主成分分析13fen

% 输入81组训练样本
[filename,pathname]=uigetfile('*.txt','请选择训练数据(此处为train1.txt)'); train1=importdata ([pathname filename]);
[filename,pathname]=uigetfile('*.txt','请选择训练数据(此处为train2.txt)'); train2=importdata ([pathname filename]);
[filename,pathname]=uigetfile('*.txt','请选择训练数据(此处为train3.txt)'); train3=importdata ([pathname filename]);
P=[train1;train2;train3];
lsum=sum(P,1); %对列求和
[a,b]=size(P);
for i=1:a
for j=1:b
s(i,j)= P(i,j)/lsum(j);
end
end
%求出矩阵Sx的全部特征值和对应的特征向量
fprintf('输出相关系数矩阵:\n')
st=CORRCOEF(s)
fprintf('特征向量V及特征值D:\n')
[V,D]=eig(st)
nd=diag(D) ;
%对各个特征值按照从大到小的顺序排列
[y,i]=sort(nd) ;
fprintf('特征根排序的结果:\n')
for z=1:length(y)
newy(z)=y(length(y)+1-z);
end
fprintf('%g\n',newy)
%计算主成分贡献率
rate=y/sum(y);
fprintf('\n主成分贡献率:\n')
newrate=newy/sum(newy)
sumrate=0;
newi=[];
for k=length(y):-1:1
sumrate=sumrate+rate(k);
newi(length(y)+1-k)=i(k);
if sumrate>0.80
break;
end
%计算累计分贡献率
fprintf('\n累计分贡献率:\n')
ljrate=sumrate/sum(newy)
end
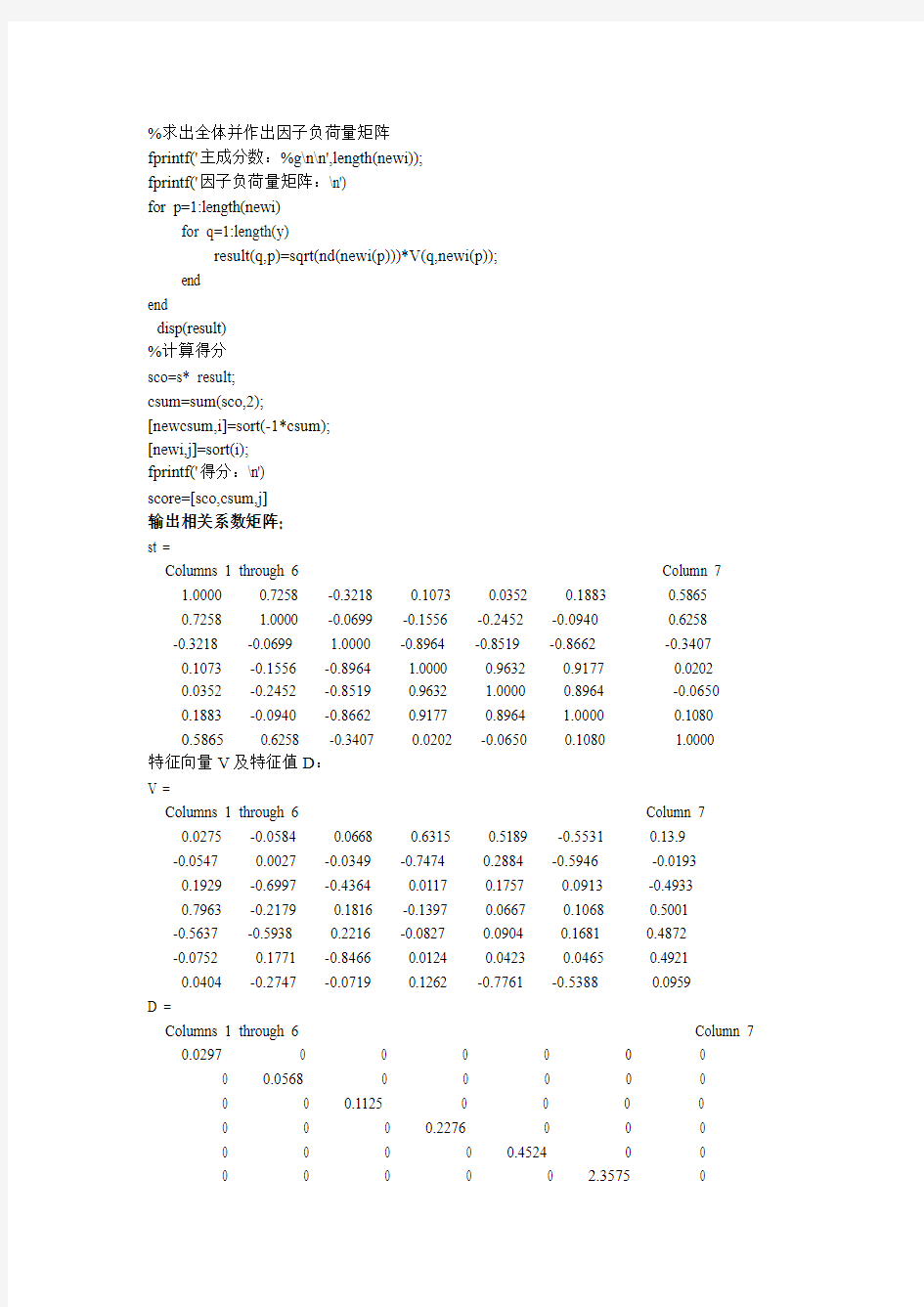
%求出全体并作出因子负荷量矩阵
fprintf('主成分数:%g\n\n',length(newi));
fprintf('因子负荷量矩阵:\n')
for p=1:length(newi)
for q=1:length(y)
result(q,p)=sqrt(nd(newi(p)))*V(q,newi(p));
end
end
disp(result)
%计算得分
sco=s* result;
csum=sum(sco,2);
[newcsum,i]=sort(-1*csum);
[newi,j]=sort(i);
fprintf('得分:\n')
score=[sco,csum,j]
输出相关系数矩阵:
st =
Columns 1 through 6 Column 7
1.0000 0.7258 -0.3218 0.1073 0.0352 0.1883 0.5865
0.7258 1.0000 -0.0699 -0.1556 -0.2452 -0.0940 0.6258
-0.3218 -0.0699 1.0000 -0.8964 -0.8519 -0.8662 -0.3407
0.1073 -0.1556 -0.8964 1.0000 0.9632 0.9177 0.0202
0.0352 -0.2452 -0.8519 0.9632 1.0000 0.8964 -0.0650
0.1883 -0.0940 -0.8662 0.9177 0.8964 1.0000 0.1080
0.5865 0.6258 -0.3407 0.0202 -0.0650 0.1080 1.0000
特征向量V及特征值D:
V =
Columns 1 through 6 Column 7
0.0275 -0.0584 0.0668 0.6315 0.5189 -0.5531 0.13.9
-0.0547 0.0027 -0.0349 -0.7474 0.2884 -0.5946 -0.0193
0.1929 -0.6997 -0.4364 0.0117 0.1757 0.0913 -0.4933
0.7963 -0.2179 0.1816 -0.1397 0.0667 0.1068 0.5001
-0.5637 -0.5938 0.2216 -0.0827 0.0904 0.1681 0.4872
-0.0752 0.1771 -0.8466 0.0124 0.0423 0.0465 0.4921
0.0404 -0.2747 -0.0719 0.1262 -0.7761 -0.5388 0.0959
D =
Columns 1 through 6 Column 7
0.0297 0 0 0 0 0 0
0 0.0568 0 0 0 0 0
0 0 0.1125 0 0 0 0
0 0 0 0.2276 0 0 0
0 0 0 0 0.4524 0 0
0 0 0 0 0 2.3575 0
0 0 0 0 0 0 3.7636
特征根排序的结果:
3.76356
2.35745
0.452422
0.227597
0.112544
0.0567676
0.029651
主成分贡献率:
newrate =
Columns 1 through 6
0.5377 0.3368 0.0646 0.0325 0.0161 0.0081
Column 7
0.0042
累计分贡献率:
ljrate =
0.0768
主成分数:2
因子负荷量矩阵:
0.2559 -0.8493
-0.0374 -0.9130
-0.9571 0.1402
0.9703 0.1640
0.9451 0.2580
0.9547 0.0714
0.1860 -0.8273
得分:
score =
0.0539 -0.0163 0.0376 24.0000 0.0528 -0.0067 0.0461 10.0000
0.0523 -0.0076 0.0447 12.0000 0.0512 -0.0074 0.0438 16.0000
0.0575 -0.0007 0.0568 2.0000 0.0317 -0.0036 0.0281 26.0000
0.0478 -0.0220 0.0259 27.0000 0.0589 -0.0146 0.0443 15.0000
0.0498 -0.0079 0.0419 18.0000 0.0553 -0.0133 0.0420 17.0000
0.0576 -0.0130 0.0446 13.0000 0.0458 -0.0058 0.0400 20.0000
0.0489 -0.0025 0.0464 9.0000 0.0532 -0.0025 0.0507 4.0000
0.0492 0.0004 0.0497 5.0000 0.0471 -0.0080 0.0391 21.0000
