面板数据模型
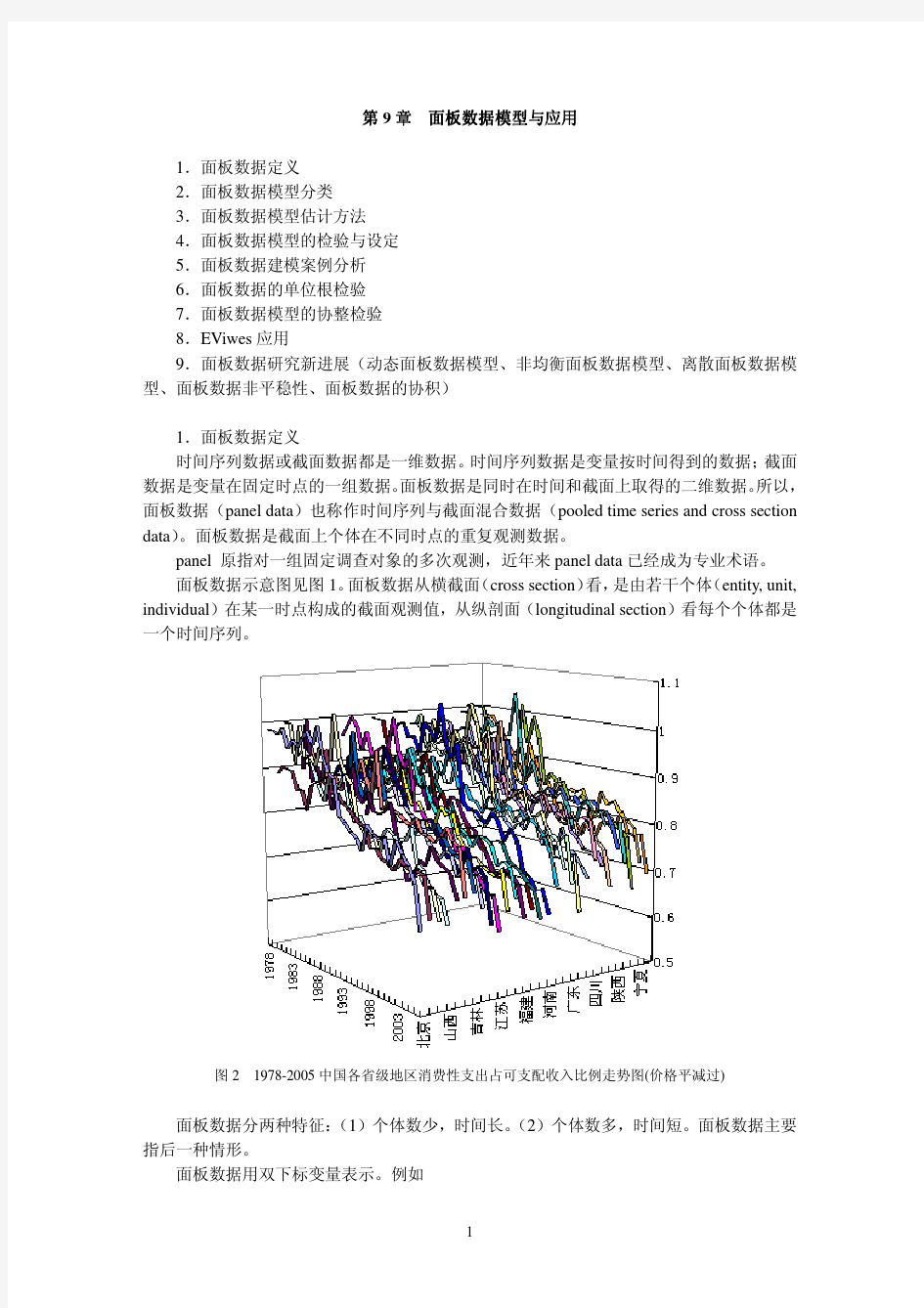

MATLAB空间面板数据模型操作介绍
MATLAB空间面板数据模型操作简介 MATLAB安装:在民主湖资源站上下载MA TLAB 2009a,或者2010a,按照其中的安装说明安装MATLAB。(MATLAB较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局: 首先我们说一下MA TLAB处理空间面板数据时,数据文件是怎么布局的,熟悉eviews的同学可能知道,eviews中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中“1-94”“1-95”“1-96”“1-97”中,1是省份的代号,94,95,96,97表示年份,eviews是将每个省份的数据放在一起,再将所有省份堆放在一起。 与eviews不同,MATLAB处理空间面板数据时,面板数据的布局是(在excel中说明):先排放一个横截面上的数据(即某年所有省份的数据),再将不同年份的横截面按时间顺序堆放在一起。如图:
这里需要说明的是,MA TLAB中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。 二、数据的输入: MATLAB与excel链接:在excel中点击“工具→加载宏→浏览”,找到MA TLAB的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为:C:\Programfiles\MATLAB\R2009a\toolbox\exlink,点击excllink.xla即可完成excel与MATLAB的链接。这样的话excel中的数据就可以直接导入MATLAB中形成MATLAB的数据文件。操作完成后excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB”即表示我们希望excel 与MATLAB实现链
16种常用数据分析方法
一、描述统计描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策 树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W 检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数卩与已知的某一总体均数卩0 (常为理论值或标准值)有无差别; B 配对样本t 检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t 检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。 A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10 以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如何,常用方法分半信度。 四、列联表分析用于分析离散变量或定型变量之间是否存在相关。对于二维表,可进行卡 方检验,对于三维表,可作Mentel-Hanszel 分层分析列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以
基于面板数据模型及其固定效应的模型分析
基于面板数据模型及其固定效应的模型分析 在20世纪80年代及以前,还只有很少的研究面板数据模型及其应用的文献,而20世纪80年代之后一直到现在,已经有大量的文献使用同时具有横截面和时间序列信息的面板数据来进行经验研究(Hsiao,20XX)。同时,大量的面板数据计量经济学方法和技巧已经被开发了出来,并成为现在中级以上的计量经济学教科书的必备内容,面板数据计量经济学的理论研究也是现在理论计量经济学最热的领域之一。 面板数据同时包含了许多横截面在时间序列上的样本信息,不同于只有一个维度的纯粹横截面数据和时间序列数据,面板数据是同时有横截面和时序二维的。