Sonar开源的Java源代码管理平台UT覆盖率

开源的Java源代码管理平台/UT覆盖率:Sonar
一。什么是Sonar
Sonar是一个开源平台,用于管理Java源代码的质量。“一个质量数据报告工具+代码质量管理平台”https://www.360docs.net/doc/966495087.html,/display/SONAR/Documentation 主要特点
·代码覆盖:通过单元测试,将会显示哪行代码被选中
·改善编码规则
·搜寻编码规则:按照名字,插件,激活级别和类别进行查询
·项目搜寻:按照项目的名字进行查询
·对比数据:比较同一张表中的任何测量的趋势
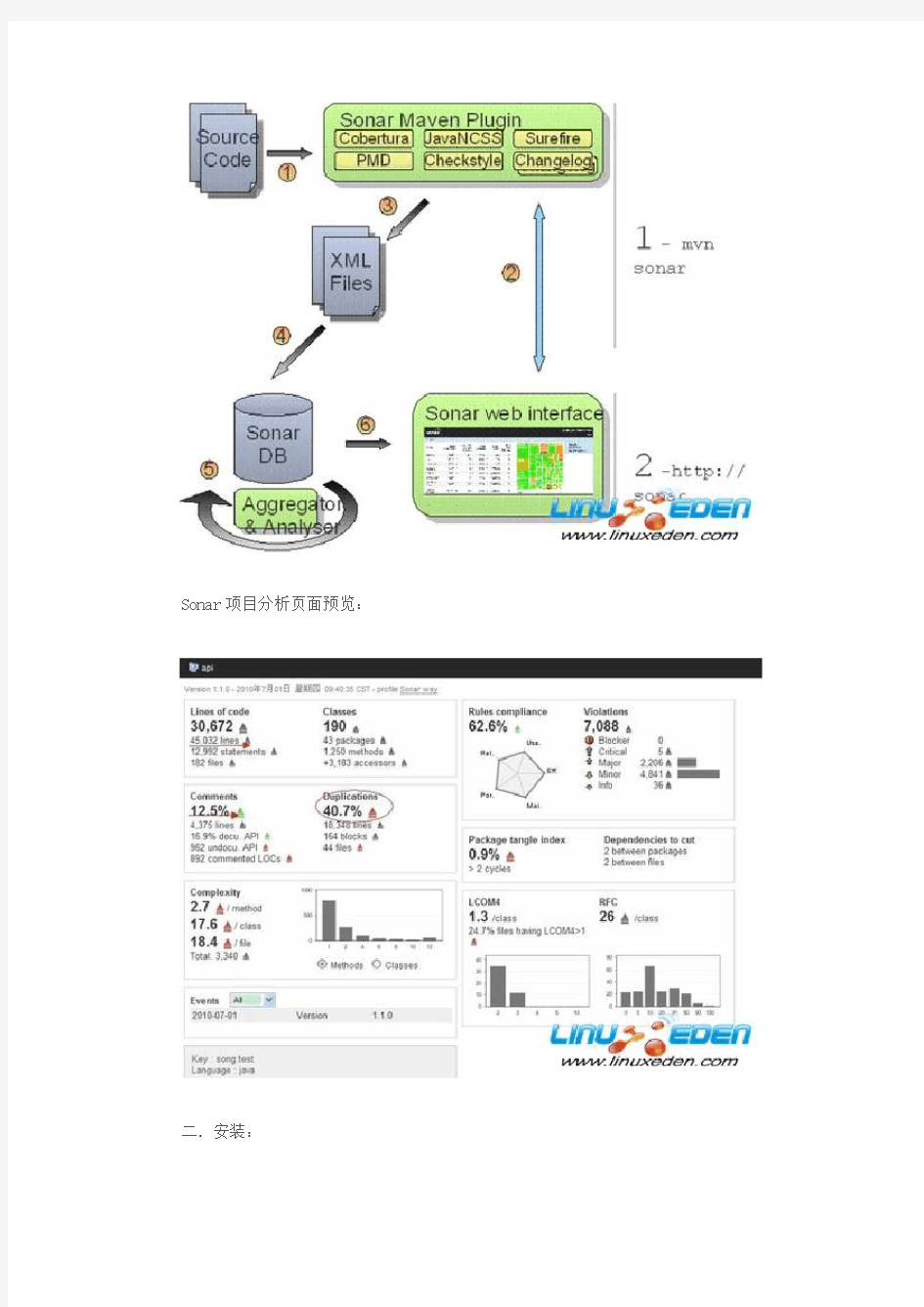
整体架构如下:
Sonar项目分析页面预览:
二.安装:
1.下载压缩包,在win/linux下面均可以运行。
自身集成jetty+java内存DB,一键启动。默认启动到http://localhost:9000
正式使用可以配置mysqlDB做持久存储。当然容器也可以切换成tomcat。具体看官站文档。
Notice:Deploy on Tomcat application server,A minimum heap size of 512Mo is required. 吃内存大户
2.环境依赖:
JDK5++
Maven2.09 ++
三。怎么分析项目
1)maven项目:(简单的讲就是带了pom.xml)
E:\>cd ws1\test 然后运行:
1.mvn clean install -Dtest=false -DfailIfNoTests=false (第一步其实可以忽略)
2. mvn sonar:sonar之后再回到页面上,查看项目分析结果。(第2步的mvn操作其实可以集成到pom.xml里面作为一个
2)非maven项目:
方法:给项目放一个pom.xml,不需要写复杂的依赖和编译操作,简单copy如下配置,改改项目名和java代码的目录路径即可!
