OpenMP程序设计

OpenMP程序设计
什么是OpenMP
应用编程接口API(Application Programming Interface )
由三个基本API部分(编译指令、运行部分和环境变量)构成
是C/C++ 和Fortan等的应用编程接口
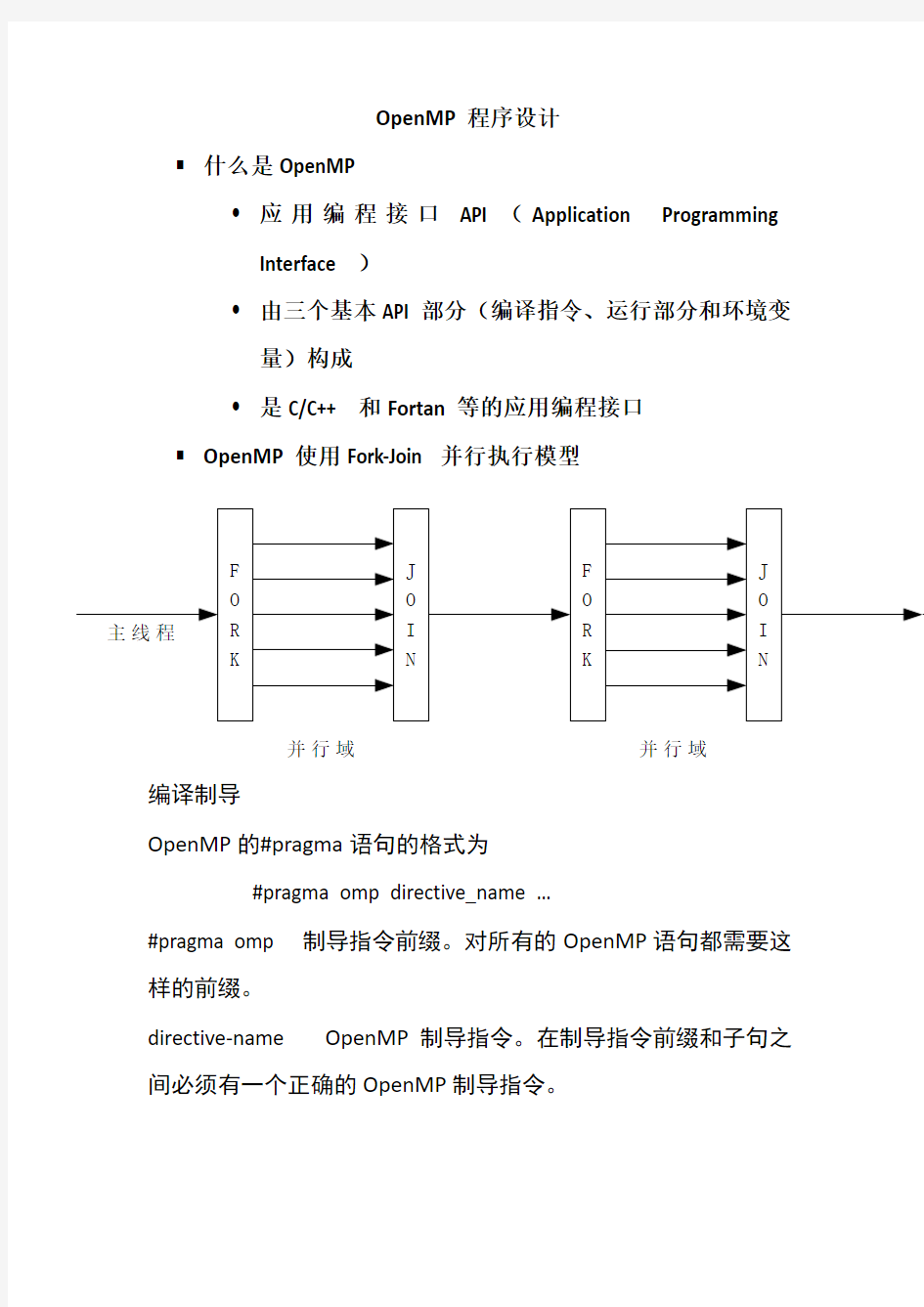
OpenMP使用Fork-Join并行执行模型
并行域并行域
编译制导
OpenMP的#pragma语句的格式为
#pragma omp directive_name …
#pragma omp 制导指令前缀。对所有的OpenMP语句都需要这样的前缀。
directive-name OpenMP制导指令。在制导指令前缀和子句之间必须有一个正确的OpenMP制导指令。
并行域结构
并行域中的代码被所有的线程执行
具体格式
#pragma omp parallel [clause[[,]clause]…]newline 并行域中的代码被所有的线程执行
具体格式
#pragma omp parallel [clause[[,]clause]…]newline
共享任务结构
共享任务结构将它所包含的代码划分给线程组的各成员来执行
并行for循环
并行sections
串行执行
线程列线程列线程列
for编译制导语句
for语句指定紧随它的循环语句必须由线程组并行执行;
语句格式
#pragma omp for [clause[[,]clause]…] newline Sections编译制导语句
sections编译制导语句指定内部的代码被划分给线程组中的各线程
不同的section由不同的线程执行
Section语句格式:
#pragma omp sections [ clause[[,]clause]…] newline
{
[#pragma omp section newline]
…
[#pragma omp section newline]
… }
single编译制导语句
single编译制导语句指定内部代码只有线程组中的一个线程执行。
线程组中没有执行single语句的线程会一直等待代码块的结束,使用nowait子句除外
语句格式:
#pragma omp single [clause[[,]clause]…] newline
组合的并行共享任务结构
parallel for编译制导语句
Parallel for编译制导语句表明一个并行域包含一个独立的for语句
语句格式
#pragma omp parallel for [clause…] newline
parallel sections编译制导语句
parallel sections编译制导语句表明一个并行域包含单独的一个sections语句
语句格式
#pragma omp parallel sections [clause…] newline
下面对以上编译制导语句的类型举例:
1、for编译制导语句
补充Schedule(type [,chunk])
schedule子句描述如何将循环的迭代划分给线程组中的线程
如果没有指定chunk大小,迭代会尽可能的平均分配给每个线程
type为static,循环被分成大小为chunk的块,静态分配给线程
type为dynamic,循环被动态划分为大小为chunk的块,动态分配给线程
串行执行的程序块为:
for(i=0;;i++)
matct();
for(j=0;;j++)
match();
并行的执行为:
#pragma omp parallel //由并行组里面的线程组并行执行{
#pragma omp for schedule(static,100) // schedule子句可以省
{
for(i=0;;i++)
match();
}
#pragma omp for schedule(static,100) // schedule子句可以省{
for(j=0;;j++)
match();
}
}
或者
#pragma omp parallel for private(i) // parallel for 后面只能跟一个for循环for (i=0; ; i++) // private说明里面的变量i是各自线程私有的match();
2、Sections编译制导语句
串行执行的程序块为:
for(i=0;i<10000;i++)
matct();
并行的执行为:
#pragma omp parallel private(i)
{
#pragma omp sections //代码被划分给线程组中的各线程
{
#pragma omp section
for (i=0;i<5000 ; i++)
match();
#pragma omp section
for (i=5000;i<10000 ; i++)
match();
}
3、single编译制导语句
串行执行的程序块为:
for(i=0;;i++)
matct();
并行的执行为:
#pragma omp parallel
{
#pragma omp single //代码只有线程组中的一个线程执行。
{
for(i=0;;i++)
match();
}
}
4、实现线程同步
#pragma omp parallel
{
#pragma omp barrier //用来线程同步
#pragma omp sections