使用二维的面板数据相对于只使用横截面数据或时序数据,在理论上被认为有一些优点,其中一个重要的优点是面板数据被认为能够控制个体的异质性。在面板数据中,人们认为不同的横截面很可能具有异质性,这个异质性被认为是无法用已知的回归元观测的,同时异质性被假定为依横截面不同而不同,但在不同时点却是稳定的,因此可以用横截面虚拟变量来控制横截面的异质性,如果异质性是发生在不同时期的,那么则用时期虚拟变量来控制。而这些工作在只有横截面数据或时序数据时是无法完成的。 然而,实际上绝大多数时候我们并不关心这个异质性究竟是多少,我们关心的仍然是回归元参数的估计结果。使用面板数据做过实际研究的人可能会发现使用的效应①不同,对回归元的估计结果经常有十分巨大的影响,在某个固定效应设定下回归系数为正显着,而另外一个效应则变为负显着,这种事情经常可以碰到,让人十分困惑。大多数的研究文献都将这种影响解释为控制了固定效应后的结果,因为不可观测的异质性(固定效应)很可能和回归元是相关的,在控制了这个效应后,由于变量之间的相关性,自然会对回归元的估计结果产生影响,因而使用的效应不同,估计的结果一般也就会有显着变化。 然而,这个被广泛接受的理论假说,本质上来讲是有问题的。我们认为,估计的效应不同,对应的自变量估计系数的含义也不同,而导致估计结果有显着变化的可能重要原因是由于面板数据是二维的数据,而在这两个不同维度上,以及将两个维度的信息放到一起时,样本信息所显现出来的自变量和因变量之间的相关关系可能是不同的。因此,我们这里提出另外一种异质性,即样本在不同维度上的相关关系是不同的,是异质的,这个异质性是发生在回归元的回归系数上,而 不是截距项。我们试图从面板数据的横截面维度和时间序列维度的样本相关异质性角
剖析大数据分析方法论的几种理论模型
剖析大数据分析方法论的几种理论模型 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 作者:佚名来源:博易股份|2016-12-01 19:10 收藏 分享 做大数据分析的三大作用,主要是:现状分析、原因分析和预测分析。什么时候开展什么样的数据分析,需要根据我们的需求和目的来确定。 利用大数据分析的应用案例更加细化的说明做大数据分析方法中经常用到的几种理论模型。 以营销、管理等理论为指导,结合实际业务情况,搭建分析框架,这是进行大数据分析的首要因素。大数据分析方法论中经常用到的理论模型分为营销方面的理论模型和管理方面的理论模型。 管理方面的理论模型: ?PEST、5W2H、时间管理、生命周期、逻辑树、金字塔、SMART原则等?PEST:主要用于行业分析 ?PEST:政治(Political)、经济(Economic)、社会(Social)和技术(Technological) ?P:构成政治环境的关键指标有,政治体制、经济体制、财政政策、税收政策、产业政策、投资政策、国防开支水平政府补贴水平、民众对政治的参与度等。?E:构成经济环境的关键指标有,GDP及增长率、进出口总额及增长率、利率、汇率、通货膨胀率、消费价格指数、居民可支配收入、失业率、劳动生产率等。?S:构成社会文化环境的关键指标有:人口规模、性别比例、年龄结构、出生率、死亡率、种族结构、妇女生育率、生活方式、购买习惯、教育状况、城市特点、宗教信仰状况等因素。
?T:构成技术环境的关键指标有:新技术的发明和进展、折旧和报废速度、技术更新速度、技术传播速度、技术商品化速度、国家重点支持项目、国家投入的研发费用、专利个数、专利保护情况等因素。 大数据分析的应用案例:吉利收购沃尔沃 大数据分析应用案例 5W2H分析法 何因(Why)、何事(What)、何人(Who)、何时(When)、何地(Where)、如何做(How)、何价(How much) 网游用户的购买行为: 逻辑树:可用于业务问题专题分析
面板数据的计量方法
1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输出结果中没有公共截距项。 (2)时刻固定效应模型。 时刻固定效应模型就是对于不同的截面(时刻点)有不同截距的模型。如果确知
MATLAB空间面板数据模型操作介绍
