第五章 光学模型及其算法实现

第五章光学模型及其算法实现
一、复习要求
1.简单光反射模型
2.增量式光反射模型
3.局部光反射模型
4.光源模型
5.简单光透射模型
6.光线跟踪显示技术
二、内容提要
1.简单光反射模型
(1)基本光学原理
①照度定律
普通物理学中的照度定律(Lambert余弦定律):
π
I=K f I L cosθ, θ∈ [0,
2
式中,反射常数K f与物体表面性质有关,也描述物体的颜色。
注意:按一般规定,入射光L是从表面上一点指向光源的矢量。
②材质分配
事实上,一个物体的颜色就是它所反射出的光的颜色,取决于光源的颜色和该物体对光的反射性。例如,将一个阳光下的红球放到只有黄灯照明的室内,它就变成黑的了,因为那里没有任何红色光可被反射,而所有黄色光都被吸收了。
在使用光照时,原有的“绘图颜色”概念已不能适用,而采用“材质”一词。
定义:材质(material)被定义为一个物体对环境光、漫反射光、镜面反射光的反射性。它们分别以一个对应的RGB值表示,称为材质的Ambient, Diffuse, Specular分量(即光学定律中的反射系数K a, K d, K s)。
材质还可以包括另一种辐射性,用于描述自身发光的物体,例如汽车尾灯或夜光表。通
4U电脑书库(https://www.360docs.net/doc/f116621288.html,) maito:wdg98@https://www.360docs.net/doc/f116621288.html,
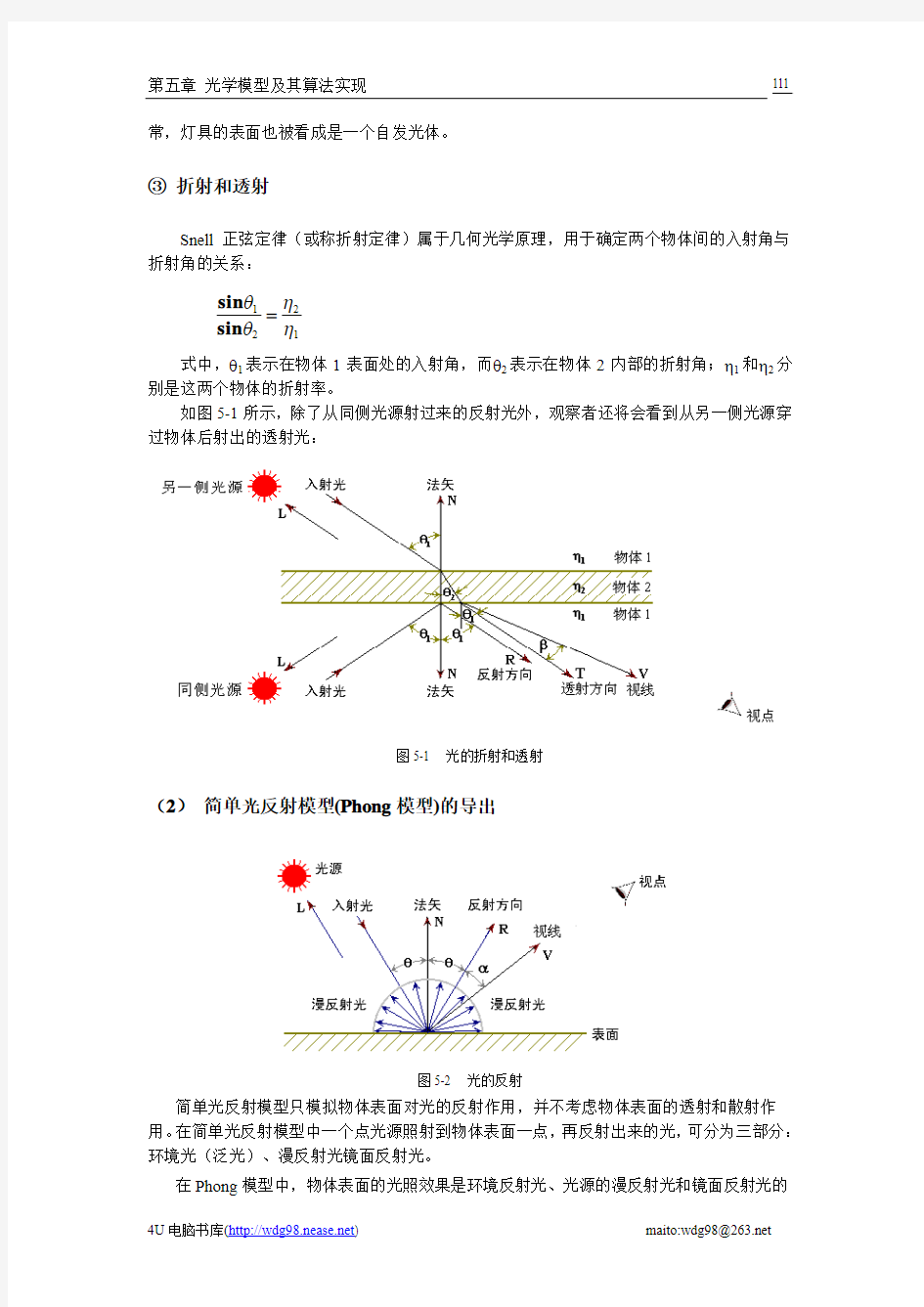
常,灯具的表面也被看成是一个自发光体。 ③ 折射和透射
Snell 正弦定律(或称折射定律)属于几何光学原理,用于确定两个物体间的入射角与折射角的关系:
1
221ηηθθ=sin sin 式中,θ1表示在物体1表面处的入射角,而θ2表示在物体2内部的折射角;η1和η2分别是这两个物体的折射率。
如图5-1所示,除了从同侧光源射过来的反射光外,观察者还将会看到从另一侧光源穿过物体后射出的透射光:
图5-1 光的折射和透射
(2) 简单光反射模型(Phong 模型)的导出
图5-2 光的反射
简单光反射模型只模拟物体表面对光的反射作用,并不考虑物体表面的透射和散射作用。在简单光反射模型中一个点光源照射到物体表面一点,再反射出来的光,可分为三部分:环境光(泛光)、漫反射光镜面反射光。
在Phong 模型中,物体表面的光照效果是环境反射光、光源的漫反射光和镜面反射光的
4U 电脑书库(https://www.360docs.net/doc/f116621288.html, ) maito:wdg98@https://www.360docs.net/doc/f116621288.html, 合成效果。
· 环境反射光(Ambient Light):从背景物体散射出来的光。可用下式计算:
I 1=K a I a
其中K a 为环境光系数
· 光源的漫反射光(Diffuse Light):从一个粗糙的、无光泽的表面反射出,它与入射角有关(即符合Lamber 定律)
I 2=K d I L cos θ
其中K d 为粗糙度
· 镜面反射光(Specular Reflection):从一个光滑的、明亮的表面反射出(或称单反射光):
I 3=K s I L cos n α
其中,K s 为单向反射率;n 控制反射光束的锥度,其值越大,光束越窄,表示该表面越明亮(如磨光金属面 大理石)(较小可表示苹果、木质等)
当α= 0(即视线位于反射方向上)时,将呈现一个高光点(hotspot)(如白光下的铜球上的亮白点)
根据Phong 模型的定义,在多边形所有的点处按下式计算光强: I=I 1+I 2+I 3 = K a I a + K d I L cos θ+ K s cos n α
注意:在具体计算中,反射系数K d 、K s 和K a 也可按RGB 分解成三个分量:(K dr , K dg , K db )、(K sr , K sg , K sb )和(K ar , K ag , K ab ),各分量范围均为0.0 ~ 1.0。
2.增量式光反射模型
(1) 双线性光强插值法(Gourand Shading)
在图像空间中,Gouraud 光照模型(双线性光强插值法)计算各像素的光强如下:
(1) 只在多边形的顶点处,按下式计算光强:
I = K a I a + K d I L cos θ(只考虑环境光和
漫反射光)
而顶点的法矢等于各邻面法矢的平均值:
∑==n 1
i i A N n 1N
(2) 对于多边形边上和内部的各点(像素),
用顶点明暗度的线性插值计算出:
图5-3 求法矢的平均值
令 ?I AB = A B A B y y I I --, ?I AD = A
D A D y y I I -- 故 I S = I A + ?I AB ??y , I T = I A + ?I AD ??y
对于多边形内部的各点(像素),用两边端点光强
的线性插值法计算出:
令 ?I ST = S T S T x x I I -- 故 I P = I S + ?I ST ??x
另一种计算多边形边上和内部的各点光强的改进方法是增量法,它利用扫描线的相关性来简化计算如下:
对于边上的点: I S, y+1 = I S, y + ?I AB ,
I T, y+1 = I T, y + ?I AD
对于内部的点: I x+1, P = I x, P + ?I ST ,
Gouraud 算法优缺点:算法简单,计算量小。但不能再现高光。适用粗糙表面 (2) 双线性法向插值法(Phong Shading)
在图像空间中,Phong 光照模型(双线性法向插值法)计算各像素的度如下:
顶点的法矢等于各邻面法矢的平均值,即∑=n 1
i i N n 1 对于多边形上和内部的各点(像素),用顶点法矢的线性插值。计算公式如下:
令 ?N S = B A B A y y N N --, ?N T = D
A D A y y N N -- 故
N S, y+1 = N S, y + ?N S , N T, y+1 = N T, y + ?N T 令 ?N P = S
T S T x x N N -- 故 ?N x+1, P = ?N x, P + ?N P 注意:这里,法矢Np 就是实际曲面上该点
的切平面法矢的近似值 Phong 算法优缺点:真实感强,但计算量较大,适用光滑表面
目前大多数渲染软件采用Gouraud 和
Phong 光照模型作为Quick(快速)和Full(完全) Rendering ,能满足一般真实感显示要求。
Gouraud 和Phong 光照模型两者比较如下:
Gouraud Shading Phong Shading
双线性光强插值法 双线性法向插值法
适用于漫反射光(粗糙表面) 适用于镜面反射光(特别是有高光的金属表面) 马赫带效应较重 马赫带效应较轻
图5-4 双线性亮度插值法
图5-5 双线性法矢插值法
生成多面体真实感图象效果差高光域准确
速度较快(算法简单、计算量小)速度较慢(计算量较大)
然而,这类简单光照模型共同存在下列的问题:
?由于光强函数的一阶导数不连续,线性插值法均有马赫带效应(光照效果在数值上不连续)。
?透明效果需要另作处理才行,而且不能产生阴影。
注:实用Phong光照模型的计算公式要考虑随距离的线性或平方反比衰减
(3)加速算法
在简单的光线跟踪算法中,每条射线都要和所有物体求交,然后再对所得的全部交点进行排序,才能确定可见点。因此对于每条射线,计算复杂度都是O(n)以上。当物体个数较少时,计算量还可以接受。但是当环境较复杂,物体个数较多时(例如成干个原子组成的分子模型或成万个多边形构成的建筑物模型),简单的光线跟踪算法的处理速度就无法接受了。然而,对于每—条射线,它实际上只与少数几个物体有交,与绝大多数物体根本不相交。也就是说,对于复杂环境,大多数求交计算都是无效运算。我们可以通过一些途经来减少这种无效运算。这就是加速算法所要考虑的主要问题。一般说来,加速算法是通过预先把物体按空间位置适当地组织起来,以便在绘制时缩小搜索范围,减少排序时间来提高效率的。常用的组织方法有包围体树、自适应八叉树和三维立方体阵列。
