OCR解决方案

IRISPdf6 Server OCR Server 解决方案
构造、索引、高度压缩并将所有文档转换为可搜索的优化文本文件的最强大的解决方案。IRISPdf 6 Server可以在一台工作站或服务器上使用来自多台工作站的图像处理大量文档。
新增功能
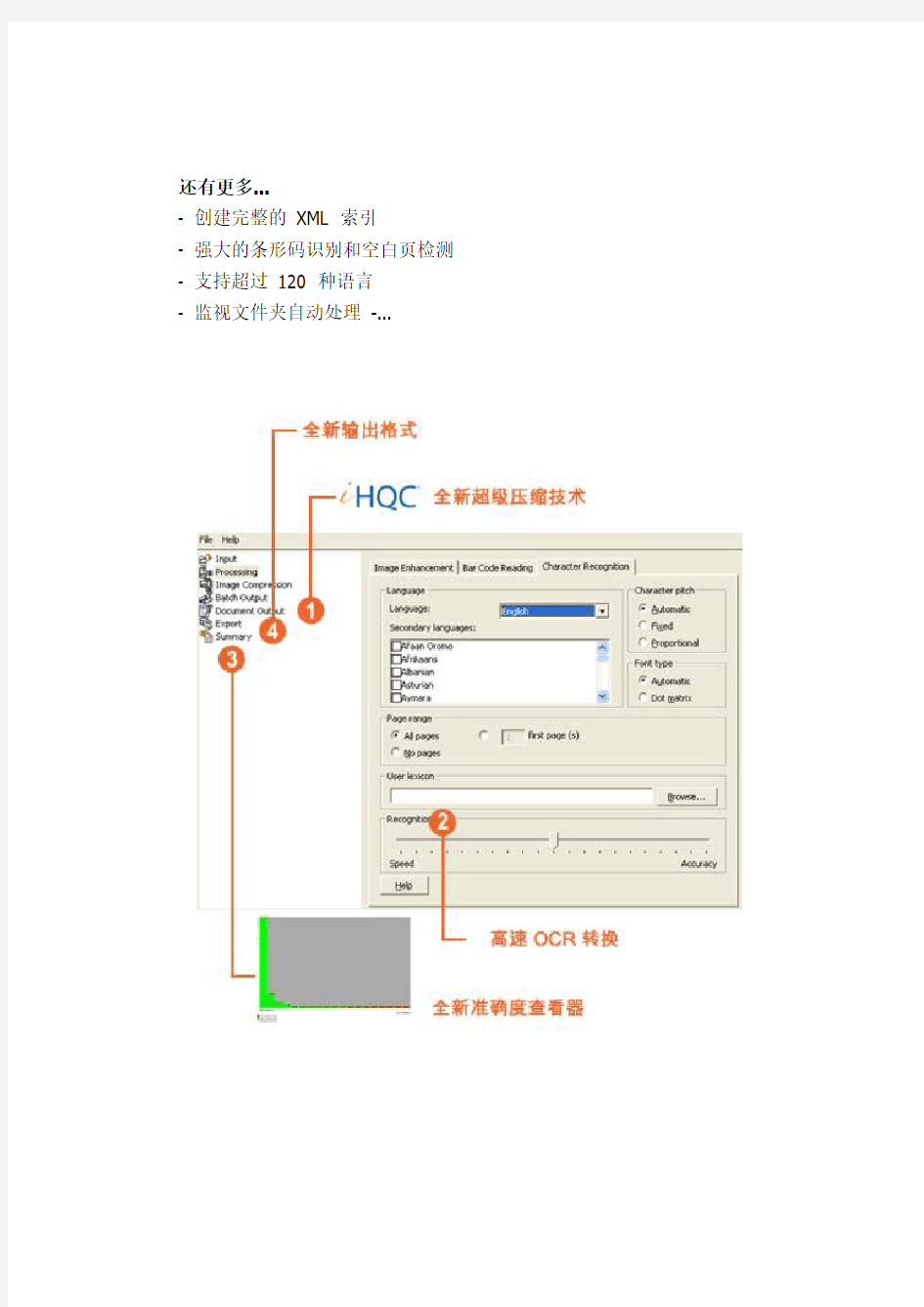
全新超级压缩技术(iHQC?) 插件
质量比JPEG2000 更高,而尺寸比PDF 更小。
高速OCR 转换
将文档高速转换为完全可搜索的PDF、RTF、TXT、DOC、WordML、SpreadsheetML、HTML、OpenDocument Text 或XML 文件。
全新OCR 准确度报告!
