一种改进的概念语义相似度计算方法

文本相似度算法
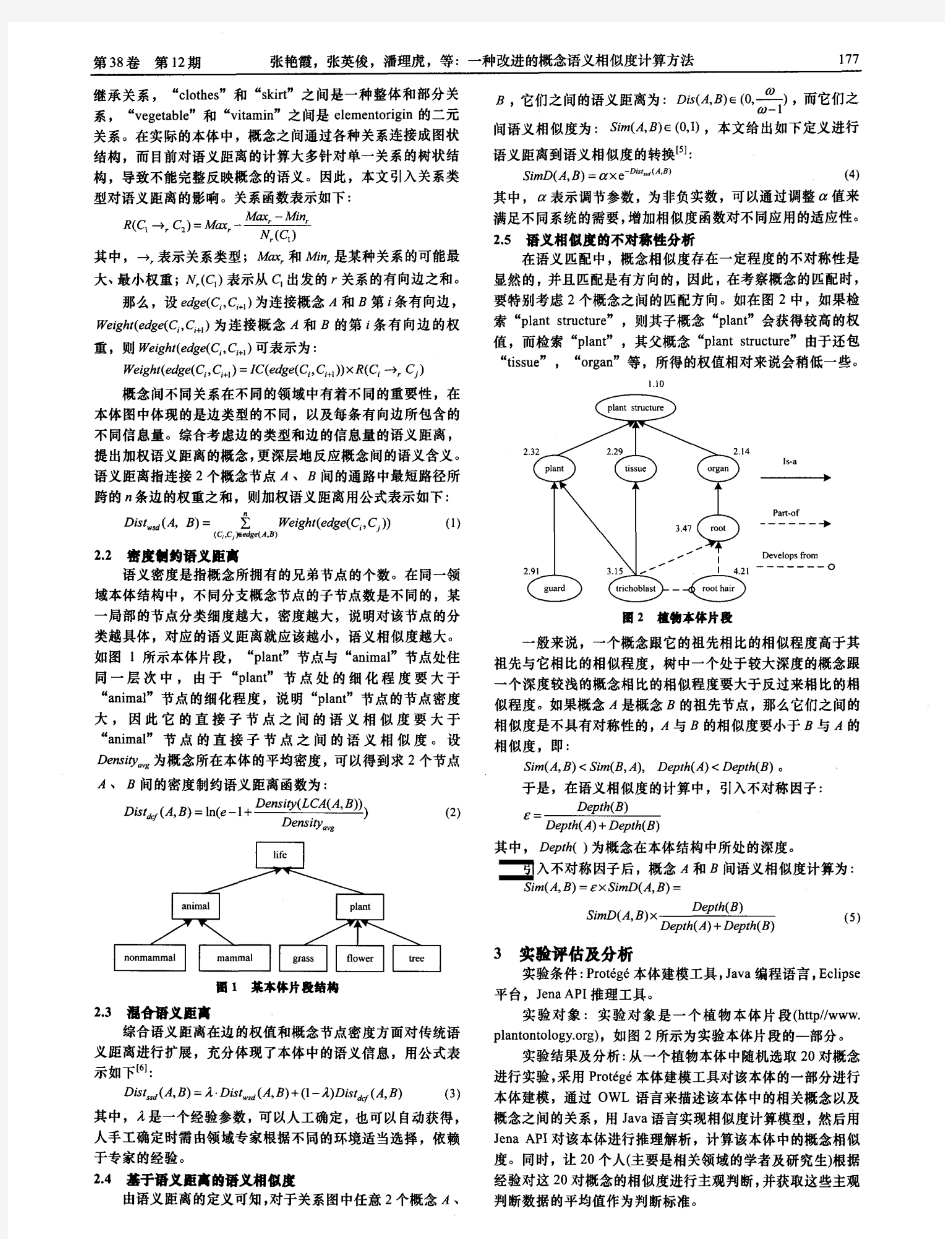
1.信息检索中的重要发明TF-IDF 1.1TF Term frequency即关键词词频,是指一篇文章中关键词出现的频率,比如在一篇M个词的文章中有N个该关键词,则 (公式1.1-1) 为该关键词在这篇文章中的词频。 1.2IDF Inverse document frequency指逆向文本频率,是用于衡量关键词权重的指数,由公式 (公式1.2-1) 计算而得,其中D为文章总数,Dw为关键词出现过的文章数。2.基于空间向量的余弦算法 2.1算法步骤 预处理→文本特征项选择→加权→生成向量空间模型后计算余弦。 2.2步骤简介 2.2.1预处理 预处理主要是进行中文分词和去停用词,分词的开源代码有:ICTCLAS。 然后按照停用词表中的词语将语料中对文本内容识别意义不大但出
现频率很高的词、符号、标点及乱码等去掉。如“这,的,和,会,为”等词几乎出现在任何一篇中文文本中,但是它们对这个文本所表达的意思几乎没有任何贡献。使用停用词列表来剔除停用词的过程很简单,就是一个查询过程:对每一个词条,看其是否位于停用词列表中,如果是则将其从词条串中删除。 图2.2.1-1中文文本相似度算法预处理流程 2.2.2文本特征项选择与加权 过滤掉常用副词、助词等频度高的词之后,根据剩下词的频度确定若干关键词。频度计算参照TF公式。 加权是针对每个关键词对文本特征的体现效果大小不同而设置的机制,权值计算参照IDF公式。 2.2.3向量空间模型VSM及余弦计算 向量空间模型的基本思想是把文档简化为以特征项(关键词)的权重为分量的N维向量表示。
这个模型假设词与词间不相关(这个前提造成这个模型无法进行语义相关的判断,向量空间模型的缺点在于关键词之间的线性无关的假说前提),用向量来表示文本,从而简化了文本中的关键词之间的复杂关系,文档用十分简单的向量表示,使得模型具备了可计算性。 在向量空间模型中,文本泛指各种机器可读的记录。 用D(Document)表示文本,特征项(Term,用t表示)指出现在文档D中且能够代表该文档内容的基本语言单位,主要是由词或者短语构成,文本可以用特征项集表示为D(T1,T2,…,Tn),其中Tk是特征项,要求满足1<=k<=N。 下面是向量空间模型(特指权值向量空间)的解释。 假设一篇文档中有a、b、c、d四个特征项,那么这篇文档就可以表示为 D(a,b,c,d) 对于其它要与之比较的文本,也将遵从这个特征项顺序。对含有n 个特征项的文本而言,通常会给每个特征项赋予一定的权重表示其重要程度,即 D=D(T1,W1;T2,W2;…,Tn,Wn) 简记为 D=D(W1,W2,…,Wn) 我们把它叫做文本D的权值向量表示,其中Wk是Tk的权重,
相似度算法比较
图像相似度计算主要用于对于两幅图像之间内容的相似程度进行打分,根据分数的高低来判断图像内容的相近程度。 可以用于计算机视觉中的检测跟踪中目标位置的获取,根据已有模板在图像中找到一个与之最接近的区域。然后一直跟着。已有的一些算法比如BlobTracking,Meanshift,Camshift,粒子滤波等等也都是需要这方面的理论去支撑。 还有一方面就是基于图像内容的图像检索,也就是通常说的以图检图。比如给你某一个人在海量的图像数据库中罗列出与之最匹配的一些图像,当然这项技术可能也会这样做,将图像抽象为几个特征值,比如Trace变换,图像哈希或者Sift特征向量等等,来根据数据库中存得这些特征匹配再返回相应的图像来提高效率。 下面就一些自己看到过的算法进行一些算法原理和效果上的介绍。 (1)直方图匹配。 比如有图像A和图像B,分别计算两幅图像的直方图,HistA,HistB,然后计算两个直方图的归一化相关系数(巴氏距离,直方图相交距离)等等。 这种思想是基于简单的数学上的向量之间的差异来进行图像相似程度的度量,这种方法是目前用的比较多的一种方法,第一,直方图能够很好的归一化,比如通常的256个bin条的。那么两幅分辨率不同的图像可以直接通过计算直方图来计算相似度很方便。而且计算量比较小。 这种方法的缺点: 1、直方图反映的是图像像素灰度值的概率分布,比如灰度值为200的像素有多少个,但是对于这些像素原来的位置在直方图中并没有体现,所以图像的骨架,也就是图像内部到底存在什么样的物体,形状是什么,每一块的灰度分布式什么样的这些在直方图信息中是被省略掉得。那么造成的一个问题就是,比如一个上黑下白的图像和上白下黑的图像其直方图分布是一模一样的,其相似度为100%。 2、两幅图像之间的距离度量,采用的是巴氏距离或者归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的办法。 3、就信息量的道理来说,采用一个数值来判断两幅图像的相似程度本身就是一个信息压缩的过程,那么两个256个元素的向量(假定直方图有256个bin条)的距离用一个数值表示那么肯定就会存在不准确性。 