SQL Server中的字段类型对应C#的变量类型
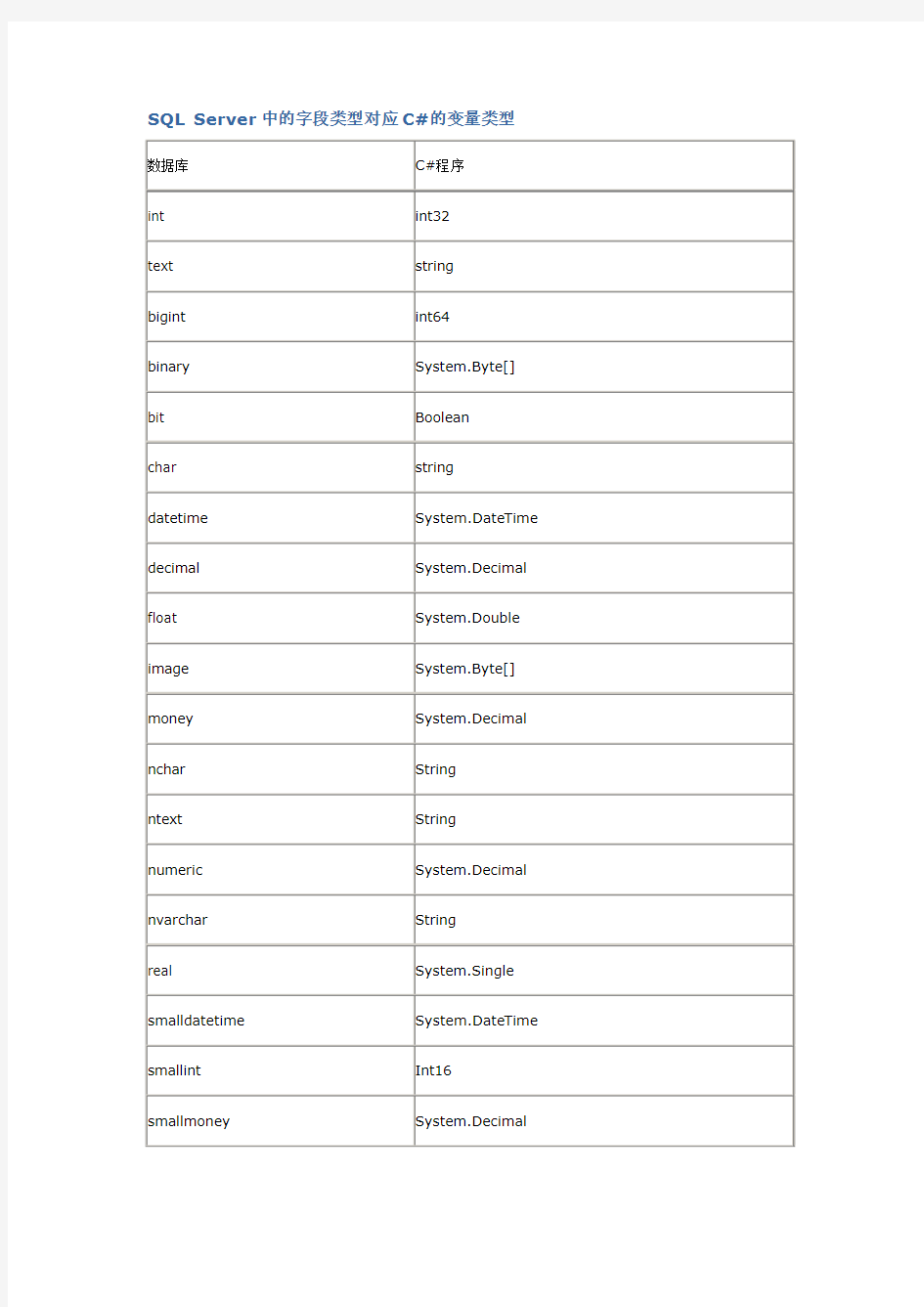

SQL Server中的字段类型对应C#的变量类型
SQLServer查询今天-昨天-本周-本月的记录
在统计的时候,经常会使用SQL查询今天、昨天、本月、本周的记录,我将这些常用的sql语句写在这里。 SQL查询今天的记录: datediff(day,[Datetime],getdate())=0 把Datetime换为你的相应字段; SQL查询昨天的记录: datediff(day,[Datetime],getdate())=1 把Datetime换为你的相应字段,getdate()-Datetime即为时间差。 本月记录: SELECT * FROM 表WHERE datediff(month,[dateadd],getdate())=0 本周记录: SELECT * FROM 表WHERE datediff(week,[dateadd],getdate())=0 本日记录: SELECT * FROM 表WHERE datediff(day,[dateadd],getdate())=0 GetDate函数的使用方法 函数参数/功能 GetDate( ) 返回系统目前的日期与时间 DateDiff (interval,date1,date2) 以interval 指定的方式,返回date2 与date1两个日期之间的差值date2-date1 DateAdd (interval,number,date) 以interval指定的方式,加上number之后的日期 DatePart (interval,date) 返回日期date中,interval指定部分所对应的整数值 DateName (interval,date) 返回日期date中,interval指定部分所对应的字符串名称 更多信息请查看IT技术专栏
数据库表及字段命名、设计规范
数据库表及字段命名、设计规范1、命名规范 1.1数据表的命名规范: 1)表的前缀应该用系统或模块的英文名的缩写(全部大写或首字母大写)。如果系统功能简单,没有划分为模块,则可以以系统英文名称的缩写作为前缀,否则以各模块的英文名称缩写作为前缀。例如:如果有一个模块叫做BBS(缩写为BBS),那么你的数据库中的所有对象的名称都要加上这个前缀:BBS_ + 数据库对象名称,BBS_CustomerInfo标示论坛模块中的客户信息表。 2)表的名称必须易于理解,使用能表达表功能的英文单词或缩写英文单词,无论是完整英文单词还是缩写英文单词,单词首字母必须大写。如果当前表可用一个英文单词表示的,请用完整的英文单词来表示;例如:系统资料中的客户表的表名可命名为:SYS_Customer。如果当前表需用两个或两个以上的单词来表示时,尽量以完整形式书写,如太长可采用两个英文单词的缩写形式;例如:系统资料中的客户物料表可命名为:SYS_CustItem。 3)表的名称一般使用名词或者动宾短语 4)表名称不应该取得太长(一般不超过三个英文单词)。 5)在命名表时,用单数形式表示名称。例如,使用Employee,而不是Employees。 6)对于有主明细的表来说。明细表的名称为:主表的名称+ 字符Dts。例如:采购定单的名称为:PO_Order,则采购定单的明细表为:PO_OrderDts 对于有主明细的表来说,明细表必须包含两个字段:主表关键字、SN,SN字段的类型为int 型,目的为与主表关键字联合组成明细表的关键字,以及标示明细记录的先后顺序,如1,2,3……。 7)表必须填写描述信息