OCR 准确度报告为所有类型的文档提供OCR 准确度效果的图形视图。
它可以帮助最终用户调节扫描软件以实现最佳OCR 效果。借助这一新增功能,您可以评估文档的OCR 处理质量并调整IRISPdf 设置以及扫描仪设置,以获得最佳效果。
新增输出格式!
- PDF/A:比普通PDF 更严格,t这是长期存档的理想PDF 格式。
- PDF 安全方法:创建受保护的PDF 文件,需要密码才能对它们进行显示、修改和打印等操作。
- OpenDocument Text (*.odt):OpenDocument Text 是一种基于XML 的完全记录式开放格式。它可以读入OpenOffice 和StarOffice 中。
还有更多...
- 创建完整的XML 索引
- 强大的条形码识别和空白页检测- 支持超过120 种语言
- 监视文件夹自动处理-...
IRISPdf6 Server OCR Server Price List
使用Office 2003自带的OCR程序进行文字识别
使用Office 2003自带的OCR程序进行文字识别 用途:我们经常从期刊网下载的PDF文件或CAJ文件的文本都是不能直接复制出来的,遇到这种情况,我们可以使用Office 2003所自带的OCR程序进行识别。 操作步骤: 1. 用CAJViewer打开准备要进行文字识别的文件,按“文件→打印”按钮打开打印选项对话框。 2. 在“打印”对话框中,首先在“名称”选择栏中必须选中“Microsoft Office Document Image 2选择打印的范围
3. 然后按确定选择保存的位置,保存在那里都不要紧,因为打印生成的文件只是一个暂时使用的文件,我们在使用完后可以把他删除了。 4. 打印成功后,系统会自动打开“Microsoft Office Document Imaging”软件打开刚才打印成功的文件。 5. “Microsoft Office Document Imaging”打开后,选择工具栏中的眼睛图标进行文字识别。 6. 等待识别完成后,在文档区拉动鼠标选择需要复制的文字,当文字出现亮蓝显示时,证明文字是可以复制出来的,然后按键盘的ctrl+c,或者按鼠标右键复制都可以把文字复制出来。
附 如果你在第二步操作选择打印机时没有看到“Microsoft Office Document Image Writer”出现,表明你还没有按照Office 2003中的这个工具,我们可以按照以下的步骤安装。 1. 打开“控制面板”——“添加删除程序”。 2. 在“添加删除程序”列表框中选中Office 2003安装项目,选中它,然后点击“更改”按钮。 3. 在新打开的“Office 2003”安装对话框中,选择“添加删除功能”,然后按下一步。 4. 然后必须选择“选择应用程序的高级自定义”选项,再点击下一步按钮。
尚书7号OCR文字识别系统完全版
尚书7号OCR文字识别系统完全版 Shocr7.0 尚书7号OCR使用方法示例 因为不断有用户来电咨询尚书7号软件的使用,为此我们这里特别写了一份关于尚书7号软件的使用方法的实际例子,来帮助用户使用好尚书7号OCR软件。其中,很多是我们自己在使用尚书软件的心得,请用户尽量按照示例来操作。 一、扫描仪驱动程序请切换到高级控制面板状态 为了得到较好的OCR使用效果,建议用户将扫描仪的驱动SCANWIZARD 5软件,由初始安装的标准控制面板,切换到高级控制面板状态。其切换的方法,如下图所示。
二、第一次使用尚书OCR7号软件 1.尚书7号OCR软件是MICROTEK中晶科技公司,向汉王科技购买授权,赠送给用户使用的软件,该软件是放在了扫描仪随机的驱动光盘中,用户可以选择安装。 2.软件安装完毕后,用户请点击桌面左下角“开始”,找到“尚书7号OCR”软件图标,并点击。打开尚书7号OCR的使用界面。