下面是一个基于直方图距离的图像相似度计算的Matlab Demo和实验结果. %计算图像直方图距离 %巴氏系数计算法 M=imread('1.jpg'); N=imread('2.jpg'); I=rgb2gray(M); J=rgb2gray(N); [Count1,x]=imhist(I); [Count2,x]=imhist(J); Sum1=sum(Count1);Sum2=sum(Count2); Sumup = sqrt(Count1.*Count2); SumDown = sqrt(Sum1*Sum2); Sumup = sum(Sumup); figure(1); subplot(2,2,1);imshow(I); subplot(2,2,2);imshow(J);
地址相似度算法
一、计算过程: 1、根据输入一个地址,生成一个地址每个字的数组: T1={w1,w2,w3..wn}; 比如:有两个地址广东省梅州市江南彬芳大道金利来步街xx号和广东省梅州市梅江区彬芳大道金利来步行街xx号,会生成 T1={广,东,省,梅,州,市,江,南,彬,芳,大,道,金,利,来,步,街,xx,号}; T2={广,东,省,梅,州,市,梅,江,区,彬,芳,大,道,金,利,来,步,行,街,xx,号}; 2、这两个地址的并集,对出现多次的字只保留一次 比如:T={广,东,省,州,市,梅,江,南,区,彬,芳,大,道,金,利,来,步,行,街,xx,号}; 3、求出每个t中每个词在t1和t2中出现的次数得到m和n m={m1,m2,m3..mn}; n={n1,n2,n3.nn}; 比如:t1和t2可以得到两个出现次数的数组 m={1,1,1,1,1,1,1,1,1,0,1,1,1,1,1,1,1,1,0,1,1,1}; n={1,1,1,1,1,2,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1}; 4、计算相似度 Sim=m1*n1+m2*n2+..mn*nn/sqrt(m1*m1+m2*m2+..mn*mn)* sqrt(n1*n1+n2*n2+..nn*nn) 二、计算原理: 假如这两个数组是只有{x1,y1}和{x2,y2}的数组,这两个数组可以在平面直角坐标系中用两个由原点出发的向量来表示,我们可以通过向量的夹角的大小来判断向量的相似度,夹角越小,相似度越高。计算向量的夹角,我们可以使用余弦定理,余弦定理用坐标表示的公式: 余弦的这种计算方法不止对于2维向量成立,对n维向量也成立,n维向量表示为: 所以我们可以使用这个公式得出余弦的值,值越接近1,夹角越小,两个向量越相似,这种计算方式叫做余弦相似性。
图像相似度计算
图像相似度计算 图像相似度计算主要用于对于两幅图像之间内容的相似程度进行打分,根据分数的高低来判断图像内容的相近程度。 可以用于计算机视觉中的检测跟踪中目标位置的获取,根据已有模板在图像中找到一个与之最接近的区域。然后一直跟着。已有的一些算法比如BlobTracking,Meanshift,Camshift,粒子滤波等等也都是需要这方面的理论去支撑。 还有一方面就是基于图像内容的图像检索,也就是通常说的以图检图。比如给你某一个人在海量的图像数据库中罗列出与之最匹配的一些图像,当然这项技术可能也会这样做,将图像抽象为几个特征值,比如Trace变换,图像哈希或者Sift特征向量等等,来根据数据库中存得这些特征匹配再返回相应的图像来提高效率。 下面就一些自己看到过的算法进行一些算法原理和效果上的介绍。 (1)直方图匹配。 比如有图像A和图像B,分别计算两幅图像的直方图,HistA,HistB,然后计算两个直方图的归一化相关系数(巴氏距离,直方图相交距离)等等。 这种思想是基于简单的数学上的向量之间的差异来进行图像相似程度的度量,这种方法是目前用的比较多的一种方法,第一,直方图能够很好的归一化,比如通常的256个bin条的。那么两幅分辨率不同的图像可以直接通过计算直方图来计算相似度很方便。而且计算量比较小。 这种方法的缺点: 1、直方图反映的是图像像素灰度值的概率分布,比如灰度值为200的像素有多少个,但是对于这些像素原来的位置在直方图中并没有体现,所以图像的骨架,也就是图像内部到底存在什么样的物体,形状是什么,每一块的灰度分布式什么样的这些在直方图信息中是被省略掉得。那么造成的一个问题就是,比如一个上黑下白的图像和上白下黑的图像其直方图分布是一模一样的,其相似度为100%。 2、两幅图像之间的距离度量,采用的是巴氏距离或者归一化相关系数,这种用分析数学向量的方法去分析图像本身就是一个很不好的办法。 3、就信息量的道理来说,采用一个数值来判断两幅图像的相似程度本身就是一个信息压缩的过程,那么两个256个元素的向量(假定直方图有256个bin条)的距离用一个数值表示那么肯定就会存在不准确性。 下面是一个基于直方图距离的图像相似度计算的Matlab Demo和实验结果.
