随机森林原理及应用
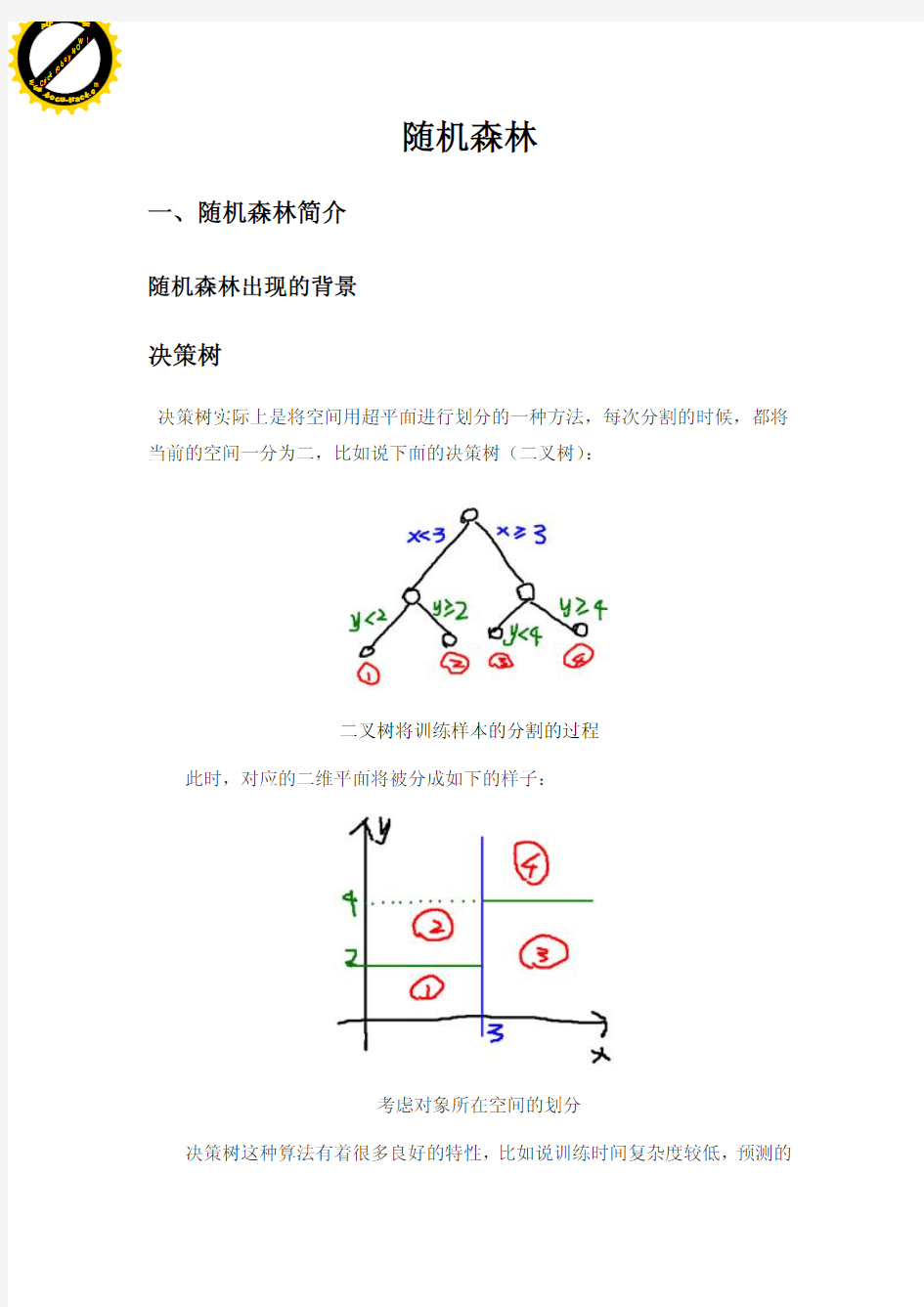
over-fitting
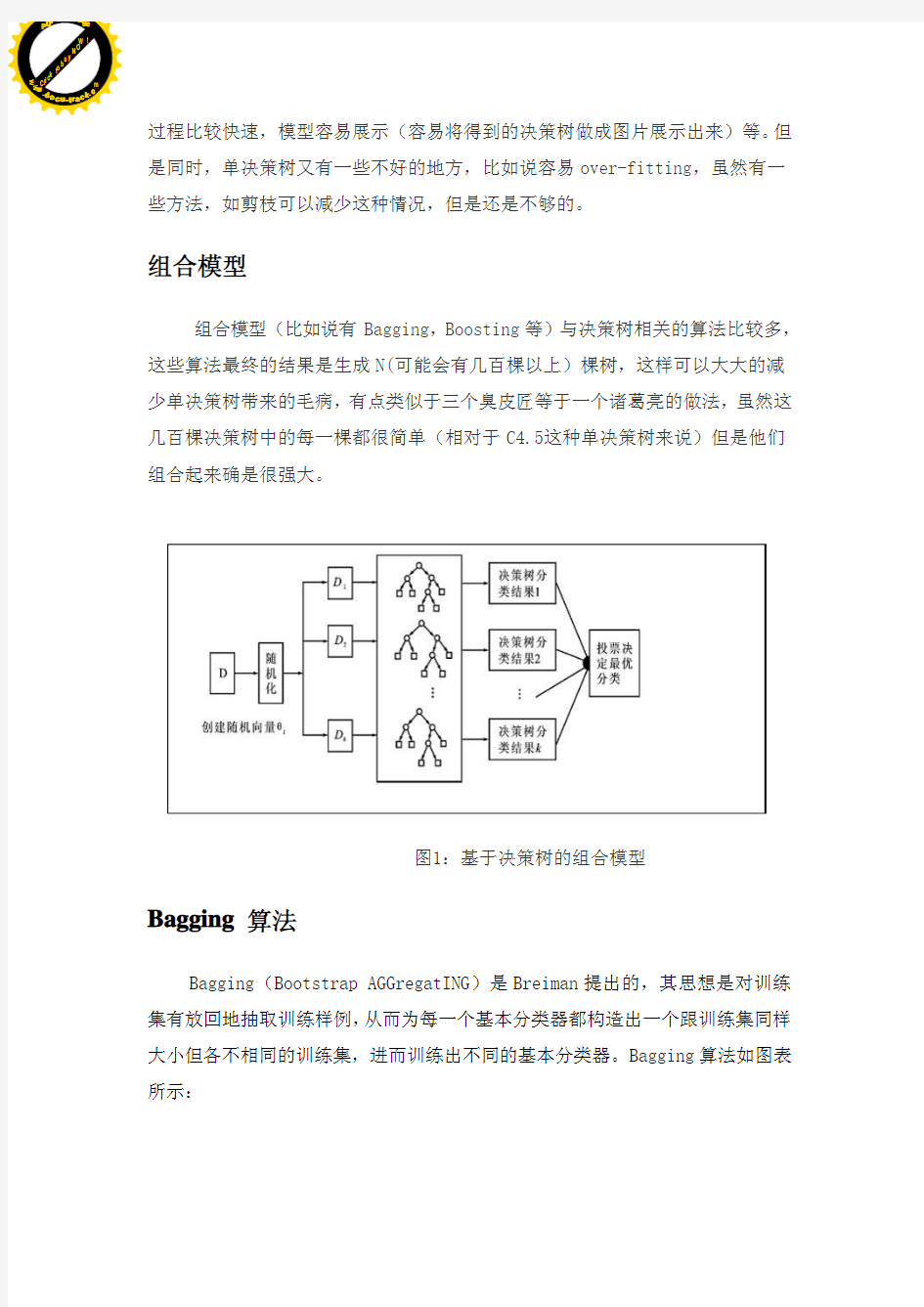
Bagging Boosting N( C4.5
Bagging
Bagging Bootstrap AGGregatING Breiman Bagging
Bagging Bagging 63.2% Breiman Bagging Bagging Bagging Bagging Bagging Bagging Bagging Breiman
Bagging Boosting
Boosting
Boosting Robert T.Schapire …… Boosting
Boosting Valiant PAC(Probably Approxi mately Correct) Valiant Kearns 1/2, ,Valiant Kearns PAC 1990 ,Schapire , Boosting ,Freund Boosting
Boosting Boosting Boosting , Boosting (BP), (C4.5)
Adaboost
Boosting Freund Schapire AdaBoost Freund AdaBoost Boosting ,AdaBoost D(x)t, Ht(x), D(x)t, , 0.15,
,AdaBoost AdaBoost :
AdaBoost
(1) 1/n
(2)
: :
e= (ht(x i) yi)Di(1)
:W t=F(e), AdaBoost boost AdaBoost
1. T
2. 1/n
3.
(1)
(2)
(3)
(4)
Adaboost Boosting
bootsrap bootsrap
2
RF ,RF
1.
2.
3.
4.
5.
6.
7.
8. outlier
9.
10.
11.
12.
13.
1.
2.
3.
4.
