Libsvm分类实验报告

一、LIBSVM介绍
LIBSVM是台湾大学林智仁(Chih-Jen Lin)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件还有一个特点,就是对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数就可以解决很多问题;并且提供了交互检验(Cross Validation)的功能。
二、准备工作
2.1软件下载安装
使用的平台是Windows XP,从命令列执行。先把一些需要的东西装好,总共需要三个软件:libsvm, python, gnuplot。这里我选择的版本是libsvm-2.88,python26。
Libsvm:到https://www.360docs.net/doc/5111627404.html,.tw/~cjlin/libsvm/下载libsvm,然后解压缩就好了。
Python:到https://www.360docs.net/doc/5111627404.html,/download/下载完直接安装就好了。
Gnuplot:下载ftp://https://www.360docs.net/doc/5111627404.html,/pub/gnuplot/gp400win32.zip解压缩。
这里全部解压安装在c盘
c:\libsvm-2.88
c:\python26
c:\gnuplot
2.2参数修改
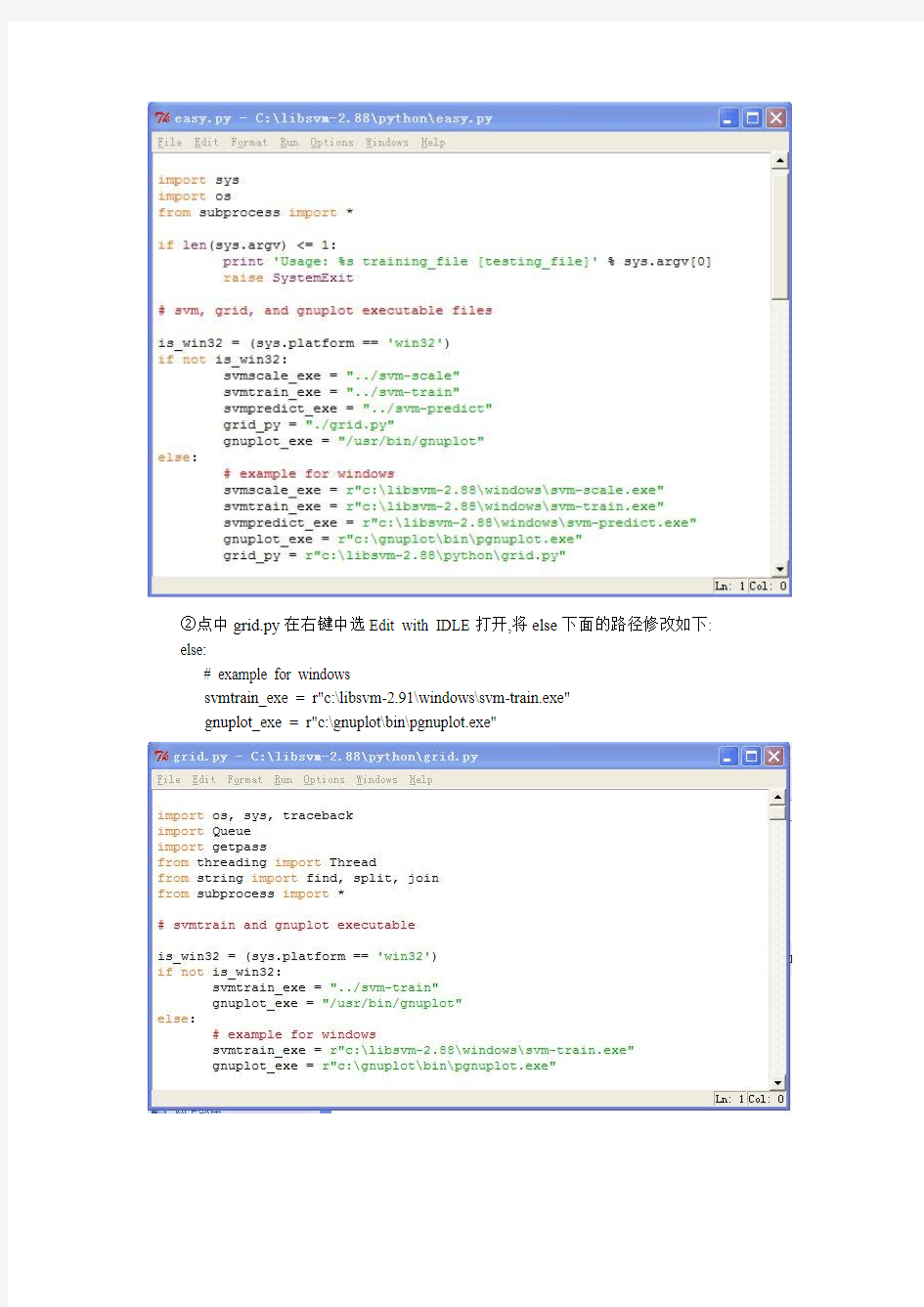
(1)把c:\libsvm-2.88\tools中的easy.py和grid.py复制到c:\libsvm-2.91\python中
(2)在c:\libsvm-2.88\python中修改easy.py和grid.py的路径:
①点中easy.py在右键中选Edit with IDLE打开,将else下面的路径修改如下:
else:
# example for windows
svmscale_exe = r"c:\libsvm-2.88\windows\svm-scale.exe"
svmtrain_exe = r"c:\libsvm-2.88\windows\svm-train.exe"
svmpredict_exe = r"c:\libsvm-2.88\windows\svm-predict.exe"
gnuplot_exe = r"c:\gnuplot\bin\pgnuplot.exe"
grid_py = r"c:\libsvm-2.88\python\grid.py"
②点中grid.py在右键中选Edit with IDLE打开,将else下面的路径修改如下: else:
# example for windows
svmtrain_exe = r"c:\libsvm-2.91\windows\svm-train.exe"
gnuplot_exe = r"c:\gnuplot\bin\pgnuplot.exe"
三、实验步骤
(1)按照LIBSVM软件包所要求的格式准备数据集;
(2)对数据进行缩放操作;
(3)选用适当的核函数;
(4)采用交叉验证选择惩罚系数C与g的最佳参数;
(5)采用获得的最佳参数对整个训练集进行训练获取支持向量机模型;
(6)利用获取的模型进行测试与预测。
四、实验操作
4.1.数据准备
https://www.360docs.net/doc/5111627404.html,.tw/~cjlin/libsvmtools/datasets/binary.html#breast-cancer 下载heart.txt作为此次分类的初始数据
heart
Source: Statlog / Heart
# of classes: 2
# of data: 270
# of features: 13
Files:
heart
heart_scale (scaled to [-1,1])
4..2具体操作
(1)据归一化处理
将数据heart.txt保存在c:\libsvm-2.88\windows文件夹下
对原始数据进行归一化,步骤如下:
打开程序--附件—命令提示符,键入
cd c:\libsvm\windows 回车
再键入
svm-scale -l 0 -u 1 heart.txt > heart.scale.txt 回车
在c:\ libsvm-2.88\windows下出现一个heart.scale.txt文件
(2)然后将路径调整到
cd c:\python27
接着输入:python C:\libsvm\python\grid.py -log2c -10,10,1 -log2g 10,-10,-1 c:\libsvm\windows\heart.scale.txt > test.txt 回车
就会产生一个test.txt文件,其中记录了参数寻优的结果
可以看到,参数分别为c 2.0,g 0.03125,正确率mse为84% 在python26文件下有heart.scale.txt.png,得:
(2)然后利用所得到的参数c ,g对heart.scale.txt进行训练,输入
cd c:\libsvm-2.88\windows 回车
svm-train –c 2.0 –g 0.03125 heart.scale.txt