{
#pragma omp section
for(i=0;;i++)
match();
#pragma omp section
for(i=0;;i++)
match();
}
}
下面再讲一些区别:
section语句是用在sections语句里用来将sections语句里的代码划分成几个不同的段,每段都并行执行
void main(int argc, char *argv)
{
#pragma omp parallel sections {
#pragma omp section
printf(“section 1 ThreadId = %d\n”, omp_get_thread_num());
#pragma omp section
printf(“section 2 ThreadId = %d\n”, omp_get_thread_num());
#pragma omp section
printf(“section 3 ThreadId = %d\n”, omp_get_thread_num());
#pragma omp section
printf(“section 4 ThreadId = %d\n”, omp_get_thread_num());
}
执行后将打印出以下结果:
section 1 ThreadId = 0
section 2 ThreadId = 2
section 4 ThreadId = 3
section 3 ThreadId = 1
从结果中可以发现第4段代码执行比第3段代码早,说明各个section里的代码都是并行执行的,并且各个section被分配到不同的线程执行。
使用section语句时,需要注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section过长就达不到并行执行的效果了。
上面的代码也可以改写成以下形式:
void main(int argc, char *argv)
{
#pragma omp parallel {
#pragma omp sections
{
#pragma omp section
printf(“section 1 ThreadId = %d\n”, omp_get_thread_num());
#pragma omp section
printf(“section 2 ThreadId = %d\n”, omp_get_thread_num());
}
#pragma omp sections
{
#pragma omp section
printf(“section 3 ThreadId = %d\n”, omp_get_thread_num());
#pragma omp section
printf(“section 4 ThreadId = %d\n”, omp_get_thread_num());
}
}
执行后将打印出以下结果:
section 1 ThreadId = 0
section 2 ThreadId = 3
section 3 ThreadId = 3
section 4 ThreadId = 1
这种方式和前面那种方式的区别是,两个sections语句是串行执行的,即第二个sections语句里的代码要等第一个sections语句里的代码执行完后才能执行。
用for语句来分摊是由系统自动进行,只要每次循环间没有时间上的差距,那么分摊是很均匀的,使用section来划分线程是一种手工划分线程的方式,最终并行性的好坏得依赖于程序员。
要使用Intel C++ Compiler8.1,如何在VC下设置
1、在projict->settings 下面如下图:
点击C/C++ 在Gategory 为General时,在Preprocessor definitions 栏里添加_USE_INTEL_COMPILER
在p roject o ptions栏里添加/Qopenmp 。如下图:
2、点击link 在Gategory 为General 时在Object/library
modules 下添加libguide.lib
3、在菜单里选择tools->Intel(R) C++ Compiler Selecttions
tool 在弹出的对话框里面把勾打上如下图:
4、在菜单里选择tools->o ptions->directories 下面分别添
加路径如下面的图:
附录一:
OpenMP的指令有以下一些:
parallel,用在一个代码段之前,表示这段代码将被多个线程并行执行
for,用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。
parallel for,parallel 和for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行。
sections,用在可能会被并行执行的代码段之前
parallel sections,parallel和sections两个语句的结合
critical,用在一段代码临界区之前
single,用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。flush,
barrier,用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行。
