CFM56-3和-7的数据对比
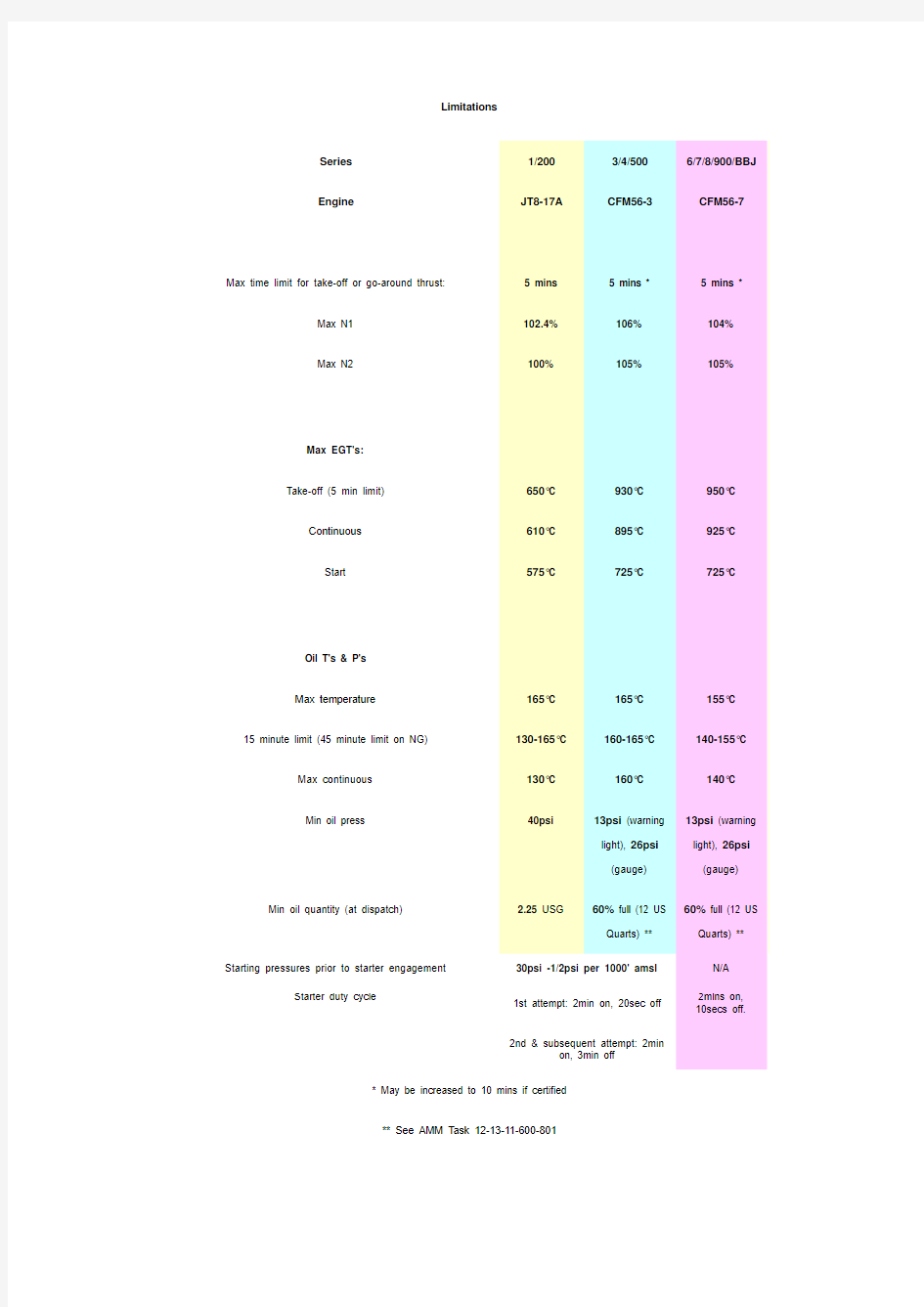
Series1/2003/4/5006/7/8/900/BBJ
Engine JT8-17A CFM56-3CFM56-7
Max time limit for take-off or go-around thrust: 5 mins 5 mins * 5 mins * Max N1 102.4% 106% 104%
Max N2 100% 105% 105%
Max EGT's:
Take-off (5 min limit) 650°C 930°C 950°C Continuous 610°C 895°C 925°C Start 575°C 725°C 725°C
Oil T's & P's
Max temperature 165°C 165°C 155°C
15 minute limit (45 minute limit on NG) 130-165°C 160-165°C 140-155°C
Max continuous 130°C 160°C 140°C
Min oil press 40psi 13psi (warning
light), 26psi
(gauge) 13psi (warning light), 26psi
(gauge)
Min oil quantity (at dispatch) 2.25 USG 60% full (12 US
Quarts) ** 60% full (12 US Quarts) **
Starting pressures prior to starter engagement 30psi -1/2psi per 1000' amsl N/A
Starter duty cycle
1st attempt: 2min on, 20sec off
2nd & subsequent attempt: 2min
on, 3min off 2mins on, 10secs off.