0.0523 -0.0066 0.0458 11.0000 0.0533 -0.0046 0.0487 7.0000
0.0571 0.0020 0.0590 1.0000 0.0522 -0.0038 0.0484 8.0000
0.0462 -0.0074 0.0389 23.0000 0.0538 0.0009 0.0547 3.0000
0.0422 -0.0135 0.0287 25.0000 0.0532 -0.0042 0.0490 6.0000
0.0461 -0.0016 0.0445 14.0000 0.0491 -0.0078 0.0413 19.0000
0.0449 -0.0059 0.0391 22.0000 -0.0031 -0.0155 -0.0186 73.0000
-0.0009 -0.0137 -0.0146 51.0000 -0.0010 -0.0136 -0.0146 50.0000
-0.0010 -0.0143 -0.0153 58.0000 -0.0005 -0.0145 -0.0150 55.0000 0.0015 -0.0103 -0.0088 34.0000 0.0001 -0.0151 -0.0150 54.0000 -0.0009 -0.0165 -0.0174 69.0000 -0.0008 -0.0140 -0.0148 52.0000 0.0021 -0.0137 -0.0116 40.0000 0.0014 -0.0135 -0.0121 42.0000 -0.0005 -0.0164 -0.0169 66.0000 -0.0001 -0.0112 -0.0113 39.0000 -0.0037 -0.0141 -0.0178 71.0000 -0.0027 -0.0168 -0.0196 75.0000 0.0003 -0.0147 -0.0144 49.0000 -0.0004 -0.0148 -0.0152 57.0000 -0.0008 -0.0120 -0.0128 43.0000 0.0015 -0.0165 -0.0151 56.0000 -0.0009 -0.0102 -0.0111 38.0000 -0.0032 -0.0122 -0.0154 59.0000 -0.0022 -0.0138 -0.0160 63.0000 -0.0030 -0.0143 -0.0173 68.0000 -0.0017 -0.0158 -0.0175 70.0000 -0.0033 -0.0153 -0.0187 74.0000 -0.0016 -0.0150 -0.0166 65.0000 -0.0015 -0.0201 -0.0216 77.0000 0.0336 -0.0519 -0.0183 72.0000 0.0338 -0.0504 -0.0165 64.0000 0.0352 -0.0525 -0.0173 67.0000 0.0340 -0.0499 -0.0159 61.0000 0.0418 -0.0505 -0.0088 33.0000 0.0401 -0.0539 -0.0138 44.0000 0.0375 -0.0516 -0.0140 46.0000 0.0361 -0.0501 -0.0139 45.0000 0.0402 -0.0557 -0.0154 60.0000 0.0395 -0.0544 -0.0149 53.0000 0.0366 -0.0509 -0.0143 47.0000 0.0371 -0.0479 -0.0108 37.0000 0.0453 -0.0613 -0.0159 62.0000 0.0365 -0.0455 -0.0090 35.0000 0.0325 -0.0443 -0.0118 41.0000 0.0338 -0.0559 -0.0221 79.0000 0.0387 -0.0468 -0.0081 32.0000 0.0346 -0.0419 -0.0073 31.0000 0.0339 -0.0399 -0.0059 30.0000 0.0343 -0.0445 -0.0102 36.0000 0.0365 -0.0413 -0.0048 28.0000 0.0346 -0.0489 -0.0143 48.0000 0.0310 -0.0530 -0.0220 78.0000 0.0309 -0.0654 -0.0345 80.0000 0.0410 -0.0467 -0.0057 29.0000 0.0328 -0.0533 -0.0206 76.0000 st =1.0000 0.9632 0.9177
0.9632 1.0000 0.8964
0.9177 0.8964 1.0000
特征向量V及特征值D:
V =
0.7604 0.2853 0.5834
-0.6358 0.5103 0.5791
-0.1325 -0.8113 0.5694
D =
0.0347 0 0
0 0.1135 0
0 0 2.8518
特征根排序的结果:
2.8518
0.113463
0.0347325
主成分贡献率:
newrate =
0.9506 0.0378 0.0116
主成分数:1
因子负荷量矩阵:0.9852 0.9780 0.9616 得分:score =
0.0597 0.0597 10.0000
0.0588 0.0588 13.0000
0.0581 0.0581 14.0000
0.0571 0.0571 15.0000
0.0632 0.0632 4.0000
0.0364 0.0364 43.0000
0.0528 0.0528 23.0000
0.0656 0.0656 1.0000
0.0562 0.0562 16.0000
0.0621 0.0621 5.0000
0.0641 0.0641 3.0000
0.0535 0.0535 21.0000
0.0556 0.0556 19.0000
0.0590 0.0590 12.0000
0.0557 0.0557 18.0000
0.0544 0.0544 20.0000
0.0594 0.0594 11.0000
0.0597 0.0597 9.0000
0.0644 0.0644 2.0000
0.0602 0.0602 7.0000
0.0520 0.0520 25.0000
0.0601 0.0601 8.0000
0.0493 0.0493 26.0000
0.0603 0.0603 6.0000
0.0533 0.0533 22.0000
0.0558 0.0558 17.0000
0.0520 0.0520 24.0000
0.0127 0.0127 81.0000
0.0134 0.0134 77.0000
0.0133 0.0133 78.0000
0.0141 0.0141 67.0000
0.0138 0.0138 71.0000
0.0142 0.0142 65.0000
0.0153 0.0153 56.0000
0.0135 0.0135 76.0000
0.0143 0.0143 62.0000