atomic,用于指定一块内存区域被制动更新
master,用于指定一段代码块由主线程执行
ordered,用于指定并行区域的循环按顺序执行
threadprivate, 用于指定一个变量是线程私有的。
OpenMP除上述指令外,还有一些库函数,下面列出几个常用的库函数:
omp_get_num_procs, 返回运行本线程的多处理机的处理器个数。
omp_get_num_threads, 返回当前并行区域中的活动线程个数。
omp_get_thread_num, 返回线程号
omp_set_num_threads, 设置并行执行代码时的线程个数
omp_init_lock, 初始化一个简单锁
omp_set_lock,上锁操作
omp_unset_lock,解锁操作,要和omp_set_lock函数配对使用。
omp_destroy_lock,omp_init_lock函数的配对操作函数,关闭一个锁
OpenMP的子句有以下一些
private, 指定每个线程都有它自己的变量私有副本。
firstprivate,指定每个线程都有它自己的变量私有副本,并且变量要被继承主线程中的初值。
lastprivate,主要是用来指定将线程中的私有变量的值在并行处理结束后复制回主线程中的对应变量。
reduce,用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的运算。
nowait,忽略指定中暗含的等待
num_threads,指定线程的个数
schedule,指定如何调度for循环迭代
shared,指定一个或多个变量为多个线程间的共享变量
ordered,用来指定for循环的执行要按顺序执行
copyprivate,用于single指令中的指定变量为多个线程的共享变量
copyin,用来指定一个threadprivate的变量的值要用主线程的值进行初始化。default,用来指定并行处理区域内的变量的使用方式,缺省是shared
附录二:
Intel C++ Compiler8.1 不是免费的产品,不过你可以去以下网址,注册为期30天的评估产品
https://www.360docs.net/doc/429716654.html,/cd/software/products/apac/zho/download/eval/index.htm
在这里面只要输入邮箱即可。
燕山大学多核程序设计实验报告
实验一Windows多线程编程 一、实验目的与要求 了解windows多线程编程机制 掌握线程同步的方法 二、实验环境和软件 WindowsXP VC6.0 三、实验内容 创建线程: HANDLECreateThread( LPSECURITY_ATTRIBUTESlpThreadAttributes, SIZE_TdwStackSize, LPTHREAD_START_ROUTINElpStartAddress, LPVOIDlpParameter, DWORDdwCreationFlags, LPDWORDlpThreadId ); 四、实验程序 #include"stdafx.h" #include
while(1) { Sleep(1000); cout<<"ThisisThreadFrunc1"< (此文档为word格式,下载后您可任意编辑修改!) 多核编程与并行计算实验报告 姓名: 日期:2014年 4月20日 实验一 // exa1.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 实验二 // exa2.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 计算机的发展按照硬件工艺可以分为 第一代(1946~1958):电子管数字计算机。 第二代(1958~1964):晶体管数字计算机。 第三代(1964~1971):集成电路数字计算机。 第四代(1971年以后):大规模集成电路数字计算机。 现代计算机发展历程可以分为两个明显的发展时代: 串行计算时代 并行计算时代。 并行计算机是由一组处理单元组成的,这组处理单元通过相互之间的通信与协作,以更快的速度共同完成一项大规模的计算任务。 并行计算机个最主要的组成部分: 计算节点 节点间的通信与协作机制 Flynn根据指令流和数据流的不同组织方式,把计算机系统的结构分为以下四类: 单指令流单数据流(SISD) 单指令流多数据流(SIMD) 多指令流单数据流(MISD) 多指令流多数据流(MIMD) 指令流(instruction stream) 指机器执行的指令序列 数据流(data stream) 指指令流调用的数据序列,包括输入数据和中间结果。 SISD 计算机是传统的顺序执行的计算机 在同一时刻只能执行一条指令(即只有一个控制流)、处理一个数据(即只有一个数据流)。 缺点: 单个处理器的处理能力有限 没有并行计算能力 在MIMD计算机中没有统一的控制部件。 在SIMD机中,各处理单元执行的是同一个程序, 而在MIMD机上,各处理器可以独立执行不同的程序。 MIMD结构比SIMD结构更加灵活。 SIMD计算机用于对不同数据的相同运算(向量和矩阵运算) 而MIMD计算机可以适应更多的并行算法 从系统结构的角度来分类,一般有以下几种: 1)对称多处理器(SMP) 2)分布式共享存储多处理机(DSM) 3)大规模并行处理机(MPP) 4)并行向量处理机(PVP) 5)集群计算机。 