数据库数据类型
MySQL 数据类型在MySQL 中,有三种主要的类型:文本、数字和日期/时间类型。 Text类型 数据类型描述 CHAR(size) 保存固定长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的长度。最多255 个字符。 VARCHAR(size) 保存可变长度的字符串(可包含字母、数字以及特殊字符)。在括号中指定字符串的最大长度。最多255 个字符。注释:如果值的长度大于255,则被转换为TEXT 类型。 TINYTEXT 存放最大长度为255 个字符的字符串。 TEXT 存放最大长度为65,535 个字符的字符串。 BLOB 用于BLOBs (Binary Large OBjects)。存放最多65,535 字节的数据。MEDIUMTEXT 存放最大长度为16,777,215 个字符的字符串。 MEDIUMBLOB 用于BLOBs (Binary Large OBjects)。存放最多16,777,215 字节的数据。LONGTEXT 存放最大长度为4,294,967,295 个字符的字符串。 LONGBLOB 用于BLOBs (Binary Large OBjects)。存放最多4,294,967,295 字节的数据。 ENUM(x,y,z,etc.) 允许你输入可能值的列表。可以在ENUM 列表中列出最大65535 个值。如果列表中不存在插入的值,则插入空值。 注释:这些值是按照你输入的顺序存储的。可以按照此格式输入可能的值:ENUM('X','Y','Z') SET 与ENUM 类似,SET 最多只能包含64 个列表项,不过SET 可存储一个以上的值。 Number类型: 数据类型描述 TINYINT(size) -128 到127 常规。0 到255 无符号*。在括号中规定最大位数。 SMALLINT(size) -32768 到32767 常规。0 到65535 无符号*。在括号中规定最大位数。 MEDIUMINT(size) -8388608 到8388607 普通。0 to 16777215 无符号*。在括号中规定最大位数。 INT(size) -2147483648 到2147483647 常规。0 到4294967295 无符号*。在括号中规定最大位数。 BIGINT(size) -9223372036854775808 到9223372036854775807 常规。0 到18446744073709551615 无符号*。在括号中规定最大位数。 FLOAT(size,d) 带有浮动小数点的小数字。在括号中规定最大位数。在d 参数中规定小数点右侧的最大位数。DOUBLE(size,d) 带有浮动小数点的大数字。在括号中规定最大位数。在d 参数中规定小数点右侧的最大位数。DECIMAL(size,d) 作为字符串存储的DOUBLE 类型,允许固定的小数点。 这些整数类型拥有额外的选项UNSIGNED。通常,整数可以是负数或正数。如果添加UNSIGNED 属性,那么范围将从0 开始,而不是某个负数。
SQLServer的数据类型