(RFC) {(,),1,2,...,}
k h X k N k RFC bootstrap
RF
{(,),1,2,...,}k h X k N :
()arg max (())i Y i
H x I h x Y ,()H x ,()i h x ,Y ),(.)I
-
37% (m < RF bagging bootstrap bagging 37% bootstrap , (Out Of Bag,OOB) OOB Bagging RFC OOB OOB OOB RF Breiman ,OOB : RF ) , CART RF bagging bo ot st rap RF , ,L [-1,1] ,RF ? Breiman 1000), OOB OOB 4000), Breiman RF 3 , ReliefF CM 1, REL IEF CM , RELIEF RELIEF CM(contextual merit) CM :1 ,r s ,r s ,r s ,r s D ,r s D ,r s ,r s D ,r s x i x x x x F1 , (TP (TN ), (FN (FP (P)=TP+FN, (N)=FP+TN, (C)=P+N ” Error rate=1-Accuracy=(FN+FP)/C (Accuracy) Accuracy= TP+TN /C (Precision) Precision=TP/(TP+FP) (Recall) Recall=TP/P F1 ——ROC AUC ROC ROC Receiver Operating Characteristic RelativeOperating Characteristic ROC Lusted ROC ROC (False Positive Rate,FPR)=FP/N (True Positive Rate.TPR)=TP/P ROC FPR TPR FPR TPR ROC (FPR=0,TPR=0) (FPR=1,TPR=1) (FPR=0,TPR=1) ROC ROC ROC ROC ROC AUC ROC curve AUC 0.5 1.0 AUC Bagging Bagging Bagging Bagging 学习算法 根据下列算法而建造每棵树: 1. 用N 来表示训练例子的个数,M表示变量的数目。 2. 我们会被告知一个数m ,被用来决定当在一个节点上做决定时,会使用到多少个变量。m应小于M 3. 从N个训练案例中以可重复取样的方式,取样N次,形成一组训练集(即bootstrap取样)。并使用这棵树来对剩余预测其类别,并评估其误差。 4. 对于每一个节点,随机选择m个基于此点上的变量。根据这m 个变量,计算其最佳的分割方式。 5. 每棵树都会完整成长而不会剪枝(Pruning)(这有可能在建完一棵正常树状分类器后会被采用)。 优点 随机森林的优点有: 1. 对于很多种资料,它可以产生高准确度的分类器。 2. 它可以处理大量的输入变量。 3. 它可以在决定类别时,评估变量的重要性。 4. 在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计。 5. 它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度。 6. 它提供一个实验方法,可以去侦测variable interactions 。 7. 对于不平衡的分类资料集来说,它可以平衡误差。 8. 它计算各例中的亲近度,对于数据挖掘、侦测偏离者(outlier)和将资料视觉化非常有用。 9. 使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料。 10. 学习过程是很快速的。 缺点 1. 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟 2. 对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。 基于随机森林的上市公司财务危机预警分析 中央财经大学杨翰林、王开骏、谢幽篁 摘要本文在现有对上市公司财务分析技术的基础上,借助于杜邦分析系 统的思路,对影响上市公司运营状况的财务变量进行了系统的分析和筛选。通 过随机森林算法建立了对上市公司财务危机预测(以ST为标志)的模型,并 对两类分类误差的权衡进行了分析,给出了变量对分类的重要性排序。其次分 类效果的反馈验证了财务变量选取的有效性。同时,相比于国内学者类似研究, 本文在分类误差上得到了更高的精度。在灵敏度分析中,针对两类误差权重设 定、训练集合样本数量、两类样本抽样比率对分类精度的影响进行了深入的讨 论,并给出了有助于提高分类精度的适应性方法。最后通过GICS对划分行业 后的样本进行了分类,对不同行业单独应用随机森林算法,得出了更好的分类 精度,验证了行业的差异性以及行业划分的必要性。 关键字:财务危机ST 随机森林 一、引言 市场经济作为竞争型的经济制度,在优胜劣汰的规律下,促进了企业生产、经营的效率和效益,同时也加速了落后企业的破产。这种竞争机制从宏观层面看,通过淘汰在当下经济环境里无法适应市场需求和发展的企业,从而成就了资源的效率最大化。