python爬虫
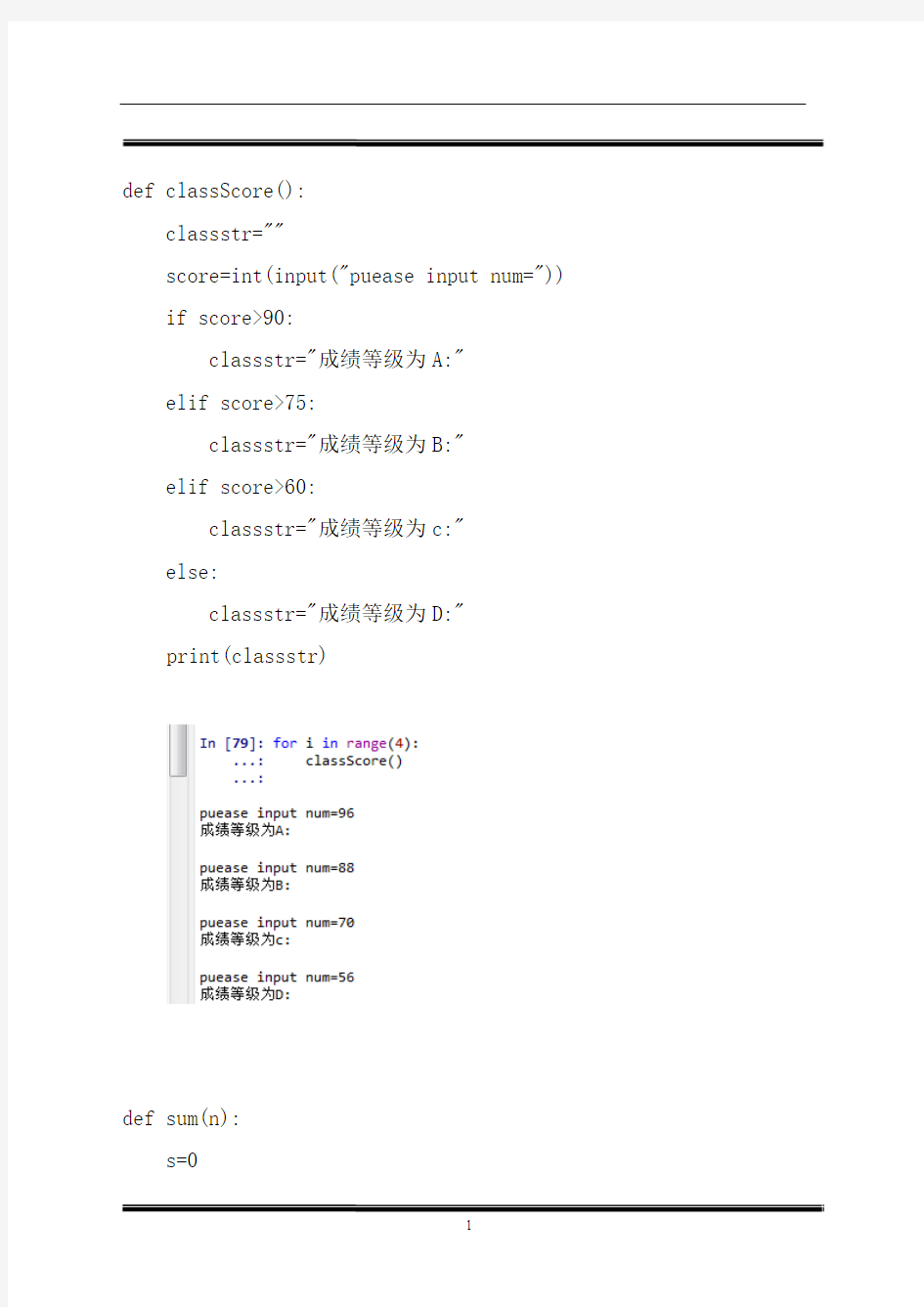

def classScore():
classstr=""
score=int(input("puease input num=")) if score>90:
classstr="成绩等级为A:"
elif score>75:
classstr="成绩等级为B:"
elif score>60:
classstr="成绩等级为c:"
else:
classstr="成绩等级为D:"
print(classstr)
def sum(n):
s=0
for i in range(n+1):
s+=i
return s
def threeSum(n):
s=0
for i in range(0,n+1,3):
s+=i
return s
#for循环 9*9乘法表
def chenfa():
for i in range(1,10):
for j in range(1,10):
if i break print("{0}*{1}={2}".format(i,j,i*j),"\t",end="") print(); #while 乘法表 def whcf(): i=1 while i<=9: j=1 while j<10: if i<=j: print("%s*%s=%s"%(i,j,i*j),"\t",end="") j+=1 i+=1 print() def get_html(url): try: header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.90 Safari/537.36 2345Explorer/9.3.2.17331', } ht=requests.get(url,headers=header,verify=True) ht.raise_for_status ht.encoding=ht.apparent_encoding return ht except Exception as e: print("error:",e) def writeHtml(url): text=get_html(url).content path="C:\\Users\\Administrator\\Desktop\\python\\baidu.html" with open(path,"wb") as f: f.write(text) print("success") def getInfor(url): finalSay=[] html=get_html(url).text soup=BeautifulSoup(html,"html.parser") print(" the saying is:") say_list=soup.select("span.text") print("-------名言--------------") print("the length=",len(say_list)) # print(say_list) for elem in say_list: te=elem.text finalSay.append(te); print(finalSay) print("-------标签--------------") finalTag=[] tag_list=soup.select("div.tags") print("the length of tag=",len(tag_list)) #print(tag_list) for tag in tag_list: a_tag=tag.select("a.tag") #print(a_tag) # for elem in a_tag: # print(elem.text) tag_list=[elem.text for elem in a_tag] #print(tag_list) finalTag.append(tag_list) print(finalTag) print("-------作者--------------") finalAuthor=[] author_list=soup.select("small.author") print("the length of authoer=",len(author_list)) for elem in author_list: finalAuthor.append(elem.text) print(finalAuthor) for i in range(len(author_list)): print("the saying:",finalSay[i],"\t","the author:",finalAuthor[i],"\t","the tag:",finalTag[i]) def getDictionary(): word=input("亲输入要翻译的词语:") url="https://https://www.360docs.net/doc/706563278.html,/dict/search?q=" hurl=url+word trant=[] html=get_html(hurl).text re0=r'(.