关于tab、shp格式转kml出现无标注及乱码的解决方案
关于tab、shp等格式转kml后标注为乱码的解决方案
1)在tab或shp等的数据结构中,需保证要标注的字段(例如name字段)排在第一位;
即数据结构中第一位的字段即为标注字段;
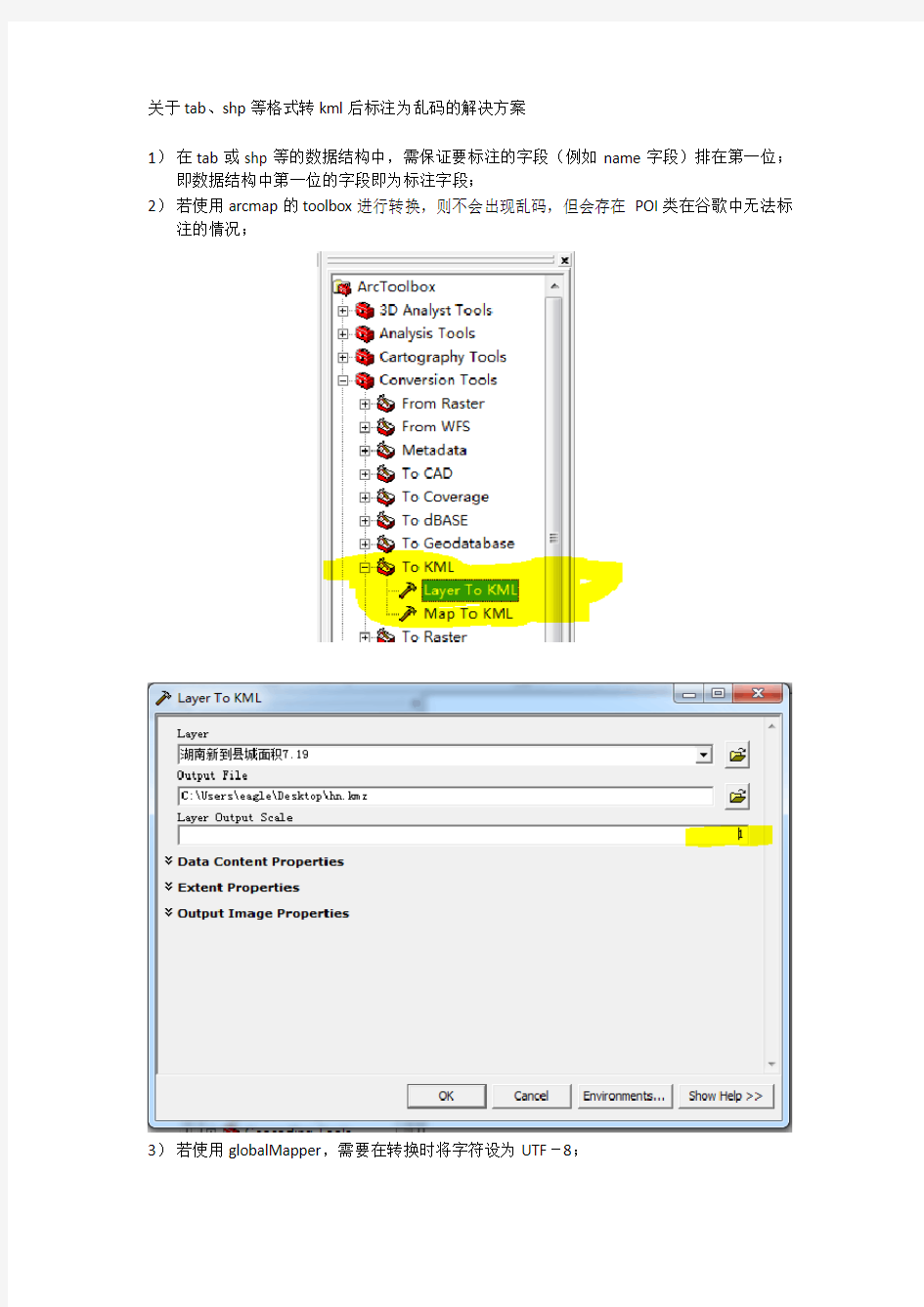
2)若使用arcmap的toolbox进行转换,则不会出现乱码,但会存在POI类在谷歌中无法标注的情况;
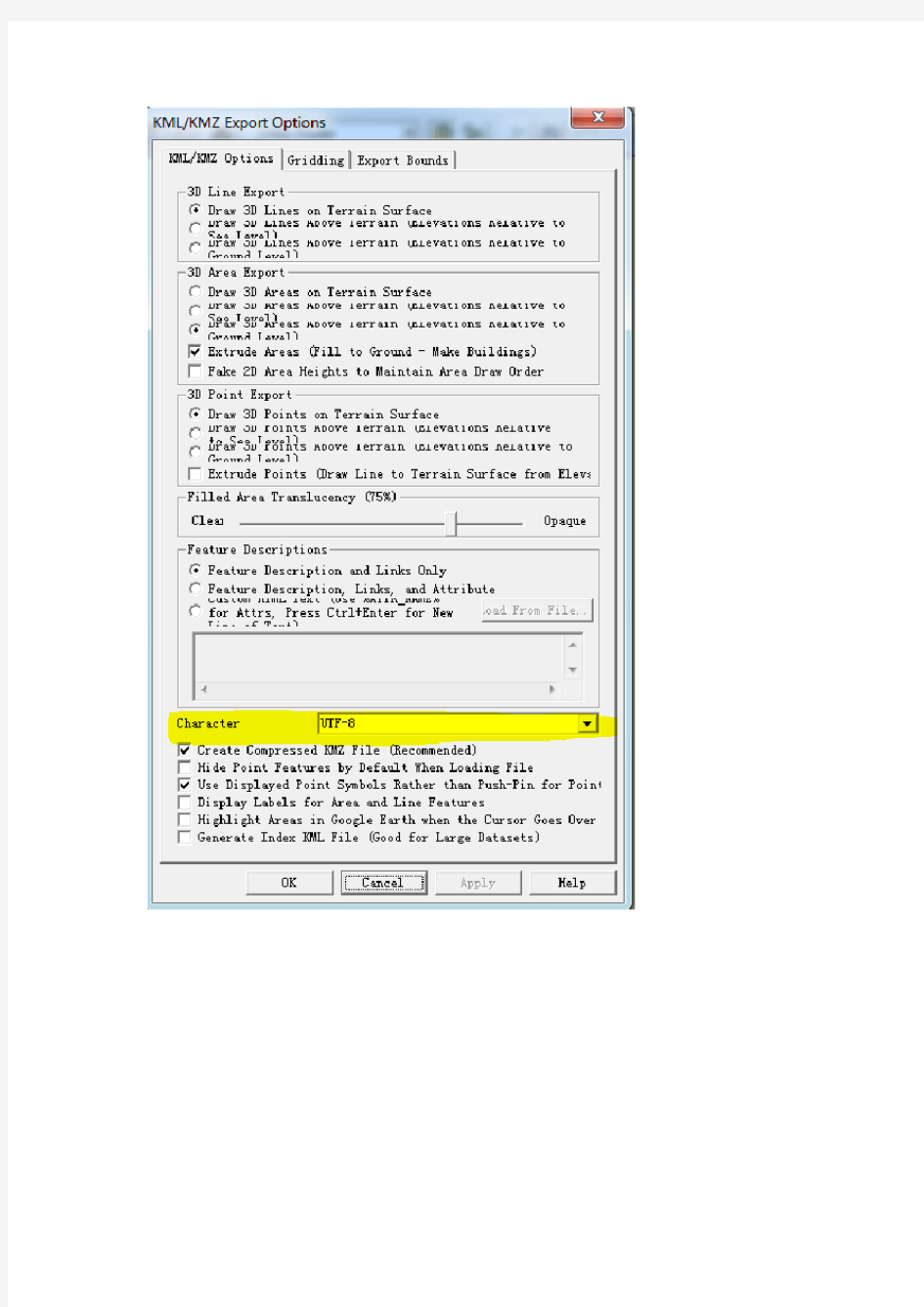
3)若使用globalMapper,需要在转换时将字符设为UTF-8;
cmd窗口显示中文乱码及无法输入中文解决方法
cmd窗口显示中文乱码及无法输入中文解决方法 (2009-05-09 19:13:12) 分类:软件应用 标签: it 中文显示为乱码 临时解决方案: 在 CMD 中运行 chcp 936。 永久解决方案: 打开不正常的 CMD 或命令提示符窗口后,单击窗口左上角的图标,选择弹出的菜单中的“默认值”,打开如下图的对话框。单击第一个“选项”选项卡,将默认的代码页改为 936 后重启 CMD。 附:
如果改了以后无法生效,窗口的“默认值”和“属性”没变,进入注册表,在 HKEY_CURRENT_USER 下找到 console 项下的 Console 以及其下可能有 的 %SystemRoot%_system32_cmd.exe(这个 %SystemRoot%_system32_cmd.exe 下有的 codepage 话就改,如果没有就不管它),codepage值改为 936(十进制)或 3a8(十六进制)。 936(十进制)/3a8(十六进制) 是简体中文的,如是其它语言,要改为对应的代码。然后再执行第二段中所述的操作。 还可能和 CMD 的默认值的“字体”设置有关。 在 CMD 的“默认值”和“属性”的“字体”选项卡中中确认设定的字体是可以显示中文字符的字体,并且确定字体文件没有被破坏。字体最好设置为默认的点阵字体。 还是不行,干脆把%SystemRoot%_system32_cmd.exe内容备份下,然后清空它。或是把以下内容保存为REG文件导入试试。 Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] "QuickEdit"=dword:00000800 "CodePage"=dword:000003a8 "WindowSize"=dword:001e005a "FontSize"=dword:000c0008 "FontFamily"=dword:00000030 "FontWeight"=dword:00000190 "FaceName"="Terminal" ============================================================= 无法输入中文 确认以下事项: 1.CMD 里中文字符可以正常显示(上文). 2.注册表中 HKEY_CURRENT_USER\Console 及 HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] 下LoadConIme 的值为 1. 3.conime.exe 这个文件存在,没有受到破坏,并且正常运行.
