SAS讲义 第二十九课完全随机设计Kruskal-Wallis秩和检验

第二十九课 完全随机设计Kruskal-Wallis
秩和检验
一、 完全随机设计的Kruskal-Wallis 秩和检验
方差分析过程关注三个或更多总体的均值是否相等的问题,数据是被假设成具有正态分布和相等的方差,此时F 检验才能奏效。但有时采集的数据常常不能完全满足这些条件。象两两样本比较时,我们不妨尝试将数据转换成秩统计量,因为秩统计量的分布与总体分布无关,可以摆脱总体分布的束缚。在比较两个以上的总体时,广泛使用非参数的Kruskal-Wallis 秩和检验,它是对两个以上的秩样本进行比较,本质上它是两样本时的Wilcoxon 秩和检验方法在多于两个样本时的推广。
Kruskal-Wallis 秩和检验,首先要求从总体中抽取的样本必须是对立的,然后将所有样本的值混合在一起看成是单一样本,再把这个单一的混合样本中值从小到大排序,序列值替换成秩值,最小的值给予秩值1,有结值时平分秩值。将数据样本转换成秩样本后,再对这个秩样本进行方差分析,但此时我们构造的统计量KW 不是组间平均平方和除以组内平均平方和,而是组间平方和除以全体样本秩方差。这个KW 统计量是我们判定各组之间是否存在差异的有力依据。
设有k 组样本,i n 是第i 组样本中的观察数,n 是所有样本中的观察总数,?i R 是第i 组样本中的秩和,ij R 是第i 组样本中的第j 个观察值的秩值。需要检验的原假设为各组之间不存在差异,或者说各组的样本来自的总体具有相同的中心或均值或中位数。在原假设为真时,各组样本的秩平均应该与全体样本的秩平均
2
121+=+++n n n 比较接近。所以组间平方和为 组间平方和2121???? ??+-=?=∑n n R n i i k i i
(29.1)
恰好是刻划这种接近程度的一个统计量,除以全体样本秩方差,可以消除量纲的影响。样本方差的自由度为1-n 。所以全体样本的秩方差为
全体样本的秩方差=2112111∑∑==??
? ??+--k i n j ij i n R n =212111∑=??? ??+--n i n i n =???
? ??+--∑=4)1(11212n n i n n i =???
? ??+-++-4)1(6)12)(1(112n n n n n n (29.2)
=12
)1(+n n 因此,Kruskal-Wallis 秩和统计量KW
)1(3)1(1221)1(121221+-+=???
? ??+-+==∑∑=??=n n R n n n n R n n n KW k i i i i i k i i 全体样本的秩方差
组间平方和
(29.3)
如果样本中存在结值,需要调整公式(29.3)中的KW 统计量,校正系数C 为
n n C j j ---=∑33
)
(1ττ (29.4)
其中j τ第j 个结值的个数。调整后的KW c 统计量为
C KW KW c /= (29.5)
如果每组样本中的观察数目至少有5个,那么样本统计量KW c 非常接近自由度为1-k 的卡方分布。因此,我们将用卡方分布来决定KW c 统计量的检验。
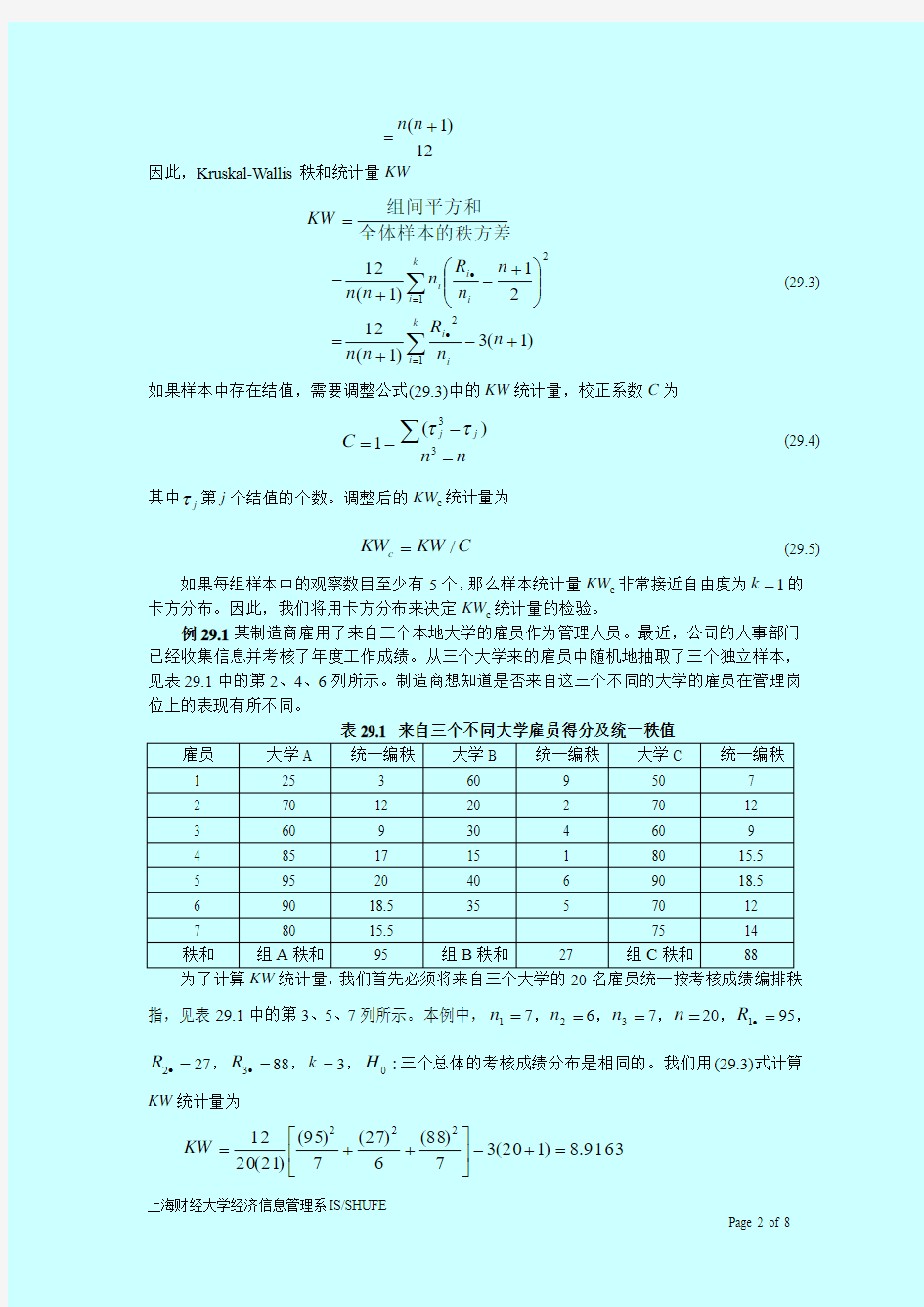
例29.1某制造商雇用了来自三个本地大学的雇员作为管理人员。最近,公司的人事部门已经收集信息并考核了年度工作成绩。从三个大学来的雇员中随机地抽取了三个独立样本,见表29.1中的第2、4、6列所示。制造商想知道是否来自这三个不同的大学的雇员在管理岗位上的表现有所不同。
表29.1 来自三个不同大学雇员得分及统一秩值 雇员
大学A 统一编秩 大学B 统一编秩 大学C 统一编秩 1
25 3 60 9 50 7 2
70 12 20 2 70 12 3
60 9 30 4 60 9 4
85 17 15 1 80 15.5 5
95 20 40 6 90 18.5 6
90 18.5 35 5 70 12 7
80 15.5 75 14 秩和 组A 秩和 95 组B 秩和 27 组C 秩和 88
为了计算KW 统计量,我们首先必须将来自三个大学的20名雇员统一按考核成绩编排秩指,见表29.1中的第3、5、7列所示。本例中,=1n 7,=2n 6,=3n 7,=n 20,=?1R 95,=?2R 27,=?3R 88,=k 3,:0H 三个总体的考核成绩分布是相同的。我们用(29.3)式计算KW 统计量为
9163.8)120(37)88(6)27(7)95()21(2012222=+-??