生成训练模型heart.scale.txt.model
数据挖掘实验报告资料
大数据理论与技术读书报告 -----K最近邻分类算法 指导老师: 陈莉 学生姓名: 李阳帆 学号: 201531467 专业: 计算机技术 日期 :2016年8月31日
摘要 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地提取出有价值的知识模式,以满足人们不同应用的需要。K 近邻算法(KNN)是基于统计的分类方法,是大数据理论与分析的分类算法中比较常用的一种方法。该算法具有直观、无需先验统计知识、无师学习等特点,目前已经成为数据挖掘技术的理论和应用研究方法之一。本文主要研究了K 近邻分类算法,首先简要地介绍了数据挖掘中的各种分类算法,详细地阐述了K 近邻算法的基本原理和应用领域,最后在matlab环境里仿真实现,并对实验结果进行分析,提出了改进的方法。 关键词:K 近邻,聚类算法,权重,复杂度,准确度
1.引言 (1) 2.研究目的与意义 (1) 3.算法思想 (2) 4.算法实现 (2) 4.1 参数设置 (2) 4.2数据集 (2) 4.3实验步骤 (3) 4.4实验结果与分析 (3) 5.总结与反思 (4) 附件1 (6)
1.引言 随着数据库技术的飞速发展,人工智能领域的一个分支—— 机器学习的研究自 20 世纪 50 年代开始以来也取得了很大进展。用数据库管理系统来存储数据,用机器学习的方法来分析数据,挖掘大量数据背后的知识,这两者的结合促成了数据库中的知识发现(Knowledge Discovery in Databases,简记 KDD)的产生,也称作数据挖掘(Data Ming,简记 DM)。 数据挖掘是信息技术自然演化的结果。信息技术的发展大致可以描述为如下的过程:初期的是简单的数据收集和数据库的构造;后来发展到对数据的管理,包括:数据存储、检索以及数据库事务处理;再后来发展到对数据的分析和理解, 这时候出现了数据仓库技术和数据挖掘技术。数据挖掘是涉及数据库和人工智能等学科的一门当前相当活跃的研究领域。 数据挖掘是机器学习领域内广泛研究的知识领域,是将人工智能技术和数据库技术紧密结合,让计算机帮助人们从庞大的数据中智能地、自动地抽取出有价值的知识模式,以满足人们不同应用的需要[1]。目前,数据挖掘已经成为一个具有迫切实现需要的很有前途的热点研究课题。 2.研究目的与意义 近邻方法是在一组历史数据记录中寻找一个或者若干个与当前记录最相似的历史纪录的已知特征值来预测当前记录的未知或遗失特征值[14]。近邻方法是数据挖掘分类算法中比较常用的一种方法。K 近邻算法(简称 KNN)是基于统计的分类方法[15]。KNN 分类算法根据待识样本在特征空间中 K 个最近邻样本中的多数样本的类别来进行分类,因此具有直观、无需先验统计知识、无师学习等特点,从而成为非参数分类的一种重要方法。 大多数分类方法是基于向量空间模型的。当前在分类方法中,对任意两个向量: x= ) ,..., , ( 2 1x x x n和) ,..., , (' ' 2 ' 1 'x x x x n 存在 3 种最通用的距离度量:欧氏距离、余弦距 离[16]和内积[17]。有两种常用的分类策略:一种是计算待分类向量到所有训练集中的向量间的距离:如 K 近邻选择K个距离最小的向量然后进行综合,以决定其类别。另一种是用训练集中的向量构成类别向量,仅计算待分类向量到所有类别向量的距离,选择一个距离最小的类别向量决定类别的归属。很明显,距离计算在分类中起关键作用。由于以上 3 种距离度量不涉及向量的特征之间的关系,这使得距离的计算不精确,从而影响分类的效果。
数据挖掘实验报告
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.360docs.net/doc/5111627404.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.360docs.net/doc/5111627404.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
校园植物种类调查实验报告
校园植物种类调查实验报告 一、目的要求 1.通过本实验使学生熟悉观察、研究区域植物及其分类的基本方法。 2.认识校园内外的常见植物。 二、材料用品 照相机、铅笔、笔记本、检索表等。 三、调查方法 实地调查、实物标本、查阅资料、访谈、小组讨论。 1、实地调查:小组成员分工参观并初步认识校园内植物,拍照,做好记录,将不认识的植物重点记录、做记号。 2、采集标本:采集植物的叶片、枝条或花朵等特征部分,压制做成植物标本。 3、采访讨教:带着植物照片及植物标本向教师或学校花工师傅请教,弄清植物的名称、特性。 4、查阅资料:到图书馆或利用网络查阅相关植物的资料,获取各种植物的详细信息。 5、整理资料:集中、收集所有成员的资料,对资料进行全面整理、筛选、分类。 6、实验报告:将资料、图片打印,汇集成实验报告。 7、制作PPT:用演示文稿形式,记录和呈现我们的探究过程,分享我们的研究心得。 三、调查内容 (一) 校园和公园植物形态特征的观察