MATLAB 空间面板数据模型操作简介 MATLAB 安装: 在民主湖资源站上下载 MA TLAB 2009a ,或者 2010a ,按照其中的安装说明 安装 MATLAB 。( MATLAB 较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局 首先我们说一下 MA TLAB 处理空间面板数据时,数据文件是怎么布局的,熟悉 eviews 的同学 可能知道, eviews 中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间 序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中 “1-94”“1-95” “1-96” “ 1-97”中, 1是省份的代号, 94,95,96,97 表示年份, eviews 是将每个省 份的数据放在一起,再将所有省份堆放在一起。 与 eviews 不同, MATLAB 处理空间面板数据时,面板数据的布局是(在 excel 中说明): 先排 放一个横截面上的数据(即某年所有省份的数据) ,再将不同年份的横截面按时间顺序堆放在一起。 如图:
这里需要说明的是, MA TLAB 中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。二、数据的输入: MATLAB 与 excel链接:在 excel中点击“工具→加载宏→浏览” ,找到 MA TLAB 的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为: C:\Programfiles\MATLAB\R2009a\toolbox\exlink ,点击 excllink.xla 即可完成 excel 与 MATLAB 的链接。这样的话 excel 中的数据就可以直接导入 MATLAB 中形成 MATLAB 的数据文件。操作完成后 excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB ”即表示我们希望 excel 与
空间面板数据分析——R的splm包资料
空间面板数据分析——R的splm包 (任建辉,暨南大学) The splm package provides methods for fitting spatial panel data by maximum likelihood and GM. 安装R软件及其编辑器Rstudio 网址:https://www.360docs.net/doc/508331077.html, https://www.360docs.net/doc/508331077.html,/ 下载好Rstudio以后,操作都可以Rstudio中完成了,包括命令的编写、命令运行、图形展示,最方便的要数查看数据了。 R界面 Rstudio界面,形如matlab
下面进入正题,了解splm包中的数据、命令及结果展示。所有命令都写在编辑窗口(studio 左上区域),可以单独的运行每行命令,也可选取一段一起执行,点run按钮。 1、首先,安装splm包并导入,命令如下: intall.packages(“splm”),选择最近的下载点 library(splm) > library(splm) 载入需要的程辑包:MASS 载入需要的程辑包:nlme 载入需要的程辑包:spdep 载入需要的程辑包:sp 载入需要的程辑包:Matrix 载入需要的程辑包:plm 载入需要的程辑包:bdsmatrix 载入程辑包:‘bdsmatrix’ 下列对象被屏蔽了from ‘package:base’: backsolve 载入需要的程辑包:Formula 载入需要的程辑包:sandwich 载入需要的程辑包:zoo 载入程辑包:‘zoo’ 下列对象被屏蔽了from ‘package:base’: as.Date, as.Date.numeric 载入需要的程辑包:spam 载入需要的程辑包:grid Spam version 0.40-0 (2013-09-11) is loaded. Type 'help( Spam)' or 'demo( spam)' for a short introduction and overview of this package. Help for individual functions is also obtained by adding the suffix '.spam' to the function name, e.g. 'help( chol.spam)'. 载入程辑包:‘spam’ 下列对象被屏蔽了from ‘package:bdsmatrix’:
16种常用数据分析方法66337
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如 何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析
面板数据的计量方法
面板数据的计量方法 1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输
六步学会用做空间计量回归详细步骤
与MATLAB链接: Excel: 选项——加载项——COM加载项——转到——没有勾选项 2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏 E:\MATLAB\toolbox\exlink 然后,Excel中就出现MATLAB工具
(注意Excel中的数据:) 3.启动matlab (1)点击start MATLAB (2)senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量)
(data表中数据进行命名) (空间权重进行命名) (3)导入MATLAB中的两个矩阵变量就可以看见
4.将elhorst和jplv7两个程序文件夹复制到MATLAB安装目录的toolbox文件夹 5.设置路径:
6.输入程序,得出结果 T=30; N=46; W=normw(W1); y=A(:,3);
x=A(:,[4,6]); xconstant=ones(N*T,1); [nobs K]=size(x); results=ols(y,[xconstant x]); vnames=strvcat('logcit','intercept','logp','logy'); prt_reg(results,vnames,1); sige=*((nobs-K)/nobs); loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*'* % The (robust)LM tests developed by Elhorst LMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释 每一行分别表示:
空间面板数据分析R的splm包
空间面板数据分析——R的s p l m包 (任建辉,暨南大学) The splm package provides methods for fitting spatial panel data by maximum likelihood and GM. 安装R软件及其编辑器Rstudio 网址:https://www.360docs.net/doc/508331077.html, 下载好Rstudio以后,操作都可以Rstudio中完成了,包括命令的编写、命令运行、图形展示,最方便的要数查看数据了。 R界面 Rstudio界面,形如matlab 下面进入正题,了解splm包中的数据、命令及结果展示。所有命令都写在编辑窗口(studio左上区域),可以单独的运行每行命令,也可选取一段一起执行,点run按钮。 1、首先,安装splm包并导入,命令如下: intall.packages(“splm”),选择最近的下载点 library(splm) > library(splm) 载入需要的程辑包:MASS 载入需要的程辑包:nlme 载入需要的程辑包:spdep 载入需要的程辑包:sp 载入需要的程辑包:Matrix 载入需要的程辑包:plm 载入需要的程辑包:bdsmatrix 载入程辑包:‘bdsmatrix’ 下列对象被屏蔽了from ‘package:base’: backsolve
