Oracle数据库同步解决方案

情景模拟
现在有两台服务器:
1)机器名:ThinkPad IP:126.33.9.190 Oracle SID:ORCL
2)机器名:DELL IP: 126.33.9.154 Oracle SID: ORCL
目的:将ThinkPad机器上用户Geosoc里面的BookMark表同步到DELL 机器里面去。
(一)高级复制
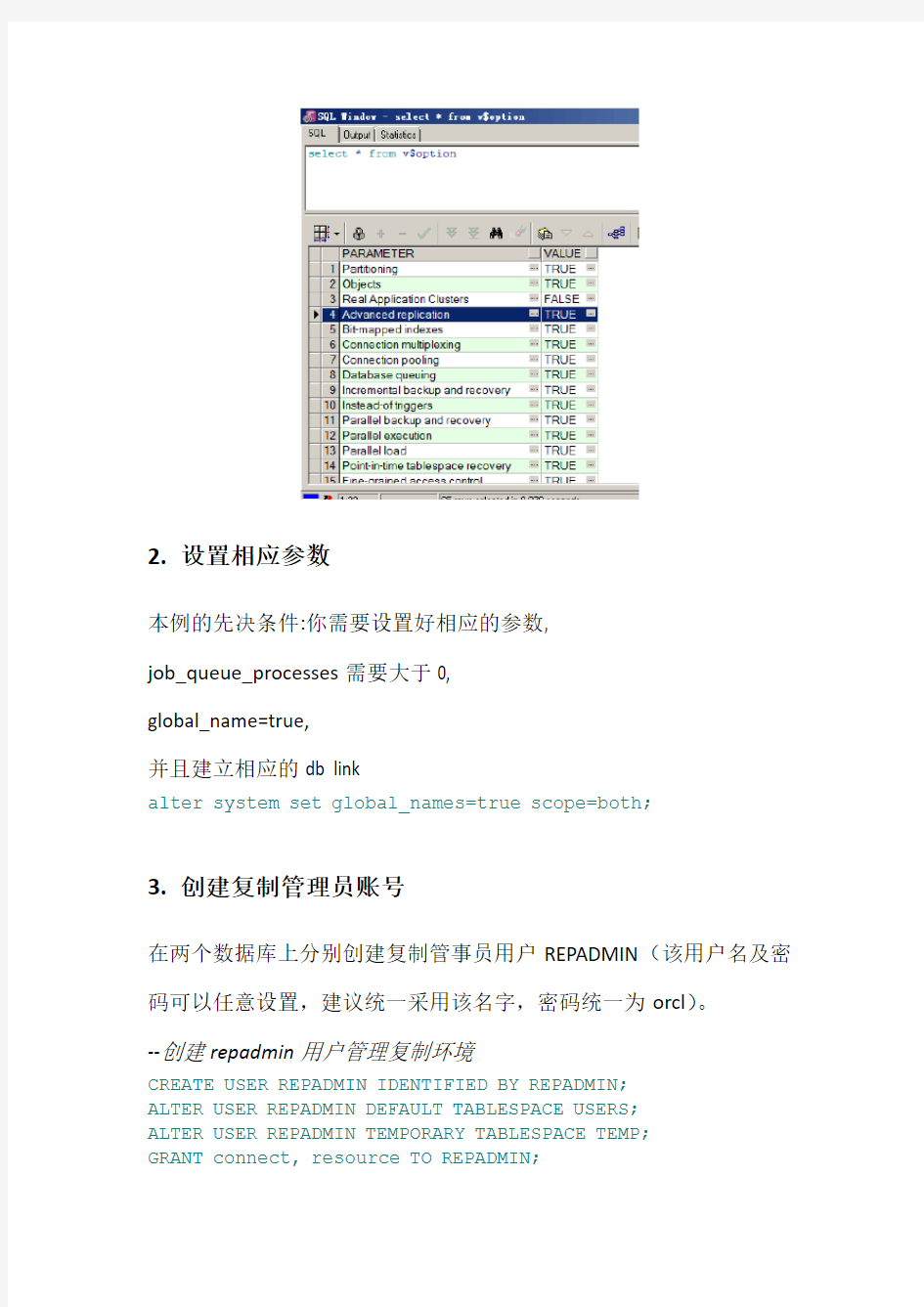
1.查看是否具备高级复制功能
首先,数据库要具备高级复制功能(用system身份登录数据库,查看v$option视图,如果其中Advanced replication为TRUE,则支持高级复制功能;否则不支持)。
select * from v$option
2.设置相应参数
本例的先决条件:你需要设置好相应的参数,
job_queue_processes需要大于0,
global_name=true,
并且建立相应的db link
alter system set global_names=true scope=both;
3.创建复制管理员账号
在两个数据库上分别创建复制管事员用户REPADMIN(该用户名及密码可以任意设置,建议统一采用该名字,密码统一为orcl)。
--创建repadmin用户管理复制环境
CREATE USER REPADMIN IDENTIFIED BY REPADMIN;
ALTER USER REPADMIN DEFAULT TABLESPACE USERS;
ALTER USER REPADMIN TEMPORARY TABLESPACE TEMP;
GRANT connect, resource TO REPADMIN;
--授予repadmin用户权限可以管理当前站点中任何主体组
EXECUTE dbms_repcat_admin.grant_admin_any_schema('REPADMI N');
--授予repadmin用户权限可以为任何表创建snapshot logs
GRANT comment any table TO REPADMIN;
GRANT lock any table TO REPADMIN;
--指定repadmin用户为propagator,并授予执行任何procedure的权限EXECUTE dbms_defer_sys.register_propagator('REPADMIN'); GRANT execute any procedure TO REPADMIN;
4.更改数据库全局名
由于后面创建数据库链接(Database link)时需要用到数据库全局名,因此遇到同名的数据库全局名时需要更改其数据库名。
ThinkPad机器:改为ORCL_THINKPAD
alter database rename global_name to ORCL_THINKPAD;
DELL机器:改为ORCL_DELL
alter database rename global_name to ORCL_THINKPAD;
5.在两个数据库上分别建立到对方的数据库链接
建立数据库链接的前提是两个数据库能互相访问,因此需要在数据库端先建立互相的连接本地命名。
由于开启了Global_names为True,因此链接名必须与Global名一致。
ThinkPad: 建立到DELL的本地命名为ORCL154。
create public database link ORCL_DELL connect to REPADMIN identified by orcl using 'ORCL154';
DELL:建立到ThinkPad的本地命名为ORCL190。
create public database link ORCL_THINKPAD connect to REPA DMIN identified by orcl using 'ORCL190';
建立好链接后,可以在各自的机器上测试链接是否成功。
Select * from BookMark@ORCL_DELL
6.创建复制组
在需要被复制的数据库上建立复制组,本例中是ThinkPad机器需要被复制,因此在此数据库上建立复制组。
以REPADMIN登录数据库ORCL
a)创建复制组:
execute dbms_repcat.create_master_repgroup('rep_geosoc');
b)在复制组里加入复制对象:
execute dbms_repcat.create_master_repobject(sname=>'geosoc',oname =>'bookmark',type=>'table',use_existing_object=>true,gname=>'rep_geo soc',copy_rows=>false);
c)对复制对象产生复制支持:
execute dbms_repcat.generate_replication_support('geosoc','bookmark' ,'table');
d)添加主体复制节点:
execute dbms_repcat.add_master_database(gname=>'rep_geosoc',mast
er=>'ORCL_DELL',use_existing_objects=>true,copy_rows=>false, propaga tion_mode => 'synchronous');
e)在主体定义站点启动复制:
execute dbms_repcat.resume_master_activity('rep_geosoc',true);
7.配置完成
Good Luck!当你走到这里什么错误都没发生,恭喜你!也恭喜我,表示我的文档写的没有那么差,比较负责任的将网上的东西抄下来经过了一番整理!