植物种类的识别、鉴定必须在严谨、细致的观察研究后进行。在对植物进行观察研究时,首先要观察清楚每一种植物的生长环境,然后再观察植物具体的形态结构特征。植物形态特征的观察应起始于根(或茎基部),结束于花、果实或种子。先用眼睛进行整体观察,细微、重要部分再借助放大镜观察。特别是对花的观察、研究要极为细致、全面,从花柄开始,通过花萼、花冠、雄蕊,最后到雌蕊。必要时要对花进行解剖,分别作横切和纵切,观察花各部分的排列情况、子房的位置、组成雌蕊的心皮数目、子房室数及胎座类型等。只有这样,才能全面、系统地掌握植物的详细特征,才能正确、快速地识别和区分植物。 (二)植物种类的识别和鉴定 在对植物观察清楚的基础上,识别、鉴定植物就会变得很容易。对校园内外特征明显、自己又很熟悉的植物,确认无疑后可直接写下名称;生疏种类须借助于植物检索表等工具书进行检索、识别。 在把区域内的所有植物鉴定、统计后,写出名录并把各植物归属到科。 (三)植物的归纳分类 在对校园内外的植物进行识别、统计后,为了全面了解、掌握园内的植物资源情况,还须对它们进行归纳分类。分类的方式可根据自己的研究兴趣和植物具体情况进行选择。对植物进行归纳分类时要学会充分利用有关的参考文献。下面是几种常见的植物归纳分类方式。 1.按植物形态特征分类木本植物、乔木、灌木、木质藤本、草本植、一年生草本、二年生草本、多年生草本 2.按植物系统分类:苔藓植物、蕨类植物、裸子植物、被子植物、双子叶植物、单子叶植物
大数据挖掘weka大数据分类实验报告材料
一、实验目的 使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。 二、实验环境 实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。 Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java 写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 三、数据预处理 Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示 图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。 实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。 实验所需的训练集和测试集均为iris.arff。 四、实验过程及结果 应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。 1、LibSVM分类 Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。 用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。 在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
模式识别第二次上机实验报告
北京科技大学计算机与通信工程学院 模式分类第二次上机实验报告 姓名:XXXXXX 学号:00000000 班级:电信11 时间:2014-04-16
一、实验目的 1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等; 二、实验内容 2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: label index1:value1 index2:value2 ... 其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。(我主要要用到回归) Index是从1开始的自然数,value是每一维的特征值。 该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。FormatDataLibsvm.xls使用说明: 先将数据按照下列格式存放(注意label放最后面): value1 value2 label value1 value2 label 然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。就可以得到libsvm要求的数据格式。将该数据存放到文本文件中进行下一步的处理。 3.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。缩放规则文件可以用文本浏览器打开,看到其格式为: y lower upper min max x lower upper index1 min1 max1 index2 min2 max2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为: (Value-lower)*(max-min)/(upper - lower)+lower 其中value为归一化后的值,其他参数与前面介绍的相同。 建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。 4.训练数据,生成模型。 用法:svmtrain [options] training_set_file [model_file] 其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默
