Face Alignment by Explicit Shape Regression

Int J Comput Vis
DOI10.1007/s11263-013-0667-3
Face Alignment by Explicit Shape Regression Xudong Cao·Yichen Wei·Fang Wen·Jian Sun
Received:28December2012/Accepted:7October2013
?Springer Science+Business Media New York2013
Abstract We present a very ef?cient,highly accurate,“Explicit Shape Regression”approach for face alignment. Unlike previous regression-based approaches,we directly learn a vectorial regression function to infer the whole facial shape(a set of facial landmarks)from the image and explic-itly minimize the alignment errors over the training data.The inherent shape constraint is naturally encoded into the regres-sor in a cascaded learning framework and applied from coarse to?ne during the test,without using a?xed parametric shape model as in most previous methods.To make the regression more effective and ef?cient,we design a two-level boosted regression,shape indexed features and a correlation-based feature selection method.This combination enables us to learn accurate models from large training data in a short time(20min for2,000training images),and run regres-sion extremely fast in test(15ms for a87landmarks shape). Experiments on challenging data show that our approach sig-ni?cantly outperforms the state-of-the-art in terms of both accuracy and ef?ciency.
Keywords Face alignment·Shape indexed feature·Correlation based feature selection·Non-parametric shape constraint·Tow-level boosted regression
X.Cao(B)·Y.Wei·F.Wen·J.Sun
Visual Computing Group,Microsoft Research Asia,Beijing, People’s Republic of China
e-mail:xudongca@https://www.360docs.net/doc/2711709638.html,
Y.Wei
e-mail:yichenw@https://www.360docs.net/doc/2711709638.html,
F.Wen
e-mail:fangwen@https://www.360docs.net/doc/2711709638.html,
J.Sun
e-mail:jiansun@https://www.360docs.net/doc/2711709638.html, 1Introduction
Face alignment or locating semantic facial landmarks such as eyes,nose,mouth and chin,is essential for tasks like face recognition,face tracking,face animation and3D face mod-eling.With the explosive increase in personal and web photos nowadays,a fully automatic,highly ef?cient and robust face alignment method is in demand.Such requirements are still challenging for current approaches in unconstrained environ-ments,due to large variations on facial appearance,illumi-nation,and partial occlusions.
A face shape S=[x1,y1,...,x N fp,y N fp]T consists of N fp facial landmarks.Given a face image,the goal of face align-ment is to estimate a shape S that is as close as possible to the true shape?S,i.e.,minimizing
||S??S||2.(1)
The alignment error in Eq.(1)is usually used to guide the training and evaluate the performance.However,during test-ing,we cannot directly minimize it as?S is unknown.Accord-ing to how S is estimated,most alignment approaches can be classi?ed into two categories:optimization-based and regression-based.
Optimization-based methods minimize another error function that is correlated to(1)instead.Such methods depend on the goodness of the error function and whether it can be optimized well.For example,the AAM approach (Matthews and Baker2004;Sauer and Cootes2011;Saragih and Goecke2007;Cootes et al.2001)reconstructs the entire face using an appearance model and estimates the shape by minimizing the texture residual.Because the learned appear-ance models have limited expressive power to capture com-plex and subtle face image variations in pose,expression,and illumination,it may not work well on unseen faces.It is also
Int J Comput Vis well known that AAM is sensitive to the initialization due to
the gradient descent optimization.
Regression-based methods learn a regression function that
directly maps image appearance to the target output.The
complex variations are learnt from large training data and
testing is usually ef?cient.However,previous such methods (Cristinacce and Cootes2007;Valstar et al.2010;Dollar et al.2010;Sauer and Cootes2011;Saragih and Goecke2007) have certain drawbacks in attaining the goal of minimizing Eq.(1).Approaches in(Dollar et al.2010;Sauer and Cootes 2011;Saragih and Goecke2007)rely on a parametric model (e.g.,AAM)and minimize model parameter errors in the training.This is indirect and sub-optimal because smaller parameter errors are not necessarily equivalent to smaller alignment errors.Approaches in(Cristinacce and Cootes 2007;Valstar et al.2010)learn regressors for individual land-marks,effectively using(1)as their loss functions.However, because only local image patches are used in training and appearance correlation between landmarks is not exploited, such learned regressors are usually weak and cannot handle large pose variation and partial occlusion.
We notice that the shape constraint is essential in all meth-ods.Only a few salient landmarks(e.g.,eye centers,mouth corners)can be reliably characterized by their image appear-ances.Many other non-salient landmarks(e.g.,points along face contour)need help from the shape constraint—the cor-relation between landmarks.Most previous works use a para-metric shape model to enforce such a constraint,such as PCA model in AAM(Cootes et al.2001;Matthews and Baker 2004)and ASM(Cootes et al.1995;Cristinacce and Cootes 2007).
Despite of the success of parametric shape models,the model?exibility(e.g.,PCA dimension)is often heuristically determined.Furthermore,using a?xed shape model in an iterative alignment process(as most methods do)may also be suboptimal.For example,in initial stages(the shape is far from the true target),it is favorable to use a restricted model for fast convergence and better regularization;in late stages (the shape has been roughly aligned),we may want to use a more?exible shape model with more subtle variations for re?nement.To our knowledge,adapting such shape model ?exibility is rarely exploited in the literature.
In this paper,we present a novel regression-based approach without using any parametric shape models.The regressor is trained by explicitly minimizing the alignment error over training data in a holistic manner—all facial land-marks are regressed jointly.The general idea of regressing non-parametric shape has also been explored by Zhou and Comaniciu(2007).
Our regressor realizes the shape constraint in an non-parametric manner:the regressed shape is always a lin-ear combination of all training shapes.Also,using fea-tures across the image for all landmarks is more discrimina-
(a
(c)(d)
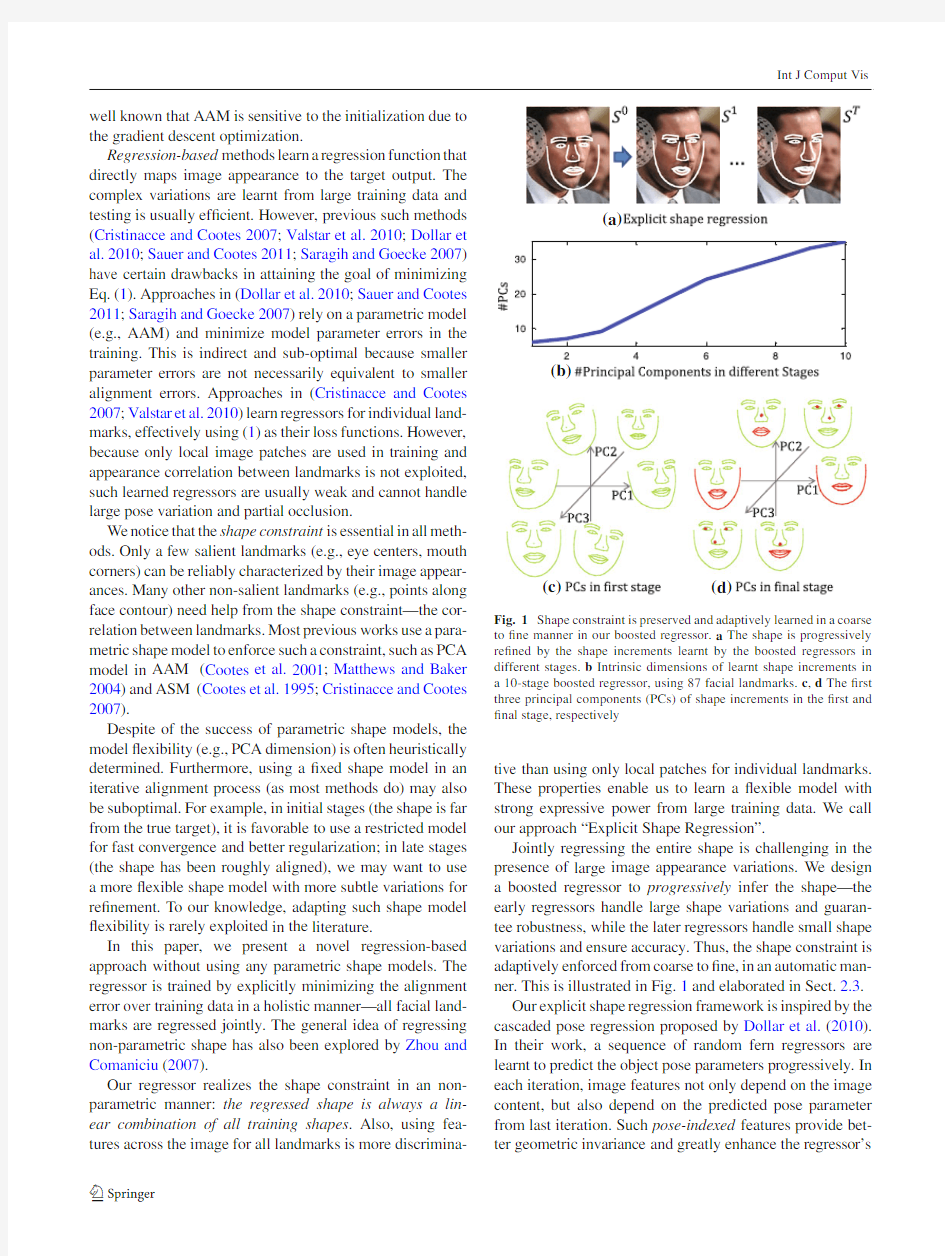
Fig.1Shape constraint is preserved and adaptively learned in a coarse to?ne manner in our boosted regressor.a The shape is progressively re?ned by the shape increments learnt by the boosted regressors in different stages.b Intrinsic dimensions of learnt shape increments in a10-stage boosted regressor,using87facial landmarks.c,d The?rst three principal components(PCs)of shape increments in the?rst and ?nal stage,respectively
tive than using only local patches for individual landmarks. These properties enable us to learn a?exible model with strong expressive power from large training data.We call our approach“Explicit Shape Regression”.
Jointly regressing the entire shape is challenging in the presence of large image appearance variations.We design a boosted regressor to progressively infer the shape—the early regressors handle large shape variations and guaran-tee robustness,while the later regressors handle small shape variations and ensure accuracy.Thus,the shape constraint is adaptively enforced from coarse to?ne,in an automatic man-ner.This is illustrated in Fig.1and elaborated in Sect.2.3.
Our explicit shape regression framework is inspired by the cascaded pose regression proposed by Dollar et al.(2010). In their work,a sequence of random fern regressors are learnt to predict the object pose parameters progressively.In each iteration,image features not only depend on the image content,but also depend on the predicted pose parameter from last iteration.Such pose-indexed features provide bet-ter geometric invariance and greatly enhance the regressor’s
Int J Comput Vis
performance.In their experiment,this method has also been
used to estimate face shape which is modeled by a simple
parametric ellipse(Dollar et al.2010).