SQLServer的数据类型 第一大类:整数数据 bit:bit数据类型代表0,1或NULL,就是表示true,false.占用1byte. int:以4个字节来存储正负数.可存储范围为:-2^31至2^31-1. smallint:以2个字节来存储正负数.存储范围为:-2^15至2^15-1 tinyint: 是最小的整数类型,仅用1字节,范围:0至此^8-1 第二大类:精确数值数据 numeric:表示的数字可以达到38位,存储数据时所用的字节数目会随着使用权用位数的多少变化. decimal:和numeric差不多 第三大类:近似浮点数值数据 float:用8个字节来存储数据.最多可为53位.范围为:-1.79E+308至1.79E+308. real:位数为24,用4个字节,数字范围:-3.04E+38至3.04E+38 第四大类:日期时间数据 datatime:表示时间范围可以表示从1753/1/1至9999/12/31,时间可以表示到3.33/1000秒.使用8个字节. smalldatetime:表示时间范围可以表示从1900/1/1至2079/12/31.使用4个字节. 第五大类:字符串数据 char:长度是设定的,最短为1字节,最长为8000个字节.不足的长度会用空白补上. varchar:长度也是设定的,最短为1字节,最长为8000个字节,尾部的空白会去掉. text:长宽也是设定的,最长可以存放2G的数据. 第六大类:Unincode字符串数据 nchar:长度是设定的,最短为1字节,最长为4000个字节.不足的长度会用空白补上.储存一个字符需要2个字节. nvarchar:长度是设定的,最短为1字节,最长为4000个字节.尾部的空白会去掉.储存一个字符需要2个字节. ntext:长度是设定的,最短为1字节,最长为2G.尾部的空白会去掉,储存一个字符需要2个字节.
实验SqlServer的基本操作
§3.1实验一Sql Server2005的基本操作(2学时) 3.1.1 实验目的 1.熟悉SQL Server2005企业版的安装过程。 2.了解企业管理器的功能,掌握企业管理器的操作方法。 3.掌握数据库服务器的注册、配置、连接等操作。 3.1.2 实验内容和步骤 上机前先阅读本实验的详细内容,简要了解SQL SERVER2005,并完成以下操作: 1. SQL Server2005的安装 参考详细内容进行安装,在安装过程中记录安装的选择,并且对所作的选择进行思考,为何要进行这样的配置,对今后运行数据库系统会有什么影响。 2.启动和停止服务 3.启动SQL Server Management Studio 4.查看数据库属性,了解数据文件、事务日志、权限 注意事项: 1.安装时选择混合方式登录; 2.赋予sa密码。
实验一Sql Server2005的基本操作(详解) 一、安装 下面以Windows xp平台为例,介绍如何安装SQL Server 2005个人开发版。 1.根据安装机器软硬件的要求,选择一个合适的版本,以下以开发版为例 2.将SQL Server 2005 DVD 插入DVD驱动器。如果DVD驱动器的自动运行功能无法启动安装程序无法启动安装程序,请导航到DVD的根目录然后启动splash.hta。 3.在自动运行的对话框中,单击“运行SQL Server 安装向导”。 4.在“最终用户许可协议”页上,阅读许可协议,再选中相应的复选框以接受许可条款和条件。接受许可协议后即可激活“下一步”按钮。若要继续,请单击“下一步”若要结束安装程序,请单击“取消”。如下图: 5.在“SQL Server 组件更新”页上,安装程序将安装SQL Server 2005 的必需软件。有关组件要求的详细信息,请单击该页底部的“帮助”按钮。若要开始执行组件更新,请单击“安装”。更新完成之后若要继续,请单击“完成”。
(整理)SQLServer数据库基本知识点.