数据挖掘实验报告(一)
数据挖掘实验报告(一) 数据预处理 姓名:李圣杰 班级:计算机1304 学号:1311610602
一、实验目的 1.学习均值平滑,中值平滑,边界值平滑的基本原理 2.掌握链表的使用方法 3.掌握文件读取的方法 二、实验设备 PC一台,dev-c++5.11 三、实验内容 数据平滑 假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45, 46, 52, 70。使用你所熟悉的程序设计语言进行编程,实现如下功能(要求程序具有通用性): (a) 使用按箱平均值平滑法对以上数据进行平滑,箱的深度为3。 (b) 使用按箱中值平滑法对以上数据进行平滑,箱的深度为3。 (c) 使用按箱边界值平滑法对以上数据进行平滑,箱的深度为3。 四、实验原理 使用c语言,对数据文件进行读取,存入带头节点的指针链表中,同时计数,均值求三个数的平均值,中值求中间的一个数的值,边界值将中间的数转换为离边界较近的边界值 五、实验步骤 代码 #include
监督分类实验报告
实验报告题目:监督分类 姓名: 学号: 日期:
一、实验目的 理解计算机图像分类的基本原理以及监督分类的过程,运用ERDAS软件达到能熟练地对遥感图像进行监督分类的目的。 二、监督分类原理 监督分类(supervised classification)又称训练场地法,是以建立统计识别函数为理论基础,依据典型样本训练方法进行分类的技术。即根据已知训练区提供的样本,通过选择特征参数,求出特征参数作为决策规则,建立判别函数以对各待分类影像进行的图像分类,是模式识别的一种方法。要求训练区域具有典型性和代表性。判别准则若满足分类精度要求,则此准则成立;反之,需重新建立分类的决策规则,直至满足分类精度要求为止。 1)平行六面体法 在多波段遥感图像分类过程中,对于被分类的每一个类别,在各个波段维上都要选取一个变差范围的识别窗口,形成一个平行六面体,如果有多个类别,则形成多个平行六边形,所有属于各个类别的多维空间点也分别落入各自的多维平行六面体空间。 2)最小距离法 使用了每个感兴趣区的均值矢量来计算每个未知象元到每一类均值矢量的欧氏距离,除非用户指定了标准差和距离的阈值,否则所有象元都将分类到感兴趣区中最接近的那一类。 3)最大似然法 假定每个波段中的每类的统计都呈现正态分布,并将计算出给定象元都被归到概率最大的哪一类里。 4)马氏距离法 是一个方向灵敏的距离分类器,分类时将使用到统计信息,与最大似然法有些类似,但是她假定了所有类的协方差都相等,所以它是一种较快的分类方法。 三、实验步骤及结果 1、定义分类模板
定义分类模板包括分类模板的生成、管理、评价和编辑等,功能主要由分类模板编辑器(Signature Editor)完成,具体步骤包括: 1)打开需要分类的影像 本实验所处理的遥感图像打开如下图所示。 图1 原始遥感图像 2)打开分类模板编辑器 3)调整属性文字 在分类编辑窗口中的分类属性表中有很多字段,可以对不需要的字段进行调整。 4)选取样本 基于先验知识,需要对遥感图像选取训练样本,包括产生AOI、合并、命名,从而建立样本。考虑到同类地物颜色的差异,因此在采样过程中对每一地类的采样点(即AOI)不少于10个。选取样本包括产生AOI和建立分类模板两个步骤。 (1)产生AOI的方法有很多种,本实验采用应用查询光标扩展方法。 (2)建立分类模板 ①在分类模板编辑窗口,单击按钮,将多边形AOI区域加载到分类模板属性表中。在同样颜色的区域多绘制一些AOI,分别加载到分类模板属性表中。本实验中每一颜色
贝叶斯实验报告
HUNAN UNIVERSITY 人工智能实验报告 题目实验三:分类算法实验 学生姓名匿名 学生学号2013080702xx 专业班级智能科学与技术1302班 指导老师袁进 一.实验目的 1.了解朴素贝叶斯算法的基本原理; 2.能够使用朴素贝叶斯算法对数据进行分类 3.了解最小错误概率贝叶斯分类器和最小风险概率贝叶斯分类器 4.学会对于分类器的性能评估方法 二、实验的硬件、软件平台 硬件:计算机 软件:操作系统:WINDOWS 10 应用软件:C,Java或者Matlab 相关知识点: 贝叶斯定理: 表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率,其基本求解公式为:
贝叶斯定理打通了从P(A|B)获得P(B|A)的道路。 直接给出贝叶斯定理: 朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。 朴素贝叶斯分类的正式定义如下: 1、设为一个待分类项,而每个a为x的一个特征属性。 2、有类别集合。 3、计算。 4、如果,则。 那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做: 1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。 2、统计得到在各类别下各个特征属性的条件概率估计。即 3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导: 因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
