《应用数理统计》吴翊李永乐第四章 回归分析课后作业参考答案

第四章 回归分析
课后作业参考答案
4.1 炼铝厂测得铝的硬度x 与抗张强度y 的数据如下:
i x
68 53 70 84 60 72 51 83 70 64 i y
288 298 349 343 290 354 283 324 340 286
(1)求y 对x 的回归方程
(2)检验回归方程的显著性(05.0=α) (3)求y 在x =65处的预测区间(置信度为0.95) 解:(1) 1、计算结果
一元线性回归模型εββ++=x y 10只有一个解释变量
其中:x 为解释变量,y 为被解释变量,10,ββ为待估参数,ε位随机干扰项。
(
)()()
(
)685.222
,959.4116,541.35555
.76725
.19745
.109610
,5.3151,5.6712
2
1
21
2
1
12
1
2
12
11=-=
=-===
=-=-==-=--==-=-======∑∑∑∑∑∑∑∑========n Q U L Q L L U y n y
y
y L y x n y x y y x x L x n x
x
x L n y n y x n x e
e yy e xx
xy
n
i i
n
i i yy n
i i i n i i i xy n
i i
n
i i xx n
i i n i i σ
使用普通最小二乘法估计参数10,ββ
上述参数估计可写为95.193??,80.1?1
01
=-===x y L L xx
xy βββ 所求得的回归方程为:x y
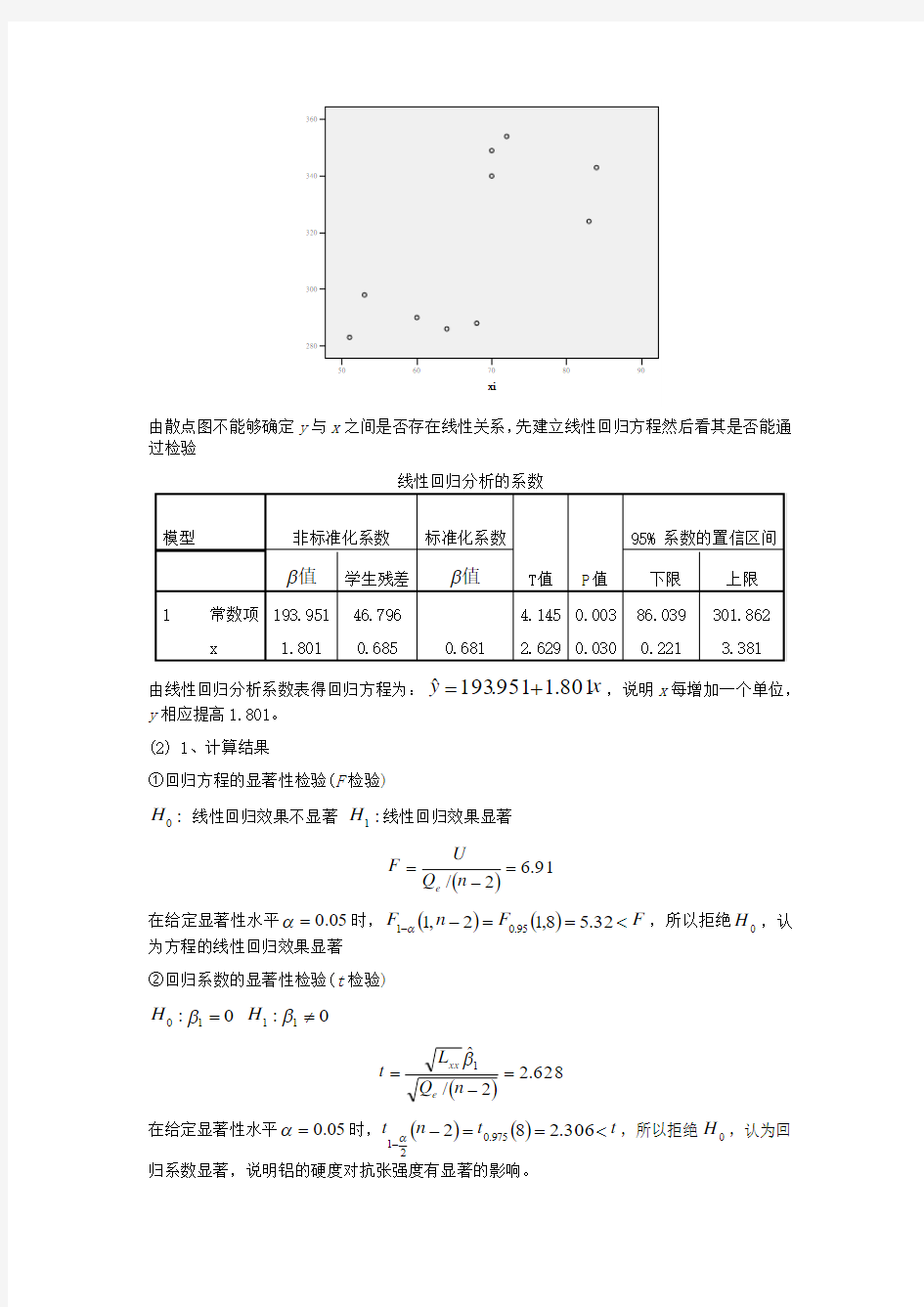
80.195.193?+= 实际意义为:当铝的硬度每增加一个单位,抗张强度增加1.80个单位。 2、软件运行结果 根据所给数据画散点图
过检验
由线性回归分析系数表得回归方程为:x y
801.1951.193?+=,说明x 每增加一个单位,
y 相应提高1.801。
(2) 1、计算结果
①回归方程的显著性检验(F 检验)
:0H 线性回归效果不显著 :1H 线性回归效果显著
()
91.62/=-=
n Q U
F e
在给定显著性水平05.0=α时,()()F F n F <==--32.58,12,195.01α,所以拒绝0H ,认为方程的线性回归效果显著 ②回归系数的显著性检验(t 检验)
0:10=βH 0:11≠βH
()
628.22/?1=-=
n Q L t e xx β
在给定显著性水平05.0=α时,()()t t n t
<==--
306.282975.02
1α
,所以拒绝0H ,认为回
归系数显著,说明铝的硬度对抗张强度有显著的影响。
③回归方程的线性显著性检验(r 检验)
:0H x 与y 线性无关 :1H x 与y 线性相关
681.0==
yy
xx xy L L L r
在给定显著性水平05.0=α时,()()r r n r <==--6319.08295.01α,所以拒绝0H ,认为x 与y 之间具有线性关系。 2、软件运行结果
由上表得r =0.681,说明y 和x 的之间具有线性关系。
由方差分析表知,p 值小于给定的α,说明回归方程通过F 检验,回归方程显著。
由线性回归分析系数表知,p 值小于给定的α,认为回归系数显著,说明铝的硬度对抗张强度有显著的影响。
综上所述,建立的回归方程通过以上的r 检验、F 检验、t 检验,证明回归方程效果显著。 (3)当0x =65时,代入上述回归方程得0y =310.996
()()()
xx
e L x
x
n
n t x 2
010112?-++-=-ασ
δ
在1-α的置信度下,0y 的置信区间为()()[]0000?,?x y x y
δδ+- 95%置信度下的预测区间为 [255.988 366.004]。
4.2 在硝酸钠(3NO N a )溶解度试验中,对不同温度C t 0
测得溶解于100ml 的水中的硝酸钠i t
0 4 10 15 21 29 36 51 68
i y
66.7
71.0
76.3
80.6
85.7
92.9
99.9
113.6 125.1
(1)求回归方程
(2)检验回归方程的显著性
(3)求y 在C t 0
25=时的预测区间(置信度为0.95) 解: (1) 1、计算结果
一元线性回归模型εββ++=x y 10只有一个解释变量
其中:t 为解释变量,y 为被解释变量,10,ββ为待估参数,ε位随机干扰项。
(
)()()
(
)015.12
,208.7,25.308646
.30938
.35394060
9,2.901,2612
2
1
21
2
1
12
1
2
12
11=-=
=-===
=-=-==-=--==-=-======∑∑∑∑∑∑∑∑========n Q U L Q L L U y n y
y
y L y x n y x y y x x L x n x
x
x L n y n y t n t e
e yy e xx
xy
n
i i
n
i i yy n
i i i n i i i xy n
i i
n
i i xx n
i i n i i σ
使用普通最小二乘法估计参数10,ββ
上述参数估计可写为5313.67??,8719.0?1
01
=-===x y L L xx
xy βββ 所求得的回归方程为:t y 8719.05313.67?+=
实际意义为:在温度为0时,硝酸钠的溶解度为67.5313,温度每升高一度,溶解度增加
0.8719。 2、软件运行结果 根据所给数据画散点图
由线性回归分析系数表得回归方程为:t y
872.0531.67?+=,说明温度每增加一度,溶解度相应提高0.872。 (2) 1、计算结果
①回归方程的显著性检验(F 检验)
:0H 线性回归效果不显著 :1H 线性回归效果显著 ()
359.29962/=-=
n Q U
F e
在给定显著性水平05.0=α时,()()F F n F <==--59.57,12,195.01α,所以拒绝0H ,认为方程的线性回归效果显著 ②回归系数的显著性检验(t 检验)
0:10=βH 0:11≠βH
()
735.542/?1=-=
n Q L t e xx β
在给定显著性水平05.0=α时,()()t t n t
<==--
3646.272975.02
1α
,所以拒绝0H ,认为
回归系数显著,说明温度对硝酸钠的溶解度有显著的影响。
③回归方程的线性显著性检验(r 检验)
:0H t 与y 线性无关 :1H t 与y 线性相关
999.0==
yy
xx xy L L L r
在给定显著性水平05.0=α时,()()r r n r <==--6664.07295.01α,所以拒绝0H ,认为t 与y 线性相关。 2、软件运行结果
由上表得r =0.999,说明y 和t 之间线性关系显著。
由方差分析表知,F 值很大,p 值很小,回归方程通过F 检验,说明回归方程显著。
由线性回归分析系数表知,p 值很小,通过t 检验,认为回归系数显著,说明温度对硝酸钠的溶解度有显著的影响。