中文乱码解决大全
SSH开发过程中的中文问题汇总 作者:Rainisic来源:博客园发布时间:2012-01-11 14:26 阅读:50 次原文链接[收藏] 在使用SSH开发的过程中,我们经常会因为各种各样的中文乱码问题而苦恼。之前开发的过程中遇到过一些,但是都没有记录下来,这次,我就遇到的中文问题进行一个汇总,希望能够对大家有所帮助。 1. 平台环境参数 操作系统:Windows 7 旗舰版64位 JDK版本:JDK 1.6 / JDK 1.7 (此处由于JDK 7 发布不久,所以对两个版本进行测试) 开发环境:Eclipse Java EE Indigo 网站容器:Tomcat 7.0 开发框架: Struts 2.3.1.1-GA Spring 3.1.0-release Hibernate 4.0.0-Final / Hibernate 3.6.9-Final (此处由于Hibernate 4 final 刚刚发布不久,所以对两个版本进行测试) 2. 中文问题汇总 (1)HTML中未指定文件编码 问题描述:在HTML中未指定文件编码,在部分浏览器中将会出现中文乱码。 解决方案:在HTML的head标签中指定文档编码,代码如下(请根据DOCTYPE选择): // HTML 4.01 Transitional
// HTML 5 (2)表单提交使用GET方法 问题描述:在HTML form 中提交表单的时候使用method="get"导致中文乱码。 解决方案:form表单的method设置为post,代码如下:
(3)JSP文件中未指定文档编码类型 问题描述:在JSP文件中未指定JSP文档编码,在浏览器中会出现中文乱码。 解决方案:在JSP文件首部增加指定文档编码的代码,代码如下: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> (4)文件编码不正确 问题描述:由于Java文件、JSP文件等文件编码不正确,导致中文乱码。 解决方案:设置文件的默认编码为UTF-8(如果需要使用其他编码,请确保上述两个编码格式与文件编码相同) 设置方法: 当前文件编码修改:该文件右键→Properties→Resource,右侧Text file encoding→Other →UTF-8 默认文件编码修改: 0. Windows→Preferences 打开Eclipse配置选项窗口。 1. General→Content Type,右侧Text 下面所需要的文件类型Default encoding设置为UTF-8mysql乱码处理
用MS SQL和oracle9 太吃内存,有点大,全给卸载了. 安装了mysql占内存小,方便使用! version:mysql-essential-5.1.36 在MySQL Command Line Client显示中文一切正常; 在eclipse中新工程,连接到mysql,读取一个表显示: 代码: package com.mch.mysql; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class Mysql1 { public static void main(String[] args) { String url ="jdbc:mysql://localhost/test"; String user="root"; String password="******"; try { Class.forName("org.gjt.mm.mysql.Driver").newInstance(); Connection conn= DriverManager.getConnection(url,user,password); Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("select * from pet"); while(rs.next()){ System.out.print("name:" + rs.getString(1)); System.out.print("\t所有者:" + rs.getString(2)); System.out.print("\tbirth:" + rs.getString("birth")); System.out.println(); } rs.close(); stmt.close(); conn.close(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } } 显示乱码?号.
JSP中文乱码的产生原因及解决方案
JSP中文乱码的产生原因及解决方案 在JSP的开发过程中,经常出现中文乱码的问题,可能一直困扰着大家,现在把JSP 开发中遇到的中文乱码的问题及解决办法写出来供大家参考。首先需要了解一下Java中文问题的由来: Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,Java和JSP文件本身编译时产生的乱码问题和Java程序于其他媒介交互产生的乱码问题。首先Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件的保存方式是基于字节流的,如果Java和JSP编译成class文件过程中,使用的编码方式与源文件的编码不一致,就会出现乱码。基于这种乱码,建议在Java文件中尽量不要写中文(注释部分不参与编译,写中文没关系),如果必须写的话,尽量手动带参数-ecoding GBK或-ecoding gb2312或-ecoding UTF-8编译;对于JSP,在文件头加上<%@ page contentType="text/html;charset=GBK"%>或 <%@ page contentType="text/html;charset=gb2312"%>基本上就能解决这类乱码问题。 下面是一些常见中文乱码问题的解决方法(下面例子中ecoding采用的是gb2312,也可设为ecoding GBK或ecoding UTF-8): 一、 JSP页面乱码 这种乱码问题比较简单,一般是页面编码不一致导致的乱码,一般新手容易出现这样的问题,具体分以下两种情况: 未指定使用字符集编码 下面的显示页面(display.jsp)就出现乱码:
SHP文件格式的研究与应用
第31卷第6期2006 年11月 测绘科学 Sc i ence o f Survey ing and M app i ng V o l 131N o 16 N ov 1 作者简介:刘锋(1980O ),男,中国测绘科学研究院摄影测量与遥感专业研究生,主要从事RS 和G IS 开发与应用研究。E O m a i:l li ufeng1980421@1261com 收稿日期:2006O 01O 05 基金项目:国土资源部土地资源遥感监测信息获取与处理软件开发(2003AA131010) S HP 文件格式的研究与应用 刘锋,张继贤,李海涛 (中国测绘科学研究院,北京 100039) 【摘 要】在全国第二次土地详查中,土地利用基础图件大部分是以S H P 文件格式存储的,因此在对土地利用基础图件进行更新的过程中,首要的问题是对SHP 文件的访问。本文以解决这一问题为目标,以S HP 文件中常用的多边形元素为例,对S H P 文件中二进制格式的元素表示方法加以阐述,并以程序实现的方式对资料进行了访问,最终在项目中得到了充分的应用。