Our method improves the cascaded pose regression frame-
work in several important aspects and works better for face
alignment problem.We adopt a non-parametric representa-
tion,directly estimate the facial landmarks by minimizing
the alignment error instead of parameter error.Consequently,
the underlying shape constraint is preserved automatically.
To address the very challenging high-dimensional regres-
sion problem,we further propose several improvements:a
two-level boosted regression,effective shape indexed fea-
tures,a fast correlation-based feature selection method and
sparse coding based model compression so that:(1)we can
quickly learn accurate models from large training data(20
min on2,000training samples);(2)the resulting regressor is
extremely ef?cient in the test(15ms for87facial landmarks);
(3)the model size is reasonably small(a few megabytes)and
applicable in many scenarios.We show superior results on
several challenging datasets.
2Face Alignment by Shape Regression
2.1The Shape Regression Framework
In this section,we describe our shape regression framework
and discuss how it?t to the face alignment task.
We cast our solution to shape regression task into the gra-
dient boosting regression(Friedman2001;Duffy and Helm-
bold2002)framework,which is a representative approach of
ensemble learning.In training,it sequentially learns a series
of weak learners to greedily minimize the regression loss
function.In testing,it simply combine the pre-learnt weak
learners in an additive manner to give the?nal prediction.
Before specifying how to resolve face alignment task in
gradient boosting framework,we?rst clarify a simple and
basic term,i.e.the normalized shape.Provided the prede?ned
mean shapeˉS,the normalized shape of an input shape S is obtained by a similarity transform which aligns the input
shape to the mean shape1to minimizes their L2distance, M S=argmin
M
||ˉS?M?S||2,(2)
where M S?S is the normalized shape.Now we are ready to describe our shape regression framework.
In training,given N training samples{I i,?S i,S0i}N i=1, the stage regressors(R1,...,R T)are sequentially learnt to
1It is also interesting to know that the mean shape is de?ned as the average of the normalized training shapes.Although it sounds like a circular de?nition,we still can compute the mean shape in an iterative way.Readers are recommended to Active Shape Model(Cootes et al. 1995)method for details.reduce the alignment errors on training set.In stage each t, the stage regressor R t is formally learnt as follows,
R t=argmin
R
N
i=1
||y i?R(I i,S t?1
i
)||2(3)
y i=M S t?1
i
?(?S i?S t?1
i
),
where S t?1
i
is the estimated shape in previous stage t?1,
M
S t?1
i
?(?S i?S t?1
i
)is the normalized regression target which will be discussed later.Please note herein we only apply the scale and rotation transformation to normalize the regression target.
In testing,given a facial image I and an initial shape S0, the stage regressor computes a normalized shape increment from image features and then updates the face shape,in a cascaded manner:
S t i=S t?1
i
+M?1
S t?1
i
?R t(I i,S t?1
i
),(4) where the stage regressor R t updates the previous shape S t?1to the new shape S t in stage t.Note we only scale and rotate(without translating)the output of the stage regression according to the angle and the scale of the previous shape.
2.1.1Discussion
Although our basic face alignment framework follows gradi-ent boosting framework,there are three components speci?-cally designed for the shape regression tasks.As these com-ponents are generic,regardless of the speci?c forms of the weak learner and the feature used for learning,it is worth clarifying and discussing them here.
Shape Indexed Feature The feature for learning the weak learner R t depends on both image I and previous estimated shape S t?1.It improves the performance by achieving geo-metric invariance.In other words,the feature is extracted relative to S t?1to eliminate two kinds of variations:the vari-ations due to scale,rotation and translation and the variations due to identity,pose and expression(i.e.the similarity trans-form M?1
S t?1
and the normalized shape M S t?1?S t?1).It is worth mentioning that although shape indexed feature sounds more complex,our designed feature is extremely cheap to be computed and does not require image warping.The details of our feature will be described in Sect.2.4.
Regressing the Normalized Target Instead of learning the
mapping from shape indexed feature to?S i?S t?1
i
,we argue the regression task will be simpli?ed if we regress the normal-
ized target M
S t?1
i
?(?S i?S t?1
i
).Because the normalized tar-get is invariant to similarity transform.To better understand its advantage,imagine two identical facial images with the estimated shape.One of them is changed by similarity trans-form while the other is kept unchanged.Due to the transform, the regression target(shape increments)of the transformed
Int J Comput Vis image are different from that of the unchanged one.Hence
the regression task is complicated.In contrast,the regression
task will keep simple if we regress the normalized targets,
which are still the same for both samples.
Data Augmentation and Multiple Initialization Unlike
typical regression task,the sample of our shape regression
task is a triple which is de?ned by the facial image,the
groundtruth shape and the initial shape i.e.{I i,?S i,S0i}.So
we can augment the samples by generating multiple initial
shapes for one image.In fact,it turns out such simple oper-
ation not only effectively improves generalization of train-
ing,but also reduces the variation of the?nal prediction by
bagging the results obtained by multiple initializations.See
Sect.3for experimental validations and further discussions.
To make the training and testing our framework clear,we
format them in the pseudo codes style.
Algorithm1Explicit Shape Regression(ESR)
Variables:Training images and labeled shapes{I l,?S l}L l=1;ESR model
{R t}T t=1;Testing image I;Predicted shape S;TrainParams{times of
data augment N aug,number of stages T};
TestParams{number of multiple initializations N int};
InitSet which contains exemplar shapes for initialization
ESRTraining({I l,?S l}L l=1,TrainParams,InitSet)
//augment training data
{I i,?S i,S0i}N i=1←Initialization({I l,?S l}L l=1,N aug,InitSet)
for t from1to T
Y←{M
S t?1
i ?(?S i?S t?1
i
)}N i=1//compute normalized targets
R t←LearnStageRegressor(Y,{I i,S t?1
i }N i=1)//using Eq.(3)
for i from1to N
S t i←S t?1
i +M?1
S t?1
i
?R t(I i,S t?1
i
)
return{R t}T t=1
ESRTesting(I,{R t}T t=1,TestParams,InitSet)
//multiple initializations
{I i,?,S0i}N int i=1←Initialization({I,?},N int,InitSet) for t from1to T
for i from1to N int
S t i←S t?1
i +M?1
S t?1
i
?R t(I i,S t?1
i
)
S←CombineMultipleResutls({S T i}N int i=1)
return S
Initialization({I c,?S c}C c=1,D,InitSet)
i←1
for c from1to C
for d from1to D
S o i←sampling an exemplar shape from InitSet
{I o i,?S o i}←{I c,?S c}
i←i+1
return{I o i,?S o i,S o i}C D i=1
The details about combining multiple results and initial-ization(including constructing InitSet and sampling from InitSet)will be discussed later in Sect.3.
As the stage regressor plays a vital role in our shape regres-sion framework,we will focus on it next.We will discuss what kinds of regressors are suitable for our framework and present a series of methods for effectively learning the stage regressor.
2.2Two-Level Boosted Regression
Conventionally,the stage regressor R t,is a quite weak regres-sor such as a decision stump(Cristinacce and Cootes 2007)or a fern(Dollar et al.2010).However,in our early experiments,we found that such regressors result in slow convergence in training and poor performance in the testing.
We conjecture this is due to two reasons:?rst,regressing the entire shape(as large as dozens of landmarks)is too dif?-cult to be handled by a weak regressor in each stage;second, the shape indexed feature will be unreliable if the previous regressors are too weak to provide fairly reliable shape esti-mation,so will the regressor based on the shape indexed feature.Therefore it is crucial to learn a strong regressor that can rapidly reduce the alignment error of all training samples in each stage.
Generally speaking,any kinds of regressors with strong ?tting capacity will be desirable.In our case,we again inves-tigate boosted regression as the stage regressor R t.Therefore threre are two-levels boosted regression in our method,i.e. the basic face alignment framework(external-level)and the stage regressor R t(internal-level).To avoid terminology con-fusion,we term the weak learner of the internal-level boosted regression,as primitive regressor.
It is worth mentioning that other strong regressors have also been investigated by two notable works.Sun et al. (2013)investigated the regressor based on convolutional neural network.Xiong and De la Torre(2013)investi-gated the linear regression with strong hand-craft feature i.e. SIFT.
Although the external-and internal-level boosted regres-sion bear some similarities,there is a key differences.The difference is that the shape indexed image features are?xed in the internal-level,i.e.,they are indexed only relative to the previous estimated shape S t?1and no longer change when those primitive regressor are being learnt.2This is impor-tant,as each primitive regressor is rather weak,allowing fea-ture indexing will frequently change the features,leading to unstable consequences.Also the?xed features can lead to much faster training,as will be described later.In our exper-iments,we found using two-level boosted regression is more accurate than one level under the same training effort,e.g., T=10,K=500is better than one level of T=5,000,as shown in Table4.
2Otherwise this degenerates to a one level boosted regression.
Int J Comput Vis
2.3Primitive Regressor
We use a fern as our primitive regressor.The fern was ?rstly introduced for classi?cation by Ozuysal et al.(2010)and later used for regression by Dollar et al.(2010).
A fern is a composition of F (5in our implementation)features and thresholds that divide the feature space and all training samples into 2F bins.Each bin b is associated with a regression output y b .Learning a fern involves a simple task and a hard task.The simple task refers to learning the outputs in bins.The hard task refers to learning the structure (the features and the splitting thresholds).We will handle the simple task ?rst,and resolve the hard task in the Sect.2.5later.
Let the targets of all training samples be {?y i }N i =1.The pre-diction/output of a bin should minimize its mean square dis-tance from the targets for all training samples falling into this bin.
y b =argmin
y
i ∈Ωb
||?y i ?y ||2,(5)where the set Ωb indicates the samples in the b th bin.It is easy to see that the optimal solution is the average over all targets in this bin.
y b =
i ∈Ωb ?y i |Ωb |.(6)To overcome over-?tting in the case of insuf?cient training data in the bin,a shrinkage is performed (Friedman 2001;Ozuysal et al.2010)as
y b =11+β/|Ωb |
i ∈Ωb ?y
i |Ωb |,(7)
where βis a free shrinkage parameter.When the bin has suf?cient training samples,βmakes little effect;otherwise,it adaptively reduces the magnitude of the estimation.2.3.1Non-parametric Shape Constraint
By directly regressing the entire shape and explicitly mini-mizing the shape alignment error in Eq.(1),the correlation between the shape coordinates is preserved.Because each shape update is additive as in Eqs.(4),(6)and (7),it can be shown that the ?nal regressed shape S is the sum of initial shape S 0and the linear combination of all training shapes:S =S 0
+
N i =1
w i ?S
i .(8)
Therefore,as long as the initial shape S 0satis?es the
shape constraint,the regressed shape is always constrained to reside in the linear subspace constructed by all train-ing shapes .In fact,any intermediate shape in the regression
also satis?es the https://www.360docs.net/doc/2711709638.html,pare to the pre-?xed PCA
shape model,the non-parametric shape constraint is adap-tively determined during the learning.