相似度计算方法
基于距离的计算方法 1. 欧氏距离(Euclidean Distance) 欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式。 (1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离: (2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离: (3)两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的欧氏距离: 也可以用表示成向量运算的形式: (4)Matlab计算欧氏距离 Matlab计算距离主要使用pdist函数。若X是一个M×N的矩阵,则pdist(X)将X矩阵M行的每一行作为一个N维向量,然后计算这M个向量两两间的距离。例子:计算向量(0,0)、(1,0)、(0,2)两两间的欧式距离 X = [0 0 ; 1 0 ; 0 2] D = pdist(X,'euclidean') 结果: D = 1.0000 2.0000 2.2361 2. 曼哈顿距离(Manhattan Distance) 从名字就可以猜出这种距离的计算方法了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除
非你能穿越大楼。实际驾驶距离就是这个“曼哈顿距离”。而这也是曼哈顿距离名称的来源,曼哈顿距离也称为城市街区距离(City Block distance)。 (1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离 (2)两个n维向量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的曼哈顿距离 (3) Matlab计算曼哈顿距离 例子:计算向量(0,0)、(1,0)、(0,2)两两间的曼哈顿距离 X = [0 0 ; 1 0 ; 0 2] D = pdist(X, 'cityblock') 结果: D = 1 2 3 5. 标准化欧氏距离 (Standardized Euclidean distance ) (1)标准欧氏距离的定义 标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集X的均值(mean)为m,标准差(standard deviation)为s,那么X的“标准化变量”表示为: 而且标准化变量的数学期望为0,方差为1。因此样本集的标准化过程(standardization)用公式描述就是: 标准化后的值= ( 标准化前的值-分量的均值) /分量的标准差 经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式: 如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。
浅议语义相似度计算
浅议语义相似度计算 摘要语义相似度研究的是两个词语的相似性,被广 泛应用于信息检索、信息提取、文本词义消歧、机器翻译等领域中。本文介绍几种主要的语义相似度计算方法,以供大 一^, 家参考。 关键词语义相似度词义相似度语义距离 、引言 自然语言的词语之间关系比较复杂,我们又时常要把这 种复杂关系进行比较,所以要将其转化为简单的数量关系,再进行比较。语音相似度计算正是这样的方法。 词语的语义相似度计算有3 种方法:基于知识体系的方 法、基于语料库的方法、基于网络的方法。基于知识体系的方法,大多以WordNet 作为基础。WordNet 是语义字典,它根据词条的意义将词语分组,每一个具有相同意义的字条组称为一个synset (同义词集合)。WordNet为每一个synset提 供了简短,概要的定义,并记录不同synset之间的语义关系。 它用概念之间的语义关系形成符合常识和语法的语义关系图。基于信息量的方法主要是通过词语上下文的信息,用统计的方法求解。基于网络的方法,主要是利用搜索引擎的搜索结果进行计算。 二、语义相似度概念
信息论中任何两个词语的相似度取决于它们的共性 Commonality )和个性( Differences )。公式如下: 其中,分子表示描述A,B 共性所需要的信息量;分母表 示完整地描述A,B 所需要的信息量。 刘群、李素建认为语义相似度就是两个词语在不同的上 文中可以互相替换使用而不改变文本的句法语义结构的程度。两个词语,如果在不同的上下文中可以互相替换且不改变文本的句法语义结构的可能性越大,二者的相似度就越高,否则相似度就越低。对于两个词语 W1,W2 如果记其相似度为Sim (W1 , W2),其词语距离为Dis (W1 , Wz),根 据刘群、李素建的公式: 其中a 是一个可变参数,含义是当相似度为0.5 时的词 语距离值。 相似度被定义为一个0到1 之间的实数,当两个词语完 全一样时,相似度为1 ;是完全不同的概念时,它们的相似度 接近于0。 三、语义相似度的计算方法常用计算方法有基于知识体系的计算,基 于大规模语料 库的计算,基于网络的计算。 一)根据分类体系计算词语语义距离的方法 这种方法也称为基于树的语义相似度计算方法,大体分 为两种:一是基于距离的语义相似性测度是基于信息内容