遥感非监督分类实验报告书
遥感非监督分类实验报告书 部门: xxx 时间: xxx 整理范文,仅供参考,可下载自行编辑
遥感图像的非监督分类实验报告 姓名:李全意 专业班级:地科二班 学号:2018214310 指导教师:段艳 日期:2018年6月3日 1. 实验目的 通过本实验加强对遥感非监督分类处理理论部分的理解,熟练掌握图像非监督分类的处理方法,并将处理前后数据进行比较。 b5E2RGbCAP 2. 实验准备工作 <1)准备遥感数据<本实验使用的是老师提供的遥感数据); <2)熟悉遥感图像非监督分类的理论部分 3.实验步骤 4. 实验数据分析与结论 <1)通过分类前后图像的比较,发现非监督分类后的图像容易区分不同地物; <2)分类过程中存在较多错分漏分现象,同种类别中有多种地物; <3)非监督分类根据地物的光谱统计特性进行分类,客观真实且方法简单,而且具有一定的精度。 5. 实验收获及需要解决的问题 <1)对非监督分类处理遥感图像方法有了总体上的认识,基本上掌握该方法的具体操作步骤,会用该方法处理一些遥感图图像。 p1EanqFDPw
Unsupervised Classification, 在Unsupervised Classification对话框中,将参数设计设计如下: Number of classes:30,一般将分类数取为最终分类数的2倍以上;Maximum Iterations:18; 点击Color Scheme Options决定输出的分类图像为黑白的;Convergence Threshold:0.95。 点击OK即可。打开完成后图像与原图像对比: 原图:完成后: <2)打开原图像,在视窗中点击File/Open/Raster Layer,选择分类监督后的图像classification1.img,在Raster Options中,取消Clear Display如下:
子网划分 实验报告
实验报告
1.实验题目:IP地址分类及子网划分 2.实验目的:1)掌握有类IP地址的使用及主机IP地址的配置; 2)掌握子网掩码及子网划分的使用 3.实验地点:计科楼201教室 4.实验设备及环境:安装win7系统的两台计算机、交换机、路 由器 5.实验过程: 1)ip地址划分 有一个公司有六个部门,申请了IP为211.237.222.0/32的地址,是给这个公司的每个部门划分一个子网。 答案:需要6个子网的话,必须要划分为8个子网,因为6不是2的整次方数。C类地址每段共有地址256个,划分为8个子网,每段有32个地址,第一个地址为子网地址,不可用;最后一个为广播地址,不可用,所以每段实际可用地址为30个。第一个子网和最后一个子网默认不用(如果不支持全0全1子网),也就是说8-2正好是6个子网。这样算下来,32*2+2*6=76,共计损失76个地址。 子网掩码是:256-32=224,255.255.255.224。 (1)理论IP:211.237.222.1~211.237.222.32,网关:211.237.222.1; 实际IP:211.237.222.2~211.237.222.31; (2)理论IP:211.237.222.33~211.237.222.64,网关:211.237.222.33; 实际IP:211.237.222.34~211.237.222.63; (3)理论IP:211.237.222.65~211.237.222.96,网关:211.237.222.65;
实际IP:211.237.222.66~211.237.222.95; (4)理论IP:211.237.222.97~211.237.222.128,网关:211.237.222.97; 实际IP:211.237.222.98~211.237.222.127; (5)理论IP:211.237.222.129~211.237.222.160,网关:211.237.222.129; 实际IP:211.237.222.130~211.237.222.159; (6)理论IP:211.237.222.161~211.237.222.192,网关:211.237.222.161; 实际IP:211.237.222.162~211.237.222.191; 2)vlan划分 第一台计算机的IP地址为:10.12.155.87 第二台计算机的IP地址为:10.12.156.173
实验报告格式
《客户关系管理》课程实验实训报告
集团、卢森堡剑桥集团、亚洲创业投资基金(原名软银中国创业基金)共同投资成立。 当当网成立于1999年11月,以图书零售起家,已发展成为领先的在线零售商:中国最大图书零售商、高速增长的百货业务和第三方招商平台。当当网致力于为用户提供一流的一站式购物体验,在线销售的商品包括图书音像、服装、孕婴童、家居、美妆和3C数码等几十个大类,在库图书超过90万种,百货超过105万种。当当网的注册用户遍及全国32个省、市、自治区和直辖市。注册用户遍及全国32个省、市、自治区和直辖市。当当网于美国时间2010年12月8日在纽约证券交易所正式挂牌上市,是中国第一家完全基于线上业务、在美国上市的B2C网上商城。 当当网于2010年12月8日在纽约证券交易所正式挂牌上市,是中国第一家完全基于线上业务、在美国上市的B2C网上商城。2012年,当当网的活跃用户数达到1570万,订单数达到5420万。 