????++=KW
用(29.4)式计算校正系数C ,从表29.1中我们可以发现,相等成绩值和相等的个数分别为60分3个,70分3个,80分2个,90分2个。所以
9925.020
20)22223333(133333=--+-+-+--=C 调整后的KW c 为
9839.89925.0/9163.8/===C KW KW c
查表可知道,自由度为21=-k 卡方分布,在05.0=α显著水平下,分布的上尾临界值为5.99,由于8.98>5.99,所以拒绝原假设。因此秩和最低的B 组至少与秩和最高的A 组是不同的。
二、 freq 频数过程
Freq 频数过程可以生成单向和n 向的频率表和交叉表。对于双向表(二维表),该过程计算检验统计量和关联度。对于n 向表,该过程进行分层分析,计算每一层和交叉层的统计量。这些频数也能够输出到SAS 数据集里。
1. freq 过程说明
proc freq 过程一般由下列语句控制:
proc freq data=数据集 <选项>;
by 变量列表 ;
tables 交叉表的表达式 ;
weight 变量;
output
该过程proc freq 语句是必须的。其余语句是供选择的。另外该过程只能使用一个output 语句。
2. proc freq 语句的选项
● order=freq/data/internal/formatted ——规定变量水平的排列次序 。freq 表示按频数下降的次序,data 表示按输入数据集中出现的次序,internal 表示按非格式化值的次序(缺省值),formatted 按格式化值的次序。
● formachar (1,2,7)=’三个字符’——规定用来构造列联表的轮廓线和分隔线的字符。缺省值为formachar (1,2,7)=’|-+’,第一个字符用来表示垂直线,第二个字符用来表示水平线,第三个字符用来表示水平与垂直的交叉线。
● page ——要求freq 每页只输出一张表。否则按每页行数允许的空间输出几张表。 ● noprint ——禁止freq 过程产生所有输出。
3. by 语句
一个by 语句能够用来得到由by 变量定义的分组观察分别进行分析。过程要求输入的数据集已按by 变量排序。
4. tables 语句
可以包括多个tables 语句。如果没有tables 语句,对数据集中的每个变量都生成一个单向
频数表。如果tables语句没有选项,则计算tables语句中规定变量每个水平的频数、累计频数、占总频数的百分比及累计百分比。
Tables语句中的交叉表的表达式,请参见第二章第二节proc tabulate过程中的table语句的用法。
Tables语句中的主要选项如下:
●all——要求计算所有选项的检验和度量,包括chisq、measures和cmh。
●chisq——要求对每层是否齐性或独立性进行卡方检验,包括pearson卡方、似然比
卡方和Mantel-Haenszel卡方。并计算依赖于卡方统计量的关联度,包括phi系数、列联系
数和Cramer V。对于2×2联列表还自动计算Fisher的精确检验。
●cmh——要求Cochran-Mantel-Haenszel卡方统计量,用于2维以上表时,检验行
变量和列变量是否有线性相关。
exact——要求对大于2×2表计算Fisher的精确检验。Fisher的精确检验是假设行与列的边缘频数固定,并且零假设为真时,各种可能的表的超几何概率之和。
●measures——要求计算若干个有关相关的统计量几它们的渐近标准误差。
alpha=p——设定100(1-p)%置信区间。缺省值为alpha=0.05。
●scores=rank/table/ridit/modridit——定义行/列得分的类型以便用于cmh统计量和pearson相关中。在非参数检验中,一般常用scores=rank,用于指定非参数分析的秩得分。
cellchi2——要求输出每个单元对总卡方统计量的贡献。
cumcol——要求在单元中输出累计列百分数。
●expected——在独立性(或齐性)假设下,要求输出单元频数的期望值。
●deviation——要求输出单元频数和期望值的偏差。
missprint——要求所有频数表输出缺失值的频数。
●missing——要求把缺失值当作非缺失值看待,在计算百分数及其他统计量时包括它们。
out=输出数据集——建立一个包括变量值和频数的输出数据集。
●sparse——要求输出在制表要求中变量水平的所有可能组合的信息。
●list——以表格形式打印二维表。
●nocum/norow/nocol/nofreq/noprint——分别不输出累计频率数、行百分率、列百分率、单元频数、频数表。
●
5. weight语句
通常每个观察对频数计数的贡献都是1。然而当使用weight语句时,每个观察对频数计数的贡献为这个观察对应的权数变量的值。
6. output语句
该语句用于创建一个包含由proc freq过程计算的统计量的SAS数据集。由output语句创建的数据集可以包括在tables语句中要求的任意统计量。当有多个tables语句时,output语句创建的数据集的内容相应于最后要求的那个表。
三、实例分析
例29.1的SAS程序如下:
data study.colleges ;
do group=1 to 3;
input n;
do i=1 to n;
input x @@;
output;
end;
end;
cards;
7
25 70 60 85 95 90 80
6
60 20 30 15 40 35
7
50 70 60 80 90 70 75
;
proc npar1way data=study.colleges wilcoxon;
class group;
var x;
run;
程序说明:建立输入数据集colleges ,数据的输入和完全随机化方差分析的数据输入完全相同,先输入本组数据的总数,然后输入组中每个数据。分组变量为group,共有三组取值为1、2和3。输入变量为x,存放每组中的数据。过程步调用npar1way 过程,后面用选择项wilcoxon,当样本数大于2个时,自动进行多样本的Kruskal-Wallis秩和检验。class语句后给出分组变量名group,var语句后给出要分析的变量x。主要结果见表29.2所示。
表29.2 用npar1way过程进行多样本比较的Kruskal-Wallis秩和检验输出结果
N P A R 1 W A Y P R O C E D U R E
Wilcoxon Scores (Rank Sums) for Variable X
Classified by Variable GROUP
Sum of Expected Std Dev Mean
GROUP N Scores Under H0 Under H0 Score
1 7 95.0 73.5000000 12.5718985 13.5714286
2 6 27.0 63.0000000 12.0786894 4.5000000
3 7 88.0 73.5000000 12.5718985 12.5714286
Average Scores Were Used for Ties
Kruskal-Wallis Test (Chi-Square Approximation)
CHISQ = 8.9839 DF = 2 Prob > CHISQ = 0.0112 结果说明:组1、组2和组3的秩和(Sum of Scores)分别为95.0、27.0和88.0。原假设(组1、组2和组3的总体分布相同)为真时,期望秩值(Expected)分别为(95+27+88)×7/(7+6+7)=73.50、(95+27+88)×6/(7+6+7)=63.00和(95+27+88)×7/(7+6+7)=73.50,各组的标准差(Std Dev)分别为12.5718985、12.0786894、12.5718985。每组平均得分(Mean Score)分别为95/7=13.5714286、27/ 6=4.50和88/7=12.5714286。按公式(29.5)调整后多样本的Kruskal-Wallis秩和检验统计量为8.9839 ,用自由度为DF=3-1=2的卡方分布近似,得到大于近似卡方检验统计量8.9839的概率为p=0.0112<0.05,拒绝原假设。结论为各组的总体分布的差异是有统计学意义的。根据平均秩和的结果,组1的最高,组2的最低,因此至少