载入需要的程辑包:Formula 载入需要的程辑包:sandwich 载入需要的程辑包:zoo 载入程辑包:‘zoo’ 下列对象被屏蔽了from ‘package:base’: 载入需要的程辑包:spam 载入需要的程辑包:grid Spam version 0.40-0 (2013-09-11) is loaded. Type 'help( Spam)' or 'demo( spam)' for a short introduction and overview of this package. Help for individual functions is also obtained by adding the suffix '.spam' to the function name, e.g. 'help( chol.spam)'. 载入程辑包:‘spam’ 下列对象被屏蔽了from ‘package:bdsmatrix’: backsolve 下列对象被屏蔽了from ‘package:base’: backsolve, forwardsolve 载入需要的程辑包:ibdreg 载入需要的程辑包:car 载入需要的程辑包:lmtest 载入需要的程辑包:Ecdat 载入程辑包:‘Ecdat’ 下列对象被屏蔽了from ‘package:car’: Mroz 下列对象被屏蔽了from ‘package:nlme’: Gasoline 下列对象被屏蔽了from ‘package:MASS’: SP500 下列对象被屏蔽了from ‘package:datasets’: Orange 载入需要的程辑包:maxLik 载入需要的程辑包:miscTools Please cite the 'maxLik' package as: Henningsen, Arne and Toomet, Ott (2011). maxLik: A package for maximum likelihood es timation in R. Computational Statistics 26(3), 443-458. DOI 10.1007/s00180-010-0217 -1. If you have questions, suggestions, or comments regarding the 'maxLik' package, plea se use a forum or 'tracker' at maxLik's R-Forge site: Warning message: 程辑包‘Matrix’是用R版本3.0.3 来建造的 注意:在导入splm时,如果发现还有其他配套的包没有安装,需要先安装。 2、接着,查看数据及结构,命令如下:
常用数据分析方法
常用数据分析方法 常用数据分析方法:聚类分析、因子分析、相关分析、对应分析、回归分析、方差分析;问卷调查常用数据分析方法:描述性统计分析、探索性因素分析、Cronbach’a信度系数分析、结构方程模型分析(structural equations modeling) 。 数据分析常用的图表方法:柏拉图(排列图)、直方图(Histogram)、散点图(scatter diagram)、鱼骨图(Ishikawa)、FMEA、点图、柱状图、雷达图、趋势图。 数据分析统计工具:SPSS、minitab、JMP。 常用数据分析方法: 1、聚类分析(Cluster Analysis) 聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 2、因子分析(Factor Analysis) 因子分析是指研究从变量群中提取共性因子的统计技术。因子分析就是从大量的数据中寻找内在的联系,减少决策的困难。 因子分析的方法约有10多种,如重心法、影像分析法,最大似然解、最小平方法、阿尔发抽因法、拉奥典型抽因法等等。