Oracle中SQL语句执行效率的查找与解决
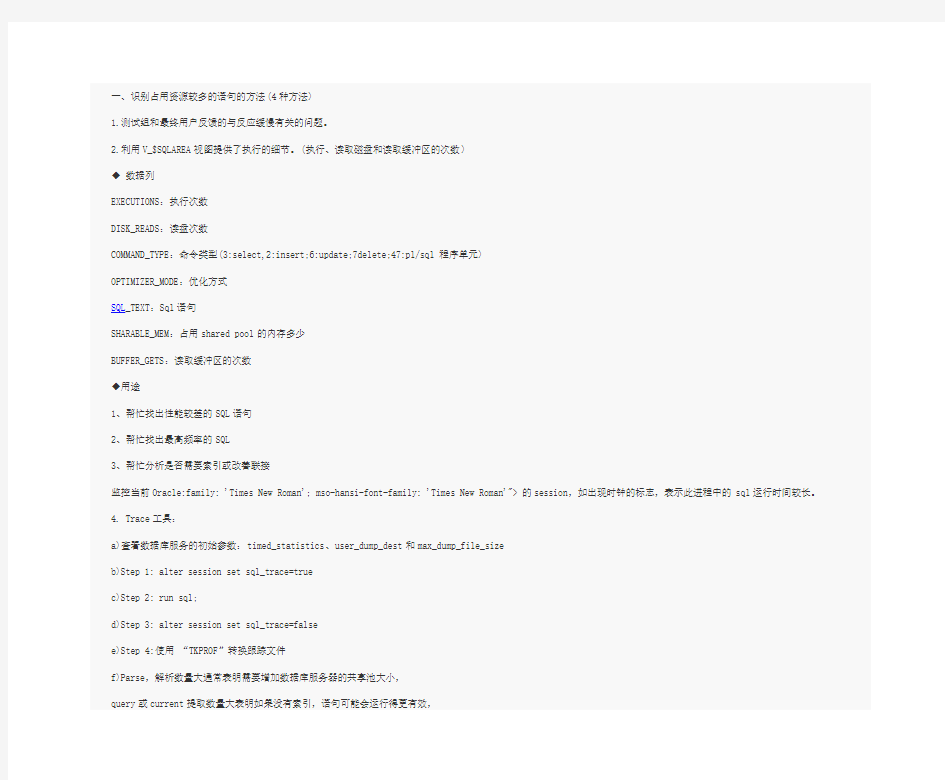

一、识别占用资源较多的语句的方法(4种方法)
1.测试组和最终用户反馈的与反应缓慢有关的问题。
2.利用V_$SQLAREA视图提供了执行的细节。(执行、读取磁盘和读取缓冲区的次数)
◆数据列
EXECUTIONS:执行次数
DISK_READS:读盘次数
COMMAND_TYPE:命令类型(3:select,2:insert;6:update;7delete;47:pl/sql程序单元)
OPTIMIZER_MODE:优化方式
SQL_TEXT:Sql语句
SHARABLE_MEM:占用shared pool的内存多少
BUFFER_GETS:读取缓冲区的次数
◆用途
1、帮忙找出性能较差的SQL语句
2、帮忙找出最高频率的SQL
3、帮忙分析是否需要索引或改善联接
监控当前Oracle:family: 'Times New Roman'; mso-hansi-font-family: 'Times New Roman'">的session,如出现时钟的标志,表示此进程中的sql运行时间较长。
4. Trace工具:
a)查看数据库服务的初始参数:timed_statistics、user_dump_dest和max_dump_file_size
b)Step 1: alter session set sql_trace=true
c)Step 2: run sql;
d)Step 3: alter session set sql_trace=false
e)Step 4:使用“TKPROF”转换跟踪文件
f)Parse,解析数量大通常表明需要增加数据库服务器的共享池大小,
query或current提取数量大表明如果没有索引,语句可能会运行得更有效,
disk提取数量表明索引有可能改进性能,
library cache中多于一次的错过表明需要一个更大的共享池大小
二、如何管理语句处理和选项
◆基于成本(Cost Based) 和基于规则(Rule Based) 两种优化器,简称为CBO 和RBO
◆Optimizer Mode参数值:
Choose:如果存在访问过的任何表的统计数据,则使用基于成本的Optimizer,目标是获得最优的通过量。如果一些表没有统计数据,则使用估计值。如果没有可用的统计数据,则将使用基于规则的Optimizer。
All_rows:总是使用基于成本的Optimizer,目标是获得最优的通过量。
First_rows_n:总是使用基于成本的Optimizer,目标是对返回前N行(“n”可以是1,10,100或者1000)获得最优的响应时间。
First_rows:用于向后兼容。使用成本与试探性方法的结合,以便快速传递前几行。
RULE:总是使用基于规则的Optimizer
三、使用数据库特性来获得有助于查看性能的处理统计信息(解释计划和AUTOTRACE)
No1: Explain Plan
A)使用Explain工具需要创建Explain_plan表,这必须先进入相关应用表、视图和索引的所有者的帐户内. (@D:\oracle\ora92\rdbms\admin\utlxplan)
B) 表结构:
STATEMENT_ID:为一条指定的SQL语句确定特定的执行计划名称。如果在EXPLAN PLAN语句中没有使用SET STATEMENT_ID,那么此值会被设为NULL。
OPERATION:在计划的某一步骤执行的操作名称,例如:Filters,Index,Table,Marge Joins and Table等。
OPTION:对OPERATION操作的补充,例如:对一个表的操作,OPERATION可能是TABLE ACCESS,但OPTION可能为by ROWID或FULL。
Object_Owner:拥有此database Object的Schema名或Oracle帐户名。
Object_name:Database Object名
Object_type:类型,例如:表、视图、索引等等
ID:指明某一步骤在执行计划中的位置。
PARENT_ID:指明从某一操作中取得信息的前一个操作。通过对与ID和PARENT_ID使用Connect By操作,我们可以查询整个执行计划树。
C)EXPLAIN搜索路径解释
◆全表扫描(Full Table Scans)(无可用索引,大量数据,小表 ,全表扫描hints,HWM(High Water Mark), Rowid扫描)
◆索引扫描
索引唯一扫描(Index Unique Scans)