组1和组2的差异是显著的。
例29.1的SAS程序我们还可以采用freq过程,在tables语句中选项用scores=rank和cmh,查看第二项统计量既为Kruskal-Wallis检验,程序如下:
程序CHAP4_04_2.SAS
proc freq data=study.colleges formachar= '|----|+--';
tables group*x /scores=rank cmh ;
run;
程序说明:freq过程选项formachar= '|----|+--',用来构造表格的轮廓线和分隔线的字符,由于不同操作系统中,符号编码可能有所不同,所以缺省值可能不符合你的要求,需要你重新定义一下。Tables group*x语句,把组变量group中3个不同大学,与成绩变量x中14个分组成绩(最小值为15,最大值为95,间隔为5,共14组),构成了一个单层3行14列二维交叉频率表,选项scores=rank指定为非参数秩得分的情况,选项cmh计算Cochran-Mantel-Haenszel卡方统计量。主要结果见表29.3所示。
表29.3 用freq过程对每层秩得分进行Kruskal-Wallis秩和检验的输出结果
TABLE OF GROUP BY X
GROUP X
Frequency|
Percent |
Row Pct |
Col Pct | 15| 20| 25| 30| 35| 40| 50| Total
---------+--------+--------+--------+--------+--------+--------+--------+
1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 7
| 0.00 | 0.00 | 5.00 | 0.00 | 0.00 | 0.00 | 0.00 | 35.00
| 0.00 | 0.00 | 14.29 | 0.00 | 0.00 | 0.00 | 0.00 |
| 0.00 | 0.00 | 100.00 | 0.00 | 0.00 | 0.00 | 0.00 |
---------+--------+--------+--------+--------+--------+--------+--------+
2 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 6
| 5.00 | 5.00 | 0.00 | 5.00 | 5.00 | 5.00 | 0.00 | 30.00
| 16.67 | 16.67 | 0.00 | 16.67 | 16.67 | 16.67 | 0.00 |
| 100.00 | 100.00 | 0.00 | 100.00 | 100.00 | 100.00 | 0.00 |
---------+--------+--------+--------+--------+--------+--------+--------+
3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 7
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 5.00 | 35.00
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 14.29 |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100.00 |
---------+--------+--------+--------+--------+--------+--------+--------+
Total 1 1 1 1 1 1 1 20
5.00 5.00 5.00 5.00 5.00 5.00 5.00 100.00
(Continued)
| 60| 70| 75| 80| 85| 90| 95| Total
---------+--------+--------+--------+--------+--------+--------+--------+
1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 7
| 5.00 | 5.00 | 0.00 | 5.00 | 5.00 | 5.00 | 5.00 | 35.00
| 14.29 | 14.29 | 0.00 | 14.29 | 14.29 | 14.29 | 14.29 |
| 33.33 | 33.33 | 0.00 | 50.00 | 100.00 | 50.00 | 100.00 |
---------+--------+--------+--------+--------+--------+--------+--------+
2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 6
| 5.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 30.00
| 16.67 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 33.33 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
---------+--------+--------+--------+--------+--------+--------+--------+
3 | 1 | 2 | 1 | 1 | 0 | 1 | 0 | 7
| 5.00 | 10.00 | 5.00 | 5.00 | 0.00 | 5.00 | 0.00 | 35.00
| 14.29 | 28.57 | 14.29 | 14.29 | 0.00 | 14.29 | 0.00 |
| 33.33 | 66.67 | 100.00 | 50.00 | 0.00 | 50.00 | 0.00 |
---------+--------+--------+--------+--------+--------+--------+--------+
Total 3 3 1 2 1 2 1 20
15.00 15.00 5.00 10.00 5.00 10.00 5.00 100.00
SUMMARY STATISTICS FOR GROUP BY X
Cochran-Mantel-Haenszel Statistics (Based on Rank Scores)
Statistic Alternative Hypothesis DF Value Prob
数(Frequency),即两个变量group和x的组合值出现的频数,第二个值为单元百分数(Percent),即出现的频数在总频数中的百分比,第三个值为行百分数(Row Pct),即出现的频数在所在行总频数中的百分比,第四个值为列百分数(Col Pct),即出现的频数在所在列总频数中的百分比。
cmh统计量假定各层是独立的,并且每层的周边总和是固定的。原假设为任一层中的行变量与列变量不相关。本例中只有一层。当原假设为真时,cmh统计量渐近卡方分布。第一项cmh统计量为相关统计量,由Mantel和Haenszel提出,首先要求行变量或列变量是有序的。原假设为每一层的行变量与列变量不线性相关,自由度始终为1,卡方值为0.101,p=0.751>0.05,因此不能拒绝group和x不线性相关。第二项cmh统计量为ANOVA统计量,首先要求列变量x是有序的。原假设为每一层的3个行的x平均得分是相等的,本例只有一层,且得分指定scores=rank选项,即用秩得分方法,因此就是Kruskal-Wallis秩和检验统计量,自由度为行数减1,即3-1=2,渐近自由度为2的卡方分布,KW= 8.984,p=0.011<0.05,拒绝3个行的x平均得分是相等的。第三项cmh统计量为一般相关统计量,不要求行变量或列变量是有序的。原假设为每一层的行变量与列变量不相关,自由度为(3-1)×(14-1)=26,修正的pearson卡方统计量为23.222,p=0.620>0.05,不能拒绝不相关。