0.0145 0.0145 61.0000
0.0153 0.0153 55.0000
0.0146 0.0146 59.0000
0.0140 0.0140 69.0000
0.0145 0.0145 60.0000 0.0148 0.0148 57.0000 0.0138 0.0138 72.0000 0.0142 0.0142 63.0000 0.0140 0.0140 68.0000 0.0142 0.0142 64.0000 0.0136 0.0136 75.0000 0.0136 0.0136 74.0000 0.0147 0.0147 58.0000 0.0142 0.0142 66.0000 0.0138 0.0138 70.0000 0.0128 0.0128 80.0000 0.0131 0.0131 79.0000 0.0137 0.0137 73.0000 0.0337 0.0337 52.0000 0.0352 0.0352 48.0000 0.0354 0.0354 46.0000 0.0345 0.0345 51.0000 0.0403 0.0403 30.0000 0.0374 0.0374 39.0000 0.0367 0.0367 42.0000 0.0380 0.0380 38.0000 0.0406 0.0406 29.0000 0.0393 0.0393 33.0000 0.0381 0.0381 37.0000 0.0391 0.0391 35.0000 0.0420 0.0420 28.0000 0.0385 0.0385 36.0000 0.0350 0.0350 49.0000 0.0355 0.0355 44.0000 0.0370 0.0370 40.0000 0.0397 0.0397 32.0000 0.0368 0.0368 41.0000 0.0355 0.0355 45.0000 0.0352 0.0352 47.0000 0.0402 0.0402 31.0000 0.0392 0.0392 34.0000 0.0349 0.0349 50.0000 0.0334 0.0334 54.0000 0.0435 0.0435 27.0000 0.0337 0.0337 53.0000
主成分分析法
一、概述 在处理信息时,当两个变量之间有一定相关关系时,可以解释为这两个变量反映此课题的信息有一定的重叠,例如,高校科研状况评价中的立项课题数与项目经费、经费支出等之间会存在较高的相关性;学生综合评价研究中的专业基础课成绩与专业课成绩、获奖学金次数等之间也会存在较高的相关性。而变量之间信息的高度重叠和高度相关会给统计方法的应用带来许多障碍。 为了解决这些问题,最简单和最直接的解决方案是削减变量的个数,但这必然又会导致信息丢失和信息不完整等问题的产生。为此,人们希望探索一种更为有效的解决方法,它既能大大减少参与数据建模的变量个数,同时也不会造成信息的大量丢失。主成分分析正式这样一种能够有效降低变量维数,并已得到广泛应用的分析方法。 主成分分析以最少的信息丢失为前提,将众多的原有变量综合成较少几个综合指标,通常综合指标(主成分)有以下几个特点: 主成分个数远远少于原有变量的个数 原有变量综合成少数几个因子之后,因子将可以替代原有变量参与数据建模,这将大大减少分析过程中的计算工作量。 主成分能够反映原有变量的绝大部分信息 因子并不是原有变量的简单取舍,而是原有变量重组后的结果,因此不会造成原有变量信息的大量丢失,并能够代表原有变量的绝大部分信息。 主成分之间应该互不相关 通过主成分分析得出的新的综合指标(主成分)之间互不相关,因子参与数据建模能够有效地解决变量信息重叠、多重共线性等给分析应用带来的诸多问题。
主成分具有命名解释性 总之,主成分分析法是研究如何以最少的信息丢失将众多原有变量浓缩成少数几个因子,如何使因子具有一定的命名解释性的多元统计分析方法。 二、基本原理 主成分分析是数学上对数据降维的一种方法。其基本思想是设法将原来众多的具有一定相关性的指标X1,X2,…,XP(比如p个指标),重新组合成一组较少个数的互不相关的综合指标Fm来代替原来指标。那么综合指标应该如何去提取,使其既能最大程度的反映原变量Xp所代表的信息,又能保证新指标之间保持相互无关(信息不重叠)。 设F1表示原变量的第一个线性组合所形成的主成分指标,即 ,由数学知识可知,每一个主成分所提取的信息量可用其方差来度量,其方差 Var(F1)越大,表示F1包含的信息越多。常常希望第一主成分F1所含的信息量最大,因此在所有的线性组合中选取的F1应该是X1,X2,…,XP的所有线性组合中方差最大的,故称F1为第一主成分。如果第一主成分不足以代表原来p个指标的信息,再考虑选取第二个主成分指标F2,为有效地反映原信息,F1已有的信息就不需要再出现在F2中,即F2与F1要保持独立、不相关,用数学语言表达就是其协方差Cov(F1, F2)=0,所以F2是与F1不相关的X1,X2,…,XP的所有线性组合中方差最大的,故称F2为第二主成分,依此类推构造出的F1、F2、……、Fm为原变量指标X1、X2……XP第一、第二、……、第m个主成分。 根据以上分析得知:
主成分分析法matlab实现,实例演示
利用Matlab 编程实现主成分分析 1.概述 Matlab 语言是当今国际上科学界 (尤其是自动控制领域) 最具影响力、也是 最有活力的软件。它起源于矩阵运算,并已经发展成一种高度集成的计算机语言。它提供了强大的科学运算、灵活的程序设计流程、高质量的图形可视化与界面设计、与其他程序和语言的便捷接口的功能。Matlab 语言在各国高校与研究单位起着重大的作用。主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。 1.1主成分分析计算步骤 ① 计算相关系数矩阵 ?? ? ???? ???? ?? ?=pp p p p p r r r r r r r r r R 2 122221 11211 (1) 在(3.5.3)式中,r ij (i ,j=1,2,…,p )为原变量的xi 与xj 之间的相关系数,其计算公式为 ∑∑∑===----= n k n k j kj i ki n k j kj i ki ij x x x x x x x x r 1 1 2 2 1 )() () )(( (2) 因为R 是实对称矩阵(即r ij =r ji ),所以只需计算上三角元素或下三角元素即可。
② 计算特征值与特征向量 首先解特征方程0=-R I λ,通常用雅可比法(Jacobi )求出特征值 ),,2,1(p i i =λ,并使其按大小顺序排列,即0,21≥≥≥≥p λλλ ;然后分别求 出对应于特征值i λ的特征向量),,2,1(p i e i =。这里要求i e =1,即112 =∑=p j ij e ,其 中ij e 表示向量i e 的第j 个分量。 ③ 计算主成分贡献率及累计贡献率 主成分i z 的贡献率为 ),,2,1(1 p i p k k i =∑=λ λ 累计贡献率为 ) ,,2,1(11 p i p k k i k k =∑∑==λ λ 一般取累计贡献率达85—95%的特征值m λλλ,,,21 所对应的第一、第二,…,第m (m ≤p )个主成分。 ④ 计算主成分载荷 其计算公式为 ) ,,2,1,(),(p j i e x z p l ij i j i ij ===λ (3)