索引范围扫描(Index Range Scans)
索引降序范围扫描(Index Range Scans Descending)
索引跳跃扫描(Index Skip Scans)
全索引扫描(Full Scans)
快速全索引扫描(Fast Full Index Scans)
索引连接(Index Joins)
位图连接(Bitmap Joins)
◆如何选择访问路径: CBO首先检查WHERE子句中的条件以及FROM子句,确定有哪些访问路径是可用的。然后CBO使用这个访问路径产生一组可能的执行计划,再通过索引、表的统计信息评估每个计划的成本,最后优化器选择成本最低的一个。
◆表的连接方式:
Nested Loops会循环外表(驱动表),逐个比对和内表的连接是否符合条件。在驱动表比较小,内表比较大,而且内外表的连接列有索引的时候比较好。当SORT_AREA空间不足的时候,Oracle也会选择使用NL。基于Cost的Oracle优化器(CBO)会自动选择较小的表做外表。(优点:嵌套循环连接比其他连接方法有优势,它可以快速地从结果集中提取第一批记录,而不用等待整个结果集完全确定下来。缺点:如果内部行源表(读取的第二张表(内表)已连接的列上不包含索引,或者索引不是高度可选时, 嵌套循环连接效率是很低的。如果驱动行源表(从驱动表中提取的记录)非常庞大时,其他的连接方法可能更加有效。)
SORT- merge JOIN,将两表的连接列各自排序然后合并,只能用于连接列相等的情况,适合两表大小相若的情况(在缺乏数据的选择性或者可用的索引时,或者两个源表都过于庞大(超过记录数的5%)时,排序合并连接将比嵌套循环连更加高效。但是,排列合并连接只能用于等价连接(WHERE D.deptno=E.dejptno,而不是WHERE D.deptno>=E.deptno)。排列合并连接需要临时的内存块,以用于排序(如果SORT_AREA_SIZE设置得太小的话)。这将导致在临时表空间占用更多的内存和磁盘I/O。)
HASH JOIN在其中一表的连接列上作散列,因此只有另外一个表做排序合并,理论上比SORT JOIN会快些,需?/td>
"FONT-FAMILY: 宋体; mso-ascii-font-family: 'Times New Roman'; mso-hansi-font-family: 'Times New Roman'">或FULL。
Object_Owner:拥有此database Object的Schema名或Oracle帐户名。
Object_name:Database Object名
Object_type:类型,例如:表、视图、索引等等
ID:指明某一步骤在执行计划中的位置。
PARENT_ID:指明从某一操作中取得信息的前一个操作。通过对与ID和PARENT_ID使用Connect By操作,我们可以查询整个执行计划树。
C)EXPLAIN搜索路径解释
◆全表扫描(Full Table Scans)(无可用索引,大量数据,小表 ,全表扫描hints,HWM(High Water Mark), Rowid扫描)
◆索引扫描
索引唯一扫描(Index Unique Scans)
索引范围扫描(Index Range Scans)
索引降序范围扫描(Index Range Scans Descending)
索引跳跃扫描(Index Skip Scans)
全索引扫描(Full Scans)
快速全索引扫描(Fast Full Index Scans)
索引连接(Index Joins)
位图连接(Bitmap Joins)
◆如何选择访问路径: CBO首先检查WHERE子句中的条件以及FROM子句,确定有哪些访问路径是可用的。然后CBO使用这个访问路径产生一组可能的执行计划,再通过索引、表的统计信息评估每个计划的成本,最后优化器选择成本最低的一个。
◆表的连接方式:
Nested Loops会循环外表(驱动表),逐个比对和内表的连接是否符合条件。在驱动表比较小,内表比较大,而且内外表的连接列有索引的时候比较好。当SORT_AREA空间不足的时候,Oracle也会选择使用NL。基于Cost的Oracle优化器(CBO)会自动选择较小的表做外表。(优点:嵌套循环连接比其他连接方法有优势,它可以快速地从结果集中提取第一批记录,而不用等待整个结果集完全确定下来。缺点:如果内部行源表(读取的第二张表(内表)已连接的列上不包含索引,或者索引不是高度可选时, 嵌套循环连接效率是很低的。如果驱动行源表(从驱动表中提取的记录)非常庞大时,其他的连接方法可能更加有效。)
来源:网络编辑:联动北方技术论坛