1 xmlns:xsi="https://www.360docs.net/doc/966495087.html,/2001/XMLSchema-instance" xsi:schemaLocation="https://www.360docs.net/doc/966495087.html,/POM/4.0.0 https://www.360docs.net/doc/966495087.html,/xsd/maven-4.0.0.xsd"> 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
详细文档在:
https://www.360docs.net/doc/966495087.html,/display/SONAR/Collect+data#Collectdata-Mavenprojects 3)将sonar集成到maven中
编辑maven中config目录下的setting文件activeByDefault,Example
1
2
3
4
5
6
7
8
9
10
11jdbc:mysql://localhost:3306/sonar?useUnicode=true&characterEncoding=utf8 12
13
14
15
16
18
19
20
21
当然,这样做的代价就是:export MAVEN_OPTS="-Xmx512m -XX:MaxPermSize=256m" maven编译的内存也需要加到512M
四。总结
1.作为代码分析工具来使用,其实很简单。下载standalone包直接运行,不需要配置db和容器,直接找到项目分析就是。(用maven管理的项目直接分析,非maven项目按上面的方法加一个最精简的pom.xml配置即可。sonar分析代码的时候并不需要复杂的jar包依赖,指定了源代码目录即可)
2.作为持续性的代码监控,比如关心代码量的变更,和质量走向,那么配置DB就是必须的了。而且要准备1.5G+空闲内存的机器跑sonar,在触发到代码分析的时候,对CPU的消耗也是比较大的。
3.将sonar集成到持续集成是非常不明智的。会导致每次编译都去分析一次。比较建议做成crontab的脚本,一个星期用定时脚本启动、分析那么一两回就可以了。
数据中心运维管理框架
6.2数据中心运维管理框架 6.2.1.运维管理框架4Ps概述 所谓数据中心运维管理框架是指管理一个数据中心所使用的方法与手段的总称。那么,应该用什么样的方法与手段来管理数据中心呢?在此,信息技术基础架构库(InformationTechnologyInfrastructureLibrary,ITIL)给出了一个比较好的管理框架,即所谓的4Ps。数据中心运维管理框架如图6-3所示。 图6-3数据中心运维管理框架 1.人员 人员是数据中心运维管理的基础,也是数据中心运维管理的核心。一个好的数据中心运维管理框架,少不了合适的技术和管理人员。从前面数据中心运维管理概述中,可以看到数据中心所需要管理的对象,包括基础设施、IT设备、系统与数据、管理工具和人员等。只有具备相应知识背景与管理经验的人,才能有效地整合上述资源,为客户提供符合质量与合同要求的IT服务。因此,在考虑建设数据中心运维管理框架时,必须要考虑到:如何建立起一套科学合理的包括选、用、培养、考核及解聘的人员管理生命周期;如何通过合理的组织架构设计与人员分工,最大限度地发挥个人的主观能动性,为组织目标贡献力量等。 2.流程
流程是数据中心运维管理质量的保证。作为客户IT服务的物理载体,数据中心存在的目的就是保证服务可以按质、按量地提供。服务与产品有着许多的不同,其中最核心的不同在于服务本身是看不见、摸不着的,但又是能通过服务商与客户的互动为客户所感受到的。为确保最终提供给客户的服务是符合服务合同的要求,数据中心需要把现在的管理工作抽象成不同的管理流程,并把流程之间的关系、流程的角色、流程的触发点、流程的输入与输出等进行详细定义。通过这种流程的建立,一方面可以使数据中心的人员能够对工作有一个统一的认识,更重要的是通过这些服务工作的流程化使得整个服务提供过程可被监控、管理,形成真正意义上的“IT服务车间”。 3.产品 产品是数据中心运维管理的加速器。数据中心运维管理涉及的对象庞杂,且重复性工作较多。若完全依靠人工去完成这些工作,一方面对人员的技能与数量有较高的要求,另一方面在工作质量的保证方面也存在风险。为此,越来越多的数据中心在开展运维管理工作时使用大量工具,目的是通过这些工具的部署取代一些监控、操作、配置文件、工作流管理等大量重复性工作,最终实现提升运维水平、降低运维风险、减少运维成本的目的。 4.服务商 服务商是数据中心运维管理的支持者。作为专业化的数据中心运维管理,有效地整合数据中心管理对象,并最终为用户提供专业化的服务才是数据中心服务提供者的核心价值所在。而且,数据中心运维管理中涉及了太多不同种类的设备,数据中心也不可能把所有的技术与管理工作独自承担。聘用一批既懂变压器、发电机、UPS,又了解空调、消防、防火设备,同时还精通IT相关软硬件的人员,对于任何一个企业或机构均是极大的成本支出。所以,数据中心需要与许多设备供应和服务提供商建立良好的战略合作关系。 6.2.2.运维管理的人员要求 如前所述,人员既是数据中心运维管理的基础,也是数据中心运维管理的核心。一个数据中心组建团队时应注意什么呢?以下重点就人员技能、人员分工与人员管理三个方面谈一下数据中心运维管理方面的人员要求。 1.人员技能
各种覆盖率方法介绍
目录 1 简介0 1.1 代码覆盖率分析0 1.2 结构化测试和功能测试(STRUCTURAL TESTING&FUNCTIONAL TESTING)1 1.3 假定1 2 基本的度量1 2.1 语句覆盖(STATEMENT COVERAGE )1 2.2 判定覆盖(DECISION COVERAGE )2 2.3 条件覆盖(CONDITION COVERAGE )3 2.4 多条件覆盖(MULTIPLE CONDITION COVERAGE )3 2.5 分支条件组合覆盖(CONDITION/DECISION COVERAGE )4 2.6 修正条件/判定覆盖(MODIFIED CONDITION/DECISION COVERAGE)4 2.6.1 覆盖率的计算公式:5 2.7 路径覆盖(PATH COVERAGE )5 3 其它度量6 3.1 函数覆盖(FUNCTION COVERAGE )6 3.2 函数出入口覆盖(FUNCTION EXITS COVERAGE)6 3.3 调用覆盖(CALL COVERAGE )6 3.4 线性代码顺序及跳转覆盖(LINEAR CODE SEQUENCE AND JUMP (LCSAJ) COVERAGE )7 3.4.1 覆盖率的计算公式:7 3.5 数据流覆盖(DATA FLOW COVERAGE )8 3.6 目标代码分支覆盖(OBJECT CODE BRANCH COVERAGE )8 3.7 循环覆盖(LOOP COVERAGE )8 3.8 竞争覆盖(RACE COVERAGE)8 3.9 比较操作符覆盖(RELATIONAL OPERATOR COVERAGE)8 3.10 弱变化覆盖(WEAK MUTATION COVERAGE)9 3.11 表覆盖(TABLE COVERAGE)9 4 比较各种覆盖9 4.1 对RELEASE版本的覆盖目标9 4.2 中间版本的覆盖目标9 5 总结10 6 参考10 7 术语表11 1 简介