这些方法本质上大都属近似方法,是以相关系数矩阵为基础的,所不同的是相关系数矩阵对角线上的值,采用不同的共同性□2估值。在社会学研究中,因子分析常采用以主成分分析为基础的反覆法。 3、相关分析(Correlation Analysis) 相关分析(correlation analysis),相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度。相关关系是一种非确定性的关系,例如,以X和Y分别记一个人的身高和体重,或分别记每公顷施肥量与每公顷小麦产量,则X 与Y显然有关系,而又没有确切到可由其中的一个去精确地决定另一个的程度,这就是相关关系。 4、对应分析(Correspondence Analysis) 对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。 5、回归分析 研究一个随机变量Y对另一个(X)或一组(X1,X2,…,Xk)变量的相依关系的统计分析方法。回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。 6、方差分析(ANOVA/Analysis of Variance) 又称“变异数分析”或“F检验”,是R.A.Fisher发明的,用于两个及两个以上样本均数差
空间面板数据计量经济分析
空间面板数据计量经济分析 空间面板数据计量经济分析 *以上分别介绍了区域创新过程中空间效应(依赖性和异质性)的空间计量检测,以及纳入空间效应的计量模型的估计方法——空间常系数回归模型(空间滞后模型,SLM 和空间误差模型,SEM )和空间变系数回归模型(地理加权回归模型,GWR );同时还介绍和分析了面板数据(Panel Data )计量经济学方法的估计和检验。 *可以看出,目前的空间计量经济学模型使用的数据集主要是截面数据,只考虑了空间单元之间的相关性,而忽略具有时空演变特征的时间尺度之间的相关性,这显然是一个美中不足。 *Anselin (1988)也认识到这一点。当然,大多学者通过将多个时期截面数据变量计算多年平均值的办法来综合消除时间波动的影响和干扰,但是这种做法仍然造成大量具有时间演变特征的创新行为信息的损失,从而无法科学和客观地认识和揭示具有时空二维特征的研发与创新过程的真实机制。*面板数据(Panel Data )计量经济模型作为目前一种前沿的计量经济估计技术,由于其可以综合创新行为变量时间尺度的信息和截面(地域空间)单元的信息,同时集成考虑了时间相关性和空间(截面)相关性,因而能够科学而客观地反映受到时空交互相关性作用的创新行为的特征和规律,是定量揭示研发、知识溢出与区域创新相互作用关系的有效方法。但是,限于在所有时刻对所有个体(空间)均相等的假定(即不考虑空间效应),面板数据计量经济学理论也有其美中不足之处,具有很大的改进余地。 *鉴于空间计量经济学理论方法和面板数据计量经济学理论方法各有所长,把面板数据模型的优点和空间计量经济学模型的特点有机结合起来,构建一个综合考虑了变量时空二维特征和信息的空间面板数据计量经济模型,则是一种新颖的研究思路。以下根据空间计量经济模型和标准的面板数据模型[1]的建模思路,提出空间面板数据(Spatial Panel Data Model ,SPDM )模型的建模思路和过程。 [1]与动态面板数据模型的建模思路类似,只要施加一些假定,引入因变量的滞后项,则为空间动态面板数据模型。 空间滞后面板数据计量分析 *考虑一个标准的面板数据模型: it it it it it y αx βμ=++*如果将变量的真实的区域空间自相关性(依赖性)(Anselin &Florax ,1995)考虑到创新行为中来,这种创新行为的空间自相关性可以视为区域创新过程中的一种外部溢出形式,这样则可以设定如下模型: it it it it it it y αWy x βμρ=+++*上式为空间滞后面板数据(Spatial Lag Panel Data Model ,SLPDM )计量经济模型。其中,是创新的空间滞后变量,主要度量在地理空间上邻近地区的外部知识溢出,是一个区域在地理上邻近的区域在时期创新行为变量的加权求和。 