第5章 主成分分析
第五章主成分分析 一、填空题 1.主成分分析就是设法将原来众多的指标,重新组合成一组新的的综合指标来代替原来指标。 2.主成分分析的数学模型可简写为,该模型的系数要求。 3.主成分分析中,利用的大小来寻找主成分。 4.第k个主成分 y的贡献率为,前k个主成分的累积贡献率 k 为。 5.确定主成分个数时,累积贡献率一般应达到,在spss中,系统默认为。 6.主成分的协方差矩阵为_________矩阵。 7.原始变量协方差矩阵的特征根的统计含义是________________。 8.原始数据经过标准化处理,转化为均值为__ __,方差为__ __的标准值,且其________矩阵与相关系数矩阵相等。 9.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为________。10.SPSS中主成分分析采用______________命令过程。
二、判断题 1.主成分分析就是设法将原来众多具有一定相关性的指标,重新组合成一组新的相互无关的综合指标来代替原来指标。 ( ) 2.主成分y 的协差阵为对角矩阵。 ( ) 3.p x x x ,,,21 的主成分就是以∑的特征向量为系数的一个组合,它们互不相关,其方差为∑的特征根。 ( ) 4.原始变量i x 的信息提取率()m i V 表示这m 个主成分所能够解释第i 个原始变量变动的程度。 ( ) 5.在spss 中,可以直接进行主成分分析。 ( ) 6.主成分分析可用于筛选回归变量。 ( ) 7.SPSS 中选取主成分的方法有两个:一种是根据特征根≥1来选取; 另一种是按照累积贡献率≥85%来选取。 ( ) 8.主成分方差的大小说明了该综合指标反映p 个原始观测变量综合变动程度的能力的大小。 ( ) 9.主成分表达式的系数向量是协方差矩阵∑的特征向量。 ( ) 10.主成分k y 与原始变量i x 的相关系数()i k x y ,ρ反映了第k 个公共因子对第i 个原始变量的解释程度。 ( )
主成分分析法及其在SPSS中的操作
一、主成分分析基本原理 概念:主成分分析是把原来多个变量划为少数几个综合指标的一种统计分析方法。从数学角度来看,这是一种降维处理技术。 思路:一个研究对象,往往是多要素的复杂系统。变量太多无疑会增加分析问题的难度和复杂性,利用原变量之间的相关关系,用较少的新变量代替原来较多的变量,并使这些少数变量尽可能多的保留原来较多的变量所反应的信息,这样问题就简单化了。 原理:假定有n 个样本,每个样本共有p 个变量,构成一个n ×p 阶的数据矩阵, 记原变量指标为x 1,x 2,…,x p ,设它们降维处理后的综合指标,即新变量为 z 1,z 2,z 3,… ,z m (m ≤p),则 系数l ij 的确定原则: ①z i 与z j (i ≠j ;i ,j=1,2,…,m )相互无关; ②z 1是x 1,x 2,…,x P 的一切线性组合中方差最大者,z 2是与z 1不相关的x 1,x 2,…,x P 的所有线性组合中方差最大者; z m 是与z 1,z 2,……,z m -1都不相关的x 1,x 2,…x P , 的所有线性组合中方差最大者。 新变量指标z 1,z 2,…,z m 分别称为原变量指标x 1,x 2,…,x P 的第1,第2,…,第m 主成分。 从以上的分析可以看出,主成分分析的实质就是确定原来变量x j (j=1,2 ,…, p )在诸主成分z i (i=1,2,…,m )上的荷载 l ij ( i=1,2,…,m ; j=1,2 ,…,p )。 ?????? ? ???????=np n n p p x x x x x x x x x X 2 1 2222111211 ?? ??? ? ?+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z 22112222121212121111............
主成分分析法精华讲义及实例
主成分分析 类型:一种处理高维数据的方法。 降维思想:在实际问题的研究中,往往会涉及众多有关的变量。但是,变量太多不但会增加计算的复杂性,而且也会给合理地分析问题和解释问题带来困难。一般说来,虽然每个变量都提供了一定的信息,但其重要性有所不同,而在很多情况下,变量间有一定的相关性,从而使得这些变量所提供的信息在一定程度上有所重叠。因而人们希望对这些变量加以“改造”,用为数极少的互补相关的新变量来反映原变量所提供的绝大部分信息,通过对新变量的分析达到解决问题的目的。 一、总体主成分 1.1 定义 设 X 1,X 2,…,X p 为某实际问题所涉及的 p 个随机变量。记 X=(X 1,X 2,…,Xp)T ,其协方差矩阵为 ()[(())(())], T ij p p E X E X X E X σ?∑==-- 它是一个 p 阶非负定矩阵。设 1111112212221122221122T p p T p p T p p p p pp p Y l X l X l X l X Y l X l X l X l X Y l X l X l X l X ?==+++? ==+++?? ??==+++? (1) 则有 ()(),1,2,...,, (,)(,),1,2,...,. T T i i i i T T T i j i j i j V ar Y V ar l X l l i p C ov Y Y C ov l X l X l l j p ==∑===∑= (2) 第 i 个主成分: 一般地,在约束条件 1T i i l l =
及 (,)0,1,2,..., 1.T i k i k C ov Y Y l l k i =∑==- 下,求 l i 使 Var(Y i )达到最大,由此 l i 所确定的 T i i Y l X = 称为 X 1,X 2,…,X p 的第 i 个主成分。 1.2 总体主成分的计算 设 ∑是12(,,...,) T p X X X X =的协方差矩阵,∑的特征值及相应的正交单位化特 征向量分别为 120p λλλ≥≥≥≥ 及 12,,...,, p e e e 则 X 的第 i 个主成分为 1122,1,2,...,,T i i i i ip p Y e X e X e X e X i p ==+++= (3) 此时 (),1,2,...,,(,)0,. T i i i i T i k i k V ar Y e e i p C ov Y Y e e i k λ?=∑==??=∑=≠?? 1.3 总体主成分的性质 1.3.1 主成分的协方差矩阵及总方差 记 12(,,...,) T p Y Y Y Y = 为主成分向量,则 Y=P T X ,其中12(,,...,)p P e e e =,且 12()()(,,...,),T T p Cov Y Cov P X P P Diag λλλ==∑=Λ= 由此得主成分的总方差为 1 1 1 ()()()()(),p p p T T i i i i i i V ar Y tr P P tr P P tr V ar X λ ==== =∑=∑=∑= ∑∑∑ 即主成分分析是把 p 个原始变量 X 1,X 2,…,X p 的总方差