2014年2月28日,当当和1号店已经签订合作协议,当当将在1号店销售图书,1号店将在当当平台上销售食品和日用百货。 公司创建: 当当网由李国庆和俞渝创立,李国庆先生任当当网CEO,俞渝女士目任当当网董事长。二人是夫妻,联手创业,早已在业内传为佳话。 李国庆毕业于北大,两次创业,均以出版为主体。在图书出版领域摸爬滚打了10年,很了解中国传统的图书出版和发行方面的所有环节。俞渝是纽约大学学金融MBA毕业的,在华尔街做融资,有过几个很成功的案例。她在美国生活了整整10年,投资者非常信任她,又有共同语言。 1996年,李国庆和俞渝邂逅,然后在纽约结婚,当当的故事也就开了头。两人从谈恋爱开始,就经常一起思考,一起聊亚马逊的商业模型与传统贸易手段的根本区别。后来夫妇俩常探讨在图书这个行业中间赚钱最关键的环节是什么,有着多年图书出版运营经验的李国庆说肯定是出版社和读者的直接联系。于是他们一起去找风险投资商,说服了IDG、LCHG(卢森堡剑桥集团,该集团公司拥有欧洲最大的出版集团)共同投资,目标锁定在凭借发达国家现代图书市场的运作模式和成熟的管理经验,结合当今世界最先进的计算机技术和网络技术,用来推动中国图书市场的“可供书目”信息事业,及“网上书店”的门户建设,成为中国最大的图书资讯集成商和供应商。 公司历史: 1999年11月,网站进入运营。 2000年2月,当当网首次获得风险投资。 2000年11月,当当网周年店庆大酬宾,在网民中引起巨大反响。 2001年6月,当当网开通网上音像店。 2001年7月,当当网日访问量超过50万(Unique Visitor),成为最繁忙的图书、音像店。 2003年4月,在“非典”肆虐之时,当当网坚持高速运转,满足读者对精神食粮的需求,被文化部等四家政府部门首推为“网上购物”优秀网站。 2003年6月,当当网、新浪网、SOHO、网通等公司举办“中国精神”活动,呼唤开放乐观的民族精神,引起轰动的社会反响。 2004年2月,当当网获得第二轮风险投资,著名风险投资机构老虎基金投资当当1100万美元。 2004年3月,当当网开通期刊频道。
数据分析与挖掘实验报告
数据分析与挖掘实验报告
《数据挖掘》实验报告 目录 1.关联规则的基本概念和方法 (1) 1.1数据挖掘 (1) 1.1.1数据挖掘的概念 (1) 1.1.2数据挖掘的方法与技术 (2) 1.2关联规则 (5) 1.2.1关联规则的概念 (5) 1.2.2关联规则的实现——Apriori算法 (7) 2.用Matlab实现关联规则 (12) 2.1Matlab概述 (12) 2.2基于Matlab的Apriori算法 (13) 3.用java实现关联规则 (19) 3.1java界面描述 (19) 3.2java关键代码描述 (23) 4、实验总结 (29) 4.1实验的不足和改进 (29) 4.2实验心得 (30)
1.关联规则的基本概念和方法 1.1数据挖掘 1.1.1数据挖掘的概念 计算机技术和通信技术的迅猛发展将人类社会带入到了信息时代。在最近十几年里,数据库中存储的数据急剧增大。数据挖掘就是信息技术自然进化的结果。数据挖掘可以从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的,人们事先不知道的但又是潜在有用的信息和知识的过程。 许多人将数据挖掘视为另一个流行词汇数据中的知识发现(KDD)的同义词,而另一些人只是把数据挖掘视为知识发现过程的一个基本步骤。知识发现过程如下: ·数据清理(消除噪声和删除不一致的数据)·数据集成(多种数据源可以组合在一起)·数据转换(从数据库中提取和分析任务相关的数据) ·数据变换(从汇总或聚集操作,把数据变换和统一成适合挖掘的形式) ·数据挖掘(基本步骤,使用智能方法提取数
据模式) ·模式评估(根据某种兴趣度度量,识别代表知识的真正有趣的模式) ·知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。 1.1.2数据挖掘的方法与技术 数据挖掘吸纳了诸如数据库和数据仓库技术、统计学、机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成等许多应用领域的大量技术。数据挖掘主要包括以下方法。神经网络方法:神经网络由于本身良好的鲁棒性、自组织自适应性、并行处理、分布存储和高度容错等特性非常适合解决数据挖掘的问题,因此近年来越来越受到人们的关注。典型的神经网络模型主要分3大类:以感知机、bp反向传播模型、函数型网络为代表的,用于分类、预测和模式识别的前馈式神经网络模型;以hopfield 的离散模型和连续模型为代表的,分别用于联想记忆和优化计算的反馈式神经网络模型;以art 模型、koholon模型为代表的,用于聚类的自组
贝叶斯分类实验报告doc
贝叶斯分类实验报告 篇一:贝叶斯分类实验报告 实验报告 实验课程名称数据挖掘 实验项目名称贝叶斯分类 年级 XX级 专业信息与计算科学 学生姓名 学号 1207010220 理学院 实验时间: XX 年 12 月 2 日 学生实验室守则 一、按教学安排准时到实验室上实验课,不得迟到、早退和旷课。 二、进入实验室必须遵守实验室的各项规章制度,保持室内安静、整洁,不准在室内打闹、喧哗、吸烟、吃食物、随地吐痰、乱扔杂物,不准做与实验内容无关的事,非实验用品一律不准带进实验室。 三、实验前必须做好预习(或按要求写好预习报告),未做预习者不准参加实验。四、实验必须服从教师的安排和指导,认真按规程操作,未经教师允许不得擅自动用仪器设备,特别是与本实验无关的仪器设备和设施,如擅自动用