SQL Server 数据库基本知识点一、数据类型
二、常用语句 (用到的数据库Northwind) 查询语句 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。例如,下面的语句查询Customers 表中公司名称为“Alfreds Futterkiste”的ContactName字段和Address字段。 SELECT ContactName, Address FROM Customers WHERE CompanyName='Alfreds Futterkiste' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。 1、选择所有列 例如,下面语句显示Customers表中所有列的数据: SELECT * FROM Customers 2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: SELECT ContactName, Address FROM Customers 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题 as 列名 列名列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题: SELECT ContactName as 联系人名称, Address as地址 FROM Customers 4、删除重复行
SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 SELECT DISTINCT(Country) FROM Customers 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT 时,说明n是 表示一百分数,指定返回的行数等于总行数的百分之几。 例如: SELECT TOP 2 * FROM Customers SELECT TOP 20 PERCENT * FROM Customers (二)FROM子句 FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列 所属的表或视图。例如在Orders和Customers表中同时存在CustomerID列,在查询两个表中的CustomerID时应 使用下面语句格式加以限定: select * from Orders,Customers where Orders.CustomerID =Customers.CustomerID 在FROM子句中可用以下两种格式为表或视图指定别名: 表名 as 别名 表名别名 select * from Orders as a,Customers as b where a.CustomerID =b.CustomerID SELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。 例如: select * from Customers where CustomerID in (select CustomerID from Orders where EmployeeID=4) 此例中,将SELECT返回的结果集合给予一别名CustomerID,然后再从中检索数据。 (三) 使用WHERE子句设置查询条件 WHERE子句设置查询条件,过滤掉不需要的数据行。例如下面语句查询年龄大于20的数据:select CustomerID from Orders where EmployeeID=4
软件连接不上SQLSERVER数据库的排查方法
关于软件连接不上sqlserver数据库的排查方法更新版 1、数据库安装不完整 安装完成后在configuration Manager 中查看是否有安装服务 如下图,如若没有SQL Server 200X服务图标则说明服务没有安装成功,需要卸载重装 2、数据库服务没有启动 在开始栏输入service.msc查看服务,然后找到SQL Server (
如果服务是启动类型是手动,且未启动,将启动类型改为自动,然后点击启动,让服务启动 3、TCP/IP设置错误 点开MSSQLERVER协议,看TCP/IP是否启用 若已启用点击TCP/IP,进入TCP/IP设置,看TCP端口和IP是否启用,若IP1-4都未启用,改
为启用,并应用,然后重启数据库服务 4、数据库用户名权限低或者browser服务未启动 当安装软件时配置数据库成功,安装完软件,按提示重启电脑后,测试连接数据库失败,进入数据库中查看,数据库中没有写入表 (1)在configuration中启动browser 服务或者到外围应用配置器中启动browser 服务
(2)查看配置数据库所用用户名权限
可用windows身份验证登录数据库,给用户名增加权限,勾选所有权限,如果增加权限不成功,则新增一个用户名再添加权限,再在软件安装目录下zkeco\units\adms\attsite.ini文件中更改原数据库配置的用户名及密码,然后再测试连接数据库 5、attsite.ini配置文件出错 zkeco\units\adms\attsite.ini 文件为空,或者显示乱码也会造成连接数据库失败,解决方法是在安装包同个文件夹下找到attsite.ini,替换进去,然后将端口号及数据库配置更改为自己所需要的,保存,重启服务 6、外部因素导致连接失败 有时在电脑防火墙、安全软件的阻止下,软件连接数据库也会失败,需将防火墙、安全软件关闭再测试连接。 7、配置数据库信息填写错误
mysql字段类型
