各种排序方法总结

常用排序算法有哪些? 冒择路希快归堆(口诀):冒泡排序,选择排序,插入排序,希尔排序,快速排序,归并排序,堆排序; 冒泡排序
冒泡排序(Bubble Sort ),是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
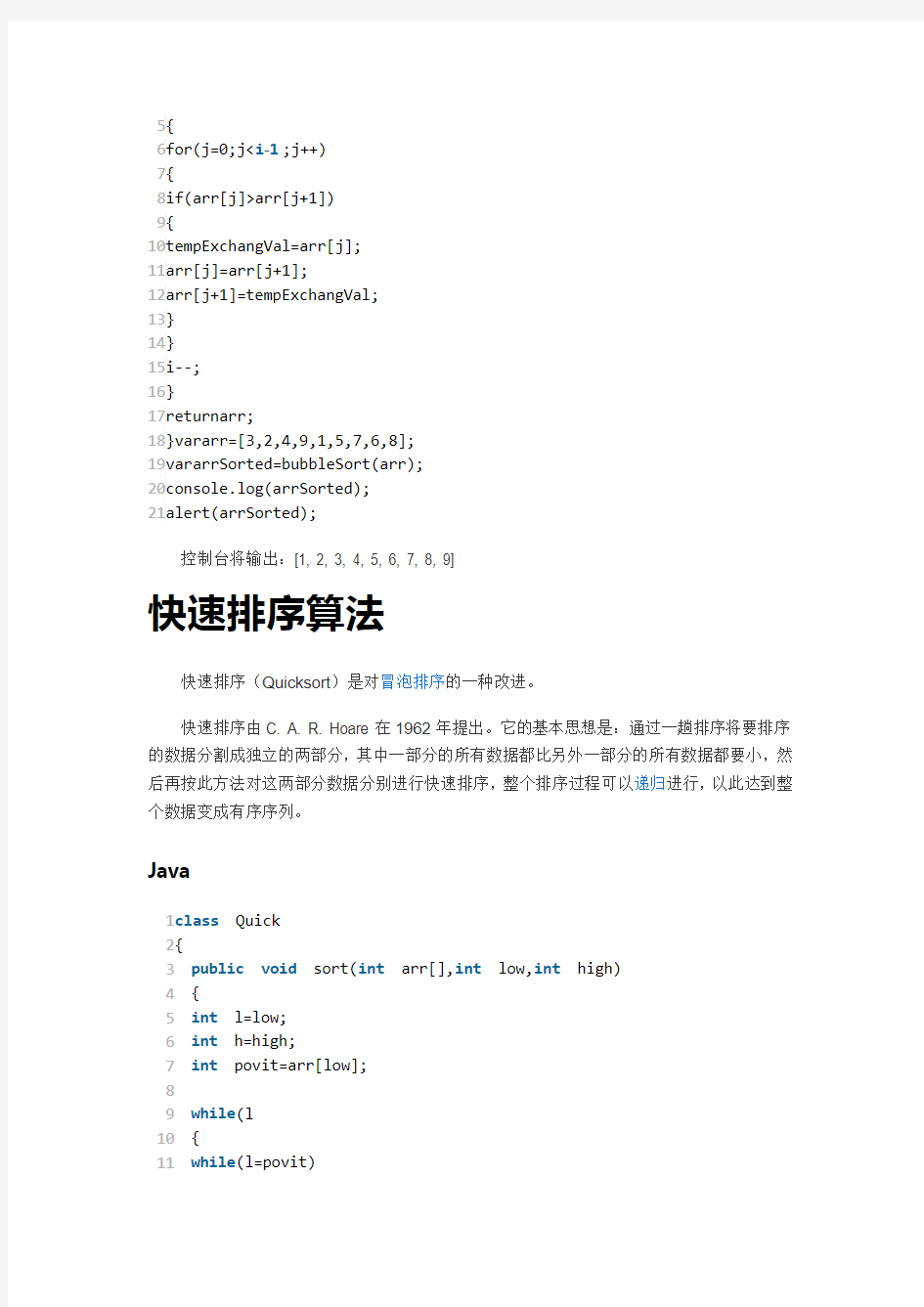
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端,故名。 JAVA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 publicclassBubbleSort
{
publicvoidsort(int[]a)
{
inttemp=0;
for(inti=a.length-1;i>0;--i)
{
for(intj=0;j { if(a[j+1] { temp=a[j]; a[j]=a[j+1]; a[j+1]=temp; } } } } } JavaScript 1 2 3 4 functionbubbleSort(arr) {vari=arr.length,j; vartempExchangVal; while(i>0) 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 { for(j=0;j { if(arr[j]>arr[j+1]) { tempExchangVal=arr[j]; arr[j]=arr[j+1]; arr[j+1]=tempExchangVal; } } i--; } returnarr; }vararr=[3,2,4,9,1,5,7,6,8]; vararrSorted=bubbleSort(arr); console.log(arrSorted); alert(arrSorted); 控制台将输出:[1, 2, 3, 4, 5, 6, 7, 8, 9] 快速排序算法 快速排序(Quicksort )是对冒泡排序的一种改进。 快速排序由C. A. R. Hoare 在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。 Java 1 2 3 4 5 6 7 8 9 10 11 class Quick { public void sort(int arr[],int low,int high) { int l=low; int h=high; int povit=arr[low]; while (l { while (l 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 h--; if(l int temp=arr[h]; arr[h]=arr[l]; arr[l]=temp; l++; } while(l l++; if(l int temp=arr[h]; arr[h]=arr[l]; arr[l]=temp; h--; } } print(arr); System.out.print("l="+(l+1)+"h="+(h+1)+"povit="+povit+"\n"); if(l>low)sort(arr,low,l-1); if(h } } /*//////////////////////////方式二////////////////////////////////*/更高效点的代码: public T[]quickSort(T[]targetArr,intstart,intend) { inti=start+1,j=end; Tkey=targetArr[start]; SortUtil if(start>=end)return(targetArr); /*从i++和j--两个方向搜索不满足条件的值并交换 * *条件为:i++方向小于key,j--方向大于key */ while(true) { 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 while (targetArr[j].compareTo(key)>0)j--; while (targetArr[i].compareTo(key)<0&&i if (i>=j)break ; sUtil.swap(targetArr,i,j); if (targetArr[i]==key) { j--; }else { i++; } } /*关键数据放到‘中间’*/ sUtil.swap(targetArr,start,j); if (start { this .quickSort(targetArr,start,i-1); } if (j+1 { this .quickSort(targetArr,j+1,end); } returntargetArr; } /*//////////////方式三:减少交换次数,提高效率/////////////////////*/ private voidquickSort(T[]targetArr,intstart,intend) { inti=start,j=end; Tkey=targetArr[start]; while (i { /*按j--方向遍历目标数组,直到比key 小的值为止*/ while (j>i&&targetArr[j].compareTo(key)>=0) { j--; } if (i { 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 /*targetArr[i]已经保存在key 中,可将后面的数填入*/ targetArr[i]=targetArr[j]; i++; } /*按i++方向遍历目标数组,直到比key 大的值为止*/ while (i /*此处一定要小于等于零,假设数组之内有一亿个1,0交替出现的话,而key 的值又恰巧是1的话,那么这个小于等于的作用就会使下面的if 语句少执行一亿次。