词语相似度算法的分析与改进
词语相似度算法的分析与改进 摘要:对现有的词语相似度算法进行分析,提出一种基于知网,面向语义、可扩展的词语相似度计算方法,通过对实验结果进行分析,所提出的词语语义相似度计算方法比以前的方法更好,在计算词语相似度时,准确率更高。 关键词:词语相似度算法;义原相似度计算;概念词的相似度计算;非概念词的相似度计算 在建立主观题评分模型时,要判断句子的相似度,计算句子的相似度时,首先要处理的就是词语的相似度计算工作。目前对词语的相似度计算人们已经做了大量的研究,提出了一些较有代表性的计算方法。主要包括以下几种: 1)基于字面信息的词语相似度计算 这种算法的核心内容是:中文词语的构成句子中,一般较核心的内容都放在句子的后面。句子后面的词语在句子中所起到的作用比靠前的词语大。因此在对句子进行分析时需要给后面的字或词赋予较高的权值。 假设a和b分别代表两个词语,按照此算法,词语之间的相似度计算公式可以表示为公式1。 使用字面信息作为相似度计算的算法较简单,实现起来也方便。但该算法准确率不高,尤其是对于语义相似的词语更是难于处理。2)基于词林的词语相似度计算 对于以同义词词林作为语义分类体系进行词语相似度计算的研
究,王斌和章成志都曾作了相关探讨[1]。其核心思想是使用两个词语的语义距离来表示词语间相似度。当处理对象是一个词组或短语时,首先将其切分为义类词,并将义类词在词林的树状结构中提取出相关的语义编码,并对两个词语的语义编码进行相似度计算。基于词林的词语相似度计算较好的解决了语义相似、词形不同的词语相似度计算,但由于语义词典的完备性问题,必然会存在部分不在语义词典中的词语而无法处理。 3)基于知网的词语相似度计算 知网以概念作为描述对象,从关系层次上揭示词语的概念含义,并建立了概念关系网络,包含词语属性以及属性间关系[2]。刘群、李素建从知网的关系描述出发,研究了同一个词义所具有的多个义原间的关系,并试图计算出这些义原在计算相似度时所起到的作用,并根据这种思想提出了使用知网的语义信息来计算词语相似度的算法。 该算法在计算概念词的相似度时较准确,但在计算概念词与非概念词,非概念词与非概念词的相似度时,准确率不高。 为克服这些问题,我们采用知网作为语义资源,结合信息论中的相关理论,提出了一种面向语义的、可扩展的、多策略混合的词语相似度计算模型。 1 义原相似度计算 词语的相似度计算,最终还是要计算各词语的义源相似度。在知网中,所有词语都包含义原信息,应用知网进行相似度计算时,第
计算文本相似度几种最常用的方法,并比较它们之间的性能
计算文本相似度几种最常用的方法,并比较它们之间的性能 编者按:本文作者为Yves Peirsman,是NLP领域的专家。在这篇博文中,作者比较了各种计算句子相似度的方法,并了解它们是如何操作的。词嵌入(word embeddings)已经在自然语言处理领域广泛使用,它可以让我们轻易地计算两个词语之间的语义相似性,或者找出与目标词语最相似的词语。然而,人们关注更多的是两个句子或者短文之间的相似度。如果你对代码感兴趣,文中附有讲解细节的Jupyter Notebook地址。以下是论智的编译。 许多NLP应用需要计算两段短文之间的相似性。例如,搜索引擎需要建模,估计一份文本与提问问题之间的关联度,其中涉及到的并不只是看文字是否有重叠。与之相似的,类似Quora之类的问答网站也有这项需求,他们需要判断某一问题是否之前已出现过。要判断这类的文本相似性,首先要对两个短文本进行embedding,然后计算二者之间的余弦相似度(cosine similarity)。尽管word2vec和GloVe等词嵌入已经成为寻找单词间语义相似度的标准方法,但是对于句子嵌入应如何被计算仍存在不同的声音。接下来,我们将回顾一下几种最常用的方法,并比较它们之间的性能。 数据 我们将在两个被广泛使用的数据集上测试所有相似度计算方法,同时还与人类的判断作对比。两个数据集分别是: STS基准收集了2012年至2017年国际语义评测SemEval中所有的英语数据 SICK数据库包含了10000对英语句子,其中的标签说明了它们之间的语义关联和逻辑关系 下面的表格是STS数据集中的几个例子。可以看到,两句话之间的语义关系通常非常微小。例如第四个例子: A man is playing a harp. A man is playing a keyboard.