云计算数据中心的运维管理
云计算数据中心的运维管理 现代信息中心已成为人们日常生活中不可缺少的部分,因此信息中心机房设备的运行正常与否就非常关键。在数据中心生命周期中,数据中心运维管理是数据中心生命周期中最后一个、也是历时最长的一个阶段。加强对云计算运维管理的要点以及相应改进方面措施的研究与探讨,以此不断提高IT运维质量,实现高效的运维管理。这就给运维是否到位提出了严格要求。 1 运维在机房中的地位 在数据中心生命周期中,数据中心运维管理是数据中心生命周期中最后一个、也是历时最长的一个阶段。数据中心运维管理是,为提供符合要求的信息系统服务,而对与该信息系统服务有关的数据中心各项管理对象进行系统地计划、组织、协调与控制,是信息系统服务有关各项管理工作的总称。数据中心运维管理主要肩负合规性、可用性、经济性、服务性等四大目标。 在信息中心机房配备有运维人员,但大都是“全才”的,即什么都管,尤其是对供电系统大都是由主机运维的人员代管。当电源系统出故障时,此代管人员一问三不知,甚至连配电柜门都没开过。这实际上就是把机房的运维放在了一个次要的地位。 当然也有的地方有所分工,看似重视,实际上也没得到真正地重视。比如说机房设备长时间一直运行正常,这时如果运维人员提出要增添运维方面的测量设备,有的领导就认为多余,很难得到批准。但他不知道机房设备所以长时间一直运行正常,正是由于这些运维人员的细心维护和努力保养所获得的。并不是这些人员每天闲着无事可干,他们的这些工作一般是领导看不见的。比如同样多款的UPS在同样的环境条件下,在某卫星地面站就极少出故障,而在同系统别的地方机房同一家同规格的机器就故障连连。原来是前者的运维人员每天都在细心观察和分析机器面板LCD上显示的数据,一旦发现异常苗头及时采取措施;而后者只限于每天抄写这些数据就算完成任务,使异常苗头不断积累,以致于导致故障。比如断路器在额定闭合状态发现触点处温度高了,就要检查是不是电流过大到超过额定值,如果不是就要检查触点接触是否牢靠,是否需要再紧固一下。这样一来,故障隐患就排除了。如果一直不管不问久而久之就会导致跳闸而使系统崩溃。这都是一些小的动作,都是在巡查中顺便做的事情。所以同是运维人员在巡查,但前者在做事而后者只是走马观花。这就是数据中心可靠与不可靠的区别。 运维人员就像幼儿园的保育员和老师。孩子交到幼儿园后,起主要作用的就是保育员和老师,这时保育员和老师就是主体。机器就好比是幼儿园的孩子,孩子是否健康成长,机器是否正常运行,除去本身的健康(可靠性质量)状况外,那就是运维人员的责任了。由于云计算的要求弹性、灵活快速扩展、降低运维成本、自动化资源监控、多租户环境等特性,除基于ITIL(IT 基础设施库)的常规数据中心运维管理理念之外,以下运维管理方面的内容,需要我们加以重点关注。 2 云计算数据中心运维管理的要点 (1)理清云计算数据中心的运维对象 数据中心的运维管理指的是与数据中心信息服务相关的管理工作的总称。云计算数据中心运维对象一般可分成5大类: ①机房环境基础设施 这里主要指的是为保障数据中心所管理的设备正常运行所必需的网络通信、供配电系统、环境系统、消防系统和安保系统等。这部分设备对于用户来说几乎是透明的,比如大多数用
云计算数据中心的运维管理-培训课件
望采纳 云计算数据中心的运维管理 现代信息中心已成为人们日常生活中不可缺少的部分,因此信息中心机房设备的运行正常与否就非常关键。在数据中心生命周期中,数据中心运维管理是数据中心生命周期中最后一个、也是历时最长的一个阶段。加强对云计算运维管理的要点以及相应改进方面措施的研究与探讨,以此不断提高IT运维质量,实现高效的运维管理。这就给运维是否到位提出了严格要求。 1 运维在机房中的地位 在数据中心生命周期中,数据中心运维管理是数据中心生命周期中最后一个、也是历时最长的一个阶段。数据中心运维管理是,为提供符合要求的信息系统服务,而对与该信息系统服务有关的数据中心各项管理对象进行系统地计划、组织、协调与控制,是信息系统服务有关各项管理工作的总称。数据中心运维管理主要肩负合规性、可用性、经济性、服务性等四大目标。 在信息中心机房配备有运维人员,但大都是“全才”的,即什么都管,尤其是对供电系统大都是由主机运维的人员代管。当电源系统出故障时,此代管人员一问三不知,甚至连配电柜门都没开过。这实际上就是把机房的运维放在了一个次要的地位。 当然也有的地方有所分工,看似重视,实际上也没得到真正地重视。比如说机房设备长时间一直运行正常,这时如果运维人员提出要增添运维方面的测量设备,有的领导就认为多余,很难得到批准。但他不知道机房设备所以长时间一直运行正常,正是由于这些运维人员的细心维护和努力保养所获得的。并不是这些人员每天闲着无事可干,他们的这些工作一般是领导看不见的。比如同样多款的UPS在同样的环境条件下,在某卫星地面站就极少出故障,而在同系统别的地方机房同一家同规格的机器就故障连连。原来是前者的运维人员每天都在细心观察和分析机器面板LCD上显示的数据,一旦发现异常苗头及时采取措施;而后者只限于每天抄写这些数据就算完成任务,使异常苗头不断积累,以致于导致故障。比如断路器在额定闭合状态发现触点处温度高了,就要检查是不是电流过大到超过额定值,如果不是就要检查触点接触是否牢靠,是否需要再紧固一下。这样一来,故障隐患就排除了。如果一直不管不问久而久之就会导致跳闸而使系统崩溃。这都是一些小的动作,都是在巡查中顺便做的事情。所以同是运维人员在巡查,但前者在做事而后者只是走马观花。这就是数据中心可靠与不可靠的区别。 运维人员就像幼儿园的保育员和老师。孩子交到幼儿园后,起主要作用的就是保育员和老师,这时保育员和老师就是主体。机器就好比是幼儿园的孩子,孩子是否健康成长,机器是否正常运行,除去本身的健康(可靠性质量)状况外,那就是运维人员的责任了。由于云计算的要求弹性、灵活快速扩展、降低运维成本、自动化资源监控、多租户环境等特性,除基于ITIL(IT基础设施库)的常规数据中心运维管理理念之外,以下运维管理方面的内容,需要我们加以重点关注。 2 云计算数据中心运维管理的要点 (1)理清云计算数据中心的运维对象 数据中心的运维管理指的是与数据中心信息服务相关的管理工作的总称。云计算数据中心运维对象一般可分成5大类: ①机房环境基础设施 这里主要指的是为保障数据中心所管理的设备正常运行所必需的网络通信、供配电系统、环境系统、消防系统和安保系统等。这部分设备对于用户来说几乎是透明的,比如大多数用户都不会忽略数据中心的供电和制冷。因为这类设备如果发生意外,对依托于该基础设施的应用来说是致命的。 ②数据中心所应用的各种设备