*?)' flag_list=[] nav_list=re.findall(re0,html) #print(hurl) #print(html) if len(nav_list)==0 and len(nav_list[0])<1: return for elem in nav_list: flag_list.append(elem[1]) print(flag_list) re1=r'(.*?)' tran_list=re.findall(re1,html) #print(tran_list) for i in range(len(nav_list)): tra="\t".join([flag_list[i],tran_list[i]]) print(tra) trant.append(tra) #trant.append("\n") return trant def writeTet(t): path="E:\\infor.txt" with open(path,"a+") as f: for txt in t: f.write(txt) f.write("\n") print("success") def weather(url): html=get_html(url).text soup=BeautifulSoup(html,"html.parser") time_list=soup.select("li > h1") print(len(time_list),time_list) wea_list=soup.select("li > p.wea") print(len(wea_list),wea_list) tem_list=soup.select("li > p.tem") print(len(tem_list),tem_list) wind_list=soup.select("li > p.win > em") print(len(wind_list),wind_list) winclas_list=soup.select("li > p.win > i") print(len(winclas_list),winclas_list) #处理成文本 infor_list=[] for i in range(len(tem_list)): windir=" " timetxt=time_list[i].text print(timetxt,end=" ") weatxt=wea_list[i].text print(weatxt,end=" ") temtxt=tem_list[i].text print(temtxt,end=" ") span_win=wind_list[i].select("span") if(len(span_win)==2): windir=span_win[0].get("title")+" --"+span_win[1].get("title") else: windir=span_win[0].get("title") print(windir) winclastxt=winclas_list[i].text print(winclastxt) infor_list.append([timetxt,weatxt,temtxt,windir,winclastxt]) print(len(infor_list),infor_list) 五、见习总结 学习了一下python语法,看到了python的奇妙,知道了大数据的一些功能。 0 前言 工作之余,时常会想能做点什么有意思的玩意。互联网时代,到处都是互联网思维,大数据、深度学习、人工智能,这些新词刮起一股旋风。所以笔者也赶赶潮流,买了本Python爬虫书籍研读起来。 网络爬虫,顾名思义就是将互联网上的内容按照自己编订的规则抓取保存下来。理论上来讲,浏览器上只要眼睛能看到的网页内容都可以抓起保存下来,当然很多网站都有自己的反爬虫技术,不过反爬虫技术的存在只是增加网络爬虫的成本而已,所以爬取些有更有价值的内容,也就对得起技术得投入。 1案例选取 人有1/3的时间在工作,有一个开心的工作,那么1/3的时间都会很开心。所以我选取招聘网站来作为我第一个学习的案例。 前段时间和一个老同学聊天,发现他是在从事交互设计(我一点也不了解这是什么样的岗位),于是乎,我就想爬取下前程无忧网(招聘网_人才网_找工作_求职_上前程无忧)上的交互设计的岗位需求: 2实现过程 我这里使用scrapy框架来进行爬取。 2.1程序结构 C:\Users\hyperstrong\spiderjob_jiaohusheji │scrapy.cfg │ └─spiderjob │ items.py │ pipelines.py │ settings.py │ __init__.py │ middlewares.py ├─spiders │ jobSpider.py │ __init__.py 其中: items.py是从网页抽取的项目 jobSpider.py是主程序 2.2链接的构造 用浏览器打开前程无忧网站 招聘网_人才网_找工作_求职_上前程无忧,在职务搜索里输入“交互设计师”,搜索出页面后,观察网址链接: 【交互设计师招聘】前程无忧手机网_触屏版 