3.局部光反射模型
局部光反射是由光源直接照射到射入点,经漫反射和镜面反射到视点而形成。
4.光源模型
在计算机图形学中,光源模型的三个基本因素是几何形状、光强分布和光谱分布。
?有向光源(directed lights):方向保持不变,即为平行光(发射出半圆柱面光);光源强度不作衰减。如太阳光、远光源。
?点光源(point lights):方向是从光源位置到面片中心,发射出圆球面光;光强分布是各向同性的,要考虑随距离的线性或平方反比衰减(falloff);可以产生阴影。
?聚光灯(spotlights):发射出圆锥形光束;要考虑随距离的线性或平方反比衰减;可以产生软阴影区域。
从几何形状上讲,一般电灯(钨丝白炽灯)理想化成点光源,而且光强分布是各向同性的;一般日光灯(长管灯)可理想化成线光源;经过特殊设计的吸顶灯可理想化成面光源。
4U电脑书库(https://www.360docs.net/doc/f116621288.html,) maito:wdg98@https://www.360docs.net/doc/f116621288.html,
5.简单光透射模型
(1)透明效果的模拟方法
①透射计算公式
最简单的透明算法不考虑折射的影响,即假定光线穿过透明体表面时不改变方向,,此时则有:(如图12.11C所示)
I TR = (1 - K T)I reflect + K T I transmit,其中K T∈ [0, 1]
K T称为物体的透明度(Transparency),可取值范围从0(不透明)至1.0(全透明)。光线照射到透明体表面的两个交点A和B处的光强分别是反射光强I reflect和透射光强I transmit。
图5-6 光的透射
显然,在全透明场合下(即K T = 1),只有光的透射效果:
I TR = K T I transmit
这也称为规则透射。
注意:1. 在颜色四元组RGBA中,ALPHA = 1 - K T,称作不透明度。
2. 对不透明物体,将会在地面上投射出阴影(Shadow)。
②漫透射、理想透明和半透明
一个点光源照射在透明体表面上,将可能产生如下三种光透射作用:
?对于表面粗糙的透明物体上,将形成漫透射。透射出来的光将朝着各方向均匀地散射,此时透射光强I t与入射光强I L及入射角的余弦cosθ成正比,即:
I t = K t I L cosθ
式中,K t称为透射系数,可取0 ~ 1.0。
?进入理想的透明物体的透射光只沿折射方向传播,而在其他方向都看不见透射光。
?进入一般较透明(或半透明)物体的透射光也往其他方向传播一部分透射光,并且某方向透射光的强度随着偏离透射方向(即下述β角的增大)而明显地衰减。
I t = K t I L cos n tβ
式中,I L是光源的强度或入射光强;K t称为透射系数,可取0 ~ 1.0。幂值n t用于控制透射光束的锥度,其范围1 ~ 2000;其值越大,光束越窄。β为视线V与透射方向T之间的夹角。
4U 电脑书库(https://www.360docs.net/doc/f116621288.html, ) maito:wdg98@https://www.360docs.net/doc/f116621288.html,
(2) Wittded 光透射模型
Whitted 光透射模型是1980年Whitted 提出的,并运用在光线跟踪算法的实现中。它考虑了环境光、漫反射光和镜面反射光(即Phong 模型)以及从环境反射或透视到视线的光。具体计算如下:
I p = K a I a + ∑+i ns s d Li K K I
)cos cos (αθ + K s I s + K t I t
= I a ?K a + K d ∑?i i Li N
L I )( + K s ∑?i
ns i
Li V R I )( + K s I s + K t I t 式中,第一部分包含了Phong 模型中的所有参数;第二部分模拟了场景光投射在光滑表面上产生的理想镜面反射作用(即α = 0),K s 为镜面反射率;第三部分模拟了场景光通过透明体表面产生的规则透射作用(即不考虑折射时的全透明),K t 为透射系数。I s 和I t 分别表示场景中其他物体反射和透射过来的光在该物体表面上的镜面映像和透射映像,如图所示。
图5-7 透明体表面上的镜面映像和透射映像
(3) Hall 光透射模型
Hall 整体光照模型要比Whitted 模型更为完善,还考虑沿着反射方向和折射(透射)方向的散射现象,以模拟“透射高光”。
在Hall 整体光照模型中,假定光源和视点都在无穷远处,使光线和视线方向简化为常向量。计算公式如下:
I p = I 局部 + I 全局
(1) I 局部 = K a I a + ∑++i
nt t
ns s d Li K K K I )cos cos cos (βαθ = I a ?K a + K d ∑?i Li N L I
)(+ K s ∑?i ns Li V R I )(+ K t ∑?i
nt Li V T I )( 即包括环境光、漫反射光、镜面反射光和透射光。
(2) I 全局 = K R I R + K T I T
即由其他物体反射或透射在透明体表面上产生的沿着视线方向的光。
6.光线跟踪显示技术
(1)基本光线跟踪算法
Ray-Tracing算法的基本思想如下:
在物体空间中,假定视点取在Z轴上,XOY平面取作为投影屏幕(其与显示器屏幕的像素布局一一对应),通过跟踪多个光源对各像素的贡献而计算出它们的色彩明暗度。
在光线遇到某一物体(不是背景)时,应继续跟踪光线,而不管光线的强度或深度如何。
图5-8 光线跟踪法
光线跟踪算法包括下列的三个步骤:
步骤一、从视点穿过某像素P发出一条射线R,它逆着光线方向跟踪所有光源在这个可见点(即离视点最近的交点)上产生的色彩明暗度:
I A = I局部+ I全局
其中I局部和I全局的具体计算按步骤二。
步骤二、首先计算出可见点处的曲面法矢(并存储它,以供备用),然后查找表面数据表(其含有表面的颜色属性、粗糙度、反射率、透明度等)进行计算:(Hall整体光照模型)
(1) I局部= K a I a + I L(K d cosθ + K s cos n sα + K t cos n tβ)
即包括环境光、漫反射光、镜面反射光和透射光。
(2) I全局= K R I R + K T I T
即由其他物体反射或折射到视线的反射或透视方向的光。
步骤三、判断可见点是否处在阴影(shadow)中:从该点向光源引射线。若射线与某个不透明的物体相交,则该点在阴影中(此时只取环境光),而返回到步骤一。
光线跟踪法的特点:
a. 同时处理消隐和渲染,并有透明效果和阴影生成。
b. Ray-Tracing本质上是一种递归算法(层次等于物体个数),效率极高
算法加速方法:
4U 电脑书库(https://www.360docs.net/doc/f116621288.html, ) maito:wdg98@https://www.360docs.net/doc/f116621288.html, 事实上每条射线只与少数几个物体相交。若预先将物体按空间位置适当地组织起来(如采用包围体),则可缩小搜索范围,避免不必要的求交运算。树:仅当射线与根结点有交时,才进行它与子结点求交
优缺点:光线跟踪法是目前最常用的高级渲染技术之一,但没有考虑物体表面之间的漫反射(如辐射度计算方法)。
在光线跟踪算法中,跟踪光线的终止条件有以下四个:
1) 被跟踪的光线与光源相交;
2) 被跟踪的光线遇到背景;
3) 被跟踪的光线对某交点处的光强贡献趋于零;
4) 光线跟踪的深度已经很深了。
(2) 光线与物体求交
①与坐标系平面求交
光线与坐标系平面的交点可以由下面
向量方程求出:s +t d =x i I +y i J
由于s =x s I +y s J +z s K ,d =x d I +y d J +z d K ,可推出:
?????=+=+=+0d s