但这里还是提醒两点:
1:同步的数据表BookMark必须具有主键!
2:同步前,两个数据表初始化是一样的,也就是说同步前,DELL机器上的BookMark表必须和ThinkPad表上的数据一致!可以采用以下的语句进行创建。
Insert Into BookMark select * from BookMark@ORCL_THINKPAD.
下面你可以尽情的在ThinkPad机器上操作BookMark表,你会即时发现DELL机器上的BookMark表也随之跟着发生变化,Amazoning!
但是,你在DELL机器上操作BOOKMARK表,ThinkPad机器上却没什么变化!So Boring!
参考文献:
[1]https://www.360docs.net/doc/f46241472.html,/link?url=ajOi6vVMYpxOZlQF8SGVMjCBIm_K CngPt28TJ20QbfPL1zR09fbvvcWSTzNvXxHkzE4ITD22ap9Fne4V1rMz1F5L N7YFS39prjUcv9dA0DK
关于XX业务系统数据同步方案简介
关于XX业务系统数据同步方案简介
修订记录
目录 1. 概述 (4) 2. 数据分析现状 (5) 3. 数据同步方案 (6) 3.1. 理论分析 (7) 3.1.1. 理论值分析 (7) 3.1.2. 必要条件 (9) 3.1.3. 差集计算 (9) 3.2. 数据处理方案 (11) 3.2.1. 历史数据处理 (11) 3.2.2. 过渡性数据处理 (12) 3.2.3. 常规数据处理 (12) 3.3. 数据时效性 (12) 4. 未知性说明 (14)
1.概述 XX业务系统技术支持人员大部分时间均在进行数据统计分析,且基本是在正式环境中进行数据分析处理,而此举在实际操作中除会给生产系统带来诸多压力之外,还可能因为操作人员新建大量临时表时操作失误而出现删表或者删数据的情况。 针对上述情况并结合可视化分析系统的现有使用情况,做本建设性思考方案,旨在针对实际问题提出理论上的建设性方案。
2. 数据分析现状 XX 业务系统数据分析一直因为数据时效性而无法很好的使用Spark 集群,且目前已建设的可视化分析环境因为历史数据存在被修改的可能性而导致用之甚少。且当前XX 业务系统集群可视化分析环境采用按月(月中)更新、人工拷贝而后转由集群导入的方式,如下图1所示。 备份库 集群库 正式库人工拷贝系统同步 图1 – XX 业务系统数据同步示意图 该方式在实际操作中非常消耗人力、物力,且集群数据利用率极低(XX 业务系统版集群可视化环境几乎没人使用)。
3.数据同步方案 近期,在处理HBase数据同步至HDFS方案时,构思如下数据更新方案,如图2所示: 近期数据 差集 全量数据 Override Append 图2 – HBase数据迁移理论方案示意图 同理,将HBase替换成XX业务系统生产数据库,则会得到下图3所示方案示意图: 近期数据 差集 全量数据 Override Append Oracle 图3– XX业务系统数据迁移理论方案示意图 该方案是采用蚂蚁搬家的思路,若在此方案思路使用至XX业务系统数据同步中将会使数据从一个月的更新周期调整为一天,从而使集群数据更接近实时数据,从而为XX业务系统日常统计使用Spark集群提供了可能性。
城市公共基础数据库建设参考方案
城市公共基础数据库建设参考方案
城市基础数据库系统建设方案
1.系统概述 长期以来,政府各部门内部拥有着大量城市基础数据资源,但由于管理分散,制度规范不健全,造成重复采集、口径多乱、数出多门;各部门的指标数据自成体系,标准不一,共享程度较差。随着政府向“经济调节、市场监管、社会管理和公共服务”管理职能的转变,就要求必须能够全面、准确掌握全地区经济社会发展态势,强化政府部门掌控决策信息资源的能力,政府部门间信息资源整合与共享需求越来越紧密,但当前部门间信息共享多是点对点方式,
没有统一的数据交换管理平台。因此各部门对加快解决数据资源分散管理、数据共享不足的问题需求十分迫切,需要建立城市基础数据库(以下简称智慧城市公共基础数据库)系统以解决以上问题。 依托智慧城市公共基础数据库系统的建设,可以实现各委办局、各所辖地区的经济社会综合数据采集交换,为各部门提供更广泛的信息共享支持,一方面数据信息从各委办局、各所辖地区整合接入,另一方面也为政府和这些接入部门提供全面的共享服务。同时,以智慧城市公共基础数据库指标体系建立为基础,整合来自各委办局和各所辖地区的、经过审核转换处理的数据资源,可实现对经济社会信息的统一和集中存储,确保数据的唯一性和准确性,为今后政府工作提供一致的基础数据支持。 数据整合共享只是手段,数据分析服务才是目的。依托智慧城市公共基础数据库系统建设,可有效整合各政府部门所掌握的全市经济社会信息资源,满足政府业务对统一数据资源共享需要,进而提升形势分析预测水平,对政府在发展规划、投资布局、资源环境、管理创新、科学决策等业务提供强有力支持,提高了政府部门掌控全市经济社会发展态势能力。 2.建设目标 1)建立科学合理的智慧城市公共基础数据库指标体系,力求全面反映地区经济和社会发展的总体情况: 2)有组织、有计划、持续地对政府统计部门、政府各部门以及国民经济行业管理部门负责统计的关系到地区经济与社会发展的信息资源进行收集、整合,建立全地区城市信息资源共建、共享的统一管理机制; 3)依托地区电子政务基础设施,充分利用现代信息技术,以科学的地区宏观经济和社会发展指标体系为基础,建设支持政府宏观经济管理和社会和谐发展的基础数据库系统,提高信息资源的建设、管理和共建共享能力; 4)为地区经济建设和社会和谐发展提供一致的城市基础数据,为各类应用系统建设提供基础数据支持,满足政府管理决策、部门信息共享和社会公共服务“三个层次”的需求。
ORACLE数据备份与数据恢复方案
O R A C L E数据备份与数据恢 复方案 Prepared on 24 November 2020