综上所述,建立的回归方程通过以上的r 检验、F 检验、t 检验,证明回归方程效果显著。 (3)当0x =25时,代入上述回归方程得0y =89.328
()()()
xx
e L x
x
n
n t x 2
010112?-++-=-ασ
δ
在1-α的置信度下,0y 的置信区间为()()[]0000?,?x y x y
δδ+- 95%置信度下的预测区间为 [86.8113 91.8450]。
4.3 对同一个问题,两人分别在做线性回归。
甲:取样本值()111,,2,1,,n i y x i i =,得回归方程x b a y 11???+= 乙:取样本值()222,,2,1,,n i y x i i =,得回归方程x b a y 2
2???+= (1)如何判断这两个回归方程是否相等(给定显著性水平α)? (2)若相等,如何求一个共同的回归方程? 解:
①检验2
22101:σσ=H
若()1,1212
12
22
1-->=
-
n n F
Q
Q F e e α
,则拒绝01H
其中2
2
21e e Q Q ≥ ②检验2102:b b H = 若()41
1???212
12
12
211-+>+-=
-
n n t
L L b b t x x x x e α
σ
,则拒绝02H
其中4
?212221-++=n n Q Q e e e σ
③检验2103:a a H = 若()41
1???212
12121212
211-+>+++-=
-
n n t
L x L x n n a a
t x x x x e α
σ
,则拒绝03H
这三步当中只有一个是拒绝原假设,则两回归方程不同。 (2)共同的回归方程为:
x b a y
???+= 其中,2
2112
22121???x x x x x x x x L L L b L b b ++=
2
122112121221122112221????n n x n x n L L L b L b n n y n y n x b y a x x x x x x x x ++?++-++=-=
4.6 某化工厂研究硝化得率y 与硝化温度1x 、硝化液中硝酸浓度2x 之间的统计相关关系。进行10次试验,得实验数据如下表:
()C x i 01 16.5
19.7 15.5 21.4 20.8 16.6 23.1 14.5 21.3 16.4 ()%2i x 93.4 90.8 86.7 83.5 92.1 94.9 89.6 88.1 87.3
83.4
()%i y 90.92 91.13 87.95 88.57 90.44 89.87 91.03
88.03 89.93 85.58
试求y 对21,x x 的回归方程。
解:用所给的数据建立多元回归方程并进行检验
由上表得r =0.927,说明y 和x 的之间线性关系显著。
由方差分析表知,F 值很大,p 值很小,回归方程通过F 检验,说明回归方程显著。
由线性回归分析系数表知,1x 和2x 的p 值都很小,通过了t 检验,认为回归系数显著,说明硝化温度和硝化液中硝酸浓度对硝化得率均有显著的影响。 通过以上的r 检验、F 检验、t 检验,证明回归方程效果显著。 最后得到的回归方程为:
21352.0336.0798.51?x x y
++= 说明硝化温度每增加一度,硝化得率增加0.336%;硝化液中硝酸浓度每增加1%,硝化得率增
加0.352%。
4.4 某建材实验室再作陶粒混凝土强度试验中,考察每立方米混凝土的水泥用量x (kg )对28天后的混凝土抗压强度y(3/kg cm )的影响,测得如下数据
(1)求y 对x 的线性回归方程,并问:每立方米混凝土中增加1公斤水泥时,可提高的抗压强度是多少?
(2)检验线性回归方程效果的显著性(0.05α=); (3)求回归系数1β的区间估计(10.95α-=); (4)求022.5()x kg =时,0y 的预测值及预测区间。 解:1.计算结果
(1)一元线性回归模型:只有一个解释变量
01Y X ββε=++
Y 为被解释变量,X
为解释变量,0β与1β为待估参数, ε为随机干扰项。 用普通最小二乘法(Ordinary least squares, OLS )估计0β和1β
记
上述参数估计量可以写成:
带入数字得:
()()()
()()1
22
2
2
1150*56.9260*89.715026056.989.712
0.304
115026015026012
i i
i
x y x
β∧
++-++++=
=
=++-++∑∑ ()0111
(56.989.7)0.304**15026010.2831212
Y X ββ∧
∧
=-=
++-++= 所以求得的回归方程为:y=10.283+0.304x ,即 x 每增加一个单位,y 相应提高0.304
()22221
)(∑∑∑∑-
=-=i i i i X n X X X x 22010111(,)()n n
i
i i i i Q Q Y X ββε
ββ=====--∑∑最小
01
01
01,??(,)min (,)Q Q ββββββ=即,∑∑∑∑∑-=--=i i i i i i i i Y X n Y X Y Y X X y x 1
))((
(2)回归方程的显著性检验:
总体平方和,简记为S 总或Lyy
回归平方和,记为S 回或U
残差平方和,记为S 残或Qe
SST=SSE(Qe)+SSR(U)
对总体参数1β提出假设
H0: β1=0, H1:β1≠0
因为
所以,拒绝原假设。 T 检验:
22
=2.393/(12-2)=0.239
i
e σ
∧=
=∑
0.9750.975(2)(10) 2.2281t n t -==
因为|t|>2.2281,所以拒绝原假设,即1
β对方程有显著影响。 线性关系的显著性检验:
2
?22-
=∑n e i
σ
22()1323.820
i i SST y Y Y ==-=∑∑22??()1321.427i i SSR y Y Y ==-=∑∑22?() 2.393i i i SSE e Y Y ==-=∑∑0.95(1,10) 1.49
F F >=()()
XY n
i i L r X X Y Y ρ=
--=
∑=
代入数据得:r=0.999 拒绝原假设,即X 与Y 有显著的线性相关关系 对总体参数0β提出假设
H0: β0=0, H1:β0≠0
因为|t|>2.2281,所以拒绝原假设,即0β对方程有显著影响 (3)回归系数的区间估计,构造统计量
11(2)e t n ββσ∧
∧
--
(1-α)的置信度下, 1β的置信区间是
得出:β1的95%
,-0.313]。
(4)求预测值
代入数据计算得: 当x=22.5时,y=17.123 求预测区间
构造统计量
其中:
)
2(~?0
?0
0--=-n t S Y Y t Y
Y )))(11(,0(~?2
2
02
00∑-++-i
x X X n N Y Y σ)
,(~20100σββX N Y +)))(1(,(~?2
2020100∑-++i
x X X n X N Y σββ0
0?