3.打开尚书7号OCR的“文件”采单下的“选择扫描仪”,选择对应扫描仪的驱动“MICROTEK SCANWIZARD 5”的选项。并选择“确 定”。
4.选择“文件”菜单下的“扫描”,将打开扫描仪的驱动。如下图,下面的界面是扫描仪的“高级控制面板”。
5.拥护请注意选择SCANWIZARD 5软件中,左面“设置”窗口中的“图像类型”,请选择“RGB色彩”或者“灰阶”的类型,并注意 扫描仪分辨率是300PPI。
6.当用户作完“预览”后,设置需要扫描的范围,就可以点击“扫描”按钮,扫描仪将开始扫描的工作。将扫描好的文件,直接传递到尚书7号OCR默认的目录中(默认的存储图像文件的目录是用户计算机C盘下的SHOCR2002目录下的IMAGE目录)。扫描完毕后,请用户关闭掉扫描仪驱动程序SCANWIZARD 5.用户可以看到需要扫描的文件已经传递给尚书7号中,默认的文件名是HW001.JPG。 7.请用户选择尚书7号软件中的“编辑”菜单下的“自动倾斜校正”,让尚书7号软件对扫描进来的图像作相应的旋转,以保证图像中的文字是水平排列,而非倾斜。因为太过倾斜的文字,将影响到尚书软件的识别效果。
OCR文字识别系统
授课内容及教学活动设计附注(教学方法、活动形式、辅助手段等) 2?删除识别区域 3?更改识别区域的顺序 多个识别区域的使用,可以较好处理图文混排的稿件。 活动二识别之前稿件画面的处理 在实际应用中,稿件画面并不都像sample文件夹中那样理想, 或多或多少会有小许倾斜、污点等,这会影响到最后识别的效果。所以最好在识别之前,先对稿件画面进行一定的处理,以增加识别的准确率。 1?擦拭图像一一用“橡皮”工具擦去图像上的杂点或部分一块图像区域。 2.旋转图像一一可以对图像旋转90、180、270度的旋转。因 为在拍摄、扫描图像的过程中,可能会出现90、180、270度的差异。 3?倾斜校正一一拍摄或扫描图像的过程中,可以会形成几度的倾斜,用此功能可以将图像校正。 活动四其它类型稿件的识别 除了对中文内容的稿件进行识别外,汉王OCR文字识别系统 还可以对繁体中文、英文、表格等内容的稿件进行有效的识别。 任务1对繁体中文、英文、表格等内容的稿件进行识别 对繁体中文、英文的识别操作与中文相冋,只是在识别之前需要在工具栏最右边的下拉列表中选择“ 繁体字集”或“纯英文识别” 的选项。 任务2对含有表格的稿件进行识别含有表格稿件的识别操作与中文稿件的识别相冋。 任务3特殊网页的识别 1 .使用屏幕硬拷贝的功能将网页画面转换成图像文件。 2.用OCR软件对此进行识别,发现效果很差。 3.用Photoshop对图像文件进行分辨率的处理。 4.再用OCR软件对此进行识别,发现效果较好。 可以使用软件自带的样例图片进行上机实验,这些图片存放在sample 文件夹中。 可以使用sample文件夹中的文件进行上机操作。 可以将学生机与因特网相联。或将现成的网页图像提供给学生。
好用的ocr文字识别软件-捷速OCR文字识别
好用的ocr文字识别软件-捷速OCR文字识别很多人在网友求助“如何把图片转换成文字”,这个时候肯定会有人看不明白,图片怎么转换成文字,这是因为这些图片中有文字,但是这些文字不能被复制和编辑属于“死文字”,所以需要转换成可以编辑的文字。在没有工具帮忙的情况下,这些图片文字就只能靠手动输入的方式进行处理,明显这样的方法实在是太落后了。在科技如此发达的今天肯定有一些好的工具,高效的完成图片转换成文字的工作。 说的没错,ocr图片文字识别软件就是这样一款工具,该软件能够识别图片文字,很快的将其提取出来。虽然你在网上搜索图片文字识别软件会出现一大堆,但是众多的用户选择了ocr图片文字识别软件,这是因为该软件拥有超强光学文字识别技术,能够对文字进行多层次深入的解析,所以软件的识别率一直保持在98%左右,同时软件还拥有极速内核,运转的速度非常快,虽然文字识别的程序很复杂但是软件还能够对识别的文件实现瞬间识别,识别速度在批量识别的时候更能体现。 如何把图片转换成文字,ocr图片文字识别软件之所以被广大用户接受的原因之一,就是因为软件的操作非常的简单,如果软件空有高识别率和识别速度,普通用户不能操作的话一切都等于零。ocr图片文字识别软件精简的操作步骤,深受用户的喜欢,用户打开软件在软件的左上角有一个“添加文件”按钮,将需要转换的文
