基于opencv的手写数字字符识别

基于OpenCV的手写数字
字符识别
2013级计算机软件与理论
摘要
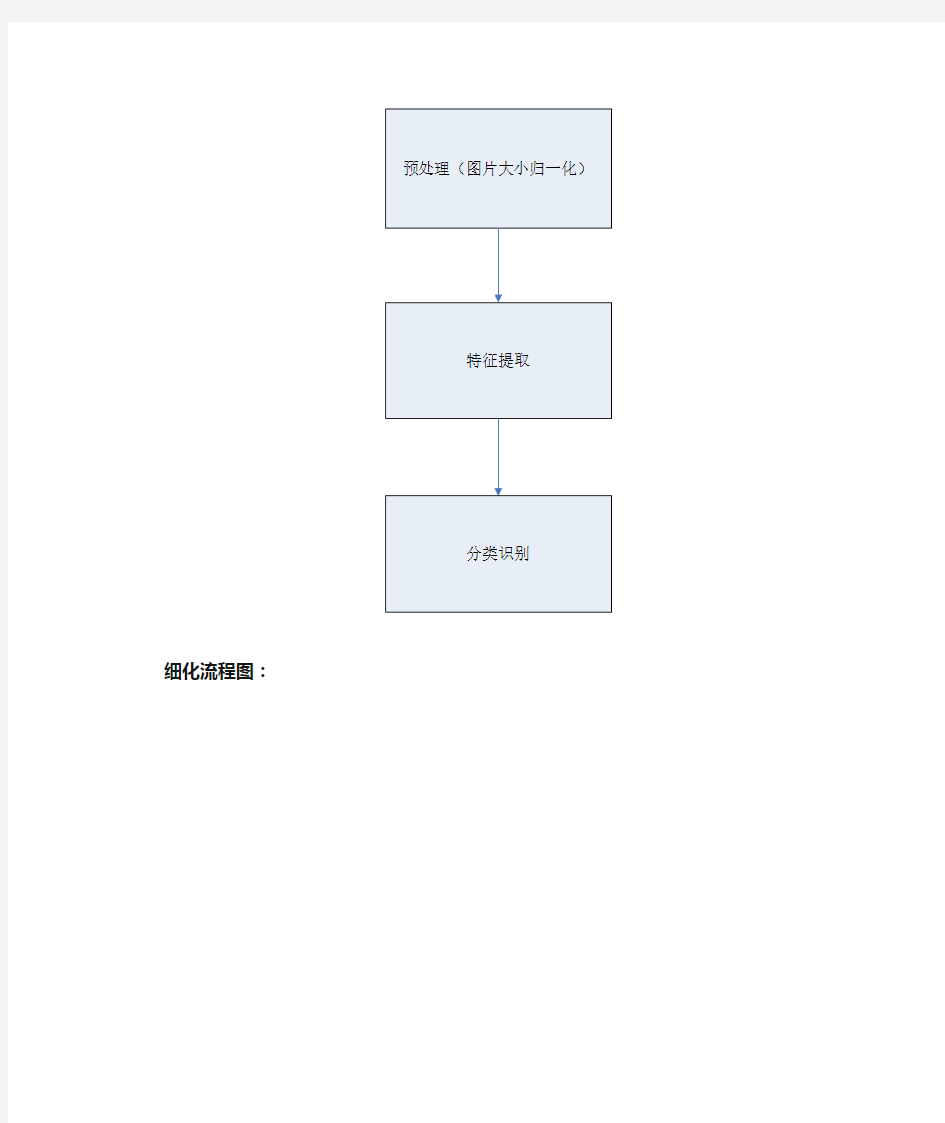
本程序主要参照论文,《基于OpenCV的脱机手写字符识别技术》实现了,对于手写阿拉伯数字的识别工作。识别工作分为三大步骤:预处理,特征提取,分类识别。预处理过程主要找到图像的ROI部分子图像并进行大小的归一化处理,特征提取将图像转化为特征向量,分类识别采用k-近邻分类方法进行分类处理,最后根据分类结果完成识别工作。
程序采用Microsoft Visual Studio 2010与OpenCV2.4.4在Windows 7-64位旗舰版系统下开发完成。并在Windows xp-32位系统下测试可用。
主流程图:
细化流程图:
1.预处理
预处理的过程就是找到图像的ROI区域的过程,如下图所示:
首先找到数字的边界框,然后大小归一化数字图片,主要流程如下图所示:
主要代码:
IplImage preprocessing(IplImage* imgSrc,int new_width, int new_height)
{
IplImage* result;
IplImage* scaledResult;
CvMat data;
CvMat dataA;
CvRect bb;//bounding box
CvRect bba;//boundinb box maintain aspect ratio
//Find bounding box找到边界框
bb=findBB(imgSrc);
cvGetSubRect(imgSrc, &data, cvRect(bb.x, bb.y, bb.width, bb.height));
int size=(bb.width>bb.height)?bb.width:bb.height;
result=cvCreateImage( cvSize( size, size ), 8, 1 );
cvSet(result,CV_RGB(255,255,255),NULL);
//将图像放中间,大小归一化
int x=(int)floor((float)(size-bb.width)/2.0f);
int y=(int)floor((float)(size-bb.height)/2.0f);
cvGetSubRect(result, &dataA, cvRect(x,y,bb.width, bb.height));
cvCopy(&data, &dataA, NULL);
//Scale result
scaledResult=cvCreateImage( cvSize( new_width, new_height ), 8, 1 );
cvResize(result, scaledResult, CV_INTER_NN);
//Return processed data
return *scaledResult;//直接返回处理后的图片
}
2.特征提取
在拿到ROI图像减少了信息量之后,就可以直接用图片作为向量矩阵作为输入:
void basicOCR::getData()
{
IplImage* src_image;
IplImage prs_image;
CvMat row,data;
char file[255];
int i,j;
for(i =0; i { for( j = 0; j< train_samples; j++)//每个数字50个样本 { //加载所有的样本pbm格式图像作为训练 if(j<10) sprintf(file,"%s%d/%d0%d.pbm",file_path, i, i , j); else sprintf(file,"%s%d/%d%d.pbm",file_path, i, i , j); src_image = cvLoadImage(file,0); if(!src_image) { printf("Error: Cant load image %s\n", file); //exit(-1); } //process file prs_image = preprocessing(src_image, size, size); //生成训练矩阵,每个图像作为一个向量 cvGetRow(trainClasses, &row, i*train_samples + j); cvSet(&row, cvRealScalar(i)); //Set data cvGetRow(trainData, &row, i*train_samples + j); IplImage* img = cvCreateImage( cvSize( size, size ), IPL_DEPTH_32F, 1 ); //转换换8 bits image to 32 位浮点数图片取值区间为[0,1] //scale = 0.0039215 = 1/255; cvConvertScale(&prs_image, img, 0.0039215, 0); cvGetSubRect(img, &data, cvRect(0,0, size,size)); CvMat row_header, *row1; //convert data matrix sizexsize to vecor row1 = cvReshape( &data, &row_header, 0, 1 ); cvCopy(row1, &row, NULL); } } } 3.分类识别 识别方法采用knn近邻分类法。这个算法首先贮藏所有的训练样本,然后通过分析(包括选举,计算加权和等方式)一个新样本周围K个最近邻以给出该样本的相应值。这种方法有时候被称作“基于样本的学习”,即为了预测,我们对于给定的输入搜索最近的已知其相应的特征向量。 K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 识别工作主要有以下几个步骤: 1. 初始化机器学习算法,及其训练 knn=new CvKNearest( trainData, trainClasses, 0, false, K ); 因为trainData, trainClasses数据已得到。训练在CvKNearest算法初始化中已经完成 2. 识别 获取识别测试的数据,testData result=knn->find_nearest(testData,K,0,0,nearest,0); result为返回的识别的结果 4.实验结果 在knn参数k=5,子图像向量大小选取128*128像素,训练样本50副图片,测试样本50副图片,系统误识率为7.4%。对于用户手写阿拉伯数字2的识别结果为2,识别比较准确。 5.