基于知网的语义相似度计算
基于《知网》的语义相似度计算 软件使用手册 1 功能简介 本软件是根据[刘群2002]一文中的原理编写的词汇语义相似度计算程序。 主要实现了以下功能: 1.1基于交互输入的义原查询、义原距离计算、义原相似度计算 1.2基于交互输入的词语义项查询、义项相似度计算、词语相似度计算; 1.3基于文件输入的词语义项查询、词语相似度计算; 1.4相似度计算中的参数调整。 2 安装说明 本软件包一共有四个文件: 《基于<知网>的词汇语义相似度计算》软件使用手册.doc:本使用手册 《基于<知网>的词汇语义相似度计算》论文.pdf:本软件所依据的论文,采用pdf 格式,用Acrobat Reader阅读时需要安装简体中文支持包。 自然语言处理开放资源许可证.doc:本软件包的授权许可证 WordSimilarity.zip:程序文件 软件安装时,将文件WordSimilarity.zip文件解压缩一个目录下即可,解压缩后有以下几个文件: WordSimilarity.exe:可执行程序; Glossary.dat:《知网》数据文件 Semdict.dat:《知网》数据文件 Whole.dat:《知网》数据文件 必须确保《知网》数据文件在程序执行时的当前目录下。 3 界面说明 软件使用简单的对话框界面,如下所示:
4 功能说明 4.1义原操作 4.1.1 义原查询 1.首先在“输入1”框中输入义原名称; 2.点击“察看义原1”按钮; 3.在“义项1”框中将依次显示出该义原及其所有上位义原的编号、中文、英文;类似的方法可以查询“输入2”框中的义原; 4.1.2 义原距离计算 1.首先在“输入1”和“输入2”框中输入两个义原; 2.点击“计算义原距离”按钮; 3.在“输出”框中显示两个义原的距离;
基于《知网》的词汇语义相似度计算
基于《知网》的词汇语义相似度计算1 刘群??李素建? {liuqun,lisujian}@https://www.360docs.net/doc/f51801721.html, ?中国科学院计算技术研究所 ?北京大学计算语言学研究所 摘要: 《知网》是一部比较详尽的语义知识词典。在基于实例的机器翻译中,词语相似度计算是一个重要的环节。不过,由于《知网》中对于一个词的语义采用的是一种多维的知识表示形式,这给词语相似度的计算带来了麻烦。这一点与WordNet和《同义词词林》不同。在WordNet和《同义词词林》中,所有同类的语义项(WordNet的synset或《同义词词林》的词群)构成一个树状结构,要计算语义项之间的距离,只要计算树状结构中相应结点的距离即可。而在《知网》中词语相似度的计算存在以下问题: 1.每一个词的语义描述由多个义原组成,例如“暗箱”一词的语义描述为:part|部件,%tool|用具,body|身,“写信”一词的语义描述为: #TakePicture|拍摄write|写,ContentProduct=letter|信件; 2.词语的语义描述中各个义原并不是平等的,它们之间有着复杂的关系,通过一种专门的知识描述语言来表示。 我们的工作主要包括: 1.研究《知网》中知识描述语言的语法,了解其描述一个词义所用的多个义原之间的关系,区分其在词语相似度计算中所起的作用; 2.提出利用《知网》进行词语相似度计算的算法; 3.通过实验验证该算法的有效性,并与其他算法进行比较。 关键词:《知网》词汇语义相似度计算自然语言处理 1 引言 在基于实例的机器翻译中,词语相似度的计算有着重要的作用。例如要翻译“张三写的小说”这个短语,通过语料库检索得到译例: 1)李四写的小说/the novel written by Li Si 2)去年写的小说/the novel written last year 通过相似度计算我们发现,“张三”和“李四”都是具体的人,语义上非常相似,而“去年”的语义是时间,和“张三”相似度较低,因此我们选用“李四写的小说”这个实例进行类比翻译,就可以得到正确的译文: the novel written by Zhang San 1本项研究受国家重点基础研究计划(973)支持,项目编号是G1998030507-4和G1998030510。
词语相似度计算方法
词语相似度计算方法分析 崔韬世麦范金 桂林理工大学广西 541004 摘要:词语相似度计算是自然语言处理、智能检索、文档聚类、文档分类、自动应答、词义排歧和机器翻译等很多领域的基础研究课题。词语相似度计算在理论研究和实际应用中具有重要意义。本文对词语相似度进行总结,分别阐述了基于大规模语料库的词语相似度计算方法和基于本体的词语相似度计算方法,重点对后者进行详细分析。最后对两类方法进行简单对比,指出各自优缺点。 关键词:词语相似度;语料库;本体 0 引言 词语相似度计算研究的是用什么样的方法来计算或比较两个词语的相似性。词语相似度计算在自然语言处理、智能检索、文本聚类、文本分类、自动应答、词义排歧和机器翻译等领域都有广泛的应用,它是一个基础研究课题,正在为越来越多的研究人员所关注。笔者对词语相似度计算的应用背景、研究成果进行了归纳和总结,包括每种策略的基本思想、依赖的工具和主要的方法等,以供自然语言处理、智能检索、文本聚类、文本分类、数据挖掘、信息提取、自动应答、词义排歧和机器翻译等领域的研究人员参考和应用。词语相似度计算的应用主要有以下几点: (1) 在基于实例的机器翻译中,词语相似度主要用于衡量文本中词语的可替换程度。 (2) 在信息检索中,相似度更多的是反映文本与用户查询在意义上的符合程度。 (3) 在多文档文摘系统中,相似度可以反映出局部主题信息的拟合程度。 (4) 在自动应答系统领域,相似度的计算主要体现在计算用户问句和领域文本内容的相似度上。 (5) 在文本分类研究中,相似度可以反映文本与给定的分类体系中某类别的相关程度。 (6) 相似度计算是文本聚类的基础,通过相似度计算,把文档集合按照文档间的相似度大小分成更小的文本簇。1 基于语料库的词语相似度计算方法 基于统计方法计算词语相似度通常是利用词语的相关性来计算词语的相似度。其理论假设凡是语义相近的词,它们的上下文也应该相似。因此统计的方法对于两个词的相似度算建立在计算它们的相关词向量相似度基础上。