??12.092
t S ββ=
=
=0010
???估计值:Y X ββ=+00010
?()()E Y E Y X ββ==+10.050.999(2)(10)0.6581
r
r n r α-=>-==2
2
1011??((2)/(2)/e e t n t n ααβσβσ∧∧
--
--+-
从而在
1-α的置信度下, Y0的置信区间为
代入数据计算得:
95%置信度的预测区间为 [15.43 18.815 ] (2)SPSS 软件运行结果: 根据数据的散点图为:
由上图可知,x 与y 基本成线性关系。建立线性模型,进行相关检验:
由上表可以看出相关系数R 接近于1,y 和x 的线性关系显著。
由方差分析表可见,F 值很大,伴随概率p 很小,说明回归方程通过F 检验,及回归方程非常显著
02
2
?000
?0??Y
Y Y Y S t Y Y S t Y --?+<
2
02
?0
∑-++=-i
Y
Y x X X n S σ
=2.393/(12-2)=0.239
(1)y 对x 的线性回归方程,由上图可得回归方程:y=10.28+0.304x 。p 很小,通过T 检验。说明x 对y 有显著影响。X 增加一个单位y 相应提高0.304。
(2)回归方程效果的显著性,以上的R 检验、F 检验和t 检验,已证明。 (3)β1的95%的置信区间为[-0.295,-0.313]。 (4)计算后的预测值表:
x y 预测值 预测值误差 预测值均数
的标准误差 预测下限 预测上限
150 56.9 55.881 1.019 0.266 55.289 56.473 160 58.3 58.921 -0.621 0.232 58.404 59.438 170 61.6 61.96 -0.36 0.201 61.512 62.409 180 64.6 65 -0.4 0.174 64.612 65.389 190 68.1 68.04 0.06 0.154 67.697 68.383 200 71.3 71.08 0.22 0.143 70.762 71.398 210 74.1 74.12 -0.02 0.143 73.802 74.438 220 77.4 77.16 0.24 0.154 76.817 77.503 230 80.2 80.2 0 0.174 79.811 80.588 240 82.6 83.24 -0.64 0.201 82.791 83.688 250 86.4 86.279 0.121 0.232 85.762 86.796 260 89.7
89.319 0.381
0.266 88.727 89.911 22.5 . 17.123 .
0.76
15.43
18.815
从上表查得,当x=22.5时,y=17.123 95%置信度的预测区间为 [15.43 18.815 ]
2
?22
-=
∑n e i
σ
4.5假设x 是一可控变量,y 是一随机变量,服从正态分布,现在不同的x 值下分别对y 进
(1)
假设x 与y 之间有线性关系,求y 对x 的经验回归方程,并求2()D y σ=的无偏估计;
(2) 求回归系数201,0.95ββσ和的置信区间;
(3) 检验x 和y 之间的线性回归方程是否显著(0.05α=); (4) 求y 的0.95预测区间;
(5)
为了把观测值y 限制在区间(1.08,1.68),需要把x 的值限制在和范围之内?(0.05α=)
解:1.计算过程及结果
(1)一元线性回归模型:只有一个解释变量
01Y X ββε=++
Y 为被解释变量,X 为解释变量,0β与1β为待估参数, ε为随机干扰项。 用普通最小二乘法(Ordinary least squares, OLS )估计0β和1β
记
上述参数估计量可以写成:
带入数据得:
()22221
)(∑∑∑∑-
=-=i i i i X n X X X x 2201011
1
(,)()n
n
i
i i i i Q Q Y X ββε
ββ=====--∑∑最小
01
0101
,??(,)min (,)Q Q ββββββ=即,∑∑∑∑∑-=--=i i i i i i i i Y X n Y X Y Y X X y x 1
))((
()()()()()
12
2
221
0.25*2.57 1.00*1.000.25 1.00 2.57 1.0017 2.070
10.25 1.000.25 1.0017i i
i x y x β∧
++-
++++==
=-++-++∑
∑ ()0111
(2.57 1.00)( 2.070)**0.25 1.00 3.0331217
Y X ββ∧
∧
=-=
++--++= 所以求得的回归方程为:y=3.033-2.070x 可以证明,2
σ的最小二乘估计量为
它是关于2
σ的无偏估计量,也称为剩余方差(残差的方差)。
代入数据得:
22
0.030
0.0022
172
i
e n σ
∧=
=
=--∑
(2)
(2)t n ∧
-
11(2)/e t n ββσ∧
∧
--
于是得到:(1-α)的置信度下的置信区间是 再由
22
(2)e
Q n χσ- ,还可得2σ的置信水平为1α-的置信区间
22122,(2)(2)e e Q Q n n ααχχ-??
??
??--????
这里, 2
2
0.9750.250.97517,(15)27.488,(15) 6.262,(15) 2.1315n t χχ==== 代入数据得到,
2
?2
2-=∑n e
i
σ
22?()0.030e i i i Q e Y Y ==-=∑
∑22
0011??((2)(2)e e t n t n ααβσβσ∧
∧
----+-
2
2
1011??((2)/(2)/e e t n t n ααβσβσ∧∧
--
--+-
β0的95%的置信区间为[2.951,3.116]; β1的95%的置信区间为[-2.183,-1.957];
2σ的95%的置信区间为
[Qe/X 2
1-α/2(n-2),Qe/X 2
α/2(n-2)]=[0.03/27.488,0.03/6.262]=[0.0011,0.0048] (3)回归方程的显著性检验:
总体平方和,简记为S 总或Lyy
回归平方和,记为S 回或U
残差平方和,记为S 残或Qe
SST=SSE(Qe)+SSR(U)
对总体参数1β提出假设
H0: β1=0, H1:β1≠0
因为
所以,拒绝原假设。 T 检验:
22
0.002
i
e σ
∧=
=∑
t
因为|t|>2.1315,所以拒绝原假设,即1β
对方程有显著影响。 线性关系的显著性检验:
2
?22-=∑n
e i
σ
22() 3.069
i i SST y Y Y ==-=∑∑22??() 3.039i i
SSR y Y Y ==-=∑∑22?()0.030
i i i SSE e Y Y ==-=∑∑0.95(1,15) 1.43
F F >=()()
XY n
i i L r X X Y Y ρ=
--=
∑=
代入数据得:r=0.995 拒绝原假设,即X 与Y 有显著的线性相关关系 对总体参数0β提出假设
H0: β0=0, H1:β0≠0
因为|t|>2.1315,所以拒绝原假设,即0β对方程有显著影响 (4)
12
()(y (),()e x t n x x αδσαδδ∧
-∧∧
=-??-+????