*/ { i++; } if (i { /*targetArr[j]已保存在targetArr[i]中,可将前面的值填入*/ targetArr[j]=targetArr[i]; j--; } } /*此时i==j*/ targetArr[i]=key; /*递归调用,把key 前面的完成排序*/ this .quickSort(targetArr,start,i-1); /*递归调用,把key 后面的完成排序*/ this .quickSort(targetArr,j+1,end); } JavaScript 1 2 3 4 5 6 7 8 9 10 11 12 function quickSort(array){ function sort(prev, numsize){ var nonius = prev; var j = numsize -1; var flag = array[prev]; if ((numsize - prev) > 1) { while (nonius < j){ for (; nonius < j; j--){ if (array[j] < flag) { array[nonius++] = array[j]; //a[i] = a[j]; i += 1; break ; }; 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 } for ( ; nonius < j; nonius++){ if (array[nonius] > flag){ array[j--] = array[nonius]; break ; } } } array[nonius] = flag; sort(0, nonius); sort(nonius + 1, numsize); } } sort(0, array.length); return array; } 选择排序 选择排序(Selection sort )是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。 选择排序是不稳定的排序方法(比如序列[5, 5, 3]第一次就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)。 Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void selectSort(int []a) { int minIndex=0; int temp=0; if ((a==null )||(a.length==0)) return ; for (int i=0;i { minIndex=i;//无序区的最小数据数组下标 for (intj=i+1;j { //在无序区中找到最小数据并保存其数组下标 if (a[j] { minIndex=j; } 17 18 19 20 21 22 23 24 25 26 } if (minIndex!=i) { //如果不是无序区的最小值位置不是默认的第一个数据,则交换之。 temp=a[i]; a[i]=a[minIndex]; a[minIndex]=temp; } } } 插入排序 有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序,这个时候就要用到一种新的排序方法——插入排序法,插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。 插入排序的基本思想是:每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。 Java 版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /** *插入排序 *@paramarr *@return */ private static int [] insertSort(int []arr){ if (arr == null || arr.length < 2){ return arr; } for (inti=1;i for (intj=i;j>0;j--){ if (arr[j] //TODO: int temp=arr[j]; arr[j]=arr[j-1]; 16 17 18 19 20 21 22 23 24 arr[j-1]=temp; }else { //接下来是无用功 break ; } } } return arr; } 希尔排序 希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL .Shell 于1959年提出而得名。 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。 JAVA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main(String [] args) { int []a={49,38,65,97,76,13,27,49,78,34,12,64,1}; System.out.println("排序之前:"); for (int i=0;i { System.out.print(a[i]+" "); } //希尔排序 int d=a.length; while (true ) { d=d/2; for (int x=0;x { for (int i=x+d;i { int temp=a[i]; int j; for (j=i-d;j>=0&&a[j]>temp;j=j-d) 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 { a[j+d]=a[j]; } a[j+d]=temp; } } if (d==1) { break ; } } System.out.println(); System.out.println("排序之后:"); for (int i=0;i { System.out.print(a[i]+" "); } } 上面写的看的人头晕 我写个好理解的 while (true ){ for (int i=0;i for (int j=i;j+d int temp; if (a[j]>a[j+d]){ temp=a[j]; a[j]=a[j+d]; a[j+d]=temp; } } } if (d==1){break ;} d--; } javascript 1 2 3 4 vararr=[49,38,65,97,76,13,27,49,55,04], len=arr.length; for (varfraction=Math.floor(len/2);fraction>0;fraction=Math.floor(fract ion/2)){ 5 6 7 8 9 10 11 1 2 for (vari=fraction;i for (varj=i-fraction;j>=0&&arr[j]>arr[fraction+j];j-=fraction){ vartemp=arr[j]; arr[j]=arr[fraction+j]; arr[fraction+j]=temp; } } } console.log(arr); 归并排序 归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer )的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i 和k 分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j 和k 分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r 中从下标k 到下标t 的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。 Java 语言 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package algorithm; public class MergeSort { // private static long sum = 0; /** * * 二路归并 * 原理:将两个有序表合并和一个有序表 * * * @param a * @param s * 第一个有序表的起始下标 * @param m * 第二个有序表的起始下标 * @param t 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 *第二个有序表的结束小标* */ private static void merge(int[]a,int s,int m,int t){ int[]tmp=new int[t-s+1]; int i=s,j=m,k=0; while(i if(a[i]<=a[j]){ tmp[k]=a[i]; k++; i++; }else{ tmp[k]=a[j]; j++; k++; } } while(i tmp[k]=a[i]; i++; k++; } while(j<=t){ tmp[k]=a[j]; j++; k++; } System.arraycopy(tmp,0,a,s,tmp.length); } /** * *@param a *@param s *@param len *每次归并的有序集合的长度 */ public static void mergeSort(int[]a,int s,int len){ int size= a.length; int mid=size/(len<<1); int c=size&((len<<1)-1); //-------归并到只剩一个有序集合的时候结束算法-------// if(mid==0) 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 return ; // ------进行一趟归并排序-------// for (int i = 0; i < mid; ++i) { s = i * 2 * len; merge(a, s, s + len, (len << 1) + s - 1); } // -------将剩下的数和倒数一个有序集合归并-------// if (c != 0) merge(a, size - c - 2 * len, size - c, size - 1); // -------递归执行下一趟归并排序------// mergeSort(a, 0, 2 * len); } public static void main(String[] args) { int [] a = new int [] { 4, 3, 6, 1, 2, 5 }; mergeSort(a, 0, 1); for (int i = 0; i < a.length; ++i) { System.out.print(a[i] + " "); } } } JavaScript 语言 使用递归的代码如下。优点是描述算法过程思路清晰,缺点是使用递归,mergeSort()函数频繁地自我调用。长度为n 的数组最终会调用mergeSort()函数 2n-1次,这意味着一个长度超过1500的数组会在Firefox 上发生栈溢出错误。可以考虑使用迭代来实现同样的功能。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 function merge(left,right){ var result=[]; while (left.length>0&&right.length>0){ if (left[0] /*shift()方法用于把数组的第一个元素从其中删除,并返回第一个元素的值。*/ result.push(left.shift()); }else { result.push(right.shift()); } } return result.concat(left).concat(right); } function mergeSort(items){ if (items.length==1){ return items; 17 18 19 20 21 22 } var middle=Math.floor(items.length/2), left=items.slice(0,middle), right=items.slice(middle); return merge(mergeSort(left),mergeSort(right)); } 堆排序 堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。 Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class HeapSort{ private static int [] sort=new int []{1,0,10,20,3,5,6,4,9,8,12, 17,34,11}; public static void main(String[] args){ buildMaxHeapify(sort); heapSort(sort); print(sort); } private static void buildMaxHeapify(int [] data){ //没有子节点的才需要创建最大堆,从最后一个的父节点开始 int startIndex=getParentIndex(data.length-1); //从尾端开始创建最大堆,每次都是正确的堆 for (int i=startIndex;i>=0;i--){ maxHeapify(data,data.length,i); } } /** *创建最大堆 * *@paramdata *@paramheapSize 需要创建最大堆的大小,一般在sort 的时候用到,因为最多值放在末尾,末尾就不再归入最大堆了 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 *@paramindex 当前需要创建最大堆的位置 */ private static void maxHeapify(int [] data,int heapSize,int index){ //当前点与左右子节点比较 int left=getChildLeftIndex(index); int right=getChildRightIndex(index); int largest=index; if (left largest=left; } if (right largest=right; } //得到最大值后可能需要交换,如果交换了,其子节点可能就不是最大堆了,需要重新调整 if (largest!=index){ int temp=data[index]; data[index]=data[largest]; data[largest]=temp; maxHeapify(data,heapSize,largest); } } /** *排序,最大值放在末尾,data 虽然是最大堆,在排序后就成了递增的 * *@paramdata */ private static void heapSort(int [] data){ //末尾与头交换,交换后调整最大堆 for (int i=data.length-1;i>0;i--){ int temp=data[0]; data[0]=data[i]; data[i]=temp; maxHeapify(data,i,0); } } /** *父节点位置 * *@paramcurrent *@return 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 */ private static int getParentIndex(int current){ return (current-1)>>1; } /** *左子节点position 注意括号,加法优先级更高 * *@paramcurrent *@return */ private static int getChildLeftIndex(int current){ return (current<<1)+1; } /** *右子节点position * *@paramcurrent *@return */ private static int getChildRightIndex(int current){ return (current<<1)+2; } private static void print(int [] data){ int pre=-2; for (int i=0;i if (pre<(int )getLog(i+1)){ pre=(int )getLog(i+1); System.out.println(); } System.out.print(data[i]+"|"); } } /** *以2为底的对数 * *@paramparam *@return */ private static double getLog(double param){ return Math.log(param)/Math.log(2); } } JavaScript 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 /** *AuthorJenaszhang */ Array.prototype.buildMaxHeap=function (){ for (var i=Math.floor(this .length/2)-1;i>=0;i--){ this .heapAdjust(i,this .length); } }; Array.prototype.swap=function (i,j){ var tmp=this [i]; this [i]=this [j]; this [j]=tmp; }; Array.prototype.heapSort=function (){ this .buildMaxHeap(); for (vari=this .length-1;i>0;i--){ this .swap(0,i); this .heapAdjust(0,i); } return this ; }; Array.prototype.heapAdjust=function (i,j){ var largest=i; var left=2*i+1; var right=2*i+2; if (left largest=left; } if (right } if (largest!=i){ 40 41 42 43 44 45 46 47 this .swap(i,largest); this .heapAdjust(largest,j); } }; var a=new Array(); [].push.apply(a,[2,3,89,57,23,72,43,105]); console.log(a.heapSort()); 各种排序算法的总结和比较 1 快速排序(QuickSort) 快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序可以由下面四步组成。 (1)如果不多于1个数据,直接返回。 (2)一般选择序列最左边的值作为支点数据。(3)将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。 (4)对两边利用递归排序数列。 快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。 2 归并排序(MergeSort) 归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。 