【关键词】土地利用基础图件;S H P 文件格式;多边形元素【中图分类号】TP311 【文献标识码】A 【文章编号】1009O 2307(2006)06O 0116O 02 1 引 言 S H P 文件格式是美国ESR I 公司生产的A rcV iew 和A rc G IS 软件的专用资料格式,它将地理空间资料以坐标点串的形式存储起来。A rcV iew 以其易用性和灵活性受到大量用户的喜爱,占有极高的市场占有率,广泛应用于国土资源、环境、地学等领域中。现在S H P 文件格式已经成为G IS 界的一种标准格式,几乎所有的G IS 软件都支持对它的转换甚至支持对其直接进行读写操作,大量的工程项目也往往把SHP 文件格式作为首选格式,因而每个从事研究G IS 人员都应该详细的了解和掌握SHP 文件格式。 2 SHP 文件格式说明 通常开发人员可以采用自带的开发软件包对资料的采集、入库、查询以及分析进行编程。但是他们开发的地理信息软件包所处理的文件格式通常与S HP 格式不兼容。但是如果清楚了S H P 文件的编码方式就可以利用常用的开发工具(如V C ,V B)等将自定义文件格式转换为S H P 文件格式。 不同于其它各种转换文件格式如M IF 、M I D 、E00等,S H P 文件格式采用编码效率较高的二进制格式。点的坐标采用双精度保存,保证了点的精确度。S HP 文件系统由三个文件组成:S H P 文件、S HX 文件和DBF 文件。S H P 文件中存储每个地物的空间资料,S HX 文件主要存储了S HP 文件中每个地物元素的起始位置和所占字节的大小,D BF 文件存储每个地物元素的属性资料。相对于向量图形中的每个元素,S H P 文件中都有相应的一个段落与之对应,所以其资料格式有一定的复杂性。 每个S H P 文件都包含一百个字节的文件头信息,文件头记录了文件中常用的基本信息,信息如表1所示: 表1 主文件头的描述 位置域值类型字节次序 Byte 0文件代码9994整型B i g Byte 4未使用0整型B i g Byte 8未使用0整型B i g B yte 12未使用0整型B i g B yte 16未使用0整型B i g B yte 20未使用0整型B i g B yte 24文件长度文件长度整型B i g B yte 28版本1000整型Littl e B yte 32形状类型形状类型整型Littl e B yte 36边界盒X 坐标最小值双精度Littl e B yte 44边界盒Y 坐标最小值双精度Littl e B yte 52边界盒X 坐标最大值双精度Littl e B yte 60边界盒Y 坐标最大值双精度Littl e B yte 68边界盒Z 坐标最小值双精度Littl e B yte 76边界盒Z 坐标最大值双精度Littl e B yte 84边界盒M 最小值双精度Littl e B yte 92 边界盒 M 最大值 双精度 Littl e 其中,0-3字节表示文件代码,固定值为9994,字节排列方式为倒序排列;3-19字节为空,固定值为0,字节排列方式为倒序排列;19-23字节为文件的大小,取值为文件的长度,字节排列方式为倒序排列(并以十六b it 存储);24-27字节为文件的版本,固定值为1000,字节排列方式为正序排列;28-31字节为地物的形状类型,取值如表二所示(x,y 为二维坐标,m 为度量坐标,z 为高程坐标),字节排列方式为正序排列: 表2 形状类型 值形状类型描述 0NULL Shap e 空地物类型 1Poi n t 单点类型(包含x ,y 坐标)3Pol yL i ne 线类型(每个点包括x ,y 坐标)5 Polygon 多边形类型(每个点包括x ,y 坐标)8M ulti Po i nt 多点类型(每个点包含x ,y 坐标)11Poi n t Z 单点类型(包含x ,y ,m,z 坐标)13Po l yL i neZ 线类型(每个点包含x ,y ,m,z 坐标)15Pol ygonZ 多边形类型(每个点包括x ,y ,m,z 坐标)18M u lti P oi n t Z 多点类型(每个点包括x ,y ,m,z 坐标) 21 Poi n M t 单点类型(包括x ,y ,m 坐标)23Pol yL i ne M 线类型(每个点包括x ,y ,m 坐标)25Polygon M 多边形类型(每个点包括x ,y ,m 坐标)28M ulti P o i nM t 多点对象(每个点包括x ,y ,m 坐标)
解决openfire在使用MySQL数据库后的中文乱码问题
解决openfire在使用MySQL数据库后的中文乱码问题 openfire是一个非常不错的IM服务器,而且是纯Java实现,具有多个平台的版本,他的数据 存储可以采用多种数据库,如MySQL,Oracle等。 在实际使用时大家遇到最多的就是采用MySQL数据库后的中文乱码问题,这个问题十分有趣, 而且从现象上可以看出openfire内部的一些机制。 实际问题是这样的:首先启动openfire服务器,然后利用客户端或直接登录到后台新建一个帐户,为该帐户指定一些中文的属性,如姓名等。如果不重启服务器,你永远不会觉得有什么不对的地方,因为所有的中文显示都是正常的。接下来重启一下openfire,再用建立的帐号登录 客户端或进入后台管理端查看,会发现所有的中文全都变成了问号。登录到数据库中进行查看,发现所有的中文字符也均为问号,这说明了两个问题: openfire具有应用层缓存 数据库编码存在问题 解决办法其实也很简单,首先要保证你为openfire创建的数据库编码是utf8的,建表语句如下: create database openfire default character set utf8 default collate utf8_general_ci 当你原来就创建好数据库时,你可以用: alter database openfire default character set utf8 default collate utf8_general_ci; 其次,在初始化openfire数据库,即第一次配置openfire服务器时,在连接数据库那里的连 接串要加入字符编码格式,必须在连接里增加UTF8的编码要求,连接字符串设置如下: jdbc:mysql://127.0.0.1:3306/openfire?useUnicode=true&characterEncoding=utf8 如果已经安装完成,这个配置也是可以改动的,直接到openfire的安装目录下,找到 conf/openfire.xml这样一个文件,打开找到如下的XML节,修改其中的serverURL即可
Python2.x 中文乱码问题解决方法
Python2.x中文乱码问题解决方法 Python中乱码问题是一个很头痛的问题。 在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文。否则会出现乱码 【问题原因】 在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码。Python默认采取的ASCII编码,字母、标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求。 代码如下: >>> import sys >>> sys.getdefaultencoding() 'ascii' 为了能在计算机中表示所有的中文字符,中文编码采用两个字节表示。如果中文编码和ASCII混合使用的话,就会导致解码错误,从而才生乱码。而CMD下默认的编码方式为:GBK,所以就造成了上面的乱码!