To illustrate the adaptive shape constraint,we perform PCA on all the shape increments stored in K ferns (2F ×K in total)in each stage t .As shown in Fig.1,the intrinsic dimension (by retaining 95%energy)of such shape spaces increases during the learning.Therefore,the shape constraint is automatically encoded in the regressors in a coarse to ?ne manner .Figure 1also shows the ?rst three principal com-ponents of the learnt shape increments (plus a mean shape)in ?rst and ?nal stage.As shown in Fig.1c,d,the shape updates learned by the ?rst stage regressor are dominated by global rough shape changes such as yaw,roll and scaling.In contrast,the shape updates of the ?nal stage regressor are dominated by the subtle variations such as face contour,and motions in the mouth,nose and eyes.2.4Shape Indexed (Image)Features
For ef?cient regression,we use simple pixel-difference features,i.e.,the intensity difference of two pixels in the image.Such features are extremely cheap to compute and powerful enough given suf?cient training data (Ozuysal et al.2010;Shotton et al.2011;Dollar et al.2010).
To let the pixel-difference achieve geometric invariance,we need to make the extracted raw pixel invariant to two kinds of variations:the variations due to similarity transform (scale,rotation and translation)and the variations due to the normalized shape (3D-poses,expressions and identities).In this work,we propose to index a pixel by the esti-mated shape.Speci?cally,we index a pixel by the local coordinate l =( x l , y l )with respect to a landmark in the normalized face.The superscript l indicates which land-mark this pixel is relative to.As Fig.2shows,such index-ing holds invariance against the variations mentioned above and make the algorithm robust.In addition,it also enable us sampling more useful candidate features distributed around salient landmarks (e.g.,a good pixel difference feature could be “eye center is darker than nose tip”or “two eye centers are similar”).
(a )(b)
Fig.2Pixels indexed by the same local coordinates have the same semantic meaning (a ),but pixels indexed by the same global coordinates have different semantic meanings due to the face shape variation (b )
Int J Comput Vis
In practical implementation,unlike previous works (Cristinacce and Cootes2007;Valstar et al.2010;Sauer and Cootes2011)which requires image warping,we instead transform the local coordinate back to the global coordinates on the original image to extract the shape indexed pixels and then compute the pixel-difference features.This leads to much faster testing speed.
Let the estimated shape of a sample be S.The location of the m th landmark is obtained byπl?S,where the operatorπl gets the x and y coordinates of m th landmark from the shape vector.Provided the local coordinate l,the corresponding global coordinates on the original image can formally repre-sented as follows.3
πl?S+M?1S? l(9) Note that although the l is identical for different samples, the global coordinates for extracting raw pixels are adaptively adjusted for different samples to ensure geometric invariance. Herein we only scale and rotate(without translating)the local coordinates according to the angle and the scale of the shape.
For each stage regressor R t in the external-level,we ran-domly generate P local coordinates{ lαα}Pα=1which de?ne P shape indexed pixels.Each local coordinate is generated by?rst randomly selecting a landmark(e.g.lαth landmark) and then draw random x-and y-offset from uniform distri-bution.The P pixels result in P2pixel-difference features. Now,the new challenge is how to quickly select effective features from such a large pool.
2.5Correlation-Based Feature Selection
To form a good fern regressor,F out of P2features are https://www.360docs.net/doc/2711709638.html,ually,this is done by randomly generating a pool of ferns and selecting the one with minimum regression error as in(5)(Ozuysal et al.2010;Dollar et al.2010).We denote this method as best-of-n,where n is the size of the pool.Due to the combinatorial explosion,it is unfeasible to evaluate(5) for all of the compositional features.As illustrated in Table5, the error is only slightly reduced by increasing n from1to 1024,but the training time is signi?cantly longer.
To better explore the huge feature space in a short time and generate good candidate ferns,we exploit the correlation between features and the regression target.We expect that a good fern should satisfy two properties:(1)each feature in the fern should be highly correlated to the regression target;
(2)correlation between features should be low so they are complementary when composed.
To?nd features satisfying such properties,we propose a correlation-based feature selection method.Let Y be the
3According to aforementioned de?nition,the global coordinates are computed via M?1S?(πl?M?1S?S+ l).By simplifying this formula, we get Eq.(9)Algorithm2Shape indexed features
Variables:images and corresponding estimated shapes{I i,S i}N i=1; number of shape indexed pixel features P;number of facial points N fp; the range of local coordinateκ;local coordinates{ lαα}Pα=1;
shape indexed pixel featuresρ∈ N×P;
shape indexed pixel-difference features X∈ N×P2; GenerateShapeIndexedFeatures({I i,S i}N i=1,N fp,P,κ)
{ lαα}Pα=1←GenerateLocalCoordinates(FeatureParams)
ρ←ExtractShapeIndexedPixels({I i,S i}N i=1,{ lαα}Pα=1)
X←pairwise difference of all columns ofρ
return{ lαα}Pα=1,ρ,X
GenerateLocalCoordinates(N fp,P,κ)
forαfrom1to P
lα←randomly drawn a integer in[1,N fp]
lαα←randomly drawn two?oats in[?κ,κ]
return{ lαα}Pα=1
ExtractShapeIndexedPixels({I i,S i}N i=1,{ lαα}Pα=1)
for i from1to N
forαfrom1to P
μα←πlα?S i+M?1S
i
? lα
ρiα←I i(μα)
returnρ
regression target with N(the number of samples)rows and 2N fp columns.Let X be pixel-difference features matrix with N rows and P2columns.Each column X j of the feature matrix represents a pixel-difference feature.We want to select F columns of X which are highly correlated with Y.Since Y is a matrix,we use a projection v,which is a column vector drawn from unit Gaussian,to project Y into a column vector Y prob=Y v.The feature which maximizes its correlation (Pearson Correlation)with the projected target is selected. j opt=argmin
j
corr(Y prob,X j)(10)
By repeating this procedure F times,with different random projections,we obtain F desirable features.
The random projection serves two purposes:it can pre-serve proximity(Bingham and Mannila2001)such that the features correlated to the projection are also discriminative to delta shape;the multiple projections have low correlations with a high probability and the selected features are likely to be complementary.As shown in Table5,the proposed corre-lation based method can select good features in a short time and is much better than the best-of-n method.
2.6Fast Correlation Computation
At?rst glance,we need to compute the correlation for all can-didate features to select a feature.The complexity is linear to the number of training samples and the number of pixel-difference features,i.e.O(N P2).As the size of feature pool scales square to the number of sampled pixels,the computa-
Int J Comput Vis
tion will be very expensive,even with moderate number of pixels (e.g.400pixels leads to 160,000candidate features!).Fortunately the computational complexity can be reduced from O (N P 2)to O (N P )by the following facts:The cor-relation between the regression target and a pixel-difference feature (ρm ?ρn )can be represented as follows.corr (Y proj ,ρm ?ρn )=
cov (Y proj ,ρm )?cov (Y proj ,ρn )
σ(Y proj )σ(ρm ?ρn )
σ(ρm ?ρn )=cov (ρm ,ρm )
+cov (ρn ,ρn )?2cov (ρm ,ρn )
(11)
We can see that the correlation is composed by two cat-egories of covariances:the target-pixel covariance and the pixel–pixel covariance.The target-pixel covariance refers to the covariance between the projected target and pixel fea-ture,e.g.,cov (Y proj ,ρm )and cov (Y proj ,ρn ).The pixel–pixel covariance refers to the covariance among different pixel fea-tures,e.g.,cov (ρm ,ρm ),cov (ρn ,ρn )and cov (ρm ,ρn ).As the shape indexed pixels are ?xed in the internal-level boosted regression,the pixel–pixel covariances can be pre-computed and reused within each internal-level boosted regression.For each primitive regressor,we only need to compute all target-pixel covariances to compose the correlations,which scales linear to the number of pixel features.Therefore the com-plexity is reduced from O (N P 2)to O (N P ).Algorithm 3Correlation-based feature selection
Input :regression targets Y ∈ N ×2N fp ;shape indexed pixel features ρ∈ N ×P ;pixel-pixel covariance cov (ρ)∈ P ×P ;number of features of a fern F ;
Output :The selected pixel-difference features {ρm f ?ρn f }F f =1and the
corresponding indices {m f ,n f }F f =1;
CorrelationBasedFeatureSelection (Y ,cov (ρ),F )
for f from 1to F
v ←randn (2N fp ,1)//draw a random projection from unit Gaussian Y prob ←Y v //random projection
cov (Y prob ,ρ)∈ 1×P ←compute target-pixel covariance σ(Y prob )←compute sample variance of Y prob m f =1;n f =1;for m from 1to P for n from 1to P
corr (Y prob ,ρm ?ρn )←compute correlation using Eq.(11)if corr (Y prob ,ρm ?ρn )>corr (Y prob ,ρm f ?ρn f )m f =m ;n f =n ;
return {ρm f ?ρn f }F f =1,{m f ,n f }F f =1
2.7Internal-Level Boosted Regression
As aforementioned,at each stage t ,we need to learn to a stage regressor to predict the normalized shape increments from the shape indexed features.Since strong ?tting capacity is vital to the ?nal performance,we again exploit the boosted regression to form the stage regressor.To distinguish it from
the external-level shape regression framework,we term it as
internal-level boosted regression.With the prepared ingredi-ents in previous three sections,we are ready to describe how to learn the internal-level boosted regression.
The internal-boosted regression consists of K primitive regressors {r 1,...,r K },which are in fact ferns.In testing,we combine them in an additive manner to predict the output.In training,the primitive regressors are sequentially learnt to greedily ?t the regression targets,in other words,each primi-tive regressor handles the residues left by previous regressors.In each iteration,the residues are used as the new targets for learning a new primitive regressor.The learning procedure are essentially identical for all primitive regressors,which can be describe as follows.
–Features Selecting F pixel-difference features using cor-relation based feature selection method.
–Thresholds Randomly sampling F i.i.d.thresholds from an uniform distribution.4
–Outputs Partitioning all training samples into different bins using the learnt features and thresholds.Then,learn-ing the outputs of the bins using Eq.(7).
Algorithm 4Internal-level boosted regression
Variables :regression targets Y ∈ N ×2N fp ;training images and corresponding estimated shapes {I i ,S i }N i =1;training parameters TrainParams {N fp ,P ,κ,F ,K };the stage regressor R ;testing image and corresponding estimated shape {I ,S };
LearnStageRegressor (Y ,{I i ,S i }N i =1,TrainParams ){ l αα}P
α=1←GenerateLocalCoordinates (N fp ,P ,κ)
ρ←ExtractShapeIndexedPixels ({I i ,S i }N i =1,{ l αα}P
α=1)cov (ρ)←pre-compute pixel-pixel covariance Y 0←Y //initialization for k from 1to K
{ρm f ?ρn f }F f =1,{m f ,n f }F f =1←
CorrelationBasedFeatureSelection (Y k ?1,cov (ρ),F ){θf }F f =1←sample F thresholds from an uniform distribution {Ωb }2F b =1←partition training samples into 2F bins {y b }2F
b =1←compute the outputs of all bins using Eq.(7)
r k ←{{m f ,n f }F f =1,{θf }F f =1,{y b }2F
b =1}//construct a fern Y k ←Y k ?1?r k ({ρm f ?ρn f }F f =1)//update the targets
R ←{{r k }K k =1,{ l αα}P α=1}//construct stage regressor
return R
ApplyStageRegressor (I ,S ,R )//i.e.R (I ,S )
ρ←ExtractShapeIndexedPixels ({I ,S },{ l αα}P α=1)
δS ←0
for k from 1to K
δS ←δS +r k ({ρm f ?ρn f }F f =1)return δS
4
Provided the range of pixel difference feature is [?c ,c ],the range of the uniform distribution is [?0.2c ,0.2c ].