3 堆排序(HeapSort) 堆排序适合于数据量非常大的场合(百万数据)。 堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。 堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。 Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。 Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。 5 插入排序(InsertSort) 插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。 C语言几种常见的排序方法 2009-04-2219:55 插入排序是这样实现的: 首先新建一个空列表,用于保存已排序的有序数列(我们称之为"有序列表")。 从原数列中取出一个数,将其插入"有序列表"中,使其仍旧保持有序状态。 重复2号步骤,直至原数列为空。 插入排序的平均时间复杂度为平方级的,效率不高,但是容易实现。它借助了"逐步扩大成果"的思想,使有序列表的长度逐渐增加,直至其长度等于原列表的长度。 冒泡排序 冒泡排序是这样实现的: 首先将所有待排序的数字放入工作列表中。 从列表的第一个数字到倒数第二个数字,逐个检查:若某一位上的数字大于他的下一位,则将它与它的下一位交换。 重复2号步骤,直至再也不能交换。 冒泡排序的平均时间复杂度与插入排序相同,也是平方级的,但也是非常容易实现的算法。 选择排序 选择排序是这样实现的: 设数组内存放了n个待排数字,数组下标从1开始,到n结束。 i=1 从数组的第i个元素开始到第n个元素,寻找最小的元素。 将上一步找到的最小元素和第i位元素交换。 如果i=n-1算法结束,否则回到第3步 选择排序的平均时间复杂度也是O(n²)的。 快速排序 现在开始,我们要接触高效排序算法了。实践证明,快速排序是所有排序算法中最高效的一种。它采用了分治的思想:先保证列表的前半部分都小于后半部分,然后分别对前半部分和后半部分排序,这样整个列表就有序了。这是一种先进的思想,也是它高效的原因。因为在排序算法中,算法的高效与否与列表中数字间的比较次数有直接的关系,而"保证列表的前半部分都小于后半部分"就使得前半部分的任何一个数从此以后都不再跟后半部分的数进行比较了,大大减少了数字间不必要的比较。但查找数据得另当别论了。 堆排序 堆排序与前面的算法都不同,它是这样的: 首先新建一个空列表,作用与插入排序中的"有序列表"相同。 找到数列中最大的数字,将其加在"有序列表"的末尾,并将其从原数列中删除。 重复2号步骤,直至原数列为空。 堆排序的平均时间复杂度为nlogn,效率高(因为有堆这种数据结构以及它奇妙的特征,使得"找到数列中最大的数字"这样的操作只需要O(1)的时间复杂度,维护需要logn的时间复杂度),但是实现相对复杂(可以说是这里7种算法中比较难实现的)。 一、插入排序 介绍 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据。 算法适用于少量数据的排序,时间复杂度为O(n^2)。 插入排算法是稳定的排序方法。 步骤 ①从第一个元素开始,该元素可以认为已经被排序 ②取出下一个元素,在已经排序的元素序列中从后向前扫描 ③如果该元素(已排序)大于新元素,将该元素移到下一位置 ④重复步骤3,直到找到已排序的元素小于或者等于新元素的位置 ⑤将新元素插入到该位置中 ⑥重复步骤2 排序演示 算法实现 二、冒泡排序 介绍 冒泡排序(Bubble Sort)是一种简单的排序算法,时间复杂度为O(n^2)。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。 这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。原理 循环遍历列表,每次循环找出循环最大的元素排在后面; 需要使用嵌套循环实现:外层循环控制总循环次数,内层循环负责每轮的循环比较。 步骤 ①比较相邻的元素。如果第一个比第二个大,就交换他们两个。 ②对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。 ③针对所有的元素重复以上的步骤,除了最后一个。 ④持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。 算法实现: 三、快速排序 介绍 快速排序(Quicksort)是对冒泡排序的一种改进,借用了分治的思想,由C. A. R. Hoare在1962年提出。 基本思想 快速排序的基本思想是:挖坑填数+ 分治法。 首先选出一个轴值(pivot,也有叫基准的),通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 实现步骤 数据结构各种排序算法总结 2009-08-19 11:09 计算机排序与人进行排序的不同:计算机程序不能象人一样通览所有的数据,只能根据计算机的"比较"原理,在同一时间内对两个队员进行比较,这是算法的一种"短视"。 1. 冒泡排序 BubbleSort 最简单的一个 public void bubbleSort() { int out, in; for(out=nElems-1; out>0; out--) // outer loop (backward) for(in=0; in swap(out, min); // swap them } // end for(out) } // end selectionSort() 效率:O(N2) 3. 插入排序 insertSort 在插入排序中,一组数据在某个时刻实局部有序的,为在冒泡和选择排序中实完全有序的。 public void insertionSort() { int in, out; for(out=1; out 这个星期做数据结构课设,涉及到两个基于链表的排序算法,分别是基于链表的选择排序算法和归并排序算法。写出来跟大家一起分享一下,希望对数据结构初学朋友有所帮助,高手就直接忽视它吧。话不多说,下面就看代码吧。 [c-sharp]view plaincopy 1.node *sorted(node *sub_root) 2.