* May be increased to 10 mins if certified ** See AMM Task 12-13-11-600-801
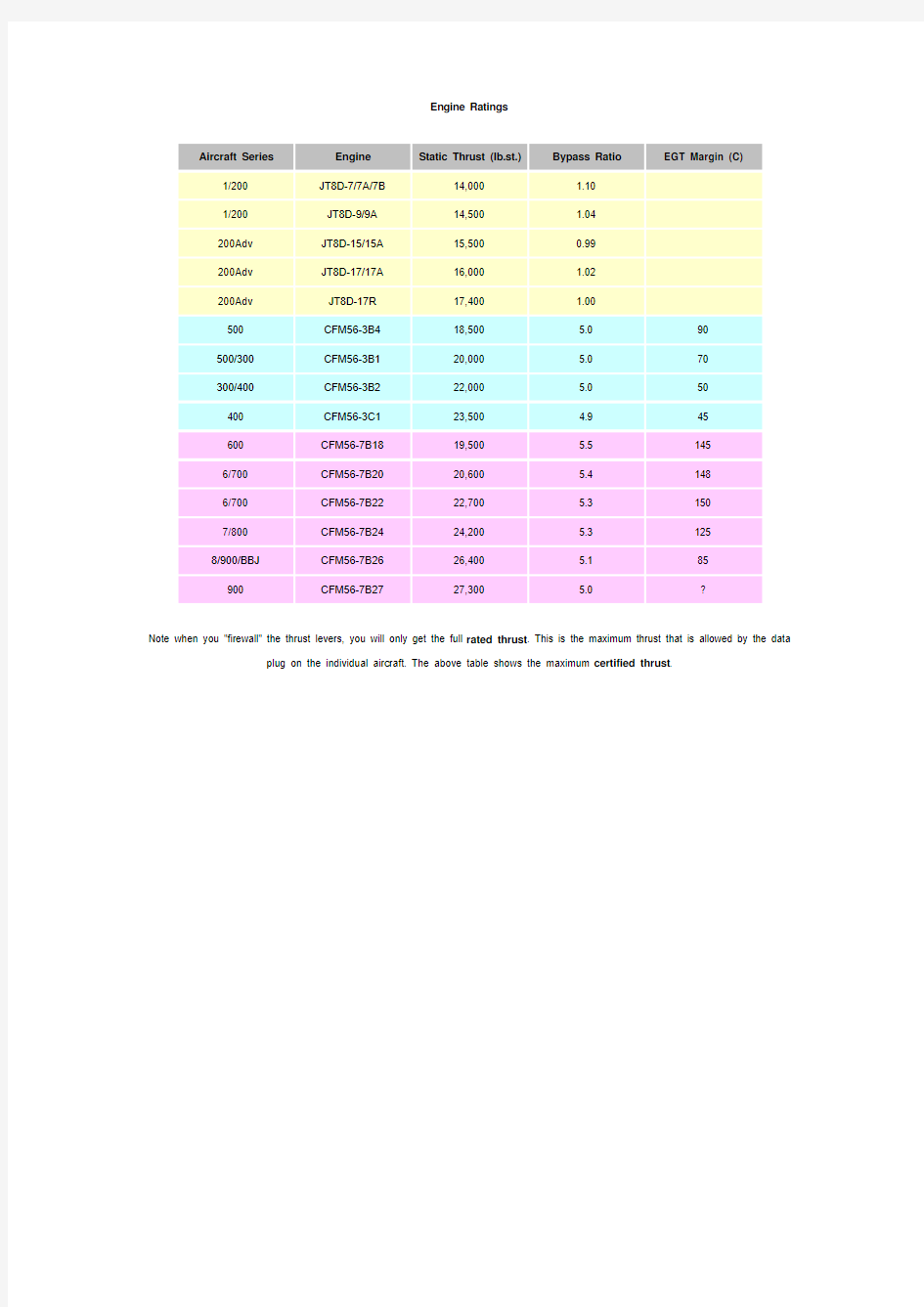
Note when you "firewall" the thrust levers, you will only get the full rated thrust. This is the maximum thrust that is allowed by the data plug on the individual aircraft. The above table shows the maximum certified thrust.
数据库复习资料
数据库复习资料 一名词解释 1.数据库 2.候选码 若关系中的一个属性组的值能够唯一地标识一个元组,则称做候选码。 3.外码 “外码”在数据库中是相对主码而言的,即外键(用于建立和加强两个表数据之间的链接的一列或多列)。 4. 关系 实体与实体之间的各种联系 5. 游标 6. 逻辑独立性和物理独立性 7. 日志事件 在数据库中用事务日志文件记录数据的修改操作,其中的每条日志记录或者记录所执行的逻辑操作,或者记录已修改数据的前像和后像。前像是操作执行前的数据复本; 后像是操作执行后的数据复本
8. 数据转储 数据转储是数据库恢复中采用的基本技术。所谓转储即DBA定期地将数据库复制到磁带或另一个磁盘上保存起来的过程。当数据库遭到破坏后可以将后备副本重新装入,将数据库恢复到转储时的状态。 9. 函数依赖 函数依赖简单点说就是:某个属性集决定另一个属性集时,称另一属性集依赖于该属性集。 设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意两个可能的关系r1、r2,若r1[x]=r2[x],则r1[y]=r2[y],或者若r1[x]不等于r2[x],则r1[y]不等于r2[y],称X决定Y,或者Y依赖X。 10.完全函数依赖和部分函数依赖 完全函数依赖 设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’→Y,则称Y完全函数依赖于X。 部分函数依赖 设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则 称Y部分函数依赖于X。 11.数据库设计 12.数据库恢复 数据库恢复是指通过技术手段,将保存在数据库中丢失的电子数据进行抢救和恢复的技术。 13.封锁 封锁就是事务T在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁。加锁后事务T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其它的事务不能更新此数据对象。 14.规范化 规范化理论正是用来改造关系模式,通过分解关系模式来消除其中不合适的数据依赖,以解决插入异常、删除异常、更新异常和数据冗余问题。
(完整word版)建设数据仓库的八个步骤
大数据技术部 建设数据仓库的八个步骤2017年04月25日编制
建设数据仓库的八个步骤 摘要: 建立数据仓库是一个解决企业问题的过程,业务人员往往不懂如何建立和使用数据仓库,发挥其决策支持的作用;信息部门的人员往往又不懂业务,不知道应该建立哪些决策主题。 关键词:数据仓库元数据 建设数据仓库 建立数据仓库是一个解决企业问题的过程,业务人员往往不懂如何建立和使用数据仓库,发挥其决策支持的作用;信息部门的人员往往又不懂业务,不知道应该建立哪些决策主题,从数据源中抽取哪些数据。因此数据仓库的项目小组应该由业务人员和信息部门的人员共同组成,双方需要相互沟通,协作开发数据仓库。 开发数据仓库的过程包括以下几个步骤。 1.系统分析,确定主题 建立数据仓库的第一个步骤就是通过与业务部门的充分交流,了解建立数据仓库所要解决的问题的真正含义,确定各个主题下的查询分析要求。 业务人员往往会罗列出很多想解决的问题,信息部门的人员应该对这些问题进行分类汇总,确定数据仓库所实现的业务功能。一旦确定问题以后,信息部门的人员还需要确定一下几个因素: ·操作出现的频率,即业务部门每隔多长时间做一次查询分析。 ·在系统中需要保存多久的数据,是一年、两年还是五年、十年。 ·用户查询数据的主要方式,如在时间维度上是按照自然年,还是财政年。 ·用户所能接受的响应时间是多长、是几秒钟,还是几小时。
由于双方在理解上的差异,确定问题和了解问题可能是一个需要多次往复的过程,信息部门的人员可能需要做一些原型演示给业务部门的人员看,以最终确定系统将要实现的功能确实是业务部门所需要的。 2.选择满足数据仓库系统要求的软件平台 在数据仓库所要解决的问题确定后,第二个步骤就是选择合适的软件平台,包括数据库、建模工具、分析工具等。这里有许多因素要考虑,如系统对数据量、响应时间、分析功能的要求等,以下是一些公认的选择标准: ·厂商的背景和支持能力,能否提供全方位的技术支持和咨询服务。 ·数据库对大数据量(TB级)的支持能力。 ·数据库是否支持并行操作。 ·能否提供数据仓库的建模工具,是否支持对元数据的管理。 ·能否提供支持大数据量的数据加载、转换、传输工具(ETT)。 ·能否提供完整的决策支持工具集,满足数据仓库中各类用户的需要。 3.建立数据仓库的逻辑模型 具体步骤如下: (1)确定建立数据仓库逻辑模型的基本方法。 (2)基于主题视图,把主题视图中的数据定义转到逻辑数据模型中。 (3)识别主题之间的关系。
数据仓库与数据挖掘课后习题答案
数据仓库与数据挖掘 第一章课后习题 一:填空题 1)数据库中存储的都是数据,而数据仓库中的数据都是一些历史的、存档的、归纳的、计算的数据。 2)数据仓库中的数据分为四个级别:早起细节级、当前细节级、轻度综合级、高度综合级。3)数据源是数据仓库系统的基础,是整个系统的数据源泉,通常包括业务数据和历史数据。4)元数据是“关于数据的数据”。根据元数据用途的不同将数据仓库的元数据分为技术元数据和业务元数据两类。 5)数据处理通常分为两大类:联机事务处理和联机事务分析 6)Fayyad过程模型主要有数据准备,数据挖掘和结果分析三个主要部分组成。 7)如果从整体上看数据挖掘技术,可以将其分为统计分析类、知识发现类和其他类型的数据挖掘技术三大类。 8)那些与数据的一般行为或模型不一致的数据对象称做孤立点。 9)按照挖掘对象的不同,将Web数据挖掘分为三类:web内容挖掘、web结构挖掘和web 使用挖掘。 10)查询型工具、分析型工具盒挖掘型工具结合在一起构成了数据仓库系统的工具层,它们各自的侧重点不同,因此适用范围和针对的用户也不相同。 二:简答题 1)什么是数据仓库?数据仓库的特点主要有哪些? 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支