1. mysql的数据类型 在mysql中有如下几种数据类型: (1)数值型 数值是诸如32 或153.4 这样的值。mysql 支持科学表示法,科学表示法由整数或浮点数后跟“e”或“e”、一个符号(“+”或“-”)和一个整数指数来表示。1.24e+12 和23.47e-1 都是合法的科学表示法表示的数。而 1.24e12 不是合法的,因为指数前的符号未给出。 浮点数由整数部分、一个小数点和小数部分组成。整数部分和小数部分可以分别为空,但不能同时为空。 数值前可放一个负号“-”以表示负值。 (2)字符(串)型 字符型(也叫字符串型,简称串)是诸如“hello,world!”或“一个馒头引起的血案”这样的值,或者是电话号码这样的值。既可用单引号也可用双引号将串值括起来。 初学者往往分不清数值和字符串的区别。都是数字啊,怎么一个要用数值型,一个要用字符型呢?关键就在于:数值型的是要参与计算的,比如它是金融中的一个货款总额;而字符型的是不参与计算的,只是表示电话号码,这样的还有街道号码、门牌号码等等,它们都不参与计算。 (3)日期和时间型 日期和时间是一些诸如“2006-07-12”或“12:30:43”这样的值。mysql还支持日期/时间的组合,如“2006-07-12 12:30:43”。 (4)null值 null表示未知值。比如填写表格中通讯地址不清楚留空不填写,这就是null 值。 我们用create table语句创建一个表(参看前面的章节),这个表中包含列的定义。例如我们在前面创建了一个joke表,这个表中有content和writer 两个列: create table (
MySql Oracle SqlServer三大数据库的数据类型列表
MySql Oracle SqlServer三大数据库的数据类型列表MySql数据类型
Oracle数据类型 一、概述 在ORACLE8中定义了:标量(SCALAR)、复合(COMPOSITE)、引用(REFERENCE)和LOB四种数据类型,下面详细介绍它们的特性。 二、标量(SCALAR) 合法的标量类型与数据库的列所使用的类型相同,此外它还有一些扩展。它又分为七个组:数字、字符、行、日期、行标识、布尔和可信。 数字,它有三种基本类型--NUMBER、PLS_INTEGER和BINARY_INTENER。NUMBER可以描述整数或实数,而PLS_INTEGER和BINARY_INTENER只能描述整数。 NUMBER,是以十进制格式进行存储的,它便于存储,但是在计算上,系统会自动的将它转换成为二进制进行运算的。它的定义方式是NUMBER(P,S),P是精度,最大38位,S是刻度范围,可在-84...127间取值。例如:NUMBER(5,2)可以用来存储表示-999.99...999.99间的数值。P、S可以在定义是省略,例如:NUMBER(5)、NUMBER 等; BINARY_INTENER用来描述不存储在数据库中,但是需要用来计算的带符号的整数值。它以2的补码二进制形式表述。循环计数器经常使用这种类型。 PLS_INTEGER和BINARY_INTENER唯一区别是在计算当中发生溢出时,BINARY_INTENER型的变量会被自动指派给一个NUMBER型而不会出错,PLS_INTEGER型的变量将会发生错误。 字符,包括CHAR、VARCHAR2(VARCHAR)、LONG、NCHAR和NVARCHAR2几种类型。 CHAR,描述定长的字符串,如果实际值不够定义的长度,系统将以空格填充。它的声明方式如下CHAR(L),L 为字符串长度,缺省为1,作为变量最大32767个字符,作为数据存储在ORACLE8中最大为2000。 VARCHAR2(VARCHAR),描述变长字符串。它的声明方式如下VARCHAR2(L),L为字符串长度,没有缺省值,作为变量最大32767个字节,作为数据存储在ORACLE8中最大为4000。在多字节语言环境中,实际存储的字符个数可能小于L值,例如:当语言环境为中文(SIMPLIFIED CHINESE_CHINA.ZHS16GBK)时,一个VARCHAR2(200)的数据列可以保存200个英文字符或者100个汉字字符。 LONG,在数据库存储中可以用来保存高达2G的数据,作为变量,可以表示一个最大长度为32760字节的可变字符串。 NCHAR、NVARCHAR2,国家字符集,与环境变量NLS指定的语言集密切相关,使用方法和CHAR、VARCHAR2相同。 行,包括RAW和LONG RAW两种类型。用来存储二进制数据,不会在字符集间转换。 RAW,类似于CHAR,声明方式RAW(L),L为长度,以字节为单位,作为数据库列最大2000,作为变量最大32767字节。 LONG RAW,类似于LONG,作为数据库列最大存储2G字节的数据,作为变量最大32760字节。 日期,只有一种类型--DATE,用来存储时间信息,站用7个字节(从世纪到秒),绝对没有“千年虫”问题。 行标识,只有一种类型--ROWID,用来存储“行标识符”,可以利用ROWIDTOCHAR函数来将行标识转换成为字符。 布尔,只有一种类型--BOOLEAN,仅仅可以表示TRUE、FALSE或者NULL。 可信,只有一种类型--MLSLABEL,可以在TRUSTED ORACLE中用来保存可变长度的二进制标签。在标准ORACLE 中,只能存储NULL值。 三、复合(COMPOSITE) 标量类型是经过预定义的,利用这些类型可以衍生出一些复合类型。主要有记录、表。 记录,可以看作是一组标量的组合结构,它的声明方式如下: TYPE record_type_name IS RECORD ( filed1 type1 [NOT NULL] [:=expr1] ....... filedn typen [NOT NULL] [:=exprn] ) 其中,record_type_name是记录类型的名字。(是不是看着象CREATE TABLE?......)引用时必须定义相关的变量,记录只是TYPE,不是VARIABLE。 表,不是物理存储数据的表,在这里是一种变量类型,也称为PL/SQL表,它类似于C语言中的数组,在处理方式上也相似。它的声明方式如下:
SQL数据库字段类型说明
SQL数据库字段类型说明