未来的工作 本程序主要参照网上的一些实例完成了部署跟实验工作,虽然仅仅完成了手写阿拉伯数字的识别工作,但是字符识别的一些原理工作都是相同的,未来能够从一下几个方面进行提高: 1.提高程序的识别准确率,从一些文献实现的结果来看,简单的模型结合 大量的训练样本,往往效果比复杂的模型结合少量训练样本实现的效果好。 2.扩展程序的功能,从实现简单的字符到最终实现识别手写汉字等。 3.提高识别速度,改进算法为并行算法,实现如联机在线识别等。 HUNAN UNIVERSITY 课程模式识别 题目基于知识库的手写体数字识别学生姓名 学生学号 专业班级 学院名称 2016 年6 月25 日 基于知识库的手写体数字识别 1案例背景: 手写体数字识别是图像识别学科下的一个分支,是图像处理和模式识别研究领域的重要应用之一,并且具有很强的通用性。由于手写数字的随意性很大,如笔画粗细、字体大小、倾斜角度等因素都有可能直接影响到字符的识别准确率,所以手写体数字识别是一个很有挑战性的课题。在过去的数十年中,研究者们提出了许多识别方法,并取得了一定的成果。在大规模数据统计如例行年检、人口普查、财务、税务、邮件分拣等应用领域都有广阔的应用前景。 本案例实现了手写阿拉伯数字的识别过程,并对手写数字识别的基于统计的方法进行了简要介绍和分析。本文实现的手写字体识别程序具有手写数字图像读取、特征提取、数字模板特征库以及识别功能。 2 理论基础: 2-1手写字体识别方法: 手写体数字识别是一个跨学科的复杂问题,综合了图像处理、模式识别、机器学习等多个领域的知识,其识别过程一般包含图像预处理、特征提取、分类器的设定及其后处理等组成。处理流程如图2-1所示。 图2-1 手写体数子识别流程图 2-2 图像预处理 手写体数字识别的首要工作是图像预处理。在图像预处理过程中需要解决的主要问题有:定位、图像二值化、平滑化(去噪)H J、字符切分、规范化等。图像二值化是指将整个图像呈现出明显的黑白效果。待识别的手写体数字图像在扫描过程中,常会带来一些噪声,用不同的扫描分辨率得到的数字图像,其质量也各不相同,故而要先将这些干扰因素排除掉。另外,还需要正确分割整幅文档图像中的手写体数字,而分割后的数字大小、字体常各不相同,故还需进行归一化处理。 2-3 特征提取 特征提取的目的是从经过预处理后的数字图像中,提取出用以区分与其它数字类别的本质属性并数值化,形成特征矢量的过程。常见的手写体数字特征有:模板特征、统计特征、结构特征和变换特征。 2-4 分类器 不同的分类方式对应不同的分类器,可选的分类器有神经网络、支持向量机 由于第十四周除了正常上课外,其余时间在整理机器学习的笔记,做中特社会调查报告,然后就是元旦放假,故第十四周没提交周报。 本周正常上课,继续完成老师都布置的课业任务,总结通信系统仿真结果,并且完成报告的撰写,分析社会调查结果,做好报告,查阅物理层安全方面的资料,翻译和整理论文。其余时间是开始学习深度学习理论和编程实践,人工神经网络(ANN)和卷积神经网络,了解深度学习几个框架(Caffe 、Torch、TensorFlow、MxNet),最主要还是TensorFlow,学习和查找了一下深度学习优化算法,并且利用人工神经网络做手写数字识别。 心得体会:第一个感受是时间过得很快,已然是15周了,要加快各方面进程。神经网络从线性分类器开始,线性分类器是产生一个超平面将两类物体分开。一层神经网络叫做感知器,线性映射加激励输出,每个神经元对输入信号利用激励函数选择输出,就像大脑神经元的兴奋或抑制,增加神经元数量、隐层数量,就可以无限逼近位置函数分布的形态,过多会出现过拟合算法。ANN的学习方法是BP后向传播算法,其主要思想是每一层的带来的预测误差是由前一层造成的,通过链式求导法则将误差对每一层的权重和偏置进行求导更新权重和偏置,以达到最优结果。因为ANN每一层神经元是全连接的,对于图像这种数据就需要非常大数量的参数,所以就出现了卷积神经网路CNN,利用一些神经元以各种模版在图像上滑动做卷积形成几张特征图,每个神经元的滑动窗口值不一样代表其关注点不一样,单个神经元对整张图的窗口权重是一样的即权值共享(这就是减少参数和神经元数量的原因),这么做的依据是像素局部关联性。CNN主要有数据数据输入层、卷积计算层、激励层、池化层(下采样层)、全连接层、Batch Normalization层(可能有)CNN学习方法也是BP算法迭代更新权重w和偏置b。CNN优点是共享卷积核,对高维数据处理无压力,无需手动选取特征,训练好权重,即得特征,深层次的网络抽取,信息丰富,表达效果好,缺点是需要调参,需要大样本量,训练最好要GPU,物理含义不明确。主要采用随机失活的方法解决过拟合问题,因为CNN网络学习能力强,如果样本量小,容易让网络将样本的所有细节记忆下来而不是学习到样本的共性规律,所以随机失活神经元让部分神经元工作就可以缓解过拟合问题。个人觉得深度学习理论不是很难,就是对硬件的要求很高,GPU真是其必备工具。深度学习学习最主要的学习框架觉得是TensorFlow,因为Google大力支持,社区很庞大,就是依赖硬件能力强。 以下是ANN MNIST手写数字识别程序和结果,数据集是经典的Yann LeCun(人工智能界大佬)MNIST数据集,每张照片大小是28 * 28的灰度图,训练集5000张图片,验证集1000张图片,测试集10000张: 版本:V1.0 手写字符识别系统设计说明书 湖南大学信息科学与工程学院 二0一四年六月 目录 1引言 (2) 1.1目的 (2) 1.2阅读对象 (2) 2项目概述 (2) 2.1项目简介 (2) 2.2项目任务 (2) 2.3实验环境介绍 (2) 3任务描述 (3) 3.1背景资料概述 (3) 3.2系统组成 (3) 3.3系统评估 (5) 4机器学习算法介绍 (5) 4.1支持向量机 (5) 4.2BP神经网络 (6) 4.3决策树方法 (7) 5特征选择 (8) 6参考资料和实用网站 (9) 1引言 1.1目的 随着图像处理技术与机器学习技术的发展,机器视觉技术已广泛应用于工业生产、日常生活及城市管理中。字符识别作为机器视觉的一种基本应用,在车牌识别、光学字符识别(OCR,Optical Character Recognition)等应用中均有涉及。 本说明书旨在介绍基于常用机器学习算法(如BP神经网络、支持向量机、朴素贝叶斯、K近邻分类)的手写字符识别系统的设计需求,设计方法和环境介绍,帮助学生了解字符识别的基本流程,常用机器学习算法的基本原理,掌握机器视觉应用的开发技术。 1.2阅读对象 本说明书的阅读对象有: ●数字媒体类相关专业学生 ●相关客户人员,体验用户等 2项目概述 2.1项目简介 本项目旨在基于机器学习算法实现手写字符(包括数字和大小写字母)的识别。该系统通过读入一张图片或通过鼠标绘制字符的方式,实现识别对象的输入,通过BP神经网络、支持向量机、朴素贝叶斯或K近邻分类方法实现手写字符的识别,并输出识别的结果。 