摘要 结合金华电信IT系统目前正在实施的备份与恢复策略,重点介绍电信业务计算机管理系统(简称97系统)和营销支撑系统的ORALCE数据库备份和恢复方案。 Oracle数据库有三种标准的备份方法,它们分别是导出/导入 (EXP/IMP)、热备份和冷备份。要实现简单导出数据(Export)和导入数据(Import),增量导出/导入的按设定日期自动备份,可考虑,将该部分功能开发成可执行程序,然后结合操作系统整合的任务计划,实现特定时间符合备份规划的备份应用程序的运行,实现数据库的本级备份,结合ftp简单开发,实现多服务器的数据更新同步,实现数据备份的异地自动备份。 关键字:数据库远程异地集中备份 目录
一、前言 目前,数据已成为信息系统的基础核心和重要资源,同时也是各单位的宝贵财富,数据的丢失将导致直接经济损失和用户数据的丢失,严重影响对社会提供正常的服务。另一方面,随着信息技术的迅猛发展和广泛应用,业务数据还将会随业务的开展而快速增加。但由于系统故障,数据库有时可能遭到破坏,这时如何尽快恢复数据就成为当务之急。如做了备份,恢复数据就显得很容易。由此可见,做好数据库的备份至关重要。因此,建立一个满足当前和将来的数据备份需求的备份系统是必不可少的。传统的数据备份方式主要采用主机内置或外置的磁带机对数据进行冷备份,这种方式在数据量不大、操作系统种类单一、服务器数量有限的情况下,不失为一种既经济又简明的备份手段。但随着计算机规模的扩大,数据量几何级的增长以及分布式网络环境的兴起,将越来越多的业务分布在不同的机器、不同的操作平台上,这种单机的人工冷备份方式越来越不适应当今分布式网络环境。 因此迫切需要建立一个集中的、自动在线的企业级备份系统。备份的内容应当包括基于业务的业务数据,又包括IT系统中重要的日志文件、参数文件、配置文件、控制文件等。本文以ORACLE数据库为例,结合金华电信的几个相关业务系统目前正在实施的备份方案,介绍ORACLE数据库的备份与恢复。 二、金华电信ORACLE数据库的备份与恢复方案 由于金华电信IT系统以前只采用逻辑备份方式进行数据库备份,速度较慢并且数据存储管理都很分散,甚至出现备份数据不完整的现象。为了提高备份数据的效率,提供可靠的数据备份,完善备份系统,保证备份数据的完整性,降低数据备份对网络和服务器的影响,对每个IT系统的备份数据进行集中管理,我们对备份工作进行了改进,将逻辑备份与物理备份相结合,在远程建立了一个异地集中、自动在线的备份系统即网络存储管理系统。(这里用到的物理备份指热备份)其具备的主要功能如下:(1)集中式管理 :网络存储备份管理系统对整个网络的数据进行管理。利用集中式管理工具的帮助,系统管理员可对全网的备份策略进行统一管理,备份服务器可以监控所有机器的备份作业,也可以修改备份策略,并可即时浏览所有目录。所有数据可以备份到同备份服
MySQL数据双向同步解决方案
1.mysql数据同步实现原理 即读写操作在两台服务器上进行,每台服务器即主也是从。当其中的任何一台服务器收到操作请求时,其进行相应的数据变化,并把变化的数据复制到另一台服务器中。 2.配置服务器master 初始服务器 通过mysql工具连接服务器master后,新建两个数据库audit,idm。导入初始化数据库文件,完成数据库的初始化 给用户授权 从开始菜单中打开mysql5的命令行,输入正确的密码,进入mysql控制台命令行模式后,输入如下命令: #授权来自192.168.0.189的backup用户拥有对所有库的复制数据的权限,该用户的密码设为123456 GRANT REPLICATION SLAVE ON *.* TO 'backup'@'192.168.0.189' IDENTIFIED BY '123456'; #刷新权限设置 FLUSH PRIVILEGES ; 修改配置文件 修改主目录中的my.inf文件,在mysqld下面加入如下内容 server-id = 1 log-bin=mysql-bin binlog-do-db = audit binlog-do-db = idm binlog-ignore-db = information_schema binlog-ignore-db = mysql binlog-ignore-db = test master-host = 192.168.0.189 master-user = backup master-password = 123456 master-port = 3306
replicate-do-db = audit replicate-do-db = idm master-connect-retry = 60 3.配置服务器slave 初始服务器 通过mysql工具连接服务器ha002后,新建两个数据库audit,idm。导入初始化数据库文件,完成数据库的初始化 给用户授权 从开始菜单中打开mysql5的命令行,输入正确的密码,进入mysql控制台命令行模式后,输入如下命令: #授权来自192.168.0.188的backup用户拥有对所有库的复制数据的权限,该用户的密码设为123456 GRANT REPLICATION SLAVE ON *.* TO 'backup'@'192.168.0.188' IDENTIFIED BY '123456'; #刷新权限设置 FLUSH PRIVILEGES ; 修改配置文件 修改主目录中的my.inf文件,在mysqld下面加入如下内容 server-id = 2 master-host = 192.168.0.188 master-user = backup master-password = 123456 master-port = 3306 relicate-do-db = audit replicate-do-db = idm master-connect-retry = 60 log-bin=mysql-bin binlog-do-db = audit binlog-do-db = idm binlog-ignore-db = information_schema
人口基础数据库建设方案【智慧城市应用】
