XX公司 编写者: XX 文档编号: 编写日期: 2020-1-25
分发列表 文档修订历史 [模板修订历史 (文档首次使用前请删除)]
目录 1.测试概述 (4) 1.1.测试项目简述 (4) 1.2.名词定义 (4) 1.3.参考文档 (4) 2.测试环境与配置 (4) 3.测试情况 (4) 3.1.测试版本情况 (4) 3.2.测试用例统计执行情况 (4) 3.3.测试组织 (4) 4.测试结果及分析 (5) 4.1.测试情况统计分析 (5) 4.2.覆盖分析 (5) 4.2.1.需求覆盖 (5) 4.2.2.测试覆盖 (5) 4.3.缺陷的统计与分析 (5) 4.3.1.缺陷汇总 (5) 4.3.2.缺陷分析 (5) 4.4.测试质量对比统计 (5) 5.遗留缺陷与未解决问题 (5) 6.测试总结及风险分析 (6) 7.测试报告批准 (6)
1. 测试概述 1.1. 测试项目简述 <大、小、临时版本确定,测试范围 1. 测试需求 那些新增的需求验证 那些变更需求的需求验证 本次版本中可验证的需求列表 2. 修改问题的测试 3. 其他的功能测试内容> 1.2. 名词定义 本轮验证测试过程中涉及到需求、更新的产品术语、新产品术语等。 1.3. 参考文档 <参考的需求分档、设计文档等> 2. 测试环境与配置 简要介绍测试环境及其配置。 3. 测试情况 3.1. 测试版本情况 测试版本版本号,是否接受该版本以及原因表述。 什么时候接收的版本,什么时间版本部署完成 测试过程中有无更新版本 更新版本对测试的影响 测试中冒烟测试是否通过 3.2. 测试用例统计执行情况 3.3. 测试组织
软件项目人力资源管理计划案例
软件项目人力资源管理计划案例 本案例选自《软件项目管理案例教程》(韩万江,机械工业出版社)一书, 项目案例为《校务通管理系统》。 1. 项目组织结构 《校务通管理系统》项目的组织结构如下图所示,它是矩阵型组织结构的 一个具体化。 用户 图1:项目的组织结构 ● 市场部 ?负责与用户的协调工作。 ?负责项目相关的商务活动。 ?负责用户需求的接口。
?配合项目经理的资源协调活动。 ?负责产品的验收活动。 ?负责系统的维护活动。 ● 项目管理 ?负责项目的组织和规划。 ?负责项目计划制定和维护。 ?负责项目的跟踪和管理。 ?负责资源的分配和协调活动。 ?负责各组织和计划之间的协调活动。 ?负责与市场部的协调活动。 ● 软件开发 ?负责项目的软件开发,包括设计、编码、单元测试和集成测试。 ? 负责产品质量控制的工作。 ?负责配合质量保证的活动,如系统测试、文档编制等。 ?配合产品验收的相关活动。 ● 质量保证 ?负责项目过程和产品规范的制定。 ?负责项目过程的质量保证活动,包括过程评审和产品审计。 ● 配置管理 ?负责项目的配置管理活动。 ?负责软件产品的提交。 ● 用户 ?确保相关责任的实施。 ?参与项目的组织和规划。 ?负责产品的验收工作。 2. 项目的沟通计划 为了保证项目开发过程的顺利进行和信息的有效沟通,要求执行如下的沟通计划:
(1)每天17:00~17:30,项目组成员进行口头交流。 (2)每周五的14:00前提交周报告。 (3)每周五的15:00~17:00,召开项目周例会,会后发布会议纪要给相关的项目人员,其中说明项目的进展和存在的问题。 及时提交问题报告,问题报告可以通过网络提交,项目经理会及时获取问题信息。出师表 两汉:诸葛亮 先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。 宫中府中,俱为一体;陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理;不宜偏私,使内外异法也。 侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下:愚以为宫中之事,事无大小,悉以咨之,然后施行,必能裨补阙漏,有所广益。 将军向宠,性行淑均,晓畅军事,试用于昔日,先帝称之曰“能”,是以众议举宠为督:愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。 亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之、信之,则汉室之隆,可计日而待也。 臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。 先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐托付不效,以伤先帝之明;故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。 愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏。臣不胜受恩感激。