1)char、varchar、text和nchar、nvarchar、ntext char和varchar的长度都在1到8000之间,它们的区别在于char是定长字符数据,而varchar是变长字符数据。所谓定长就是长度固定的,当输入的数据长度没有达到指定的长度时将自动以英文空格在其后面填充,使长度达到相应的长度;而变长字符数据则不会以空格填充。text存储可变长度的非Unicode数据,最大长度为2^31-1(2,147,483,647)个字符。 后面三种数据类型和前面的相比,从名称上看只是多了个字母n,它表示存储的是Unicode数据类型的字符。写过程序的朋友对Unicode应该很了解。字符中,英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。nchar、nvarchar的长度是在1到4000之间。和char、varchar比较:nchar、nvarchar则最多存储4000个字符,不论是英文还是汉字;而char、varchar 最多能存储8000个英文,4000个汉字。可以看出使用nchar、nvarchar数据类型时不用担心输入的字符是英文还是汉字,较为方便,但在存储英文时数量上有些损失。 (2)datetime和smalldatetime datetime:从1753年1月1日到9999年12月31日的日期和时间数据,精确到百分之三秒。 smalldatetime:从1900年1月1日到2079年6月6日的日期和时间数据,精确到分钟。 (3)bitint、int、smallint、tinyint和bit bigint:从-2^63(-9223372036854775808)到2^63-1(9223372036854775807)的整型数据。 int:从-2^31(-2,147,483,648)到2^31-1(2,147,483,647)的整型数据。smallint:从-2^15(-32,768)到2^15-1(32,767)的整数数据。 tinyint:从0到255的整数数据。 bit:1或0的整数数据。 (4)decimal和numeric 这两种数据类型是等效的。都有两个参数:p(精度)和s(小数位数)。p指定小数点左边和右边可以存储的十进制数字的最大个数,p必须是从 1到38之间的值。s指定小数点右边可以存储的十进制数字的最大个数,s必须是从0到p 之间的值,默认小数位数是0。 (5)float和real float:从-1.79^308到1.79^308之间的浮点数字数据。 real:从-3.40^38到3.40^38之间的浮点数字数据。在SQL Server中,real 的同义词为float(24)。
有用的字段类型和数据类型
有用的字段类型和数据类型 在vfp中,共有13种字段类型和7种数据类型.13种字段类型是:字符型,数值型,浮点型,双精度型,整型,货币型,日期型,日期时间型,逻辑型,备注型,通用型,二进制字符型和二进制备注型;而7种数据类型是:字符型,数值型,货币型,日期型,日期时间型,逻辑型和通用型.字段为表文件所特有,而数据既可做表文件中的字段内容,也可以做内存变量或常量使用. 1.字符型字段和字符型数据: 字符型字段用于存放字符型数据.字符型数据是指一切可印刷的字符,包括英文字母,阿拉伯数字,各种符号,汉字及空格. 上述"职工档案"表中的"编号"和"姓名"字段就属于字符型字段,而其中存储的编号和姓名就属于字符型数据.字符型字段的宽度为1~字节. 2.数值型,浮点型,双精度型,整型字段与数值型数据: 数值型字段按每位数1个字节存放数值型数据,而浮点型字段存放浮点型数据.这两者最大宽度为20位.整型字段存放整数,用该类型字段存放较大的整数可节省存储容量,因为它只占4个字节.双精度型字段用于存放双精度型数,常用于科学计算,可得15位精度,但只占8个字节.这些字段中存放在数据统称为数值型数据. 3.货币型字段和货币型数据:货币型字段用于存放货币型数据,但只占8个字节. 4.日期型字段和日期型数据:日期型字段用于存放日期型数据.常用格式为:"年.月.日"和"月/日/年".在"职工档案"表中,"出生日期"字段就是日期型字段,而其中存放的数据就是日期型数据. 5.日期时间型字段和日期时间型数据:日期时间型字段存放日期时间型数据,格式为:年.月.日小时:分:秒Am或pm. 6.逻辑型字段和逻辑型数据:逻辑型字段用于存放逻辑型数据.逻辑型数据只有两个值,即"真"和"假",常用于描述只有两种状态的数据.例如:在"职工档案"表中,"婚否"字段就是逻辑型字段,用"真"表示已婚,"假"值表示未婚.在输入逻辑型数据时,可用T,t,Y,y中的任一个代表"真",而用F,f,N,n中的任一个代表"假". 7.备注型字段:备注型字段用于存放字符型,如文本、源代码等,使其得到了广泛应用.它常用于记录可有可无、可长可短的情况.例如,假如要在"职工档案"表中增加一个"简历"字段,定义成备注型最合适,因为有些人的简历可能长些,有些人的简历可能短些.此外,备注型字段还可用于提供运行时的帮助. 记录在备注型字段中的,实际上并不存放在表文件中,而是存放在与表文件同名,但扩展名为.fpt的文件中.当创建表文件时,假如定义了备注型字段,则相应的备注文件会自动生成,会随表文件的打开而自动打开.
SQLSERVER排查阻塞
SQL Server允许并发操作,BLOCKING是指在某一操作没有完成之前,其他操作必须等待,以便于保证数据的完整性。BLOCKING的解决方法要查看BLOCKING的头是什么,为什么BLOCKING头上的语句执行的很慢。通常来讲只要我们能找到BLOCKING头上的语句,我们总能够想出各种各种的办法,来提升性能,缓解或解决BLOCKING的问题。 但是问题的关键是,我们不知道BLOCKING什么时候会发生。用户跟我们抱怨数据库性能很差,等我们连上数据库去查看的时候,那时候有可能BLOCKING可能就已经过去了。性能又变好了。或者由于问题的紧急性,我们直接重新启动服务器以恢复运营。但是问题并没有最终解决,我们不知道下次问题会在什么时候发生。 BLOCKING问题的后果比较严重。因为终端用户能直接体验到。他们提交一个订单的时候,无论如何提交不上去,通常几秒之内能完成的一个订单提交,甚至要等待十几分钟,才能提交完成。更有甚者,极严重的BLOCKING能导致SQL Server 停止工作。