多核编程与并行计算实验报告 姓名: 日期:2014年 4月20日 实验一 // exa1.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 实验二 // exa2.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 环/球/I T | 计算机教育 2007.7 | 39 ★英特尔多核课程园地★ 《多核程序设计》概述 浙江大学计算机学院 陈天洲 英特尔中国公司大学合作部 曹 捷 王靖淇/文 半导体技术的进步使单芯片多处理器成为现实并推动着多核计算技术的不断进步。浙江大学从2006年开设单独的多核课程,并联合国内五所重点高校设计编写了《多核程序设计》作为该课程的教材,对多核计算技术进行了全面深入的讲解,以期由此完善学生的知识结构。 1 多核计算技术的概述 随着新材料的应用和新技术的发展,VLSI 技术取得长足进步,在单个芯片上集成多个处理器核心构成多核处理器已经成为处理器技术的主流。按计算内核的对等与否,CMP 可分为同构多核和异构多核。计算内核相同,地位对等的称为同构多核。然而,一般认为处理器通用核的数目在超过16个后,再增加通用处理核的数目就难以带来更大的性能提升。于是出现了一些为特别任务专门定制的专用处理核,包括面向科学计算等的“领域专用核”、图形图像处理和数字信号处理(DSP)等“行业专用核”。这些专用核的体系结构利用特定应用的特征进行定制,从而达到定制应用的高性能和高效率。 从2005年出现的英特尔与AMD 的双核处理器、2006年推出的4核处理器到2007年2月英特尔公司展示的80核处理器,处理器中集成核的数目呈现迅速增多的趋势。除此之外,具有更多核和不同功能核的处理器也在研发,例如整合了1025个简单处理器的芯片Kilocore ,包括1024个8位处理器和1个Power PC 核。 伴随着多核处理器的发展尤其是处理器核数目的增加与处理器核功能的变化,在体系结构、软件、 功耗和安全性设计等方面,巨大的挑战也随之而来。处理器的发展使得原有面向单核或者多处理器的软件架构不适于在单芯片多处理器的硬件结构上充分利用多计算核心的能力,需要相应的软件层面的共同发展。为此,软件结构的变化尤其是针对多核硬件体系结构的程序设计成为有效发挥多核计算能力的重要方面。 为了适应技术的发展,为社会培养合格的计算机人才,在大学计算机教学中开设相应的多核计算课程势在必行。计算机方向课程的开设尤其是教材的设计,不仅要注意到满足完善学生知识结构,适应计算机技术迅速发展的情况,同时也需注意到社会对于多核计算技术方面人才的需求,通过合理的设计,满足知识更新与就业两方面的要求。 2 多核课程设计 多核计算技术的发展使得计算机教学发生了变化,这种变化主要来自于多核计算技术所带来的新的知识点。这些新的知识点主要包括:多核SOC 芯片技术;多核芯片与传统单核微处理器、SMP 的区别;多核下的各种硬件设计技术(Cache 与存储一致性、网络互连、IO 管理);并行体系与多核体系结构;典型多核芯片介绍;嵌入式多核芯片技术;多核平台结构与芯片组支持技术(包括固件技术);多核操作系统;多核系统软件对并行编程的支持;多线程编程对多核的支持;多核多线程编程技术(主要是关于Windows 与Linux 操作系统);OpenMP 对多核的支持;多核平台上的编译工具与编译优化技术;多核API 优化函数库;多核多线程程序的性能评测工具与方法。 选择题:20% 1.下列不是多核处理器的是B A.INTEL酷睿2 E4500 B.AMD闪龙3000+ C.cell处理器 2.若对于一个给定的应用,用串行算法执行的时间为24秒,用并行算法执行的时间为32秒,则加速比为:A A.0.75 B.1.33 C.1 3.OpenMP是哪种并行编程环境的代表? C A.消息传递 B.数据并行 C.共享存储 4.针对“降低处理器二分之一的频率,会增加二分之一的功率消耗”的说法,下面的选项中哪个是正确的:B A、这个说法是正确的 B、这个说法是错误的 C、对于台式机和服务器,这个说法是正确的,但对于笔记本电脑,这个说法是错误的 5.下面是线程创建函数,其中线程函数定义参数是: A HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpThreadAttributes, SIZE_T dwStackSize, LPTHREAD_START_ROUTINE lpStartAddress, LPVOID IpParameter, DWORD dwCreationFlags, LPDWORD IpThreadId, ); A.lpParamenter B.lpStartSddress C.lpThreadAttributes 填空题:20% 1并行计算机的两个最主要的组成部分是计算节点和节点间的通信与协作机制 2.按计算内核的对等与否,CMP可分为同构多核和异构多核 3.目前比较主流的片上高效通信机制有两种,一种是基于总线共享的cache结构,一种是基于片上的互联结构. 4.进程具有两个明显的特征,一个是资源特征,另一个是执行特征. 5.线程有4个基本状态:就绪,运行,阻塞,终止 判断题10% 1.