https://www.360docs.net/doc/706563278.html,/jobsearch/search_result.php?fromJs=1&k eyword=%E4%BA%A4%E4%BA%92%E8%AE%BE%E8%AE%A1%E5%B8%88&keywordty pe=2&lang=c&stype=2&postchannel=0000&fromType=1&confirmdate=9 网址链接中并没有页码,于是选择第二页,观察链接: https://www.360docs.net/doc/706563278.html, python爬虫入门到精通必备的书籍 python是一种常见的网络爬虫语言,学习python爬虫,需要理论与实践相结合,Python生态中的爬虫库多如牛毛,urllib、urllib2、requests、beautifulsoup、scrapy、pyspider都是爬虫相关的库,但是如果没有理论知识,纯粹地学习如何使用这些API如何调用是不会有提升的。所以,在学习这些库的同时,需要去系统的学习爬虫的相关原理。你需要懂的技术包括Python编程语言、HTTP协议、数据库、Linux等知识。这样才能做到真正从入门python爬虫到精通,下面推荐几本经典的书籍。 1、Python语言入门的书籍: 适合没有编程基础的,入门Python的书籍 1、《简明Python教程》 本书采用知识共享协议免费分发,意味着任何人都可以免费获取,这 https://www.360docs.net/doc/706563278.html, 本书走过了11个年头,最新版以Python3为基础同时也会兼顾到Python2的一些东西,内容非常精简。 2、《父与子的编程之旅》 一本正儿八经Python编程入门书,以寓教于乐的形式阐述编程,显得更轻松愉快一些。 3、《笨办法学Python》 这并不是关于亲子关系的编程书,而是一本正儿八经Python编程入门书,只是以这种寓教于乐的形式阐述编程,显得更轻松愉快一些。 4、《深入浅出Python》 Head First 系列的书籍一直饱受赞誉,这本也不例外。Head First Python主要讲述了Python 3的基础语法知识以及如何使用Python https://www.360docs.net/doc/706563278.html, 快速地进行Web、手机上的开发。 5、《像计算机科学家一样思考python》 内容讲解清楚明白,非常适合python入门用,但对于学习过其他编程语言的读者来说可能会觉得进度比较慢,但作者的思路和想法确实给人很多启发,对于菜鸟来说收益匪浅,书中很多例子还是有一定难度的,完全吃透也不容易。 6、《Python编程:入门到实践》 厚厚的一本书,本书的内容基础而且全面,适合纯小白看。Python学习进阶书籍 1、《Python学习手册》 本书解释详细,例子丰富;关于Python语言本身的讲解全面详尽而 Python基础入门课程 --学习笔记 近期忽然有点迷上了爬虫Python,可能原因是最近人工智能,深度学习炒的比较热火有关。所以在网上搜了一大圈,想找点基础教程看看,发现还真不少,不过还真没有发现比较适合我这种菜鸟的教程,要么是英文的,要么一开始就讲的比较深,连测试环境都搭建不起了。让人一看就有点畏难放弃了。最后终于发现了唐老师的视频教程,好了,废话不多说,我就把我最近一段时间的学习笔记给大家分享一下。 要想学习Python,首先要搭建测试环境。本教程所用的环境如下: 一、测试环境: 系统:64位win7中文版 浏览器:Google Chrome,尽量不要用IE浏览器,测试中可能不能使用。 Python:Anaconda3-4.3.1-Windows-x86_64.exe Python可以自行通过Baidu自行搜索下载安装即可。 二、Python安装: 如果你能下载到上面的版本,直接双击运行安装即可,可以更改安装路径到D盘,因为占用空间比较大。我就是安装到D盘。安装完成后你就可以在开始菜单-所有程序-Anaconda3找到Jupyter Notebook。本次教程所有脚本全部在该notebook中运行和测试。 三、入门学习: 如果你顺利看到这里,并能在你的电脑上看到上面的截图,那么恭喜你,你已经成功的拥有了本次学习测试的环境。 1、打开Jupyter notebook。 路径:开始菜单-所有程序- Anaconda3找到Jupyter Notebook单击打开, 界面如下。如能打开Dos窗口,不能出现下面的截图,请尝试安装Google Chrome,并设置成默认浏览器即可解决。 单击上图中的New,从下来菜单中选择Python 3即可打开代码编辑窗口。 如下两图: 【黑马程序员】Python教程、Python下载、Python爬虫、Python学习路线图、Python就业方向 一、Python学习路线图 二、Python就业方向 三、Python各阶段技能 四、Python学习教程下载 免费领取网盘提取码+ Q 1679806262 适合人群:零基础小白 学习周期:15天 课程章节:2章(每章包含1-100小节课程) 学习后目标:1.掌握基本的Linux系统操作。2.掌握Python基础编程语法。3.建立起编程思维和面向对象思想。 