主成分分析分析法
第四节 主成分分析方法 地理环境是多要素的复杂系统,在我们进行地理系统分析时,多变量问题 是经常会遇到的。 变量太多, 无疑会增加分析问题的难度与复杂性, 而且在许多 实际问题中, 多个变量之间是具有一定的相关关系的。 因此,我们就会很自然地 想到,能否在各个变量之间相关关系研究的基础上, 用较少的新变量代替原来较 多的变量,而且使这些较少的新变量尽可能多地保留原来较多的变量所反映的信 息?事实上, 这种想法是可以实现的, 本节拟介绍的主成分分析方法就是综合处 理这种问题的一种强有力的方法。 第一节 主成分分析方法的原理 主成分分析是把原来多个变量化为少数几个综合指标的一种统计分析方法, 从数学角度来看, 这是一种降维处理技术。 假定有 n 个地理样本, 每个样本共有 p 个变量描述,这样就构成了一个 n ×p 阶的地理数据矩阵: 如何从这么多变量的数据中抓住地理事物的内在规律性呢?要解决这一问 题,自然要在 p 维空间中加以考察,这是比较麻烦的。为了克服这一困难,就需 要进行降维处理, 即用较少的几个综合指标来代替原来较多的变量指标, 而且使 这些较少的综合指标既能尽量多地反映原来较多指标所反映的信息, 同时它们之 间又是彼此独立的。那么,这些综合指标(即新变量 ) 应如何选取呢?显然,其 最简单的形式就是取原来变量指标的线性组合, 适当调整组合系数, 使新的变量 指标之间相互独立且代表性最好。 如果记原来的变量指标为 x 1, 为 x 1,x 2,?, zm (m ≤p ) 。则 x 2 ,?, x p ,它们的综合指标——新变量指标
在(2)式中,系数l ij 由下列原则来决定: (1)z1 2与z j(i ≠j ;i ,j=1 ,2,?,m)相互无关; (2)z 1是x1,x2,?,x p的一切线性组合中方差最大者;z2是与z1不相关的x1,x2,?,x p的所有线性组合中方差最大者;??;z m是与z1,z2,??z m-1 都不相关的x1,x2,?,x p的所有线性组合中方差最大者。 这样决定的新变量指标z1,z2,?,zm分别称为原变量指标x1,x2,?,x p 的第一,第二,?,第m主成分。其中,z1在总方差中占的比例最大,z2,z3,?,z m的方差依次递减。在实际问题的分析中,常挑选前几个最大的主成分,这样既减少了变量的数目,又抓住了主要矛盾,简化了变量之间的关系。 从以上分析可以看出,找主成分就是确定原来变量x j(j=1 ,2,?,p)在诸主成分z i (i=1 ,2,?,m)上的载荷l ij (i=1 ,2,?,m;j=1 ,2,?,p),从数学上容易知道,它们分别是x1,x2,?,x p的相关矩阵的m个较大的特征值所对应的特征向量。 第二节主成分分析的解法 主成分分析的计算步骤 通过上述主成分分析的基本原理的介绍,我们可以把主成分分析计算步骤归纳如下:在公式(3)中,r ij (i ,j=1 ,2,?,p)为原来变量x i与x j的相关系数,其计 算公式为 因为R是实对称矩阵(即r ij =r ji ),所以只需计算其上三角元素或下三角元素即可。 1 计算相关系数矩阵 2 计算特征值与特征向量
主成分分析法实例
1、主成分法: 用主成分法寻找公共因子的方法如下: 假定从相关阵出发求解主成分,设有p 个变量,则可找出p 个主成分。将所得的p 个主成分按由大到小的顺序排列,记为1Y ,2Y ,…,P Y , 则主成分与原始变量之间存在如下关系: 11111221221122221122....................p p p p p p p pp p Y X X X Y X X X Y X X X γγγγγγγγγ=+++?? =+++??? ?=+++? 式中,ij γ为随机向量X 的相关矩阵的特征值所对应的特征向量的分量,因为特征向量之间彼此正交,从X 到Y 得转换关系是可逆的,很容易得出由Y 到 X 得转换关系为: 11112121212122221122....................p p p p p p p pp p X Y Y Y X Y Y Y X Y Y Y γγγγγγγγγ=+++?? =+++??? ?=+++? 对上面每一等式只保留钱m 个主成分而把后面的部分用i ε代替,则上式变为: 111121211 2121222221122................. ...m m m m p p p mp m p X Y Y Y X Y Y Y X Y Y Y γγγεγγγεγγγε=++++??=++++????=++++? 上式在形式上已经与因子模型相一致,且i Y (i=1,2,…,m )之间相互独立,且i Y 与i ε之间相互独立,为了把i Y 转化成合适的公因子,现在要做的工作只是把主成分i Y 变为方差为1的变量。为完成此变换,必须将i Y 除以其标准差,由主成分分析的知识知其标准差即为特征根的平方根 i λ/i i i F Y λ=, 1122m m λγλγλγ,则式子变为:
第6章 因子分析
第六章 因子分析 一、填空题 1.因子分析常用的两种类型为 和 。 2.因子分析是将具有错综复杂关系的变量(或样品)综合为数量较少的几个因子,以再现_____________与____________之间的相互关系。 3.因子分析就是通过寻找众多变量的 来简化变量中存在的复杂关系的一种方法。 4.因子分析是把每个原始变量分解成两个部分即 、 。 5.变量共同度是指因子载荷矩阵中_______________________。 6.公共因子方差与特殊因子方差之和为_______。 7.求解因子载荷矩阵常用的方法有 和 。 8.常用的因子旋转方法有 和 。 9.Spss 中因子分析采用 命令过程。 10.变量i X 的方差由两部分组成,一部分为 ,另一部分为 。 二、判断题 1.在因子分析中,因子载荷阵不是唯一的。 ( ) 2.因子载荷阵经过正交旋转后,各变量的共性方差和各个因子的贡献都发生了变化。 ( ) 3.因子分析和主成分分析的核心思想都是降维。 ( ) 4.因子分析有两大类,R 型因子分析和Q 型因子分析;其中R 型因子分析是从变量的相似矩阵出发,而Q 型因子分析是从样品的相关矩阵出发。( ) 5.特殊因子与公共因子之间是相互独立的。( ) 6.变量共同度是因子载荷矩阵列元素的平方和。( ) 7.公共因子的方差贡献是衡量公共因子相对重要性指标。( ) 8.对因子载荷阵进行旋转的目的是使结构简化。( ) 三、简答题 1. 因子分析的基本思想是什么,它与主成分分析有什么区别和联系? 2.因子模型的矩阵形式ε+=X UF ,其中:
() () () u F F ij m p P m U F ?=' =' =εεε,,,,1 1 请解释式中F 、 ε、U 的统计意义。 3.因子旋转的意义何在?如何进行最大方差因子旋转? 4.因子分析主要应用在哪几个方面? 四、计算题 4.假设某地固定资产投资率1x , 通货膨胀率2x 和失业率3x 的约相关矩阵为: ??????? ????? ????----=525 25 152******** 51* R 并且已知该相关矩阵的各特征根和相应的非零特征根的单位特征向量分别为: 9123.01=λ ()' -=657.0657.0369 .01α 0877.02=λ ()'-=261.0261 .0929 .02α 03=λ 要求求解因子分析模型,计算各变量的共同度和各公共因子的方差贡献并解释它们的统计意义。 2.设变量x 1,x 2和x 3已标准化,其样本相关系数矩阵为: ?? ?? ??????=135.045.035.0163.045.063.01 R (1)对变量进行因子分析。 (2)取q=2进行正交因子旋转。 3.已知我国某年各地区的国有及非国有规模以上的工业企业经济效益资料,现做因子分析,结果如下,请说明每一个输出结果的含义及目的,并回答以下问题: (1)什么是方差贡献率? 计算方差贡献率的目的何在? (2) 如何利用因子分析结果进行综合评价? 结合本例写出计算综合评价结果的公式。
主成分分析案例
姓名:XXX 学号:XXXXXXX 专业:XXXX 用SPSS19软件对下列数据进行主成分分析: ……
一、相关性 通过对数据进行双变量相关分析,得到相关系数矩阵,见表1。 表1 淡化浓海水自然蒸发影响因素的相关性 由表1可知: 辐照、风速、湿度、水温、气温、浓度六个因素都与蒸发速率在0.01水平上显著相关。 分析:各变量之间存在着明显的相关关系,若直接将其纳入分析可能会得到因多元共线性影响的错误结论,因此需要通过主成份分析将数据所携带的信息进行浓缩处理。 二、KMO和球形Bartlett检验 KMO和球形Bartlett检验是对主成分分析的适用性进行检验。 KMO检验可以检查各变量之间的偏相关性,取值范围是0~1。KMO的结果越接近1,表示变量之间的偏相关性越好,那么进行主成分分析的效果就会越好。实际分析时,KMO统计量大于0.7时,效果就比较理想;若当KMO统计量小于0.5时,就不适于选用主成分分析法。 Bartlett球形检验是用来判断相关矩阵是否为单位矩阵,在主成分分析中,若拒绝各变量独立的原假设,则说明可以做主成分分析,若不拒绝原假设,则说明这些变量可能独立提供一些信息,不适合做主成分分析。
由表2可知: 1、KMO=0.631<0.7,表明变量之间没有特别完美的信息的重叠度,主成分分析得到的模型又可能不是非常完善,但仍然值得实验。 2、显著性小于0.05,则应拒绝假设,即变量间具有较强的相关性。 三、公因子方差 公因子方差表示变量共同度。表示各变量中所携带的原始信息能被提取出的主成分所体现的程度。 由表3可知: 几乎所有变量共同度都达到了75%,可认为这几个提取出的主成分对各个变量的阐释能力比较强。 四、解释的总方差 解释的总方差给出了各因素的方差贡献率和累计贡献率。
主成分分析法概念及例题
主成分分析法 主成分分析(principal components analysis,PCA)又称:主分量分析,主成分回归分析法 [编辑] 什么是主成分分析法 主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析(principal components analysis,PCA)是一种简化数据集的技术。它是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。 [编辑] 主成分分析的基本思想
在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [编辑] 主成分分析的主要作用
主成分分析PCA(含有详细推导过程以及案例分析matlab版)
主成分分析法(PCA) 在实际问题中,我们经常会遇到研究多个变量的问题,而且在多数情况下,多个变量之间常常存在一定的相关性。由于变量个数较多再加上变量之间的相关性,势必增加了分析问题的复杂性。如何从多个变量中综合为少数几个代表性变量,既能够代表原始变量的绝大多数信息,又互不相关,并且在新的综合变量基础上,可以进一步的统计分析,这时就需要进行主成分分析。 I. 主成分分析法(PCA)模型 (一)主成分分析的基本思想 主成分分析是采取一种数学降维的方法,找出几个综合变量来代替原来众多的变量,使这些综合变量能尽可能地代表原来变量的信息量,而且彼此之间互不相关。这种将把多个变量化为少数几个互相无关的综合变量的统计分析方法就叫做主成分分析或主分量分析。 主成分分析所要做的就是设法将原来众多具有一定相关性的变量,重新组合为一组新的相互无关的综合变量来代替原来变量。通常,数学上的处理方法就是将原来的变量做线性组合,作为新的综合变量,但是这种组合如果不加以限制,则可以有很多,应该如何选择呢?如果将选取的第一个线性组合即第一个综合变量记为1F ,自然希望它尽可能多地反映原来变量的信息,这里“信息”用方差来测量,即希望)(1F Var 越大,表示1F 包含的信息越多。因此在所有的线性组合中所选取的1F 应该是方差最大的,故称1F 为第一主成分。如果第一主成分不足以代表原来p 个变量的信息,再考虑选取2F 即第二个线性组合,为了有效地反映原来信息,1F 已有的信息就不需要再出现在2F 中,用数学语言表达就是要求 0),(21=F F Cov ,称2F 为第二主成分,依此类推可以构造出第三、四……第p 个主成分。 (二)主成分分析的数学模型 对于一个样本资料,观测p 个变量p x x x ,,21,n 个样品的数据资料阵为: ??????? ??=np n n p p x x x x x x x x x X 21 222 21112 11()p x x x ,,21=
主成分分析计算方法和步骤
在对某一事物或现象进行实证研究时,为了充分反映被研究对象个体之间的差异, 研究者往往要考虑增加测量指标,这样就会增加研究问题的负载程度。但由于各指标都是对同一问题的反映,会造成信息的重叠,引起变量之间的共线性,因此,在多指标的数据分析中,如何压缩指标个数、压缩后的指标能否充分反映个体之间的差异,成为研究者关心的问题。而主成分分析法可以很好地解决这一问题。 主成分分析的应用目的可以简单地归结为: 数据的压缩、数据的解释。它常被用来寻找和判断某种事物或现象的综合指标,并且对综合指标所包含的信息给予适当的解释, 从而更加深刻地揭示事物的内在规律。 主成分分析的基本步骤分为: ①对原始指标进行标准化,以消除变量在数量极或量纲上的影响;②根据标准化后的数据矩阵求出相关系数矩阵 R; ③求出 R 矩阵的特征根和特征向量; ④确定主成分,结合专业知识对各主成分所蕴含的信息给予适当的解释;⑤合成主成分,得到综合评价值。 结合数据进行分析 本题分析的是全国各个省市高校绩效评价,利用全国2014年的相关统计数据(见附录),从相关的指标数据我们无法直接评价我国各省市的高等教育绩效,而通过表5-6的相关系数矩阵,可以看到许多的变量之间的相关性很高。如:招生人数与教职工人数之间具有较强的相关性,教育投入经费和招生人数也具有较强的相关性,教工人数与本科院校数之间的相关系数最高,到达了,而各组成成分之间的相关性都很高,这也充分说明了主成分分析的必要性。 表5-6 相关系数矩阵 本科院校 数招生人数教育经费投入 相关性师生比 重点高校数 教工人数 本科院校数 招生人数 教育经费投 入