Int J Comput Vis 2.8Model Compression
By memorizing the?tting procedures in the regression
model,our method gains very ef?cient testing speed.How-
ever,comparing with optimization based approaches,our
regression based method leads higher storage cost.The stored
delta shapes in the ferns’leaves contributes to the main
cost in the total storage,which can be quantitatively com-
puted via8N fp T K2F,where T K2F gives the number of all
leaves of T K random ferns in T stages,8N fp is the stor-
age of a delta shape in a single leaf.For example,provided
T=10,K=500,F=5and N fp=194,the storage is
around240mb,which is unaffordable in many real scenarios
such as mobile phones and embedded devices.
A straight forward way to compress model size is via
principal component analysis(Jolliffe2005).However,since
PCA only exploits orthogonal undercompleted basis in cod-
ing,its compression capability is limited.To further com-
press the model size,we adopt sparse coding which not only
takes the advantage of overcompleted basis but also enforces
sparse regularization in its objective.
Formally,the objective of sparse coding in a certain leave
of fern can be expressed as follows:
min x
i∈Ωb
?y i?Bx 22,s.t. x 0≤Q,(12)
where the?y i is the regression target;B is the basis for sparse coding;Q the is the upper bound of the number of non-zero codes(Q=5in our implementation).
The learning procedure of our model compression method consists of two steps in each stage.In the?rst step,the basis B of this stage is constructed.To learn the basis,we?rst run the non-sparse version of our method to obtain K ferns of this stage as well as the outputs stored in their leaves.Then the basis is constructed by random sampling5from the outputs in the leaves.
In the second step,we use the same method in Sect.2.5 to learn the structure of a fern.For each leaf,sparse codes are computed by optimizing the objective in Eq.(12)using the orthogonal matching pursuit method(Tropp and Gilbert 2007).Comparing with the shape increment,sparse codes require much less storage in leaves,especially when the dimension of the shape is high.
In testing,for K ferns in one stage,their non-zero codes in the leaves which are visited by the testing sample are lin-early summed up to form the?nal coef?cient x,then the output is computed via Bx,which contributes to the main computation.It is worth noting although the training of the 5We use random sampling for basis construction due to its simplicity and effectiveness.We also tried more sophisticated K-SVD method (Elad and Aharon2006)for learning basis.It yields similar performance comparing with random https://www.360docs.net/doc/2711709638.html,pressed version is more time-consuming,the testing is still as ef?cient as the original version.
3Implementation Details
We discuss more implementation details,including the shape initialization in training and testing,parameter setting and running performance.
3.1Initialization
As aforementioned,we generate a initial shape by sampling from an InitSet which contains exemplar shapes.The exem-plar shapes could be representative shapes selected from the training data,or the groundtruth shapes of the training data {?S i}N i=1.In training,we choose the later as the InitSet.While, in testing,we use the?rst for its storage ef?ciency.For one image,we draw the initial shapes without replacement to avoid duplicated samples.The scale and translation of the sampled shape should be adjusted to ensure that the corre-sponding face rectangle is the same with the face rectangle of the input facial image.
3.2Training Data Augmentation
Each training sample consists of a training image,an initial shape and a ground truth shape.To achieve better general-ization ability,we augment the training data by sampling multiple initializations(20in our implementation)for each training image.This is found to be very effective in obtain-ing robustness against large pose variation and rough initial shapes during the testing.
3.3Multiple Initializations in Testing
The regressor can give reasonable results with different initial shapes for a test image and the distribution of multiple results indicates the con?dence of estimation.As shown in Fig.3
, Fig.3Left results of5facial landmarks from multiple runs with differ-ent initial shapes.The distribution indicates the estimation con?dence: left eye and left mouth corner estimations are widely scattered and less stable,due to the local appearance noises.Right the average alignment error increases as the standard deviation of multiple results increases
Int J Comput Vis
Table1Training and testing times of our approach,measured on an Intel Core i72.93GHz CPU with C++implementation
Landmarks52987
Training(min)51021 Testing(ms)0.320.91 2.9
when multiple landmark estimations are tightly clustered, the result is accurate,and vice versa.In the test,we run the regressor several times(5in our implementation)and take the median result6as the?nal estimation.Each time the initial shape is randomly sampled from the training shapes.This further improves the accuracy.
3.4Running Time Performance
Table1summarizes the computational time of training(with 2,000training images)and testing for different number of landmarks.Our training is very ef?cient due to the fast fea-ture selection method.It takes minutes with40,000training samples(20initial shapes per image),The shape regression in the test is extremely ef?cient because most computation is pixel comparison,table look up and vector addition.It takes only15ms for predicting a shape with87landmarks(3ms ×5initializations).
3.5Parameter Settings
The number of features in a fern F and the shrinkage para-meterβadjust the trade off between?tting power in training and generalization ability in testing.They are set as F=5,β=1,000by cross validation.
Algorithm accuracy consistently increases as the number of stages in the two-level boosted regression(T,K)and num-ber of candidate features P2increases.Such parameters are empirically chosen as T=10,K=500,P=400for a good tradeoff between computational cost and accuracy.
The parameterκis used for generating the local coordi-nates relative to landmarks.We setκequal to0.3times of the distance between two pupils on the mean shape.
4Experiments
The experiments are performed in two parts.The?rst part compares our approach with previous works.The second part 6The median operation is performed on x and y coordinates of all landmarks individually.Although this may violate the shape constraint mentioned before,the resulting median shape is mostly correct as in most cases the multiple results are tightly clustered.We found such a simple median based fusion is comparable to more sophisticated strate-gies such as weighted combination of input shapes.validates the proposed approach and presents some interest-ing discussions.
We brie?y introduce the datasets used in the experiments. They present different challenges,due to different numbers of annotated landmarks and image variations.
BioID The dataset was proposed by Jesorsky et al.(2001) and widely used by previous methods.It consists of1,521 near frontal face images captured in a lab environment,and is therefore less challenging.We report our result on it for completeness.
LFPW The dataset was created by Belhumeur et al.(2011). Its full name is Labeled Face Parts in the Wild.The images are downloaded from internet and contain large variations in pose,illumination,expression and occlusion.It is intended to test the face alignment methods in unconstraint condi-tions.This dataset shares only web image URLs,but some URLs are no longer valid.We only downloaded812of the 1,100training images and249of the300test images.To acquire enough training data,we augment the training images to2,000in the same way as Belhumeur et al.(2011)did and use the available testing images.
LFW87The dataset was created by Liang et al.(2008).The images mainly come from the Labeled Face in the Wild (LFW)dataset(Huang et al.2008),which is acquired from uncontrolled conditions and is widely used in face recog-nition.In addition,it has87annotated landmarks,much more than that in BioID and LFPW,therefore,the perfor-mance of an algorithm relies more on its shape constraint. We use the same setting in Liang et al.(2008)’s work:the training set contains4,002images mainly from LFW,and the testing set contains1,716images which are all from LFW.
Helen The dataset was proposed by Le et al.(2012).It consists of2,330high resolution web images with194 annotated landmarks.The average size of face is550pix-els.Even the smallest face in the dataset is larger than 150pixels.It serves as a new benchmark which provides richer and more detailed information for accurate face alignment.
4.1Comparison with previous works
For comparisons,we use the alignment error in Eq.(1)as the evaluation metric.To make it invariant to face size,the error is not in pixels but normalized by the distance between the two pupils,similar to most previous works.
The following comparison shows that our approach out-performs the state of the art methods in both accuracy and ef?ciency,especially on the challenging LFPW and LFW87 datasets.Figures4,5,6and7show our results on challenging examples with large variations in pose,expression,illumina-tion and occlusion from the four datasets.
Int J Comput
Vis Fig.4Selected results from
LFPW
Fig.5Selected results from LFW87
4.1.1Comparison on LFPW
The consensus exemplar approach proposed by Belhumeur et al.(2011)is one of the state of the art methods.It was the best on BioID when published,and obtained good results on LFPW.
Comparison in Fig.8shows that most landmarks esti-mated by our approach are more than10%accurate7than 7The relative improvement is the ratio between the error reduction and the original error.
Int J Comput
Vis
Fig.6Selected results from
BioID
Fig.7Selected results from Helen dataset
Fig.8Results on the LFPW
circle radius is the average error
sents relative accuracy improvement
exemplars(CE)method proposed
accurate.Right top relative accuracy improvement of all landmarks over the results of CE method.Right bottom average error of all landmarks (Color?gure online)
the method proposed by Belhumeur et al.(2011)and our overall error is smaller.
In addition,our method is thousands of times faster.It takes around5ms per image(0.91×5initializations for29 landmarks).The method proposed by Belhumeur et al.(2011) uses expensive local landmark detectors(SIFT+SVM)and it takes more than10s8to run29detectors over the entire image.
on LFW87
(2008)proposed a component-based discrimina-
(CDS)method which trains a set of direction clas-
pre-de?ned facial components to guide the ASM
Their algorithm outperform previous ASM based works by a large margin.
the same root mean square error(RMSE)used in
et al.2008)as the evaluation metric.Table2
method is signi?cantly better.For the strict error
(5pixels),the error rate is reduced nearly by half, from25.3to13.9%.The superior performance on a large number of landmarks veri?es the effectiveness of proposed holistic shape regression and the encoded adaptive shape con-straint.
8Belhumeur et al.(2011)discussed in their work:“The localizer requires less than1s per?ducial on an Intel Core i73.06GHz machine”. We conjecture that it takes more than10s to locate29landmarks.
Int J Comput Vis
Table2Percentages of test images with root mean square error (RMSE)less than given thresholds on the LFW87dataset
RMSE<5Pixels<7.5Pixels<10Pixels
CDS(%)74.793.597.8
Our method(%)86.195.298.2
Bold values represent the best results under certain settings
Table3Comparison on Helen dataset
Method Mean Median Min Max
STASM0.1110.0940.0370.411 CompASM0.0910.0730.0350.402 Our method0.0570.0480.0240.16 The error of each sample is?rst individually computed by averaging the errors of194landmarks,and then the mean error across all testing samples is computed
Bold values represent the best results under certain settings
4.1.3Comparison on Helen
We adopt the same training and testing protocol as well as the same error metric used by Le et al.(2012).Speci?cally, we divide the Helen dataset into training set of2,000images and testing set of330images.As the pupils are not labeled in the Helen dataset,the distance between the centroids of two eyes are used to normalize the deviations from groundtruth.