持管理决策。 主要特点:面向主题组织的、集成的、稳定的、随时间不断变化的、数据的集合性、支持决策作用 2)简述数据挖掘的技术定义。 从技术角度看,数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程。 3)什么是业务元数据? 业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够读懂数据仓库中的数据 4)简述数据挖掘与传统分析方法的区别。 本质区别是:数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和实用三个特征。 5)简述数据仓库4种体系结构的异同点及其适用性。 a.虚拟的数据仓库体系结构 b.单独的数据仓库体系结构 c.单独的数据集市体系结构 d.分布式数据仓库结构
数据库设计和编码规范
数据库设计和编码规范 Version
目录
简介 读者对象 此文档说明书供开发部全体成员阅读。 目的 一个合理的数据库结构设计是保证系统性能的基础。一个好的规范让新手容易进入状态且少犯错,保持团队支持顺畅,系统长久使用后不至于紊乱,让管理者易于在众多对象中,获取所需或理清问题。 同时,定义标准程序也需要团队合作,讨论出大家愿意遵循的规范。随着时间演进,还需要逐步校订与修改规范,让团队运行更为顺畅。 数据库命名规范 团队开发与管理信息系统讲究默契,而制定服务器、数据库对象、变量等命名规则是建立默契的基本。 命名规则是让所有的数据库用户,如数据库管理员、程序设计人员和程序开发人员,可以直观地辨识对象用途。而命名规则大都约定俗成,可以依照公司文化、团队习惯修改并落实。 规范总体要求 1.避免使用系统产品本身的惯例,让用户混淆自定义对象和系统对象或关键词。 例如,存储过程不要以sp_或xp_开头,因为SQL SERVER的系统存储过程以 sp_开头,扩展存储过程以xp_开头。 2.不要使用空白符号、运算符号、中文字、关键词来命名对象。 3.名称不宜过于简略,要让对象的用途直观易懂,但也不宜过长,造成使用不方 便。 4.不用为数据表内字段名称加上数据类型的缩写。 5.名称中最好不要包括中划线。
6.禁止使用[拼音]+[英语]的方式来命名数据库对象或变量。 数据库对象命名规范 我们约定,数据库对象包括表、视图(查询)、存储过程(参数查询)、函数、约束。对象名字由前缀和实际名字组成,长度不超过30。避免中文和保留关键字,做到简洁又有意义。前缀就是要求每种对象有固定的开头字符串,而开头字符串宜短且字数统一。可以讨论一下对各种对象的命名规范,通过后严格按照要求实施。例如:
库存管理系统数据库设计
库存管理系统数据库设计 系统需求分析: 入库管理: 供货单位将货物连同填好的入库单一起送到仓库,仓库管理员将验收货物,首先将货物的代码、类型、规格和数量与入库单进行核对,在核对无误后将货物按名称分类入库,并填写货物入库登记表。 出库管理: 提货单位向仓库保管员出示出库单,仓库保管员根据有效产品出库单及时付货,取货人员将货物与出库单核对无误后,提取货物,同时把出库单交给仓库保管员,仓库保管员则按照出库单登记货物的出库信息。 库存管理: 每天入库、出库处理结束后,仓库管理员将根据入库登记表和出库登记表对货物分别进行累计,并将累计结果填入库存台账; 数据流图
数据字典 1.数据项 入库单号 数据项名:入库单号 说明:标识货物的入库登记表 类型:CHAR 长度:10 别名:空 取值范围:(10000000000,9999999999)2.数据结构
?入库单 数据结构名:入库单 说明:入库货物的入库单号,入库产品代码、货物类型、规格和数量。 组成:入库单号,入库产品代码、货物类型、规格和数量 3.数据流 ?入库登记 数据流名:入库登记 说明:货物连同填好的入库单一起送到仓库时,仓库管理员依据入库单验收产品,在核对无误后将产品按名称分类入库,同时对入库的货物做登记,以便于仓库的管理。 数据流来源:仓库管理员 数据流去向:货物 数据结构:入库登记表 数据结构名:入库登记表 说明:入库货物的入库单号,入库产品代码,入库数量, 入库时间等 组成:入库日期、入库单号、货物编码、数量、进货价、 总额、已付货款、供货单位编码、供货单位、经办人编 码、经办人、增值税率、备注 4.数据存储
数据仓库建设的几点建议.doc
北京甲骨文软件有限公司咨询经理鲁百年博士 一、国内信息化的现状 1、信息化建设的发展历史:在国内信息化建设过程中,基本上是按照当时业务系统的需求进行建设,例如:在一个企业中,财务部门为了减少工资发放的差错,提高发放的效率,先建设一个工资发放和管理程序;为了报账和核对的需求,建设一个财务管理程序;在银行首先为了业务处理的方便,将最基本的手工记帐和处理的业务建成一个系统,过一段时间,如果有新的业务推出,就再建设一个新的系统,或在原系统的基础上增加新的业务处理。这样的结果使每个系统和系统之间缺少真正的信息沟通和信息交换。 2、为何要建立数据仓库:前面我们讲过,业务系统各自为政,相互独立。当很多业务系统建立后,由于领导的要求和决策的需求,需要一些指标的分析,在相应的业务系统基础上再增加分析和相应的报表功能,这样每个系统就增加了报表和分析功能。但是,由于数据源不统一导致了对同一个指标分析的结果不相同。为了解决该问题,Bell Inman提出了数据仓库的概念,其目的是为了分析和决策的需要,将相互分离的业务系统的数据源整合在一起,可以为领导和决策层提供分析和辅助决策。 3、国内企业对数据仓库建设认识的误区: 大家对数据仓库的认识是将业务系统的数据进行数据抽取、迁移和加载(ETL),将这些数据进行整合存放在一起,统一管理,需要什么样的分析就可提供什么样的分析,这就是数据仓库。这样做的结果是花了一年到两年的时间都无法将整个企业业务系统的数据整合在一起,花钱多、见效慢、风险大。一年后领导问起数据仓库项目时,回答往往是资金不足,人力不够,再投入一些资源、或者再延长半年的时间就会见到效果,但是往往半年过后还是仅仅可以看到十几张或者几十张报表。领导不满意,项目负责人压力也很大,无法交待。这时,项目经理或者项目负责人才意识到,项目有问题,但是谁也不敢说项目有问题,因为这样显然是自己当时的决策失误。怎么办?寻找咨询公司或者一些大的厂商,答案往往是数据仓库缺乏数据模型,应该考虑数据模型。如果建设时考虑到整个企业的数据模型,就可以建设成企业级的数据仓库(EDW。什么是数据模型,就是满足整 个企业分析要求的所有数据源。结果会如何,我个人认为:这样做企业级数据仓