数据中心运维操作标准及流程
数据中心运维操作标准及流程 郑州向心力通信技术股份有限公司 二零一八年
1 机房运维管理前期准备 1.1 管理目标 机房基础设施运维团队应与业主管理层、IT部门、相关业务部门共同讨论确定运维管理目标。制定目标时,应综合考虑机房所支持的应用的可用性要求、机房基础设施设施的等级、容量等因素。目标宜包括可用性目标、能效目标、可以用服务等级协议(SLA)的形式呈现。不同应用的可用性目标的机房,可设定不同等级的机房基础设施的运维管理目标。 1.2 参与数据中心建设过程 机房运维团队应充分了解自己将要管理的场地基础设施。对于新建机房,应尽早参与机房基础设施的建设过程,以便将运维阶段的需求在规划、设计、建造、安装和调试等过程中得到充分的考虑;同时为后期做好运维工作打下基础。 1.2.1 应参与规划设计 机房的规划设计是一个谨慎和严谨的过程,需要所有参与机房建设的相关方共同完成,才能确保规划和设计的有效性、实用性等要求。其中,基础设施运维团队应提出运维要求,从运维经验、实际运维难度、提高运维可易性等方面对规划和设计过程进行配合。 1.2.2 应参与相关供应商遴选 机房基础设施运维团队应参与机房基础设施设备供应商选择的全过程,及时地了解各种产品及服务的品牌、型号、规格等关键参数,使之更能满足运维的要求。并就在安装、调试过程中的注意事项等提
出建议,还需要对后续的设备保修等服务提出要求。 1.2.3 应参与建造管理 机房的基础设施运维团队应积极参与机房基础设施的建造工作,并协助做好建设项目的项目管理工作,着重关注工程建造中如材料的使用、工序、建造过程等工作,重点关注隐蔽工程的安装工艺和质量。 机房基础设施运维团队应充分了解施工过程中的工艺。对于新建数据中心,从施工质量和日后运维方便性出发,尽早发现施工过程的问题,及时纠正,方便日后运维和节省日后整改成本。 1.3 测试验证 机房基础设施投产前的测试验证是确保机房基础设施满足设计要求和运行要求的关键环节。 1.3.1 时间和预算 机房的业主应设立测试验证专项预算,预算应包括外部测试验证服务提供商的相关费用,以及在测试验证阶段产生的电费、水费、油费等相关费用。应制定测试验证的工期规划,以更准确地预测机房基础设施交付投产的日期。 1.3.2 测试验证参与方 项目建设管理部门可作为测试验证工作的主体责任单位;运维管理部门可作为测试验证工作的主体审核单位;第三方测试服务商可作为测试验证的实施单位及整体组织工作的协调单位。但运维管理部门应要求测试服务商预先提供测试方案,在运维管理部门审核后方可进行。机房基础设施运维团队可参与测试验证工作,在此过程中熟悉设
如何保证测试的覆盖率
如何保证黑盒测试的覆盖率 1、首先测试需求分析要全面。 测试需求分析分两步: 1,测试需求的获取 需求的来源: 显式需求:(1)原始需求说明书 (2)产品规格书 (3)软件需求文档 (4)有无继承性文档 (5)经验库 (6)通用的协议规范 隐式需求:用户的主观感受,市场的主流观点,专业人士的评价分析 2,需求的分析,产生测试需求文档 将不同的需求来源划分成一个个需求点,针对每一点进行测试分析: (1)界定测试范围(2)利用各种测试设计的方法产生测试点 在测试方法方面,可做如下注意: 其一,分析出口入口。从入口分析,将可能出现的环境,条件,操作等内容分类组合,然后根据各位测试达人的方法进行整合,逐一验证。从出口分析,将可能出现的结果进行统计,根据结果的不同追根溯源,再找到不同的操作以及条件等内容,统计成文档,逐一验证。 其二,多种测试手法的学习和使用。大家可能更多的关心测试方法,但是具体操作的手法也是需要注意的。毕竟测试方法比较容易找到,各位达人都很熟悉。如果将每个人不同的测试手法总结出来并在自己的测试实施中加以使用,可能会收到意想不到的成果。 在测试流程方面,可作如下注意: 其一,初期要做好需求分析。将需求逐渐细化到小功能点,针对每个功能点进行测试设计。对于完成的测试设计文档,经过项目相关人员的检查评审,做成所需要的初稿。 其二,在测试过程中,根据需求变更和具体测试执行过程中遇到的问题完善测试设计文档。 其三,测试执行结束后,对于出现的问题进行总结。其中包含自己本身发现的问题,也可能会有客户提出的问题。将总结出来的结果融合到测试设计当中去,进一步完善测试设计文档。 对于一次测试,是不可能有覆盖度全面的测试的。需要多次去总结积累,才会使测试越来越全面。 在测试流思维方面,可作如下注意: 其一,测试全面不等于全面测试。不同阶段对于软件测试有不同的要求,比如在0.8版本以前,对于不重要的画面问题或是细小的功能问题就不需要关心。但是在验收阶段,这些内容可能更需要注意。 其二,学无止境,只有不断的去学习不断的去思考,才能使自己测试的能力更强,测试对象的全面性也更完整。 2、当测试需求分析完成,并且形成文档后,要进行测试需求评审,保证需求的准确性以及 完整性。 3、测试需求完成以后,可以根据测试需求设计测试用例。
大型数据中心一体化运维管理平台的建设模式研究
【摘要】为了建设和运营一个高效的数据中心,通过分析当前基地运维管理面临的挑战,结合当前数据中心运维管理工具的发展趋势,从运维管理平台的系统架构、组织架构、技术构架、组网结构等方面详细介绍了大型数据中心一体化运维管理平台的建设模式,从而实现智能化运维的管理目标,减少运维成本并提升运维效率。 【关键词】大型数据中心智能化运维一体化运维云化架构 doi:10.3969/j.issn.1006-1010.2016.14.014 中图分类号:tn929.5 文献标志码:a 文章编号:1006-1010(2016)14-0066-05 引用格式:邓颂清,程尧. 大型数据中心一体化运维管理平台的建设模式研究[j]. 移动通信, 2016,40(14): 66-70. large data center intelligent operation and maintenance integrated operation and maintenance 1 引言 随着移动互联网、大数据、云计算的飞速发展,全国各地数据中心的规模迅速扩张,如何建设和运营一个高效的数据中心,是数据中心管理人员的重大挑战[1]。 