i d s i d s tz z y ty y x tx x
下面两种情况,光线与平面不相交:
z d =0时,光线平行于xy 平面
z s =0时,光线起始点在xy 平面上
z d ≠0,且z s ≠0时
d
s z z t -
= 如果t>0,光线与平面相交
如果t<0,光线的反向延长线与平面相交 ②与任意平面求交
右图中,n =x n I +y n J +z n K ,为给定平面的法线向
量,P 0(x 0,y 0,z 0)为平面上一点,则平面向量方程为:
x n (x-x 0)+y n (y-y 0)+z n (z-z 0)=0
令r (t)=s +t d 与该平面相
交,又
s =x s I +y s J +z s K ,d =x d I +y d J +z d K ,则
x n (x s +tx d -x 0)+y n (y s +ty d -y 0)+z n (z s +tz d -z 0)=0
可推出下式:
d
n d n d n s n s n s n z z y y x x z z z y y y x x x t ++-+-+--=)()()(000 另K z z J y y I x x p s s s )()()(000-+-+-=,则
d
n p n t ??= 当d n ?=0时,光线平行于该平面,即不相交。
如果t=0,光线起始点在平面上
如果t>0,光线与平面相交
如果t<0,光线的反向延长线与平面相交
③与球面求交
右图为一半径为R ,中心点为(x c ,y c ,z c ) 的球
体,(x,y,z)是球面上的任意一点。
设向量c =x c I +y c J +z c K ,p =x I +y J +z K
则球体的向量方程为:
|p -c |=R
令r (t)=s +t d 与该平面相交,则
|s +t d -c |2=R 2
展开得:
|d|2t 2+2|s -c||d|t+|s -c |2=R 2
令A=|d|2,B=|s -c||d|,C=|s -c |2-R 2
,则
At 2+2Bt+C=0
A
AC B B t -±-=2 ??
???>=<-两个(可能的)交点与球体相切光线(或负的延长线)不相交0002AC B
(3) 光线跟踪中的简单阴影
定义5-1:阴影(shadow)是指景物中那些没有被光源直接照射到的暗区。
4U 电脑书库(https://www.360docs.net/doc/f116621288.html, ) maito:wdg98@https://www.360docs.net/doc/f116621288.html,
图5-10 阴影生成
阴影生成从原理上来说非常简单:只有那些从视点可见的、而从光源不可见的面(多边形)才会落在阴影内。换句话说,若将视点放在光源处,那末它看不到所该光源产生的阴影。 因此,阴影生成的一般性算法如下:
步骤一、将光源位置作为视点,利用消隐算法求出它的不可见面(包括背面和被其他面遮挡的面)和可见面。这样,将所有面分为两大类。
步骤二、在实际的视点处,对上述面进行消隐,并选用一种光照模型双重可见面的明暗度,而对上述不可见面的可见部分采用环境光,形成阴影。
步骤三、将不可见面的可见部分投射到地面上,即表示影
子(shadow)。
注意:仅当存在某一投影面(如地面、墙面)时,
物体才有可能在该平面上投射出其影子。
定义5-2:阴影可分为全阴影(whole-shadow)和半阴影
(half-shadow)两种。全阴影就是物体表面上那些没有被所有光
源直接照射的部分,而半阴影是指物体表面上那些只被一部分
光源直接照射的部分。
定义5-3:全阴影加上在它周围的半阴影而组成一个软阴影
(soft-shadow)区域,使影子边缘有较缓慢的过渡。
显然,单个点光源只能形成全阴影,而半阴影则是由多个点光源或线光源、面光源产生的,如图5-11所示。由于半阴影
的计算量较大,许多场合下(除聚光灯外)我们只考虑由点光源产生的全阴影。
因为光源在物体表面上产生的阴影区域均为它们的不可见面。若取光源作为视点,那么任何隐藏面消除算法都能用于阴影计算。在实际应用中,还需根据阴影计算的特点考虑如何减少其时间和空间耗费。
三、例题分析
例1.设n =I +J +2K 为通过点P 0=(1,1,0)的平面的法线矢量。试判断s =-2I +J +2K ,d =I -K 的光线是否与平面相交。
解答:因为01)1(20111≠-=-?+?+?=?d n
故而可以引入:
图5-11 半阴影区
K I K
J I K z z J y y I x x p s s s 23)20()11()]2(1[)()()(000-=-+-+--=-+-+-=
11
)2(20131=--?+?+?=??=d n p n t >0,光线与平面相交 所以交点是(x s +x d ,y s +y d ,z s +z d )=(-1,1,1)
四、习 题
1.写出简单光反射模型近似公式,并说明其适用范围及能产生的光照效果。
2.写出线光源的光强公式及其积分算法。
3.试描述Witted 光透射反射模型和Hall 光透射模型。
4.简单叙述光线跟踪算法。 5.试描述光线与几种常见物体面的求交算法。
五、解题指导与习题解答
1.答案:简单光反射模型只模拟物体表面对光的反射作用,并不考虑物体表面的透射和散射作用。在简单光反射模型中一个点光源照射到物体表面一点,再反射出来的光,可分为三部分:环境光(泛光)、漫反射光镜面反射光。
根据Phong 模型的定义,在多边形所有的点处按下式计算光强: I=I 1+I 2+I 3 = K a I a + K d I L cos θ+ K s cos n α
在Phong 模型中,物体表面的光照效果是环境反射光、光源的漫反射光和镜面反射光的合成效果。
2.答案:线光源的光强公式如下:
其中 表示漫反射系数, 表示漫反射率, 是来自光源的光亮度, 是 朝
辐射方向的投影角。 是被照射表面的法向, 是单位光线向量。
在一般情况下,上述公式只能用数值算法做近似的计算。其实质是用多个点光源来近似线光源。
3.答案:Whitted 光照模型是一种全局光照模型,它模拟了由环境引起的镜面反射分量和规则透射分量。在这个模型中,假定被照明物体的表面非常光滑,从而可以用理想镜面反射分布函数来模拟镜面反射;同样,对于透射也采用理想的情况。它可以用如下公式描述:
其中 是局部光照模型计算的反射光亮度, 表示镜面反射分量,
表示透射分量。
表示衰减系数, 表示镜面反射系数,
表示镜面反射率, 是环境的光亮度, 环境的透射光亮度,
表示光线向量的规则
透射向量。
Hall模型对Whitted模型进行了改进,它的特点是:
1)引入光源引起的规则透射分量,用以模拟“透射高光”。
2)显式表示表面光谱漫反射率、光谱镜面反射率和光谱规则透射率,且用菲涅耳反射函数和折射函数分别表示镜面反射率和透射率。
3)用反映材料滤光特性的函数表示传输过程中的衰减因子。
以上特点使Hall模型成为整体光谱光照模型,并能表现更精致的照明效果。
4.答案:在物体空间中,假定视点取在Z轴上,XOY平面取作为投影屏幕(其与显示器屏幕的像素布局一一对应),通过跟踪多个光源对各像素的贡献而计算出它们的色彩明暗度。
光线跟踪算法包括下列的三个步骤:
步骤一、从视点穿过某像素P发出一条射线R,它逆着光线方向跟踪所有光源在这个可见点(即离视点最近的交点)上产生的色彩明暗度:
I A = I局部+ I全局
其中I局部和I全局的具体计算按步骤二。
步骤二、首先计算出可见点处的曲面法矢(并存储它,以供备用),然后查找表面数据表(其含有表面的颜色属性、粗糙度、反射率、透明度等)进行计算:(Hall整体光照模型)
(1) I局部= K a I a + I L(K d cosθ + K s cos n sα + K t cos n tβ)
即包括环境光、漫反射光、镜面反射光和透射光。
(2) I全局= K R I R + K T I T
即由其他物体反射或折射到视线的反射或透视方向的光。
步骤三、判断可见点是否处在阴影(shadow)中:从该点向光源引射线。若射线与某个不透明的物体相交,则该点在阴影中(此时只取环境光),而返回到步骤一。