SAS讲义1-3
第三章:对SAS 数据文件的合并与存取 本章主要内容,是介绍SAS 软件对整个数据文件的存取及合并的方法,而上一章则主要是介绍对一个数据文件内变量的读取及处理方法。 我们先讲一讲如何用SAS 指令合并两个或多个数据文件。 一、 S AS 软件对两个及以上数据文件的合并 在数据分析时,将两个不同的数据文件并为一个,以进行进一步的综合研究,有时是很必要的。 SAS 软件有两种合并两个数据文件的方法。 1、 垂直合并: 垂直合并的方法,适用于已经用DA TA 类指令建立起的两个或多个SAS 数据文件,这些数据文件必须具有完全相同的变量(名称及内容),换句话说,两个数据矩阵应具有相同的列数。 这种合并是在一个新的DA TA 阶段里,通过“垂直合并表格指令”SET 来实现的。合并后,一个表格接在另一个表格之下......... 。 下面是一个这类合并的图例: 我们有两张分别叫作“Table 1”和“Table 2”的SAS 表格,如下图: Table 1 Table 2 obs v1 v2 obs v1 v2 可为地址,人名 观测单位 用DA TA 类指令建立合并这两张表的程式可如下编写:
在程式运行后,我们可以得到一个新的叫作Table3的SAS表格,这张新表包含有名叫Table1与Table 2的两张SAS数据表,是这两张表的垂直合并。其形式如下图(Table2被接在表Table1之下): Table3 如果被合并的表格(如上例Table1、Table2)并没有完全一样的结构,或者说没有一样的变量,合并指令仍会执行,所有有问题的数据在新的合并表中,将会以残缺数据符号“·”代替。 2、水平合并: 与“垂直合并”一样,水平合并也是将已经建立好的两个或多个SAS数据文件,合并成一个新的数据文件,供数据分析之用。被合并的数据文件,必须具有完全相同的观测单位。 或者说,两个数据矩阵的“行数”要完全相同,在合并前 ...,两个矩阵各自的第一列的元素也应当完全相同。
SAS讲义 第十六课用在PROC步中的通用语句
第十六课用在PROC步中的通用语句 当我们用DATA步创建好SAS数据集后,可以用SAS的一些PROC过程步来进一步的分析和处理它们。在DATA步中用户可以使用SAS的语句来编写自己的程序,以便能通过读入、处理和描述数据,创建符合自己特殊要求的SAS数据集。而后由一组组PROC步组成的程序进行后续分析和处理。 一.PROC程序的主要作用 ●读出已创建好的SAS数据集 ●用数据集中的数据计算统计量 ●将统计的结果按一定形式输出 在SAS系统中,计算统计量时,对于许多常用的和标准的统计计算方法,并不需要用户自己编写这些复杂的程序,而是通过过程的名字来调用一个已经为用户编写好的程序。用户通常只要编写调用统计过程前的准备处理程序和输出统计结果后的分析和管理程序。只有用户自己非常特殊的统计计算方法才需要用户自己编写相应的计算程序。 二.PROC过程语句 PROC语句用在PROC步的开始,并通过过程名来规定我们所要使用的SAS过程,对于更进一步的分析,用户还可以在PROC语句中使用一些任选项,或者附加其它语句及它们的任选项(如BY语句)来对PROC步规定用户所需要分析的更多细节。PROC语句的格式为: PROC 过程名<选项>; 过程名规定用户想使用的SAS过程的名字。例如,我们在前面常使用的打印过程名PRINT,对数值变量计算简单描述统计量的过程名MEANS。 选项规定这个过程的一个或几个选项。不同的过程规定的选项是不同的,因此,只有知道具体的过程才能确定具体的选项是什么。但是,在各个不同过程中使用选项时,下面三种选项的使用格式是共同的: ●Keyword ●Keyword=数值 ●Keyword=数据集 Keyword是关键字,第一种选项格式是某个具体过程进一步要求某个关键字;第二种选项格式是某个具体过程要求某个关键字的值,值可能是数值或字符串;第三种选项格式是某个具体过程要求输入或输出数据集。例如: PROC Print Data=class ; 过程Print,作用为打印输出数据集中的数据。选项为Data=class,关键字是Data,进一步说明要打印输出的数据集名为class。如果省略这个选项,将用最近产生的SAS数据集。
SAS讲义_第二十七课符号检验和Wilcoxon符号秩检验
第二十七课 符号检验和Wilcoxon 符号秩 检验 在统计推断和假设检验中,传统的检验统计量都叫做参数检验,因为它们都依赖于确定的概率分布,这个分布带有一组自由的参数。参数检验被认为是依赖于分布假定的。通常情况下,我们对数据进行分析时,总是假定误差项服从正态分布,这是人们易于接受的事实,因为正态分布的原始出发点就是来自于误差分布,至于当样本相当大时,数据的正态近似,这是由于大样本理论所保证的。但有些资料不一定满足上述要求,或不能测量具体数值,其观察结果往往只有程度上的区别,如颜色的深浅、反应的强弱等,此时就不适用参数检验的方法,而只能用非参数统计方法(non-parametric statistical analysis )来处理。这种方法对数据来自的总体不作任何假设或仅作极少的假设,因此在实用中颇有价值,适用面很广。 一、 单样本的符号检验 符号检验(sign test )是一种最简单的非参数检验方法。它是根据正、负号的个数来假设检验。首先需要将原始观察值按设定的规则,转换成正、负号,然后计数正、负号的个数作出检验。该检验可用于样本中位数和总体中位数的比较,数据的升降趋势的检验,特别适用于总体分布不服从正态分布或分布不明的配对资料,有时当配对比较的结果只能定性的表示,如试验前后比较结果为颜色从深变浅、程度从强变弱,成绩从一般变优秀,即不能获得具体数字,也可用符号检验,例如用正号表示颜色从深变浅,用负号表示颜色从浅变深。 用于配对资料时,符号检验的计算步骤为:首先定义成对数据指定正号或负号的规则,然后计数正号的个数+ S 及负号的个数- S ,由于在具体比较配对资料时,可能存在配对资料的前后没有变化,或等于假设中的中位数,此时仅需要将这些观察值从资料中剔除,当然样本大小n 也随之减少,故修正样本大小- + +=S S n 。当样本n 较小时,应使用二项分布确切概率计算法,当样本n 较大时,常利用二项分布的正态近似。 1. 小样本时的二项分布概率计算 当20≤n 时,+S 或- S 的检验p 值由精确计算尺度二项分布的卷积获得。在比较配对资 料试验前后有否变化,或增加或减小的假设检验时,如果我们定义试验后比试验前增加为正号,反之为负号,那么对于原假设:试验前后无变化来说,正号的个数+ S 和负号的个数- S 可 能性应当相等,即正号出现的概率p =0.5,于是+S 与- S 均服从二项分布)5.0,(n B ,对于太 大的+S 相应太小的-S ,或者太大的-S 相应太小的+ S ,都将拒绝接受原假设;对于原假设:试验后比试验前有增加来说,正号的个数+ S 大于负号的个数- S 的可能性应该大,即正号出现的概率5.0>p ,对于太小的+ S 相应太大的- S ,将拒绝接受原假设;对于原假设:试验后比试验前减小来说,正号的个数+ S 小于等于负号的个数- S 的可能性应该大,即正号出现
SAS基础讲义
目标 ?了解SAS系统的功能特点; ?熟悉AS系统操作环境; ?掌握SAS系统的有关概念; ?学会使用DATA Step读入外部数据文件以及对现有的数据集进行读入、修改、拼接以及合并; ?学会使用PROC Step的几个重要过程对数据集进行操作; ?学会使用ODS(输出传递系统)控制输出; ?了解SAS宏语言;