2.2项目任务 项目名称:手写字符识别系统的设计 项目内容:1)手写字符的输入; 2)图片预处理与特征提取; 3)机器学习与字符分类; 项目周期:1个月(2014年8月25日——2014年9月20日) 参与人数:2~4人。 2.3实验环境介绍 A)Visual Studio 2010 基于OpenCV识别库的面部图像识别系统的设计 本系统采用J2EE技术并以OpenCV开源计算机视觉库技术为基础,实现一套具有身份验证功能的面部图像识别信息管理系统。系统使用MySQL数据库提供数据支撑,依托于J2EE的稳定性和Java平台的可移植性使得本系统可以在各个操作系统平台中运行,同时提供在互联网中使用面部识别技术的一套较为完备的解决方案。 标签:OpenCV;人脸识别;生物学特征 引言 随着信息技术的飞速发展以及互联网的深入普及,越来越多的行业和领域使用信息技术产品以提高工作效率和管理水平。但是由于人们隐私信息的保护意识薄弱,出现了许多信息安全的问题。在人们对于信息安全越来越重视的情况下,许多技术被应用到信息安全领域中来。较为先进的技术有虹膜识别技术、遗传基因识别技术以及指纹识别技术等。而论文采用的是当前热点的面部图像识别技术。 1 系统实现算法及功能分析 1.1 面部图像的生物学特征模型的建立 本系统是利用面部图形的生物学特征来识别不同的人。由于每个人的面部图像都有各自的特征但又具有一定的通性,需要应用生物学中相关知识加以解决。可以利用已有的生物学测量手段以及现有的算法构建人的面部图像生物学特征模型(简称:面部模型),并应用于系统中,面部模型的建立为面部图像识别的功能提供实现依据。 1.2 知识特征库及面部识别引擎的建立 在前述面部模型建立完成后,需要建立相应的知识库以及面部识别引擎方可进行身份的识别。可经过大量数据的采集和分析后建立知识库,并根据知识库的特点建立相应的识别引擎。此识别引擎对外开放,在本系统中提供其它外来程序的调用接口,其它系统能够通过本接口实现识别引擎的调用实现对于面部图形的识别,从而达到识别引擎的可复用性。在技术条件允许的情况下,提供知识库的智能训练以及半自动构建支持。 1.3 面部图像的采集与预处理 本系统中采用了预留API接口,利用USB图形捕获设备采集数据图像。经过USB设备的捕获,使用JMF(Java Media Framework)来处理已捕获的图像数据,对捕获的图像进行面部图行检测和实时定位跟踪。 燕山大学 课程设计说明书 题目:手写数字识别的实现 学院(系):电气工程学院 年级专业: 08-自动化仪表 学号: 080103020179 学生姓名:付成超 指导教师:林洪彬程淑红 教师职称:讲师讲师 2010年 12 月 24 日 燕山大学课程设计(论文)任务书 院(系):电气工程学院基层教学单位:自动化仪表系 学号080103020179 学生姓名付成超专业(班级)自动化仪表设计题目手写数字识别实现 设 计技术参数 通过由数字构成的图像,自动实现几个不同数字的识别,设计识别方法,有较高的识别率 设计要求 设计图像中不同数字的识别方法,可以先从两个数字的识别开始,尽量实现多个不同数字的识别。设计中应该有自己的思想、设计体会 工作量1.分析图像特征,查阅相关资料,根据图像的特征提出解决问题的思路。2.查阅相关资料,学会MATLAB的编程方法 3.根据解决思路,编辑程序,根据调试结果,修改相应思路,找出最佳解决方案 工作计划周一分析图像,查阅各种资料,提出可行的解决方案。周二熟悉MATLAB软件,学会软件的简单编程方法。 周三根据可行的方法,编写程序,调试并修改方案。周四根据调试结果,选取最佳方案并完成设计论文。周五进一步完善设计论文,准备论文答辩。 参考资料[] MICHAEL SIPSER著,张立昂等译,《计算理论导引》,机械工业出版社,2000。 [2] 王晓龙,关毅等编,《计算机自然语言处理》,清华大学出版社,2005。 [3] R.C.Gonzales等著,阮秋崎等译,《数字图像处理》,电子工业出版社,2002。 [4] 王文杰等编,《人工智能原理》,人民邮电出版社,2003。 指导教师签字基层教学单位主任签字 2010年 12 月 24 日 ] 手写数字识别系统的设计与实现 摘要本手写数字识别系统是一个以VISUAL STUDIO C++ 为编译环境,使用MFC进行图形图像界面开发的系统。主要功能是通过在点击手写数字识别菜单下的绘制数字标签弹出的绘制数字窗口中完成数字的手写,在此窗口中可以进行数字的保存及清屏,然后通过文件菜单中的打开标签打开所绘制的数字,从而进行数字的预处理,其中包括灰度化及二值化处理,然后进行特征提取,最后实现数字的识别。本系统的界面设计友好,流程正确,功能也较为完善。实验结果表明,本系统具有较高的识别率。 关键词:绘制数字;预处理;特征提取;特征库;数字识别 / ; 目录 前言 (1) 概述 (2) 1 需求分析 (4) 功能需求分析 (4) , 性能需求分析 (4) 数据需求分析 (5) 相关软件介绍 (5) 2 手写数字识别系统的设计与基本原理 (6) 系统整体功能模块设计 (6) 手写数字识别系统的基本原理 (6) 数字图像的绘制 (6) 图像的预处理 (6) ) 图像的特征提取 (7) 特征库的建立 (8) 图像数字的识别 (8) 3 手写数字识别系统程序设计 (8) 数字图像的绘制 (8) 数字的特征提取 (15) 模板特征库的建立 (18) 数字的识别 (20) ( 总结 (23) 致谢 (24) 参考文献 (25) 前言 自上世纪六十年代以来,计算机视觉与图像处理越来越受到人们的关注,并逐渐成为一门重要的学科领域。而作为它们的研究对象的数字图像,也因为它含有研究目标的丰富信息而成为越来越重要的研究对象。图像识别的目标是用计算机自动完成某些信息的处理,用来替代人工去处理图像分类及识别的任务。 手写数字识别是图像识别学科下的一个分支,是图像处理和模式识别领域研究的课题之一,由于其具有很强的实用性一直是多年来的研究热点。由于手写体数字的随意性很大,例如,笔画的粗细,字体的大小,倾斜等等都直接影响到字符的正确识别,所以手写体数字识别是一个很有挑战性的课题。在过去的数十年中,研究者们提出了许多的识别方法,取得了较大的成果。手写体数字识别实用性很强,在大规模数据统计(如例行年检,人口普查),财务,税务,邮件分拣等等应用领域中都有广阔的应用前景。本课题拟研究手写体数字识别的理论和方法,开发一个小型的手写体数字识别系统。 在研究手写体数字识别理论和方法的基础上,开发这样一个小型的手写体数字识别系统需要完成以下主要方面的研究与设计工作:手写数字绘制的问题、数字的预处理问题、特征提取问题、特征库的建立问题、数字识别问题。 毕业设计开题报告 计算机科学与技术 基于SVM的手写数字识别的应用与实现 一、综述本课题国内外研究动态,说明选题的依据和意义 阿拉伯数字作为唯一被世界各国通用的符号,是人类文明发展的标志之一,也是人类交流沟通的主要媒介。