5.答案: 见本章光线与物体求交部分详述。
4U电脑书库(https://www.360docs.net/doc/f116621288.html,) maito:wdg98@https://www.360docs.net/doc/f116621288.html,
蚁群算法的数学模型
蚁群算法的数学模型 蚂蚁),2,1(k m k ???=在运动过程中,运动转移的方向由各条路径上的信息量浓度决定。为方便记录可用),,2,1(t m k abu k ???=来记录第 k 只蚂蚁当前已走过的所有节点,这里可以称存放节点的表为禁忌表;这个存放节点的集合会随着蚂蚁的运动动态的调整。在算法的搜索过程中,蚂蚁会智能地选择下一步所要走的路径。 设 m 表示蚂蚁总数量,用)1,,1,0,(d -???=n j i ij 表示节点 i 和节点 j 之间的距离,)(ij t τ表示在 t 时刻ij 连线上的信息素浓度。 在初始时刻,m 只蚂蚁会被随机地放置,各路径上的初始信息素浓度是相同的。在 t 时刻,蚂蚁 k 从节点i 转移到节点 j 的状态转移概率为 ??? ????=∈=∑∈other p allowed t t t t k ij k allowed k ij ij ij ij k ij ,0j ,) ()()()(p k βαβαητητ ()1-2 其中,{}k k tabu c allowed -=表示蚂蚁 k 下一步可以选择的所有节 点,C 为全部节点集合;α为信息启发式因子,在算法中代表轨迹相对重要程度,反映路径上的信息量对蚂蚁选择路径所起的影响程度,该值越大,蚂蚁间的协作性就越强;β可称为期望启发式因子,在算法中代表能见度的相对重要性。ij η是启发函数,在算法中表示由节点i 转移到节点 j 的期望程度,通常可取ij ij d /1=η。在算法运行时每只蚂蚁将根据(2-1)式进行搜索前进。 在蚂蚁运动过程中,为了避免在路上残留过多的信息素而使启发
一种自适应蚁群算法及其仿真研究
一种自适应蚁群算法及其仿真研究 作者:王颖, 谢剑英 作者单位:上海交通大学自动化研究所,上海,200030 刊名: 系统仿真学报 英文刊名:JOURNAL OF SYSTEM SIMULATION 年,卷(期):2002,14(1) 被引用次数:191次 参考文献(3条) 1.Dorigo M;Maniezzo Vittorio;Colorni Alberto The Ant System: Optimization by a colony of cooperating agents 1996(01) 2.Dorigo M;Gambardella L M Ant Colony System: A Cooperative Learning Approach to the Traveling Salesman Problem[外文期刊] 1997(01) 3.Schoonderwoerd R;Holland O;Bruten J;Rothkrantz L Ant-based Load Balancing in Telecommunications Networks 1997(02) 本文读者也读过(2条) 1.陈崚.沈洁.秦玲.陈宏建基于分布均匀度的自适应蚁群算法[期刊论文]-软件学报2003,14(8) 2.张纪会.高齐圣.徐心和.ZHANG Jihui.GAO Qisheng.XU Xinhe自适应蚁群算法[期刊论文]-控制理论与应用2000,17(1) 引证文献(194条) 1.颜晨阳前馈神经网络连续二元蚁群训练模型[期刊论文]-软件导刊 2011(6) 2.马军.王岩改进的蚁群算法求解旅行Agent问题[期刊论文]-计算机工程与应用 2010(11) 3.楼小明一种改进的自适应蚁群算法求解TSP问题[期刊论文]-黑龙江科技信息 2009(24) 4.闵亨峰供应链节点间配送线路规划蚁群算法[期刊论文]-天津科技大学学报 2006(3) 5.卢正鼎.刘会明基于蚁群算法的理性自适应路由研究[期刊论文]-计算机工程与科学 2006(12) 6.方崇.黄伟军南宁市内河水质的投影寻踪回归分析[期刊论文]-人民长江 2010(8) 7.唐连生.程文明.梁剑.张则强基于行程时间可靠性的车辆路径问题研究[期刊论文]-统计与决策 2008(10) 8.刘学辉P2P网络架构下蚁群算法的应用研究[期刊论文]-无线电通信技术 2007(3) 9.许鹏动态车间调度算法[期刊论文]-航空制造技术 2007(z1) 10.李卓君改进的蚁群算法在VRP中的应用研究[期刊论文]-武汉商业服务学院学报 2006(1) 11.李少辉.刘弘.王静莲蚁群算法在P2P网络架构下的Web服务中的应用[期刊论文]-计算机工程与应用 2006(20) 12.梁栋.霍红卫自适应蚁群算法在序列比对中的应用[期刊论文]-计算机仿真 2005(1) 13.许志红.张培铭基于蚁群算法的智能交流接触器优化设计[期刊论文]-电工电能新技术 2005(3) 14.刘鹏.姜伟.刘新妹.殷俊龄基于蚂蚁算法的PCB板路径优化研究[期刊论文]-电子世界 2012(2) 15.徐滨.张亦改进的蚂蚁算法车辆运行调度算法研究[期刊论文]-计算机仿真 2011(10) 16.陆克芬.方崇.张春乐基于人工鱼群算法的投影寻踪评价方法研究[期刊论文]-安徽农业科学 2009(23) 17.付永强.王启志一种快速收敛的蚁群算法[期刊论文]-福建电脑 2009(9) 18.方崇.李慧颋PMA-PP分析模型在内河水质科学评价中的应用[期刊论文]-地球与环境 2009(4) 19.马洪伟.赵志刚.吕慧显.李京基于蚁群聚类和裁剪方法的RBF神经网络优化算法[期刊论文]-青岛大学学报(工
云模型在机器人路径规划算法中的研究
工程技术 Project technique 云模型在机器人路径规划算法中的研究 马文辉 崔 莹 (齐齐哈尔医学院现代教育技术中心 161000 中国一重技师学院黑龙江省齐齐哈尔市 161000) 【摘 要】传统的遗传算法由于在进化过程中易出现早熟收敛、不能保证种群多样性的现象。本文提出了一种基于云模型的简单、有效的移动机器人避障路径规划算法,采用一维云算子进化变异,同时进化式变异和突变均利用了历史搜索结果,有效避免遗传算法的缺点。模拟数据也证明了该算法的可行性。 【关键词】云模型;进化算法;路径规划;机器人 1 引 言 机器人规划是在已有环境下绕过障碍物找到一个可行的或最优路径从源位置到目标位置,这个问题已得到广泛的研究,各种智能算法不断涌现,这些方法应用于路径规划会使移动机器人在动态环境中更灵活,更具智能化。如人工势场,随机路标规划,基于传感器的方法等。它们都有其优点和缺点。基于遗传算法的机器人路径规划是一种借鉴生物界自然选择和进化机制发展起来的高度并行、随机、自适应搜索算法。由于其思想简单、易于实现以及表现出来的健壮性,但是因为遗传算法本身的缺陷(早熟、局部能力搜索差),还不能保证计算机效率和路径的可靠性,因此还存在很大的改进发展空间。云模型是对模糊理论隶属函数概念的创新与发展,已成功应用于智能控制、大系统评估、网络安全等。 2 云模型改进机器人路径规划方法 云模型所表达的概念的整体特性可以用期望Ex(Expected value),熵En(Entropy),超熵He(Hyper entropy)这3个数字特征来整体表征。Ex是云滴在论域空间分布的期望,是最能够代表定性概念的点,或者说是这个概念量化的最典型样本。En代表定性概念的可度量粒度,反映了能够代表这个定性概念的云滴的离散程度,亦是在论域空间可被概念接受的云滴的取值范围。He是熵的不确定性度量,即熵的熵,由熵的随机性和模糊性共同决定。用3个数字特征表示的定性概念的整体特征记做C(Ex,En,He)。 基于云模型的优良特性,结合遗传算法的基本原理,本文使用一种自适应、高精度、快速随机搜索机器人路径规划的算法,该算法不但比传统遗传算法精度高,而且能够很好地避免遗传算法易陷入局部最优解和选择压力过大造成的早熟收敛等问题。