件进行添加操作,当然你还可以直接拖曳文件至软件中,这是该软件爱你独有的一个功能。然后点击“开始转换”即可完成转换,没有任何多余额达步骤,识别得出的结果会存放在原文件夹内。 如果你也有图片需要转换成文字,不妨试试ocr图片文字识别软件,相信不管是从用户体验度还是识别效果各个方面都能让你满意。
如何在电脑中进行图片文字识别
如何在电脑中进行图片文字识别 说到图片文字识别,大家在使用电脑办公的时候经常会遇到这样的情况,该如何去解决呢?接下来给大家分享到一种在电脑中进行的文字识别的方法,比较的简单,而且识别出来的效果也很不错,有需要的小伙伴们可以来学习一下。 使用工具:迅捷OCR文字识别软件。 软件介绍:这款软件可以将不同文件格式的图片转换成可编辑的文档形式,支持JPG、PNG、BMP格式的图片,可以进行票证识别,还可以实现CAJ、PDF文件转换到其它的文档里,精准识别、自动解析、完美还原、超强纠错是这款软件的特点,所以如果你想要在电脑中进行图片文字识别的话,迅捷OCR文字识别软件 https://https://www.360docs.net/doc/597815845.html,/ocr就可以帮你解决这个问题了。 操作步骤: 1、打开电脑,在浏览器中搜索迅捷办公然后找到迅捷OCR文字 识别软件将其下载安装到自己的电脑中去,接下来的步骤会使用到。
2、打开软件,会出来这样一个页面,点击退出按钮退出该页面。 3、接着点击软件上方图片上方图片局部识别功能。
4、来到图片局部识别页面,点击“添加文件”将需要转换的图片添 加进来,如下图:
5、图片添加进来之后,点击图片下方的第二个小工具(框选工具) 在图片上框选出想要识别的文字范围,框选完软件就会自动去识别了。
6、识别结束之后提取出来的文字会显示在右边方框内,可以看到 识别出来的文字还是比较精准的,下面还有个语种翻译功能,如果你想将识别出来的文字翻译成其它语言的话可以点击下拉框,找到需要翻译成的语言,再点击翻译就好了。
7、接下来点击图片下方保存为TXT就可以将识别出来的文字保 存到TXT里面,整个的步骤操作到这里也就结束了。
OCR 分析报告
OCR定义 OCR(Optical Character Recognition)即光学字符识别,是指电子设备(如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程:即对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。 目前项目使用需求 项目名称:吉凯随访系统; 项目甲方:吉凯基因技术有限公司;。 需求目标:吉凯随访系统中规划的OCR技术需求范围:利用OCR技术功能模块,解析用户所上传的病历文档图片(包含病历、医嘱、检查、检验等文书),将图片转换为计算机可识别的文字语言;根据转换的结果进行分析、统计等应用; 对所建议开发的软件基本要求如下: ●病例图片文字识别; ●识别率90%以上,识别时间小于10分钟; ●输出病例相关内容,需要按照病例格式输出,否则无法判断最终结果; ●患者上传相关病例文档图片,上传之后后台识别反馈结果给患者或者医生。; ●数据词库自己训练,需要程序自动带有学习功能; ●开发周期两个月。