{ 3.if (sub_root->next) 4. { 5. node * second_half = NULL; 6. node * first_half = sub_root; 7. node * temp = sub_root->next->next; 8.while (temp) 9. { 10. first_half = first_half->next; 11. temp = temp->next; 12.if(temp) 13. temp = temp->next; 14. } 15. second_half = first_half->next; 16. first_half->next = NULL; 17. node * lChild = sorted(sub_root); 18. node * rChild = sorted(second_half); 19.if (lChild->data < rChild->data) 20. { 21. sub_root = temp = lChild; 22. lChild = lChild->next; 23. } 24.else 25. { 26. sub_root = temp = rChild; 27. rChild = rChild->next; 28. } 29.while (lChild&&rChild) 30. { 31.if (lChild->data < rChild->data ) 32. { 33. temp->next = lChild; 34. temp = temp->next; 35. lChild = lChild->next; 36. } 37.else 38. { C语言9种常用排序法 1.冒泡排序 2.选择排序 3.插入排序 4.快速排序 5.希尔排序 6.归并排序 7.堆排序 8.带哨兵的直接插入排序 9.基数排序 例子:乱序输入n个数,输出从小到大排序后的结果1.冒泡排序 #include for(i=0;i int i, j, n, a[100], t, temp; while(scanf("%d",&n)!=EOF) { for(i=0;i 数据结构-各类排序算法总结 原文转自: https://www.360docs.net/doc/1315813146.html,/zjf280441589/article/details/38387103各类排序算法总结 一. 排序的基本概念 排序(Sorting)是计算机程序设计中的一种重要操作,其功能是对一个数据元素集合或序列重新排列成一个按数据元素 某个项值有序的序列。 有n 个记录的序列{R1,R2,…,Rn},其相应关键字的序列是{K1,K2,…,Kn},相应的下标序列为1,2,…,n。通过排序,要求找出当前下标序列1,2,…,n 的一种排列p1,p2,…,pn,使得相应关键字满足如下的非递减(或非递增)关系,即:Kp1≤Kp2≤…≤Kpn,这样就得到一个按关键字有序的记录序列{Rp1,Rp2,…,Rpn}。 作为排序依据的数据项称为“排序码”,也即数据元素的关键码。若关键码是主关键码,则对于任意待排序序列,经排序后得到的结果是唯一的;若关键码是次关键码,排序结果可 能不唯一。实现排序的基本操作有两个: (1)“比较”序列中两个关键字的大小; (2)“移动”记录。 若对任意的数据元素序列,使用某个排序方法,对它按关键码进行排序:若相同关键码元素间的位置关系,排序前与排序后保持一致,称此排序方法是稳定的;而不能保持一致的排序方法则称为不稳定的。 二.插入类排序 1.直接插入排序直接插入排序是最简单的插入类排序。仅有一个记录的表总是有序的,因此,对n 个记录的表,可从第二个记录开始直到第n 个记录,逐个向有序表中进行插入操作,从而得到n个记录按关键码有序的表。它是利用顺序查找实现“在R[1..i-1]中查找R[i]的插入位置”的插入排序。 数据挖掘十大经典算法,你都知道哪些? 当前时代大数据炙手可热,数据挖掘也是人人有所耳闻,但是关于数据挖掘更具体的算法,外行人了解的就少之甚少了。 数据挖掘主要分为分类算法,聚类算法和关联规则三大类,这三类基本上涵盖了目前商业市场对算法的所有需求。而这三类里又包含许多经典算法。而今天,小编就给大家介绍下数据挖掘中最经典的十大算法,希望它对你有所帮助。 一、分类决策树算法C4.5 C4.5,是机器学习算法中的一种分类决策树算法,它是决策树(决策树,就是做决策的节点间的组织方式像一棵倒栽树)核心算法ID3的改进算法,C4.5相比于ID3改进的地方有: 1、用信息增益率选择属性 ID3选择属性用的是子树的信息增益,这里可以用很多方法来定义信息,ID3使用的是熵(shang),一种不纯度度量准则,也就是熵的变化值,而 C4.5用的是信息增益率。区别就在于一个是信息增益,一个是信息增益率。 2、在树构造过程中进行剪枝,在构造决策树的时候,那些挂着几个元素的节点,不考虑最好,不然容易导致过拟。 3、能对非离散数据和不完整数据进行处理。 该算法适用于临床决策、生产制造、文档分析、生物信息学、空间数据建模等领域。 二、K平均算法 K平均算法(k-means algorithm)是一个聚类算法,把n个分类对象根据它们的属性分为k类(kn)。它与处理混合正态分布的最大期望算法相似,因为他们都试图找到数据中的自然聚类中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。 从算法的表现上来说,它并不保证一定得到全局最优解,最终解的质量很大程度上取决于初始化的分组。由于该算法的速度很快,因此常用的一种方法是多次运行k平均算法,选择最优解。 k-Means 算法常用于图片分割、归类商品和分析客户。 三、支持向量机算法 支持向量机(Support Vector Machine)算法,简记为SVM,是一种监督式学习的方法,广泛用于统计分类以及回归分析中。 SVM的主要思想可以概括为两点: (1)它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分; (2)它基于结构风险最小化理论之上,在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。 四、The Apriori algorithm Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,其核心是基于两阶段“频繁项集”思想的递推算法。其涉及到的关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支 #i n c l u d e #include if(i 一插入排序 1.1 直接插入排序 基本思想:每次将一个待排序额记录按其关键码的大小插入到一个已经排好序的有序序列中,直到全部记录排好序。 