从而得到的置信水平为1-的预测区间为y y
其中
12()(0.0445 2.13150.1125e x t n αδσ-=-?=(5)因
011
2
011
2
1
()1
()
e e x y u
x y u
α
α
σββσββ∧
∧
-
∧
∧
-
''=+-''''=
+-
代入数据得
(
)(
)
()(
)01210
12
1
11 1.68 1.96 3.0330.6115
2.070
11 1.08 1.96 3.0330.90132.070e e
x y u x y u αασββσββ
--'''=
--=+-=-'''=+-=+-=-
2.SPSS 软件运行结果
根据数据得到散点图:
0?
??78.354
t S ββ=
=
=10.050.995(2)(15)0.4821
r
r n r α-=>-==
由上表可以看出相关系数R接近于1,y和x的线性关系显著。
由上图可得回归方程:y=3.033+(-2.070)x。p很小,通过T检验。说明x对y有显著影响。
由方差分析表可见,F值很大,伴随概率sig.p很小,说明回归方程通过F检验,及回归方程非常显著
22
0.030
0.0022
172
i
e n σ
∧=
=
=--∑
(2)
由上表可以看出β0的95%的置信区间为[2.951,3.116];β1的95%的置信区间为[-2.183,
-1.957];σ2的置信区
间为[Qe/X 2
1-α/2(n-2),
Qe/X 2
α/2(n-2)]=[0.030/27.488,0.030/6.262]=[0.0011,0.0048] (3)回归方程的显著性已在(1)中证明。 (4)可以得到L xx =n σx 2
=17*(0.21056)2
=0.7103,
17
2
1
0.702917
i
i x
x ==
=∑
12()(0.0445 2.13150.1125e x t n αδσ-=-?=y 的置信度为95%预测区间为[ (),()y x y x δδ∧
∧
-+]
4.7某种商品的需求量y,消费者的平均收入x 以及商品的价格x 的统计数据如下表
求y 对1x 、2x 的回归方程。
由上图可知 012111.692,0.014,7.188βββ===-,得到回归方程: 0121212
111.6920.0147.188y x x x x βββ=++=+-。 从表中得出,x1的T 检验未通过,x1和x2有较强的共线性。
则由后退法,删除第一个变量,得到线性回归分析的系数表如下:
a.因变量:商品的需求y
得到回归方程: 0222
140.00010.000y x x ββ=+=-
4.8 铝合金化学铣切工艺中,为了便于生产操作,需要对腐蚀速度进行控制,因此要考查腐蚀液温度()C x 0
1
、
碱浓度()l g x /2
、腐蚀液含铝量()l g x /3
对腐蚀速度()min /mm y 的影响,
应用回归分析,第5章课后习题参考答案.docx
第5 章自变量选择与逐步回归 思考与练习参考答案 自变量选择对回归参数的估计有何影响? 答:回归自变量的选择是建立回归模型得一个极为重要的问题。如果模型中丢 掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关 性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。 自变量选择对回归预测有何影响? 答:当全模型(m元)正确采用选模型(p 元)时,我们舍弃了m-p 个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差, 所以全模型正确而误用选模型有利有弊。当选模型(p 元)正确采用全模型(m 元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选 模型的大,所以回归自变量的选择应少而精。 如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣? 答:如果所建模型主要用于预测,则应使用C p 统计量达到最小的准则来衡量回 归方程的优劣。 试述前进法的思想方法。 答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm 建立m个一元线性回归方程, 并计算 F 检验值,选择偏回归平方和显著的变量(F 值最大且大于临界值)进入回归方程。每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的 F 检验值,选择偏回归平方和显著的两变量变 量(F 值最大且大于临界值)进入回归方程。在确定引入的两个自变量以后,再 引入一个变量,建立m-2 个三元线性回归方程,计算它们的 F 检验值,选择偏
1.第一章课后习题及答案
第一章 1.(Q1) What is the difference between a host and an end system List the types of end systems. Is a Web server an end system Answer: There is no difference. Throughout this text, the words “host” and “end system” are used interchangeably. End systems inc lude PCs, workstations, Web servers, mail servers, Internet-connected PDAs, WebTVs, etc. 2.(Q2) The word protocol is often used to describe diplomatic relations. Give an example of a diplomatic protocol. Answer: Suppose Alice, an ambassador of country A wants to invite Bob, an ambassador of country B, over for dinner. Alice doesn’t simply just call Bob on the phone and say, come to our dinner table now”. Instead, she calls Bob and suggests a date and time. Bob may respond by saying he’s not available that particular date, but he is available another date. Alice and Bob continue to send “messages” back and forth until they agree on a date and time. Bob then shows up at the embassy on the agreed date, hopefully not more than 15 minutes before or after the agreed time. Diplomatic protocols also allow for either Alice or Bob to politely cancel the engagement if they have reasonable excuses. 3.(Q3) What is a client program What is a server program Does a server program request and receive services from a client program Answer: A networking program usually has two programs, each running on a different host, communicating with each other. The program that initiates the communication is the client. Typically, the client program requests and receives services from the server program.
应用回归分析,第8章课后习题参考答案
第8章 非线性回归 思考与练习参考答案 8.1 在非线性回归线性化时,对因变量作变换应注意什么问题? 答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。如: (1) 乘性误差项,模型形式为 e y AK L αβε =, (2) 加性误差项,模型形式为y AK L αβ ε = + 对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。 一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。 8.2为了研究生产率与废料率之间的关系,记录了如表8.15所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。 表8.15 生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%) 5.2 6.5 6.8 8.1 10.2 10.3 13.0 解:先画出散点图如下图: 5000.00 4000.003000.002000.001000.00x 12.00 10.00 8.006.00 y
从散点图大致可以判断出x 和y 之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。 (1)二次曲线 SPSS 输出结果如下: Model Summ ary .981 .962 .942 .651 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x. ANOVA 42.571221.28650.160.001 1.6974.424 44.269 6 Regression Residual Total Sum of Squares df Mean Square F Sig.The independent variable is x. Coe fficients -.001.001-.449-.891.4234.47E -007.000 1.417 2.812.0485.843 1.324 4.414.012 x x ** 2 (Constant) B Std. E rror Unstandardized Coefficients Beta Standardized Coefficients t Sig. 从上表可以得到回归方程为:72? 5.8430.087 4.4710y x x -=-+? 由x 的系数检验P 值大于0.05,得到x 的系数未通过显著性检验。 由x 2的系数检验P 值小于0.05,得到x 2的系数通过了显著性检验。 (2)指数曲线 Model Summ ary .970 .941 .929 .085 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x.