本文中Ex代表父代个体的优良特征即代表父代路径;En和He表示继承过程的不确定性和模糊性即可被接受的路径范围,利用正态云算子完成概念空间到数值空间的转换,产生种群下一代路径,实现遗传操作。在遗传算法中,当种群的多数个体适应值相差不大时交叉操作就显得无能为力,算法陷入局部解而不能由交换解决,突然变异能够使之摆脱局部收敛而跃出局部解,但是后期的变异可能破坏已产生最优解模块。基于云模型的改进算法可以有效避免遗传算法的这个缺点,因为进化式变异和突变均利用了历史搜索结果。 3 实验方法 3.1 实验的初始设置。P(Eχ,En,He),Eχ=20,En=0.618, He=0.05,k=10,λlocal=3,λglobal=9。 3.2 将优秀路径带入公式(1)产生下一代 Θ[j]=1/(sqrt(2×pi)×sqrt(He))×pow(e,-(j-En)^2/(2×En)) (2) X[j]=(sqrt(2×pi)×sqrt(Θ[j]))×pow(e,-(j-qath[i] [j]))×(j-qath[i][j])/(qath[i][j])(3) path[i][j]=pow(e,-(X[j])-quani[j])×(X[j]-qath[i] [j])/(2×Θ[j])(4) 其中:i∈优秀路径群,j∈路径基因 3.3 计算适应函数fit()。ppercent[i]为第i条路径长度, qpercent[i]为第i条路径惩罚算子 fit[i]=1/appercent[i]+βqpercent[i](5) 其中:α为路径长度因子,β惩罚因子。 3.4 进化过程。进化过程中,若出现跨代精英,En和He减小 为原来的1/k(k为大于1的实数)。当若干进化代没有发现新的跨代精英,即连续平凡代数达到一定的阈值λlocal时,路径可能陷入了一个局部最优邻域,此时需要跳出这个小局部,并在该局部附近尝试寻找新的局部最优,方法是提高En和He为原来的k倍。 3.5 变异过程。当经过若干代进化没有得到适应性更加优 异的路径,而且进化式变异没有效果时,路径可能陷入局部,需要进行一次突变操作。进行局部求变和突变的连续平凡代数阈值之间的关系为λglobal>λlocal。突变方法为取历史跨代精英个体的平均值,熵为相应历史精英个体的方差。 在本算法中进化和变异是统一的,进化式变异是进化和变异融合,可以用来进行局部求精或跳出小局部,而突变则用来在全局范围内寻找新的极值搜索区域.算法可以判断出当前的进化状况,进而可以自适应地进行调整 。 图1 初始最优路径状态 图2 第12代精英路径状态4 结 论 本文采用云模型理论改遗传算法在机器人路径中的应用,不需要繁琐的交叉、变异,具有良好的可操作性。模拟数据验证了这种方法对全局优化性能改善的可行性,可以使该算法优化速度获得一定程度的提高,有效地克服了基本遗传算法收敛速度慢、易限于局部最优解的缺陷。 【参考文献】 [1]Rosell,J.,Iniguez,P.:Pat h planning using Harmonic Functions and Probabilistic Cell Decomposition.Proc.of t he IEEE Int.Conf.on Robotics and Automation(2005):1803-1808. [2]Kazemi,M.,Mehrandezh,M.:RoboticNavigationUsing Harmon2 icFunction-basedProbabilisticRoadmaps.Proc.of t he IEEE Int. Conf.on Robotics and Automation(2004):4765-4770. [3]李德毅,杜益.不确定性人工智能[M].北京:国防工业出版社,2005. [4]戴朝华,朱云芳,陈维荣,林建辉.云遗传算法及其应用[J].电子学 报,2007-7. [5]段海滨,王道波等.基于云模型理论的蚁群算法改进研究[J].哈尔 滨工业大学学报,2005-1. [6]周明,孙树栋.遗传算法原理及应用[J].北京:国防工业出版社,2002-5. [7]陈国良.遗传算法及其应用[M].北京:人民邮电出版社,2001. — 1 2 1 —
云模型简介及个人理解maab程序
随着不确定性研究的深入,越来越多的科学家相信,不确定性是这个世界的魅力所在,只有不确定性本身才是确定的。在众多的不确定性中,随机性和模糊性是最基本的。针对概率论和模糊数学在处理不确定性方面的不足,1995年我国工程院院士李德毅教授在概率论和模糊数学的基础上提出了云的概念,并研究了模糊性和随机性及两者之间的关联性。自李德毅院士等人提出云模型至今,云模型已成功的应用到自然语言处理、数据挖掘、 设是一个普通集合。 , 称为论域。关于论域中的模糊集合,是指对于任意元素都存在一个有稳定倾向的随机 数,叫做对的隶属度。如果论域中的元素是简单有序的,则可以看作是基础变量,隶属度在上的分布叫做隶属云;如果论域中的元素不是简单有序的,而根据某个法则,可将映射到另一个有序的论域上,中的一个且只有一个和对应,则为基础变量,隶属度在上的分布叫做隶属云[1] 。 数字特征 云模型表示自然语言中的基元——语言值,用云的数字特征——期望Ex,熵En和超熵He表示语言值的数学性质[3] 。
期望 Ex:云滴在论域空间分布的期望,是最能够代表定性概念的点,是这个概念量化的最典型样本。 熵 En:“熵”这一概念最初是作为描述热力学的一个状态参量,此后又被引入统计物理学、信息论、复杂系统等,用以度量不确定的程度。在云模型中,熵代表定性概念的可度量粒度,熵越大,通常概念越宏观,也是定性概念不确定性的度量,由概念的随机性和模糊性共同决定。一方面, En是定性概念随机性的度量,反映了能够代表这个定性概念的云滴的离散程度;另一方面,又是定性概念亦此亦彼性的度量,反映了在论域空间可被概念接受的云滴的取值范围。用同一个数字特征来反映随机性和模糊性,也必然反映他们之间的关联性。 超熵 He:熵的不确定性度量,即熵的熵,由熵的随机性和模糊性共同决定。反映了每个数值隶属这个语言值程度的凝聚性,即云滴的凝聚程度。超熵越大,云的离散程度越大,隶属度的随机性也随之增大,云的厚度也越大。 1.绘制云图 Ex=18 En=2
蚁群算法
蚁群算法报告及代码 一、狼群算法 狼群算法是基于狼群群体智能,模拟狼群捕食行为及其猎物分配方式,抽象出游走、召唤、围攻3种智能行为以及“胜者为王”的头狼产生规则和“强者生存”的狼群更新机制,提出一种新的群体智能算法。 算法采用基于人工狼主体的自下而上的设计方法和基 于职责分工的协作式搜索路径结构。如图1所示,通过狼群个体对猎物气味、环境信息的探知、人工狼相互间信息的共享和交互以及人工狼基于自身职责的个体行为决策最终实现了狼群捕猎的全过程。 二、布谷鸟算法 布谷鸟算法 布谷鸟搜索算法,也叫杜鹃搜索,是一种新兴启发算法CS 算法,通过模拟某些种属布谷鸟的寄生育雏来有效地求解最优化问题的算法.同时,CS 也采用相关的Levy 飞行搜索机制 蚁群算法介绍及其源代码。 具有的优点:全局搜索能力强、选用参数少、搜索路径优、多目标问题求解能力强,以及很好的通用性、鲁棒性。 应用领域:项目调度、工程优化问题、求解置换流水车间调度和计算智能 三、差分算法 差分算法主要用于求解连续变量的全局优化问题,其主要工作步骤与其他进化算法基本一致,主要包括变异、交叉、选择三种操作。 算法的基本思想是从某一随机产生的初始群体开始,利用从种群中随机选取的两个个体