0基础小白也能学会的人工智能 视频网盘:https://www.360docs.net/doc/706563278.html,/course/534.html?1912sxkqq 资料网盘:https://https://www.360docs.net/doc/706563278.html,/s/1EDaAE9eG0fhW7V5haowbig 内容简介: 本套课程从零开始,讲解人工智能的全部核心基础,4天课让你掌握机器学习、线性代数、微积分和概率论,学完课程你可以自己推导损失函数,实现梯度下降,手写神经网络,把控无人驾驶,完成手写字识别... 2019年python入门到精通(19天全) 视频网盘:https://www.360docs.net/doc/706563278.html,/course/542.html?1912sxkqq 资料网盘:https://https://www.360docs.net/doc/706563278.html,/s/1UzxLIXhkRppccqf2vGyOhA 内容简介: python基础学习课程,从搭建环境到判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python 的编程殿堂 免费领取网盘提取码+ Q 1679806262 Python入门教程完整版(懂中文就能学会) 视频网盘:https://www.360docs.net/doc/706563278.html,/course/273.html?1912sxkqq 资料网盘:https://https://www.360docs.net/doc/706563278.html,/s/12-dymJ8FjWzh6b5NKJuP3Q 内容简介: 1-3 天内容为Linux基础命令;4-13 天内容为Python基础教程;14-15 天内容为飞机大战项目演练。 python进阶深入浅出完整版 视频网盘:https://www.360docs.net/doc/706563278.html,/course/541.html?1912sxkqq 资料网盘:https://https://www.360docs.net/doc/706563278.html,/s/1Y83bFUKz1Z-gM5x_5b_r7g 内容简介: python高级学习课程,从linux操作系统到网络编程,再到多任务编程以及http同学协议,熟练掌握mysql数据库的使用,构建完整python编程技能,进入python殿堂,一窥python 编程之美。 Python进阶之Django框架 视频网盘:https://www.360docs.net/doc/706563278.html,/course/257.html?1912sxkqq 资料网盘:https://https://www.360docs.net/doc/706563278.html,/s/1OJ4SE8wClgV_53GclWPXDQ P y t h o n爬虫总结 Python总结 目录 Python总结 (2) 前言 (3) (一)如何学习Python (3) (二)一些Python免费课程推荐 (4) (三)Python爬虫需要哪些知识? (5) (四)Python爬虫进阶 (7) (五)Python爬虫面试指南 (8) (六)推荐一些不错的Python博客 (10) (七)Python如何进阶 (11) (八)Python爬虫入门 (12) (九)Python开发微信公众号 (14) (十)Python面试概念和代码 (17) (十一)Python书籍 (26) 前言 知乎:路人甲 微博:玩数据的路人甲 微信公众号:一个程序员的日常 在知乎分享已经有一年多了,之前一直有朋友说我的回答能整理成书籍了,一直偷懒没做,最近有空仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本是有关于Python方面的。 还有另外几本包括我的一些数据分析方面的读书笔记、增长黑客的读书笔记、机器学习十大算法等等内容。将会在我的微信公众号:一个程序员的日常进行更新,同时也可以关注我的知乎账号:路人甲及时关注我的最新分享用数据讲故事。 (一)如何学习Python 学习Python大致可以分为以下几个阶段: 1.刚上手的时候肯定是先过一遍Python最基本的知识,比如说:变量、数据结构、语法等,基础过的很快,基本上1~2周时间就能过完了,我当时是在这儿看的基础:Python 简介 | 菜鸟教程 2.看完基础后,就是做一些小项目巩固基础,比方说:做一个终端计算器,如果实在找不到什么练手项目,可以在Codecademy - learn to code, interactively, for free上面进行练习。 3. 如果时间充裕的话可以买一本讲Python基础的书籍比如《Python编程》,阅读这些书籍,在巩固一遍基础的同时你会发现自己诸多没有学习到的边边角角,这一步是对自己基础知识的补充。 4.Python库是Python的精华所在,可以说Python库组成并且造就了Python,Python库是Python开发者的利器,所以学习Python库就显得尤为重要:The Python爬虫8个常用的爬虫技巧分析总结 用python也差不多一年多了,python应用最多的场景还是web快速开发、爬虫、自动化运维:写过简单网站、写过自动发帖脚本、写过收发邮件脚本、写过简单验证码识别脚本。 