分析化学课后作业答案汇总
2014年分析化学课后作业参考答案 P25: 1.指出在下列情况下,各会引起哪种误差?如果是系统误差,应该采用什么方法减免? (1) 砝码被腐蚀; (2) 天平的两臂不等长; (3) 容量瓶和移液管不配套; (4) 试剂中含有微量的被测组分; (5) 天平的零点有微小变动; (6) 读取滴定体积时最后一位数字估计不准; (7) 滴定时不慎从锥形瓶中溅出一滴溶液; (8) 标定HCl 溶液用的NaOH 标准溶液中吸收了CO 2。 答:(1)系统误差中的仪器误差。减免的方法:校准仪器或更换仪器。 (2)系统误差中的仪器误差。减免的方法:校准仪器或更换仪器。 (3)系统误差中的仪器误差。减免的方法:校准仪器或更换仪器。 (4)系统误差中的试剂误差。减免的方法:做空白实验。 (5)随机误差。减免的方法:多读几次取平均值。 (6)随机误差。减免的方法:多读几次取平均值。 (7)过失误差。 (8)系统误差中的试剂误差。减免的方法:做空白实验。 3.滴定管的读数误差为±0.02mL 。如果滴定中用去标准溶液的体积分别为2mL 和20mL 左右,读数的相对误差各是多少?从相对误差的大小说明了什么问题? 解:因滴定管的读数误差为mL 02.0±,故读数的绝对误差mL a 02.0±=E 根据%100?T E = E a r 可得 %1%100202.02±=?±= E mL mL mL r %1.0%1002002.020±=?±=E mL mL mL r 这说明,量取两溶液的绝对误差相等,但他们的相对误差并不相同。也就是说,当被测定的量较大时,测量的相对误差较小,测定的准确程度也就较高。 4.下列数据各包括了几位有效数字? (1)0.0330 (2) 10.030 (3) 0.01020 (4) 8.7×10-5 (5) pKa=4.74 (6) pH=10.00 答:(1)三位有效数字 (2)五位有效数字 (3)四位有效数字 (4) 两位有效数字 (5) 两位有效数字 (6)两位有效数字 9.标定浓度约为0.1mol ·L -1的NaOH ,欲消耗NaOH 溶液20mL 左右,应称取基准物质H 2C 2O 4·2H 2O 多少克?其称量的相对误差能否达到0. 1%?若不能,可以用什么方法予以改善?若改用邻苯二甲酸氢钾为基准物,结果又如何? 解:根据方程2NaOH+H 2C 2O 4·H 2O==Na 2C 2O 4+3H 2O 可知, 需H 2C 2O 4·H 2O 的质量m 1为: g m 13.007.1262 020 .01.01=??=
应用回归分析第章课后习题答案
第6章 6.1 试举一个产生多重共线性的经济实例。 答:例如有人建立某地区粮食产量回归模型,以粮食产量为因变量Y,化肥用量为X1,水浇地面积为X2,农业投入资金为X3。由于农业投入资金X3与化肥用量X1,水浇地面积X2有很强的相关性,所以回归方程效果会很差。再例如根据某行业企业数据资料拟合此行业的生产函数时,资本投入、劳动力投入、资金投入与能源供应都与企业的生产规模有关,往往出现高度相关情况,大企业二者都大,小企业都小。 6.2多重共线性对回归参数的估计有何影响? 答:1、完全共线性下参数估计量不存在; 2、参数估计量经济含义不合理; 3、变量的显著性检验失去意义; 4、模型的预测功能失效。 6.3 具有严重多重共线性的回归方程能不能用来做经济预测? 答:虽然参数估计值方差的变大容易使区间预测的“区间”变大,使预测失去意义。但如果利用模型去做经济预测,只要保证自变量的相关类型在未来期中一直保持不变,即使回归模型中包含严重多重共线性的变量,也可以得到较好预测结果;否则会对经济预测产生严重的影响。 6.4多重共线性的产生于样本容量的个数n、自变量的个数p有无关系? 答:有关系,增加样本容量不能消除模型中的多重共线性,但能适当消除多重共线性造成的后果。当自变量的个数p较大时,一般多重共线性容易发生,所以自变量应选择少而精。 6.6对第5章习题9财政收入的数据分析多重共线性,并根据多重共线性剔除变量。将所得结果与逐步回归法所得的选元结果相比较。 5.9 在研究国家财政收入时,我们把财政收入按收入形式分为:各项税收收入、企业收入、债务收入、国家能源交通重点建设收入、基本建设贷款归还收入、国家预算调节基金收入、其他收入等。为了建立国家财政收入回归模型,我们以财政收入y(亿元)为因变量,自变量如下:x1为农业增加值(亿元),x2为工业增加值(亿元),x3为建筑业增加值(亿元),x4为人口数(万人),x5为社
课后习题及答案
1 文件系统阶段的数据管理有些什么缺陷试举例说明。 文件系统有三个缺陷: (1)数据冗余性(redundancy)。由于文件之间缺乏联系,造成每个应用程序都有对应的文件,有可能同样的数据在多个文件中重复存储。 (2)数据不一致性(inconsistency)。这往往是由数据冗余造成的,在进行更新操作时,稍不谨慎,就可能使同样的数据在不同的文件中不一样。 (3)数据联系弱(poor data relationship)。这是由文件之间相互独立,缺乏联系造成的。 2 计算机系统安全性 (1)为计算机系统建立和采取的各种安全保护措施,以保护计算机系统中的硬件、软件及数据; (2)防止其因偶然或恶意的原因使系统遭到破坏,数据遭到更改或泄露等。 3. 自主存取控制缺点 (1)可能存在数据的“无意泄露” (2)原因:这种机制仅仅通过对数据的存取权限来进行安全控制,而数据本身并无安全性标记 (3)解决:对系统控制下的所有主客体实施强制存取控制策略 4. 数据字典的内容和作用是什么 数据项、数据结构 数据流数据存储和加工过程。 5. 一条完整性规则可以用一个五元组(D,O,A,C,P)来形式化地表示。 对于“学号不能为空”的这条完整性约束用五元组描述 D:代表约束作用的数据对象为SNO属性; O(operation):当用户插入或修改数据时需要检查该完整性规则; A(assertion):SNO不能为空; C(condition):A可作用于所有记录的SNO属性; P(procdure):拒绝执行用户请求。 6.数据库管理系统(DBMS)
:①即数据库管理系统(Database Management System),是位于用户与操作系统之间的 一层数据管理软件,②为用户或应用程序提供访问DB的方法,包括DB的建立、查询、更 新及各种数据控制。 DBMS总是基于某种数据模型,可以分为层次型、网状型、关系型、面 向对象型DBMS。 7.关系模型:①用二维表格结构表示实体集,②外键表示实体间联系的数据模型称为关系模 型。 8.联接查询:①查询时先对表进行笛卡尔积操作,②然后再做等值联接、选择、投影等操作。 联接查询的效率比嵌套查询低。 9. 数据库设计:①数据库设计是指对于一个给定的应用环境,②提供一个确定最优数据模 型与处理模式的逻辑设计,以及一个确定数据库存储结构与存取方法的物理设计,建立起 既能反映现实世界信息和信息联系,满足用户数据要求和加工要求,又能被某个数据库管 理系统所接受,同时能实现系统目标,并有效存取数据的数据库。 10.事务的特征有哪些 事务概念 原子性一致性隔离性持续性 11.已知3个域: D1=商品集合=电脑,打印机 D3=生产厂=联想,惠普 求D1,D2,D3的卡尔积为: 12.数据库的恢复技术有哪些 数据转储和和登录日志文件是数据库恢复的
应用回归分析第2章课后习题参考答案