空间误差面板数据计量分析 *如果在创新行为的空间依赖性存在误差扰动项中来测度邻近地区创新因变量的误差冲击对本地区创新行为的影响程度,则可以通过空间误差模型的空间依赖性原理可得: it it it it it y αx βμ=++it it it W μλμε=+*上式即为空间误差面板数据(Spatial Error Panel Data Model ,SEPDM )计量经济模型。其中,参数衡量了样本观察值的误差项引进的一个区域间溢出成分。 *因为已经在面板数据模型中考虑了创新行为变量的空间依赖性,因此采用一般面板数据模型的估计技术如OLS 或GLS 等将具有良好的估计效果。如果能够综合考虑面板数据模型中的一些假定,如时间加权(Period Weights )或截面加权(Cross-section Weights ),则可获得更加符合创新现实的估计结果。
面板数据模型入门讲解
第十四章 面板数据模型 在第五章,当我们分析城镇居民的消费特征时,我们使用的是城镇居民的时间序列数据;而当分析农村居民的消费特征时,我们使用农村居民的时间序列数据。如果我们想要分析全体中国居民的消费特征呢?我们有两种选择:一是使用中国居民的时间序列数据进行分析,二是把城镇居民和农村居民的样本合并,实际上就是两个时间序列的样本合并为一个样本。 多个观测对象的时间序列数据所组成的样本数据,被称为面板数据(Panel Data )。通常也被称为综列数据,意即综合了多个时间序列的数据。当然,面板数据也可以看成多个横截面数据的综合。在面板数据中,每一个观测对象,我们称之为一个个体(Individual )。例如城镇居民是一个观测个体,农村居民是另一个观测个体。 如果面板数据中各观测个体的观测区间是相同的,我们称其为平衡的面板数据,反之,则为非平衡的面板数据。基于面板数据所建立的计量经济学模型则被称为面板数据模型。例如,表5.3.1中城镇居民和农村居民的样本数据具有相同的采样区间,所以,它是一个平衡的面板数据。 §14.1 面板数据模型 一、两个例子 1. 居民消费行为的面板数据分析 让我们重新回到居民消费的例子。在表5.1.1中,如果我们将城镇居民和农村居民的时间序列数据作为一个样本,以分析中国居民的消费特征。那么,此时模型(5.1.1)的凯恩斯消费函数就可以表述为: it it it Y C εββ++=10 (14.1.1) it t i it u ++=λμε (14.1.2) 其中:it C 和it Y 分别表示第i 个观测个体在第t 期的消费和收入。i =1、2分别表示城镇居民和农村居民两个观测个体,t =1980、…、2008表示不同年度。it u 为经典误差项。 在(14.1.2)中,i μ随观测个体的变化,而不随时间变化,它反映个体之间不随时间变化的差异性,被称为个体效应。t λ反映不随个体变化的时间上的差异性,被称为时间效应。在本例中,城镇居民和农村居民的消费差异一部分来自收入差异和随机扰动,还有一部分差
大数据数据分析方法 数据处理流程实战案例
方法、数据处理流程实战案例时代,我们人人都逐渐开始用数据的眼光来看待每一个事情、事物。确实,数据的直观明了传达出来的信息让人一下子就能领略且毫无疑点,不过前提是数据本身的真实性和准确度要有保证。今天就来和大家分享一下关于方法、数据处理流程的实战案例,让大家对于这个岗位的工作内容有更多的理解和认识,让可以趁机了解了解咱们平时看似轻松便捷的数据可视化的背后都是有多专业的流程在支撑着。 一、大数据思维 在2011年、2012年大数据概念火了之后,可以说这几年许多传统企业也好,互联网企业也好,都把自己的业务给大数据靠一靠,并且提的比较多的大数据思维。 那么大数据思维是怎么回事?我们来看两个例子: 案例1:输入法 首先,我们来看一下输入法的例子。 我2001年上大学,那时用的输入法比较多的是智能ABC,还有微软拼音,还有五笔。那时候的输入法比现在来说要慢的很多,许多时候输一个词都要选好几次,去选词还是调整才能把这个字打出来,效率是非常低的。 到了2002年,2003年出了一种新的输出法——紫光拼音,感觉真的很快,键盘没有按下去字就已经跳出来了。但是,后来很快发现紫光拼音输入法也有它的问题,比如当时互联网发展已经比较快了,会经常出现一些新的词汇,这些词汇在它的词库里没有的话,就很难敲出来这个词。