或违反操作规程造成损坏,应按规定赔偿,严重者给予纪律处分。 五、实验中要节约水、电、气及其它消耗材料。 六、细心观察、如实记录实验现象和结果,不得抄袭或随意更改原始记录和数据,不得擅离操作岗位和干扰他人实验。 七、使用易燃、易爆、腐蚀性、有毒有害物品或接触带电设备进行实验,应特别注意规范操作,注意防护;若发生意外,要保持冷静,并及时向指导教师和管理人员报告,不得自行处理。仪器设备发生故障和损坏,应立即停止实验,并主动向指导教师报告,不得自行拆卸查看和拼装。 八、实验完毕,应清理好实验仪器设备并放回原位,清扫好实验现场,经指导教师检查认可并将实验记录交指导教师检查签字后方可离去。 九、无故不参加实验者,应写出检查,提出申请并缴纳相应的实验费及材料消耗费,经批准后,方可补做。 十、自选实验,应事先预约,拟订出实验方案,经实验室主任同意后,在指导教师或实验技术人员的指导下进行。 十一、实验室内一切物品未经允许严禁带出室外,确需带出,必须经过批准并办理手续。 学生所在学院:理学院专业:信息与计算科学班级:信计121
数据挖掘实验报告 超市商品销售分析及数据挖掘
通信与信息工程学院 课程设计说明书 课程名称: 数据仓库与数据挖掘课程设计题目: 超市商品销售分析及数据挖掘专业/班级: 电子商务(理) 组长: 学号: 组员/学号: 开始时间: 2011 年12 月29 日完成时间: 2012 年01 月 3 日
目录 1.绪论 (1) 1.1项目背景 (1) 1.2提出问题 (1) 2.数据仓库与数据集市的概念介绍 (1) 2.1数据仓库介绍 (1) 2.2数据集市介绍 (2) 3.数据仓库 (3) 3.1数据仓库的设计 (3) 3.1.1数据仓库的概念模型设计 (4) 3.1.2数据仓库的逻辑模型设计 (5) 3.2 数据仓库的建立 (5) 3.2.1数据仓库数据集成 (5) 3.2.2建立维表 (8) 4.OLAP操作 (10) 5.数据预处理 (12) 5.1描述性数据汇总 (12) 5.2数据清理与变换 (13) 6.数据挖掘操作 (13) 6.1关联规则挖掘 (13) 6.2 分类和预测 (17) 6.3决策树的建立 (18) 6.4聚类分析 (22) 7.总结 (25) 8.任务分配 (26)
数据挖掘实验报告 1.绪论 1.1项目背景 在商业领域中使用计算机科学与技术是当今商业的发展方向,而数据挖掘是商业领域与计算机领域的乔梁。在超市的经营中,应用数据挖掘技术分析顾客的购买习惯和不同商品之间的关联,并借由陈列的手法,和合适的促销手段将商品有魅力的展现在顾客的眼前, 可以起到方便购买、节约空间、美化购物环境、激发顾客的购买欲等各种重要作用。 1.2提出问题 那么超市应该对哪些销售信息进行挖掘?怎样挖掘?具体说,超市如何运用OLAP操作和关联规则了解顾客购买习惯和商品之间的关联,正确的摆放商品位置以及如何运用促销手段对商品进行销售呢?如何判断一个顾客的销售水平并进行推荐呢?本次实验为解决这一问题提出了解决方案。 2.数据仓库与数据集市的概念介绍 2.1数据仓库介绍 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它并不是所谓的“大型数据库”。........ 2.2数据集市介绍 数据集市,也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库。....... 3.数据仓库 3.1数据仓库的设计 3.1.1数据库的概念模型 3.1.2数据仓库的模型 数据仓库的模型主要包括数据仓库的星型模型图,我们创建了四个
主观贝叶斯实验报告
主观贝叶斯实验报告 学生姓名 程战战 专业/班级 计算机91 学 号 09055006 所在学院 电信学院 指导教师 鲍军鹏 提交日期 2012/4/26
根据初始证据E 的概率P (E )及LS 、LN 的值,把H 的先验概率P (H )更新为后验概率P (H/E )或者P(H/!E)。在证据不确定的情况下,用户观察到的证据具有不确定性,即0 数据预处理 一、实验原理 预处理方法基本方法 1、数据清洗 去掉噪声和无关数据 2、数据集成 将多个数据源中的数据结合起来存放在一个一致的数据存储中 3、数据变换 把原始数据转换成为适合数据挖掘的形式 4、数据归约 主要方法包括:数据立方体聚集,维归约,数据压缩,数值归约,离散化和概念分层等二、实验目的 掌握数据预处理的基本方法。 三、实验内容 1、R语言初步认识(掌握R程序运行环境) 2、实验数据预处理。(掌握R语言中数据预处理的使用) 对给定的测试用例数据集,进行以下操作。 1)、加载程序,熟悉各按钮的功能。 2)、熟悉各函数的功能,运行程序,并对程序进行分析。 对餐饮销量数据进统计量分析,求销量数据均值、中位数、极差、标准差,变异系数和四分位数间距。 