数据挖掘技术在临床决策中的应用研究

收稿日期:2007209221
作者简介:彭柳芬(19802),女,27,硕士研究生,现于广东药学院医药信息工程学院数据决策教研室任教。研究方向:数据库与数据挖掘,智能信息处理。
△基金项目:广东省科技攻关基金项目(44949001) 3暨南大学理工学院
文章编号:100424337(2008)0320350204 中图分类号:TP391 文献标识码:A ?成果应用?
数据挖掘技术在临床决策中的应用研究△
彭柳芬 周 怡 夏毓荣 冯博华3
(广东药学院医药信息工程学院 广州510006)
摘 要: 介绍数据挖掘技术的概念、工作原理,在阐述医学数据特点的基础上,探讨数据挖掘技术在临床决策中的应用过程,并以糖尿病为例,提出基于数据挖掘的辅助临床决策支持系统设想,以利于提高医院的临床决策能力。
关键词: 数据挖掘; 临床决策; 决策树
1 前言
随着国家信息基础结构建设目标的实施,企业在各种活动中普遍采用现代信息技术来提高竞争力。传统的基于数据的管理信息系统已不能满足决策者对数据质量的需求,面向决策的知识管理系统正在蓬勃兴起,智能决策支持技术成为目前迫切需要发展的方向。
医学领域也不例外,临床决策研究已成为临床医学中的一个重要领域,当下的临床决策问题涉及到医学信息学、循证医学、费用2效益评估、卫生技术评估、医学伦理与法律等学科领域,因此在临床决策中单一的经验2描述的研究纲领已不适应当代医学发展的需要,需要引入综合的决策方法,以使临床医疗达到最佳疗效。
2 数据挖掘
近年来,随着电子信息技术的迅速发展,医院信息系统
(hospital information system ,HIS )和医疗设备的广泛应用,医
院数据库的信息容量不断膨胀。数据库技术的发展解决了海量数据的存储和数据检索的效率问题,但无法改变“数据爆炸但知识贫乏”的现象。如何充分利用些宝贵的医学信息资源来为疾病的诊断和治疗提供科学的决策,促进医学研究?如何在医院信息系统中积累了大量的管理信息和临床信息资源中挖掘深层次的、隐含的、有价值的知识?数据挖掘有解决这方面问题的能力,利用数据挖掘技术开展科学研究,提高医学技术和医院管理水平是很有必要的。
211 数据挖掘的概念
数据挖掘(Data Mining )是从大量的、不完全的、有噪声的、模糊的、随机的数据集中识别有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。它是一门涉及面
很广的交叉学科,包括机器学习、数理统计、神经网络、数据库、模式识别、粗糙集、模糊数学等相关技术。
数据挖掘可粗略地理解为三部曲:数据准备(Data Prepa 2
ration )、数据挖掘,以及结果的解释评估(Iterpretation and E 2valuation )。将数据挖掘技术应用到医学信息数据库中,可以
发现其中的医学诊断规则和模式,从而辅助医生进行疾病诊断,实现临床决策支持的效果。
212 临床决策支持系统
在医院信息系统(Hospital Information System ,HIS )中,主要有两大分支:医院管理信息系统(Hospital Management
Information System ,HMIS )和临床信息系统(Clinical Infor 2mation System ,CIS )。HMIS 主要目标是支持医院的行政管
理与事务处理业务;而CIS 主要目标是支持医护人员的临床活动,收集和处理病人的临床医疗信息,丰富和积累临床医学知识,提供临床咨询、辅助诊疗、辅助临床决策,提高医护人员的工作效率。
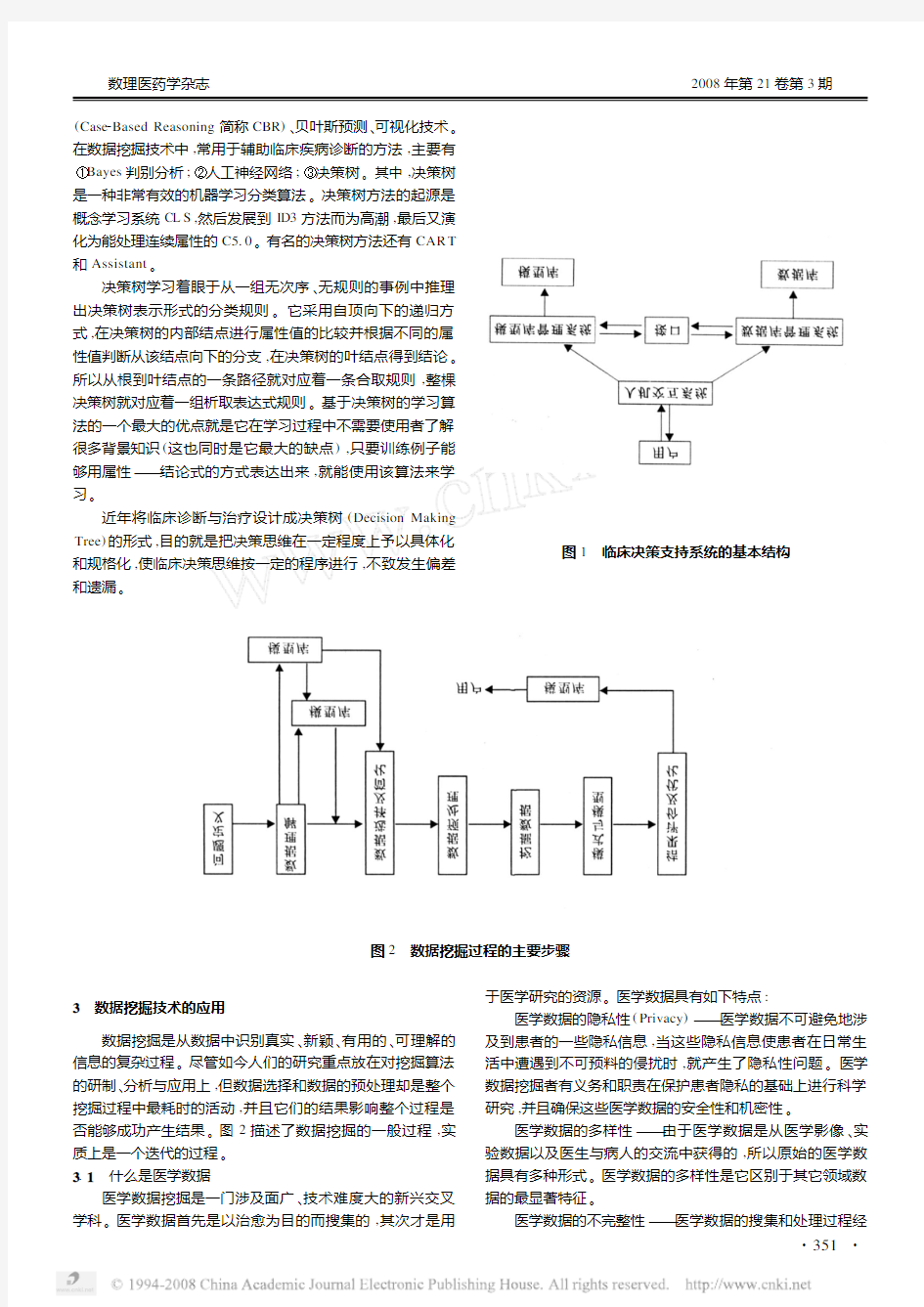
临床决策支持系统(Clinical Decision Support System ,
CDSS )是属于CIS 中的一部分。CDSS 是用人工智能技术对
临床医疗工作予以辅助支持的信息系统,它可以根据收集到的病人资料,做出整合型的诊断和医疗意见,提供给临床医务人员参考。系统主要采用基于决策树和真值表的方法,接着出现了基于统计学方法的系统,研究人员针对不同医疗领域开发不同的临床CDSS 。基本的临床CDSS 由数据库、模型库和对话系统(人机交互系统)3个部分组成,如图1所示。
213 挖掘算法
对医学数据库进行数据挖掘和知识发现的主要目的是预测疾病和对疾病进行分类。分类和预测是两种数据分析形式,可以用于描述重要数据类的模型或预测未来的数据趋势。
常用的数据挖掘算法有:关联规则、决策树、粗糙集、统计分析、神经网络、支持向量机、模糊聚类、基于范例的推理
(Case 2Based Reasoning 简称CBR )、贝叶斯预测、可视化技术。