现状 目前市面上OCR技术应用于医疗行业的APP及软件如下: 汉王OCR(PC端软件): 汉王OCR是一个带有 PDF 文件处理功能的 OCR 软件;具有识别正确率高,识别速度快的特 点。有批量处理功能,避免了单页处理的麻烦;支持处理灰度、彩色、黑白三种色彩的BMP、 TIF、JPG、PDF多种格式的图像文件;可识别简体、繁体和英文三种语言;具有简单易用的表格识别功能;具有TXT、RTF、HTM和XLS多种输出格式,并有所见即所得的版面还原功 能。新增打开与识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别, 既可以采用OCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转 换文字型PDF文件为RTF文件或文本文件; 实际测试汉王OCR后发现其受图片质量、图片格式、图片灰度、图片大小等因素影响,实 际对于病历文档的识别率不到30%,不能满足项目需求; 但其可接受定制化需求,定制化需要额外付费,初步估计在10W以上一个病历模板,目前 病历的模板种类数量非常大,项目成本将无法预估; 易道博识 北京易道博识科技有限公司(简称“易道博识”)成立于2013年,由来自中科院、清华大学、北京大学的多名顶尖的模式识别专家共同组建。创始人朱军民获得了国家科技进步二等奖等多项业界成就。核心技术包括:3D人脸识别、银行表单识别、增值税发票识别、支票识别、各类证照识别、一维码识别、二维码识别、联机手写识别等。 实际测试该公司OCR产品后发现其OCR对于证件识别率较高,但达不到90%。识别病历图片的准确率达不到20%。但其可接受定制化需求,定制化需要额外付费,基础功能起步价10W,病历模板定制10W一个。项目成本无法预估。 泰比(ABBYY) 泰比(ABBYY)是一个在文档转换、数据捕获和语言软件领域领先的供应商。泰比(ABBYY)研究和发展的关键领域包括文档识别技术及应用语言学。
ocr文字识别软件如何对图片内的文字进行编辑和提取修改
ocr文字识别软件如何对图片内的文字进行编辑 和提取修改 提起对图片内的文字内容进行修改和编辑,我相信不 少人都认为小编是说在做平面广告的时候,对广告宣传用语或平面设计的内容进行修改呢,那些都是平面设计人员通过专门和平面设置软件干的活,这里小编的意思提完全把图片 内的文字信息提取出来,再对这些文件进行通过word或者是txt等文档格式进行编辑,现在跟着小编一起看一下具体的操作方法。 1、编辑图片内的文字,还不能像office 等软件 图片内的文字进行修改和编辑,所以我们需要借助ocr文字 识别软件进行修改和提取,通过这个文字识别的技术我们可以很方便的对文字进行提取。
2、下载好这个软件之后,就安装到你的电脑上,然后打 开这个软件就可以了,现在要做的第一步就是添加文件到软件上面,你可以通过软件上的功能键来添加,也可以自己直接拉到软件上来,具体操作可以参照下面的图;
勿做商业用途 I 3、接下来就是要设置好这个文件在你电脑上保存的地点, 你可以在软件下面找到文件输出的选项,这里默认的是电脑 的桌面,你可以点最右边的浏览菜单来设置文件夹,具体操 作如图,小编一般都放在桌面上,因为操作起来方便,找文 件也方便; I M I w j 'ftfesais 昭讯摹 \> o It Hr 婆用何iS ?範AM ?酣討£ 19看a 宜轉買 II ?抄二1 !■ 1~ [个人收集整理 liTk in ' rrtWFti 空SifiE w* 直* £列k !ir 理K ■ 焉 ■ft £旳 「卫是 』■计sn 皿 Tgft iC) 」E4 ◎■ ^"*=- 二 节<■ AZH3
OCR文字识别的杂谈