第一章SAS系统简介 ?SAS提供的基本运行环境:显示管理系统。 介绍显示管理系统中的有关窗口、菜单及操作。 ?运行一个简单的SAS程序: proc print data=sasuser.admit; varname sex age where age gt30; run;
第一章SAS系统简介?SAS系统对数据的管理: *SAS数据集(data set): *SAS数据视图(data view): *SAS数据库(library)和库标记:
第一章SAS系统简介 *标记一个SAS数据库的两种方法: 1、通过菜单进行; 2、libname 库标记引擎数据源选项; 练习:用两种方法分别建立: 1、一个默认的SAS数据库; 2、一个包含ORACLE数据的SAS数据库; 3、一个包含ODBC数据的SAS数据库。
第一章SAS系统简介 *SAS文件快捷方式(File Shortcut): *SAS文件的两级名: 库标记.文件名 *SAS的永久库和临时库: 永久库:SASUSER、SASHELP、自定义的库; 临时库:WORK
第一章SAS系统简介 练习:1、建立一个文件快捷方式。 2、使用SAS Notepad窗口来创建和保存SAS 程序
SAS讲义 第十八课SAS宏功能简介
第十八课SAS宏功能简介* SAS系统提供了强大的宏功能(macro facility),通过创建宏变量和宏能方便地完成: ●重复分析任务,大大精减了程序量 ●从系统获取一些如SAS启动时间、日期、版本号等信息 ●有条件地执行数据步和过程步 ●保持程序的对立性和移植性,产生与数据无关的程序 ●用宏变量在不同数据步和过程步之间传递数据 一.SAS宏变量 宏变量(也称符号变量)属于SAS宏语言的范畴,和数据步中的变量概念是不一样的。除了数据行外,可以在SAS程序的任何地方定义和使用宏变量。数据步变量是和数据集相联系的,而宏变量是独立于数据集的。数据集变量的值取决于正在处理的观测,而一个宏变量的值总是保持不变,直到被明确改变。 1宏变量的定义 定义一个宏变量的最简单方法是使用宏语句%LET,它的一般形式如下: %LET宏变量名=值; 宏变量的命名遵从一般的SAS命名规则。宏变量的值不需要加引号,如果值加入引号,则引号被作为宏变量值的一部分。宏变量的值可以是固定的字符串、其它宏变量的引用、宏函数和宏调用。 2宏变量的引用 为了引用一个宏变量的值,在宏变量前加上一个符号&,格式如下: &宏变量名 宏变量被引用的效果就是用宏变量的内容直接替代宏变量名。 3宏变量的使用举例 例如,我们想要打印、图示和分析几个数据集,但又希望避免重复键入每一个数据集名字以修改相同的程序代码。解决方法是用%LET语句创建一个宏变量DSNAME,该宏变量赋值了一个数据集名SURVEY。然后这个宏变量在PROC PRINT等许多过程和TITLE语句中被引用。程序如下:
%Let dsname=survey ; Proc print data=&dsname ; Var name sex bdate income ; Title “Display of Data Set &dsname” ; Run ; 要注意标题语句Title平时既可以用单引号又可以用双引号围住标题,但如果有宏变量引用,则必须用双引号,否则用单引号将当作字符串处理。上面的程序中,我们只要修改宏变量dsname的赋值,就能对多个数据集执行相同的打印输出等操作。 可用几个%LET语句来创建多个宏变量进一步增强过程的通用性。例如,我们可用WHERE语句来规定用作打印和分析的一个范围。如用%LET语句把宏变量START和END 分别定义为开始和结束的日期。程序如下: %Let dsname=survey ; %Let start=?01jan79?d ; %Let end= …31dec80?d ; Proc print data=&dsname ; Var name sex bdate income ; Where &start 第三十四课 非线性回归分析 现实世界中严格的线性模型并不多见,它们或多或少都带有某种程度的近似;在不少情况下,非线性模型可能更加符合实际。由于人们在传统上常把“非线性”视为畏途,非线性回归的应用在国内还不够普及。事实上,在计算机与统计软件十分发达的令天,非线性回归的基本统计分析已经与线性回归一样切实可行。在常见的软件包中(诸如SAS 、SPSS 等等),人们已经可以像线性回归一样,方便的对非线性回归进行统计分析。因此,在国内回归分析方法的应用中,已经到了“更上一层楼”,线性回归与非线性回归同时并重的时候。 对变量间非线性相关问题的曲线拟合,处理的方法主要有: ● 首先决定非线性模型的函数类型,对于其中可线性化问题则通过变量变换将其线 性化,从而归结为前面的多元线性回归问题来解决。 ● 若实际问题的曲线类型不易确定时,由于任意曲线皆可由多项式来逼近,故常可 用多项式回归来拟合曲线。 ● 若变量间非线性关系式已知(多数未知),且难以用变量变换法将其线性化,则进 行数值迭代的非线性回归分析。 一、 可变换成线性的非线性回归 在实际问题中一些非线性回归模型可通过变量变换的方法化为线性回归问题。例如,对非线性回归模型 ()t i t i t i t ix b ix a y εα+++=∑=2 1 0sin cos (34.1) 即可作变换 t t t t t t t t x x x x x x x x 2sin ,2cos ,sin ,cos 4321==== 将其化为多元线性回归模型。一般地,若非线性模型的表达式为 ()()()t m m t t t x g b x g b x g b b y ++++= 22110 (34.2) 则可作变量变换 ()()() t m m t t t t t x g x x g x x g x ===* 2*21*1,,, (34.3) 将其化为线性回归模型的表达式,从而用前面线性模型的方法来解决,其中(34.3)中的x t 也 可为自变量构成的向量。 这种变量变换法也适用于因变量和待定参数 b i 。如 ()[]1exp 2132211-++=t t t t t x x b x b x b a y (34.4) 时上式两边取对数得 ()1ln ln 2132211-+++=t t t t t x x b x b x b a y (34.5) 现作变换 1,ln ,ln 2130*-===t t t t t x x x a b y y (34.6) 则可得线性表达式 第三十课 Spearman 等级相关分析 一、 秩相关的Spearman 等级相关分析 前面介绍了使用非参数方法比较总体的位置或刻度参数,我们同样也可以用非参数方法比较两总体之间相关问题。秩相关(rank correlation )又称等级相关,它是一种分析i x 和i y 等级间是否相关的方法。适用于某些不能准确地测量指标值而只能以严重程度、名次先后、反映大小等定出的等级资料,也适用于某些不呈正态分布或难于判断分布的资料。 设i R 和i Q 分别为i x 和i y 各自在变量X 和变量Y 中的秩,如果变量X 与变量Y 之间存在着正相关,那么X 与Y 应当是同时增加或减少,这种现象当然会反映在(i x ,i y )相应的秩(i R ,i Q )上。反之,若(i R ,i Q )具有同步性,那么(i x ,i y )的变化也具有同步性。因此 ∑∑==-==n i n i i i i Q R d d 1 1 22 )( (30.1) 具有较小的数值。如果变量X 与变量Y 之间存在着负相关,那么X 与Y 中一个增加时,另一个在减小,d 具有较大的数值。既然由(i x ,i y )构成的样本相关系数反映了X 与Y 之间相关与否的信息,那么在参数相关系数的公式),(Y X r 中以i R 和i Q 分别代替i x 和i y ,不是同样地反映了这种信息吗?基于这种想法,Charles Spearman 秩相关系数),(Q R r s 应运而生: ∑∑∑∑∑∑∑---- = 2 2)1 ()1()1 )(1(),(i i i i i i i i s Q n Q R n R Q n Q R n R Q R r (30.2) ),(Q R r s 与),(Y X r 形式上完全一致,但在),(Q R r s 中的秩,不管X 与Y 取值如何,总是只 取1到n 之间的数值,因此它不涉及X 与Y 总体其他的内在性质,例如秩相关不需要总体具有有限两阶矩的要求。