首先要选择一组特征词,然后计算这一组特征词与每一个词的相关性(一般用这组词在实际的大规模语料中在该词的上下文中出现的频率来度量),于是,对于每一个词都可以得到一个相关性的特征词向量,然后计算这些向量之间的相似度,一般用向量夹角余弦的计算结果作为这两个词的相似度。 Lee利用相关熵,Brown采用平均互信息来计算词语之间的相似度。李涓子(1999)利用这种思想来实现语义的自动排歧;鲁松(2001)研究了如何利用词语的相关性来计算词语的相似度。PBrownetc采用平均互信息来计算词语之间的相似度。基于统计的定量分析方法能够对词汇间的语义相似性进行比较精确和有效的度量。基于大规模语料库进行的获取受制于所采用的语料库,难以避免数据稀疏问题,由于汉语的一词多义现象,统计的方法得到的结果中含有的噪声是相当大的,常常会出现明显的错误。 2 基于本体库的词语相似度计算方法 2.1 常用本体库 关于Ontology的定义有许多,目前获得较多认同的是R.Studer的解释:“Ontology是对概念体系的明确的、形式
信息检索几种相似度计算方法作对比
句子相似度地计算在自然语言处理具有很重要地地位,如基于实例地机器翻译( )、自 动问答技术、句子模糊匹配等.通过对术语之间地语义相似度计算,能够为术语语义识别[]、术语聚类[]、文本聚类[]、本体自动匹配[]等多项任务地开展提供重要支持.在已有地术语相似度计算方法中,基于搜索引擎地术语相似度算法以其计算简便、计算性能较高、不受特定领域语料库规模和质量制约等优点而越来越受到重视[]. 相似度计算方法总述: 《向量空间模型信息检索技术讨论》,刘斌,陈桦发表于计算机学报, 相似度():指两个文档内容相关程度地大小,当文档以向量来表示时,可以使用向量文 档向量间地距离来衡量,一般使用内积或夹角地余弦来计算,两者夹角越小说明似度 越高.由于查询也可以在同一空间里表示为一个查询向量(见图),可以通过相似度计算 公式计算出每个档向量与查询向量地相似度,排序这个结果后与设立地阈值进行比较. 如果大于阈值则页面与查询相关,保留该页面查询结果;如果小于则不相关,过滤此页.这样就可以控制查询结果地数量,加快查询速度.资料个人收集整理,勿做商业用途 《相似度计算方法综述》 相似度计算用于衡量对象之间地相似程度,在数据挖掘、自然语言处理中是一个基础 性计算.其中地关键技术主要是两个部分,对象地特征表示,特征集合之间地相似关系. 在信息检索、网页判重、推荐系统等,都涉及到对象之间或者对象和对象集合地相似 性地计算.而针对不同地应用场景,受限于数据规模、时空开销等地限制,相似度计算 方法地选择又会有所区别和不同.下面章节会针对不同特点地应用,进行一些常用地相 似度计算方法进行介绍.资料个人收集整理,勿做商业用途 内积表示法: 《基于语义理解地文本相似度算法》,金博,史彦君发表于大连理工大学学报, 在中文信息处理中,文本相似度地计算广泛应用于信息检索、机器翻译、自动问答系统、文本挖掘等领域,是一个非常基础而关键地问题,长期以来一直是人们研究地热点和难点.计算机对于中文地处理相对于对于西文地处理存在更大地难度,集中体现在对文本分词 地处理上.分词是中文文本相似度计算地基础和前提,采用高效地分词算法能够极大地提 高文本相似度计算结果地准确性.本文在对常用地中文分词算法分析比较地基础上,提出 了一种改进地正向最大匹配切分()算法及歧义消除策略,对分词词典地建立方式、分词 步骤及歧义字段地处理提出了新地改进方法,提高了分词地完整性和准确性.随后分析比 较了现有地文本相似度计算方法,利用基于向量空间模型地方法结合前面提出地分词算法,给出了中文文本分词及相似度计算地计算机系统实现过程,并以科技文本为例进行了 测试,对所用方法进行了验证.这一课题地研究及其成果对于中文信息处理中地多种领域 尤其是科技类文本相似度地计算比较,都将具有一定地参考价值和良好地应用前景.资料 个人收集整理,勿做商业用途
深度学习解决 NLP 问题:语义相似度计算
导语 在NLP领域,语义相似度的计算一直是个难题:搜索场景下query和Doc的语义相似度、feeds场景下Doc和Doc的语义相似度、机器翻译场景下A句子和B句子的语义相似度等等。本文通过介绍DSSM、CNN-DSSM、LSTM-DSSM 等深度学习模型在计算语义相似度上的应用,希望给读者带来帮助。 0. 提纲 1. 背景 2. DSSM 3. CNN-DSSM 4. LSTM-DSSM 5. 后记 6. 引用 1. 背景 以搜索引擎和搜索广告为例,最重要的也最难解决的问题是语义相似度,这里主要体现在两个方面:召回和排序。
在召回时,传统的文本相似性如BM25,无法有效发现语义类query-Doc 结果对,如"从北京到上海的机票"与"携程网"的相似性、"快递软件"与"菜鸟裹裹"的相似性。 在排序时,一些细微的语言变化往往带来巨大的语义变化,如"小宝宝生病怎么办"和"狗宝宝生病怎么办"、"深度学习"和"学习深度"。 DSSM(Deep Structured Semantic Models)为计算语义相似度提供了一种思路。 本文的最后,笔者结合自身业务,对DSSM 的使用场景做了一些总结,不是所有的业务都适合用DSSM。 2. DSSM DSSM [1](Deep Structured Semantic Models)的原理很简单,通过搜索引擎里Query 和Title 的海量的点击曝光日志,用DNN 把Query 和Title 表达为低纬语义向量,并通过cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。 DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层
本体相似度计算方法