在人们日常生活当中,离不开数字的使用,我们每天都要进行大量的数字工作处理,比如邮政编码、统计报表、财务报表、银行汇款转账等等,如此繁琐的数字工作处理占去了我们很大一部分时间,空间。而对于,计算机大范围普及,人工智能高度发展的当今社会,利用手写数字识别系统代替人们进行这样繁重的手工劳动,备受国内外人士的高度重视。 由于手写数字识别本身的一些特点,对它的研究有及其重要的理论价值: ⑴阿拉伯数字是唯一被世界各国通用的符号,对手写体数字识别的研究基本上与文化背景无关,各地的研究工作者基于同一平台开展工作,有利于研究的比较和探讨。 ⑵手写数字识别应用广泛,如邮政编码自动识别,税表系统和银行支票自动处理等。这些工作以前需要大量的手工录入,投入的人力物力较多,劳动强度较大。手写数字识别的研究适应了无纸化办公的需要,能大大提高工作效率。 ⑶由于数字类别只有10个,较其他字符识别率较高,可用于验证新的理论和做深入的分析研究。许多机器学习和模式识别领域的新理论和算法都是先用手写数字识别进行检验,验证理论的有效性,然后才应用到更复杂的领域当中。这方面的典型例子就是人工神经网络和支持向量机(Support Vector Machine)。 ⑷手写数字的识别方法很容易推广到其它一些相关问题,如对英文之类拼音文字的识别。事实上,很多学者就是把数字和英文字母的识别放在一起研究的。 手写数字识别的一般原理为:首先把数字图像经过预处理,然后得到的数据进行特征提取或不用进行特征提取就可以直接输入识别器进行识别得到结果。手写数字识别的预处理通常包括数字图像的二值化处理、细化处理等步骤。数字图像的二值化处理是将上一步骤所得到的灰度数字图像转化为二值数字图像,即在数字图像中区分出字符和背景。二值化处理方法很多,但考虑到大量数字识别的需要,一般只能采用一维的阈值分割算法进行处理以获得二值化数字图像,预处理技术在当前比较成熟。 基于SVM的手写数字识别系统主要是利用支持向量机在识别领域良好的识别性能。对于一个完整的识别系统应包括从图像采集到得出识别结果的过程,由于本系统主要是用来检验支持向量机在手写数字识别系统中的应用,所以在本系统中图像采集、样本预处理等就不在 石河子大学 信息科学与技术学院毕业论文 课题名称:手写体数字识别系统设计 学生姓名: 学号: 学院:信息科学与技术学院 专业年级:电子信息工程2007级指导教师: 职称: 完成日期:二○一一年六月十一日 手写体数字识别系统设计 学生: 指导教师: [摘要] 随着科学技术的迅速发展,在邮政编码、统计报表、财务报表、银行票据等处理大量字符信息录入的场合,手写数字识别系统的应用需求越来越强烈,如何将数字方便、快速地输入到计算机中已成为关系到计算机技术普及的关键问题。本文设计实现了一个基于Matlab软件的手写体数字识别系统,采用模块化设计方法,编写了摄像头输入、直接读取图片、写字板输入三个模块,利用摄像头等工具,将以文本形式存在的手写体数字输入进计算机,完成对手写体数字图片的采集,并设计了一种手写数字识别方法,对手写体数字图像进行预处理、结构特征提取、分类识别,最终以文本形式输出数字,从而实现手写体数字的识别。 [关键词] 预处理,结构特征提取,分类识别,手写体数字识别 Handwritten Digit Recognition System Students: Teacher: Abstract:With the rapid development of science and technology, in zip code, statistics, reports, financial statements, Bank bills dealing with a large number of characters, such as information recorded occasions, handwritten digit recognition system of requirement has become stronger and stronger, how easily and quickly the number entered in the computer has become a key issue relates to the popularization of computer technology. This article design implementation has a based on Matlab software of handwriting body digital recognition system, used module of design method, write has camera entered, and directly read pictures, and write Board entered three a module, using camera, tools, will to text form exists of handwriting body digital entered into computer, completed on handwriting body digital pictures of collection, and design has a handwriting digital recognition method, on handwriting body digital image for pretreatment, and structure features extraction, and classification recognition, eventually to text form output digital, to implementation handwriting body digital of recognition. Key words: Pretreatment, structure feature extraction, classification and recognition, handwritten digit recognition. 基于2DPCA的人脸识别算法研究 摘要 人脸识别技术是对图像和视频中的人脸进行检测和定位的一门模式识别技术,包含位置、大小、个数和形态等人脸图像的所有信息。由于近年来计算机技术的飞速发展,为人脸识别技术的广泛应用提供了可能,所以图像处理技术被广泛应用了各种领域。该技术具有广阔的前景,如今已有大量的研究人员专注于人脸识别技术的开发。本文的主要工作内容如下: 1)介绍了人脸识别技术的基础知识,包括该技术的应用、背景、研究方向以及 目前研究该技术的困难,并对人脸识别系统的运行过程以及运行平台作了简单的介绍。 