2.1 一元线性回归模型有哪些基本假定? 答:1. 解释变量 1x , ,2x ,p x 是非随机变量,观测值,1i x ,,2 i x ip x 是常数。 2. 等方差及不相关的假定条件为 ? ? ? ? ? ? ??????≠=====j i n j i j i n i E j i i ,0),,2,1,(,),cov(,,2,1, 0)(2 σεεε 这个条件称为高斯-马尔柯夫(Gauss-Markov)条件,简称G-M 条件。在此条件下,便可以得到关于回归系数的最小二乘估计及误差项方差2σ估计的一些重要性质,如回归系数的最小二乘估计是回归系数的最小方差线性无偏估计等。 3. 正态分布的假定条件为 ???=相互独立 n i n i N εεεσε,,,,,2,1),,0(~212 在此条件下便可得到关于回归系数的最小二乘估计及2σ估计的进一步结果,如它们分别是回归系数的最及2σ的最小方差无偏估计等,并且可以作回归的显著性检验及区间估计。 4. 通常为了便于数学上的处理,还要求,p n >及样本容量的个数要多于解释变量的个数。 在整个回归分析中,线性回归的统计模型最为重要。一方面是因为线性回归的应用最广泛;另一方面是只有在回归模型为线性的假设下,才能的到比较深入和一般的结果;再就是有许多非线性的回归模型可以通过适当的转化变为线性回归问题进行处理。因此,线性回归模型的理论和应用是本书研究的重点。 1. 如何根据样本),,2,1)(;,,,(21n i y x x x i ip i i =求出p ββββ,,,,210 及方差2σ的估计; 2. 对回归方程及回归系数的种种假设进行检验; 3. 如何根据回归方程进行预测和控制,以及如何进行实际问题的结构分析。 2.2 考虑过原点的线性回归模型 n i x y i i i ,,2,1,1 =+=εβ误差n εεε,,,21 仍满足基本假定。求1β的最小二 乘估计。 答:∑∑==-=-=n i n i i i i x y y E y Q 1 1 2112 1)())(()(ββ
仪器分析课后习题答案
第十二章 【12.5】 如果要用电解的方法从含1.00×10-2mol/L Ag +,2.00mol/L Cu 2+的溶液中,使Ag+完全析出(浓度达到10-6mol/L)而与Cu 2+完全分离。铂阴极的电位应控制在什么数值上?(VS.SCE,不考虑超电位) 【解】先算Cu 的 起始析出电位: Ag 的 起始析出电位: ∵ Ag 的析出电位比Cu 的析出电位正 ∴ Ag 应当先析出 当 时,可视为全部析出 铂阴极的电位应控制在0.203V 上,才能够完全把Cu2+ 和Ag+分离 【12.6】 (5)若电解液体积为100mL ,电流维持在0.500A 。问需要电解多长时间铅离子浓度才减小到 0.01mol/L ? 【解】(1)阳极: 4OH - ﹣4e - →2H 2O+O 2 Ea θ =1.23V 阴极:Pb 2++2e - → Pb Ec θ =﹣ 0.126V ()220.059,lg 0.3462 Cu Cu Cu Cu v ??Θ++ ??=+ =??(,)0.059lg[]0.681Ag Ag Ag Ag v ??Θ++=+=6[]10/Ag mol l +-=3 3 -63 SCE =0.799+0.059lg10=0.445v 0.445v-0.242v=0.203v ????'=-=
Ea=1.23+(0.0592/4)×4×lg10﹣5=0.934V Ec=﹣0.126+(0.0592/2)×lg0.2=﹣0.147V E=Ec﹣Ea=﹣1.081V (2)IR=0.5×0.8=0.4V (3)U=Ea+ηa﹣(Ec+ηc)+iR=2.25V (4)阴极电位变为:﹣0.1852 同理:U=0.934+0.1852+0.77+0.4=2.29V (5)t=Q/I=nzF/I=(0.200-0.01)×0.1×2×96487/0.500=7.33×103S 【12.7】 【12.8】用库仑滴定法测定某有机一元酸的摩尔质量,溶解 0.0231g纯净试样于乙醇与水的混合溶剂中, 以电解产生的 OH-进行滴定,用酚酞作指示剂,通过0.0427A 的恒定电流,经6min42s到达终点,试计算此有机酸的摩尔质量。【解】 m=(M/Fn)×it t=402s;i=0.0427;m=0.0231g;F=96485;n=1 解得 M = 129.8g/mol
回归分析练习题及参考答案
地区人均GDP/元人均消费水平/元 22460 11226 34547 4851 5444 2662 4549 7326 4490 11546 2396 2208 1608 2035 求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。 (5)检验回归方程线性关系的显著性(0.05 α=)。 (6)如果某地区的人均GDP为5000元,预测其人均消费水平。 (7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 解:(1) 可能存在线性关系。 (2)相关系数:
有很强的线性关系。 (3)回归方程:734.6930.309 y x =+ 回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 系数(a) 模型非标准化系数标准化系数 t 显著性B 标准误Beta 1 (常量)734.693 139.540 5.265 0.003 人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% (4) 模型汇总 模型R R 方调整R 方标准估计的误 差 1 .998a.996 .996 247.303 a. 预测变量: (常量), 人均GDP。 人均GDP对人均消费的影响达到99.6%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 模型摘要 模型R R 方调整的R 方估计的标准差 1 .998(a) 0.996 0.996 247.303
应用回归分析课后答案
应用回归分析课后答案 第二章一元线性回归 解答:EXCEL结果: SUMMARY OUTPUT 回归统计 Multiple R R Square Adjusted R Square 标准误差 观测值5 方差分析 df SS MS F Significance F 回归分析125 残差3 总计410 Coefficients标准误差t Stat P-value Lower 95%Upper 95%下限%上限% Intercept X Variable 15 RESIDUAL OUTPUT 观测值预测Y残差 1 2 3 4 5 SPSS结果:(1)散点图为:
(2)x 与y 之间大致呈线性关系。 (3)设回归方程为01y x ββ∧ ∧ ∧ =+ 1β∧ = 12 2 1 7()n i i i n i i x y n x y x n x -- =- =-=-∑∑ 0120731y x ββ-∧- =-=-?=- 17y x ∧ ∴=-+可得回归方程为 (4)22 n i=1 1()n-2i i y y σ∧∧=-∑ 2 n 01i=1 1(())n-2i y x ββ∧∧=-+∑ =222 22 13???+?+???+?+??? (10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1 169049363 110/3= ++++= 1 330 6.13 σ∧=≈ (5)由于2 11(, )xx N L σββ∧ :
t σ ∧ == 服从自由度为n-2的t分布。因而 /2 |(2)1 P t n α α σ ?? ?? <-=- ?? ?? 也即: 1/211/2 (p t t αα βββ ∧∧ ∧∧ -<<+=1α - 可得 1 95% β∧的置信度为的置信区间为(7-2.3537+2.353即为:(,) 2 2 00 1() (,()) xx x N n L ββσ - ∧ + : t ∧∧ == 服从自由度为n-2的t分布。因而 /2 (2)1 P t n α α ∧ ?? ?? ?? <-=- ?? ?? ?? ?? ?? 即 0/200/2 ()1 pβσββσα ∧∧∧∧ -<<+=- 可得 1 95%7.77,5.77 β∧- 的置信度为的置信区间为() (6)x与y的决定系数 2 21 2 1 () 490/6000.817 () n i i n i i y y r y y ∧- = - = - ==≈ - ∑ ∑ (7)