根据Amdahl定理,程序的加速比决定于串行部分的性能. . T 2.K-路组关联映射策略很容易产生cache颠簸. F 3.在忙等待条件下发生的饥饿,称为"死锁" F 4.在任何一个线程中调用exit将会结束整个进程. . T 5.墙上时间包括:计算CPU时间,通信CPU时间,同步开销时间和进程空闲时间. T 简答题:30% 1.简述什么是cache映射策略及当前的三种cache映射策略. Cache映射策略指的是内存块和cache线之间如何建立相互映射的关系. 《多核程序设计》概述 陈天洲1 曹捷 王靖淇 (浙江大学计算机学院, 杭州 310027) 摘 要: 随着半导体技术的进步,多核芯片已经成为处理器技术的主流。浙江大学根据多核计算技术的发展趋势,以经典体系理论为基础,以培养动手实践能力为目标,开设了多核课程,并以此进行了教材设计,联合清华大学等高校编写了适合于《多核程序设计》,作为多核计算课程教学设计的一种探索。 关键词: 多核计算;课程设计;教材设计;实践 半导体技术的进步使单芯片多处理器成为现实并推动着多核计算技术的不断进步。浙江大学从2006年开设单独的多核课程,并联合国内五所重点高校设计编写了《多核程序设计》作为该课程的教材,对多核计算技术进行了全面深入的讲解,以期由此完善学生的知识结构。 1 多核计算技术的概述 随着新材料的应用和新技术的发展,VLSI技术取得长足进步,在单个芯片上集成多个处理器核心构成多核处理器[1][2][3]已经成为处理器技术的主流。按计算内核的对等与否,CMP可分为同构多核和异构多核。计算内核相同,地位对等的称为同构多核。然而,一般认为处理器通用核的数目在超过16个后,再增加通用处理核的数目就难以带来更大的性能提升。于是出现了一些为特别任务专门定制的专用处理核,包括面向科学计算等的“领域专用核”、图形图像处理和数字信号处理(DSP)等“行业专用核”[5, 6]。这些专用核的体系结构利用特定应用的特征进行定制,从而达到定制应用的高性能和高效率。 从2005年出现的英特尔与AMD的双核处理器[4]、2006年推出的4核处理器到2007年2月英特尔公司展示的80核处理器,处理器中集成核的数目呈现迅速增多的趋势。除此之外,具有更多核和不同功能核的处理器也在研发,例如整合了1025个简单处理器的芯片Kilocore [7],包括1024个8位处理器和1个Power PC核。 伴随着多核处理器的发展尤其是处理器核数目的增加与处理器核功能的变化,在体系结构、软件、功耗和安全性设计等方面,巨大的挑战也随之而来。处理器的发展使得原有面向单核或者多处理器的软件架构不适于在单芯片多处理器的硬件结构上充分利用多计算核心的能力,需要相应的软件层面的共同发展。为此,软件结构的变化尤其是针对多核硬件体系结构的程序设计成为有效发挥多核计算能力的重要方面。 为了适应技术的发展,为社会培养合格的计算机人才,在大学计算机教学中开设相应的多核计算课程势在必行。计算机方向课程的开设尤其是教材的设计,不仅要注意到满足完善学生知识结构,适应计算机技术迅速发展的情况,同时也需要到社会对于多核计算技术方面人才的需求,通过合理的设计,满足知识更新与就业两方面的要求。 2 多核课程设计 1收稿日期: 2007-05-16 作者简介: 陈天洲(1970-),男,浙江,博士,教授,主要研究方向:计算机系统结构、嵌入式系统。 曹捷,男,英特尔中国大学合作部 王靖淇,女,英特尔中国大学合作部 多核编程并不是最近才兴起的新鲜事物。早在intel发布双核cpu之前,多核编程已经在业内存在了,只不过那时候是多处理器编程而已。为了实现多核编程,人们开发实现了几种多核编程的标准。open-mp就是其中的一种。对于open-mp还不太熟悉的朋友,可以参照维基百科的相关解释。 open-mp的格式非常简单,原理也不难。它的基本原理就是创建多个线程,操作系统把这几个线程分到几个核上面同时执行,从而可以达到快速执行代码的目的。比如说,我们可以编写一个简单的例子。 在编写open-mp程序之前,朋友们应该注意下面三点, (1) 使用vs2005或者以上的版本编写open-mp程序; (2) 编写程序的时候,选择【Property Pages】->【Configuration Properties】->【c/c++】->【language】->【OpenMp Support】,打开开关; (3) 添加#include 《多核架构及编程技术》设计报告 基于OpenMP的二维方阵相乘及 基于IPP的函数DFT及反变换 学院:电子信息学院 专业:通信工程 学号: 2011301200237 姓名:叶子童 指导老师:谢银波 时间: 2013年6月 基于OpenMP的二维方阵相乘 姓名:叶子童专业:通信工程学号:2011301200237 指导教师:谢银波 [设计原理] 声明3个800阶的矩阵,用srand函数对A,B矩阵随机赋值,在主程序中用3个for循环来进行计算,用OpenMP实现循环并行化,用clock()函数统计运算时间并输出时间及C矩阵。 [主要功能] 计算2个随机生成的800阶二维矩阵相乘的结果,统计运算时间并输出结果矩阵。 [设计的主要内容] 实验代码为: #include"stdafx.h" #include int main() { int i, j, t, k; double duration; clock_t start, finish; for (int i=0;i<800;i++) for (int j=0;j<800;j++) a[i][j]=rand()%100; //随机产生-100的随机整数 for (int i=0;i<800;i++) for (int j=0;j<800;j++) b[i][j]=rand()%100; start=clock(); #pragma omp parallel shared(a,b,c) private(i,j,k) #pragma omp for schedule(dynamic) //循环动态分割成大小为chunk的块,动态分割给线程for(i=0;i<800;i++) { for(j=0;j<800;j++) { c[i][j]=0; for(k=0;k<800;k++) { c[i][j]+=a[i][k]*b[k][j]; } } } printf( "Time to do the calculate is "); finish = clock(); duration = (double)(finish - start) / CLOCKS_PER_SEC; printf( "%2.6f seconds\n", duration ); Sleep(2000); for(i = 0;i < 800;i++) { for(j = 0;j < 800;j++) { printf("%d ",c[i][j]); } printf("\n"); } return 0; } 输出的运算时间为3.483s。 实验一Windows多线程编程一、实验目的与要求 了解windows多线程编程机制 掌握线程同步的方法 二、实验环境和软件 Windows XP VC 6.0 三、实验内容 创建线程: HANDLE CreateThread ( LPSECURITY_ATTRIBUTES lpThreadAttributes, SIZE_T dwStackSize, LPTHREAD_START_ROUTINE lpStartAddress, LPVOID lpParameter, DWORD dwCreationFlags, LPDWORD lpThreadId ); 四、实验程序 #include"stdafx.h" #include while(1) { Sleep(1000); cout<<"This is ThreadFrunc1"< 第四章Windows多线程编程及 调优->web课件 返回 在Windows平台下可以通过Windows的线程库来实现多线程编程,可以利用Win32 API或MF C以及.Net Framework提供的接口来实现。实现方式的多样化给Windows编程带来了很大的灵活性,但也使得多线程编程变得复杂。对于多线程的程序我们可以使用Visual Studio调试工具进行调试,也可以使用多核芯片厂家的线程分析与调试工具进行调试及优化。 Windows线程库介绍 Win32 API是Windows操作系统为内核以及应用程序之间提供的接口,将内核提供的功能进行函数封装,应用程序通过调用相关的函数获得相应的系统功能。Win32 API提供了一系列处理线程的函数接口,来向应用程序提供多线程的功能。 MFC是微软基础函数类库(Microsoft Foundation Classes),由微软提供的,用类库的方式将Wi n32 API 进行封装, 以类的方式提供给开发者。在MFC类库中,提供了对多线程的支持。由于MF C是在Win32 API 基础之上进行封装的,其基本原理与Win32 API的基本实现原理很类似。MFC 对同步对象作了封装,因此对用户编程实现来说更加方便。 .NET Framework由两部分构成:公共语言运行库(Common Language Runtime ,CLR)和Fra mework类库(Framework Class Library ,FCL)。CLR包括自己的文件加载器、垃圾收集器、安全系统等。CRL提供了一个可靠而完善的多语言运行环境。CLR是一个软件引擎,用于加载应用程序、检查错误、进行安全许可认证、执行和清空内存。Framework类库提供了所有应用程序模型都要使用的一个面向对象的API集合。.NET 基础类库的System.Threading命名空间提供了大量的类和接口来支持多线程。所有与多线程机制相关的类都存放在System.Threading命名空间中。其中Thread类用于创建及管理线程,ThreadPool类用于管理线程池等,此外还提供线程间通讯等实际问题的机制。 使用win32线程API Win32 函数库中提供了操作多线程的函数,包括创建线程、管理线程、终止线程、线程同步等接口。 线程必须从一个指定的函数开始执行,该函数称为线程函数,具有如下原型: DWORD WINAPI ThreadFunc (LPVOID lpvThreadParm); 线程创建 创建线程的函数如下: 一、多项选择 1.计算机的硬件工艺发展的顺序是:(A) A.电子管数字计算机、晶体管数字计算机、集成电路数字计算机、大规模集成 电路数字计算机。 B.晶体管数字计算机、电子管数字计算机、集成电路数字计算机、大规模集成 电路数字计算机。 C.电子管数字计算机、集成电路数字计算机、大规模集成电路数字计算机、晶 体管数字计算机。 D.电子管数字计算机、集成电路数字计算机、晶体管数字计算机、大规模集成 电路数字计算机 2.