如下面的SQL ERRORLOG所表示, 在短短的几分钟之内,SPID数据从158增长到694, 并马上导致SQL Server打了一个dump, 停止工作。我们很容易推断出问题的原因是由于BLOCKING导致的,但是我们无法得知BLOCKING HEADER是什么,我们必须要等下次问题重现时,辅之以工具,才能得知BLOCKING HEADER在做什么事情。如果信息抓取时机不对,我们可能要等问题发生好几次,才能抓到。这时候,客户和经理就会有抱怨了。因为我们的系统是生产系统,问题每发生一次,都会对客户带来损失。 2011-06-01 16:22:30.98 spid1931 Alert There are 158 Active database sessions which is too high. 2011-06-01 16:23:31.16 spid3248 Alert There are 342 Active database sessions which is too high. 2011-06-01 16:24:31.06 spid3884 Alert There are 517 Active database sessions which is too high. 2011-06-01 16:25:31.08 spid3688 Alert There are 694 Active database sessions which is too high. 2011-06-01 16:26:50.93 Server Using 'dbghelp.dll' version '4.0.5' 2011-06-01 16:26:50.97 Server **Dump thread - spid = 0, EC = 0x0000000000000000 2011-06-01 16:26:50.97 Server ***Stack Dump being sent to D:\MSSQL10.INSTANCE\MSSQL\LOG\SQLDump0004.txt 2011-06-01 16:26:50.97 Server * *******************************************************************************
数据库、表、字段的命名规则
数据库、表、字段的命名规则 每个公司或者企业数据库、表、字段等都有自己命名规则,数据库开发时数据库、表、字段、视图、触发器、存储过程、变量名、主键、外键、索引等的命名规则。 一、数据库(Database) 数据库名称 = 数据库内容标识(首字大写)。 二、表(Table) 命名应尽量反映存储的数据内容。 表名前缀:以该表及与该表相关联的一系列表的内容而得到一个代表统一的标识。 表名称 = T +‘_’+ 表名前缀+‘_’+ 表内容标识(首字大写) 。 如客户端信息ClientInfo相关联的一系的表以ci作为前缀,Record记录表即有表名:T_ci_Record。 数据库中不论是表名还是字段名,都一律用英文,不准出现其它语言;且保留原来的字段名,保留它们的规范。 为了不增加数据库当中的表名的长度,一般不允许出现如Form或者Table的字样,如:记录表:应为Record,而不是RecordTable。 数据库当中的表名的命名,一般不准出现空格,假如有几个单词出现的话,每个单词之间不允许留有空格,用”_”隔开如人事信息表:应为Human_Info,而不是Human Info;每个单词的第一个字母必须大写;如果太长,为了不增加编程的难度可采用缩写的方式,每个单词可取三到四个字母表示,也可根据实际情况,实际习惯进行缩写。 三、字段(Field) 字段是数据库中的用途最广泛的,它的类型非常多,所以必须加类型前缀来标示它的类型。 字段名称 = F + 字段类型前缀 + 字段内容标识(首字大写) 。 为了编程的方便性,可在前面加上字段类型的前缀,一般取用类型的三个字母,但是不需要下化线,而且这三个字母必须小写;如姓名字段为字符型的话就应该为chrName;尝用字段类型的缩写可参考下面的形式: 缩写- 类型 chr- char nvr- nvarchar vcr -varchar num -number flt -float dtm -date lng -long clb- clob blb- blob 四、视图名(View) 视图的名称 = "v_" + 视图内容标识(首字大写) 如 v_Record。 五、触发器名(Triger)
SQLServer数据查询的优化方法
SQLServer数据查询的优化方法聂文燕 摘要:SQLServer是一种功能强大的数据库管理系统,许多数据库应用系统都是以它作为后台数据库。本文在分析影响SQLSERVER数据查询效率的因素的基础上,提出了几种优化数据查询的方法。 关键词:SQLServer,数据,查询,优化 一、引言 SQLServer是是由微软公司开发的基于Windows操作系统的关系型数据库管理系统,它是一个全面的、集成的、端到端的数据解决方案,为企业中的用户提供了一个安全、可靠和高效的平台用于企业数据管理和商业智能应用。目前,许多中小型企业的数据库应用系统都是用SQLServer作为后台数据库管理系统设计开发的。设计一个应用系统并不难,但是要想使系统达到最优化的性能并不是一件容易的事。根据多年的实践,由于初期的数据库中表的记录数比较少,性能不会有太大问题,但数据积累到一定程度,达到数百万甚至上千万条,全面扫描一次往往需要数十分钟,甚至数小时。20%的代码用去了80%的时间,这是程序设计中的一个著名定律,在数据库应用程序中也同样如此。如果用比全表扫描更好的查询策略,往往可以使查询时间降为几分钟。而且我们知道,目前数据库系统应用中,查询操作占了绝大多数,查询优化成为数据库性能优化最为重要的手段之一。 二、影响查询效率的因素 SQLServer处理查询计划的过程是这样的:在做完查询语句的词法、语法检查之后,将语句提交给SQLServer的查询优化器,查询优化器通过检查索引的存在性、有效性和基于列的统计数据来决定如何处理扫描、检索和连接,并生成若干执行计划,然后通过分析执行开销来评估每个执行计划,从中选出开销最小的执行计划,由预编译模块对语句进行处理并生成查询规划,然后在合适的时间提交给系统处理执行,最后将执行结果返回给用户。