在数据挖掘技术中,常用于辅助临床疾病诊断的方法,主要有①Bayes 判别分析;②人工神经网络;③决策树。其中,决策树是一种非常有效的机器学习分类算法。决策树方法的起源是概念学习系统CL S ,然后发展到ID3方法而为高潮,最后又演化为能处理连续属性的C5.0。有名的决策树方法还有CAR T 和Assistant 。
决策树学习着眼于从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部结点进行属性值的比较并根据不同的属性值判断从该结点向下的分支,在决策树的叶结点得到结论。所以从根到叶结点的一条路径就对应着一条合取规则,整棵决策树就对应着一组析取表达式规则。基于决策树的学习算法的一个最大的优点就是它在学习过程中不需要使用者了解很多背景知识(这也同时是它最大的缺点),只要训练例子能够用属性———结论式的方式表达出来,就能使用该算法来学习。
近年将临床诊断与治疗设计成决策树(Decision Making
Tree )的形式,目的就是把决策思维在一定程度上予以具体化
和规格化,使临床决策思维按一定的程序进行,不致发生偏差和遗漏
。
图1
临床决策支持系统的基本结构
图2 数据挖掘过程的主要步骤
3 数据挖掘技术的应用
数据挖掘是从数据中识别真实、新颖、有用的、可理解的信息的复杂过程。尽管如今人们的研究重点放在对挖掘算法的研制、分析与应用上,但数据选择和数据的预处理却是整个挖掘过程中最耗时的活动,并且它们的结果影响整个过程是否能够成功产生结果。图2描述了数据挖掘的一般过程,实质上是一个迭代的过程。
311 什么是医学数据
医学数据挖掘是一门涉及面广、技术难度大的新兴交叉学科。医学数据首先是以治愈为目的而搜集的,其次才是用
于医学研究的资源。医学数据具有如下特点:
医学数据的隐私性(Privacy )———医学数据不可避免地涉及到患者的一些隐私信息,当这些隐私信息使患者在日常生活中遭遇到不可预料的侵扰时,就产生了隐私性问题。医学数据挖掘者有义务和职责在保护患者隐私的基础上进行科学研究,并且确保这些医学数据的安全性和机密性。
医学数据的多样性———由于医学数据是从医学影像、实验数据以及医生与病人的交流中获得的,所以原始的医学数据具有多种形式。医学数据的多样性是它区别于其它领域数据的最显著特征。
医学数据的不完整性———医学数据的搜集和处理过程经
常相互脱节,以及一些人为因素使得医学数据库不可能对任何疾病信息都能全面地反映。
医学数据的冗余性———医学数据库是一个庞大的数据资源,每天都会有大量的记录存储到数据库中,其中可能会包含重复的、无关紧要的、甚至是相互矛盾的记录。
此外,医学数据还具有时间性特征。
312 构建数据仓库
数据仓库是支持决策过程的、面向主题的、集成的、与时间有关的、持久的数据集合,它以传统的数据库技术作为存储数据和管理资源的基本手段,以统计分析技术作为分析数据和提取信息的有效方法,以人工智能技术作为挖掘知识和发现规律的科学途径,是与网络通信技术、面向对象技术、并行技术、多媒体技术、人工智能技术等相互浸透、互相结合与综合应用的技术。
创建基于HIS的数据仓库,是从已有数据出发的数据仓库的设计方法,称之为“数据驱动”的系统设计方法,它的基本思路是:利用以前建设的数据库系统的数据,按照分析领域对数据及数据之间的联系重新考虑,组织数据仓库中的主题,利用数据模型有效地识别数据和数据仓库中的主题的数据的“共同性”(即建立主题间相互联系的属性)。
从数据仓库的定义我们可以知道,构建一个HIS数据仓库需要完成:抽取主题;组织数据;获取与集成数据和建立应用。随着数据仓库的数据量增长,日积月累的数据之间有无关系,是否存在着一些潜在的模式或趋势?这些我们都无法用眼或简单的通过某种计算方式获知,而必须对这些数据加以证明或修正,这时,数据挖掘技术就派上用场了。
313 数据挖掘应用举例
数据挖掘是一个利用各种分析工具在海量数据中发现模型和数据间关系的过程。
疾病的诊断过程实际上也是一个疾病分类的过程,是根据病人的疾病特征划归到某个疾病或疾病类的过程。一般的医学书上把这一复杂的问题逐次分解成一个个小问题(疾病)的体系结构,患者根据症状特征及不适部位定位到具体疾病类的具体疾病,这一过程与现实中的分类过程十分相似。
以判断糖尿病为例,建立决策树。
采用决策树的方法,判断患者所患糖尿病的类型。起点是血糖高,分支的条件是是否处于妊娠期,如果答案是肯定的,那决策树就直接指向了妊娠糖尿病。因为如果患者是正在妊娠期的女性,在她们身上检测出高血糖,是归于妊娠糖尿病的。
如果答案是否定的,则属于其他类型糖尿病,就要判断患者是1型糖尿病还是2型糖尿病了。那我们应该根据什么来判断呢?