2012.12 52 本体相似度计算方法研究 张路 长江大学工程技术学院 湖北 434020 摘要:MD3模型是一种系统的跨本体概念间相似度的计算方法,这种方法无需建立一个集成的共享本体。本文在MD3 模型的基础上,充分利用本体对概念的描述信息,重点讨论了跨本体概念间非层次关系相似度的计算,把MD3 模型扩展到 EMD3 模型,使得概念间相似度的计算理论上更全面、更精确。 关键词:本体;元数据模型;语义相似度;MD3模型 0 引言 本体映射算法以两个本体作为输入,然后为这两个本体的各个元素(概念、属性或者关系) 建立相应的语义关系。相似性提取是本体映射的一个重要步骤,它主要是进行概念相似度的计算,提高语义相似度计算精度成为提高语义信息检索质量的关键之一。语义相似度一般是指计算本体概念间的相似度,多数方法所考虑的概念是基于一个本体的,跨本体 概念间的方法比较少。MD3模型是一种典型的计算跨本体概念间相似度的方法。 1 MD3模型 Triple Matching-Distance Model(MD3)模型是一种跨本体概念间相似度计算框架。计算实体类a 和b 之间的相似度通过计算同义词集、特征属性和语义邻居之间的加权和,公式如下: Sim(a,b)=wS synsets (a,b)+uS features (a, b)+vS neighborhoods (a,b) 其中w, u, v 表示了各组成部分的重要性。特征属性细化为组成部分、功能以及其他属性。概念a 和b 的语义邻居及其特征属性(即概念的部分、功能及其他属性)也通过同义词集合描述,每一个相似度的计算都通过Tversky 公式: (,)(,)(1(,))A B S a b A B a b A B a b B A αα=+-+-- 其中A, B 分别表示概念a 和b 的描述集合,A-B 表示属于A 但不属于B 的术语集(B-A 相反)。参数(,)a b α由概念a 和b 和在各自层次结构中的深度确定。 2 EMD3模型 MD3模型的不足在于没有考虑对象实例对概念的影响,同 时其语义邻居只考虑语义关系中层次之间的相似度,没有考虑非层次之间的相似度。本文在MD3模型的基础上,参考了其概念名称相似度、特征属性,对本体的结构以及概念描述两方面做了扩充,重点讨论了跨本体概念间非层次关系的相似度的比较和实例对概念相似度的影响,把MD3模型扩展到Extension of Triple Mapping Distance model (EMD3)模型。 2.1 概念属性的相似度 属性有属性名称、属性数据类型、属性实例数据等要素,因此判断两个属性是否相似主要从这三个要素来考虑。属性名称、属性类型本身是文本类型,是字符串,因此可以采用字符串相似度计算方法进行判定。例如用Humming distance 来比较两字符串。设两字符串s 和t ,则它们之间的相似度可由下式给出: min(,) 1 (,)1[( ())]/max(,)s t i Sim s t f i s t s t ==-+-∑ 其中:若s[i]=t[i],则f(i)=0;否则f(i)=1。由于每个概念的实例对该概念的每个属性都分配了一个相应的值,对于其他类型的数据,可以采用下面介绍的方法进行计算。 设概念A 的属性为a i ,概念B 的属性为b j ,两个属性之间的相似度的计算公式为: Sim(a i ,b j )= w 1s 1(a i ,b j )+ w 2s 2(a i ,b j )+ w 3s 3(a i ,b j ) 其中w i 是权重,代表属性名称、数据类型、属性实例数据对属性相似度计算的重要程度,且和为1。设概念A,B 之间总共计算出m 个sim(a i ,b j ),并设置相应的权值k l ,则概念之间基于属性的相似度为: 1 1 (,)/(,)m m l i j l l l k Sim a b k Sim A B ==∑∑ =
向量的相似度计算常用方法个
向量的相似度计算常用方法 相似度的计算简介 关于相似度的计算,现有的几种基本方法都是基于向量(Vector)的,其实也就是计算两个向量的距离,距离越近相似度越大。在推荐的场景中,在用户-物品偏好的二维矩阵中,我们可以将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,或者将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法。 共8种。每人选择一个。第9题为选做。 编写程序实现(这是第一个小练习,希望大家自己动手,java实现)。计算两个向量的相似性: 向量1(0.15, 0.45, 0.l68, 0.563, 0.2543, 0.3465, 0.6598, 0.5402, 0.002) 向量2(0.81, 0.34, 0.l66, 0.356, 0.283, 0.655, 0.4398, 0.4302, 0.05402) 1、皮尔逊相关系数(Pearson Correlation Coefficient) 皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值在[-1,+1] 之间。 s x , s y 是 x 和 y 的样品标准偏差。 类名:PearsonCorrelationSimilarity 原理:用来反映两个变量线性相关程度的统计量 范围:[-1,1],绝对值越大,说明相关性越强,负相关对于推荐的意义小。 说明:1、不考虑重叠的数量;2、如果只有一项重叠,无法计算相似性(计算过程被除数有n-1);3、如果重叠的值都相等,也无法计算相似性(标准差为0,做除数)。
该相似度并不是最好的选择,也不是最坏的选择,只是因为其容易理解,在早期研究中经常被提起。使用Pearson线性相关系数必须假设数据是成对地从正态分布中取得的,并且数据至少在逻辑范畴内必须是等间距的数据。Mahout中,为皮尔森相关计算提供了一个扩展,通过增加一个枚举类型(Weighting)的参数来使得重叠数也成为计算相似度的影响因子。 2、欧几里德距离(Euclid ean Distance) 最初用于计算欧几里德空间中两个点的距离,假设 x,y 是 n 维空间的两个点,它们之间的欧几里德距离是: 可以看出,当 n=2 时,欧几里德距离就是平面上两个点的距离。当用欧几里德距离表示相似度,一般采用以下公式进行转换:距离越小,相似度越大。 类名:EuclideanDistanceSimilarity 原理:利用欧式距离d定义的相似度s,s=1 / (1+d)。 范围:[0,1],值越大,说明d越小,也就是距离越近,则相似度越大。 说明:同皮尔森相似度一样,该相似度也没有考虑重叠数对结果的影响,同样地,Mahout通过增加一个枚举类型(Weighting)的参数来使得重叠数也成为计算相似度的影响因子。 3、Cosine 相似度(Cosine Similarity) Cosine 相似度被广泛应用于计算文档数据的相似度: 类名: UncenteredCosineSimilarity 原理:多维空间两点与所设定的点形成夹角的余弦值。 范围:[-1,1],值越大,说明夹角越大,两点相距就越远,相似度就越小。 说明:在数学表达中,如果对两个项的属性进行了数据中心化,计算出来的余弦相似度和皮尔森相似度是一样的,在mahout中,实现了数据中心化的过程,所以皮尔森相似度值也是数据中心化后的余弦相似度。另外在新版本