智慧城市应用之人口基础数据库 转型期的中国是人口发展的关键时期,经济发展和社会建设面临的重大问题无不与人口密切相关,人口问题的聚集与凸显是当前政府面临的重要问题。如何运用信息化的手段进行人口数据的科学有效管理,建立人口基础数据库(简称“人口库”),从而切实提高社会管理与民生服务水平就显得相当重要和紧迫。 人口库建设的意义和重要性 人口基础信息是国家重要的基础信息之一,现行人口管理模式和信息应用模式是一种“条块分割”式的管理,各个相关部门只是从本部门的角度出发对人口信息进行管理,相互间不能很好地协调起来。随着市场经济体制的建立和完善,这种“条块分割”式的、孤立的人口信息管理和应用模式的弊病已显端倪:一方面是造成了许多不必要的重复劳动,另一方面各部门间信息不能共享,不能更好地服务百姓。 1、建立人口基础数据库平台是有效实施人口战略的重要依据,是提高政府决策科学化的支撑。 人口信息是社会的基础信息,是政府进行科学决策和公共行政管理的重要依据。长期以来,我国人口管理建立在户籍制度基础上,随着社会主义市场经济体制改革的深入发展,人口流动性越来越大,旧的管理模式已经不适应社会的发展需要。公安局、劳保局、建交委、社发局、工商局等部门都在实施对部分人口的专门管理,其要求是对实际居住地人口的管理,取得一定成效。由于各部门对人口管理和发展存在差异,统计口径也不一致,造成人口管理、统计的基础和基数始终不能统一,致使不能得到准确的人口及其分布状况信息。因此,迫切需要建立一个以公安人口信息为基础,以公民身份号码(境外人口为护照号)为唯一代码,以其他部门为补充和核准的,具有权威性、基础性和战略性的人口基础数据
oracle数据库恢复方案
目录 数据库恢复方案 (1) 文档控制 (1) 一、相关概念 (3) 1,恢复的两个阶段 (3) 2,Oracle实例启动的三个阶段 (3) 3,RMAN信息的保存位置 (3) 二、完全恢复 (3) (一) 控制文件 (3) 1) 丢失部分控制文件: (3) 2) 丢失全部控制文件 (3) (二) 重做日志文件 (4) 1) 非当前使用的重做日志文件: (4)
2) 当前使用的重做日志文件(未归档): (4) (三) 数据文件 (4) 1) 无归档模式下的完全恢复 (4) 2) 归档模式下的完全恢复 (5) 三、不完全恢复 (6) (一) 基于SCN的不完全恢复 (6) 1) 准备工作 (6) 2) 使用RMAN进行恢复 (7) (二) 基于时间点的不完全恢复 (8) 1) 准备工作 (8) 2) 使用RMAN进行恢复 (8) 四、高级篇 (9)
(一) 使用RMAN进行异机同目录 (9) 1) 准备工作 (9) 2) 通过RMAN进行异机恢复 (10) (二)使用RMAN进行异机异目录 (11) 1) 准备工作 (11) 2) 通过RMAN进行异机恢复 (11) (三)使用RMAN进行在线数据块恢复 (14) 一、相关概念 1,恢复的两个阶段 数据库无论采取哪种方式进行恢复都分为Restore和Recover两个步骤。Restore(还原):把控制文件、重做日志文件和数据文件还原到正确位置。Recover(恢复):恢复还原后的数据文件,使数据库达到一致状态。
2,Oracle实例启动的三个阶段 Oracle实例启动经过三个阶段: l NOMOUNT(未装载):读入参数文件,验证参数文件中的目录是否存在。 l MOUNT(装载):读入参数文件指定位置的控制文件。 l OPEN(打开):验证控制文件中指定的重做日志文件和数据文件是否正确、数据文件是否一致,然后读入数据文件中的数据。 所以按照如下顺序使数据库正确打开。 1) SHUTDOWN(关闭)状态下,确保参数文件指定的文件夹存在,启动到NOMMUNT 状态。 2) NOMOUNT状态下,保证控制文件的位置和命名与参数文件中相同,控制文件中指定的重做日志文件和数据文件存在,然后启动到MOUNT状态。 3) MOUNT状态下,执行RMAN还原和恢复操作。
XXX基础数据库系统建设可行性研究报告 (1)
XX城市基础数据库系统建设可行性 方案
1.系统概述 长期以来,政府各部门内部拥有着大量城市基础数据资源,但由于管理分散,制度规范不健全,造成重复采集、口径多乱、数出多门;各部门的指标数据自成体系,标准不一,共享程度较差。随着政府向“经济调节、市场监管、社会管理和公共服务”管理职能的转变,就要求必须能够全面、准确掌握全地区经济社会发展态势,强化政府部门掌控决策信息资源的能力,政府部门间信息资源整合与共享需求越来越紧密,但当前部门间信息共享多是点对点方式,没有统一的数据交换管理平台。因此各部门对加快解决数据资源分散管理、数据共享不足的问题需求十分迫切,需要建立城市基础数据库(以下简称智慧城市公共基础数据库)系统以解决以上问题。 依托智慧城市公共基础数据库系统的建设,可以实现各委办局、各所辖地区的经济社会综合数据采集交换,为各部门提供更广泛的信息共享支持,一方面数据信息从各委办局、各所辖地区整合接入,另一方面也为政府和这些接入部门提供全面的共享服务。同时,以智慧城市公共基础数据库指标体系建立为基础,整合来自各委办局和各所辖地区的、经过审核转换处理的数据资源,可实现对经济社会信息的统一和集中存储,确保数据的唯一性和准确性,为今后政府工作提供一致的基础数据支持。 数据整合共享只是手段,数据分析服务才是目的。依托智慧城市公共基础数据库系统建设,可有效整合各政府部门所掌握的全市经济社会信息资源,满足政府业务对统一数据资源共享需要,进而提升形势分析预测水平,对政府在发展规划、投资布局、资源环境、管理创新、科学决策等业务提供强有力支持,提高了政府部门掌控全市经济社会发展态势能力。 2.建设目标 1)建立科学合理的智慧城市公共基础数据库指标体系,力求全面反映地区经济和
Oracle Export/Import数据库备份与恢复的三种方法