我们使用频数计算法进行判断。首先,这两种糖尿病之间的差别主要体现在3个方面:是否有自发性酮症,年龄,以及起病的快慢和病情的轻重。频数是指所患疾病表现的临床症状出现的频率,频数越大,说明越多的患者在患此种疾病是会表现出这种症状。把上述3种症状进行调查,得出相应的频数,就可以根据病人的表现症状,把对应的频数相加,最后我们就可以得出患者患有某种类型糖尿病的概率。
假设,经过调查之后,我们得出的1型糖尿病的频数表格见表1。
表1 1型糖尿病频数表
频 数临床表现症状
4有自发性酮症
2年龄>40
3.5起病快,病情重
把频数转变成百分数,即40%,20%,35%。然后建立如图3所示的决策树。
其中,在图3中的各个节点与结论所表示的是:
节点1:有自发性酮症
节点2:无自发性酮症
节点3:有自发性酮症,起病急,病情重
节点4:有自发性酮症,起病慢,病情轻
节点5:无自发性酮症,起病急,病情重
节点6:无自发性酮症,起病慢,病情轻
节点3.1:年龄小于40;结论:患有1型糖尿病百分比是(40+35+20=95)%
节点3.2:年龄大于40;结论:患有1型糖尿病百分比是(40+35=55)%
节点4.1:年龄小于40;结论:患有1型糖尿病百分比是(40+20=60)%
节点4.2:年龄大于40;结论:患有1型糖尿病百分比是(40)%
节点5.1:年龄小于40;结论:患有1型糖尿病百分比是(-40+35+20=15)%
节点5.2:年龄大于40;结论:患有1型糖尿病百分比是(-40+35-20=-25)%
节点6.1:年龄小于40;结论:患有1型糖尿病百分比是(-40-35+20=-55)%
节点6.2:年龄大于40;结论:患有1型糖尿病百分比是(-40-35-20=-95)%
如果患者性别为男性,起病较急,病情较重,年龄是25岁,有自发性酮症表现。那么,根据上述算法进行决策,可以得出结论:患者患有1型糖尿病的几率为95%。这就达到了辅助医生决策的目的。
无论最终挖掘出来的结果是用来描述/理解、预测或是干预,我们寻求只是的目的就是为了运用知识,提高决策支持的能力。由于数据挖掘技术的发展,为决策支持系统开辟了新的发展方向,数据挖掘作为决策支持系统中的一部分发挥着重要的作用。
图3 决策树4 结束语
数据挖掘的目的是利用所获取的知识理解事物、预侧未来情况、进行积极的干预,为下一步的工作或决策提供基础。
医学领域的数据是一个复杂的数据库,包括电子病历、医学影像、病理参数、化验结果等,而目前数据挖掘技术主要应用于以结构化数据为主的关系数据库、事务数据库和数据仓库,对复杂类型数据的挖掘尚处在起步阶段。但是,随着数据库技术的发展,数据挖掘技术作为一种解决方案,成为医学信息技术领域重要的研究方法,必将为决策支持、科学研究带来很大的方便和可观的效益。
参 考 文 献
1 周爱华,郑应平,王令群.医学数据挖掘综述.中华医学实践杂志,2005,4(2):126~128.
2 屈景辉,廖琪梅,许卫中,等.医学信息数据库的建立与数据挖掘.第四军医大学学报.2001,22(1):88~89.
3 胡于进,凌玲.决策支持系统的开发与应用.北京:机械工业出版社,2006,9:16~88.
4 王向辉,匡晓宁,刘伟达,等.数据挖掘技术及其在决策支持系统中的应用.计算技术与自动化.2004,23(4):99~102.
决策树算法研究及应用概要
决策树算法研究及应用? 王桂芹黄道 华东理工大学实验十五楼206室 摘要:信息论是数据挖掘技术的重要指导理论之一,是决策树算法实现的理论依据。决 策树算法是一种逼近离散值目标函数的方法,其实质是在学习的基础上,得到分类规则。本文简要介绍了信息论的基本原理,重点阐述基于信息论的决策树算法,分析了它们目前 主要的代表理论以及存在的问题,并用具体的事例来验证。 关键词:决策树算法分类应用 Study and Application in Decision Tree Algorithm WANG Guiqin HUANG Dao College of Information Science and Engineering, East China University of Science and Technology Abstract:The information theory is one of the basic theories of Data Mining,and also is the theoretical foundation of the Decision Tree Algorithm.Decision Tree Algorithm is a method to approach the discrete-valued objective function.The essential of the method is to obtain a clas-sification rule on the basis of example-based learning.An example is used to sustain the theory. Keywords:Decision Tree; Algorithm; Classification; Application 1 引言 决策树分类算法起源于概念学习系统CLS(Concept Learning System,然后发展 到ID3
数据挖掘相关论文
数据挖掘论文 题目:数据挖掘技术在电子商务中的应用系别:计算机学院 专业:11网络工程1班 学生姓名:黄坤 学号:1110322111 指导教师:江南 2014年11月06 日
数据挖掘技术在电子商务中的应用 一、研究原因 电子商务在现代商务活动中的正变得日趋重要,随着大数据时代的到来,商务信息显得尤为重要,在电子商务中谁掌握了有利的市场信息,谁就能在这个竞争激烈电商行业中占据绝对的优势。而数据挖掘技术是获取信息的最有效的技术工具。本文讨论了数据挖掘的主要方法,具体阐述了数据挖掘技术在电子商务中的作用及应用。 在信息经济时代,对企业来说,谁对市场变化反应速度快,谁将在激烈的市场竞争中占据有利的地位,竞争的结果最终将促使企业价值从市场竞争输家转移到赢家,这样就使企业面临一个问题:如何才能把大量的数据资源,转化成自身价值呢?要想使数据真正成为一个公司的资源,只有充分利用它为公司自身的业务决策和战略发展服务才行,否则大量的数据可能成为包袱,甚至成为垃圾。因此,面对“人们被数据淹没,人们却饥饿于知识”的挑战,数据挖掘和知识发现(DMKD)技术应运而生,并得以蓬勃发展,越来越显示出其强大的生命力。 二、2.1国内研究现状 KDD(从数据库中发现知识)一词首次出现在1989年8月举行的第11届国际联合人工智能学术会议上。迄今为止,由美国人工智能协会主办的KDD已经召开了7次,规模由原来的专题讨论会发展到国际学术大会,人数由二三十人到七八百人,论文收录比例从2X1到6X1,研究重点也逐渐从发现方法转向系统应用,并且注重多种发现策略和技术的集成,以及多种学科之间的相互渗透。其他内容的专题会议也把数据挖掘和知识发现列为议题之一,成为当前计算机科学界的一大热点。此外,数据库、人工智能、信息处理、知识工程等领域的国际学术刊物也纷纷开辟了KDD专题或专刊。IEEE的Knowledge and Data Engineering 会刊领先在1993年出版了KDD技术专刊,所发表的5篇论文代表了当时KDD研究的最新成果和动态,较全面地论述了KDD 系统方法论、发现结果的评价、KDD系统设计的逻辑方法,集中讨论了鉴于数据库的动态性冗余、高噪声和不确定性、空值等问题,KDD系统与其它传统的机器学习、专家系统、人工神经网络、数理统计分析系统的联系和区别,以及相应的基本对策。6篇论文摘要展示了KDD在从建
数据挖掘-决策树