(完整版)多元线性回归模型习题及答案
多元线性回归模型 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定系数为0.8500,则调整后的多重决定系数为( D ) A. 0.8603 B. 0.8389 C. 0.8655 D.0.8327 2.下列样本模型中,哪一个模型通常是无效的(B ) A. i C (消费)=500+0.8 i I (收入) B. d i Q (商品需求)=10+0.8i I (收入)+0.9i P (价格) C. s i Q (商品供给)=20+0.75i P (价格) D. i Y (产出量)=0.650.6i L (劳动)0.4 i K (资本) 3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在0.05的显著性水 平上对1 b 的显著性作t 检验,则1 b 显著地不等于零的条件是其统计量t 大于等于( C ) A. )30(05.0t B. ) 28(025.0t C. ) 27(025.0t D. ) 28,1(025.0F 4.模型 t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明模型中存在( C ) A.异方差性 B.序列相关 C.多重共线性 D.高拟合优度 6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) A.t(n-k+1) B.t(n-k-2) C.t(n-k-1) D.t(n-k+2)
课后习题答案及讲解
5-1 设二进制符号序列为,试以矩形脉冲为例,分别画出相应的单极性码波形、双极性码波形、单极性归零码波形、双极性归零码波形、二进制差分码波形及八电平码波形。 解: 1 1 0 0 1 0 0 0 1 1 1 0 单极性码: 双极性码: 单极性归零码: 双极性归零码: 二进制差分码: 八电平码: 5-7 已知信息代码为,求相应的AMI码、HDB3码、PST码及双相码。解:信息代码: AMI码:++1 HDB3码:+1000+V-B00+V0-1+1 PST码:+0-+-+-+-++- 双相码: 5-8 已知信息代码为011,试确定相应的AMI码及HDB3码,并分别
画出它们的波形图。 解: 1 0 1 0 0 0 0 0 1 1 0 0 0 0 1 1 AMI码:+1 0 -1 0 0 0 0 0 +1 –1 0 0 0 0 +1 -1 HDB3码:+1 0 -1 0 0 0 –V 0 +1 –1 +B 0 0 +V –1 +1 5-9 某基带传输系统接收滤波器输出信号的基本脉冲为如图P5-5所示的三角形脉冲: (1)求该基带传输系统的传输函数H(ω); (2)假设信道的传输函数C(ω)=1,发送滤波器和接收滤波器具有相同的传输函数,即G T(ω)=G R(ω),试求这时G T(ω)或G R(ω)的表示式。 P5-5 解:(1)H(ω)=∫∞ -∞ h(t)e-jωt dt =∫0Ts/2(2/T s)te-jωt dt +∫Ts Ts/22(1-t/T s)e-jωt dt
=2∫Ts Ts/2 e-jωt dt+2/T s∫ Ts/2 t e-jωt dt-2/T s ∫Ts Ts/2 t e-jωt dt =- 2 e-jωt/(jω)︱Ts Ts/2+2/T s [-t/(jω)+1/ω2] e-jωt︱ Ts/2 -2/T s [-t/(jω)+1/ω2] e-jωt︱Ts Ts/2 =2 e-jωTs/2(2- e-jωTs/2- e-jωTs/2)/(ω2T s) =4 e-jωTs/2[1-cos(ωT s/2)]/(ω2T s) =8 e-jωTs/2sin2(ωT s/4)/(ω2T s) =2/T s·Sa2(ωT s/4) e-jωTs/2(2)∵H(ω)=G T(ω)C(ω)G R(ω) C(ω)=1, G T(ω)=G R(ω) ∴G T(ω)=G R(ω)=√2/T s·Sa(ωT s/4) e-jωTs/4 5-11 设基带传输系统的发送滤波器、信道及接收滤波器组成总特性为H(ω),若要求以2/T s波特的速率进行数据传输,试检验图P5-7各种H(ω)满足消除抽样点上的码间干扰的条件否? s s s s (a) (b) s s s s
应用回归分析,第7章课后习题参考答案
第7章岭回归 思考与练习参考答案 7.1 岭回归估计是在什么情况下提出的? 答:当自变量间存在复共线性时,|X’X|≈0,回归系数估计的方差就很大,估计值就很不稳定,为解决多重共线性,并使回归得到合理的结果,70年代提出了岭回归(Ridge Regression,简记为RR)。 7.2岭回归的定义及统计思想是什么? 答:岭回归法就是以引入偏误为代价减小参数估计量的方差的一种回归方法,其统计思想是对于(X’X)-1为奇异时,给X’X加上一个正常数矩阵 D, 那么X’X+D接近奇异的程度就会比X′X接近奇异的程度小得多,从而完成回归。但是这样的回归必定丢失了信息,不满足blue。但这样的代价有时是值得的,因为这样可以获得与专业知识相一致的结果。 7.3 选择岭参数k有哪几种方法? 答:最优 是依赖于未知参数 和 的,几种常见的选择方法是: 岭迹法:选择 的点能使各岭估计基本稳定,岭估计符号合理,回归系数没有不合乎经济意义的绝对值,且残差平方和增大不太多;
方差扩大因子法: ,其对角线元 是岭估计的方差扩大因子。要让 ; 残差平方和:满足 成立的最大的 值。 7.4 用岭回归方法选择自变量应遵循哪些基本原则? 答:岭回归选择变量通常的原则是: 1. 在岭回归的计算中,我们通常假定涉及矩阵已经中心化和标准化了,这样可以直接比较标准化岭回归系数的大小。我们可以剔除掉标准化岭回归系数比较稳定且绝对值很小的自变量; 2. 当k值较小时,标准化岭回归系数的绝对值并不很小,但是不稳定,随着k的增加迅速趋近于零。像这样岭回归系数不稳定、震动趋于零的自变量,我们也可以予以剔除; 3. 去掉标准化岭回归系数很不稳定的自变量。如果有若干个岭回归系数不稳定,究竟去掉几个,去掉那几个,要根据去掉某个变量后重新进行岭回归分析的效果来确定。
数学分析课后习题答案(华东师范大学版)
习题 1.验证下列等式 (1) C x f dx x f +='?)()( (2)?+=C x f x df )()( 证明 (1)因为)(x f 是)(x f '的一个原函数,所以?+='C x f dx x f )()(. (2)因为C u du +=?, 所以? +=C x f x df )()(. 2.求一曲线)(x f y =, 使得在曲线上每一点),(y x 处的切线斜率为x 2, 且通过点 )5,2(. 解 由导数的几何意义, 知x x f 2)(=', 所以C x xdx dx x f x f +=='= ??22)()(. 于是知曲线为C x y +=2 , 再由条件“曲线通过点)5,2(”知,当2=x 时,5=y , 所以 有 C +=2 25, 解得1=C , 从而所求曲线为12 +=x y 3.验证x x y sgn 2 2 =是||x 在),(∞+-∞上的一个原函数. 证明 当0>x 时, 22x y =, x y ='; 当0 应用回归分析课后习题 参考答案 Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】 第二章一元线性回归分析 思考与练习参考答案 一元线性回归有哪些基本假定 答:假设1、解释变量X是确定性变量,Y是随机变量; 假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(ε i )=0 i=1,2, …,n Var (ε i )=2i=1,2, …,n Cov(ε i, ε j )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X之间不相关: Cov(X i , ε i )=0 i=1,2, …,n 假设4、ε服从零均值、同方差、零协方差的正态分布 ε i ~N(0, 2) i=1,2, …,n 考虑过原点的线性回归模型 Y i =β 1 X i +ε i i=1,2, …,n 误差εi(i=1,2, …,n)仍满足基本假定。