采用两个字节的中文编码标准有:GB2312、GBK、BIG5等。 【处理办法】 为了将各种不同的语言包含在统一的字符集中,满足国际间的信息交流,国际上制订了UNICODE字符集,包含了世界上所有语言字符,这些字符具有唯一的编码,通过使用UNICODE字符集可以满足跨语言的文字处理,避免乱码的产生。 i) 交互式命令中:一般不会出现乱码,无需做处理 ii) py脚本文件中:跨字符集必须做设置,否则乱码。 首先在开头一句添加:
代码如下: # coding = utf-8 # 或 # coding = UTF-8 # 或 # -*- coding: utf-8 -*- 其次需将文件保存为UTF-8的格式! 上面那一句仅仅是告诉Python编译器:脚本中包含了非ASCII字符,并未进行转换。 如果要将字符编码从默认的ASCII改为UTF-8,需要在保存的时候选择保存为UTF-8格式。 如果是用NODEPAD打开,【另存为】-->UTF-8即可 如果是用IDLE打开,【Options】-> 【Configure IDLE】->【General】
下载SHP矢量格式的等高线
如何下载SHP矢量格式的等高线 一、什么是等高线? 等高线指的是地形图上高程相等的相邻各点所连成的闭合曲线,把地面上海拔高度相同的点连成的闭合曲线,并垂直投影到一个水平面上,并按比例缩绘在图纸上,就得到等高线。等高线也可以看作是不同海拔高度的水平面与实际地面的交线,所以等高线是闭合曲线,在等高线上标注的数字为该等高线的海拔。 二、如何下载SHP矢量格式的等高线 首先,请确保水经注万能地图下载器软件版本为X3.0build1469以上,然后我们只需要以下几步即可下载到SHP矢量格式的等高线。 第一步:切换到在线高程数据地图 点击视图中的“高程”可以切换到高程数据视图,你可以在视图中看到即时渲染的半透明高程数据图,如下图所示。
第二步:按行政区下载高程 点击软件顶部的“下载”工具,会有多种确定下载范围的方式供你选择。 如果选择的“屏幕范围”,将会按当前屏幕显示的范围下载,另外也可以通过框选、绘制多边型或导入面状的DXF\SHP\KML\KMZ文件的方式来确定下载区域。 这里我们以下载“工布江达县”行政区域为例。 首先在软件的右上角点击“区划”并选择“西藏自治区”,然后选择“林芝地区”下的“工布江达县”,最后会在地图中显示行政区域并同时显示“下载”按钮,如下图所示。
点击“下载”按钮,在“新建任务”对话框中选择第15级(该级别对应的高程采样间距为10米左右),并确保存储格式为TIF、勾选裁剪功能和背景透明功能,如下图所示。 点击对话框中的“确认”按钮之后将会自动生成并导出TIF格式的高程数据。 第三步:提取SHP矢量等高线 TIF高程数据必须用 Global Mapper 或ArcGIS等专业软件中才能看到地形起伏的渲染
解决PHP+mysql处理中文乱码的独家方案
解决PHP+mysql处理中文乱码的独家方案 本方案适用于所有页面文件均为php(已成功测试过),如果有混合文件读者可以亲自测试。 问题现象如下图,1所示为修复过的头部引用文件header.php,中文能正常显示,2所示为未修复过的standard.php页面文件。 一、为了解决问题,首先应该设置数据库的字符编码,如下图所示,本例将所有编码设置为UTF-8。 同样将数据库中的所有表的字符编码设置成UTF-8。
这样,数据库中可以正常显示中文字符了,如下图所示。 如果要导入外来数据,也要设置好字符编码,对于非mysql数据库的导入(如从ACCESS数据库中导入),需要设置分隔字段的字符,然后执行便可,如下图所示。 ---------------------------------------- 二、数据库的字符编码完成后,便要将页面文件的编码设置好。 这里的要点有如下三点(红色为说明文字):
为了实现上述三点要求,本例采用的方案如下: 1.创建一个数据库连接文件conn.php ,其中在开头设置header 编码,并在创建数据连接后设置SQL 请求的编码,如下图所示: 2.设置页面文件的文件类型。可以在页面文件中的
标签中设置字符编 码。 2.1如果之前的字符编码为gb2312,则该文件类型为ANSI (本例使用DW 和notepad++软件,读者也可用UE 编辑软件,只不过类型显示名称不一样而已),如下图所示: 2.2将标签的编码设置成utf-8并保存文件后,再次打开,会发现文件类型变成了ANSI as UTF-8,如下图所示:win7系统常见的乱码问题解决方法
win7系统常见的乱码问题解决方法 win7系统乱码的问题,经常会碰到一些软件是简体中文的,可是在win7系统中却出来乱码的问题?400pc小编教你破解是哪些原因造成win7系统乱码。 近期,居住香港的姐姐也安装了Windows 7,不过,令她烦恼的是使用一些简体中文的软件出现了乱码。而这些软件都无法找到繁体版本,比如:迅雷,即使勉强安装好也无法轻松使用。难道香港用户就无法使用这些简体软件了吗?其实,Windows 7自身已经提供了完善的解决方案了。 一、Windows 7乱码问题来龙去脉 旅居香港的姐姐安装的是我提供的简体中文版本的Windows 7旗舰版,按理是可以顺利兼容简体软件的,然而问题就出在姐姐对默认的安装设置进行了修改。因为姐姐经常使用繁体软件,她将系统的“区域和语言”的“格式”、“位置”、“默认输入语言”、“非Unicode程序的语言”都设置成了更加顺手的香港繁体。 我们知道Unicode也可称为统一码,为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换处理的要求,然而,还是有不少程序并不支持该编码,这时就有必要设置非Unicode程序使用的语言编码了。像迅雷这样的软件就支持简体中文编码,而不支持Unicode,当设置了香港繁体的非Unicode 就会出现乱码,同理,将非Unicode设置为简体后,很多不支持Unicode的繁体软件也会出现乱码。这个乱码问题难道是两难的吗?其实,我们使用Windows 7的语言包补丁安装功能就可以顺利解决。 二、巧妙解决Windows 7乱码 1.安装合适的语言包 首先,要能安装多种语言包的Windows 7只能是旗舰版或者企业版,接着我们就来解决这个问题吧。我们点击“开始-Windows Update”打开自动更新窗口。 在窗口中点击“34个可选更新”链接,在可以下载安装的语言包列表中选择“繁体中文语言包”,确定即可。 回到刚才的窗口点击“安装更新”按钮开始下载安装。 安装完语言包补丁需要重启。重启的过程需要配置补丁。