在2006年左右,搜狗输入法出现了。搜狗输入法基于搜狗本身是一个搜索,它积累了一些用户输入的检索词这些数据,用户用输入法时候产生的这些词的信息,将它们进行统计分析,把一些新的词汇逐步添加到词库里去,通过云的方式进行管理。 比如,去年流行一个词叫“然并卵”,这样的一个词如果用传统的方式,因为它是一个重新构造的词,在输入法是没办法通过拼音“ran bing luan”直接把它找出来的。然而,在大数据思维下那就不一样了,换句话说,我们先不知道有这么一个词汇,但是我们发现有许多人在输入了这个词汇,于是,我们可以通过统计发现最近新出现的一个高频词汇,把它加到司库里面并更新给所有人,大家在使用的时候可以直接找到这个词了。 案例2:地图 再来看一个地图的案例,在这种电脑地图、手机地图出现之前,我们都是用纸质的地图。这种地图差不多就是一年要换一版,因为许多地址可能变了,并且在纸质地图上肯定是看不出来,从一个地方到另外一个地方怎么走是最好的?中间是不是堵车?这些都是有需要有经验的各种司机才能判断出来。 在有了百度地图这样的产品就要好很多,比如:它能告诉你这条路当前是不是堵的?或者说能告诉你半个小时之后它是不是堵的?它是不是可以预测路况情况? 此外,你去一个地方它可以给你规划另一条路线,这些就是因为它采集到许多数据。比如:大家在用百度地图的时候,有GPS地位信息,基于你这个位置的移动信息,就可以知道路的拥堵情况。另外,他可以收集到很多
空间数据分析模型
第7 章空间数据分析模型 7.1 空间数据 按照空间数据的维数划分,空间数据有四种基本类型:点数据、线数据、面数据和体数据。 点是零维的。从理论上讲,点数据可以是以单独地物目标的抽象表达,也可以是地理单元的抽象表达。这类点数据种类很多,如水深点、高程点、道路交叉点、一座城市、一个区域。 线数据是一维的。某些地物可能具有一定宽度,例如道路或河流,但其路线和相对长度是主要特征,也可以把它抽象为线。其他的 线数据,有不可见的行政区划界,水陆分界的岸线,或物质运输或思想传播的路线等。 面数据是二维的,指的是某种类型的地理实体或现象的区域范围。国家、气候类型和植被特征等,均属于面数据之列。 真实的地物通常是三维的,体数据更能表现出地理实体的特征。一般而言,体数据被想象为从某一基准展开的向上下延伸的数,如 相对于海水面的陆地或水域。在理论上,体数据可以是相当抽象的,如地理上的密度系指单位面积上某种现象的许多单元分布。 在实际工作中常常根据研究的需要,将同一数据置于不同类别中。例如,北京市可以看作一个点(区别于天津),或者看作一个面 (特殊行政区,区别于相邻地区),或者看作包括了人口的“体”。 7.2 空间数据分析 空间数据分析涉及到空间数据的各个方面,与此有关的内容至少包括四个领域。 1)空间数据处理。空间数据处理的概念常出现在地理信息系统中,通常指的是空间分析。就涉及的内容而言,空间数据处理更多的偏重于空间位置及其关系的分析和管理。 2)空间数据分析。空间数据分析是描述性和探索性的,通过对大量的复杂数据的处理来实现。在各种空间分析中,空间数据分析是 重要的组成部分。空间数据分析更多的偏重于具有空间信息的属性数据的分析。 3)空间统计分析。使用统计方法解释空间数据,分析数据在统计上是否是“典型”的,或“期望”的。与统计学类似,空间统计分析与空间数据分析的内容往往是交叉的。 4)空间模型。空间模型涉及到模型构建和空间预测。在人文地理中,模型用来预测不同地方的人流和物流,以便进行区位的优化。在自然地理学中,模型可能是模拟自然过程的空间分异与随时间的变化过程。空间数据分析和空间统计分析是建立空间模型的基础。 7.3 空间数据分析的一些基本问题 空间数据不仅有其空间的定位特性,而且具有空间关系的连接属性。这些属性主要表现为空间自相关特点和与之相伴随的可变区域 单位问题、尺度和边界效应。传统的统计学方法在对数据进行处理时有一些基本的假设,大多都要求“样本是随机的”,但空间数据可能不一定能满足有关假设,因此,空间数据的分析就有其特殊性(David,2003 )。