大数据仓库与大数据挖掘技术复习资料
数据仓库与数据挖掘技术复习资料 一、单项选择题 1.数据挖掘技术包括三个主要的部分( C ) A.数据、模型、技术 B.算法、技术、领域知识 C.数据、建模能力、算法与技术 D.建模能力、算法与技术、领域知识 2.关于基本数据的元数据是指: ( D ) A.基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B.基本元数据包括与企业相关的管理方面的数据和信息; C.基本元数据包括日志文件和简历执行处理的时序调度信息; D.基本元数据包括关于装载和更新处理,分析处理以及管理方面的信息。 3.关于OLAP和OLTP的说法,下列不正确的是: ( A) A.OLAP事务量大,但事务内容比较简单且重复率高 B.OLAP的最终数据来源与OLTP不一样 C.OLTP面对的是决策人员和高层管理人员 D.OLTP以应用为核心,是应用驱动的 4.将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( C ) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘5.下面哪种不属于数据预处理的方法? ( D ) A.变量代换 B.离散化 C. 聚集 D. 估计遗漏值 6.在ID3 算法中信息增益是指( D ) A.信息的溢出程度 B.信息的增加效益 C.熵增加的程度最大 D.熵减少的程度最大 7.以下哪个算法是基于规则的分类器 ( A ) A. C4.5 B. KNN C. Bayes D. ANN 8.以下哪项关于决策树的说法是错误的( C ) A.冗余属性不会对决策树的准确率造成不利的影响 B.子树可能在决策树中重复多次 C.决策树算法对于噪声的干扰非常敏感 D.寻找最佳决策树是NP完全问题 9.假设收入属性的最小与最大分别是10000和90000,现在想把当前值30000映射到区间[0,1],若采用最大-最小数据规范方法,计算结果是( A )
实时工情数据库表结构及标识符
实时工情数据库表结构及标识符 ICSCCS中华人民共和国水利行业标准SL实时工情数据库表结构及标识符 Standardforstructureandidentifierinreal-timeengineeringinformationdatabaseoffloodampd roughtmanagement征求意见稿发布发布发布发布实施实施实施实施中华人民共和国水利部中华人民共和国水利部中华人民共和国水利部中华人民共和国水利部发布发布发布发布SL目次1范 围.................................................................. ........................................................................ .....12规范性引用文 件.................................................................. .........................................................13术语和定义...................................................................... .............................................................14表结构设计.................................................................. .................................................................24.1基本内 容.................................................................. .........................................................24.2数据类型...................................................................... .....................................................35标识符设
食堂管理系统数据库设计
一、需求分析 1.系统分析 随着时代的进步,如今各个服务行业也都逐渐发展壮大起来,尤其是食堂服务业,其在服务范围、服务数量和服务内容上都有着非常大的膨胀幅度,因此如何对如此复杂而频繁的服务活动进行管理就属于“食堂管理”的内容。其主要包括:职员资料管理、物品管理、消费内容管理、席位管理、客户评价管理,工资管理等,它是现代食堂管理中的一个重要组成部分。 2.功能需求分析 “食堂管理” 包括很多项目,以前食堂管理人员要记录大量的用户消费内容,然后通过计算器进行一系列的加减乘除运算,最后得出一位顾客的“应付金额”,这样做的效率和准确度可想而知。如果使用计算机来实现对食堂服务业的智能管理,从选择菜、酒水、主食,到计算“应付金额”,最后到打印消费内容,计算机都可以很准确、很快捷地进行处理,这些都是“食堂管理系统”的功能。一个完善的“食堂管理系统”可以很好地管理食堂服务业的各项内容,这样不仅能更好地服务顾客,而且可以为经营者创造更大的利润。 针对每部分的具体功能我们又做了如下的详细分析:
二、涉及的表 职员资料 物品表 席位表
销售记录 评价情况 工资表
SQL 命令 创建数据库 create database 食堂管理系统 on primary (name= stglxt_data,'e:\stglxt_data.mdf') log on (name=stglxt_log1,'e:\stglxt _log.ldf') 创建表 create table 职员资料 (职员编号char(6) not null primary key check(职员编号like'[0-9][0-9][0-9][0-9][0-9][0-9]'), 姓名varchar(20) not null, 职位varchar(20) not null, 性别char(2) not null check(性别='男' or 性别='女') default '男', 民族varchar(8) null default '汉族', 出生日期datetime not null, 身份证号码char(18) not null unique, 婚姻状况char(4) not null check(婚姻状况='已婚' or 婚姻状况='未婚') default '未婚', 联系电话varchar(11) not null unique, 备注varchar(30) ) create table 物品表 (物品编号 char(6) not null primary key, 物品名字 varchar(20) not null, 所属类型 char(4) not null check(所属类型='主食'or 所属类型='酒水' or 所属类型='其他') default '主食', 价格 money not null, 是否售馨 char(2) not null check(是否售馨='是' or 是否售馨='否') default '否', 品牌 varchar(30), 备注 varchar(30) ) create table 席位表 (席位号char(6) not null primary key, 负责人编号char(6) not null foreign key references 职员资料(职员编号) on update cascade on delete cascade, 人数int not null, 状态char(4) not null check(状态='使用' or 状态='预定' or 状态='空闲') default '空闲', 日期datetime not null, 备注varchar(30)
建设数据仓库7个步骤
成功实施数据仓库项目的七个步骤 建立一个数据仓库并不是一个简单的任务,不应该由一个人单独完成。由于数据仓库最佳结合了业务惯例和信息系统技术,因此,一个成功的数据仓库实施需要这两方面的不断协调,以均衡其所有的需要,要求,任务和成果。我很乐意与大家分享我在规划和管理任何数据库项目时采用的方法,这些数据库包括交易数据库,数据仓库,和混合型数据库。由于我生活在关系数据库和数据仓库以及用以支撑它们的数据提取,转换和加载(ETL )过程中,所以我会集中在这些领域讨论我的方法。然而,您可以将这些方法扩展到整个栈--OLAP立方体和如报告,特征分析(ad-hoc analysis),记分卡和仪表盘展示之类的信息传递应用。 我不是吃撑了要告诉一个真正的项目经理( PM )如何做他或她的工作,相反,我写的这些是为那些数据库管理员和开发者,他们没有好运气能与有经验的项目经理一起工作;同样也适合这样的IT专业人员,他们被突然要求:“建立一个数据仓库“,并且需要自己扮演项目经理的角色。我的讨论不会是完整的,但我希望这会给您足够的信息来让您的项目球滚起来。 如图1所示,数据仓库项目有3个轨道(tracks):数据轨道,技术轨道和应用层轨道。当您在整理任何数据库项目计划时,我建议您以这三个轨道为模板来管理和同步您的活动。当您向技术决策者( TDMs ) ,商业决策者( BDMs ) ,和所有其他该数据仓库项目参与者讲解您的计划时,您也可以把图1当作一个高级的概要图来使用。 使用一种生命周期管理方法 我鼓励您利用您的组织可以提供的资源,比如设计,开发和部署系统和软件的技术和方法。如果贵公司对于这些工作没有采用任何正式的方法,继续前进吧,您可采用我为我自己的数据库项目开发的7D数据库生
数据仓库与数据挖掘试题
武汉大学计算机学院 20XX级研究生“数据仓库和数据挖掘”课程期末考试试题 要求:所有的题目的解答均写在答题纸上,需写清楚题目的序号。每张答题纸都要写上姓名和学号。 一、单项选择题(每小题2分,共20分) 1. 下面列出的条目中,()不是数据仓库的基本特征。B A.数据仓库是面向主题的 B.数据仓库是面向事务的 C.数据仓库的数据是相对稳定的 D.数据仓库的数据是反映历史变化的 2. 数据仓库是随着时间变化的,下面的描述不正确的是()。 A.数据仓库随时间的变化不断增加新的数据内容 B.捕捉到的新数据会覆盖原来的快照 C.数据仓库随事件变化不断删去旧的数据内容C D.数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合 3. 以下关于数据仓库设计的说法中()是错误的。A A.数据仓库项目的需求很难把握,所以不可能从用户的需求出发来进行数据仓库的设计,只能从数据出发进行设计 B.在进行数据仓库主题数据模型设计时,应该按面向部门业务应用的方式来设计数据模型 C.在进行数据仓库主题数据模型设计时要强调数据的集成性 D.在进行数据仓库概念模型设计时,需要设计实体关系图,给出数据表的划分,并给出每个属性的定义域 4. 以下关于OLAP的描述中()是错误的。A A.一个多维数组可以表示为(维1,维2,…,维n) B.维的一个取值称为该维的一个维成员 C.OLAP是联机分析处理 D.OLAP是数据仓库进行分析决策的基础 5. 多维数据模型中,下列()模式不属于多维模式。D A.星型模式 B.雪花模式 C.星座模式 D.网型模式 6. 通常频繁项集、频繁闭项集和最大频繁项集之间的关系是()。C A.频繁项集?频繁闭项集?最大频繁项集 B.频繁项集?最大频繁项集?频繁闭项集 C.最大频繁项集?频繁闭项集?频繁项集 D.频繁闭项集?频繁项集?最大频繁项集