dcim(data center infrastructure management,数据中心基础设施管理)是近年兴起的数据中心基础设施管理工具,不同的机构有不同的解读。本文在dcim的理念基础上,针对大型数据中心(即在全国各地拥有多个基地的大型数据中心),就其一体化运维管理的建设模式提出探讨性方案。 2 基地运维面临的挑战与趋势 数据中心运维管理的主要目的是保障基础设施的可用性及降低风险,提高资产的利用率,降低能耗消耗和运维成本,提高服务水平以及数据中心的效率和效益[2]。 作为承载信息系统运行的数据中心,运维管理的关键是对it设备以及支撑it设备运行的风火水电等场地基础设施的管理,包括:对这些基础设施的日常监控和维护;对这些设备进行全生命周期的管理;运维业务管理的流程与规则;对数据中心内基础设施日常运行数据的分析、对比与挖掘。 对于大型数据中心产业基地,特征为辐射全国、规模分布、虚拟资源、弹性调度、安全防护、绿色节能。随着数据中心的发展,功能需求越来越多,管理的规模越来越大,系统间的数据交互越来越广,系统对接口的复杂度急剧上升。由于业务、维护复杂,对管理系统的要求也更高。 现阶段大型数据中心运维面临的挑战如下: (1)经济性:资源如何有效利用,包括网络、空间、动环资源;如何缩减运行费用,包括能源、维护人员。 (2)灵活性:如何识别及降低过度部署和冗余;如何灵活扩展容量(空间、制冷和供电);如何更快响应业务。 (3)可用性:如何实现精细化管理;如何及时排除隐患,处理复杂故障;如何实现动态资源管理和电子流管理。 (4)管理性:需要有效的数据分析支撑决策和规划;如何实现系统一体化,统一协作、快速响应;如何满足大客户sla(service-level agreement,服务等级协议)和自服务管理。 面对以上挑战,数据中心应建设“集中化运维、一体化管理、智能化分析、流程化控制”的it支撑系统,才能实现智能化运维的管理目标,减少运维人员和维护成本,优化资源管理,提升运维效率。 3 平台系统架构、组织架构和技术架构 3.1 平台系统架构
软件测试代码覆盖率分析
软件测试成为IT领域热门职业,软件测试求职者逐渐增加。今天给大家介绍一下软件测试代码覆盖率的知识。 代码覆盖率到底是什么?代码覆盖率是衡量多少测试的一组所涵盖的产品代码。它可以测量的通过线、块、弧形的、由类,或文件,等等……在大多数情况下,我们作为代码覆盖率单元使用块。注:我们只收集基于自动化测试的代码覆盖率,不考虑手动测试。 在大多数的microsoft产品团队,我们规定收集代码覆盖率编号。有不同的代码覆盖率,我们收集的数字根据不同类型的测试中,例如,代码覆盖率的单元测试,对于组件测试,代码覆盖率和方案测试 (e2e)的代码覆盖率。只要得到了运行单元测试,自动收集的单元测试的代码覆盖率。所以开发整理编写代码 /单元测试在签入之前,它们运行一组测试(签入质量大门),包括单元测试。所以你得单位自动测试代码覆盖率。组件测试和方案测试的代码覆盖率收集代码覆盖率生成peroidically,例如每周一次或上的需求。 总是有关于代码覆盖率的真正好处的争论。一些表示代码覆盖率数字代表的产品质量,越高,号码是,产品的质量就越高。一些表示,更高的代码覆盖率并不意味着更高的质量,因为100%coverred代码仍有bug,哪个是正确的。 这里是我作为代码覆盖率上: 1、代码覆盖率是重要的。很容易和简单,收集和快速的方式,让您了解如何测试代码上。它让您直观显示和检查如何测试代码。有点像在黑暗中闪烁的灯光,让你更清楚地看到许多对象。它没有保障,您不会当然看到黑暗中的对象。但没有闪光灯,它将很难看到该对象。 2、虽然代码覆盖率100%不并不意味着bug免费的但代码覆盖率为0%不会意味着巨大的风险,产品质量。 3、代码覆盖率唯一的措施如何测试代码,不如何测试产品。 所以,我们需要对代码覆盖数的要求吗?如果是的是最好的有多少? 第一,任何数量是相聚的上下文。号本身不是目的。它是任何行动需要遵循的指标。它像你这样有100点学校测试,是好事吗?坏吗?答案是:这取决于。它取决于什么是总积分,容易/困难的测试中,您的同行得到什么点,等等...它是相同的代码覆盖率数目的。60%、80%或100%没有任何意义没有上下文。 然后应怎么用它后收集代码覆盖率?这是完全收集代码覆盖率编号的意思,找出你应如何处理您的代码覆盖率号码,或如何使用/解释数目:
云计算数据中心运维管理要点
云计算数据中心运维管理要点 在数据中心生命周期中,数据中心运维管理是数据中心生命周期中最后一个、也是历时最长的一个阶段。数据中心运维管理就是:为提供符合要求的信息系统服务,而对与该信息系统服务有关的数据中心各项管理对象进行系统的计划、组织、协调与控制,是信息系统服务有关各项管理工作的总称。数据中心运维管理主要肩负起以下重要目标:合规性、可用性、经济性、服务性等四大目标。 由于云计算的要求弹性、灵活快速扩展、降低运维成本、自动化资源监控、多租户环境等特性除基于ITIL的常规数据中心运维管理理念之外,以下运维管理方面的内容,也需要我们加以重点分析和关注。 一、理清云计算数据中心的运维对象 数据中心的运维管理指的是与数据中心信息服务相关的管理工作的总称。云计算数据中心运维对象共可分成5类: (1) 机房环境基础设施部分。这里主要指为保障数据中心所管理设备正常运行所必需的网络通信、电力资源、环境资源等。这部分设备对于用户来说几乎是透明的,因为大多数用户基本并不会关注到数据中心的风火水电。但是,这类设备如发生意外,对依托于该基础设施的应用来说,却是致命的。 (2) 在提供IT服务过程中所应用的各种设备,包括存储、服务器、网络设备、安全设备等硬件资源。这类设备在向用户提供IT服务过程中提供了计算、存储与通信等功能,是IT服务最直接的物理载体。 (3) 系统与数据,包括操作系统、数据库、中间件、应用程序等软件资源;还有业务数据、配置文件、日志等各类数据。这类管理对象虽然不像前两类管理对象那样“看得见,摸得着”,但却是IT服务的逻辑载体。 (4) 管理工具,包括了基础设施监控软件、监控软件、工作流管理平台、报表平台、短信平台等。这类管理对象是帮助管理主体更高效地管理数据中心内各种管理对象,并在管理活动中承担起部分管理功能的软硬件设施。通过这些工具,可以直观感受并考证到数据中心如何管理好与其直接相关的资源,从而间接地提升的可用性与可靠性。 (5) 人员,包括了数据中心的技术人员、运维人员、管理人员以及提供服务的厂商人员。人员一方面作为管理的主体负责管理数据中心运维对象,另一方面也作为管理的对象,支持IT的运行。这类对象与其他运维对象不同,具有很强的主观能动性,其管理的好坏将直接影响到整个运维管理体系,而不仅仅是运维对象本身。
JUnit使用方法以及测试代码覆盖率