创建Analysis Services 项目 更改存储数据挖掘对象的实例 创建数据源视图 创建用于目标邮件方案的挖掘结构 创建目标邮件方案的第一步是使用Business Intelligence Development Studio 中的数据挖掘向导创建新的挖掘结构和决策树挖掘模型。 在本任务中,您将基于Microsoft 决策树算法创建初始挖掘结构。若要创建此结构,需要首先选择表和视图,然后标识将用于定型的列和将用于测试的列 1.在解决方案资源管理器中,右键单击“挖掘结构”并选择“新建挖掘 结构”启动数据挖掘向导。 2.在“欢迎使用数据挖掘向导”页上,单击“下一步”。 3.在“选择定义方法”页上,确保已选中“从现有关系数据库或数据仓 库”,再单击“下一步”。 4.在“创建数据挖掘结构”页的“您要使用何种数据挖掘技术?”下, 选择“Microsoft 决策树”。 5.单击“下一步”。 6.在“选择数据源视图”页上的“可用数据源视图”窗格中,选择 Targeted Mailing。可单击“浏览”查看数据源视图中的各表,然后单击“关闭”返回该向导。 7.单击“下一步”。
8.在“指定表类型”页上,选中vTargetMail 的“事例”列中的复选 框以将其用作事例表,然后单击“下一步”。稍后您将使用 ProspectiveBuyer 表进行测试,不过现在可以忽略它。 9.在“指定定型数据”页上,您将为模型至少标识一个可预测列、一 个键列以及一个输入列。选中BikeBuyer行中的“可预测”列中的复选框。 10.单击“建议”打开“提供相关列建议”对话框。 只要选中至少一个可预测属性,即可启用“建议”按钮。“提供相关列建议”对话框将列出与可预测列关联最密切的列,并按照与可预测属性的相互关系对属性进行排序。显著相关的列(置信度高于95%)将被自动选中以添加到模型中。 查看建议,然后单击“取消”忽略建议。 11.确认在CustomerKey行中已选中“键”列中的复选框。 12.选中以下行中“输入”列中的复选框。可通过下面的方法来同 时选中多个列:突出显示一系列单元格,然后在按住Ctrl 的同时选中一个复选框。 1.Age https://www.360docs.net/doc/9e15657908.html,muteDistance 3.EnglishEducation 4.EnglishOccupation 5.Gender 6.GeographyKey
决策树算法介绍(DOC)
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
浅谈数据挖掘技术及其应用
浅谈数据挖掘技术及其应用 數据挖掘就是从海量数据中提取潜在有趣模式的过程。数据挖掘技术现已广泛应用于零售业、金融业、电信、网络安全分析、农业、医疗卫生等领域,研究十分广泛。 标签:海量数据;数据挖掘;应用研究 一、数据挖掘概念 数据挖掘比较公认的定义是由U.M.Fayyad等人提出的:数据挖掘就是从海量数据中提取潜在有趣模式的过程[1]。还有一些术语,具有和数据挖掘类似但稍有不同的含义,如数据库中知识挖掘、知识提取、数据/模式分析、数据考古等。数据挖掘技术最初是面向应用层面的,不光可以实现检索和统计专门数据库的操作,还能够在大量的数据集中实现小型、中型乃至大型系统的分析、归纳、推理等工作。 二、数据挖掘的基本任务 数据挖掘的目的就是发现有用的知识(即概念、规则和模式)。数据挖掘的基本任务主要有以下几个方面: (1)分类与预测。 分类属于有监督的学习,在构建分类模型之前,在数据源中选取训练集数据并作分类标记,然后运用分类模型对训练集数据进行分类,实在是按照样本属性相近的划入一类,最后将完成训练的分类模型应用到在未知类别的数据集中,获得相应的分类。预测是依据历史数据和现有的数据建立两种或两种以上变量间相互依赖的函数模型,然后进行预测或控制。 (2)聚类分析。 聚类分析是在识别数据的内在规则后,将数据分成相似数据对象组,从而获得数据的分布规律,划分的原则是不同组间距离尽可能大,组内距离尽可能小。聚类分析进一步是打算从一组杂乱的数据中发掘隐藏其中的分类规则。聚类分析与分类模式模型不同,分类模式是使用有标记样本构成的训练集的一种有监督学习方法,则聚类模型是使用在无标记的数据上的一种无监督学习方法。近年来,聚类分析在图像处理、商业分析、模式识别等有广泛应用。 (3)关联规则。 关联分析是通过对数据集中数据之间隐藏的相互关系的分析,揭露了具有相同类别的数据之间未知的关系。关联分析就是将给定一组项集和一个记录集合,
(完整版)生物数据挖掘-决策树实验报告
实验四决策树 一、实验目的 1.了解典型决策树算法 2.熟悉决策树算法的思路与步骤 3.掌握运用Matlab对数据集做决策树分析的方法 二、实验内容 1.运用Matlab对数据集做决策树分析 三、实验步骤 1.写出对决策树算法的理解 决策树方法是数据挖掘的重要方法之一,它是利用树形结构的特性来对数据进行分类的一种方法。决策树学习从一组无规则、无次序的事例中推理出有用的分类规则,是一种实例为基础的归纳学习算法。决策树首先利用训练数据集合生成一个测试函数,根据不同的权值建立树的分支,即叶子结点,在每个叶子节点下又建立层次结点和分支,如此重利生成决策树,然后对决策树进行剪树处理,最后把决策树转换成规则。决策树的最大优点是直观,以树状图的形式表现预测结果,而且这个结果可以进行解释。决策树主要用于聚类和分类方面的应用。 决策树是一树状结构,它的每一个叶子节点对应着一个分类,非叶子节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。构造决策树的核心问题是在每一步如何选择适当的属性对样本进行拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下分而治之的过程。 2.启动Matlab,运用Matlab对数据集进行决策树分析,写出算法名称、数据集名称、关键代码,记录实验过程,实验结果,并分析实验结果 (1)算法名称: ID3算法 ID3算法是最经典的决策树分类算法。ID3算法基于信息熵来选择最佳的测试属性,它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少个不同的取值就将样本集划分为多少个子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论的理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的划分,从而得到较小的决策树。 ID3算法的具体流程如下: 1)对当前样本集合,计算所有属性的信息增益; 2)选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集; 3)若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。 (2)数据集名称:鸢尾花卉Iris数据集 选择了部分数据集来区分Iris Setosa(山鸢尾)及Iris Versicolour(杂色鸢尾)两个种类。
数据挖掘技术及其应用