的差向量作为第三个个体的随机变化源,将差向量加权后按照一定的规则与第三个个体求和而产生变异个体,该操作称为变异。然后,变异个体与某个预先决定的目标个体进行参数混合,生成试验个体,这一过程称之为交叉。如果试验个体的适应度值优于目标个体的适应度值,则在下一代中试验个体取代目标个体,否则目标个体仍保存下来,该操作称为选择。在每一代的进化过程中,每一个体矢量作为目标个体一次,算法通过不断地迭代计算,保留优良个体,淘汰劣质个体,引导搜索过程向全局最优解逼近。 四、免疫算法 免疫算法是一种具有生成+检测的迭代过程的搜索算法。从理论上分析,迭代过程中,在保留上一代最佳个体的前提下,遗传算法是全局收敛的。 五、人工蜂群算法 人工蜂群算法是模仿蜜蜂行为提出的一种优化方法,是集群智能思想的一个具体应用,它的主要特点是不需要了解问题的特殊信息,只需要对问题进行优劣的比较,通过各人工蜂个体的局部寻优行为,最终在群体中使全局最优值突现出来,有着较快的收敛速度。为了解决多变量函数优化问题,科学家提出了人工蜂群算法ABC模型。 六、万有引力算法 万有引力算法是一种基于万有引力定律和牛顿第二定律的种群优化算法。该算法通过种群的粒子位置移动来寻找最优解,即随着算法的循环,粒子靠它们之间的万有引力在搜索空间内不断运动,当粒子移动到最优位置时,最优解便找到了。 GSA即引力搜索算法,是一种优化算法的基础上的重力和质量相互作用的算法。GSA 的机制是基于宇宙万有引力定律中两个质量的相互作用。 七、萤火虫算法 萤火虫算法源于模拟自然界萤火虫在晚上的群聚活动的自然现象而提出的,在萤火虫的群聚活动中,每只萤火虫通过散发荧光素与同伴进行寻觅食物以及求偶等信息交流。一般来说,荧光素越亮的萤火虫其号召力也就越强,最终会出现很多萤火虫聚集在一些荧光素较亮的萤火虫周围。人工萤火虫算法就是根据这种现象而提出的一种新型的仿生群智能优化算法。在人工萤火虫群优化算法中,每只萤火虫被视为解空间的一个解,萤火虫种群作为初始解随机的分布在搜索空间中,然后根据自然界萤火虫的移动方式进行解空间中每只萤火虫的移动。通过每一代的移动,最终使的萤火虫聚集到较好的萤火虫周围,也即是找到多个极值
第三章 云模型简介
第三章云模型简介 在人类认知以及进行决策过程中,语言文字是一种强有力的思维工具,它是人类智能和其他生物智能的根本区别。人脑进行思维不是纯粹地应用数学知识,而是靠自然语言特别是客观事物在人脑中的反映而形成的概念。以概念为基础的语言、理论、模型是人类描述和理解世界的方法。 自然语言中,常常通过语言值,也就是词来表示概念。而语言值、词或概念与数学和物理的符号的最大区别就是其中包含太多的不确定性。在人工智能领域,不确定性的研究方法有很多,主要有概率理论,模糊理论,证据理论和粗糙集理论;对于确定性系统的不确定性的研究还有混沌和分形的方法。这些方法从不同的视角研究了不确定性,优点是:有切入点明确、边界条件约束清楚、能够对问题进行深入研究等,但是在研究中常常将不确定性分成模糊性和随机性分开进行研究,然而两者之间有很强的关联性,往往不能完全的分开。随机性是指有明确定义但是不一定出现的事件中所包含的不确定性。例如在投掷硬币试验中,硬币落地时要么有国徽的一面向上,要么标有分值的一面向上,结果是明确的可以预知的,但是每次试验结果是随机的。概率论和数理统计是研究和揭示这种随机现象的一门学科,至今已有几百年的研究历史.模糊性是另一种不确定性,是已经出现的但是很难精确定义的事件中所包含的不确定性。在日常工作和生活中存在着许多模糊概念,如“胖子”“年轻人”“收入较高”等。为处理这些模糊概念,引入了模糊集的概念[41],使用隶属度来刻画模糊事物彼此间的程度。隶属度函数常用的确定方法有模糊统计法、例证法专家经验法等,这些方法确定隶属度函数的过程是确定的,本质上说是客观的,但每个人对于同一个模糊概念的认识理解存在差异,因此有很强的主观性,而且一旦隶属度函数确定之后,得到的概念、定理等包含着严密的数学思维,其不具有任何模糊性。 针对上述问题李德毅院士在传统的概率统计理论和模糊理论的基础上提出了定性定量不确定性转换模型——云模型,实现定性概念和定量值之间的不确定性转换。在此工作上,一些学者对云模型做了深入系统的研究,使其日趋成熟,并将它成功地应用于不确定性推理、关联规则挖掘,空间数据的挖掘,智能控制及时间序列预测等领域。 云模型能模拟人类思维灵活划分属性空间,在较高的概念层上泛化属性值,完成定量数值到定性概念间的转换,同时允许相邻属性值或语言之间有重叠,这种划分使发现的知识具有稳健性。而由于计算机系统的行为存在随机性和不确定性,云模型能够很好地处理具有随机性和不确定性的数据,所以可将云模型引入到入侵检测中来,通过云模型建立的入侵检测系统具有较准确的检测能力和适应能力。
matlab蚁群算法精讲及仿真图
蚁群算法matlab精讲及仿真 4.1基本蚁群算法 4.1.1基本蚁群算法的原理 蚁群算法是上世纪90年代意大利学者M.Dorigo,v.Maneizz。等人提出来的,在越来越多的领域里得到广泛应用。蚁群算法,是一种模拟生物活动的智能算法,蚁群算法的运作机理来源于现实世界中蚂蚁的真实行为,该算法是由Marco Dorigo 首先提出并进行相关研究的,蚂蚁这种小生物,个体能力非常有限,但实际的活动中却可以搬动自己大几十倍的物体,其有序的合作能力可以与人类的集体完成浩大的工程非常相似,它们之前可以进行信息的交流,各自负责自己的任务,整个运作过程统一有序,在一只蚂蚁找食物的过程中,在自己走过的足迹上洒下某种物质,以传达信息给伙伴,吸引同伴向自己走过的路径上靠拢,当有一只蚂蚁找到食物后,它还可以沿着自己走过的路径返回,这样一来找到食物的蚂蚁走过的路径上信息传递物质的量就比较大,更多的蚂蚁就可能以更大的机率来选择这条路径,越来越多的蚂蚁都集中在这条路径上,蚂蚁就会成群结队在蚁窝与食物间的路径上工作。当然,信息传递物质会随着时间的推移而消失掉一部分,留下一部分,其含量是处于动态变化之中,起初,在没有蚂蚁找到食物的时候,其实所有从蚁窝出发的蚂蚁是保持一种随机的运动状态而进行食物搜索的,因此,这时,各蚂蚁间信息传递物质的参考其实是没有价值的,当有一只蚂蚁找到食物后,该蚂蚁一般就会向着出发地返回,这样,该蚂蚁来回一趟在自己的路径上留下的信息传递物质就相对较多,蚂蚁向着信息传递物质比较高的路径上运动,更多的蚂蚁就会选择找到食物的路径,而蚂蚁有时不一定向着信
息传递物质量高的路径走,可能搜索其它的路径。这样如果搜索到更短的路径后,蚂蚁又会往更短的路径上靠拢,最终多数蚂蚁在最短路径上工作。【基于蚁群算法和遗传算法的机器人路径规划研究】 该算法的特点: (1)自我组织能力,蚂蚁不需要知道整体环境信息,只需要得到自己周围的信息,并且通过信息传递物质来作用于周围的环境,根据其他蚂蚁的信息素来判断自己的路径。 (2)正反馈机制,蚂蚁在运动的过程中,收到其他蚂蚁的信息素影响,对于某路径上信息素越强的路径,其转向该路径的概率就越大,从而更容易使得蚁群寻找到最短的避障路径。 (3)易于与其他算法结合,现实中蚂蚁的工作过程简单,单位蚂蚁的任务也比较单一,因而蚁群算法的规则也比较简单,稳定性好,易于和其他算法结合使得避障路径规划效果更好。 (4)具有并行搜索能力探索过程彼此独立又相互影响,具备并行搜索能力,这样既可以保持解的多样性,又能够加速最优解的发现。 4.1.2 基本蚁群算法的生物仿真模型 a为蚂蚁所在洞穴,food为食物所在区,假设abde为一条路径,eadf为另外一条路径,蚂蚁走过后会留下信息素,5分钟后蚂蚁在两条路径上留下的信息素的量都为3,概率可以认为相同,而30分钟后baed路径上的信息素的量为60,明显大于eadf路径上的信息素的量。最终蚂蚁会完全选择abed这条最短路径,由此可见,
云模型