数据仓库与数据挖掘-教学大纲
《数据仓库与数据挖掘》教学大纲 一、课程概况 课程名称:数据仓库与数据挖掘 英文名称:Data warehousing and data mining 课程性质:选修 课程学时:32 课程学分:2 授课对象:信息类的大学本科高年级学生 开课时间:三年级下学期 讲课方式:课堂+实验 主讲老师: 二、教学目的 本课程把数据视为基础资源,根据软件工程的思想,总结了数据利用的历程,讲述了数据仓库的基础知识和工具,研究了数据挖掘的任务及其挑战,给出了经典的数据挖掘算法,介绍了数据挖掘的产品,剖析了税务数据挖掘的案例,探索了大数据的管理和应用问题。 三、教学任务 完成《数据仓库与数据挖掘》教材内容,及教学计划中的互动实践内容,另有学生自主选题的大作业、选作的论文报告。32学时:课堂24、实验2、课外2、研讨4学时。 四、教学内容的结构 课程由9个教学单元组成,对应于《数据仓库与数据挖掘》的内容。 第1章数据仓库和数据挖掘概述 1.1概述1 1.2数据中心4 1.2.1关系型数据中心 1.2.2非关系型数据中心
1.2.3混合型数据中心(大数据平台)1.3混合型数据中心参考架构 第2章数据 2.1数据的概念 2.2数据的内容 2.2.1实时数据与历史数据 2.2.2时态数据与事务数据 2.2.3图形数据与图像数据 2.2.4主题数据与全部数据 2.2.5空间数据 2.2.6序列数据和数据流 2.2.7元数据与数据字典 2.3数据属性及数据集 2.4数据特征的统计描述22 2.4.1集中趋势22 2.4.2离散程度23 2.4.3数据的分布形状25 2.5数据的可视化26 2.6数据相似与相异性的度量29 2.7数据质量32 2.8数据预处理32 2.8.1被污染的数据33 2.8.2数据清理35 2.8.3数据集成36 2.8.4数据变换37 2.8.5数据规约38 第3章数据仓库与数据ETL基础39 3.1从数据库到数据仓库39 3.2数据仓库的结构39 3.2.1两层体系结构41 3.2.2三层体系结构41 3.2.3组成元素42 3.3数据仓库的数据模型43 3.3.1概念模型43 3.3.2逻辑模型43 3.3.3物理模型46 3.4 ETL46 3.4.1数据抽取47 3.4.2数据转换48 3.4.3数据加载49 3.5 OLAP49 3.5.1维49 3.5.2 OLAP与OLTP49 3.5.3 OLAP的基本操作50
销售管理系统数据库设计
某制造企业销售管理系统数据库设计 一、需求分析 (一)业务流程: 1、销售部统计商品信息,向客户发布商品信息。 2、客户根据销售部发布的商品信息,向销售部发送订单。 3、销售部将订单发送给主管部门审核。 4、主管部门对订单进行核对: (1)如果不批准订单,主管部门向客户发布不批准的信息; (2)如果批准,主管部门向客户发布批准的信息;销售部获取批准的订单,核对客户信息,登记新客户的基本资料或修改原有客户的基本资料,同时及时发布商品修改后的信息;生产部门接受订单,生产客户所需的商品,生产完成后,将发货单与商品一同发出。 5、客户确认发货单。 (二)数据流程图 员客客 填写上报核对确认 P3发货P2订单基本信息处理订单P1基本处理处理信息 客户信息员工信息 销售管理系统第一层数据流程图
第二层数据流程图: 核对员工客户上报填写 客P1.1员P1.2 户信息工信息 客户信息员工信息 P1 基本信息 客主管部 订单数审P2.P2.P2.理订核订预订订下
发货确认预订单商品信息订单 信贷状况客户 P2订单处理 (三)数据字典 1、订单号数据项可以描述如下 : 数据项 : 订单号 含义说明 : 唯一标识每张订单 别名 : 订单编号 类型 : 字符型 长度 : 4 取值范围 : 0000至 9999 取值含义 : 前 2 位标别所在地区,后 2 位按顺序编号 与其他数据项的逻辑关系 :唯一识别订单 2、商品信息是该系统中的一个重要数据结构,它可以描述如下 : 数据结构 : 商品信息 含义说明 : 是销售管理系统的重要数据结构,定义了销售商品的具体信息组成 : 产品号,产品名,单价,重量 3、数据流“订单数据可描述如下 : 数据流 : 订单数据 说明 : 客户选购商品所下的初始订单 数据流来源 : 客户 数据流去向 : 接受订单 组成 : 客户基本信息+商品编号+数量等 平均流量 : 5张/天 高峰期流量 : 100张/天 4、数据存储“订单可描述如下 : 数据存储 : 订单表 说明 : 记录每张订单的具体情况 流入数据流 : 订单处理 流出数据流 : …… 订单号,客户编号,产品,数量,单价等 : 组成 数据量 : 每年2000张 存取方式 : 随机存取 5、处理过程“接收订单尠可描述如下 : 处理过程 : 接收订单 说明 : 核准客户所下订单 输入 : 订单数据,商品信息,主管审批 输出 : 核对订单至主管部门,是否确认信息给客户 处理 : 接收到客户订购产品的初始订单后,根据商品信息以及客户以往
数据仓库建设方案详细
第1章数据仓库建设 1.1数据仓库总体架构 专家系统接收增购项目车辆TCMS或其他子系统通过车地通信传输的实时或离线数据,经过一系列综合诊断分析,以各种报表图形或信息推送的形式向用户展示分析结果。针对诊断出的车辆故障将给出专家建议处理措施,为车辆的故障根因修复提供必要的支持。 根据专家系统数据仓库建设目标,结合系统数据业务规,包括数据采集频率、数据采集量等相关因素,设计专家系统数据仓库架构如下: 数据仓库架构从层次结构上分为数据采集、数据存、数据分析、数据服务等几个方面的容: 数据采集:负责从各业务自系统中汇集信息数据,系统支撑Kafka、Storm、Flume