We compare our method with STASM(Milborrow and Nicolls2008)and recently proposed CompASM(Le et al. 2012).As shown in Table3,our method outperforms them by a large https://www.360docs.net/doc/2711709638.html,paring with STASM and CompASM,our method reduces the mean error by50and40%respectively, meanwhile,the testing speed is even faster.
4.1.4Comparison to Previous Methods on BioID
Our model is trained on augmented LFPW training set and tested on the entire BioID dataset.
Figure9compares our method with previous methods (Vukadinovic and Pantic2005;Cristinacce and Cootes2006; Milborrow and Nicolls2008;Valstar et al.2010;Belhumeur et al.2011).Our result is the best but the improvement is mar-ginal.We believe this is because the performance on BioID is nearly maximized due to its simplicity.Note that our method is thousands of times faster than the second best method(Bel-humeur et al.2011).
4.2Algorithm Validation and Discussions
We verify the effectiveness of different components of the proposed approach.Such experiments are performed on the our augmented LFPW dataset.The dataset is split into two
Fig.9Cumulative error curves on the BioID dataset.For compari-son with previous results,only17landmarks are used(Cristinacce and Cootes2006).As our model is trained on LFPW images,for those land-marks with different de?nitions between the two datasets,a?xed offset is applied in the same way in Belhumeur et al.(2011)
Table4Tradeoffs between two levels boosted regression
Stage regressors(T)151******** Primitive regressors(K)50001000500501 Mean error(×10?2)15 6.2 3.3 4.5 5.2 Bold value represents the best results under certain settings
parts for training and testing.The training set contains1,500 images and the testing set contains500images.Parameters are?xed as in Sect.3,unless otherwise noted.
4.2.1Two-Level Boosted Regression
As discussed in Sect.2,the stage regressor exploits shape indexed features to obtain geometric invariance and decom-pose the original dif?cult problem into easier sub-tasks.The shape indexed features are?xed within the internal-level boosted regression to avoid instability.
Different tradeoffs between two-level boosted regression are presented in Table4,using the same number of ferns. On one extreme,regressing the whole shape in a single stage(T=1,K=5000)is clearly the worst.On the other extreme,using a single fern as the stage regressor (T=5000,K=1)also has poor generalization ability in the test.The optimal tradeoff(T=10,K=500)is found in between via cross validation.
4.2.2Shape Indexed Feature
We compare the global and local methods of shape indexed features.The mean error of local index method is0.033, which is much smaller than the mean error of global index method0.059.The superior accuracy supports the proposed local index method.
Int J Comput Vis
Table5Comparison between correlation based feature selection (CBFS)method and best-of-n feature selection methods
Best-of-n n=1n=32n=1024CBFS
Error(×10?2) 5.01 4.924.83 3.32 Time(s)0.1 3.0100.30.12 The training time is for one primitive regressor
Bold value represents the best results under certain
settings
Fig.10Average ranges of selected features in different stages.In stage 1,5and10,an exemplar feature(a pixel pair)is displayed on an image 4.2.3Feature Selection
The proposed correlation based feature selection method (CBFS)is compared with the commonly used best-of-n method(Ozuysal et al.2010;Dollar et al.2010)in Table5.CBFS can select good features rapidly and this is crucial to learn good models from large training data.
4.2.4Feature Range
The range of a feature is the distance between the pair of pixels normalized by the distance between the two pupils. Figure10shows the average ranges of selected features in the10stages.As observed,the selected features are adaptive to the different regression tasks.At?rst,long range features (e.g.,one pixel on the mouth and the other on the nose)are often selected for rough shape https://www.360docs.net/doc/2711709638.html,ter,short range features(e.g.,pixels around the eye center)are often selected for?ne tuning.
4.2.5Model Compression
We conduct experiments on both LFW87and Helen datasets to compare the sparse coding(SC)based compression method with PCA based compression method.
For sparse coding based method,the number of non-zero codes is5and the number of basis is512.For PCA based method,The principle components are computed by preserv-ing95%energy.Table6Model compression experiment
Dataset Raw PCA SC
Mean error(×10?2)LFW87 4.23 4.35 4.34 Model size(mb)LFW87118308 Comp.ratio LFW87–415 Mean error(×10?2)Helen194 5.70 5.83 5.79 Model size(mb)Helen1942404212 Comp.ratio Helen194–620 The suf?x of the name of the dataset means the number of annotated landmarks
As shown in Table6,the sparse coding based method outperforms the PCA based method both in the sense of compression ratio and accruacy.For example,on Helen dataset,the sparse coding based method archives20times compression.In contrast,the PCA based method achieves only6times compression at the cost of even lager mean error.
5Discussion and Conclusion
We have presented the explicit shape regression method for face alignment.By jointly regressing the entire shape and minimizing the alignment error,the shape constraint is auto-matically encoded.The resulting method is highly accurate, ef?cient,and can be used in real time applications such as face tracking.The explicit shape regression framework can also be applied to other problems like articulated object pose estimation and anatomic structure segmentation in medical images.
References
Belhumeur,P.,Jacobs,D.,Kriegman,D.,&Kumar,N.(2011).Local-izing parts of faces using a concensus of exemplars.In IEEE Con-ference on Computer Vision and Pattern Recognition(CVPR). Bingham,E.,&Mannila,H.(2001).Random projection in dimensional-ity reduction:Applications to image and text data.In ACM SIGKDD Conference on Knowledge Discovery and Data Mining(KDD). Cootes,T.,Edwards,G.,&Taylor,C.(2001).Active appearance models.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(6),681–685.
Cootes,T.,Taylor,C.,Cooper,D.,Graham,J.,et al.(1995).Active shape models-their training and https://www.360docs.net/doc/2711709638.html,puter Vision and Image Understanding,61(1),38–59.
Cristinacce,D.,&Cootes,T.(2006).Feature detection and tracking with constrained local models.In British Machine Vision Conference (BMVC).
Cristinacce,D.,&Cootes,T.(2007).Boosted regression active shape models.In British Machine Vision Conference(BMVC).
Dollar,P.,Welinder,P.,&Perona,P.(2010).Cascaded pose regression.
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Int J Comput Vis
Duffy,N.,&Helmbold,D.P.(2002).Boosting methods for regression.
Machine Learning,47(2–3),153–200.
Elad,M.,&Aharon,M.(2006).Image denoising via sparse and redun-dant representations over learned dictionaries.IEEE Transactions on Image Processing,15(12),3736–3745.
Friedman,J.H.(2001).Greedy function approximation:A gradient boosting machine.The Annals of Statistics,29(5),1189–1232. Huang,G.,Mattar,M.,Berg,T.,Learned-Miller,E.et al.(2008)Labeled faces in the wild:A database forstudying face recognition in uncon-strained environments.In Workshop on Faces in’Real-Life’Images: Detection,Alignment,and Recognition.
Jesorsky,O.,Kirchberg,K.J.,&Frischholz,R.W.(2001).Robust face detection using the hausdorff distance(pp.90–95).New York: Springer.
Jolliffe,I.(2005).Principal component analysis.Wiley Online Library. Le,V.,Brandt,J.,Lin,Z.,Bourdev,L.,&Huang,T.(2012).Interactive facial feature localization.In European Conference on Computer Vision.
Liang,L.,Xiao,R.,Wen,F.,&Sun,J.(2008).Face alignment via component-based discriminative search.In European Conference on Computer Vision(ECCV).
Matthews,I.,&Baker,S.(2004).Active appearance models revisited.
International Journal of Computer Vision,60(2),135–164. Milborrow,S.,&Nicolls,F.(2008).Locating facial features with an extended active shape model.In European Conference on Computer Vision(ECCV).
Ozuysal,M.,Calonder,M.,Lepetit,V.,&Fua,P.(2010).Fast key-point recognition using random ferns.IEEE Transactions on Pattern Analysis and Machine Intelligence,32(3),448–461.Saragih,J.,&Goecke,R.(2007).A nonlinear discriminative approach to aam?tting.In International Conference on Computer Vision (ICCV).
Sauer,P.,&Cootes,C.T.T.(2011).Accurate regression procedures for active appearance models.In British Machine Vision Conference (BMVC).
Shotton,J.,Fitzgibbon,A.,Cook,M.,Sharp,T.,Finocchio,M.,Moore, R.,et al.(2011).Real-time human pose recognition in parts from single depth images.In IEEE Conference on Computer Vision and Pattern Recognition(CVPR).
Sun,Y.,Wang,X.,&Tang,X.(2013).Deep convolutional network cascade for facial point detection.In:IEEE Conference on Computer Vision and Pattern Recognition(CVPR).
Tropp,J.,&Gilbert,A.(2007).Signal recovery from random mea-surements via orthogonal matching pursuit.IEEE Transactions on Information Theory,53(12),4655–4666.
Valstar,M.,Martinez,B.,Binefa,X.,&Pantic,M.(2010).Facial point detection using boosted regression and graph models.In IEEE Con-ference on Computeer Vision and Pattern Recognition(CVPR). Vukadinovic,D.,&Pantic,M.(2005).Fully automatic facial feature point detection using gabor feature based boosted classi?ers.Interna-tional Conference on Systems,Man and Cybernetics,2,1692–1698. Xiong,X.,De la Torre,F.(2013)Supervised descent method and its applications to face alignment.In IEEE Conference on Computer Vision and Pattern Recognition(CVPR).
Zhou,S.K.,&Comaniciu,D.(2007).Shape regression machine.In Information Processing in Medical Imaging,(pp.13–25).Heidel-berg:Springer.