师生比重点高校数教工人数 相关性师生比 重点高校数 教工人数 本科院校数 招生人数 教育经费投 入(元) 表5-7给出的是各主成分的方差贡献率和累计贡献率,我们选取主成分的标准有两个:第一,特征根大于1,因为,如果特征根小于1,说明该主成分的解释力度太弱,还比不上直接引入一个原始变量的平均解释力度大;第二,方差贡献率大于85%,如果这两个标准不能同时符合要求,则往往是因为选择的指标不合理或者样本容量太小,应继续调整。表5-7还显示,只有前2个特征根大于1,因此SPSS只提取了前两个主成分,而这两个主成分的方差贡献率达到了%,因此选取前两个主成分已经能够很好地描述我国高等教育地区现状。
主成分分析法概念及例题
主成分分析法 主成分分析(principal components analysis,PCA)又称:主分量分析,主成分回归分析法 [编辑] 什么就是主成分分析法 主成分分析也称主分量分析,旨在利用降维的思想,把多指标转化为少数几个综合指标。 在统计学中,主成分分析(principal components analysis,PCA)就是一种简化数据集的技术。它就是一个线性变换。这个变换把数据变换到一个新的坐标系统中,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。主成分分析经常用减少数据集的维数,同时保持数据集的对方差贡献最大的特征。这就是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但就是,这也不就是一定的,要视具体应用而定。 [编辑] 主成分分析的基本思想
在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量与增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正就是适应这一要求产生的,就是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果就是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取就是个重点与难点。如上所述,主成分分析法正就是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量就是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量就是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发与利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用与开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [编辑] 主成分分析法的基本原理 主成分分析法就是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [编辑] 主成分分析的主要作用
主成分分析法概念及例题
主成分分析法 [ 编辑 ] 什么是主成分分析法 主成分分析也称 主分量分析 ,旨在利用降维的思想,把多 指标 转化为少数几个综合指标。 在 统计学 中,主成分分析( principal components analysis,PCA )是一种简化数据集的技 术。它是一个线性变换。 这个变换把数据变换到一个新的坐标系统中, 使得任何数据投影的第一 大方差 在第一个坐标 (称为第一主成分 )上,第二大方差在第二个坐标 (第二主成分 )上,依次类推。 主成分分析经常用减少数据集的维数, 同时保持数据集的对 方差 贡献最大的特征。 这是通过保留 低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是, 这也不是一定的,要视具体应用而定。 [ 编辑 ] , PCA ) 又称: 主分量分析,主成分回归分析法 主成分分析( principal components analysis
主成分分析的基本思想 在实证问题研究中,为了全面、系统地分析问题,我们必须考虑众多影响因素。这些涉及的因素一般称为指标,在多元统计分析中也称为变量。因为每个变量都在不同程度上反映了所研究问题的某些信息,并且指标之间彼此有一定的相关性,因而所得的统计数据反映的信息在一定程度上有重叠。在用统计方法研究多变量问题时,变量太多会增加计算量和增加分析问题的复杂性,人们希望在进行定量分析的过程中,涉及的变量较少,得到的信息量较多。主成分分析正是适应这一要求产生的,是解决这类题的理想工具。 同样,在科普效果评估的过程中也存在着这样的问题。科普效果是很难具体量化的。在实际评估工作中,我们常常会选用几个有代表性的综合指标,采用打分的方法来进行评估,故综合指标的选取是个重点和难点。如上所述,主成分分析法正是解决这一问题的理想工具。因为评估所涉及的众多变量之间既然有一定的相关性,就必然存在着起支配作用的因素。根据这一点,通过对原始变量相关矩阵内部结构的关系研究,找出影响科普效果某一要素的几个综合指标,使综合指标为原来变量的线性拟合。这样,综合指标不仅保留了原始变量的主要信息,且彼此间不相关,又比原始变量具有某些更优越的性质,就使我们在研究复杂的科普效果评估问题时,容易抓住主要矛盾。上述想法可进一步概述为:设某科普效果评估要素涉及个指标,这指标构成的维随机向量为。对作正交变换,令,其中为正交阵,的各分量是不相关的,使得的各分量在某个评估要素中的作用容易解释,这就使得我们有可能从主分量中选择主要成分,削除对这一要素影响微弱的部分,通过对主分量的重点分析,达到对原始变量进行分析的目的。的各分量是原始变量线性组合,不同的分量表示原始变量之间不同的影响关系。由于这些基本关系很可能与特定的作用过程相联系,主成分分析使我们能从错综复杂的科普评估要素的众多指标中,找出一些主要成分,以便有效地利用大量统计数据,进行科普效果评估分析,使我们在研究科普效果评估问题中,可能得到深层次的一些启发,把科普效果评估研究引向深入。 例如,在对科普产品开发和利用这一要素的评估中,涉及科普创作人数百万人、科普作品发行量百万人、科普产业化(科普示范基地数百万人)等多项指标。经过主成分分析计算,最后确定个或个主成分作为综合评价科普产品利用和开发的综合指标,变量数减少,并达到一定的可信度,就容易进行科普效果的评估。 [ 编辑] 主成分分析法的基本原理 主成分分析法是一种降维的统计方法,它借助于一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,这在代数上表现为将原随机向量的协方差阵变换成对角形阵,在几何上表现为将原坐标系变换成新的正交坐标系,使之指向样本点散布最开的p 个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。 [ 编辑] 主成分分析的主要作用
(整理)实验六主成分分析.