Oracle数据库备份与恢复的三种方法 Oracle数据库有三种标准的备份方法,它们分别是导出/导入(EXP/IMP)、热备份和冷备份。导出备件是一种逻辑备份,冷备份和热备份是物理备份。 一、导出/导入(Export/Import) 利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中去。 1、简单导出数据(Export)和导入数据(Import) Oracle支持三种方式类型的输出: (1)、表方式(T方式),将指定表的数据导出。 (2)、用户方式(U方式),将指定用户的所有对象及数据导出。 (3)、全库方式(Full方式),瘵数据库中的所有对象导出。 数据导入(Import)的过程是数据导出(Export)的逆过程,分别将数据文件导入数据库和将数据库数据导出到数据文件。 2、增量导出/导入 增量导出是一种常用的数据备份方法,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。在进行此种导出时,系统不要求回答任何问题。导出文件名缺省为export.dmp,如果不希望自己的输出文件定名为export.dmp,必须在命令行中指出要用的文件名。 增量导出包括三种类型: (1)、“完全”增量导出(Complete) 即备份三个数据库,比如: exp system/manager inctype=complete file=040731.dmp (2)、“增量型”增量导出 备份上一次备份后改变的数据,比如: exp system/manager inctype=incremental file=040731.dmp
数据中心同步平台建设方案
数据中心同步平台建设 方案 Hessen was revised in January 2021
数据中心同步平台建设方案 第一章概述 平台建设背景 当前政府、企业的信息化的状况是,各政府和企业一般都设计和建设了属于机构、业务本身的应用、流程以及数据的信息处理系统,独立、异构、涵盖各自业务内容的信息处理系统,系统设计建设的时期不同、业务模式不同,信息化建设缺乏有效的总体规划,重复建设;缺乏统一的设计标准,大多数系统都是由不同的厂商在不同的平台上,使用不同的语言进行开发的,信息交互共享困难,存在大量的信息孤岛和流程孤岛。为了有效整合分散异构的信息资源,消除“信息孤岛”现象,提高政府和企业的信息化水平。宇思公司要开发的数据共享交换平台,主要目的是有效整合分散异构系统的信息资源,消除“信息孤岛”现象,提高政府和企业的信息化水平,灵活实现不同系统间的信息交换、信息共享与业务协同,加强信息资源管理,开展数据和应用整合,进一步发挥信息资源和应用系统的效能,提升信息化建设对业务和管理的支撑作用。 要求新构建的数据共享交换平台要遵循标准的、面向服务架构(SOA)的方式,基于先进的企业服务总线ESB技术,遵循先进技术标准和规范,为跨地域、跨部门、跨平台不同应用系统、不同数据库之间的互连互通提供包含提取、转换、传输和加密等操作的数据交换服务,实现扩展性良好的“松耦合”结构的应用和数据集成;同时要求数据共享交换平台,能够通过分布式部署和集中式管理架构,可以有效解决各节点之间数据的及时、高效地上传下达,在安
全、方便、快捷、顺畅的进行信息交换的同时精准的保证数据的一致性和准确性,实现数据的一次 数据共享交换平台-设计方案 采集、多系统共享;要求数据交换平台节点服务器适配器的可视化配置功能,可以有效解决数据交换平台的“最后一公里”问题,快速实现不同机构、不同应用系统、不同数据库之间基于不同传输协议的数据交换与信息共享,为各种应用和决策支持提供良好的数据环境。要求数据共享交换平台能够把各种纷繁复杂的数据系统集成在一起完成特定业务,提供同构数据、异构数据之间的数据抽取、格式转换、内容过滤、内容转换、同异步传输、动态部署、可视化管理监控等方面功能,支持的数据包括各主流数据库(如Oracle、SQL Server、MySQL等)、地理空间数据(如卫星影像、矢量数据)、常规文件(word、excel、pdf)等各种格式,并可以根据用户需求定制开发特定业务服务。 应用场景 场景一:中国科学院电子学研究所的信息交换需求 实现各个数据中心间的数据库层面的数据共享交换,各中心之间是双向的、实时的数据交换,各数据节点的数据库是同构的数据库系统(即Oracle),数据的类型是基于数据库表格的规则数据,字段类型包含BLOB字段类型。目前各数据节点的数据结构(表)是相同的,主要是一表对一表的数据交换,数据抽取和过滤需求比较简单。目前数据共享交换是通过Oracle GoldenGate数据库同步工具来实现的。 用户具体需求包括:
Oracle数据库恢复
Oracle 数据库恢复 一、停止ORACLE数据库 用oracle用户登录,用sqlplus的sysdba用户登录,执行shutdown immediate oracle@JSBC-SIHUA-DB01:~> sqlplus /nolog SQL*Plus: Release 10.2.0.1.0 - Production on Mon Feb 6 14:02:45 2012 Copyright (c) 1982, 2005, Oracle. All rights reserved. SQL> conn /as sysdba Connected. SQL> shutdown immediate SQL>quit 停止监听 oracle@JSBC-SIHUA-DB01:~> lsnrctl stop oracle@JSBC-SIHUA-DB01:~> ps -ef |grep ora root 4655 4524 0 Nov11 ? 