下面关于Intel8086芯片与8088芯片的描述,不正确的是:(D) A.8086是第一个16位的微处理器。 B.8088是第一个16位的微处理器。 C.8086每周期能传送或接受16位整数。 D.8088每周期能传送或接受16位整数。 3.针对内存的速度瓶颈,英特尔为80386设计了--------来解决这个速度瓶颈:(B)A.虚拟86. B.高速缓存(Cache). C.浮点运算单元。 D.多媒体扩展指令集。 4.对一个具体的问题做性能优化时,可以同时在这多个层次上考虑可能的优化手段,一般来说:(AB) A.在越高的层次上进行优化,可能获得的效益越高。 B.在越高的层次上进行优化工作则相对越容易实现。 C.在越高的层次上进行优化,可能获得的效益越低。 D.在越低的层次上进行优化工作则相对越难于实现。 5.VTune性能分析器中的取样功能有哪几种方式?(AC) A.基于时间取样 B.随机取样。 C.基于事件取样。 D.线性取样。 6.Intel调优助手能够给我们自动推荐代码改进方法,主要有以下哪些方面?(BCD) A.算法自动改进。 B.处理器瓶颈以及改进。 C.取样向导增强。 D.超线程。 7.使用-O3编译选项所得的程序,执行效率比使用-O2编译选项所得的程序--:(D) 重庆邮电大学 多核编程与并行计算实验报告 姓名: 班级: 学号: 日期:2014年 4月11 日 一实验目的和要求 积分法计算圆周率 如图 2-1所示:梯形积分——每一竖条都拥有固定宽度的“梯级”。每个竖条的高度便是被积函数的值。将所有竖条的面积加在一起便得出曲线下面积的近似值,即被积函数的值。 若选择一个被积函数及积分极限,那么该积分在数值上便等于π。这样就构成了利用积分法计算圆周率的基本思路。 图2-1 编写多线程程序,计算圆周率π值,并在Visual Studio 2005上调试、运行输出结果;说明程序设计的基本思路,以及如何实现线程的互斥和同步? 二实验环境与软件 Visual studio 2010 三实验内容 积分法计算圆周率 四实验步骤 编写多线程程序,计算圆周率π值,并在Visual Studio 2005上调试、运行输出结果 五实验结果 源代码 #include VxWorks SMP多核编程指南 本文摘自vxworks_kernel_programmers_guide_6.8 第24章 1.介绍 VxWorks SMP是风河公司为VxWorks设计的symmetric multiprocessing(SMP)系统。它与风河公司的uniporcessor(UP)系统一样,具备实时操作系统的特性。 本章节介绍了风河VxWorks SMP系统的特点。介绍了VxWorks SMP的配置过程、它与UP编程的区别,还有就是如何将UP代码移植为SMP代码。 2.关于VxWorks SMP 多核系统指的是一个系统中包含两个或两个以上的处理单元。SMP是多核技巧中的一个,它的主要特点是一个OS运行在多个处理单元上,并且内存是共享的。另一种多核技巧是asymmetric multiprocessing(AMP)系统,即多个处理单元上运行多个OS。 (1)技术特点 关于CPU与处理器的概念在很多计算机相关书籍里有所介绍。但是,在此我们仍要对这二者在SMP系统中的区别进行详细说明。 CPU:一个CPU通常使用CPU ID、物理CPU索引、逻辑CPU索引进行标示。一个CPU ID通常由系统固件和硬件决定。物理CPU索引从0开始,系统从CPU0开始启动,随着CPU个数的增加,物理CPU索引也会增加。逻辑CPU索引指的是OS实例。例如,UP 系统中逻辑CPU的索引永远是0;对于一个4个CPU的SMP系统而言,它的CPU逻辑索引永远是0到3,无论硬件系统中CPU的个数。 处理器(processor):是一个包含一个CPU或多个CPU的硅晶体单元。 多处理器(multiprocessor):在一个独立的硬件环境中包含两个以上的处理器。 单核处理器(uniprocessor):一个包含了一个CPU的硅晶体单元。 例如:a dual-core MPC8641D指的是一个处理器上有两个CPU;a quad-core Broadcom 1480指的是一个处理器上有四个CPU。 在SMP系统上运行UP代码总会遇到问题,即使将UP代码进行了更新,也很难保证代码很好的利用了SMP系统的特性。对于在SMP上运行的代码,我们分为两个级别:SMP-ready:虽然可以正常的运行在SMP系统上,但是并没有很充分的利用SMP系统的特点,即没有利用到多核处理器的优势; SMP-optimized:不仅可以正常的运行在SMP系统上,而且还能很好的利用SMP系统的特点,使用多个CPU使多个任务可以同时执行,提高系统的效率,比UP系统的效果更加明显。 (2)VxWorks SMP OS特点 VxWorks单核编程(UP)与SMP编程在多数情况下是一样的。类似的,多数API在 对于多核cpu和多核编程模型的讨论 多内核定义: 多内核(multicore chips)是指在一枚处理器(chip)中集成两个或多个完整的计算引擎(内核)。 背景: 为什么不能用单核的设计达到用户对处理器性能不断提高的要求呢? 答案是功耗问题限制了单核处理器不断提高性能的发展途径。 多核技术的开发源于工程师们认识到,仅仅提高单核芯片(one chip)的速度会产生过多热量且无法带来相应的性能改善,先前的处理器产品就是如此。