但从微观层面看,若企业在竞争中出于劣势或与市场规律不兼容,企业往往陷入财务危机,由此引发的破产风险也意味着利益相关者的损失。因此基于市场经济导向性,企业经营风险以及其利益相关者的考虑,资本市场有必要发展一种自我评估技术以分析企业的经营能力。对企业自身来说,一种有效的分析和预警机制可以管理和控制风险并对企业经营策略进行及时的调整与改进;对投资者而言,投资者可以以此技术分析对上市公司的投资风险,确保投资盈利;对银行等债权人而言,可以评估借款企业的信用风险、确定借款利率并跟踪贷款公司违约风险。 一般来说,财务危机是指企业无力按时偿还到期的无争议的债务的困难与危机。Altman (1968)认为“企业失败包括在法律上的破产、被接管和重组等”,其实质是把财务危机等同于企业破产,这是最准确也是最极端的标准;Beaver 随机森林 基础内容: 这里只是准备简单谈谈基础的内容,主要参考一下别人的文章,对于随机森林与GBDT,有两个地方比较重要,首先是information gain,其次是决策树。这里特别推荐Andrew Moore大牛的Decision Trees Tutorial,与Information Gain Tutorial。Moore的Data Mining Tutorial系列非常赞,看懂了上面说的两个内容之后的文章才能继续读下去。 决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,比如说下面的决策树: 就是将空间划分成下面的样子: 这样使得每一个叶子节点都是在空间中的一个不相交的区域,在进行决策的时候,会根据输入样本每一维feature的值,一步一步往下,最后使得样本落入N个区域中的一个(假设有N个叶子节点) 随机森林(Random Forest): 随机森林是一个最近比较火的算法,它有很多的优点: ?在数据集上表现良好 ?在当前的很多数据集上,相对其他算法有着很大的优势 ?它能够处理很高维度(feature很多)的数据,并且不用做特征选择 ?在训练完后,它能够给出哪些feature比较重要 ?在创建随机森林的时候,对generlization error使用的是无偏估计 ?训练速度快 ?在训练过程中,能够检测到feature间的互相影响 ?容易做成并行化方法 ?实现比较简单 随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。 在建立每一棵决策树的过程中,有两点需要注意- 采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M 个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤- 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。 按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。 随机森林的过程请参考Mahout的random forest。这个页面上写的比较清楚了,其中可能不明白的就是Information Gain,可以看看之前推荐过的Moore的页面。 深度学习文字识别论文综述 深度学习文字识别论文综述 深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习是无监督学习的一种,深度学习采用了神经网络的分层结构,系统包括输入层、隐层(多层)、输出层组成的多层网络,只有相邻的节点之间有连接,同一层以及跨层节点之间相互无连接。深度学习通过建立类似于人脑的分层模型结构,对输入数据逐级提取从底层到高层的特征,从而能很好地建立从底层信号到高层语义的映射关系。近年来,谷歌、微软、百度等拥有大数据的高科技公司相继投入大量资源进行深度学习技术研发,在语音、图像、自然语言、在线广告等领域取得显著进展。从对实际应用的贡献来说,深度学习可能是机器学习领域最近这十年来最成功的研究方向。深度学习模型不仅大幅提高了图像识别的精度,同时也避免了需要消耗大量的时间进行人工特征提取的工作,使得在线运算效率大大提升。 深度学习用于文字定位 论文Thai Text Localization in Natural Scene Images using Convolutional Neural Network主要采用CNN的方法进行自然场景中的文本分类,并根据泰字的特点进行分类后的后处理,得到更加精确的定位效果。如图1所示为CNN网络模型,CNN网络由一个输入层,两个卷积层和两个下采样层以及一个全连接层组成,输出为一个二分类向量,即文本和非文本。 图1 CNN网络模型 该文主要思路为将图像切块后进行训练,采用人工标注样本的方法,使得网络具有识别文本和非文本的能力。由于样本数量较少,文中采用了根据已有字体生成训练数据集的方法,包括对字体随机添加背景、调整字体风格以及应用滤波器。如图2为生成的泰字样本,文中在标签的过程中将半个字或者整个字都标记为文本,增加了网络对文字的识别率。 图2训练样本集 在使用生成好的网络进行文字定位的过程中,论文采用的编组方法结合了泰字的特点,如图3为对图像文字的初步定位,其中被标记的区域被网络识别为文字。 图3图像文字的初步定位 小微企业信用评估的数据挖掘方法综述 2016-05-03 14:54:05 《金融理论与实践》高俊光刘旭朱辰辰 一、序言 小微企业是指小型和微型企业。