爬虫在开发过程中也有很多复用的过程,这里总结一下,以后也能省些事情。 1、基本抓取网页 get方法 import urllib2url "http://baidu"respons = urllib2.urlopen(url)print response.read() post方法 import urllibimport urllib2url = "http://abcde"form = {name:abc,password:1234}form_data = urllib.urlencode(form)request = urllib2.Request(url,form_data)response = urllib2.urlopen(request)print response.read() 2、使用代理IP 在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到代理IP; 在urllib2包中有ProxyHandler类,通过此类可以设置代理访问网页,如下代码片段:import urllib2proxy = urllib2.ProxyHandler({http: 127.0.0.1:8087})opener = urllib2.build_opener(proxy)urllib2.install_opener(opener)response = urllib2.urlopen(http://baidu)print response.read() 3、Cookies处理 cookies是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密),python提供了cookielib模块用于处理cookies,cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源. 代码片段: import urllib2, cookielibcookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())opener = urllib2.build_opener(cookie_support)urllib2.install_opener(opener)content = urllib2.urlopen(http://XXXX).read() Python总结 目录 Python总结 (1) 前言 (2) (一)如何学习Python (2) (二)一些Python免费课程推荐 (3) (三)Python爬虫需要哪些知识? (4) (四)Python爬虫进阶 (6) (五)Python爬虫面试指南 (7) (六)推荐一些不错的Python博客 (8) (七)Python如何进阶 (9) (八)Python爬虫入门 (10) (九)Python开发微信公众号 (12) (十)Python面试概念和代码 (15) (十一)Python书籍 (23) 前言 知乎:路人甲 微博:玩数据的路人甲 微信公众号:一个程序员的日常 在知乎分享已经有一年多了,之前一直有朋友说我的回答能整理成书籍了,一直偷懒没做,最近有空仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本是有关于Python方面的。 还有另外几本包括我的一些数据分析方面的读书笔记、增长黑客的读书笔记、机器学习十大算法等等内容。将会在我的微信公众号:一个程序员的日常进行更新,同时也可以关注我的知乎账号:路人甲及时关注我的最新分享用数据讲故事。 (一)如何学习Python 学习Python大致可以分为以下几个阶段: 1.刚上手的时候肯定是先过一遍Python最基本的知识,比如说:变量、数据结构、语法等,基础过的很快,基本上1~2周时间就能过完了,我当时是在这儿看的基础:Python 简介 | 菜鸟教程 2.看完基础后,就是做一些小项目巩固基础,比方说:做一个终端计算器,如果实在找不到什么练手项目,可以在Codecademy - learn to code, interactively, for free上面进行练习。 3. 如果时间充裕的话可以买一本讲Python基础的书籍比如《Python编程》,阅读这些书籍,在巩固一遍基础的同时你会发现自己诸多没有学习到的边边角角,这一步是对自己基础知识的补充。 4.Python库是Python的精华所在,可以说Python库组成并且造就了Python,Python 库是Python开发者的利器,所以学习Python库就显得尤为重要:The Python Standard Library,Python库很多,如果你没有时间全部看完,不妨学习一遍常用的Python库:Python常用库整理 - 知乎专栏 Python爬虫实战(1):爬取糗事百科段子 大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧。那么这次为大家带来,Python爬取糗事百科的小段子的例子。 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来。 本篇目标 1.抓取糗事百科热门段子 2.