2)预处理工作是在原始0RL人脸库上进行的。在图像的预处理阶段,经过了图 象的颜色处理,图像的几何归一化,图像的均衡化和图象的灰度归一化四个过程。所有人脸图像通过上述处理后,就可以在一定程度上减小光照、背景等一些外在因素的不利影响。 3)介绍了目前主流的一些人脸检测算法,本文采用并详细叙述了Adaboost人脸 检测算法。Adaboost算法首先需要创建人脸图像的训练样本,再通过对样本的训练,得到的级联分类器就可以对人脸进行检测。 4)本文介绍了基于PCA算法的人脸特征点提取,并在PCA算法的基础上应用了 改进型的2DPCA算法,对两者的性能进行了对比,得出后者的准确度和实时性均大于前者,最后将Adaboost人脸检测算法和2DPCA算法结合,不仅能大幅度降低识别时间,而且还相互补充,有效的提高了识别率。 关键词:人脸识别 2DPCA 特征提取人脸检测 2DPCA Face Recognition Algorithm Based on The Research Abstract:Face recognition is a technology to detect and locate human face in an image or video streams,Including location, size, shape, number and other information of human face in an image or video streams.Due to the rapid development of computer operation speed makes the image processing technology has been widely applied in many fields in recent years. This paper's work has the following several aspects: 1)Explained the background, research scope and method of face recognition,and introduced the theoretical method of face recognition field in general. 2)The pretreatments work is based on the original ORL face database. In the image preprocessing stage, there are the color of the image processing, image geometric normalization, image equalization and image gray scale normalization four parts. After united processing, the face image is standard, which can eliminate the adverse effects of some external factors. 3)All kinds of face detection algorithm is introduced, and detailed describing the Adaboost algorithm for face detection. Through the Adaboost algorithm to create a training sample,then Training the samples of face image,and obtaining the cascade classifier to detect human face. 4)This paper introduces the facial feature points extraction based on PCA ,and 2DPCA is used on the basis of the PCA as a improved algorithm.Performance is compared between the two, it is concluds that the real time and accuracy of the latter is greater than the former.Finally the Adaboost face detection algorithm and 2DPCA are combined, which not only can greatly reduce the recognition time, but also complement each other, effectively improve the recognition rate. Key words:Face recognition 2DPCA Feature extraction Face detection 中南大学 本科生毕业论文(设计) 题目基于神经网络的手写数字 识别系统的设计与实现 目录 摘要 (Ⅰ) ABSTRACT (Ⅱ) 第一章绪论 (1) 1.1手写体数字识别研究的发展及研究现状 (1) 1.2神经网络在手写体数字识别中的应用 (2) 1.3 论文结构简介 (3) 第二章手写体数字识别 (4) 2.1手写体数字识别的一般方法及难点 (4) 2.2 图像预处理概述 (5) 2.3 图像预处理的处理步骤 (5) 2.3.1 图像的平滑去噪 (5) 2.3.2 二值话处理 (6) 2.3.3 归一化 (7) 2.3.4 细化 (8) 2.4 小结 (9) 第三章特征提取 (10) 3.1 特征提取的概述 (10) 3.2 统计特征 (10) 3.3 结构特征 (11) 3.3.1 结构特征提取 (11) 3.3.2 笔划特征的提取 (11) 3.3.3 数字的特征向量说明 (12) 3.3 知识库的建立 (12) 第四章神经网络在数字识别中的应用 (14) 4.1 神经网络简介及其工作原理 (14) 4.1.1神经网络概述[14] (14) 4.1.2神经网络的工作原理 (14) 4.2神经网络的学习与训练[15] (15) 4.3 BP神经网络 (16) 4.3.1 BP算法 (16) 4.3.2 BP网络的一般学习算法 (16) 4.3.3 BP网络的设计 (18) 4.4 BP学习算法的局限性与对策 (20) 4.5 对BP算法的改进 (21) 第五章系统的实现与结果分析 (23) 5.1 软件开发平台 (23) 5.1.1 MATLAB简介 (23) 