及传统的ETL采集工具。 数据存储:本系统提供Hdfs、Hbase及RDBMS相结合的存储模式,支持海量数据的分布式存储。 数据分析:数据仓库体系支持传统的OLAP分析及基于Spark常规机器学习算法。 数据服务总线:数据系统提供数据服务总线服务,实现对数据资源的统一管理和调度,并对外提供数据服务。 1.2数据采集 专家系统数据仓库数据采集包括两个部分容:外部数据汇集、部各层数据的提取与加载。外部数据汇集是指从TCMS、车载子系统等外部信息系统汇集数据到专家数据仓库的操作型存储层(ODS);部各层数据的提取与加载是指数据仓库各存储层间的数据提取、转换与加载。 1.2.1外部数据汇集 专家数据仓库数据源包括列车监控与检测系统(TCMS)、车载子系统等相关子系统,数据采集的容分为实时数据采集和定时数据采集两大类,实时数据采集主要对于各项检测指标数据;非实时采集包括日检修数据等。 根据项目信息汇集要求,列车指标信息采集具有采集数据量大,采集频率高的特点,考虑到系统后期的扩展,因此在数据数据采集方面,要求采集体系支持高吞吐量、高频率、海量数据采集,同时系统应该灵活可配置,可根据业务的需要进行灵活配置横向扩展。 本方案在数据采集架构采用Flume+Kafka+Storm的组合架构,采用Flume和ETL 工具作为Kafka的Producer,采用Storm作为Kafka的Consumer,Storm可实现对海量数据的实时处理,及时对问题指标进行预警。具体采集系统技术结构图如下:
数据仓库与数据挖掘习题
数据仓库与数据挖掘习题 1.1什么是数据挖掘?在你的回答中,强调以下问题: (a) 它是又一个骗局吗? (b) 它是一种从数据库,统计学和机器学习发展的技术的简单转换吗? (c) 解释数据库技术发展如何导致数据挖掘 (d) 当把数据挖掘看作知识发现过程时,描述数据挖掘所涉及的步骤。 1.2 给出一个例子,其中数据挖掘对于一种商务的成功至关重要的。这种商务需要什么数据挖掘功能?他们能够由数据查询处理或简单的统计分析来实现吗? 1.3 假定你是Big-University的软件工程师,任务是设计一个数据挖掘系统,分析学校课程数据库。该数据库包括如下信息:每个学生的姓名,地址和状态(例如,本科生或研究生),所修课程,以及他们累积的GPA(学分平均)。描述你要选取的结构。该结构的每个成分的作用是什么? 1.4 数据仓库和数据库有何不同?它们有那些相似之处? 1.5简述以下高级数据库系统和应用:面向对象数据库,空间数据库,文本数据库,多媒体数据库和WWW。 1.6 定义以下数据挖掘功能:特征化,区分,关联,分类,预测,聚类和演变分析。使用你熟悉的现实生活中的数据库,给出每种数据挖掘的例子。 1.7 区分和分类的差别是什么?特征化和聚类的差别是什么?分类和预测呢?对于每一对任务,它们有何相似之处? 1.8 根据你的观察,描述一种可能的知识类型,它需要由数据挖掘方法发现,但未在本章中列出。它需要一种不同于本章列举的数据挖掘技术吗? 1. 9 描述关于数据挖掘方法和用户交互问题的三个数据挖掘的挑战。 1. 10 描述关于性能问题的两个数据挖掘的挑战。 2.1 试述对于多个异种信息源的集成,为什么许多公司宁愿使用更新驱动的方法(构造使用数据仓库),而不愿使用查询驱动的方法(使用包装程序和集成程序)。描述一些情况,其中查询驱动方法比更新驱动方法更受欢迎。 2.2 简略比较以下概念,可以用例子解释你的观点 (a)雪花模式、事实星座、星型网查询模型 (b)数据清理、数据变换、刷新 (c)发现驱动数据立方体、多特征方、虚拟仓库 2.3 假定数据仓库包含三个维time,doctor和patient,两个度量count 和charge,其中charge 是医生对一位病人的一次诊治的收费。 (a)列举三种流行的数据仓库建模模式。 (b)使用(a)列举的模式之一,画出上面数据仓库的模式图。 (c)由基本方体[day,doctor,patient]开始,为列出2000年每位医生的收费总数,应当执行哪些OLAP操作? (d)为得到同样的结果,写一个SQL查询。假定数据存放在关系数据库中,其模式如下:fee(day,month,year,doctor,hospital,patient,count,charge) 2.4 假定Big_University的数据仓库包含如下4个维student, course, semester和instructor,2个度量count和avg_grade。在最低的概念层(例如对于给定的学生、课程、学期和教师的组合),度量avg_grade存放学生的实际成绩。在较高的概念层,avg_grade存放给定组合的
数据仓库与数据挖掘学习心得
数据仓库与数据挖掘学习心得 通过数据仓库与数据挖掘的这门课的学习,掌握了数据仓库与数据挖掘的一些基础知识和基本概念,了解了数据仓库与数据库的区别。下面谈谈我对数据仓库与数据挖掘学习心得以及阅读相关方面的论文的学习体会。 《浅谈数据仓库与数据挖掘》这篇论文主要是介绍数据仓库与数据挖掘的的一些基本概念。数据仓库是支持管理决策过程的、面向主题的、集成的、稳定的、不同时间的数据集合。主题是数据数据归类的标准,每个主题对应一个客观分析的领域,他可为辅助决策集成多个部门不同系统的大量数据。数据仓库包含了大量的历史数据,经集成后进入数据仓库的数据极少更新的。数据仓库内的数据时间一般为5年至10年,主要用于进行时间趋势分析。数据仓库的数据量很大。 数据仓库的特点如下: 1、数据仓库是面向主题的; 2、数据仓库是集成的,数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出来,进行加工与集成,统一与综合之后才能进入数据仓库; 3、数据仓库是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询; 4、数据仓库是随时间而变化的,传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求,它在商业领域取得了巨大的成功。
作为一个系统,数据仓库至少包括3个基本的功能部分:数据获取:数据存储和管理;信息访问。 数据挖掘的定义:数据挖掘从技术上来说是从大量的、不完全的、有噪音的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程。 数据开采技术的目标是从大量数据中,发现隐藏于其后的规律或数据间的的关系,从而服务于决策。数据挖掘的主要任务有广义知识;分类和预测;关联分析;聚类。 《数据仓库与数据挖掘技术在金融信息化中的应用》论文主要通过介绍数据额仓库与数据挖掘的起源、定义以及特征的等方面的介绍引出其在金融信息化中的应用。在金融信息化的应用方面,金融机构利用信息技术从过去积累的、海量的、以不同形式存储的数据资料里提取隐藏着的许多重要信息,并对它们进行高层次的分析,发现和挖掘出这些数据间的整体特征描述及发展趋势预测,找出对决策有价值的信息,以防范银行的经营风险、实现银行科技管理及银行科学决策。 现在银行信息化正在以业务为中心向客户为中心转变6银行信息化不仅是数据的集中整合,而且要在数据集中和整合的基础上向以客为中心的方向转变。银行信息化要适应竞争环境客户需求的变化,创造性地用信息技术对传统过程进行集成和优化,实现信息共享、资源整合综合利用,把银行的各项作用统一起来,优势互补统一调配各种资源,为银行的客户开发、服务、综理财、管理、风险防范创立坚实的基础,从而适应日益发展的数据技术需要,全面提高银行竞争力,为金融创新和提高市场反映能力