依据工信部2011年6月发布的小微企业划型标准,截至2013年年底,全国小微企业数量占到企业总数的94.15%,为GDP做出了近60%的贡献,税收占比达到50%,解决就业1.5亿人,新增就业和再就业人口的70%以上集中在小微企业[1]。小微企业作为我国市场经济的重要主体,发挥了不可替代的作用。然而,小微企业的信贷融资约束却成为制约其进一步发展的主要障碍,严重影响小微企业潜在的市场发展和企业创新。究其原因,主要由于银行信贷对企业信用等级有严格要求,而与大中型企业相比,小微企业抗冲击能力弱,且信贷信息不对称问题更加突出,导致小微金融服务面临更大的风险和不确定性。 笔者通过文献梳理和实证研究,发现小微企业信用评估困难的原因可归结为如下三方面:小微企业用于信用评估的数据不充分,缺乏针对小微企业建立的分类方法以及因类别不均导致的分类可靠性不高。基于此,大数据于信用评估领域的应用、信用评估的数据挖掘方法,以及类别不均问题的解决方法逐渐成为近年来小微企业信用评估领域的研究焦点。 二、大数据、数据挖掘与小微企业信用评估 (一)大数据与数据挖掘的基本内涵 2008年,《Nature》杂志出版专刊《Big Data》,系统地介绍了“大数据”所蕴含的 潜在价值与挑战,“大数据”正式成为各个学科中的研究热点。2011年,《Science》杂志出版的专刊《Dealing with Data》标志着“大数据”时代的到来,此后,“大数据”这一术语逐渐被用于指代因收集和处理海量数据而产生的机会和挑战[2]。“大数据”的定义主要围绕“数据体量大”“复杂性程度大”和“价值大”三个角度进行界定。 大数据规模庞大,其中隐含着巨大价值,在各行各业都备受关注,特别是那些有着大量原始数据的行业,如医疗业和金融业[3]。然而,大数据要求的数据分析已经远非目前的统计数据处理技术能够实现,唯一的解决方法就是“数据挖掘”。数据挖掘是一个多学科的交叉领域,它利用自动学习或经验配合等方式进行分析,从大量的数据中提取出隐含的、未知的、有价值的潜在信息[4]。与传统数据分析不同,数据挖掘不需事先对数据提出假设,因而更能真实地反映出数据的隐藏特征[5]。近年来数据挖掘技术渐受重视,影响范围逐步扩大,部分学者的研究关注于数据挖掘技术本身的发展,也有学者侧重于解决实际应用中的问题,如在金融领域的应用[6]。 (二)大数据与小微企业信用评估的关系 随机森林 定义:随机森林是一个分类器,它有一系列的单株树决策器{h (X,,θk );k=1,......} 来组成,其中{θk }是独立同分布的随机变量。再输入X 时,每一棵树只投一票给它认为最合适的类。在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定,构成随机森林的基础分类器称为决策树。 Leo Breiman 和Adele Cutler 发展出推论出随机森林的算法。 这个术语是1995年由贝尔实验室的Tin Kam Ho 所提出的随机决策森林(random decision forests )而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"" 以建造决策树的集合。 随机森林是一个组合分类器,构成随机森林的基础分类器是决策树。 决策树算法 决策树可以视为一个树状预测模型,它是由结点和有向边组成的层次结构。树中包含3个节点:根节点。内部节点,终节点(叶子节点)。决策树只有一个根节点,是全体训练集的结合。树中的每个内部节点都是一个分裂问题,它将到达该节点的样本按某个特定的属性进行分割,可以将数据集合分割成2块或若干块。每个终结点(叶子节点)是带有分裂标签的数据集合,从决策树的根节点到叶子节点的每一条路径都形成一个类;决策树的算法很多,例如ID3算法,CART 算法等。这些算法均采用自上而下的贪婪的算法,每个内部节点选择分类效果最好的属性进行分裂节点,可以分为两个或若干个子节点,继续此过程到这可决策树能够将全部训练数据准确的分类,或所有属性都被用到为止。具体步骤如下: 1)假设T 为训练样本集。 2)选择一个最能区分T 中样本的一个属性。 3)创建一个数的节点,它的值是所选择的属性,创建此节点的子节点,每个子链代表所选属性的唯一值,适用子链的值进一步将样本细分为子类。 对于3)创建的三个子类 (1)如果子类的样本满足预定义的标准,或者树的这条路的剩余可选属性集为空,为沿此路径的新的样本指定类别。 (2)如果子类不满足于定义的标准,或者至少有一个属性能细分树的路径,设T 为当前子类样本的集合,返回步骤2),以下简单的给出二分树的结构图示: 根节点 中间节点 叶节点 规则1 叶节点 规则2 中间节点 随机森林算法介绍及R语言实现 随机森林算法介绍 算法介绍: 简单的说,随机森林就是用随机的方式建立一个森林,森林里面有很多的决策树,并且每棵树之间是没有关联的。得到一个森林后,当有一个新的样本输入,森林中的每一棵决策树会分别进行一下判断,进行类别归类(针对分类算法),最后比较一下被判定哪一类最多,就预测该样本为哪一类。 随机森林算法有两个主要环节:决策树的生长和投票过程。 决策树生长步骤: 1. 从容量为N的原始训练样本数据中采取放回抽样方式(即bootstrap取样) 随机抽取自助样本集,重复k(树的数目为k)次形成一个新的训练集N,以此生成一棵分类树; 2. 