实验课:主成分分析 实验目的 理解主成分(因子)分析的基本原理,熟悉并掌握SPSS中的主成分(因子)分析方法及其主要应用。 一、相关知识 1 概念 因子分析(Factor analysis):就是用少数几个因子来描述许多指标或因素之间的联系,以较少几个因子来反映原资料的大部分信息的统计学分析方法。 主成分分析(Principal component analysis):是因子分析的一个特例,是使用最多的因子提取方法。它通过坐标变换手段,将原有的多个相关变量,做线性变化,转换为另外一组不相关的变量。选取前面几个方差最大的主成分,这样达到了因子分析较少变量个数的目的,同时又能与较少的变量反映原有变量的绝大部分的信息。从数学角度来看,主成分分析是一种化繁为简的降维处理技术。 两者关系:主成分分析(PCA)和因子分析(FA)是两种把变量维数降低以便于描述、理解和分析的方法,而实际上主成分分析可以说是因子分析的一个特例。 2 特点 (1)因子变量的数量远少于原有的指标变量的数量,因而对因子变量的分析能够减少分析中的工作量。 (2)因子变量不是对原始变量的取舍,而是根据原始变量的信息进行重新组构,它能够反映原有变量大部分的信息。 (3)因子变量之间不存在显著的线性相关关系,对变量的分析比较方便,但原始部分变量之间多存在较显著的相关关系。 (4)因子变量具有命名解释性,即该变量是对某些原始变量信息的综合和反映。 在保证数据信息丢失最少的原则下,对高维变量空间进行降维处理(即通过因子分析或主成分分析)。显然,在一个低维空间解释系统要比在高维系统容易的多。 3 类型 根据研究对象的不同,把因子分析分为R型和Q型两种。 当研究对象是变量时,属于R型因子分析; 当研究对象是样品时,属于Q型因子分析。 但有的因子分析方法兼有R型和Q型因子分析的一些特点,如因子分析中的对应分析
第5章 主成分分析
第五章 主成分分析 一、填空题 1.主成分分析就是设法将原来众多 的指标,重新组合成一组新的 的综合指标来代替原来指标。 2.主成分分析的数学模型可简写为 ,该模型的系数要求 。 3.主成分分析中,利用 的大小来寻找主成分。 4.第k 个主成分k y 的贡献率为 ,前k 个主成分的累积贡献率为 。 5.确定主成分个数时,累积贡献率一般应达到 ,在spss 中,系统默认为 。 6.主成分的协方差矩阵为_________矩阵。 7.原始变量协方差矩阵的特征根的统计含义是________________。 8.原始数据经过标准化处理,转化为均值为__ __,方差为__ __的标准值,且其________矩阵与相关系数矩阵相等。 9.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为________。 10.SPSS 中主成分分析采用______________命令过程。 二、判断题 1.主成分分析就是设法将原来众多具有一定相关性的指标,重新组合成一组新的相互无关的综合指标来代替原来指标。 ( ) 2.主成分y 的协差阵为对角矩阵。 ( ) 3.p x x x ,,,21 的主成分就是以∑的特征向量为系数的一个组合,它们互不相关,其方差为 ∑的特征根。 ( ) 4.原始变量i x 的信息提取率()m i V 表示这m 个主成分所能够解释第i 个原始变量变动的程度。 ( ) 5.在spss 中,可以直接进行主成分分析。 ( ) 6.主成分分析可用于筛选回归变量。 ( ) 7.SPSS 中选取主成分的方法有两个:一种是根据特征根≥1来选取; 另一种是按照累积贡献率≥85%来选取。 ( ) 8.主成分方差的大小说明了该综合指标反映p 个原始观测变量综合变动程度的能力的大小。 ( ) 9.主成分表达式的系数向量是协方差矩阵∑的特征向量。 ( ) 10.主成分k y 与原始变量i x 的相关系数()i k x y ,ρ反映了第k 个公共因子对第i 个原始变量的解释程度。 ( ) 三、简答题 1.简述主成分的概念及几何意义。 2.主成分分析的基本思想是什么? 3.简述主成分分析的计算步骤。 4.主成分有哪些性质? 5.主成分主要应用在哪些方面? 四、计算题 1.假设3个变量1x 、2x 和3x 的协方差矩阵为: ???? ??????--=∑20 05 3 032 要求用此协差阵和相应的相关阵对这3个变量进行主成分分析,根据计算结果说明应选取多 少个主成分以代表原来的3个变量,并说明理由。 2.在一项研究中,测量了376只鸡的骨骼,并利用相关系数矩阵进行主成分分析,见下表:
主成分分析法介绍
主成分分析方法 我们进行系统分析评估或医学上因子分析等时,多变量问题是经常会遇到的。变量太多,无疑会增加分析问题的难度与复杂性,而且在许多实际问题中,多个变量之间是具有一定的相关关系的。因此,我们就会很自然地想到,能否在各个变量之间相关关系研究的基础上,用较少的新变量代替原来较多的变量,而且使这些较少的新变量尽可能多地保留原来较多的变量所反映的信息事实上,这种想法是可以实现的,本节拟介绍的主成分分析方法就是综合处理这种问题的一种强有力的方法。 第一节 主成分分析方法的原理 主成分分析是把原来多个变量化为少数几个综合指标的一种统计分析方法,从数学角度来看,这是一种降维处理技术。假定有n 样本,每个样本共有p 个变量描述,这样就构成了一个n×p 阶的数据矩阵: 11121212221 2 .....................p p n n np x x x x x x X x x x ?? ? ? = ? ? ??? (1)
如何从这么多变量的数据中抓住事物的内在规律性呢要解决这一问题,自然要在p 维空间中加以考察,这是比较麻烦的。为了克服这一困难,就需要进行降维处理,即用较少的几个综合指标来代替原来较多的变量指标,而且使这些较少的综合指标既能尽量多地反映原来较多指标所反映的信息,同时它们之间又是彼此独立的。那么,这些综合指标(即新变量)应如何选取呢显然,其最简单的形式就是取原来变量指标的线性组合,适当调整组合系数,使新的变量指标之间相互独立且代表性最好。 如果记原来的变量指标为p x x x ,,21Λ,它们的综合指标——新变量指标为Λ21,z z ,m z (m≤p)。则 )2.........(..........22112222121212121111??? ?? ? ?+++=+++=+++=p mp m m m p p p p x l x l x l z x l x l x l z x l x l x l z ΛΛ ΛΛΛΛΛΛΛΛΛΛΛΛΛ 在(2)式中,系数l ij 由下列原则来决定: (1)z i 与z j (i≠j ;i ,j=1,2,…,m)相互无关; (2)z 1是x 1,x 2,…,x p 的一切线性组合中方差最大者;z 2是与z 1不相关的x 1,x 2,…,x p 的所有线性组合中方差最大者;……;z m 是与z 1,z 2,……z m-1都不相关的x 1,x 2,…,x p 的所有线性组合中方差最大者。