由于 2 ) 1(211 1 += +++==∑∑==n n n Q R n i i n i i 6 ) 12)(1(212221 21 2++= +++==∑∑==n n n n Q R n i i n i i 因此公式(30.2)可以化简为 SAS讲义-第九课 一、Do循环 1、大家回看第四课的例11,可以发现Do循环应该要和End搭配使用。下面都是可行的Do语句。 do i=5; do i=2,3,5,7; do i=1 to 100; do i=1 to 100 by 2; do i=100 to 1 by -1; do i=1 to 5,7 to 9; do i=’01jan99’d,’25feb99’d; do i=’01jan99’d to ‘01jan2000’d by 1; 例1 产生1,2,9,8 的序列。 data a; do i=1,2,9,8; output; end; run; 思考:若output放在end之后,或者去掉output,那会怎样呢? 例2 产生1-20的奇数序列。 data a; do i=1 to 20 by 2; output; end; run; 例3 求1-100的自然数之和。 data a; do i=1 to 100 ; n+i; output; end; run; 例4 求1-100的自然数的平方和。 data a; do i=1 to 100 ; n+i**2; output; end; run; 例5用do循环处理数组。(下课还会深入说数组) data a(drop=i); array day{7} d1-d7; do i=1 to 7; day{i}=i+1; end; run; 2、do while语句。先判断while表达式,若成立则执行,否则推测循环。例6 data a; n=0; do while (n<5); n+1; output; end; run; 例7 计算1加到100的过程中,第一个大于等于2000的数。 data a; do i=1 to 100 while (n<2000) ; n+i; output; end; run; 3、do until 语句。先执行,直到until的表达式为真,推出循环。 4、do over 语句。我们到下课再说。 二、select语句。 Select-when 相当于一般编程语言里面的swich-case语句。直接看例子。例8 data a; set resdat.class; x=0; obs=_n_; select(obs); when(2) x=2; when(3,7)x=5; otherwise x=3; end; run; 三、return语句。 Return语句可以让系统返回到data步开头。 例9return语句与if-then共用 data a; input x y z; if x=y then return; s=x+y; cards; 1 2 3 2 2 3 ; S A S讲义第二课显示 管理系统 第二课显示管理系统 一.显示管理系统窗口 1显示管理系统(Display Manager)三个主要窗口: ●PROGRAM EDITOR窗口:提供一个编写 SAS程序的文本 编缉器 ●LOG窗口:显示有关程序运行的信息 ●OUTPUT窗口:显示程序运算结果的输出 2显示管理系统的常用窗口 ●KEYS 查看及改变功能键的设置 ●LIBNAME 查看已经存在的SAS数据库 ●DIR 查看某个SAS数据库的内容 ●VAR 查看SAS数据集的有关信息 ●OPTIONS 查看及改变SAS的系统设置 假设我们准备自定义F12功能键为OPTIONS命令,打开KEYS 窗口后在F12的右边的空白区键入OPTIONS,完毕之后在命令框中键入END命令退出KEYS窗口 二.显示管理系统命令 1显示管理系统命令的发布 有四种命令的发布方式都可达到相同结果。 ●在命令框中直接键入命令 ●按功能键 ●使用下拉式菜单 ●使用工具栏 例如我们要增加一个OUTPUT窗口,相应地四种操作如下: ●命令框中直接键入OUTPUT和Enter ●功能键F7 ●Window/Output ●Options / Edit tools ①Add按钮选择Tool,新增了一个空白按钮 ②Command命令框中输入:OUTPUT;Help Text命令框中输入:Add new button create by DZX;Tip Text命令框中输入:Output。 ③再单击Browse命令挑选一个合适的按钮。 ④单击Move Dn按钮将OUTPUT按钮移动到最后Help按钮之后 ⑤单击Add按钮选择Separator,使Help按钮和新增OUTPUT命令按 钮之间有一个空白的分组间隙。 ⑥单击Save按钮 2文本编辑行命令 文本编辑行命令的主要作用是为在PROGRAM EDITOR窗口方便和高效地输入和修改SAS程序提供一组编辑命令。文本编辑行命令可归两个子类: ●命令行命令——在命令框中输入NUMS命令 ●行命令——在行号上键入执行指定功能的字母来完成编辑功能 例如,我们在PROGRAM EDITOR窗口中的第一行到第三行输入假设的数据和程序:“Data and program line one ”,“Data and program line two”,“Data and program line three”。 若想在第1行与第2行之间插入空行: ●在第1行的行号前键入 i(或I,或i1、I1) ●若想保存和调入程序: ●在命令框中键入:FILE "D:\SAS\ABC02.SAS" ●先光标定位到指定某行,再在命令框中键入:INCLUDE "D:\SAS\ABC02.SAS" 三.SAS系统的几组重要命令 1向SAS系统寻求帮助命令 ●F1键和F2键提供信息相当于简明的SAS使用手册 2显示管理系统命令框常用命令 第三十七课 典型相关分析 典型相关分析(Canonical Correlation Analysis )是研究两组变量间相关关系的一种多元统计分析方法。它能够揭示两组变量之间的内在联系,真正反映两组变量间的线性相关情况。 一、 典型相关分析 我们研究过两个随机变量间的相关,它们可以用相关系数表示。然而,在实际问题中常常会遇到要研究两组随机变量间),,,(21p x x x 和),,,(21q y y y 的相关关系。 ),,,(21p x x x 和),,,(21q y y y 可能是完全不同的, 但是它们的线性函数可能存在密切的关系,这种密切的关系能反映),,,(21p x x x 和),,,(21q y y y 之间的相关关系。因此就要找出),,,(21p x x x 的一个线性组合u 及),,,(21q y y y 的一个线性组合v ,希望找到的u 和v 之间有最大可能的相关系数,以充分反映两组变量间的关系。这样就把研究两组随机变量间相关关系的问题转化为研究两个随机变量间的相关关系。如果一对变量(u ,v )还不能完全刻划两组变量间的相关关系时,可以继续找第二对变量,希望这对变量在与第一对变量(u ,v )不相关的情况下也具有尽可能大的相关系数。直到进行到找不到相关变量对时为止。这便引导出典型相关变量的概念。 1. 典型相关系数与典型相关变量 设有两组随机变量),,,(21p x x x 和),,,(21q y y y ,假定它们都已经标准化了,即p i x D x E i i ,,2,1= ,1=)(,0=)( ,q i y D y E i i ,,2,1= ,1=)(,0=)( ,若记 ?????? ? ??=??????? ??=p p y y y y x x x x 2121, 此时它们的协方差矩阵(也是相关系数矩阵)为, R R R R R y x D yy xy yx xx =??? ? ??=???? ?? 其中()()yx xy yy xx R R y x Cov R y D R x D ====),(,, 实际上,我们要找 y m v x l u 111 1,'='= 使1u 和1v 的相关系数),(11v u ρ达到最大。