云模型 云模型(Cloud model)是我国学者李德毅教授提出的定性和定量转换模型。 随着不确定性研究的深入,越来越多的科学家相信,不确定性是这个世界的魅力所在,只有不确定性本身才是确定的。在众多的不确定性中,随机性和模糊性是最基本的。针对概率论和模糊数学在处理不确定性方面的不足,1995年我国工程院院士李德毅教授在概率论和模糊数学的基础上提出了云的概念,并研究了模糊性和随机性及两者之间的关联性。自李德毅院士等人提出云模型至今短短的十多年,其已成功的应用到数据挖掘、决策分析、智能控制、图像处理等众多领域。 定义在随机数学和模糊数学的基础上,提出用"云模型"来统一刻画语言值中大量存在的随机性、模糊性以及两者之间的关联性,把云模型作为用语言值描述的某个定性概念与其数值表示之间的不确定性转换模型.以云模型表示自然语言中的基元——语言值,用云的数字特征——期望Ex,熵En和超熵He表示语言值的数学性质.“熵”这一概念最初是作为描述热力学的一个状态参量,以后又被引入统计物理学、信息论、复杂系统等,用以度量不确定的程度.在云模型中,熵代表一个定性概念的可度量粒度,熵越大粒度越大,可以用于粒度计算;同时,熵还表示在论域空间可以被定性概念接受的取值范围,即模糊度,是定性概念亦此亦彼性的度量.云模型中的超熵是不确定性状态变化的度量,即熵的熵.云模型既反映代表定性概念值的样本出现的随机性,又反映了隶属程度的不确定性,揭示了模糊性和随机性之间的关联. 相关系数期望Ex是云在论域空间分布的期望,是最能够代表定性概念的点,或者说是这个概念量化的最典型样本;熵En代表定性概念的可度量粒度,熵越大,通常概念越宏观,也是定性概念不确定性的度量,由概念的随机性和模糊性共同决定.一方面, En是定性概念随机性的度量,反映了能够代表这个定性概念的云滴的离散程度;另一方面,又是定性概念亦此亦彼性的度量,反映了在论域空间可被概念接受的云滴的取值范围;超熵He是熵的不确定性度量,即熵的熵,由熵的随机性和模糊性共同决定。 作者简介: 于少伟( 1981 ) , 男, 讲师, 硕士, 研究方向为智能控制技术、金融工程. Emai:lyushaowei0505@ https://www.360docs.net/doc/f116621288.html, 基于区间分析和云模型的实物期权定价研究 摘要: 针对实物期权定价中预期现金流收益的现值和投资成本采用精确值给出不太合理的实际情况, 深入分析了现有的基于模糊集理论和基于云模型的实物期权定价方法, 提出了基于区间分析和云模型的实物期权定价方法。首先, 在基于云X 信息的逆向云算法的启发下, 结合区间分析理论, 提出一种新的逆向正态云构建算法; 然后, 用生成的云模型表示预期现金流收益的现值和投资成本, 结合期权定价理论和基于区间数的逆向云算法, 运用云运算, 给出了一种将专家评估区间数据转化成正态云模型的形式, 并提出了利用逆向正态云估计预期现金流收益波动率的实物期权定价方法; 最后, 通过实例模拟证明了该方法的有效性。 关键词: 区间分析; 正态云模型; 实物期权; 预期现金流收益; B-S公式 0 引言近年来, 实物期权广泛应用于项目投资决策分析, 弥补了传统财务分析方法(如资本预算的净现值方法)的不足, 其思想主要体现为: 当市场条件不确定时, 投资者可以选
蚁群算法
蚁群算法的改进与应用 摘要:蚁群算法是一种仿生优化算法,其本质是一个复杂的智能系统,它具有较强的鲁棒性、优良的分布式计算机制和易于与其他方法结合等优点。但是现在蚁群算法还是存在着缺点和不足,需要我们进一歩改进,如:搜索时间长、容易出现搜索停滞现象、数学基础还不完整。本文首先说明蚁群算法的基本思想,阐述了蚁群算法的原始模型及其特点,其次讨论如何利用遗传算法选取蚁群算法的参数,然后结合对边缘检测的蚁群算法具体实现过程进行研究分析,最后对本论文所做的工作进行全面总结,提出不足之处,并展望了今后要继续研究学习的工作内容。 关键词:蚁群算法;边缘检测;阈值;信息素;遗传算法; 1 前言 蚁群算法是近年来提出的一种群体智能仿生优化算法,是受到自然界中真实的蚂蚁群寻觅食物过程的启发而发现的。蚂蚁之所以能够找到蚁穴到食物之间的最短路径是因为它们的个体之间通过一种化学物质来传递信息,蚁群算法正是利用了真实蚁群的这种行为特征,解决了在离散系统中存在的一些寻优问题。该算法起源于意大利学者 Dorigo M 等人于 1991 年首先提出的一种基于种群寻优的启发式搜索算法,经观察发现,蚂蚁在寻找食物的过程中其自身能够将一种化学物质遗留在它们所经过的路径上,这种化学物质被学者们称为信息素。这种信息素能够沉积在路径表面,并且可以随着时间慢慢的挥发。在蚂蚁寻觅食物的过程中,蚂蚁会向着积累信息素多的方向移动,这样下去最终所有蚂蚁都会选择最短路径。该算法首先用于求解著名的旅行商问题(Traveling Salesman Problem,简称 TSP)并获得了较好的效果,随后该算法被用于求解组合优化、函数优化、系统辨识、机器人路径规划、数据挖掘、网络路由等问题。 尽管目前对 ACO 的研究刚刚起步,一些思想尚处于萌芽时期,但人们已隐隐约约认识到,人类诞生于大自然,解决问题的灵感似乎也应该来自大自然,因此越来越多人开始关注和研究 ACO,初步的研究结果已显示出该算法在求解复杂优化问题(特别是离散优化问题)方面的优越性。虽然 ACO 的严格理论基础尚未奠定,国内外的有关研究仍停留在实验探索阶段,但从当前的应用效果来看,这种自然生物的新型系统寻优思想无疑具有十分光明的前景。但该算法存在收敛速度慢且容易出现停滞现象的缺点,这是因为并不是所有的候选解都是最优解,而候选解却影响了蚂蚁的判断以及在蚂蚁群体中,单个蚂蚁的运动没有固定的规则,是随机的,蚂蚁与蚂蚁之间通过信息素来交换信息,但是对于较大规模的优化问题,这个信息传递和搜索过程比较繁琐,难以在较短的时间内找到一个最优的解。 由于依靠经验来选择蚁群参数存在复杂性和随机性,因此本文最后讨论如何利用遗传算法选取蚁群算法的参数。遗传算法得到的蚁群参数减少了人工选参的不确定性以及盲目性。 2 基本蚁群算法 2.1 蚁群算法基本原理 根据仿生学家的研究结果表明,单只蚂蚁不能找到从巢穴到食物源的最短路 径,而大量蚂蚁之间通过相互适应与协作组成的群体则可以,蚂蚁是没有视觉的,但是是通过蚂蚁在它经过的路径上留下一种彼此可以识别的物质,叫信息素,来相互传递信息,达到协作的。蚂蚁在搜索食物源的过程中,在所经过的路径上留下信息素,同时又可以感知并根据信息素的浓度来选择下一条路径,一条路径上的浓度越浓,蚂蚁选择该条路径的概率越大,并留下信息素使这条路径上的浓度加强,这样会有更多的蚂蚁选择次路径。相反,信息素浓度少的路
数学建模中常见的十大模型
数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MA TLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的插值计算,还有吵的沸沸扬扬可能会考的“非典”问题也要用到数据拟合算法,观察数据的
图论模型简介
图论模型简介 一、图及其矩阵表示 1、起源:哥尼斯堡七桥问题: 欧拉为了解决这个问题,建立数学模型:陆地——点,桥——边,得到一个有四个“点”,七条“边”的“图”。问题转化为能否从任一点出发一笔画出七条边再回到起点。欧拉考察了一般一笔画的结构特点,给出了一笔画判定法则:图是连通的,且每个顶点都与偶数条边相关联(这种图称为欧拉图)。由此可以得出结论:七桥问题无解。
2、基本概念: 图(graph):由顶点和边(又称线,边的两端必须是顶点)组成的一个结构。 邻接:一条边的两个端点称是邻接的;关联:边与其两端的顶点称是关联的。 无向图(graph):边无方向的图;有向图(digraph):边有方向的图。 路(path):由相邻边组成的序列,其中中间顶点互不相同。 圈(cycle):首、尾顶点相同的路,即闭路。 连通图(connected graph):图中任意两顶点间都存在路的图。 树(tree):无圈连通图 完全图(complete graph):任意两个顶点之间都有边相连的无向图,记为K n。 竞赛图(tournament):由完全图给每条边定向而得到的有向图。 二部图(bipartite graph):图的顶点分成两部分,只有不同部分顶点之间才有边相连。图G的子图H(subgraph):H是一个图,H的顶点(边)是图G的顶点(边)。 网络(Network):边上赋了权的有向图。
3、图的矩阵表示 无向图 有向图 0100010 11001011 011000 1 00???????????????? ???? ? ? ? ? ????????0110010100000100100000110
matlab_蚁群算法_机器人路径优化问题