FMECAD转GISshp格式文档操作方法
MFE使用文档:CAD格式专程GIS的shp文件 一、CAD文件的查看和预览 目的:确定CAD文件每个图层包含的数据集,点point,线line,面polygon 数据,以及CAD文件的扩展属性。 1、用FME Universal Viewer 打开要转换的CAD文件 1,File——opendataset 打开CAD文件 2,选择输入数据的格式DWG和数据的路径 如下图: 3,如图 图中viewspace 中各个数据集是CAD的各图层名称
以axes图层为例关闭其他图层,只打开axes图层 可以发现axes图层只有Line 数据 注:所以在以后的转化中axes图层只有线line数据其他数据为空不需要转换 4,点击:按钮,可以选侧对象的要素 点击view中的一条线段要素,可以查看这条线段要素的扩展属性 其中extended_data_list{0-6}为选中要素的扩展属性,可以看到我们需要的扩展属性如:中路,10025,这些重要的扩展属性 其他图层的查看方法相同,有的图层没有扩展属性。 例如:JMD图层 可以查看,有三个要素集area line text 有数据 所以在以后的转换中药有三个要素的转换面,线,点的要素的转换。
二,应用FME Workbench自定义转换CAD数据 目的:按照要求把CAD的数据转换到GIS shp文件中,扩展属性读取在shp文件的表中1,打开FME Workbench 选择 2,选择读入数据的类型DWG和数据的路径,和目标文件的格式ESRI Shape 3,选择要读入的数据的图层 本文以读入axes图层为例,选择读入axes图层
mysql数据库乱码问题
数据库读出乱码解决 一、分析常见数据库问题 修改MYSQL数据库,数据表,字段的编码(解决JSP乱码) 要解决JSP乱码,首先就要了解JSP乱码的原因 1.架设服务器安装MYSQL时的会让你选择一种编码,如果这种编码与你的网页不一致,可能就会造成JSP页面乱码 2.在PHPMYADMIN或mysql-front等系统创建数据库时会让你选择一种编码,如果这种编码与你的网页不一致,也有可能造成JSP页面乱码 3.创建表时会让你选择一种编码,如果这种编码与你的网页编码不一致,也可能造成JSP页面乱码 4.创建表时添加字段是可以选择编码的,如果这种编码与你的网页编码不一致,也可能造成JSP 页面乱码 5.用户提交JSP页面的编码与显示数据的JSP页面编码不一致,就肯定会造成JSP页面乱码. 如用户输入资料的JSP页面是big5码,显示用户输入的JSP页面却是gb2312,这种100%会造成JSP页面乱码 6.字符集不正确 要注意: 1.平时你在某些网站看到的文字可能有几种编码,如你看到一个繁体字,它有可能是big5编码,也有可能是utf-8编码的,更有可能是gb码的,没错,也就是说有简体编码的繁体字,也有繁体编码的简体字,一定要了解这一点. 如果你是做一个简体编码的网页,编码定为GB2312,如果有香港和台湾地区的访客提交繁体的信息,就可能会造成乱码,解决方法就是(1)将网站编码设为utf-8,这样可以兼容世界上所有字符,(2)如果网站已经运作了好久,已有很多旧数据,不能再更改简体中文的设定,那么建议将页面的编码设为GBK, GBK与GB2312的区别就在于:GBK能比GB2312显示更多的字符,要显示简体码的繁体字,就只能用GBK 7.JSP连接MYSQL数据库语句指定的编码不正确 8.JSP页面没有指定数据提交的编码,就会造成乱码: 所以,JSP乱码的原因无非就是以上几种,知道原因之后,要解决JSP乱码的方法也容易多了 我们一一来表达: 1.如果安装mysql的编码已不能更改,很多朋友是购买虚拟主机建立网站,无权更改MYSQL的安装编码,这一关我们可以跳过,因为只要后面的步聚正确,一样能解决乱码问题 2.修改数据库编码,如果是数据库编码不正确:可以在phpmyadmin执行如下命令:ALTER DATABASE`test`DEFAULT CHARACTER SET utf8COLLATE utf8_bin 以上命令就是将test数据库的编码设为utf8
XPE终端常见问题及解决办法V10