国内的OCR扫描识别软件。 一般通用的文档扫描软件,只能扫描识别简单的简体中文。 对于像纯英文、韩语、日语等的识别技术相对来说难度较大。 对于像这种外文文字的识别,需要更强大的识别核心技术。要具备高性能的文字识别引擎。包括编码格式都需要达到国际的编码标准,比如UNICODE编码。 目前对于韩语、日语等外籍文字的扫描识别,一般还是集中在对于大幅面的文档扫描识别。简体中文和繁体中文,大都集中在报社的报纸以及出版物数字化方面的应用。 要把印刷的文档转化为可以供阅读和可编辑的高质量电子文档。已经是现代的一种市场需求。只有转化为电子版,才能应用到各类数据库、电子出版物、数字图书馆等。。。 但是目前很多报社都是采取手工录入的方式。 耗费的人力成本和浪费的时间更是让行业内人员苦不堪言。 其实对于这种行业市场趋势和行业问题的解决。有很多厂商和技术开发厂商已经有所斩获。比如报纸来说。排版相对来说比较规范,文本、图片、表格。无非就是这几种表现形式。 只要针对这几个方面进行相应的开发和版面分析。不难做到精准识别。
识别软件大同小异。但是往往区别就体现在识别率上、出错率上、版面还原度高不高上。想必大家用过一些免费的识别软件,不是出现乱码,就是横七竖八的一大堆东西。 总之很头疼。不过也无可厚非。免费的东西总是不尽人意。 而这些免费的测试版,只是商家的一个前期广告推广,市场推广。 想要体验或使用成熟的产品。为公司的运行提升效率,还是建议读者购买正式版。 国内这几年也在大力的研发和钻研这种OCR识别技术。 如同那些默默无闻制造CPU、相机镜头、HIWI组件的厂商一样。 OCR 行业内也存在着这种现象。有些公司在这方面相当的技术成熟,但是却很少为人所知。 打个比方,冰箱品牌也数不胜数。但是大家知道海尔、容声之类的大品牌。 但是不可否认人家花大价钱投入了市场的宣传和开拓,才有了这样的广告效应。 可是不代表那些提不上名的冰箱就质量不行。只是没有那样烧钱而已。 最近和很多集成商打交道。 总是在提北京一家公司的OCR技术很成熟。但是着实没有在业界听过。 所以特意上网搜索了一下。公司名字是北京文通科技有限公司。
文字识别OCR文档
文字识别OCR文档 文档创建时间:2010-01-05 文档最后修改时间:2015-04-20 All rights reserved by Tianrui Workroom ? 1 Introduction 天瑞文字识别OCR适用于名片、卡片、杂志和报纸期刊等各种复杂版面上的文字识别,也同样适用于扫描文档等一般文档类版面的识别工作,支持中、日、韩、英、法、德、意、俄、西班牙、葡萄牙等共计70门语言,服务于世界各国的相关软件研发公司,是目前世界上支持语言最多的商用OCR引擎之一。 ? 2 API Description 本SDK共有8个API接口,分别是: 打开引擎"int openOcrEngine(String strDatFilePath);" 设置识别语言“int setOcrLanguage(int language);" 识别文字"int recognizeImage(int []imagePixels, int w, int h);" 关闭引擎"int closeOcrEngine();" 注意:识别文本成功后,以下接口返回识别结果,否则返回null。文本词与文本行识别结果区别在于文本输出后的组织形式不同。 得到文本词结果"String[] getWholeWordResult();" 得到文本词位置"int[] getWholeWordRect();" 得到文本行结果"String[] getWholeTextLineResult();" 得到文本行位置"int[] getWholeTextLineRect();" 2.1 打开引擎 int openOcrEngine(String strDatFilePath); 函数功能:打开引擎,完成引擎初始化工作,程序运行时调用一次即可 输入参数:strDatFilePath,dat文件的路径; 返回值:1,表示初始化成功