由于对任意常数a ,b ,c ,d ,有 第七课建立SAS系统的数据集 (FSP/FSEDIT) 与使用SAS/ASSIST软件相比,SAS/ASSIST只要用MOUSE点击就行了,而用SAS/FSP,需要在PROGRAM EDITOR窗口中输入一些简单程序,主要是调用FSEDIT过程,其他操作的环境和步骤很相似。但是用FSEDIT过程所编写的一些数据产生程序比用SAS/ASSIST软件更容易控制产生所需的数据集。 仍然通过创建一个相同SURVEY数据集,并对这个数据集进行一些简单修改的例子,来说明SAS/FSP软件的FSEDIT过程的具体的操作步骤: 一、在PROGRAM EDITOR 窗口中输入如下程序 Libname study 'd:\sasdata\mydir'; Proc fsedit new=study.survey; Run; 中,提交运行。后面课件中的程序都可以进行类似操作。 在程序中过程FSEDIT用以创建一个新的SAS数据集study.survey。 ●如果study.survey数据集不是第一次新建,而是一个已经存在的SAS数据集,则 将上面的程序修改为如下: Proc fsedit data=study.survey ; Run ; 在程序过程FSEDIT中使用DATA=选项,来指定所要修改的数据集。 二、发布SUBMIT命令提交这段程序 出现了一个标题为FSEDIT new STUDY.SURVEY的变量描述窗口。 ●要注意,如果库标记STUDY指定的目录“d:\sasdata\mydir”下已经存在此SAS数 据集SURVEY,就不会出现变量描述窗口。 1 解决的办法是到目录下将文件SURVEY.SD2删除。 三、单击主菜单Locals,选择Format / Informat 这样的操作将把窗口中的输出格式Format,修改成输入格式Informat。同样操作也可以将输入格式Informat修改成输出格式Format。注意,不要认为只能定义输入和输出格式两者中的一个,可以同时定义两者。 四、输入将要创建的数据集的所有变量及其属性 如下表所示,是我们将要键入的study.survey数据集的变量名、对应的类型(字符型或数字型)、长度、变量标签(用以说明该变量)和该变量的输入格式。 上表中我们定义了一个新的数据集study.survey所有变量的属性,但没有包括输出格式的属性。按表格中的内容输入到窗口中相应的位置。在输入各个变量和它的属性时,注意用非Insert编辑状态(即Overstrike状态)、用Delete键删除已输入的字符和用空格键向右移动光标,描述完一个变量(即一行)后按Enter键。 五、发布END,进入FSEDIT编辑窗口,输入数据 开始输入前: 要单击工具栏上Add Record按钮增加一条空白记录 2 SAS讲义-第四课 一、data语句 例1 规定要创建的SAS数据集。 data; /*系统自动规定数据集名datan * / data a; /*创建临时数据集a */ data ResDat .a; /*创建永久数据集resdat.a */ data data1 data2; /*创建两个临时数据集data1和data2 */ data _null_; /*特殊名,不创建SAS数据集,用于输出*/ 例2 数据集选项举例。 data new (drop=var1); /*去掉数据集new中变量var1*/ data new (keep=_numeric_); /*保留数据集new中所有数值变量*/ data new (label=’股本变动历史’);/*规定数据集new标签名为”股本变动历史”*/ data new (rename=(var1=u var2=v)); /*将数据集new中变量var1和var2更名为u和v*/ 例3 观测子集的形成。 data year1998 year1999 year2000; set ResDat.stk000001 ; if year (date)=1998 then output year1998; /* year为函数名*/ else if year (date)=1999 then output year1999; else if year (date)=2000 then output year2000; run; 例中,根据条件产生三个观测子集,名字分别为year1998, year1999和year2000。 例4 变量子集的形成。 data open (keep=date oppr) close (keep=date clpr); set resdat.stk000001; run; 二、set语句 Set语句从一个或多个数据集中读取观测值并实现纵向合并。每一个set语句被执行时,SAS就会读一个观测到PDV中。 Set语句的语法格式: set+数据集+(数据集选项)+选项; (1)数据集选项 keep=变量指定的变量进入PDV drop=变量指定的变量不进入PDV rename=表达式对指定的变量在PDV更换变量名 where=表达式执行PDV之前满足表达式 IN=变量创建一个标识变量,如果当前观测属于数据集, 标识为1,否则为0 firstobs=常数如常数=3,表示从第三个观测读数据集 obs=常数如常数=10,表示最后一个观测是第十个观测 (2)选项 对应分析SAS程序 2010年5月 一、对应分析的统计思想 二、对应分析的原理 三、对应分析的SAS程序与应用 四、对应分析练习题 第一节对应分析的基本理论 对应分析又称相应分析,于1970年由法国统计学家J.P.Beozecri提出的. 对应分析是将频数或计数表的各种联系用图来表示的方法。 对应分析本质是一种在低维空间中用图形方法表示联系的技术。 对应分析(Correspondence Analysis):通过分析由定性变量构成的交互汇总表来揭示变量间的联系。对应分析可以揭示同一变量的各个类别之间的差异,不同变量各个类别之间的对应关系。可以将两个变量的联系做在一个图里表示出来。 它是在R型和Q型因子分析基础上发展起来的多元统计分析方法,故也称为R-Q型因子分析. 因子分析方法是用少数几个公共因子去 提取研究对象的绝大部分信息,既减少了因子的数目,又把握住了研究对象的相互关系.在因子分析中根据研究对象的不同,分为R型和Q型,如果研究变量间的相互关系时采用R型因子分析;如果研究样品间相互关系时采用Q型因子分析. 第二节对应分析原理 5、将因子载荷为座标作图,得到对应分析图 ()2 2 11 p q ij i j i j i j p p p n p p χ ??==??-= =∑∑ 总惯量 奇异值是惯量(特征值)的平方根。惯量用于说明对 应分析各个维度的结果能够解释列联表中两个变量联系的程度。 第三节SAS对应分析程序 例: Data ex2; Input zipin$ zili renshu; datalines; a 1 129 a 2 14 a 3 8 b 1 931 b 2 146 b 3 96 c 1 660 c 2 116 c 3 74 d 1 251 d 2 104 d 3 81 e 1 11 e 2 7 e 3 23 f 1 15 f 2 13 f 3 24 ; Proc corresp data=ex2 all outc=result; tables zipin , zili ; weight renshu; Run; %plotit(data= result, datatype=corresp) SAS? 9.2 FOUNDATION for Windows 安裝導引 V1.00, 12 Oct 2009 SAS and all other SAS Institute Inc. product or service names are registered trademarks or trademarks of SAS Institute Inc. in the USA and other countries. ? indicates USA registration. Other brand and product names are registered trademarks or trademarks of their respective companies. Copyright 2008 SAS Institute Inc. All Rights Reserved. 