数据挖掘毕业论文 ---------数据挖掘技术及其应用 摘要:随着网络、数据库技术的迅速发展以及数据库管理系统的广泛应用,人们积累的数据越来越多。数据挖掘(Data Mining)就是从大量的实际应用数据中提取隐含信息和知识,它利用了数据库、人工智能和数理统计等多方面的技术,是一类深层次的数据分析方法。本文介绍了数据库技术的现状、效据挖掘的方法以及它在Bayesian网建网技术中的应用:通过散据挖掘解决Bayesian网络建模过程中所遇到的具体问题,即如何从太规模效据库中寻找各变量之间的关系以及如何确定条件概率问题。 关键字:数据挖掘、知识获取、数据库、函数依赖、条件概率 一、引言: 数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥有知识的有局限性,所以对于获得知识的可信度就应该打个 折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。 数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行科学研究、商业决策或者企业管理,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是为了解决传统分析方法的不足,并针对大规模数据的分析处理而出现的。数据挖掘通过在大量数据的基础上对各种学习算法的训练,得到数据对象间的关系模式,这些模式反映了数据的内在特性,是对数据包含信息的更高层次的抽象[1]。目前,在需要处理大数据量的科研领域中,数据挖掘受到越来越多
数据挖掘及其应用
数据挖掘及其应用 Revised by Jack on December 14,2020
《数据挖掘论文》 数据挖掘分类方法及其应用 课程名称:数据挖掘概念与技术 姓名 学号: 指导教师: 数据挖掘分类方法及其应用 作者:来煜 摘要:社会的发展进入了网络信息时代,各种形式的数据海量产生,在这些数据的背后隐藏这许多重要的信息,如何从这些数据中找出某种规律,发现有用信息,越来越受到关注。为了适应信息处理新需求和社会发展各方面的迫切需要而发展起来一种新的信息分析技术,这种局势称为数据挖掘。分类技术是数据挖掘中应用领域极其广泛的重要技术之一。各种分类算法有其自身的优劣,适合于不同的领域。目前随着新技术和新领域的不断出现,对分类方法提出了新的要求。 。 关键字:数据挖掘;分类方法;数据分析 引言 数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我
们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥有知识的有局限性,所以对于获得知识的可信度就应该打个折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。 数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行科学研究、商业决策或者企业管理,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是为了解决传统分析方法的不足,并针对大规模数据的分析处理而出现的。数据挖掘通过在大量数据的基础上对各种学习算法的训练,得到数据对象间的关系模式,这些模式反映了数据的内在特性,是对数据包含信息的更高层次的抽象。目前,在需要处理大数据量的科研领域中,数据挖掘受到越来越多的关注,同时,在实际问题中,大量成功运用数据挖掘的实例说明了数据挖掘对科学研究具有很大的促进作用。数据挖掘可以帮助人们对大规模数据进行高效的分析处理,以节约时间,将更多的精力投入到更高层的研究中,从而提高科研工作的效率。 分类技术是数据挖掘中应用领域极其广泛的重要技术之一。至今已提出了多种分类算法,主要有决策树、关联规则、神经网络、支持向量机和贝叶斯、k-临近法、遗传算法、粗糙集以及模糊逻辑技术等。大部分技术都是使用学习算法确定分类模型,拟合输入数据中样本类别和属性集之间的联系,预测未知样本的类别。训练算法的主要目标是建立具有好的泛化能力的模型,该模型能够准确地预测未知样本的类别。 1.数据挖掘概述 数据挖掘又称库中的知识发现,是目前人工智能和领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平
数据挖掘技术及应用综述
作者简介:韩少锋,男,1980年生,中北大学在读硕士研究生。研究方向:人工智能技术。 引言 “人类正被信息淹没,却饥渴于知识.”这是1982年 趋势大师JohnNaisbitt的首部著作《大趋势》(Mega-trends)中提到的。 随着数据库技术的迅速发展,如何从含有海量信息的数据库中提取更有价值、更直观的信息和知识?人们结合统计学﹑数据库﹑机器学习﹑神经网络﹑模式识别﹑模糊数学﹑粗糙集理论等技术,提出‘数据挖掘’这一新的数据处理技术来解决这一难题。数据挖掘(DataMining)就是从大量的﹑不完全的﹑有噪声的﹑模糊的﹑随机的数据中,提取隐含在其中的﹑人们事先不知道的﹑但又是潜在的有用的信息和知识的过程。这些数据可以是:结构化的,半结构化的,分布在网络上的异构性数据。数据挖掘在许多领域得到了成功的应用,使数据库技术进入了一个更高级的发展阶段,很多专题会议也把数据挖掘和知识发现列为议题之一。 1数据挖掘技术概述 1.1数据挖掘的概念 数据挖掘的概念有多种描述,最常见的有两种:(1)G.PiatetskyShapior,W.J.Frawley数据挖掘定义为:从数据库的大量数据中揭示出隐含的、先进而未知的、潜在有用信息的频繁过程。(2)数据挖掘的广义观点:数据挖掘是从存放在数据库、数据仓库或其他信息库中的大量数据中挖掘有趣知识的过程。数据挖掘的特点有:1)用户需要借助数据挖掘技术从大量的信息中找到感兴趣的信息;2)处理的数据量巨大;3)要求对数据的变化做出及时的响应;4)数据挖掘既要发现潜在的规则,也要管理和维护规则,规则的改变随着新数据的不断更新而更新;5)数据挖掘规则的发现基于统计规律,发现的规则不必适用于全部的数据。 数据挖掘要面对的是巨大的信息来源;通过数据挖 掘,有价值的知识、规则或高层次的信息就能从数据库的相关数据集合中抽取出来,并从不同角度显示,从而使大型数据库作为一个丰富可靠的资源为知识归纳服务。 1.2数据挖掘的简史 从数据库中知识发现(KDD)一词首先出现在1989 年举行的第十一届国际联合人工智能学术会议上。目前为止,由美国人工智能协会主办的KDD国际研讨会已经召开了8次,规模由原来的专题讨论会发展到国际学术大会,研究重点也从发现方法转向系统应用。1999年,亚太地区在北京召开的第三届PAKDD会议收到158篇论文,研讨空前热烈。 目前,数据挖掘技术在零售业的购物篮分析﹑金融风险预测﹑产品质量分析﹑通讯及医疗服务﹑基因工程研究等许多领域得到了成功的应用。 1.3数据挖掘的对象 数据挖掘的对象包含大量数据信息的各种类型数 据库。如关系数据库,面向对象数据库等,文本数据数据源,多媒体数据库,空间数据库,时态数据库,以及 Internet等类型数据或信息集均可作为数据挖掘的对 象。 1.4数据挖掘的工具 许多软件公司和研究机构,根据商业的实际需要 开发出许多数据挖掘工具。例如:有多种数据操控和转换特点的SASEnterpriseMiner;采用决策树、神经网络和聚类技术综合的数据挖掘工具集-IBMInterlligentMiner;可以提供多种统计分析、 决策树和回归方法,在Teradata数据库管理系统上原地挖掘的Teradata WarehouseMiner;以及同时具有数据管理和数据概括能力,能够用于多种商业平台的SPSSClementine。以上 主流数据挖掘工具都能提供常用的挖掘过程和挖掘模 数据挖掘技术及应用综述 韩少锋 陈立潮 (中北大学计算机科学与技术系 山西 太原 030051) 【摘要】介绍了数据挖掘技术的背景、概念、流程、数据挖掘算法,并阐述了数据挖掘技术的应用现状。 【关键词】数据挖掘 知识发现 人工智能 数据仓库 【中图分类号】TP311.138 【文献标识码】B 【文章编号】1003-773X(2006)02-0023-02 第2期(总第89期)机械管理开发 2006年4月No.2(SUMNo.89)MECHANICALMANAGEMENTANDDEVELOPMENT Apr.2006 23??