C++中explicit关键字的作用
C++中explicit关键字的作用 explicit用来防止由构造函数定义的隐式转换。 要明白它的作用,首先要了解隐式转换:可以用单个实参来调用的构造函数定义了从形参类型到该类类型的一个隐式转换。 例如: class things { public: things(const std::string&name = ""): m_name(name),height(0),weight(10){} int CompareTo(const things & other); std::string m_name; int height; int weight; }; 复制代码 这里things的构造函数可以只用一个实参完成初始化。所以可以进行一个隐式转换,像下面这样: things a; ................//在这里被初始化并使用。 std::string nm = "book_1"; //由于可以隐式转换,所以可以下面这样使用 int result = https://www.360docs.net/doc/2711709638.html,pareTo(nm); 复制代码 这段程序使用一个string类型对象作为实参传给things的CompareTo函数。这个函数本来是需要一个tings对象作为实参。现在编译器使用string nm来构造并初始化一个things对象,新生成的临时的things对象被传递给CompareTo函数,并在离开这段函数后被析构。 这种行为的正确与否取决于业务需要。假如你只是想测试一下a的重量与10的大小之比,这么做也许是方便的。但是假如在CompareTo函数中还涉及到了要除以初始化为0的height 属性,那么这么做可能就是错误的。需要在构造tings之后更改height属性不为0。所以要限制这种隐式类型转换。 那么这时候就可以通过将构造函数声明为explicit,来防止隐式类型转换。
java关键字
Java 关键字速查表 访问控制: private 私有的 protected 受保护的 public 公共的 类、方法和变量修饰符abstract 声明抽象 class 类 extends 扩允,继承 final 终极,不可改变的implements实现 interface 接口 native 本地 new 新,创建 static 静态 strictfp 严格,精准synchronized 线程,同步transient 短暂 volatile 易失 程序控制语句 break 跳出循环 continue 继续 return 返回 do 运行 while 循环 if 如果 else 反之 for 循环 instanceof 实例 switch 开关 case 返回开关里的结果 default 默认 错误处理 catch 处理异常 finally 有没有异常都执行 throw 抛出一个异常对象throws 声明一个异常可能被抛出try 捕获异常 包相关 import 引入 package 包
基本类型 boolean 布尔型 byte 字节型 char 字符型 double 双精度, float 浮点 int 整型 long 长整型 short 短整型 null 空 true 真 false 假 变量引用 super 父类,超类 this 本类 void 无返回值 java关键字 关键字是电脑语言里事先定义的,有特别意义的标识符,有时又叫保留字。Java的关键字对java的编译器有特殊的意义,他们用来表示一种数据类型,或者表示程序的结构等,关键字不能用作变量名、方法名、类名、包名。一个Java语言中的关键字,用在类的声明中来指明一个类是不能被实例化的,但是可以被其它类继承。一个抽象类可以使用抽象方法,抽象方法不需要实现,但是需要在子类中被实现break 一个Java的关键字,用来改变程序执行流程,立刻从当前语句的下一句开始执行从。如果后面跟有一个标签,则从标签对应的地方开始执行case Java语言的关键字,用来定义一组分支选择,如果某个值和switch中给出的值一样,就会从该分支开始执行。catch :Java的一个关键字,用来声明当try语句块中发生运行时错误或非运行时异常时运行的一个块。char :Java语言的一个关键字,用来定义一个字符类型 abstract boolean break byte case catch char class continue default do double else extends final finally float for if implements import instanceof int interface long native new package private protected public return short static super switch synchronized this throw throws transient try void volatile while 详细介绍
几种视频文件的插入方法
几种视频文件的插入方法: 一、avi、asf、asx、mlv、mpg、wmv等视频文件的插入方法: 1、使用PoerPoint“插入”菜单中的“插入影片”命令法方法简单常用,在这里不再赘述; 2、使用PoerPoint“插入”菜单中的“插入对象”命令法; 3、使用插入控件法 使用这种方法必须保证系统中安装有Windows MediaPlayer或者RealPlayer播放器,首先将视频文件作为一个控件插入到幻灯片中,然后通过修改控件属性,达到播放视频的目的。 步骤如下: (1)运行PowerPoint程序,打开需要插入视频文件的幻灯片; (2)打开“视图”菜单,通过“工具栏”子项调出“控件工具箱”面板,从中选择“其他控件” 按钮单击; (3)在打开的控件选项界面中,选择“Windows Media Player”选项,再将鼠标移动到PowerPoint的幻灯片编辑区域中,画出一个合适大小的矩形区域,这个矩形区域会自动转变 为Windows Media Player播放器的界面; (4)用鼠标选中该播放界面,然后单击鼠标右键,从弹出的快捷菜单中选择“属性”命令, 打开该媒体播放界面的“属性”窗口; (5)在“属性”窗口中,在“URL”设置项处正确输入需要插入到幻灯片中视频文件的详细路径(绝对路径和相对路径都可以)和完整文件名,其他选项默认即可; (6)在幻灯片播放时,可以通过媒体播放器中的“播放”、“停止”、“暂停”和“调节音量” 以及“进度条”等按钮对视频进行自如的控制。 二、rm、ra、rmvb等视频文件的插入方法 使用Windows Media Player控件可以实现mpg、asf、avi、wmv等视频文件的播放,但它不支持RM视频文件的播放,那么如何在PowerPoint中实现RM视频文件的播放呢? 如果通过其他的视频转换软件把RM视频文件转换成A VI或MPG格式的文件再插入,速度慢且转换后的文件体积也大,我们同样可以通过利用PowerPoint中的“控件工具箱”来插 入RM格式的视频文件,方法如下: 1、打开PowerPoint幻灯片文件,打开需要插入视频文件的幻灯片;
认识 C++ 中的 explicit 关键字
认识C++ 中的explicit 关键字 (Danny Kalev发表于2004-12-28 11:01:04) 带单一参数的构造函数在缺省情况下隐含一个转换操作符,请看下面的代码: class C { int i; //... public: C(int i);//constructor and implicit conversion operator //as well }; void f() { C c(0); c = 5; //将5 隐式转换为C 对象,然后赋值 } 编译器重新编辑上述例子代码,如下: ////////////////////////////////////////////////////////////////////////////////////////// //"c=5;" 被编译器转换成下面这个样子: ///////////////////////////////////////////////////////////////////////////////////////// C temp(5);// 实例化一个临时对象, c = temp; // 用= 赋值 temp.C::~C(); // temp 的析构函数被激活 在很多情况下,这个转换是有意的,并且是正当的。但有时我们不希望进行这种自动的转换,例如: class String { int size; char *p; //.. public: String (int sz); //这里不希望进行隐式转换操作 }; void f () { String s(10); // 下面是一个程序员的编码;发生一个意想不到的转换:
提高多晶Si薄膜太阳电池转换效率的途径
提高多晶S i薄膜太阳电池转换效率的途径 Prepared on 22 November 2020
本文由【】搜集整理。免费提供海量教学资料、行业资料、范文模板、应用文书、考试学习和社会经济等w o r d文档“微纳电子技术”2008年第4期 专家论坛 187-提高多晶Si薄膜太阳电池转换效率的途径 纳米器件与技术 193-小尺寸超高频双极晶体管工艺及特性模拟 198-单电子晶体管的蒙特卡罗模拟及宏观建模 纳米材料与结构 205-腐蚀法制备绒面ZnO透明导电薄膜 209-Bi2O3/TiO2纳米复合物的微波合成及光催化性质MEMS器件与技术 214-基于MEMS技术的微波滤波器研究进展 219-新型三轴MEMS热对流加速度传感器的研究 显微、测量、微细加工技术与设备 222-纳米光刻对准方法及其原理 231-变温腐蚀法制备纳米光纤探针 235-一维纳米结构的拉伸力学测试 240-Si 基GaN薄膜的制备方法及结构表征 ======================================= 专家论坛 187-提高多晶Si薄膜太阳电池转换效率的途径 彭英才1,2,姚国晓3,马蕾1,王侠1 (1. 河北大学电子信息工程学院,河北保定071002; 2. 中国科学院半导体研究所半导体材料科学重点实验室,北京 100083; 3. 中国天威英利新能源有限公司,河北保定071051)
摘要:多晶Si薄膜对可见光进行有效地吸收、光照稳定性好、制作成本低,被公认为是高效率和低成本的光伏器件材料。以提高多晶Si薄膜太阳电池转换效率为主线,介绍了增大晶粒尺寸以增加载流子迁移率、进行表面和体内钝化以减少复合中心、设计p-I-n结构以增加光收集效率、制作绒面结构以提高对入射光的吸收效果、改进电池结构以谋求最大效率等工艺措施;综述了近5年来多晶Si薄膜电池在材料生长、结构制备和性能参数方面取得的最新进展,并对其发展前景做了预测。 关键词:多晶Si薄膜;大晶粒;氢钝化;p-I-n结构;太阳电池;转换效率纳米器件与技术 193-小尺寸超高频双极晶体管工艺及特性模拟 赵守磊,李惠军,吴胜龙,刘岩 (山东大学孟尧微电子研发中心,济南250100) 摘要:基于通信系统中射频电路设计的特殊要求,对小尺寸(基区宽度低于100 nm)、超高频(特征频率高于15 GHz)双极晶体管工艺制程和器件的物理特性进行了模拟,为工艺线流片进行可行性研究。该器件采用BiCMOS制程结构实现,在对小尺寸、超高频双极性器件物理模型进行详尽分析的基础上,实现了该器件工艺级(Sentaurus Process)及器件物理特性级(Sentaurus Device)的仿真,提出TCAD工艺及器件的一体化设计方案。模拟结果表明,在高频指标参数 17GHz下,所得β值接近于80,满足设计要求。 关键词:小尺寸;双极器件;频率特性;工艺仿真;特性模拟 198-单电子晶体管的蒙特卡罗模拟及宏观建模 孙海定,江建军 (华中科技大学电子科学与技术系,武汉430074) 摘要:以单电子晶体管为研究对象,系统阐述了库仑阻塞、库仑台阶、单电子隧穿等物理现象的产生机理。微观模拟与宏观建模相结合,着重介绍了如何用蒙特卡罗方法和Matlab相结合对上述各种物理现象进行数值模拟,同时对单电子晶体管进行宏观电路等效,用一些常用元器件进行宏观建模。采用强大的模拟集成电路软件Hspice进行分析模拟,大大减少了计算及仿真时间。通过分析比较,两者曲线得到了较好的吻合,直观地反映了单电子晶体管的电学特性,为进一步研究复杂系统提供了理论依据。
阅读教学中“关键词”的作用
阅读教学中“关键词”的作用 【摘要】阅读教学在语文教学中占有较大比重,然而,如何有效地指导学生阅读却是我们每个语文老师都迫切需要解决却又无法彻底解决的一个问题。面对这一矛盾,笔者主张抓住一篇文章中的关键词,如题目、文眼、过渡段、小序等“点”,运用“抓关键词”法来指导学生实现轻松、高效地阅读目标。 【关键词】关键词教学;阅读教学;选取;实效 阅读教学向来是语文教师最为重视却又最不易取得实效的板块,我们往往通过五花八门的技巧来提高学生的阅读能力,殊不知,看似热闹的训练中,学生真正吸收的东西少之又少,如何在语文阅读教学中找到有力的“抓手”,让我们的阅读教学真正切实有效,笔者在教学实践中经过不断地摸索、尝试,认为可以使用“关键词教学”这“一发”来拎起解读文本的“全身”。 1 关键词教学大义 教育部2011年最新颁布的《初中语文新课程标准》提出:欣赏文学作品,能有自己的情感体验,初步领悟作品的内涵,从中获得对自然、社会、人生的有益启示。对作品的思想感情倾向,能联系文化背景作出自己的评价;对作品中感人的情境和形象,能说出自己的体验;品味作品中富于表现力的语言。而在我们的语文课堂上,往往有的只是分段落、理大意、记主旨等传统的步骤。学生的阅读兴趣越来越小,阅读效率越来越低,他们对于文本的了解也只是限于教师传授的“死水”而已,很难在文章中得到有益的启示,形成自己的独特体验。于是,语文教学中就形成了学生怕阅读、不阅读的局面。如何在枯燥机械地阅读模式中另辟一条蹊径,无论是对于学生还是教师而言,都显得尤为重要。那么,何谓关键词教学呢?在这里,笔者先简单列举执教的几篇课例供大家参考。在人教版九年级上册的《孤独之旅》中,抓住“孤独”一词,就可以准确地把握全文的脉络,这时候,整个教学就可以划分成清晰的三大步:感受杜小康的孤独——理解孤独的真正含义——学会战胜孤独,当然,看似简单的三个步骤下其实还需要教师精心地备课。然而这样的关键词一旦找出,在课堂上,学生便不再像无头的苍蝇,乱撞、乱飞。例如人教版八年级上册的《湖心亭看雪》,属于文言文。拿到这样的文章,学生有时候连读的兴趣都没有,更不要说读懂、读透了。其实,只要我们换一种教法,引导学生抓住文中的关键字“痴”,就不难体会作者的写作意图了。此外,在古典文学名著《智取生辰纲》一文中,我带领学生着重去品味一个“智”字,将吴用的“智”和杨志的“智”作一个比较,不仅让学生在轻松的氛围中解读了文本,更培养了他们客观评价历史人物的意识。纵观以上几个课例,我们不难发现,无论是所谓的长文短教,还是短文长教,都绕不开文章中的一些“文眼”,准确地找到这个文眼,并利用现有的知识去挖掘它,拓展它,就成了我们语文教师需要去做的功课。那么,如何有效地选取这个阅读教学的关键词,就成了我们语文教师要去思考和斟酌的内容。 2 语文关键词的选取