目錄 1事前準備 (1) 1.1SAS Software DVD 光碟版本 (1) 1.2軟體需求 (1) 1.3硬體需求 (2) 1.4其他注意事項 (2) 2安裝 SAS 系統 (3) 2.1安裝 SAS 9.2 Foundation (3) 3更多資訊 (15) 3.1SAS Notes (15) 3.2SAS Tech Support (15) 1 事前準備 本安裝導引提供 SAS 9.2 Foundation 單機安裝之標準安裝基本說明,目的在於協助SAS使用者完成安裝 SAS 系統。在開始安裝之前請先檢視本章之事前準備事項,以確保安裝工作可以順利完成。 1.1 SAS Software DVD 光碟版本 本安裝導引主要說明 SAS 9.2 DVD 光碟為版本920_09W32 (含)之後的SAS 9.2 Foundation安裝。您可以在SAS Software DVD 光碟盒子封面,確認您的SAS 9.2 DVD 光碟版本。 1.2 軟體需求 SAS 9.2 Foundation 支援下列的 Microsoft Windows 作業平台: ●Microsoft Windows Server 2003, Standard Edition SP1 ●Microsoft Windows Server 2003, Enterprise Edition SP1 ●Microsoft Windows Server 2003, Datacenter Edition SP1 ●Microsoft Windows XP Professional SP2 ●Microsoft Windows Vista ‐ Enterprise, Business 及 Ultimate 版本等 此外,SAS 9.2 Foundation 安裝過程中,會安裝下列系統元件: ●Microsoft Windows Installer 3.0 ●Microsoft Runtime Components 8.0 SP1 ●Microsoft .NET Framework 2.0 ●Microsoft WSE 3.0 Runtime 檔案系統之建議: SAS Macros Workshop I.Why use SAS Macros? A SAS macro is way of defining parts of or collections of SAS statements which can be carried out repeatedly or which can substitute names of datasets or variables with symbolic names. SAS macro language also gives you the opportunity to insert programming steps inside a SAS code. SAS Macro Advantages: ?Reduce coding time ?Reduce programming errors by not having to edit so many lines of code ?In some cases, it could be even more time efficient in execution SAS Macro Disadvantages: ?Harder to understand if multiple people work on it ?Harder to debug ?Some of the macro features (call symput) do not resolve in execution in the log file until the very end of a data step ?Not easily adaptable All the usual programming elements: if-then-else statements, loops for I=1 to N do, and other similar operators can be used in SAS macros. II.Overview of elements of the macro language The three different main elements of the macro language are: ?macro variables; ?macro program statements; ?macro functions. III.Macro variables Macro variables are tools that enable you to modify text in a SAS program through a symbolic substitution. It assigns a value (either string or integer) to a variable that you can invoke several times in a program after that. To define a macro variable you can use the %let statement. EXAMPLE 1: For example to assign the value 24 to the variable named sto, you do: SAS应用讲义 (中高级教材) Statistical Analysis System简称为SAS,可用来分析数据和编写报告。它是美国SAS研究所的产品,在国际上被誉为标准软件,在我国深受医学、农林、财经、社会科学、行政管理等众多领域的专业工作者的好评。 有关SAS的最新信息,可以查看。 SAS采用积木式模块结构,其中的SAS/STAT模块是目前功能最强的多元统计分析程序集,可以做回归分析、聚类分析、判别分析、主成分分析、因子分析、典型相关分析以及各种试验设计的方差分析和协方差分析。 本讲义围绕SAS的应用,讲述以下八部分内容: (1)SAS应用基础;(2)SAS常用语句; (3)SAS服务过程;(4)描述性统计程式; (5)方差分析程式;(6)回归分析程式; (7)聚类分析及判别分析程式;(8)互依性分析程式。 第一讲SAS应用基础 1.1SAS的显示管理系统 启动计算机,点击SAS图标后,即可进入SAS的显示管理系统DMS。 DMS是Display Manager System的缩写。在DMS中有四个主要的窗口: (1)编辑窗口(PROGRAM EDITOR)——编辑程式和数据文件; (2)日志窗口(LOG)——记录运行情况,显示ERROR信息; (3)输出窗口(OUTPUT)——输出运行的结果; (4)图形窗口(GRAPH)——输出图形。 点击Globals 菜单中的Program editor、Log、Output、Graph 命令可以进入编辑、日志、输出及图形窗口。 按功能键F5、F6、F7也可以进入编辑、日志及输出窗口。 退出DMS有两种方法: (1)点击File 菜单中的Exit 命令; (2)点击窗口右上角的×。 1.2 SAS的功能键 用功能键可以代替对菜单的点击,有时比较方便。 最常用的功能键有F1 :显示帮助信息(HELP); F4 :显示已经运行的程式(RECALL); F5 :进入编辑窗口(PGM);SAS讲义 第三十四课非线性回归分析
SAS讲义 第三十课Spearman等级相关分析
SAS讲义-第九课
最新sas讲义第二课显示系统
SAS讲义 第三十七课典型相关分析
【SAS精品讲义】Unit07【WORD可编辑版本】
SAS讲义-第四课
对应分析 SAS讲义12
SAS92讲义
sas_180412_哈佛的SAS宏程序讲义
SAS应用讲义