00:00:48 hald-addon-storage: polling /dev/sr0 (every 16 sec) root 42514 42162 0 11:40 pts/0 00:00:00 su - oracle oracle 42515 42514 0 11:40 pts/0 00:00:00 -bash root 42853 42815 0 12:02 pts/2 00:00:00 su - oracle oracle 42854 42853 0 12:02 pts/2 00:00:00 -bash root 42924 42889 0 12:03 pts/1 00:00:00 su - oracle oracle 42925 42924 0 12:03 pts/1 00:00:00 -bash oracle 42975 42854 0 12:09 pts/2 00:00:00 ps -ef oracle 42976 42854 0 12:09 pts/2 00:00:00 grep ora 二、数据库备份 #root用户,创建sihua.bak目录 JSBC-SIHUA-DB01:/oradata # mkdir sihua.bak JSBC-SIHUA-DB01:/oradata # chown oracle:dba /oradata/sihua.bak JSBC-SIHUA-DB01:/oradata # ll total 24 drwx------ 2 root root 16384 Sep 16 11:53 lost+found drwxr-x--- 4 oracle dba 4096 Nov 8 14:16 sihua drwxr-xr-x 2 oracle dba 4096 Nov 28 12:15 sihua.bak #oracle用户 JSBC-SIHUA-DB01:/oradata # su - oracle oracle@JSBC-SIHUA-DB01:~> cd /oradata oracle@JSBC-SIHUA-DB01:/oradata> cp -r sihua sihua.bak oracle@JSBC-SIHUA-DB01:/oradata> cd sihua.bak/ oracle@JSBC-SIHUA-DB01:/oradata/sihua.bak> cd sihua/
mysql数据库主主同步方案
Mysql 数据库主主(master-master)同步方案 一、MySQL同步概述 1.MySQL数据的复制的基本介绍 目前MySQL数据库已经占去数据库市场上很大的份额,其一是由于MySQL数据的开源性和高性能,当然还有重要的一条就是免费~不过不知道还能免费多久,不容乐观的未来,但是我们还是要能熟练掌握MySQL数据的架构和安全备份等功能,毕竟现在它还算是开源界的老大吧! MySQL数据库支持同步复制、单向、异步复制,在复制的过程中一个服务器充当主服务,而一个或多个服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。 请注意当你进行复制时,所有对复制中的表的更新必须在主服务器上进行。否则,你必须要小心,以避免用户对主服务器上的表进行的更新与对从服务器上的表所进行的更新之间的冲突。 单向复制有利于健壮性、速度和系统管理: 健壮性:主服务器/从服务器设置增加了健壮性。主服务器出现问题时,你可以切换到从服务器作为备份。
速度快:通过在主服务器和从服务器之间切分处理客户查询的负荷,可以得到更好的客户响应时间。SELECT查询可以发送到从服务器以降低主服务器的查询处理负荷。但修改数据的语句仍然应发送到主服务器,以便主服务器和从服务器保持同步。如果非更新查询为主,该负载均衡策略很有效,但一般是更新查询。 系统管理:使用复制的另一个好处是可以使用一个从服务器执行备份,而不会干扰主服务器。在备份过程中主服务器可以继续处理更新。 2.MySQL数据复制的原理 MySQL复制基于主服务器在二进制日志中跟踪所有对数据库的更改(更新、删除等等)。因此,要进行复制,必须在主服务器上启用二进制日志。 每个从服务器从主服务器接收主服务器已经记录到其二进制日志的保存的更新,以便从服务器可以对其数据拷贝执行相同的更新。 认识到二进制日志只是一个从启用二进制日志的固定时间点开始的记录非常重要。任何设置的从服务器需要主服务器上的在主服务器上启用二进制日志时的数据库拷贝。如果启动从服务器时,其数据库与主服务器上的启动二进制日志时的状态不相同,从服务器很可能失败。 将主服务器的数据拷贝到从服务器的一个途径是使用LOAD DATA FROM MASTER语句。请注意LOAD DATA FROM MASTER目前只在
城市公共基础数据库建设方案.
城市基础数据库系统建设方案
1.系统概述 长期以来,政府各部门内部拥有着大量城市基础数据资源,但由于管理分散,制度规范不健全,造成重复采集、口径多乱、数出多门;各部门的指标数据自成体系,标准不一,共享程度较差。随着政府向“经济调节、市场监管、社会管理和公共服务”管理职能的转变,就要求必须能够全面、准确掌握全地区经济社会发展态势,强化政府部门掌控决策信息资源的能力,政府部门间信息资源整合与共享需求越来越紧密,但当前部门间信息共享多是点对点方式,没有统一的数据交换管理平台。因此各部门对加快解决数据资源分散管理、数据共享不足的问题需求十分迫切,需要建立城市基础数据库(以下简称智慧城市公共基础数据库)系统以解决以上问题。 依托智慧城市公共基础数据库系统的建设,可以实现各委办局、各所辖地区的经济社会综合数据采集交换,为各部门提供更广泛的信息共享支持,一方面数据信息从各委办局、各所辖地区整合接入,另一方面也为政府和这些接入部门提供全面的共享服务。同时,以智慧城市公共基础数据库指标体系建立为基础,整合来自各委办局和各所辖地区的、经过审核转换处理的数据资源,可实现对经济社会信息的统一和集中存储,确保数据的唯一性和准确性,为今后政府工作提供一致的基础数据支持。 数据整合共享只是手段,数据分析服务才是目的。依托智慧城市公共基础数据库系统建设,可有效整合各政府部门所掌握的全市经济社会信息资源,满足政府业务对统一数据资源共享需要,进而提升形势分析预测水平,对政府在发展规划、投资布局、资源环境、管理创新、科学决策等业务提供强有力支持,提高了政府部门掌控全市经济社会发展态势能力。 2.建设目标 1)建立科学合理的智慧城市公共基础数据库指标体系,力求全面反映地区经济和社会发展的总体情况: 2)有组织、有计划、持续地对政府统计部门、政府各部门以及国民经济行业管理部门负责统计的关系到地区经济与社会发展的信息资源进行收集、整合,
数据库实时同步技术解决方案