监控系统安装流程(视频监控安装教程)
监控安装指导与注意事项 A、线路安装与选材 1、电源线:要选“阻燃”电缆,皮结实,在省成本前提下,尽量用粗点的,以减少电源的衰减。 2、视频线:SYV75-3线传输在300米内,75-5线传输500米内,75-7的线可传输800米;超过500米距离,就要考虑采用“光缆”。另外,要注意“同轴电缆”的质量。 3、控制线:一般选用“带屏蔽”2*1.0的线缆,RVVP2*1.0。 4、穿线管:一般用“PVC管”即可,要“埋地、防爆”的工程,要选“镀锌”钢管。 B、控制设备安装 1、控制台与机柜:安装应平稳牢固,高度适当,便于操作维护。机柜架的背面、侧面,离墙距离,考虑到便于维修。 2、控制显示设备:安装应便于操作、牢靠,监视器应避免“外来光”直射,设备应有“通风散热”措施。 3、设置线槽线孔:机柜内所有线缆,依位置,设备电缆槽和进线孔,捆扎整齐、编号、标志。
4、设备散热通风:控制设备的工作环境,要在空调室内,并要清洁,设备间要留的空间,可加装风扇通风。 5、检测对地电压:监控室内,电源的火线、零线、地线,按照规范连接。检测量各设备“外壳”和“视频电缆”对地电压,电压越高,越易造成“摄像机”的损坏,避免“带电拔插”视频线。 C、摄像机的安装 1、监控安装高度:室内摄像机的安装高度以2.5~5米,为宜,室外以3.5~10米为宜;电梯内安装在其顶部。 2. 防雷绝缘:强电磁干扰下,摄像机安装,应与地绝缘;室外安装,要采取防雷措施。 3、选好BNC:BNC头非常关键,差的BNC头,会让你生不如死,一点都不夸张。 4、红外高度:红外线灯安装高度,不超过4米,上下俯角20度为佳,太高或太过,会使反射率低。 5、红外注意:红外灯避免直射光源、避免照射“全黑物、空旷处、水”等,容易吸收红外光,使红外效果大大减弱。 6、云台安装:要牢固,转动时无晃动,检查“云台的转动范围”,是否正常,解码器安装在云台附近。
super关键字用法
使用super来引用父类的成分,用this来引用当前对象一、super关键字 在JAVA类中使用super来引用父类的成分,用this来引用当前对象,如果一个类从另 外一个类继承,我们new这个子类的实例对象的时候,这个子类对象里面会有一个父类对象。怎么去引用里面的父类对象呢?使用super来引用,this指的是当前对象的引用,super是当前对象里面的父对象的引用。 1.1.super关键字测试 1package cn.galc.test; 2 3/** 4 * 父类 5 * @author gacl 6 * 7*/ 8class FatherClass { 9public int value; 10public void f() { 11 value=100; 12 System.out.println("父类的value属性值="+value); 13 } 14 } 15 16/** 17 * 子类ChildClass从父类FatherClass继承 18 * @author gacl 19 * 20*/ 21class ChildClass extends FatherClass { 22/**
23 * 子类除了继承父类所具有的valu属性外,自己又另外声明了一个value属性, 24 * 也就是说,此时的子类拥有两个value属性。 25*/ 26public int value; 27/** 28 * 在子类ChildClass里面重写了从父类继承下来的f()方法里面的实现,即重写了f()方法的方法体。 29*/ 30public void f() { 31super.f();//使用super作为父类对象的引用对象来调用父类对象里面的f()方法 32 value=200;//这个value是子类自己定义的那个valu,不是从父类继承下来的那个value 33 System.out.println("子类的value属性值="+value); 34 System.out.println(value);//打印出来的是子类自定义的那个value的值,这个值是200 35/** 36 * 打印出来的是父类里面的value值,由于子类在重写从父类继承下来的f()方法时, 37 * 第一句话“super.f();”是让父类对象的引用对象调用父类对象的f()方法, 38 * 即相当于是这个父类对象自己调用f()方法去改变自己的value 属性的值,由0变了100。 39 * 所以这里打印出来的value值是100。 40*/ 41 System.out.println(super.value); 42 } 43 } 44 45/** 46 * 测试类 47 * @author gacl 48 * 49*/ 50public class TestInherit { 51public static void main(String[] args) { 52 ChildClass cc = new ChildClass();
Java super关键字用法源代码
public class HelloWorld { public static void main(String[] args) { Dog d=new Dog(); d.shout(); d.printName(); } } class Animal{ String name="动物"; void shout() { System.out.println("动物发出叫声"); } } class Dog extends Animal{ String name="犬类"; void shout() { super.shout();//使用super关键字访问父类的成员方法} public void printName() { System.out.println("它的名字是name="+https://www.360docs.net/doc/2711709638.html,); //使用super关键字访问父类的成员变量
} public class HelloWorld { public static void main(String[] args) { Dog d=new Dog(); } } class Animal{ String name="动物"; public Animal(String name){ System.out.println("它是一只"+name); } void shout() { System.out.println("动物发出叫声"); } } class Dog extends Animal{ String name="犬类"; public Dog() { super("二哈");
C 中的EXPLICIT关键字
c++中的explicit关键字用来修饰类的构造函数,表明该构造函数是显式的,既然有"显式"那么必然就有"隐式",那么什么是显示而什么又是隐式的呢? 如果c++类的构造函数有一个参数,那么在编译的时候就会有一个缺省的转换操作:将该构造函数对应数据类型的数据转换为该类对象,如下面所示: class MyClass { public: MyClass(int num); } .... MyClass obj=10;//ok,convert int to MyClass 在上面的代码中编译器自动将整型转换为MyClass类对象,实际上等同于下面的操作: MyClass temp(10); MyClass obj=temp; 上面的所有的操作即是所谓的"隐式转换". 如果要避免这种自动转换的功能,我们该怎么做呢?嘿嘿这就是关键字explicit的作用了,将类的构造函数声明为"显示",也就是在声明构造函数的时候前面添加上explicit即可,这样就可以防止这种自动的转换操作,如果我们修改上面的MyClass类的构造函数为显示的,那么下面的代码就不能够编译通过了,如下所示: class MyClass { public: explicit MyClass(int num);
} .... MyClass obj=10;//err,can‘t non-explict convert class isbn_mismatch:public std::logic_error{public:explicit isbn_missmatch(const std::string &s):std:logic_error(s){}isbn_mismatch(const std::string&s,const std::string&lhs,const std::string &rhs):std::logic_error(s),left(lhs),right(rhs){}const std::string left,right;virtual~isbn_mismatch() throw(){}}; Sales_item&operator+(const Sales_item&lhs,const Sales_item rhs){if(!lhs.same_isbn(rhs)) throw isbn_mismatch("isbn missmatch",lhs.book(),rhs.book());Sales_item ret(lhs);ret+rhs;return ret;} Sales_item item1,item2,sum;while(cinitem1item2){try{sun=item1+item2;}catch(const isbn_mismatch&e){cerre.what()"left isbn is:"e.left"right isbn is:"e.rightendl;}} 用于用户自定义类型的构造函数,指定它是默认的构造函数,不可用于转换构造函数。因为构造函数有三种:1拷贝构造函数2转换构造函数3一般的构造函数(我自己的术语^_^) 另:如果一个类或结构存在多个构造函数时,explicit修饰的那个构造函数就是默认的 class isbn_mismatch:public std::logic_error{public:explicit isbn_missmatch(const std::string &s):std:logic_error(s){}isbn_mismatch(const std::string&s,const std::string&lhs,const std::string &rhs):std::logic_error(s),left(lhs),right(rhs){}const std::string left,right;virtual~isbn_mismatch() throw(){}}; Sales_item&operator+(const Sales_item&lhs,const Sales_item rhs){if(!lhs.same_isbn(rhs)) throw isbn_mismatch("isbn missmatch",lhs.book(),rhs.book());Sales_item ret(lhs);ret+rhs;return ret;}
光刻技术新进展
光刻技术新进展 刘泽文李志坚 一、引言 目前,集成电路已经从60年代的每个芯片上仅几十个器件发展到现在的每个芯片上可包含约10亿个器件,其增长过程遵从一个我们称之为摩尔定律的规律,即集成度每3年提高4倍。这一增长速度不仅导致了半导体市场在过去30年中以平均每年约15%的速度增长,而且对现代经济、国防和社会也产生了巨大的影响。集成电路之所以能飞速发展,光刻技术的支持起到了极为关键的作用。因为它直接决定了单个器件的物理尺寸。每个新一代集成电路的出现,总是以光刻所获得的线宽为主要技术标志。光刻技术的不断发展从三个方面为集成电路技术的进步提供了保证:其一是大面积均匀曝光,在同一块硅片上同时作出大量器件和芯片,保证了批量化的生产水平;其二是图形线宽不断缩小,使用权集成度不断提高,生产成本持续下降;其三,由于线宽的缩小,器件的运行速度越来越快,使用权集成电路的性能不断提高。随着集成度的提高,光刻技术所面临的困难也越来越多。 二、当前光刻技术的主要研究领域及进展 1999年初,0.18微米工艺的深紫外线(DUV)光刻机已相继投放市场,用于 1G位DRAM生产。根据当前的技术发展情况,光学光刻用于2003年前后的0.13微米将没有问题。而在2006年用到的0.1微米特征线宽则有可能是光学光刻的一个技术极限,被称为0.1微米难关。如何在光源、材料、物理方法等方面取得突破,攻克这一难关并为0.07,0.05微米工艺开辟道路是光刻技术和相应基础研究领域的共同课题。