数据挖掘决策树算法Java实现
import java.util.HashMap; import java.util.HashSet; import java.util.LinkedHashSet; import java.util.Iterator; //调试过程中发现4个错误,感谢宇宙无敌的调试工具——print //1、selectAtrribute中的一个数组下标出错 2、两个字符串相等的判断 //3、输入的数据有一个错误 4、selectAtrribute中最后一个循环忘记了i++ //决策树的树结点类 class TreeNode { String element; //该值为数据的属性名称 String value; //上一个分裂属性在此结点的值 LinkedHashSet
浅谈数据挖掘技术及其应用
1 数据挖掘的起源 2数据挖掘的定义 3数据挖掘的过程 3.1目标定义阶段 3.2数据准备阶段 3.3数据挖掘阶段 3.4结果解释和评估阶段 面对信息社会中数据和数据库的爆炸式增长,人们分析数据和从中提取有用信息的能力,远远不能满足实际需要。但目前所能做到的只是对数据库中已有的数据进行存储、查询、统计等功能,但它却无法发现这些数据中存在的关系和规则,更不能根据现有的数据预测未来的发展趋势。这种现象产生的主要原因就是缺乏挖掘数据背后隐藏的知识的有力手段,从而导致“数据爆炸但知识贫乏”的现象。数据挖掘就是为迎合这种要求而产生并迅速发展起来的,可用于开发信息资源的一种新的数据处理技术。数据挖掘(DataMining),又称数据库中的知识发现(KnowledgeDiscoveryinDatabase,简称KDD),比较公认的定义是由U.M.Fayyad等人提出的:数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的数据集中,提取隐含在其中的、人们事先不知道的、但又是潜在的有用的信息和知识的过程,提取的知识表示为概念(Concepts)、规则(Rules)、规律(Regularities)、模式(Patterns)等形式。数据挖掘是一种决策支持过程,分析各组织原有的数据,做出归纳的推理,从中挖掘出潜在的模式,为管理人员决策提供支持。KDD的整个过程包括在指定的数据库中用数据挖掘算法提取模型,以及围绕数据挖掘所进行的预处理和结果表达等一系列的步骤,是一个需要经过反复的多次处理的过程。整个知识发现过程是由若干挖掘步骤组成的,而数据 挖掘仅是其中的一个主要步骤。整个知识发现的主要步骤有以下几点。要求定义出明确的数据挖掘目标。目标定义是否适度将影响到数据挖掘的成败,因此往往需要具有数据挖掘经验的技术人员和具有应用领域知识的专家以及最终用户紧密协作,一方面明确实际工作中对数据挖掘的要求,另一方面通过对各种学习算法的对比进而确定可用的算法。数据准备在整个数据挖掘过程中占的比例最大,通常达到60%左右。这个阶段又可以进一步划分成三个子步骤:数据选择(DataSelection),数据预处理(DataProcessing)和数据变换(DataTransformation)。数据选择主要指从已存在的数据库或数据仓库中提取相关数据,形成目标数据(TargetData)。数据预处理对提取的数据进行处理,使之符合数据挖掘的要求。数据变换的主要目的是精减数据维数,即从初始特征中找出真正有用的特征以减少数据挖掘时要考虑的特征或变量个数。这一阶段进行实际的挖掘工作。首先是算法规划,即决定采用何种类型的数据挖掘方法。然后,针对该挖掘方法选择一种算法。完成了上述的准备工作后,就可以运行数据挖掘算法模块了。这个阶段是数据挖掘分析者和相关领域专家最关心的阶段,也可以称之为真正意义上的数据挖掘。 浅谈数据挖掘技术及其应用 舒正渝1、2 (1.西北师范大学数信学院计算机系,甘肃兰州730070;2.兰州理工中等专业学校,甘肃兰州730050)摘要:科技的进步,特别是信息产业的发展,把我们带入了一个崭新的信息时代。数据库管理系统的应用领域涉及到了各行各业,但目前所能做到的只是对数据库中已有的数据进行存储、查询、统计等功能,通过这些数据获得的信息量仅占整个数据库信息量的一小部分,如何才能从中提取有价值的知识,进一步提高信息量利用率,因此需要新的技术来自动、智能和快速地分析海量的原始数据,以使数据得以充分利用,由此引发了一个新的研究方向:数据挖掘与知识发现的理论与技术研究。数据挖掘技术在分析大量数据中具有明显优势,基于数据挖掘的分析技术在金融、保险、电信等有大量数据的行业已有着广泛的应用。关键词:数据挖掘;知识发现 Abstract:Key words:The progress of science and technology,especially the development of the information industry,brings us into a brand-new information age.The application of the data base management system has involved all trades and professions,but only the store,inquire and statistic function can be applied,account a little part of the whole database.How to improve the utilization ratio of the information has initiated a new research direction,the data mining and knowledge found theory and technique.The data mining has the advantage in analyzing a large number of data.The data mining analytical technology has been largely used finance,insurance,telecommunication industry,etc..Data mining;Knowledge discovery 收稿日期:2010-01-15修回日期:2010-02-11 作者简介:舒正渝(1974-),女,重庆籍,硕士研究生,研究方向为数据库、多媒体。 中国西部科技2010年02月(中旬)第09卷第05期第202期 总38
论电子商务中数据挖掘技术的应用
摘要 电子商务作为蓬勃发展的新经济里的典型代表,冲击着人们千百年来形成的商务观念与模式。但随着Internet的普及,信息过量问题使得我们必须及时发现有用知识,提高信息利用率。数据挖掘被认为是解决“数据爆炸”和“数据丰富,数据贫乏”的一种有效方法。 本文首先探讨了在电子商务环境下,信息服务以及企业对信息服务需求的新特点。其次阐述了能够应用于电子商务活动中的数据挖掘技术。再者分析了电子商务中数据挖掘技术的应用方案和企业案例。全文旨在说明数据挖掘技术(尤其是聚类分析和关联分析)将在未来的市场竞争中发挥越来越重要的作用,为企业赢得更多的商业价值。 【关键词】电子商务信息过量数据挖掘聚类分析