求β1的最小二乘估计解: 得: 证明(式),e i =0 ,e i X i=0 。 证明: ∑ ∑+ - = - = n i i i n i X Y Y Y Q 1 2 1 2 1 )) ? ?( ( )? (β β 其中: 即:e i =0 ,e i X i=0 2 1 1 1 2) ? ( )? ( i n i i n i i i e X Y Y Y Qβ ∑ ∑ = = - = - = ) ? ( 2 ?1 1 1 = - - = ? ?∑ = i i n i i e X X Y Q β β ) ( ) ( ? 1 2 1 1 ∑ ∑ = = = n i i n i i i X Y X β 01 ?? ?? i i i i i Y X e Y Y ββ =+=- 01 00 ?? Q Q ββ ?? == ?? 电子商务概论复习思考题 第一章电子商务概述 一、判断题 1、网络商务信息是指通过计算机传输的商务信息,包括文字、数据、表格、图形、影像、声音以及内容能够被人工或计算机察知的符号系统。(√) 2、电子商务的核心是人。(√) 3、电子商务是一种以消费者为导向,强调个性化的营销方式。(×) 二、选择题(包括单选题和多选题) 1、下列关于电子商务与传统商务的描述,正确的是(A) A、传统商务受到地域的限制,通常其贸易伙伴是固定的,而电子商务充分利用Internet,其贸易伙伴可以不受地域的限制,选择范围很大 B、随着计算机网络技术的发展,电子商务将完全取代传统商务 C、客户服务职能采用传统的服务形式,电子商务在这一方面还无能为力 D、客服购买的任何产品都只能通过人工送达 2、电子商务以满足企业、商人和顾客的需要为目的,增加(D),改善服务质量,降低交易费用。 A、交易时间 B、贸易机会 C、市场范围 D、服务传递速度 3、电子商务实质上形成了一个(ABC )的市场交换场所。 A、在线实时B虚拟C、全球性D、网上真实 三、问答题 1、E-Commerce和E-Business的区别在哪里? 答:E-Commerce是实现整个贸易过程中各贸易活动的电子化,从涵盖范围方面可以定义为:交易各方以电子交易方式而不是通过当面交换或直接面谈方式进行的任何形式的商业交易;从技术方面可以定义为:E―Commerce是一种多技术的集合体,包括交换数据、获得数据以及自动捕获数据等。它的业务包括:信息交换、售前售后服务、销售、电子支付、运输、组建虚拟企业、公司和贸易伙伴可以共同拥有和运营共享的商业方法等。 E-Business是利用网络实现所有商务活动业务流程的电子化,不仅包括了E-Commerce 面向外部的所有业务流程,还包括了企业内部的业务流程,如企业资源计划、管理信息系统、客户关系管理、供应链管理、人力资源管理、网上市场调研、战略管理及财务管理等。E-Commerce集中于电子交易,强调企业与外部的交易和合作,而E-Business则把涵盖范围扩大到企业外部。 2、试述电子商务活动中的三流分离的各种可能性。 答:在电子商务活动中,信息流、资金流和物流本身是相互独立的。信息流是电子商务交易过程中各个主体之间不断进行的双向交流。物流进行的是一个正向的流程,即从原材料供应商到制造商,再通过经销商或配送中心到顾客。而资金流进行的是一个反向的流程,顾客付款时需要通过他的开户银行将货款汇给经销商,经销商再汇给制造商,制造商汇款给原材料供应商。 信息流、资金流和物流的形成是商品流通不断发展的必然结果。它们在商品价值形态的转化过程中有机地统一起来,共同完成商品的生产—分配—交换—消费—生产的循环。 y1 1 x11 x12 x1p 0 1 3.1 y2 1 x21 x22 x2p 1 + 2 即y=x + yn 1 xn1 xn2 xnp p n 基本假定 (1) 解释变量x1,x2…,xp 是确定性变量,不是随机变量,且要求 rank(X)=p+1 n 注 tr(H) h 1 3.4不能断定这个方程一定很理想,因为样本决定系数与回归方程中 自变量的数目以及样本量n 有关,当样本量个数n 太小,而自变量又较 多,使样本量与自变量的个数接近时, R 2易接近1,其中隐藏一些虚 假成分。 3.5当接受H o 时,认定在给定的显著性水平 下,自变量x1,x2, xp 对因变量y 无显著影响,于是通过x1,x2, xp 去推断y 也就无多大意 义,在这种情况下,一方面可能这个问题本来应该用非线性模型去描 述,而误用了线性模型,使得自变量对因变量无显著影响;另一方面 可能是在考虑自变量时,把影响因变量y 的自变量漏掉了,可以重新 考虑建模问题。 当拒绝H o 时,我们也不能过于相信这个检验,认为这个回归模型 已经完美了,当拒绝H o 时,我们只能认为这个模型在一定程度上说明 了自变量x1,x2, xp 与自变量y 的线性关系,这时仍不能排除排除我 们漏掉了一些重要的自变量。 3.6中心化经验回归方程的常数项为0,回归方程只包含p 个参数估计 值1, 2, p 比一般的经验回归方程减少了一个未知参数,在变量较 SSE (y y)2 e12 e22 1 2 1 E( ) E( - SSE* - n p 1 n p n 2 [D(e) (E(e ))2 ] 1 n (1 1 n 2 en n E( e 1 1 n p 1 1 n p 1 1 "1 1 n p 1 J (n D(e) 1 (p 1)) 1_ p 1 1 1 n p 1 2 2 n E(e 2 ) (1 h ) 2 1 《工作分析》课后习题答案 第一章 1.什么是工作分析?从不同的层面进行描述 答:从不同的角度出发,根据侧重的方面不同,可以对工作分析给出不同的定义国内外学者对工作分析(Job Analysis)做出了许多定义比如:蒂芬&麦格米克的定义:从广义上说,工作分析是针对某种目的,通过某种手段来收集和分析与工作相关的各种信息的过程;高培德&阿特齐森定义:工作分析是组织的一项管理活动,它旨在通过收集、分析、综合整理有关工作方面的信息,为组织计划、组织设计、人力资源管理和其他管理职能提供基础性服务格雷·代斯勒从工作分析的具体目的出发对工作分析做出定义:工作分析就是与此相关的一道程序,通过这一程序,我们可以确定某一工作的任务和性质是什么,以及哪些类型的人(从技能和经验的角度)适合被雇佣来从事这一工作 具体说来,就是可以从组织层面与岗位层面来分别界定其含义: 1.基于组织层面的工作分析 基于组织层面的工作分析是站在企业的角度,侧重于从宏观层面进行分析与研究,其研究的对象包括企业的组织结构、业务流程和岗位体系这一层面的工作分析更多的要考虑如何更好的实现组织的战略目标,因此需要对企业战略的透彻理解和对企业所处环境的透彻分析 2.基于岗位层面的工作分析 基于岗位层面的工作分析侧重于从组织的微观角度——即具体的岗位出发,通过系统分析的方法来确定具体岗位的职责、工作范围以及胜任此岗位工作所需要的知识和技能的过程这一层面的工作分析是为了使具体岗位的职责、任职要求等要素更加规范合理,从而更科学、高效地对岗位任职者进行管理,以及对招聘、培训工作做出科学的指导 2.简述组织层面工作分析和岗位层面工作分析的内容 答:组织层面的工作分析,就是从组织的宏观角度出发,通过系统分析的方法来实现组织结构优化、业务流程再造及岗位再设计的目的的过程可以说,组织层面的工作分析,是实现组织战略传递的重要工具应用回归分析课后习题参考答案
电子商务课后习题及答案
应用回归分析第三章课后习题整理
工作分析课后习题答案