数据仓库与数据挖掘课后习题答案
数据仓库与数据挖掘课后习 题答案 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
数据仓库与数据挖掘 第一章课后习题 一:填空题 1)数据库中存储的都是数据,而数据仓库中的数据都是一些历史的、存档的、归纳的、计算的数据。 2)数据仓库中的数据分为四个级别:早起细节级、当前细节级、轻度综合级、高度综合级。 3)数据源是数据仓库系统的基础,是整个系统的数据源泉,通常包括业务数据和历史数据。 4)元数据是“关于数据的数据”。根据元数据用途的不同将数据仓库的元数据分为技术元数据和业务元数据两类。 5)数据处理通常分为两大类:联机事务处理和联机事务分析 6)Fayyad过程模型主要有数据准备,数据挖掘和结果分析三个主要部分组成。 7)如果从整体上看数据挖掘技术,可以将其分为统计分析类、知识发现类和其他类型的数据挖掘技术三大类。 8)那些与数据的一般行为或模型不一致的数据对象称做孤立点。 9)按照挖掘对象的不同,将Web数据挖掘分为三类:web内容挖掘、web结构挖掘和web使用挖掘。 10)查询型工具、分析型工具盒挖掘型工具结合在一起构成了数据仓库系统的工具层,它们各自的侧重点不同,因此适用范围和针对的用户也不相同。 二:简答题 1)什么是数据仓库数据仓库的特点主要有哪些 2) 数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 主要特点:面向主题组织的、集成的、稳定的、随时间不断变化的、数据的集合性、支持决策作用 3)简述数据挖掘的技术定义。 从技术角度看,数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程。 4)什么是业务元数据? 业务元数据从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够读懂数据仓库中的数据 5)简述数据挖掘与传统分析方法的区别。 本质区别是:数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先前未知、有效和实用三个特征。 6)简述数据仓库4种体系结构的异同点及其适用性。 a.虚拟的数据仓库体系结构 b.单独的数据仓库体系结构
04.数据库设计说明书
编号:002 版本:数据库设计说明书 项目名称: 委托单位: 承担单位: 编写:年月日 校对:年月日 审核: 年月日
《数据库设计说明书》的编制,是对于设计中的数据库的所有标识、逻辑结构和物理结构做出具体的设计规定。《数据库设计说明书》编制指导如下。 1引言 1.1编写说明 说明编写这份《数据库设计说明书》的目的,指出预期的读者。 1.2背景 说明待开发数据库的名称、版本号说明、使用范围并列出本项目的任务提出者和开发者。 1.3 修订审批记录 说明编写这份《数据库设计说明书》的修订过程、审批过程。参见文档修订记录表及文档审批记录表。 表1 文档修订记录表 1.4术语和缩写词 列出本文件中用到的专门术语的定义、外文首字母组词的原词组。 1.5参考资料 列出本文件中用到的参考资料(参考格式:作者、名称、出版单位、发表日期等)。 2外部设计 2.1标识符和状态 列出用于标识该数据库的编码、名称、标识符或标号,并给出附加的描述性信息。如果该数据库是在实验中的或者暂时性的,则要说明这一特点和有效期。 2.2使用该数据库的程序 列出将要使用或访问此数据库的所有应用程序,给出其名称和版本号。 2.3约定 叙述使用该数据库所必须了解的建立标号、标识的有关约定。例如,用于标识库内各个文卷、记录、数据项的命名约定等。 2.5支持软件
叙述与此数据库有关的支持软件,如数据库管理系统、存储定位程序等。概要说明这些支持软件的名称、功能及为使用这些支持软件所需的操作命令。列出这些支持软件的有关资料。 2.6专门说明 向准备从事此数据库的生成、测试、维护人员所提供的专门说明。 3结构设计 在概念结构设计和逻辑结构设计部分仅需描述与新增表、修订表有关的内容,可以引用未做修改的表,但不进行详细描述,系统完整的数据库逻辑结构做为附件附在该文档之后。数据库逻辑结构字典格式参见附件1。 3.1概念结构设计 详细说明本数据库的用户视图,即反映现实世界中的实体、属性和它们之间关系的原始数据形式。包括各数据项、记录、数据表的标识符、定义、类型、计量单位和值域;描述数据模型的设计考虑,并绘制E_R图。 3.2逻辑结构设计 详细说明本数据库的数据库管理员视图,即把上述原始数据进行分解、合并后重新组织起来的数据库全局逻辑结构,包括所确定的关键字和属性、重新确定的记录结构和数据表结构、所建立的各个数据表之间的相互关系,并参照新疆油田公司《勘探开发数据库数据表编码规范(Q/SY XJ0204-2009)》以及《数据库逻辑结构管理规范(Q/SY XJ0205-2009)》等相关标准设计《数据库逻辑结构》。并绘制E_R图,要求达到第二范式。 3.3物理结构设计 详细说明本数据库的系统程序员视图,即数据在内存中的安排,包括对索引区、缓冲区的设计;所使用的外存设备及外存空间的组织,包括索引区、数据块的组织与划分以及访问数据的方式方法。 4、应用设计 详细说明数据库应用开发所产生的存储过程、包、视图、函数、触发器等设计,并做为附件附在该文档之后。具体格式参见附件2。 5、其它设计 5.1完整性设计 说明为保持数据库中数据的完整性所作的设计考虑,如数据库的后援频率、数据共享、数据冗余等。 5.2安全保密设计 说明在数据库的设计中,将如何通过区分不同的访问者、不同的访问类型和不同的数据对象等而获得数据库安全保密的设计考虑。以及将要采用的保证数据安全保密的措施和机制,如数据库安全破坏标识、资源保护方式、存取控制方式等。 5.3 其它设计 说明其它设计考虑。