对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 3)数据预处理 缺省值的处理:用均值替换、回归查补和多重查补对缺省值进行处理 对连续属性离散化:用等频、等宽等方法对数据进行离散化处理 四、实验步骤 1、R语言运行环境的安装配置和简单使用 (1)安装R语言 R语言下载安装包,然后进行默认安装,然后安装RStudio 工具(2)R语言控制台的使用 1.2.1查看帮助文档 1.2.2 安装软件包 1.2.3 进行简单的数据操作 (3)RStudio 简单使用 1.3.1 RStudio 中进行简单的数据处理 1.3.2 RStudio 中进行简单的数据处理 2、R语言中数据预处理 (1)加载程序,熟悉各按钮的功能。 (2)熟悉各函数的功能,运行程序,并对程序进行分析 2.2.1 销量中位数、极差、标准差,变异系数和四分位数间距。 , 2.2.2对餐饮企业菜品的盈利贡献度(即菜品盈利帕累托分析),画出帕累托图。 作业6 编程题实验报告 (一)实验内容: 编程实现朴素贝叶斯分类器,假设输入输出都是离散变量。用讲义提供的训练数据进行试验,观察分类器在 121.x x m ==时,输出如何。如果在分类器中加入Laplace 平滑(取?=1) ,结果是否改变。 (二)实验原理: 1)朴素贝叶斯分类器: 对于实验要求的朴素贝叶斯分类器问题,假设数据条件独立,于是可以通过下式计算出联合似然函数: 12(,,)()D i i p x x x y p x y =∏ 其中,()i p x y 可以有给出的样本数据计算出的经验分布估计。 在实验中,朴素贝叶斯分类器问题可以表示为下面的式子: ~1*arg max ()()D i y i y p y p x y ==∏ 其中,~ ()p y 是从给出的样本数据计算出的经验分布估计出的先验分布。 2)Laplace 平滑: 在分类器中加入Laplace 平滑目的在于,对于给定的训练数据中,有可能会出现不能完全覆盖到所有变量取值的数据,这对分类器的分类结果造成一定误差。 解决办法,就是在分类器工作前,再引入一部分先验知识,让每一种变量去只对应分类情况与统计的次数均加上Laplace 平滑参数?。依然采用最大后验概率准则。 (三)实验数据及程序: 1)实验数据处理: 在实验中,所用数据中变量2x 的取值,对应1,2,3s m I === 讲义中所用的两套数据,分别为cover all possible instances 和not cover all possible instances 两种情况,在实验中,分别作为训练样本,在给出测试样本时,输出不同的分类结果。 2)实验程序: 比较朴素贝叶斯分类器,在分类器中加入Laplace 平滑(取?=1)两种情况,在编写matlab 函数时,只需编写分类器中加入Laplace 平滑的函数,朴素贝叶斯分类器是?=0时,特定的Laplace 平滑情况。 实现函数:[kind] =N_Bayes_Lap(X1,X2,y,x1,x2,a) 输入参数:X1,X2,y 为已知的训练数据; x1,x2为测试样本值; a 为调整项,当a=0时,就是朴素贝叶斯分类器,a=1时,为分类器中加入Laplace 平滑。 输出结果:kind ,输出的分类结果。 时间序列的模型法和数据挖掘两种方法比较分析研究 实验目的:通过实验能对时间序列的模型法和数据挖掘两种方法的原理和优缺点有更清楚的认识和比较. 实验内容:选用1952-2006年的中国GDP,分别对之用自回归移动平均模型(ARIMA) 和时序模型的数据挖掘方法进行分析和预测,并对两种方法的趋势和预测结果进行比较并 给出解释. 实验数据:本文研究选用1952-2006年的中国GDP,其资料如下 日期国内生产总值(亿元)日期国内生产总值(亿元) 2006-12-312094071997-12-3174772 2005-12-311830851996-12-31 2004-12-311365151995-12-31 2003-12-311994-12-31 2002-12-311993-12-31 2001-12-311992-12-31 2000-12-31894041991-12-31 1999-12-31820541990-12-31 1998-12-31795531989-12-31 1988-12-311969-12-31 1987-12-311968-12-31 1986-12-311967-12-31 1985-12-311966-12-311868 1984-12-3171711965-12-31 1983-12-311964-12-311454 1982-12-311963-12-31 1981-12-311962-12-31 1980-12-311961-12-311220 1979-12-311960-12-311457 1978-12-311959-12-311439 1977-12-311958-12-311307 1976-12-311957-12-311068 1975-12-311956-12-311028 1974-12-311955-12-31910 1973-12-311954-12-31859 1972-12-311953-12-31824 1971-12-311952-12-31679 1970-12-31 表一 国内生产总值(GDP)是指一个国家或地区所有常住单位在一定时期内生产活动的最终成果。这个指标把国民经济全部活动的产出成果概括在一个极为简明的统计数字之中为评价和衡量国家经济状况、经济增长趋势及社会财富的经济表现提供了一个最为综合的尺度,可以说,数据挖掘实验报告一
统计学习_朴素贝叶斯分类器实验报告
数据挖掘实验报告(参考)