用ACO 算法求解机器人路径优化问题 4.1 问题描述 移动机器人路径规划是机器人学的一个重要研究领域。它要求机器人依据某个或某些优化原则(如最小能量消耗,最短行走路线,最短行走时间等),在其工作空间中找到一条从起始状态到目标状态的能避开障碍物的最优路径。机器人路径规划问题可以建模为一个有约束的优化问题,都要完成路径规划、定位和避障等任务。 4.2 算法理论 蚁群算法(Ant Colony Algorithm,ACA),最初是由意大利学者Dorigo M. 博士于1991 年首次提出,其本质是一个复杂的智能系统,且具有较强的鲁棒性,优良的分布式计算机制等优点。该算法经过十多年的发展,已被广大的科学研究人员应用于各种问题的研究,如旅行商问题,二次规划问题,生产调度问题等。但是算法本身性能的评价等算法理论研究方面进展较慢。 Dorigo 提出了精英蚁群模型(EAS),在这一模型中信息素更新按照得到当前最优解的蚂蚁所构造的解来进行,但这样的策略往往使进化变得缓慢,并不能取得较好的效果。次年Dorigo 博士在文献[30]中给出改进模型(ACS),文中 改进了转移概率模型,并且应用了全局搜索与局部搜索策略,来得进行深度搜索。 Stützle 与Hoos给出了最大-最小蚂蚁系统(MAX-MINAS),所谓最大-最小即是为信息素设定上限与下限,设定上限避免搜索陷入局部最优,设定下限鼓励深度搜索。 蚂蚁作为一个生物个体其自身的能力是十分有限的,比如蚂蚁个体是没有视觉的,蚂蚁自身体积又是那么渺小,但是由这些能力有限的蚂蚁组成的蚁群却可以做出超越个体蚂蚁能力的超常行为。蚂蚁没有视觉却可以寻觅食物,蚂蚁体积渺小而蚁群却可以搬运比它们个体大十倍甚至百倍的昆虫。这些都说明蚂蚁群体内部的某种机制使得它们具有了群体智能,可以做到蚂蚁个体无法实现的事情。经过生物学家的长时间观察发现,蚂蚁是通过分泌于空间中的信息素进行信息交流,进而实现群体行为的。 下面简要介绍蚁群通过信息素的交流找到最短路径的简化实例。如图 2-1 所示,AE 之间有
数学建模中常见的十大模型讲课稿
数学建模中常见的十 大模型
精品文档 数学建模常用的十大算法==转 (2011-07-24 16:13:14) 转载▼ 1. 蒙特卡罗算法。该算法又称随机性模拟算法,是通过计算机仿真来解决问题的算法,同时可以通过模拟来检验自己模型的正确性,几乎是比赛时必用的方法。 2. 数据拟合、参数估计、插值等数据处理算法。比赛中通常会遇到大量的数据需要处理,而处理数据的关键就在于这些算法,通常使用MA TLAB 作为工具。 3. 线性规划、整数规划、多元规划、二次规划等规划类算法。建模竞赛大多数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通常使用Lindo、Lingo 软件求解。 4. 图论算法。这类算法可以分为很多种,包括最短路、网络流、二分图等算法,涉及到图论的问题可以用这些方法解决,需要认真准备。 5. 动态规划、回溯搜索、分治算法、分支定界等计算机算法。这些算法是算法设计中比较常用的方法,竞赛中很多场合会用到。 6. 最优化理论的三大非经典算法:模拟退火算法、神经网络算法、遗传算法。这些问题是用来解决一些较困难的最优化问题的,对于有些问题非常有帮助,但是算法的实现比较困难,需慎重使用。 7. 网格算法和穷举法。两者都是暴力搜索最优点的算法,在很多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种暴力方案,最好使用一些高级语言作为编程工具。 8. 一些连续数据离散化方法。很多问题都是实际来的,数据可以是连续的,而计算机只能处理离散的数据,因此将其离散化后进行差分代替微分、求和代替积分等思想是非常重要的。 9. 数值分析算法。如果在比赛中采用高级语言进行编程的话,那些数值分析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编写库函数进行调用。 10. 图象处理算法。赛题中有一类问题与图形有关,即使问题与图形无关,论文中也会需要图片来说明问题,这些图形如何展示以及如何处理就是需要解决的问题,通常使用MATLAB 进行处理。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 以下将结合历年的竞赛题,对这十类算法进行详细地说明。 2 十类算法的详细说明 2.1 蒙特卡罗算法 大多数建模赛题中都离不开计算机仿真,随机性模拟是非常常见的算法之一。 举个例子就是97 年的A 题,每个零件都有自己的标定值,也都有自己的容差等级,而求解最优的组合方案将要面对着的是一个极其复杂的公式和108 种容差选取方案,根本不可能去求解析解,那如何去找到最优的方案呢?随机性模拟搜索最优方案就是其中的一种方法,在每个零件可行的区间中按照正态分布随机的选取一个标定值和选取一个容差值作为一种方案,然后通过蒙特卡罗算法仿真出大量的方案,从中选取一个最佳的。另一个例子就是去年的彩票第二问,要求设计一种更好的方案,首先方案的优劣取决于很多复杂的因素,同样不可能刻画出一个模型进行求解,只能靠随机仿真模拟。 2.2 数据拟合、参数估计、插值等算法 数据拟合在很多赛题中有应用,与图形处理有关的问题很多与拟合有关系,一个例子就是98 年美国赛A 题,生物组织切片的三维插值处理,94 年A 题逢山开路,山体海拔高度的 收集于网络,如有侵权请联系管理员删除
蚁群算法讲课
蚁群算法 主讲人:郝娟指导老师:张著洪
目录 1蚁群算法概述 (21) 1.1蚁群算法的提出与发展 (21) 1.2蚁群算法原理 (22) 1.3数学模型的建立 (25) 2蚁群算法的仿真分析 (29) 2.1蚁群算法流程 (30) 2.2蚁群算法的计算机仿真 (30) 2.3分析与总结 (34) 3蚁群算法的优化 (38) 3.1基本蚁群算法的缺点 (38) 3.2改进与优化方法 (40) 3.3优化蚁群算法方案的仿真分析 (43) 4小结 (44)
第一章蚁群算法概述 生物学家通过对蚂蚁的长期研究发现,虽然每只蚂蚁智能不高,也没有集中的指挥,但它们却可以协同工作,依靠群体能力发挥出超出个体的智能。蚁群算法(ant colony algorithm, ACA)是最新发展的一种模拟蚂蚁群体智能行为的仿生优化算法,具有较强的鲁棒性、分布式计算机制、易于与其它算法结合等优点。尽管目前蚁群算法的严格理论基础尚未奠定,国内外的相关研究还处在实验探索和初步应用阶段,但蚁群算法己经由当初的单一TSP旅行商问题领域渗透到多个应用领域,有着广泛的应用前景。 1蚁群算法的提出与发展 根据蚂蚁“寻找食物”的群体智能行为,意大利学者M.Dorigo于1991年在法国召开的第一届欧}}l}l人工生命会议(European Conference on Artificial Life, ECAL中第一次提出了蚁群算法的基本模型。到1992年,M.Dorigo又在其博士学位论文中进一步阐述了蚁群算法的核心思想。由于在模拟仿真中使用了人工蚂蚁的概念,因此也称蚂蚁系统(ant system, AS )。 近年来,蚁群算法逐渐被国内学者了解和研究,相继出现了一些介绍性的文献,其后在蚁群算法的应用研究方面(如组合优化问题、网络路由调度问题等)开展了许多研究工作。 2蚁群算法原理 2.1生物学原型 蚂蚁系统是最早建立的蚁群算法模型,其模型的建立来源于对蚂蚁寻找食物行为的研究。蚂蚁视力很有限,但是蚂蚁寻找食物的过程中却有能力在没有任何可见提示下找出从蚁穴到食物源的最短路径,并且能随环境的变化而变化,适应性地搜索新的路径,产生新的选择。 经过研究发现,在从食物源到蚁穴并返回的过程中,蚂蚁能在其走过的路径上分泌一种化学物质一信息素,通过这种方式形成信息素轨迹。信息素轨迹可以使蚂蚁找到其返回食物源(或蚁穴)的路径,其他蚂蚁也可以利用该轨迹找到由同伴发现的食物源的位置。由蚂蚁个体的特征可以看出,蚂蚁除了对信息素有感知外几乎无法获知环境的信息,因而当环境中不存在信息素时,蚂蚁的行为是完全随机的。也就是说,蚂蚁在一个新的环境中的初始行走是完全随机的。另外,蚂蚁的搜索不是孤立的。事实上,假如只有一只蚂蚁进行搜索,由于蚂蚁的短视,很难找到最佳路径。当蚂蚁走过一条路径时,在上面留下的信息素会吸引更多的蚂蚁走这条路。当这条路径上通过的蚂蚁越来越多,以至信息素强度增大,后来蚂蚁选择该路径的概率也越高,从而更增加了该路径的信息素强度。 图2.1 蚁群的初始路径