数据库实时同步技术解决方案 一、前言 随着企业的不断发展,企业信息化的不断深入,企业内部存在着各种各样的异构软、硬件平台,形成了分布式异构数据源。当企业各应用系统间需要进行数据交流时,其效率及准确性、及时性必然受到影响。为了便于信息资源的统一管理及综合利用,保障各业务部门的业务需求及协调工作,常常涉及到相关数据库数据实时同步处理。基于数据库的各类应用系统层出不穷,可能涉及到包括ACCESS、SQLSERVER、ORACLE、DB2、MYSQL等数据库。目前国内外几家大型的数据库厂商提出的异构数据库复制方案主要有:Oracle的透明网关技术,IBM的CCD表(一致变化数据表)方案,微软公司的出版者/订阅等方案。但由于上述系统致力于解决异构数据库间复杂的交互操作,过于大而全而且费用较高,并不符合一些中小企业的实际需求。 本文结合企业的实际应用实践经验,根据不同的应用类型,给出了相应的数据库实时同步应用的具体解决方案,主要包括: (1) SQLSERVER 到SQLSERVER 同步方案 (2) ORACLE 到SQLSERVER 同步方案 (3) ACCESS 到SQLSERVER/ORACLE 同步方案
二、异构数据库 异构数据库系统是相关的多个数据库系统的集合,可以实现数据的共享和透明访问,每个数据库系统在加入异构数据库系统之前本身就已经存在,拥有自己的DMBS。异构数据库的各个组成部分具有自身的自治性,实现数据共享的同时,每个数据库系统仍保有自己的应用特性、完整性控制和安全性控制。异构数据库的异构性主要体现在以下几个方面: 1、计算机体系结构的异构 各数据库可以分别运行在大型机、小型机、工作站、PC嵌入式系统中。 2、基础操作系统的异构 各个数据库系统的基础操作系统可以是Unix、Windows NT、Linux等。 3、DMBS本身的异构 可以是同为关系型数据库系统的Oracle、SQL Server等,也可以是不同数据模型的数据库,如关系、模式、层次、网络、面向对象,函数型数据库共同组成一个异构数据库系统。 三、数据库同步技术
实验8 Oracle数据库备份与恢复
实验8 Oracle数据库备份与恢复 1 实验目的 (1)掌握Oracle数据库各种物理备份方法。 (2)掌握Oracle数据库各种物理恢复方法。 (3)掌握利用RMAN工具进行数据库的备份与恢复。 (4)掌握数据的导入与导出操作。 2 实验要求 (1)对BOOKSALES数据库进行一次冷备份。 (2)对BOOKSALES数据库进行一次热备份。 (3)利用RMAN工具对BOOKSALES数据库的数据文件、表空间、控制文件、初始化参数文件、 归档日志文件进行备份。 (4)利用热备份恢复数据库。 (5)利用RMAN备份恢复数据库。 (6)利用备份进行数据库的不完全恢复。 3 实验步骤 (1)关闭BOOKSALES数据库,进行一次完全冷备份。 select file_name from dba_data_files; select member from v$logfile; select value from v$parameter where name='control_files';
(2)启动数据库后,在数据库中创建一个名为cold表,并插入数据,以改变数据库的状态。 CREATE TABLE COLD( ID NUMBER PRIMARY KEY, NAME VARCHAR2(25) );
(3)利用数据库冷备份恢复BOOKSALES数据库到备份时刻的状态并查看恢复后是否存在cold表。 (4)将BOOKSALES数据库设置为归档模式。 shutdown immediate 正常关闭数据 startup mount;将数据库启动到mount状态 3)、关闭flash闪回数据库模式,如果不关闭的话,在后面关闭归档日志的时候就会出现讨厌的ora-38774错误。 alter database flashback off alter database archivelog;发出设置归档模式的命令 alter database open;打开数据库 再次正常关闭数据库,并备份所有的数据文件和控制文件 archive log list;在将数据库设置为归档模式后,可以执行此命令进行确认 Database log mode 为Archive Mode说明当前的数据库为归档模式 Automatic archival为Enable说明启动了自动归档。
浅谈Oracle 数据库之间数据同步方案
随着信息技术的飞速发展,企业信息化建设的不断深入,使得企业业务系统数量不断增加。这时,各业务系统之间数据交互,各子业务系统与核心业务系统之间数据交互,诸如此类场景的应用需求不断出现。因此,IT部门应对此类需求的压力越来越大。比较突出的问题,主要有实时性与性能的冲突,数据交互方案的安全性与健壮性等。下面浅谈下Oracle数据库之间数据同步方案,不涉及方案的好坏选择,可供参考。 Oracle 提供的数据同步方案: 1,比较原始的,触发器/Job + DBLINK的方式,可同步和定时刷新。 2,物化视图刷新的方式,有增量刷新和完全刷新两种模式,定时刷新。 3,高级复制,分为多主复制和物化视图复制两种模式。其中多主复制能进行双向同步复制和异步复制,物化视图用于单向复制,定时刷新,与2类似。 4,流复制,可实时和非实时同步。 5,GoldenGate复制,Oracle新买的复制产品,后面应该会取代流复制。它不仅能提供Oracle数据库之间的数据复制支持,还支持在不同种数据库之间的数据同步,也可设置实时和非实时同步。 6,DataGurd,此技术主要用于灾备方案,不过在最新11gR2版本中加入了备库实时应用日志,同时能open 提供read only访问的功能。因此,可以作为读写分离,或者作为report数据库,降低系统负载的一个好的方案。 其中上面1,2,3,是采用Oracle数据库内部的机制来实现,而4,5,6是采用挖掘数据库日志的方式实现的。因此,后面3中方式在性能上会更好些。 第三方提供的数据同步方案: 主要根据实现机制分为两大类: 1,采用挖掘数据库日志的方式实现 市场上用的比较多的,如Quest SharePlex, DSG RealSync 。此类软件与Oracle 新收购的GoldenGate 工具类似。 2,采用相关软件在存储级进行复制 IBM,EMC等存储厂商可以实现,使用第三方存储管理软件,如Veritas Replication也可实现。此类方式应用场景与上面6类似。