Abstract E-commerce has become the typical representation in the flourish, new economy that is impacting the Business concepts and models of people formed for thousands of years. But with the popularity of the Internet, information overload has enabled us to discover useful knowledge timely, increase the rate of utilization of information. Data mining is considered to be one of effective methods to resolve "data explosion" and "data rich, information poor". This paper firstly discusses information services and new features of demand of that to enterprises. Secondly it expounds data mining technology and that can be used for e-commerce activities. Then it analyzes of application programme and business cases with data mining technology in e-commerce. The full text seeks to clarify data mining technology ( clustering analysis and association analysis especially ) will play an increasingly major role in the rather stiff market competition in the future, which enable enterprises to gain more commercial value. 【Key Words】E-commerce; Information overload; Data mining; Clustering analysis
数据挖掘及决策树
理工大学信息工程与自动化学院学生实验报告 ( 2016 — 2017 学年第学期) 信自楼444 一、上机目的及容 目的: 1.理解数据挖掘的基本概念及其过程; 2.理解数据挖掘与数据仓库、OLAP之间的关系 3.理解基本的数据挖掘技术与方法的工作原理与过程,掌握数据挖掘相关工具的使用。 容: 给定AdventureWorksDW数据仓库,构建“Microsoft 决策树”模型,分析客户群中购买自行车的模式。 要求: 利用实验室和指导教师提供的实验软件,认真完成规定的实验容,真实地记录实验中遇到的 二、实验原理及基本技术路线图(方框原理图或程序流程图) 请描述数据挖掘及决策树的相关基本概念、模型等。 1.数据挖掘:从大量的、不完全的、有噪音的、模糊的、随机的数据中,提取隐含在其中的、 人们事先不知道的、但又潜在有用的信息和知识的过程。
项集的频繁模式 分类与预测分类:提出一个分类函数或者分类模型,该模型能把数据库中的数据项 映射到给定类别中的一个; 预测:利用历史数据建立模型,再运用最新数据作为输入值,获得未来 变化趋势或者评估给定样本可能具有的属性值或值的围 聚类分析根据数据的不同特征,将其划分为不同数据类 偏差分析对差异和极端特例的描述,揭示事物偏离常规的异常现象,其基本思想 是寻找观测结果与参照值之间有意义的差别 3.决策树:是一种预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个 节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从 根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输 出,可以建立独立的决策树以处理不同输出。 算法概念 ID3 在实体世界中,每个实体用多个特征来描述。每个特征限于在一 个离散集中取互斥的值 C4.5 对ID3算法进行了改进: 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选 择取值多的属性的不足;在树构造过程中进行剪枝;能够完成对 连续属性的离散化处理;能够对不完整数据进行处理。 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及Microsoft SQL Server套件 四、实验方法、步骤(或:程序代码或操作过程) (一)准备 Analysis Services 数据库 1.Analysis Services 项目创建成功
数据挖掘技术在软件工程中的应用研究
数据挖掘技术在软件工程中的应用研究 发表时间:2018-06-20T10:03:11.023Z 来源:《电力设备》2018年第5期作者:张佳鑫李爱萍 [导读] 摘要:社会发展的信息化水平在不断提高,越来越多的信息资源被相应的数据所替代,而实现这些信息资源充分利用的前提即是对其相应的数据进行管理与分析。 (太原理工大学计算机科学与技术学院山西太原 030024) 摘要:社会发展的信息化水平在不断提高,越来越多的信息资源被相应的数据所替代,而实现这些信息资源充分利用的前提即是对其相应的数据进行管理与分析。数据挖掘技术作为一种新型的网络技术,在软件工程的大数据分析中占据核心地位,有利于提高数据的可靠性与安全性。本文主要分析了数据挖掘技术在软件工程中的应用策略。 关键词:数据挖掘;软件工程;策略;发展 随着信息技术的不断发展,日常生活中人们所接触的信息量越来越多,如何在众多信息量中找到自己有用的信息,成为影响人们工作效率和工作质量的关键因素,而数据挖掘技术的应用则能很好的解决这个问题。所谓数据挖掘是指在大量、无序、模糊的数据中挖掘出其中有用的信息的过程,它能实现信息的分类、聚类并进行偏差分析。数据挖掘技术一般流程为数据预处理、数据挖掘、模式评估与知识表示等等,笔者结合实际经验,分析了数据挖掘技术在软件工程中的应用策略,对数据挖掘技术的发展提出了几点思考。 1数据挖掘技术概述 1.1数据挖掘技术的定义 数据挖掘技术,也成为数据库中的知识发现,发展于上个世纪末,是当前数据库领域内最新的应用研究技术。历经多年的发展,数据挖掘技术已成为当前数据库领域内最为关键的组成部分,但是还没有较为统一的定义。当前数据挖掘技术定义认可度最高的便是由W.J.Frawley等人所提出的,将数据挖掘技术理解为从数据中提炼出更为高效、更为新颖、更具潜在应用价值,并最终可理解模式的非平凡过程中。主要具有如下多方面内容: (1)数据源务必真实、数据量较大、并含噪音,不完全; (2)应用于获取终端用户兴趣较高的未知知识信息; (3)所获取的知识具备有效性、新颖性,且为潜在的; (4)更用于发现特定的问题,对知识量没有过多要求; 综合而言,数据挖掘属于复杂度较高的交叉学科,包括人工智能、模式识别、统计学、数据可视化等等交叉性相对较大的新型学科,未来拥有良好的发展空间。 1.2数据挖掘技术一般流程 一般而言,数据挖掘主要由数据预处理、数据挖掘以及模式评估和知识表示等三阶段组成。具体如下: (1)数据预处理。主要由原始信息获取、数据清洗、数据抽取及数据交换等构成。原始数据获取在于获取发现任务的处理对象,主要按照相应的需求而获取数据。数据清洗目的在于完善原始数据所缺失的数据。数据抽取指将特定的数据源中获取与分析任务相关的数据。数据转换在于规格化数据,以满足特定范围要求。 (2)数据挖掘,第一步便是明确挖掘任务,包括数据分类、数据总结等等,紧接着便是确定挖掘算法,应结合数据实际特点以及具体系统特定需求来确定算法。 (3)模式评估与知识表示。模式用于表示数据挖掘所形成的结果,用特定的兴趣度进行度量,用于识别表示知识的真正有趣模式。在此之中所使用的度量特定值通常由领域专家、用户标准等给出 2数据挖掘技术在软件工程中的应用情况 2.1执行记录 对于执行记录挖掘来说,就是分析程序执行路径,找寻存在于程序中的代码关系,将数据挖掘及时应用到软件工程中就是跟踪相关执行路径,在逆向建模的作用下达到既定目标,其主要作用是维护与验证程序。在执行记录的过程中,主要是插装系统,然后用相关软件接口编程,同时记录相关变量等,最终将收集来的信息整合在一起,构建相应的系统模型。 2.2漏洞检测 在软件工程中利用数据挖掘技术进行漏洞检测,主要是为了及时发现存在于软件开发中的问题,这样就可以尽快将漏洞弥补,对提高软件质量有很好的作用。