在0.1微米之后用于替代光学光刻的所谓下一代光刻技术(NGL)主要有极紫外、X射线、电子束的离子束光刻。由于光学光刻的不断突破,它们一直处于"候选者"的地位,并形成竞争态势。这些技术能否在生产中取得应用,取决于它们的技术成熟程度、设备成本、生产效率等。下面我们就各种光刻技术进展情况作进一步介绍。 1.光学光刻 光学光刻是通过光学系统以投影方法将掩模上的大规模集成电路器件的结 构图形"刻"在涂有光刻胶的硅片上,限制光刻所能获得的最小特征尺寸直接与光刻系统所能获得的分辨率直接相关,而减小光源的波长是提高分辨率的最有效途径。因此,开发新型短波长光源光刻机一直是国际上的研究热点。目前,商品化光刻机的光源波长已经从过去的汞灯光源紫外光波段进入到深紫外波段(DUV),如用于0.25微米技术的KrF准分子激光(波长为248纳米)和用于0.18微米技术的ArF准分子激光(波长为193纳米)。 除此之外,利用光的干涉特性,采用各种波前技术优化工艺参数也是提高光刻分辨率的重要手段。这些技术是运用电磁理论结合光刻实际对曝光成像进行深入的分析所取得的突破。其中有移相掩膜、离轴照明技术、邻近效应校正等。运用这些技术,可在目前的技术水平上获得更高分辨率的光刻图形。如1999年初Canon公司推出的FPA-1000ASI扫描步进机,该机的光源为193纳米ArF,通过采用波前技术,可在300毫米硅片上实现0.13微米光刻线宽。 光刻技术包括光刻机、掩模、光刻胶等一系列技术,涉及光、机、电、物理、化学、材料等多个研究领域。目前科学家正在探索更短波长的F2激光(波长为157纳米)光刻技术。由于大量的光吸收,获得用于光刻系统的新型光学及掩模衬底材料是该波段技术的主要困 难。
super关键字
如果子类中定义的成员变量和父类中成员变量同名时,子类就隐藏了从父类继承的成员变量。当子类中定义了一个方法,并且这个方法的名字、返回类型、参数个数和类型和父类的某个方法完全相同盟时,子类从父类继承的这个方法将被隐藏。如果在子类中想使用被隐藏的成员变量或方法就可以使用关键字 super。 1 使用关键字super调用父类的构造方法 子类不继承父类的构造方法,因此,子类如果想使用父类的构造方法,必须在子类的构造方法中使用,并且必须使用关键字super来表示,而且super必须是子类构造方法中的关一条语句,如例子4.23所示. 例子4.23 class Student { int number; String name; public Student() { } public Student(int number,String name) { this.number=number; https://www.360docs.net/doc/2711709638.html,=name; System.out.println(" I am "+name+" my number is "+ number); } } class Univer_Student extends Student { boolean marry; public Univer_Student(int number,String name,boolean b) { super(number,name); marry=b; System.out.println("婚否=" + marry); }
} public static void Example4_23 { public static void main(String args[]) { Univer_Student zhang=new Univer_Student(9901,"和晓林",false); } } 运行结果: I am 和晓林my number is 9901 婚否=false; 需要注意的是:如果在子类的构造方法中,没有使用关键字super调用父类的某个构造方法,那么默认有 super(); 语句,即调用父类的不带参数的构造方法。 如果类时定义了一个或多个构造方法,那么Java不提供默认的构造方法(不带参数的构造方法),因此,当在父类中定义多个构造方法时,应当包括一个不带参数的构造方法,以防子类省略super时出现错 误。
软光刻技术的研究现状
大连理工大学研究生试卷 系别:机械工程学院 课程名称:微制造与微机械电子系统 学号: 姓名: 考试时间:2015年1 月15日
PDMS软光刻技术的研究现状 摘要:软光刻技术作为一种新型的微图形复制技术,和传统的光刻技术相比,软光刻技术更加灵活,而且 有许多技术方面的优势。软光刻技术已经广泛应用于光学、生物技术、微电子、传感器以及微全分析系统 的加工诸领域,并且取得了一定的进展。本文,从软光刻技术的原理、分类、国内外以及我们实验室的应 用上来说明软光刻技术的研究现状,是一种很有发展的重要光刻技术。 关键词:软光刻技术研究现状应用 Research Status of PDMS Soft Lithography Abstract:Soft lithography technology as a new type of micro-replication technology graphics, and compared to conventional lithographic techniques, soft lithography technology is more flexible and has many technical advantages. Soft lithography technology has been widely used in optical processing areas such as biotechnology, microelectronics, sensors and micro total analysis system, and has made some progress. In this paper, the principle soft lithography techniques, classification, abroad and in our lab up on the status of the application of soft lithography, photolithography technique is a very important development. Keywords:Soft lithography technologyResearch StatusApplication 1. 软光刻技术概况 20世纪90年代末,一种新的微图形复制技术脱颖而出。该技术用弹性模(大多为PDMS 材料制作)替代传统光刻技术中使用的硬模来产生微结构或者微模具,被称作软光刻技术[1]。软光刻技术作为一种新型的微图形复制技术,和传统的光刻技术相比,软光刻技术更加灵活,而且有许多技术方面的优势,主要有:能制造复杂的多层结构或者三维结构,甚至能在不规则曲面上来制作模具,而且不受材料和化学表面的限制;能突破光刻技术100nm 的限制,实现更为精细的微加工等。此外,它所需设备比较简单,进而在制作成本上也比以前的光刻技术更经济使用。在普通的实验室环境下就能应用,因此软光刻是一种便宜、方便、适于实验室使用的技术。 目前,软光刻技术已经广泛应用于光学、生物技术、微电子、传感器以及微全分析系统的加工诸领域,并且取得了一定的进展。 1.1 软光刻技术的分类 软光刻的核心技术是制作弹性模印章(elastomeric stamp)。通过光刻蚀和模塑的方法,可以快速、高效的获得这种印章。PDMS,即聚二甲基硅氧烷,是软光刻中最常用的弹性模印章制作材料,在设计过程中应该注意防止在PDMS弹性模上产生缺陷,此外,由于PDMS 材料的弹性,过大的深宽比也会导致弹性模结构的倒塌。软光刻的关键技术包括:毛细管成模(micromolding in capillaries,MIMIC)、再铸模(replica molding,REM)、微接触印刷(microcontact printing,uCP)、溶剂辅助成模(solventassistedmicromolding,SAMIM)、
光刻机的技术原理和发展趋势
光刻机的技术原理和发展趋势 王平0930******* 摘要: 本文首先简要介绍了光刻技术的基本原理。现代科技瞬息万变,传统的光刻技术已经无法满足集成电路生产的要求。本文又介绍了提高光刻机性能的关键技术和下一代光刻技术的研究进展情况。 关键字:光刻;原理;提高性能;浸没式光刻;下一代光刻 引言: 光刻工艺直接决定了大规模集成电路的特征尺寸,是大规模集成电路制造的关键工艺。作为光刻工艺中最重要设备之一,光刻机一次次革命性的突破,使大模集成电路制造技术飞速向前发展。因此,了解光刻技术的基本原理,了解提高光刻机性能的关键技术以及了解下一代光刻技术的发展情况是十分重要的。本文就以上几点进行了简要的介绍。 光刻技术的基本原理: 光刻工艺通过曝光的方法将掩模上的图形转移到涂覆于硅片表面的光刻胶上,然后通过显影、刻蚀等工艺将图形转移到硅片上。 1、涂胶 要制备光刻图形,首先就得在芯片表面制备一层均匀的光刻胶。截止至2000年5月23日,已经申请的涂胶方面的美国专利就达118项。在涂胶之前,对芯片表面进行清洗和干燥是必不可少的。目前涂胶的主要方法有:甩胶、喷胶和气相沉积,但应用最广泛的还是甩胶。甩胶是利用芯片的高速旋转,将多余的胶甩出去,而在芯片上留下一层均匀的胶层,通常这种方法可以获得优于+2%的均匀性(边缘除外)。胶层的厚度由下式决定: 式中:F T为胶层厚度,ω为角速度,η为平衡时的粘度,ρ为胶的密度,t为时间。由该式可见,胶层厚度和转速、时间、胶的特性都有关系,此外旋转时产生的气流也会有一定的影响。甩胶的主要缺陷有:气泡、彗星(胶层上存在的一些颗粒)、条纹、边缘效应等,其中边缘效应对于小片和不规则片尤为明显。
java笔记(super关键字的使用)
super 关键字的使用 super 关键字出现在子类中,主要功能就是完成子类调用父类中的内容,也就是调用父类中的属性或方法。 super 调用父类中的构造方法: class Person { String name; int age; public Person(String name,int age) { https://www.360docs.net/doc/2711709638.html,=name; this.age=age; } } class Student extends Person { String school; public Student() { super("张三",27); } } public class TestPersonStudentDemo { public static void main(String args[]) { Student s=new Student(); S.shchool=”北京”; System.out.println("我是:"+https://www.360docs.net/doc/2711709638.html,+",今年:"+s.age+"岁,学校:"+s.school) ; } } 输出结果为:我是张三,今年27岁,学校:北京 本程序在子类的构造方法中明确地指明了调用的是父类中有两个参数的构造方法,所以程序在编译时不再去找父类中无参的构造方法。 用super 调用父类中的构造方法,只能放在子类的第一行。 通过super 调用父类的属性和方法: class Person 父类构造方法 子类构造方法 调用父类构造方法
{ String name; int age; public Person() { } public String talk() { return "我是:"+https://www.360docs.net/doc/2711709638.html,+",今年:"+this.age+"岁"; } } class Student extends Person { String school; public Student(String name,int age,String school) { //在这里用super 调用父类中的属性 https://www.360docs.net/doc/2711709638.html,=name; super.age=age; //调用父类中的talk()方法 System.out.print(super.talk()); //调用本类中属性 this.school=school; } } public class TestPersonStudentDemo3 { public static void main(String args[]) { Student s=new Student("张三",27,"北京"); System.out.println(",学校:"+s.school); } } 输出结果为: 我是:张三,今年:27岁,学校:北京 限制子类的访问 有些时候,父类并不希望子类可以访问自己的类中全部的属性或方法,所以需要将一些属性父类构造方法 子类构造方法 父类一般方法
explicit关键字的作用
谈谈explicit关键字 2004-08-19 20:35 16677人阅读评论(7) 收藏举报 今天看到公司的代码内有大量的explicit关键字,但是老版的MSDN内例子并不完善,实在是不明白,最终从网上一篇文章内找到了答案:原来explicit是为了防止隐式使用拷贝构造函数的.以下附上从新版MSDN中找到的例子和网上那篇文章: // Copy From MSDN This keyword is a declaration specifier that can only be applied to in-class constructor declarations. An explicit constructor cannot take part in implicit conversions. It can only be used to explicitly construct an object. The following program will fail to compile because of the explicit keyword. To resolve the error, remove the explicit keywords and adjust the code in g. // spec1_explicit.cpp // compile with: /EHsc #include class C { public: int i; explicit C(const C&) // an explicit copy constructor { printf("/nin the copy constructor"); } explicit C(int i ) // an explicit constructor { printf("/nin the constructor"); } C() { i = 0; } }; class C2 { public: int i;