过滤带有图片的段子 3.实现每按一次回车显示一个段子的发布时间,发布人,段子内容,点赞数。 糗事百科是不需要登录的,所以也没必要用到Cookie,另外糗事百科有的段子是附图的,我们把图抓下来图片不便于显示,那么我们就尝试过滤掉有图的段子吧。 好,现在我们尝试抓取一下糗事百科的热门段子吧,每按下一次回车我们显示一个段子。 1.确定URL并抓取页面代码 首先我们确定好页面的URL是https://www.360docs.net/doc/706563278.html,/hot/page/1,其中最后一个数字1代表页数,我们可以传入不同的值来获得某一页的段子内容。 我们初步构建如下的代码来打印页面代码内容试试看,先构造最基本的页面抓取方式,看看会不会成功 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # -*- coding:utf-8 -*- importurllib importurllib2 page =1 url ='https://www.360docs.net/doc/706563278.html,/hot/page/'+str(page) try: request =urllib2.Request(url) response =urllib2.urlopen(request) printresponse.read() excepturllib2.URLError, e: ifhasattr(e,"code"): printe.code ifhasattr(e,"reason"): printe.reason 运行程序,哦不,它竟然报错了,真是时运不济,命途多舛啊 1 2 3 line 373, in_read_status raiseBadStatusLine(line) httplib.BadStatusLine: '' 好吧,应该是headers验证的问题,我们加上一个headers验证试试看吧,将代码修改如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # -*- coding:utf-8 -*- importurllib importurllib2 page =1 url ='https://www.360docs.net/doc/706563278.html,/hot/page/'+str(page) user_agent ='Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers ={ 'User-Agent': user_agent } try: request =urllib2.Request(url,headers =headers) response =urllib2.urlopen(request) printresponse.read() excepturllib2.URLError, e: ifhasattr(e,"code"): printe.code ifhasattr(e,"reason"): printe.reason Python网络爬虫实习报告 目录 一、选题背景.................................................................................... - 1 - 二、爬虫原理.................................................................................... - 1 - 三、爬虫历史和分类......................................................................... - 1 - 四、常用爬虫框架比较..................................................................... - 1 - 五、数据爬取实战(豆瓣网爬取电影数据)................................... - 2 -1分析网页 .. (2) 2爬取数据 (2) 3数据整理、转换 (3) 4数据保存、展示 (8) 5技术难点关键点 (9) 六、总结 ......................................................................................... - 12 - 一、选题背景 二、爬虫原理 三、爬虫历史和分类 四、常用爬虫框架比较 Scrapy框架:Scrapy框架是一套比较成熟的Python爬虫框架,是使用Python开发的快速、高层次的信息爬取框架,可以高效的爬取web页面并提取出结构化数据。Scrapy应用范围很广,爬虫开发、数据挖掘、数据监测、自动化测试等。 Crawley框架:Crawley也是Python开发出的爬虫框架,该框架致力于改变人们从互联网中提取数据的方式。 Portia框架:Portia框架是一款允许没有任何编程基础的用户可视化地爬取网页的爬虫框架。 newspaper框架:newspaper框架是一个用来提取新闻、文章以及内容分析的Python爬虫框架。 