语义相似度的计算方法研究
语义相似度的计算方法研究 信息与计算科学余牛指导教师:冉延平 摘要语义相似度计算在信息检索、信息抽取、文本分类、词义排歧、基于实例的机器翻译等很多领域中都有广泛的应用.特别是近几十年来随着Internet技术的高速发展,语义相似度计算成为自然语言处理和信息检索研究的重要组成部分.本文介绍了几种典型的语义相似度的计算方法,总结了语义相似度计算的两类策略,其中重点介绍了一种基于树状结构中语义词典Hownet的语义相似度计算方法,最后对两类主要策略进行了简单的比较.关键词语义相似度;语义距离;知网;语料库 The Reseach of Computing Methods about Semantic Similarity YU Niu (Department of Mathematics and Statistics,Tianshui Normal University , 741000) Abstract Semantic similarity is broadly used in many applications such as information retrieval, information extraction, text classification, word sense disambiguation, example-based machine translation and so on.Especially with the rapid development of Internet technology in recent decades, Calculation of semantic similarity has always been an important part of natural language processing and information retrieval research .This paper introduces several main methods of calculating semantic similarity , then two strategies of semantic similarity measurement are summarized, and we focuse on the Hownet based on the stucture of tree and use them to calculate the semantic similarity ,and finally the two strategies are easily compared . Key words Semantic similarity, Semantic distance,Hownet, Corpus
相似度计算公式资料
相似度计算 在数据挖掘中经常需要用到比较两个东西的相似度。比如搜索引擎要避免非常相似的文档出现在结果的前几页,再比如很多网站上都有的“查找与你口味相似的用户”、“你可能喜欢什么什么”之类的功能。后者其实是很大的一块叫做“协同过滤”的研究领域,留待以后详谈。 首先我们定义两个集合S,T的Jaccard相似度: Sim(S,T) = |S,T的交集| / |S,T的并集|。直观上就容易感觉出这是一个很简单而且比较合理的度量,我不清楚有没有什么理论上的分析,在此省略。下面先主要说一下文档的相似度。 如果是判断两个文档是否完全相同,问题就变得很简单,只要简单地逐字符比较即可。但是在很多情况下并不是这样,比如网站文章的转载,主体内容部分是相同的,但是不同网页本身有自己的Logo、导航栏、版权声明等等,不能简单地直接逐字符比较。这里有一个叫做Shingling的方法,其实说起来很圡,就是把每相邻的k个字符作为一个元素,这样整篇文档就变成了一个集合。比如文档是"banana",若k=2,转化以后得到集合为{"ba","an","na"},于是又变成了前述集合相似度的问题。关于k值的设置,显然过小或过大都不合适,据说比较短的比如email之类可以设k=5,比如长的文章如论文之类可以设k=9。 当然,这是一个看上去就很粗糙的算法,这里的相似度比较只是字符意义上的,如果想进行语义上的比较就不能这么简单了(我觉得肯定有一摞摞的paper在研究这个)。不过同样可以想见的是,在实际中这个粗糙算法肯定表现得不坏,速度上更是远优于复杂的NLP方法。在实际工程中,必然糙快猛才是王道。 有一点值得注意的是,Shingling方法里的k值比较大时,可以对每个片段进行一次hash。比如k=9,我们可以把每个9字节的片段hash成一个32bit的整数。这样既节省了空间又简化了相等的判断。这样两步的方法和4-shingling占用空间相同,但是会有更好的效果。因为字符的分布不是均匀的,在4-shingling中实际上大量的4字母组合没有出现过,而如果是9-shingling再hash成4个字节就会均匀得多。 在有些情况下我们需要用压缩的方式表示集合,但是仍然希望能够(近似)计算出集合之间的相似度,此时可用下面的Minhashing方法。 首先把问题抽象一下,用矩阵的每一列表示一个集合,矩阵的行表示集合中所有可能的元素。若集合c包含元素r,则矩阵中c列r行的元素为1,否则为0。这个矩阵叫做特征矩阵,往往是很稀疏的。以下设此矩阵有R行C列。 所谓minhash是指把一个集合(即特征矩阵的一列)映射为一个0..R-1之间的值。具体方法是,以等概率随机抽取一个0..R-1的排列,依此排列查找第一次出现1的行。例如有集合S1={a,d}, S2={c}, S3 = {b,d,e}, S4 = {a,c,d},特征矩阵即如下S1 S2 S3 S4 0a 1 0 0 1 1b 0 0 1 0 2c 0 1 0 1