Junit 一、什么是junit 采用测试驱动开发的方式,在开发前先写好测试代码,主要说明被测试的代码会被如何使用,错误处理等,然后开始写代码。并在测试代码中逐步测试这些代码。直到最后在测试代码中完全通过。 二、Junit功能 1)管理测试用例。修改了哪些代码。这些代码的修改会对哪些部分由影响,通过junit将这次的修改做完成测试。 2)定义了测试代码,textcase根据源代码的测试需要定义每个textcase,并将Textcase添加到相应的Textsuit以方便管理。 3)定义测试环境,在Textcase测试前会先调用“环境”配置。在测试中使用,当然也可以在测试用例中直接定义测试环境。 4)检测测试结果。对于每种正常、异常情况下的测试,运行结果是什么。 结果是够是我们预料的等。都需要有明确的定义。Junit在这方面提供了强大的功能。 三、Junit核心类 Textsuit:测试用例的集合 Textcase:定义运行多个测试用例 TextListener:测试中若产生事件,会通知TextListener BaseTextRunner:TextRunner用来启动测试界面 TextResult:收集一个测试案例的结果。测试结果分为失败和错误。 Assert:当条件成立时,assert方法保持沉默,但若条件不成立就抛出异常 四、使用举例 4.1方法一: 第一步、新建一个Android项目JUnit_Test,file-new-android project,然后编写一个Calculator类,new java class,实现简单的加、减、乘、除的计算器,然后对这些功能进行单元测试。 类的代码如下: package com.neusoft; public class Calculator { private int result; public void add(int n) { result = result + n; } public void substract(int n) { result = result - 1; //Bug: 正确的应该是 result =result-n
覆盖率统计公式
1DT测试 1.1覆盖率(%) 电信集团规定: 覆盖率=DO覆盖区域内“终端接收功率>=-90dBm,且SINR>=-6dB,且终端发射功率<=15dBm”的采样点数目占所有采样点比例。 方法: 1.CAN->Analysis->Data Query,在Edit Fiter中设定“终端接收功率>=-90dBm,且SINR>=-6dB,且终端发射功率<=15dBm”查询条件, 2. 点“Apply”显示覆盖百分比
1.2SINR信噪比 (1)出覆盖路径图,指标采用“Best ASP SINR”,图例请参考《中国电信EVDO RevA网络评估报告图例.doc》 (2)出数据的区间分布,区间分布请参考《中国电信EVDO RevA网络评估报告图例.doc》,方法:CAN->Analysis->Data Statistic-> Best ASP SINR 1.3终端接收功率 (1)出覆盖路径图,指标采用“Rx Power0”,图例请参考《中国电信EVDO RevA网络评估报告图例.doc》 (2)出数据的区间分布,区间分布请参考《中国电信EVDO RevA网络评估报告图例.doc》,方法:CAN->Analysis->Data Statistic-> Rx Power0 1.4终端发射功率 (1)出覆盖路径图,指标采用“Tx Total Power”,图例请参考《中国电信EVDO RevA网络评 估报告图例.doc》
(2)出数据的区间分布,区间分布请参考《中国电信EVDO RevA网络评估报告图例.doc》,方法:CAN->Analysis->Data Statistic-> Tx Total Power 1.5分组业务建立成功率(%) 请参考1.6的分析方法; 1.6分组业务建立时延(s) 出数据的区间分布,区间分布请参考《中国电信EVDO RevA网络评估报告图例.doc》 方法: 1.CAN->Data Service Analysis->PPP Delay Analysis 2.点Export导出PPP时延数据明细,采用附录A的工具统计区间分布(V7.01.0 3.0320统计的PPP时延偏大,补丁版本正在开发) 1.7分组业务掉话率(%) 电信集团规定:
数据中心综合运维服务平台
数据中心综合运维平台 一、产品概述 1.1产品背景 随着互联网和计算机技术的发展以及信息化建设步伐的不断加快,各行业都开始大规模的建立和使用网络,并且越来越多的单位对网络办公、各种在线的信息管理系统的依赖程度不断增加。网络的使用者不仅仅是在数量上增长迅速,同时对网络应用的需求也更加多样化,因此网络的运维和管理比以往任何时刻都显得更加重要。 1.2产品定位 数据中心综合运维支撑管理系统正是为了解决在产品背景中描述的问题而设计和开发的。系统包含了网络设备管理、服务器与应用管理、监控与告警管理、机房与布线管理、机房环境监控、等几个模块,将以往需要人工或者从多个不同渠道和系统收集的信息通过一个系统进行整合;将以往各种复杂的网络管理工作简单化、自动化,在极大的提高网络管理的效率同时提高网络服务的质量。 1.3系统构架 网络运维支撑系统采用基于64位Linux操作系统以及mysql数据库进行开发,采用纯粹的B/S构架,WEB展现部分与业务逻辑分离,用户可以自己定制WEB界面;支持分布式数据采集;采用基于角色和分组的权限管理方式,用户可以根据自己单位的管理模式任意制定角色和分组,从而做到权限的横向纵向的任意划分。 1.4技术优势 1. 支持不同厂商的设备 不仅支持思科、华为、H3C、锐捷、神舟数码、中兴、juniper、extreme等厂商的网络设备,同时支持allot、acenet等厂商的安全流控设备。 2. 高可靠性、高稳定性、高安全性 基于Linux操作系统和mysql数据库,不用担心病毒与升级打补丁的麻烦;支持https,保证数据的传输安全。
3. 高性能 基于64位操作系统开发,优化系统配置和自定制内核,发挥64位的最大优势4. 用户、角色、权限自定义 采用基于角色和分组的权限管理方式,用户可以根据自己单位的管理模式任意制定角色和分组,从而做到权限的横向纵向的任意划分 5. 对服务器的监控采用被动方式 对服务器监控不需要在服务器上进行任何的设置,系统根据服务器对外提供服务的情况依据协议规定进行外部探测。 6. 整合机房环境监控与布线管理模块 采用自行设计开发的传感器通过网络对机房、配线间的环境(温度、湿度等)进行实时控和数据记录、结合系统告警功能对环境变化进行实时告警,将布线系统和网管系统结合,提高网络管理的效率。 二、基础网络设备管理 2.1拓扑自动发现与计算 系统支持自动拓扑发现功能,可以进行二层和三层设备的拓扑自动发现. 2.2拓扑管理 可以根据网络的具体情况和用户的使用习惯任意定义网络拓扑图,将任意区域的网络设备放置到一个定义好的拓扑中进行展现。 2.3拓扑展示 通过拓扑图可以选择查看交换机的各种信息,包括端口信息、配线信息、端口状态、用户情况等;如果拓扑图中设备的下级设备(没有显示在本级拓扑中)出现故障,也会在当前拓扑中得到告警体现,同时可以直接从本级拓扑展开到下一级拓扑中。 2.4网络设备管理 可以查看交换机IP地址、描述、厂商、类型、当前状态、在线用户、端口状态、链接关系等信息,也可以直接通过IP查找交换机。 2.5交换机端口状态管理 可以查看被管理交换机的端口列表,包括该交换机所有的物理端口的端口名