5.1.2 MATLAB的特点 (23) 5.1.3 使用MATLAB的优势 (23) 5.2 系统设计思路 (24) 5.3 系统流程图 (24) 5.4 MATLAB程序设计 (24) 5.5 实验数据及结果分析 (26) 结论 (27) 参考文献 (28) 致谢 (30) 附录 (31) 手写体数字识别 第一章绪论 (4) 1.1课题研究的意义 (4) 1.2国内外究动态目前水平 (4) 1.3手写体数字识别简介 (5) 1.4识别的技术难点 (5) 1.5主要研究工作 (6) 第二章手写体数字识别基本过程: (6) 2.1手写体数字识别系统结构 (6) 2.2分类器设计 (7) 2.2.1 特征空间优化设计问题 (7) 2.2.2分类器设计准则 (8) 2.2.3分类器设计基本方法 (9) 3.4 判别函数 (9) 3.5训练与学习 (10) 第三章贝叶斯方法应用于手写体数字识别 (11) 3.1贝叶斯由来 (11) 3.2贝叶斯公式 (11) 3.3贝叶斯公式Bayes决策理论: (12) 3.4贝叶斯应用于的手写体数字理论部分: (16) 3.4.1.特征描述: (16) 3.4.2最小错误分类器进行判别分类 (17) 第四章手写体数字识别的设计流程及功能的具体实现 (18) 4.1 手写体数字识别的流程图 (18) 4.2具体功能实现方法如下: (19) 结束语 (25) 致谢词 (25) 参考文献 (26) 附录 (27) 摘要 数字识别就是通过计算机用数学技术方法来研究模式的自动处理和识别。随着计算机技术的发展,人类对模式识别技术提出了更高的要求。特别是对于大量己有的印刷资料和手稿,计算机自动识别输入己成为必须研究的课题,所以数字识别在文献检索、办公自动化、邮政系统、银行票据处理等方面有着广阔的应用前景。 对手写数字进行识别,首先将汉字图像进行处理,抽取主要表达特征并将特征与数字的代码存储在计算机中,这一过程叫做“训练”。识别过程就是将输入的数字图像经处理后与计算机中的所有字进行比较,找出最相近的字就是识别结果。 本文主要介绍了数字识别的基本原理和手写的10个数字字符的识别系统的设计实现过程。第一章介绍了数字识别学科的发展状况。第二章手写体数字识别基本过程。第三章贝叶斯方法应用于手写体数字识别。第四章手写体数字识别的设计流程及功能的具体实现,并对实验结果做出简单的分析。 关键词:手写体数字识别分类器贝叶斯vc++6.0 错误!未找到引用源。 基于opencv 对图像的预处理 1.问题描述 本次设计是基于opencv 结合c++语言实现的对图像的预处理,opencv 是用于开发实时的图像处理、计算机视觉及模式识别程序;其中图像的预处理也就是利用opencv 对图像进行简单的编辑操作;例如对图像的对比度、亮度、饱和度进行调节,同时还可以对图像进行缩放和旋转,这些都是图像预处理简单的处理方法;首先通过opencv 加载一幅原型图像,显示出来;设置五个滑动控制按钮,当拖动按钮时,对比度、亮度、饱和度的大小也会随之改变,也可以通过同样的方式调节缩放的比例和旋转的角度,来控制图像,对图像进行处理,显示出符合调节要求的图像,进行对比观察他们的之间的变化。 2.模块划分 此次设计的模块分为五个模块,滑动控制模块、对比度和亮度调节模块、饱和度调节模块、缩放调节模块、旋转调节模块,他们之间的关系如下所示: 图一、各个模块关系图 调用 调用 调用 调用 滑动控制模块 对比度和亮度调节模块 饱和度调节模块 缩放调节模块 旋转调节模块 滑动控制模块处于主函数之中,是整个设计的核心部分,通过createTrackbar创建五个滑动控制按钮并且调用每个模块实现对图像相应的调节。 3.算法设计 (1)滑动控制: 滑动控制是整个设计的核心部分,通过创建滑动控制按钮调节大小来改变相应的数据,进行调用函数实现对图像的编辑,滑动控制是利用createTrackbar(),函数中包括了滑动控制的名称,滑动控制显示在什么窗口上,滑动变量的地址和它调节的最大围,以及每个控制按钮应该调用什么函数实现什么功能; (2)对比度和亮度的调节: 对比度和亮度的调节的原理是依照线性理论,它的公式如下所示:g(x)=a* f(x) +b,其中f(x)表示源图像的像素,g(x)表示输出图像的像素,参数a(需要满足a>0)被称为增益(gain),常常被用来控制图像的对比度,参数b通常被称为偏置(bias),常常被用来控制图像的亮度; (3)饱和度的调节: 饱和度调节利用cvCvtColor( src_image, dst_image, CV_BGR2HSV )将RGB 颜色空间转换为HSV颜色空间,其中“H=Hue”表示色调,“S=Saturation”表示饱和度,“V=Value ”表示纯度;所以饱和度的调节只需要调节S的大小,H 和V的值不需要做任何的改变; (4)旋转的调节: 旋转是以某参考点为圆心,将图像的个点(x,y)围绕圆心转动一个逆时针角度θ,变为新的坐标(x1,y1),x1=rcos(α+θ),y1=rsin(α+θ),其中r是图像的极径,α是图像与水平的坐标的角度的大小; (5)缩放的调节: 首先得到源图像的宽度x和高度y,变换后新的图像的宽度和高度分别为x1和y1,x1=x*f,y1=y*f,其中f是缩放因子; 4.函数功能描述 (1)主函数main()用来设置滑动控制按钮,当鼠标拖动按钮可以得到相应的数据大小,实现手动控制的功能,当鼠标拖动对比度和亮度调节是,主函数调用 大学生研究计划项目 论文报告 项目名称:_手写体数字识别系统的设计与实现 负责人:_________ _______________ 学院/专业:_____ ______ 学号:____ ________ 申请经费:_____ _________________ 指导教师:______ _______ 项目起止时间:2011年6月-2012年3月 摘要 手写体数字识别系统依托计算机应用软件为载体,利用C++程序设计的相关知识,运用模块设计等相关技术,最终完成手写体设计系统的程序综合设计。 关键字:手写体数字处理模式识别程序设计 一、论题概述 模式识别是六十年代初迅速发展起来的一门学科。由于它研究的是如何用机器来实现人(及某些动物)对事物的学习、识别和判断能力,因而受到了很多科技领域研究人员的注意,成为人工智能研究的一个重要方面。 字符识别是模式识别的一个传统研究领域。从50年代开始,许多的研究者就在这一研究领域开展了广泛的探索,并为模式识别的发展产生了积极的影响。 字符识别一般可以分为两类:1.联机字符识别;2.光学字符识别(Optical Chara- cter Recognition,OCR)或称离线字符识别。在联机字符识别中,计算机能够通过与计算机相连的输入设备获得输入字符笔划的顺序、笔划的方向以及字符的形状,所以相对OCR来说它更容易识别一些。