Python-goose框架:Python-goose框架可提取的信息包括:<1>文章主体内容;<2>文章主要图片;<3>文章中嵌入的任heYoutube/Vimeo视频;<4>元描述;<5>元标签 Python爬虫速成指南让你快速的学会写一个最简单的爬虫 本文主要内容:以最短的时间写一个最简单的爬虫,可以抓取论坛的帖子标题和帖子内容。 本文受众:没写过爬虫的萌新。 入门 0.准备工作 需要准备的东西:Python、scrapy、一个IDE或者随便什么文本编辑工具。 1.技术部已经研究决定了,你来写爬虫。 随便建一个工作目录,然后用命令行建立一个工程,工程名为miao,可以替换为你喜欢的名字。 scrapy startproject miao 随后你会得到如下的一个由scrapy创建的目录结构 在spiders文件夹中创建一个python文件,比如miao.py,来作为爬虫的脚本。 内容如下: import scrapyclass NgaSpider(scrapy.Spider): name = "NgaSpider" host = "https://www.360docs.net/doc/706563278.html,/" # start_urls是我们准备爬的初始页 start_urls = [ "https://www.360docs.net/doc/706563278.html,/thread.php?fid=406", ] # 这个是解析函数,如果不特别指明的话,scrapy抓回来的页面会由这个函数进行解析。 # 对页面的处理和分析工作都在此进行,这个示例里我们只是简单地把页面内容打印出来。 def parse(self, response): print response.body 2.跑一个试试? 如果用命令行的话就这样: cd miao scrapy crawl NgaSpider 你可以看到爬虫君已经把你坛星际区第一页打印出来了,当然由于没有任何处理,所以混杂着html标签和js脚本都一并打印出来了。 Python爬虫视频教程全集下载 python作为一门高级编程语言,在编程中应用非常的广泛,近年来随着人工智能的发展python人才的需求更大。当然,这也吸引了很多人选择自学Python爬虫。Python爬虫视频教程全集在此分享给大家。 千锋Python课程教学高手晋级视频总目录: https://www.360docs.net/doc/706563278.html,/s/1hrXwY8k Python课程windows知识点:https://www.360docs.net/doc/706563278.html,/s/1kVcaH3x Python课程linux知识点:https://www.360docs.net/doc/706563278.html,/s/1i4VZh5b Python课程web知识点:https://www.360docs.net/doc/706563278.html,/s/1jIMdU2i Python课程机器学习:https://www.360docs.net/doc/706563278.html,/s/1o8qNB8Q 看完Python爬虫视频教程全集,来看看Python爬虫到底是什么。 Python的市场需求每年都在大规模扩展。网络爬虫又被称为网页蜘蛛,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域。搜索引擎使用网络爬虫抓取Web网页、文档甚至图片、音频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询。 Python 如此受欢迎,主要是它可以做的东西非常多,小到一个网页、一个网站的建设,大到人工智能AI、大数据分析、机器学习、云计算等尖端技术,都是基于Python 来实现的。强大的编程语言,你一定会觉得很难学吧?但事实上,Python是非常容易入门的。 因为它有丰富的标准库,不仅语言简洁易懂,可读性强,代码还具有很强的可拓展性,比起C语言、Java等编程语言要简单得多: C语言可能需要写1000行代码,Java可能需要写几百行代码,而Python 可能仅仅只需几十行代码就能搞定。Python 应用极其广泛的场景就是爬虫,很多新手刚入门Python,也是因为爬虫。 网络爬虫是Python极其简单、基本、实用的技术之一,它的编写也非常简单,无许掌握网页信息如何呈现和产生。掌握了Python的基本语法后,是能够轻易写出一个爬虫程序的。 还没想好去哪家机构学习Python爬虫技术?千锋Python讲师风格独特,深入浅出,常以简单的视角解决复杂的开发难题,注重思维培养,授课富有激情,Python爬虫入门:如何爬取招聘网站并进行分析
python爬虫入门到精通必备的书籍
Python基础入门课程-学习笔记
【黑马程序员】 Python教程、Python下载、Python爬虫、Python学习路线图、Python就业方向
Python爬虫总结教学提纲
Python爬虫8个常用的爬虫技巧分析总结
Python爬虫总结材料
Python爬虫实战
Python网络爬虫实习报告[精品文档]
Python爬虫速成指南让你快速的学会写一个最简单的爬虫
Python爬虫视频教程全集下载