产品型号:XPE终端 现象描述:开机普通用户自动登录,如何进管理员或者其它用户? 故障分析: 解决办法:点击“注销”后,按住Shift键一直不放,可看到用户登录界面。 (二) 产品型号:XPE终端 现象描述:忘记管理员密码,如何以管理员身份登录系统? 故障分析: 解决办法:在用户登录界面,连续两下快按Shift+Ctrl+Delete键,会出现另一种用户登录界面,用户名输入:administrator 密码输入:gwixpe登入超级管理员。然后通过本地监控程序(本地管理软件)修改用户名密码。 (三) 产品型号:XPE终端 现象描述:忘记本地监控程序登录密码 故障分析: 解决办法:本地监控程序忘记密码后,只能在注册表查看登录密码。在注册表HKEY_LOCAL_MA CHINE\SYSTEM\GWI下ChangePassword的值就是密码。 (四) 产品型号:XPE终端 现象描述:运行U盘或者D盘中.exe文件报错 故障分析:报错是因为在组策略中设置了软件限制策略。 解决办法:在“运行”输入gpedit.msc回车打开策略管理器中,计算机配置---windows设置---软件限制策略中可以看到相关设置(详细设置在可以在网上搜索得到)。 (五) 产品型号:XPE终端 现象描述:管理员用户下能运行的软件却在普通用户下不能运行 故障分析: 解决办法:在管理员下,把安装后的软件目录的USERS权限提升为完全控制。如不行把软件发回技术中心。设置方法,目录文件右键属性,安全标签,选择Users,把下面的“完全控制”的勾勾上。 (六) 产品型号:XPE终端 现象描述:系统登录界面,密码输入框没有光标不能输入登录密码 故障分析: 解决办法:连续两下快按Shift+Ctrl+Delete键,在另一种用户登录界面中输入用户名和密码。
Android读取中文文件乱码解决方法
最近在做个MP3播放器,出现中文乱码问题,在网上找了很多解决办法,我整理了出现乱码的点和解决方案,拿出来和大家共享一下 1.读取中文文件乱码解决方法 package com.apj.conv; import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import android.app.Activity; import android.os.Bundle; import android.os.Environment; import android.widget.TextView; public class ConverActivity extends Activity { private TextV iew textview ; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(https://www.360docs.net/doc/0511174934.html,yout.main); textview = (TextView) findView ById(R.id.lrctext); System.out.println("==============convertCodeAndGetText begin============== ") ; ///获得SDCard中文件的路径 String path = Environment.getExternalStorageDirectory().getAbsolutePath()+ File.separator ; String tochinese = convertCodeAndGetText(path+"a.txt"); System.out.println(tochinese); System.out.println("==============cconvertCodeAndGetText end=============="); textview.setText(tochinese); }
shp文件详细格式
2.2.2Shape files数据说明 Shape files是ESRI提供的一种矢量数据格式,它没有拓扑信息,一个Shape files由一组文件组成,其中必要的基本文件包括坐标文件(.shp)、索引文件(.shx)和属性文件(.dbf)三个文件。 1.坐标文件的结构说明 坐标文件(.shp)用于记录空间坐标信息。它由头文件和实体信息两部分构成(如图2.1所示)。 1)坐标文件的文件头 坐标文件的文件头是一个长度固定(100 bytes)的记录段,一共有9个int型和7个double型数据,主要记录内容见表2.2。 …… …… 图2.1 坐标文件的结构
表2.2 shapefiles 头文件表 注:最后4个加星号特别标示的四个数据只有当这个Shapefile文件包含Z方向坐标或者具有Measure值时才有值,否则为0.0。所谓Measure值,是用于存储需要的附加数据,可以用来记录各种数据,例如权值、道路长度等信息。 (1)位序 细心的读者会注意到表2.2中的数值的位序有Little和big的区别,对于位序是big 的数据我们在读取时要小心。通常,数据的位序都是Little,但在有些情况下可能会是big,二者的区别在于它们位序的顺序相反。一个位序为big的数据,如果我们想得到它的真实数值,需要将它的位序转换成Little即可。转换原理非常简单,就是交换字节顺序,下面是作者实现的在两者间进行转换的程序,代码如下: //位序转换程序 unsigned long OnChange ByteOrder (int indata) { char ss[8]; char ee[8]; unsigned long val = unsigned long(indata); _ultoa( val, ss, 16 );//将十六进制的数(val)转到一个字符串(ss)中 int i; int length=strlen(ss); if(length!=8) { for(i=0;i<8-length;i++) ee[i]='0';
mysql+php中文乱码问题及mysql时间函数
mysql+php中文显示乱码的解决mysql+php中文显示乱码的解决 建议数据库用utf8编码 问题汇总: 1.mysql数据库默认的编码是utf8,如果这种编码与你的PHP网页不一致,可能就会造成MYSQL乱码. 2.MYSQL中创建表时会让你选择一种编码,如果这种编码与你的网页编码不一致,也可能造成MYSQL乱码. 3.MYSQL创建表时添加字段是可以选择编码的,如果这种编码与你的网页编码不一致,也可能造成MYSQL乱码. 4.用户提交页面的编码与显示数据的页面编码不一致,就肯定会造成PHP 页面乱码. 5.如用户输入资料的页面是big5码, 显示用户输入的页面却是gb2312,这种100%会造成PHP页面乱码. 6.PHP页面字符集不正确. 7.PHP连接MYSQL数据库语句指定的编码不正确. 使用mysql+php产生乱码的原因都了解得很清楚了,那么解决就不困难