但联机字符识别有一个重要的不足就是要求输入者必须在指定的设备上书写,然而人们在生活中大部分的书写情况是不满足这一要求的,比如人们填写各种表格资料,开具支票等。如果需要计算机去认识这些己经成为文字的东西,就需要OCR技术。比起联机字符识别来,OCR不要求书写者在特定输入设备上书写,它可以与平常一样书写,所以OCR 的应用更为广泛。OCR所使用的输入设备可以是任何一种图像采集设备,如CCD、扫描仪、数字相机等。通过使用这类采集设备,OCR系统将书写者已写好的文字作为图像输入到计算机中,然后由计算机去识别。由于OCR的输入只是简单的一副图像,它就不能像联机输入那样比较容易的从物理特性上获得字符笔划的顺序信息,因此OCR是一个更具挑战性的问题。 数字识别是多年来的研究热点,也是字符识别中的一个特别问题,它是本文研究的重点。数字识别在特定的环境下应用特别广泛,如邮政编码自动识别系统,税表和银行支票自动处理系统等。一般情况下,当涉及到数字识别时,人们往往要求识别器有很高的识别可靠性,特别是有关金额的数字识别时,如支票中填写 手写数字系统实践指导手册 1 问题描述 设计一个简单的手写数字识别系统,能够识别手写输入的数字1-9并且能够识别选中的文本文件中的数字,应具有简单方便的操作界面,输入输出等。 1.1功能需求分析 通过分析,以及从用户的角度考虑,系统应该具有以下功能: (1)数字的手写输入。作为一个手写数字识别系统,首先应该能够让用户过绘制窗口进行数字绘制,系统得到用户的手写输入进行处理。 (2)直接选择文件。用户还可以选择系统中的文本文件进行处理。 (3)数据预处理。包括计算数据大小、二值化、格式化处理等。 (4)数字提取。将经过二值化后的图像中的个数字区域进行提取,只有能够将数字进行准确的提取,才能将其一一识别。 (5)基准库的选择与建立。选择一个可供系统训练和测试的样本库非常重要,本系统的训练集和测试集选择的是《机器学习实战》中所给的数据。 (6)识别数字。经过训练集进行训练后,使用knn算法对需要识别的数字识别。 2 数据集获取 ●任务要求: 从网上爬取或者下载适合进行手写数字识别系统的训练集和测试集 ●实践指导: 方式一:自己从网上找适合的数据下载 方式二:推荐数据集:“手写数字数据集的光学识别”一文中的数据集合,该文登载与2010年10月3日的UCI机器学习资料库中https://www.360docs.net/doc/a611883990.html,/ml 3 功能设计与实现 3.1手写数字识别系统结构图: 图一:系统结构图 3.2识别用户选择手选文件功能设计与实现 ●任务要求: 用户可以自己从电脑中选择文本文件进行识别。 ●实践指导: KNN分类器的构造思路及原理如下: 1)选择训练集和测试集。系统所采用的数据集选用的是“手写数字数据集的光学识别”一文中的数据集合。0-9每个数字大约有200个训练数据20个测试数据。数字的文本格式如图所示。 基于libsvm的手写字体识别 程序: 用的是faruto大神的程序,在此做声明 程序有自己的注释 【思路】:整个程序的流程是:1、首先用遗传算法GA和交叉验证的方式,对参数c(损失函数系数)和参数g(核函数参数)进行寻优;2、然后将两个参数和训练样本进行训练:model = svmtrain(TrainLabel, TrainData, cmd);3、最后导入测试样本集进行测试:preTestLabel = svmpredict(TestLabel, TestData, model); 【注意:】训练和测试所使用的data和label都必须是doubel型,可以用double()函数或者是str2doubel进行转换。(不知道在哪里看到的) 如有疑问请咨询qq:778961303 -g r(gama):核函数中的gamma函数设置(针对多项式/rbf/sigmoid核函数) -c cost:设置C-SVC,e -SVR和v-SVR的参数(损失函数)(默认1) %% close all; clear; clc; format compact; %紧凑显示 %% 载入训练数据 [FileName,PathName,FilterIndex] = uigetfile( ... {'*.bmp';'*.jpg'},'请导入训练图片','*.bmp','MultiSelect','on'); %打开文件的导向操作 if ~FilterIndex return; end num_train = length(FileName); TrainData = zeros(num_train,16*16); TrainLabel = zeros(num_train,1); for k = 1:num_train pic = imread([PathName,FileName{k}]); %读取训练用的图片 pic = pic_preprocess(pic); %将图片变成16*16的矩阵 % imshow(pic); TrainData(k,:) = double(pic(:)'); %将图片改写成一个double类型的行向量 TrainLabel(k) = str2double(FileName{k}(1)); %图片的类标签 end %% 建立支持向量机 手写数字识别的原理及应用 林晓帆丁晓青吴佑寿 一、引言 手写数字识别(Handwritten Numeral Recognition)是光学字符识别技术(Optical Character Recognition,简称OCR)的一个分支,它研究的对象是:如何利用电子计算机自动辨认人手写在纸张上的阿拉伯数字。 在整个OCR领域中,最为困难的就是脱机手写字符的识别。到目前为止,尽管人们在脱机手写英文、汉字识别的研究中已取得很多可喜成就,但距实用还有一定距离。而在手写数字识别这个方向上,经过多年研究,研究工作者已经开始把它向各种实际应用推广,为手写数据的高速自动输入提供了一种解决方案。 二、研究的实际背景 字符识别处理的信息可分为两大类:一类是文字信息,处理的主要是用各国家、各民族的文字(如:汉字,英文等)书写或印刷的文本信息,目前在印刷体和联机手写方面技术已趋向成熟,并推出了很多应用系统;另一类是数据信息,主要是由阿拉伯数字及少量特殊符号组成的各种编号和统计数据,如:邮政编码、统计报表、财务报表、银行票据等等,处理这类信息的核心技术是手写数字识别。这几年来我国开始大力推广的“三金”工程在很大程度上要依赖数据信息的输入,如果能通过手写数字识别技术实现信息的自动录入,无疑会促进这一事业的进展。因此,手写数字的识别研究有着重大的现实意义,一旦研究成功并投入应用,将产生巨大的社会和经济效益。 三、研究的理论意义 手写数字识别作为模式识别领域的一个重要问题,也有着重要的理论价值: 1.阿拉伯数字是唯一的被世界各国通用的符号,对手写数字识别的研究基本上与文化背景无关,这样就为各国,各地区的研究工作者提供了一个施展才智的大舞台。