所以,SQLServer中影响查询效率的因素主要有以下几种:1.没有索引或者没有用到索引。索引是数据库中重要的数据结构,使用索引的目的是避免全表扫描,减少磁盘I/O,以加快查询速度。 2.没有创建计算列导致查询不优化。 3.查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)。 4.返回了不必要的行和列。 5.查询语句不好,没有优化。其中包括:查询条件中操作符使用是否得当;查询条件中的数据类型是否兼容;对多个表查询时,数据表的次序是否合理;多个选择条件查询时,选择条件的次序是否合理;是否合理安排联接选择运算等。 三、SQLServer数据查询优化方法 3.1建立合适的索引索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。当根据索引码的值搜索数据时,索引提供了对数据的快速访问。事实上,没有索引,数据库也能根据SELECT语句成功地检索到结果,但随着表变得越来越大,使用“适当”的索引的效果就越来越明显。索引的使用要恰到好处,其使用原则有: (1)对于基本表,不宜建立过多的索引; (2)对于那些查询频度高,实时性要求高的数据一定要建立索引,而对于其他的数据不考虑建立索引; (3)在经常进行连接,但是没有指定为外键的列上建立索引; (4)在频繁进行排序或分组(即进行groupby或orderby操作)的列上建立索引;
Northwind数据库表字段介绍
Northwind数据库表字段介绍 2010-06-03 10:30:08| 分类:SQL | 标签:|举报|字号大中小订阅 ①Categories:种类表 相应字段: CategoryID :类型ID; CategoryName:类型名; Description:类型说明; Picture:产品样本 ②CustomerCustomerDemo:客户类型表1 相应字段: CustomerID:客户ID; CustomerTypeID:客户类型ID ③CustomerDemographics:客户类型表2 相应字段: CustomerTypeID:客户类型ID; CustomerDesc:客户描述 ④Customers:客户表 相应字段: CustomerID:客户ID; CompanyName:所在公司名称; ContactName:客户姓名; ContactTitle:客户头衔; Address:联系地址; City:所在城市; Region:所在地区; PostalCode:邮编; Country:国家 Phone:电话; Fax:传真 ⑤Employees:员工表 相应字段: EmployeeID:员工代号; LastName + FirstName:员工姓名; Title:头衔; TitleOfCourtesy:尊称; BirthDate:出生日期; HireDate:雇用日期; Address:家庭地址; City:所在城市; Region:所在地区;
PostalCode:邮编; Country:国家用; HomePhone:宅电; Extension:分机; Photo:手机; notes:照片; ReportsTo:上级; PhotoPath:照片 ⑥EmployeeTerritories:员工部门表相应字段: EmployeeID:员工编号; TerritoryID:部门代号 ⑦Order Details:订单明细表 相应字段: OrderID:订单编号; ProductID:产品编号; UnitPrice:单价; Quantity:订购数量; Discount:折扣 ⑧Orders:订单表 相应字段: OrderID:订单编号; CustomerID:客户编号; EmployeeID:员工编号; OrderDate:订购日期;RequiredDate:预计到达日期; ShippedDate:发货日期; ShipVia:运货商; Freight:运费; ShipName:货主姓名; ShipAddress:货主地址 ShipCity:货主所在城市; ShipRegion:货主所在地区;ShipPostalCode:货主邮编; ShipCountry:货主所在国家 ⑨Products:产品表 相应字段: ProductID:产品ID; ProductName:产品名称; SupplierID:供应商ID; CategoryID:类型ID;QuantityPerUnit:数量;
SQLServer常用关键字数据类型和常用语法
SQL Server 2008 常用关键字、数据类型和常用语法 常用关键字: SQL server 2008一共大约有180多个关键字。简要分为主要关键字、辅助关键字和函数类关键字。本文就常用的这三类关键字进行语法说明和用例。 说明:1、比较好的习惯是,数据库名以D_开头,表名用T_开头,字段名以F_开头,这样可以防止和关键字重名。 2、如果确实用到了系统关键字,就要在关键上加[]方括号,以与关键字进行区别。例如有一个用户表被命名为USER,则查询该表内容的时候:SELECT * FROM USER语句是错误的,应该是SELECT * FROM [USER]。因为USER是关键字。
数据类型: SQL Server 2008一共有36种数据类型。具体如下:
常用语法: 一、数据库 【创建数据库】 CREATE DATABASE
查询SQLServer正在执行的语句
查询,统计股票主要财务数据,查询Oracle正在执行的SQL语句,查询python模块的帮助文档,查询SQLServer正在执行的语句 查找/etc/passwd下bash为/bin/bash用户的数,查找两个有序数组中的中位数,查找数组中最大值最小值的另一种思路 [代码] [C/C++]代码 #include
//c#删除指定文件夹下的文件方法封装 //C#设置开机启动程序 [代码] [C/C++]代码 #include