Oracle数据库文件及恢复方法
1参数文件 对于参数文件,启动根据如下顺序查找参数文件,先查找spfile
表空间的名字 联机日志文件、数据文件的位置、个数、名字 联机日志的Sequence号码 检查点的信息 撤销段的开始或结束 归档信息 备份信息 2.1控制文件恢复: 损坏或丢失部分控制文件: SQL>shutdown immediate; SQL>startup nomount; 修改数据库控制文件,将坏的那个排除在外: SQL>alter system set control_files='+DG_ORA/ora11g/','+DG_ORA/ora11g/' scop e=spfile"; SQL>alter database open; 损坏或丢失全部控制文件: (获取恢复脚本SQL>alter database backup controlfile to trace;) STARTUP NOMOUNT CREATE CONTROLFILE REUSE DATABASE "ORA11G" NORESETLOGS FORCE LOGGING ARCHIVELOG MAXLOGFILES 200 MAXLOGMEMBERS 3 MAXDATAFILES 1024 MAXINSTANCES 8 MAXLOGHISTORY 2920 LOGFILE GROUP 1 '+DG_ORA/ora11g/ora_redo01_1' SIZE 1000M BLOCKSIZE 512, GROUP 2 '+DG_ORA/ora11g/ora_redo02_2' SIZE 1000M BLOCKSIZE 512, GROUP 3 '+DG_ORA/ora11g/ora_redo03_3' SIZE 1000M BLOCKSIZE 512, GROUP 4 '+DG_ORA/ora11g/ora_redo04_4' SIZE 1000M BLOCKSIZE 512, GROUP 5 '+DG_ORA/ora11g/ora_redo05_5' SIZE 1000M BLOCKSIZE 512,
SqlServer数据库同步方案详解
SqlServer数据库同步是项目中常用到的环节,若一个项目中的数据同时存在于不同的数据库服务器中,而这些数据库需要被多个不同的网域调用时,配置SqlServer数据库同步是个比较好的解决方案。SqlServer数据库同步的配置比较烦锁,下面对其配置详细步骤进行介绍: 一、数据复制前提条件 1. 数据库故障还原模型必需为完全还原模型。 2. 所有被同步的数据表都必须要用主键。 3. 发布服务器、分发服务器和订阅服务器必须使用计算机名称来进行SQLSERVER服务器的注册。 4. SQLSERVER必需启动代理服务,且代理服务必需以本地计算机的帐号运行。 二、解决前提条件实施步骤 1. 将数据库故障还原模型调整为完全还原模型。具体步骤如下: 打开SQLSERVER企业管理器à选择对应的数据库à单击右键选择属性à选择”选项”à 故障还原模型选择完全还原模型。 2. 所有被同步的数据表都必须要用主键。(主要指事务复制)如果没有主键的数据表,增加一个字段名称为id,类型为int 型,标识为自增1的字段。 3. 发布服务器、分发服务器和订阅服务器必须使用计算机名称来进行SQLSERVER服务器的注册。 在企业管理器里面注册的服务器,如果需要用作发布服务器、分发服务器和订阅服务器,都必需以服务器名称进行注册。不得使用IP地址以及别名进行注册,比如LOCAL, “.”以及LOCALHOST等。
如果非同一网段或者远程服务器,需要将其对应关系加到本地系统网络配置文件中。文件的具体位置在%systemroot%\system32\drivers\etc\hosts 配置方式: 用记事本打开hosts文件,在文件的最下方添加IP地址和主机名的对应关系。如图: SQLSERVER必需启动代理服务,且代理服务必需以本地计算机的帐号运行。 启动SQLSERVER代理的方法:我的电脑à单击右键”管理”à服务à SQLSERVERAGENT 将其设为自动启动。如图:
城市公共基础数据库建设方案.
1.系统概述 长期以来,政府各部门内部拥有着大量城市基础数据资源,但由于管理分散,制度规范不健全,造成重复采集、口径多乱、数出多门;各部门的指标数据自成体系,标准不一,共享程度较差。随着政府向“经济调节、市场监管、社会管理和公共服务”管理职能的转变,就要求必须能够全面、准确掌握全地区经济社会发展态势,强化政府部门掌控决策信息资源的能力,政府部门间信息资源整合与共享需求越来越紧密,但当前部门间信息共享多是点对点方式,没有统一的数据交换管理平台。因此各部门对加快解决数据资源分散管理、数据共享不足的问题需求十分迫切,需要建立城市基础数据库(以下简称智慧城市公共基础数据库)系统以解决以上问题。 依托智慧城市公共基础数据库系统的建设,可以实现各委办局、各所辖地区的经济社会综合数据采集交换,为各部门提供更广泛的信息共享支持,一方面数据信息从各委办局、各所辖地区整合接入,另一方面也为政府和这些接入部门提供全面的共享服务。同时,以智慧城市公共基础数据库指标体系建立为基础,整合来自各委办局和各所辖地区的、经过审核转换处理的数据资源,可实现对经济社会信息的统一和集中存储,确保数据的唯一性和准确性,为今后政府工作提供一致的基础数据支持。 数据整合共享只是手段,数据分析服务才是目的。依托智慧城市公共基础数 据库系统建设,可有效整合各政府部门所掌握的全市经济社会信息资源,满足政府业务对统一数据资源共享需要,进而提升形势分析预测水平,对政府在发展规划、投资布局、资源环境、管理创新、科学决策等业务提供强有力支持,提高了政府部门掌控全市经济社会发展态势能力。 2.建设目标 1)建立科学合理的智慧城市公共基础数据库指标体系,力求全面反映地区经济和社会发展的总体情况: 2)有组织、有计划、持续地对政府统计部门、政府各部门以及国民经济行业管理部门负责统计的关系到地区经济与社会发展的信息资源进行收集、整合,