每个自助样本集生长为单棵分类树,该自助样本集是单棵分类树的全部训 练数据。设有M个输入特征,则在树的每个节点处从M个特征中随机挑选m(m < M)个特征,按照节点不纯度最小的原则从这m个特征中选出一个特征进行分枝生长,然后再分别递归调用上述过程构造各个分枝,直到这棵树能准确地分类训练集或所有属性都已被使用过。在整个森林的生长过程中m将保持恒定; 3. 分类树为了达到低偏差和高差异而要充分生长,使每个节点的不纯度达到 最小,不进行通常的剪枝操作。 投票过程: 随机森林采用Bagging方法生成多个决策树分类器。 基本思想: 1. 给定一个弱学习算法和一个训练集,单个弱学习算法准确率不高,可以视 为一个窄领域专家; 2. 将该学习算法使用多次,得出预测函数序列,进行投票,将多个窄领域专 家评估结果汇总,最后结果准确率将大幅提升。 随机森林的优点: ?可以处理大量的输入变量; ?对于很多种资料,可以产生高准确度的分类器; ?可以在决定类别时,评估变量的重要性; ?在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计; ML算法工程师面试指南,完整的面试知识点、编程题及题解春季到来,春招不久也会开始。在本项目中,作者为大家准备了ML 算法工程师面试指南,它提供了完整的面试知识点、编程题及题解、各科技公司的面试题锦等内容。目前该GitHub 项目已经有1 万+的收藏量,想要跳一跳的同学快来试试吧。 项目地址:https://github/imhuay/Algorithm_Interview_Notes-Chinese 如下所示为整个项目的结构,其中从机器学习到数学主要提供的是笔记与面试知识点,读者可回顾整体的知识架构。后面从算法到笔试面经主要提供的是问题及解答方案,根据它们可以提升整体的解题水平与编程技巧。 面试知识点 面试题多种多样,但机器学习知识就那么多,那么为了春招或春季跳槽,何不过一遍ML 核心知识点?在这个GitHub 项目中,作者前一部分主要介绍了机器学习及各子领域的知识点。其中每一个知识点都只提供最核心的概念,如果读者遇到不熟悉的算法或者遇到知识漏洞,可以进一步阅读相关文献。 项目主要从机器学习、深度学习、自然语言处理和数学等方面提供详细的知识点,因为作者比较关注NLP,所以并没有提供详细的计算机视觉笔记。 机器学习 首先对于机器学习,项目主要从基础概念、基本实践、基本算法和集成学习专题这四个方面概括ML 的总体情况。其中基础概念可能是最基本的面试问题,例如「偏差方差怎么权衡?」、「生成模型和判别模型的差别是什么?」、「先验和后验概率都是什么,它们能转换吗?」。 这些知识点一般是入门者都需要了解的,而对于ML 基本实践,主要会从如何做好传统ML 开发流程的角度提问。例如「你如何选择超参数,能介绍一些超参数的基本搜索方法吗?」、「混淆矩阵、准确率、精确率、召回率或F1 值都是什么,如何使用它们度量模型的好坏?」、「你能介绍数据清洗和数据预处理的主要流程吗,举个例子?」。 Vol. 34,No. 2Apr. ,2019 第34卷第2期 2019年4月遥感信息Remote Sensing Information 随机森林遥感信息提取研究进展及应用展望 于新洋2 ,赵庚星1,2 ,常春艳2 ,袁秀杰1,2 ,王卓然1,2 (1. 土肥资源高效利用国家工程实验室,山东泰安271028,2.山东农业大学资源与环境学院,山东泰安271028)摘要:针对国内外随机森林集成分类方法的相关成果及发展趋势尚未有研究进行梳理与展望这一问题,首 先,系统介绍随机森林分类方法的基本原理及应用优势、重要参数及其具体设定;其次,综述该方法在多光谱影 像、高光谱数据、雷达及激光测距仪等多源遥感数据信息提取领域以及分类参量遴选中的研究应用;最后,在分类 精度检验、可移植性以及算法改进等方面对其发展及应用趋势进行了展望。该研究可为随机森林分类方法初学 者提供参考,有助于随机森林分类方法在遥感信息提取领域的推广及应用。 关键词:随机森林;分类方法;研究进展;信息提取;展望 doi-10. 3969/j. issn. 1000-3177. 2019. 02. 002 中图分类号:TP79 文献标志码: 文章编号:1000-3177(2019)162-0008-07 Random Forest Classifier in Remote Sensing Information Extraction : A Review of Applications and Future Development YU Xinyang 1'2 ,ZHAO Gengxing 1'2,CHANG Chunyan 1'2 .YUAN Xiujie 1'2 ,WANG Zhuoran 1'2 (1. National Engineering laboratory for Efficient Utilization of Soil and Fertilizer Resources , Tai ? an , Shandong 271018, C/izna ; 2. College of Resources and Environment , Taiwan , Shandong 271018 ,CAina) Abstract : The random forest classifier (RFC) is an ensemble method that produces multiple decision trees , using a randomly selected subset of training samples and feature variables. The classifier has become popular in remote sensing studies due to its classification accuracy,while no literature review has been done to cover its application in remote sensing ? The objective of this study is to review the utilization of RFC in remote sensing , and the application of RFC in the classification of multi-sensor images and relevant data selection. Further investigations are recommended into less commonly exploited use of this classifier, such as outliers detecting in training samples and novel approaches improving. Key words : random forest ; classification method ; review ; information extraction ; development trend 0引言遥感分类作为遥感技术应用最重要的组成部 分,研究方法日渐多样。典型的遥感监督分类法如 分类回 归树(classification and regression tree , CART)m 幻、支持向量机(support vector machine , SVM)[3_4]及人工神经网络(artificial neural network , ANN)&6]算法目前应用较多。然而,随着土地利用 范围及程度的不断拓展深化以及区域资源环境变 化,陆表土地利用已趋于类型复杂化、格局破碎化, “物谱两异”现象普遍存在⑺,单分类器已难以满足 更高的分类精度需求⑷。随机森林分类器(random forest classifier , RFC)页自2001年提出伊始便以处理流程稳健高效收稿日期:2017-10-19 修订日期:2017-12-26 基金项目:"十二五”国家科技支撑计划(2015BAD23B0202);中国科学院陆地表层格局与模拟重点实验室开放基金(LBKF201802);山 东省双一流建设项目(SYL2017XTTD02) s 山东省博士后创新基金(222016);山东农业大学博士后基金(010-76562)。作者简介:于新洋(1986-),男,博士,讲师,主要研究方向为农业遥感监测。 E-mail : xyyu@ yic. ac. cn 通信作者:赵庚星(1964-),男,博士,教授,主要研究方向为遥感技术及应用。 E-mail : zhaogx@ sdau. edu. cn 8 人脸识别技术总结 人脸识别技术大总结——Face Detection Alignment 20XX-04-08 搞了一年人脸识别,寻思着记录点什么,于是 想写这么个系列,介绍人脸识别的四大块:Face detection,alignment,verification and identification(recognization),本别代表从一张图中识别出人 脸位置,把人脸上的特征点定位,人脸校验和人脸识别。(后两者的区别在于,人脸校验是要给你两张脸问你是不是同一个人,人 脸识别是给你一张脸和一个库问你这张脸是库里的谁。 人脸校准(alignment)是给你一张脸,你给我找出我需要的 特征点的位置,比如鼻子左侧,鼻孔下侧,瞳孔位置,上嘴唇下 侧等等点的位置。如果觉得还是不明白,看下图: 如果知道了点的位置做一下位置驱动的变形,脸就成正的了,如何驱动变形不是本节的重点,在此省略。 首先介绍一下下面正文要写的东西,由于干货非常多所以可 能会看着看着就乱了,所以给出框架图: ================================= 废话说了这么多,正文开始~ detection 作者建立了一个叫post classifier的分类器,方法如下: 1.样本准备:首先作者调用opencv的Viola-Jones分类器,将recal阀值设到XX%,这样能够尽可能地检测出所有的脸,但是同时也会有非常多的不是脸的东东被检测出来。于是,检测出来的框框们被分成了两类:是脸和不是脸。这些图片被resize到96*96。 2.特征提取:接下来是特征提取,怎么提取呢?作者采用了三种方法: 第一种:把window划分成6*6个小windows,分别提取SIFT 特征,然后连接着XXX个sift特征向量成为图像的特征。 