通常情况下,利用数据挖掘及时检测软件漏洞看,就是先对软件进行系统测试看,同时根据用户需求制定出科学合理的应对措施。然后将各种漏洞数据收集整理在一起,逐一做好数据清理与转换。通过分析这些数据信息能够得知,为做好数据清理工作,就需要将多余数据清理出去,然后对丢失项目进行补充,这样再将数据属性以数值的形式体现出来。其次,要构建合适的数据模型,做好验证与训练。在这一过程中应重视与项目实际的联系,选择与之相匹配的挖掘方式,以便构成测试集,获得相应结果。此外,还要做好漏洞扫描与分类,将所有漏洞整理起来构成漏洞库,然后再次扫描,防止漏洞遗失,最后将通过挖掘得来的数据知识应用到软件测试中。 2.3开源软件 对于开源软件来说,其挖掘环境带有明显的开放性与全面性特征,所以,在管理这样的软件时,就不能使用传统软件的开发方式。一般而言,较为成熟的开源软件,能够详细记录开发中所遇到的错误,同时也包括软件开发者的一些活动,以及软件在市场中的应用情况。对于参与软件开发的人员来说,他们是社会网络的主要创造者,然而,由于开源软件的开放特征较为明显,所以也就让这些参与人员随之发生变化。同时,由于开源软件还带有动态特征,所以就需要重视开源项目的进一步管理,也就是由专业人士管理软件系统,在这项工作中做的最好的莫过于英国牛津大学的Sima系统。 2.4版本信息控制 在版本信息控制应用中,主要是确保项目参与者所使用的档案相同,这样也有利于全面更新。对于软件工程开发来说,通常会用版本控制系统管理与开发软件。同时利用版本信息控制,选择合适的变更历史信息的方法,以便获取不同模块,在这种情况下子系统也可以相互映衬,这对深度挖掘程序变化,做好漏洞检测具有重要作用。随着数据挖掘技术在软件工程中的应用,不仅可以有效减少系统维护资
基于大数据的数据挖掘技术与应用
基于大数据的数据挖掘技术与应用 发表时间:2019-07-17T12:49:19.997Z 来源:《基层建设》2019年第12期作者:汪洋 [导读] 摘要:科技前进的步伐越来越快,数据挖掘与传统行业相结合,在各行各业展现出了十分强大的生命力。 中国联合网络通信有限公司黄石市分公司湖北黄石 435000 摘要:科技前进的步伐越来越快,数据挖掘与传统行业相结合,在各行各业展现出了十分强大的生命力。本文从数据挖掘的基本概念和功能谈起,进一步再分析其在金融和人力资源两个方面的具体运用。 关键词:数据挖掘;大数据;金融;人力资源 一、数据挖掘的概念和功能 (一)数据挖掘概念。数据挖掘是指从庞大繁杂的数据中通过算法搜索隐藏于表面数据背后信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习和模式识别等多种方法来实现上述目标。 (二)数据挖掘的方法和过程。数据挖掘的理论技术一般可分为传统技术和改良技术两支。就传统技术而言,以统计分析为主要代表;就改良技术而言,以决策树理论、类神经网络和规则归纳法等为主要代表。 (三)数据挖掘的主要功能。数据挖掘的功能十分强大,在与各行各业结合之后,都能为各行业带来新的发展契机。一般来说,数据挖掘的功能分为两类:一类是描述性功能,是指对目标数据的属性进行特征描述;另一类是预测性功能,是指对当前数据进行归纳,以进行发展趋势的预测。 二、数据挖掘技术的应用实践 (一)在金融方面的应用。大数据金融以庞大繁杂的数据作为基础,利用如互联网等信息化技术,分析处理对客户的消费数据,将客户及时全面的信息及时地反馈给金融企业,如此一来,使得金融企业给零散化的客户群体提供定制化的服务成为可能。数据挖掘技术在金融领域的表现十分优异,在第三方支付、p2p网络借贷、供应链金融、互联网消费金融等方面均有广泛的运用。 就第三方支付而言,因为其运用场景多样化,使用方便快捷,因而,第三方支付与上下游的交易者联系紧密。当相关数据累积到一定程度时,便可推出更多的增值服务,进一步增加利润来源。在众多增值服务中,近年来,值得一提的是由蚂蚁金服推出的蚂蚁花呗。蚂蚊花呗本质上而言是一款消费信贷产品。蚂蚁花呗利用大数据,以自身的风控模型为基础,结合对消费者在互联网上的各种网购情况、支付习惯、信用风险等的分析结果,对不同的用户根据其近期的消费情况给予不同数额的消费额度。 第三方互联网支付交易规模由于互联网理财等大额交易场景的推动保持高速增长。在2013年,第三方互联网支付交易额仅为6万亿元,但据可靠预测,在2020年,此交易额可到39万亿元。再看第三方移动支付交易额。由于移动支付场景的多样化、用户渗透率越来越高、各种第三方支付企业进军市场等原因,移动交易量不断上升。在2013年,第三方移动支付交易额仅为1万亿元。但据估计,在2020年,第三方移动支付交易额可达144万亿元。 (二)在人力资源管理方面的运用。 (1)数据挖掘与人力资源规划:通过数据挖掘技术,组织管理者可以利用搜集到的每一个员工的组织内外部的信息资料,联系企业的整体战略目标,以事实为依据,制定未来人力资源规划。 (2)数据挖掘与人才的招聘与配置:招聘时,招聘者对于求职者的了解一般都比较肤浅,对于求职者的专业技能掌握情況、工作效率等无法有效进行认知。而新兴的社交网络呈现了—个人各方面的信息,如工作经历、社会关系、工作效率等,从而能助招聘者一臂之力,达到精准的人岗匹配。 (3)数据挖掘与员工的开发:利用数据挖掘,管理者将职业生涯规划建立在员工全方位数据的基础上,如员工的应聘岗位、晋升意愿和期望薪酬等结构化与非结构化的数据信息,从而精准地为员工提供职业培训。 三、注意区分数据挖掘与个人信息侵犯 当今时代,科学技术的不断提高,使得各种数码产品更新换代速度加快,手机、电脑、照相机等电脑产品基本是一年更新换代一次甚至两三次。其中由于手机应用功能随着经济发展而逐渐增加,从原来的按键机发展到如今的触屏手机乃至折叠手机,其功能也从原来的拨打电话、发送短信、彩信功能而增加到如今的视频通话、语音通话以及上网功能。网络的普遍化丰富了人们的生活,使得人们可以便捷广泛的了解、认知自身以外的整个中国乃至整个世界,可以通过网络媒介了解到其他国家的风土民俗、地形地貌,了解自己所喜欢的明星网红的日常喜好,或是通过网络媒介得到想获得的知识、达到一个学习的作用。但网络媒介是一把双刃剑,通过网络世界了解到诸多信息时,也可能因为自己在网络上所说的一句话、所发的一个定位从而导致自身隐私泄露,个人信息被公布在大众眼中。要运用好大数据时代中网络媒体这一把双刃剑,就必须要求到人们提高自我隐私保护意识,规范网络世界中的一言一语。 (一)大数据时代信息量过大导致信息泄露 当今时代是科技不断发展的时代,是大数据时代。在大数据时代里,各种数码产品纷呈展现其自身的广泛性、普遍性,充斥在人类日常生活中。尤其是手机的发展从原始的只能打电话接电话的大哥大,渐渐变成能够发短信、收短信的按键机,为满足人们日常生活中的娱乐要求,在信息传播的同时又增加了照相机、听音乐、玩游戏等等娱乐功能。在科技发展的基础上,为满足人们日常生活中的各种精神需求,仅仅五六年时间内,按键手机逐渐演变成如今的触屏手机、智能手机。如今的手机已不仅是一个只能打电话、接电话的功能机,在满足了人们的基本通讯要求后,增加了上网的功能。如今微博app、微信app、qqapp各种社交app的崛起,使得人们日常生活充满了娱乐性、便捷性、广泛性,所接收的信息不仅来自自身以外的中国各地,而且也可以接触到中国以外其它国家,甚至来自地球以外的各大恒星的知识。如今你将会看到,越来越多的人在超市里、商场中、地铁上、公园里拿起手机刷微博、拍抖音、视频通话、拍照片等等,在大数据时代,由于网络的普遍,人们上一秒在抖音app上传了一段视频、微博上发布了一篇文章、朋友圈发表了几张照片,以网络传播速度快的特点,下一秒这个视频、这篇文章、这些照片就极有可能出现在大众视线中。网络带来便捷性的同时也带来过大的信息量以及一定性的安全隐患,人们通过信息库了解某一样东西的同时,也可能导致自身定位被人知道、自身隐私被泄露出去。 (二)大数据时代侵犯个人信息方法更多 由于科学技术进步速度快,数码产品更新换代的速度也日益加快。当手机硬件设施提高了,相应的各类软件应用层出不穷,给予了人们日常生活中的精神满足,同时也给予了不法分子有机可图的条件。人们隐私安全问题日益堪忧,由于手机等各种数码产品的普遍性,大