图解: 1.//直接顺序排序 2.void InsertSort(int r[], int n) 3.{ 4.for (int i=2; i 代码实现: [cpp]view plain copy 1.//希尔排序 2.void ShellSort(int r[], int n) 3.{ 4.int i; 5.int d; 6.int j; 7.for (d=n/2; d>=1; d=d/2) //以增量为d进行直接插入排序 8. { 9.for (i=d+1; i //1. 希尔排序, 时间复杂度:O(nlogn)~ O(n^2) // 另称:缩小增量排序(Diminishing Increment Sort) void ShellSort(int v[],int n) { int gap, i, j, temp; for(gap=n/2; gap>0; gap /= 2) /* 设置排序的步长,步长gap每次减半,直到减到1 */ { for(i=gap; i } else /* 如果中间元素比当前元素小,但前元素要插入到中间元素的右侧 */ { low = mid+1; } } /* 找到当前元素的位置,在low和high之间 */ for (j=i-1; j>high; j--)/* 元素后移 */ { a[j+1] = a[j]; } a[high+1] = temp; /* 插入 */ } } //3. 插入排序 //3.1 直接插入排序, 时间复杂度:O(n^2) void StraightInsertionSort(int input[],int len) { int i, j, temp; for (i=1; i C语言实现各种排序方法: 1.快速排序: #include right--; } } if(left kuai_pai(a,0,n-1); printf("排序后为:\n"); for(i=0;i!=n;++i) printf("%d ",a[i]); printf("\n"); free(a); } 2.shell排序 #include 【一】需求分析 课程题目是排序算法的实现,课程设计一共要设计八种排序算法。这八种算法共包括:堆排序,归并排序,希尔排序,冒泡排序,快速排序,基数排序,折半插入排序,直接插入排序。 为了运行时的方便,将八种排序方法进行编号,其中1为堆排序,2为归并排序,3为希尔排序,4为冒泡排序,5为快速排序,6为基数排序,7为折半插入排序8为直接插入排序。 【二】概要设计 1.堆排序 ⑴算法思想:堆排序只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间。将序列所存储的元素A[N]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的元素均不大于(或不小于)其左右孩子(若存在)结点的元素。算法的平均时间复杂度为O(N log N)。 ⑵程序实现及核心代码的注释: for(j=2*i+1; j<=m; j=j*2+1) { if(j temp=su[i]; su[i]=su[0]; su[0]=temp; head(0,i-1); } cout<<"排序之后的数组为:"< C/C++笔试面试题目汇总3——各种排序算法 原文:https://www.360docs.net/doc/1315813146.html,/u/1222/showart_318070.html 排序算法是一种基本并且常用的算法。由于实际工作中处理的数量巨大,所以排序算法对算法本身的速度要求很高。而一般我们所谓的算法的性能主要是指算法的复杂度,一般用O方法来表示。在后面我将给出详细的说明。对于排序的算法我想先做一点简单的介绍,也是给这篇文章理一个提纲。 我将按照算法的复杂度,从简单到难来分析算法。 第一部分是简单排序算法,后面你将看到他们的共同点是算法复杂度为O(N*N)(因为没有使用word,所以无法打出上标和下标)。 第二部分是高级排序算法,复杂度为O(Log2(N))。这里我们只介绍一种算法。另外还有几种算法因为涉及树与堆的概念,所以这里不于讨论。 第三部分类似动脑筋。这里的两种算法并不是最好的(甚至有最慢的),但是算法本身比较奇特,值得参考(编程的角度)。同时也可以让我们从另外的角度来认识这个问题。 第四部分是我送给大家的一个餐后的甜点——一个基于模板的通用快速排序。由于是模板函数可以对任何数据类型排序(抱歉,里面使用了一些论坛专家的呢称)。 一、简单排序算法 由于程序比较简单,所以没有加什么注释。所有的程序都给出了完整的运行代码,并在我的VC环境下运行通过。因为没有涉及MFC和WINDOWS的内容,所以在BORLAND C++的平台上应该也不会有什么问题的。在代码的后面给出了运行过程示意,希望对理解有帮助。 1.冒泡法:(Gilbert:点这里有视频) 这是最原始,也是众所周知的最慢的算法了。他的名字的由来因为它的工作看来象是冒泡: #include 排序算法: (1) 直接插入排序 (2) 折半插入排序(3) 冒泡排序 (4) 简单选择排序 (5) 快速排序(6) 堆排序 (7) 归并排序 【算法分析】 (1)直接插入排序;它是一种最简单的排序方法,它的基本操作是将一个记录插入到已排好的序的有序表中,从而得到一个新的、记录数增加1的有序表。 (2)折半插入排序:插入排序的基本操作是在一个有序表中进行查找和插入,我们知道这个查找操作可以利用折半查找来实现,由此进行的插入排序称之为折半插入排序。折半插入排序所需附加存储空间和直接插入相同,从时间上比较,折半插入排序仅减少了关键字间的比较次数,而记录的移动次数不变。 (3)冒泡排序:比较相邻关键字,若为逆序(非递增),则交换,最终将最大的记录放到最后一个记录的位置上,此为第一趟冒泡排序;对前n-1记录重复上操作,确定倒数第二个位置记录;……以此类推,直至的到一个递增的表。 (4)简单选择排序:通过n-i次关键字间的比较,从n-i+1个记录中选出关键字最小的记录,并和第i(1<=i<=n)个记录交换之。 (5)快速排序:它是对冒泡排序的一种改进,基本思想是,通过一趟排序将待排序的记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 (6)堆排序: 使记录序列按关键字非递减有序排列,在堆排序的算法中先建一个“大顶堆”,即先选得一个关键字为最大的记录并与序列中最后一个记录交换,然后对序列中前n-1记录进行筛选,重新将它调整为一个“大顶堆”,如此反复直至排序结束。 (7)归并排序:归并的含义是将两个或两个以上的有序表组合成一个新的有序表。假设初始序列含有n个记录,则可看成是n个有序的子序列,每个子序列的长度为1,然后两两归并,得到n/2个长度为2或1的有序子序列;再两两归并,……,如此重复,直至得到一个长度为n的有序序列为止,这种排序称为2-路归并排序。 【算法实现】 (1)直接插入排序: void InsertSort(SqList &L){ for(i=2;i<=L.length ;i++) if(L.elem[i] 专题——句子 句子之排序 1、考点 定义:排序类题就是把一组顺序错乱的句子按照正确的顺序重新排列,解这类题的关键是要找出这组句子的行文顺序,再把它们重新排列。 2、例题分析 例题1:将下列句子排列正确。 ()科学家对此进行研究。 ()正常人的眼睛能感知这个世界的五彩缤纷,识别红、橙、黄、绿、青、蓝、紫,以及它们之间的各种过渡色,总共约六十多种。 ()如牛、羊、马等,几乎不会分辨颜色,反映到它们眼里的只有黑、白、灰三种颜色,很单调。 ()那么,动物的感色能力又如何呢? ()研究证实,大多数哺乳动物是色盲。 试题分析: 此题着重考察学生的语言组织能力。对于众多的句子如何确定第一句是解此题的关键。接着找出几个句子之间的联系点,这也是至关重要的一个因素。 解题思路: 首先,要通读所有的句子,整体感知这段文字,初步明确这段文字主要写的是什么,围绕什么来写的。在这段文字中,首先写的是人的眼睛对色彩的感知,而后过渡到动物。中间一句设问句是很好的承接,接下来是科学家投入了研究,最后是研究的结果,并以此举例说明。所有的句子试填好后,要将句子按正确的排列顺序通读一遍,最后检查序号是否正确。 参考答案:3 1 5 2 4。 例题2 : 将①-④句填在横线上,顺序恰当的一项是()。 沿池环水四周,新筑一道长600多米的环池路,还有那修复完美的明代遗迹“临流亭”, 四周环水,兀立池中,游客观望,流连忘返。 ①形态各异的飞禽雕塑,浮游水面 ②水上画舫往返,笑声朗朗 ③路面铺设的鹅卵石,在碧波辉映下,色彩鲜艳,晶莹闪烁 ④路边垂柳依依,清风送爽 ③④②① B、④②③① C、③④①② D、④③①② 解题指导: 这是一道在所给的语段中选择恰当的选项填空题。考查的是思维的连贯与严密。解答此类题目,要瞻前顾后,从空缺处的前文或后文找出句与句之间内在的联系,通过上下文要通畅连贯或句式要前后一致等方面来确定正确的选项。 此题空缺处前文是写“环池路”,与之文气连贯的当然是选项中③句,接着介绍“路面”,接着就为第④句介绍“路边”,然后由“沿池环水四周”的“路边”,自然引出第②句,介绍“水上”,最后第①句交待水上的“飞禽雕塑”,则“雕塑”又与后句的“临流亭”同属建筑,自然衔接。所以正确答案为“A”。参考答案:A 例题3 : ()这时,我们才发现社区里的工作人员虽然很多,但是在一些死角里还会看见灰尘。 ()到了社区,同学们都冻得发抖,但又不敢松懈。 ( )虽然很冷,但我们每个人额头上都有豆大的汗珠。 ()有的同学在擦窗户,有的同学在扫水泥地面,有的同学在捡石头,有的同学在除草,还有同学在推小车送垃圾,我也和一些同学捡石块。 ()由于风太大的缘故,扫起来了许多的尘土,把大家呛得直打喷气,但大家都不觉得苦,继续埋头苦干。 ()我们各自分工之后,都开始行动起来了。 ( ) 同学们把自己的活干完之后又去帮忙干别的事了。 解题思路: 乱句排文的练习可以帮助学生训练思维,此题是按事件发展顺序排列,先是事件的起因,再是事件的过程,最后是结果。 题目答案:2 1 7 4 5 3 6 排序算法学习报告 一、学习内容 所谓排序,就是要整理文件中的记录,使之按关键字递增(或递减)次序排列起来。当待 排序记录的关键字都不相同时,排序结果是惟一的,否则排序结果不惟一。 在待排序的文件中,若存在多个关键字相同的记录,经过排序后这些具有相同关键字的记录之间的相对次序保持不变,该排序方法是稳定的;若具有相同关键字的记录之间的相对次序发生改变,则称这种排序方法是不稳定的。 要注意的是,排序算法的稳定性是针对所有输入实例而言的。即在所有可能的输入实例中,只要有一个实例使得算法不满足稳定性要求,则该排序算法就是不稳定的。 常见的排序算法 2.1插入排序 插入排序是这样实现的: 首先新建一个空列表,用于保存已排序的有序数列(我们称之为"有序列表")。 从原数列中取出一个数,将其插入"有序列表"中,使其仍旧保持有序状态。重复2号步骤,直至原数列为空。 插入排序的平均时间复杂度为平方级的,效率不高,但是容易实现。它借助了"逐步扩大成果"的思想,使有序列表的长度逐渐增加,直至其长度等于原列表的长度。 【示例】: [初始关键字][49] 38 65 97 76 13 27 49 J=2(38) [38 49] 65 97 76 13 27 49 J=3(65) [38 49 65] 97 76 13 27 49 J=4(97) [38 49 65 97] 76 13 27 49 J=5(76) [38 49 65 76 97] 13 27 49 J=6(13) [13 38 49 65 76 97] 27 49 J=7(27) [13 27 38 49 65 76 97] 49 J=8(49) [13 27 38 49 49 65 76 97] 2.2冒泡排序冒泡排序是这样实现的:首先将所有待排序的数字放入工作列表中。 从列表的第一个数字到倒数第二个数字,逐个检查:若某一位上的数字大于他的下一位,则将它与它的下一位交换。 重复2号步骤,直至再也不能交换。 C语言排序总汇 1、插入法排序 算法如下: voidInsertsort(int n) { inti,j; for(i=2;i<=n;i++) /*依次插入R[2],R[3],.....R[n]*/ if(R[i] voidInsertsort(int n) { inti,j; for(i=2;i<=n;i++) /*依次插入R[2],R[3],.....R[n]*/ if(R[i]各种排序算法的总结和比较
C语言几种常见的排序方法
Python学习笔记:八大排序算法!
数据结构 各种排序算法
链表排序算法总结
C语言9种常用排序法
数据结构-各类排序算法总结
十 大 经 典 排 序 算 法 总 结 超 详 细
c语言各种排序方法及其所耗时间比较程序
c语言各种排序法详细讲解
各大常用排序方法
c语言实现各种排序程序
各种排序实验报告
C C++笔试面试题目汇总3——各种排序算法
数据结构课程设计排序算法总结
小学语文排序题方法技巧汇总排序
排序算法学习报告
C语言排序总汇