第二种:先求出一个固定的脸的平均shape(XXX个特征点的位置,比如眼睛左边,嘴唇右边等等),然后以这XXX个特征点为中心提取sift特征,然后连接后作为特征。第三种:用他们组去年的另一个成果Face Alignment at 3000 FPS via Regressing Local Binary Features (CVPR14),也就是图中的3000FPS方法,回归出每张脸的shape,然后再以每张脸自己的XXX个shape points为中心做sift,然后连接得到特征。 3.分类:将上述的三种特征分别扔到线性SVM中做分类,训练出一个能分辨一张图是不是脸的SVM模型。 紧接着作者将以上三种方法做出的分类器和初始分类器进行比对,画了一个样本分布的图: 这个图从左到右依次是原始级联分类器得到的样本分类分布和第一种到第三种方法提取的特征得到的样本分类分布。可见做 随机森林 为了克服决策树容易过度拟合的缺点,Breiman(2001)提出了一种新的组合分类器算法——随机森林算法(Random Forests , RF)。他把分类决策树组合成随即森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度,对多元共线性不敏感,可以很好地预测多达几千个解释变量的作用,被称为当前最好的算法之一。 基本原理 1.随机森林的定义 随机森林是一个由决策树分类器集合{} θ构成的组合分类器模 x ,2,1 k h (= ), , k 型,其中参数集{} θ是独立同分布的随机向量,x是输入向量。当给定输入向量 k 时每个决策树有一票投票权来选择最优分类结果。每一个决策树是由分类回归树(CART)算法构建的未剪枝的决策树。因此与CART相对应,随机森林也分为随机分类森林和随机回归森林。目前,随机分类森林的应用较为普遍,它的最终结果是单棵树分类结果的简单多数投票。而随机回归森林的最终结果是单棵树输出结果的简单平均。 2.随机森林的基本思想 随机森林是通过自助法(Bootstrap)重复采样技术,从原始训练样本集N 中有放回地重复随机抽取k个样本生成新的训练集样本集合,然后根据自助样本生成k决策树组成的随机森林。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖一个独立抽取的样本,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它之间的相关性。 3.随机森林的生成过程 根据随机森林的原理和基本思想,随机森林的生成主要包括以下三个步骤:首先,通过Bootstrap方法在原始样本集S中抽取k个训练样本集,一般情况下每个训练集的样本容量与S一致; 其次,对k个训练集进行学习,以此生成k个决策树模型。在决策树生成过 随机森林 θk);k=1,......}定义:随机森林是一个分类器,它有一系列的单株树决策器{h(X,, θk}是独立同分布的随机变量。再输入X时,每一棵树只投一票给来组成,其中{ 它认为最合适的类。在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定,构成随机森林的基础分类器称为决策树。Leo Breiman和Adele Cutler发展出推论出随机森林的算法。这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合Breimans 的"Bootstrap aggregating" 想法和Ho 的"random subspace method"" 以建造决策树的集合。随机森林是一个组合分类器,构成随机森林的基础分类器是决策树。 决策树算法 决策树可以视为一个树状预测模型,它是由结点和有向边组成的层次结构。树中包含3个节点:根节点。内部节点,终节点(叶子节点)。决策树只有一个根节点,是全体训练集的结合。树中的每个内部节点都是一个分裂问题,它将到达该节点的样本按某个特定的属性进行分割,可以将数据集合分割成2块或若干块。每个终结点(叶子节点)是带有分裂标签的数据集合,从决策树的根节点到叶子节点的每一条路径都形成一个类;决策树的算法很多,例如ID3算法,CART算法等。这些算法均采用自上而下的贪婪的算法,每个内部节点选择分类效果最好的属性进行分裂节点,可以分为两个或若干个子节点,继续此过程到这可决策树能够将全部训练数据准确的分类,或所有属性都被用到为止。具体步骤如下: 1)假设T为训练样本集。 2)选择一个最能区分T中样本的一个属性。 3)创建一个数的节点,它的值是所选择的属性,创建此节点的子节点,每个子链代表所选属性的唯一值,适用子链的值进一步将样本细分为子类。 对于3)创建的三个子类 (1)如果子类的样本满足预定义的标准,或者树的这条路的剩余可选属性集为空,为沿此路径的新的样本指定类别。 (2)如果子类不满足于定义的标准,或者至少有一个属性能细分树的路径,设T为当前子类样本的集合,返回步骤2),以下简单的给出二分树的结构图示:随机森林
基于随机森林的上市公司财务危机预警分析
随机森林
深度学习文字识别论文综述
小微企业信用评估的数据挖掘方法综述
随机森林
随机森林算法介绍及R语言实现
ML算法工程师面试指南,完整的面试知识点、编程题及题解
随机森林遥感信息提取研究进展及应用展望
人脸识别技术总结
随机森林
随机森林(精)