了. 针对不同问题的解决方法: 1.mysql数据库默认的编码是utf8,如果这种编码与你的PHP网页不一致,可能就会造成MYSQL乱码. 修改数据库编码,如果是数据库编码不正确,可以在phpmyadmin 执行如下命令: ALTER DATABASE 'test' DEFAULT CHARACTER SET utf8 COLLATE utf8_bin 以上命令就是将test数据库的编码设为utf8. 2.MYSQL中创建表时会让你选择一种编码,如果这种编码与你的网页编码不一致,也可能造成MYSQL乱码. 修改表的编码: ALTER TABLE 'category' DEFAULT CHARACTER SET utf8 COLLATE utf8_bin 以上命令就是将一个表category的编码改为utf8. 3.MYSQL创建表时添加字段是可以选择编码的,如果这种编码与你的网页编码不一致,也可能造成MYSQL乱码. 修改字段的编码: ALTER TABLE 'test' CHANGE 'dd' 'dd' VARCHAR( 45 ) CHARACTER SET utf8
U盘乱码修复
U盘文件夹名称变为类似如下情形:佞愳亠?仠或者@?等等不一,还不能删除,删除时提示:无法删除文件,无法读源文件或磁盘。注意看乱码文件大都特别大,甚至几十G都有。 出现这种问题的原因通常是因为不正常的插拔等情况造成的,导致U盘的文件分配表错乱了 建议:此时运行chkdsk 盘符: /f 可以检查出一些错误。当有提示修改文件夹为文件名时,输入Y选择是。此时一般问题就会解决了。 如果还有问题,将一些重要的文件能保存下来就尽量保存下来,然后对U 盘进行格式化,或者进行低级格式化,再把重要文件COPY回去~ 其他解决方案: 1.在问题U盘图标上点右键选择"属性"——"工具"——点“差错"下的"开始检查"结束后问题即解决.如果不行,请继续往下尝试。 2. 尝试为文件重命名,如果可以重命名的话。运行cmd 打开任务管理器,结束explorer进程,切换到cmd命令提示符状态下输入“Del 文件名”后就可以删除文件了,这种方法只适用于可以重命名的文件。在进行操作时先关闭其他一切不相关的程序。 3. 如果重命名文件时系统提示“拒绝访问”,那么在cmd运行模式下运行“chkdsk 盘符: /f”命令检查磁盘错误并修复。 如果出现找到磁盘错误,一般的错误都是可以修复的,在修复完成后就可以删除乱码文件了。 注意:有时,由于乱码文件所在分区为系统区,系统会提示“另一个进程正在调用该卷,是否希望下次开机时检查该卷?”我建议用这样的方法运行chkdsk 命令,使用Windows安装盘引导系统,在选择新安装windows界面时,按“R”修复已有系统,进入命令提示符状态,在这里运行“chkdsk /f”命令。我测试过,这样运行的效果要比在Windows下的cmd模式中好很多。再运行“fixmbr”命令修复分区表。也可以修复系统其他的问题。 4.如果进行完上一步仍然无法删除乱码文件,可以使用我们最常用的WinRAR压缩工具来删除,具体的方法是压缩乱码文件并选中“压缩后删除源文件”选项。这样,一般的乱码文件就可以删除了。
CASS输出SHP文件说明
CASS输出SHP文件说明 CASS输出SHP文件的定义主要在其安装目录下的AttriBute.def文件中。 文件作用:SHP文件格式定义文件。 例: *T_ReferPoint,1,A01,测量控制点 FeatureID,100,6,0,要素代码 ReferPointID,12,20,0,内部编号 PntName,0,24,0,点名 PntNo,0,16,0,点号 说明:AttriBute.def文件中有所有的表及字段名。 1、我们先看第一行,“*”用来标示新的表的开始,“T_ReferPoint”为表名。 2、第二位为数据类型,即几何类型,用一位数字来表示,数据类型对应表如下: 数据类型对应表: 12345 点线面注记复合 3、第三位对应于数据组织表中的层号。可以和数据分层表进行联系。 4、“测量控制点”,即为这个表的说明文字,用来描述此表。 5、我们再来看看第二行,第一位是本表的主键,一般用要素代码来标示,用该主键名来描述,上例中即为“FeatureID ”。 6、第二位为判断码,程序实现时用来判断要读取的编码类型,10:南方CASS代码,100:用户代码。我们做数据接口时,要采用用户标准,所以用100来填充此位。 7、第三位为字长,用户提供的标准中有采用的数据库的数据类型表,根据此表,我们可以确定每个字段对应的类型和字长。比如:“Numeric(10,3)”,我们这里要特别注意,根据程序角度来处理,字长应该为10,而不是10+3=13。 8、第四位为小数点位,即为要保留的小数点后位数,同理,我们可以根据数据类型表来确定。 9、最后一位是文字说明,也就是字段说明。 10、这里要注意时间类型,还有Blob类型,即影象数据,字长应该为2,小数点位应该为0。 11、从第三行开始,到下个表开始之前,每行的结构都相同。 12、第一位是除主键的其他字段名, 13、第二位是数据类型,具体对应表见: 14、后面几位就对应到第二行的后面几位,用同样的方式来处理。 数据类型表: 标示符具体类型注释标示符具体类型注释 0Varchar Char 字符串 30文本注记字体Char 1短整33文字符号大小2Numeric长整43X坐标 3Decimal Date 浮点 53Y坐标