在这一领域大家可以探讨,比较各种研究方法。 2.由于数字识别的类别数较小,有助于做深入分析及验证一些新的理论。这方面最明显的例子就是人工神经网络(ANN)------相当一部分的ANN模型和算法都以手写数字识别作为具体的实验平台,验证理论的有效性,评价各种方法的优缺点。 3.尽管人们对手写数字的识别已从事了很长时间的研究,并已取得了很多成果,但到目前为止机器的识别本领还无法与人的认知能力相比,这仍是一个有难度的开放问题(Open problem)。 脱机手写体汉字识别综述 赵继印1,郑蕊蕊2,吴宝春1,李 敏1 (1.大连民族学院机电信息工程学院,辽宁大连116600;2.吉林大学通信工程学院,吉林长春130025) 摘 要: 脱机手写体汉字识别是模式识别领域最具挑战性的课题之一.本文分析了近年来脱机手写体汉字识别 的最新进展,讨论了脱机手写体汉字分割、特征提取和分类器设计等关键技术的各种主流方法,介绍了3种典型的汉字识别数据库,并提出了脱机手写体汉字识别的难点问题和今后发展的趋势,为该领域的研究者指明研究方向,共同促进脱机手写体汉字识别技术的发展. 关键词: 脱机手写体汉字识别;字符分割;特征提取;分类器设计;汉字识别数据库中图分类号: TP39114 文献标识码: A 文章编号: 037222112(2010)022******* A Review of Off 2Line Handwritten Chine se Character Recognition ZH AO Ji 2yin 1,ZHE NG Rui 2rui 2,W U Bao 2chun 1,LI Min 1 (1.College o f Electormechanical and Information Engineering ,Dalian Nationalities Univer sity ,Dalian ,Liaoning 116600,China ; 2.College o f Communication Engineering ,Jilin Univer sity ,Changchun ,Jilin 130025,China ) Abstract : Off 2line handwritten Chinese character recognition is one of the most challenging problems in pattern recognition field.This paper analyzed the latest developments of off 2line handwritten Chinese character recognition in recent years.Main meth 2ods of the key technologies such as Chinese characters segmentation ,feature extraction and classifier design were discussed.This pa 2per also introduced 3typical off 2line handwritten Chinese character recognition databases.Finally ,remain difficult issues and future trends of off 2line handwritten Chinese character recognition were proposed.This paper will guide researchers in this field and pro 2mote development of off 2line handwritten Chinese character recognition technology. K ey words : off 2line handwritten Chinese character Recognition ;characters segmentation ;feature extraction ;classifier design ;Chinese recognition database 1 引言 汉字识别是模式识别的一个重要分支,也是文字识 别领域最为困难的问题之一,它涉及模式识别、图像处理、统计理论等学科,呈现出综合性的特点,在办公和教学自动化、银行票据自动识别、邮政自动分拣、少数民族语言文字信息处理等技术领域,都有着重要的理论意义和实用价值[1].汉字识别技术可分为印刷体和手写体汉字识别两大类.手写体汉字识别又可分为联机(on 2line )和脱机(off 2line )手写体汉字识别.脱机手写体汉字识别可分为受限和非受限两种情况,如图1所示. 清华大学、中科院自动化所等著名高校和科研院所都致力于汉字识别的研究,以汉王科技股份有限公司为首的科技企业也推出了一系列成熟的商业产品[2].目前,很多论文提出的脱机手写体汉字识别的方法在不同的字符数据库试验中,取得了95%~99%的识别率,但是对真正的手写文档的识别效果却难以达到实际应用的要求. 目前脱机手写体汉字识别仍处于实验室研究阶 段,成功的商业产品仍未发布[2~4].本文着重讨论脱机手写体汉字识别的现状和存在的问题,明确今后的发展趋势,为脱机手写体汉字识别领域的广大研究人员提供参考和借鉴. 2 手写汉字字体特点 从识别的角度分析,汉字具有如下4个特点.2.1 汉字类别多 汉字的个数很多,国家标准G B1803022000《信息交换用汉字编码字符集基本集的扩充》收录27484个汉字[5].汉字个数在模式识别问题中体现为汉字的类别,因此汉字识别问题属于超大规模数据集的模式识别问题. 收稿日期:2009202216;修回日期:2009206213 基金项目:大连民族学院科研基金(N o.20086201);吉林省科技厅科技引导计划(N o.20090511) 第2期2010年2月 电 子 学 报 ACT A E LECTRONICA SINICA V ol.38 N o.2 Feb. 2010基于知识库的手写体数字识别
ANN MNIST手写数字识别总结
手写字符识别系统设计
基于OpenCV识别库的面部图像识别系统的设计
手写数字识别的实现
手写数字识别系统的设计与实现
开题报告-基于SVM的手写数字识别的应用与实现
(完整版)手写体数字识别系统设计毕业设计
基于OpenCv的图像识别
基于神经网络的手写数字识别系统的设计与实现
手写体数字的识别
基于opencv对图像的预处理
手写体数字识别系统的设计与实现
手写数字识别实践指导手册
基于libsvm的手写字体识别
手写数字识别的原理及应用
脱机手写体汉字识别综述