他们认识到,在先前产品中以那种速率,处理器产生的热量很快会超过太阳表面。即便是没有热量问题,其性价比也令人难以接受,速度稍快的处理器价格要高很多。 上世纪八九十年代以来,推动微处理器性能不断提高的因素主要有两个:半导体工艺技术的飞速进步和体系结构的不断发展。半导体工艺技术的每一次进步都为微处理器体系结构的研究提出了新的问题,开辟了新的领域;体系结构的进展又在半导体工艺技术发展的基础上进一步提高了微处理器的性能。这两个因素是相互影响,相互促进的。一般说来,工艺和电路技术的发展使得处理器性能提高约20倍,体系结构的发展使得处理器性能提高约4倍,编译技术的发展使得处理器性能提高约1.4倍。但这种规律性的东西却很难维持。 多核的出现是技术发展和应用需求的必然产物。这主要基于以下事实: 1.晶体管时代即将到来 根据摩尔定律,微处理器的速度以及单片集成度每18个月就会翻一番。多核通过在一个芯片上集成多个简单的处理器核充分利用这些晶体管资源,发挥其最大的能效。 2.门延迟逐渐缩短,而全局连线延迟却不断加长 3.符合Pollack规则 按照Pollack规则,处理器性能的提升与其复杂性的平方根成正比。如果一个处理器的硬件逻辑提高一倍,至多能提高性能40%,而如果采用两个简单的处理器构成一个相同硬件规模的双核处理器,则可以获得70%~80%的性能提升。同时在面积上也同比缩小。 4.能耗不断增长 5.设计成本的考虑 6.体系结构发展的必然 研究人员提出了两种新型体系结构: 单芯片多处理器(CMP)与同时多线程处理器(Simultaneous Multithreading,SMT),这两种体系结构可以充分利用这些应用的指令级并行性和线程级并行性,从而显著提高了这些应用的性能。 从体系结构的角度看,SMT比CMP对处理器资源利用率要高,在克服线延迟影响方面更具优势。CMP相对SMT的最大优势还在于其模块化设计的简洁性。复制简单设计非常容易,指令调度也更加简单。同时SMT中多个线程对共享资源的争用也会影响其性能,而CMP对共享资源的争用要少得多,因此当应用的线程级并行性较高时,CMP性能一般要优于SMT。此外在设计上,更短的芯片连线使CMP比长导线集中式设计的SMT更容易提高芯片的运行频率,从而在一定程度上起到性能优化的效果。 总之,单芯片多处理器通过在一个芯片上集成多个微处理器核心来提高程序的并行 第13章 多线程与多核编程 多任务的并发执行会用到多线程(multithreading ),而CPU 的多核(mult-core )化又将原来只在巨型机中才使用的并行计算(parallel computing )带入普通PC 应用的多核程序设计(multi-core programming )中。 13.1 进程与线程 进程(process )是执行中的程序,线程(thread )是一种轻量级的进程。 13.1.1 进程与多任务 现代的操作系统都是多任务(multitask )的,即可同时运行多个程序。进程(process )是位于内存中正被CPU 运行的可执行程序。参见图15-1。 图15-1 程序与进程 目前的主流计算机采用的都是冯·诺依曼(John von Neumann )体系结构——存储程序计算模型,程序(program )就是在内存中顺序存储并以线性模式在CPU 中串行执行的指令序列。对于传统的单核CPU 计算机,多任务操作系统的实现是通过CPU 分时(time-sharing )和程序并发(concurrency )完成的。即在一个时间段内,操作系统将CPU 分配给不同的程序,虽然每一时刻只有一个程序在CPU 中运行,但是由于CPU 的速度非常快,在很短的时间段中可在多个进程间进行多次切换,所以用户的感觉就像多个程序在同时执行,我们称之为多任务的并发。 13.1.2 进程与线程 程序一般包括代码段、数据段和堆栈,对具有GUI (Graphical User Interfaces ,图形用户界面)的程序还包含资源段。进程(process )是应用程序的执行实例,即正在被执行的程序。每个进程都有自己的虚拟地址空间,并拥有操作系统分配给它的一组资源,包括堆栈、寄存器状态等。 线程(thread )是CPU 的调度单位,是进程中的一个可执行单元,是一条独立的指令执行路径。线程只有一组CPU 指令、一组寄存器和一个堆栈,它本身没有其他任何资源,而是与拥有它的进程共享几乎一切,包括进程的数据、资源和环境变量等。线程的创建、维护和管理给操作系统的负担比进程要轻得多,所以才叫轻量级的进程(lightweight process )。 一个进程可以拥有多个线程,而一个线程只能属于一个进程。每个进程至少包含一个线程——主线程,它负责程序的初始化工作,并执行程序的起始指令。随后,主线程可为执行各种不同的任务而分别创建多个子线程。 一个程序的多个运行,可以通过启动该程序的多个实例(即多个进程)来完成,也可以进程(内存中) 可执行文件(磁/U/光盘上) 运行多核编程与并行计算实验报告 (1)
多核程序设计
多核编程与并行计算实验报告 (1)
多核程序设计概述
多核程序设计考题(样本)
《多核程序设计》概述
02多线程的那点儿事(之多核编程)
多核架构及编程技术
燕山大学多核程序设计实验报告
并行计算与多核程序设计
多核程序设计(最重要的)
积分计算pai 多核编程 cqupt
(完整word版)VxWorksSMP多核编程指南
对于多核cpu和多核编程模型的讨论
多线程与多核编程