单元测试的代码覆盖率统计
单元测试的代码覆盖率统计 今天广州中软卓越软件测试培训课程简要讲解一下单元测试的代码覆盖率统计。 单元测试的代码覆盖率统计,是衡量测试用例好坏的一个的方法,有的公司直接把代码测试覆盖率作为一个硬性要求。尤其在多人合作的情况下。很有可能在后期维护时候牵一发而动全身的代码修改中起到至关重要的检测。不过代码覆盖率也不是唯一标准,测试用例的好坏主要还是看能不能覆盖尽可能多的情况。 一、打包编译JS代码覆盖率问题 之前代码覆盖率在JS代码不需要编译的情况下。直接可以使用KARMA的karma-coverage这个工具就可以直接统计结果。不过由于我的项目用上了WEBPACK的打包和babel的ES6编译。所以单单使用karma-coverage统计的代码覆盖率统计的是,编译打包后的代码,这个覆盖率直接没有了参考价值。一般打包后代码的覆盖率只有可怜的10%-20%因为WEBPACK帮你加入了很多它的代码。而测试要做到这些代码的覆盖是完全没有意义的。所以就需要找一个可以查看编译前代码覆盖率的一个方法。 二、单元测试覆盖率 做测试时,想要知代码覆盖道是否所有代码都测试到了。这就是所谓的率。 单元测试覆盖率有四个测量维度: 1、行覆盖率(line coverage):是否每一行都执行 2、函数覆盖率(function coverage):是否每个函数都调用 3、分支覆盖率(branch coverage):是否每个if代码块都执行 4、语句覆盖率(statement coverage):是否每个语句都执行 常用的前端js测试覆盖率框架:istanbul 我们代码使用ES6来编写的,使用babel来转码,所以选择了另一个专门针对es6的babel 转码工具isparta 生成报告 isparta使用istanbul来生成报告
数据中心运维服务-术语
1.1术语 数据中心基础设施:包括供配电系统、空调与制冷系统、制冷自控(BA)系统、动环监控系统、防雷接地系统、综合布线、安防消防及安全防护。 供配电系统:包括供电设备与供电路由。供电设备包括高低压成套柜、变压器、发动机组、UPS、高压直流、蓄电池组、列头柜等;供电路由包括高低压供电线缆及母排。 空调与制冷系统:包括制冷设备与制冷回路。制冷设备包括冷水机组、冷冻水机房空调、蓄冷设备、冷却塔、水泵、热交换设备、直膨式机房空调、新风设备等。制冷回路包括冷冻水管道、冷却水管道、水处理设备、定压补水装置、阀门仪表、气流组织等。 动环监控系统:包括监控硬件与监控软件。监控硬件包括服务器硬件、传输网络、采集单元、传感器变送器、智能设备等。监控软件包括数据库软件、系统软件等。 制冷自控(BA)系统:包括软件、系统服务器、监控主机、配套设备、网络传输设备、计算机监控网络、DDC控制器及前端点位采集设备。 防雷接地系统:包括外部防雷装置和内部防雷装置。外部防雷装置主要用于防护直击雷,主要包括接闪器、引下线、接地系统等。内部防雷装置主要用于减小和防止雷电流产生的电磁危害,包括等电位连接系统、接地系统、屏蔽系统、SPD等。 安防系统:包括视频监控系统、出入口控制系统、入侵报警系统、电子巡更系统等。 消防系统:包括早期报警系统、火灾自动报警系统、水/气体灭火系统、消防联动控制系统等。 服务等级协议(SLA):服务提供商和客户之间签署的描述服务范围和约定服务级别的协议。 日常巡视:定期对机房环境及设备进行巡视检查,以确认环境和设备处于正常工作状态,开展方式一般为目测。 例行维护:定期对机房环境及设备进行的维护工作,以防止设备在运行过程中出现故障。 预防性维护:有计划地对设备进行深度维护或易损件更换,包括定期维护保养、定期使用检查、定期功能检测等几种类型;让设备处于一个常新的工作状态,降低设备出现故障的概率。 预测性维护:通过各种测试手段进行数据采集及分析,判断设备的裂化趋势、预测可能发生的潜在威胁,并提出相应的防范措施。 标准操作流程(SOP):SOP是将某一项工作的标准操作步骤和要求以统一的格式描述出来,用来指导和规范日常的运维工作。 维护操作流程(MOP):MOP用于规范和明确数据中心基础设施运维工作中各项设施的维护保养审批流程、操作步骤。 应急操作流程(EOP):EOP用于规范应急操作过程中的流程及操作步骤。确保运维人员可以迅速启动,确保有序、有效地组织实施各项应对措施。 场地配置流程(SCP):动态管理数据中心基础设施系统与设备运行配置。 事件管理:事件是指较大的、对数据中心运行会产生一定影响的事情,故障属于事件的一种。事件管理是指识别事件、确定支持资源、快速解决事件的过程。事件管理的目的是在出现事件时尽可能快地恢复正常运行,把对业务的影响降为
关于覆盖率
关于覆盖率,网络上最常见的两个词应该是“测试覆盖率”(Test Coverage)和”代码覆盖率“(Code Coverage)。今天就来探探这两个东西。 在测试里面,一般会将测试覆盖率分为两个部分,即”需求覆盖率“和” 代码覆盖率“。可以看到,代码覆盖率其实是测试覆盖率的一部分而已。其中,最常讨论和关心的是”代码覆盖率“,代码覆盖率又分为程序语句和代码行覆盖,分支覆盖和条件覆盖。对于这些概念,我们逐个解释。 需求覆盖率:如果需求已经定义好,这个时侯我们就需要考虑需求覆盖率了。这个时候需要注意的是,这里的需求不仅仅是指功能需求,还要包括性能需求。衡量需求覆盖率的最直观的方式是我们有多少功能点,我们有多少性能点 要求,这些将作为分母;我们写了多少测试用例,覆盖了多少模块,多少功能点,我们的性能测试用例考虑了待测程序多少性能点,这些作为分子。 代码覆盖率:为了更加全面的覆盖,我们可能还需要测试程序的流程,我们可能会考虑到一个函数的数据的输入与输出,甚至是每一行代码的执行情况, 代码的每一条逻辑和分支,这个时候我们的测试执行情况就以代码覆盖率来衡量,这也是我们常在单元测试中念叨的覆盖率覆盖率的问题。 语句覆盖率:换个名字叫做代码行覆盖率,这就是监视每行代码是否在用例(当然之所有的)中是否被执行到,准确点说是我们的用例里面大概执行了百 分之多少的语句/代码行数。需要注意的是,即使所有的语句都被执行到,也不 一定执行到了所有的路径。比如有五条语句:ABCDE,如果我们执行了用例覆盖了ABCDE,另外一个用例这个时候我们覆盖了所有语句,但是可能还存在一个路径(如ABC)没有执行,例如:
大数据中心机房基础设施运维管理系统体系
目录 一、概述 (1) 二、维护职能划分 (1) 三、供配电系统 (1) 3.1 日常巡检内容 (1) 3.2 巡视检查频次 (2) 3.3 维护保养 (2) 3.3.1 月维护 (2) 3.3.2 季维护 (2) 3.3.3 年维护 (3) 3.4 巡视检查注意事项 (3) 四、 UPS系统 (4) 4.1 UPS的日常巡检 (4) 4.2 巡检频次 (4) 4.3 UPS设备维护保养 (4) 4.3.1 月维护 (4) 4.3.2 季度维护(主要进行放电测试) (5) 4.3.3 半年维护 (5) 4.3.4 年检维护(主要进行电气部件紧固操作) (5) 五、精密空调系统 (6) 5.1 日常巡检内容 (6) 5.2 日常巡检频次 (6) 5.3 维护保养 (6) 5.3.1 季度维护 (6) 5.3.2 半年维护(春秋季换季维护)。 (7) 六、新风系统 (7) 6.1 巡检内容 (8)
6.2 巡检频次 (8) 6.3 维护保养 (8) 七、应急发电系统 (8) 7.1 巡检内容 (8) 7.2 巡检频次 (9) 7.3 应急发电设备维护保养 (9) 7.3.1 月保养(空载启动) (9) 7.3.2 季度保养 (10) 7.3.3 半年保养 (11) 7.3.4 年度保养 (11) 7.3.5 每二年保养 (11) 八、安防系统 (12) 8.1 巡视检查内容 (12) 8.2 巡视检查频次 (12) 8.3 保养维护 (13) 8.3.1 月维护 (13) 8.3.2 季度维护 (13) 九、消防灭火系统 (14) 9.1 巡视检查内容 (14) 9.1.1 消防灭火系统 (14) 9.1.2 安全疏散设施 (14) 9.1.3 消防器材 (14) 9.2 巡视检查频次 (15) 9.3 保养维护 (15) 9.3.1 月维护 (15) 9.3.2 季度维护 (15) 9.3.3 半年维护 (16) 9.3.4 年维护 (16) 十、相关表格 (17)
测试用例的设计 提高测试覆盖率
说到测试用例的设计,我想每个有过测试经历的测试工程师都会认为很简单,不就是:按需求或概要设计,得到软件功能划分图,然后据此按每个功能,采用等价类划分、临界值、因果图等方法来设计用例就行了。 但事实上撇开测试数据的设计不谈,仅就测试项来说,我们发现,对同一个项目,有经验的测试人员,在写用例或测试时总会有更多的测试考虑点,从而发现更多的问题;而有些测试人员测试用例的撰写却只有那么三板斧,表面看好象已经把页面所有信息的测试都考虑到了,实际上却还是遗漏了大量测试覆盖点,导致其测试出来的程序总是比较脆弱。 究其原因,我觉得还是测试用例的撰写水平不到位,更确切地说是测试用例的覆盖度太低。说实话我认为系统测试用例真正做到100%覆盖是很难的。难道说按设计中的功能划分,每个功能都写到了这个用例就覆盖完整了?错,这还远远不够。因为我们知道还有大量的内部处理、转换、业务逻辑、相互影响的关系等都是需求或设计中所不会点明的。而这些一方面需要靠测试人员对项目本身的了解,另一方面要靠测试人员的经验,来一一找到这些隐藏点并予以测试,才能真正地保证我们的测试覆盖度。 所以本文抛开具体的测试数据设计方法,主要从测试覆盖度的角度来介绍用例设计时,如何才能考虑地更周全,如何才能将隐藏的测试项一一找出,从而使我们的测试更全面更完整。 想法虽然美好,可是毕竟每个测试的项目都是各不相同,针对不同项目我们的经验也会告诉给我们不同的想法,这些想法通常很感性,很难用严密的逻辑理论来把它升华。因此本文的内容仍是很简陋且不成熟,只是希望能以本文为砖,引起大家的思考,一起来补充完善,以使我们的测试用例设计水平不断提高。 正文 一、测试用例的切面设计 1、功能点切面 2、特定切面 3、隐含切面 (1)、后台功能 (2)、完整业务流程的测试
数据中心运维服务方案
数据中心运维服务方案文档编制序号:[KK8UY-LL9IO69-TTO6M3-MTOL89-FTT688]
数据中心机房及信息化终端设备维护方案 一、概况 xxx客户数据中心机房于XX年投入使用,目前即将过保和需要续保运维的设备清单如下: 另外,全院网络交换机设备使用年限较长,已全部过保,存在一定的安全隐患。
二、维保的意义 通过机房设备维护保养可以提高设备的使用寿命,降低设备出现故障的概率,避免重特大事故发生,避免不必要的经济损失。设备故障时,可提供快速的备件供应,技术支持,故障处理等服务。 通过系统的维护可以提前发现问题,并解决问题。将故障消灭在萌芽状态,提高系统的安全性,做到为客户排忧解难,减少客户人力、物力投入的成本。为机房内各系统及设备的正常运行提供安全保障。可延迟客户设备的淘汰时间,使可用价值最大化。 通过引入专业的维护公司,可以将客户管理人员从日常需要完成专业性很强的维护保养工作中解放出来,提升客户的工作效率,更好的发挥信息或科技部门的自身职能。 通过专业的维护,将机房内各设备的运行数据进行整理,进行数据分析,给客户的机房基础设施建设、管理和投入提供依据。 三、维护范围 1、数据中心供配电系统 2、数据中心信息化系统 3、全院信息化终端设备 4、数据库及虚拟化系统
四、提供的服务 为更好的服务好客户,确实按质按量的对设备进行维护;我公司根据国家相关标准及厂商维护标准,结合自身多年经验积累和客户需求,制定了一套自有的服务内容: 1、我公司在本地储备相应设备的备品备件,确保在系统出现故障 时,及时免费更换新的器件,保障设备使用安全。 2.我公司和客户建立24小时联络机制,同时指定一名负责人与使用方 保持沟通,确保7*24小时都可靠联系到工程技术人员,所有节日都照此标准执行。 3.快速进行故障抢修:故障服务响应时间不多于30分钟,2小时内至少 2人以上携带相关工具、仪器到达故障现场,直到设备恢复正常运行。 4.我公司对维修维护的设施设备的使用性能负责,在维修维护过程中 严格执行技术规范,保证设施设备的性能符合相关技术标准要求。在维修维护间,我方应对设施设备可能存在的故障隐患做出评估,并进行恰当的预防性处理,以保证设施设备的安全运行。若故障隐患超出维修维护范围的,及时书面通知客户,并提出消除隐患建议。 5.维护巡检中我公司提供设备系统图或使用说明书:将机房内设备的 整个系统等汇编成资料,由维护人员进行统一放置,便于应急查询。 6.巡检次数每年不少于四次,每次巡检后,由维修维护方提供巡检报 告,并由使用方签字确认。每月由我公司客户服务人员定期进行回访,听取客户意见反馈,搭建起双方的沟通渠道。